1. Introduction
With the explosive growth of information, it becomes more difficult for people to find what they are interested in. To address this problem, Recommender System (RS) [
1] is proposed to provide users with personalized recommendations which we call items. Its key idea is to profile users and items and model the relation between them. As one of the most popular techniques for building RSs, Collaborative Filtering (CF) [
2] is based on the past behavior of users such as their previous viewing history and rating records.
Challenges. In real-world applications, although CF has proven to be effective and scalable in predicting user preferences, it still suffers from some problems.
(1) Conventional CF models have possible risks to privacy.
Most service providers in CF tend to collect users’ historical behaviors to train the recommendation model, which might jeopardize user privacy since the plaintext information is exposed to the service provider. Thus, some data privacy regulations, such as General Data Protection Regulation (GDPR) [
3], have been published. These regulations attempt to place restrictions on the collection, storage, and use of user data. To tackle this privacy problem, federated learning (FL) [
4] is proposed to legally and efficiently make use of users’ data. FL distributes the model learning process to users’ end devices, making it possible to train a global model from user-specific local models, which ensures that user’s private data never leaves their end devices. However, CF under federated learning still has privacy issues as it is susceptible to some attacks. For example, Mothukuri et al. [
5] prove the practicality in conducting backdoor attacks in federated learning. Zhang et al. [
6] study and evaluate poisoning attack in federated learning system based on generative adversarial nets (GAN). Recently, decentralized learning (DL) [
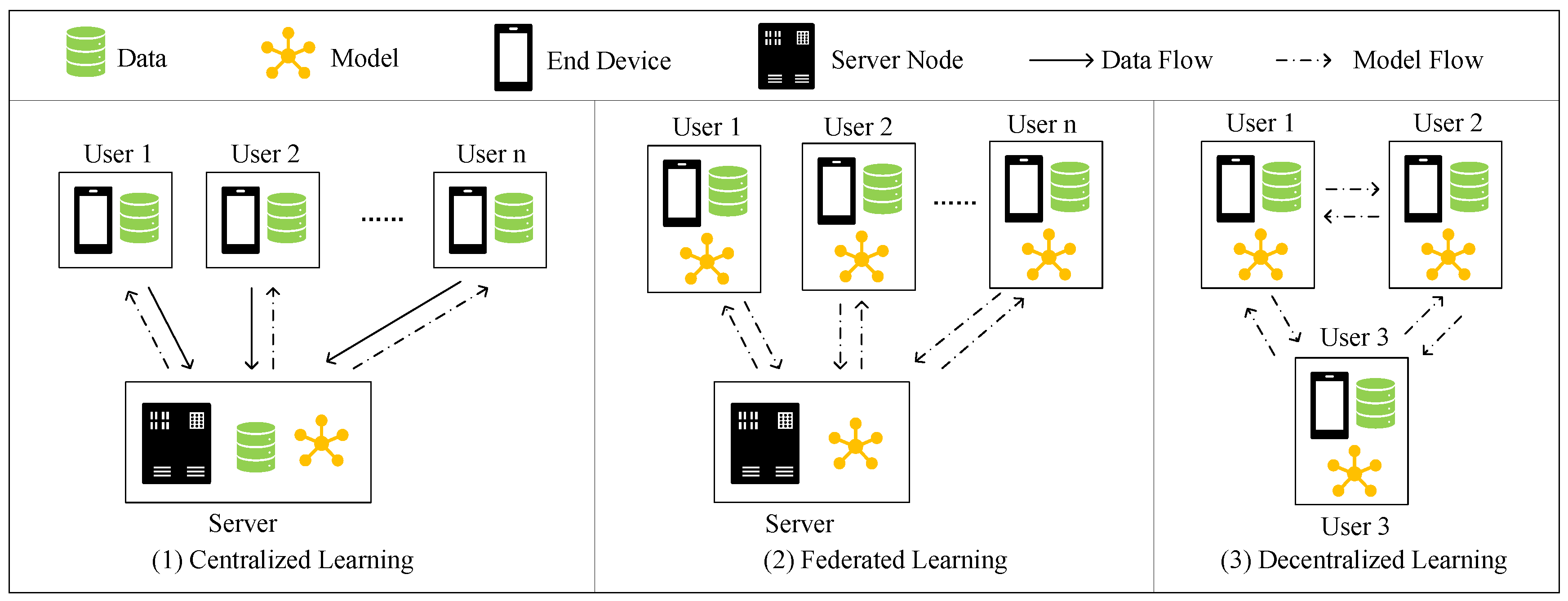
7] has drawn people’s attention in many real-world applications. As shown in
Figure 1, in decentralized learning the model is learned collaboratively by a group of users without needing a centralized server. However, malicious participants might steal privacy from other users in the communication phase [
8]. Thus, we propose a decomposing strategy in our decentralized scheme to ensure that users exchanging only non-private information with each other, which shows practicality in preserving user privacy.
