
A Comprehensive Study on Integrating Clustering with Regression for Short-Term Forecasting of Building Energy Consumption: Case Study of a Green Building


Abstract
:1. Introduction
- First, there are many types of regression models. What types of regression models are suited for integrating clustering?
- Second, previous studies have demonstrated that the ensemble model can improve the prediction performance of the regression using the cluster number determined by clustering evaluation metrics. However, this number is only the optimal number for the clustering algorithm. Is it also the optimal number for the prediction performance of ensemble models?
- Third, which ensemble model has the best performance for short-term forecasting of building energy consumption?
2. Methodology
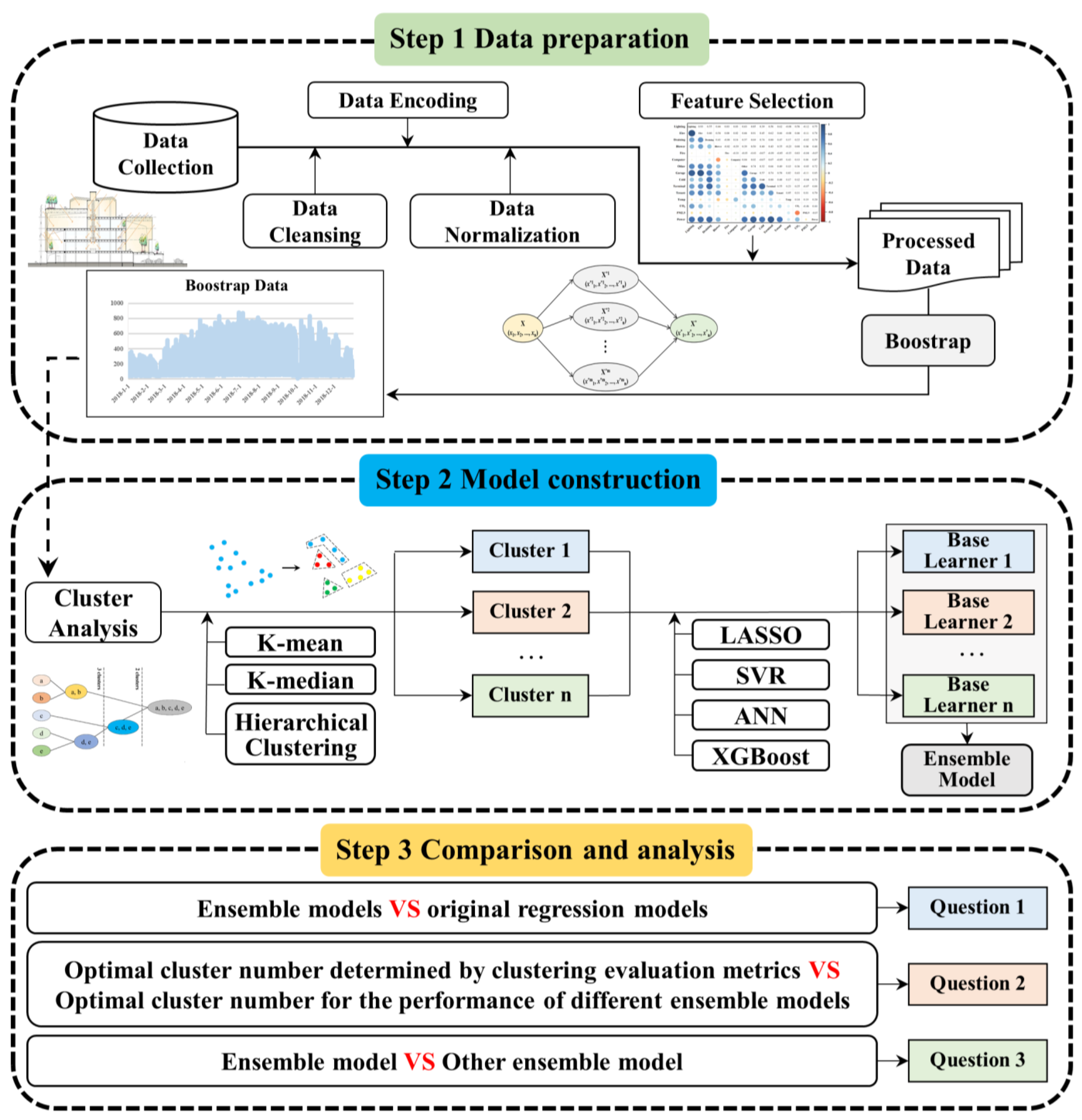
2.1. Research Outline
2.2. Data Preparation
2.2.1. Data Cleansing
2.2.2. Data Encoding and Normalization
