
FedAAR: A Novel Federated Learning Framework for Animal Activity Recognition with Wearable Sensors



Abstract
:Simple Summary
Abstract
1. Introduction
- We propose a novel FL framework called FedAAR to automatically recognise animal activities based on distributed data. This gives it the considerable potential that multiple farms jointly train a shared model using their private dataset while protecting data privacy and ownership. To the best of our knowledge, this is the first time the FL method has been explored in automated AAR across multiple data sources.
- To alleviate client-drift issues, we devise a PLU module to replace the traditional local training process. The PLU module forces all clients to learn consistent feature knowledge by imposing a global prototype guidance constraint to local optimisation, further reducing the divergence between client updates.
- Different from existing aggregation mechanisms, we design a GRA module to reduce conflicts among local gradients. The GRA module eliminates conflicting components between local gradients during global aggregation, effectively guaranteeing that all refined local gradients point in a positive direction to improve the agreement among clients.
- Our experimental results demonstrate that our proposed FedAAR outperforms the state-of-the-art FL strategies and exhibits performance close to that of the centralised learning algorithm. This proves the promising capability of our method to enhance AAR performance without privacy leakage. We also validate the performance advantages of our approach compared to the baseline in different practical scenarios (i.e., local data sizes, communication frequency, and client numbers), providing rich insights into the appropriate future applications of our method.
