
A Machine Learning Approach to Predicting Academic Performance in Pennsylvania’s Schools

Abstract
:1. Introduction
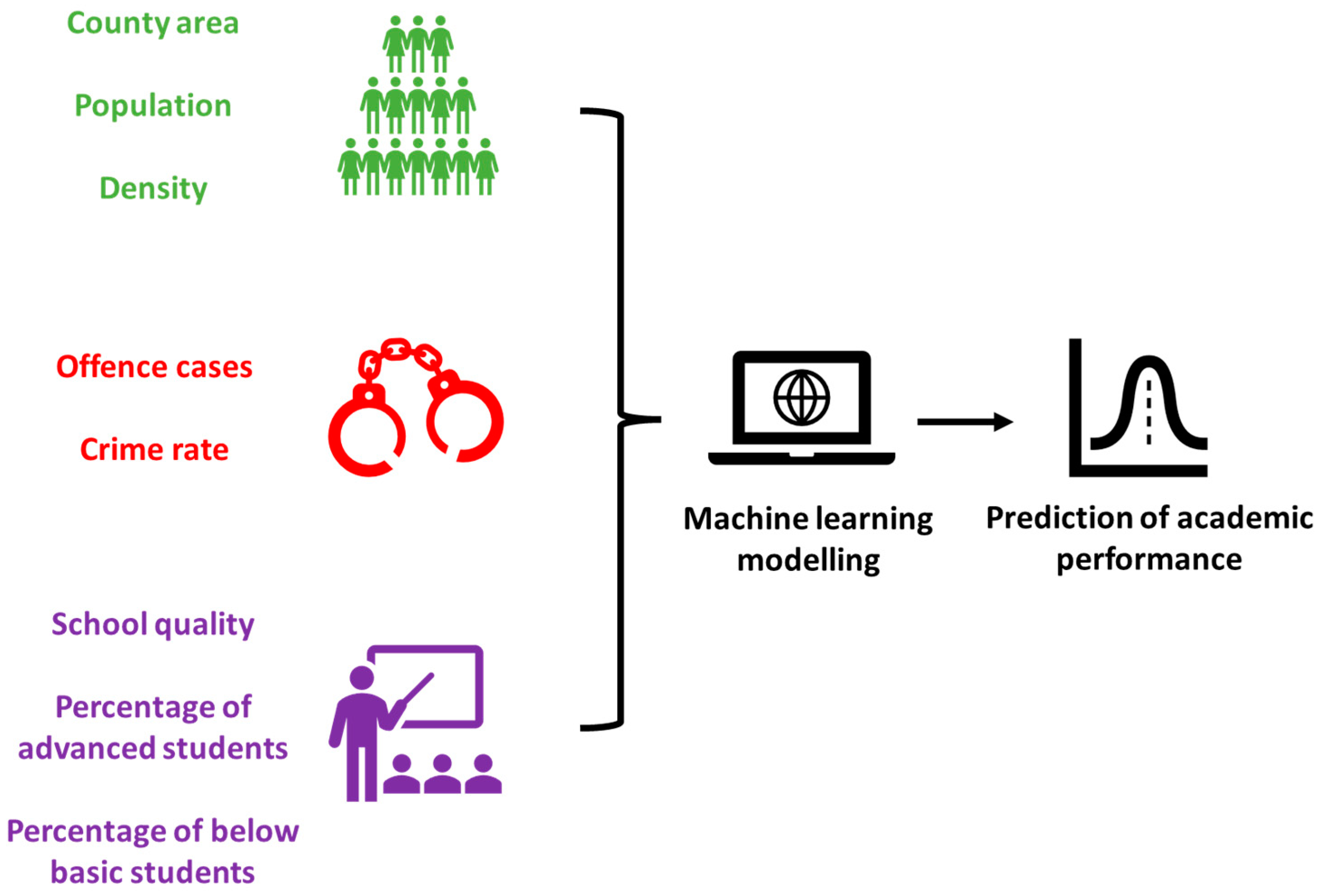
2. Materials and Methods
2.1. Data Collection
2.2. ML Models
3. Results
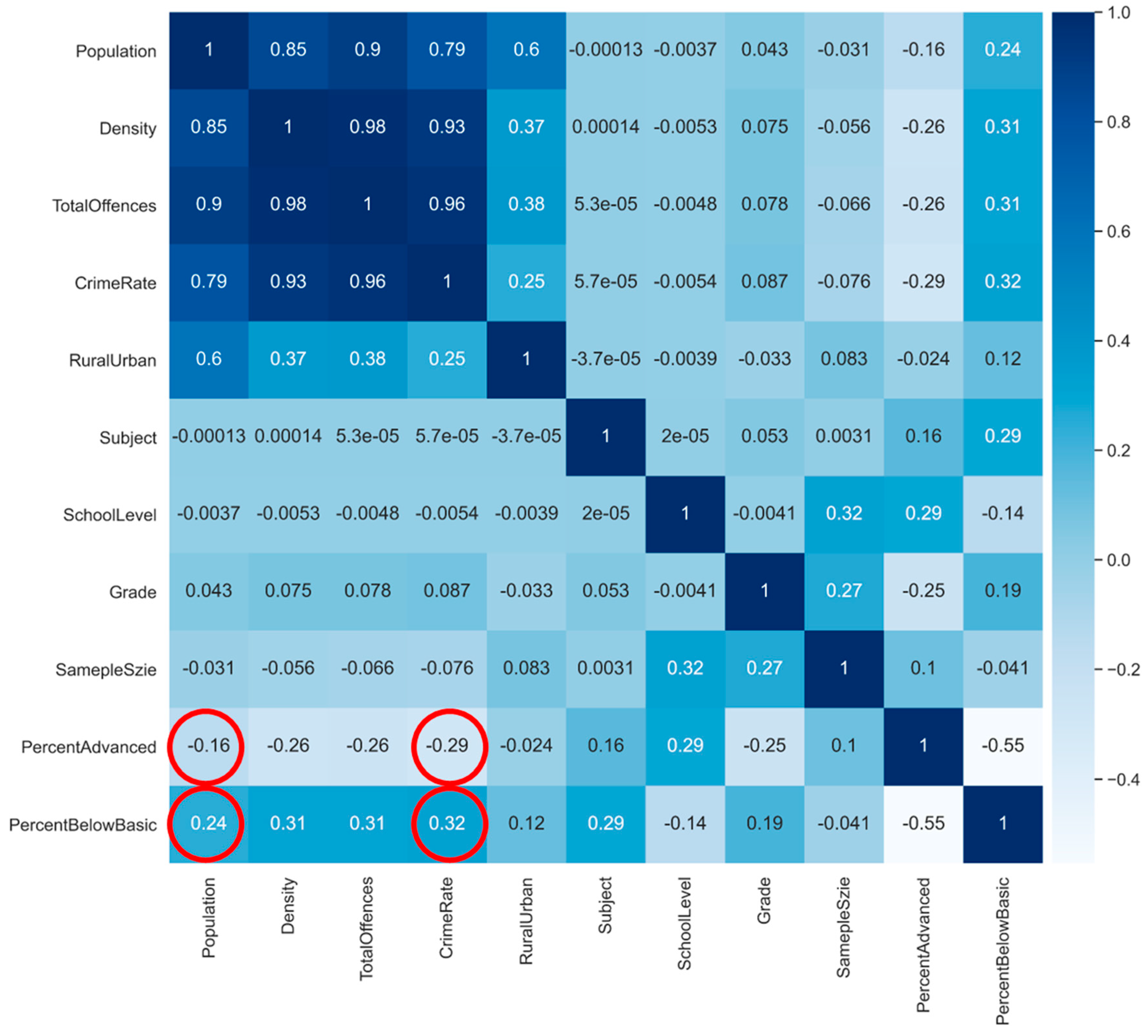
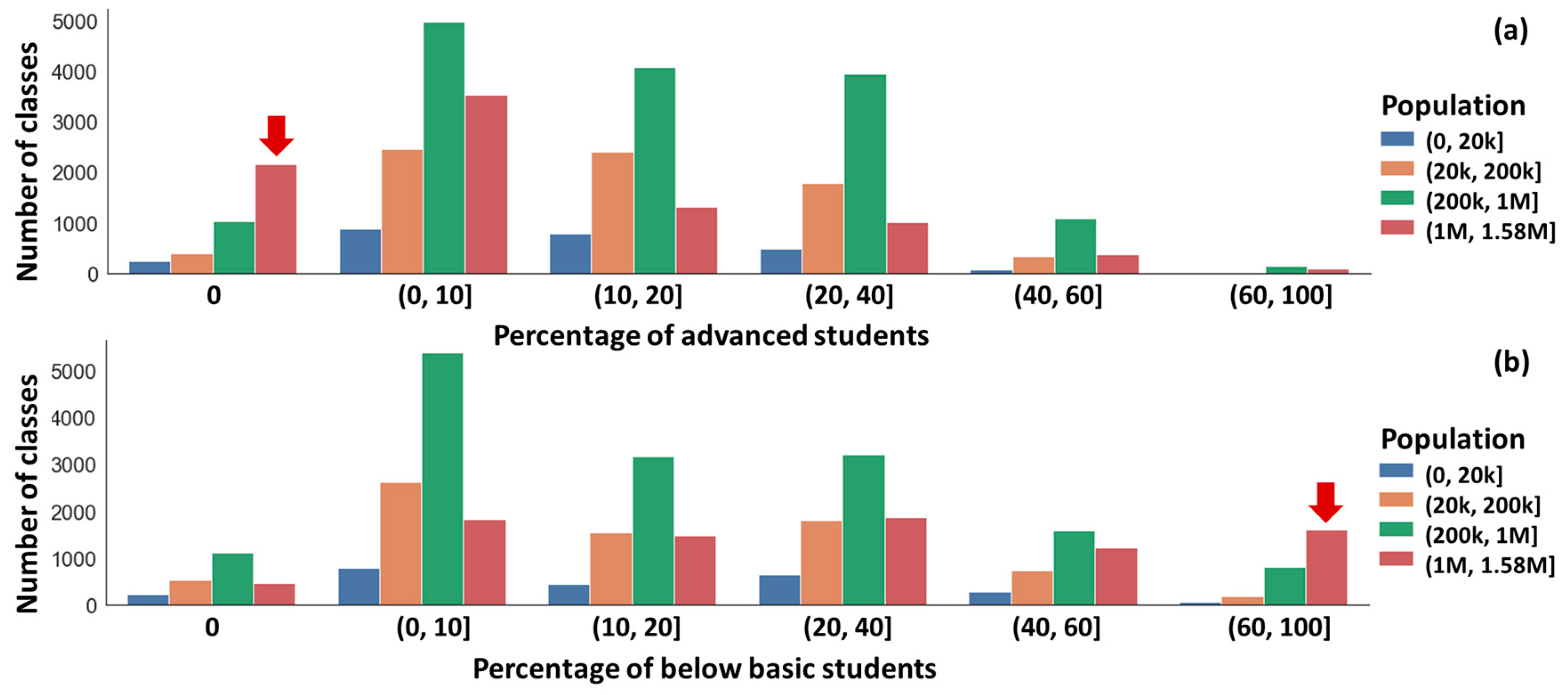
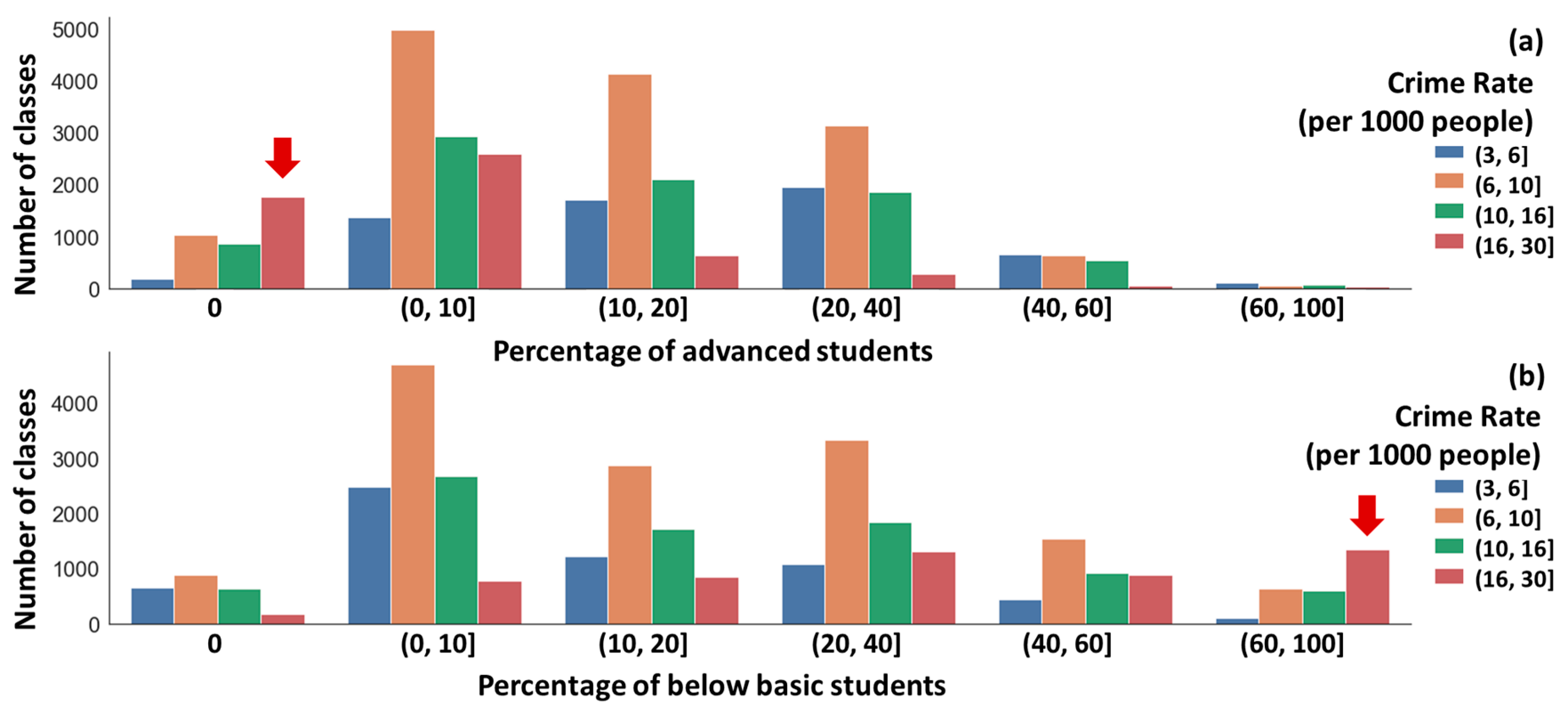
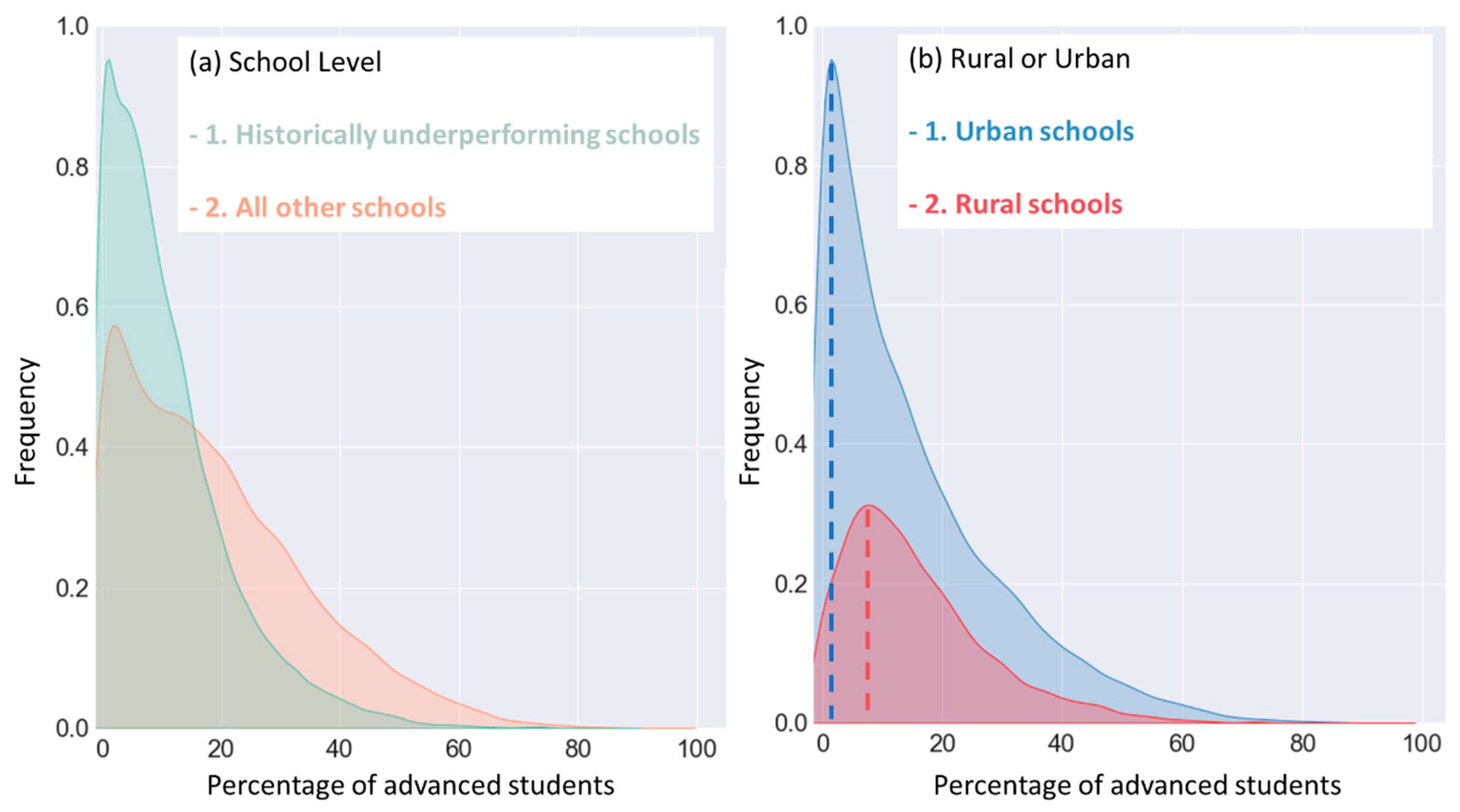
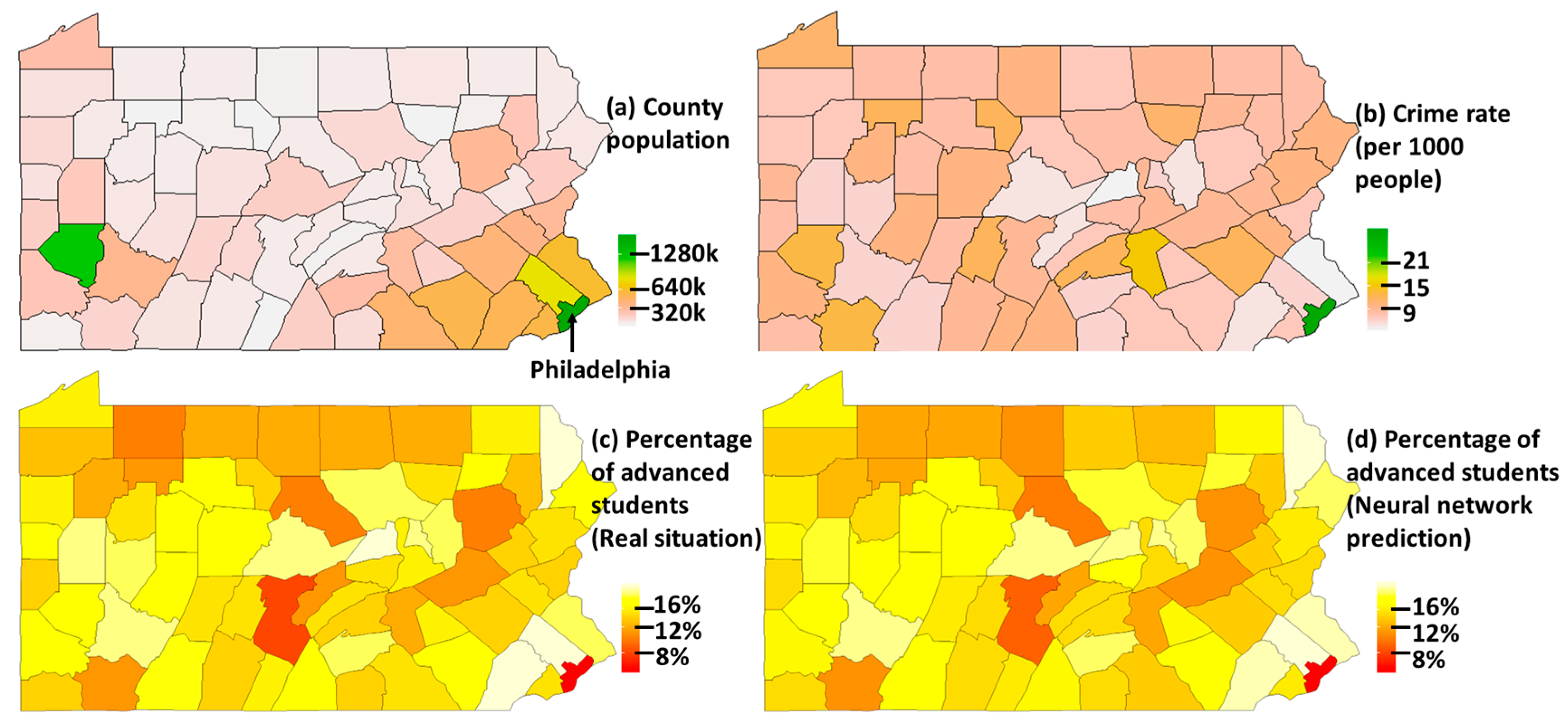
3.1. Educational Data Analysis
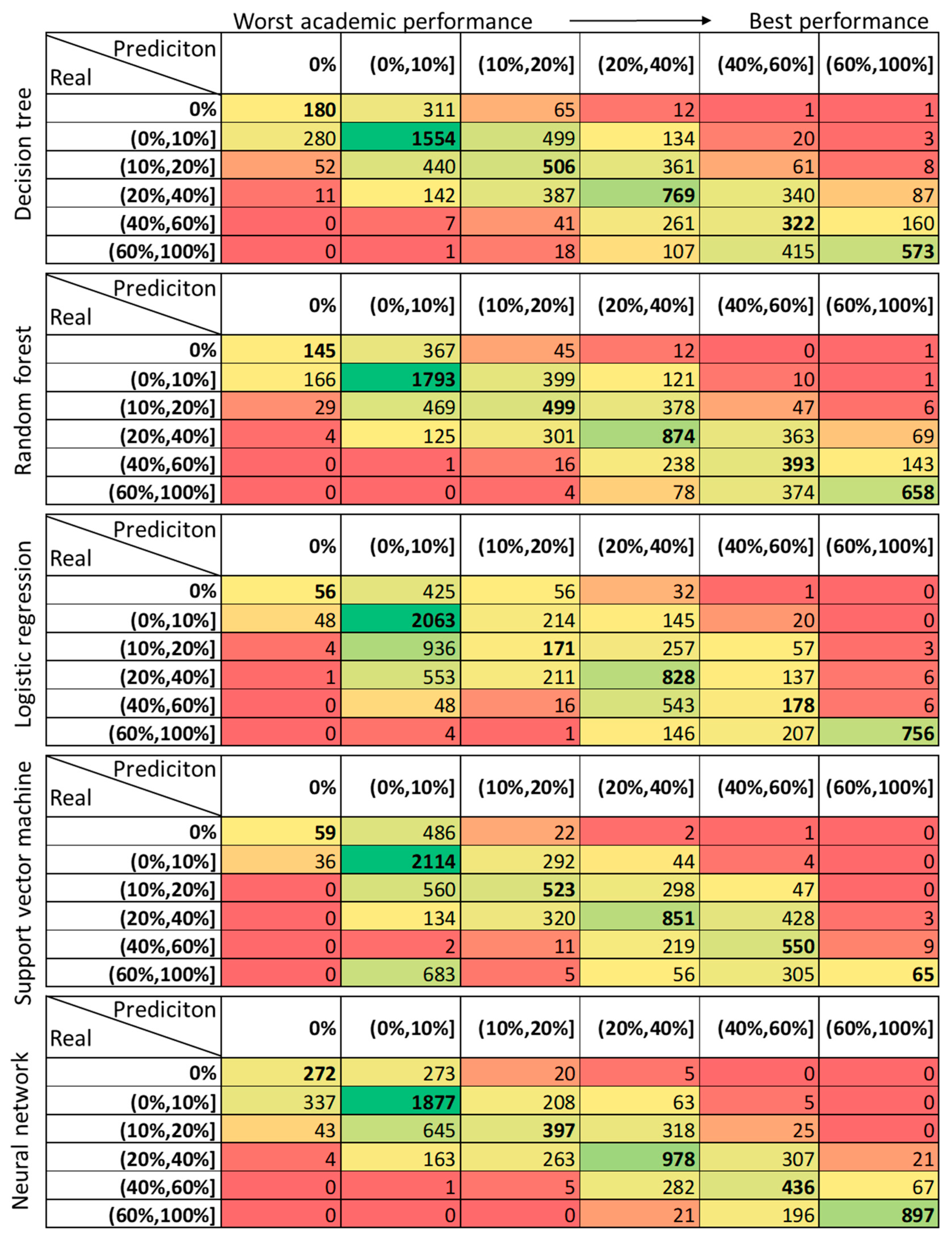
3.2. Academic Performance (Prediction versus Reality)
4. Discussion
4.1. Academic Performance in Pennsylvania Schools
4.2. Advantages and Limitations of the ML Model
4.3. Future Improvement of the ML Model
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Al-Jarrah, Omar, Paul Yoo, Sami Muhaidat, George Karagiannidis, and Kamal Taha. 2015. Efficient machine learning for big data: A review. Big Data Research 2: 87–93. [Google Scholar] [CrossRef] [Green Version]
- Alyahyan, Eyman, and Dilek Düştegör. 2020. Predicting academic success in higher education: Literature review and best practices. International Journal of Educational Technology in Higher Education 17: 1–21. [Google Scholar] [CrossRef] [Green Version]
- Batrouni, Marwan, Aurélie Bertaux, and Christophe Nicolle. 2018. Scenario analysis, from BigData to black swan. Computer Science Review 28: 131–39. [Google Scholar] [CrossRef]
- Boxer, Paul, Grant Drawve, and Joel M Caplan. 2020. Neighborhood violent crime and academic performance: A geospatial analysis. American Journal of Community Psychology 65: 343–52. [Google Scholar] [CrossRef] [PubMed]
- Buenaño-Fernández, Diego, David Gil, and Sergio Luján-Mora. 2019. Application of machine learning in predicting performance for computer engineering students: A case study. Sustainability 11: 2833. [Google Scholar] [CrossRef] [Green Version]
- Bujang, Siti Dianah Abdul, Ali Selamat, Roliana Ibrahim, Ondrej Krejcar, Enrique Herrera-Viedma, Hamido Fujita, and Nor Azura Md. Ghani. 2021. Multiclass prediction model for student grade prediction using machine learning. IEEE Access 9: 95608–21. [Google Scholar] [CrossRef]
