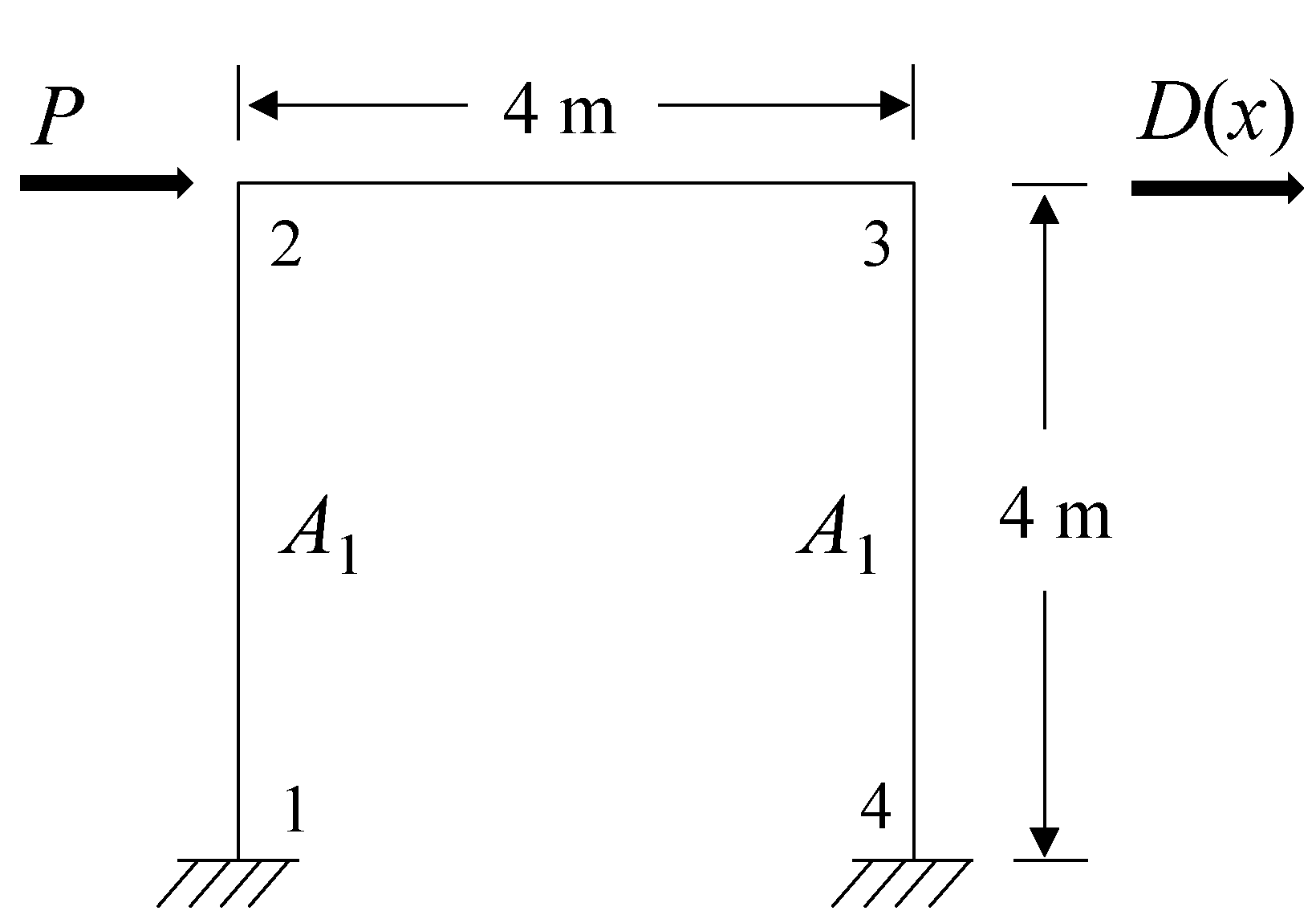
2.1. GOA
In 2017, a swarm intelligence optimization algorithm called GOA emerged, showing excellent global optimization capability [
29]. The algorithm regards a single individual as a search operator and simulates the large-range fast movement of imagoes and local slow movement of larvae into global and local optimization, respectively. In the optimization process, with additional iterations, the global optimization stage is gradually transformed into the local optimization stage [