2. Materials and Methods
2.1. Data Description
2.2. Preliminaries for Federated Learning
- Step 1.
- All clients synchronously download a global model wglobal from a global server.
- Step 2.
- Each client k uses the global model wglobal to initialise its local model wk (i.e., ) and then conducts local training for E epochs, i.e., minimising the local optimisation objective by using a gradient descent algorithm:
- Step 3.
- Each client k then uploads its local gradient gk to the global server. These local gradients from all clients are aggregated by directly averaging to generate global gradients gglobal:
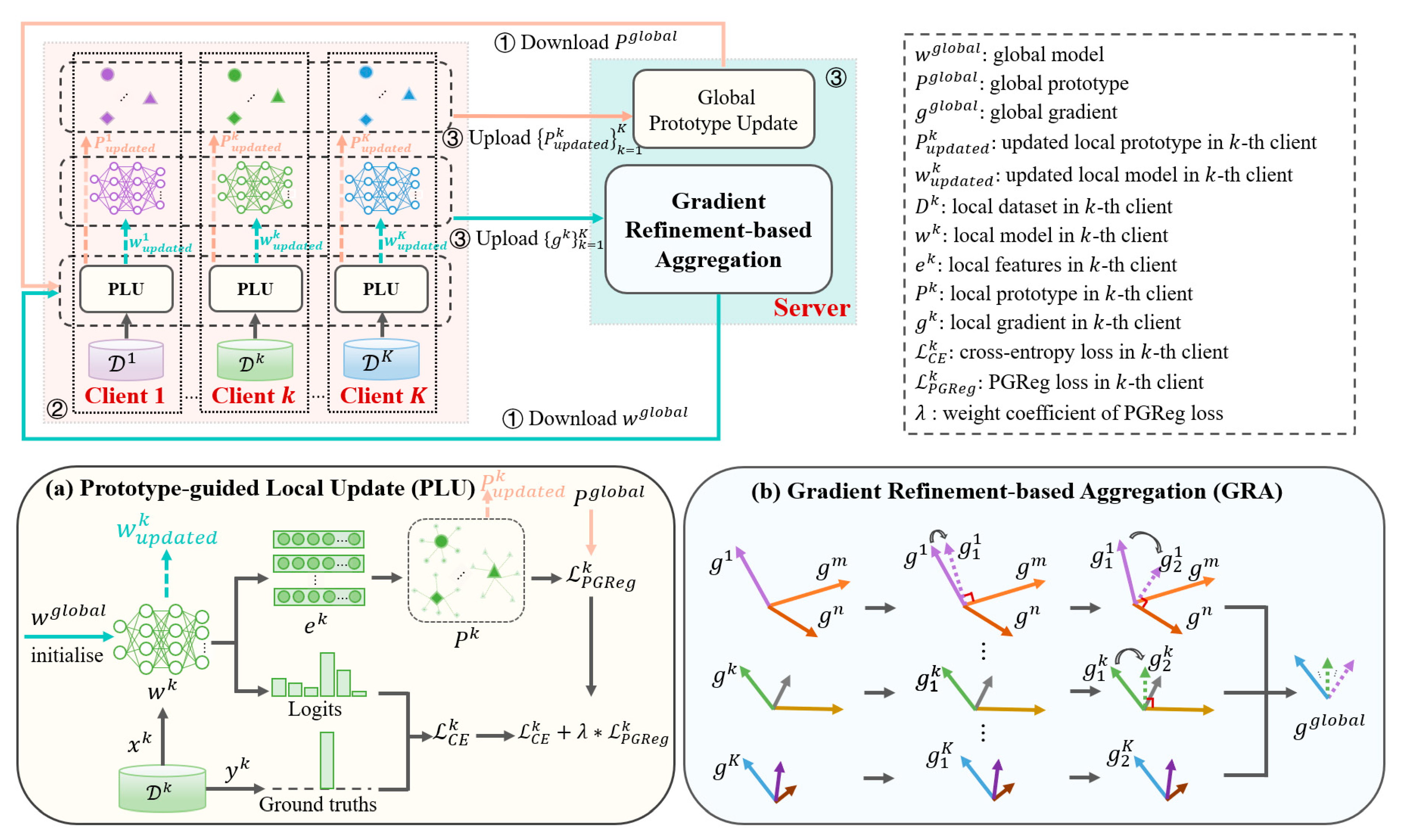
2.3. Our Proposed FL Framework for AAR
2.3.1. Overview
2.3.2. Prototype-Guided Local Update
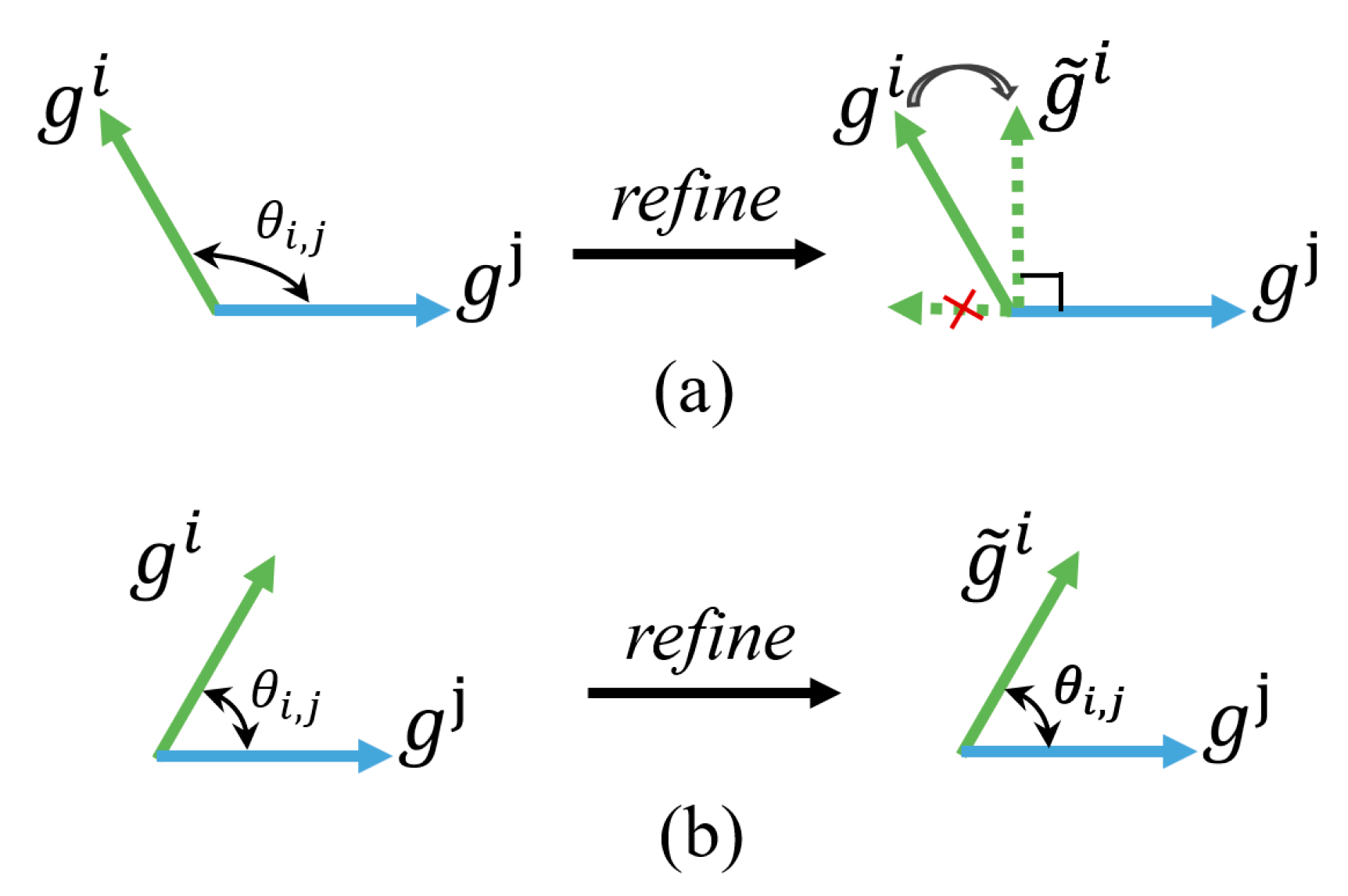
2.3.3. Gradient-Refinement-Based Aggregation
2.4. Evaluation Methods
2.5. Implementation Details
3. Results and Discussion
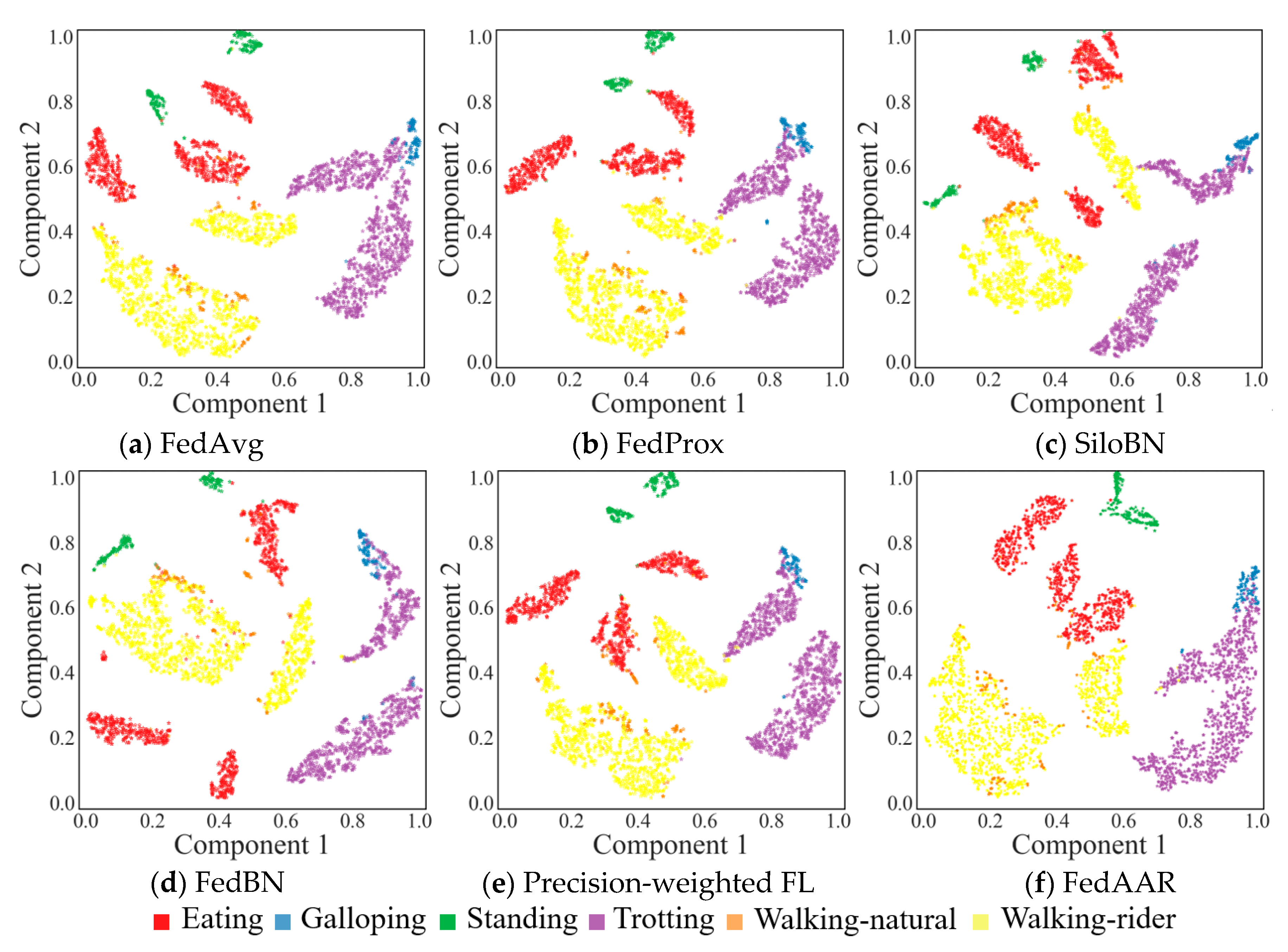
3.1. Comparisons with State-of-the-Art Methods
3.2. Ablation Studies
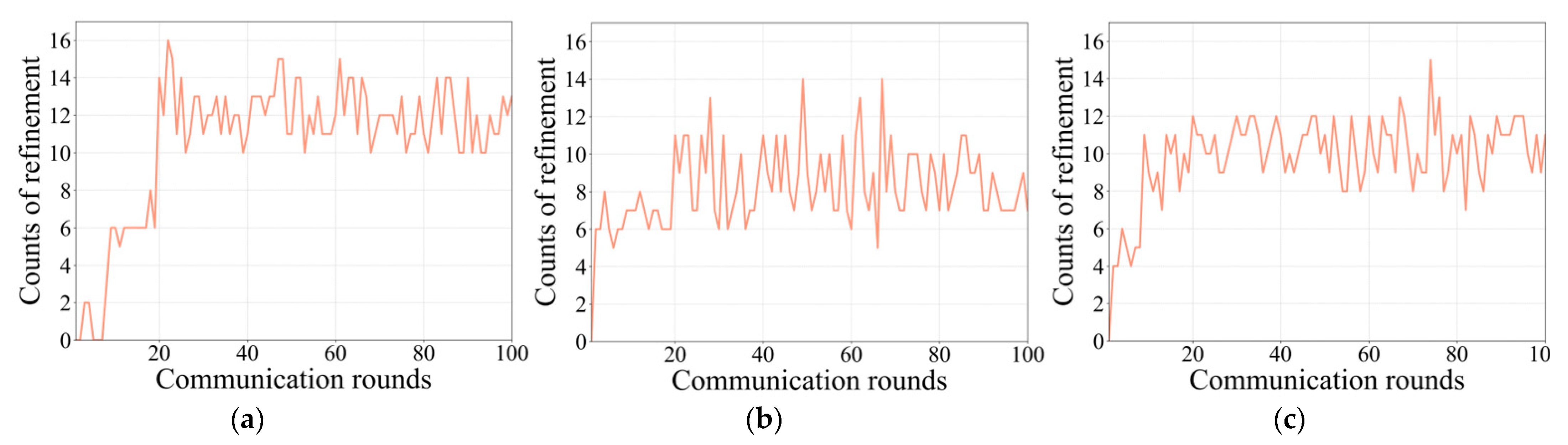
3.2.1. Evaluation of PLU and GRA Module
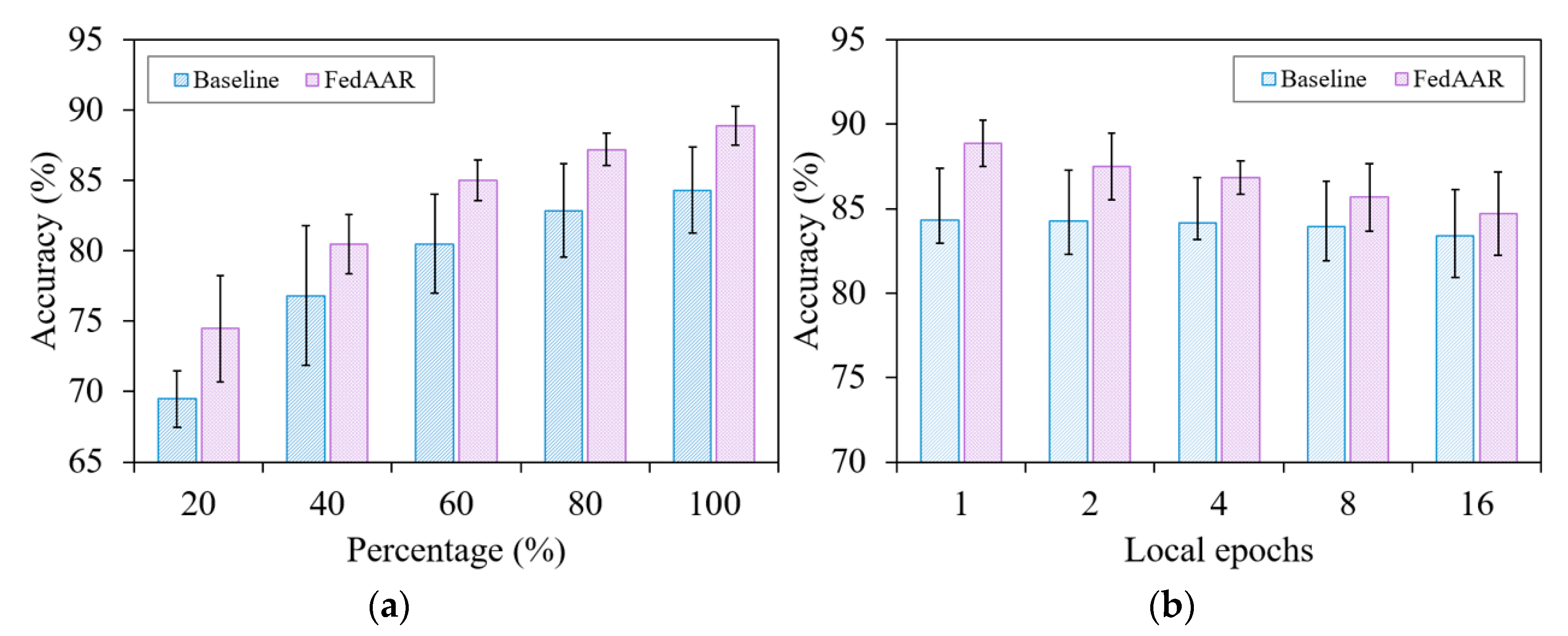
3.2.2. Analysis of Local Dataset Size
3.2.3. Analysis of Communication Frequency
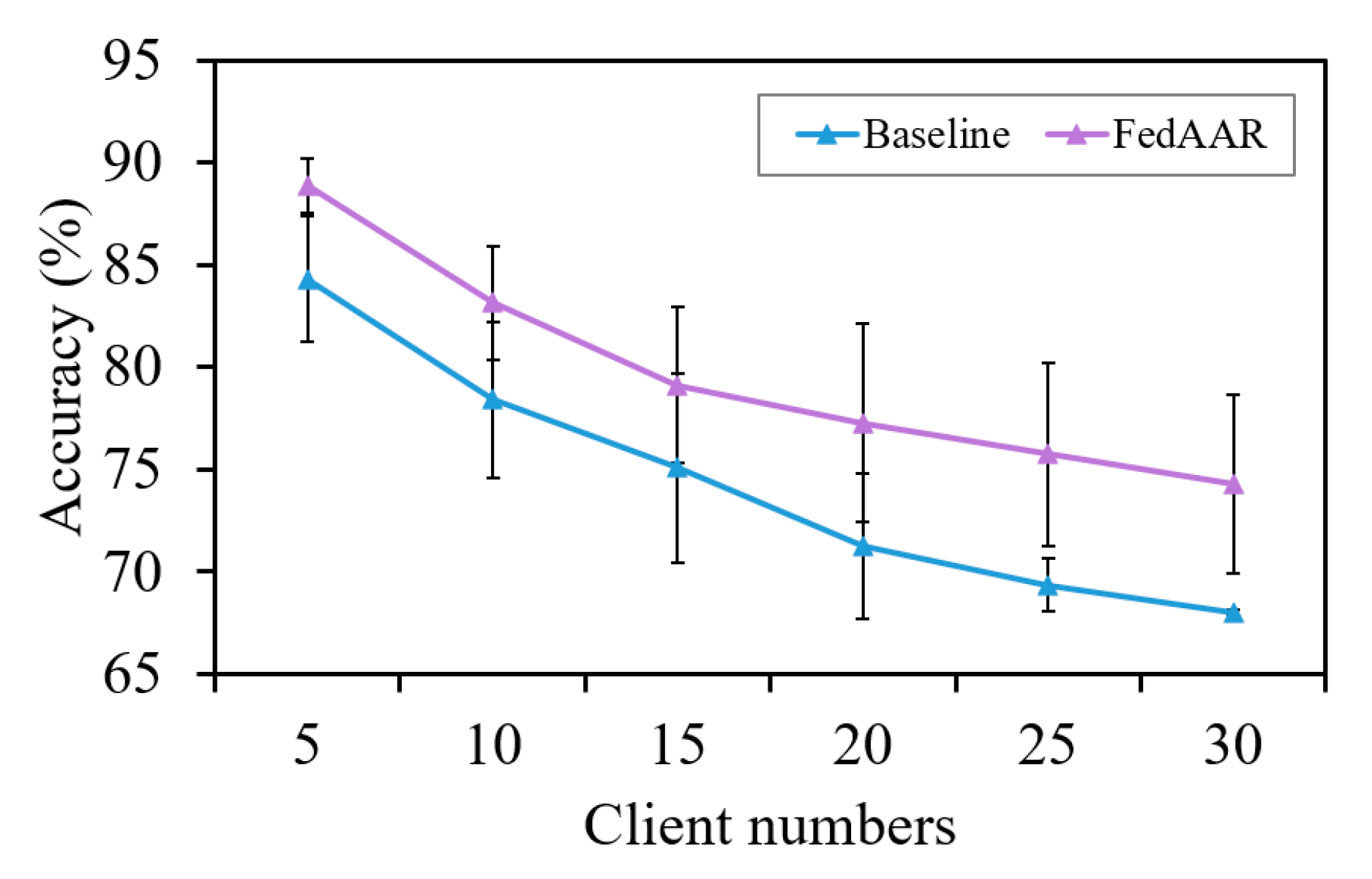
3.2.4. Analysis of Client Numbers
3.3. Limitations and Implications
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Uenishi, S.; Oishi, K.; Kojima, T.; Kitajima, K.; Yasunaka, Y.; Sakai, K.; Sonoda, Y.; Kumagai, H.; Hirooka, H. A novel accelerometry approach combining information on classified behaviors and quantified physical activity for assessing health status of cattle: A preliminary study. Appl. Anim. Behav. Sci. 2021, 235, 105220. [Google Scholar] [CrossRef]