- Chang, Chi, Joseph Gardiner, Richard Houang, and Yan-Liang Yu. 2020. Comparing multiple statistical software for multiple-indicator, multiple-cause modeling: An application of gender disparity in adult cognitive functioning using MIDUS II dataset. BMC Medical Research Methodology 20: 275. [Google Scholar] [CrossRef]
- Chen, Shan, and Yuanzhao Ding. 2022. Machine Learning and Its Applications in Studying the Geographical Distribution of Ants. Diversity 14: 706. [Google Scholar] [CrossRef]
- Chen, Shan, Yuanzhao Ding, and Xin Liu. 2021. Development of the growth mindset scale: Evidence of structural validity, measurement model, direct and indirect effects in Chinese samples. Current Psychology, 1–15. [Google Scholar] [CrossRef]
- Ciolacu, Monica, Ali Fallah Tehrani, Rick Beer, and Heribert Popp. 2017. Education 4.0—Fostering student’s performance with machine learning methods. Paper presented at 2017 IEEE 23rd International Symposium for Design and Technology in Electronic Packaging (SIITME), Constanta, Romania, October 26–29; pp. 438–43. [Google Scholar]
- Claver, Fernando, Luis Manuel Martínez-Aranda, Manuel Conejero, and Alexander Gil-Arias. 2020. Motivation, discipline, and academic performance in physical education: A holistic approach from achievement goal and self-determination theories. Frontiers in Psychology 11: 1808. [Google Scholar] [CrossRef]
- Considine, Gillian, and Gianni Zappalà. 2002. The influence of social and economic disadvantage in the academic performance of school students in Australia. Journal of Sociology 38: 129–48. [Google Scholar] [CrossRef]
- Correa-Baena, Juan-Pablo, Kedar Hippalgaonkar, Jeroen van Duren, Shaffiq Jaffer, Vijay R. Chandrasekhar, Vladan Stevanovic, Cyrus Wadia, Supratik Guha, and Tonio Buonassisi. 2018. Accelerating materials development via automation, machine learning, and high-performance computing. Joule 2: 1410–20. [Google Scholar] [CrossRef] [Green Version]
- Duivesteijn, Wouter, and Ad Feelders. 2008. Nearest neighbour classification with monotonicity constraints. In Machine Learning and Knowledge Discovery in Databases. Berlin/Heidelberg: Springer, pp. 301–316. [Google Scholar]
- Ebel, Robert, and David Frisbie. 1972. Essentials of Educational Measurement. New Delhi: Prentice Hall of India, pp. 1–352. [Google Scholar]
