
Vision Transformer-Based Tailing Detection in Videos


Abstract
:1. Introduction
- For the first time, we define and formulate the tailing detection problem as an anomaly detection problem.
- To address the difficulties of empirical evaluation of tailing detection, we introduce the very first tailing detection dataset and define the metrics to evaluate and compare the tailing detectors.
- Unlike traditional multi-input CNN-based architectures or Recurrent Neural Networks (RNN), we propose the Time-Series Vision Transformer (TSViT) as a new method for solving time-series image data for tailing detection.
- Most previous anomaly detection methods process the complete input frame. Consequently, their performance is highly dependent upon context information. In contrast, to make the proposed tailing detection scheme robust against view changes, lighting conditions or cluttered background, we only pass the spatial information of the pedestrian to the TSViT, by encoding frames with the pedestrian’s location information into embedding tokens.
- We also show the successful use of Ordered Random Sampling (ORS) method to not only avoid overfitting, but also to augment the data and increase the probability of detection of the anomalous event.
2. Related Work
3. Proposed Methods
3.1. Anomaly Modeling with Ordered Random Sampling
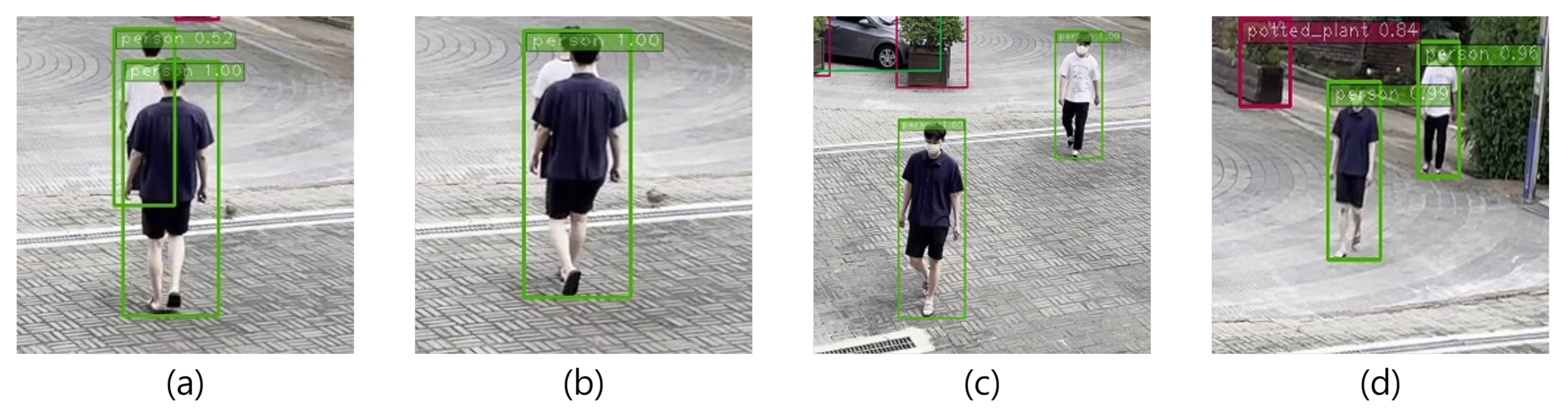