- Eerdekens, A.; Deruyck, M.; Fontaine, J.; Martens, L.; De Poorter, E.; Plets, D.; Joseph, W. A framework for energy-efficient equine activity recognition with leg accelerometers. Comput. Electron. Agric. 2021, 183, 106020. [Google Scholar] [CrossRef]
- Lin, H.; Lou, J.; Xiong, L.; Shahabi, C. SemiFed: Semi-supervised federated learning with consistency and pseudo-labeling. arXiv 2021, arXiv:2108.09412. [Google Scholar]
- Li, C.; Tokgoz, K.; Fukawa, M.; Bartels, J.; Ohashi, T.; Takeda, K.I.; Ito, H. Data augmentation for inertial sensor data in CNNs for cattle behavior classification. IEEE Sens. Lett. 2021, 5, 7003104. [Google Scholar] [CrossRef]
- Chambers, R.D.; Yoder, N.C.; Carson, A.B.; Junge, C.; Allen, D.E.; Prescott, L.M.; Bradley, S.; Wymore, G.; Lloyd, K.; Lyle, S. Deep learning classification of canine behavior using a single collar-mounted accelerometer: Real-world validation. Animals 2021, 11, 1549. [Google Scholar] [CrossRef] [PubMed]
- Brendan McMahan, H.; Moore, E.; Ramage, D.; Hampson, S.; Agüera y Arcas, B. Communication-efficient learning of deep networks from decentralized data. In Proceedings of the 20th International Conference on Artificial Intelligence and Statistics, Fort Lauderdale, FL, USA, 9–11 May 2017; pp. 1273–1282. [Google Scholar]
- Huang, Y.; Chu, L.; Zhou, Z.; Wang, L.; Liu, J.; Pei, J.; Zhang, Y.; Canada, H.T. Personalized cross-silo federated learning on non-iid data. In Proceedings of the 35th AAAI Conference on Artificial Intelligence, Virtual, 2–9 February 2021; pp. 7865–7873. [Google Scholar]