- Elsebakhi, Emad, Frank Lee, Eric Schendel, Anwar Haque, Nagarajan Kathireason, Tushar Pathare, Najeeb Syed, and Rashid Al-Ali. 2015. Large-scale machine learning based on functional networks for biomedical big data with high performance computing platforms. Journal of Computational Science 11: 69–81. [Google Scholar] [CrossRef]
- Fan, Xitao, and Michael Chen. 1998. Academic achievement of rural school students: A multi-year comparison with their peers in suburban and urban schools. Journal of Research in Rural Education 15: 31–46. [Google Scholar]
- Fedushko, Solomia, and Taras Ustyianovych. 2019. Predicting pupil’s successfulness factors using machine learning algorithms and mathematical modelling methods. In Advances in Computer Science for Engineering and Education II. Berlin/Heidelberg: Springer, pp. 625–36. [Google Scholar]
- Fox, Geoffrey, James Glazier, J. C. S. Kadupitiya, Vikram Jadhao, Minje Kim, Judy Qiu, James Sluka, Endre Somogyi, Madhav Marathe, Abhijin Adiga, and et al. 2019. Learning everywhere: Pervasive machine learning for effective high-performance computation. Paper presented at 2019 IEEE International Parallel and Distributed Processing Symposium Workshops (IPDPSW), Rio de Janeiro, Brazil, May 20–24; pp. 422–29. [Google Scholar]
- Ginsburg, Golda, and Phyllis Bronstein. 1993. Family factors related to children’s intrinsic/extrinsic motivational orientation and academic performance. Child Development 64: 1461–74. [Google Scholar] [CrossRef] [PubMed]
- Hussain, Mushtaq, Wenhao Zhu, Wu Zhang, Syed Muhammad Raza Abidi, and Sadaqat Ali. 2019. Using machine learning to predict student difficulties from learning session data. Artificial Intelligence Review 52: 381–407. [Google Scholar] [CrossRef]
- Izenman, Alan Julian. 2013. Linear discriminant analysis. In Modern Multivariate Statistical Techniques. Berlin/Heidelberg: Springer, pp. 237–80. [Google Scholar]
- Jana, Strakova, Vladislav Tomasek, and Douglas Willms. 2006. Educational inequalities in the Czech Republic. Prospects 36: 517–27. [Google Scholar]
- Jung, Seok-Ki, and Tae-Woo Kim. 2016. New approach for the diagnosis of extractions with neural network machine learning. American Journal of Orthodontics and Dentofacial Orthopedics 149: 127–33. [Google Scholar] [CrossRef] [Green Version]
