
Korean Semantic Role Labeling with Bidirectional Encoder Representations from Transformers and Simple Semantic Information


Abstract
:1. Introduction
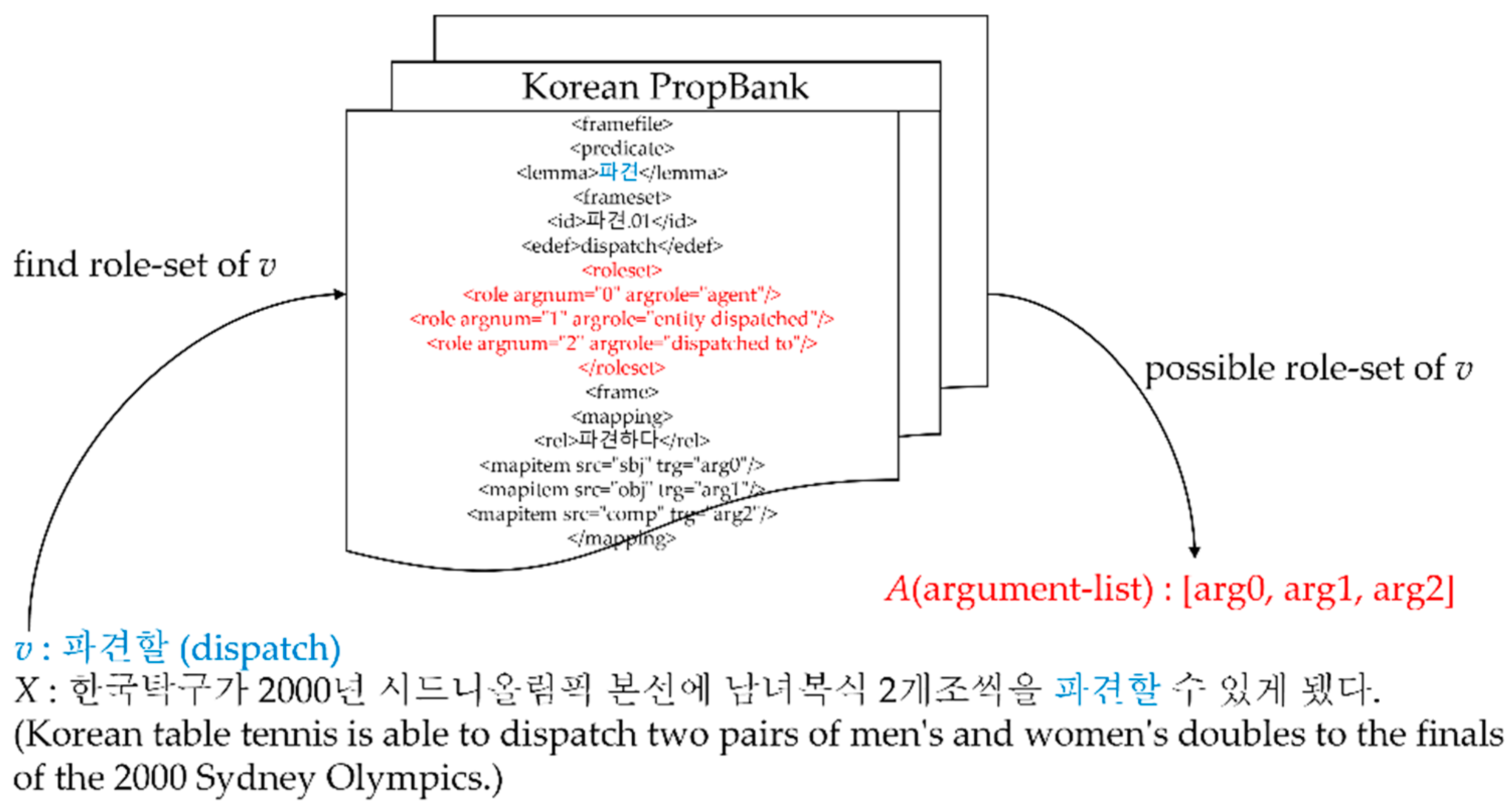
2. Korean Semantic Role Labeling
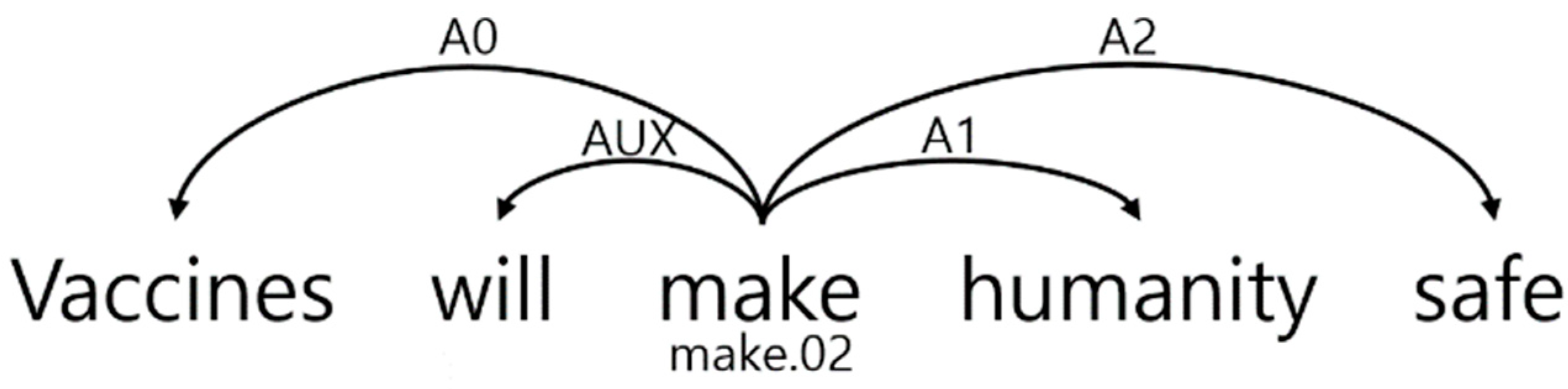
2.1. Task Definition
2.2. Argument Identification and Classification
2.3. Simple Features
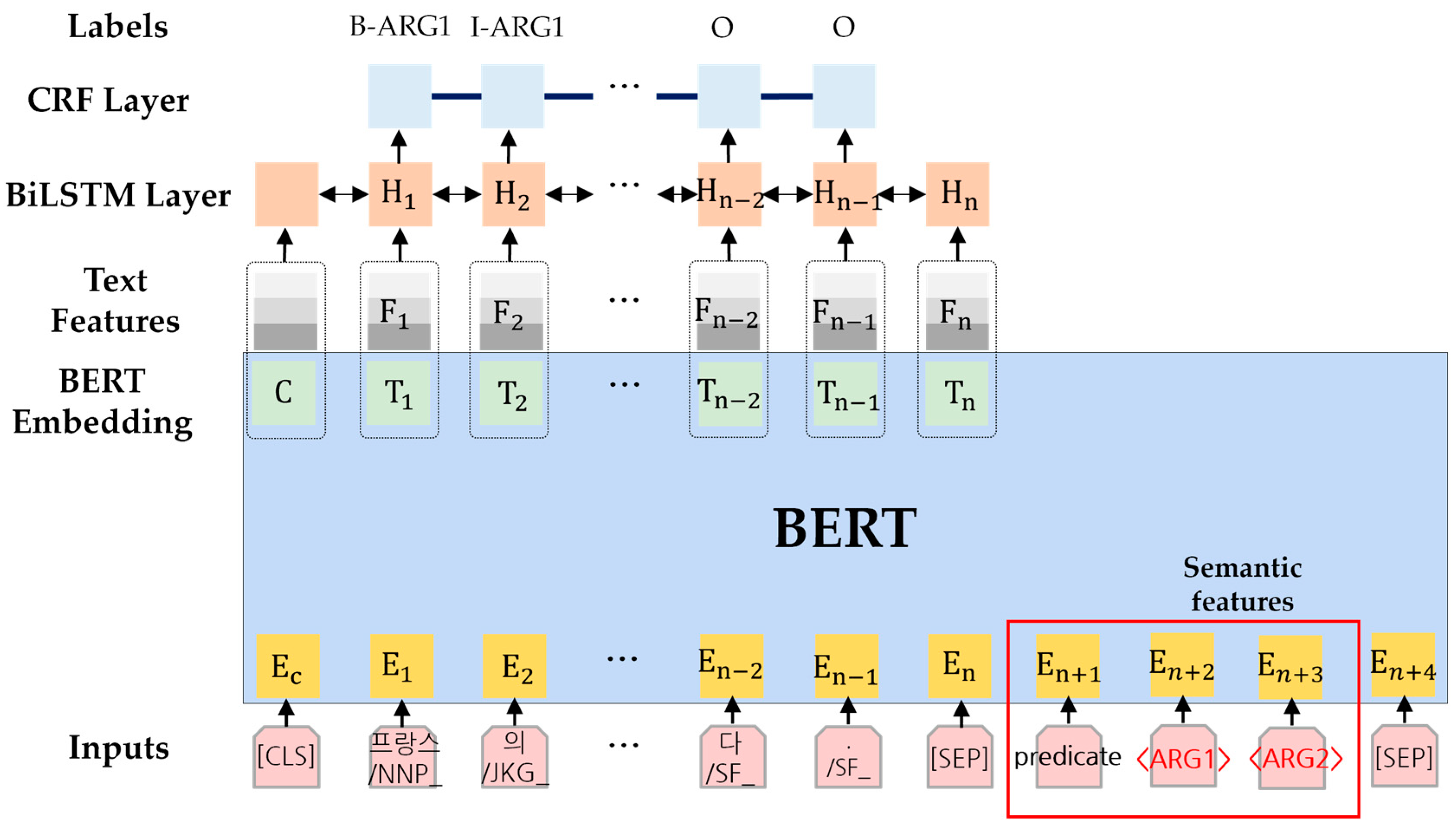
2.3.1. Semantic Feature
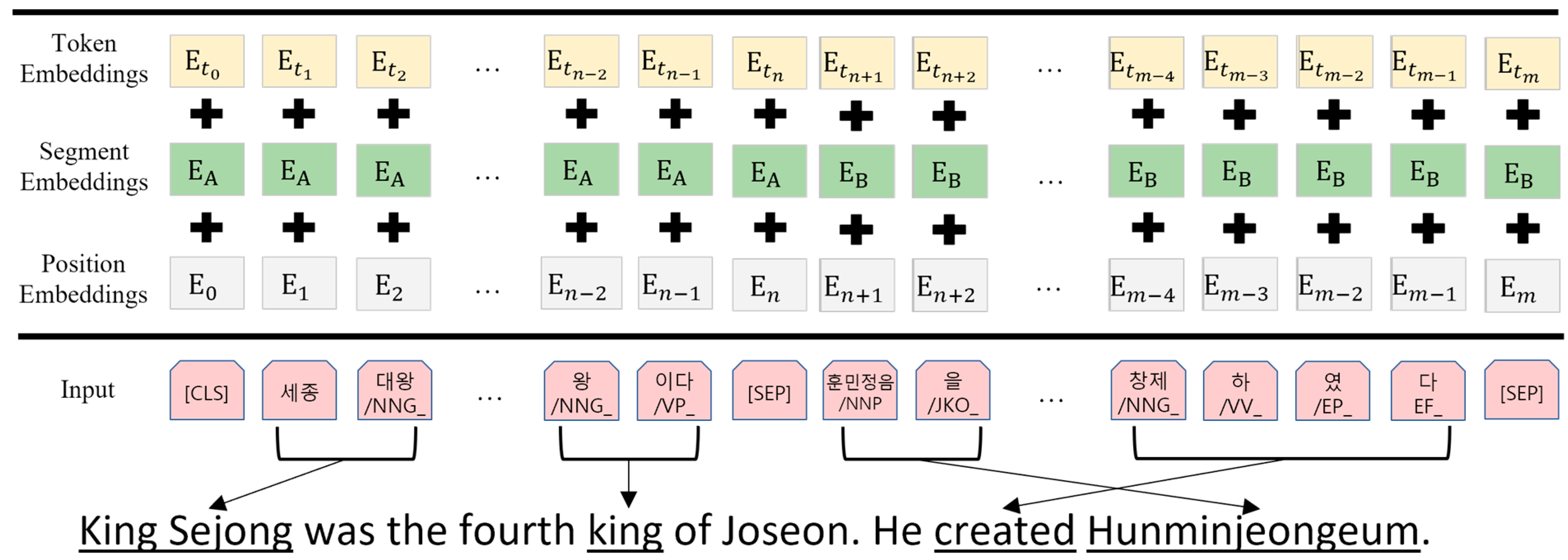
2.3.2. Text Feature
2.4. Pre-Training Korean BERT
2.5. Fine-Tuning Korean SRL Model
3. Experiments
3.1. Experimental Setup
3.2. Experimental Results
4. Discussion
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Chen, Y.N.; Wang, W.Y.; Rudnicky, A.I. Unsupervised induction and filling of semantic slots for spoken dialogue systems using frame-semantic parsing. In Proceedings of the 2013 IEEE Workshop on Automatic Speech Recognition and Understanding, Olomouc, Czech Republic, 8–12 December 2013. [Google Scholar]
- Shen, D.; Lapata, M. Using semantic roles to improve question answering. In Proceedings of the 2007 Joint Conference on Empirical Methods in Natural Language Processing and Computational Natural Language Learning (EMNLP-CoNLL), Prague, Czech Republic, 28–30 June 2007. [Google Scholar]
- Yih, W.; Richardson, M.; Meek, C.; Chang, M.; Suh, J. The value of semantic parse labeling for knowledge base question answering. In Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics (ACL), Berlin, Germany, 7–12 August 2016. [Google Scholar]
- Fader, A.; Soderland, S.; Etzioni, O. Identifying relations for open information extraction. In Proceedings of the Conference on Empirical Methods in Natural Language Processing, Edinburgh, UK, 27–31 July 2011. [Google Scholar]
