Driver Attention Area Extraction Method Based on Deep Network Feature Visualization


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:Featured Application
Abstract
1. Introduction
2. Driver Attention Area Extraction Method
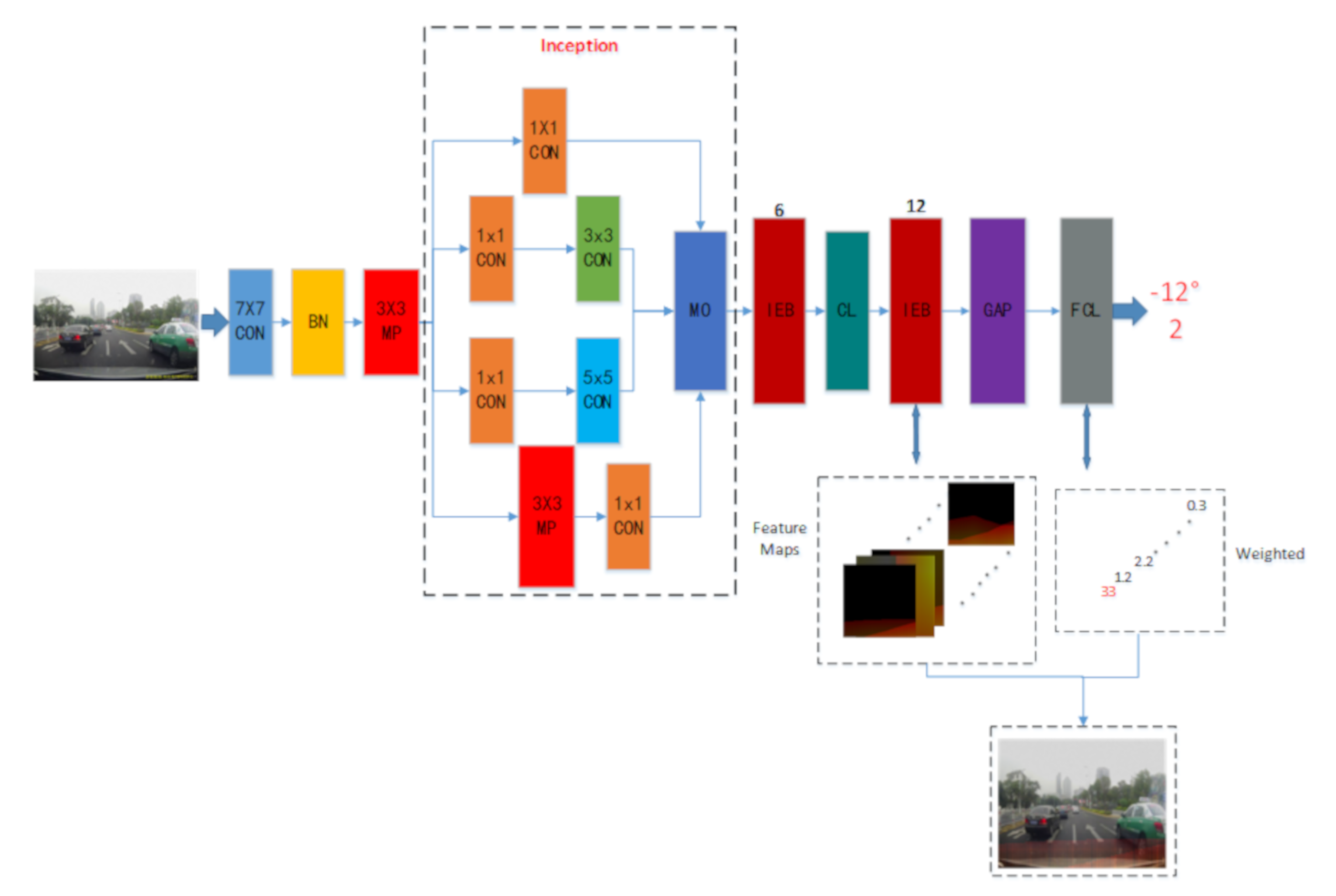
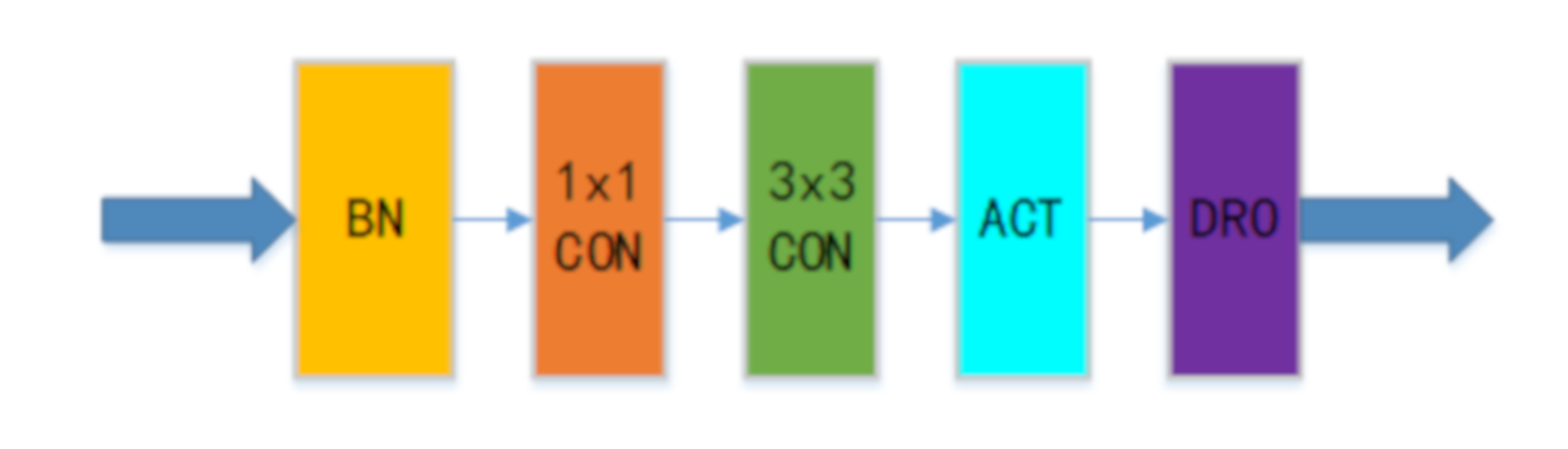
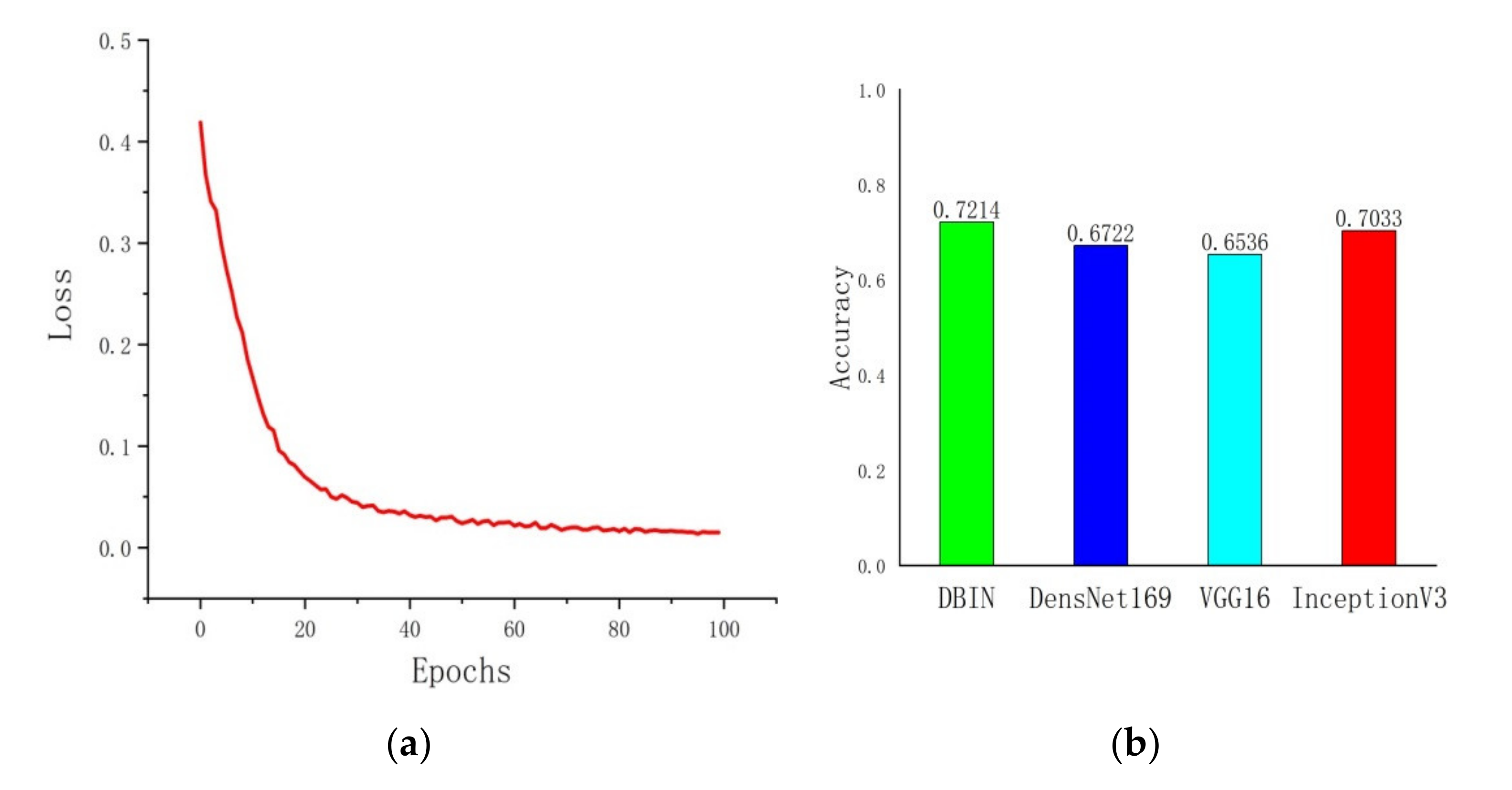
2.1. Driving Behavior Information Network (DBIN)
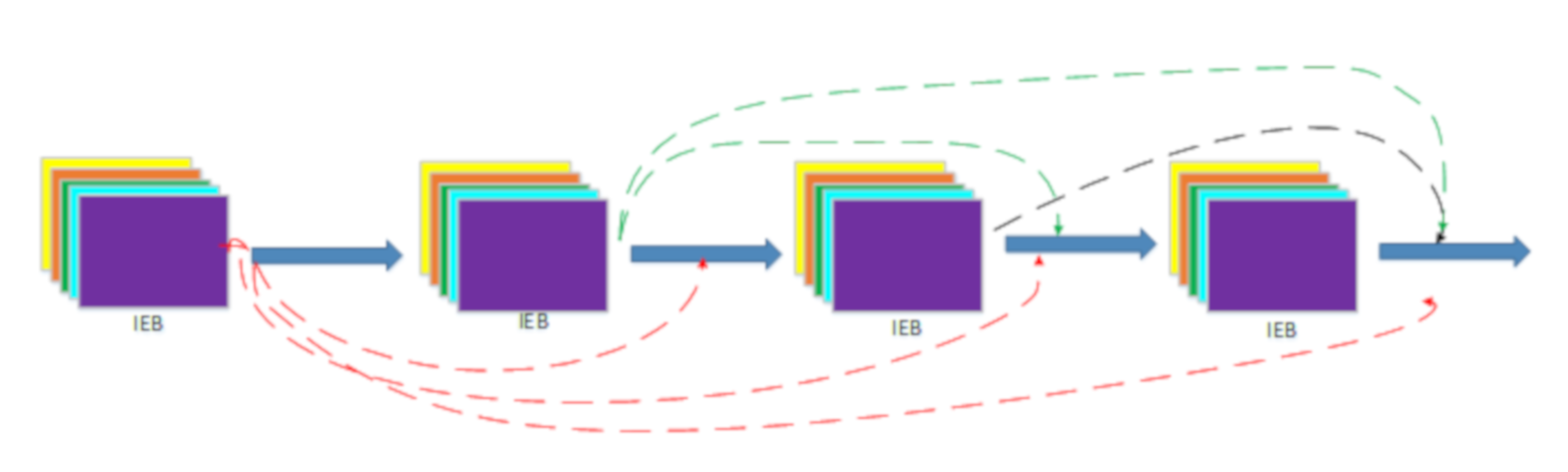
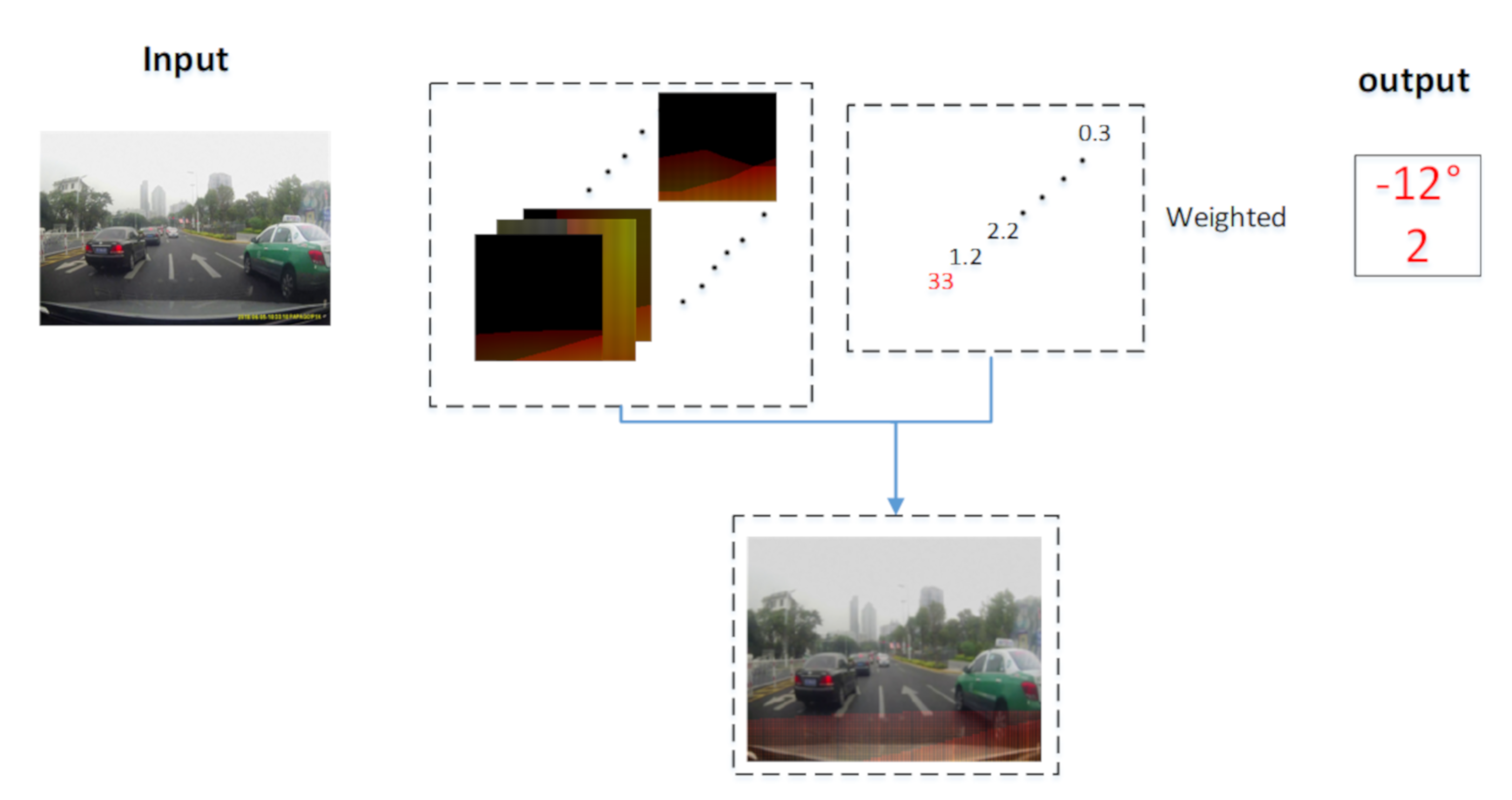
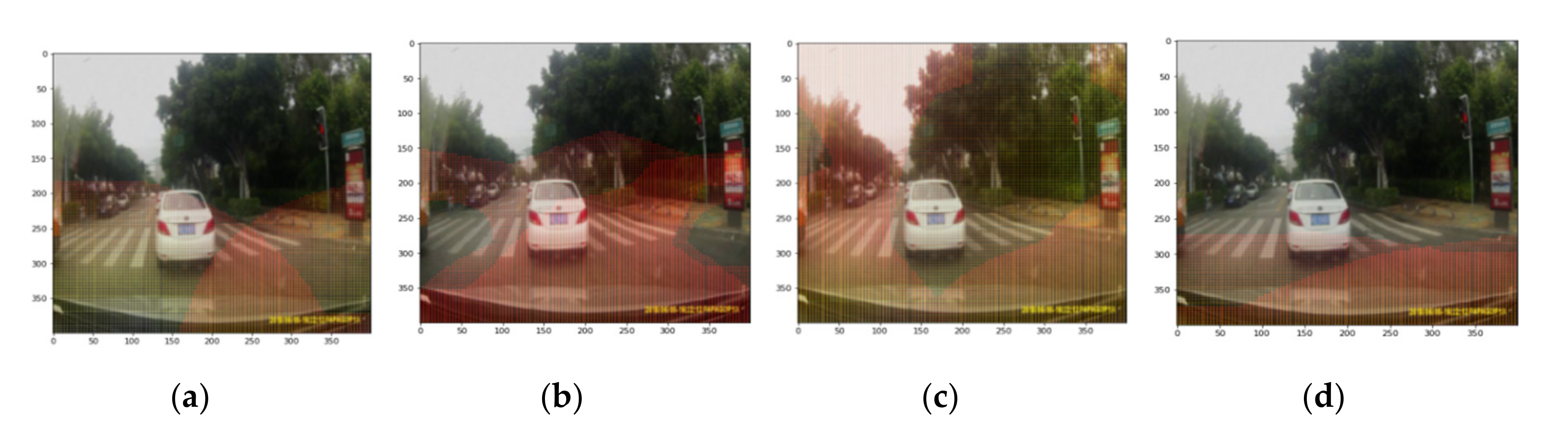
2.2. The Deep Network Feature Visualization Method (DNFV)
3. Experiment
3.1. Dataset Description
3.2. Experimental Details
