
Predictive Analytics for Early-Stage Construction Costs Estimation

 ,
,
Abstract
:1. Introduction
2. Background
2.1. Cost Estimation
- Planning contingency (e.g., planning restrictions, legal requirements, environmental concerns, and statutory constraints);
- Design contingency (e.g., inadequate brief, aesthetics and space concerns, changes in estimating data, incomplete drawings, and little or no information about M&E services).
2.2. Predictive Analytics
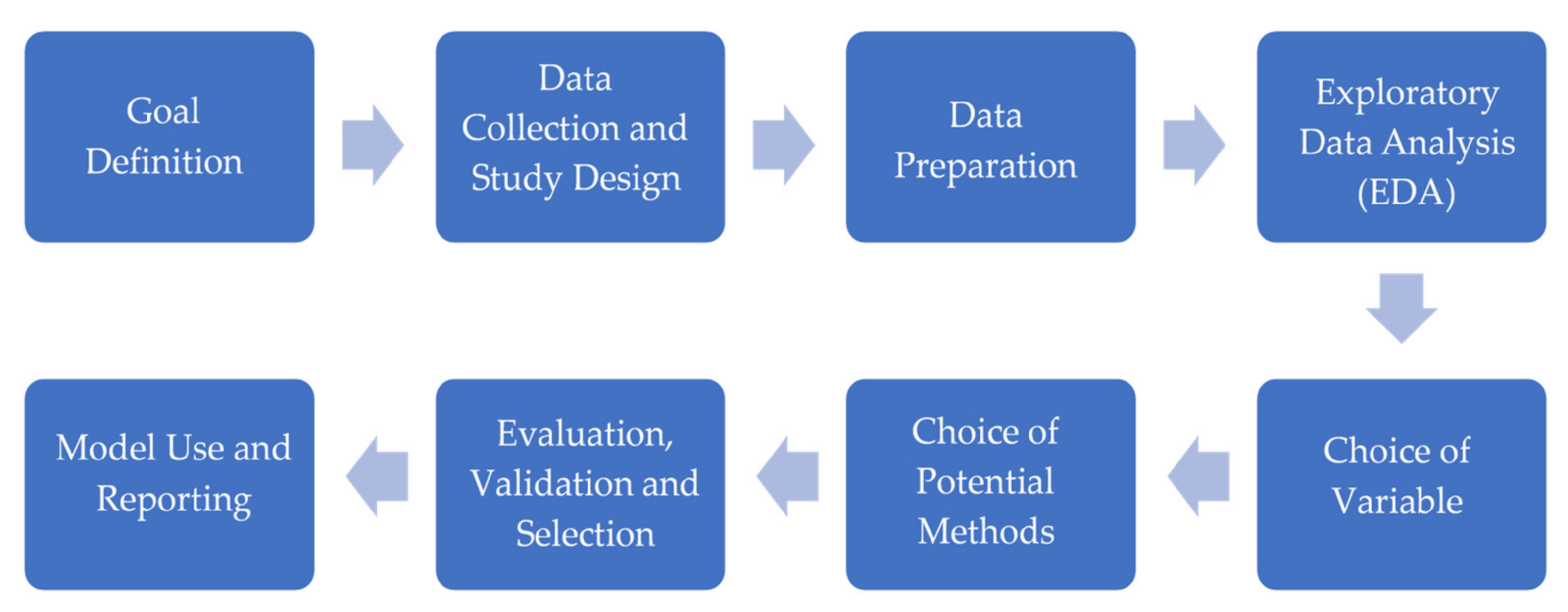
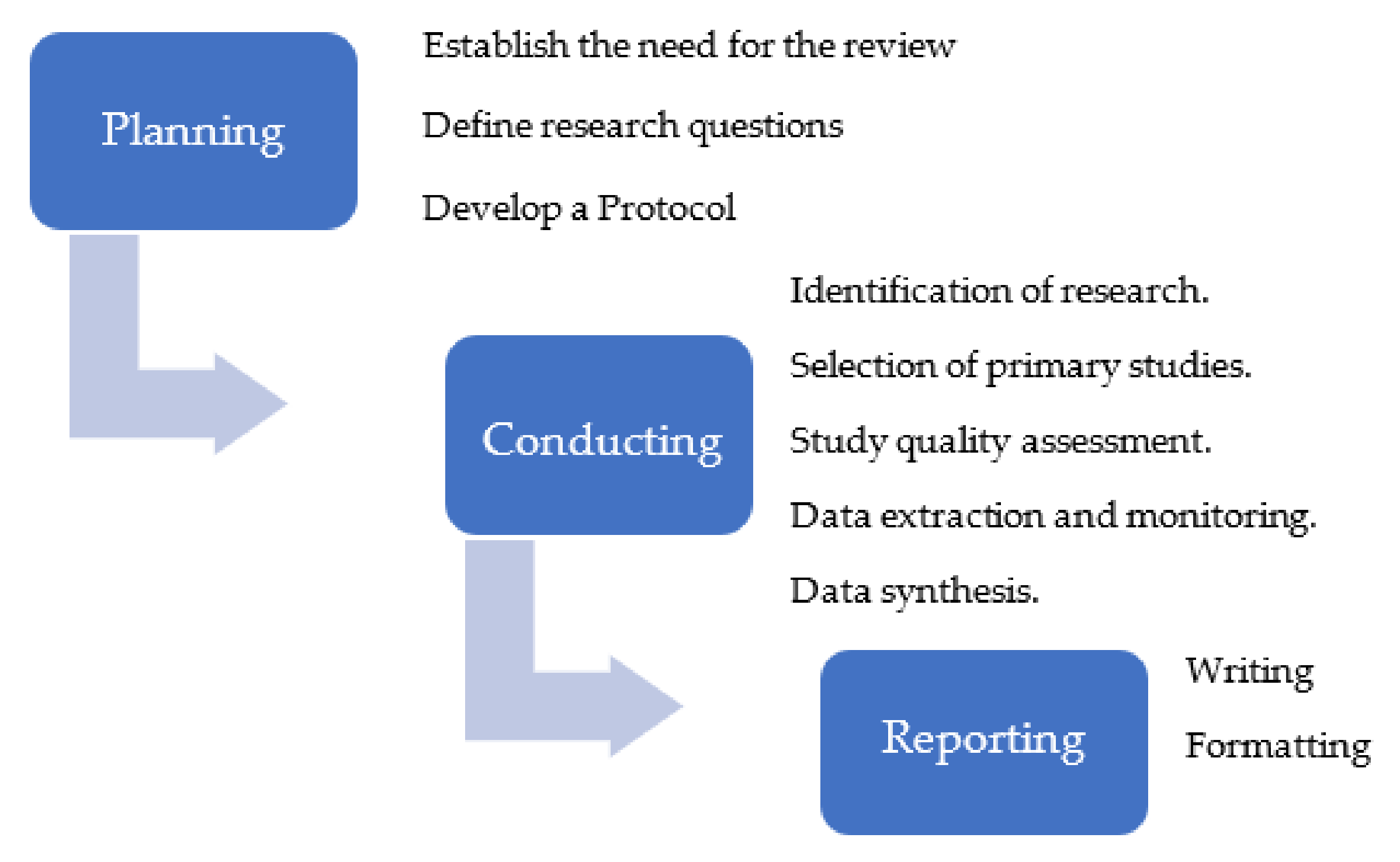
3. Methodology
- Only literature published between 1974 and May 2022;
- Only studies from journals and conferences written in English;
- Only studies focusing on early-stage cost estimation;
- Only studies implementing predictive analytic models to estimate cost;
- Only focusing on building projects;
- Only studies using percentage error as accuracy measure of the final cost;
