
A Hard Example Mining Approach for Concealed Multi-Object Detection of Active Terahertz Image


Abstract
:1. Introduction
- Provide an active terahertz imaging dataset for concealed multi-object detection. To our knowledge, there is no public dataset in terahertz imaging to evaluate multi-object detection algorithm. We provide an active terahertz imaging dataset for multi-object detection with 3157 image samples with 1347 concealed objects.
- An image-based Hard Example Mining scheme based on RetinaNet is designed, and four state-of-the-art object detectors are evaluated on this dataset. The experiment indicates that HEM further improves the performance of the RetinaNet.
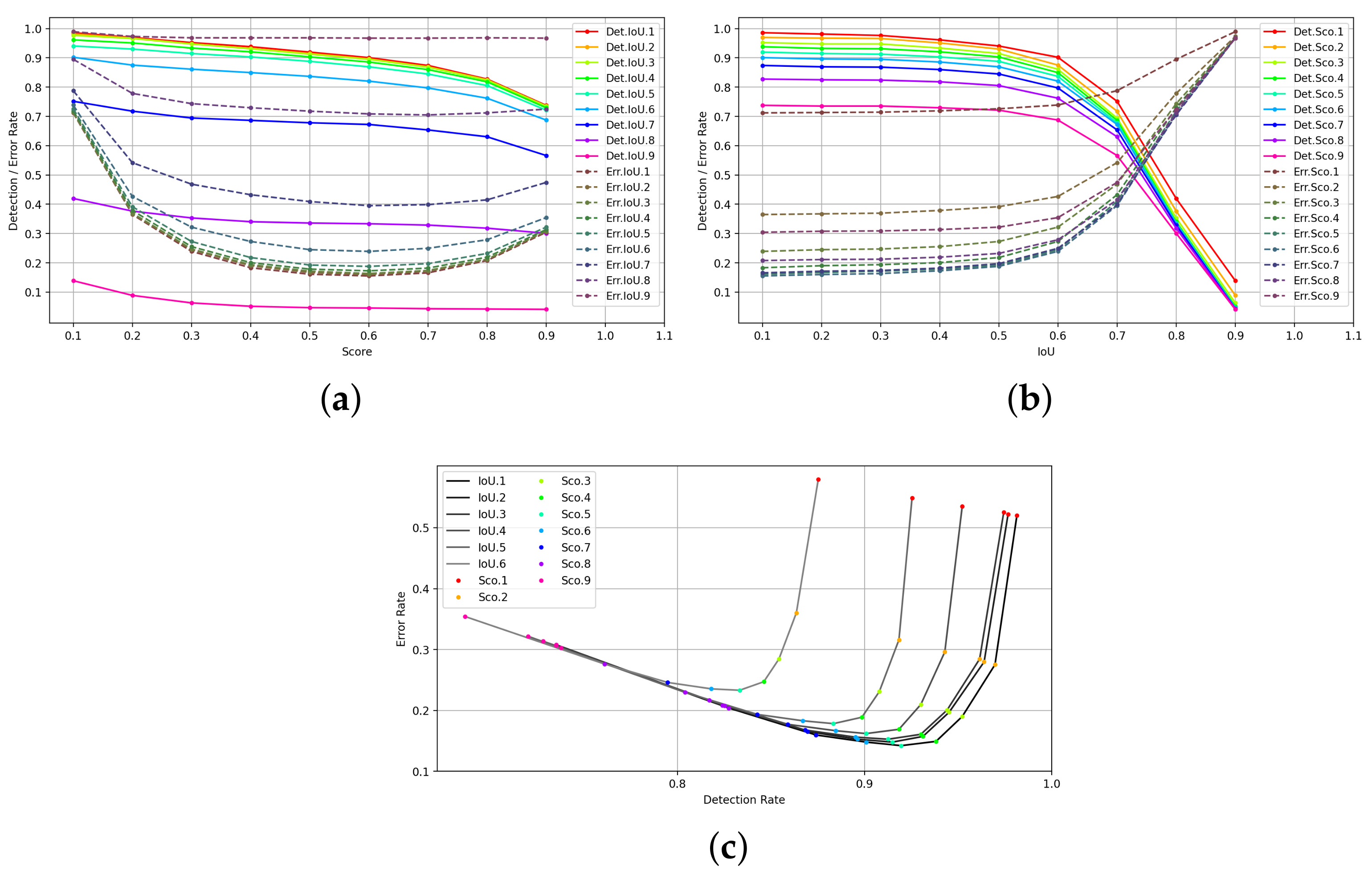
- The experiment indicates that hiding objects in different parts of the human body affect detection accuracy. The parameters affecting the single-image detection metrics are summarized and analyzed in the experiments.