- Kemper, Lorenz, Gerrit Vorhoff, and Berthold U. Wigger. 2020. Predicting student dropout: A machine learning approach. European Journal of Higher Education 10: 28–47. [Google Scholar] [CrossRef]
- Kotsiantis, Sotiris, Ioannis Zaharakis, and Panagiotis Pintelas. 2006. Machine learning: A review of classification and combining techniques. Artificial Intelligence Review 26: 159–90. [Google Scholar] [CrossRef]
- Kryst, Erica, Stephen Kotok, and Katerina Bodovski. 2015. Rural/urban disparities in science achievement in post-socialist countries: The evolving influence of socioeconomic status. Global Education Review 2: 60–77. [Google Scholar]
- Kurdek, Lawrence, and Sinclair Ronald. 1988. Relation of eighth graders’ family structure, gender, and family environment with academic performance and school behavior. Journal of Educational Psychology 80: 90. [Google Scholar] [CrossRef]
- Li, Liang, Jia Wang, and Xuetao Li. 2020. Efficiency analysis of machine learning intelligent investment based on K-means algorithm. IEEE Access 8: 147463–147470. [Google Scholar] [CrossRef]
- Likas, Aristidis, Nikos Vlassis, and Jakob J. Verbeek. 2003. The global k-means clustering algorithm. Pattern Recognition 36: 451–61. [Google Scholar] [CrossRef] [Green Version]
- Liu, Yanli, Yourong Wang, and Jian Zhang. 2012. New machine learning algorithm: Random forest. In Information Computing and Applications. Berlin/Heidelberg: Springer, pp. 246–52. [Google Scholar]
- Lorey, Johannes, Felix Naumann, Benedikt Forchhammer, Andrina Mascher, Peter Retzlaff, Armin ZamaniFarahani, Soeren Discher, Cindy Faehnrich, Stefan Lemme, Thorsten Papenbrock, and et al. 2011. Black swan: Augmenting statistics with event data. Paper presented at 20th ACM International Conference on Information and Knowledge Management, Glasgow, UK, October 24–28; pp. 2517–20. [Google Scholar]
- Lykourentzou, Ioanna, Ioannis Giannoukos, Vassilis Nikolopoulos, George Mpardis, and Vassili Loumos. 2009. Dropout prediction in e-learning courses through the combination of machine learning techniques. Computers & Education 53: 950–65. [Google Scholar]
