1. Introduction
Human activities in urban areas will continuously consume a lot of energy and emit carbon dioxide and pollutants into the environment. For the sustainable development of the city and society, planners and engineers are committed to improving energy efficiency and reducing the environmental impact of energy production and consumption. A district energy system is a kind of proven solution that can meet the above demands. By definition, the district energy system refers to an integrated energy system that can solve the multiple energy requirements of human activities in a specific district (e.g., heating, cooling, hot water, gas and power supply, etc.). The “district” referred to can be an urban street block divided by administration, an industrial/research park, or a community with multiple types of buildings [
1]. Through the rational planning, design and operation control of district energy systems, the efficient production, transmission, distribution and consumption of various forms of energy in cities can be realized. In addition, district energy systems can utilize many new energy technologies such as cogeneration, renewable energy and smart grids to further promote energy conservation and emission reduction [
2]. At present, society is taking “carbon neutralization” as the goal of energy planning, which means that district energy systems will have a broader application prospect.
High-quality planning and design are the foundation of a successful district energy system. During the planning and design stage, the accurate prediction of community loads and energy demands can provide a reliable calculation basis for the configuration of the energy system [
3]. The load prediction is also a significant step to further optimize the design of the system [
4]. For example, load levelling, which refers to smoothing the load profile by reducing the difference between the on-peak and off-peak loads, is an effective technique to lower the operation cost and prolong the life cycle of the system [
5]. The simplest and most convenient approach to estimate the load in engineering practice is to multiply the load intensity index per unit area by the building area. However, these “load indices” are mainly based on experiences and very likely to result in overestimation of loads; their values are static in the calculation, which means they cannot reflect the dynamic characteristics of loads on the annual scale [
6]. In many application and research scenarios such as economic analysis or community load levelling, a prediction of the hourly loads of buildings is required. Although designers and engineers can calculate the hourly loads using BPS (building performance simulation) tools (e.g., eQuest, DeST, EnergyPlus, etc.) for a project at the planning and design stage [
7], they need to collect sufficient geometric and physical information about the buildings, which is usually quite difficult in this preliminary stage of a project [
8]. Thus, this paper proposes a new method to predict the hourly loads of buildings for district energy systems at the planning stage. To meet practical needs, this new method should ensure both the accuracy of the prediction and the convenience of use.
The loads of a district energy system refer to the superposition of the instantaneous loads of multiple buildings at the same time pace. Therefore, the load prediction of district energy can be divided into two main steps: load prediction for every individual building with different types and functions in the district; and the superposition and correction of multiple prediction results on the scale of cities or communities. For the former step, there have already been a lot of related studies. In 2012, Zhao and Magoules published a review on the prediction methods of building energy consumption and the proposal for future prospects [
9]. At present, using BPS software is still the most commonly used method for the load prediction of individual buildings. For example, Han et al. predicted the annual and peak cooling load for several types of buildings based on the prototypical building models established with DeST [
10]. Ourghi et al. proposed an approach to predict the annual energy consumption of office buildings by DOE-2 models, while the influence of building shape on cooling and heating loads was also considered [
11]. Nihar et al. used an EnergyPlus model to predict the energy consumption of a building to realize the optimal control of the operable windows [
12]. Lim and Zhai proposed a Monte Carlo simulation method combined with EnergyPlus modelling to obtain the regression formula of the building energy consumption [
13]. Zhu et al. also used the stochastic modelling method based on EnergyPlus models to predict the cooling and heating loads of buildings at the planning stage [
14]. However, modellers can only establish the BPS models on a case-by-case basis, which is not very convenient to the nonprofessional users in practice. Another common load prediction method is the statistical method based on monitoring data [
15]. Many types of data-driven model, such as multiple nonlinear regression [
16], time series [
17], artificial neural network (ANN) [
18], support vector machine (SVM) [
19] and grey-box models [
20], have been successfully applied to the load prediction for a single building. It can be seen that an accurate prediction result will be obtained based on correct detailed building information (for the simulation method) or sufficient monitoring data (for the statistical method).
The latter step is the superposition of the predicted results of multiple individual buildings in space and time on the district scale. Researchers have independently completed some related studies in decades. For example, Chow et al. used DOE-2 models to predict the cooling load of a new community for the optimal design of the district cooling system [
21]. Shimoda et al. established a series of detailed building models to predict the energy consumption and CO2 emissions at the city scale [
22]. Ren et al. created a prototypical building model database and used it to predict the end-use electricity consumption in a residential area [
23]. The data-driven model has also been applied in the load prediction of a district energy system, although a larger scale of data is required than the individual building. Warnken et al. used the regression model method to forecast the sector-wide building energy consumption of the tourism accommodation industry in Australia [
24]. Jiang et al. used the ANN model to predict the hourly cooling loads for a community with a district cooling system based on the annual monitoring data [
25]. Wan et al. established a correlation model of cooling/heating loads and weather parameters using the principal component analysis method [
26]. Shamshirband et al. utilized the adaptive neuro-fuzzy algorithm to predict district heating loads [
27]. Al-Shammari et al. trained a data-driven model that combines SVMs with FFA to predict the loads of a district heating system [
28]. Ferracuti et al. analysed three types of data-driven models for the load prediction in real buildings and found that they can show good accuracy at short-term prediction periods [
29]. In sum, the statistical methods are more suitable for the buildings or district energy systems in operation instead of the planning and design phase due to the requirement for the monitoring data of loads.
In recent year, the concept of “UBEM (urban building energy modelling)” has gradually attracted the attention of academic and engineering communities [
30]. Urban energy planning is one of very important domains of applications of UBEM. Some bottom-up physical-based UBEM tools have had the function of guiding the planning and design of district energy systems, such as CityBES, OpenIDEAS, CEA, URBANopt, TEASER, etc. [
31]. Some other scholars also reviewed the statistical methods used for UBEM [
32] or established the data-driven framework for UEUM (urban energy use modelling) by case studies [
33], which both reveal that big data is a very important part and one of the future trends in the development of UBEM. However, there is still a slight deviation from the focus of UBEM tools and the requirement of district load prediction in practice. Now, a major challenge of UBEM is the shortage of computing resources [
34]. Therefore, the analysis of a single building is usually simplified in many UBEM tools, which is reasonable on the urban scale. As the object of district energy planning, the scale of a community is much smaller than that of a city, and planners often need more accurate load prediction data; in addition, in many actual planning projects, the available building information is limited, and the relevant staff are likely to be nonprofessional in modelling and simulation. Therefore, it is necessary to develop a load prediction tool that can strike a balance between convenience and accuracy to better meet the actual needs of engineers.
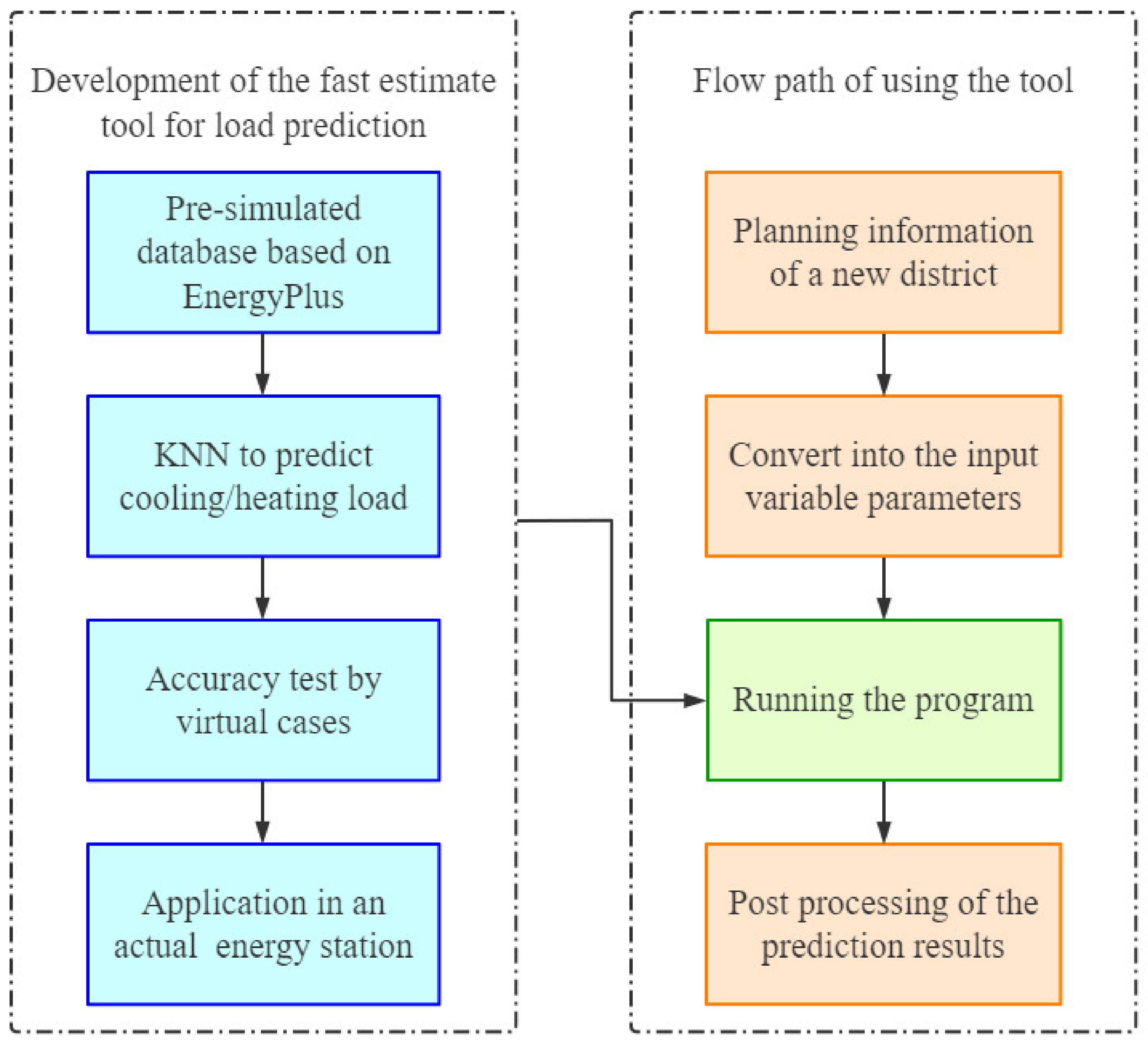
This paper proposes a fast load prediction method for district energy systems based on a presimulated building model database and KNN (K-nearest neighbor) algorithm. In general, a district energy system is usually an integrated system combined with centralized heating, cooling and electricity supply to meet the demands of a specific district/community. On the scale of hourly time-step, the electricity load is relatively stable and periodic throughout the whole year, but the cooling and heating loads have a strong correlation with the state of indoor environment and outdoor climate. Thus, the method proposed in this paper is only aimed at the prediction of cooling and heating loads. The novelty of this method is to provide a new idea of utilizing a large number of forward simulation models and machine learning technology (KNN) to develop a practical tool for cooling/heating load prediction at the planning stage of district energy systems. The decision makers who are not professional in BPS can easily use this tool to perform load prediction in actual projects without a tedious modelling process, but with guaranteed accuracy.