3.2. Removing Context Dependency
3.3. Baseline Method 1: Handcrafted Rule-Based Tailing Detection
3.3.1. Trajectory Similarity
3.3.2. Cosine Similarity
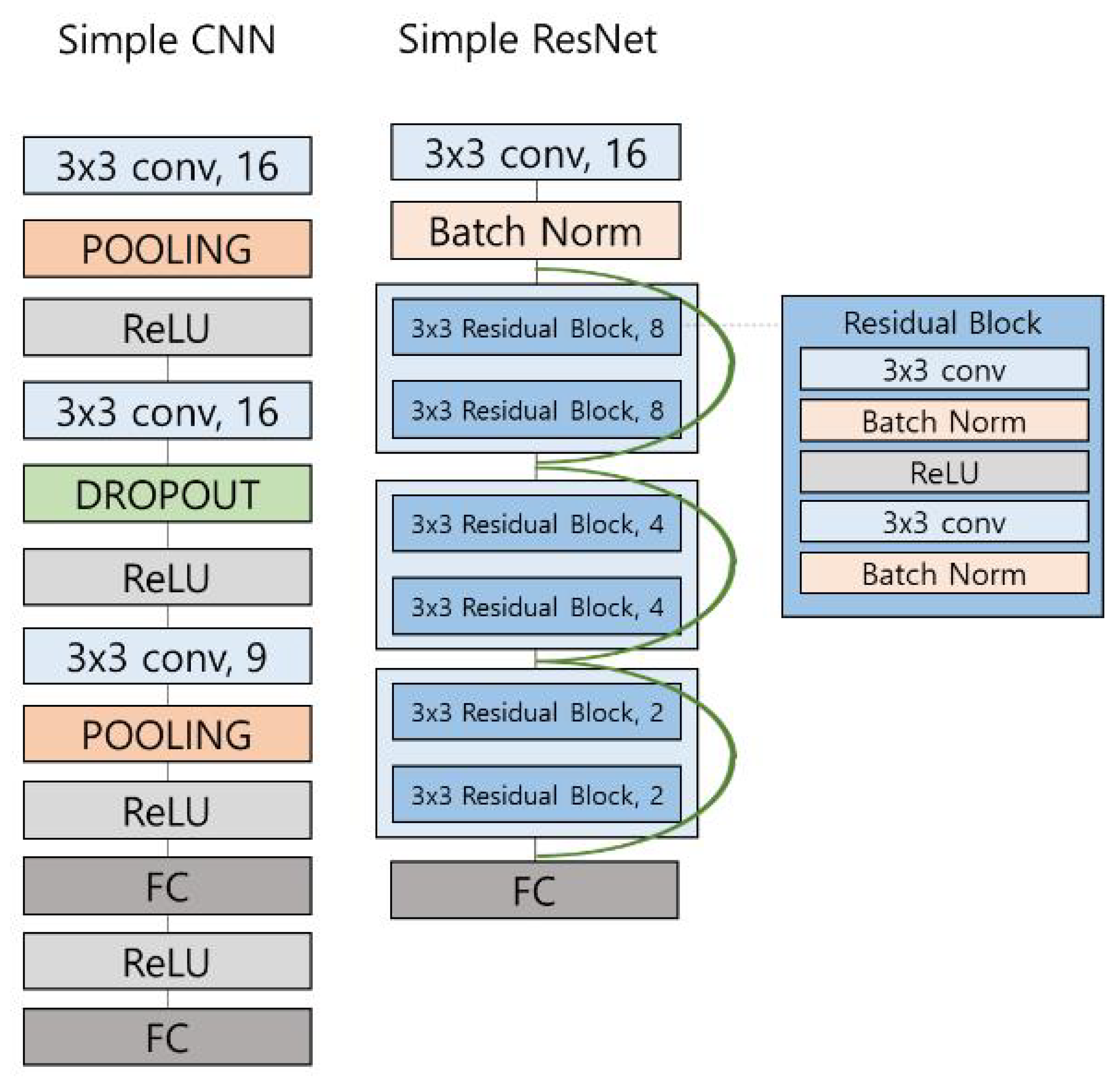
3.4. Baseline Method 2: CNN-Based Detection
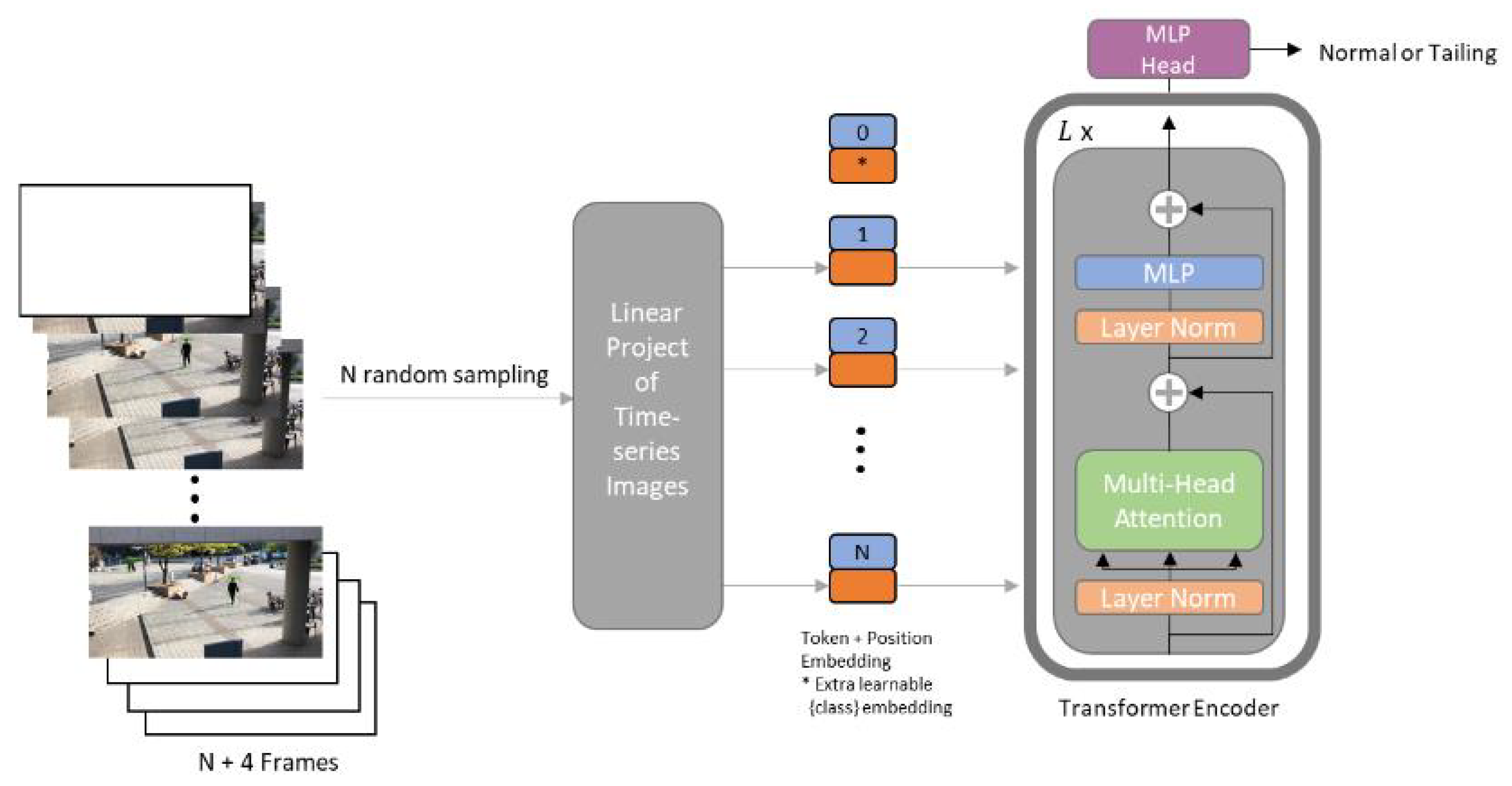
3.5. Method 3: Proposed Tsvit Method
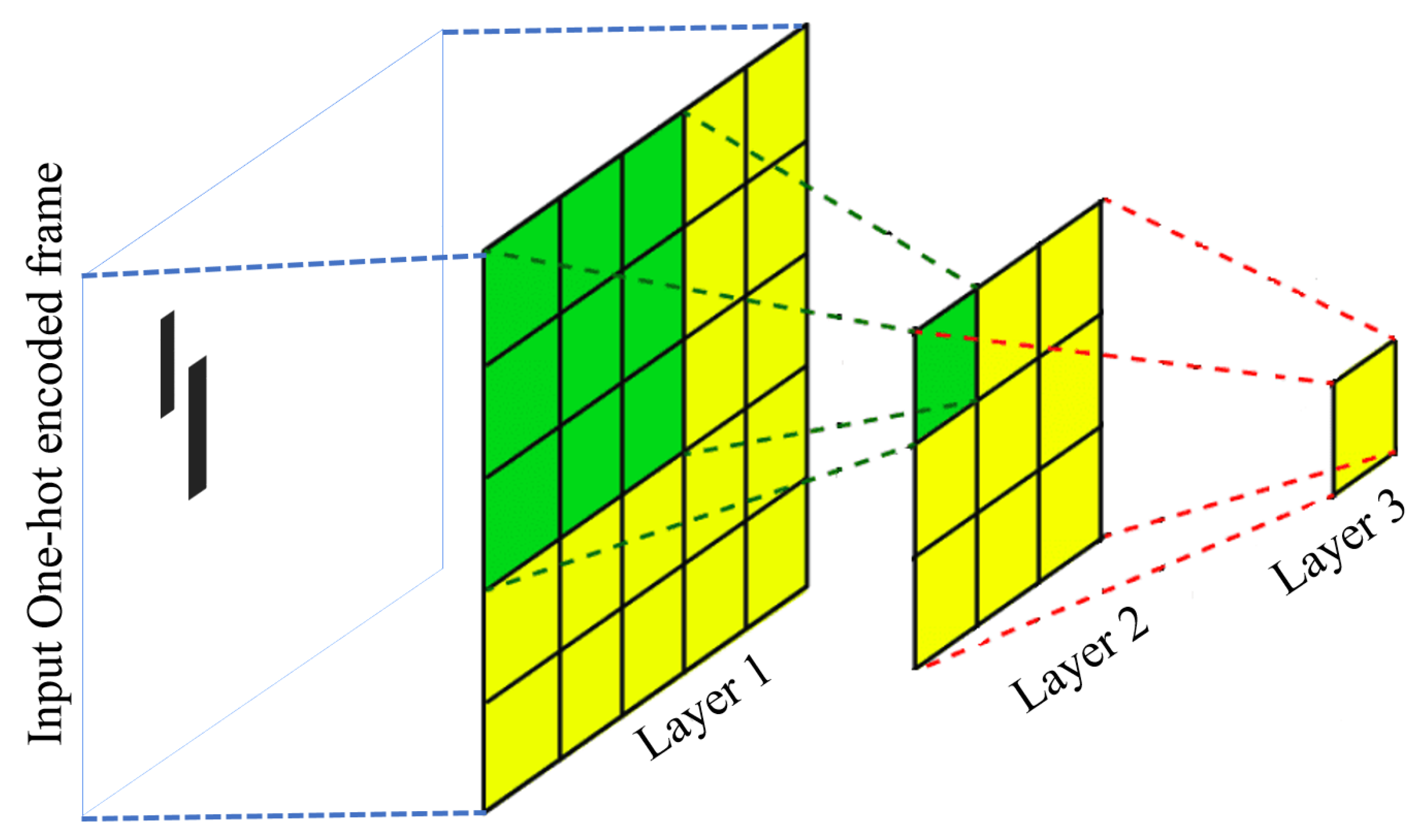
Embedding Time-Series Images
4. Experiments and Analysis
4.1. Sogang Tailing Detection Dataset
4.2. Experimental Settings
4.2.1. Method 1: Handcrafted Rule-Based Method
4.2.2. Method 2: CNN-Based Method
- Training configurations. We trained all the CNN architectures used in this experiment for 100 epochs using SGD [45] with momentum = 0.9, weight decay = 0.0001, and a batch size of 64. We performed a grid search with a learning rate (lr) in [0.001 0.01]. We use MultiplicativeLR as the lr scheduler.
4.2.3. Method 3: Proposed TSViT
- Model variants.
- Training configurations. We trained all TSViT for 100 epochs using AdamW [47] with , , weight decay = 0.01, and a batch size of 64. We performed five ordered random sampling per video in each epoch. We performed grid search with a learning rate in [0.0025, 0.1]. We used a learning rate with gradual warmup [48] up to 20 epochs and then cosine annealing decay [49] for the remaining epochs. For data augmentation, we only used random horizontal flipping.