2.2.3. Feature Selection
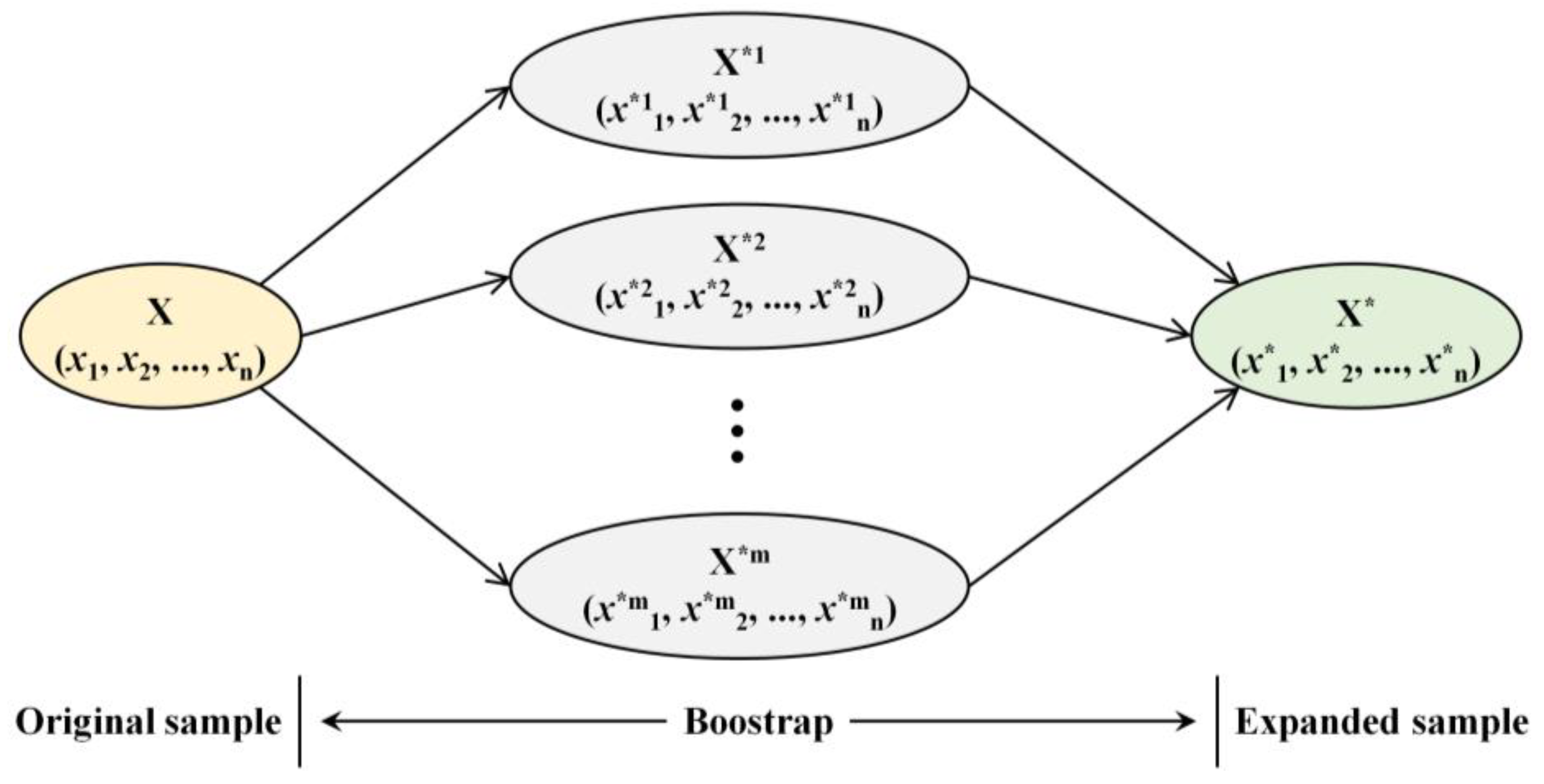
2.2.4. Data Expansion
2.3. Clustering Algorithms
2.3.1. K-Means Algorithm
2.3.2. K-Medians Algorithm
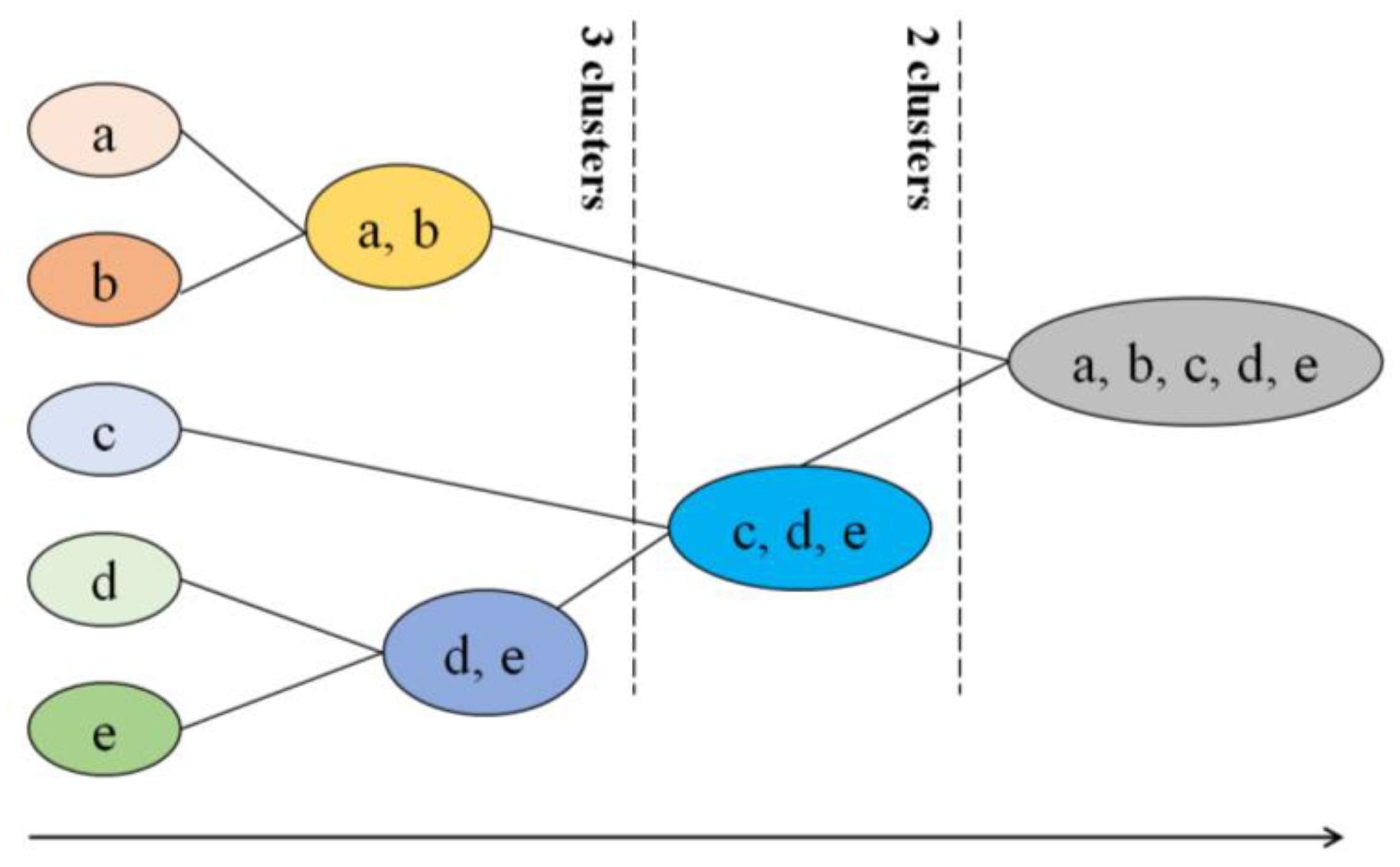
2.3.3. Hierarchical Clustering
2.4. Regression Models
2.4.1. Least Absolute Shrinkage and Selection Operator