3. Test and Result
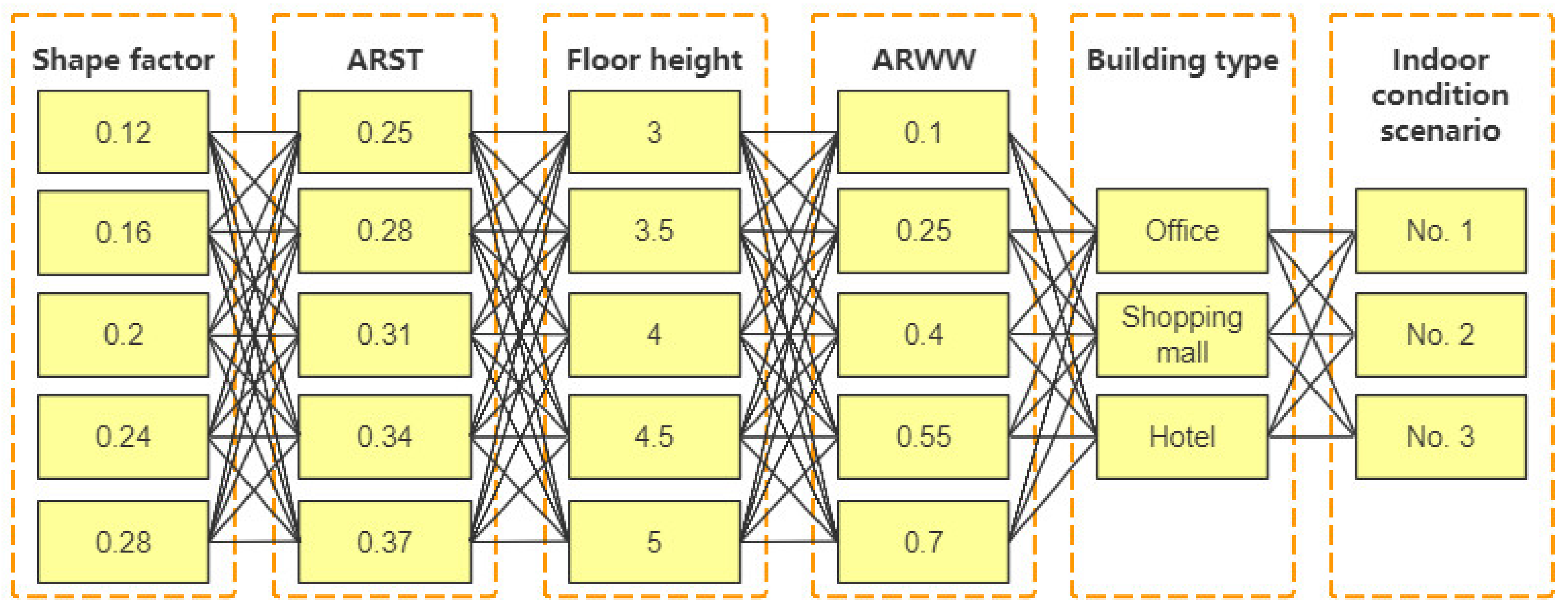
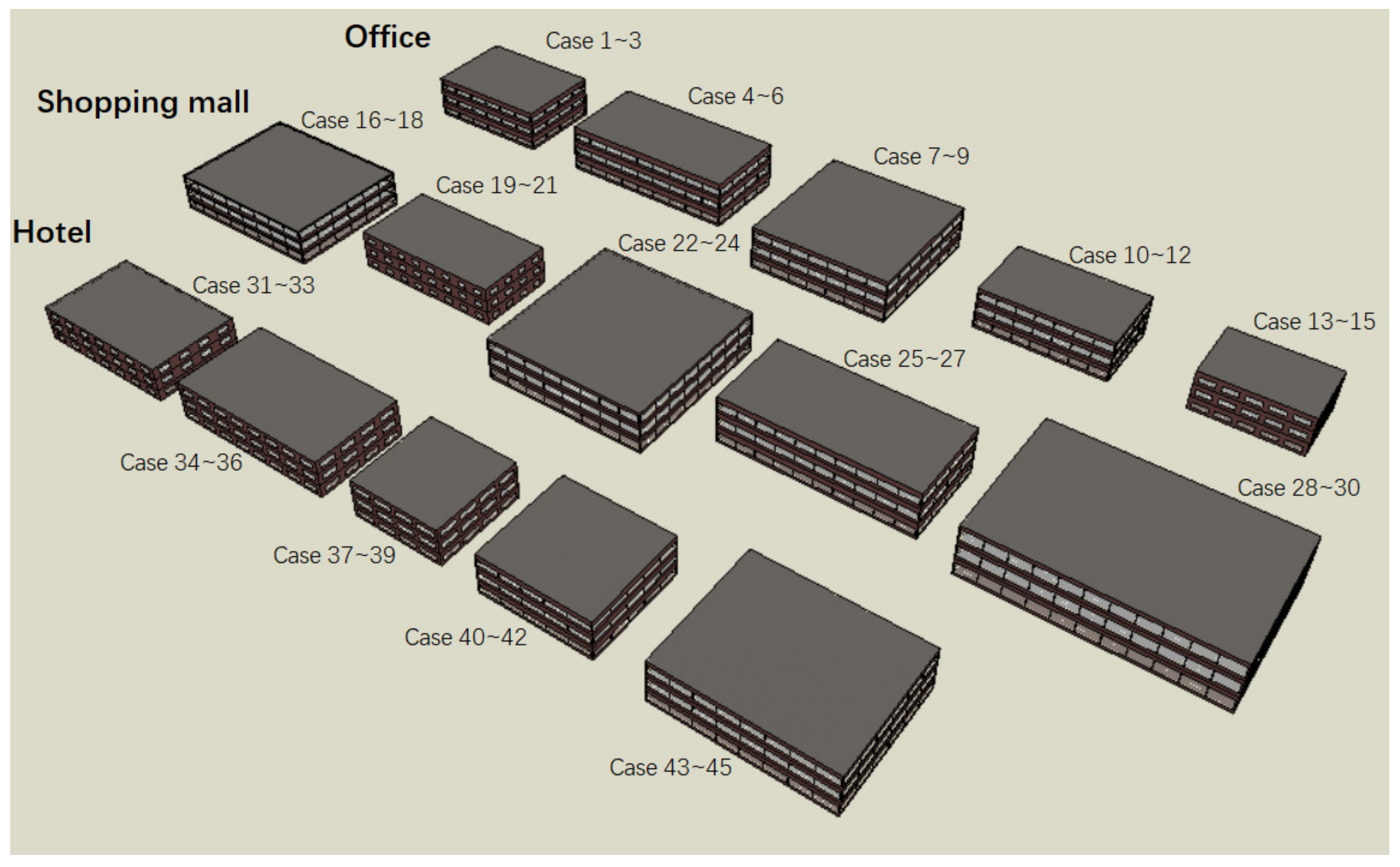
The developed tool requires a test to verify its accuracy and effectiveness. The test objects are 15 randomly generated BPS models with different input information. Among these 15 buildings, there are 5 of each type (office, shopping mall and hotel). For the sake of simplicity, the geometric parameters of the five models in each group are the same. In the load prediction tool, there are three kinds of settings to be chosen as the indoor condition scenarios for each type of building. Therefore, we arranged and combined these 15 virtual buildings with three different scenarios to create a total of 45 test cases. The model parameters of these test cases are presented in
Table 6.
The development goal of the fast estimate tool for load prediction is to replace the detailed modelling method in the planning stage of a district energy system, improve the working efficiency without losing the accuracy of the prediction results and facilitate its use for nonprofessionals. This means that the simulation result of the detailed BPS model can be regarded as the baseline for the accuracy test of the tool. Thus, for all 45 of these test cases, their detailed BPS models are established in DesignBuilder (
Figure 12) to output the baseline values, while the predicted values are also obtained by the fast load estimate tool. The difference (relative error) between the predicted and the baseline values presents the accuracy of the prediction results.
In the comparison between the prediction results and the baseline, a total of 8760 pairs of load values need to be compared with each other. Through preliminary observation of the prediction results, we find that the baseline and predicted loads are both very small in some hours. This may lead to a problem, in that the relative errors of these hours would be very large due to the small baseline value, although the absolute value of the gap between the baseline and the prediction is not big. For example, supposing that one of the baseline values of the cooling load is 1 W/m
2 and the predicted value is 1.5 W/m
2, the relative error would be very large (50%) in this hour. The aim of the development is to make the prediction results of the fast estimate tool close to the baseline value in the hours with significant cooling and heating loads, but this does not require benchmarking with the baseline value at every time. Therefore, a new index, “ratio of the hours with effective prediction”, is used to evaluate the accuracy of the prediction results on an annual scale. This index is defined as the ratio of the hours whose relative error of predicted load is less than 15% (referring to the requirement in ASHRAE Guideline [
37]) to the hours with nonzero values of loads in the whole year. Moreover, the RE (relative error) of the peak value and the accumulated value of annual cooling and heating loads (equivalent to the cooling/heating energy consumed by the building during the whole year) are also computed as the test results.