3.3. Experimental Results and Analysis
4. Validation
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Putra, M.H.; Yussof, Z.M.; Lim, K.C.; Salim, S.I. Convolutional neural network for person and car detection using YOLO framework. J. Telecommun. Electron. Comput. Eng. 2018, 10, 67–71. [Google Scholar]
- Zhongbao, Z.; Hongyuan, W.; Ji, Z.; Yang, W. A vehicle real-time detection algorithm based on YOLOv2 framework. In Real-Time Image and Video Processing 2018; International Society for Optics and Photonics: Bellinghamm, WA, USA, 2018; Volume 10670. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.; Berg, A.C. SSD: Single shot multibox detector. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 8–16 October 2016; pp. 21–37. [Google Scholar]
- Yun, S.K.; Haet, B.L.; Jung, S.K.; Myung, K.; Kwang, S.P. ECG, EOG detection from helmet based system. In Proceedings of the International Special Topic Conference on Information Technology Applications in Biomedicine, Tokyo, Japan, 8–11 November 2007; pp. 191–193. [Google Scholar]
- Nayak, B.P.; Kar, S.; Routray, A.; Akhaya, K.P. A biomedical approach to retrieve information on driver’s fatigue by integrating EEG, ECG and blood biomarkers during simulated driving session. In Proceedings of the International Conference on Intelligent