(2) Conventional CF models might be limited by high resource requirements.
Except for privacy concerns, Kairouz et al. [
9] point out that in order to maintain the user data and train the CF model, centralized learning needs a server with high storage and computing capacity. Although the server in federated learning is only responsible for aggregating and distributing the model, it still has to store a large amount of model information and coordinate communication with various users. This might become a bottleneck when the learning scale becomes large and further lead to single point of failure in practice [
10]. Thus, in this study, we focus on implementing a decentralized learning scheme for building a CF model. As shown in
Figure 1, by performing local training and exchanging some non-private information with neighbors, users collaboratively learn a global model. In this way, the storage and computing load are transferred to users which improves the scalability and stability of the system.
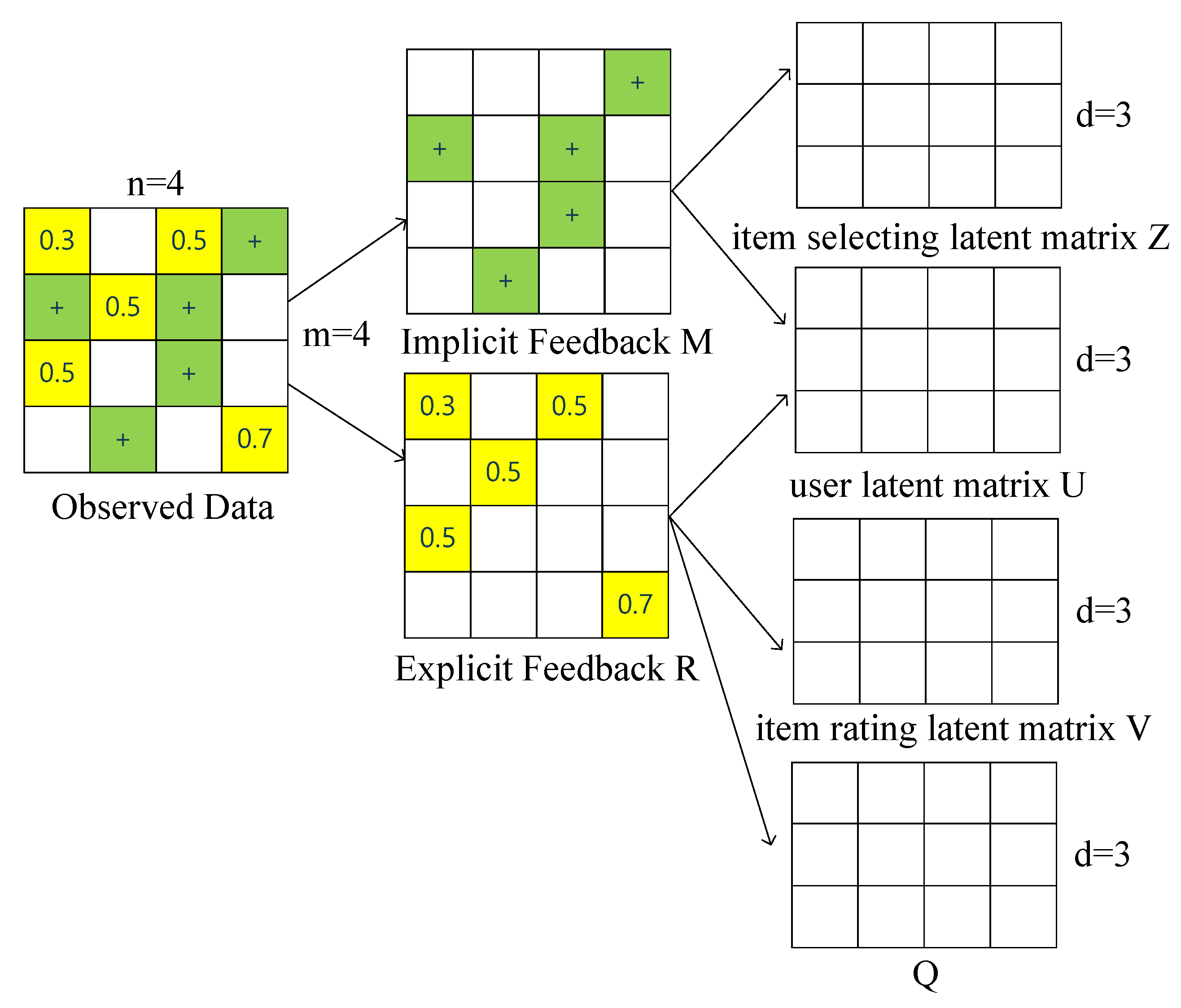
Most CF models cannot learn from both explicit and implicit feedback simultaneously.
CF aims to model user preference based on user feedback, which generally has two categories: explicit feedback and implicit feedback [
11]. Explicit feedback is often the form of numeric ratings given by users to express the extent to which they like the items. It could measure user preference in a direct and granular way, but some users are reluctant to have such extra operations [
12]. In contrast, implicit feedback is easier to be collected. It includes users’ behaviors that indirectly reflect their opinion (e.g., browse history, clicking record). However, compared with explicit feedback, it has lower accuracy and granularity. For example, a woman buys a skirt online and finds out she dislikes it after wearing it. Through the above analysis, it is clear that these two forms of feedback are complementary to each other since explicit feedback is higher in quality while implicit feedback is higher in quantity. As far as we know, few CF models are based both on explicit and implicit feedback. Thus, in this study we devise a matrix co-factorization model to cope with the heterogeneity between these two forms of feedback.
Our contributions. In this study, we first explore a probabilistic model specifically suitable for handling both explicit and implicit feedback and then devise a decentralized method called DPMF to protect users’ sensitive information. To the best of our knowledge, this is the first privacy-preserving framework for recommendation with both explicit and implicit feedback. The main contributions are listed as follows.
We devise a novel probabilistic matrix factorization method for recommender systems. It uses both explicit and implicit feedback simultaneously to model user preferences and item characteristics, which is practical and interpretable in rating prediction and item recommendation.