- Bastianelli, E.; Castellucci, G.; Croce, D.; Basili, R. Textual inference and meaning representation in human robot interaction. In Proceedings of the Joint Symposium on Semantic Processing, Textual Inference and Structures in Corpora, Trento, Italy, 20–23 November 2013. [Google Scholar]
- Zhou, J.; Xu, W. End-to-end learning of semantic role labeling using recurrent neural networks. In Proceedings of the 53rd Annual Meeting of the Association for Computational Linguistics and the 7th International Joint Conference on Natural Language Processing, Beijing, China, 27–31 July 2015. [Google Scholar]
- He, L.; Lee, K.; Lewis, M.; Zettlemoyer, L. Deep semantic role labeling: What works and what’s next. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics, Vancouver, BC, Canada, 30 July–4 August 2017. [Google Scholar]
- Tan, Z.; Wang, M.; Xie, J.; Chen, Y.; Shi, X. Deep semantic role labeling with self-attention. In Proceedings of the Thirty-Second AAAI Conference on Artificial Intelligence (AAAI-18), New Orleans, LA, USA, 2–7 February 2018. [Google Scholar]
- He, L.; Lee, K.; Levy, O.; Zettlemoyer, L. Jointly predicting predicates and arguments in neural semantic role labeling. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics, Melbourne, Australia, 15–20 July 2018. [Google Scholar]
- Levin, B. English Verb Classes and Alternations: A Preliminary Investigation; University of Chicago Press: Chicago, IL, USA, 1993. [Google Scholar]
- Punyakanok, V.; Roth, D.; Yih, W. The importance of syntactic parsing and inference in semantic role labeling. Comput. Linguist. 2008, 34, 257–287. [Google Scholar] [CrossRef]