Human Computer Interaction, IEEE, Kharagpur, India, 27–29 December 2012; pp. 1–6. [Google Scholar]
- Wu, Q.; Zhao, Y.; Bi, X. Driving fatigue classified analysis based on ECG signal. In Proceedings of the Computational Intelligence and Design (ISCID) Fifth International Symposium, Hangzhou, China, 28–29 October 2012; pp. 544–547. [Google Scholar]
- Li, W.K.; Wei, K.L.; Wei, G.L.; Chun, H.C.; Shao, W.L.; Yi, C.L.; Tien, Y.H.; Hsuan, W.; Chin, T.L. Single channel wireless EEG device for real-time fatigue level detection. In Proceedings of the 2015 International Joint Conference on Neural Networks (IJCNN), Killarney, Ireland, 12–17 July 2015; pp. 1–5. [Google Scholar]
- Xiao, D.; Feng, C. Detection of drivers visual attention using smartphone. Int. Conf. Natural Comput. IEEE 2016, 10, 630–635. [Google Scholar]
- Chuang, M.C.; Bala, R.; Bernal, E.A.; Peter, P. Estimating gaze direction of vehicle drivers using a smartphone camera. IEEE Conf. Comput. Vis. Pattern Recognit. Workshops 2014, 30, 165–170. [Google Scholar]
- Francisco, V.; Zehua, H.; Xuehan, X.; Fernando, D.T.; Wende, Z.; Dan, L.G.; Motors, C.; Herzliya, I. Driver gaze tracking and eyes off the road detection system. IEEE Trans. Intell. Transp. Syst. 2015, 16, 2014–2027. [Google Scholar]
- Jha, S.; Busso, C. Analyzing the relationship between head pose and gaze to model drivervisual attention. IEEE Int. Conf. Intell. Transp. Syst. 2016. [Google Scholar] [CrossRef]
- Ashish, T.; Andreas, M.; Sujitha, M.; Thomas, B.M.; Mohan, M.T. Attention estimation by simultaneous analysis of viewer and view. In Proceedings of the IEEE International Conference on Intelligent Transportation Systems, Qingdao, China, 8–11 October 2014; pp. 1381–1387. [Google Scholar]
- Lex, F.; Philipp, L.; Joonbum, L.; Bryan, R. Driver gaze regionestimation without use of eye movement. arXiv 2016, arXiv:1507.04760. Available online: https://arxiv.org/abs/1507.04760 (accessed on 1 March 2016).