2. Related Work
2.1. Object Detection in Terahertz Image
2.2. Hard Example Mining in Object Detection
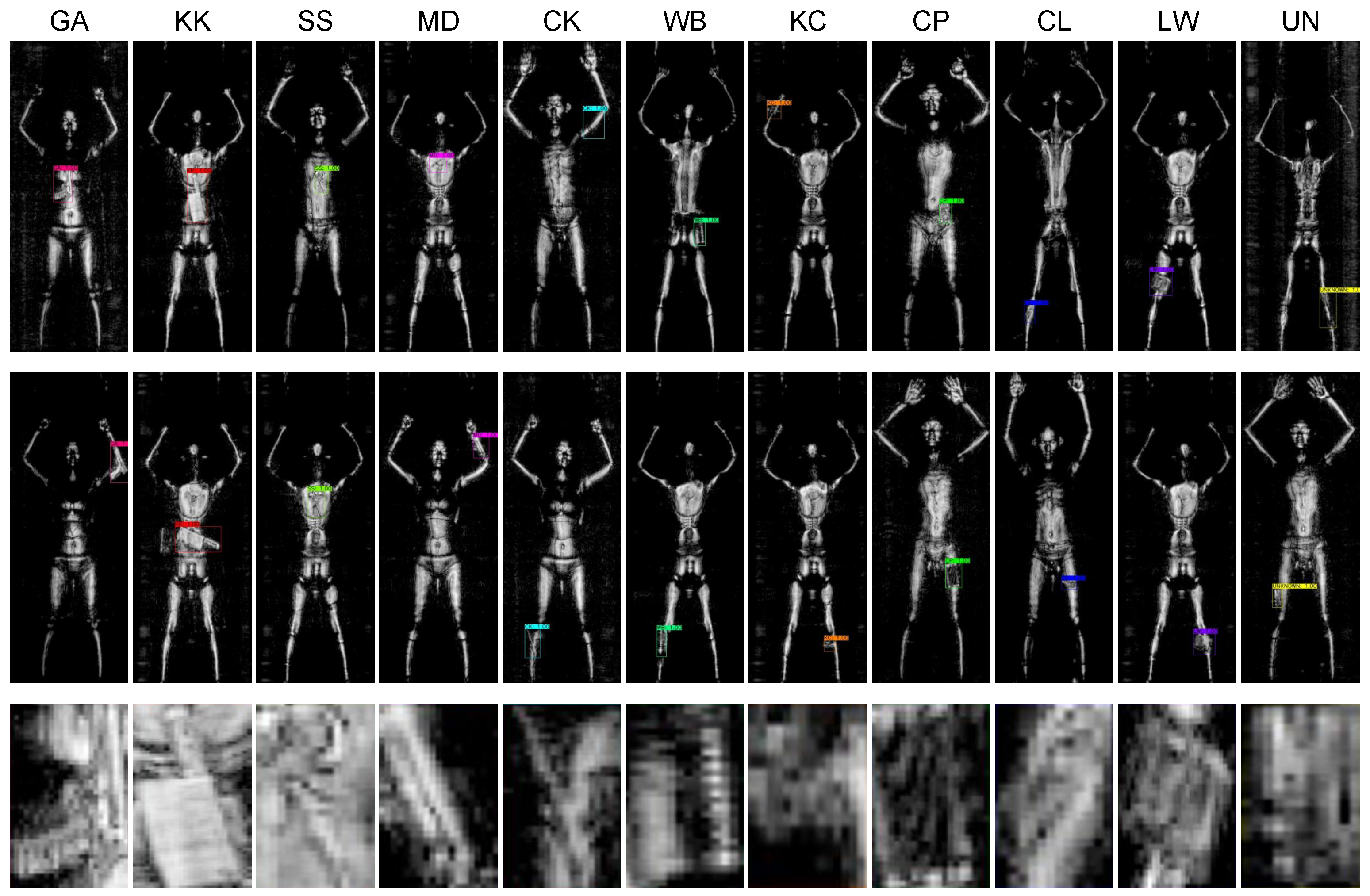
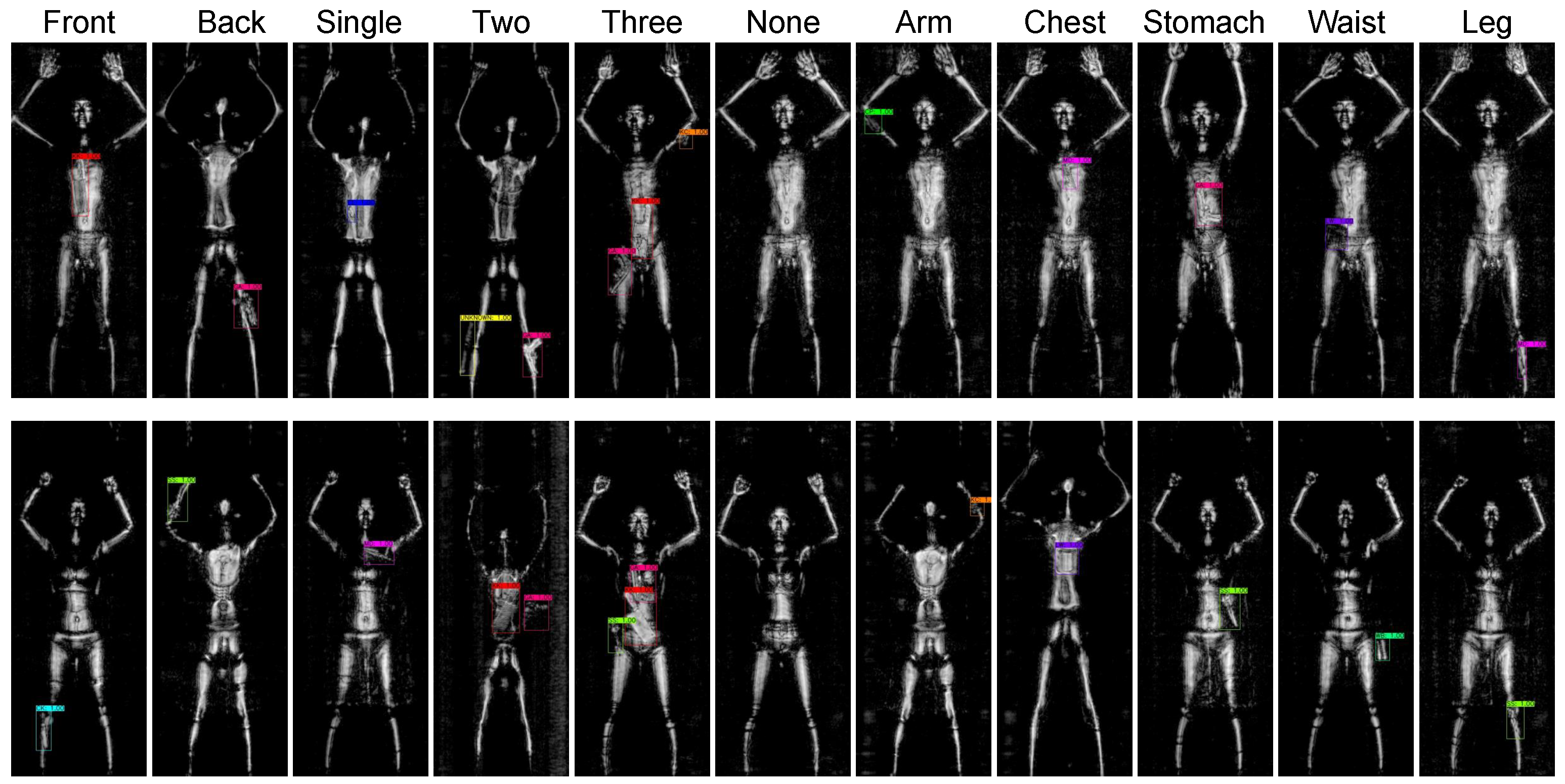
3. Active Terahertz Object Detection Dataset
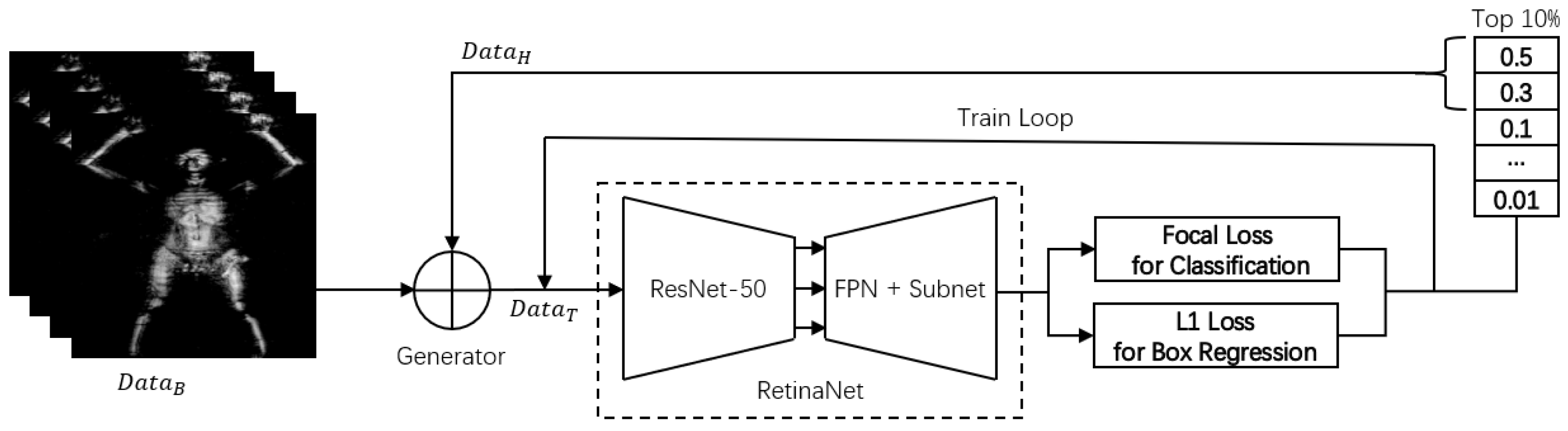
4. Methodology
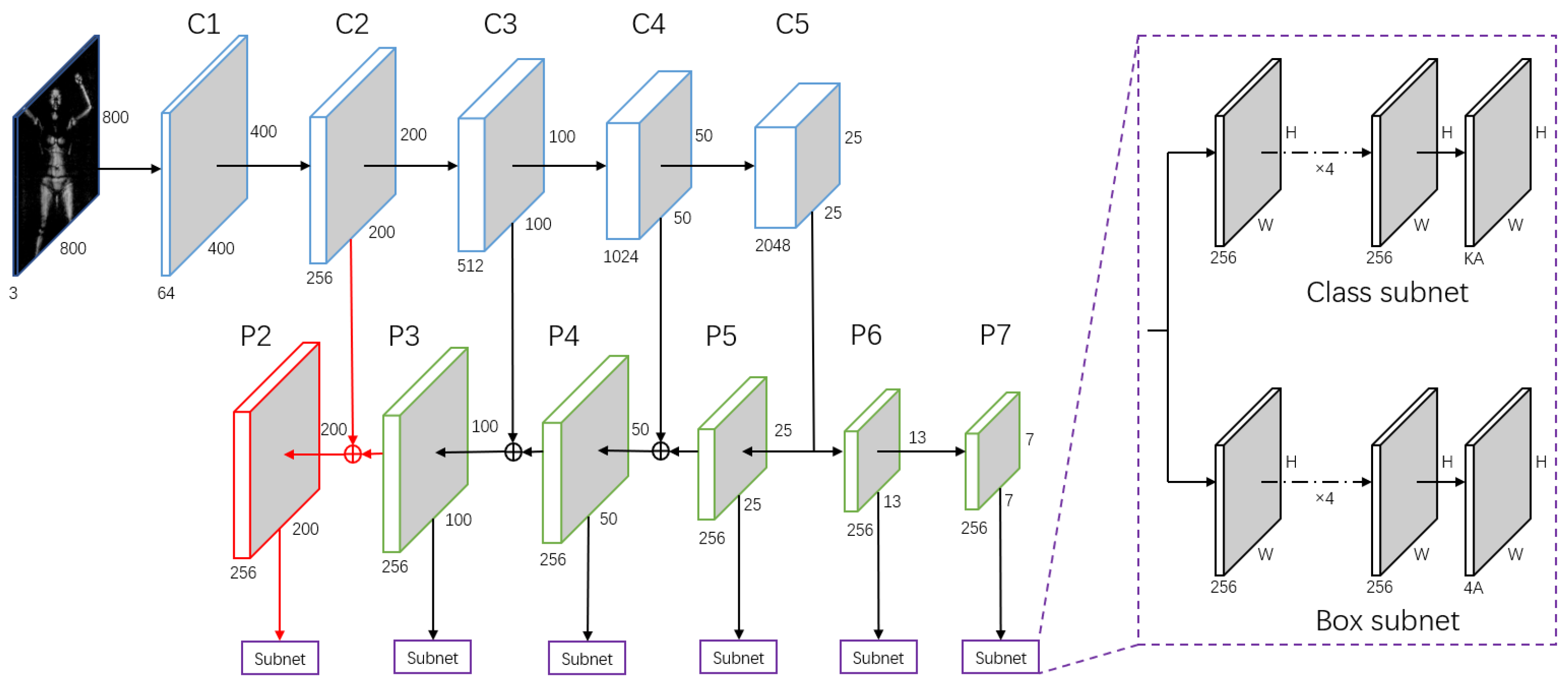
4.1. The Basic Detector
