
Towards Contactless Learning Activities during Pandemics Using Autonomous Service Robots

 ,
,  ,
,  and
and {kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
2. Materials and Methods
2.1. Proposed System Overview
2.2. Robot Body
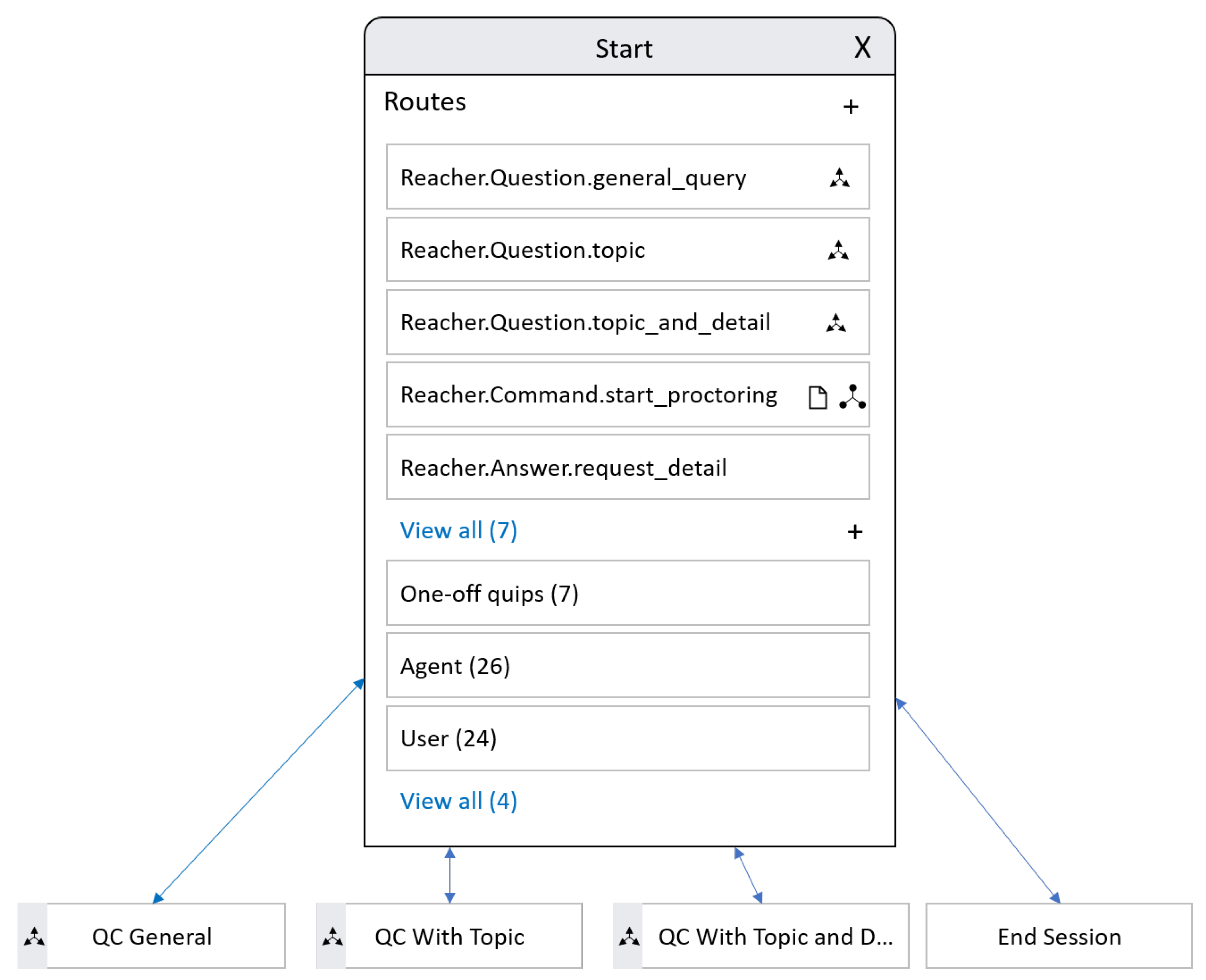
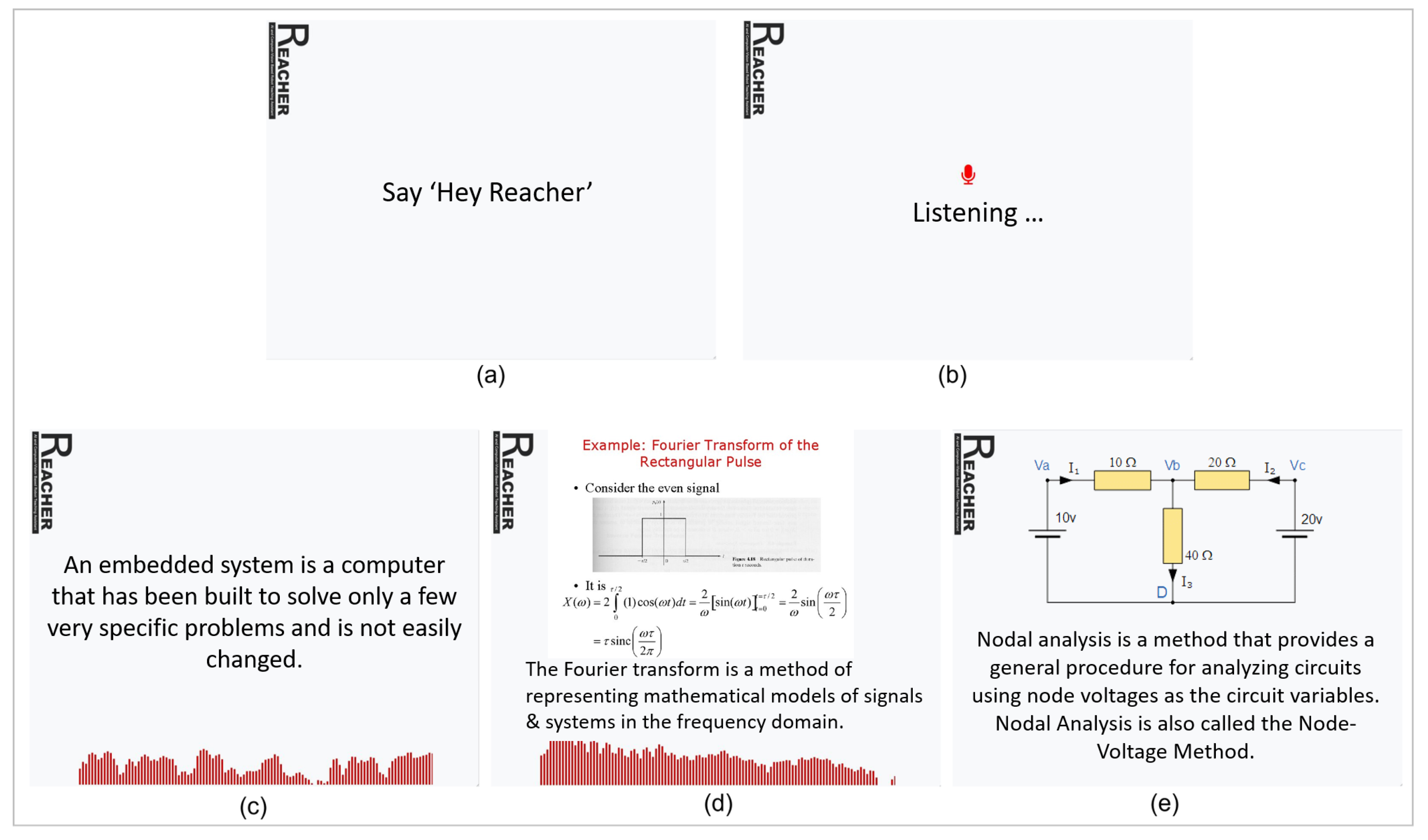
2.3. Human–Robot Voice Interaction
2.4. Autonomous Navigation
2.5. Content Retrieval and Recommendation
2.6. Cheating Detection
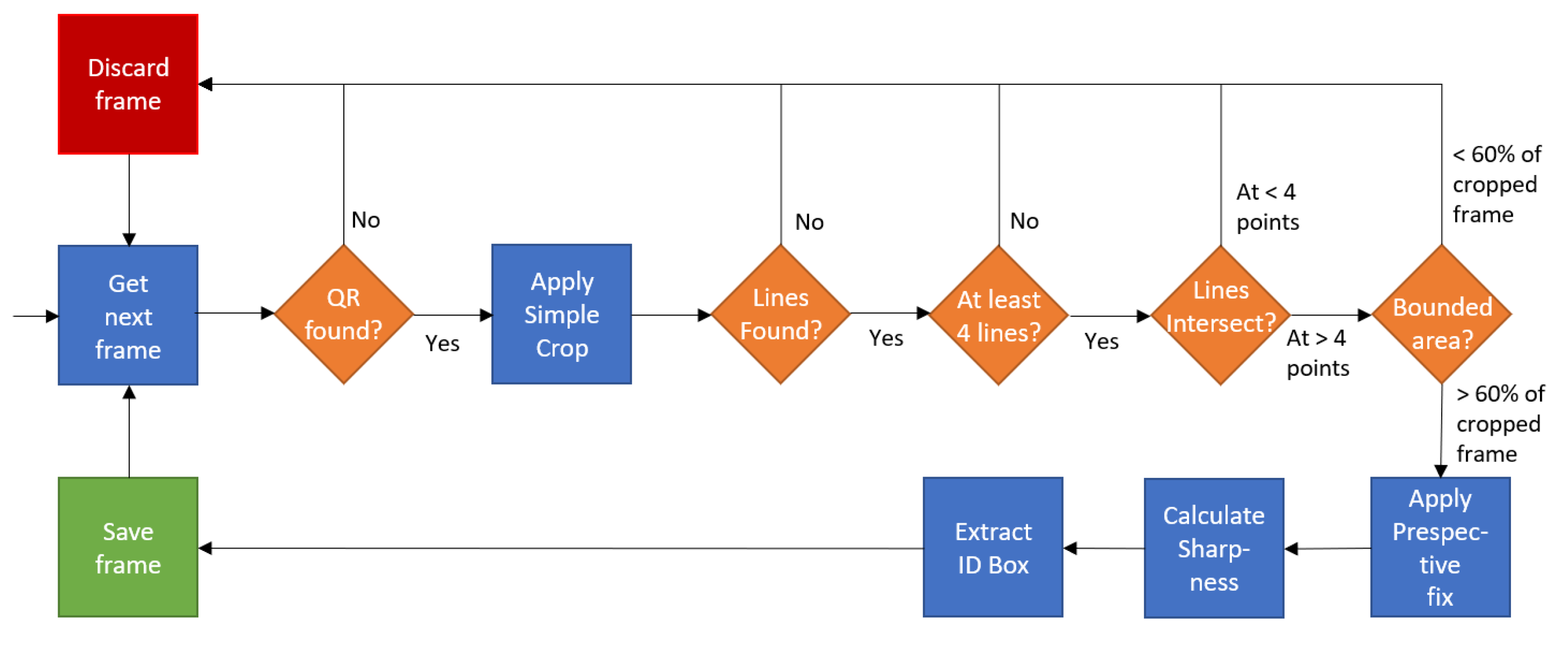
2.7. Image-Based Exam Paper Scanning
3. Discussion
3.1. Human–Robot Voice Interaction Results
3.2. Autonomous Navigation Results
3.3. Content Retrieval and Recommendation Results
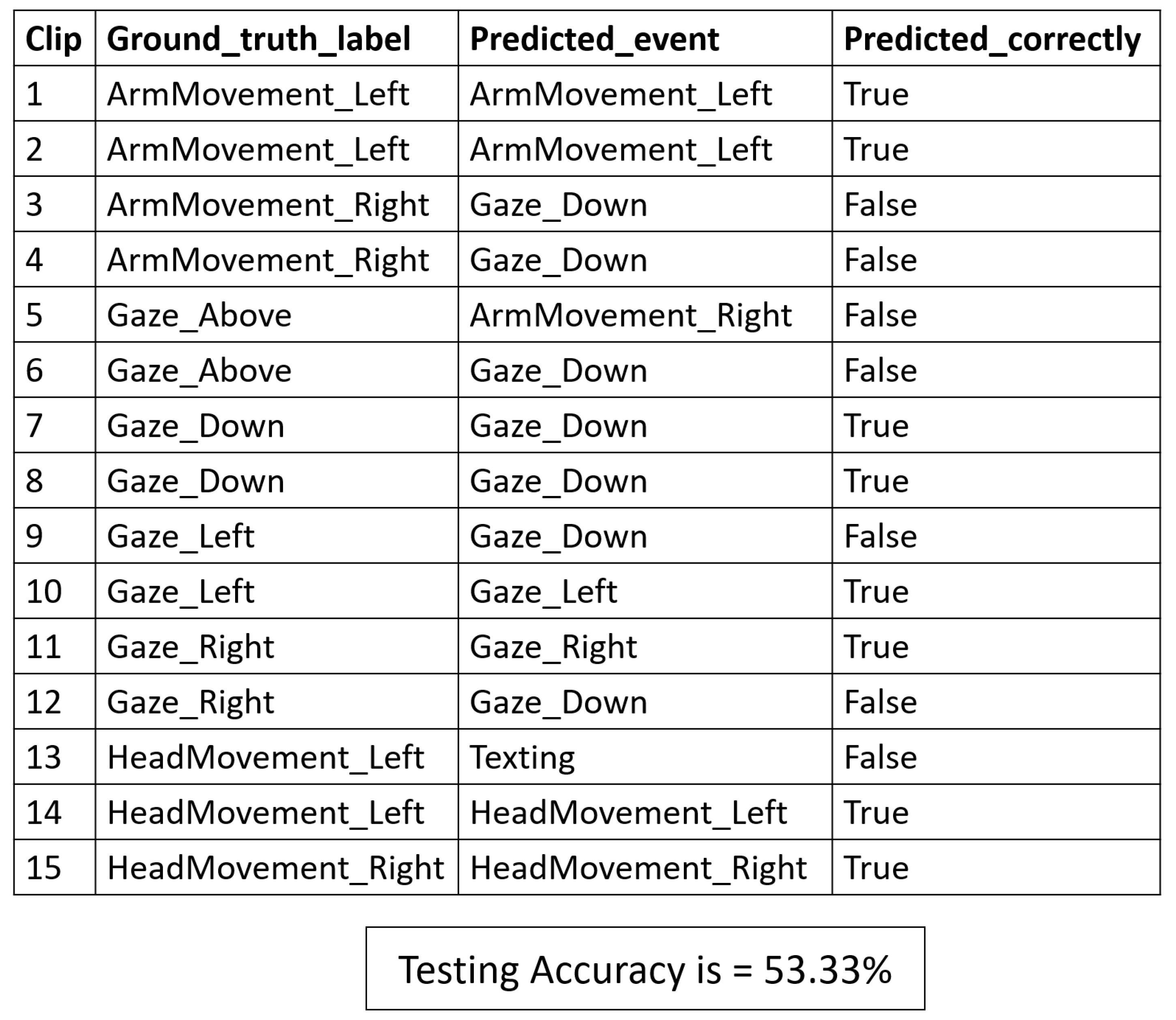
3.4. Cheating Detection Results
3.5. Image-Based Exam Paper Scanning Results
3.6. End-to-End Integration Testing and Validation
4. Analysis and Discussion
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Sharkey, A. Should we welcome robot teachers? Ethics Inf. Technol. 2016, 18, 283–297. [Google Scholar] [CrossRef] [Green Version]