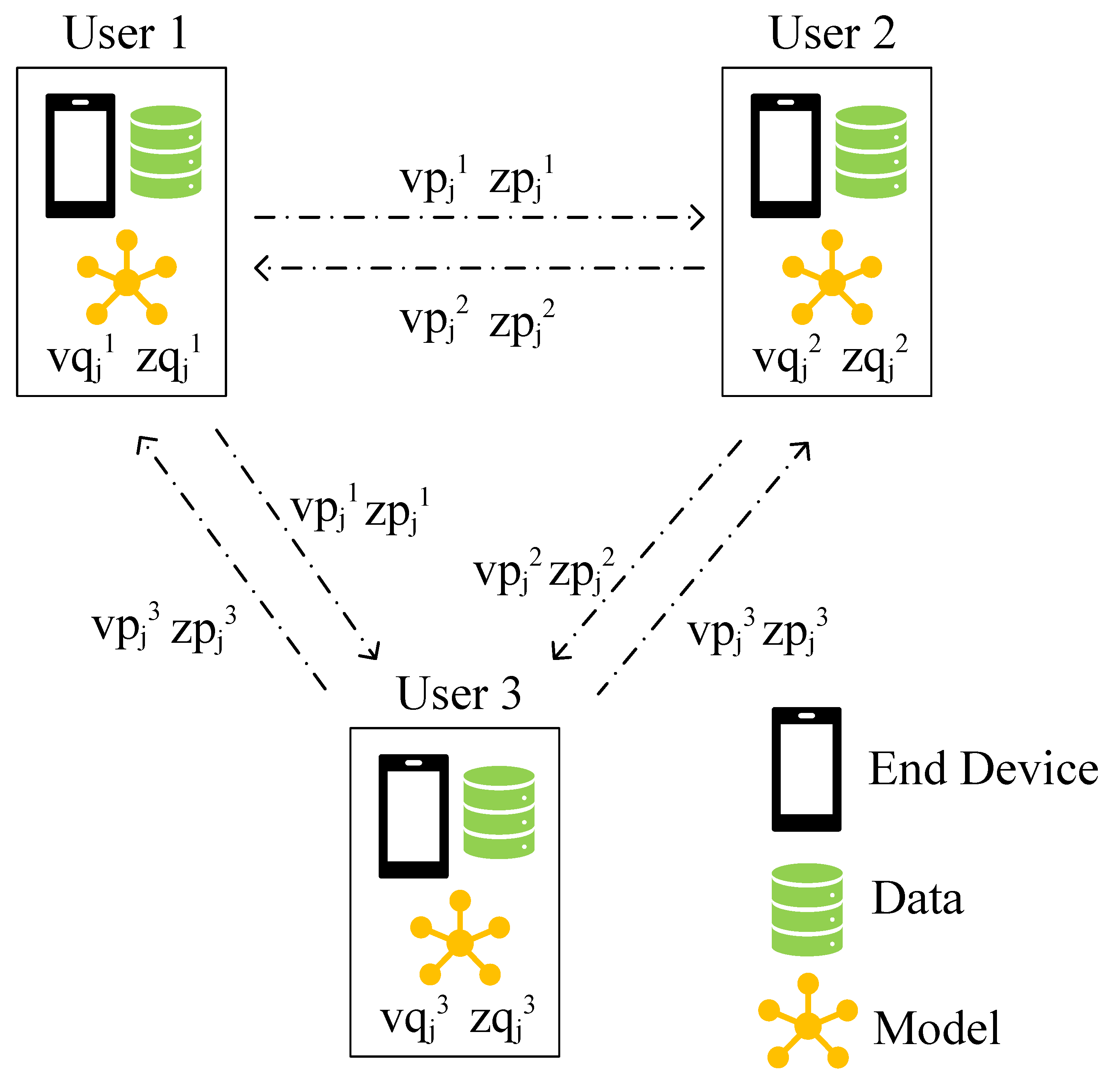
We propose a novel decomposing strategy to decompose the shared information among users into two parts, and only share the non-private part. In this way, the model not only gains a guarantee of convergence by exchanging the public information, but also maintains user privacy as the private information is kept locally by users.