4.2. Hard Example Mining Approach
| Algorithm 1: Hard example mining process. |
Input: : Detector : Basic terahertz images : Hard examples : Training examples : Percentage of hard example : Training loops for hard examples 1 /* Stage one */ 2 Initialize Use to train until convergence 3 /* Stage two */ 4 while
Loss reduction
do  13end |
5. Results and Discussion
5.1. Single Class Comparison Experiments
5.2. Multi-Class Comparison Experiments
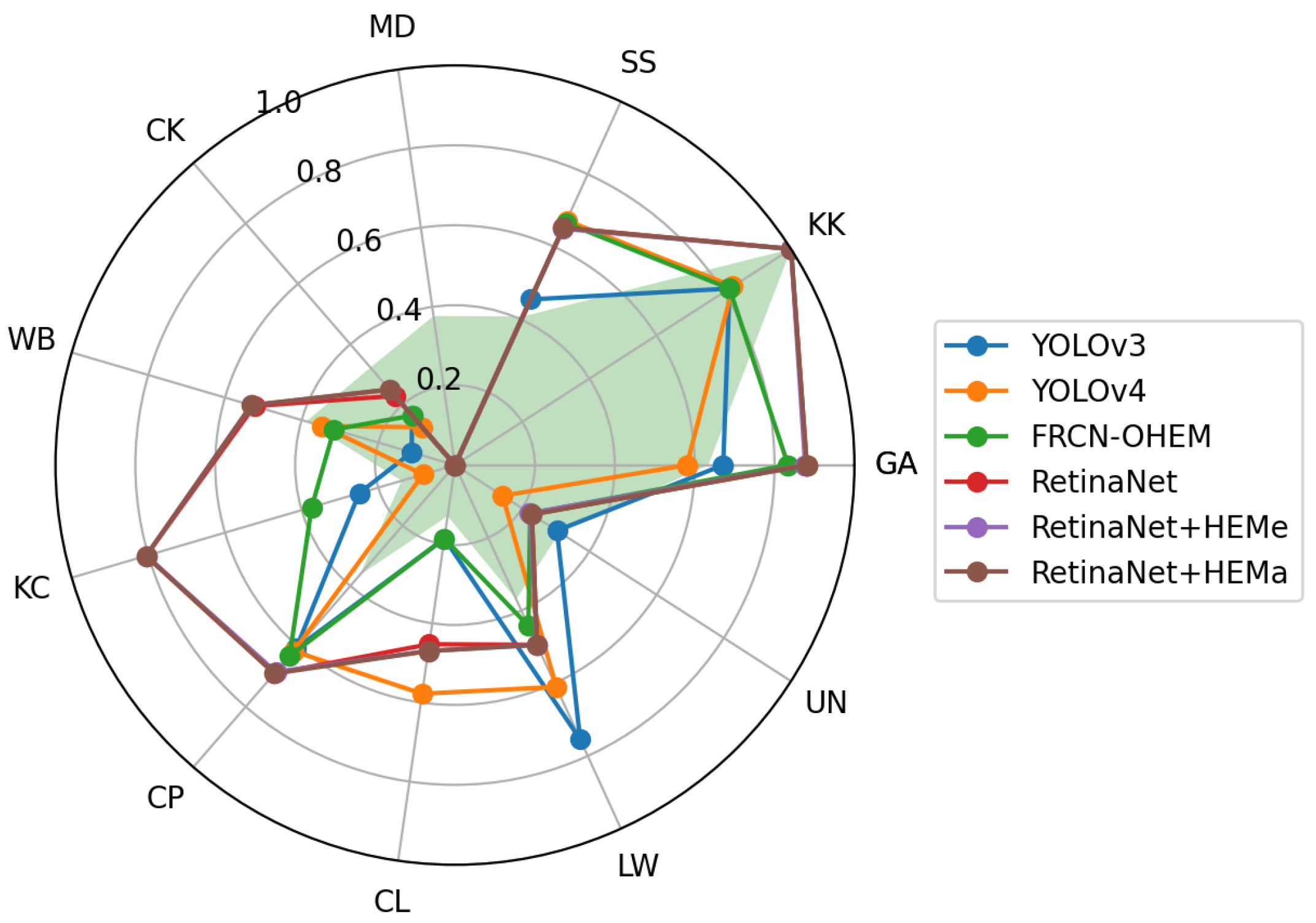
5.3. Position Analysis of Object in Terahertz Imaging
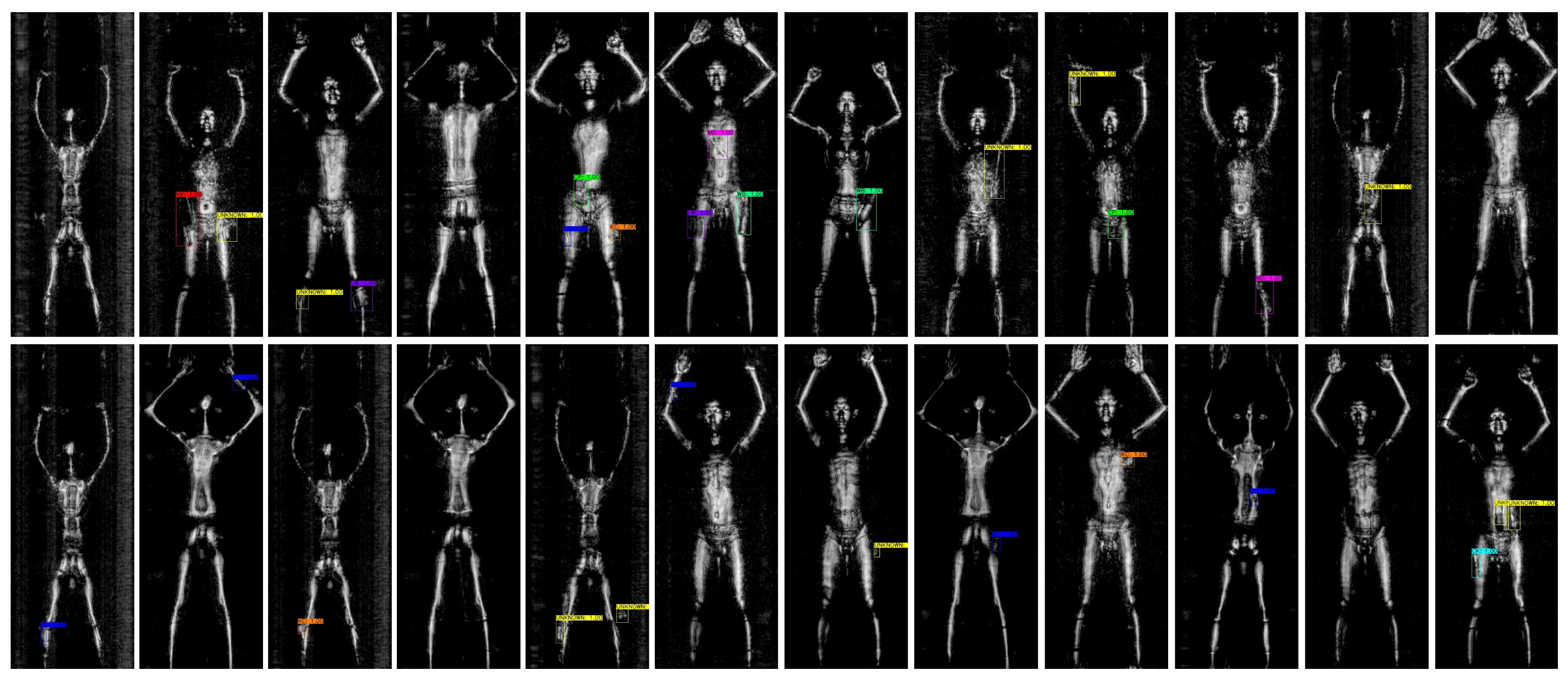
5.4. Image-Level Detection Performance
5.4.1. The General Test Result
- ObjDetection: the detector marks the location of the hidden object, and the IoU between the detection bounding box and the ground truth bounding box is more than 50%.
- ObjFalseAlarm: the detector marks the location of the hidden object, but there are no objects.
- ImgDetection: if some or all of the hidden objects in a terahertz image are ObjDetection.
- ImgFalseAlarm: if there is any ObjFalseAlarm in a terahertz image.