- Acar, D.A.E.; Zhao, Y.; Navarro, R.M.; Mattina, M.; Whatmough, P.N.; Saligrama, V. Federated learning based on dynamic regularization. In Proceedings of the 9th International Conference on Learning Representations, Virtual, 3–7 May 2021; pp. 1–43. [Google Scholar]
- Deng, Y.; Kamani, M.M.; Mahdavi, M. Distributionally robust federated averaging. Adv. Neural Inf. Process. Syst. 2020, 33, 15111–15122. [Google Scholar]
- Lin, T.; Kong, L.; Stich, S.U.; Jaggi, M. Ensemble distillation for robust model fusion in federated learning. Adv. Neural Inf. Process. Syst. 2020, 33, 2351–2363. [Google Scholar]
- Durrant, A.; Markovic, M.; Matthews, D.; May, D.; Enright, J.; Leontidis, G. The role of cross-silo federated learning in facilitating data sharing in the agri-food sector. Comput. Electron. Agric. 2021, 193, 106648. [Google Scholar] [CrossRef]
- Yu, B.; Lv, Y. A survey on federated learning in data mining. WIREs Data Min. Knowl. Discov. 2022, 12, e1443. [Google Scholar] [CrossRef]
- Mustaqeem; Kwon, S. CLSTM: Deep feature-based speech emotion recognition using the hierarchical convlstm network. Mathematics 2020, 8, 2133. [Google Scholar] [CrossRef]
- He, Y.; Chen, Y.; Yang, X.; Zhang, Y.; Zeng, B. Class-wise adaptive self distillation for heterogeneous federated learning. In Proceedings of the 36th AAAI Conference on Artificial Intelligence, Virtual, 22 February–1 March 2022. [Google Scholar]
- Karimireddy, S.P.; Kale, S.; Mohri, M.; Reddi, S.J.; Stich, S.U.; Suresh, A.T. SCAFFOLD: Stochastic controlled averaging for federated learning. In Proceedings of the 37th International Conference on Machine Learning, Virtual, 12–18 July 2020; pp. 5132–5143. [Google Scholar]
