
Crowdsourced Evaluation of Robot Programming Environments: Methodology and Application


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
Problem Statement
- Is the crowdsourcing approach a feasible and repeatable method of evaluation of web-based robotic programming interfaces?
- To what extent can crowdsourcing support the usability evaluation of a web-based robotic programming interface?
- How diversified is the audience in a crowdsourcing platform of choice (i.e., Amazon mTurk) both from a demographic and technical expertise point of view?
- What are the strengths and weaknesses of the simplified robot programming tool used during the evaluation (i.e., Assembly—https://assembly.comemak.at accessed on 11 November 2021)?
2. Related Work: Crowdsourcing in the Context of User Studies
- Traditional user studies: These studies are being conducted in the field or in the lab, requiring both study participants and evaluators to come to a certain location. This obviously takes more time to perform and means higher costs, since the required effort is higher, having a lower number of participants as a consequence. Applying this in the context of evaluation of robotic programming interfaces, additional limitations in terms of finding knowledgeable or voluntary study participants, robot access, safety, and platform availability emerge. As the authors of [11] define it, the typical research cycle passes through four main stages, starting with the method formulation, method implementation, conducting the user study, and, finally, presentation of the results. The last step is where the next delay due to lack of time mostly happens, because neither the presented results nor the lessons learned are significant if not implemented into the final product [11].
- Crowdsourced user studies: Following [11], in order to progress in robotics, it is indispensable to build professional-grade robots and create user evaluation research appropriate for and available to the masses. Conducting web evaluations seems an obvious answer to this issue, benefiting even more from the use of crowdsourcing platforms.
- possible and relatively simple to use for an inexperienced user programming interface;
- complex enough for more advanced users to allow for developing more complex or completely new use cases.
3. Materials and Methods
3.1. Assembly
- Actors (Blocks)Assembly implements block-based actors. As visible from Figure 1, most of the basic programming concepts already exist. The first row consists of the actors who are meant for precise movement of the entire robot (move to), adjusting the robot’s gripper position (dp, dr), opening and closing the gripper, and defining a dynamic action. The second row consists of basic conditional statements, such as if, else, elseif, and also loops such as while and repeat. The final row is meant for explicit parameter, variable, and condition setting.Assembly’s core idea is to simplify block creation, use, and reuse by standardizing them.Additional help is offered to the end user via the “help option” (Figure 2). It can be easily accessed merely by clicking on each actor and appears as follows:
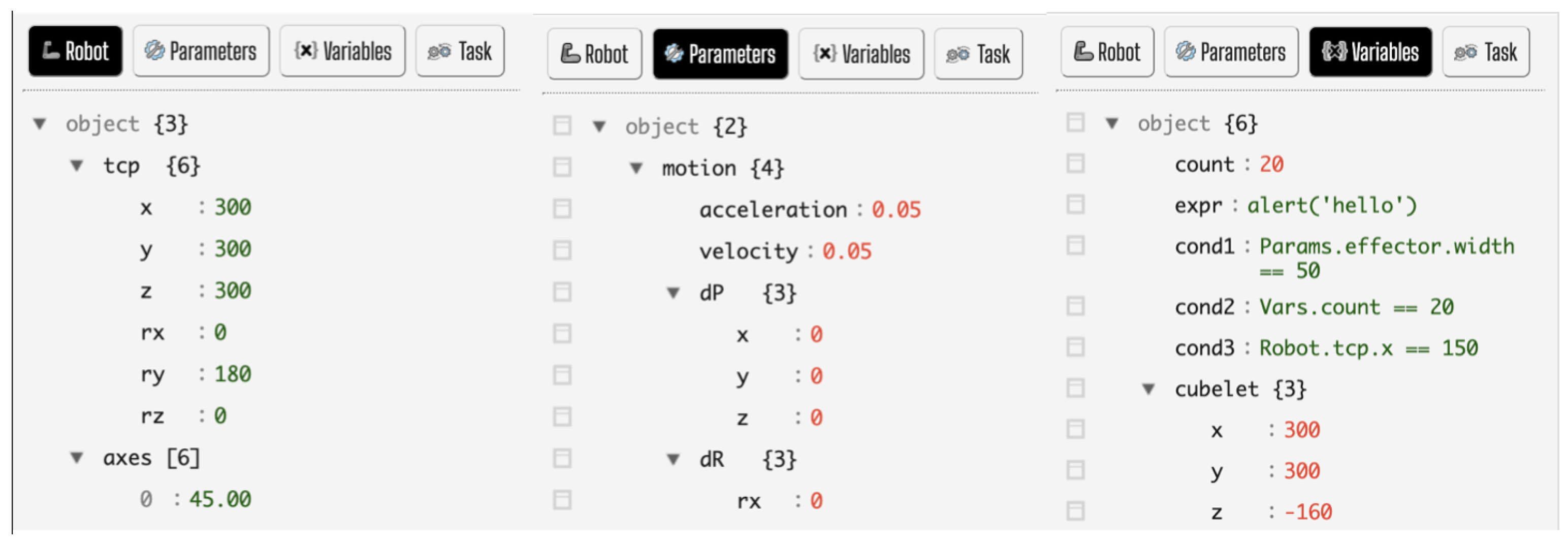
- BlackboardThe blackboard is a behavioral design pattern used in computer programming, which is used to prioritize the actors of different systems that are bound to work either in parallel or sequentially in certain programs [38]. In Assembly, this concept is used to ease the creation and management of the actors.As visible from Figure 3, the Assembly blackboard uses the following three objects:
- (a)
- “Robot” is a read-only object containing the state of the robot, including the joint angles and the coordinates of the end effector.
- (b)
- “Parameters” object contains a list of parameters used by the actors from the actor library. Only their values can be modified; the object’s name or structure cannot.
- (c)
- “Variables” object is editable by end users, and the input is then used for the conditional and loop enabling statements.
The “Parameters” and ”Variables“ objects can be edited by users using an embedded JSON editor [39]. - TasksA workflow can be created by linking a series of actors together. This workflow can then be easily saved via a bookmarking option and subsequently reused as a standalone task or part of another task. Creating a new task is as easy as dragging and dropping necessary actors between the start and stop buttons, automatically triggering the saving of snapshots of the “Parameters” and “Variables” objects. When loading a task, the content of the global “Parameters” and “Variables” objects is overwritten by the content of the saved snapshots.When loading a bookmarked task, it will appear as an additional task actor in the actor and task library region. To create compound tasks by reusing, it is essential to load each task individually. The best practice suggests saving an empty task, loading it, and subsequently loading all the other saved tasks within it. This will be the final use case scenario.The intention behind task creation is threefold:
- (a)
- simplified creation and organization of the robot programs within the browser;
- (b)
- reusing tasks via aggregation;
- (c)
- sharing with other users and exporting tasks effortlessly as browser bookmarks.
- SimulatorAssembly uses an adapted version of a six degrees of freedom (DOF) robot simulator by [40]. The simulator is embedded in the right-hand side of the Assembly environment. The “Robot” object contains the axis angles corresponding to a certain tool center point (TCP) position. The robot can be controlled either using the text input boxes on the upper right side of the page or using the mouse. The TCP needs to be clicked to move the robot around. This currently only works on Windows systems. The exact position of the robot’s TCP is updated in the controls area and the “Robot” object on the blackboard:A snapshot of each robot pose is stored as a thumbnail within the “move to” actor. When used in a workflow, this actor will move the robot to this pose. This way, different poses can be stored by first dragging the robot to the desired position and then dragging a “move to” actor to the workflow. This corresponds to a teach-in procedure, which is a common method of programming robot behaviors.
- RobotAssembly is set to be used both for online and offline robot programming. In the former case, the generated Assembly code will be sent to a web service, which will then trigger low-level robot handling functions. Currently, only Universal Robots [41] are supported. Connecting to the robot is relatively straightforward and is done by activating the “Connect to robot” switch in the upper part of the simulator. Connecting to an actual robot is beyond the scope of this paper.