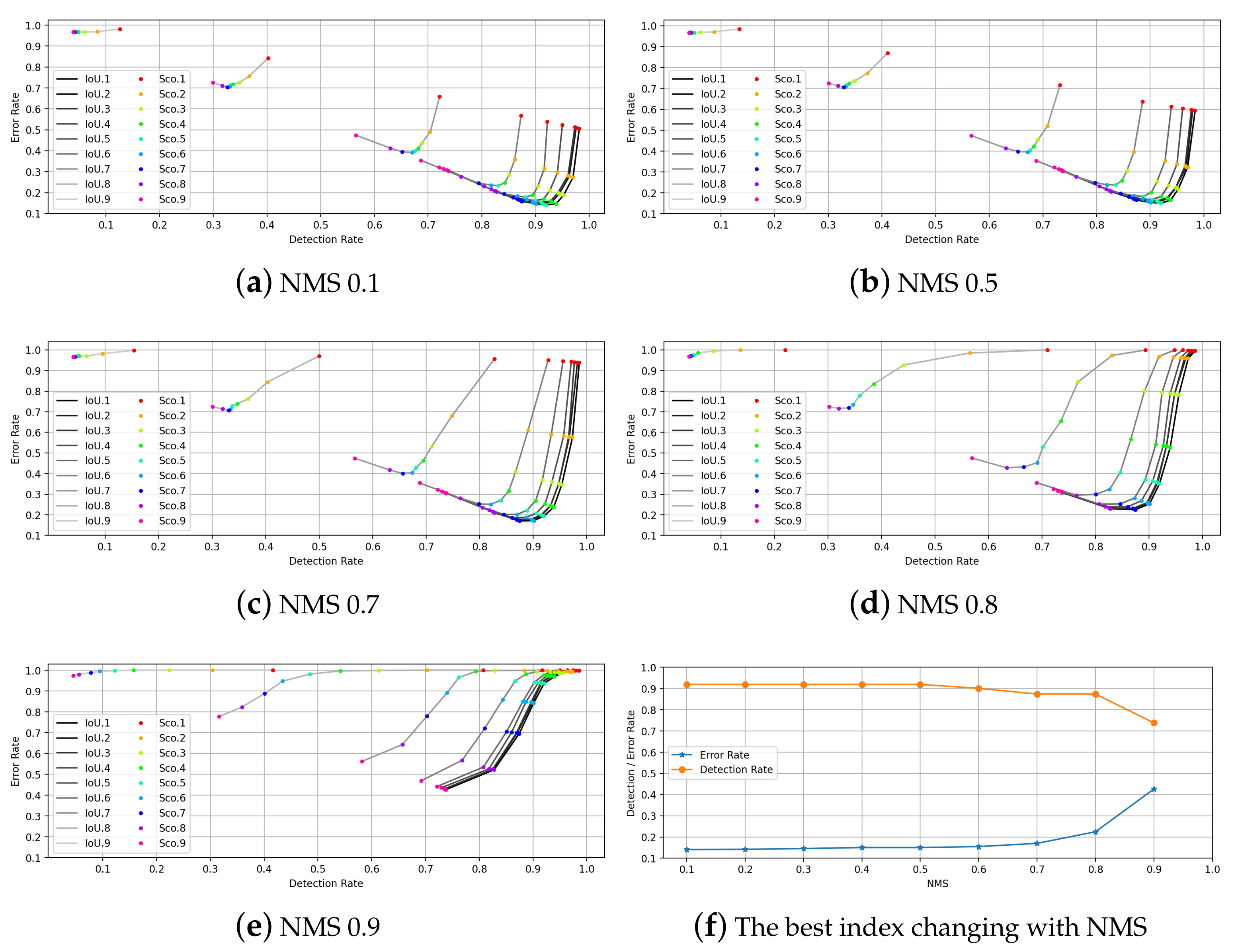
5.4.2. Balance of Detection Rate and False-Alarm Rate
- (1)
- Ranking of all candidate bounding boxes according to their confidence scores;
- (2)
- Select the bounding box with the highest confidence score to add to the final output list and remove it from the list of candidate bounding boxes;
- (3)
- Calculate the IoU of the bounding box with the highest confidence score against the other candidate boxes and remove the bounding boxes with an IoU greater than a threshold;
- (4)
- Repeat the above (2)∼(3) process until the list of bounding boxes is empty.
