
Improved Training of CAE-Based Defect Detectors Using Structural Noise


Abstract
:Featured Application
Abstract
1. Introduction
2. Contrasts between the Classic Usage of Autoencoders and Ours
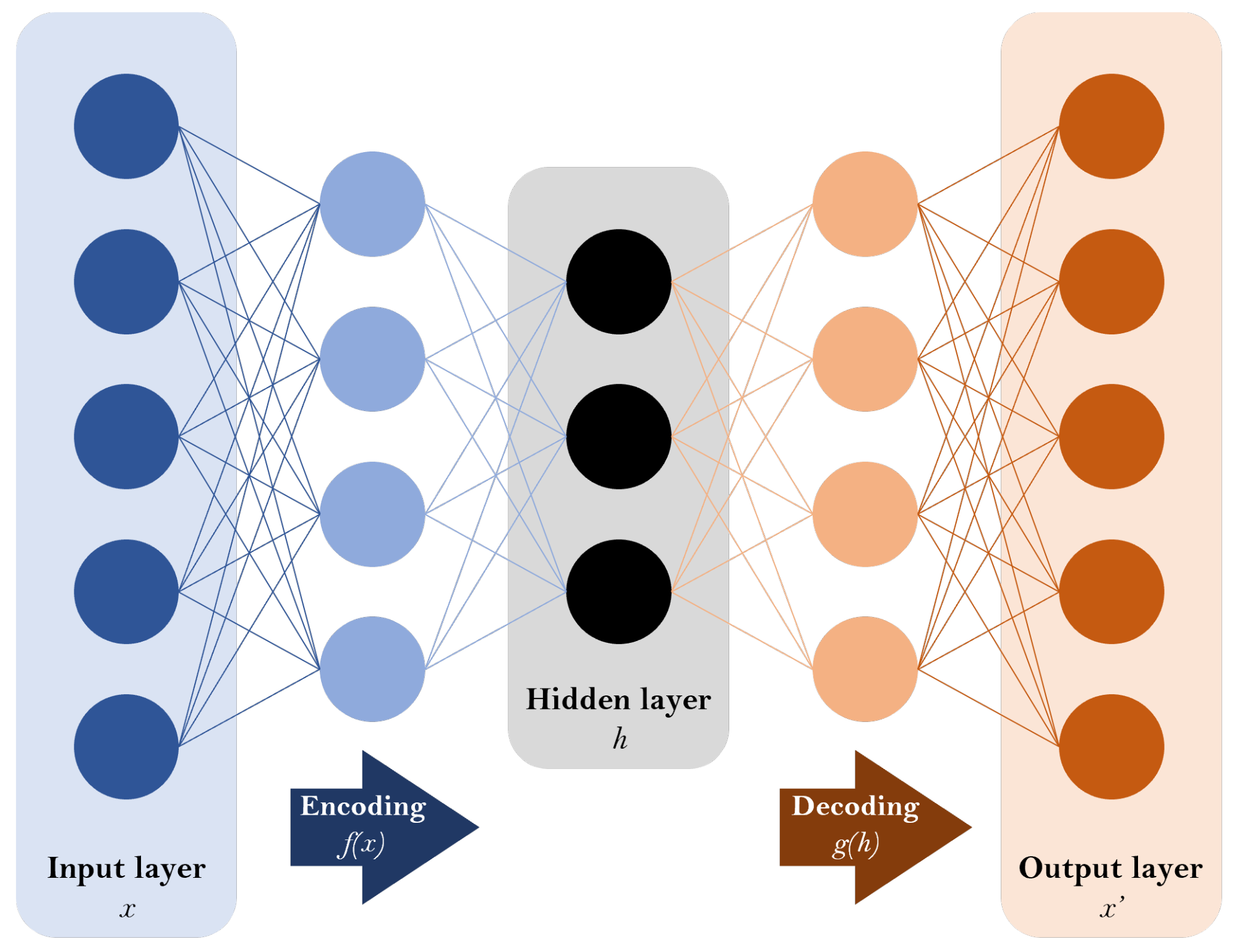
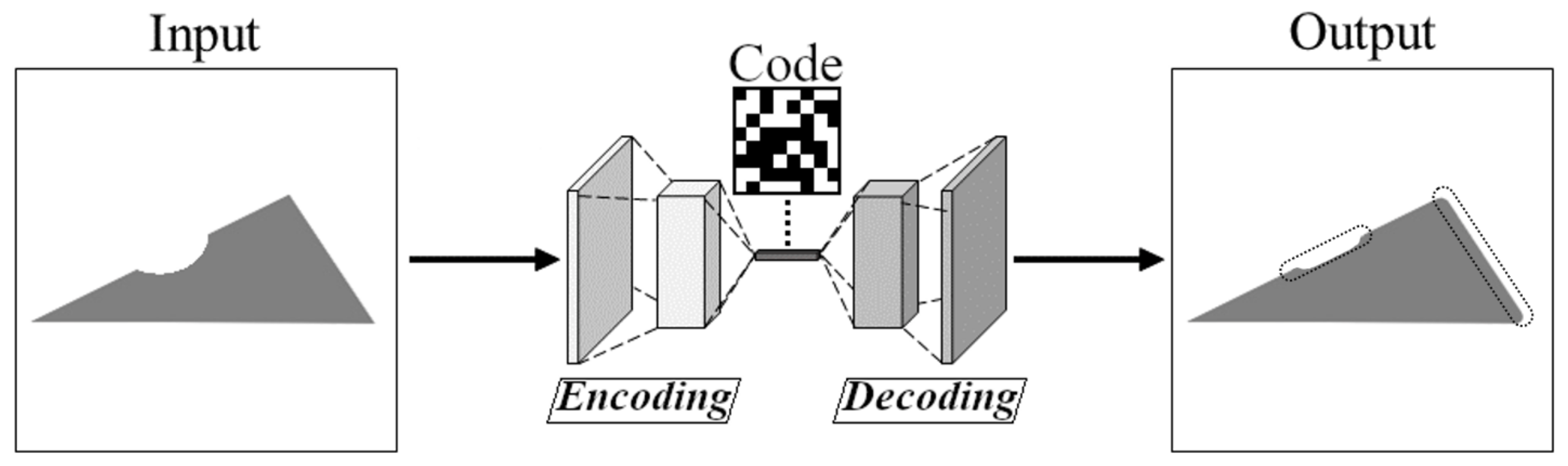
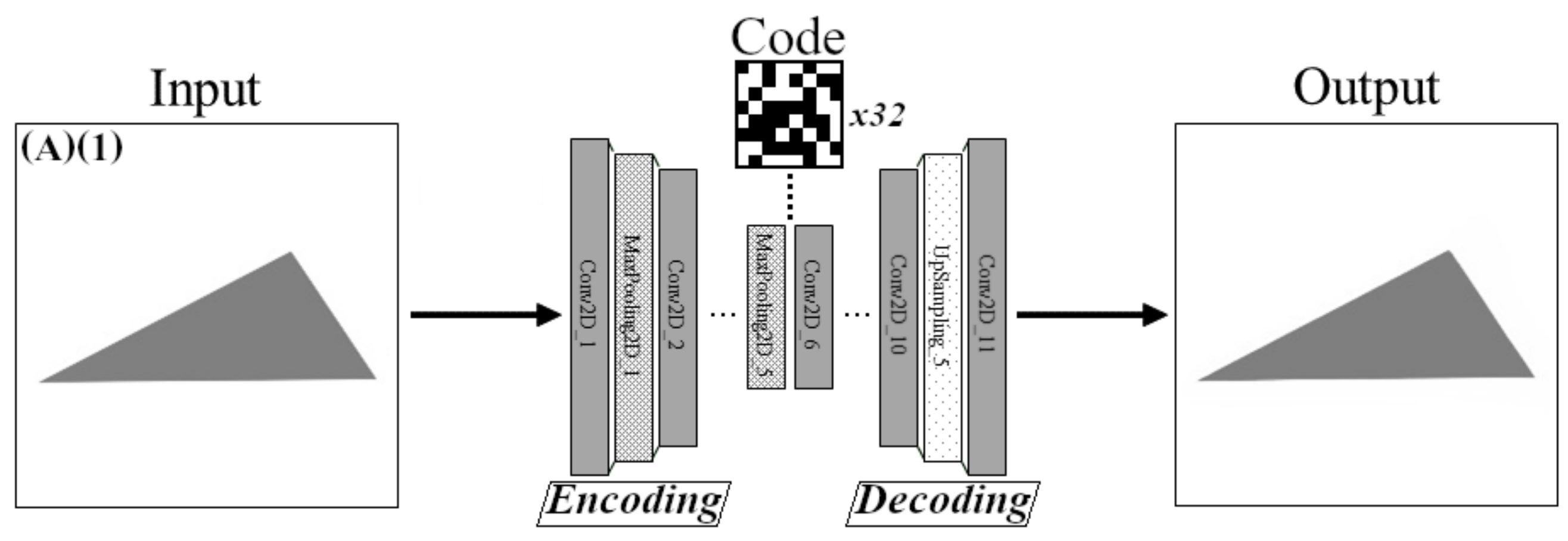
2.1. Working Principle of Autoencoders
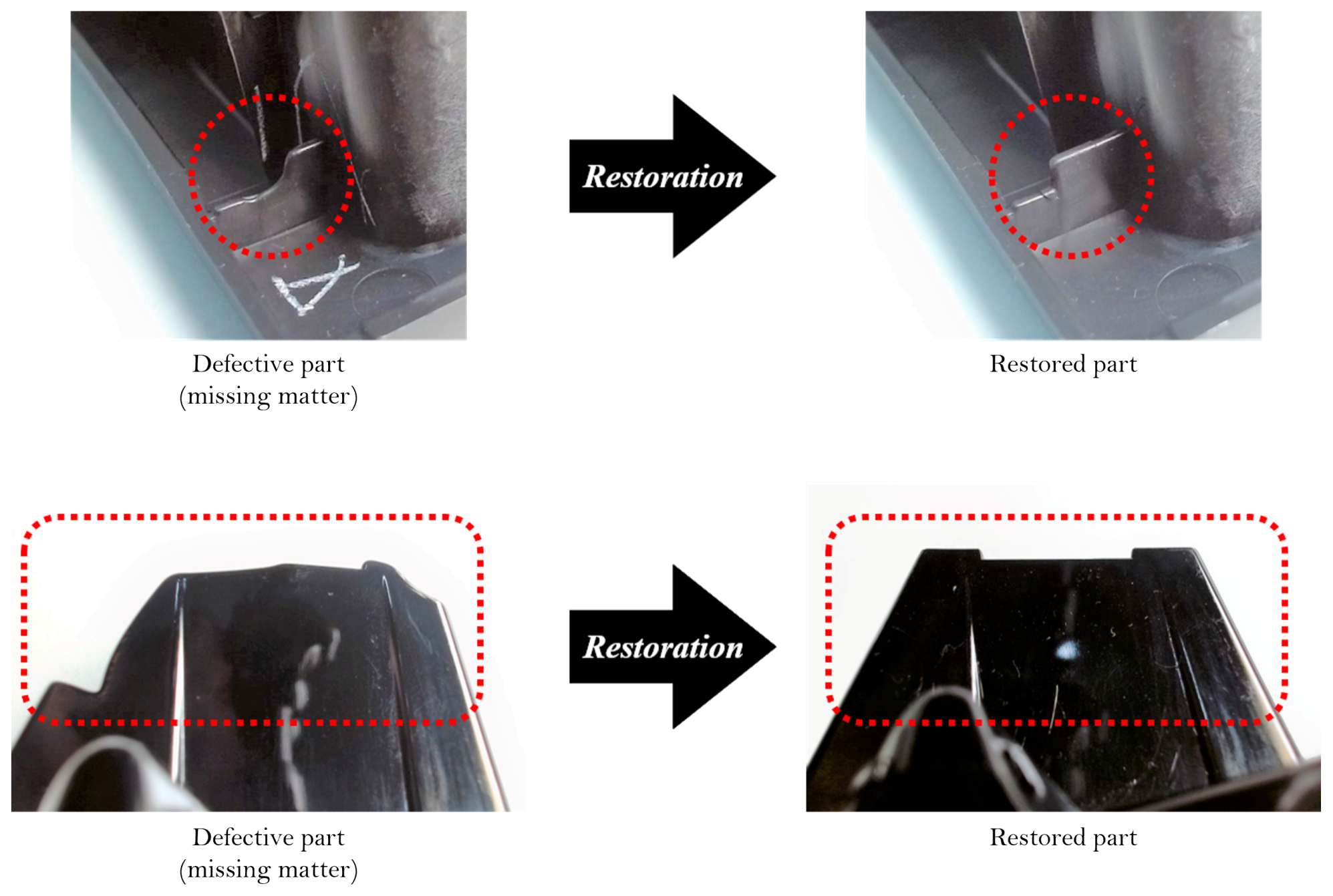
2.2. Alternative Use of Autoencoders in Our Research
3. Improvement of Defect Detection Accuracy Using Structural Noise
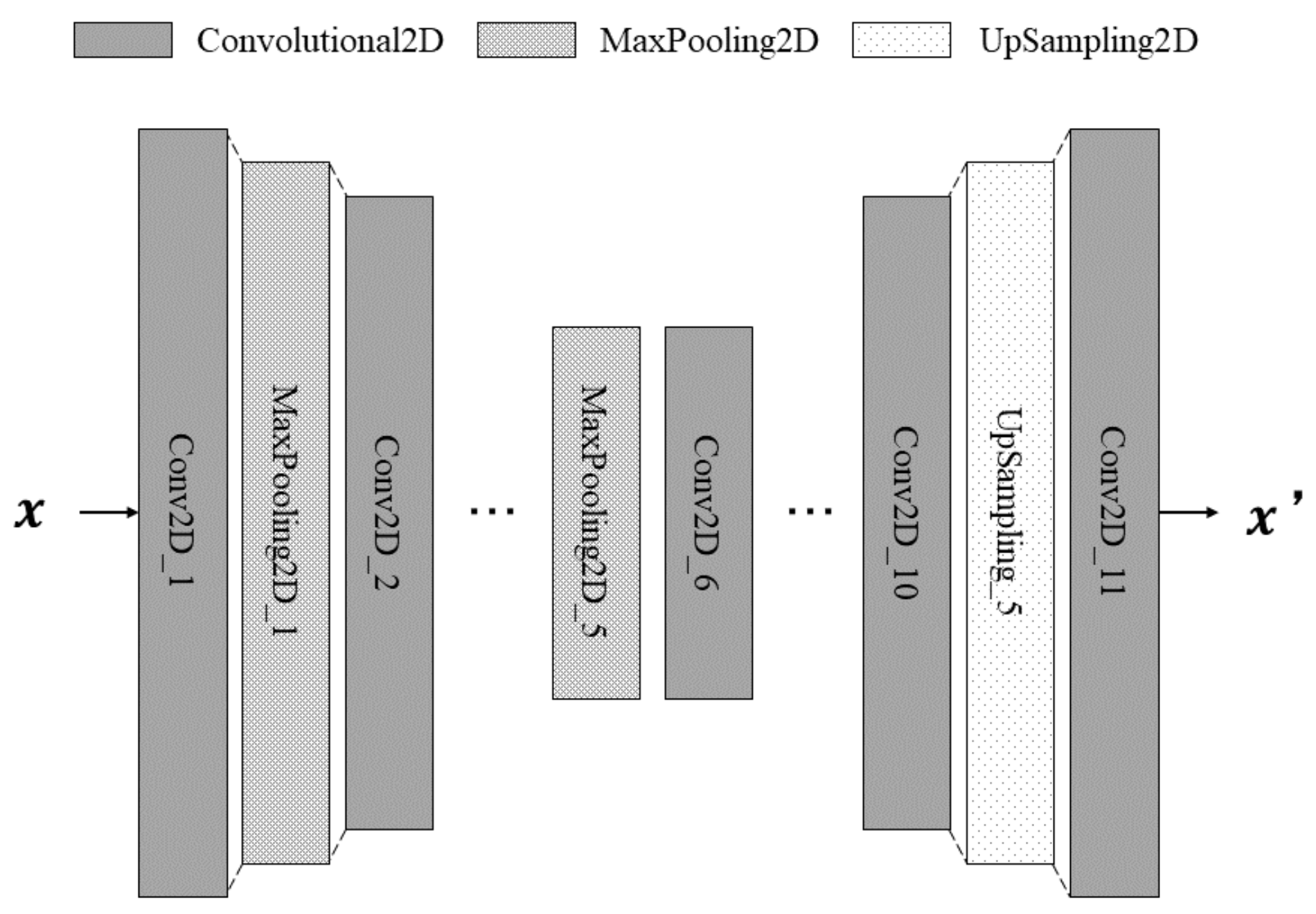
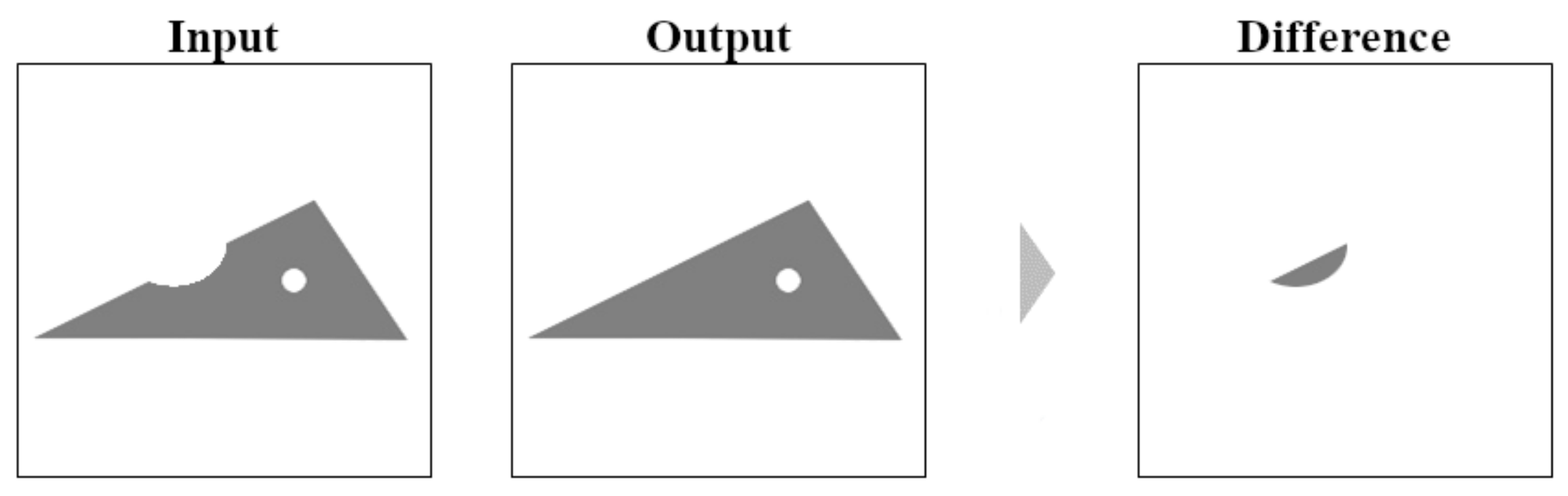
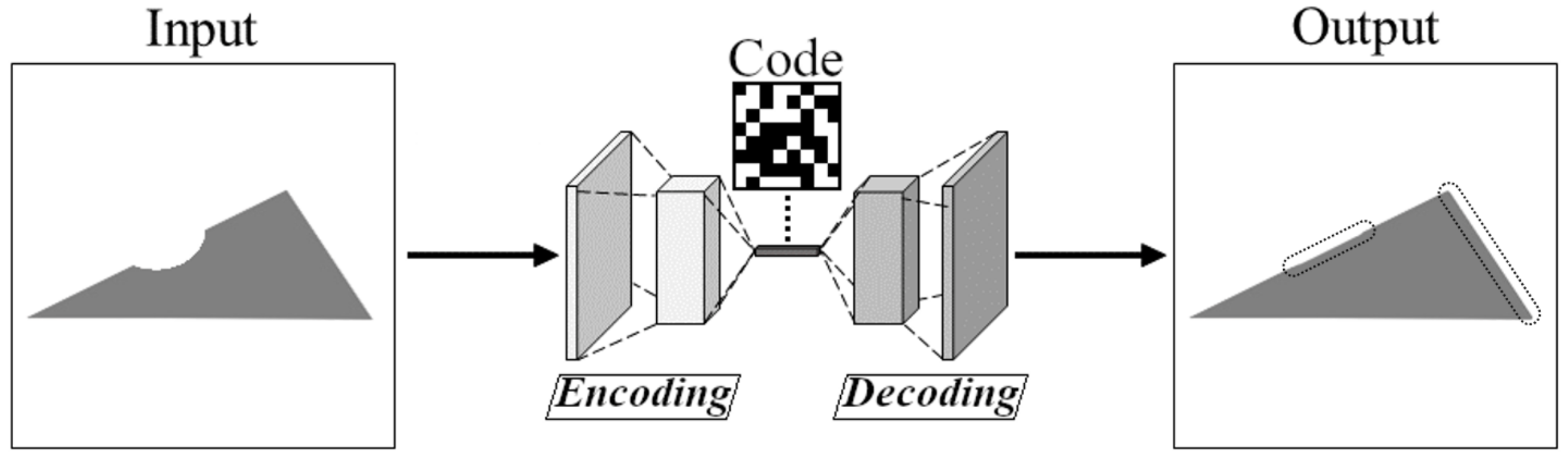
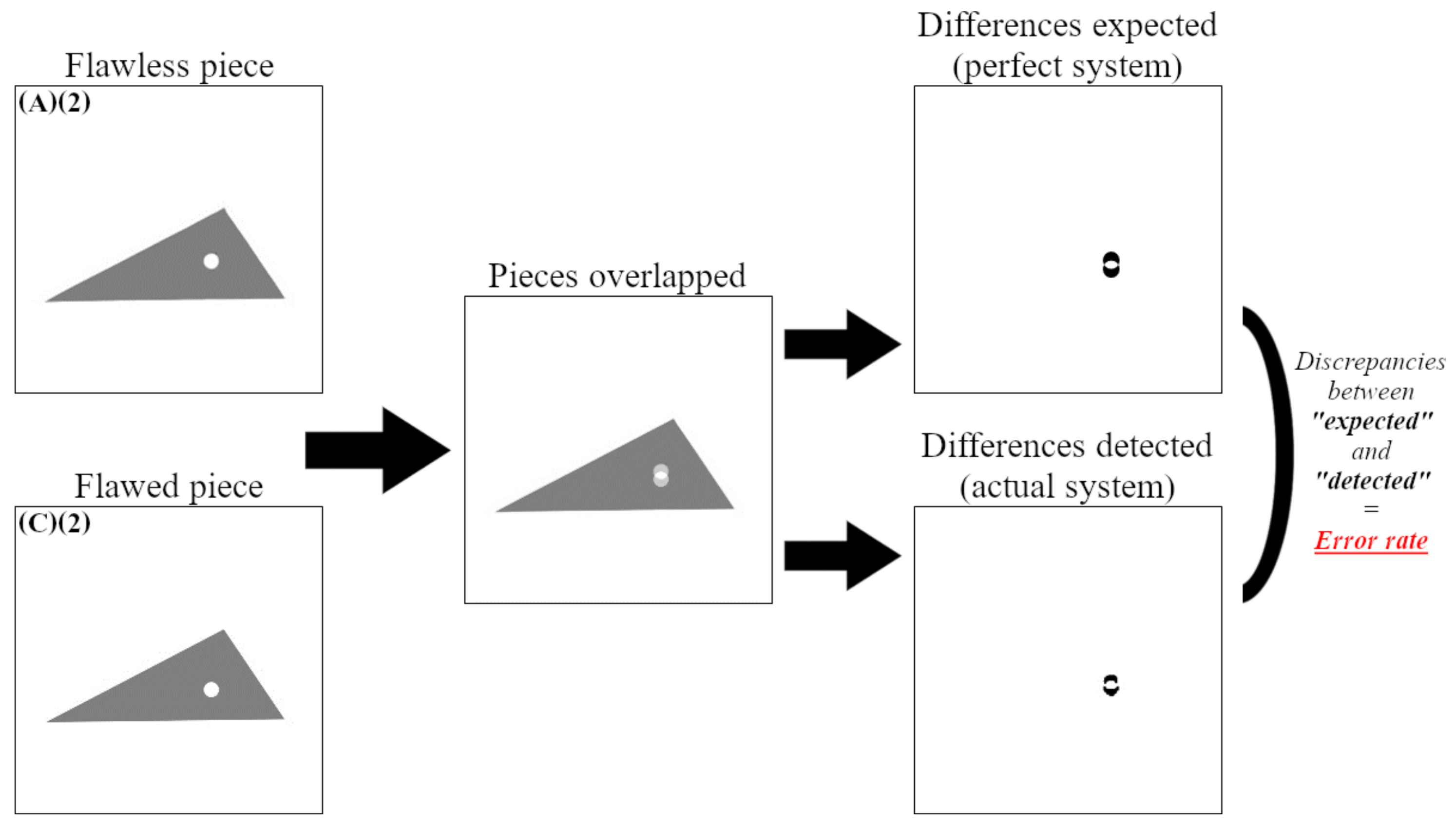
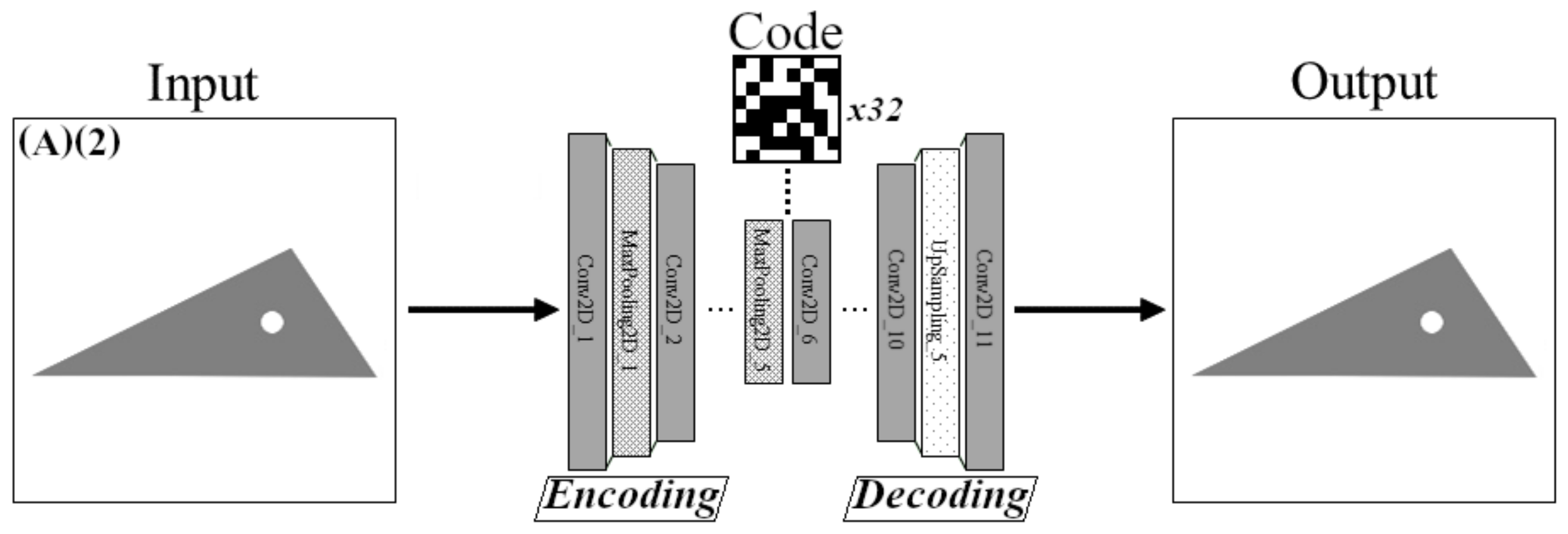
3.1. Defect Detection Using CAEs
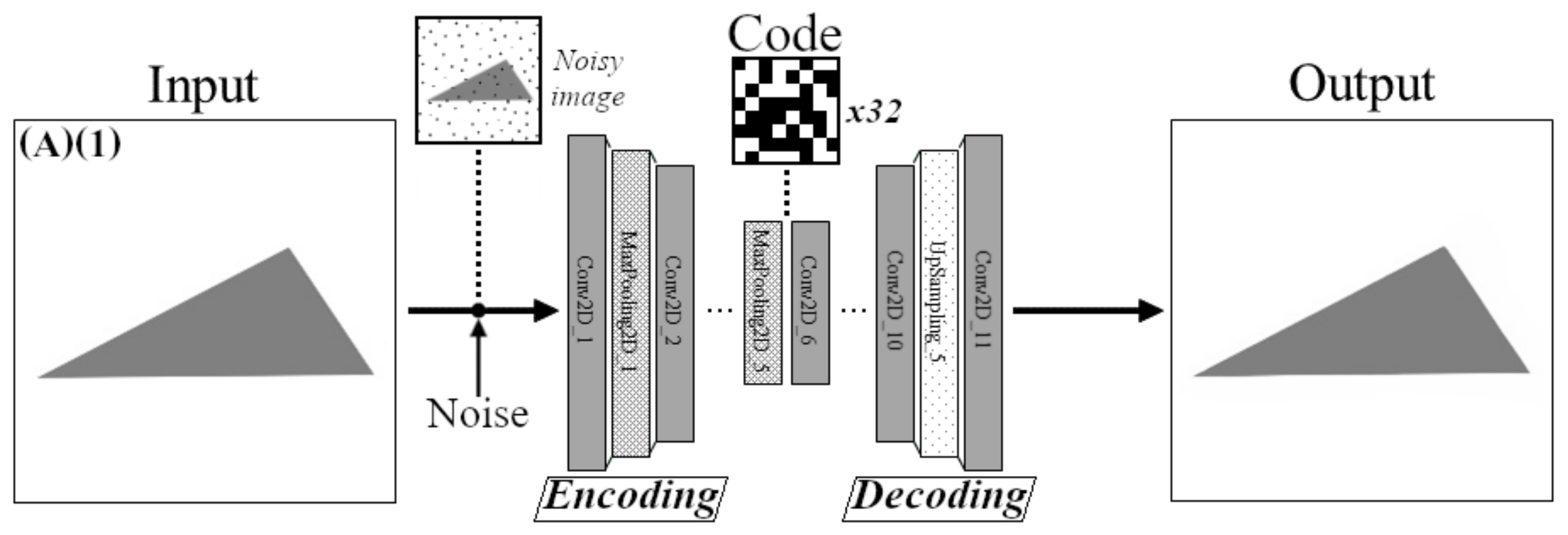
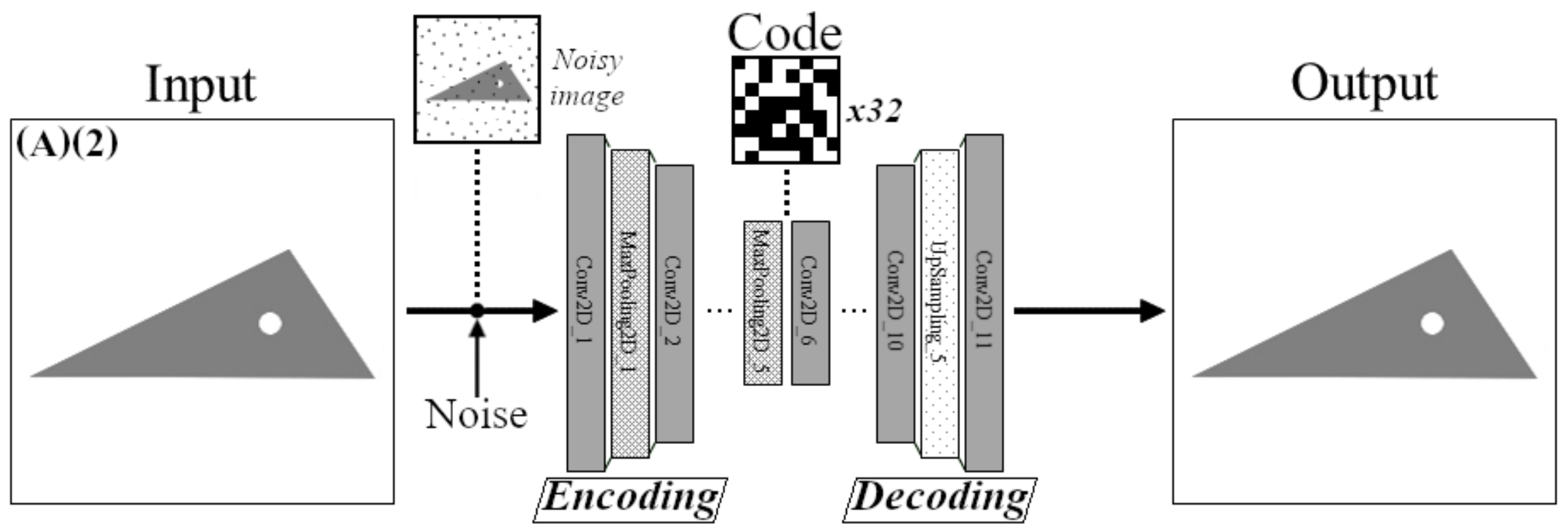
3.2. Network Training with Noisy Data
4. Experiments
4.1. Experimental Settings
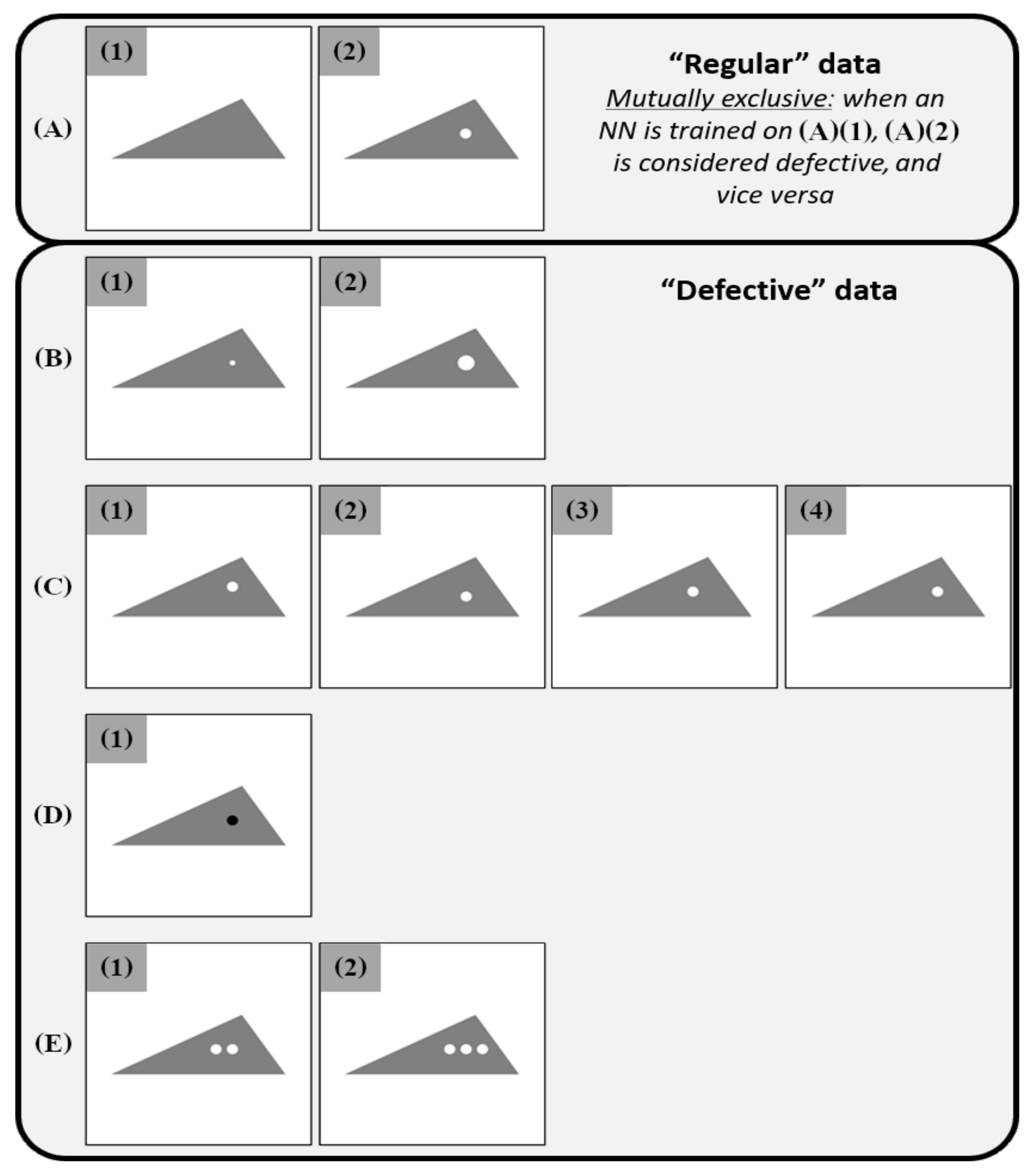
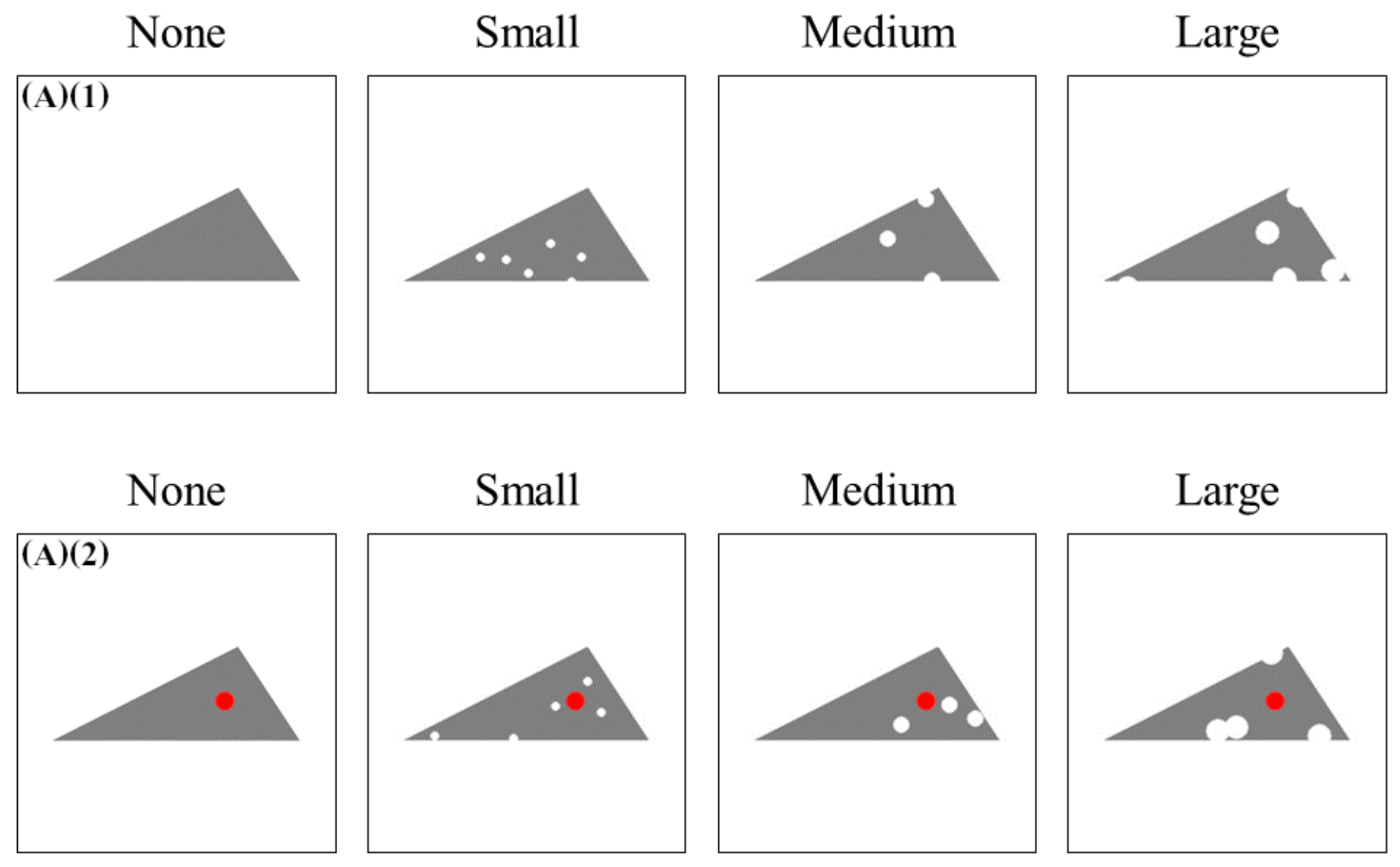
4.1.1. Compositions of the Training/Test Datasets
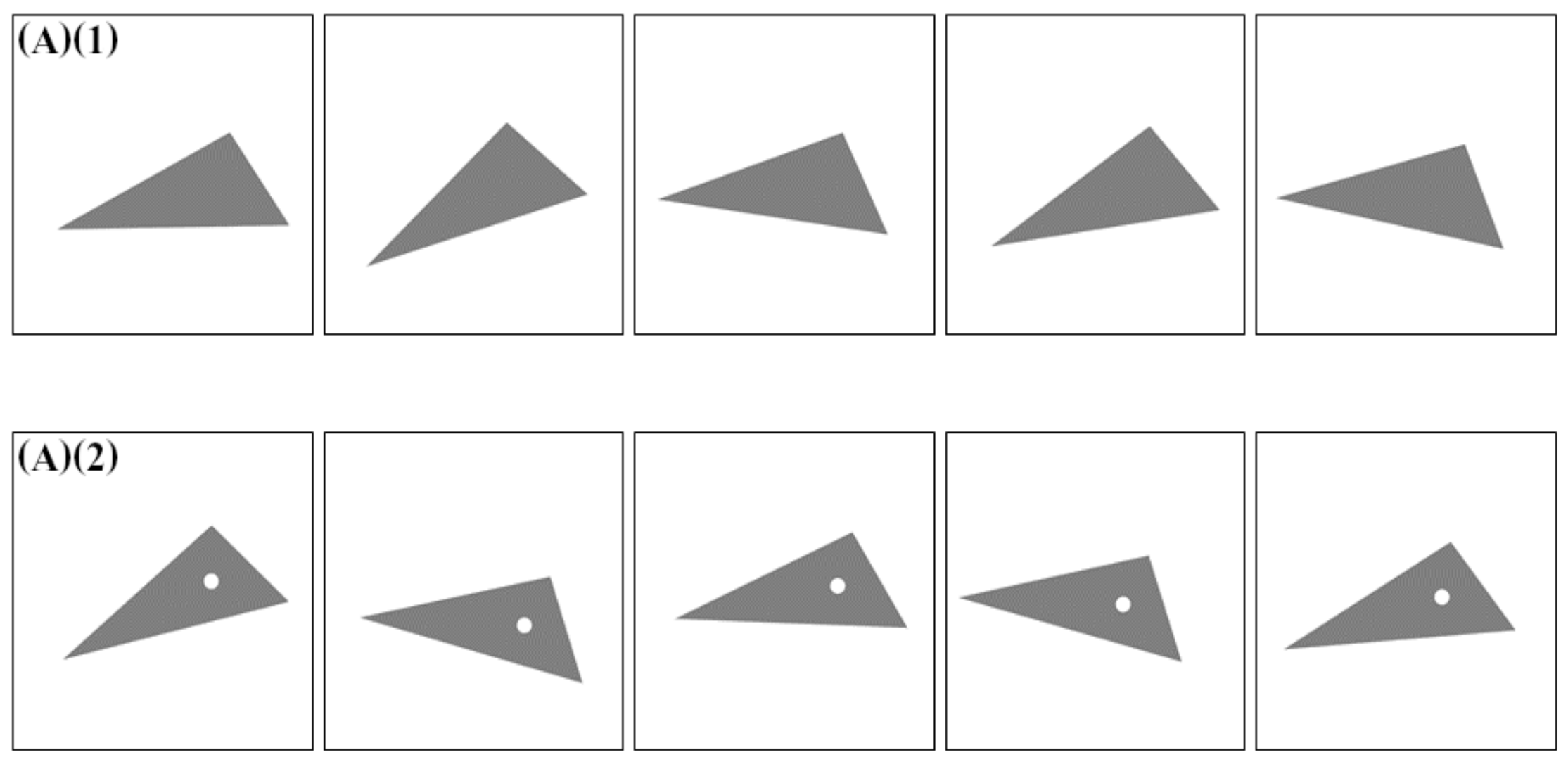