- Only studies providing the accuracy results and parameters used; and
- Only studies using real data of buildings.
- -
- Venue type;
- -
- Venue name;
- -
- Country of study;
- -
- Publication date;
- -
- Number of citations;
- -
- Scimago H index;
- -
- Google h5 index;
- -
- Type of buildings;
- -
- Data source;
- -
- Sample size of data set;
- -
- Number of parameters used in the models;
- -
- Mean absolute percentage error;
- -
- Parameter identification method;
- -
- Method to optimise parameters;
- -
- Rankings of parameters;
- -
- Type of technique;
- -
- Sub technique compared;
- -
- Component of the model improved;
- -
- Techniques compared;
- -
- Type of validation;
- -
- Sample size;
- -
- Benefits; and
- -
- Challenges.
4. Results and Discussion
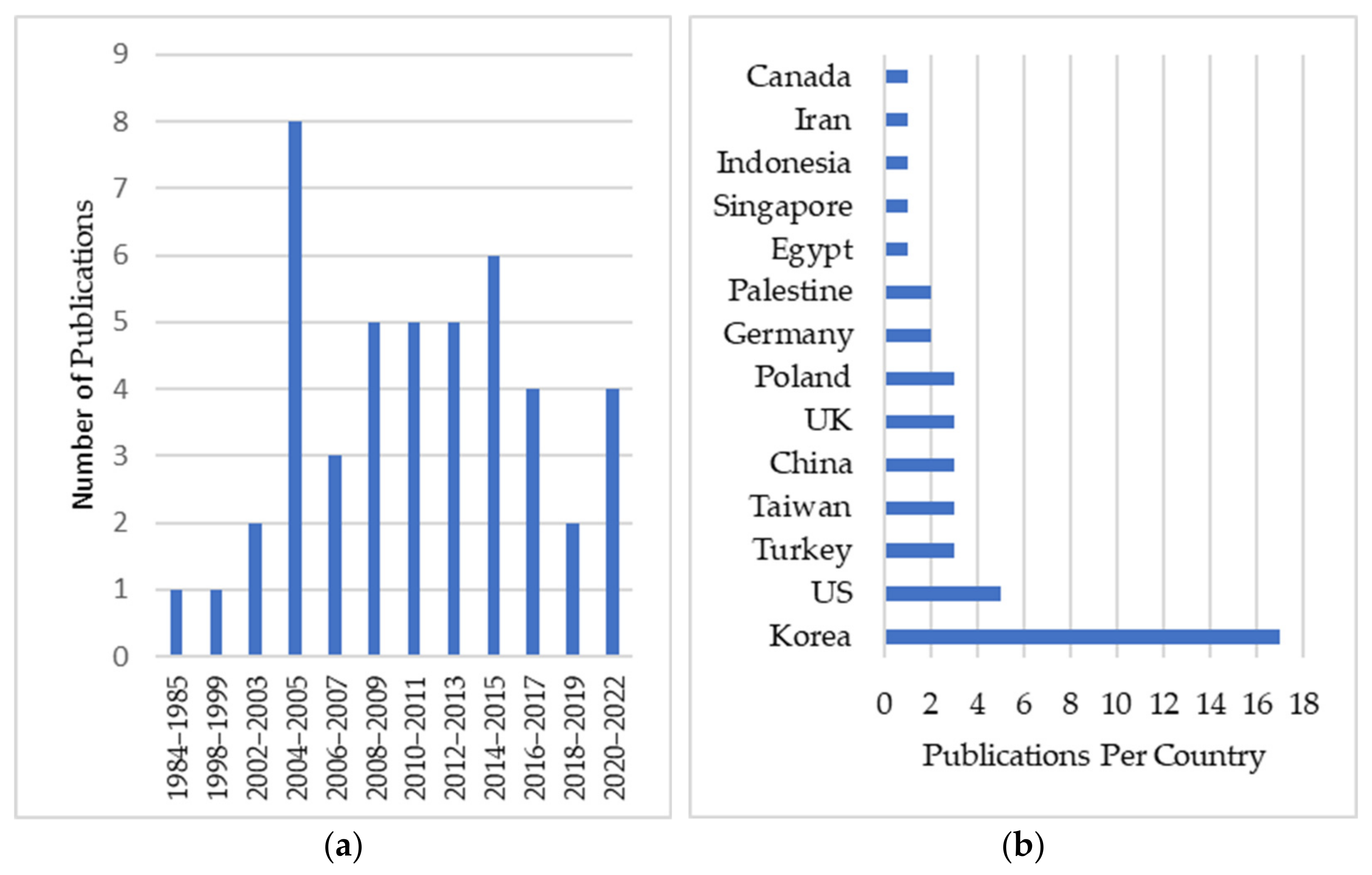
4.1. Studies Description
4.2. Models Input Parameters
4.2.1. Data Utilised in the Studies
4.2.2. Qualitative Identification/Selection Approach
