

Failure Mode Identification and Shear Strength Prediction of Rectangular Hollow RC Columns Using Novel Hybrid Machine Learning Models
 , , ,
, , ,
Abstract
:1. Introduction
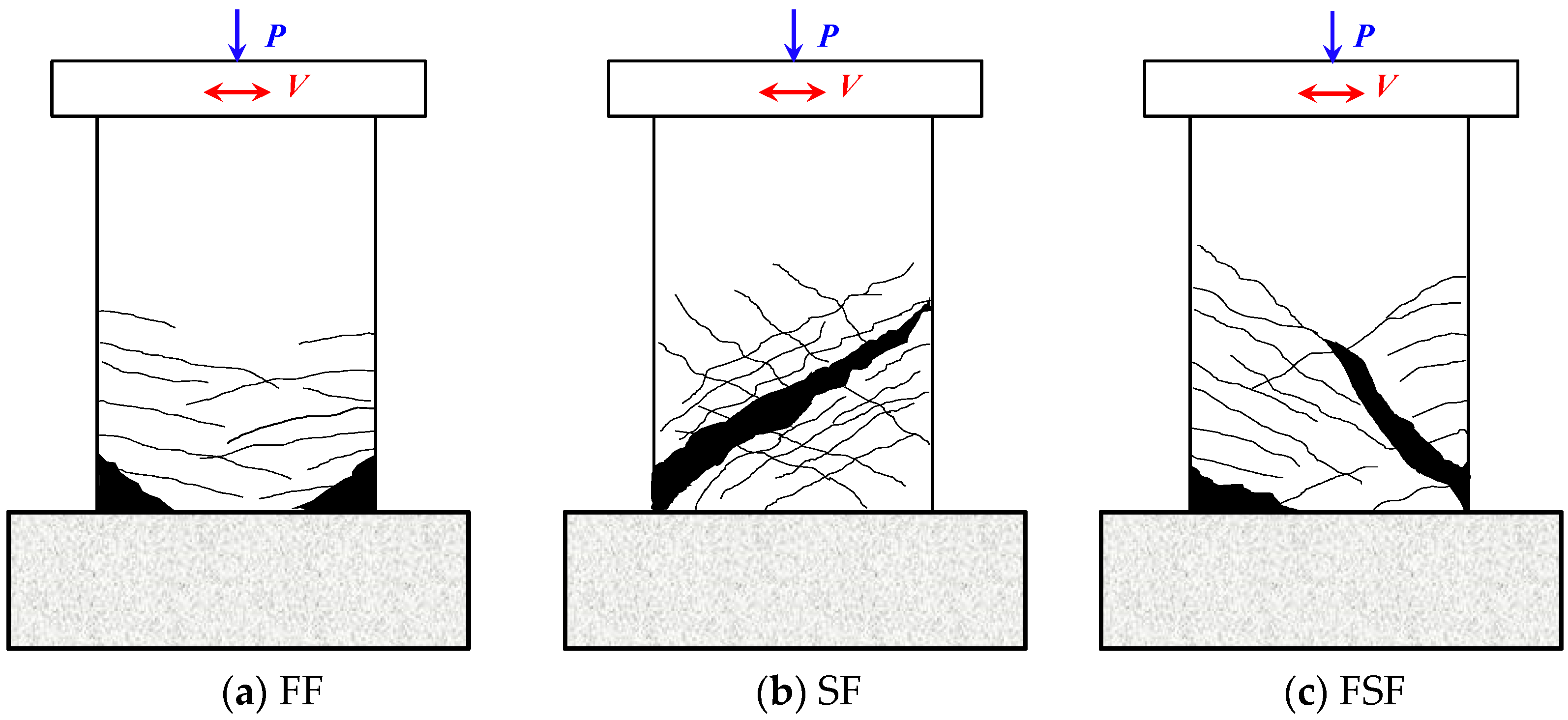
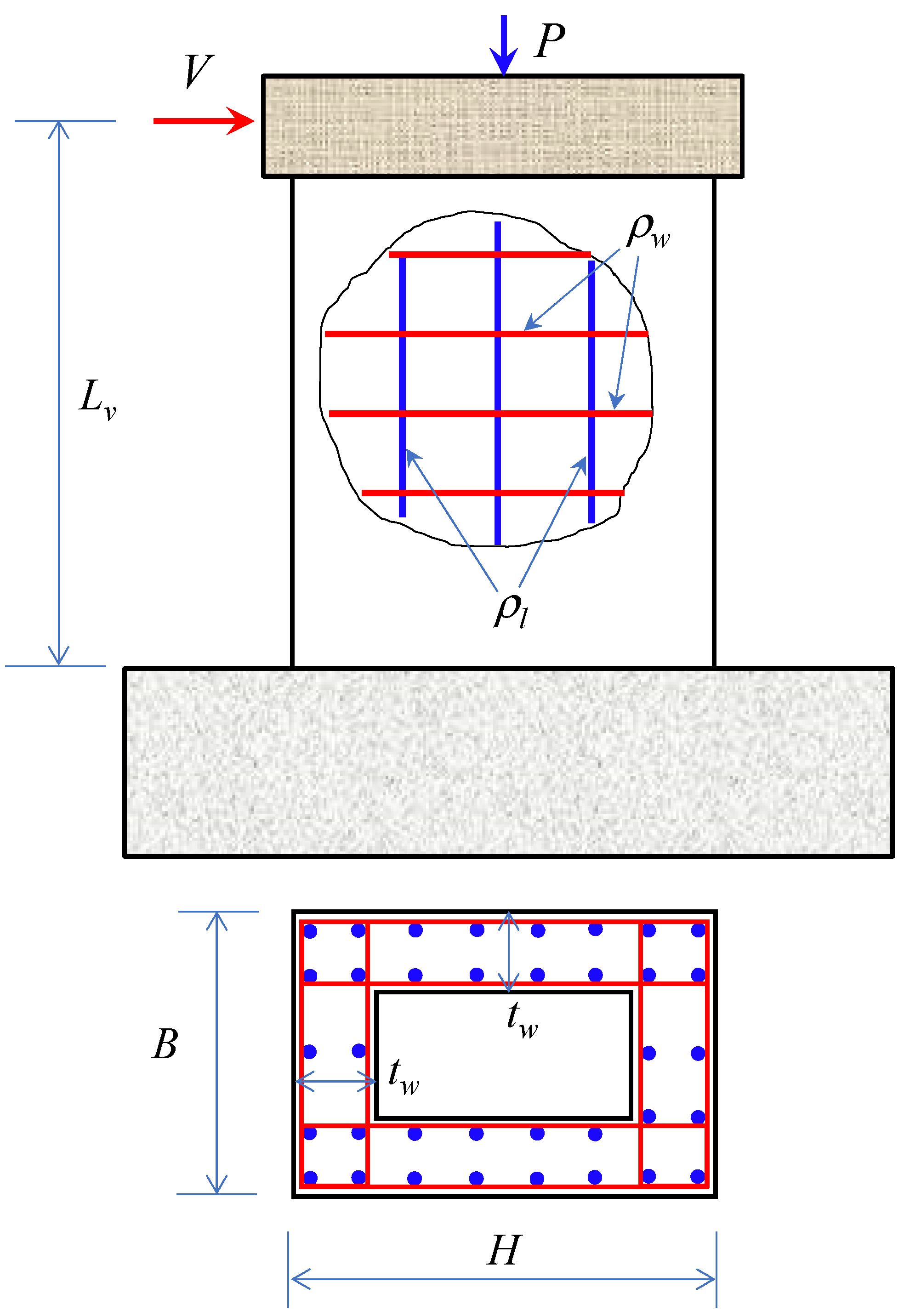
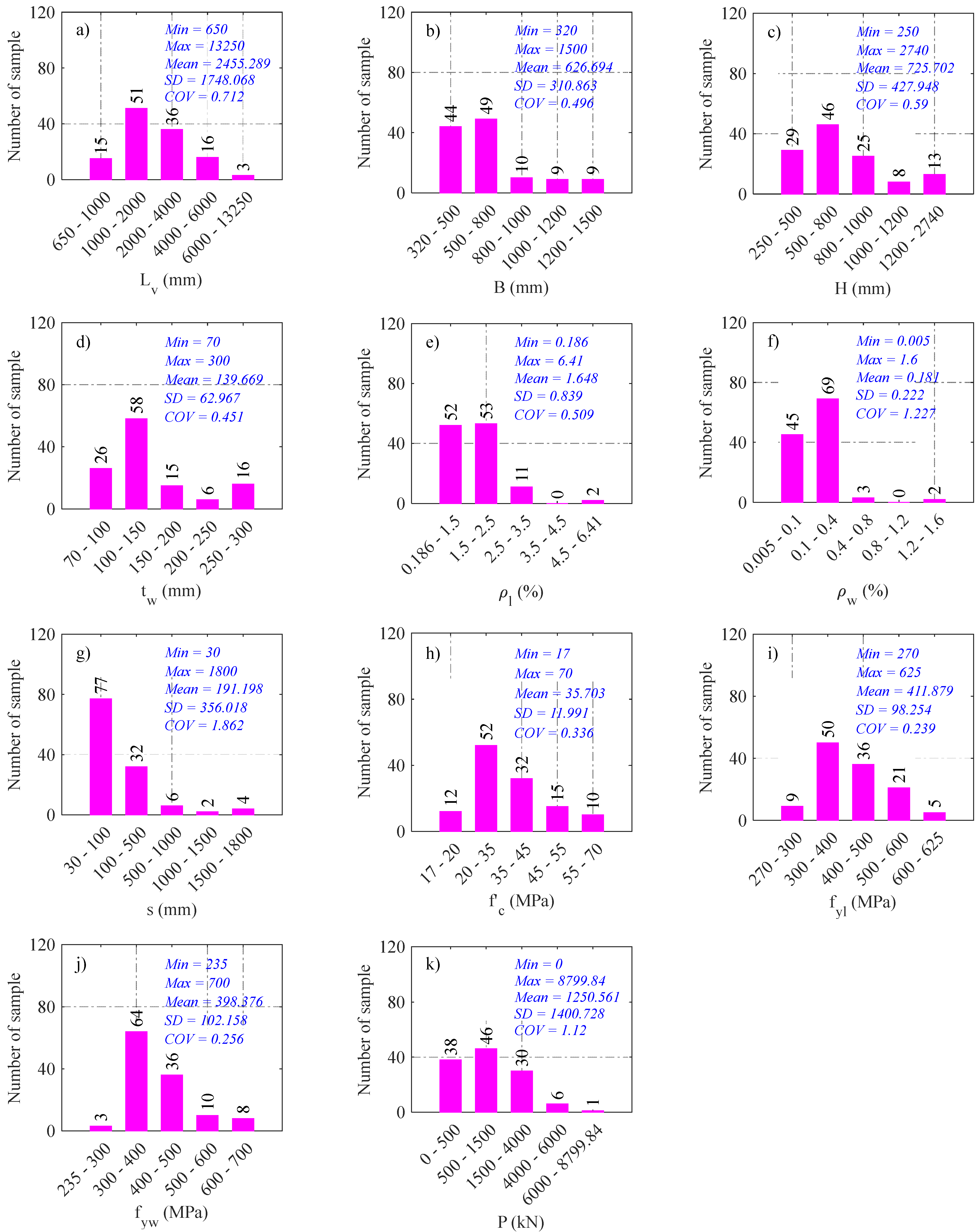
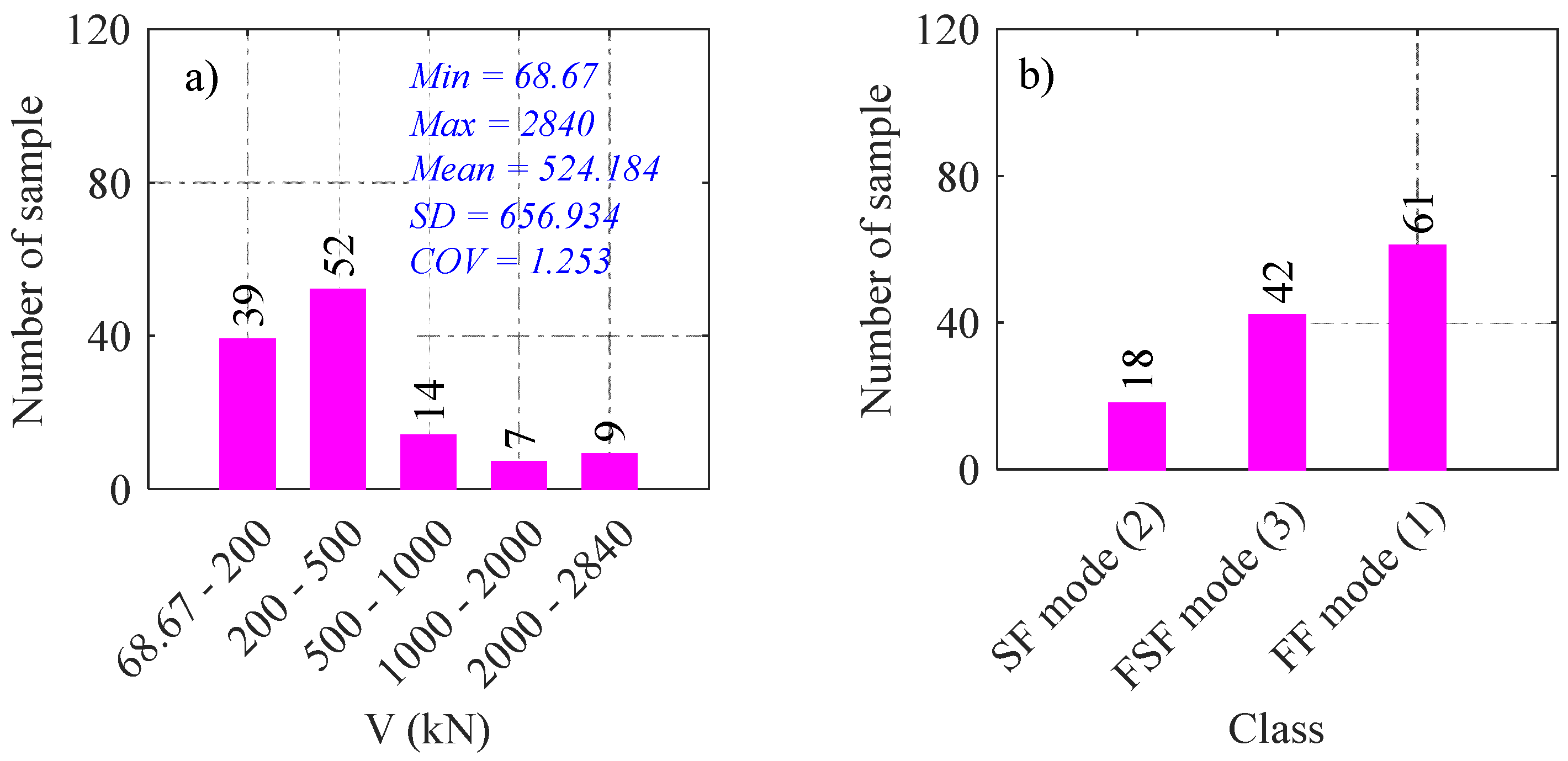
2. Description of Data Collected
3. Overview of ML and Optimization Algorithms
3.1. Support Vector Machine
3.2. Multi-Layer Perceptron
3.3. K-Nearest Neighbors
3.4. Decision Tree
3.5. Random Forest
3.6. Boosting Algorithm
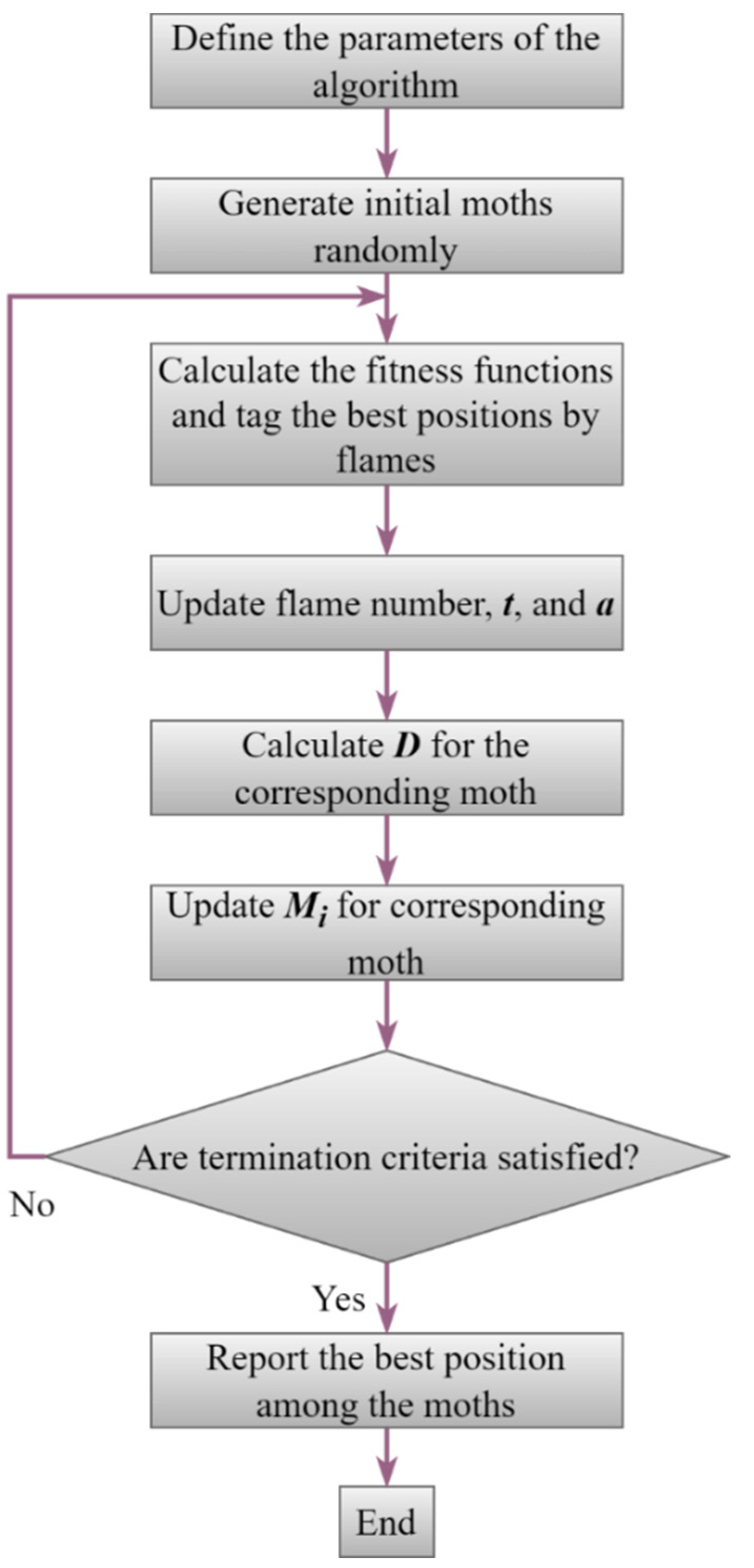
3.7. Moth-Flame Optimization Algorithm