3.2. Amazon mTurk
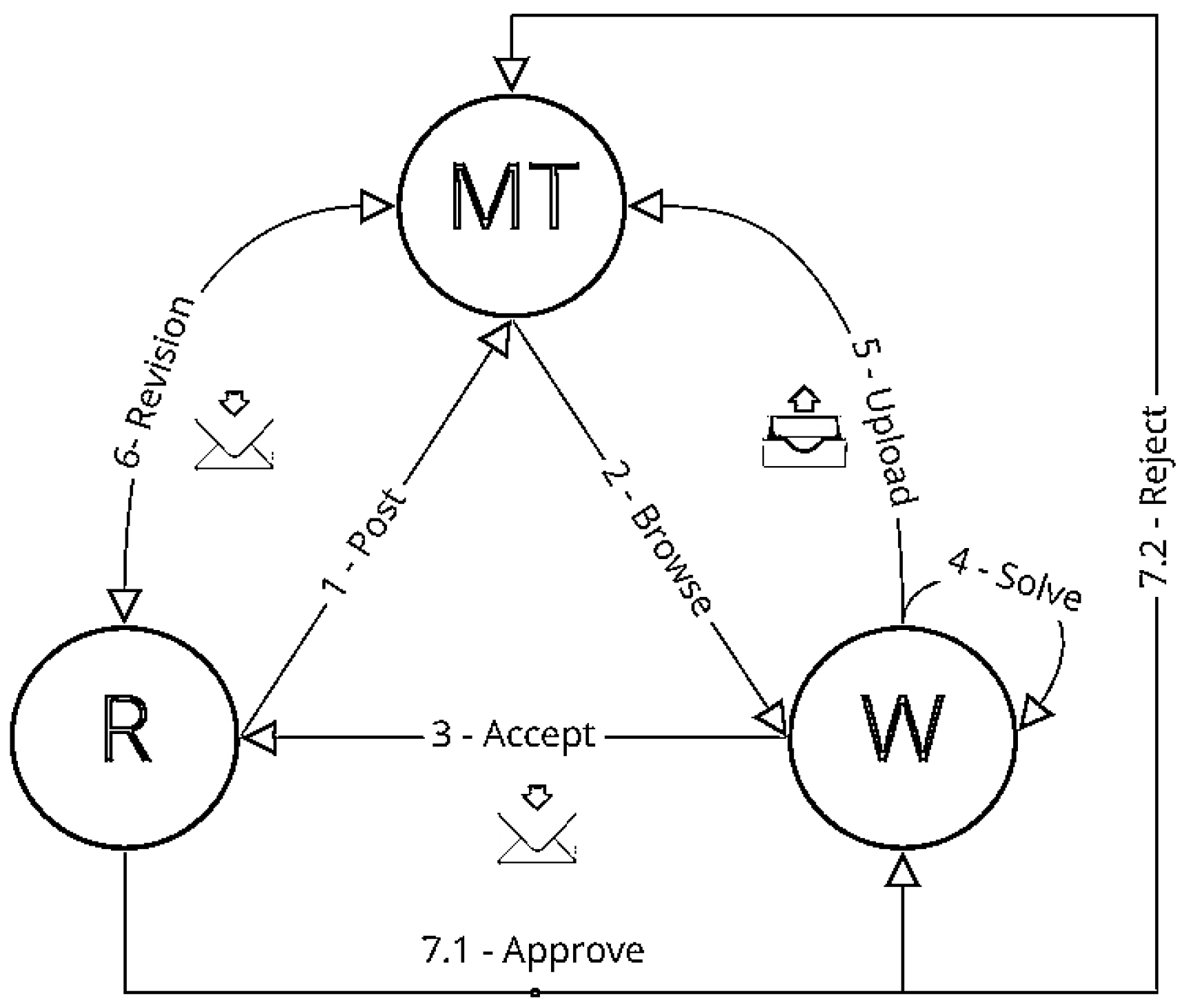
- Starting from the lower left circle, marked with “R” for “Requester”, the work is published on the crowdsourcing platform in the form of a HIT. Requesters are usually companies, research institutions, or any other individual offering the digital task.
- mTurk [42] (marked with “MT”) is the crowdsourcing platform of choice, which hosts and shows all available assignments to all potential mTurk workers. mTurk grants the “R” high-level control of who can see or accept their tasks by keeping a set of metrics for each registered worker. There are three system qualifications available free of cost:
- (a)
- Number of HITs approvedThis is the number of HITs that one worker has successfully completed since their registration on mTurk. This is the base rate that requesters use to select workers with existing experience. According to [22], higher than the 90% mark provides a good rule of thumb.
- (b)
- HIT approval rateThis is the rate of accepted and completed HITs. For example, if a worker has completed 1000 HITs, out of which 150 were rejected, the worker’s approval rate is 85%.Experienced requesters report that the combination of these two qualifications usually delivers results of significantly higher quality.
- (c)
- LocationThis qualification is important if a requester needs to filter workers by geographical location, which the workers usually specify in their profile. The location filter can be used to include or exclude workers from a specific continent, country, county, or even city.
Additionally, the possibility of setting up two premium or entirely customized qualifications exists. These kinds of qualifications induce additional charges and include age, gender, frequency of participation in the platform, or the type of smartphone owned by workers (important for smartphone software usability testing) [42]. - To complete the first cycle, the mTurk workers (marked with “W”), on their own initiative, browse and decide to accept the offered assignment. “R” is notified about every assignment acceptance or rejection.
- “W” starts solving the assignment immediately or according to the given time frame.
- Subsequently, “W” uploads its results to the platform.
- “R” is notified about the uploaded solution and has a limited, previously arranged, timeframe for revision.
- The requester then has two options:
- (a)
- In case of approved assignment, ”R” sends the agreed payment to “W”, with the non-obligatory possibility of offering and later paying the bonus, and also pays the fee to “MT” for providing the platform.
- (b)
- The other possibility is rejecting the assignment, which can only be authorized by “MT” if a valid argument for doing so is offered.
4. Crowdsourced Evaluation Methodology
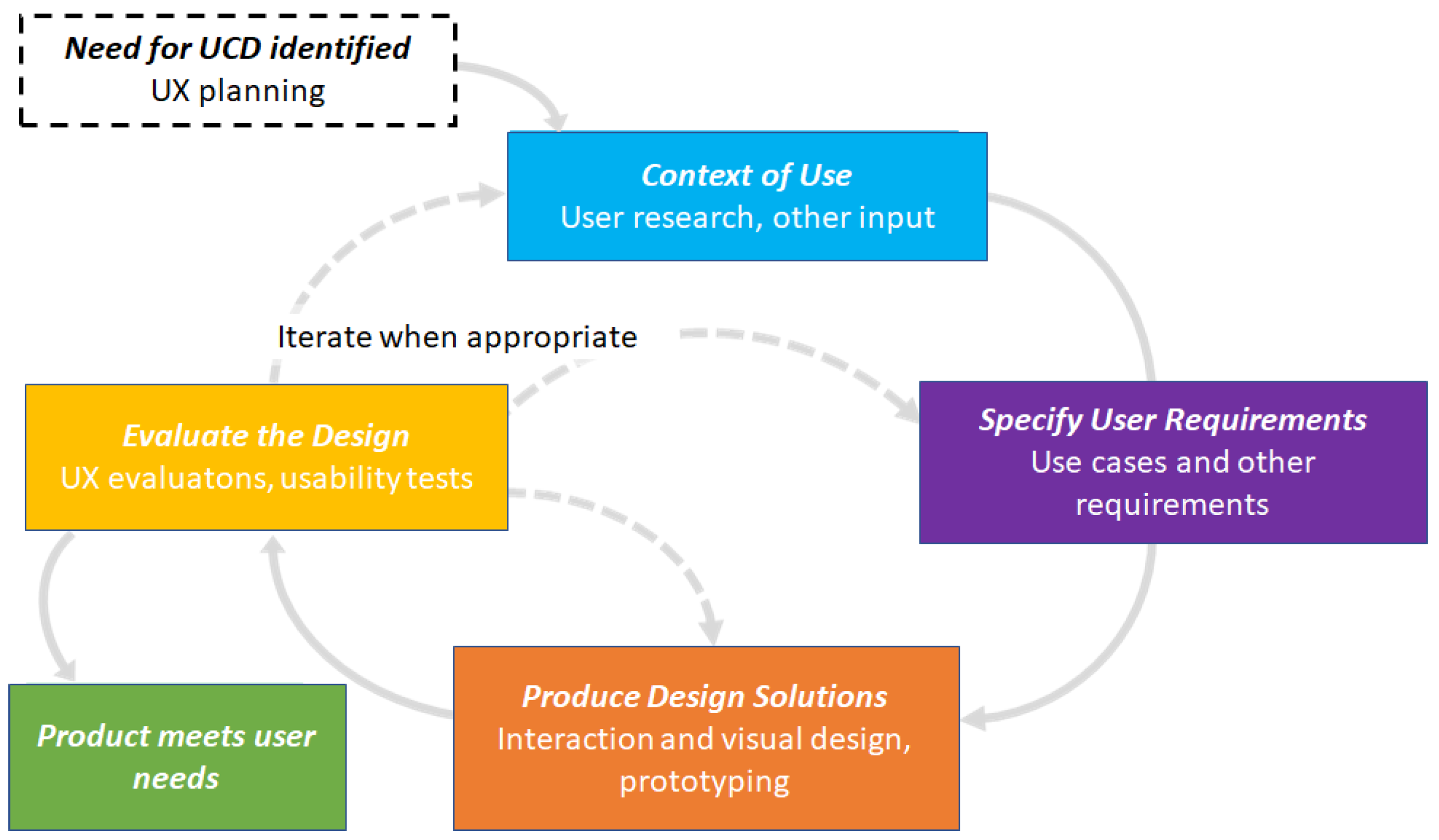
Methodological Framework
- Firstly, the need for a specific UCD task is identified through input and requirements from various stakeholders. In parallel, the work on the UX is planned considering time and other resources. This paper had a clear UCD task based on Assembly.