4.2.3. Quantitative Identification/Selection Approach
4.2.4. Parameters Used
4.3. Predictive Power
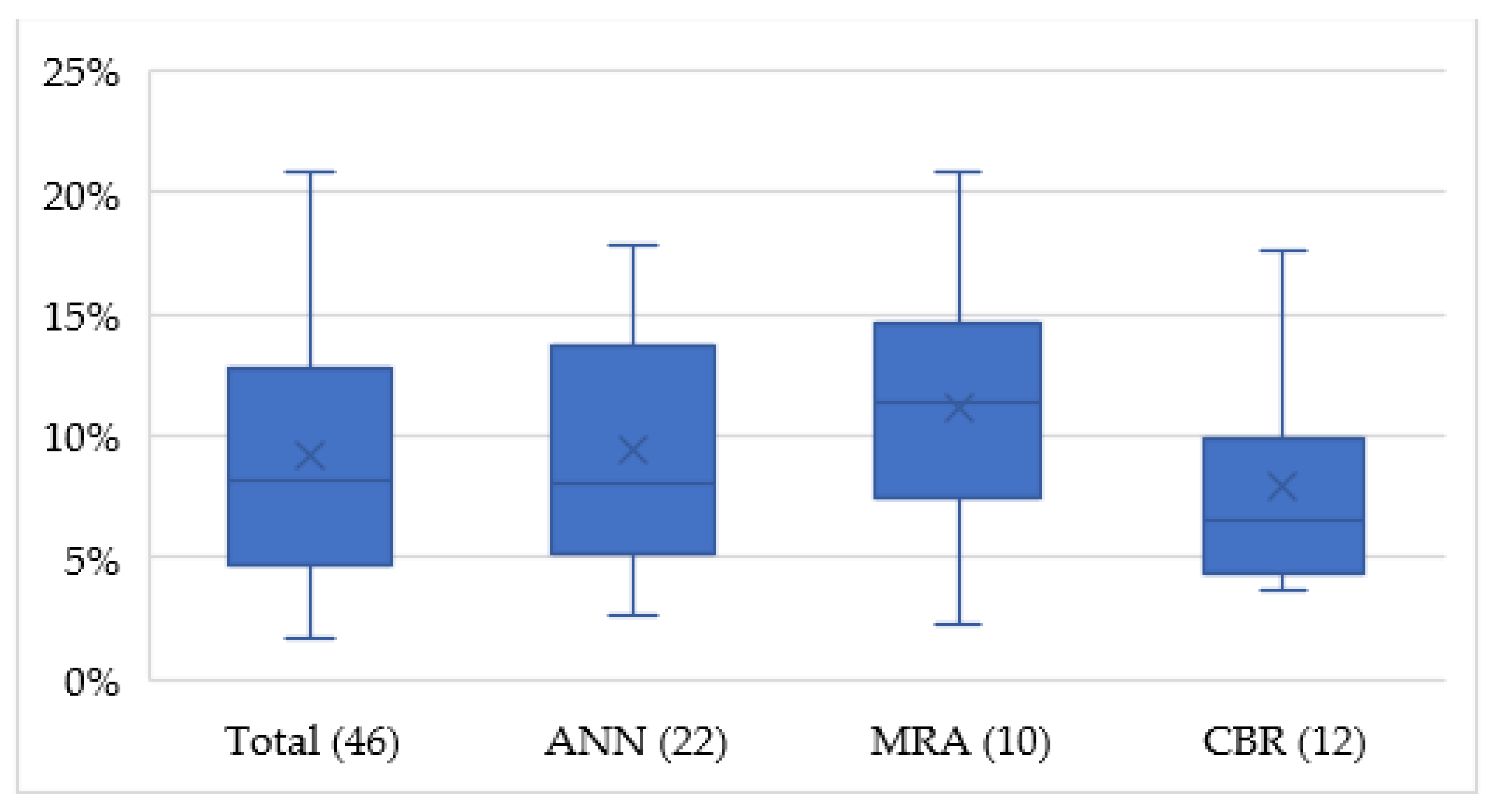
4.3.1. Accuracy
4.3.2. Validation
4.4. Modelling Techniques
- -
- Artificial Neural Networks (ANN);
- -
- Case-Based Reasoning (CBR);
- -
- Multiple Regression Analysis (MRA);
- -
- Boosting Regression Trees (BRT); and
- -
- Support Vector Machine (SVM).
4.4.1. Artificial Neural Networks
4.4.2. Case-Based Reasoning
4.4.3. Multiple-Regression Analysis
4.5. Benefits and Challenges
5. Conclusions
- An extensive database of 46 relevant publications on the use of predictive analytics for construction-costs estimations at the early stages of the development process was compiled and analysed;
- A large number of cost-drivers were identified and ranked;
- The various predictive analytics tools were compared to understand their applicability and ability to predict construction costs at the early stages of the development process.