- a training dataset made of 800 regular spotless triangles (A)(1) and a test dataset mixing 2000 defective samples (200 of each other class in the Table 1, including (A)(2))
- a training dataset made of 800 regular spotted triangles (A)(2) and a test dataset mixing 2000 defective samples (200 of each other class in the Table 1, including (A)(1))
4.1.2. Noise Injection
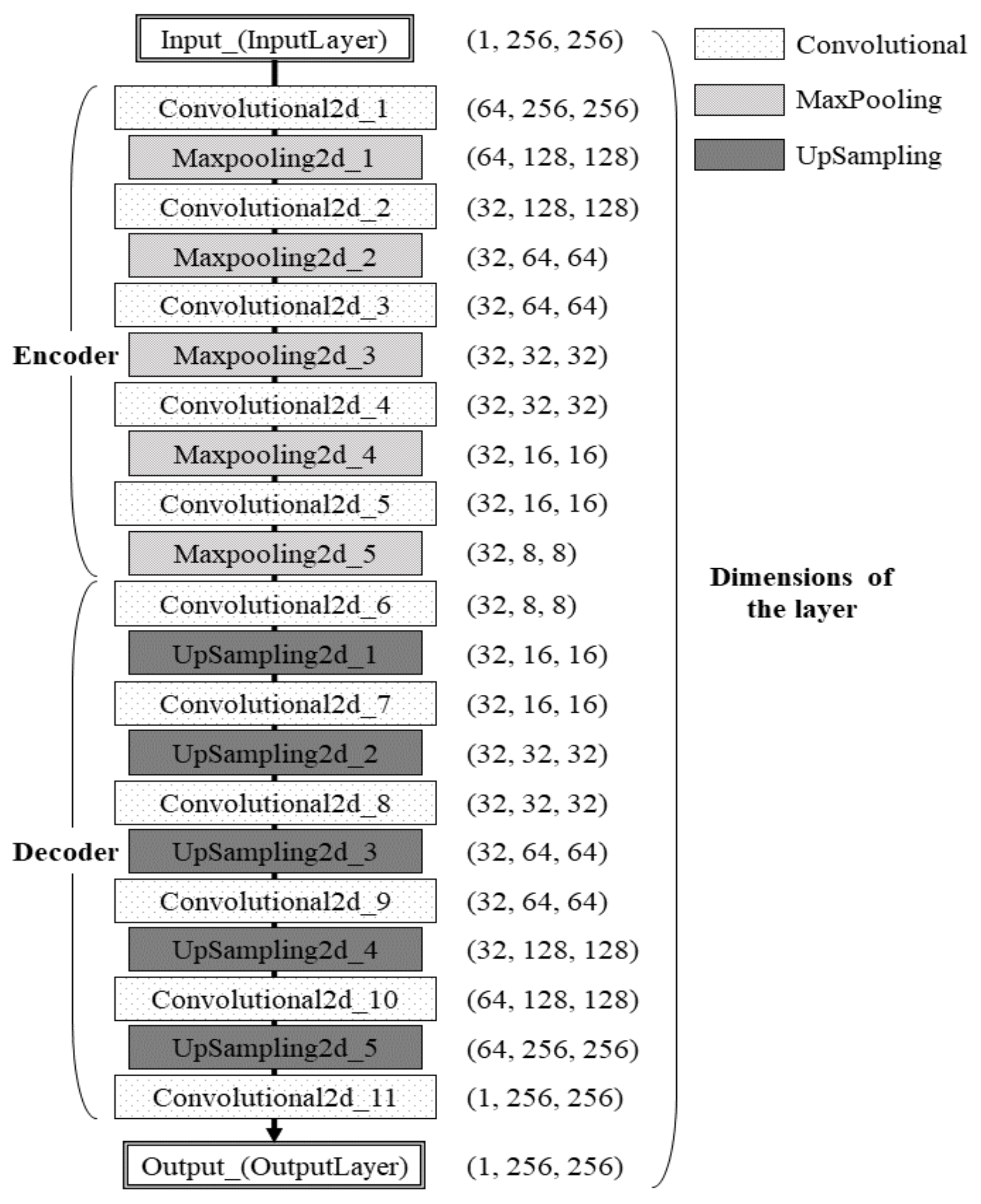
4.1.3. Network Structure
4.2. Experimental Results
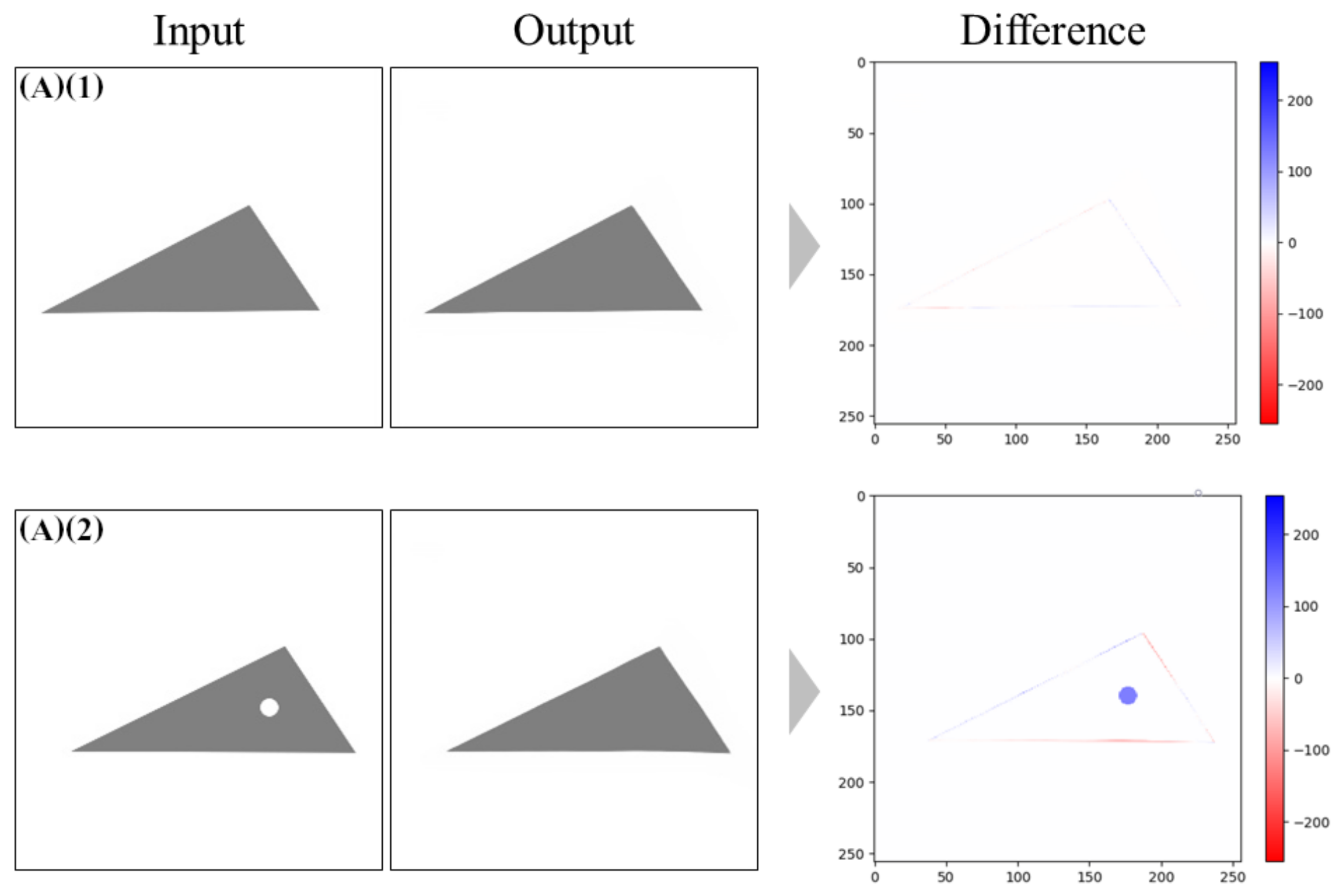
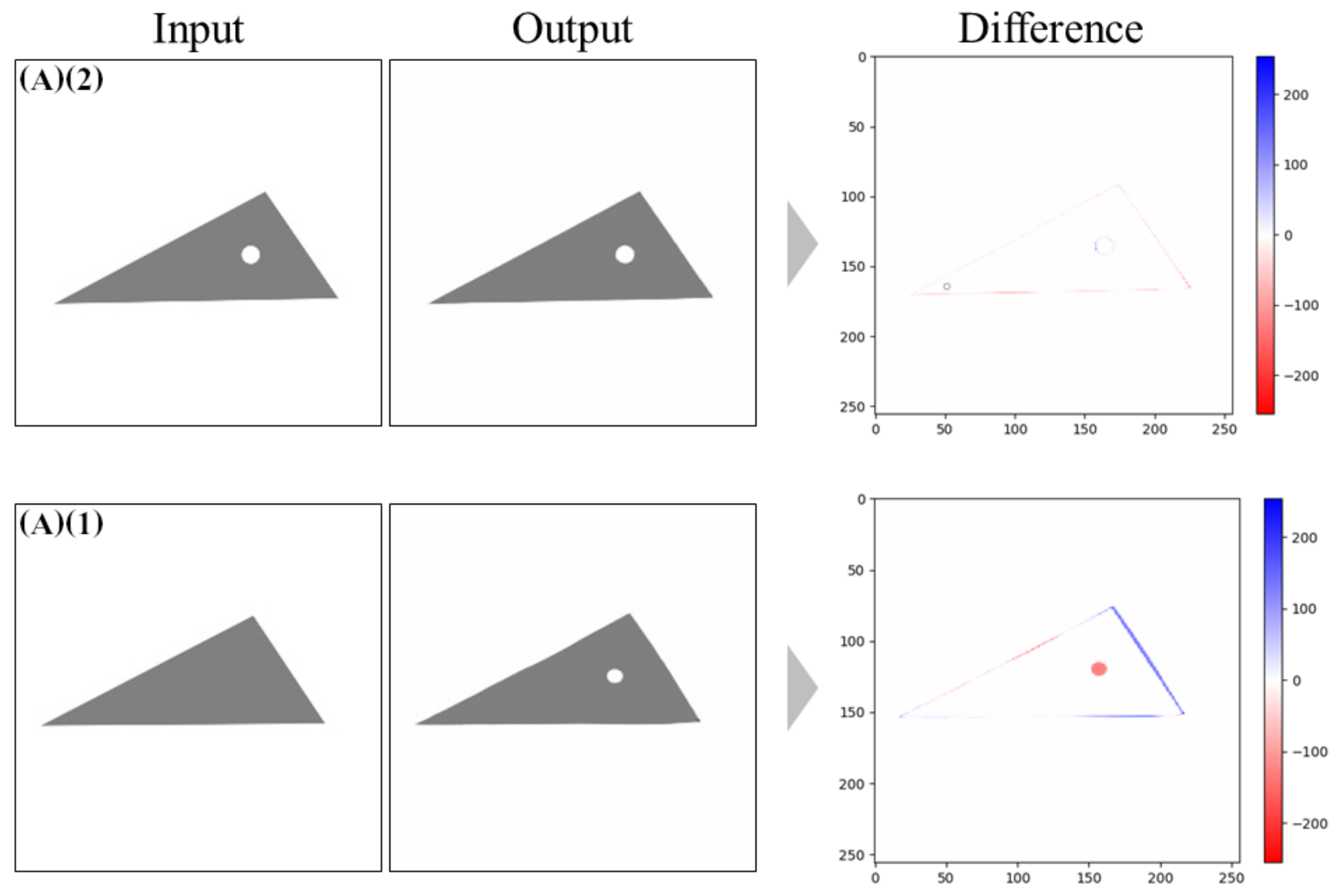
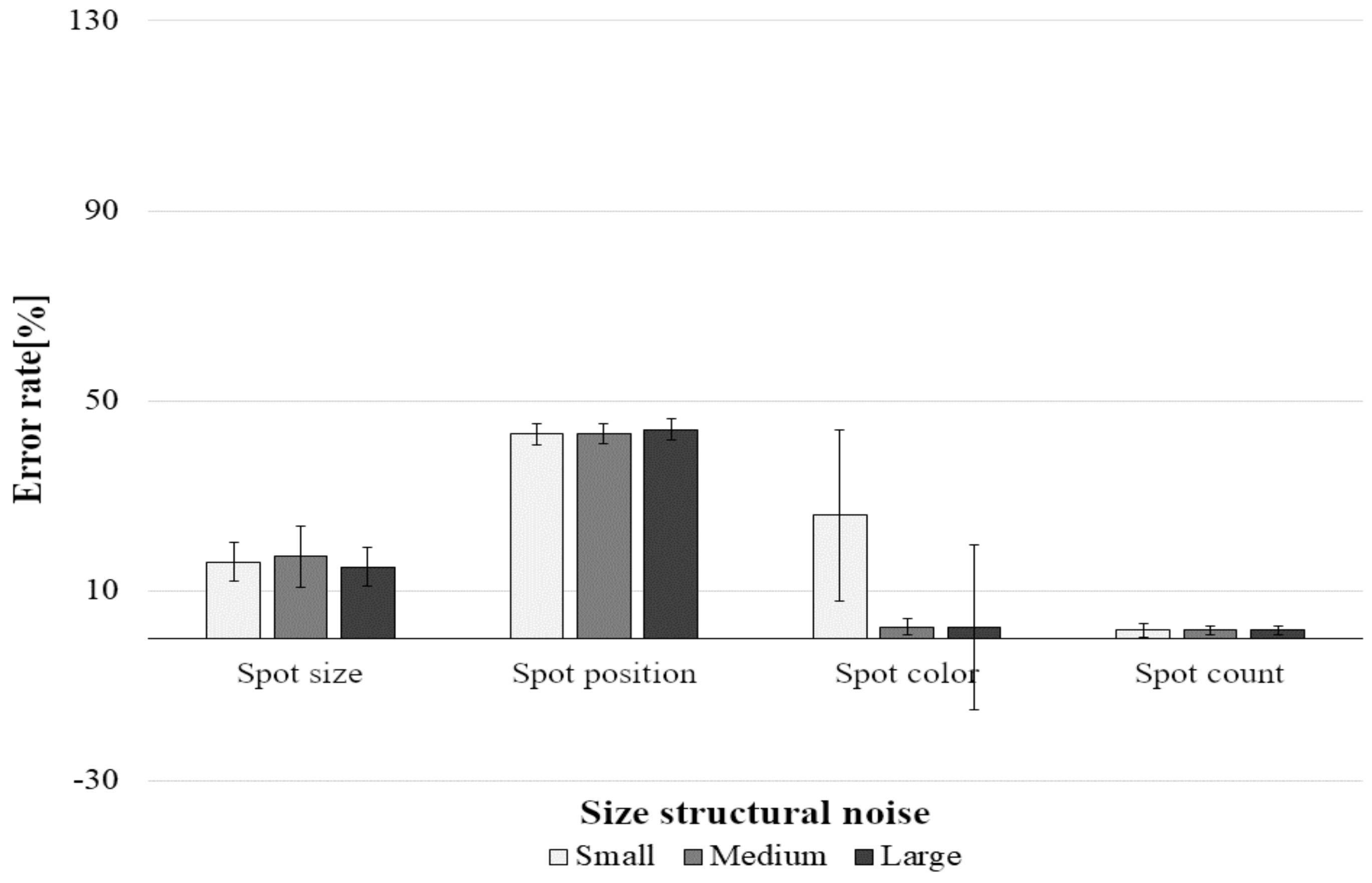
4.2.1. Models Trained without Noise
4.2.2. Models Trained with Noise
- spotless triangles (A)(1) noised by a Gaussian distribution
- spotted triangles (A)(2) noised by a Gaussian distribution
- spotless triangles (A)(1) noised by a known structure (medium)
- spotted triangles (A)(2) noised by a known structure (medium)
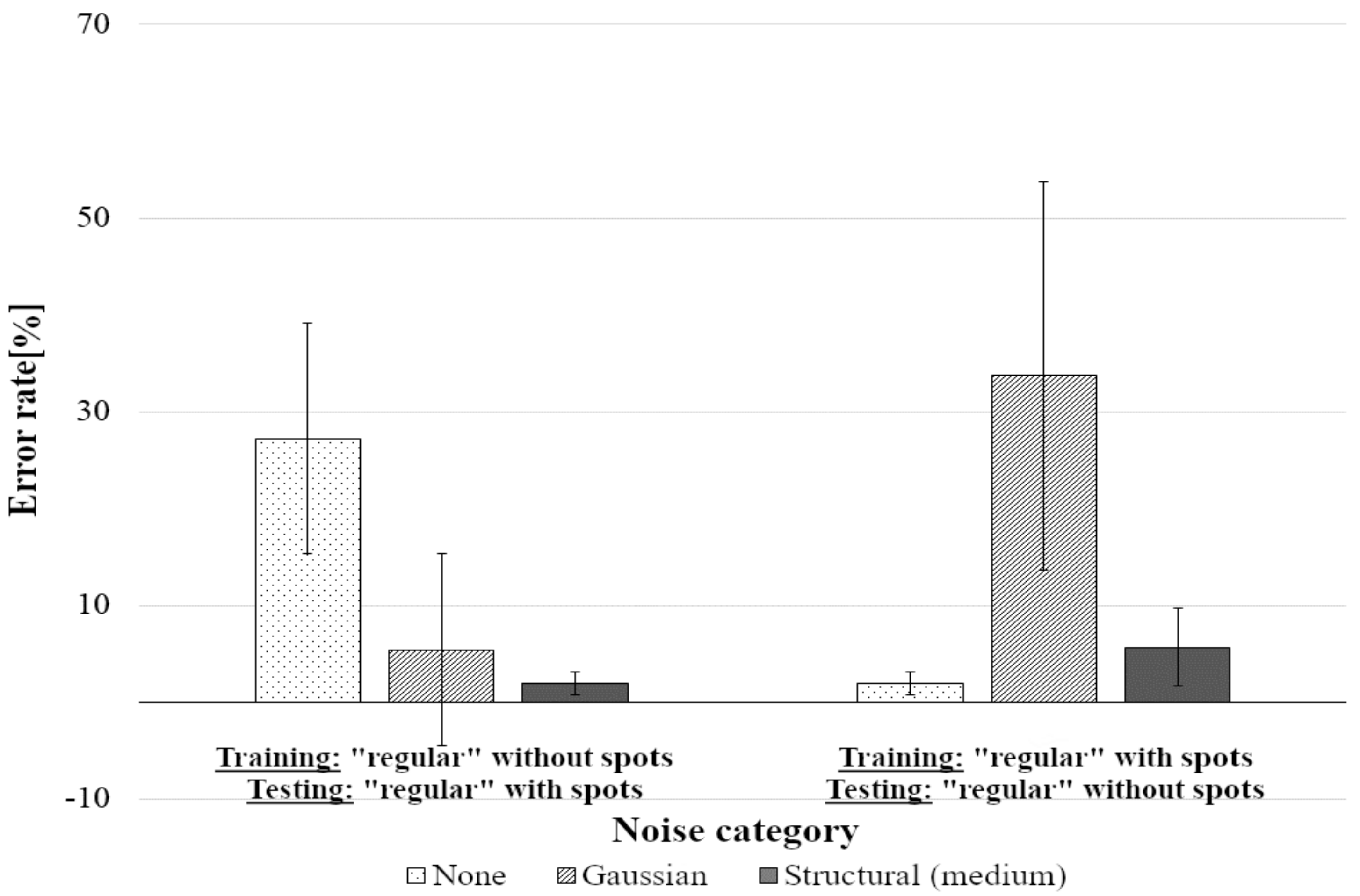
Tests on “Regular” Pictures
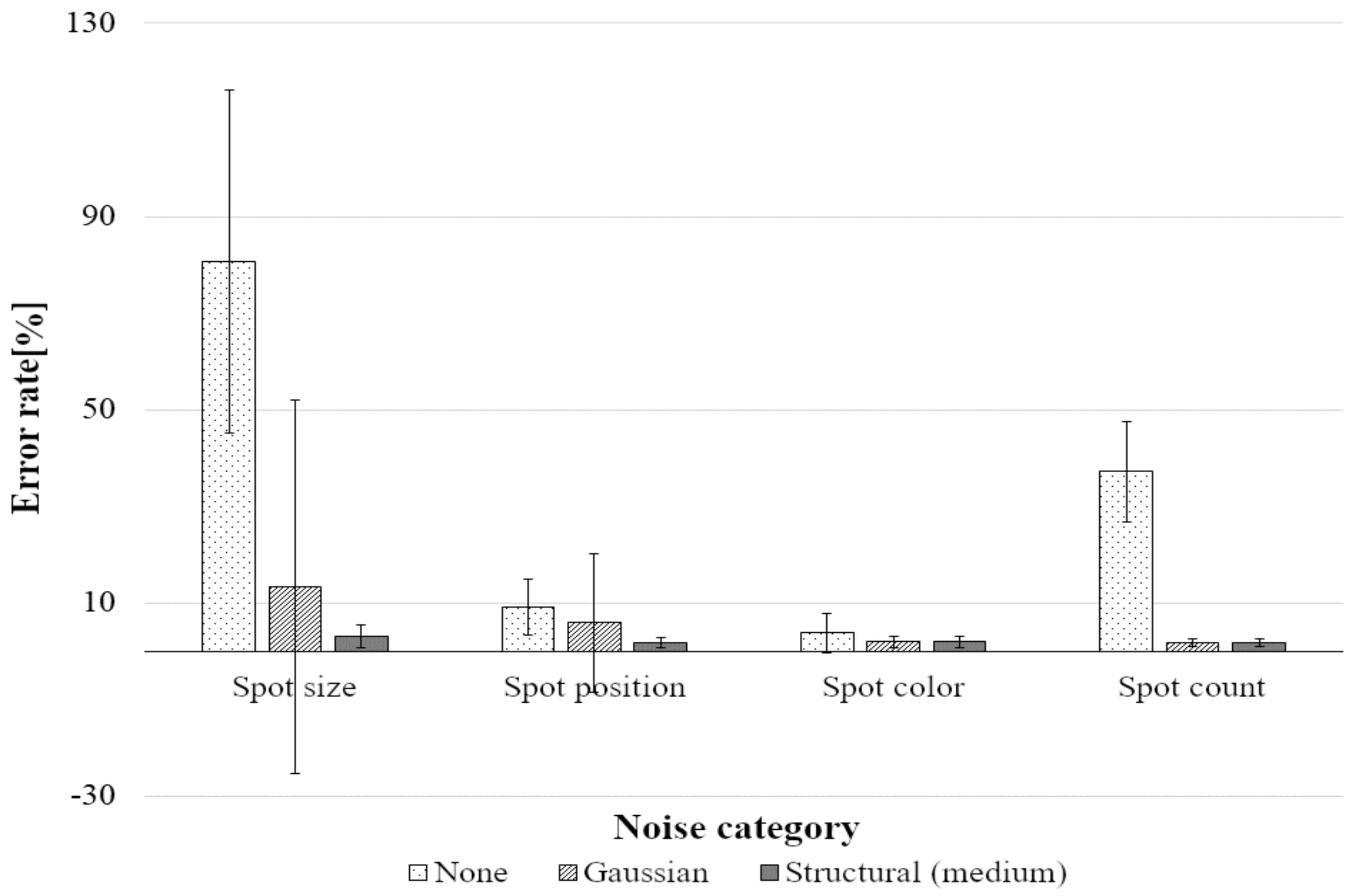
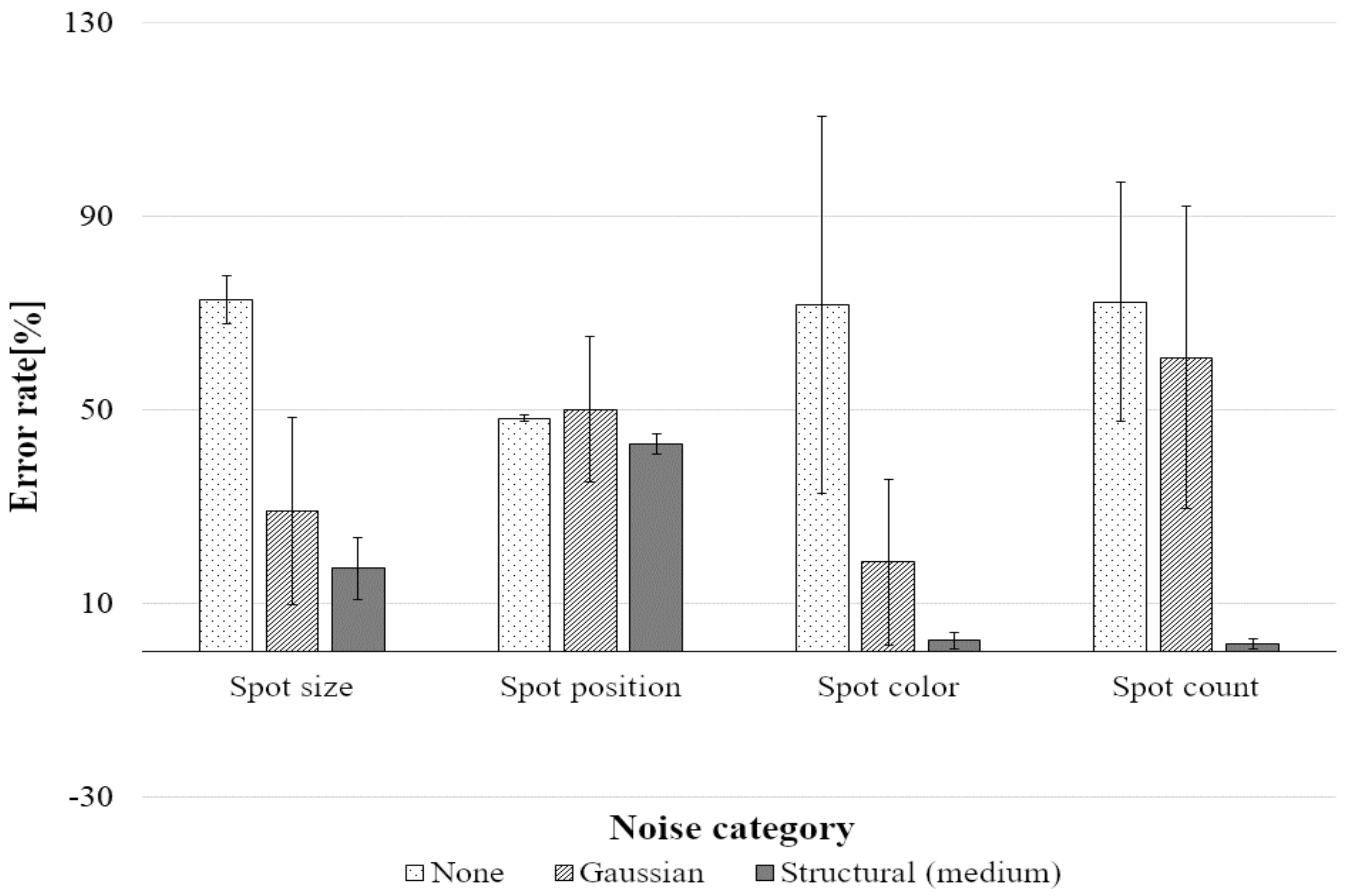
Tests on the Full Set of Data