- Li, T.; Sahu, A.K.; Zaheer, M.; Sanjabi, M.; Talwalkar, A.; Smith, V. Federated optimization in heterogeneous networks. In Proceedings of the 3rd Machine Learning and Systems Conference, Austin, TX, USA, 2–4 March 2020; pp. 429–450. [Google Scholar]
- Lee, G.; Shin, Y.; Jeong, M.; Yun, S.-Y. Preservation of the global knowledge by not-true self knowledge distillation in federated learning. arXiv 2021, arXiv:2106.03097. [Google Scholar]
- Xiao, J.; Du, C.; Duan, Z.; Guo, W. A novel server-side aggregation strategy for federated learning in non-iid situations. In Proceedings of the 20th International Symposium on Parallel and Distributed Computing, Cluj-Napoca, Romania, 28–30 July 2021; pp. 17–24. [Google Scholar]
- Reyes, J.; Di Jorio, L.; Low-Kam, C.; Kersten-Oertel, M. Precision-weighted federated learning. arXiv 2021, arXiv:2107.09627. [Google Scholar]
- Xia, Y.; Yang, D.; Li, W.; Myronenko, A.; Xu, D.; Obinata, H.; Mori, H.; An, P.; Harmon, S.; Turkbey, E.; et al. Auto-FedAvg: Learnable federated averaging for multi-institutional medical image segmentation. arXiv 2021, arXiv:2104.10195. [Google Scholar]
- Yeganeh, Y.; Farshad, A.; Navab, N.; Albarqouni, S. Inverse distance aggregation for federated learning with non-iid data. In Domain Adaptation and Representation Transfer, and Distributed and Collaborative Learning; Springer: Cham, Switzerland, 2020; pp. 150–159. [Google Scholar]
- Kamminga, J.W.; Janßen, L.M.; Meratnia, N.; Havinga, P.J.M. Horsing around—A dataset comprising horse movement. Data 2019, 4, 131. [Google Scholar] [CrossRef] [Green Version]
- Mao, A.; Huang, E.; Gan, H.; Parkes, R.S.V.; Xu, W. Cross-modality interaction network for equine activity recognition using imbalanced multi-modal data. Sensors 2021, 21, 5818. [Google Scholar] [CrossRef] [PubMed]