4.3. Effectiveness of the Proposed Sampling Method
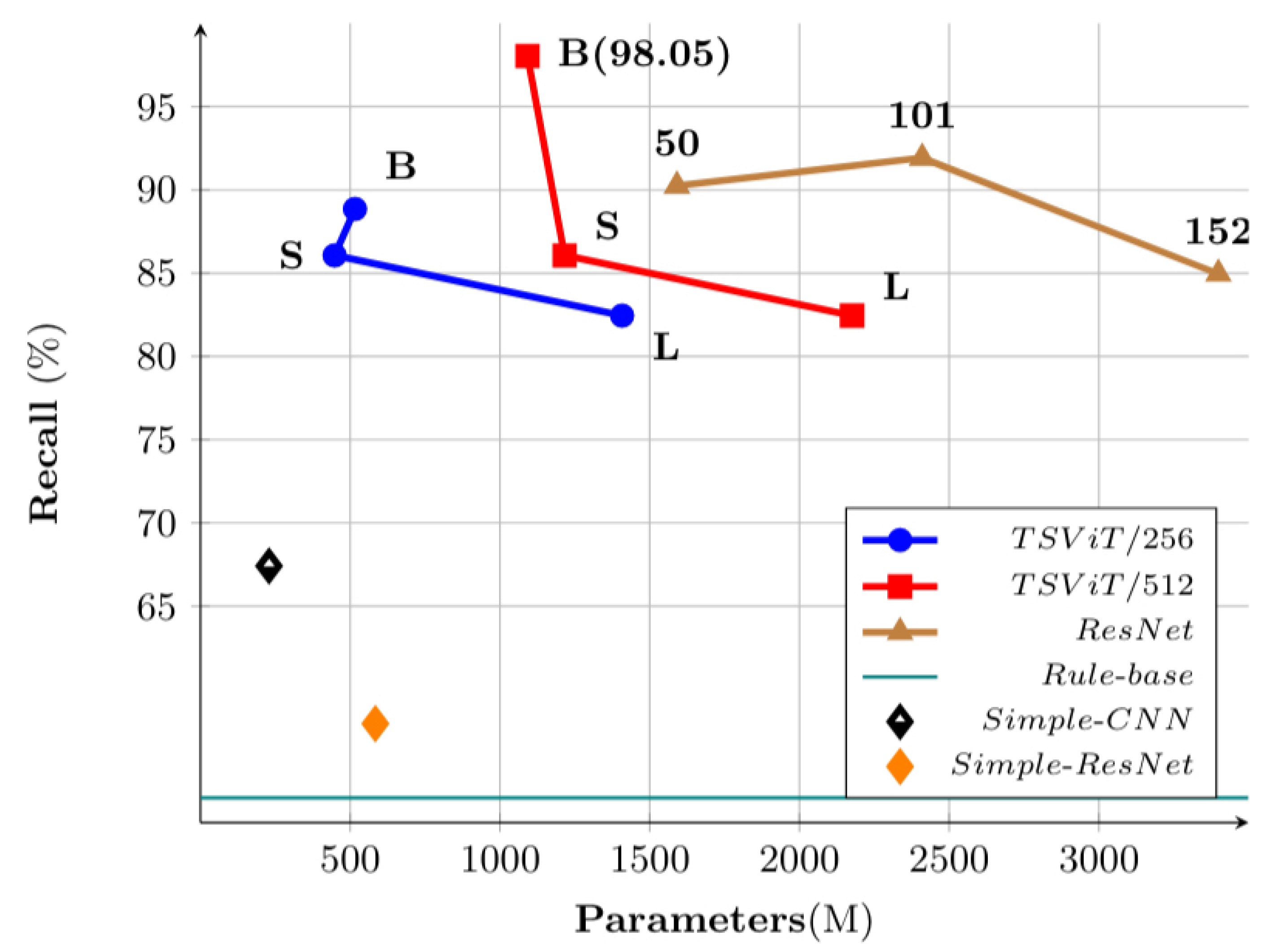
4.4. Discussion on Tailing Detection Performance with Model Size
5. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Conflicts of Interest
References
- Data-Kidnapping-United Nations Office on Drugs and Crime. Available online: https://www.unodc.org/documents/data-and-analysis/Crime-statistics/Kidnapping.xls (accessed on 13 September 2021).