- Secondly, the context of use is specified based on user background research or other input. Since the main goal of the CoMeMak project is ensuring all interested stakeholders access to cobots in makerspaces and additionally addressing other issues regarding robots, the context of the use of Assembly here is defined rather broadly, with user profiles being diverse and unspecified. The projected users of the Assembly tool should have basic computer skills and technical understanding. These prerequisites are also required of mTurk workers in order for them to be able to navigate the platform.
- The third step handles user requirement specification. It is suggested to define and document relevant use cases in order to model the specifications. The use cases should be initially simple to allow the user to get to know and use the program and then gradually upgrading the complexity. The business relevance should not be disregarded here. One strategy is to use simple tasks as a part of the assessment test to encourage only qualified users to participate in the entire crowdsourcing project and later raise the difficulty bar. If every participant can solve all the tasks, then the use cases should be made more difficult; otherwise, the results will not be within the scale.
- The fourth step delivers design solutions, such as UX concepts, tutorials, interaction evaluations, and prototyping.
- Finally, the UX design is evaluated by testers or real users. This paper will focus only on crowdsourced results. Normally, if the users’ design or functional needs are met, the entire UCD process is done. Otherwise, one or several iterations of one or more of the previous steps are necessary.
- The end result should be a ISO 9241-210 standard [44] approved product.
5. Application of the Framework
5.1. Task Specification: Evaluation of Web-Based Robotic Programming Interfaces
5.1.1. Evaluation Platform Selection: Amazon mTurk
5.1.2. Submission Tool Selection: ufile.io
5.1.3. Methodology Selection
5.1.4. Crowd Selection: Worker Profile
5.2. Validation
- number of submitted files;
- content of submitted files;
- content of the open-ended answers;
- minimum time needed to finish the study;
- overtaking placeholder values.
5.2.1. Test Run
5.2.2. Use Case Definition
HIT Instructions
Use Case Instructions
Use Case 1: Robot Motion
- Create a program that performs a robot motion between two points.
- The first point should be set to x = 100, y = 200, z = 300.
- Subsequently, drag the “move to” actor to a location between the “Start” and “Stop” actors in the workflow (i.e., robot task or program) to create/memorize the first waypoint.
- You can freely choose the second waypoint, but it has to be different from the first one.
- Then, add another “move to” actor to the workflow to create/memorize the second waypoint in the program.
- Repeat the motion a few times by clicking the play button.
- Note the correct order of successfully creating instructions.
- Do not refresh or close the browser tab, as you will need the current state for the next use case.
Use Case 2: Robot Motion in a Loop
- As you could see in the previous use case, you could repeat the movement manually by repeatedly clicking on the start button.
- Now, you want to automatize this by creating a simple programming loop. For this, you will use the repetition block called “repeat count”.
- Note that, when added to a workflow, the “repeat” block has two parts—a head part (a yellow box with the text “repeat count” on it) and a tail part (empty yellow box).
- Put both of the previously created “move to” actors between the head and the tail of the “repeat” actor simply by dragging and dropping them at the corresponding place. This actor uses a variable named “count”. Open the variables panel (i.e., “xVariables”) and set count = 3.
- Make sure to store this value in the program by adding the “Set variables” (i.e., “x”) actor to the workflow before dropping the “repeat” block.
- Now, click on the play button. Both movements should now be repeated three times.
Use Case 3: Creating a Placeholder Task
- You are now familiar with the basic robotic arm operations.
- Refresh the browser window to start with a clean task. Please don’t skip this step.
- Then, simply rename the task from “Untitled” to “mturk” (double click) and save it by dragging the disc icon to the browser’s bookmarks bar to save it.
- You will need it in the final task.
- No screenshot of this screen is necessary.
Use Case 4: Creating a Personalized Task
- Refresh the browser window to start with a clean task. Please don’t skip this step.
- You will now teach a robot to pick up the small blue cube. Set it to the following position: x = 300, y = 300, z = 89 and add the “move to” actor, same as in the 1st use case.
- Now, add the “close” actor to the workflow to close the gripper and grab the cube. Then, drive the robot to x = 300, y = 300, z = 300, and add another “move to” actor.
- Finally, rename the task from “Untitled” to pick and save it by dragging the disc icon to the browser’s bookmarks bar.
- Run the task to pick the blue cube up.
- You have now created your first example of a personalized task.
Use Case 5: Building Upon Personalized Task
- Refresh the browser window to start with a clean task.
- Now, drive the robot to a “pre-place” location at about z = 200 above the table, then down to the table level (z = 89), and use the “open” actor to the workflow to release the gripper.
- Then, use the “relative motion” actor (->dP < dR) to drive the robot back up to z = 200 (the relative motion actor uses dP, dR parameters).
- So, select the parameters tab and set z = 111 so as for the robot to go to z = 200.
- After setting this parameter, drag and drop the “set parameters” actor into the workflow before the “relative motion” (->dP < Dr) actor.
- Rename the task to place and save it to the bookmarks, just as you did with the previous tasks.
Use Case 6: Building a Compound Task
- Refresh the browser window to start with a clean task.
- Now, load all of the previously saved tasks from the browser’s bookmarks, in the following order: pick, place and “mturk”.
- You will notice that they now appear in the “Actor and Task Library” and that you are currently in the “mturk” task. This allows you to load a fresh task without losing the pick and place tasks from the library.
- Finally, create one last task called Pick and place, merely containing the pick and place tasks as actors, and save it to the bookmarks bar.
5.2.3. Instruction Writing
- Read instructions carefully!
- Solve as many use cases as you can, documenting thoroughly in the feedback section if you got stuck somewhere.
- Before starting to solve the use cases, make sure you click on the dashboard icon on the lower right part of the screen.
- By doing so, the generated code will be shown in each screenshot you’re about to make.
- Make a screenshot after EVERY solved use case and UPLOAD it using [45].
- Make sure to refresh the browser after completing a program when you are asked to. You should upload 5 screenshots in total.
- Solve questionnaire.
- Skipping or not solving any use case without documenting the reason or missing 5 screenshot uploads will unfortunately result in a rejected HIT. Note that it is perfectly fine if you can’t solve one of the use cases but you MUST document the reason WHY you couldn’t finish it in the textual feedback section.
- Not refreshing the browser between the tasks when prompted will result in wrongly generated code.
- Not following all the instructions will result in not receiving credit for accomplishing our interactive experiment.
5.2.4. Demographic Questionnaire
- What is your age/gender/country you live in/highest finished level of education?
- Which university did you attend (university name + country)?
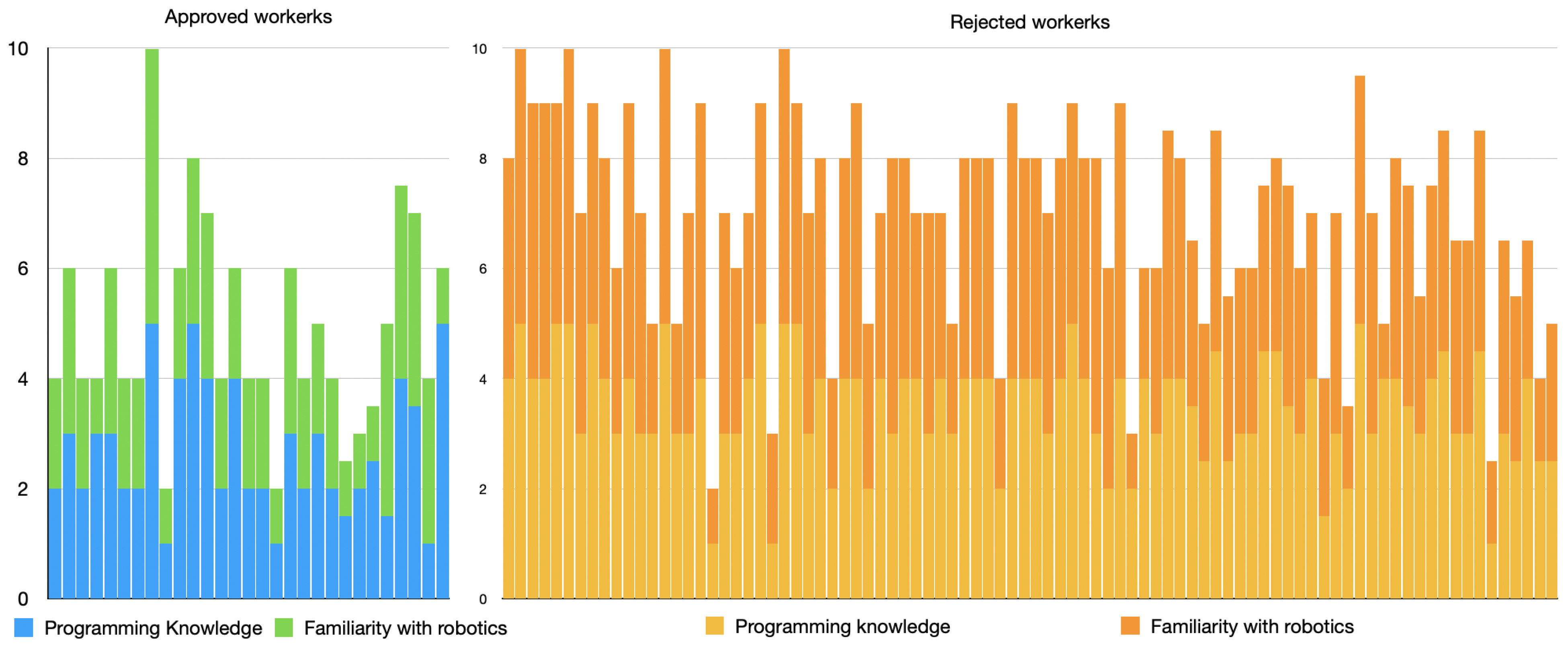
- On a scale of 1–5 (1 being the least and 5 the most), how much familiarity with programming/robotics do you have?