- Tan, Y.; Long, G.; Liu, L.; Zhou, T.; Lu, Q.; Jiang, J.; Zhang, C. FedProto: Federated prototype learning across heterogeneous clients. In Proceedings of the 36th AAAI Conference on Artificial Intelligence, Virtual, 22 February–1 March 2022; p. 3. [Google Scholar]
- Snell, J.; Swersky, K.; Zemel, R. Prototypical networks for few-shot learning. In Proceedings of the 31st Conference on Neural Information Processing Systems, Long Beach Convention Center, Long Beach, CA, USA, 4–9 December 2017. [Google Scholar] [CrossRef] [Green Version]
- Kim, H.; Joung, S.; Kim, I.J.; Sohn, K. Prototype-guided saliency feature learning for person search. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Virtual, 19–25 June 2021; pp. 4863–4872. [Google Scholar] [CrossRef]
- Andreux, M.; du Terrail, J.O.; Beguier, C.; Tramel, E.W. Siloed federated learning for multi-centric histopathology datasets. In Domain Adaptation and Representation Transfer, and Distributed and Collaborative Learning; Springer: Cham, Switzerland, 2020; pp. 129–139. [Google Scholar] [CrossRef]
- Li, X.; Jiang, M.; Zhang, X.; Kamp, M.; Dou, Q. FedBN: Federated learning on non-iid features via local batch normalization. In Proceedings of the 9th International Conference on Learning Representations, Virtual, 3–7 May 2021. [Google Scholar]
- Van der Maaten, L.; Hinton, G. Visualizing data using t-SNE. J. Mach. Learn. Res. 2008, 9, 2579–2605. [Google Scholar] [CrossRef]
- Li, T.; Sahu, A.K.; Talwalkar, A.; Smith, V. Federated learning: Challenges, methods, and future directions. IEEE Signal Process. Mag. 2020, 37, 50–60. [Google Scholar] [CrossRef]
- Li, L.; Fan, Y.; Tse, M.; Lin, K.Y. A review of applications in federated learning. Comput. Ind. Eng. 2020, 149, 106854. [Google Scholar] [CrossRef]
