
Fake Sentence Detection Based on Transfer Learning: Applying to Korean COVID-19 Fake News


Abstract
:1. Introduction
2. Related Works
2.1. Previous Research on Fake News Detection
2.2. BERT-Based Korean Embedding
2.3. Transfer Learning
3. Constructing Datasets
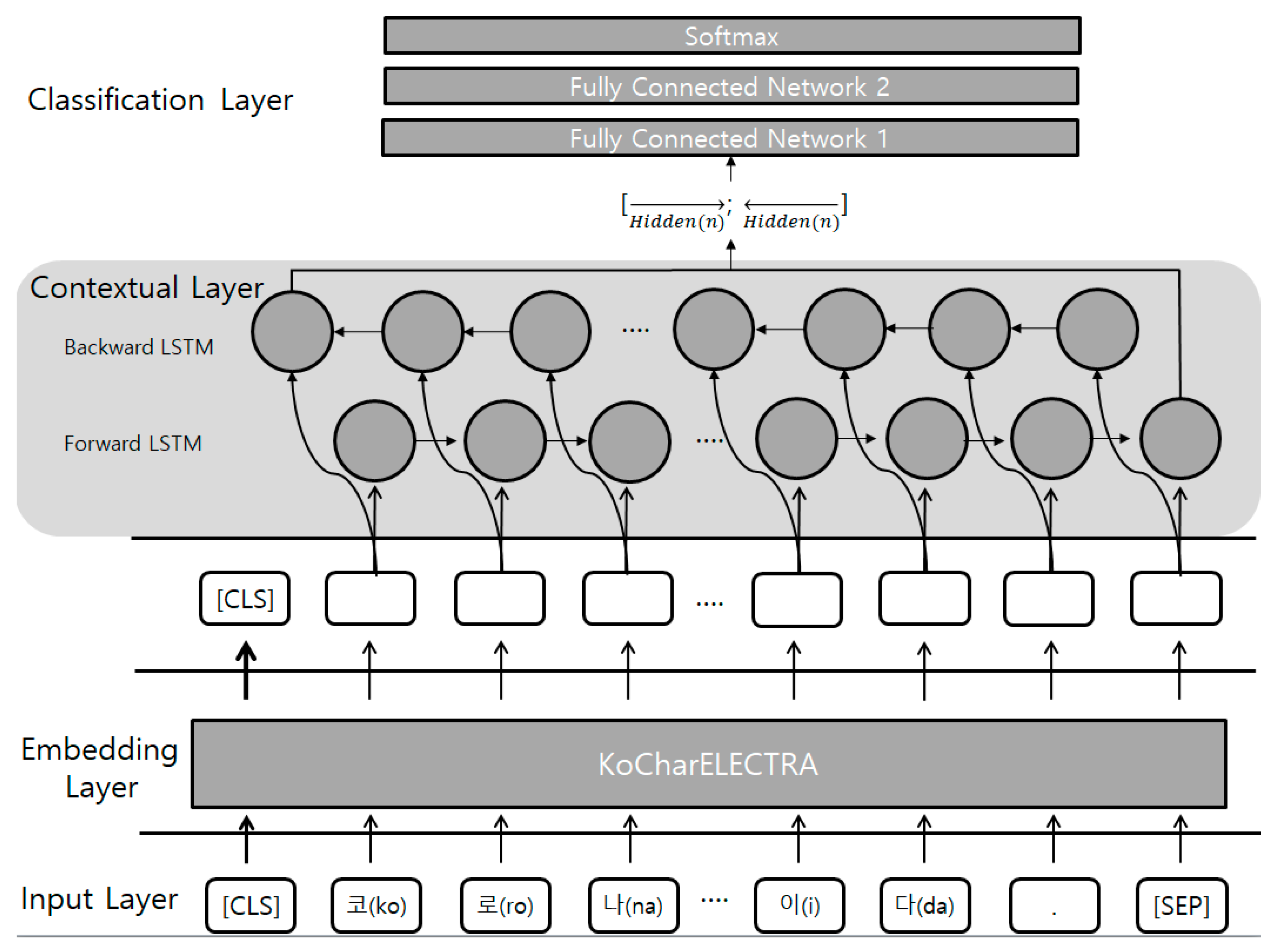
4. Fake Sentence Detection Based on Deep Learning