- During the initialization stage, a population of moths is randomly placed in the search space. Each moth is represented by a potential solution to the optimization problem.
- In the attraction stage, moths are attracted to a flame, representing the global best solution found so far. The intensity of the flame is determined by the fitness value of the current best solution. Moths are then attracted to the flame based on their proximity to it, with closer moths having a stronger attraction.
- In the updating stage, moths update their positions based on their current position, the position of the flame, and a randomization factor. This movement promotes exploration of the search space, allowing the moths to potentially find better solutions.
3.8. Synthetic Minority Over-Sampling Technique
- (1)
- Identify the imbalanced dataset: Determine which class in your dataset is the minority class that needs to be oversampled.
- (2)
- Import necessary libraries: Depending on the programming language used, the required libraries or packages for SMOTE implementation are imported. In this study, we adopt the scikit-learn library for Python.
- (3)
- Split the dataset: Divide the dataset into features (X) and the corresponding class labels (Y).
- (4)
- Apply SMOTE: the SMOTE algorithm is employed to generate synthetic samples for the minority class. This involves the following sub-steps:
- Identify the minority class samples: Separate the minority class samples from the majority class samples.
- Determine the number of synthetic samples to generate: Decide on the desired ratio of minority to majority class samples after oversampling. This ratio can be adjusted based on the specific problem and dataset.
- Compute the k-nearest neighbors: For each minority class sample, identify its k-nearest neighbors from the minority class samples.
- Generate synthetic samples: Randomly select one of the k-nearest neighbors and create a new synthetic sample along the line connecting the two points. Repeat this process for the desired number of synthetic samples.
- (5)