5.2.5. Scam Detection
- per-participant minimum and/or maximum processing time.
- the question about the attended university as an adaption of the so-called “instructional manipulation check” (IMC) from [47]. An Ivy League university (Harvard) was set as the default placeholder answer here. The idea was that a worker who either did not read the question properly or used a software robot that solved the task would simply overtake the placeholder text. The assumption behind this test is that someone with a Harvard University degree is unlikely to be active on Amazon mTurk.
- the presence of arbitrary text in required free-text fields.
- the presence of fake uploaded files or no uploaded files at all.
5.2.6. Payment
5.2.7. Test Runs QA
5.3. Execution
Test Setting and Procedure
5.4. Evaluation
- Qualitative analysisAfter the finished HIT, the following questions were asked per use case:
- –
- How understandable was this task’s description?
- –
- Could you easily understand what was asked of you in this task?
- –
- Did you manage to solve this task? (Yes/No)
- –
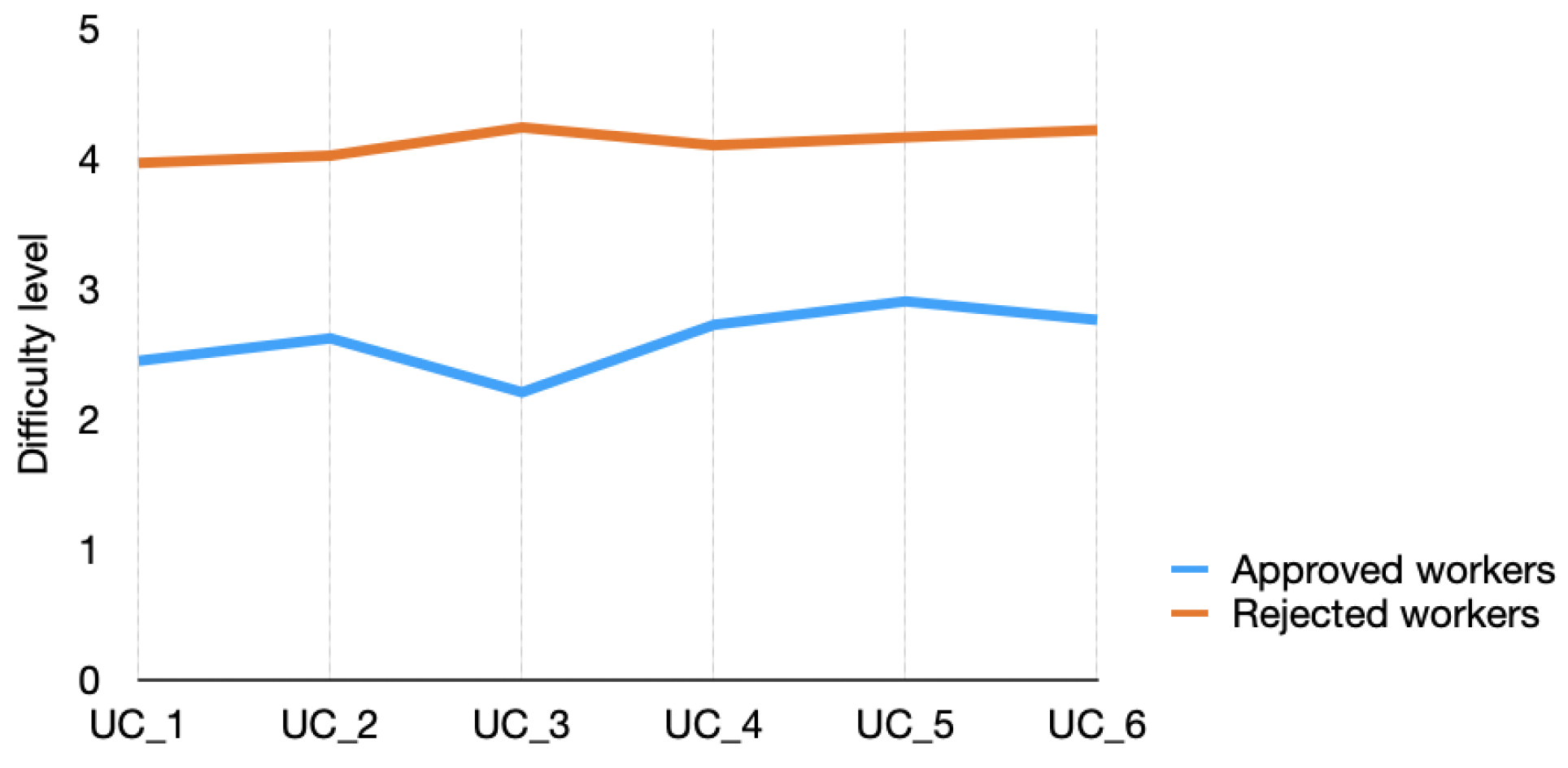
- How difficult did you find this task? (Likert scale 1–5)
- –
- If the response to the previous question was between 3 and 5: What was the most difficult thing about this task?
- –
- Do you think this UI has improvement potential?
- –
- What is one (any) thing you would like to change?
- Quantitative analysisCrowdsourced evaluation works hand in hand with quantitative testing because it automatically measures the performance of the design and tracks usability metrics easily since the data are being recorded automatically [48]. Predefined SUS questions were as follows:
- I think that I would like to use this system frequently.
- I found the system unnecessarily complex.
- I thought the system was easy to use.
- I think that I would need the support of a technical person to be able to use this system.
- I found the various functions in this system were well integrated.
- I thought there was too much inconsistency in this system.
- I would imagine that most people would learn to use this system very quickly.
- I found the system very cumbersome to use.
- I felt very confident using the system.
- I needed to learn a lot of things before I could get going with this system.
5.5. Results
6. Study Results
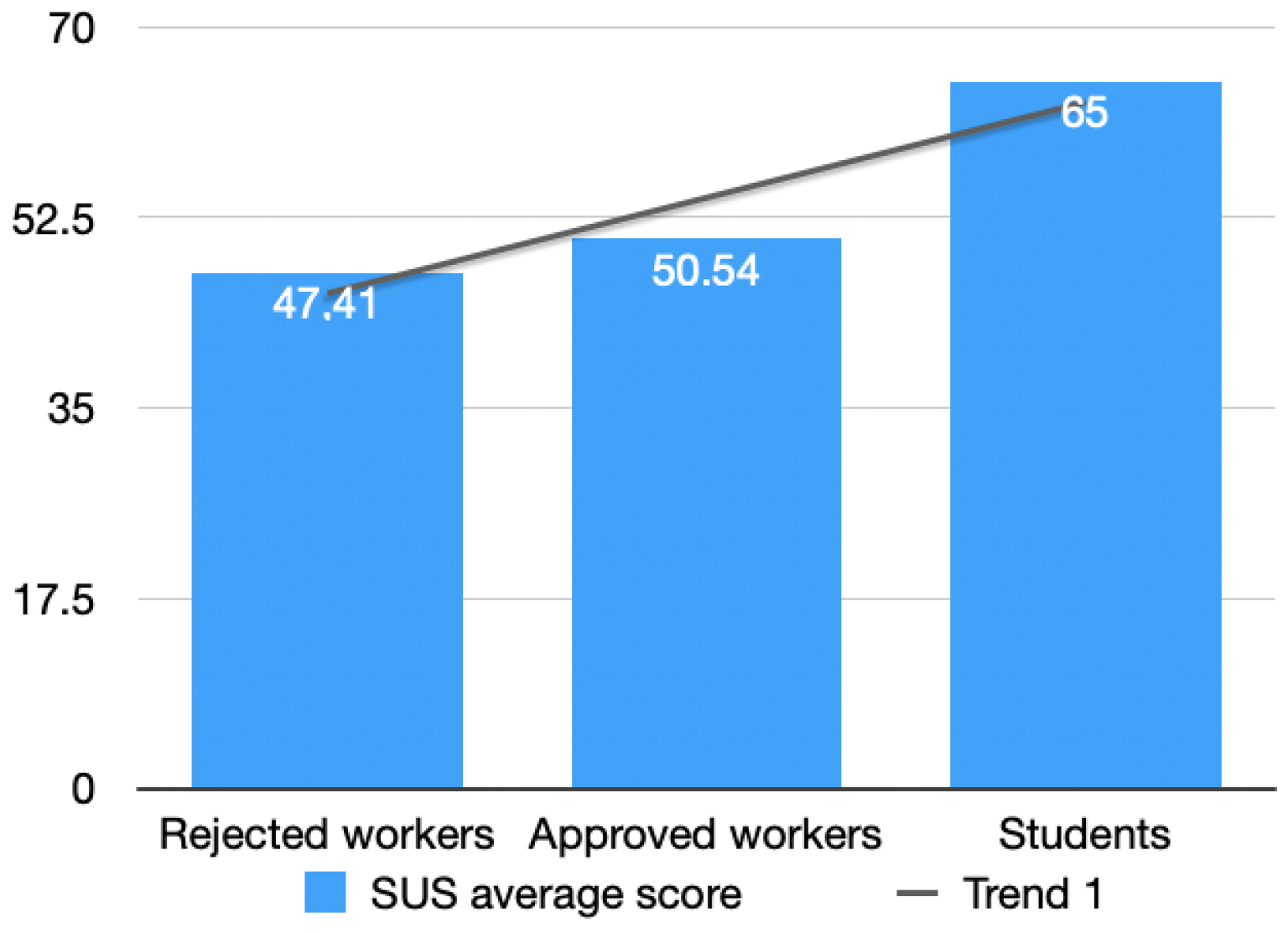
6.1. Student Study Results
6.2. Statistical Findings across All Groups
- Could the SUS evaluation results be considered relevant even if they originate from mTurk rejected worker’s input?