- Song, H.; Sun, C.; Wu, X.; Chen, M.; Jia, Y. Learning Normal Patterns via Adversarial Attention-Based Autoencoder for Abnormal Event Detection in Videos. IEEE Trans. Multimed. 2020, 22, 2138–2148. [Google Scholar] [CrossRef]
- Vats, K.; Fani, M.; Walters, P.; Clausi, D.; Zelek, J. Event Detection in Coarsely Annotated Sports Videos Via Parallel Multi Receptive Field 1D Convolutions; CVPR Workshop: Seattle, WA, USA, 2020; pp. 3856–3865. [Google Scholar]
- Gabeur, V.; Sun, C.; Alahari, K.; Schmid, C. Multi-Modal Transformer for Video Retrieval; ECCV: Aurora, CO, USA, 2020. [Google Scholar]
- Kanafani, H.; Ghauri, J.A.; Hakimov, S.; Ewerth, R. Unsupervised Video Summarization via Multi-source Features. In Proceedings of the ACM International Conference on Multimedia Retrieval (ICMR), Taipei, Taiwan, 21–24 August 2021; pp. 466–470. [Google Scholar]
- Ye, F.; Zheng, H.; Huang, C.; Zhang, Y. Deep Unsupervised Image Anomaly Detection: An Information Theoretic Framework. In Proceedings of the IEEE International Conference on Image Processing (ICIP), Anchorage, AK, USA, 19–22 September 2021; pp. 1609–1613. [Google Scholar]
- Lu, C.; Shi, J.; Jia, J. Abnormal Event Detection at 150 FPS in MATLAB; ICCV: Seoul, Korea, 2013; pp. 2720–2727. [Google Scholar]
- Cong, Y.; Yuan, J.; Liu, J. Abnormal Event Detection in Crowded Scenes Using Sparse Representation. Pattern Recognit. 2013, 46, 1851–1864. [Google Scholar] [CrossRef]
- Yuan, Y.; Fang, J.; Wang, Q. Online Anomaly Detection in Crowd Scenes via Structure Analysis. IEEE Trans. Cybern. 2015, 45, 548–561. [Google Scholar] [CrossRef]
- Chan, A.B.; Vasconcelos, N. Mixture of Dynamic Textures; ICCV: Beijing, China, 2005; pp. 641–647. [Google Scholar]
- Bera, A.; Kim, S.; Manocha, D. Realtime Anomaly Detection Using Trajectory-Level Crowd Behavior Learning; CVPR Workshops: Las Vegas, NV, USA, 2016; pp. 1289–1296. [Google Scholar]
- Chen, Z.; Li, W.; Fei, C.; Liu, B.; Yu, N. Robust Anomaly Detection via Fusion of Appearance and Motion Features. In Proceedings of the IEEE Visual Communications and Image Processing (VCIP), Taichung, Taiwan, 9–12 December 2018; pp. 1–4. [Google Scholar]
- Kwon, J.; Lee, K.M. A Unified Framework for Event Summarization and Rare Event Detection from Multiple Views. PAMI 2015, 37, 1737–1750. [Google Scholar] [CrossRef]
- Li, W.; Mahadevan, V.; Vasconcelos, N. Anomaly Detection and Localization in Crowded Scenes. PAMI 2014, 36, 18–32. [Google Scholar]
- Zhao, B.; Fei-Fei, L.; Xing, E.P. Online Detection of Unusual Events in Videos via Dynamic Sparse Coding; CVPR: Colorado Springs, CO, USA, 2011; pp. 3313–3320. [Google Scholar]
- Trichet, R.; Nevatia, R.; Burns, B. Video Event Classification with Temporal Partitioning. In Proceedings of the IEEE International Conference on Advanced Video and Signal Based Surveillance (AVSS), Karlsruhe, Germany, 25–28 August 2015; pp. 1–6. [Google Scholar]
- Shu, X.; Tang, J.; Qi, G.J.; Liu, W.; Yang, J. Hierarchical Long Short-Term Concurrent Memory for Human Interaction Recognition. PAMI 2021, 43, 1110–1118. [Google Scholar] [CrossRef] [Green Version]
- Lee, D.G.; Lee, S.W. Human Interaction Recognition Framework based on Interacting Body Part Attention. arXiv 2021, arXiv:2101.08967. [Google Scholar]