- Combine the original and synthetic samples: Combine the original minority class samples with the newly generated synthetic samples to create a balanced dataset.
4. Performance Metrics
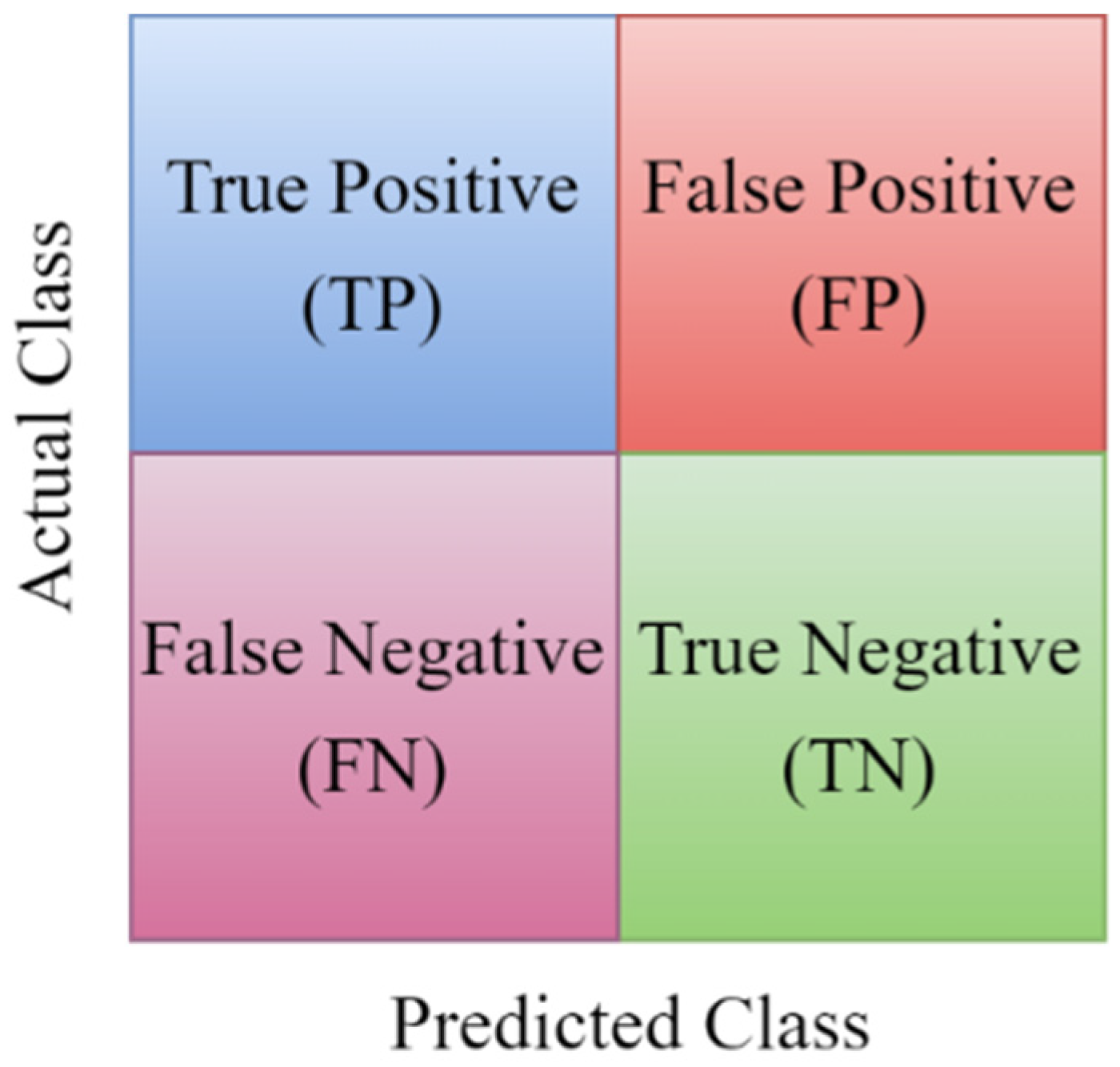
4.1. Classification Metrics
4.2. Regression Metrics
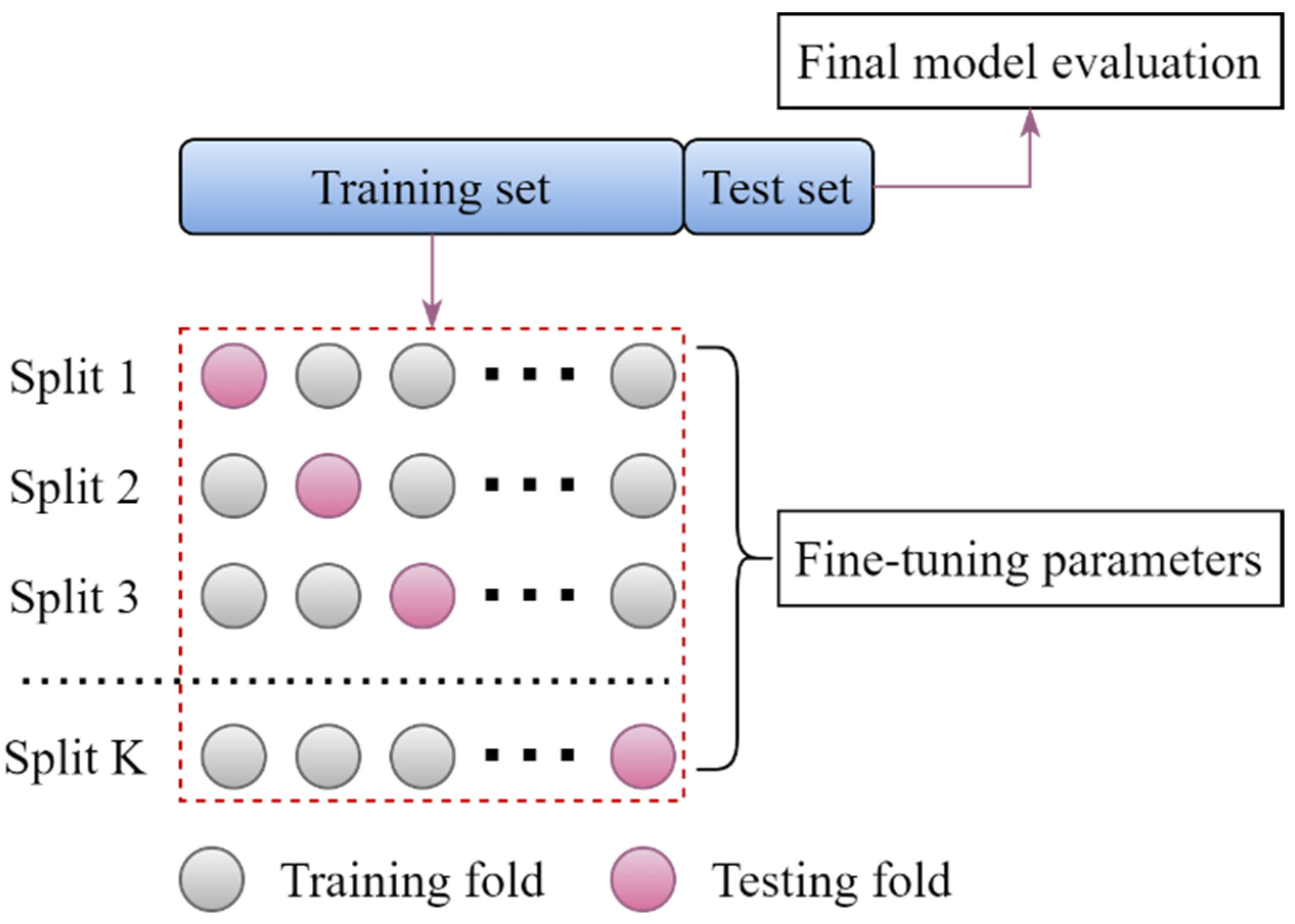
4.3. K-Fold Cross-Validation
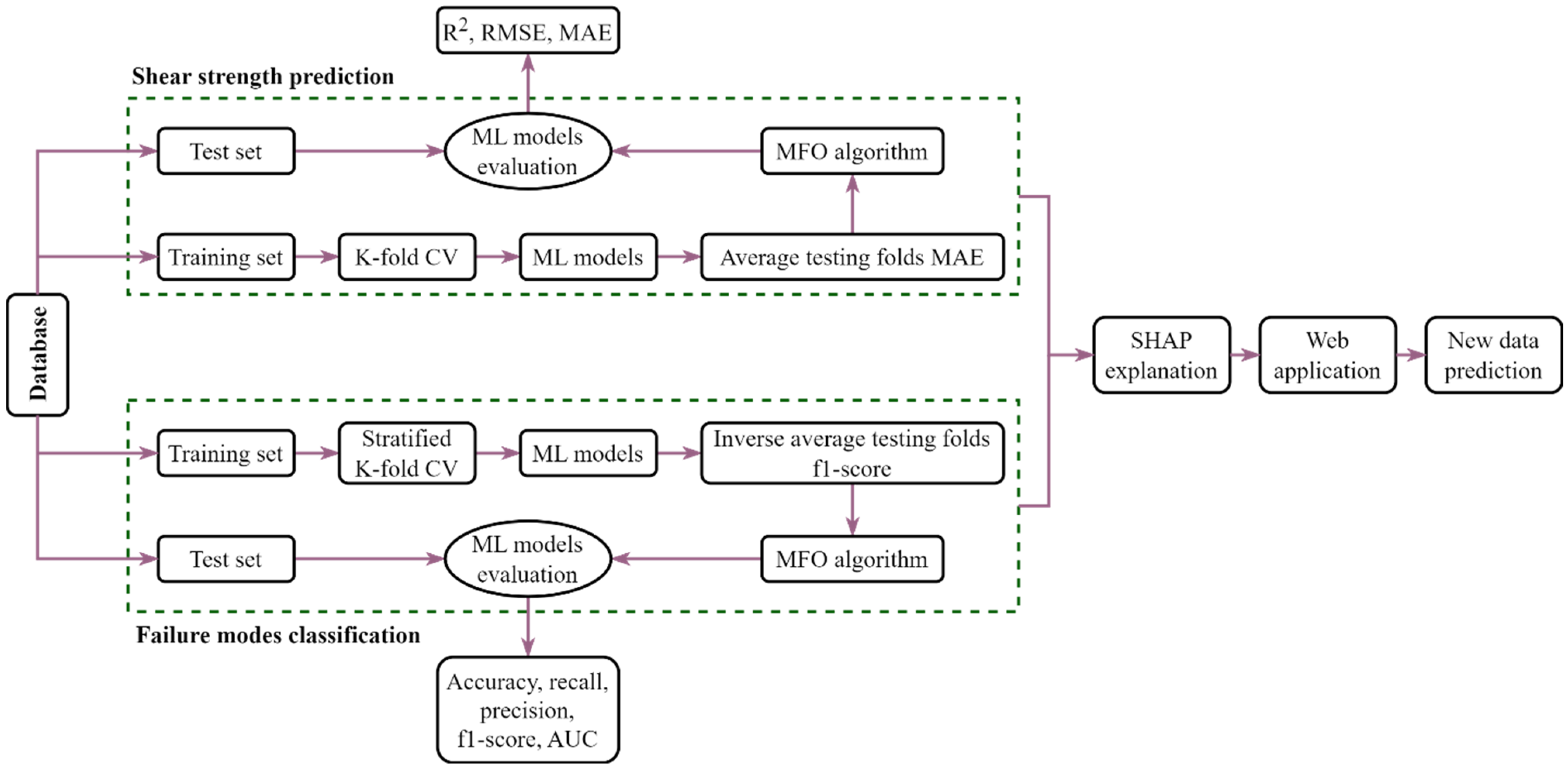
5. Development of ML Models
5.1. Input and Output Variables
5.2. Hyperparameter Tuning
6. Results and Discussions
6.1. Choosing the Best Regression and Classification Models
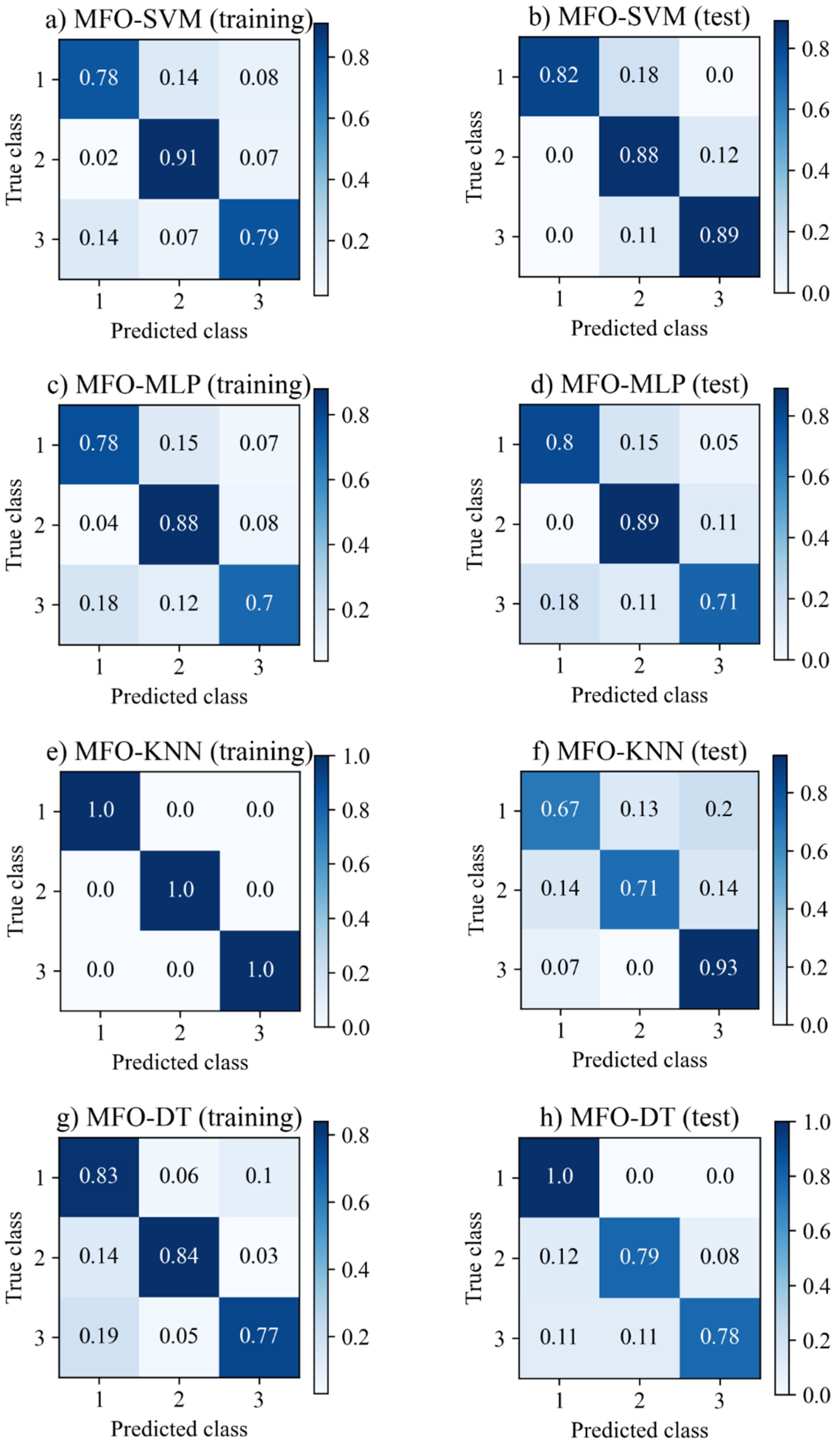
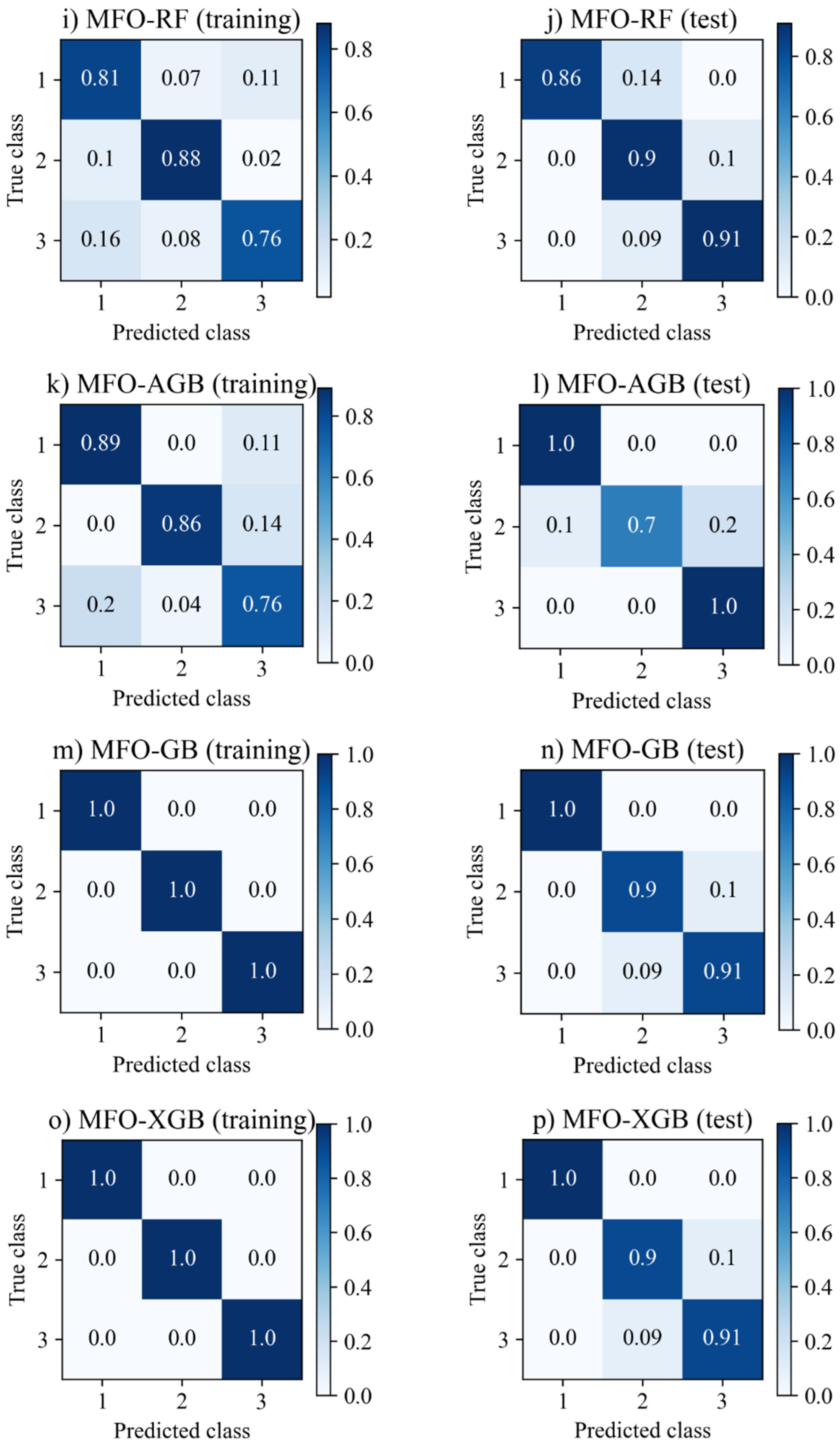
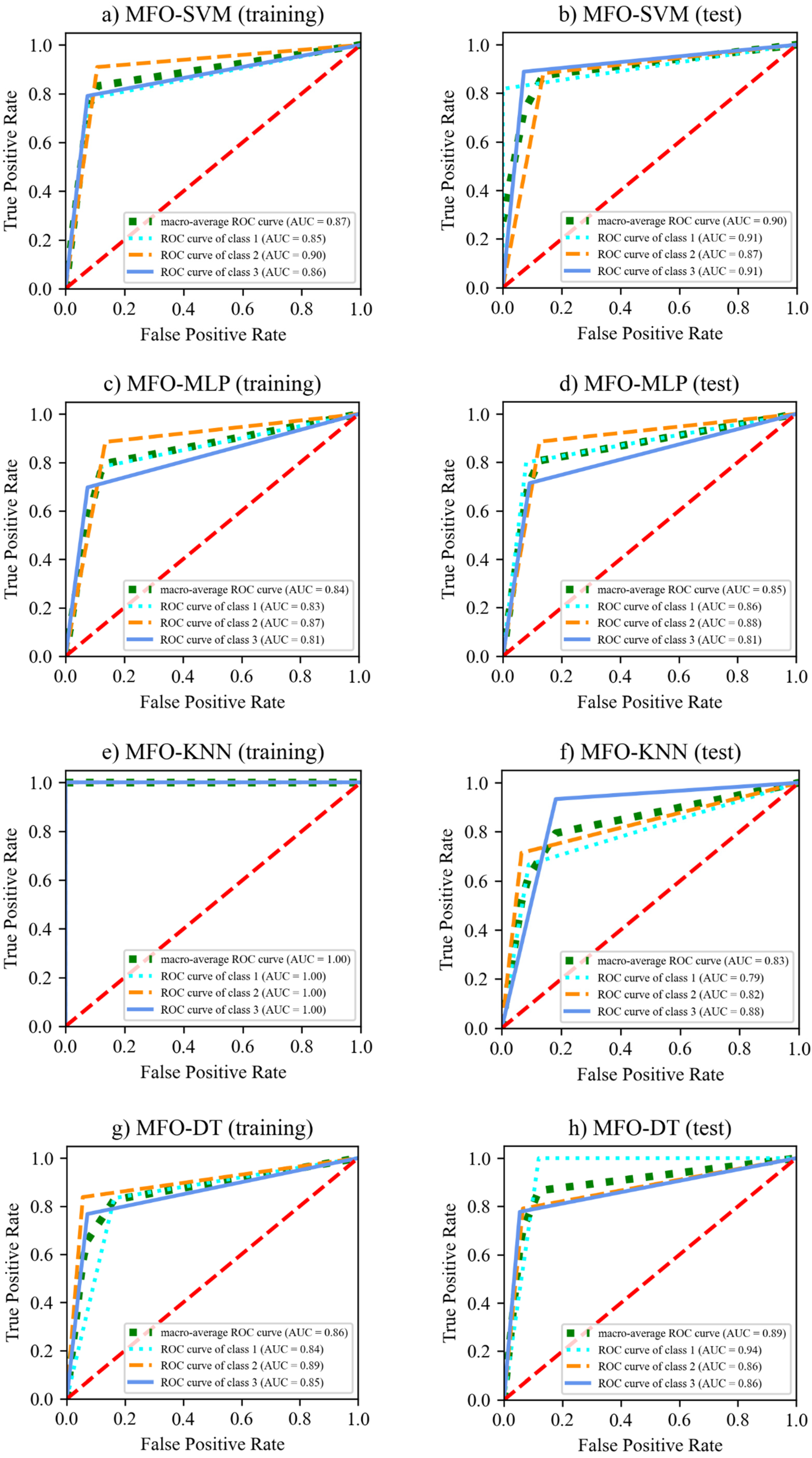
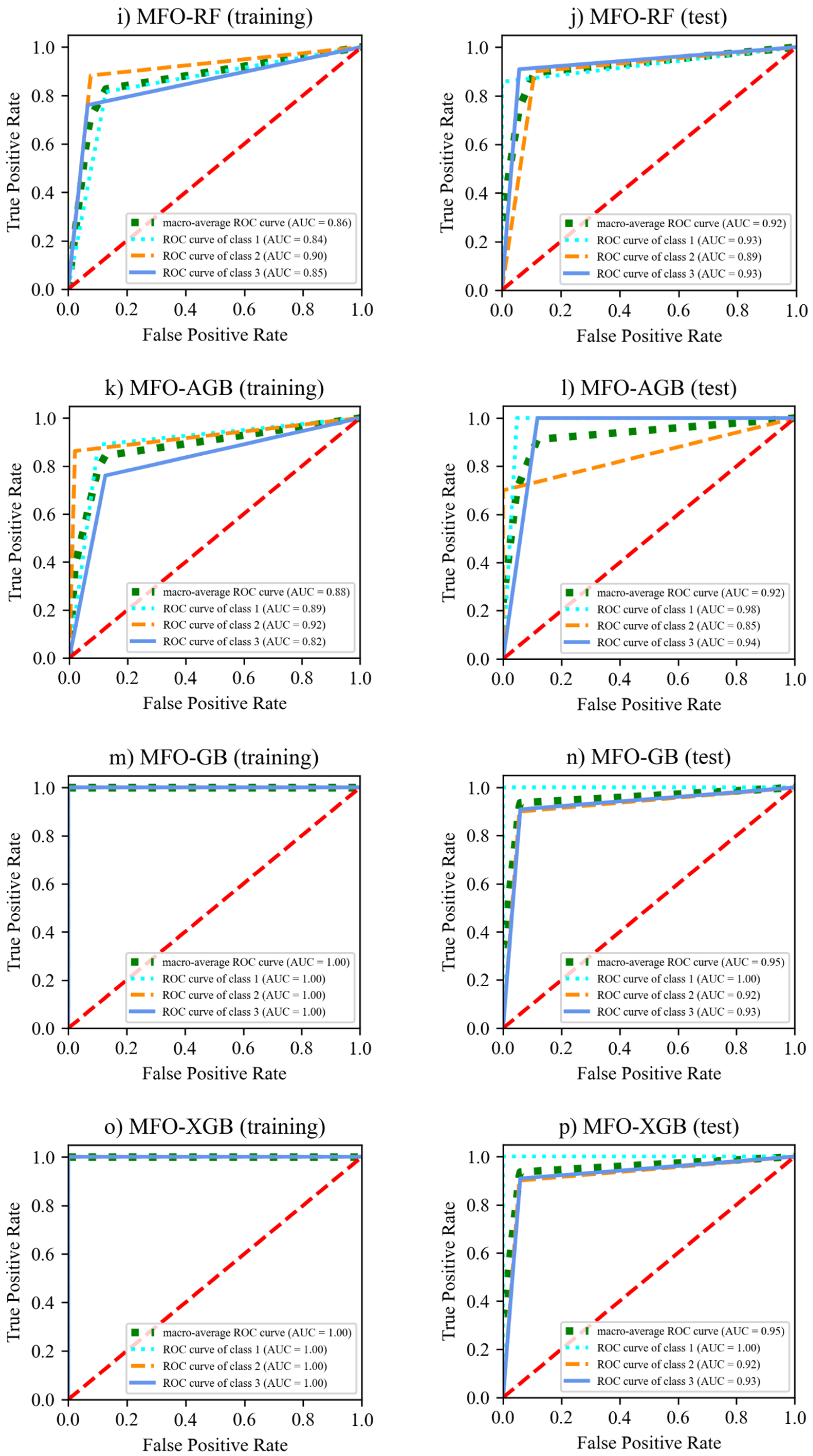
6.2. Performance of ML Models for Failure Modes