- Predictive analytics for cost-estimation research has not widely followed the best practices and standard methodologies. By following more strict parameters identification methods, using better data and predictive power considerations, models would produce more reliable predictions. Methodologies to apply predictive analytics for cost estimation have been recently standardised by Elmousalami [15] and Elfaki et al. [17];
- The already accurate predictive analytics techniques investigated in previous studies and the tested modelling methodologies represent the necessary evidence to lead research into the next stage of progress, focusing on adoption and implementation of predictive analytics by the industry;
- The study serves as a reference for high-level decision-makers in organisations developing building projects, providing them with the incremental developments in predictive analytics applications to promote a change of paradigm in the practice of cost estimation.
Author Contributions
Funding
Institutional Review Board Statement
Data Availability Statement
Conflicts of Interest
References
- Sanvido, V.; Grobler, F.; Parfitt, K.; Guvenis, M.; Coyle, M. Critical Success Factors for Construction Projects. J. Constr. Eng. Manag. 1992, 118, 94–111. [Google Scholar] [CrossRef]
- Project Management Institute (PMI). Construction Extension to the PMBOK® Guide, 2nd ed.; Project Management Institute: Newtown Square, PA, USA, 2016. [Google Scholar]
- Amos, S. Skills & Knowledge of Cost Engineering: A Project of the Education Board of AACE International, 5th ed.; AACE International: Morgantown, WV, USA, 2004. [Google Scholar]
- Ashworth, A.; Perera, S. Cost Studies of Buildings, 6th ed.; Routledge: Abingdon Oxon, UK; New York, NY, USA, 2015. [Google Scholar]
- Royal Institution of Chartered Surveyors. RICS New Rules of Measurement. In NRM 1, Order of Cost Estimating and Cost Planning for Capital Building Works; RICS: London, UK, 2012. [Google Scholar]
- Abourizk, S.M.; Babey, G.M.; Karumanasseri, G. Estimating the cost of capital projects: An empirical study of accuracy levels for municipal government projects. Can. J. Civ. Eng. 2002, 29, 653–661. [Google Scholar] [CrossRef]
- Ashworth, A. Pre-Contract Studies: Development Economics, Tendering, and Estimating; Blackwell: Oxford, UK; Melden, MA, USA, 2008. [Google Scholar]
- Nisbet, R.; Miner, G.; Yale, K. The Data Mining and Predictive Analytic Process. In Handbook of Statistical Analysis and Data Mining Applications; Nisbet, R., Miner, G., Yale, K., Eds.; Academic Press: Cambridge, MA, USA, 2018; pp. 39–54. [Google Scholar] [CrossRef]
- Yan, X.; Su, X. Linear Regression Analysis: Theory and Computing; World Scientific: Singapore, 2009. [Google Scholar]
- Ngo, J.; Hwang, B.-G.; Zhang, C. Big Data and Predictive Analytics in the Construction Industry: Applications, Status Quo, and Potential in Singapore’s Construction Industry. In Proceedings of the Construction Research Congress 2020: Computer Applications, Tempe, AZ, USA, 8–10 March 2020; American Society of Civil Engineers (ASCE): Reston, VA, USA, 2020; pp. 715–724. [Google Scholar]
- Waller, M.A.; Fawcett, S.E. Data Science, Predictive Analytics, and Big Data: A Revolution That Will Transform Supply Chain Design and Management. J. Bus. Logist. 2013, 34, 77–84. [Google Scholar] [CrossRef]
- Shmueli, G.; Koppius, O.R. Predictive Analytics in Information Systems Research. MIS Q. Manag. Inf. Syst. 2011, 35, 553–572. [Google Scholar] [CrossRef] [Green Version]
- Mishra, N.; Silakari, S. Predictive Analytics: A Survey, Trends, Applications. Int. J. Comput. Sci. Inf. Technol. 2012, 3, 4434–4438. [Google Scholar]
- Shah, N.D.; Steyerberg, E.W.; Kent, D.M. Big Data and Predictive Analytics: Recalibrating Expectations. JAMA—J. Am. Med. Assoc. 2018, 320, 27–28. [Google Scholar] [CrossRef]
- Elmousalami, H.H. Artificial Intelligence and Parametric Construction Cost Estimate Modeling: State-of-The-Art Review. J. Constr. Eng. Manag. 2020, 146, 03119008. [Google Scholar] [CrossRef]
- Forgues, D.; Iordanova, I.; Valdivesio, F.; Staub-French, S. Rethinking the Cost Estimating Process through 5D BIM: A Case Study. Constr. Res. Congr. 2012, 778–786. [Google Scholar] [CrossRef] [Green Version]
- Elfaki, A.O.; Alatawi, S.; Abushandi, E. Using Intelligent Techniques in Construction Project Cost Estimation: 10-Year Survey. Adv. Civ. Eng. 2014, 2014, 107926. [Google Scholar] [CrossRef] [Green Version]
- Kitchenham, B.; Charters, S.M. Guidelines for Performing Systematic Literature Reviews in Software Engineering; Keele University: Keele, UK; University of Durham: Durham, UK, 2007. [Google Scholar]
- Kirkham, R.; Brandon, P.; Ferry, D. Ferry and Brandon’s Cost Planning of Buildings; Blackwell: Oxford, UK; Malden, MA, USA, 2007. [Google Scholar]
- Potts, K. Construction Cost Management: Learning from Case Studies; Taylor & Francis: London, UK; New York, NY, USA, 2008. [Google Scholar]
- Fellows, R. New research paradigms in the built environment. Constr. Innov. 2010, 10, 5–13. [Google Scholar] [CrossRef]
