BFRVSR: A Bidirectional Frame Recurrent Method for Video Super-Resolution


Abstract
:1. Introduction
2. Related Work
3. Methods
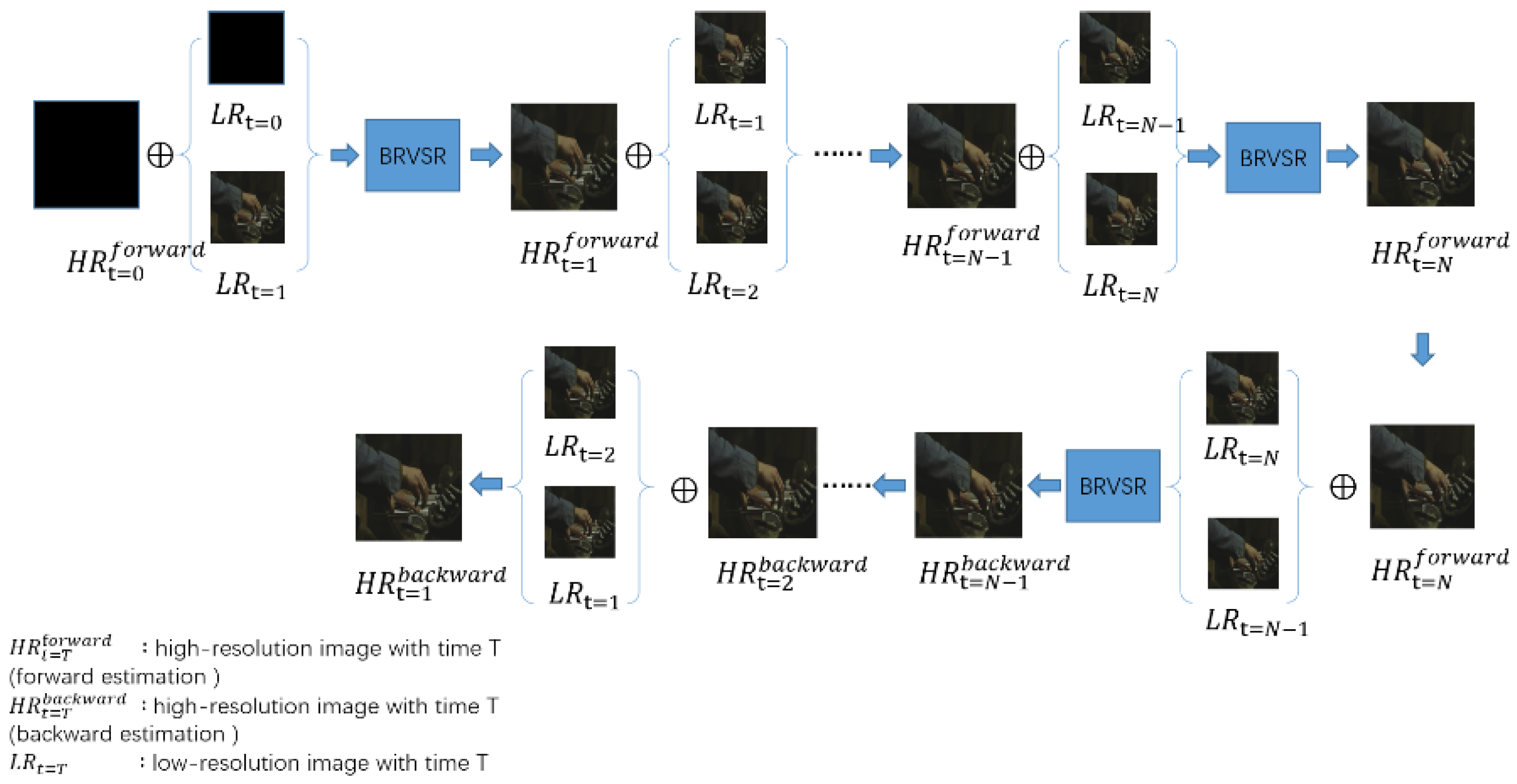
3.1. Bidirectional Frame Recurrent Video Super-Resolution (BFRVSR)
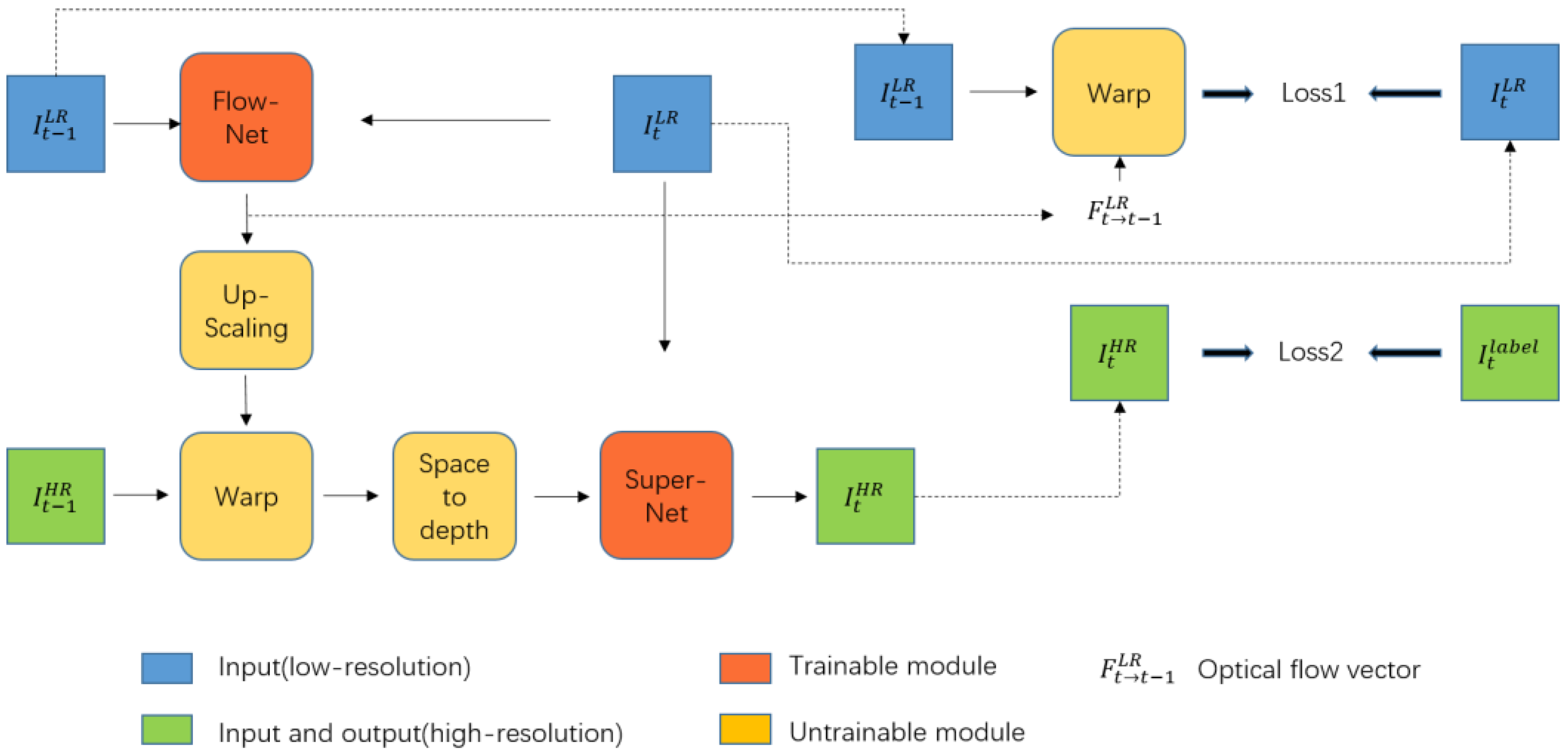
3.1.1. Flow Estimation
3.1.2. Upscaling Flow
3.1.3. Warping HR Image
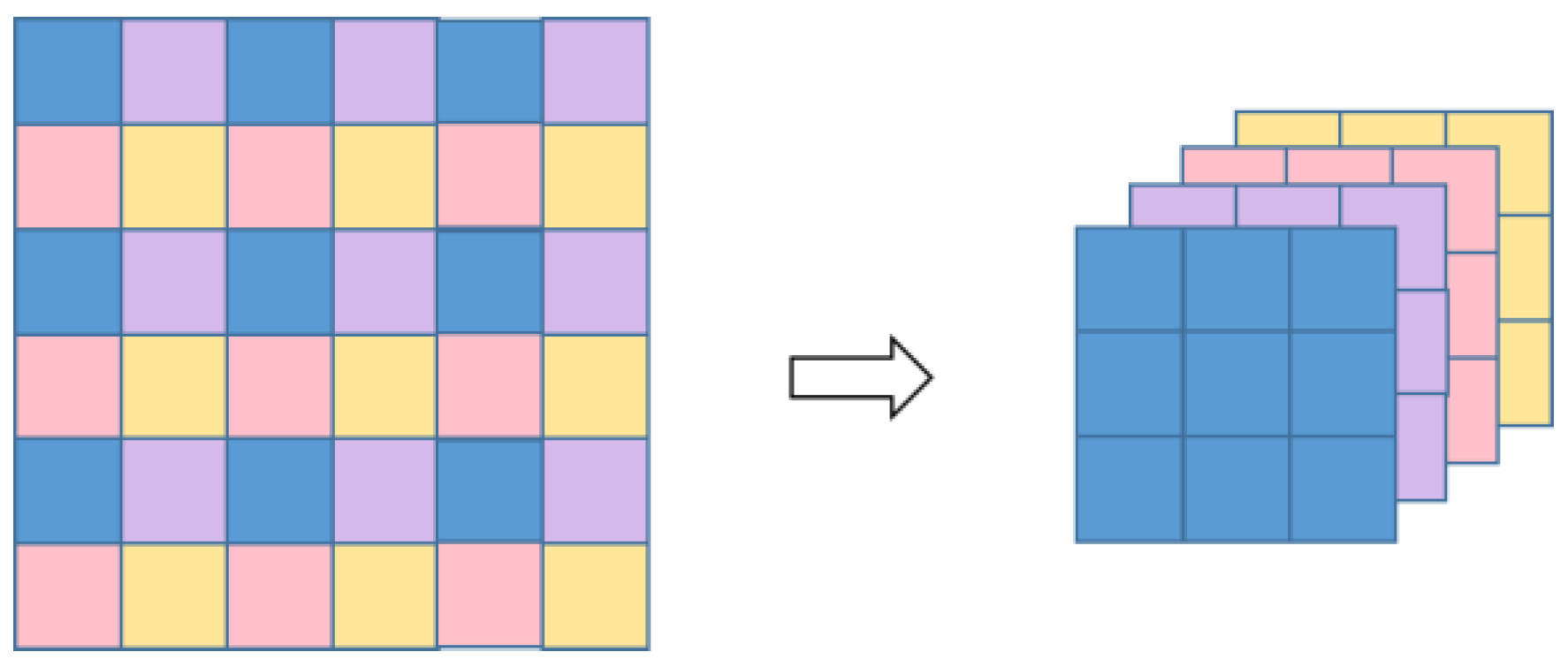
3.1.4. Mapping to Low Resolution (LR) Space
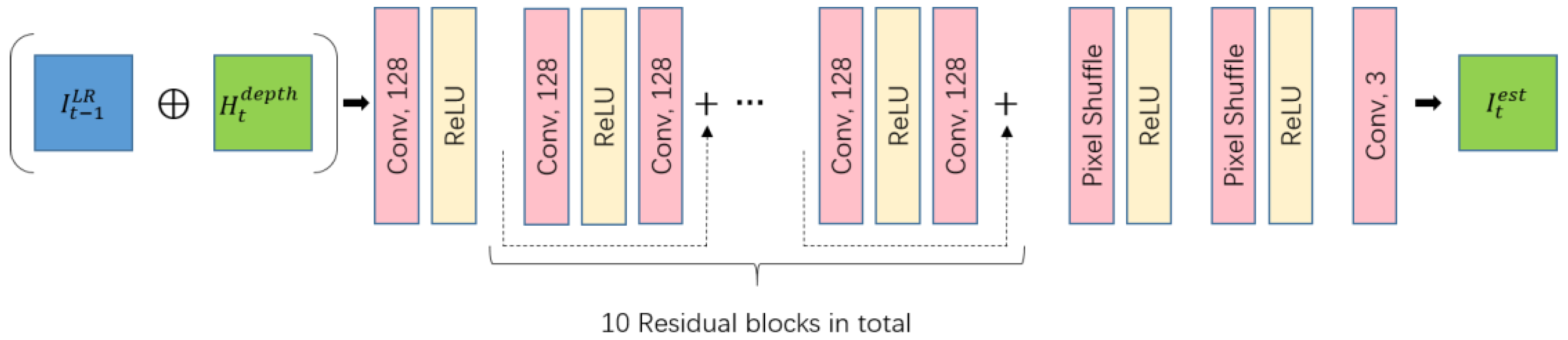
3.1.5. Super-Resolution
3.2. Loss Functions
4. Experiment
4.1. Training Datasets and Details
4.1.1. Training Datasets
4.1.2. Training Details
4.2. Baselines
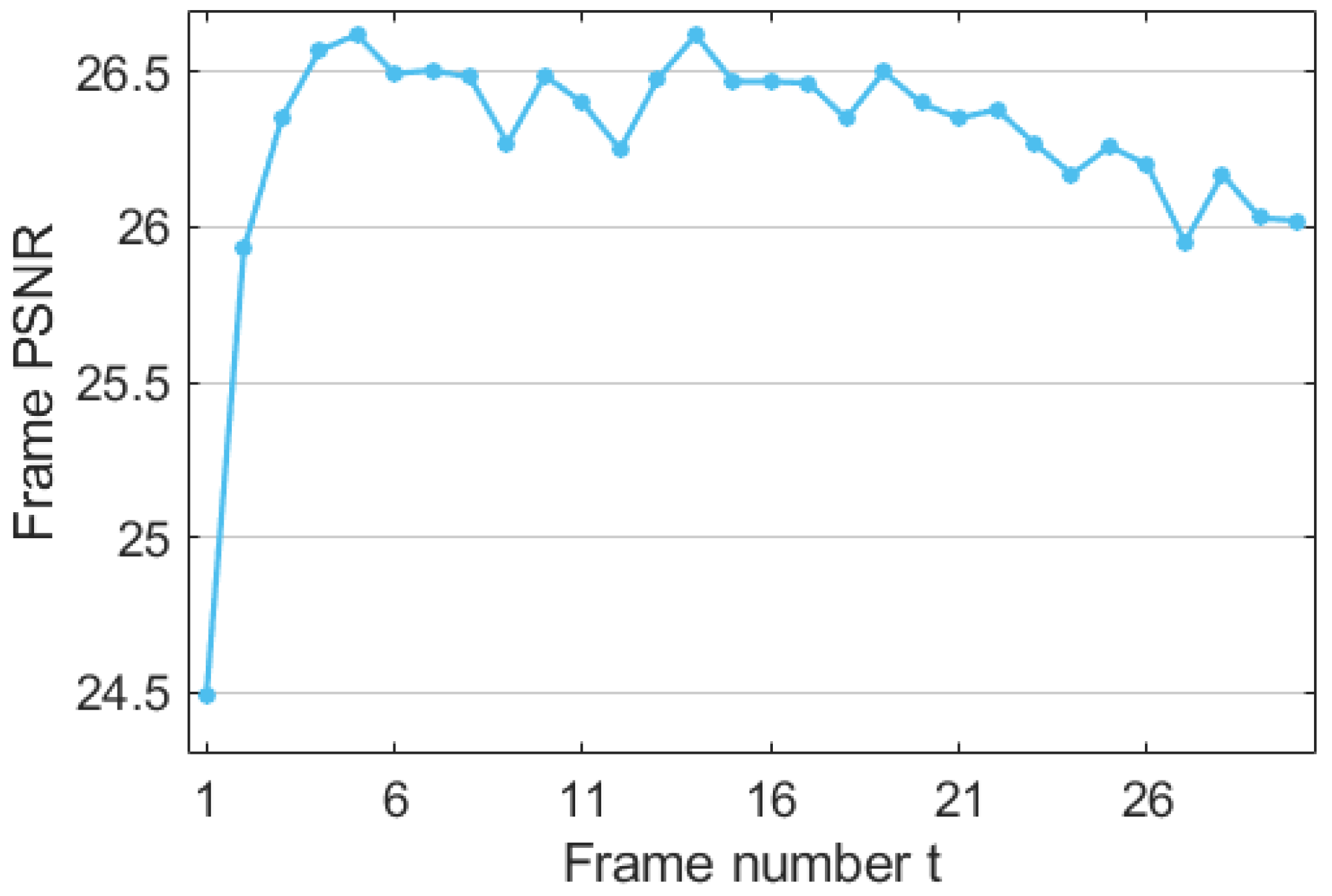
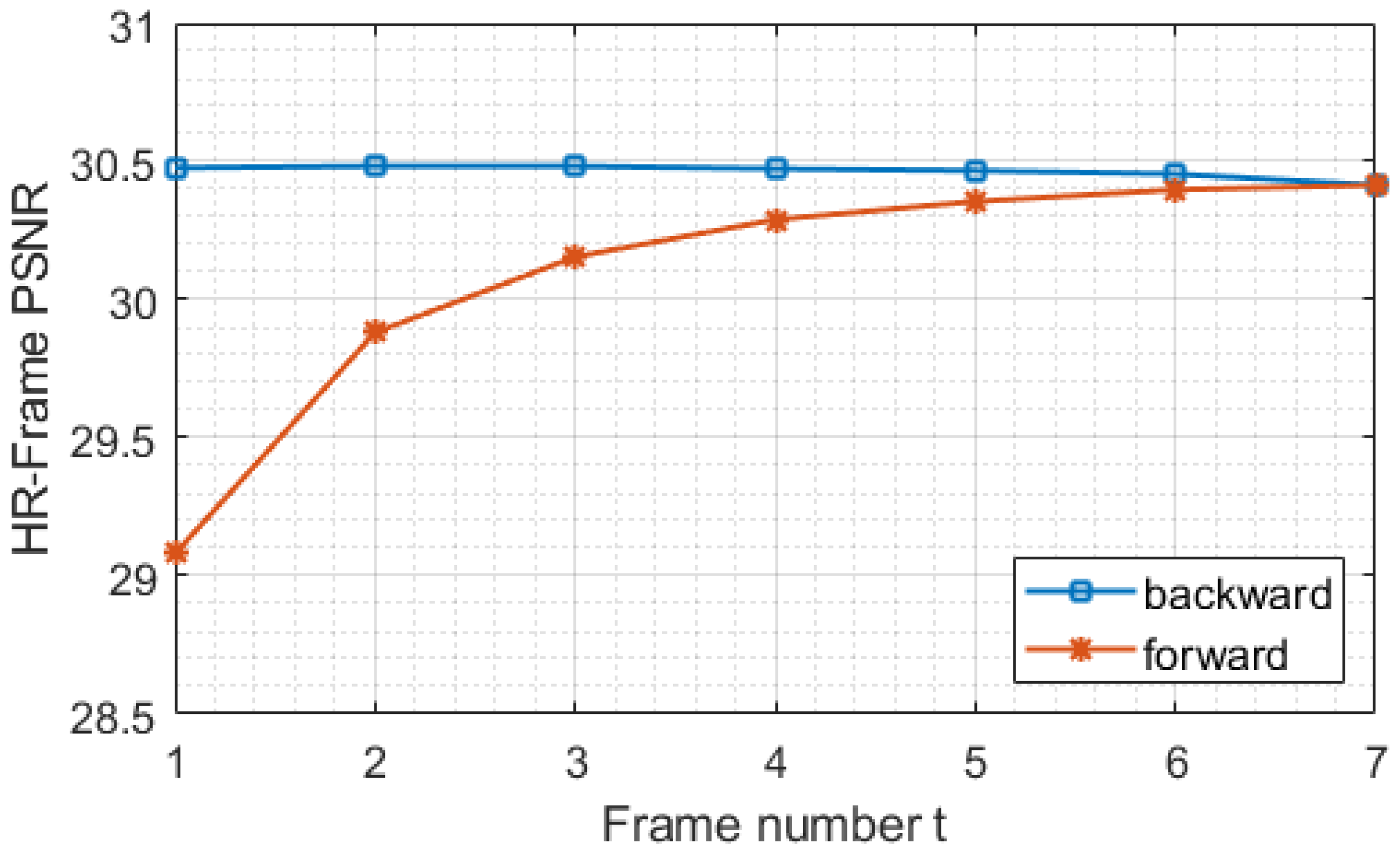
4.3. Analysis
5. Conclusions
6. Future Work
Author Contributions
Funding
Conflicts of Interest
References
- Rajnoha, M.; Mezina, A.; Burget, R. Multi-frame labeled faces database: Towards face super-resolution from realistic video sequences. Appl. Sci. 2020, 10, 7213. [Google Scholar] [CrossRef]
- Nam, J.H.; Velten, A. Super-resolution remote imaging using time encoded remote apertures. Appl. Sci. 2020, 10, 6458. [Google Scholar] [CrossRef]
- Li, J.; Peng, Y.; Jiang, T.; Zhang, L.; Long, J. Hyperspectral image super-resolution based on spatial group sparsity regularization unmixing. Appl. Sci. 2020, 10, 5583. [Google Scholar] [CrossRef]