- Nian, L.; Junwei, H.; Dingwen, Z.; Shifeng, W.; Tianming, L. Predicting eye fixations using convolutional neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; IEEE: Boston, MA, USA, 2015. [Google Scholar]
- Zhao, S.; Han, G.; Zhao, Q.; Wei, P. Prediction of driver’s attention points based on attention model. Appl. Sci. 2020, 10, 1083. [Google Scholar] [CrossRef] [Green Version]
- Alletto, S.; Palazzi, A.; Solera, F.; Calderara, S.; Cucchuara, R. Dr (eye) ve: A dataset for attention-based tasks with applications to autonomous and assisted driving. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 54–60. [Google Scholar]
- Alletto, S.; Palazzi, A.; Solera, F.; Calderara, S.; Cucchuara, R. Learning where to attend like a human driver. In Proceedings of the IEEE Intelligent Vehicles Symposium, Redondo Beach, CA, USA, 11–14 June 2017; pp. 920–925. [Google Scholar]
- Palazzi, A.; Abati, D.; Calderara, S. Predicting the driver’s focus of attention: The DR (eye) VE project. IEEE Intell. Veh. Symp. 2019, 41, 1720–1733. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Tawari, A.; Kang, B. A computational framework for driver’s visual attention using a fully convolutional architecture. In Proceedings of the IEEE Intelligent Vehicles Symposium, Redondo Beach, CA, USA, 11–14 June 2018; pp. 887–894. [Google Scholar]
- Chen, Y.P.; Wang, J.K.; Li, J.T.; Lu, C.W.; Luo, Z.P.; Xue, X.; Cheng, W. LiDAR-Video driving dataset: Learning driving policies effectively. IEEE Conf. Comput. Vis. Pattern Recognit. 2018. [Google Scholar] [CrossRef]
- Christian, S.; Wei, L.; Yangqing, J.; Pierre, S.; Scott, R.; Dragomir, A.; Dumitru, E.; Vincent, V.; Andrew, R.C. Going deeper with convolution. arXiv 2014, arXiv:1409.4842. Available online: https://arxiv.org/abs/1409.4842 (accessed on 7 September 2014).
- Mariusz, B.; Davide, D.T.; Daniel, D.; Bernhard, F.; Beat, F.; Prasoon, G.; Lawrence, D.J.; Mathew, M.; Urs, M.; Jiakai, Z.; et al. End to end learning for self-driving cars. arXiv 2016, arXiv:1604.07316. Available online: https://arxiv.org/abs/1604.07316 (accessed on 25 April 2016).
- Geiger, A.; Lenz, P.; Urtasun, R. Are we ready for autonomous driving? The KITTI vision benchmark suite. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012. [Google Scholar]
- Geiger, A.; Lenz, P.; Stiller, C.; Urtasun, R. Vision meets robotics: The kitti dataset. Int. J. Robot. Res. 2013, 32, 1231–1237. [Google Scholar] [CrossRef] [Green Version]
- Gao, H.; Zhuang, L.; Laurens, V.D.M.; Kilian, Q.; Weinberger. Densely connected counvolutional networks. arXiv 2016, arXiv:1608.06993. Available online: https://arxiv.org/abs/1608.06993 (accessed on 28 January 2018).
- Christian, S.; Vincent, V.; Sergey, I.; Jonathon, S.; Zbigniew, W. Rethinking the inception architecture for computer vision. arXiv 2015, arXiv:1512.00567. Available online: https://arxiv.org/abs/1512.00567 (accessed on 11 December 2015).
- Karen, S.; Andrew, Z. Very deep convolution networks for large_scale image recognition. arXiv 2015, arXiv:1409.1556. Available online: https://arxiv.org/pdf/1409.1556.pdf (accessed on 10 April 2015).









© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Han, G.; Zhao, S.; Wang, P.; Li, S. Driver Attention Area Extraction Method Based on Deep Network Feature Visualization. Appl. Sci. 2020, 10, 5474. https://doi.org/10.3390/app10165474
Han G, Zhao S, Wang P, Li S. Driver Attention Area Extraction Method Based on Deep Network Feature Visualization. Applied Sciences. 2020; 10(16):5474. https://doi.org/10.3390/app10165474
Chicago/Turabian StyleHan, Guodong, Shuanfeng Zhao, Pengfei Wang, and Shijun Li. 2020. "Driver Attention Area Extraction Method Based on Deep Network Feature Visualization" Applied Sciences 10, no. 16: 5474. https://doi.org/10.3390/app10165474