- Is there an observable pattern sample in rejected workers’ SUS evaluation results that can lead to early scammer recognition?
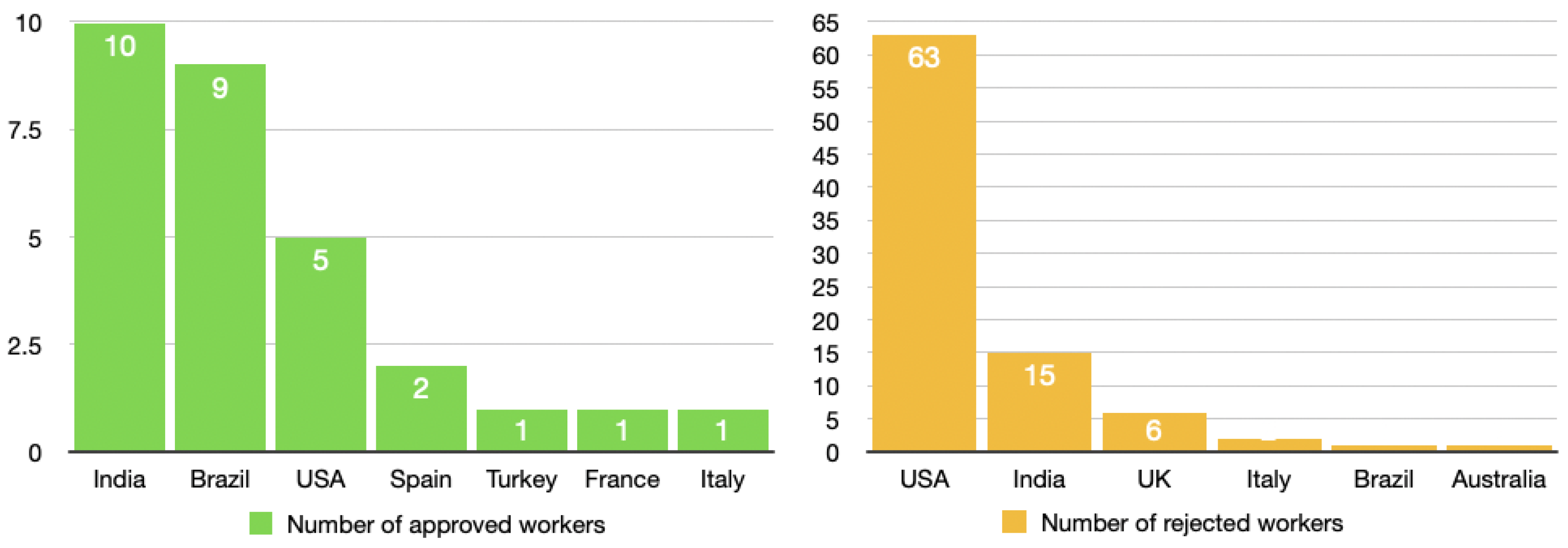
6.3. Demographic Analysis across All Groups
6.4. Improvement Suggestions Proposed by Workers across All Groups
- Did not understand what was meant by:
- Driving the robot;
- Taking a screenshot of the entire code or just the visible chunk.
- Had a hard time figuring out how to:
- Bookmark a task;
- Understand when the code is generated and subsequently copy it from the clipboard;
- Set variables, parameters, and the specific “relative motion” actor dp.
- Not functioning properly:
- Play button after the first use not executing correctly or at all;
- Browsers other than Google Chrome (robot disappearing from Safari);
- Saving tasks and also disappearance of individual tasks when refreshing the page;
- Cube on wrong coordinates;
- Glitch between the execution of pick and place tasks where robot drops the cube while continues its waypoint.
- Suggestions:
- The bookmarked actors should be shown separately after reloading the task;
- More specific instructions needed; image or video tutorials suggested, such as simplifying the help section;
- Less cluttered UI;
- Robotic arm should move using the mouse and keyboard.
- Uncategorized:
- Curiosity to observe the interaction with the real robot;
- More than three workers claimed not to have an idea where to even begin;
- Overtaking placeholder values was a recurring issue in open-ended questions;
- Even though the workers were kindly asked not to repeat the HIT, two did anyway and reported high learning effects, a shorter completion time, and a higher rating of the tool in the SUS scale;
- The file upload via external tool was cumbersome and probably more difficult than the entire task and took the longest time.
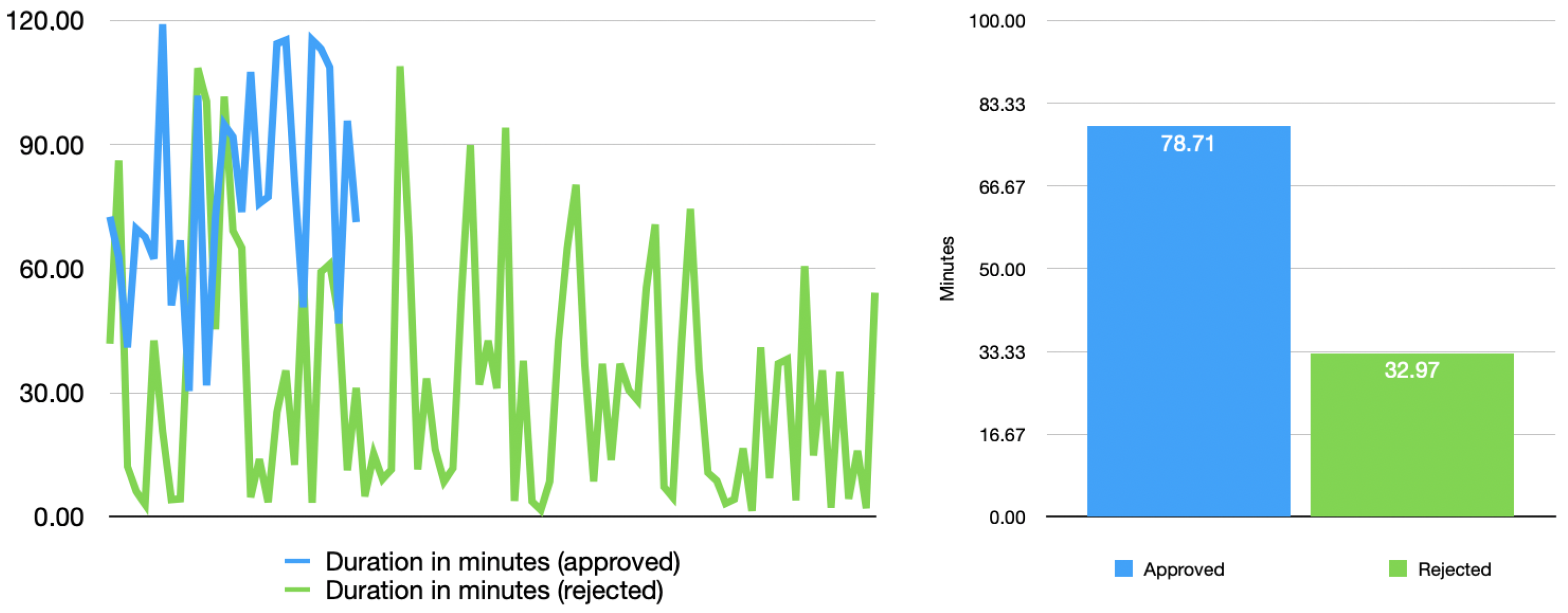
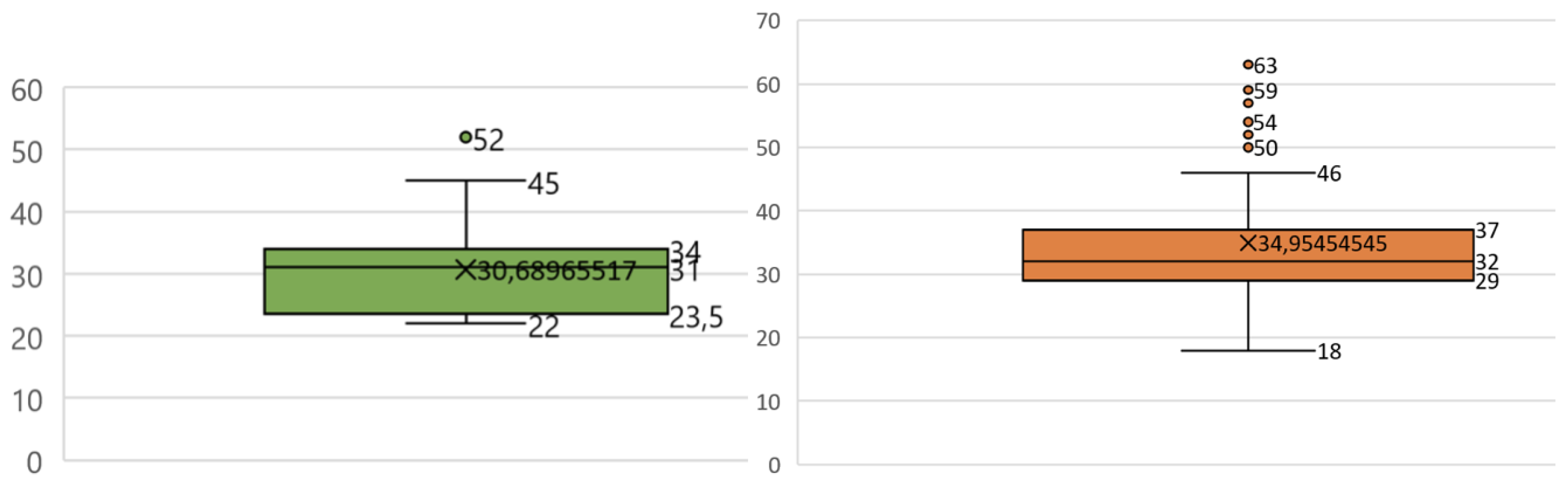
6.5. SUS Score of Approved Tasks
6.6. SUS Score of Rejected Tasks
7. Discussion and Outlook
7.1. Limitations of the Approach and Results
- data resulting from interactions that were not compliant with the instructions provided;
- solving the assignment using identical inputs from different mTurk accounts;
- random, automatically filled in content, mostly completely out of context.
7.2. Conclusions
Author Contributions
Funding
Informed Consent Statement
Conflicts of Interest
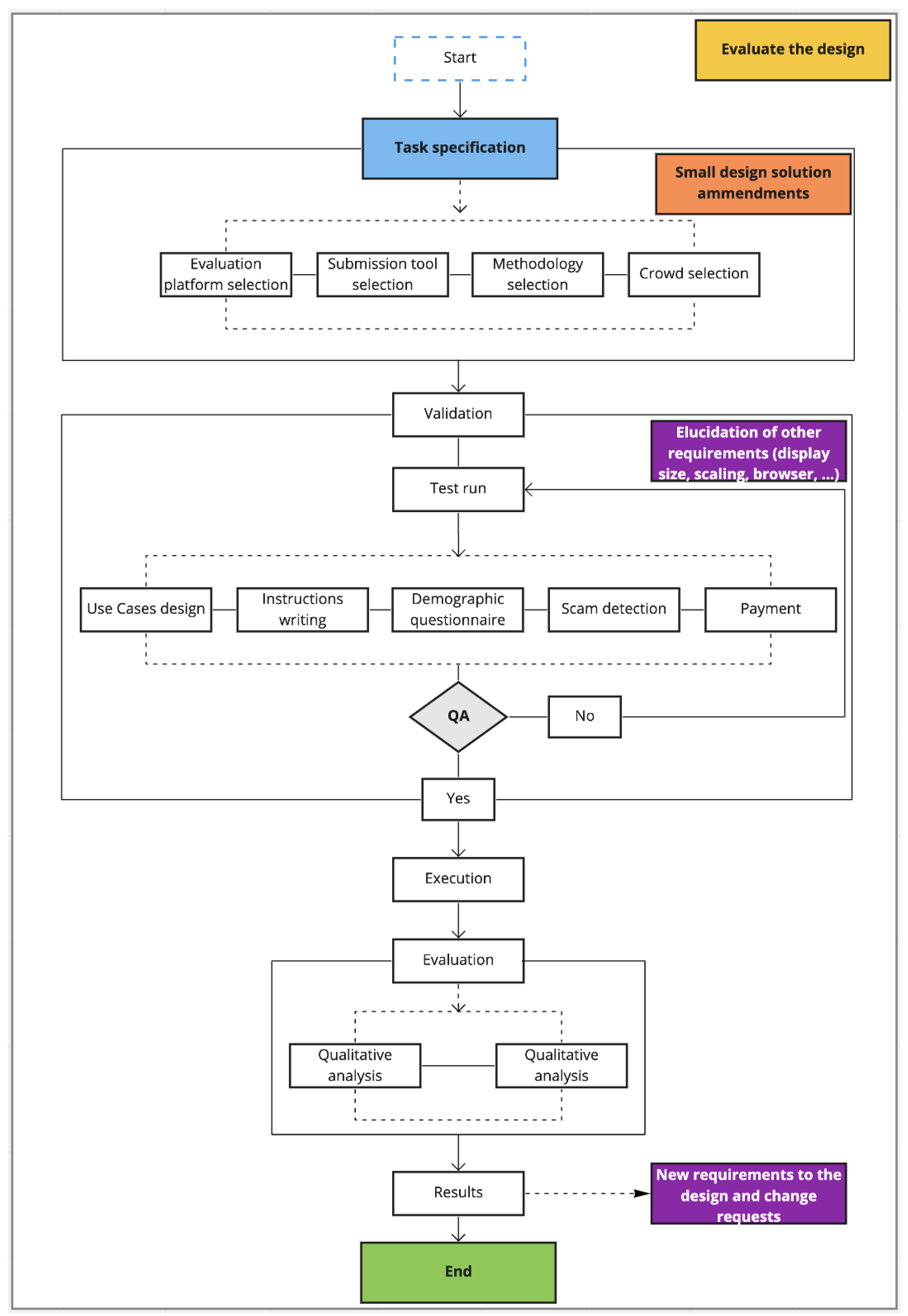
Appendix A. Detailed ISO 9241-210 Framework
Appendix A.1. Evaluation Platform Selection
Submission Tool Selection