- Wang, X.; Chan, K.C.K.; Yu, K.; Dong, C.; Loy, C.C. EDVR: Video restoration with enhanced deformable convolutional networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Los Angeles, CA, USA, 16–19 June 2019. [Google Scholar]
- Tai, Y.; Yang, J.; Liu, X. Image super-resolution via deep recursive residual network. In Proceedings of the Internaltional Conference on Computer Vision and Pattern Recogintion, Hawaii, HI, USA, 21–26 July 2017. [Google Scholar]
- Sajjadi, M.S.M.; Vemulapalli, R.; Brown, M. Frame-recurrent video super-resolution. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018. [Google Scholar]
- Wahab, A.W.A.; Bagiwa, M.A.; Idris, M.Y.I.; Khan, S.; Razak, Z.; Ariffin, M.R.K. Passive video forgery detection techniques: A survey. In Proceedings of the International Conference on Information Assurance & Security IEEE, Okinawa, Japan, 28–30 November 2014. [Google Scholar]
- Bagiwa, M.A.; Wahab, A.W.A.; Idris, M.Y.I.; Khan, S.; Choo, K.-K.R. Chroma key background detection for digital video using statistical correlation of blurring artifact. Digit. Investig. 2016, 19, 29–43. [Google Scholar] [CrossRef]
- Bagiwa, M.A.; Wahab, A.W.A.; Idris, M.Y.I.; Khan, S. Digital video inpainting detection using correlation of hessian matrix. Malays. J. Comput. Sci. 2016, 29, 179–195. [Google Scholar] [CrossRef]