- Cooney, M.; Leister, W. Using the Engagement Profile to Design an Engaging Robotic Teaching Assistant for Students. Robotics 2019, 8, 21. [Google Scholar] [CrossRef] [Green Version]
- The Eye Tribe. Available online: https://theeyetribe.com/theeyetribe.com/about/index.html (accessed on 8 August 2021).
- Chuang, C.; Craig, S.; Femiani, J. Detecting probable cheating during online assessments based on time delay and head pose. High. Educ. Res. Dev. 2017, 36, 1123–1137. [Google Scholar] [CrossRef]
- Shamqoli, M.; Khosravi, H. Border detection of document images scanned from large books. In Proceedings of the 2013 8th Iranian Conference on Machine Vision and Image Processing (MVIP), Zanjan, Iran, 10–12 September 2013. [Google Scholar] [CrossRef]
- Boudraa, O.; Hidouci, W.; Michelucci, D. An improved skew angle detection and correction technique for historical scanned documents using morphological skeleton and progressive probabilistic hough transform. In Proceedings of the 2017 5th International Conference on Electrical Engineering-Boumerdes (ICEE-B), Boumerdes, Algeria, 29–31 October 2017. [Google Scholar] [CrossRef]
- Tariq, W.; Khan, N. Click-Free, Video-Based Document Capture—Methodology and Evaluation. In Proceedings of the 2017 14th IAPR International Conference on Document Analysis and Recognition (ICDAR), Kyoto, Japan, 9–15 November 2017; pp. 21–26. [Google Scholar] [CrossRef]
- Gomez-Uribe, C.; Hunt, N. The Netflix Recommender System. Acm Trans. Manag. Inf. Syst. 2016, 6, 1–19. [Google Scholar] [CrossRef] [Green Version]
- Zanardi, V.; Capra, L. Social ranking. In Proceedings of the 2008 ACM Conference on Recommender Systems—RecSys ’08, Lausanne, Switzerland, 23–25 October 2008. [Google Scholar] [CrossRef]
- Fortuna, B.; Fortuna, C.; Mladenić, D. Real-Time News Recommender System. In Machine Learning and Knowledge Discovery in Databases; Springer: Berlin/Heidelberg, Germany, 2010; pp. 583–586. [Google Scholar] [CrossRef] [Green Version]
- Bogers, T. Tag-Based Recommendation. In Social Information Access; Springer: Cham, Switzerland, 2018; pp. 441–479. [Google Scholar] [CrossRef]
- Chin, K.; Wu, C.; Hong, Z. A Humanoid Robot as a Teaching Assistant for Primary Education. In Proceedings of the 2011 Fifth International Conference on Genetic and Evolutionary Computing, Kitakyushu, Japan, 29 August–1 September 2011; pp. 21–24. [Google Scholar] [CrossRef]
- Sun, Z.; Li, Z.; Nishimori, T. Development and Assessment of Robot Teaching Assistant in Facilitating Learning. In Proceedings of the 2017 International Conference of Educational Innovation through Technology (EITT), Osaka, Japan, 7–9 December 2017; pp. 165–169. [Google Scholar] [CrossRef]
- Rosen, W.A.; Carr, M.E. An autonomous articulating desktop robot for proctoring remote online examinations. In Proceedings of the 2013 IEEE Frontiers in Education Conference (FIE), Oklahoma City, OK, USA, 23–26 October 2013; pp. 1935–1939. [Google Scholar] [CrossRef]
- Home|p5.js, P5js.org. 2021. Available online: https://p5js.org/ (accessed on 8 August 2021).