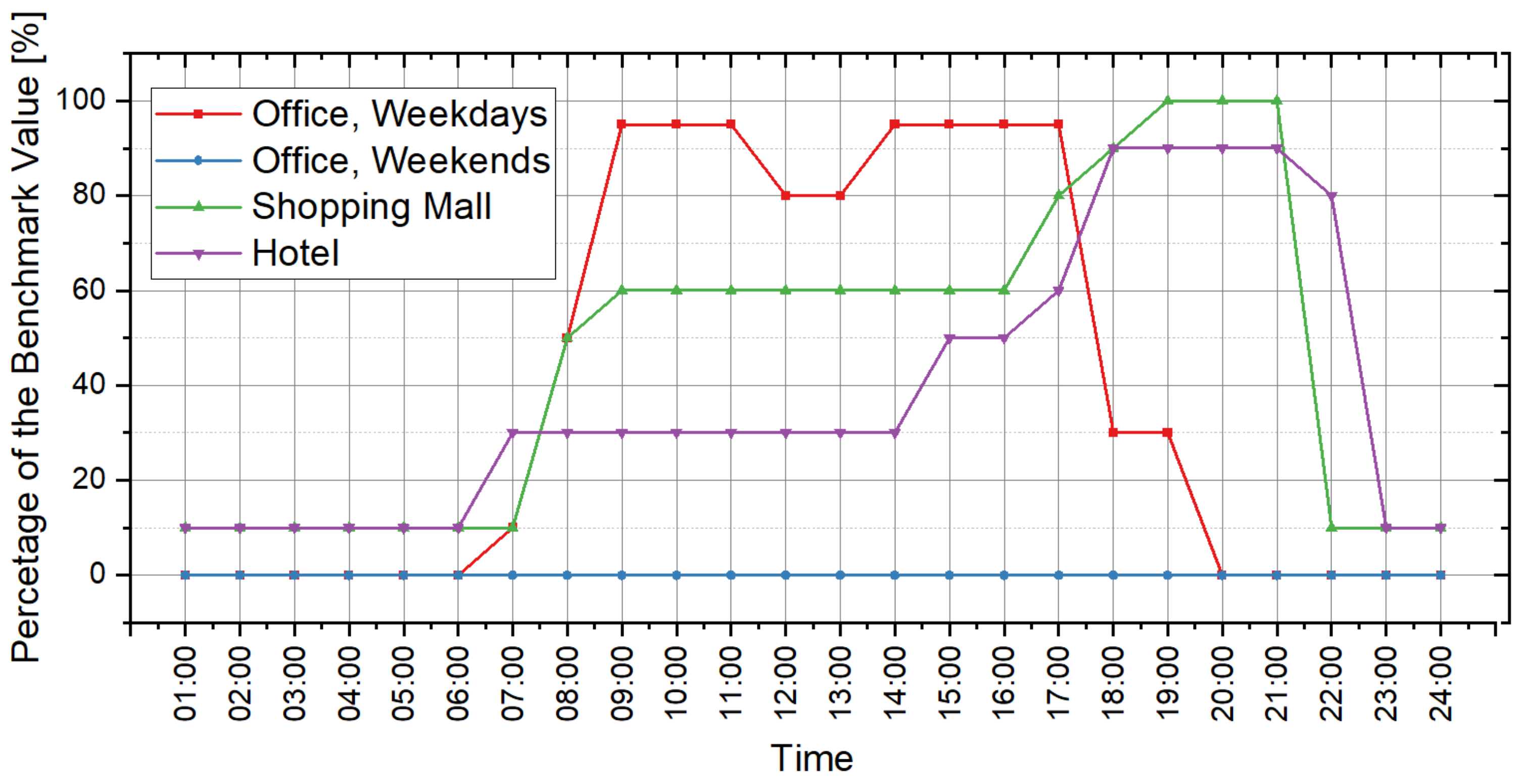
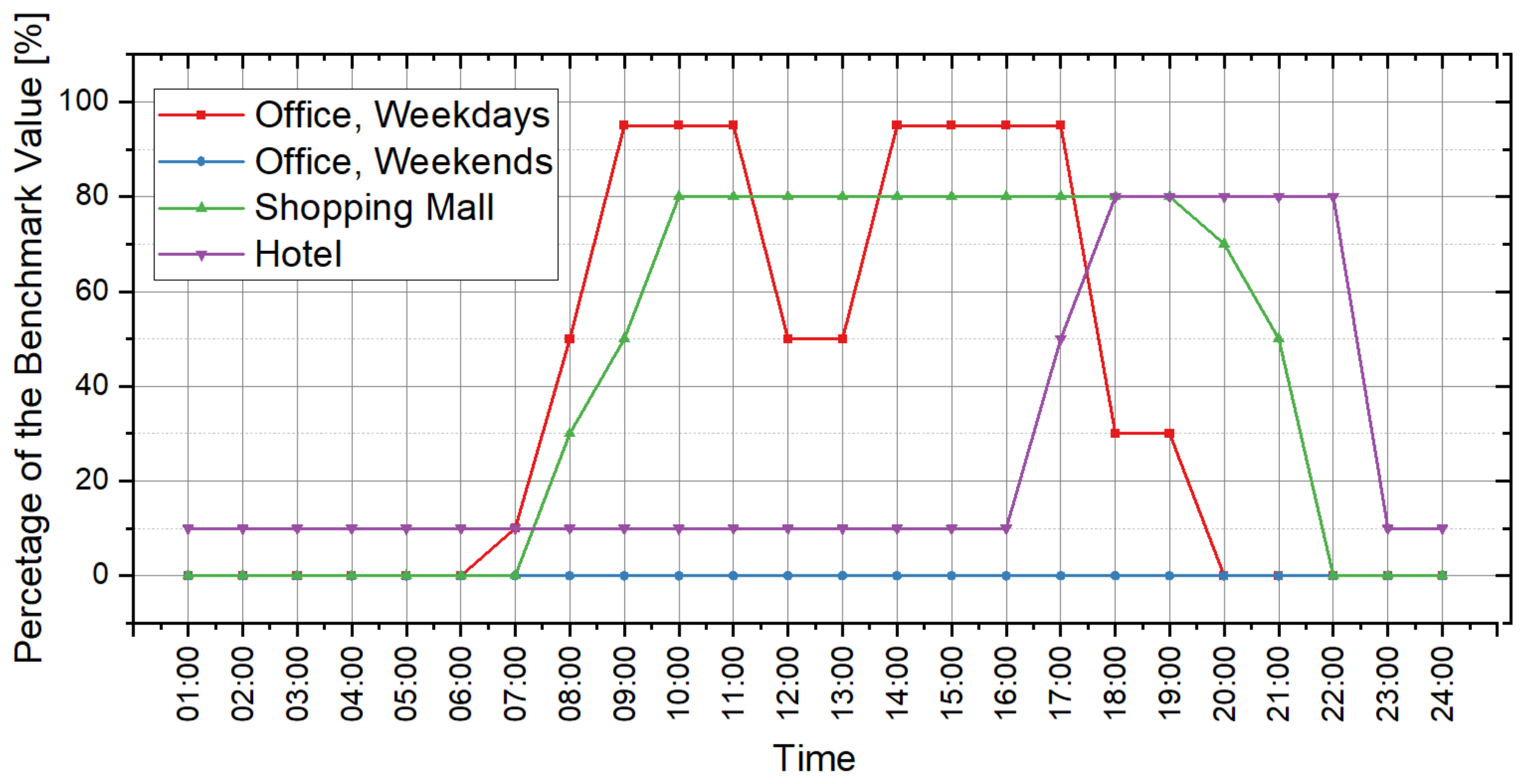
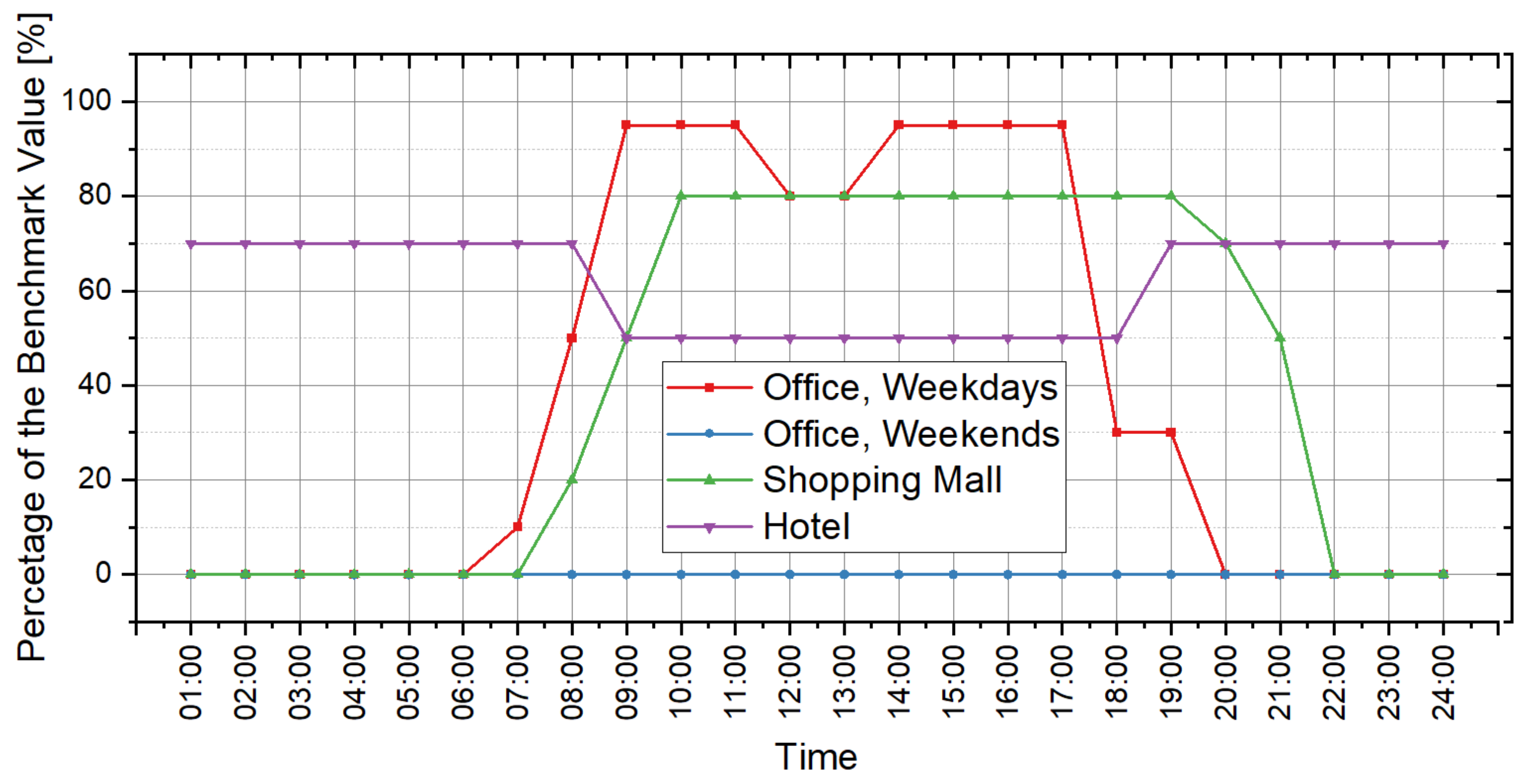
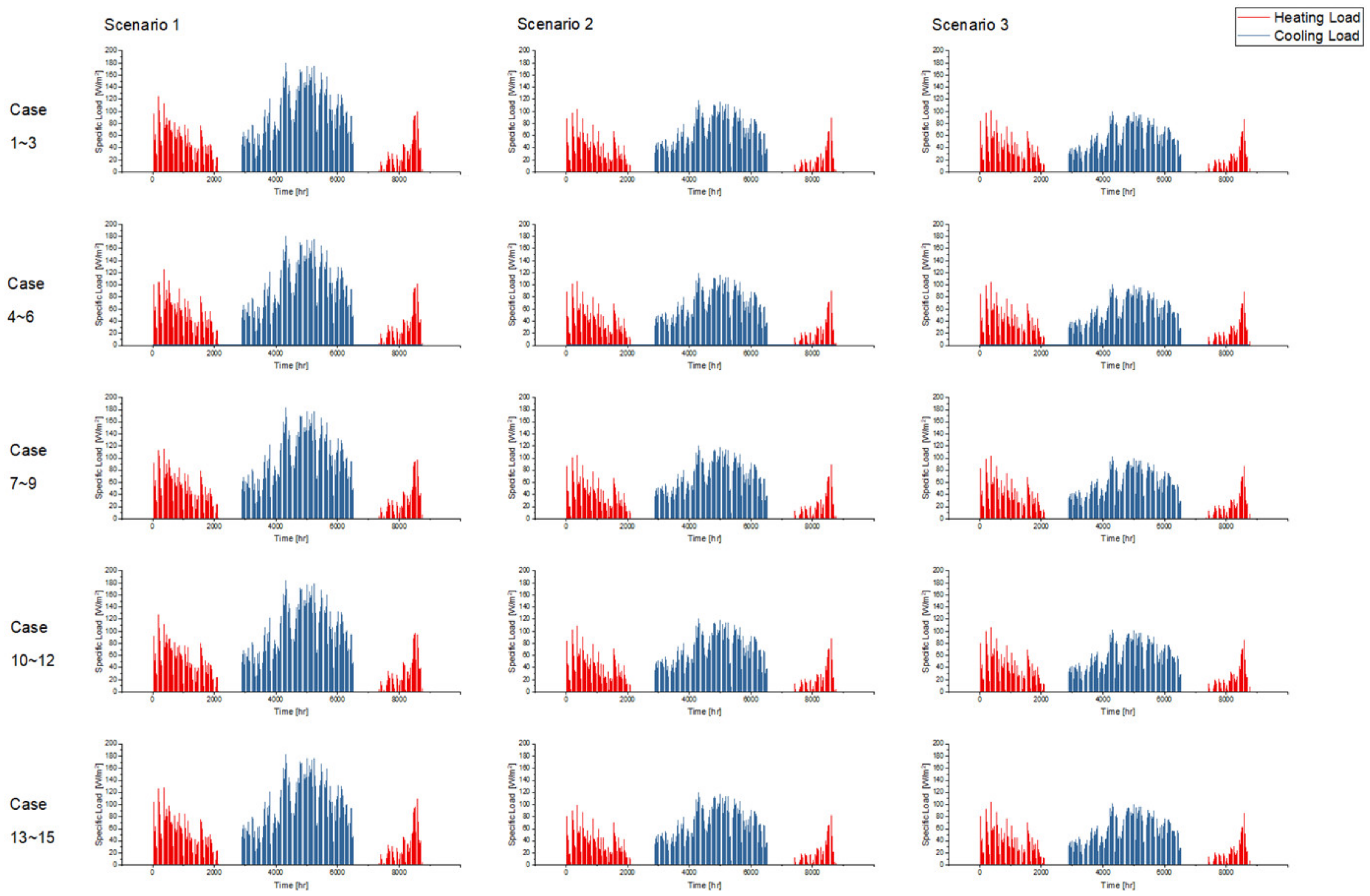
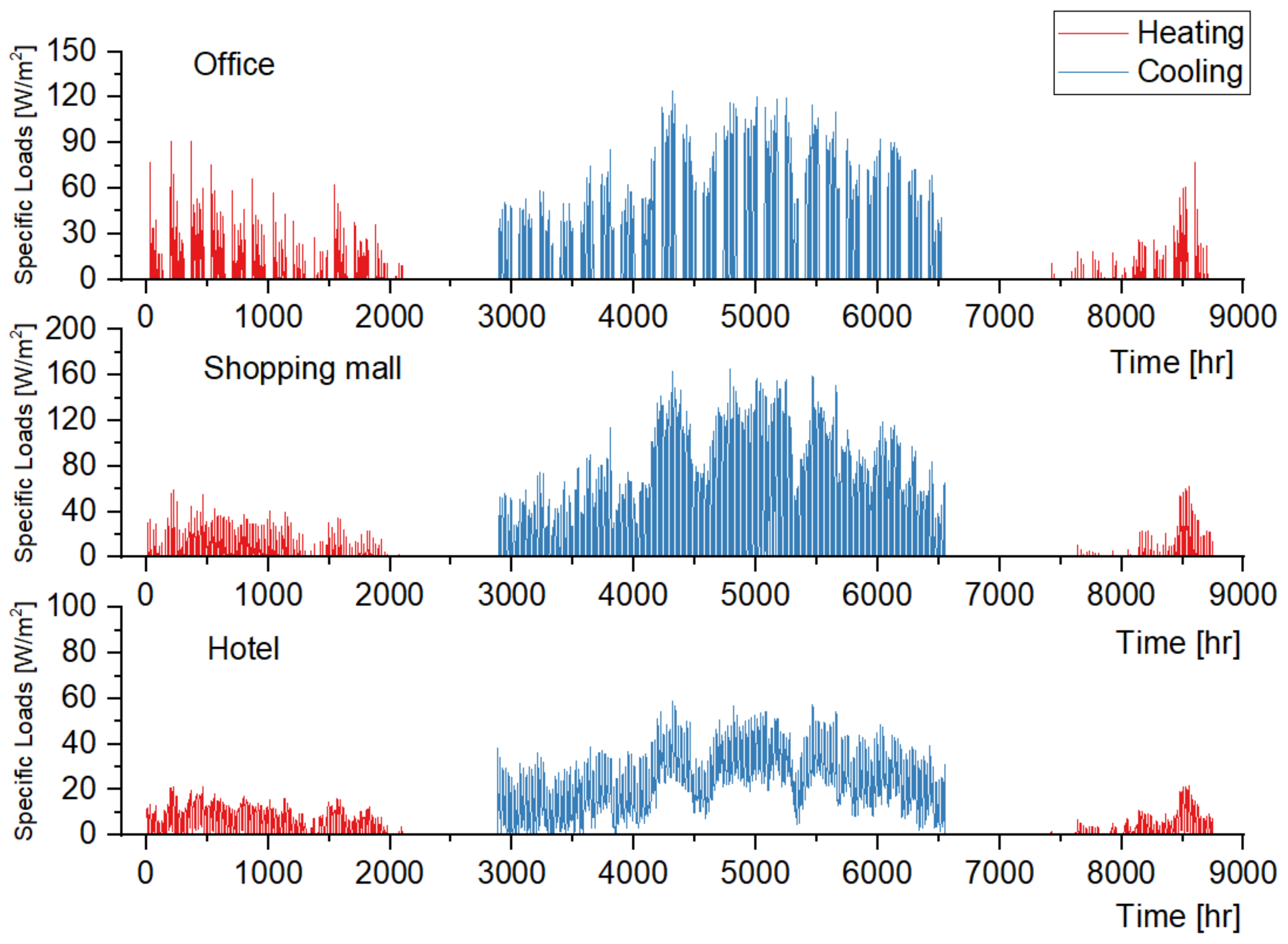
Figure 13,
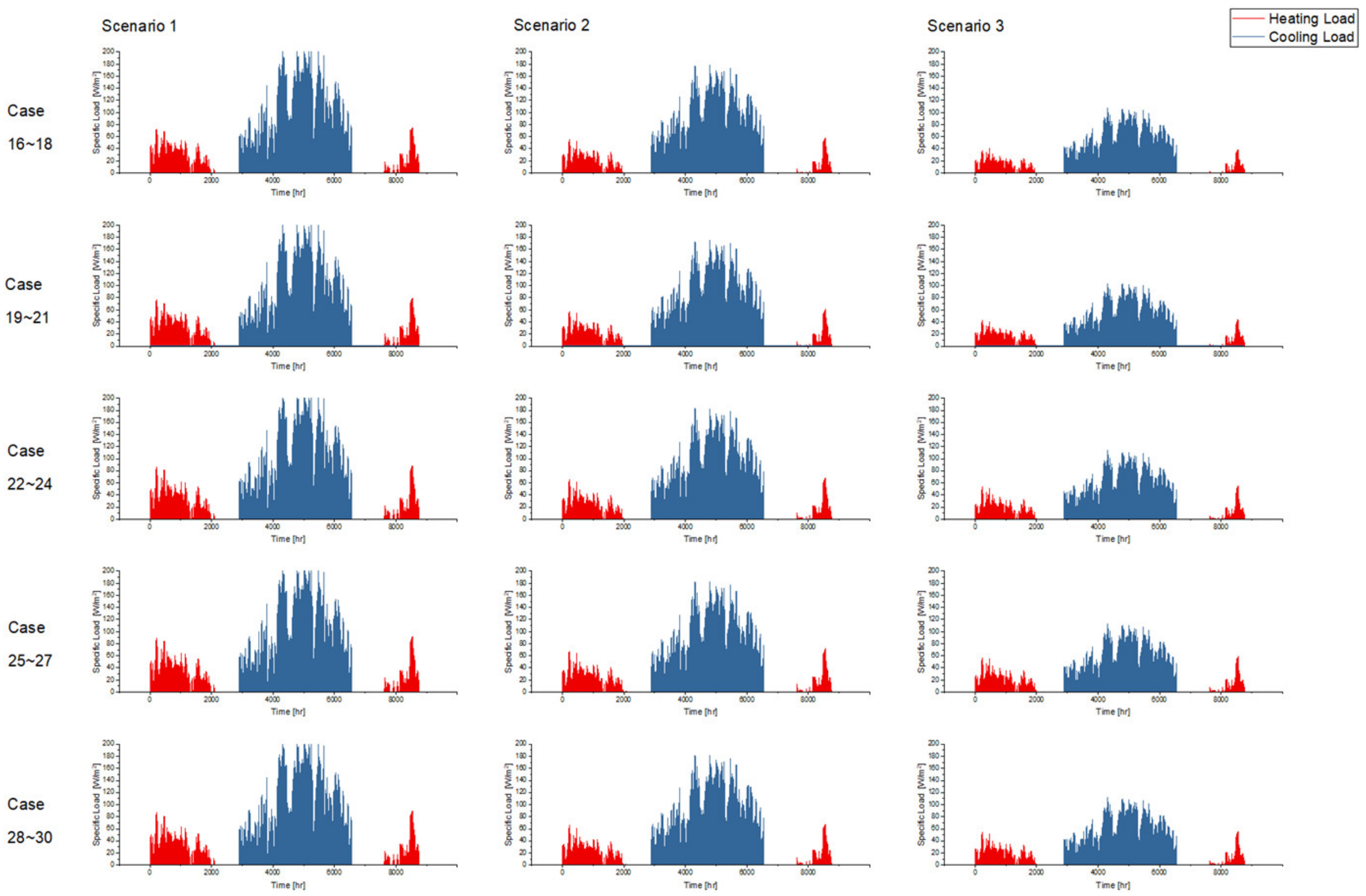