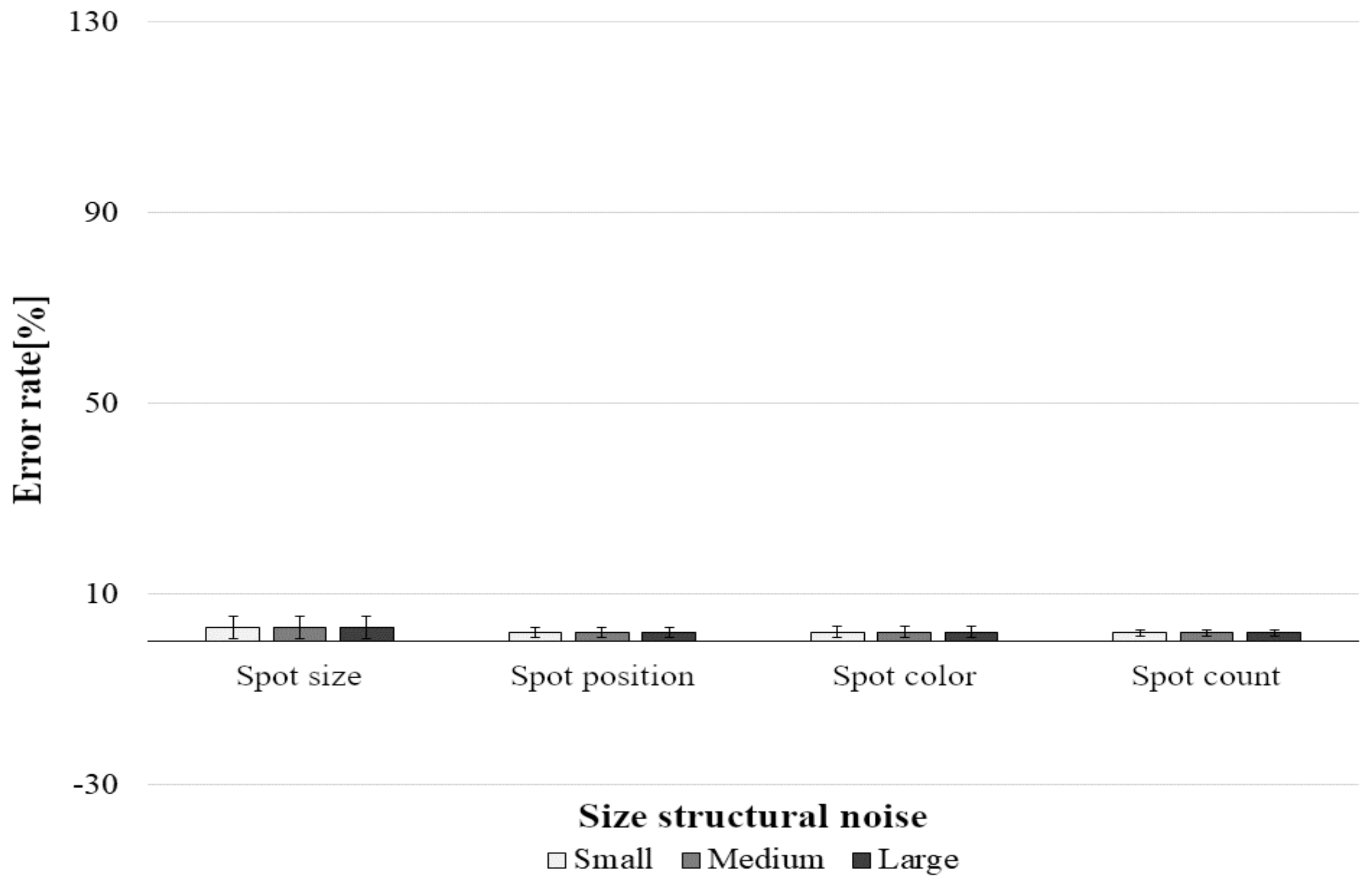
Tests on Different Sizes of Structural Noise
- spotless triangles (A)(1) noised by a known structure (small)
- spotted triangles (A)(2) noised by a known structure (small)
- spotless triangles (A)(1) noised by a known structure (large)
- spotted triangles (A)(2) noised by a known structure (large)
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- See, J.E.; Drury, C.G.; Speed, A.; Williams, A.; Khalandi, N. The Role of Visual Inspection in the 21st Century. Proc. Hum. Factors Ergon. Soc. Annu. Meet. 2017, 61, 262–266. [Google Scholar] [CrossRef]
- Szeliski, R. Computer Vision: Algorithms and Applications, 1st ed.; Springer: London, UK, 2011; pp. 578–631. [Google Scholar]
- Goudail, F.; Lange, E.; Iwamoto, T.; Kyuma, K.; Otsu, N. Fast face recognition method using high order autocorrelations. In Proceedings of the International Conference on Neural Networks (1993), Nagoya, Japan, 25–29 October 1993; Volume 2, pp. 1297–1300. [Google Scholar]