- Roth, M.; Lapata, M. Neural semantic role labeling with dependency path embeddings. In Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics, Berlin, Germany, 7–12 August 2016. [Google Scholar]
- Strubell, E.; Verga, P.; Andor, D.; Weiss, D.; McCallum, A. Linguistically-informed self-attention for semantic role labeling. In Proceedings of the Conference on Empirical Methods in Natural Language Processing, Brussels, Belgium, 2–4 November 2018. [Google Scholar]
- He, S.; Li, Z.; Zhao, H.; Bai, H. Syntax for semantic role labeling, to be, or not to be. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Melbourne, Australia, 15–20 July 2018. [Google Scholar]
- Shi, P.; Zhang, Y. Joint bi-affine parsing and semantic role labeling. In Proceedings of the 2017 International Conference on Asian Language Processing (IALP), Singapore, 5–7 December 2017. [Google Scholar]
- Peters, M.; Neumann, M.; Iyyer, M.; Gardner, M.; Clark, C.; Lee, K.; Zettlemoyer, L. Deep contextualized word representations. In Proceedings of the Conference of the North American Chapter of the Association or Computational Linguistics: Human Language Technologies, New Orleans, LA, USA, 1–6 June 2018. [Google Scholar]
- Radford, A.; Narasimhan, K.; Salimans, T.; Sutskever, I. Improving language understanding by generative pre-training. arXiv 2018, arXiv:2012.11747. [Google Scholar]
- Devlin, J.; Chang, M.; Lee, K.; Toutanova, K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.; Kaiser, L.; Polosukhin, I. Attention is all you need. arXiv 2017, arXiv:1706.03762. [Google Scholar]