- Manogaran, Gunasekaran, Vijayakumar Varadarajan, Ramachandran Varatharajan, Priyan Malarvizhi Kumar, Revathi Sundarasekar, and Ching-Hsien Hsu. 2018. Machine learning based big data processing framework for cancer diagnosis using hidden Markov model and GM clustering. Wireless Personal Communications 102: 2099–116. [Google Scholar] [CrossRef]
- Mduma, Neema, Khamisi Kalegele, and Dina Machuve. 2019. A survey of machine learning approaches and techniques for student dropout prediction. Data Science Journal 18: 14. [Google Scholar] [CrossRef] [Green Version]
- Miller, Portia, Elizabeth Votruba-Drzal, and Rebekah Levine Coley. 2019. Poverty and academic achievement across the urban to rural landscape: Associations with community resources and stressors. RSF: The Russell Sage Foundation Journal of the Social Sciences 5: 106–22. [Google Scholar] [CrossRef]
- Mohr, Felix, Marcel Wever, and Eyke Hüllermeier. 2018. ML-Plan: Automated machine learning via hierarchical planning. Machine Learning 107: 1495–515. [Google Scholar] [CrossRef] [Green Version]
- Musso, Mariel, Carlos Felipe Rodríguez Hernández, and Eduardo Cascallar. 2020. Predicting key educational outcomes in academic trajectories: A machine-learning approach. Higher Education 80: 875–94. [Google Scholar] [CrossRef] [Green Version]
- Owens, Ann. 2018. Income segregation between school districts and inequality in students’ achievement. Sociology of Education 91: 1–27. [Google Scholar] [CrossRef] [Green Version]
- Papernot, Nicolas, Patrick McDaniel, Ian Goodfellow, Somesh Jha, Berkay Celik, and Ananthram Swami. 2017. Practical black-box attacks against machine learning. Paper presented at 2017 ACM on Asia Conference on Computer and Communications Security, Abu Dhabi, United Arab Emirates, April 2–6; pp. 506–19. [Google Scholar]
- Paulick, Isabell, Rainer Watermann, and Matthias Nückles. 2013. Achievement goals and school achievement: The transition to different school tracks in secondary school. Contemporary Educational Psychology 38: 75–86. [Google Scholar] [CrossRef]
- Pedregosa, Fabian, Gael Varoquaux, Alexandre Gramfort, Vincent Michel, Bertrand Thirion, Olivier Grisel, Mathieu Blondel, Peter Prettenhofer, Ron Weiss, Vincent Dubourg, and et al. 2011. Scikit-learn: Machine learning in Python. The Journal of Machine Learning Research 12: 2825–30. [Google Scholar]