- Chauhan, A.P.S.; Bhardwaj, S.C. Detection of Bare PCB Defects by Image Subtraction Method using Machine Vision. In Proceedings of the World Congress on Engineering (2011), London, UK, 6–8 July 2011; Volume 2. [Google Scholar]
- Elgendy, M. Deep Learning for Vision Systems, 1st ed.; Manning Publications Co.: Shelter Island, NY, USA, 2020; pp. 27–33. [Google Scholar]
- Kattan, M.W. Encyclopedia of Medical Decision Making, 1st ed.; SAGE Publications: Thousand Oaks, CA, USA, 2009; pp. 323–328. [Google Scholar]
- Cristianini, N.; Shawe-Taylor, J. An Introduction to Support Vector Machines and Other Kernel-based Learning Methods, 1st ed.; Cambridge University Press: Cambridge, UK, 2000; pp. 93–124. [Google Scholar]
- Chen, Z.; Yeo, C.K.; Lee, B.S.; Lau, C.T. Autoencoder-based network anomaly detection. In Proceedings of the Wireless Telecommunications Symposium (WTS), Phoenix, AZ, USA, 18–20 April 2018; pp. 1–5. [Google Scholar]
- Vincent, P.; Larochelle, H.; Bengio, Y.; Manzagol, P. Extracting and Composing Robust Features with Denoising Autoencoders. In Proceedings of the 25th International Conference on Machine Learning (ICML ’08), Helsinki, Finland, 5–9 July 2008; pp. 1096–1103. [Google Scholar]