- Brandon, P. Building Cost Research: Need for a Paradigm Shift? In Building Cost Techniques: New Directions; E&FN Spon: London, UK, 1982. [Google Scholar]
- Contasfor; Egan, S.J.; Williams, D. [Summary of] “Rethinking construction”—The report of the construction task force. Ice briefing sheet. Proc. Inst. Civ. Eng. Munic. Eng. 1998, 127, 199–203. [Google Scholar] [CrossRef]
- Koskela, L. Theory of Lean Construction. In Lean Construction; Tzortzopoulos, P., Kagioglou, M., Koskela, L., Eds.; Routledge: Oxfordshire, UK, 2020; pp. 2–13. [Google Scholar] [CrossRef]
- Kim, Y.; Ballard, G. Activity-Based Costing and Its Application to Lean Construction. In Proceedings of the 9th Annual Conference of the International Group for Lean Construction, Singapore, 6–8 August 2001; pp. 6–8. [Google Scholar]
- Ballard, G. The Lean Project Delivery System: An Update. Lean Constr. J. 2008, 1, 1–19. [Google Scholar]
- Smith, J.; Jaggar, D. Building Cost Planning for the Design Team, 2nd ed.; Elsevier: Oxford, UK, 2007. [Google Scholar]
- Finlay, S. Predictive Analytics, Data Mining and Big Data; Springer: Amsterdam, The Netherlands, 2014. [Google Scholar] [CrossRef] [Green Version]
- Shmueli, G. To Explain or to Predict? Stat. Sci. 2010, 25, 289–310. [Google Scholar] [CrossRef]
- Wu, J.; Coggeshall, S. Foundations of Predictive Analytics; CRC Press: Boca Raton, FL, USA, 2012. [Google Scholar] [CrossRef]
- Boyacioglu, M.A.; Kara, Y.; Baykan, K. Predicting bank financial failures using neural networks, support vector machines and multivariate statistical methods: A comparative analysis in the sample of savings deposit insurance fund (SDIF) transferred banks in Turkey. Expert Syst. Appl. 2009, 36 Pt 2, 3355–3366. [Google Scholar] [CrossRef]
- Mamuda, M.; Sathasivam, S. Predicting the Survival of Diabetes Using Neural Network. AIP Conf. Proc. 2017, 1870, 040046. [Google Scholar] [CrossRef]
- Saggi, M.K.; Jain, S. A survey towards an integration of big data analytics to big insights for value-creation. Inf. Process. Manag. 2018, 54, 758–790. [Google Scholar] [CrossRef]
- Blanco, J.L.; Fuchs, S.; Parsons, M.; Ribeirinho, M.J. Artificial intelligence: Construction technology’s next frontier. Build. Econ. 2018, 7–13. Available online: https://search.informit.org/doi/abs/10.3316/informit.048712291685521 (accessed on 7 May 2022).
- Russell, S.; Norvig, P. Artificial Intelligence a Modern Approach, 3rd ed.; Pearson: London, UK, 2010. [Google Scholar]
- Tranfield, D.; Denyer, D.; Smart, P. Towards a Methodology for Developing Evidence-Informed Management Knowledge by Means of Systematic Review. Br. J. Manag. 2003, 14, 207–222. [Google Scholar] [CrossRef]
- Borrego, M.; Foster, M.J.; Froyd, J.E. Systematic Literature Reviews in Engineering Education and Other Developing Interdisciplinary Fields. J. Eng. Educ. 2014, 103, 45–76. [Google Scholar] [CrossRef]
- Denyer, D.; Tranfield, D. Producing a Systematic Review. In The SAGE Handbook of Organizational Research Methods; SAGE: Thousand Oaks, CA, USA, 2009; pp. 671–689. [Google Scholar] [CrossRef]
- Pan, M.; Yang, Y.; Zheng, Z.; Pan, W. Artificial Intelligence and Robotics for Prefabricated and Modular Construction: A Systematic Literature Review. J. Constr. Eng. Manag. 2022, 148, 03122004. [Google Scholar] [CrossRef]
- Page, M.J.; McKenzie, J.E.; Bossuyt, P.M.; Boutron, I.; Hoffmann, T.C.; Mulrow, C.D.; Shamseer, L.; Tetzlaff, J.M.; Akl, E.A.; Brennan, S.E.; et al. The PRISMA 2020 Statement: An Updated Guideline for Reporting Systematic Reviews. Syst. Rev. 2021, 10, 89. [Google Scholar] [CrossRef] [PubMed]
- Ayodele, O.A.; Chang-Richards, A.; González, V. Factors Affecting Workforce Turnover in the Construction Sector: A Systematic Review. J. Constr. Eng. Manag. 2020, 146, 03119010. [Google Scholar] [CrossRef]
- Wohlin, C. Guidelines for Snowballing in Systematic Literature Studies and a Replication in Software Engineering. In Proceedings of the 18th International Conference on Evaluation and Assessment in Software Engineering, London, UK, 13–14 May 2014; pp. 1–10. [Google Scholar] [CrossRef]
- Kitchenham, B.; Brereton, P.A. Systematic Review of Systematic Review Process Research in Software Engineering. Inf. Softw. Technol. 2013, 55, 2049–2075. [Google Scholar] [CrossRef]
- Rosenthal, R.; DiMatteo, M.R. Meta-Analysis: Recent Developments in Quantitative Methods for Literature Reviews. Annu. Rev. Psychol. 2001, 52, 59–82. [Google Scholar] [CrossRef] [Green Version]
- Lin, S. Rank Aggregation Methods. Wiley Interdiscip. Rev. Comput. Stat. 2010, 2, 555–570. [Google Scholar] [CrossRef]
- Fields, E.B.; Okudan, G.E.; Ashour, O.M. Rank aggregation methods comparison: A case for triage prioritization. Expert Syst. Appl. 2013, 40, 1305–1311. [Google Scholar] [CrossRef]
- Wang, Y.-M.; Yang, J.-B.; Xu, D.-L. A preference aggregation method through the estimation of utility intervals. Comput. Oper. Res. 2005, 32, 2027–2049. [Google Scholar] [CrossRef]