- Pomerat, John, Aviv Segev, and Rituparna Datta. 2019. On neural network activation functions and optimizers in relation to polynomial regression. Paper presented at 2019 IEEE International Conference on Big Data (Big Data), Los Angeles, CA, USA, December 9–12; pp. 6183–85. [Google Scholar]
- Qazdar, Aimad, Brahim Er-Raha, Chihab Cherkaoui, and Driss Mammass. 2019. A machine learning algorithm framework for predicting students performance: A case study of baccalaureate students in Morocco. Education and Information Technologies 24: 3577–89. [Google Scholar] [CrossRef]
- Qi, Xinbo, Guofeng Chen, Yong Li, Xuan Cheng, and Changpeng Li. 2019. Applying neural-network-based machine learning to additive manufacturing: Current applications, challenges, and future perspectives. Engineering 5: 721–29. [Google Scholar] [CrossRef]
- Ramos, Raul, Juan Carlos Duque, and Sandra Nieto. 2012. Decomposing the rural-urban differential in student achievement in Colombia using PISA microdata. SSRN Electronic Journal 34: 379–412. [Google Scholar] [CrossRef]
- Rymarczyk, Tomasz, Edward Kozłowski, Grzegorz Kłosowski, and Konrad Niderla. 2019. Logistic regression for machine learning in process tomography. Sensors 19: 3400. [Google Scholar] [CrossRef] [Green Version]
- Samworth, Richard. 2012. Optimal weighted nearest neighbour classifiers. The Annals of Statistics 40: 2733–63. [Google Scholar] [CrossRef]
- Şara, Nicolae-Bogdan, Rasmus Halland, Christian Igel, and Stephen Alstrup. 2015. High-school dropout prediction using machine learning: A Danish large-scale study. Paper presented at 23rd European Symposium on Artificial Neural Networks, Bruges, Belgium, April 22–24; pp. 319–24. [Google Scholar]
- Sekeroglu, Boran, Kamil Dimililer, and Kubra Tuncal. 2019. Student performance prediction and classification using machine learning algorithms. Paper presented at 2019 8th International Conference on Educational and Information Technology, Cambridge, UK, March 2–4; pp. 7–11. [Google Scholar]
- Shakhovska, Natalya, Olena Vovk, Roman Hasko, and Yuriy Kryvenchuk. 2017. The method of big data processing for distance educational system. In Advances in Intelligent Systems and Computing II. Berlin/Heidelberg: Springer, pp. 461–73. [Google Scholar]