- Yang, Z.; Dai, Z.; Yang, Y.; Carbonell, J.; Salakhutdinov, R.; Le, Q. XLNet: Generalized Autoregressive Pretraining for Language Understanding. arXiv 2020, arXiv:1906.08237v2. [Google Scholar]
- Brown, T.; Mann, B.; Ryder, N.; Subbiah, M.; Kaplan, J.; Dhariwal, P.; Neelakantan, A.; Shyam, P.; Sastry, G.; Askell, A.; et al. Language Models Are Few-Shot Learners. arXiv 2020, arXiv:2005.14165v4. [Google Scholar]
- Shi, P.; Lin, J. Simple BERT Models for Relation Extraction and Semantic Role Labeling. arXiv 2019, arXiv:1904.05255. [Google Scholar]
- Kingsbury, P.; Palmer, M. From treebank to propbank. In Proceedings of the Third International Conference on Language Resources and Evaluation (LREC’02). European Language Resources Association (ELRA), Las Palmas, Spain, 29–31 May 2002. [Google Scholar]
- Li, X.; Bing, L.; Zhang, W.; Lam, W. Exploiting BERT for End-to-End Aspect-based Sentiment Analysis. In Proceedings of the 2019 EMNLP Workshop W-NUT: The 5th Workshop on Noisy User-Generated Text, Hong Kong, China, 4 November 2019. [Google Scholar]
- Huang, Z.; Xu, W.; Yu, K. Bidirectional LSTM-CRF Models for Sequence Tagging. arXiv 2015, arXiv:1508.01991. [Google Scholar]
- Palmer, M.; Ryu, S.; Choi, J.; Yoon, S.; Jeon, Y. Korean Propbank LDC2006T03. Available online: https://catalog.ldc.upenn.edu/LDC2006T03 (accessed on 19 May 2022).
- Bae, J.; Lee, C. Korean Semantic Role Labeling Using Stacked Bidirectional LSTM-CRFs. J. KIISE 2016, 44, 36–43. [Google Scholar] [CrossRef]
- Bae, J.; Lee, C. Korean Semantic Role Labeling with Highway BiLSTM-CRFs. In Proceedings of the HCLT, Daegu, Korea, 13–14 October 2017. [Google Scholar]