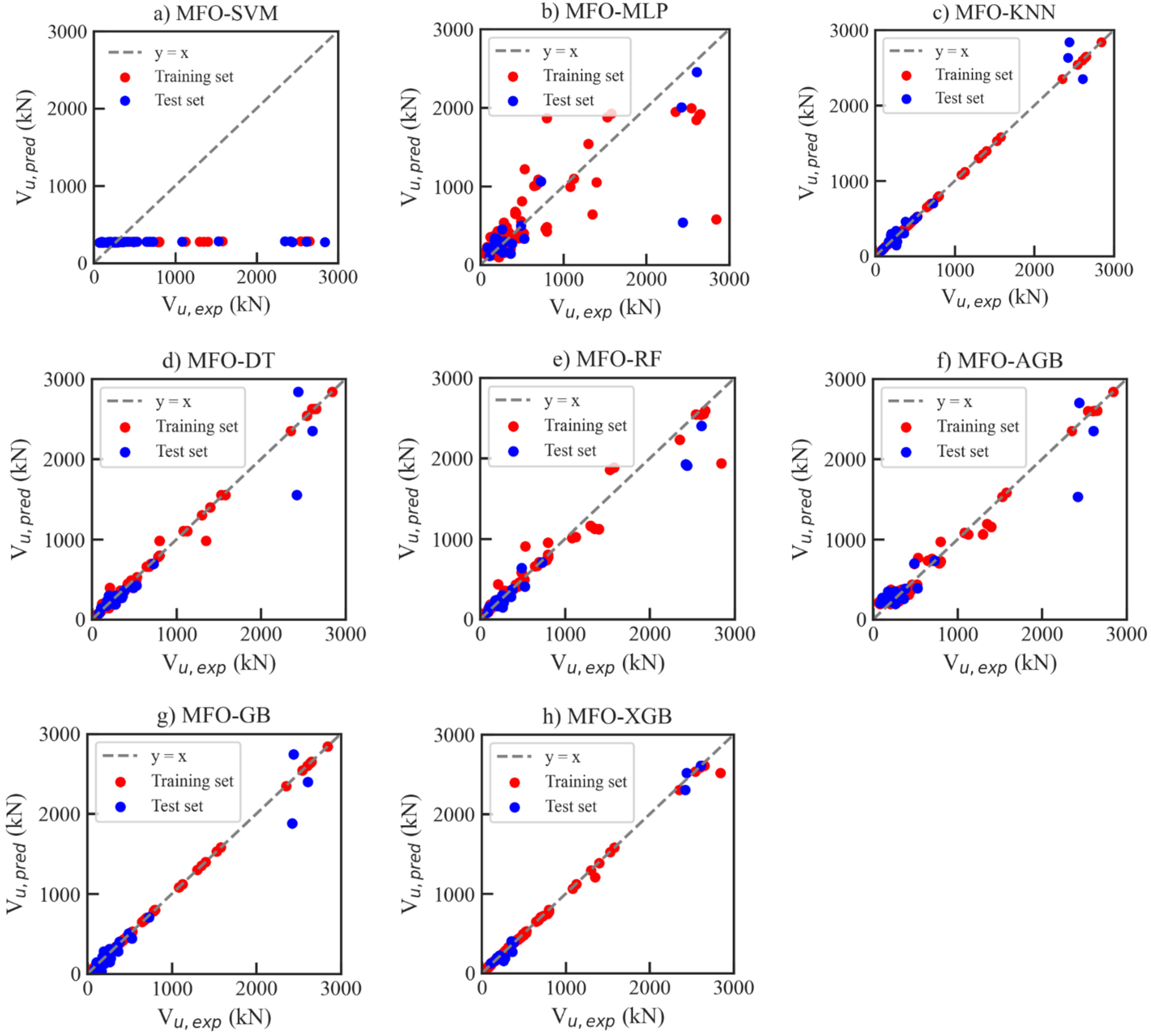
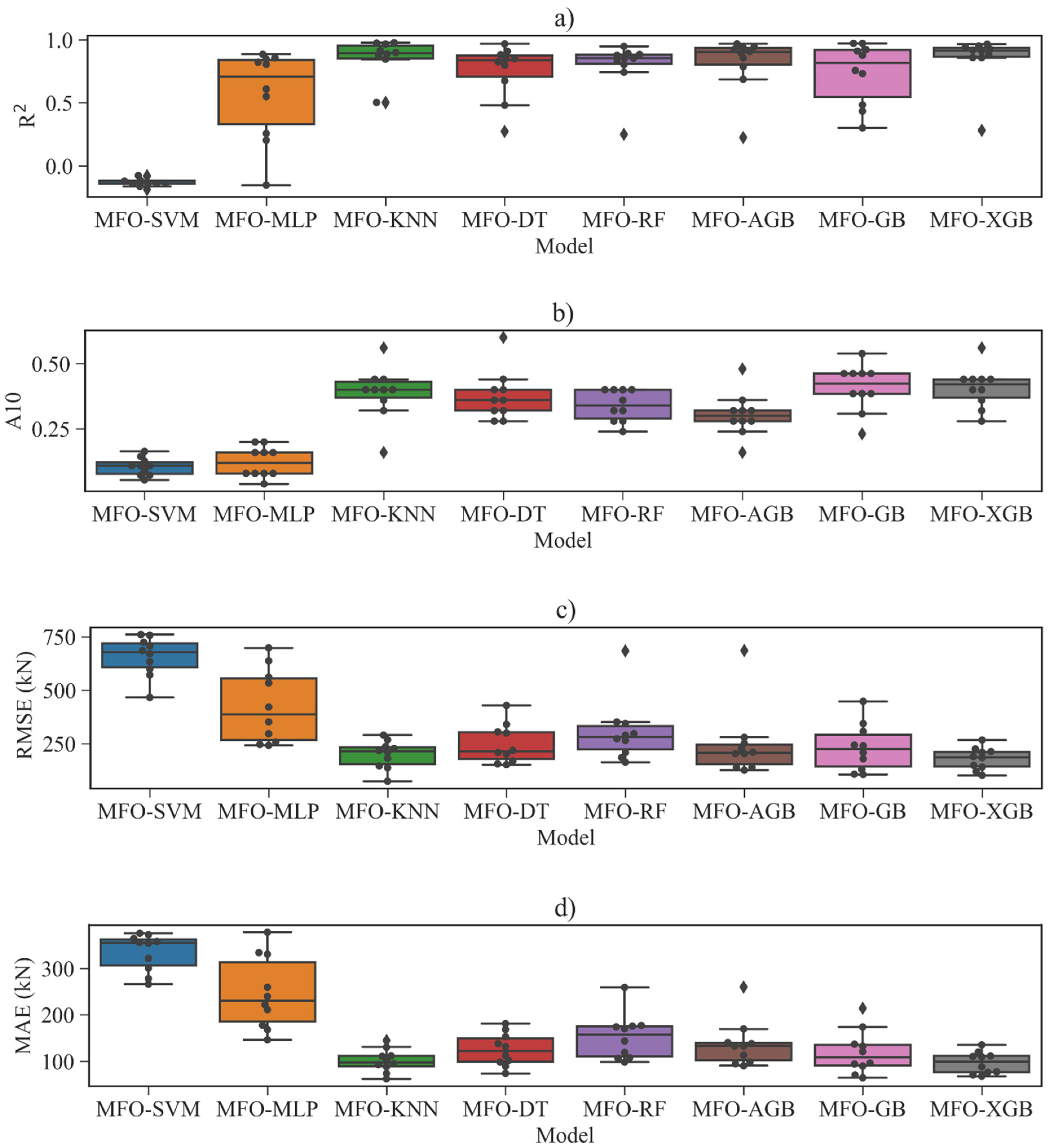
6.3. Performance of ML Models for Shear Strength
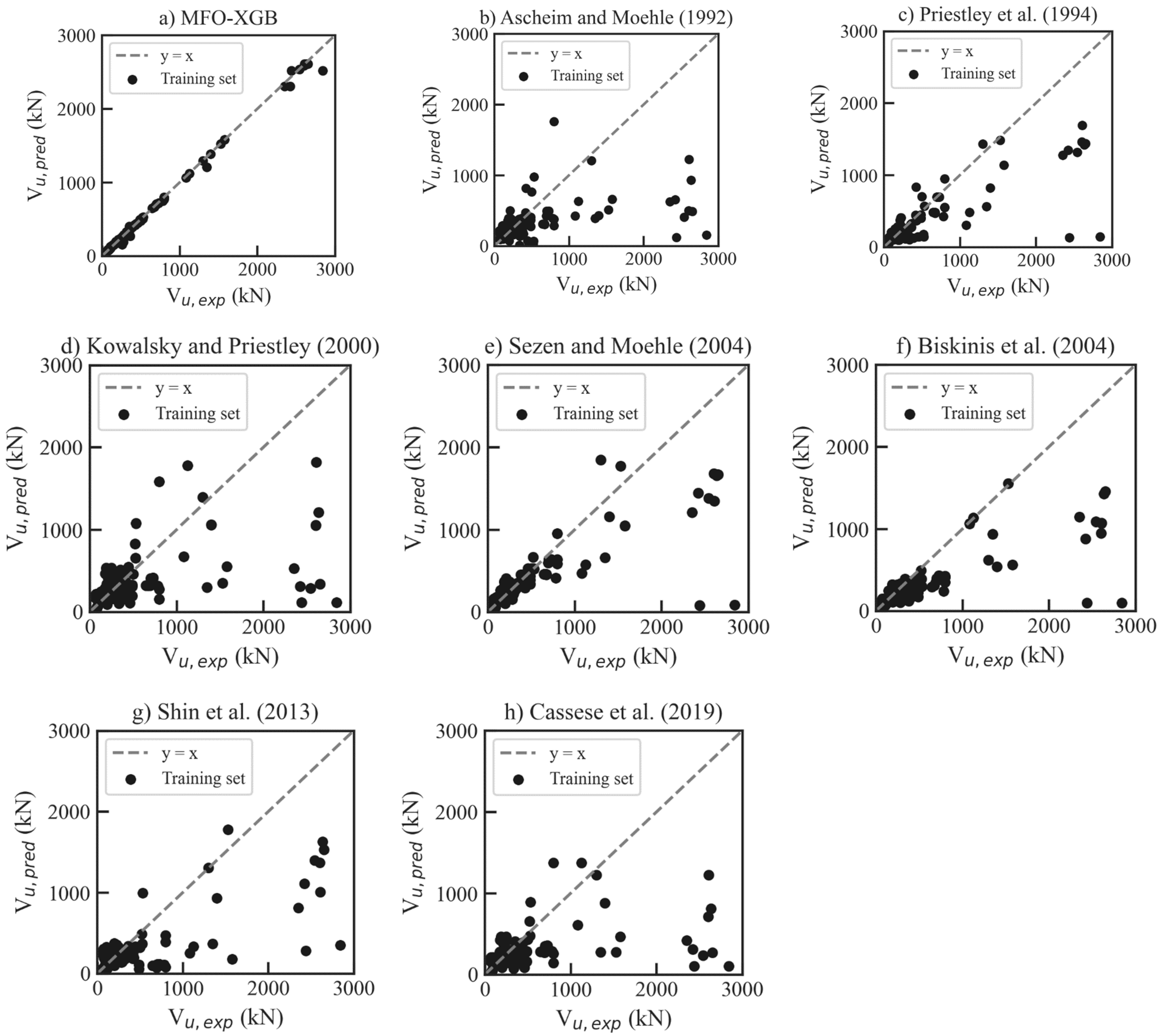
6.4. Comparison of Shear Strength between Different Predictive Models
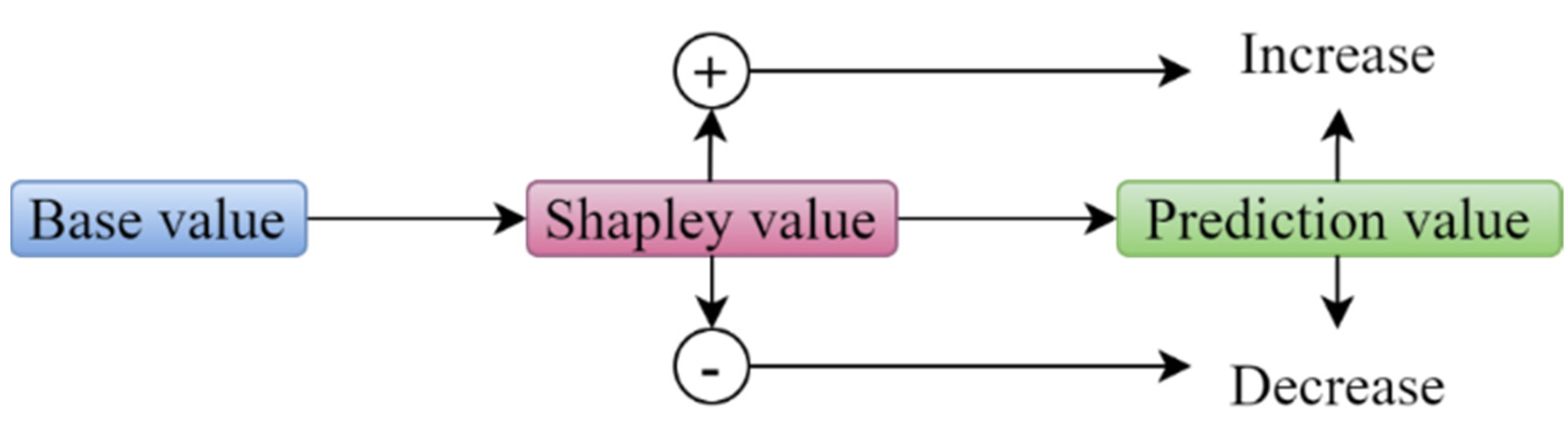
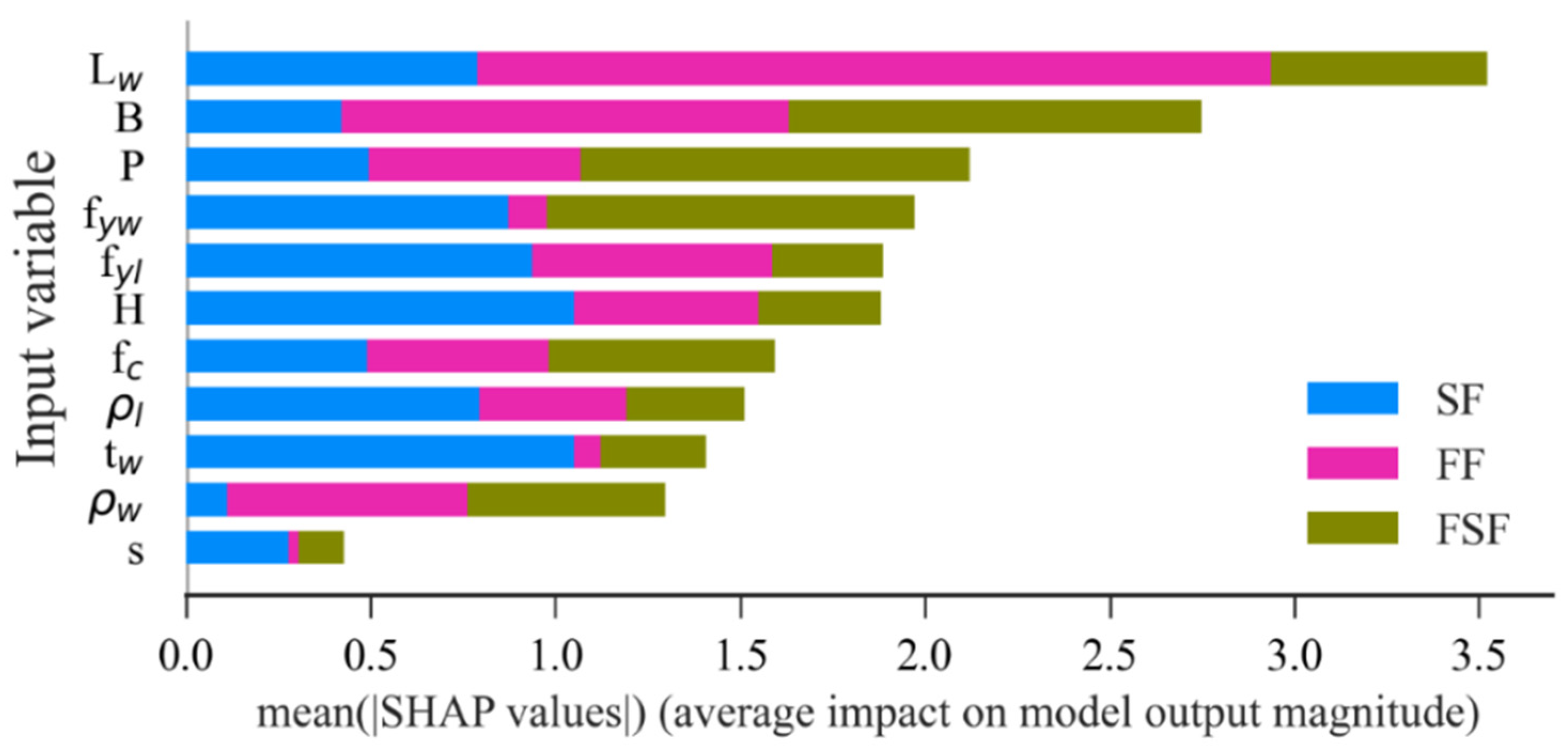
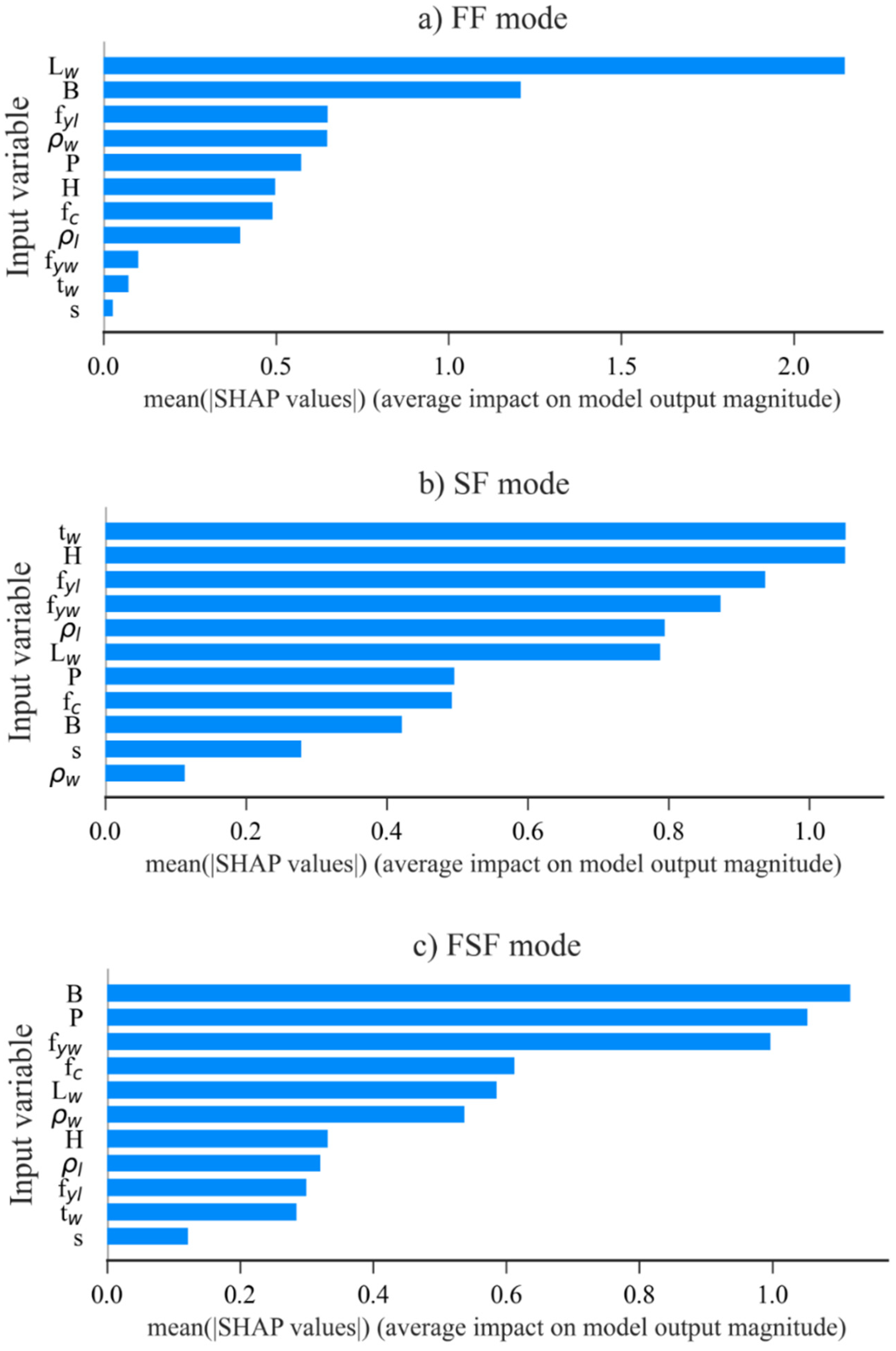
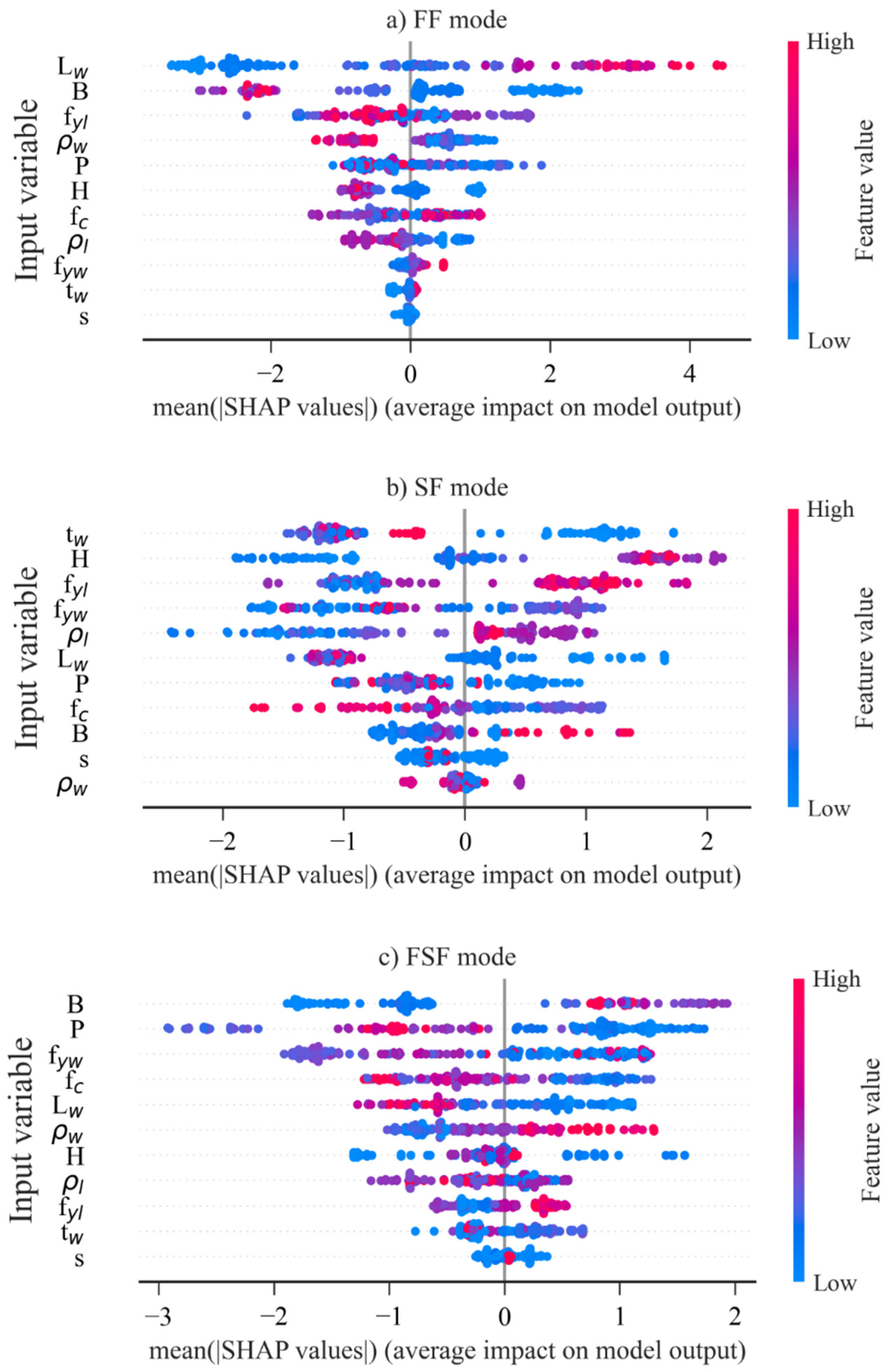
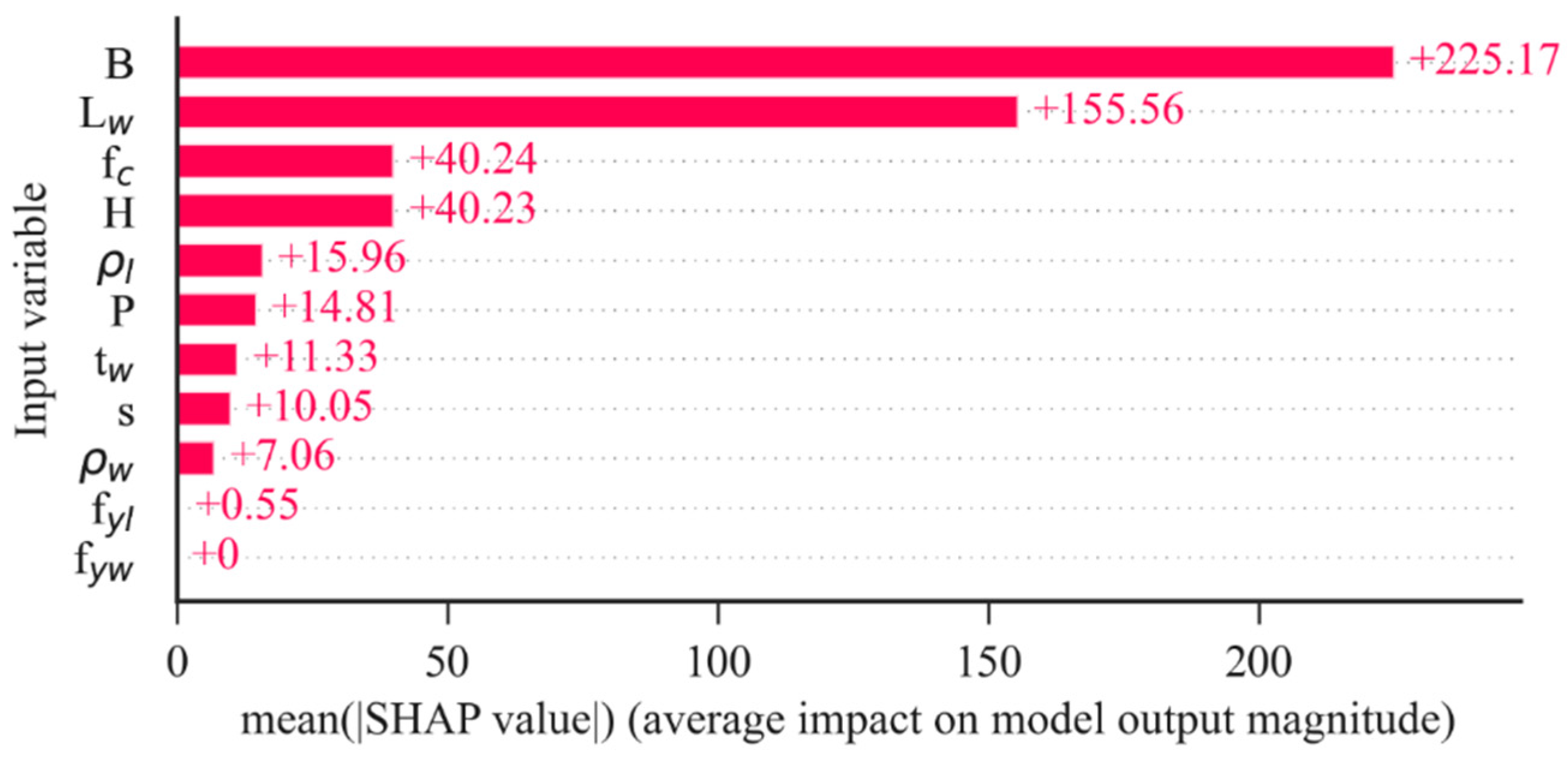
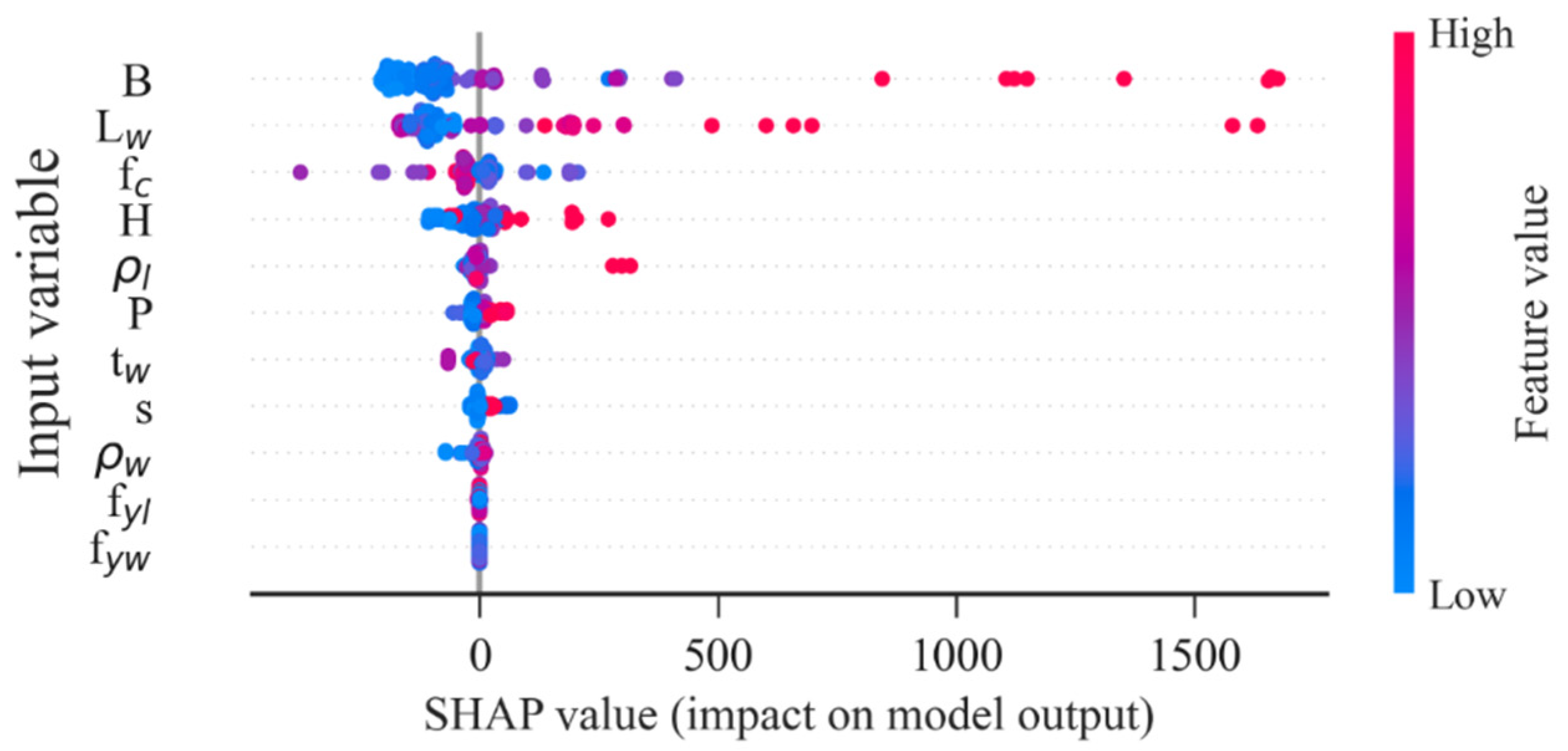
6.5. Explanation of the ML Models Using the SHAP Method
7. Conclusions
- Since failure modes are highly unbalanced, the SMOTE technique deals with the class imbalance of the database for the failure mode problems.