- Vincent, P.; Larochelle, H.; Lajoie, I.; Bengio, Y.; Manzagol, P. Stacked Denoising Autoencoders: Learning Useful Representations in a Deep Network with a Local Denoising Criterion. J. Mach. Learn. Res. 2010, 11, 3371–3408. [Google Scholar]
- Mao, X.-J.; Shen, C.; Yang, Y.-B. Image Restoration Using Very Deep Convolutional Encoder-Decoder Networks with Symmetric Skip Connections. In Proceedings of the 30th International Conference on Neural Information Processing Systems (NIPS’16), Barcelona, Spain, 5–10 December 2016; pp. 2810–2818. [Google Scholar]
- Inayoshi, H.; Kurita, T. Improved Generalization by Adding both Auto-Association and Hidden-Layer-Noise to Neural-Network-Based-Classifiers. In Proceedings of the IEEE Workshop on Machine Learning for Signal Processing, Mystic, CT, USA, 28–30 September 2005; pp. 141–146. [Google Scholar]
- Poole, B.; Sohl-Dickstein, J.; Ganguli, S. Analyzing noise in autoencoders and deep networks. arXiv 2014, arXiv:1406.1831. [Google Scholar]
- Meng, X.; Liu, C.; Zhang, Z.; Wang, D. Noisy training for deep neural networks. In Proceedings of the IEEE China Summit and International Conference on Signal and Information Processing (ChinaSIP), Xi’an, China, 9–13 July 2014; pp. 16–20. [Google Scholar]
- An, G. The effects of adding noise during backpropagation training on a generalization performance. Neural Comput. 1996, 8, 643–674. [Google Scholar] [CrossRef]
- Grandvalet, Y.; Canu, S.; Boucheron, S. Noise injection: Theoretical prospects. Neural Comput. 1997, 9, 1093–1108. [Google Scholar] [CrossRef]
- DeVries, T.; Taylor, G.W. Improved Regularization of Convolutional Neural Networks with Cutout. arXiv 2017, arXiv:1708.04552. [Google Scholar]
- Zhong, Z.; Zheng, L.; Kang, G.; Li, S.; Yang, Y. Random Erasing Data Augmentation. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; pp. 13001–13008. [Google Scholar]
























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Category | Class | Parameter |
|---|---|---|
| (A) Presence of a spot | (1) Without a spot | - |
| (2) With a spot | Spot radius r = 25 px | |
| (B) Defective spot size | (1) Small | Spot radius r = 12.5 px |