5.5. Discussion
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Kowalski, M.; Kastek, M.; Walczakowski, M.; Palka, N.; Szustakowski, M. Passive Imaging of Concealed Objects in Terahertz and Long-Wavelength Infrared. Appl. Opt. 2015, 54, 3826–3833. [Google Scholar] [CrossRef]
- Cooper, K.; Dengler, R.; Llombart, N.; Bryllert, T.; Chattopadhyay, G.; Mehdi, I.; Siegel, P. An Approach for Sub-Second Imaging of Concealed Objects Using Terahertz (THz) Radar. J. Infrared Millim. Terahertz Waves 2009, 30, 1297–1307. [Google Scholar] [CrossRef]
- Yan, X.; Liang, L.; Yang, J.; Liu, W.; Ding, X.; Xu, D.; Zhang, Y.; Cui, T.; Yao, J. Broadband, Wide-Angle, Low-Scattering Terahertz Wave by a Flexible 2-Bit Coding Metasurface. Opt. Express 2015, 23, 29128–29137. [Google Scholar] [CrossRef] [PubMed]
- Helal, S.; Sarieddeen, H.; Dahrouj, H.; Al-Naffouri, T.Y.; Alouini, M.S. Signal Processing and Machine Learning Techniques for Terahertz Sensing: An Overview. arXiv 2021, arXiv:2104.06309. [Google Scholar]
- Yeom, S.; Lee, D.S.; Son, J.Y.; Jung, M.K.; Jang, Y.; Jung, S.W.; Lee, S.J. Real-time outdoor concealed-object detection with passive millimeter wave imaging. Opt. Express 2011, 19, 2530–2536. [Google Scholar] [CrossRef]
- Shen, X.; Dietlein, C.R.; Grossman, E.; Popovic, Z.; Meyer, F.G. Detection and segmentation of concealed objects in terahertz images. IEEE Trans. Image Process. 2008, 17, 2465–2475. [Google Scholar] [CrossRef] [PubMed]
- Liang, D.; Pan, J.; Yu, Y.; Zhou, H. Concealed object segmentation in terahertz imaging via adversarial learning. Optik 2019, 185, 1104–1114. [Google Scholar] [CrossRef]
- Redmon, J.; Farhadi, A. Yolov3: An Incremental Improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Bochkovskiy, A.; Wang, C.Y.; Liao, H.Y.M. YOLOv4: Optimal Speed and Accuracy of Object Detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Shrivastava, A.; Gupta, A.; Girshick, R. Training Region-Based Object Detectors with Online Hard Example Mining. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 761–769. [Google Scholar]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal Loss for Dense Object Detection. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]
- Jia-Xiong, Y.; Ming-Hui, Y.; Yu-Kung, Z.; Liang, W.; Xiao-Wei, S. Using convolutional neural network to localize forbidden object in millimeter-wave image. J. Infrared Millim. Waves 2017, 36, 354–360. [Google Scholar]
- Wang, C.J.; Sun, X.W.; Yang, K.H. A low-complexity method for concealed object detection in active millimeter-wave images. J. Infrared Millim. Waves 2019, 38, 32–38. [Google Scholar]
- Kowalski, M. Hidden Object Detection and Recognition in Passive Terahertz and Mid-Wavelength Infrared. Infrared Millim. Terahertz Waves 2019, 40, 1074–1091. [Google Scholar] [CrossRef] [Green Version]
- Kowalski, M. Real-Time Concealed Object Detection and Recognition in Passive Imaging at 250 GHz. Appl. Opt. 2019, 58, 3134–3140. [Google Scholar] [CrossRef] [PubMed]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. SSD: Single Shot Multibox Detector. In European Conference on Computer Vision; Springer: Amsterdam, The Netherlands, 2016; pp. 21–37. [Google Scholar]
- Dai, J.; Li, Y.; He, K.; Sun, J. R-FCN: Object Detection via Region-Based Fully Convolutional Networks. In Advances in Neural Information Processing Systems; NeurIPS: Barcelona, Spain, 2016; pp. 379–387. [Google Scholar]