Figure 14 and
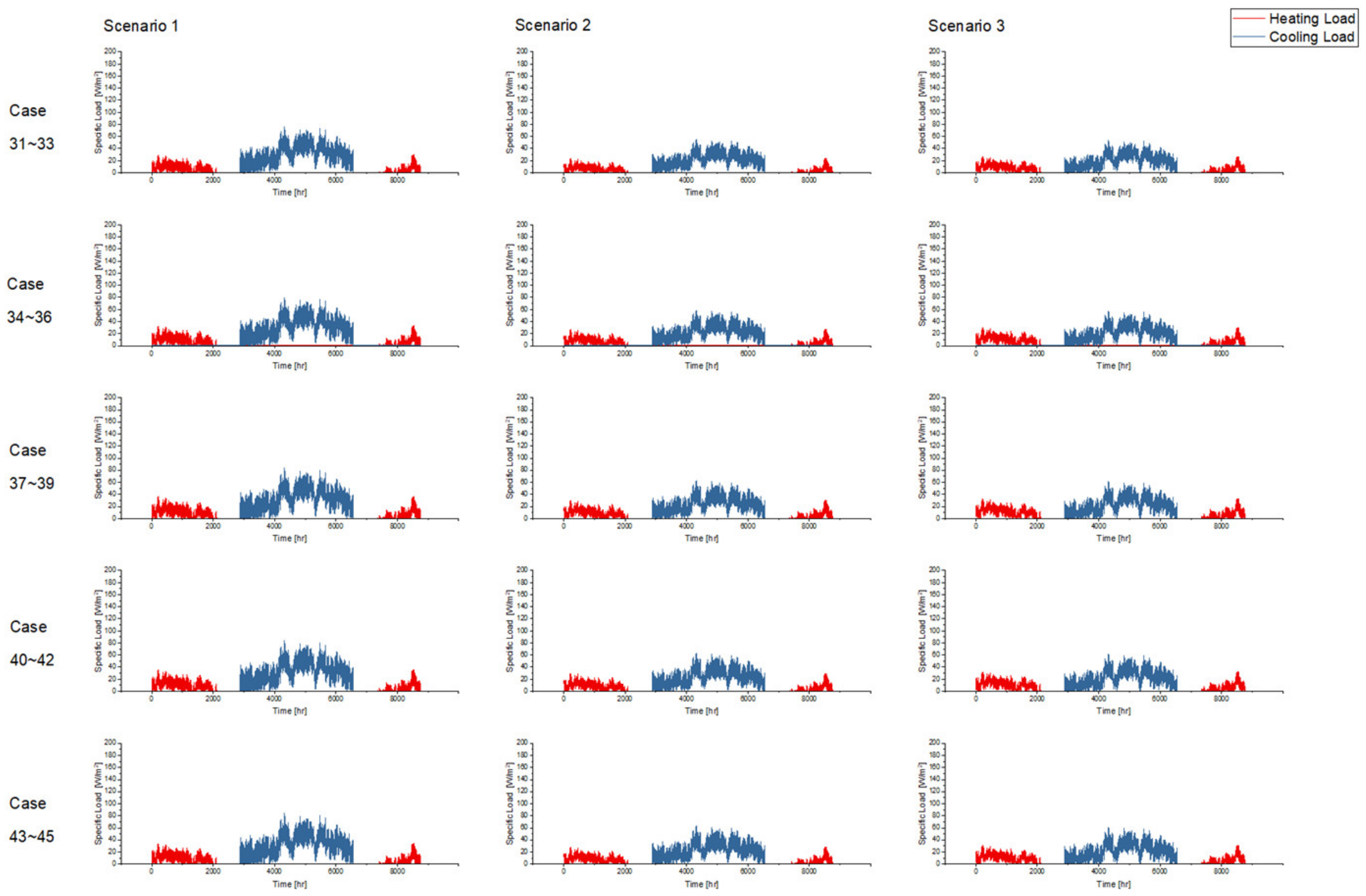
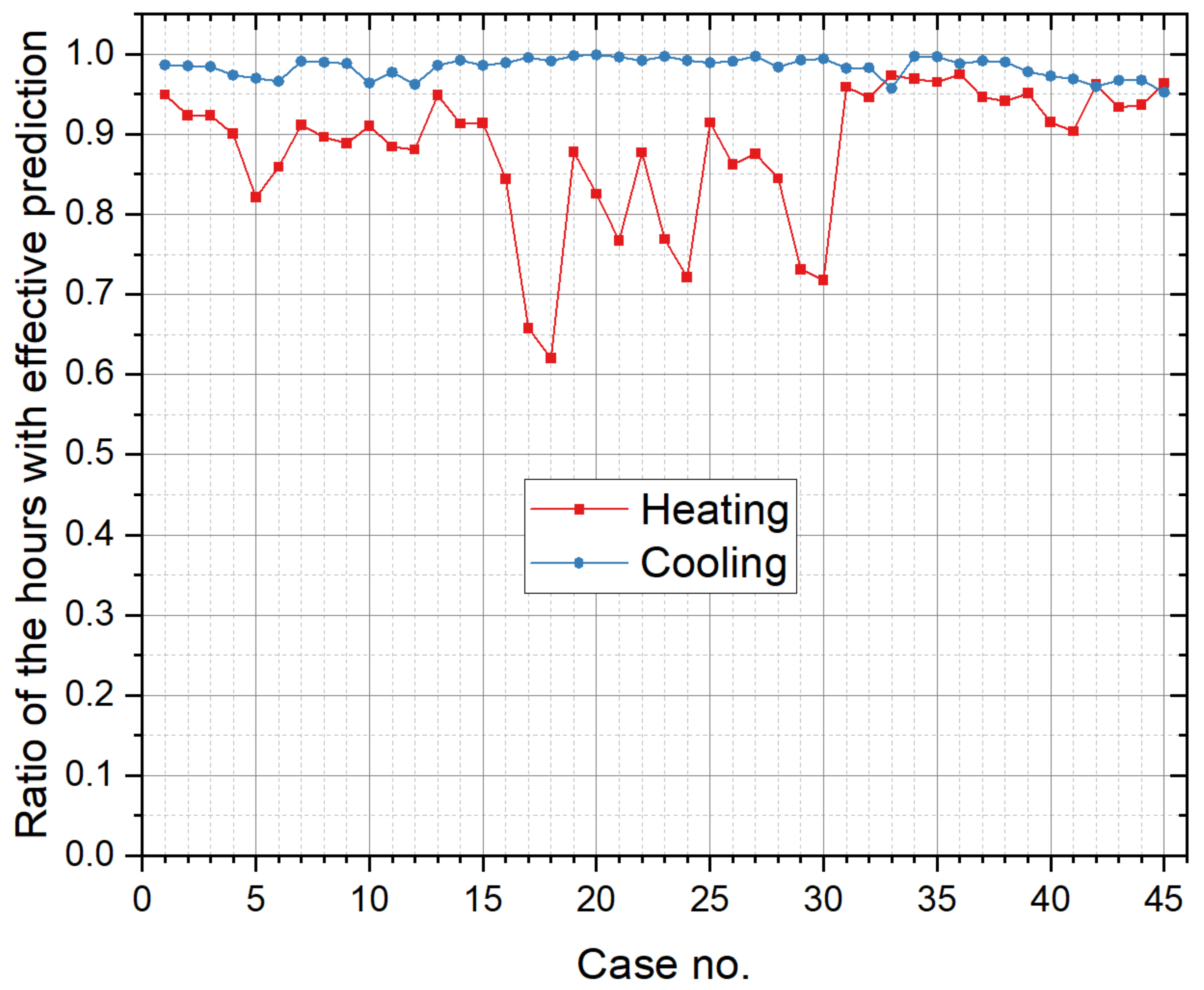
Figure 15 illustrate the original prediction results of all the 45 cases. To show the overall condition of the prediction results, a line graph is