- MFO has proven to be highly appropriate for fine-tuning the hyperparameters of the ML models.
- Among the ML models, the MFO-XGB model outperforms others in both classifying the failure modes (accuracy of 92.9% for test set) and predicting the shear strength (= 0.996 for test set) of RHRC columns. In addition, the results indicate that the MFO-XGB model is more accurate than the empirical models for shear strength prediction.
- According to the SHAP method, is the most influential feature to the FF mode and for the SF and FSF modes. is the most influential feature to the shear strength prediction of RHRC columns.
- This study develops a web application, an engineer-friendly tool, that civil engineers can conveniently use in practice with less computational cost and effort. The web link of the WA can be found at https://sakat92-rhrc-rhrc-yqci89.streamlit.app (accessed on 6 June 2023).
Supplementary Materials
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Kim, T.-H.; Lee, J.-H.; Shin, H.M. Performance assessment of hollow RC bridge columns with triangular reinforcement details. Mag. Concr. Res. 2014, 66, 809–824. [Google Scholar] [CrossRef]
- Cassese, P. Seismic Performance of Existing Hollow Reinforced Concrete Bridge Columns. Ph.D. Thesis, Department of Structures for Engineering and Architecture, University of Naples Federico II, Naples, Italy, 2017. [Google Scholar]
- Cassese, P.; De Risi, M.T.; Verderame, G.M. Seismic assessment of existing hollow circular reinforced concrete bridge piers. J. Earthq. Eng. 2020, 24, 1566–1601. [Google Scholar] [CrossRef]
- Cassese, P.; De Risi, M.T.; Verderame, G.M. A modelling approach for existing shear-critical RC bridge piers with hollow rectangular cross section under lateral loads. Bull. Earthq. Eng. 2019, 17, 237–270. [Google Scholar] [CrossRef]
- Qi, Y.-L.; Han, X.-L.; Ji, J. Failure mode classification of reinforced concrete column using Fisher method. J. Cent. South Univ. 2013, 20, 2863–2869. [Google Scholar] [CrossRef]
- Feng, D.-C.; Liu, Z.-T.; Wang, X.-D.; Jiang, Z.-M.; Liang, S.-X. Failure mode classification and bearing capacity prediction for reinforced concrete columns based on ensemble machine learning algorithm. Adv. Eng. Inf. 2020, 45, 101126. [Google Scholar] [CrossRef]
- Zhu, L.; Elwood, K.; Haukaas, T. Classification and seismic safety evaluation of existing reinforced concrete columns. J. Struct. Eng. 2007, 133, 1316–1330. [Google Scholar] [CrossRef]
- Ma, Y.; Gong, J.-X. Probability identification of seismic failure modes of reinforced concrete columns based on experimental observations. J. Earthq. Eng. 2018, 22, 1881–1899. [Google Scholar] [CrossRef]
- Ghee, A.B.; Priestley, M.N.; Paulay, T. Seismic shear strength of circular reinforced concrete columns. Struct. J. 1989, 86, 45–59. [Google Scholar]
- Ning, C.-L.; Feng, D.-C. Probabilistic indicator to classify the failure mode of reinforced-concrete columns. Mag. Concr. Res. 2019, 71, 734–748. [Google Scholar] [CrossRef]
- Berry, M.; Parrish, M.; Eberhard, M. PEER Structural Performance Database User’s Manual (Version 1.0); University of California: Berkeley, CA, USA, 2004. [Google Scholar]
- Yang, C.; Xie, L.; Li, A. Full-scale Experimental and Numerical Investigations on Seismic Performance of Square RC Frame Columns with Hollow Sections. J. Earthq. Eng. 2022, 26, 427–448. [Google Scholar] [CrossRef]
- Yeh, Y.-K.; Mo, Y.; Yang, C. Full-scale tests on rectangular hollow bridge piers. Mater. Struct. 2002, 35, 117–125. [Google Scholar] [CrossRef]
- Hwang, S.-J.; Lee, H.-J. Strength prediction for discontinuity regions by softened strut-and-tie model. J. Struct. Eng. 2002, 128, 1519–1526. [Google Scholar] [CrossRef]
- Sezen, H. Shear deformation model for reinforced concrete columns. Struct. Eng. Mech. 2008, 28, 39–52. [Google Scholar] [CrossRef]
- Vecchio, F.J.; Collins, M.P. The modified compression-field theory for reinforced concrete elements subjected to shear. ACI Struct. J. 1986, 83, 219–231. [Google Scholar]
- Bentz, E.C.; Vecchio, F.J.; Collins, M.P. Simplified modified compression field theory for calculating shear strength of reinforced concrete elements. ACI Struct. J. 2006, 103, 614–624. [Google Scholar]
- Hsu, T.T. Softened truss model theory for shear and torsion. Struct. J. 1988, 85, 624–635. [Google Scholar]
- Pang, X.-B.D.; Hsu, T.T. Fixed angle softened truss model for reinforced concrete. Struct. J. 1996, 93, 196–208. [Google Scholar]
- Muttoni, A.; Fernández Ruiz, M. Shear strength of members without transverse reinforcement as function of critical shear crack width. A ACI Struct. J. 2008, 105, 163–172. [Google Scholar]
- Feng, D.-C.; Wu, G.; Sun, Z.-Y.; Xu, J.-G. A flexure-shear Timoshenko fiber beam element based on softened damage-plasticity model. Eng. Struct. 2017, 140, 483–497. [Google Scholar] [CrossRef]
- Ascheim, M.; Moehle, J. Shear Strength and Deformability of RC Bridge Columns Subjected to Inelastic Cyclic Displacements; Technical Report No. UCB/EERC-92/04; University of California: Berkeley, CA, USA, 1992. [Google Scholar]
- Priestley, M.N.; Verma, R.; Xiao, Y. Seismic shear strength of reinforced concrete columns. J. Struct. Eng. 1994, 120, 2310–2329. [Google Scholar] [CrossRef]
- Kowalsky, M.J.; Priestley, M.N. Improved analytical model for shear strength of circular reinforced concrete columns in seismic regions. ACI Struct. J. 2000, 97, 388–396. [Google Scholar]
- Sezen, H.; Moehle, J.P. Shear strength model for lightly reinforced concrete columns. J. Struct. Eng. 2004, 130, 1692–1703. [Google Scholar] [CrossRef]
- Biskinis, D.E.; Roupakias, G.K.; Fardis, M.N. Degradation of shear strength of reinforced concrete members with inelastic cyclic displacements. ACI Struct. J. 2004, 101, 773–783. [Google Scholar]
- ACI-318; ACI 318-14: Building Code Requirements for Structural Concrete and Commentary. American Concrete Institution: Indianapolis, IN, USA, 2014.
- EN-1998-1; Eurocode 8: Design of Structures for Earthquake Resistance-Part 1: General Rules. Seismic Actions and Rules for Buildings. European Committee for Standardization: Brussels, Belgium, 2004.
- Shin, M.; Choi, Y.Y.; Sun, C.-H.; Kim, I.-H. Shear strength model for reinforced concrete rectangular hollow columns. Eng. Struct. 2013, 56, 958–969. [Google Scholar] [CrossRef]
- Zhang, Y.-Y.; Harries, K.A.; Yuan, W.-C. Experimental and numerical investigation of the seismic performance of hollow rectangular bridge piers constructed with and without steel fiber reinforced concrete. Eng. Struct. 2013, 48, 255–265. [Google Scholar] [CrossRef]
- Xie, Y.; Ebad Sichani, M.; Padgett, J.E.; DesRoches, R. The promise of implementing machine learning in earthquake engineering: A state-of-the-art review. Earthq. Spectra 2020, 36, 1769–1801. [Google Scholar] [CrossRef]
- Gharehbaghi, S.; Yazdani, H.; Khatibinia, M. Estimating inelastic seismic response of reinforced concrete frame structures using a wavelet support vector machine and an artificial neural network. Neural Comput. Appl. 2020, 32, 2975–2988. [Google Scholar] [CrossRef]
- Khademi, F.; Akbari, M.; Nikoo, M. Displacement determination of concrete reinforcement building using data-driven models. Int. J. Sustain. Built Environ. 2017, 6, 400–411. [Google Scholar] [CrossRef]
- Zhang, Y.; Burton, H.V.; Sun, H.; Shokrabadi, M. A machine learning framework for assessing post-earthquake structural safety. Struct. Saf. 2018, 72, 1–16. [Google Scholar] [CrossRef]
- Huang, H.; Burton, H.V. Classification of in-plane failure modes for reinforced concrete frames with infills using machine learning. J. Build. Eng. 2019, 25, 100767. [Google Scholar] [CrossRef]
- Mangalathu, S.; Sun, H.; Nweke, C.C.; Yi, Z.; Burton, H.V. Classifying earthquake damage to buildings using machine learning. Earthq. Spectra 2020, 36, 183–208. [Google Scholar] [CrossRef]
- Mangalathu, S.; Hwang, S.-H.; Choi, E.; Jeon, J.-S. Rapid seismic damage evaluation of bridge portfolios using machine learning techniques. Eng. Struct. 2019, 201, 109785. [Google Scholar] [CrossRef]
- Naderpour, H.; Mirrashid, M. Shear failure capacity prediction of concrete beam–column joints in terms of ANFIS and GMDH. Pract. Period. Struct. Des. Constr. 2019, 24, 04019006. [Google Scholar] [CrossRef]
- Mangalathu, S.; Hwang, S.-H.; Jeon, J.-S. Failure mode and effects analysis of RC members based on machine-learning-based SHapley Additive exPlanations (SHAP) approach. Eng. Struct. 2020, 219, 110927. [Google Scholar] [CrossRef]
- Thai, D.-K.; Tu, T.M.; Bui, T.Q.; Bui, T.-T. Gradient tree boosting machine learning on predicting the failure modes of the RC panels under impact loads. Eng. Comput. 2021, 37, 597–608. [Google Scholar] [CrossRef]
- Mangalathu, S.; Jeon, J.-S. Machine learning–based failure mode recognition of circular reinforced concrete bridge columns: Comparative study. J. Struct. Eng. 2019, 145, 04019104. [Google Scholar] [CrossRef]
- Phan, V.-T.; Tran, V.-L.; Nguyen, V.-Q.; Nguyen, D.-D. Machine learning models for predicting shear strength and identifying failure modes of rectangular RC columns. Buildings 2022, 12, 1493. [Google Scholar] [CrossRef]
- Mander, J.; Priestley, M.; Park, R. Behaviour of ductile hollow reinforced concrete columns. Bull. N. Z. Soc. Earthq. Eng. 1983, 16, 273–290. [Google Scholar] [CrossRef]
- Sun, Z.; Wang, D.; Wang, T.; Wu, S.; Guo, X. Investigation on seismic behavior of bridge piers with thin-walled rectangular hollow section using quasi-static cyclic tests. Eng. Struct. 2019, 200, 109708. [Google Scholar] [CrossRef]
- Calvi, G.M.; Pavese, A.; Rasulo, A.; Bolognini, D. Experimental and numerical studies on the seismic response of RC hollow bridge piers. Bull. Earthq. Eng. 2005, 3, 267–297. [Google Scholar] [CrossRef]
- Mo, Y.; Nien, I. Seismic performance of hollow high-strength concrete bridge columns. J. Bridge Eng. 2002, 7, 338–349. [Google Scholar] [CrossRef]
- Han, Q.; Zhou, Y.; Du, X.; Huang, C.; Lee, G.C. Experimental and numerical studies on seismic performance of hollow RC bridge columns. Earthq. Struct. 2014, 7, 251–269. [Google Scholar] [CrossRef]