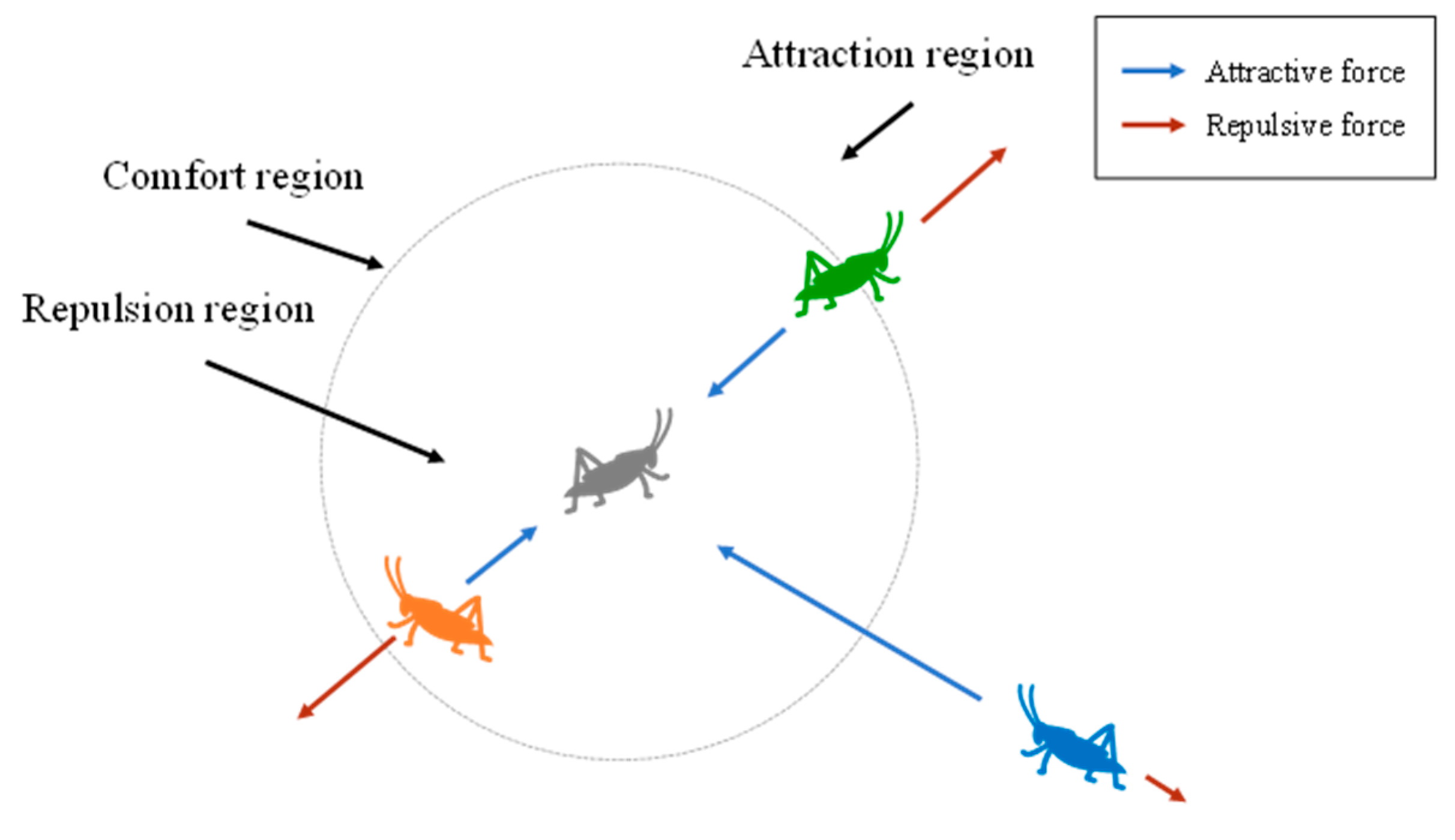
30]. In the stage of global optimization, the operator performs a rapid search in the model space over a large range to obtain the overall information of the model space and lock down a local area. In the stage of local optimization, the operator searches carefully in this local area and optimizes the accuracy of the solution through continuous iteration. According to the distance between the two operators, spatial regions can be divided into attractive regions, comfortable regions and repulsive regions (
Figure 1).