used to illustrate the frequency distribution of “ratio of the hours with effective prediction” (
Figure 16).
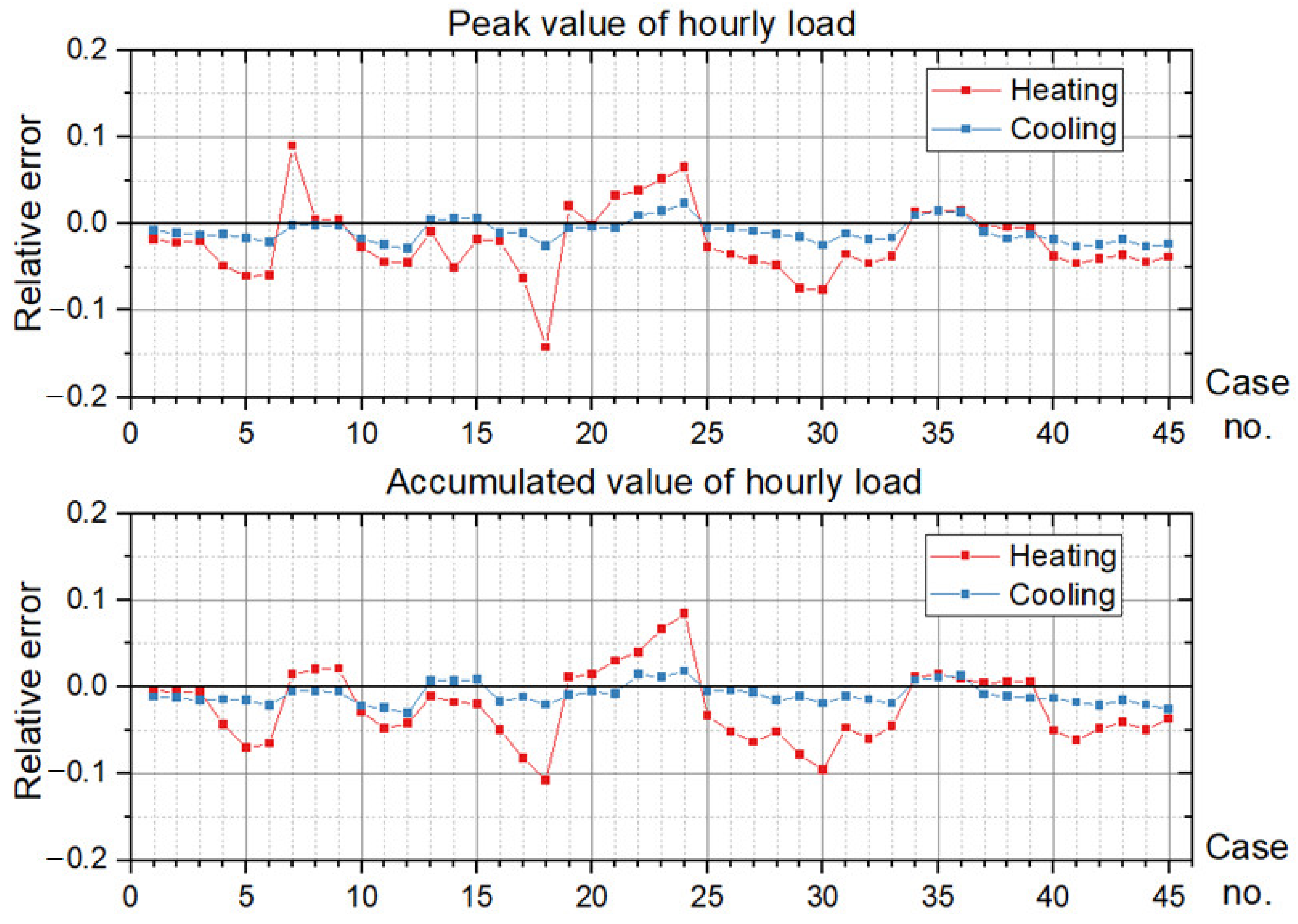
Figure 17 presents the RE of the peak and the accumulated value of annual cooling and heating loads.