- Amraee, S.; Vafaei, A.; Jamshidi, K.; Adibi, P. Anomaly Detection and Localization in Crowded Scenes Using Connected Component Analysis. Multimed. Tools Appl. 2018, 77, 14767–14782. [Google Scholar] [CrossRef]
- Sikdar, A.; Chowdhury, A.S. An Adaptive Training-less Framework for Anomaly Detection in Crowd Scenes. Neurocomputing 2020, 415, 317–331. [Google Scholar] [CrossRef]
- Zhang, Y.; Lu, H.; Zhang, L.; Ruan, X. Combining Motion and Appearance Cues for Anomaly Detection. Pattern Recognit. 2016, 51, 443–452. [Google Scholar] [CrossRef]
- Ma, Q. Abnormal Event Detection in Videos Based on Deep Neural Networks. Mach. Learn. Image Video Process. 2021, 2021, 6412608. [Google Scholar] [CrossRef]
- Xu, M.; Zhang, Z.; Hu, H.; Wang, J.; Wang, L.; Wei, F.; Bai, X.; Liu, Z. End-to-End Semi-Supervised Object Detection with Soft Teacher; ICCV: Montreal, QC, Canada, 2021; pp. 3060–3069. [Google Scholar]
- Yuan, Y.; Fu, R.; Huang, L.; Zhang, C.; Chen, X.; Wang, J. HRT: High-Resolution Transformer for Dense Prediction. arXiv 2021, arXiv:2110.09408. [Google Scholar]
- Wang, W.; Chang, F.; Mi, H. Intermediate Fused Network with Multiple Timescales for Anomaly Detection. Neurocomputing 2021, 433, 37–49. [Google Scholar] [CrossRef]
- Ilg, E.; Mayer, N.; Saikia, T.; Keuper, M.; Dosovitskiy, A.; Brox, T. FlowNet 2.0: Evolution of Optical Flow Estimation with Deep Networks; CVPR: Honolulu, HI, USA, 2017; pp. 1647–1655. [Google Scholar]
- Zhao, Y.; Deng, B.; Shen, C.; Liu, Y.; Lu, H.; Hua, X.S. Spatio-Temporal AutoEncoder for Video Anomaly Detection. In Proceedings of the 25th ACM International Conference on Multimedia. Association for Computing Machinery, Mountain View, CA, USA, 23–27 October 2017; pp. 1933–1941. [Google Scholar]
- Stauffer, C.; Grimson, W. Learning Patterns of Activity Using Real-Time Tracking. PAMI 2000, 22, 747–757. [Google Scholar] [CrossRef] [Green Version]
- Zhang, T.; Lu, H.; Li, S. Learning Semantic Scene Models by Object Classification and Trajectory Clustering; CVPR: Miami, FL, USA, 2009; pp. 1940–1947. [Google Scholar]
- Basharat, A.; Gritai, A.; Shah, M. Learning Object Motion Patterns for Anomaly Detection and Improved Object Detection; CVPR: Anchorage, AK, USA, 2008; pp. 1–8. [Google Scholar]
- Cui, X.; Liu, Q.; Gao, M.; Metaxas, D.N. Abnormal Detection Using Interaction Energy Potentials; CVPR: Colorado Springs, CO, USA, 2011; pp. 3161–3167. [Google Scholar]
- Jiang, F.; Yuan, J.; Tsaftaris, S.; Katsaggelos, A. Anomalous Video Event Detection Using Spatiotemporal Context. Comput. Vis. Image Underst. 2011, 115, 323–333. [Google Scholar] [CrossRef]
- LeCun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-Based Learning Applied to Document Recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef] [Green Version]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Hasan, M.; Choi, J.; Neumann, J.; Chowdhury, A.K.R.; Davis, L.S. Learning Temporal Regularity in Video Sequences; CVPR: Las Vegas, NV, USA, 2016; pp. 733–742. [Google Scholar]
- Are You Being Followed on Foot or By Car? What to, Do. Available online: https://www.huffpost.com/entry/are-you-being-followed-on_b_5096448 (accessed on 15 October 2021).