Appendix A.2. Methodology Selection
- Iterative improvementsEspecially suitable for design assignments, these tasks are designed as competitions so that the workers are building upon each other’s solutions. In this model, workers are anonymously shown previous results from other workers and are basically asked to improve or build upon them.
- Non-iterative (linear) competitionThis kind of competition can be performed as a single or multistage task, which either compensates workers with rank payments or the best-rated result takes the largest financial award. In this model, competing workers do not collaborate, which is more appropriate for the purpose of evaluating software tools.
Appendix A.3. Crowd Selection
Appendix A.4. Validation
Appendix A.5. Test Run
Appendix A.6. Use Case Definition
Appendix A.7. Instruction Writing
Appendix A.8. Demographic Questionnaire
Appendix A.9. Scam Detection
Appendix A.10. Payment
Appendix A.11. Execution
- Moderated
- Non-moderatedThe most obvious advantage of non-moderated usability testing is that no moderator or location (such as lab spot) is necessary, which entails lower costs and quicker implementation. This implies that participants can complete the assignments at the time and place of their choosing, which is the definition of an uncontrolled environment. This setting also resembles more closely how a real user would interact with the program in their natural environment and therefore generates more authentic results.As with the remoteness factor, non-moderated execution contributes to the speed of result collection merely because it is not necessary to find a moderator or set a location and time for each session.Nonetheless, this usability testing execution method comes with disadvantages, notably in terms of less control over the entire test environment and evaluation procedure as a whole. In order to minimize the risk of misunderstanding and the need to ask questions during the evaluation itself, a great deal of thought and effort needs to be invested in the instruction writing phase. The author in [48] suggests writing an introductory context and guidelines at the beginning of the test to inform the participant of the session’s goals and to provide them with relevant contextual information that clears the participants’ doubts.In [65], both study participant groups delivered rather similar arguments, with non-moderating users reporting a higher percentage of high-relevance input. This could be the result of the positive effect of not being monitored, which seems to make participants more relaxed and creative.