- Lim, S.; Kim, H. A Study of Korean Semantic Role Labeling using Word Sense. In Proceedings of the HCLT, Jeonju, Korea, 16–17 October 2015. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | Test F1 |
|---|---|
| Stacked BiLSTM RNN CRF [27] | 78.57 |
| Highway BiLSTM RNN CRF [28] | 78.84 |
| S-SVM with syntactic information and extra knowledge [29] | 79.54 |
| BERT-BiLSTM-RNN-CRF (our model) | |
| (Bert-base) | 83.62 |
| + Semantic features | 84.95 |
| + Text features | 85.77 |
| + Semantic features + Text features | 86.36 |
| Model | Dev F1 | Test F1 |
|---|---|---|
| LSTM-GCNs [14] | 84.2 | - |
| Bi-Affine [15] | 85.6 | - |
| BERT-BiLSTM-RNN-MLP [22] | ||
| (Bert-large) | 88.7 | 89.8 |
| (Bert-base) | 89.3 | 90.3 |
| BERT-BiLSTM-RNN-CRF (our model) | ||
| (Bert-base) | 87.05 | 88.29 |
| + Semantic features | 87.66 | 88.90 |
| + Text features | 88.84 | 89.87 |
| + Semantic features + Text features | 89.08 | 90.16 |
| (Bert-large) | 89.02 | 90.13 |
| + Semantic features + Text features | 89.34 | 90.39 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Bae, J.; Lee, C. Korean Semantic Role Labeling with Bidirectional Encoder Representations from Transformers and Simple Semantic Information. Appl. Sci. 2022, 12, 5995. https://doi.org/10.3390/app12125995
Bae J, Lee C. Korean Semantic Role Labeling with Bidirectional Encoder Representations from Transformers and Simple Semantic Information. Applied Sciences. 2022; 12(12):5995. https://doi.org/10.3390/app12125995
Chicago/Turabian StyleBae, Jangseong, and Changki Lee. 2022. "Korean Semantic Role Labeling with Bidirectional Encoder Representations from Transformers and Simple Semantic Information" Applied Sciences 12, no. 12: 5995. https://doi.org/10.3390/app12125995