- Elhag, T.M.S.; Boussabaine, A.H. An Artificial Neural System for Cost Estimation of Construction Projects. In Proceedings of the 14th Annual ARCOM Conference, Reading, UK, 1 September 1998; Volume 1, pp. 219–226. [Google Scholar]
- Karshenas, S. Predesign Cost Estimating Method for Multistory Buildings. J. Constr. Eng. Manag. 1984, 110, 79–86. [Google Scholar] [CrossRef]
- Kim, G.-H.; An, S.-H.; Kang, K.-I. Comparison of construction cost estimating models based on regression analysis, neural networks, and case-based reasoning. Build. Environ. 2004, 39, 1235–1242. [Google Scholar] [CrossRef]
- Günaydın, H.M.; Doğan, S.Z. A neural network approach for early cost estimation of structural systems of buildings. Int. J. Proj. Manag. 2004, 22, 595–602. [Google Scholar] [CrossRef] [Green Version]
- Lowe, D.J.; Emsley, M.W.; Harding, A. Predicting Construction Cost Using Multiple Regression Techniques. J. Constr. Eng. Manag. 2006, 132, 750–758. [Google Scholar] [CrossRef] [Green Version]
- An, S.-H.; Kim, G.-H.; Kang, K.-I. A case-based reasoning cost estimating model using experience by analytic hierarchy process. Build. Environ. 2007, 42, 2573–2579. [Google Scholar] [CrossRef]
- Emsley, M.W.; Lowe, D.J.; Duff, A.R.; Harding, A.; Hickson, A. Data modelling and the application of a neural network approach to the prediction of total construction costs. Constr. Manag. Econ. 2002, 20, 465–472. [Google Scholar] [CrossRef]
- Sonmez, R. Conceptual cost estimation of building projects with regression analysis and neural networks. Can. J. Civ. Eng. 2004, 31, 677–683. [Google Scholar] [CrossRef]
- Cheng, M.-Y.; Tsai, H.-C.; Sudjono, E. Conceptual cost estimates using evolutionary fuzzy hybrid neural network for projects in construction industry. Expert Syst. Appl. 2010, 37, 4224–4231. [Google Scholar] [CrossRef]
- Kim, G.-H.; Yoon, J.-E.; An, S.-H.; Cho, H.-H.; Kang, K.-I. Neural network model incorporating a genetic algorithm in estimating construction costs. Build. Environ. 2004, 39, 1333–1340. [Google Scholar] [CrossRef]
- Chan, S.L.; Park, M. Project cost estimation using principal component regression. Constr. Manag. Econ. 2005, 23, 295–304. [Google Scholar] [CrossRef]
- Doğan, S.Z.; Arditi, D.; Günaydın, H.M. Determining Attribute Weights in a CBR Model for Early Cost Prediction of Structural Systems. J. Constr. Eng. Manag. 2006, 132, 1092–1098. [Google Scholar] [CrossRef] [Green Version]
- Park, U.Y.; Kim, G.H. A Study on Predicting Construction Cost of Apartment Housing Projects Based on Support Vector Regression at the Early Project Stage. J. Archit. Inst. Korea 2007, 23, 165–172. [Google Scholar]
- Skitmore, M. The Effect of Project Information on the Accuracy of Building Price Forecasts. In Building Cost Modelling and Computers; E& FN Spon: London, UK, 1987; pp. 327–336. [Google Scholar]
- Picken, D.H.; Ilozor, B.D. Height and construction costs of buildings in Hong Kong. Constr. Manag. Econ. 2003, 21, 107–111. [Google Scholar] [CrossRef]
- Elhag, T.M.S.; Boussabaine, A.H.; Ballal, T.M.A. Critical determinants of construction tendering costs: Quantity surveyors’ standpoint. Int. J. Proj. Manag. 2005, 23, 538–545. [Google Scholar] [CrossRef]
- Wheaton, W.C.; Simonton, W.E. The Secular and Cyclic Behavior of “True” Construction Costs. J. Real Estate Res. 2007, 29, 1–25. [Google Scholar] [CrossRef]
- Stoy, C.; Pollalis, S.; Schalcher, H.-R. Drivers for Cost Estimating in Early Design: Case Study of Residential Construction. J. Constr. Eng. Manag. 2008, 134, 32–39. [Google Scholar] [CrossRef]
- Ahn, J.; Ji, S.-H.; Park, M.; Lee, H.-S.; Kim, S.; Suh, S.-W. The attribute impact concept: Applications in case-based reasoning and parametric cost estimation. Autom. Constr. 2014, 43, 195–203. [Google Scholar] [CrossRef]
- Ahn, J.; Park, M.; Lee, H.-S.; Ahn, S.J.; Ji, S.-H.; Song, K.; Son, B.-S. Covariance effect analysis of similarity measurement methods for early construction cost estimation using case-based reasoning. Autom. Constr. 2017, 81, 254–266. [Google Scholar] [CrossRef]
- Doğan, S.Z.; Arditi, D.; Günaydin, H.M. Using Decision Trees for Determining Attribute Weights in a Case-Based Model of Early Cost Prediction. J. Constr. Eng. Manag. 2008, 134, 146–152. [Google Scholar] [CrossRef] [Green Version]
- Jin, R.; Cho, K.; Hyun, C.; Son, M. MRA-based revised CBR model for cost prediction in the early stage of construction projects. Expert Syst. Appl. 2012, 39, 5214–5222. [Google Scholar] [CrossRef]
- Kim, G.-H.; Shin, J.-M.; Kim, S.; Shin, Y. Comparison of School Building Construction Costs Estimation Methods Using Regression Analysis, Neural Network, and Support Vector Machine. J. Build. Constr. Plan. Res. 2013, 1, 29576. [Google Scholar] [CrossRef] [Green Version]
- Ji, S.-H.; Park, M.; Lee, H.-S. Data Preprocessing–Based Parametric Cost Model for Building Projects: Case Studies of Korean Construction Projects. J. Constr. Eng. Manag. 2010, 136, 844–853. [Google Scholar] [CrossRef]
- Kim, S.-Y.; Choi, J.-W.; Kim, G.-H.; Kang, K.-I. Comparing Cost Prediction Methods for Apartment Housing Projects: CBR versus ANN. J. Asian Arch. Build. Eng. 2005, 4, 113–120. [Google Scholar] [CrossRef]