- Yang, J.; Wang, Z.; Lin, Z.; Cohen, S.; Huang, T. Coupled dictionary training for image super-resolution. IEEE Trans. Image Process. 2012. [Google Scholar] [CrossRef]
- Shi, W.; Caballero, J.; Huszar, F.; Totz, J.; Aitken, A.P.; Bishop, R.; Rueckert, D.; Wang, Z. Real-time single image and video super-resolution using an efficient sub-pixel convolutional neural network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016. [Google Scholar]
- Duchon, C.E. Lanczos filtering in one and two dimensions. J. Appl. Meteorol. 1979, 18, 1016–1022. [Google Scholar] [CrossRef]
- Freedman, G.; Fattal, R. Image and video upscaling from local self-examples. ACM Trans. Graph. 2011, 28, 1–10. [Google Scholar] [CrossRef] [Green Version]
- Freeman, W.T.; Jones, T.R.; Pasztor, E.C. Example-based super-resolution. IEEE Comput. Graph. Appl. 2002, 22, 56–65. [Google Scholar] [CrossRef] [Green Version]
- Timofte, R.; Rothe, R.; Van Gool, L. Seven ways to improve example-based single image super resolution. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016. [Google Scholar]
- Yang, J.; Lin, Z.; Cohen, S. Fast image super-resolution based on in-place example regression. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Portland, Oregon, OR, USA, 23–28 June 2013. [Google Scholar]