When the distance between the two operators is relatively close (less than 2.079 units), they repulse each other, and the operator is in the repulsion region or within the repulsion distance. When the distance between the two operators is exactly 2.079 units, there is neither an attractive nor repulsive force, which is called the comfort region or the comfortable distance. In the same way, when the distance between two operators is more than 2.079 units, they attract each other, and thus this distance is called the attraction region or the distance of attraction [
31]. According to this principle, grasshopper operators constantly adjust their positions with other operators to achieve optimization results.
It is important to note that there is no clear boundary between global and local optimization. With increasing iteration times, the search area gradually decreases, and the search gradually changes from global optimization to local optimization. The current grasshopper operator
xi is defined by the grasshopper operator
xj, as follows:
where
dij is the spatial distance between the current
ith grasshopper operator and the
jth grasshopper operator
m and
n are parameters to evaluate the effect of other agents on the agent;
m represents the intensity of attraction, and
n represents the spatial scale of attraction.
The next position of the grasshopper operator
xi is defined as follows:
where
is the position to which the
i-th grasshopper operator moves next in the
k-th dimension;
N represents the total number of grasshopper operators;
ulk and
flk represent the upper and lower limits of the agent in the
k-th dimension, respectively;
denotes the spatial distance between the
i-th grasshopper and the
j-th grasshopper in the
k-th dimension;
and
represent the current position of the
i-th and
j-th grasshoppers in the
k-th dimension, respectively;
represents the component of the best solution found thus far in the
k-th dimension, and
c1 and
c2 are known as adaptive shrinkage parameters, which maintain the relative balance between global and local optimization. If
c1 and
c2 are represented by
c, their linear change can be calculated as:
where
t represents the current iteration number;
tmax represents the maximum number of iterations;
cmax is the maximum value of the adaptive shrinkage parameter, and
cmin is the minimum value of the adaptive shrinkage parameter.
The algorithm mainly contains six hyperparameters: the population number N, the maximum number of iterations tmax, and the upper and lower limits of the search ul and fl, respectively. The upper and lower limits of the search represent the search space of the model, which can be reasonably estimated according to actual problems. The number of populations and iterations have similar effects on the operation of the algorithm: when the number of populations or iterations increases, the search operator searches in more detail in the whole model space. If the population or iteration is too large, it causes many unnecessary searches, greatly increasing the running time of the algorithm and reducing the efficiency. However, if the population or iteration number is too small, the global optimal solution cannot be searched, which affects the accuracy of understanding. Therefore, it is necessary to constantly adjust these two parameters in a scientific way and select a group of population and iteration times that are more suitable for the current problem. The adaptive shrinkage parameter c gradually decreases with additional iterations so that the grasshopper algorithm does not converge quickly, thus affecting the proportion of the global optimization stage and local optimization stage. A large value of c in the early stage of the algorithm encourages the grasshopper operator to conduct global optimization, while a small value of c in the late stage of optimization encourages the grasshopper operator to conduct local optimization as much as possible and move towards the target.