- Zhang, J.; Xing, W.; Xing, M.; Sun, G. Terahertz Image Detection with the Improved Faster Region-Based Convolutional Neural Network. Sensors 2018, 18, 2327. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. In Advances in Neural Information Processing Systems; NeurIPS: Montreal, QC, Canada, 2015; pp. 91–99. [Google Scholar]
- Li, M.; Zhang, Z.; Yu, H.; Chen, X.; Li, D. S-OHEM: Stratified Online Hard Example Mining for Object Detection. In CCF Chinese Conference on Computer Vision; Springer: Tianjin, China, 2017; pp. 166–177. [Google Scholar]
- Everingham, M.; Van Gool, L.; Williams, C.K.; Winn, J.; Zisserman, A. The Pascal Visual Object Classes (VOC) Challenge. Int. J. Comput. Vis. 2010, 88, 303–338. [Google Scholar] [CrossRef] [Green Version]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
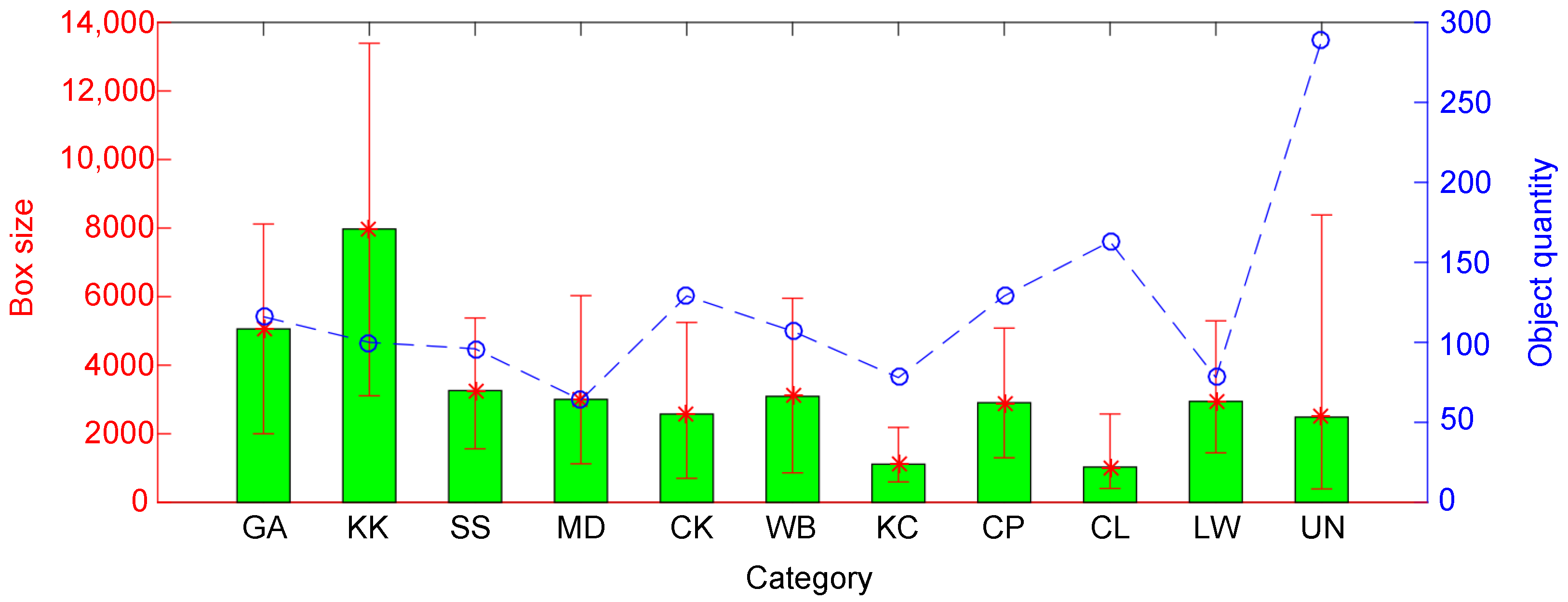
| Class | GA | KK | SS | MD | CK | WB | KC | CP | CL | LW | UN |
|---|---|---|---|---|---|---|---|---|---|---|---|
| Item | Gun | Kitchen Knife | Scissors | Metal Dagger | Ceramic Knife | Water Bottle | Key Chain | Cell Phone | Cigarette Lighter | Leather Wallet | Unknown |
| Qty. | 116 | 100 | 96 | 64 | 129 | 107 | 78 | 129 | 163 | 78 | 289 |
| Item | Detail |
|---|---|
| Number of images | 3157 |
| Image size and format | 335 × 880 p.x. JPEG |
| Imaging resolution | 5 × 5 mm |
| Models | 4 males, 6 females |
| Number of categories | 11 |
| Objects per image | 0, 1, 2, 3 |
| Maximum object size | 13,390 p.x. |
| Average object size | 3222 p.x. |
| Minimum object size | 390 p.x. |
| Testing set | 316 images |
| Hard Example Ratio (%)∖Training Loop | 10 | 20 | 30 |
|---|---|---|---|
| 0 | 68.01 | 68.01 | 68.01 |
| 5 | 69.55 | 69.57 | 69.49 |
| 10 | 69.58 | 69.63 | 69.59 |
| 20 | 69.56 | 69.60 | 69.55 |
| Method | GA | KK | SS | MD | CK | WB | KC | CP | CL | LW | UN | mAP |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| YOLOv3 | 67.15 | 81.69 | 45.56 | 0.0 | 16.39 | 11.29 | 25.00 | 60.74 | 18.57 | 75.43 | 30.35 | 39.29 |
| YOLOv4 | 58.05 | 82.72 | 67.27 | 0.0 | 12.50 | 34.72 | 8.33 | 61.62 | 54.79 | 61.02 | 14.23 | 41.39 |
| FRCN-OHEM | 83.39 | 81.69 | 66.67 | 0.0 | 16.39 | 31.56 | 37.38 | 63.21 | 18.57 | 44.23 | 22.38 | 42.32 |
| RetinaNet | 88.07 | 100.0 | 65.24 | 0.0 | 22.92 | 52.38 | 80.56 | 69.00 | 45.28 | 49.44 | 22.86 | 54.16 |
| RetinaNet + HEM | 87.67 | 100.0 | 65.00 | 0.0 | 25.01 | 53.12 | 80.56 | 68.48 | 47.00 | 49.44 | 22.23 | 54.41 |
| RetinaNet + HEM | 88.07 | 100.0 | 65.24 | 0.0 | 25.01 | 53.12 | 80.56 | 69.00 | 47.00 | 49.44 | 22.86 | 54.57 |
| Model | On Arms (8) | On Body (69) | On Legs (70) | Parallel (95) | Perpendicular (52) |
|---|---|---|---|---|---|
| YOLOv4 | 0.2500 | 0.4783 | 0.6143 | 0.5789 | 0.4423 |
| FRCN-OHEM | 0.375 | 0.4638 | 0.5000 | 0.5158 | 0.4038 |
| RetinaNet | 0.5000 | 0.4928 | 0.7000 | 0.6105 | 0.5577 |
| Method | DR (%) | FAR (%) |
|---|---|---|
| YOLOv4 | 84.49 | 0.63 |
| FRCN-OHEM | 88.86 | 18.99 |
| RetinaNet | 91.46 | 1.27 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, L.; Xue, F.; Liang, D.; Chen, X. A Hard Example Mining Approach for Concealed Multi-Object Detection of Active Terahertz Image. Appl. Sci. 2021, 11, 11241. https://doi.org/10.3390/app112311241
Li L, Xue F, Liang D, Chen X. A Hard Example Mining Approach for Concealed Multi-Object Detection of Active Terahertz Image. Applied Sciences. 2021; 11(23):11241. https://doi.org/10.3390/app112311241
Chicago/Turabian StyleLi, Ling, Fei Xue, Dong Liang, and Xiaofei Chen. 2021. "A Hard Example Mining Approach for Concealed Multi-Object Detection of Active Terahertz Image" Applied Sciences 11, no. 23: 11241. https://doi.org/10.3390/app112311241