4.1. Embedding Layer
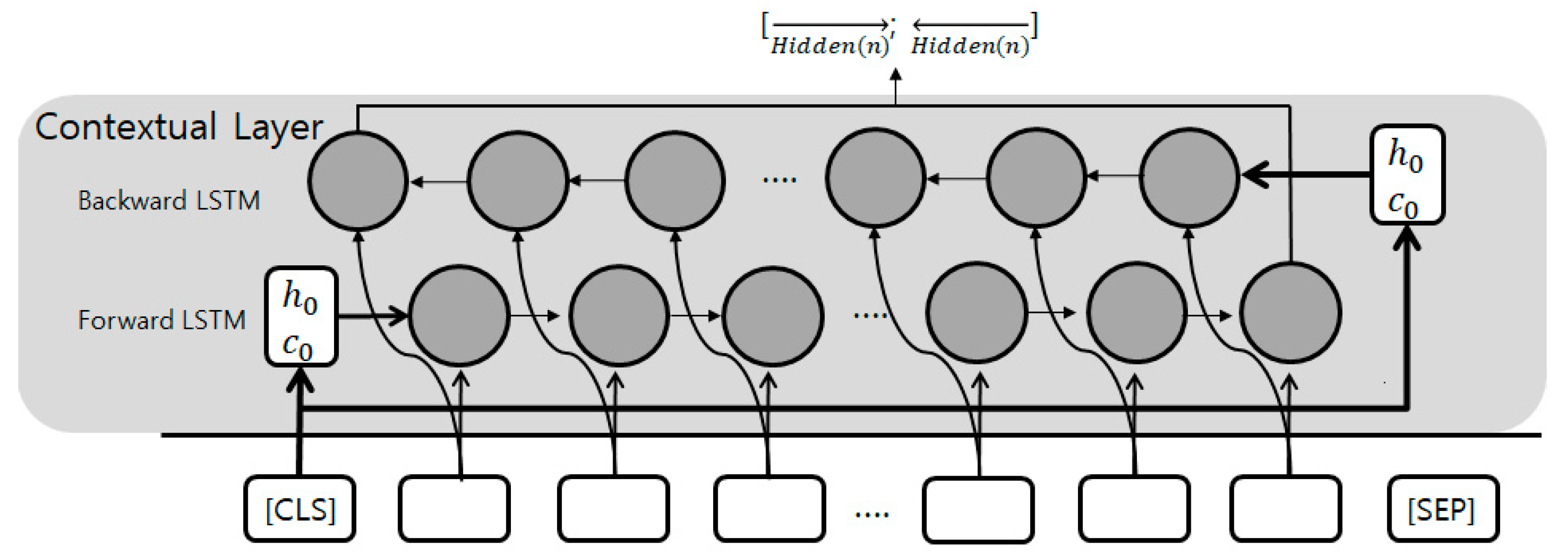
4.2. Contextual Layer
BiLSTM
4.3. Classification Layer
5. Experiments and Evaluation
5.1. Dataset Configuration
5.2. Performance Evaluation
5.3. Performance Improvements
5.4. Cohen’s Kappa
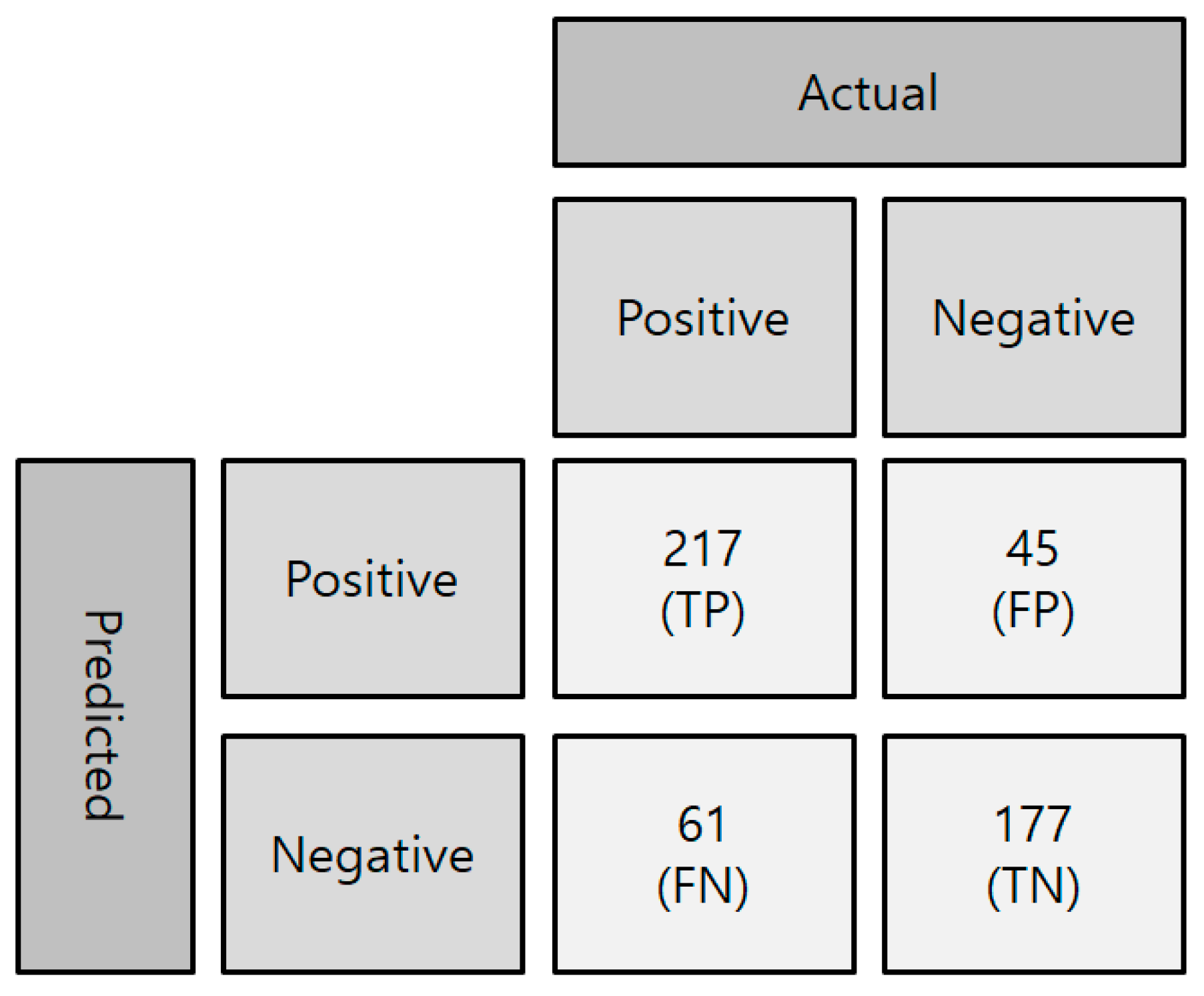
- True Positive (TP): a result that correctly indicates the positive;
- True Negative (TN): a result that correctly indicates the negative;
- False Positive (FP): a result that wrongly indicates the positive when in fact the result belongs to the negative;
- False Negative (FN): a result that wrongly indicates the negative when in fact the result belongs to the positive.