- Frank, R.J.; Davey, N.; Hunt, S.P. Time Series Prediction and Neural Networks. J. Intell. Robot. Syst. 2001, 31, 91–103. [Google Scholar] [CrossRef]
- Magdy, N.; Sakr, M.A.; Mostafa, T.; El-Bahnasy, K. Review on Trajectory Similarity Measures. In Proceedings of the IEEE Seventh International Conference on Intelligent Computing and Information Systems (ICICIS), Cairo, Egypt, 12–14 December 2015; pp. 613–619. [Google Scholar]
- Eiter, T.; Mannila, H. Computing Discrete Fréchet Distance; Technical Report; Citeseer: Princeton, NJ, USA, 1994. [Google Scholar]
- Lahitani, A.R.; Permanasari, A.E.; Setiawan, N.A. Cosine Similarity to Determine Similarity Measure: Study Case in Online Essay Assessment. In Proceedings of the 4th International Conference on Cyber and IT Service Management, Bandung, Indonesia, 26–27 April 2016; pp. 1–6. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet Classification with Deep Convolutional Neural Networks. Adv. Neural Inf. Process. Syst. 2012, 25, 1097–1105. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition; CVPR: Las Vegas, NV, USA, 2016; pp. 770–778. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is All You Need. In Advances in Neural Information Processing Systems; The MIT Press: Cambridge, MA, USA, 2017; pp. 5998–6008. [Google Scholar]
- Mahadevan, V.; Li, W.; Bhalodia, V.; Vasconcelos, N. Anomaly Detection in Crowded Scenes; CVPR: San Francisco, CA, USA, 2010; pp. 1975–1981. [Google Scholar]
- Robbins, H.; Monro, S. A Stochastic Approximation Method. Ann. Math. Stat. 1951, 22, 400–407. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Loshchilov, I.; Hutter, F. Decoupled Weight Decay Regularization. arXiv 2017, arXiv:1711.05101. [Google Scholar]
- Goyal, P.; Dollár, P.; Girshick, R.; Noordhuis, P.; Wesolowski, L.; Kyrola, A.; Tulloch, A.; Jia, Y.; He, K. Accurate, Large Minibatch SGD: Training Imagenet in 1 h. arXiv 2017, arXiv:1706.02677. [Google Scholar]
- Loshchilov, I.; Hutter, F. SGDR: Stochastic Gradient Descent with Warm Restarts. arXiv 2016, arXiv:1608.03983. [Google Scholar]
- Kannojia, S.P.; Jaiswal, G. Effects of Varying Resolution on Performance of CNN Based Image Classification: An Experimental Study. Int. J. Comput. Sci. Eng. 2018, 6, 451–456. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Tailing | ||||
|---|---|---|---|---|
| Model | Params (M) | Accuracy (%) | Precision | Recall |
| Simple-CNN | 229 | 63.54 | 0.7224 | 0.6741 |
| Simple-ResNet | 584 | 59.37 | 0.7148 | 0.5794 |
| ResNet-50/512 | 1591 | 60.24 | 0.6255 | 0.9025 |
| ResNet-101/512 | 2410 | 62.32 | 0.6371 | 0.9192 |
| ResNet-152/512 | 3399 | 61.63 | 0.6462 | 0.8496 |
| Model | Layers | Hidden Size D | MLP Size | Heads | Params(M) |
|---|---|---|---|---|---|
| TSViT-S/256 | 6 | 1024 | 2048 | 16 | 448 |
| TSViT-B/256 | 12 | 768 | 3072 | 12 | 516 |
| TSViT-L/256 | 24 | 1024 | 4096 | 16 | 1408 |
| TSViT-B/512 | 12 | 768 | 3072 | 12 | 1092 |
| TSViT-S/512 | 6 | 1024 | 2048 | 16 | 1216 |
| TSViT-L/512 | 24 | 1024 | 4096 | 16 | 2176 |
| Tailing | ||||
|---|---|---|---|---|
| Model | Params (M) | Accuracy (%) | Precision | Recall |
| TSViT-S/256 | 448 | 74.65 | 0.7631 | 0.8607 |
| TSViT-B/256 | 516 | 71.35 | 0.7185 | 0.8886 |
| TSViT-L/256 | 1408 | 73.09 | 0.7629 | 0.8245 |
| TSViT-B/512 | 1092 | 76.56 | 0.7333 | 0.9805 |
| TSViT-S/512 | 1216 | 74.65 | 0.7631 | 0.8607 |
| TSViT-L/512 | 2176 | 73.09 | 0.7629 | 0.8245 |
| Model | Accuracy (%) | Precision | Recall |
|---|---|---|---|
| TSViT with Sliding Window | 71.03 | 0.7860 | 0.7362 |
| TSViT with ORS | 73.90 | 0.7506 | 0.8732 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lee, J.; Lee, S.; Cho, W.; Siddiqui, Z.A.; Park, U. Vision Transformer-Based Tailing Detection in Videos. Appl. Sci. 2021, 11, 11591. https://doi.org/10.3390/app112411591
Lee J, Lee S, Cho W, Siddiqui ZA, Park U. Vision Transformer-Based Tailing Detection in Videos. Applied Sciences. 2021; 11(24):11591. https://doi.org/10.3390/app112411591
Chicago/Turabian StyleLee, Jaewoo, Sungjun Lee, Wonki Cho, Zahid Ali Siddiqui, and Unsang Park. 2021. "Vision Transformer-Based Tailing Detection in Videos" Applied Sciences 11, no. 24: 11591. https://doi.org/10.3390/app112411591