Appendix A.12. Evaluation
- Qualitative analysisThe qualitative data are usually obtained using individual, subjective satisfaction questionnaires [67] or observations and analysis of participants’ input, in the form of task solutions or open-ended answers. Based on the requester’s own expertise in UX, and keeping the program’s known UX difficulties and limitations in mind, acknowledging and comparing these insights with the participants’ output should lead to clear ideas if a certain part of the UI needs to be redesigned [68].
- Quantitative analysisThe quantitative data include all numerical data, such as the time necessary to complete a task, amount of usability defects identified [67], or task completion rate.Crowdsourced evaluation works hand in hand with quantitative testing because it automatically measures the performance of the design and tracks usability metrics easily, since most of the data are calculated and reported automatically [48].
Appendix A.13. Results
References
- Huber, A.; Weiss, A. Developing Human-Robot Interaction for an Industry 4.0 Robot: How Industry Workers Helped to Improve Remote-HRI to Physical-HRI. In Proceedings of the Companion of the 2017 ACM/IEEE International Conference on Human-Robot Interaction, Vienna, Austria, 6–9 March 2017; pp. 137–138. [Google Scholar] [CrossRef]
- Linsinger, M.; Stecken, J.; Kutschinski, J.; Kuhlenkötter, B. Situational task change of lightweight robots in hybrid assembly systems. Procedia CIRP 2019, 81, 81–86. [Google Scholar] [CrossRef]
- Lehmann, C.; Städter, J.P.; Berger, U. Anwendungsbeispiele zur Integration heterogener Steuerungssysteme bei robotergestützten Industrieanlagen. In Handbuch Industrie 4.0 Bd. 2; Springer: Berlin/Heidelberg, Germany, 2017; pp. 45–58. [Google Scholar]
- Weintrop, D.; Afzal, A.; Salac, J.; Francis, P.; Li, B.; Shepherd, D.C.; Franklin, D. Evaluating CoBlox: A comparative study of robotics programming environments for adult novices. In Proceedings of the 2018 CHI Conference on Human Factors in Computing Systems, Montreal, QC, Canada, 21–26 April 2018; pp. 1–12. [Google Scholar]
- Biggs, G.; Macdonald, B. A Survey of Robot Programming Systems. In Proceedings of the Australasian Conference on Robotics and Automation, CSIRO, Taipei, Taiwan, 14–19 September 2003; p. 27. [Google Scholar]
- Pan, Z.; Polden, J.; Larkin, N.; van Duin, S.; Norrish, J. Recent Progress on Programming Methods for Industrial Robots. In Proceedings of the ISR/ROBOTIK, Munich, Germany, 7–9 June 2010. [Google Scholar]
- Nielsen Norman Group. Available online: https://www.nngroup.com (accessed on 30 June 2021).
- Ionescu, T. Leveraging graphical user interface automation for generic robot programming. Robotics 2021, 10, 3. [Google Scholar] [CrossRef]
- Ionescu, T. Adaptive Simplex Architecture for Safe, Real-Time Robot Path Planning. Sensors 2021, 21, 2589. [Google Scholar] [CrossRef] [PubMed]
- Howe, J. The rise of crowdsourcing. Wired Mag. 2006, 14, 1–4. [Google Scholar]
- Toris, R.; Chernova, S. RobotsFor.Me and Robots For You. 2013. Available online: http://citeseerx.ist.psu.edu/viewdoc/summary?doi=10.1.1.365.38 (accessed on 11 November 2021).
- Wu, H.; Corney, J.; Grant, M. An evaluation methodology for crowdsourced design. Adv. Eng. Inform. 2015, 29, 775–786. [Google Scholar] [CrossRef] [Green Version]
- Van Waveren, S.; Carter, E.J.; Örnberg, O.; Leite, I. Exploring Non-Expert Robot Programming Through Crowdsourcing. Front. Robot. AI 2021, 242. [Google Scholar] [CrossRef] [PubMed]
- Ionescu, T.B.; Fröhlich, J.; Lachenmayr, M. Improving Safeguards and Functionality in Industrial Collaborative Robot HMIs through GUI Automation. In Proceedings of the 2020 25th IEEE International Conference on Emerging Technologies and Factory Automation (ETFA), Vienna, Austria, 8–11 September 2020; Volume 1, pp. 557–564. [Google Scholar]
- Ionescu, T.B.; Schlund, S. A participatory programming model for democratizing cobot technology in public and industrial Fablabs. Procedia CIRP 2019, 81, 93–98. [Google Scholar] [CrossRef]
- Ionescu, T.B.; Schlund, S. Programming cobots by voice: A human-centered, web-based approach. Procedia CIRP 2021, 97, 123–129. [Google Scholar] [CrossRef]
- Komarov, S.; Reinecke, K.; Gajos, K.Z. Crowdsourcing Performance Evaluations of User Interfaces. In Proceedings of the SIGCHI Conference on Human Factors in Computing Systems, Paris, France, 27 April–2 May 2013; Association for Computing Machinery: New York, NY, USA, 2013; pp. 207–216. [Google Scholar] [CrossRef]
- Grossman, T.; Balakrishnan, R. The bubble cursor: Enhancing target acquisition by dynamic resizing of the cursor’s activation area. In Proceedings of the SIGCHI Conference on Human Factors in Computing Systems, Portland, OR, USA, 2–7 April 2005; pp. 281–290. [Google Scholar]
- Sears, A.; Shneiderman, B. Split menus: Effectively using selection frequency to organize menus. ACM Trans. Comput.-Hum. Interact. (TOCHI) 1994, 1, 27–51. [Google Scholar] [CrossRef]
- Gajos, K.Z.; Czerwinski, M.; Tan, D.S.; Weld, D.S. Exploring the design space for adaptive graphical user interfaces. In Proceedings of the Working Conference on Advanced Visual Interfaces, Venezia, Italy, 23–26 May 2006; pp. 201–208. [Google Scholar]
- Crick, C.; Osentoski, S.; Jay, G.; Jenkins, O.C. Human and robot perception in large-scale learning from demonstration. In Proceedings of the 6th International Conference on Human-Robot Interaction, Lausanne, Switzerland, 6–9 March 2011; pp. 339–346. [Google Scholar]
- Sorokin, A.; Berenson, D.; Srinivasa, S.S.; Hebert, M. People helping robots helping people: Crowdsourcing for grasping novel objects. In Proceedings of the 2010 IEEE/RSJ International Conference on Intelligent Robots and Systems, Taipei, Taiwan, 18–22 October 2010; pp. 2117–2122. [Google Scholar]
- Emeli, V. Robot learning through social media crowdsourcing. In Proceedings of the 2012 IEEE/RSJ International Conference on Intelligent Robots and Systems, Vilamoura-Algarve, Portugal, 7–12 October 2012; pp. 2332–2337. [Google Scholar]
- Amazon Alexa. Available online: https://developer.amazon.com/en-US/alexa (accessed on 1 May 2021).
- Apple Siri. Available online: https://www.apple.com/siri/ (accessed on 1 May 2021).
- Google Assistant. Available online: https://assistant.google.com (accessed on 1 May 2021).
- Tellex, S.; Kollar, T.; Dickerson, S.; Walter, M.; Banerjee, A.; Teller, S.; Roy, N. Understanding natural language commands for robotic navigation and mobile manipulation. In Proceedings of the AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 7–11 August 2011; Volume 25. [Google Scholar]
- Von Ahn, L.; Dabbish, L. Designing games with a purpose. Commun. ACM 2008, 51, 58–67. [Google Scholar] [CrossRef]
- Chernova, S.; DePalma, N.; Morant, E.; Breazeal, C. Crowdsourcing human-robot interaction: Application from virtual to physical worlds. In Proceedings of the 2011 RO-MAN, Atlanta, GA, USA, 31 July–3 August 2011; pp. 21–26. [Google Scholar]
- Chung, M.J.Y.; Forbes, M.; Cakmak, M.; Rao, R.P. Accelerating imitation learning through crowdsourcing. In Proceedings of the 2014 IEEE International Conference on Robotics and Automation (ICRA), Hong Kong, China, 31 May–7 June 2014; pp. 4777–4784. [Google Scholar]
- Verma, D.; Rao, R.P. Goal-based imitation as probabilistic inference over graphical models. In Advances in Neural Information Processing Systems; Citeseer: Princeton, NJ, USA, 2006; pp. 1393–1400. [Google Scholar]
- Toris, R.; Kent, D.; Chernova, S. The robot management system: A framework for conducting human-robot interaction studies through crowdsourcing. J. Hum.-Robot Interact. 2014, 3, 25–49. [Google Scholar] [CrossRef] [Green Version]
- Kormushev, P.; Calinon, S.; Caldwell, D.G. Imitation learning of positional and force skills demonstrated via kinesthetic teaching and haptic input. Adv. Robot. 2011, 25, 581–603. [Google Scholar] [CrossRef] [Green Version]
- Huang, J.; Lau, T.; Cakmak, M. Design and evaluation of a rapid programming system for service robots. In Proceedings of the 2016 11th ACM/IEEE International Conference on Human-Robot Interaction (HRI), Christchurch, New Zealand, 7–10 March 2016; pp. 295–302. [Google Scholar]
- Blockly. Available online: https://developers.google.com/blockly (accessed on 1 June 2021).