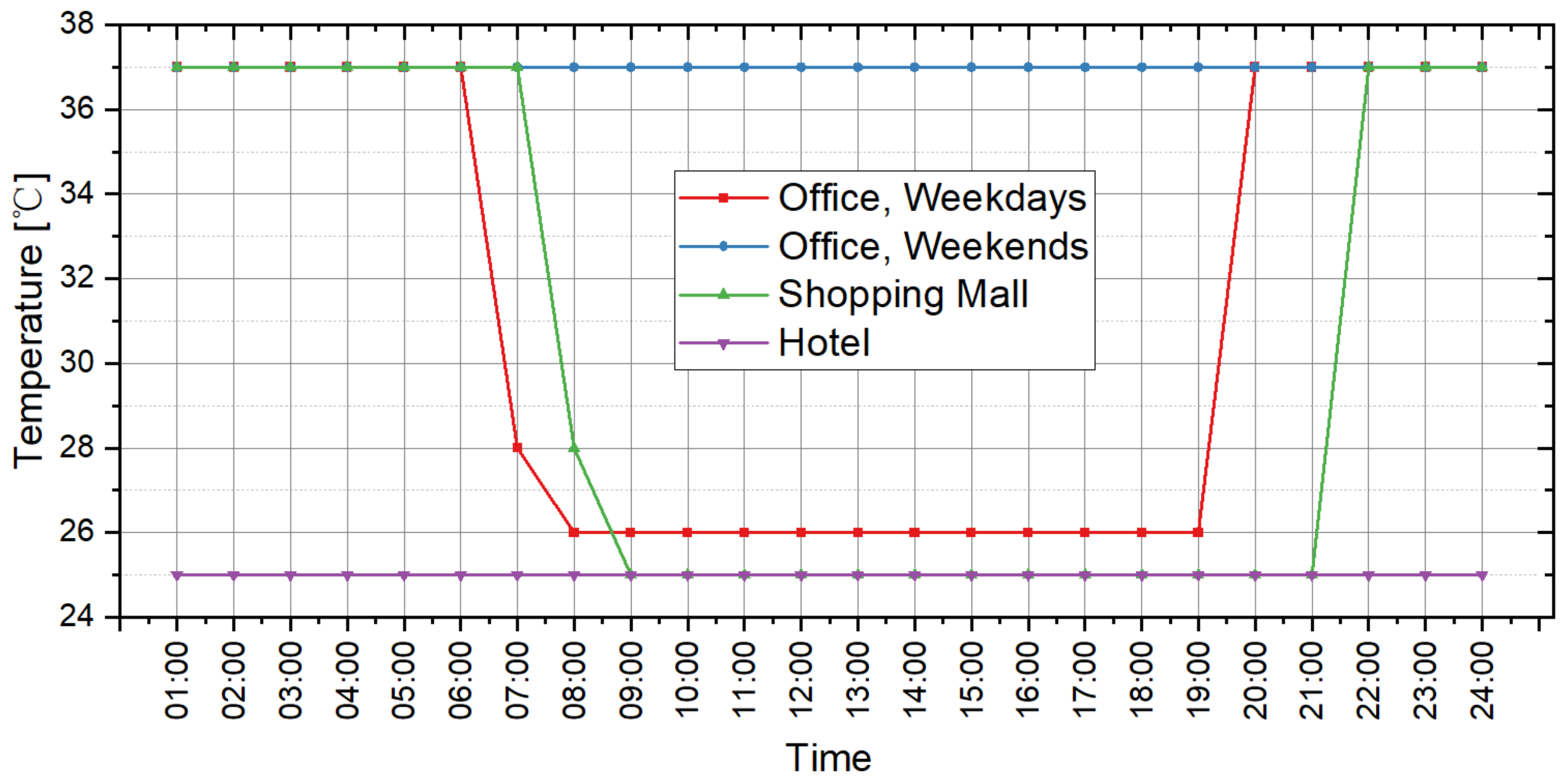
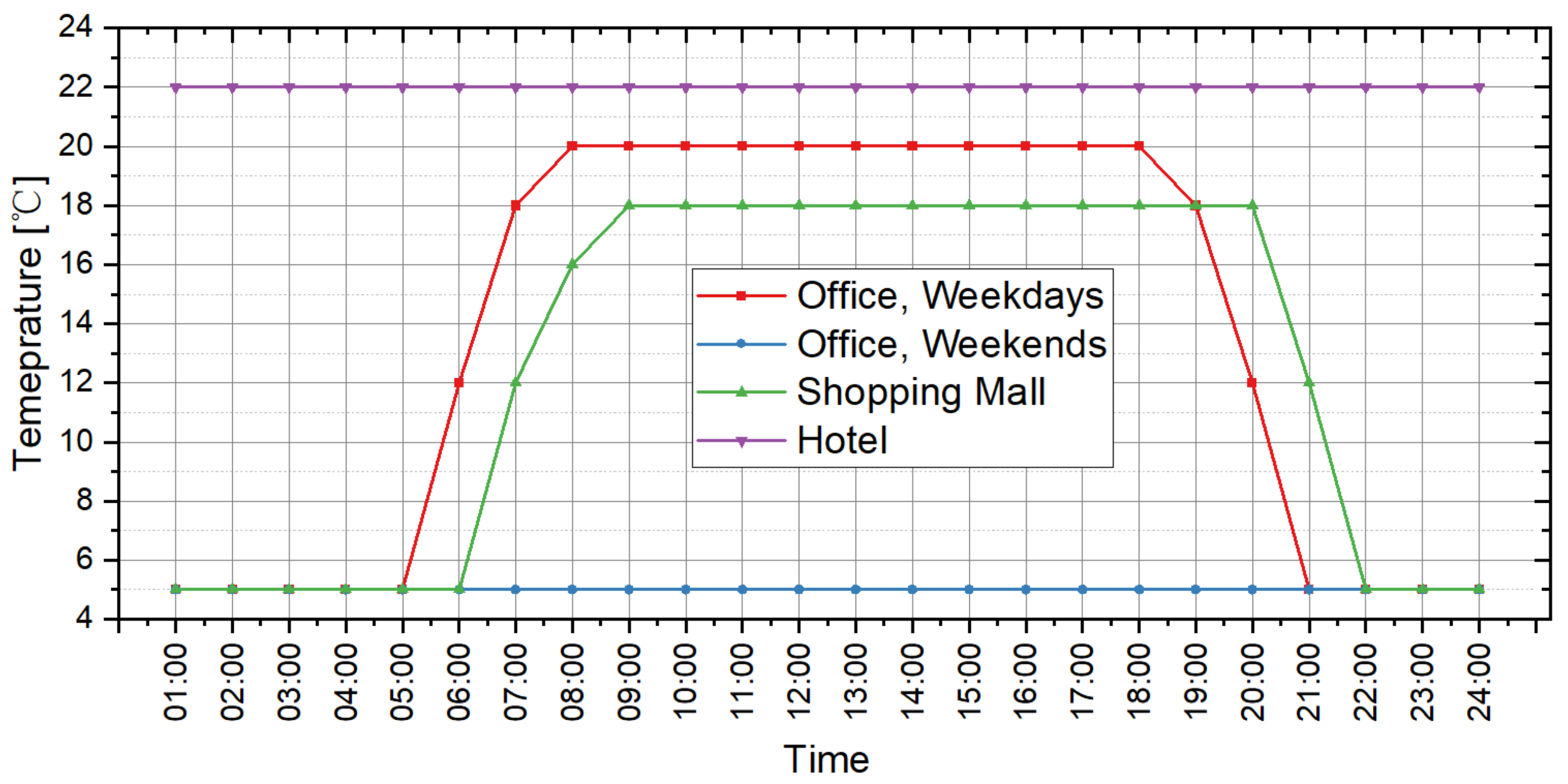
From the perspective of cooling load prediction, the test results of all cases are good: the “ratios of the hours with effective prediction” of the 45 test cases are higher than 0.95, which means that more than 95% of hours with nonzero cooling loads can be accurately predicted in all test cases; and the RE of the peak and the accumulated values of hourly load are both less than 0.05 in all test cases. This verifies that the method proposed in this paper has good performance in cooling load prediction. For heating load prediction, the test results show that the predictions of heating load in office and hotel cases (Cases 1~15 and Cases 31~45) are fairly good: the “ratio of the hours with effective prediction” is higher than 0.9 in most cases (25 of the 30 cases) and higher than 0.8 in all cases; the RE of the peak values of hourly load is less than 0.05 in 26 of the 30 cases and less than 0.1 in all cases; and the RE of the accumulated values of hourly load is less than 0.05 in 25 of the 30 cases and less than 0.1 in all cases. For the heating load prediction in the shopping mall cases (Cases 16~30), the accuracy is relatively worse than other cases on the scale of a single building: the “ratio of the hours with effective prediction” varies in the range of 0.6~0.95, and the RE of the peak and the accumulated values of hourly load are both less than 0.1 in all test cases except Case 18 (less than 0.15). According to the parameter settings of indoor conditions and operation schedules, the indoor design temperature in winter is relatively low (18 °C in shopping mall, 20 °C in office and 22 °C in hotel), and the occupancy density is relatively high. This results in the small absolute values of heating load in shopping malls, which leads to the poor performance of the indices that quantify the prediction accuracy. However, we can trust that this error will not cause a big bias for district energy planning since the error is still small in the terms of absolute values, although it is quite large in the terms of relative values. The application of the load prediction tool in an actual project of district energy planning, introduced in the next section, will confirm this view.
4. Application in an Actual Project
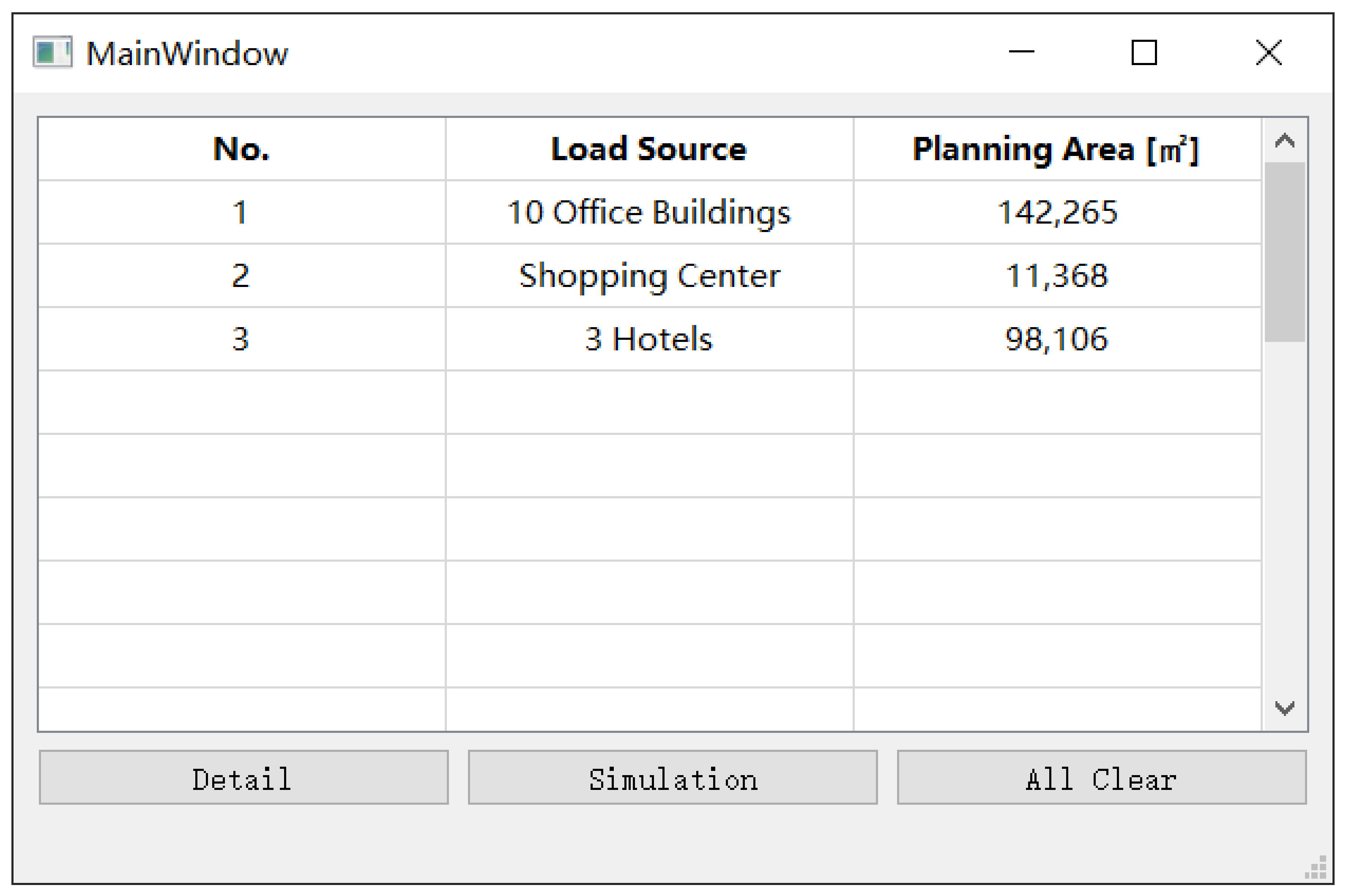