- Liu, C.; Sun, D. A bayesian approach to adaptive video super resolution. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Colorado Springs, CO, USA, 21–25 June 2011. [Google Scholar]
- Huang, J.-B.; Singh, A.; Ahuja, N. Single image super-resolution from transformed self-exemplars. In Proceedings of the Internaltional Conference on Computer Vision and Pattern Recogintion, Boston, MA, USA, 7–12 June 2015. [Google Scholar]
- Makansi, O.; Ilg, E.; Brox, T. End-to-end learning of video super-resolution with motion compensation. In Proceedings of the Global Conference on Psychology Researches, Lara-Antalya, Turkey, 16–18 March 2017. [Google Scholar]
- Ranjan, A.; Black, M.J. Optical flow estimation using a spatial pyramid network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Hawaii, HI, USA, 21–26 July 2017. [Google Scholar]
- Anwar, S.; Khan, S.; Barnes, N. A Deep Journey into Super-resolution: A survey. ACM Comput. Surv. 2020, 53. [Google Scholar] [CrossRef]
- Wang, Z.; Chen, J.; Hoi, S.C.H. Deep Learning for Image Super-resolution: A Survey. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 1. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Nasrollahi, K.; Moeslund, T.B. Super-resolution: A comprehensive survey. Mach. Vis. Appl. 2014, 25, 1423–1468. [Google Scholar] [CrossRef] [Green Version]