- Speech-to-Text: Automatic Speech Recognition|Google Cloud, Google Cloud. 2021. Available online: https://cloud.google.com/speech-to-text (accessed on 13 August 2021).
- Dialogflow CX documentation|Google Cloud, Google Cloud. 2021. Available online: https://cloud.google.com/dialogflow/cx/docs (accessed on 15 August 2021).
- Getting Started. 2021. Available online: https://websockets.readthedocs.io/en/stable/intro/index.html (accessed on 4 August 2021).
- Rozario, A. FAQ: How Was GMAT Held Using AI Proctors? Can It Detect Cheating? TheQuint. 2021. Available online: https://www.thequint.com/news/education/what-is-an-artificial-intelligence-proctored-test-can-it-detect-cheating-faq (accessed on 8 August 2021).
- Base_LOCAL_PLANNER-ROS Wiki. 2021. Available online: http://wiki.ros.org/base_local_planner (accessed on 20 August 2021).
- Pech-Pacheco, J.L.; Cristobal, G.; Chamorro-Martinez, J.; Fernandez-Valdivia, J. Diatom autofocusing in brightfield microscopy: A comparative study. In Proceedings of the 15th International Conference on Pattern Recognition. ICPR-2000, Barcelona, Spain, 3–7 September 2000; Volume 3, pp. 314–317. [Google Scholar] [CrossRef]
- MNIST Handwritten Digit Database, Yann LeCun, Corinna Cortes and Chris Burges. 2021. Available online: http://yann.lecun.com/exdb/mnist (accessed on 8 August 2021).
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar] [CrossRef] [Green Version]
- Donahue, J.; Jia, Y.; Vinyals, O.; Hoffman, J.; Zhang, N.; Tzeng, E.; Darrell, T. DeCAF: A Deep Convolutional Activation Feature for Generic Visual Recognition. arXiv 2013, arXiv:1310.1531. [Google Scholar]
- Nigam, A.; Pasricha, R.; Singh, T.; Churi, P. A Systematic Review on AI-based Proctoring Systems: Past, Present and Future. Educ. Inf. Technol. 2021, 26, 6421–6445. [Google Scholar] [CrossRef] [PubMed]
- Holden, O.; Norris, M.; Kuhlmeier, V. Academic Integrity in Online Assessment: A Research Review. Front. Educ. 2021, 6, 258. [Google Scholar] [CrossRef]





















Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Al Tarabsheh, A.; Yaghi, M.; Younis, A.; Sarker, R.; Moussa, S.; Eldigair, Y.; Hajjdiab, H.; El-Baz, A.; Ghazal, M. Towards Contactless Learning Activities during Pandemics Using Autonomous Service Robots. Appl. Sci. 2021, 11, 10449. https://doi.org/10.3390/app112110449
Al Tarabsheh A, Yaghi M, Younis A, Sarker R, Moussa S, Eldigair Y, Hajjdiab H, El-Baz A, Ghazal M. Towards Contactless Learning Activities during Pandemics Using Autonomous Service Robots. Applied Sciences. 2021; 11(21):10449. https://doi.org/10.3390/app112110449
Chicago/Turabian StyleAl Tarabsheh, Anas, Maha Yaghi, AbdulRehman Younis, Razib Sarker, Sherif Moussa, Yazeed Eldigair, Hassan Hajjdiab, Ayman El-Baz, and Mohammed Ghazal. 2021. "Towards Contactless Learning Activities during Pandemics Using Autonomous Service Robots" Applied Sciences 11, no. 21: 10449. https://doi.org/10.3390/app112110449