- Li, Q.; He, B.; Song, D. Model-contrastive federated learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Virtual, 19–25 June 2021; pp. 10713–10722. [Google Scholar] [CrossRef]
- Michieli, U.; Ozay, M. Prototype guided federated learning of visual feature representations. arXiv 2021, arXiv:2105.08982. [Google Scholar]
- Vimalajeewa, D.; Kulatunga, C.; Berry, D.; Balasubramaniam, S. A Service-based Joint Model Used for Distributed Learning: Application for Smart Agriculture. IEEE Trans. Emerg. Top. Comput. 2022, 10, 838–854. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Activity | Eating | Galloping | Standing | Trotting | Walking-Natural | Walking-Rider | Total | |
|---|---|---|---|---|---|---|---|---|
| Subject | ||||||||
| Happy | 5063 | 696 | 1186 | 7038 | 746 | 8896 | 23,625 | |
| Zafir | 1091 | 835 | 347 | 3559 | 161 | 5078 | 11,071 | |
| Driekus | 2496 | 323 | 341 | 2673 | 270 | 4024 | 10,127 | |
| Galoway | 4331 | 1043 | 1750 | 6423 | 1402 | 9653 | 24,602 | |
| Patron | 1951 | 714 | 1244 | 3402 | 388 | 5150 | 12,849 | |
| Bacardi | 1116 | 328 | 245 | 1981 | 360 | 1317 | 5347 | |
| Method | Precision (%) | Recall (%) | F1-Score (%) | Accuracy (%) |
|---|---|---|---|---|
| Centralised learning [23] | 83.34 ± 10.81 | 78.81 ± 2.40 | 77.96 ± 2.28 | 92.37 ± 3.84 |
| FedAvg [6] | 71.10 ± 4.42 | 64.96 ± 9.81 | 65.40 ± 8.93 | 84.31 ± 3.05 |
| FedProx [16] | 71.10 ± 4.42 | 64.93 ± 9.83 | 65.37 ± 8.96 | 84.30 ± 3.06 |
| IDA [21] | 70.67 ± 5.45 | 64.35 ± 10.68 | 64.27 ± 10.02 | 84.36 ± 3.33 |
| SiloBN [27] | 71.15 ± 2.73 | 64.57 ± 9.41 | 64.96 ± 7.94 | 83.18 ± 2.64 |
| FedBN [28] | 70.90 ± 2.84 | 65.45 ± 8.81 | 65.82 ± 7.14 | 83.72 ± 2.16 |