- Perkel, D. Copy and paste literacy? Literacy practices in the production of a MySpace profile. Informal Learn. Digit. Media 2006, 21–23. [Google Scholar]
- Ionescu, B.T. Assembly. Available online: http://assembly.comemak.at (accessed on 30 April 2021).
- Blackboard Design Pattern. Available online: https://social.technet.microsoft.com/wiki/contents/articles/13215.blackboard-design-pattern.aspx (accessed on 1 June 2021).
- de Jong, J. JSON Editor Online. Available online: https://jsoneditoronline.org/ (accessed on 30 June 2021).
- Beck, M. Glumb. Available online: http://robot.glumb.de/ (accessed on 30 April 2021).
- Universal Robots. Available online: https://www.universal-robots.com/ (accessed on 30 April 2021).
- Amazon Mechanical Turk. Available online: https://blog.mturk.com (accessed on 30 June 2021).
- Hara, K.; Adams, A.; Milland, K.; Savage, S.; Callison-Burch, C.; Bigham, J.P. A data-driven analysis of workers’ earnings on Amazon Mechanical Turk. In Proceedings of the 2018 CHI Conference on Human Factors in Computing Systems, Montreal, QC, Canada, 21–26 April 2018; pp. 1–14. [Google Scholar]
- Usability Is a Key Element of User Experience. Available online: https://eu.landisgyr.com/better-tech/usability-is-a-key-element-of-user-experience (accessed on 30 June 2020).
- ufile. Available online: https://ufile.io (accessed on 1 June 2021).
- Montage II: Advanced Manufacturing (TU Wien). Available online: https://tiss.tuwien.ac.at/course/courseDetails.xhtml? courseNr=330288&semester=2021W&dswid=5005&dsrid=624 (accessed on 5 August 2021).
- Oppenheimer, D.M.; Meyvis, T.; Davidenko, N. Instructional manipulation checks: Detecting satisficing to increase statistical power. J. Exp. Soc. Psychol. 2009, 45, 867–872. [Google Scholar] [CrossRef]
- Sirjani, B. maze.co. Available online: https://maze.co/guides/usability-testing/ (accessed on 30 June 2020).
- Brooke, J. Sus: A ‘Quick and Dirty’ Usability. Usability Eval. Ind. 1996, 189, 4–7. [Google Scholar]
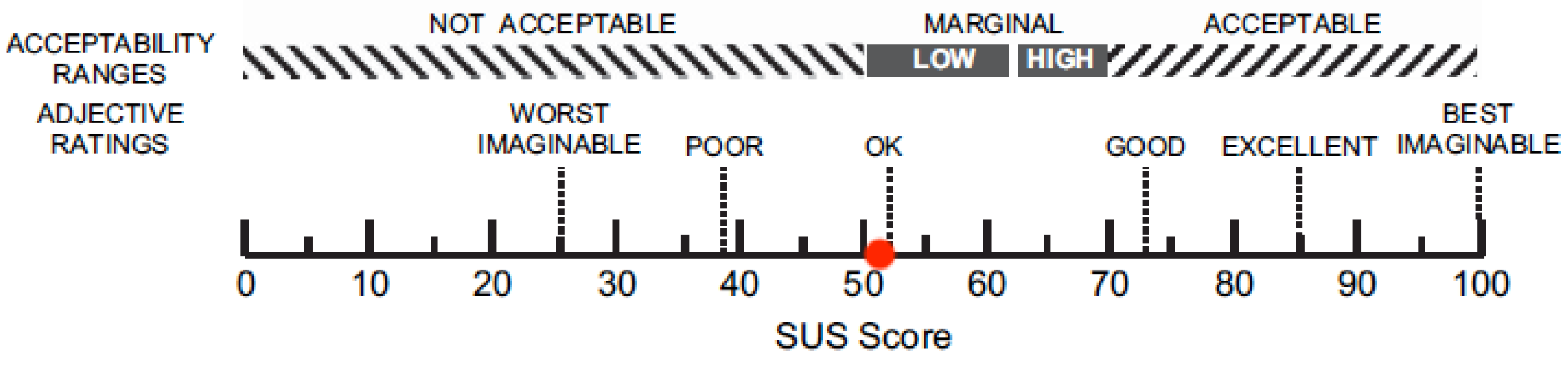
- Bangor, A.; Kortum, P.; Miller, J. Determining what individual SUS scores mean: Adding an adjective rating scale. J. Usability Stud. 2009, 4, 114–123. [Google Scholar]
- Crowdflower. Available online: https://visit.figure-eight.com/People-Powered-Data-Enrichment_T (accessed on 1 July 2021).
- HitBuilder. Available online: https://ga-dev-tools.appspot.com/hit-builder/ (accessed on 1 July 2021).
- Forbes, M.; Chung, M.; Cakmak, M.; Rao, R. Robot programming by demonstration with crowdsourced action fixes. In Proceedings of the AAAI Conference on Human Computation and Crowdsourcing, Pittsburgh, PA, USA, 2–4 November 2014; Volume 2. [Google Scholar]
- Design Hill. Available online: https://www.designhill.com (accessed on 1 June 2021).
- Designcrowd. Available online: https://www.designcrowd.com (accessed on 1 June 2021).
- 99Designs. Available online: https://99designs.at (accessed on 1 June 2021).
- Guerra Creativa. Available online: https://www.guerra-creativa.com/en/ (accessed on 1 June 2021).
- Microworkers. Available online: https://www.microworkers.com (accessed on 1 June 2021).
- Crowdspring. Available online: https://www.crowdspring.com (accessed on 1 June 2021).
- Nielsen, J.; Landauer, T.K. A mathematical model of the finding of usability problems. In Proceedings of the INTERACT’93 and CHI’93 Conference on Human Factors in Computing Systems, Amsterdam, The Netherlands, 24–29 April 1993; pp. 206–213. [Google Scholar]
- UML. Available online: https://www.uml-diagrams.org/use-case-diagrams.html (accessed on 4 May 2021).
- Zaidan, O.F.; Callison-Burch, C. Crowdsourcing Translation: Professional Quality from Non-Professionals. In Proceedings of the 49th Annual Meeting of the Association for Computational Linguistics: Human Language Technologies, Portland, OR, USA, 19–24 June 2011; Association for Computational Linguistics: Portland, OR, USA, 2011; pp. 1220–1229. [Google Scholar]
- Wu, H.; Corney, J.; Grant, M. Relationship between quality and payment in crowdsourced design. In Proceedings of the 2014 IEEE 18th International Conference on Computer Supported Cooperative Work in Design (CSCWD), Hsinchu, Taiwan, 21–23 May 2014; pp. 499–504. [Google Scholar]
- Shaw, A.D.; Horton, J.J.; Chen, D.L. Designing incentives for inexpert human raters. In Proceedings of the ACM 2011 Conference on Computer Supported Cooperative Work, Hangzhou, China, 19–23 March 2011; pp. 275–284. [Google Scholar]
- Hertzum, M.; Borlund, P.; Kristoffersen, K.B. What do thinking-aloud participants say? A comparison of moderated and unmoderated usability sessions. Int. J. Hum.-Comput. Interact. 2015, 31, 557–570. [Google Scholar] [CrossRef] [Green Version]
- Albert, W.; Tullis, T. Measuring the User Experience: Collecting, Analyzing, and Presenting Usability Metrics; Elsevier: Amsterdam, The Netherlands, 2013. [Google Scholar]
- Nielsen, J.; Levy, J. Measuring usability: Preference vs. performance. Commun. ACM 1994, 37, 66–75. [Google Scholar] [CrossRef]
- Quantitative vs. Qualitative Usability Testing. Available online: https://www.nngroup.com/articles/quant-vs-qual/ (accessed on 30 June 2021).
- PSSUQ. Available online: https://uiuxtrend.com/pssuq-post-study-system-usability-questionnaire/ (accessed on 30 June 2021).














Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Piacun, D.; Ionescu, T.B.; Schlund, S. Crowdsourced Evaluation of Robot Programming Environments: Methodology and Application. Appl. Sci. 2021, 11, 10903. https://doi.org/10.3390/app112210903
Piacun D, Ionescu TB, Schlund S. Crowdsourced Evaluation of Robot Programming Environments: Methodology and Application. Applied Sciences. 2021; 11(22):10903. https://doi.org/10.3390/app112210903
Chicago/Turabian StylePiacun, Daria, Tudor B. Ionescu, and Sebastian Schlund. 2021. "Crowdsourced Evaluation of Robot Programming Environments: Methodology and Application" Applied Sciences 11, no. 22: 10903. https://doi.org/10.3390/app112210903