- Dong, C.; Loy, C.C.; He, K.; Tang, X. Learning a deep convolutional network for image super-resolution. In Proceedings of the Europeon Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014. [Google Scholar]
- Zhang, K.; Zuo, W.; Chen, Y.; Meng, D.; Zhang, L. Beyond a gaussian denoiser: Residual learning of deep cnn for image denoising. IEEE Trans. Image Process. 2017, 26, 3142–3155. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Lai, W.-S.; Huang, J.-B.; Ahuja, N.; Yang, M.-H. Deep laplacian pyramid networks for fast and accurate superresolution. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Dong, C.; Loy, C.C.; He, K.M.; Tang, X.O. Image Super-Resolution Using Deep Convolutional Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 38, 295–307. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Perez-Pellitero, E.; Salvador, J.; Ruiz-Hidalgo, J.; Rosenhahn, B. PSyCo: Manifold span reduction for super resolution. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016. [Google Scholar]
- Drulea, M.; Nedevschi, S. Total variation regularization of local-global optical flow. In Proceedings of the International IEEE Conference on Intelligent Transportation Systems, Washington, DC, USA, 5–7 October 2011. [Google Scholar]
- Tao, X.; Gao, H.; Liao, R.; Wang, J.; Jia, J. Detail-revealing deep video super-resolution. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017. [Google Scholar]
- Yang, C.-Y.; Huang, J.-B.; Yang, M.-H. Exploiting selfsimilarities for single frame super-resolution. In Proceedings of the Asian Conference on Computer Vision, Queenstown, New Zealand, 8–12 November 2010. [Google Scholar]
- Johnson, J.; Alahi, A.; Fei-Fei, L. Perceptual losses for realtime style transfer and super-resolution. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 8–16 October 2016. [Google Scholar]
- Ledig, C.; Theis, L.; Huszar, F.; Caballero, J.; Cunningham, A.; Acosta, A.; Aitken, A.P.; Tejani, A.; Totz, J.; Wang, Z.; et al. Photorealistic single image super-resolution using a generative adversarial network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Milanfar, P. Super-Resolution Imaging; CRC Press: Boca Raton, FL, USA, 2010. [Google Scholar]
- Tian, Y.P.; Zhang, Y.L.; Fu, Y.; Xu, C.L. TDAN: Temporally Deformable Alignment Network for Video Super-Resolution. In Proceedings of the Internaltional Conference on Computer Vision and Pattern Recogintion, Seattle, WA, USA, 16–20 June 2020. [Google Scholar]
- Xiang, X.; Tian, Y.; Zhang, Y.; Fu, Y.; Allebach, J.P.; Xu, C. Zooming slow-mo: Fast and accurate one-stage space-time video super-resolution. In Proceedings of the Internaltional Conference on Computer Vision and Pattern Recogintion, Seattle, WA, USA, 16–20 June 2020. [Google Scholar]