- Somvanshi, Madan, Pranjali Chavan, Shital Tambade, and Swati Shinde. 2016. A review of machine learning techniques using decision tree and support vector machine. Paper presented at 2016 International Conference on Computing Communication Control and automation (ICCUBEA), Pune, India, August 12–13; pp. 1–7. [Google Scholar]
- Willms, Douglas, Thomas Smith, Yanhong Zhang, and Lucia Tramonte. 2006. Raising and levelling the learning bar in central and Eastern Europe. Prospects 36: 411–18. [Google Scholar] [CrossRef]
- Xanthopoulos, Petros, Panos Pardalos, and Theodore Trafalis. 2013. Linear discriminant analysis. In Robust Data Mining. Berlin/Heidelberg: Springer, pp. 27–33. [Google Scholar]
- Yousafzai, Bashir Khan, Maqsood Hayat, and Sher Afzal. 2020. Application of machine learning and data mining in predicting the performance of intermediate and secondary education level student. Education and Information Technologies 25: 4677–97. [Google Scholar] [CrossRef]
- Zhou, Lina, Shimei Pan, Jianwu Wang, and Athanasios Vasilakos. 2017. Machine learning on big data: Opportunities and challenges. Neurocomputing 237: 350–61. [Google Scholar] [CrossRef] [Green Version]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Classical Statistical Method | ML Method | Reference | |
|---|---|---|---|
| Rationale | Necessary for understanding the relationship between academic performance and relevant factors (e.g., crime rate and population density) | Prediction of academic performance by ML algorithms | (Bujang et al. 2021; Chang et al. 2020; Lykourentzou et al. 2009; Mduma et al. 2019; Papernot et al. 2017; Paulick et al. 2013; Sara et al. 2015) |
| Methods | The use of programs such as Mplus to identify relationships between academic performance and relevant factors; calculation based on the relationships | Prediction via ‘black box’ models without consideration for relationships | (Bujang et al. 2021; Chang et al. 2020; Lykourentzou et al. 2009; Mduma et al. 2019; Papernot et al. 2017; Paulick et al. 2013; Sara et al. 2015) |
| Accuracy | Existing relationships and assumptions | Quality and quantity of data | (Al-Jarrah et al. 2015; Ciolacu et al. 2017; Sekeroglu et al. 2019) |
| Advantages | Matured methods with clear processes | Rapid and convenient prediction for reasonable results | (Ciolacu et al. 2017; Sekeroglu et al. 2019) |