- Dursun, O.; Stoy, C. Conceptual Estimation of Construction Costs Using the Multistep Ahead Approach. J. Constr. Eng. Manag. 2016, 142, 04016038. [Google Scholar] [CrossRef]
- Li, H.; Shen, Q.; Love, P.E. Cost modelling of office buildings in Hong Kong: An exploratory study. Facilities 2005, 23, 438–452. [Google Scholar] [CrossRef]
- Jin, R.; Han, S.; Hyun, C.; Kim, J. Improving Accuracy of Early Stage Cost Estimation by Revising Categorical Variables in a Case-Based Reasoning Model. J. Constr. Eng. Manag. 2014, 140, 04014025. [Google Scholar] [CrossRef]
- Sonmez, R. Parametric Range Estimating of Building Costs Using Regression Models and Bootstrap. J. Constr. Eng. Manag. 2008, 134, 1011–1016. [Google Scholar] [CrossRef]
- Ji, S.-H.; Park, M.; Lee, H.-S. Case Adaptation Method of Case-Based Reasoning for Construction Cost Estimation in Korea. J. Constr. Eng. Manag. 2012, 138, 43–52. [Google Scholar] [CrossRef]
- Juszczyk, M. Application of PCA-Based Data Compression in the ANN-Supported Conceptual Cost Estimation of Residential Buildings. In Proceedings of the AIP Conference, Rhodes, Greece, 22 September 2015; American Institute of Physics: College Park, MD, USA, 2016; Volume 1738, p. 200007. [Google Scholar] [CrossRef]
- Ahn, J.; Ji, S.-H.; Ahn, S.J.; Park, M.; Lee, H.-S.; Kwon, N.; Lee, E.-B.; Kim, Y. Performance evaluation of normalization-based CBR models for improving construction cost estimation. Autom. Constr. 2020, 119, 103329. [Google Scholar] [CrossRef]
- Hyung, W.-G.; Kim, S.; Jo, J.-K. Improved similarity measure in case-based reasoning: A case study of construction cost estimation. Eng. Constr. Arch. Manag. 2019, 27, 561–578. [Google Scholar] [CrossRef]
- Ji, S.-H.; Park, M.; Lee, H.-S. Cost estimation model for building projects using case-based reasoning. Can. J. Civ. Eng. 2011, 38, 570–581. [Google Scholar] [CrossRef]
- Wang, R.; Asghari, V.; Cheung, C.M.; Hsu, S.-C.; Lee, C.-J. Assessing effects of economic factors on construction cost estimation using deep neural networks. Autom. Constr. 2021, 134, 104080. [Google Scholar] [CrossRef]
- Shin, Y. Application of Boosting Regression Trees to Preliminary Cost Estimation in Building Construction Projects. Comput. Intell. Neurosci. 2015, 2015, 149702. [Google Scholar] [CrossRef] [Green Version]
- Feng, K.; Xiaojuan, W.; Liya, C. Application of RS-SVM in Construction Project Cost Forecasting. In Proceedings of the 2008 4th International Conference on Wireless Communications, Networking and Mobile Computing, Dalian, China, 12–17 October 2008; pp. 3–6. [Google Scholar] [CrossRef]
- Wang, W.-C.; Bilozerov, T.; Dzeng, R.-J.; Hsiao, F.-Y.; Wang, K.-C. Conceptual Cost Estimations Using Neu-ro-Fuzzy and Multi-Factor Evaluation Methods for Building Projects. J. Civ. Eng. Manag. 2017, 23, 1–14. [Google Scholar] [CrossRef] [Green Version]
- Loeppky, J.L.; Sacks, J.; Welch, W.J. Choosing the Sample Size of a Computer Experiment: A Practical Guide. Technometrics 2009, 51, 366–376. [Google Scholar] [CrossRef] [Green Version]
- Fraenkel, J.; Grofman, B. The Borda Count and its real-world alternatives: Comparing scoring rules in Nauru and Slovenia. Aust. J. Polit. Sci. 2014, 49, 186–205. [Google Scholar] [CrossRef]
- Hyndman, R.; Koehler, A.B. Another look at measures of forecast accuracy. Int. J. Forecast. 2006, 22, 679–688. [Google Scholar] [CrossRef] [Green Version]
- Kim, G.H.; Seo, D.S.; Kang, K.I. Hybrid Models of Neural Networks and Genetic Algorithms for Predicting Preliminary Cost Estimates. J. Comput. Civ. Eng. 2005, 19, 208–211. [Google Scholar] [CrossRef]
- Cheng, M.-Y.; Tsai, H.-C.; Hsieh, W.-S. Web-based conceptual cost estimates for construction projects using Evolutionary Fuzzy Neural Inference Model. Autom. Constr. 2009, 18, 164–172. [Google Scholar] [CrossRef]
- Sonmez, R. Range estimation of construction costs using neural networks with bootstrap prediction intervals. Expert Syst. Appl. 2011, 38, 9913–9917. [Google Scholar] [CrossRef]
- Rafiei, M.H.; Adeli, H. Novel Machine-Learning Model for Estimating Construction Costs Considering Economic Variables and Indexes. J. Constr. Eng. Manag. 2018, 144, 04018106. [Google Scholar] [CrossRef]
- Jumas, D.; Mohd-Rahim, F.A.; Zainon, N.; Utama, W.P. Improving accuracy of conceptual cost estimation using MRA and ANFIS in Indonesian building projects. Built Environ. Proj. Asset Manag. 2018, 8, 348–357. [Google Scholar] [CrossRef] [Green Version]
- Badawy, M. A hybrid approach for a cost estimate of residential buildings in Egypt at the early stage. Asian J. Civ. Eng. 2020, 21, 763–774. [Google Scholar] [CrossRef]
- Jung, S.; Pyeon, J.-H.; Lee, H.-S.; Park, M.; Yoon, I.; Rho, J. Construction Cost Estimation Using a Case-Based Reasoning Hybrid Genetic Algorithm Based on Local Search Method. Sustainability 2020, 12, 7920. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| No. | Authors/Year | Title | Country | Citations |
|---|---|---|---|---|