- Cheng, C.-T.; Yang, J.-C.; Yeh, Y.-K.; Chen, S.-E. Seismic performance of repaired hollow-bridge piers. Constr. Build. Mater. 2003, 17, 339–351. [Google Scholar] [CrossRef]
- Faria, R.; Pouca, N.V.; Delgado, R. Simulation of the cyclic behaviour of R/C rectangular hollow section bridge piers via a detailed numerical model. J. Earthq. Eng. 2004, 8, 725–748. [Google Scholar] [CrossRef]
- Mangalathu, S.; Jeon, J.-S. Classification of failure mode and prediction of shear strength for reinforced concrete beam-column joints using machine learning techniques. Eng. Struct. 2018, 160, 85–94. [Google Scholar] [CrossRef]
- Gao, X.; Lin, C. Prediction model of the failure mode of beam-column joints using machine learning methods. Eng. Failure Anal. 2021, 120, 105072. [Google Scholar] [CrossRef]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-learn: Machine learning in Python. J. Mach. Learn Res. 2011, 12, 2825–2830. [Google Scholar]
- Smola, A.J.; Schölkopf, B. A tutorial on support vector regression. Stat. Comput. 2004, 14, 199–222. [Google Scholar] [CrossRef]
- Deka, P.C. Support vector machine applications in the field of hydrology: A review. Appl. Soft Comput. 2014, 19, 372–386. [Google Scholar]
- Rumelhart, D.E.; Hinton, G.E.; Williams, R.J. Learning representations by back-propagating errors. Nature 1986, 323, 533–536. [Google Scholar] [CrossRef]
- Cover, T.; Hart, P. Nearest neighbor pattern classification. IEEE Trans. Inf. Theory 1967, 13, 21–27. [Google Scholar] [CrossRef]
- Breiman, L.; Friedman, J.; Stone, C.J.; Olshen, R.A. Classification and Regression Trees; CRC Press: Boca Raton, FL, USA, 1984. [Google Scholar]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Ferreira, A.J.; Figueiredo, M.A. Boosting algorithms: A review of methods, theory, and applications. In Ensemble Machine Learning: Methods and Applications; Springer: New York, NY, USA, 2012; pp. 35–85. [Google Scholar]
- Mirjalili, S. Moth-flame optimization algorithm: A novel nature-inspired heuristic paradigm. Knowl. Based Syst. 2015, 89, 228–249. [Google Scholar] [CrossRef]
- Chawla, N.V.; Bowyer, K.W.; Hall, L.O.; Kegelmeyer, W.P. SMOTE: Synthetic minority over-sampling technique. J. Artif. Intell. Res. 2002, 16, 321–357. [Google Scholar] [CrossRef]
- Hutter, F.; Kotthoff, L.; Vanschoren, J. Automated Machine Learning: Methods, Systems, Challenges; Springer Nature: Berlin/Heidelberg, Germany, 2019. [Google Scholar]
- Yang, L.; Shami, A. On hyperparameter optimization of machine learning algorithms: Theory and practice. Neurocomputing 2020, 415, 295–316. [Google Scholar] [CrossRef]
- Nguyen, V.-Q.; Tran, V.-L.; Nguyen, D.-D.; Sadiq, S.; Park, D. Novel hybrid MFO-XGBoost model for predicting the racking ratio of the rectangular tunnels subjected to seismic loading. Transp. Geotech. 2022, 37, 100878. [Google Scholar] [CrossRef]
- Duan, J.; Asteris, P.G.; Nguyen, H.; Bui, X.-N.; Moayedi, H. A novel artificial intelligence technique to predict compressive strength of recycled aggregate concrete using ICA-XGBoost model. Eng. Comput. 2021, 37, 3329–3346. [Google Scholar] [CrossRef]
- Tran, V.-L.; Kim, J.-K. Ensemble machine learning-based models for estimating the transfer length of strands in PSC beams. Expert Syst. Appl. 2023, 221, 119768. [Google Scholar] [CrossRef]
- Nayak, J.; Naik, B.; Dash, P.B.; Souri, A.; Shanmuganathan, V. Hyper-parameter tuned light gradient boosting machine using memetic firefly algorithm for hand gesture recognition. Appl. Soft Comput. 2021, 107, 107478. [Google Scholar] [CrossRef]
- Tran, V.-L.; Nguyen, D.-D. Novel hybrid WOA-GBM model for patch loading resistance prediction of longitudinally stiffened steel plate girders. Thin-Walled Struct. 2022, 177, 109424. [Google Scholar] [CrossRef]
- Roth, A.E. Introduction to the Shapley value. In The Shapley Value; Cambridge University Press: Cambridge, UK, 1988; pp. 1–27. [Google Scholar]






















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | No. | Hyperparameters | Range | Optimal Value |
|---|---|---|---|---|
| SVM | 1 | C | (0.01, 1.0) | 0.968473 |
| 2 | degree | (1, 5) | 2 | |
| 3 | tol | (0.01, 1.0) | 0.056104 | |
| MLP | 1 | alpha | (0.01, 1.0) | 0.711483 |
| 2 | batch_size | (1, 100) | 26 | |
| 3 | hidden_layer_sizes | (1, 100) | 10 | |
| 4 | momentum | (0.01, 1.0) | 0.155035 | |
| KNN | 1 | leaf_size | (1, 100) | 64 |
| 2 | n_neighbors | (1, 50) | 1 | |
| 3 | p | (1, 2) | 1 | |
| DT | 1 | max_depth | (1, 100) | 79 |
| 2 | min_samples_leaf | (1, 10) | 5 | |
| 3 | min_samples_split | (1, 10) | 8 | |
| 4 | min_weight_fraction_leaf | (0.1, 1.0) | 0.036477 | |
| RF | 1 | max_depth | (1, 100) | 17 |
| 2 | min_samples_leaf | (1, 10) | 5 | |
| 3 | min_samples_split | (1, 10) | 3 | |
| 4 | n_estimators | (5, 1000) | 23 | |
| AGB | 1 | learning_rate | (0.01, 1.0) | 0.629896 |
| 2 | n_estimators | (5, 1000) | 165 | |
| GB | 1 | learning_rate | (0.01, 1.0) | 0.681775 |
| 5 | n_estimators | (5, 1000) | 689 | |
| 3 | min_samples_split | (1, 10) | 3 | |
| 2 | min_samples_leaf | (1, 10) | 9 | |
| 1 | max_depth | (1, 100) | 16 | |
| XGB | 1 | learning_rate | (0.01, 1.0) | 0.557980 |
| 2 | max_depth | (1, 100) | 8 | |
| 3 | n_estimators | (5, 1000) | 921 |
| Model | No. | Hyperparameters | Range | Optimal Value |
|---|---|---|---|---|
| SVM | 1 | C | (0.01, 1.0) | 0.999992 |
| 2 | gama | (0.01, 1.0) | 0.086386 | |
| 3 | degree | (1, 5) | 2 | |
| 4 | epsilon | (0.01, 1.0) | 0.602402 | |
| MLP | 1 | alpha | (0.01, 1.0) | 0.541640 |
| 2 | batch_size | (1, 100) | 4 | |
| 3 | hidden_layer_sizes | (1, 100) | 66 | |
| 4 | momentum | (0.01, 1.0) | 0.752071 | |
| KNN | 1 | leaf_size | (1, 100) | 27 |
| 2 | n_neighbors | (1, 50) | 1 | |
| 3 | p | (1, 2) | 2 | |
| DT | 1 | max_depth | (1, 100) | 53 |
| 2 | min_samples_leaf | (1, 10) | 1 | |
| 3 | min_samples_split | (1, 10) | 4 | |
| 4 | min_weight_fraction_leaf | (0.1, 1.0) | 0.1 | |
| RF | 1 | max_depth | (1, 100) | 100 |
| 2 | min_samples_leaf | (1, 10) | 1 | |
| 3 | min_samples_split | (1, 10) | 2 | |
| 4 | n_estimators | (5, 1000) | 649 | |
| AGB | 1 | learning_rate | (0.01, 1.0) | 0.543211 |
| 2 | n_estimators | (5, 1000) | 452 | |
| GB | 1 | learning_rate | (0.01, 1.0) | 0.343455 |
| 2 | n_estimators | (5, 1000) | 204 | |
| 3 | subsample | (0.1, 1.0) | 0.916063 | |
| 4 | max_depth | (1, 100) | 4 | |
| 5 | alpha | (0.1, 1.0) | 0.468587 | |
| XGB | 1 | learning_rate | (0.01, 1.0) | 0.745099 |
| 2 | max_depth | (1, 100) | 55 | |
| 3 | n_estimators | (5, 1000) | 5 |
| Model | Training Set | Test Set | ||||||
|---|---|---|---|---|---|---|---|---|
| Accuracy | Precision | Recall | F1-Score | Accuracy | Precision | Recall | F1-Score | |
| MFO-SVM | 0.825 | 0.827 | 0.825 | 0.824 | 0.870 | 0.879 | 0.870 | 0.871 |
| MFO-MLP | 0.780 | 0.789 | 0.780 | 0.780 | 0.807 | 0.807 | 0.807 | 0.806 |
| MFO-KNN | 1.0 | 1.0 | 1.0 | 1.0 | 0.784 | 0.788 | 0.784 | 0.779 |
| MFO-DT | 0.812 | 0.816 | 0.812 | 0.813 | 0.836 | 0.852 | 0.836 | 0.836 |
| MFO-RF | 0.819 | 0.821 | 0.819 | 0.819 | 0.893 | 0.899 | 0.893 | 0.894 |
| MFO-AGB | 0.839 | 0.843 | 0.839 | 0.840 | 0.893 | 0.908 | 0.893 | 0.888 |
| MFO-GB | 1.0 | 1.0 | 1.0 | 1.0 | 0.925 | 0.925 | 0.925 | 0.925 |
| MFO-XGB | 1.0 | 1.0 | 1.0 | 1.0 | 0.929 | 0.929 | 0.929 | 0.929 |
| Model | Training Set | Test Set | ||||||
|---|---|---|---|---|---|---|---|---|
| R2 | A10 | RMSE (kN) | MAE (kN) | R2 | A10 | RMSE (kN) | MAE (kN) | |
| MFO-SVM | 0.136 | 0.106 | 667.668 | 337.376 | 0.139 | 0.145 | 731.866 | 367.893 |
| MFO-MLP | 0.695 | 0.188 | 349.179 | 192.981 | 0.675 | 0.320 | 416.404 | 203.310 |
| MFO-KNN | 1.0 | 1.0 | 0.0 | 0.0 | 0.975 | 0.400 | 116.123 | 71.106 |
| MFO-DT | 0.992 | 0.854 | 55.347 | 22.437 | 0.922 | 0.360 | 203.606 | 97.192 |
| MFO-RF | 0.962 | 0.677 | 123.997 | 50.529 | 0.952 | 0.400 | 160.101 | 88.156 |
| MFO-AGB | 0.977 | 0.365 | 96.286 | 75.644 | 0.916 | 0.360 | 212.269 | 120.163 |
| MFO-GB | 1.0 | 1.0 | 0.008 | 0.006 | 0.963 | 0.488 | 140.724 | 79.073 |
| MFO-XGB | 0.997 | 0.944 | 35.186 | 10.514 | 0.996 | 0.615 | 62.427 | 46.027 |
| No. | Reference | Equation | |
|---|---|---|---|
| 1 | Ascheim and Moehle [22] | , is the displacement ductility ; | (18) |
| 2 | Priestley et al. [23] | for for for | (19) |
| 3 | Kowalsky and Priestley [24] | ; for for | (20) |
| 4 | Sezen and Moehle [25] | ; for for is the shear span. | (21) |
| 5 | Biskinis et al. [26] | ) is the neutral axis depth, is the depth of the compression reinforcement layer. ( is the effective depth). | (22) |
| 6 | Shin et al. [29] | ; ; ); | (23) |
| 7 | Cassese et al. [4] | ; ; | (24) |
| Model | R2 | RMSE (kN) | MAE (kN) | Mean | SD | COV |
|---|---|---|---|---|---|---|
| MFO-XGB | 0.996 | 39.035 | 14.329 | 1.015 | 0.089 | 0.088 |
| Ascheim and Moehle [22] | 0.219 | 615.668 | 310.073 | 2.351 | 4.949 | 2.105 |
| Priestley et al. [23] | 0.635 | 458.767 | 219.070 | 1.687 | 2.367 | 1.408 |
| Kowalsky and Priestley [24] | 0.216 | 606.427 | 300.966 | 1.838 | 3.135 | 1.705 |
| Sezen and Moehle [25] | 0.617 | 443.584 | 188.419 | 1.617 | 3.990 | 2.468 |
| Biskinis et al. [26] | 0.600 | 513.379 | 241.413 | 1.890 | 3.314 | 1.753 |
| Shin et al. [29] | 0.533 | 518.671 | 282.644 | 2.021 | 2.166 | 1.072 |
| Cassese et al. [4] | 0.178 | 637.842 | 306.089 | 2.116 | 3.555 | 1.680 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tran, V.-L.; Lee, T.-H.; Nguyen, D.-D.; Nguyen, T.-H.; Vu, Q.-V.; Phan, H.-T. Failure Mode Identification and Shear Strength Prediction of Rectangular Hollow RC Columns Using Novel Hybrid Machine Learning Models. Buildings 2023, 13, 2914. https://doi.org/10.3390/buildings13122914
Tran V-L, Lee T-H, Nguyen D-D, Nguyen T-H, Vu Q-V, Phan H-T. Failure Mode Identification and Shear Strength Prediction of Rectangular Hollow RC Columns Using Novel Hybrid Machine Learning Models. Buildings. 2023; 13(12):2914. https://doi.org/10.3390/buildings13122914
Chicago/Turabian StyleTran, Viet-Linh, Tae-Hyung Lee, Duy-Duan Nguyen, Trong-Ha Nguyen, Quang-Viet Vu, and Huy-Thien Phan. 2023. "Failure Mode Identification and Shear Strength Prediction of Rectangular Hollow RC Columns Using Novel Hybrid Machine Learning Models" Buildings 13, no. 12: 2914. https://doi.org/10.3390/buildings13122914