| (2) Large | spot radius r = 37.5 px | |
| (C) Defective spot position | (1) Up | Spot position 25 px to the top |
| (2) Down | Spot position 25 px to the bottom | |
| (3) Left | Spot position 25 px to the left | |
| (4) Right | Spot position 25 px to the right | |
| (D) Defective spot color | (1) Black | Spot color (r, g, b) = (0, 0, 0) |
| (E) Defective spot count | (1) Two | 2 spots |
| (2) Three | 3 spots |
| Additive Noise | ||||
|---|---|---|---|---|
| None | Gaussian | Structural | ||
| Training dataset | Without spots | 27.2 | 5.4 | 1.9 |
| With spots | 1.9 | 33.7 | 5.7 | |
| Defect | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Spot Size | Spot Position | Spot Color | Spot Count | |||||||
| Small | Large | Up | Down | Left | Right | Black | Two | Three | ||
| Category of noise | None | 50.2 | 111.0 | 9.1 | 9.8 | 9.1 | 8.3 | 3.9 | 27.9 | 46.1 |
| Gaussian | 2.0 | 24.5 | 5.2 | 6.1 | 8.3 | 4.1 | 2.0 | 1.9 | 1.8 | |
| Structural | 1.4 | 4.6 | 2.0 | 1.9 | 1.7 | 1.8 | 2.0 | 1.9 | 1.7 | |
| Defect | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Spot Size | Spot Position | Spot Color | Spot Count | |||||||