5.5. Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Akram, W.; Kumar, R. A study on positive and negative effects of social media on society. Int. J. Comput. Sci. Eng. 2017, 5, 351–354. [Google Scholar] [CrossRef]
- Jwa, H.; Oh, D.; Lim, H. Research analysis in automatic fake news detection. J. Korea Converg. Soc. 2008, 10, 15–21. [Google Scholar]
- Chen, Y.; Conroy, N.J.; Rubin, V.L. Misleading online content: Recognizing clickbait as “false news”. In Proceedings of the ICMI ‘15: International Conference on Multimodal Interaction, Seattle, WA, USA, 13 November 2015; pp. 15–19. [Google Scholar]
- Choi, S.; Youn, S. The implications of collaborative fact-check service: Case of <SNU FactCheck>. J. Cybercommun. Acad. Soc. 2017, 34, 173–205. [Google Scholar]
- Islam, N.; Shaikh, A.; Qaiser, A.; Asiri, Y.; Almakdi, S.; Sulaiman, A.; Moazzam, V.; Babar, S.A. Ternion: An autonomous model for fake news detection. Appl. Sci. 2021, 11, 9292. [Google Scholar] [CrossRef]
- Ahmed, B.; Ali, G.; Hussain, A.; Baseer, A.; Ahmed, J. Analysis of text feature extractors using deep learning on fake news. Eng. Technol. Appl. Sci. Res. 2021, 11, 7001–7005. [Google Scholar] [CrossRef]
- Jung, H. Fake News Detection Using Content-Based Feature Extraction Method. Master’s Thesis, Ewha Womans University, Seoul, Korea, 2019. [Google Scholar]
- Goldberg, Y.; Levy, O. Word2Vec explained: Deriving Mikolov et al.’s negative-sampling word-embedding method. arXiv 2014, arXiv:1402.3722. [Google Scholar]
- Lau, J.H.; Baldwin, T. An empirical evaluation of doc2vec with practical insights into document embedding generation. arXiv 2016, arXiv:1607.05368. [Google Scholar]
- Truică, C.-O.; Apostol, E.-S. MisRoBÆRTa: Transformers versus misinformation. Mathematics 2022, 10, 569. [Google Scholar] [CrossRef]
- Kula, S.; Choraś, M.; Kozik, R. Application of the BERT-based architecture in fake news detection. In Proceedings of the Computational Intelligence in Security for Information Systems Conference, Seville, Spain, 13–15 May 2019; pp. 239–249. [Google Scholar]
- Shu, K.; Wang, S.; Liu, H. Beyond news contents: The role of social context for fake news detection. In Proceedings of the Twelfth ACM International Conference on Web Search and Data Mining, Melbourne, Australia, 11–15 February 2019; pp. 312–320. [Google Scholar]
- Kim, Y. Third-person effect on fake news in social media: Focusing on false information related to infectious diseases. Korean J. Broadcast. Telecommun. Stud. 2021, 35, 5–32. [Google Scholar]
- Bang, Y.; Ishii, E.; Cahyawijaya, S.; Ji, Z.; Fung, P. Model generalization on COVID-19 fake news detection. In Proceedings of the International Workshop on Combating Online Hostile Posts in Regional Languages during Emergency Situation, Virtual Event, 8 February 2021; pp. 128–140. [Google Scholar]
- Al-Ahmad, B.; Al-Zoubi, A.M.; Abu Khurma, R.; Aljarah, I. An evolutionary fake news detection method for COVID-19 pandemic information. Symmetry 2021, 13, 1091. [Google Scholar] [CrossRef]
- Rubin, V.L.; Conroy, N.J.; Chen, Y.; Cornwell, S. Fake news or truth? Using satirical cues to detect potentially misleading news. In Proceedings of the Second Workshop on Computational Approaches to Deception Detection, San Diego, CA, USA, 12–17 June 2016; pp. 7–17. [Google Scholar]
- Tacchini, E.; Ballarin, G.; della Vedova, M.L.; Moret, S.; de Alfaro, L. Some like it hoax: Automated fake news detection in social networks. arXiv 2017, arXiv:1704.07506. [Google Scholar]