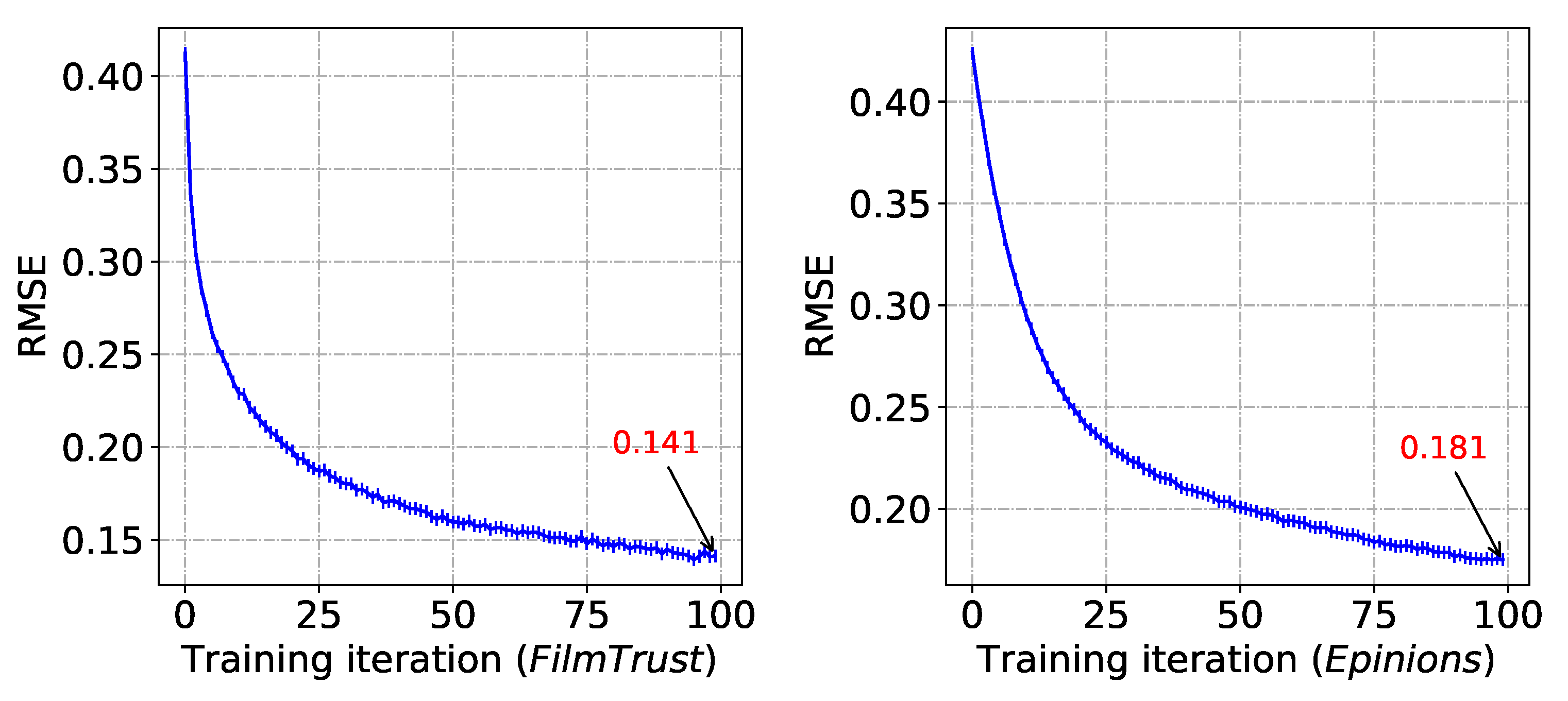
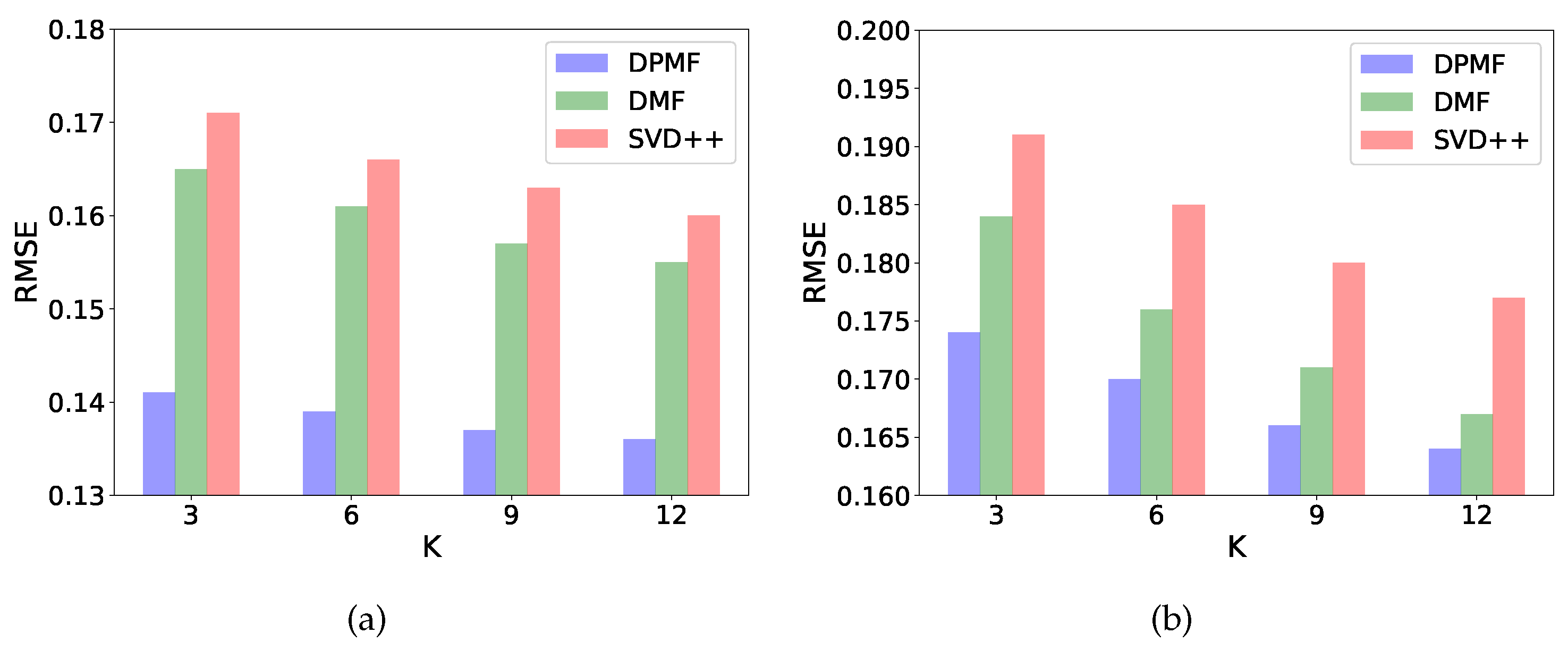
We propose a secure and efficient method to train our model. By finding neighbors from the trust statement, users exchange public model information with others. The public and personal model gradients are updated through stochastic gradient descent. Extensive experiments on two real-world datasets show that our method outperforms the existing state-of-the-art CF methods with lower RMSE loss in rating prediction task and higher precision in item recommendation task.
The rest of this study is organized as follows. We introduce the background in
Section 2 and then discuss the preliminaries and the system model in
Section 3. We conduct experiment and discuss the model performance in
Section 4. Finally, we conclude this study in
Section 5.
5. Conclusions
In this study, we propose a privacy-preserving recommendation framework based on decentralized probabilistic matrix factorization called DPMF. Specifically, we devise a novel model combining explicit and implicit feedback into a probabilistic matrix co-factorization model by decomposing observed data into explicit and implicit data matrixes and mapping users and items to a shared subspace of low dimensionality. Besides, we propose a novel decomposing strategy under decentralized settings to keep users’ private information at their end while users’ public information is shared and helps to learn the model collaboratively. The experiments on two real-world datasets demonstrate that compared with classic models, the proposed model improves its performance in lower loss in rating prediction task and higher precision in item recommendation task. Furthermore, the complexity analysis shows that our method is practical with linear computation and communication complexity.
In the future, we will focus on model compression. The recommendation model has made significant progress in using users’ data to predict user preferences and model item characteristics. However, the scale of recommendation model is becoming larger since there are increasing parameters, thus the storage overhead is becoming higher. How to reduce the storage of the recommendation model will be our next stage of work.












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}