| Precision-weighted FL [19] | 71.48 ± 3.78 | 65.78 ± 9.15 | 66.36 ± 8.03 | 84.66 ± 2.68 |
| FedAAR (ours) | 75.23 ± 1.01 | 75.17 ± 3.92 | 74.70 ± 2.49 | 88.88 ± 1.36 |
| Method | Precision (%) | Recall (%) | F1-Score (%) | Accuracy (%) |
|---|---|---|---|---|
| Baseline | 71.10 ± 4.42 | 64.96 ± 9.81 | 65.40 ± 8.93 | 84.31 ± 3.05 |
| Baseline + PLU | 73.04 ± 2.89 | 65.98 ± 9.34 | 67.10 ± 8.02 | 84.92 ± 3.00 |
| Baseline + GRA | 74.17 ± 0.95 | 74.19 ± 2.96 | 73.74 ± 1.30 | 87.78 ± 0.78 |
| FedAAR | 75.23 ± 1.01 | 75.17 ± 3.92 | 74.70 ± 2.49 | 88.88 ± 1.36 |
| λ | Precision (%) | Recall (%) | F1-Score (%) | Accuracy (%) |
|---|---|---|---|---|
| 0.01 | 74.39 ± 1.07 | 74.56 ± 2.81 | 74.08 ± 1.07 | 88.17 ± 0.61 |
| 0.03 | 75.10 ± 0.82 | 74.87 ± 3.39 | 74.53 ± 1.93 | 88.55 ± 0.80 |
| 0.05 | 75.23 ± 1.01 | 75.17 ± 3.92 | 74.70 ± 2.49 | 88.88 ± 1.36 |
| 0.07 | 74.97 ± 1.08 | 74.66 ± 4.07 | 74.18 ± 2.59 | 88.88 ± 1.65 |
| 0.09 | 75.94 ± 2.14 | 72.50 ± 5.21 | 72.80 ± 3.85 | 88.89 ± 1.67 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Mao, A.; Huang, E.; Gan, H.; Liu, K. FedAAR: A Novel Federated Learning Framework for Animal Activity Recognition with Wearable Sensors. Animals 2022, 12, 2142. https://doi.org/10.3390/ani12162142
Mao A, Huang E, Gan H, Liu K. FedAAR: A Novel Federated Learning Framework for Animal Activity Recognition with Wearable Sensors. Animals. 2022; 12(16):2142. https://doi.org/10.3390/ani12162142
Chicago/Turabian StyleMao, Axiu, Endai Huang, Haiming Gan, and Kai Liu. 2022. "FedAAR: A Novel Federated Learning Framework for Animal Activity Recognition with Wearable Sensors" Animals 12, no. 16: 2142. https://doi.org/10.3390/ani12162142