- Vo, N.; Lee, K. The rise of guardians: Fact-checking URL recommendation to combat fake news. In Proceedings of the 41st International ACM SIGIR Conference on Research & Development in Information Retrieval, Ann Arbor, MI, USA, 8–12 July 2018; pp. 275–284. [Google Scholar]
- Kang, M.; Seo, J.; Lim, H. Korean fake news detection with user graph. Hum. Lang. Technol. 2021, 97–102. [Google Scholar]
- Nguyen, V.H.; Sugiyama, K.; Nakov, P.; Kan, M.Y. Fang: Leveraging social context for fake news detection using graph representation. In Proceedings of the 29th ACM International Conference on Information & Knowledge Management, Virtual Event, 19–23 October 2020; pp. 1165–1174. [Google Scholar]
- Kumar, S.; Asthana, R.; Upadhyay, S.; Upreti, N.; Akbar, M. Fake news detection using deep learning models: A novel approach. Trans. Emerg. Telecommun. Technol. 2020, 31, e3767. [Google Scholar] [CrossRef]
- Rodríguez, Á.I.; Iglesias, L.L. Fake news detection using deep learning. arXiv 2019, arXiv:1910.03496. [Google Scholar]
- Shahi, G.K.; Nandini, D. FakeCovid—A multilingual cross-domain fact check news dataset for COVID-19. arXiv 2020, arXiv:2006.11343. [Google Scholar]
- Al-Rakhami, M.S.; Al-Amri, A.M. Lies kill, facts save: Detecting COVID-19 misinformation in twitter. IEEE Access 2020, 8, 155961–155970. [Google Scholar] [CrossRef]
- Shim, J.; Lee, J.; Jeong, I.; Ahn, H. A study on Korean fake news detection model using word embedding. Korean Soc. Comput. Inf. 2020, 28, 199–202. [Google Scholar]
- Joulin, A.; Grave, E.; Bojanowski, P.; Douze, M.; Jégou, H.; Mikolov, T. FastText.zip: Compressing text classification models. arXiv 2016, arXiv:1612.03651. [Google Scholar]
- Lim, D.; Kim, G.; Choi, K. Development of a fake news detection model using text mining and deep learning algorithms. Inf. Syst. Rev. 2021, 23, 127–146. [Google Scholar]
- Park, C.; Kang, J.; Lee, D.; Lee, M.; Han, J. COVID-19 Korean fake news detection using named entity and user reproliferation information. Hum. Lang. Technol. 2021, 85–90. [Google Scholar]
- Hur, Y.; Son, S.; Shim, M.; Lim, J.; Lim, H. K-EPIC: Entity-perceived context representation in Korean relation extraction. Appl. Sci. 2021, 11, 11472. [Google Scholar] [CrossRef]
- Clark, K.; Luong, M.-T.; Le, Q.V.; Manning, C.D. Electra: Pre-training text encoders as discriminators rather than generators. arXiv 2020, arXiv:2003.10555. [Google Scholar]
- Park, J.; Kim, M.; Oh, Y.; Lee, S.; Min, J.; Oh, Y. An empirical study of topic classification for Korean newspaper headlines. Hum. Lang. Technol. 2021, 287–292. [Google Scholar]
- Weiss, K.; Khoshgoftaar, T.; Wang, D. A survey of transfer learning. J. Big Data 2016, 3, 9. [Google Scholar] [CrossRef] [Green Version]
- Endo, P.; Santos, G.L.; Xavier, M.E.D.L.; Campos, G.R.N.; de Lima, L.C.; Silva, I.; Egli, A.; Lynn, T. Illusion of Truth: Analysing and classifying COVID-19 fake news in Brazilian Portuguese language. Big Data Cogn. Comput. 2022, 6, 36. [Google Scholar] [CrossRef]
- Graves, A.; Jaitly, N.; Mohamed, A.R. Hybrid speech recognition with deep bidirectional LSTM. In Proceedings of the 2013 IEEE Workshop on Automatic Speech Recognition and Understanding, Olomouc, Czech Republic, 8–12 December 2013; pp. 273–278. [Google Scholar]
- Sutskever, I.; Vinyals, O.; Le, Q.V. Sequence to sequence learning with neural networks. In Proceedings of the Annual Conference on Neural Information Processing Systems 2014, Montreal, QC, Canada, 8–13 December 2014; p. 27. [Google Scholar]