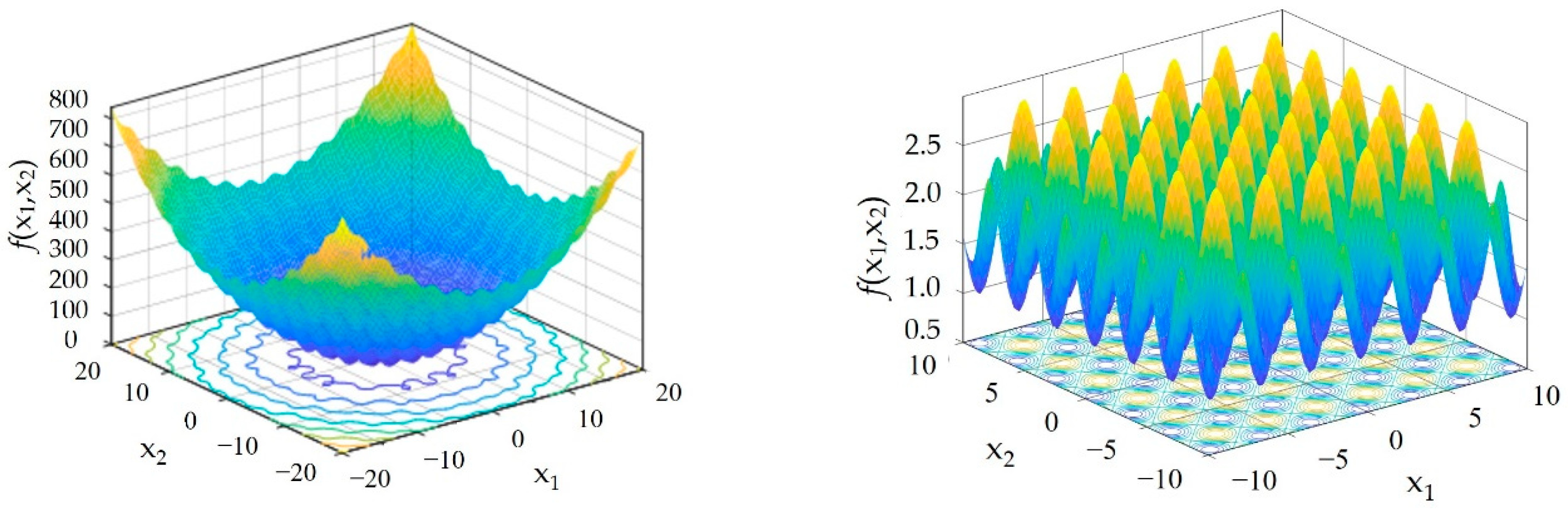
To demonstrate the good performance of the GOA, we adopt two common multi-modal test functions: the egg crate function and the periodic function (
Figure 2), which are shown as Equations (4) and (5):
In the test process for the above two test functions, the dimension
D of the test function is 5. In the egg crate function test, the parameter settings of the GOA are as follows: the population size
N is 200, and the maximum number of iterations
tmax is 500. In the periodic function test, the parameter settings of the GOA are as follows: the population size
N is 100, and the maximum number of iterations
tmax is 500. The calculation results are shown in
Table 1. It can be seen that the difference between the optimal value searched by the algorithm and the minimum value of the function is very small. The difference between the average optimal value of the egg rate function and the minimum value of the function is only 3.99 × 10
−11, and the difference between the average optimal value of the periodic function and the minimum value of the function is only 4.65 × 10
−5, indicating that the grasshopper algorithm has a strong global optimization ability.
2.2. SVM
The SVM [
32] originated from pattern recognition in machine learning and is widely used, including portrait recognition, text classification, handwritten character recognition, bioinformatics and so on. In recent years, it has been applied to solve implicit nonlinear problems and has achieved good results. On the one hand, the SVM is very suitable for small sample fitting problems; on the other hand, the SVM can accurately represent high-dimensional functions and overcome the problem of dimension disaster. It can be divided into support vector classification (SVC) and support vector regression (SVR) according to the different functions used [
33]. According to the properties of the hyperplane, the SVM can also be divided into linear and nonlinear.
In the SVM, the input is the sample of basic random variables, and the output is the response of the physical system. For a linearly separable problem
yi ∈
y = {1, −1}, the analytic expression of the SVM is:
where <.,.> represents the inner product in
Rn, w∈Rn is the weight vector, and
b ∈
R is the threshold.
Compared to SVC machines, the margin of SVR is replaced by a loss function. The original optimization model of the SVR problem can be expressed as:
where
is the relaxation variable and
C is the penalty parameter.
By introducing the corresponding Lagrange function, the SVM formula for linear problems can be derived:
where (
α −
αi) is a Lagrange multiplier and must be positive.
However, real problems are often non-linear. To extend Equation (8) to nonlinear functions, we can replace the inner product directly with the kernel function:
where
is the kernel function.
There are many kinds of kernel functions of SVM, such as linear kernels, polynomial kernels, neural network kernels, and Markov kernels. One of its advantages is that the model performance can be improved by selecting appropriate kernel functions. Therefore, it is very important to choose an appropriate kernel function for a particular problem. The Gaussian RBF kernel is adopted in this paper, whose expression is given below:
where
σ is the width parameter.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}