To make the research achievements practically valuable, we developed a fast estimate tool of load prediction with Python and QT Designer. The main UI is shown in
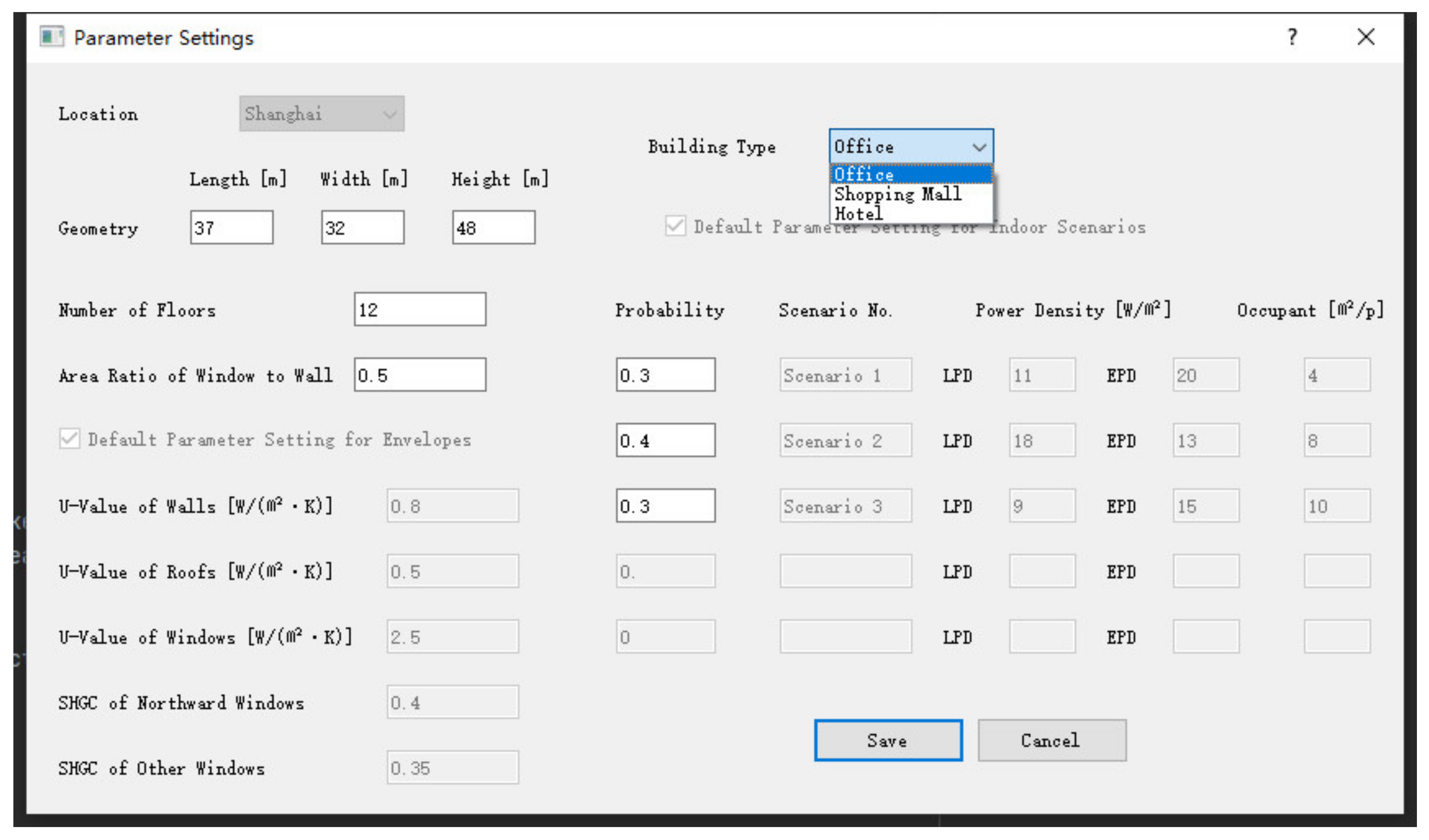
Figure 18. In this software, users can set multiple types of load source (buildings) in the community as the input to predict the hourly cooling and heating loads for district energy planning. The maximum number of load sources is 20, and for each type of source, the detail parameter settings can be edited by clicking the “Detail” button with the table cell highlighted. The UI of detail parameter settings is as illustrated by
Figure 19.
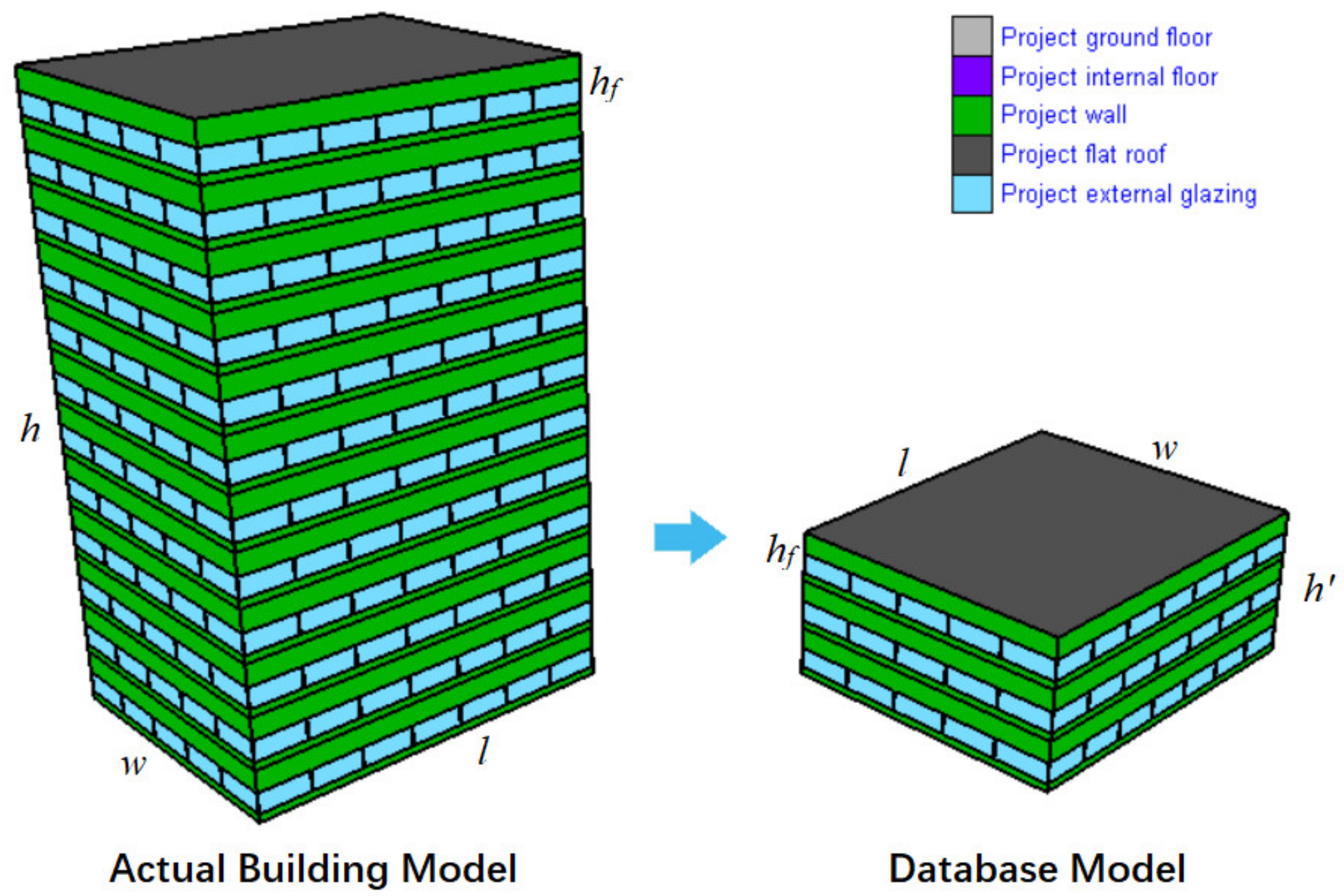
In this UI, users can input the length, width, height, the number of floors and the ARWW of the corresponding building to the highlighted load source. In the background of the software, the program will transfer the original geometric parameters (length, width and height) into the database parameters (shape factor, ARST and floor height). The building type for selection includes office, shopping mall and hotel, and after determining the building type, three default indoor scenarios will be displayed in the following boxes. At this time, the users need to input the probability of these scenarios. Obviously, some boxes in this UI are disable. For the parameter boxes of the envelopes and the indoor conditions, they are regarded as the constants for the application scenarios in this paper, so the values in these boxes are only used to exhibit the settings of the model parameters in the software. However, in further studies, we will expand the scale of the presimulated building model database to enable these values as the variable inputs. This provides an orientation for the software to upgrade.
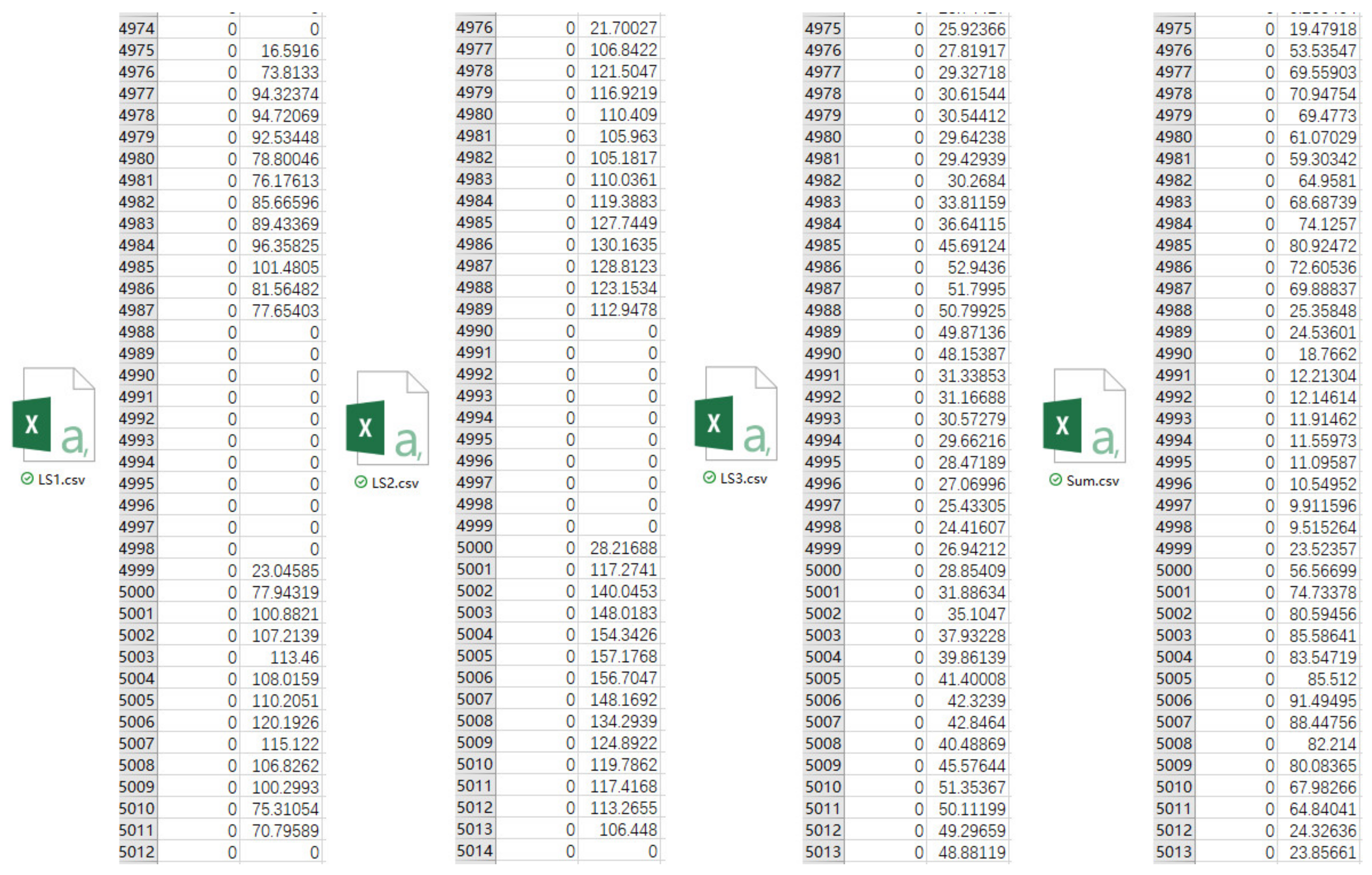
After all variables have been input, the user should click the “Save” button to return to the main UI. Then, the software can start the computation by clicking the “Simulation” button, and a total of four csv files will be generated and opened automatically to show the results (as illustrated by
Figure 20). LS1.csv, LS2.csv and LS3.csv are the hourly loads of three types of load source (10 office buildings and shopping malls and 3 hotels, respectively), and Sum.csv is the total hourly cooling and heating loads of the community.