- Cohen, J. A coefficient of agreement for nominal scales. Educ. Psychol. Meas. 1960, 20, 37–46. [Google Scholar] [CrossRef]
- Landis, J.R.; Koch, G.G. The Measurement of observer agreement for categorical data. Biometrics 1977, 33, 159–174. [Google Scholar] [CrossRef] [Green Version]
- Chicco, D.; Warrens, M.J.; Jurman, G. The Matthews correlation coefficient (MCC) is more informative than Cohen’s Kappa and Brier score in binary classification assessment. IEEE Access 2021, 9, 78368–78381. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Category | Description | Content |
|---|---|---|
| Index | Sequence No. | 1 |
| Title | The title of a document | 3월 22일 SBS, 연합뉴스, 뉴시스 “4차 백신...수십만 명분 폐기 불가피” (Translated in English: March 22, SBS, Yonhap News, Newsis “Fourth vaccine dose... Disposal of vaccines for hundreds of thousands inevitable”) |
| Body | The main content of a document | 전국 요양병원과 시설에 공급된 4차 백신이 남아돌고 있음. 접종 대상자들이 잇따라 확진 판정을 받거나, 접종을 꺼리기 때문인데, 이번 주 안에 수십만 명분의 백신이 폐기될 것으로 보임 (Translated in English: Excessive fourth vaccine doses have been provided to nursing hospitals and other institutions. Individuals subject to vaccination have recently tested positive for COVID-19 or are reluctant to get vaccinated, which will result in the disposal of vaccines for hundreds of thousands of people this week.) |
| Speaker | The source of a document | SBS, Yonhap News, Newsis |
| Veracity | The validation of a document | Fake |
| Source | Datasets | No. of Sentences |
|---|---|---|
| AI FactChecknet | Training | 51,290 |
| COVID | 2500 | |
| AI FactChecknet | Test | 3332 |
| COVID | 500 |
| Datasets | Test 1-1 | Test 1-2 | Test 2 | Test 3 |
|---|---|---|---|---|
| Training | AI FactChecknet (training data) | +AI FactChecknet (test data) | +COVID (training data) | |
| Test | AI FactChecknet (test data) | COVID (test data) | COVID (test data) | COVID (test data) |
| Model | Test 1-1 | Test 1-2 | Test 2 | Test 3 |
|---|---|---|---|---|
| Linear | 59.34 | 49.61 | 50.78 | 70.70 |
| BiLSTM | 60.54 | 50.78 | 52.21 | 74.51 |
| Model | Input of the Classification Layer | Initial State of BiLSTM | |
|---|---|---|---|
| Hidden | Cell | ||
| Model 1 | 0 | 0 | |
| Model 2 | 0 | 0 | |
| Model 3 | [CLS] | 0 | |
| Model 4 | [CLS] | [CLS] | |
| Model | Test 1-1 | Test 1-2 | Test 2 | Test 3 |
|---|---|---|---|---|
| Model 1 | 60.54 | 50.78 | 52.21 | 74.51 |
| Model 2 | 61.72 | 49.22 | 52.0 | 75.78 |
| Model 3 | 61.7 | 53.52 | 53.12 | 75.61 |
| Model 4 | 64.2 | 55.86 | 55.86 | 78.80 |
| Strength of Agreement | |
|---|---|
| >0.000 | Poor |
| 0.000–0.200 | Slight |
| 0.201–0.400 | Fair |
| 0.401–0.600 | Moderate |
| 0.601–0.800 | Substantial |
| 0.801–1.000 | Almost Perfect |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lee, J.-W.; Kim, J.-H. Fake Sentence Detection Based on Transfer Learning: Applying to Korean COVID-19 Fake News. Appl. Sci. 2022, 12, 6402. https://doi.org/10.3390/app12136402
Lee J-W, Kim J-H. Fake Sentence Detection Based on Transfer Learning: Applying to Korean COVID-19 Fake News. Applied Sciences. 2022; 12(13):6402. https://doi.org/10.3390/app12136402
Chicago/Turabian StyleLee, Jeong-Wook, and Jae-Hoon Kim. 2022. "Fake Sentence Detection Based on Transfer Learning: Applying to Korean COVID-19 Fake News" Applied Sciences 12, no. 13: 6402. https://doi.org/10.3390/app12136402