| Small | Large | Up | Down | Left | Right | Black | Two | Three | ||
| Category of noise | None | 77.5 | 68.1 | 48.3 | 48.3 | 48.2 | 48.2 | 71.8 | 47.3 | 96.6 |
| Gaussian | 25.2 | 33.0 | 44.0 | 70.9 | 36.9 | 48.3 | 18.6 | 87.2 | 43.6 | |
| Structural | 15.9 | 18.5 | 43.1 | 43.0 | 43.7 | 42.5 | 2.3 | 1.7 | 1.7 | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Murakami, R.; Grave, V.; Fukuda, O.; Okumura, H.; Yamaguchi, N. Improved Training of CAE-Based Defect Detectors Using Structural Noise. Appl. Sci. 2021, 11, 12062. https://doi.org/10.3390/app112412062
Murakami R, Grave V, Fukuda O, Okumura H, Yamaguchi N. Improved Training of CAE-Based Defect Detectors Using Structural Noise. Applied Sciences. 2021; 11(24):12062. https://doi.org/10.3390/app112412062
Chicago/Turabian StyleMurakami, Reina, Valentin Grave, Osamu Fukuda, Hiroshi Okumura, and Nobuhiko Yamaguchi. 2021. "Improved Training of CAE-Based Defect Detectors Using Structural Noise" Applied Sciences 11, no. 24: 12062. https://doi.org/10.3390/app112412062