| 1 | Kim et al. [50] | Comparison of construction-cost-estimating models based on regression analysis, neural networks, and case-based reasoning. | Korea | 617 |
| 2 | Günaydin and ΞDoǧan [51] | A neural network approach for early cost estimation of structural systems of buildings. | Turkey | 314 |
| 3 | Lowe et al. [52] | Predicting construction cost using multiple regression techniques. | UK | 320 |
| 4 | An et al. [53] | A case-based reasoning cost-estimating model using experience by analytic hierarchy process. | Korea | 248 |
| 5 | Emsley et al. [54] | Data modelling and the application of a neural network approach to the prediction of total construction costs. | UK | 192 |
| 6 | Sonmez [55] | Conceptual cost estimation of building projects with regression analysis and neural networks. | US | 176 |
| 7 | Cheng et al. [56] | Conceptual cost estimates using evolutionary fuzzy hybrid neural network for projects in the construction industry. | Taiwan | 176 |
| 8 | Kim et al. [57] | Neural network model incorporating a genetic algorithm in estimating construction costs. | Korea | 173 |
| 9 | Chan and Park [58] | Project cost estimation using principal component regression. | Singapore | 147 |
| 10 | Doğan et al. [59] | Determining attribute weights in a case-based reasoning model for early cost prediction of structural systems. | Turkey | 139 |
| Parameter Identification Method | Number of Studies |
|---|---|
| Not mentioned | 14 |
| Literature review | 10 |
| Literature review and expert survey | 9 |
| Author criteria | 6 |
| Expert survey | 4 |
| From data available | 2 |
| Expert survey and MCA | 1 |
| Grand Total | 46 |
| Parameter Identification Method | Studies | Number of Studies |
|---|---|---|
| Stepwise Regression Analysis | [52,55,70,71,72,73,74,75,76] | 9 |
| Principal Component Analysis | [58,77,78] | 3 |
| Correlation Analysis | [67,79,80] | 3 |
| ANOVA | [50,65] | 2 |
| Genetic Algorithm | [59,81] | 2 |
| Attribute Impact | [66] | 1 |
| Shapley Additive Explanations | [82] | 1 |
| MRA Standard Coefficients | [69] | 1 |
| Analytic Hierarchy Process | [53] | 1 |
| Boosting Regression Trees | [83] | 1 |
| Rough Set | [84] | 1 |
| Multifactor Evaluation | [85] | 1 |
| Factor Analysis | [54] | 1 |
| Decision Tree | [68] | 1 |
| Parameter | Rank | Score |
|---|---|---|
| GFA | 1 | 1301 |
| Number of floors | 2 | 1137 |
| Foundation type | 3 | 803 |
| Number of units | 4 | 647 |
| Number of elevators | 5 | 589 |
| Type of roof | 6 | 506 |
| Structure type | 7 | 434 |
| Duration | 8 | 373 |
| Number of unit floor households | 9 | 304 |
| Location | 10 | 299 |
| Author | Year | Model Component Improvement | Technique or Method Used |
|---|---|---|---|
| Elhag and Boussabaine [48] | 1998 | Input parameters | Inclusion of additional parameters |
| Kim et al. [52] | 2004 | ANN Architecture | GA |
| Kim et al. [89] | 2005 | ANN Architecture | GA |
| Cheng et al. [90] | 2009 | ANN Architecture | FL/GA |
| Cheng et al. [56] | 2010 | ANN Architecture | High Order NN/FL/GA |
| Sonmez [91] | 2011 | Input parameters/ANN Architecture | Bayesian regularisation/Bootstraps prediction intervals |
| Rafiei and Adeli [92] | 2018 | Model architecture | DBM combination |
| Jumas et al. [93] | 2018 | Input parameters | MRA |
| Badawy [94] | 2020 | Model architecture | MRA combination |
| Author | Year | Model Component Improvement | Technique or Method Used |
|---|---|---|---|
| An, et al. [53] | 2006 | Attribute weighting | Analytic Hierarchy Process (AHP) |
| Doğan et al. [59] | 2006 | Attribute weighting | GA |
| Doğan et al. [68] | 2008 | Attribute weighting | Decision Trees |
| Ji et al. [81] | 2011 | Case Similarity Measurement Attribute weighting | Euclidean distance-based similarity function GA |
| Jin et al. [69] | 2012 | Result error | MRA-based revision method |
| Ji et al. [77] | 2012 | Case adaptation | MRA |
| Jin et al. [75] | 2014 | Input parameters | Inclusion of categorical attributes |
| Ahn et al. [66] | 2014 | Attribute weighting | Attribute impact method |
| Ahn et al. [67] | 2017 | Case Similarity Measurement | Euclidean distance Mahalanobis distance Arithmetic summation Fractional function |
| Ahn et al. [79] | 2020 | Input parameters | GA Euclidean distance |
| Jung et al. [95] | 2020 | Attribute weighting | GA Local search technique |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Castro Miranda, S.L.; Del Rey Castillo, E.; Gonzalez, V.; Adafin, J. Predictive Analytics for Early-Stage Construction Costs Estimation. Buildings 2022, 12, 1043. https://doi.org/10.3390/buildings12071043
Castro Miranda SL, Del Rey Castillo E, Gonzalez V, Adafin J. Predictive Analytics for Early-Stage Construction Costs Estimation. Buildings. 2022; 12(7):1043. https://doi.org/10.3390/buildings12071043
Chicago/Turabian StyleCastro Miranda, Sergio Lautaro, Enrique Del Rey Castillo, Vicente Gonzalez, and Johnson Adafin. 2022. "Predictive Analytics for Early-Stage Construction Costs Estimation" Buildings 12, no. 7: 1043. https://doi.org/10.3390/buildings12071043