| Limitations | Sample selection bias | The ‘black swan’ effect | (Batrouni et al. 2018; Lorey et al. 2011) |
| County Area (km2) | Approximate Number | County Population (People) | Approximate Number | Crime Rate (per 1000 People) | Approximate Number |
| ≤1000 | 500 | ≤50,000 | 25,000 | (3, 6] | 5 |
| (1000, 2000] | 1500 | (50,000, 200,000] | 100,000 | (6, 10] | 8 |
| (2000, 3000] | 2500 | (200,000, 1,000,000] | 500,000 | (10, 16] | 13 |
| (3000, 4040] | 3500 | (1,000,000, 1,584,064] | 1,500,000 | (16, 30] | 29 |
| Population Density (people/km2) | Approximate Number | Total Offenses Cases | Approximate Number | Percentage of Advanced/Below-Basic Students | Approximate Number |
| ≤100 | 50 | ≤10,000 | 5,000 | 0% | 0% |
| (100, 500] | 300 | (10,000, 50,000] | 25,000 | (0%, 10%] | 5% |
| (500, 1300] | 900 | (50,000, 200,000] | 100,000 | (10%, 20%] | 15% |
| (1300, 4564] | 3000 | (200,000, 859,411] | 500,000 | (20%, 40%] | 30% |
| (40%, 60%] | 50% | ||||
| (60%, 100%] | 80% | ||||
| Subject | Assigned Number | School Level | Assigned Number | Rural/Urban | Assigned Number |
| English language | 1 | Historically under performance | 1 | Rural | 1 |
| Math | 2 | All group | 2 | Urban | 2 |
| Science | 3 |
| Method | Classifier | Training Accuracy | Testing Accuracy |
|---|---|---|---|
| Decision tree | DecisionTreeClassifier | 94% | 48% |
| Random forest | RandomForestClassifier | 94% | 54% |
| Logistic regression | LogisticRegression | 48% | 50% |
| Support vector machine | SupportVectorClassifier | 59% | 51% |
| Neural network | MLPClassifier | 61% | 60% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, S.; Ding, Y. A Machine Learning Approach to Predicting Academic Performance in Pennsylvania’s Schools. Soc. Sci. 2023, 12, 118. https://doi.org/10.3390/socsci12030118
Chen S, Ding Y. A Machine Learning Approach to Predicting Academic Performance in Pennsylvania’s Schools. Social Sciences. 2023; 12(3):118. https://doi.org/10.3390/socsci12030118
Chicago/Turabian StyleChen, Shan, and Yuanzhao Ding. 2023. "A Machine Learning Approach to Predicting Academic Performance in Pennsylvania’s Schools" Social Sciences 12, no. 3: 118. https://doi.org/10.3390/socsci12030118