To demonstrate how to apply the software in an actual project, an actual application case is conducted in this paper. We used the fast estimate tool to predict the cooling and heating load of a new community at the planning stage of Shanghai West Hongqiao energy station. This actual project has been analysed by the authors’ team in the previous study [
34]. In that paper, we completed the load prediction for community load levelling based on the prototypical model method. Different from the traditional methodology, the predicted loads can be obtained without modelling for the buildings in the community in this study. Up to now, since the energy station has been put into operation for more than one year (only Stage 1 has been completed in total 3 stages), the measurement data of annual cooling and heating energy in the metering system of the energy station can be utilized to show the difference between the predicted results made at the planning stage and the actual values in operation.
The planning information of the district is as follows: the settings of input parameters are listed in
Table 7; and the planning building areas and the scenario settings of the three types of buildings in this district are listed in
Table 8. The input information of this actual case in the software UI has been already shown in
Figure 18 and
Figure 19. The three types of load source in
Figure 18 are consistent with the three building types in
Table 7. As a display of the prediction result, the predicted values of hourly specific cooling and heating loads of these three buildings for the whole year are shown in
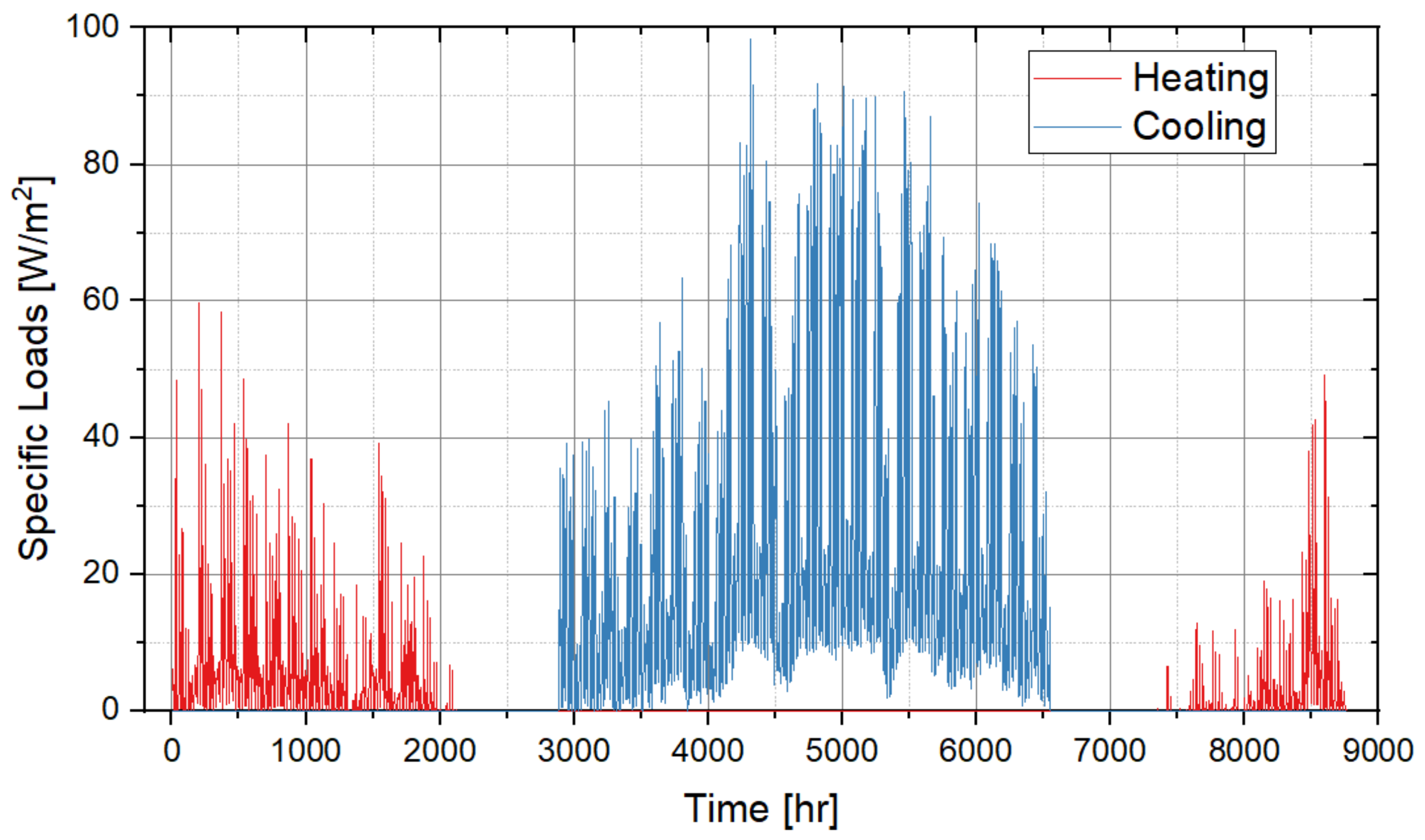
Figure 21. The hourly cooling and heating load of the district can be obtained by multiplying the specific loads per unit floor area of the three buildings with the building area and adding them together. The result is as illustrated by
Figure 22.
By adding 8760 hourly cooling and heating loads of the whole year together, the annual cooling and heating energy that the energy station supplies to the district would be obtained. According to the energy audit data of the past year, we can determine the actual cooling and heating energy generated by the energy station in 2020. In
Table 9, the actual values of annual cooling and heating energy and the predicted values calculated by the fast estimate tool and the detailed modelling method are compared with each other. The result shows that this fast load estimate tool can provide the same level of prediction accuracy as traditional simulation methods. To a certain extent, the prediction result obtained by the fast estimate tool is smaller and better than the simulation result of detailed modelling, since the design load is generally much greater than the actual load. In addition, the index used in
Section 3, “ratio of the hours with effective prediction”, which reflects the prediction accuracy on the hourly scale, is also computed based on the predicted loads of the planning district in this section. Since the measurement data of hourly loads is unavailable, this paper only compares the predicted values by detailed modelling (selected as the reference values) and the values by fast estimate tool (as listed in
Table 10). The result further indicates that there are not any significant differences between the prediction accuracy of the fast estimate tool and the traditional modelling method on the one hand, and it confirms the conclusion drawn in the previous section on the other hand: the prediction error at the hours with small absolute values of predicted loads will not cause a big bias for district energy planning.
5. Conclusions
The present research introduces a new method for fast cooling/heating load prediction of a district energy system at the planning stage. Based on this new method, a practical tool has been developed in this paper. Firstly, we established a presimulated building model database to provide sufficient data for the machine learning-based load prediction method. Then, we developed the fast estimate tool for load prediction based on the KNN algorithm and the presimulated database. Next, we conducted a test that contains 45 virtual test cases to compare the prediction performance of this tool and detailed modelling. Finally, we also introduced a case of a real energy station to demonstrate the application of this tool in actual project. As the main achievement of this study, the fast estimate tool for load prediction developed in this study has been verified to be able to provide the same level of prediction accuracy as traditional simulation methods, while it is easy to be used by nonprofessionals and saves a lot time for modelling.
However, there are some shortcomings to this study that can be improved in further research. The improvement work could mainly be carried out in following two respects:
(1) A presimulated database with more input parameters.
Considering the actual situation in the planning stage, the thermal property of the envelope and the indoor condition are not available for users to change in the settings, but they are only involved in the selection of different design scenarios. This may be good just for the situation in this study, but more variable model parameters for load prediction can make the new method also applicable for work in the stage of detailed scheme design. For example, the U-values of the exterior wall/window/roof, the SHGC of the exterior window, the density of lighting power, plug equipment power and occupancy can all be set as variable parameters for users to input, and thereby this fast estimate tool can be used to analyse a more detailed design scheme.
To reveal the deviation caused by ignoring the differences between the envelope parameters in different design scenarios, we used the fast estimate tool to carry out an additional simulation test based on the results of the case study in Chapter 4. The main steps of the test are as follows:
Step 1. Find the original EnergyPlus models that were used to output the predicted annual cooling/heating energy “by detailed modelling” and check the settings of the envelope parameters. Their values should be set according to
Table 3.
Step 2. Assume that there would be two other virtual communities; the types, areas and indoor conditions of the buildings in these communities are the same as the real community in the case study, but only the envelopes are different. For one virtual community (VC 1), the buildings are all well-insulated; and for another (VC 2), the envelopes are very light. Therefore, the envelope parameters of the EnergyPlus models should be adjusted to the values in
Table 11 to simulate the annual cooling/heating load of these two virtual communities.
Step 3. Compare the predicted values between the original models and VC 1 or 2 (
Table 12). It indicates that the relative errors of −1.61%~6.26% (annual specific cooling energy) and −11.12%~30.06% (annual specific heating energy) caused by ignoring the differences in the thermal properties of building envelope will be probably introduced to the results when using this tool to analyse a community in Shanghai. On one hand, this deviation can be sometimes accepted at the planning stage of a district energy system, even though the RE of the specific heating energy is relatively high, but the absolute value of the error is still acceptable. On the other hand, it also shows that making more input parameters editable in the estimate tool is a valuable research direction, which will further improve the computation accuracy of the tool.
An upgraded estimate tool with more input parameters means a larger presimulated database. The approach to establish such a larger database is similar to what is introduced in this paper. However, the main difficulty is too much computation. If all the parameters listed above are considered, the dimension number of the database will be 11. Supposing that there are five levels on each dimension and also three types of building, the number of models in the database will be more than 1.46 × 108 (3 × 511). The establishment and storage of such a large database is extremely inconvenient. The method of sampling or clustering may be needed to reduce the size of the database.
(2) More applications in actual conditions.
The new load prediction tool has been only applied in one actual project in this paper. Even in this application case, we can still find that the predicted value of load in the design phase is often larger than the real situation. In the goal of this paper, the benchmarking object of the fast load prediction tool is only the simulation method based on BPS models. Therefore, the gap between predicted and actual values would be the next problem to be solve. By applying this tool in more actual energy stations with measurement data, the key factors that affect the actual cooling and heating load and make it deviate from the predicted result may be found. This work can further improve the practical application value of this new load prediction tool.


























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}