- Huang, Y.; Wang, W.; Wang, L. Bidirectional recurrent convolutional networks for multi-frame super-resolution. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 11–12 December 2015. [Google Scholar]
- Kim, T.H.; Lee, K.M.; Scholkopf, B.; Hirsch, M. Online video deblurring via dynamic temporal blending network. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017. [Google Scholar]
- Chen, D.; Liao, J.; Yuan, L.; Yu, N.; Hua, G. Coherent online video style transfer. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017. [Google Scholar]
- Gupta, A.; Johnson, J.; Alahi, A.; Fei-Fei, L. Characterizing and improving stability in neural style transfer. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017. [Google Scholar]
- Dai, J.; Qi, H.; Xiong, Y.; Li, Y.; Zhang, G.; Hu, H.; Wei, Y. Deformable convolutional networks. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017. [Google Scholar]
- Jaderberg, M.; Simonyan, K.; Zisserman, A.; Kavukcuoglu, K. Spatial transformer networks. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 11–12 December 2015. [Google Scholar]
- Xue, T.; Chen, B.; Wu, J.; Wei, D.; Freeman, W.T. Video enhancement with task-oriented flow. Int. J. Comput. Vis. 2019, 127, 1066–1125. [Google Scholar] [CrossRef] [Green Version]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Frame1 | Frame2 | Frame3 | Frame4 | Frame5 | Frame6 | Frame7 | Average | |
|---|---|---|---|---|---|---|---|---|
| BICUBIC | 29.3057 | 27.3187 | 29.3173 | 29.3120 | 27.3087 | 27.3051 | 27.2900 | 27.3082 |
| SISR | 28.5332 | 28.5633 | 28.5240 | 28.5468 | 28.5523 | 28.5447 | 28.5593 | 28.5462 |
| VSR | 28.7632 | 29.4320 | 29.8012 | 29.8122 | 29.8310 | 29.9001 | 29.9212 | 29.6373 |
| RVSR | 29.0803 | 29.8807 | 30.1547 | 30.2898 | 30.3553 | 30.3980 | 30.3991 | 30.0797 |
| BFRVSR (ours) | 30.4772 | 30.4836 | 30.4833 | 30.4739 | 30.4670 | 30.4547 | 30.4145 | 30.4649 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xue, X.; Han, Z.; Tong, W.; Li, M.; Liu, L. BFRVSR: A Bidirectional Frame Recurrent Method for Video Super-Resolution. Appl. Sci. 2020, 10, 8749. https://doi.org/10.3390/app10238749
Xue X, Han Z, Tong W, Li M, Liu L. BFRVSR: A Bidirectional Frame Recurrent Method for Video Super-Resolution. Applied Sciences. 2020; 10(23):8749. https://doi.org/10.3390/app10238749
Chicago/Turabian StyleXue, Xiongxiong, Zhenqi Han, Weiqin Tong, Mingqi Li, and Lizhuang Liu. 2020. "BFRVSR: A Bidirectional Frame Recurrent Method for Video Super-Resolution" Applied Sciences 10, no. 23: 8749. https://doi.org/10.3390/app10238749