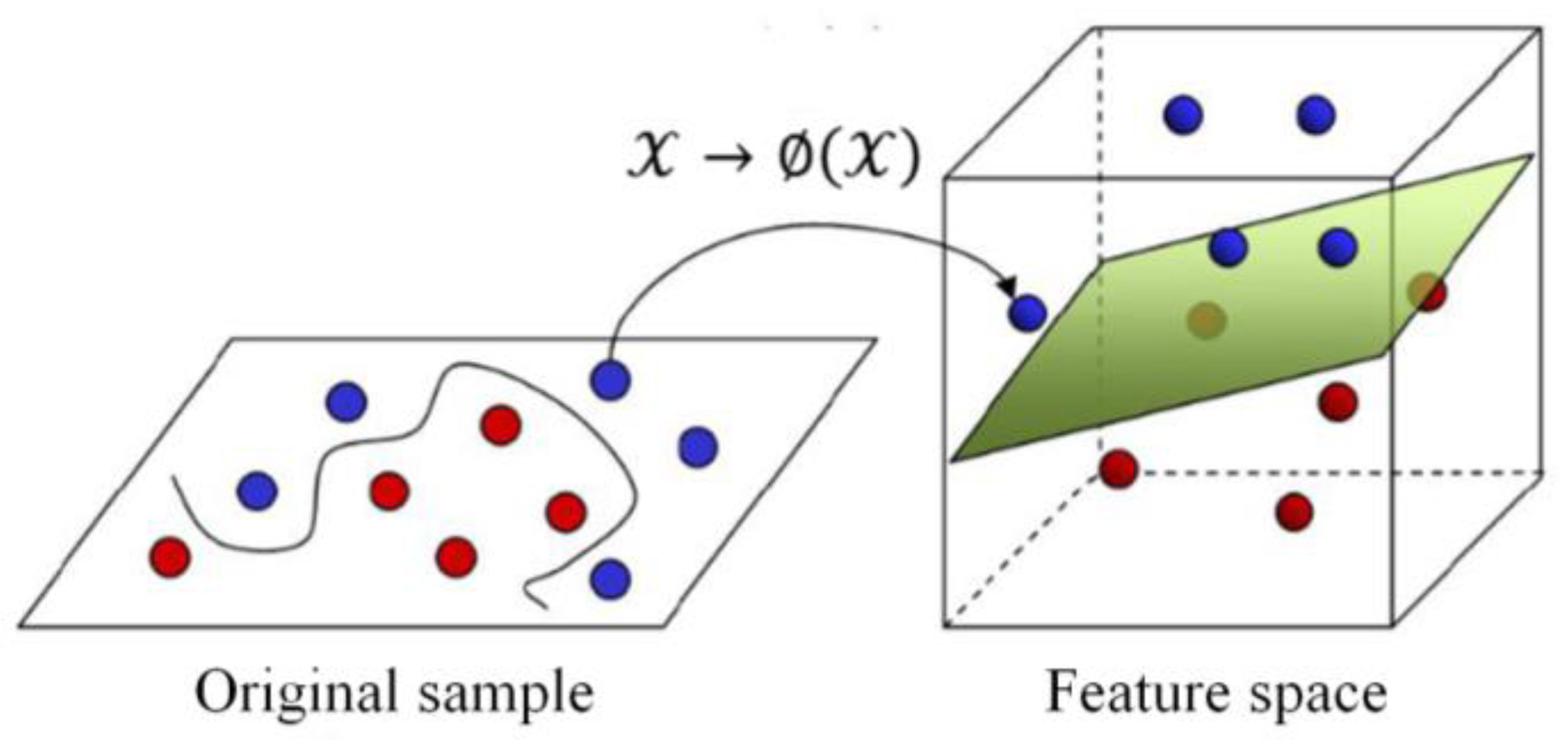
2.4.2. Support Vector Regression
2.4.3. Artificial Neural Network
2.4.4. Extreme Gradient Boosting
2.5. Performance Evaluation Index
2.5.1. Clustering Evaluation Metrics
2.5.2. Prediction Performance Evaluation
3. Case Study
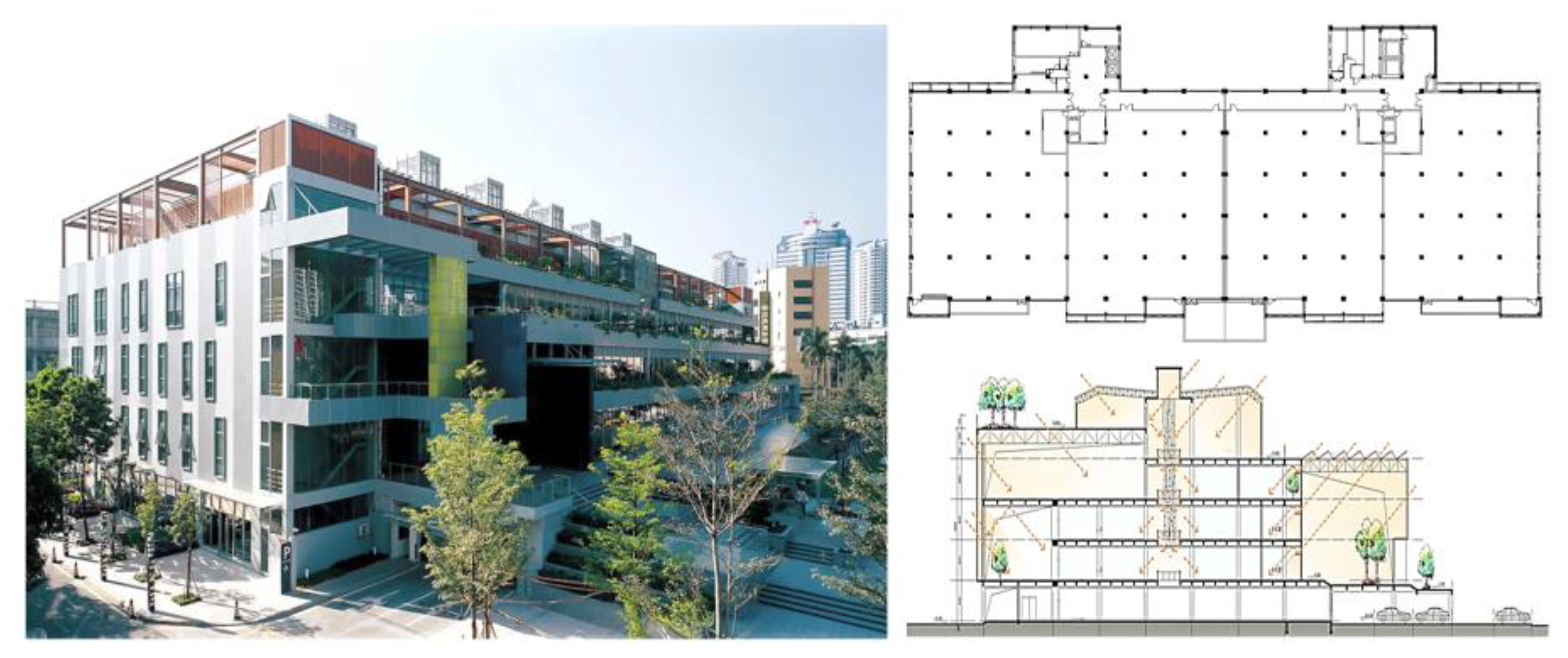
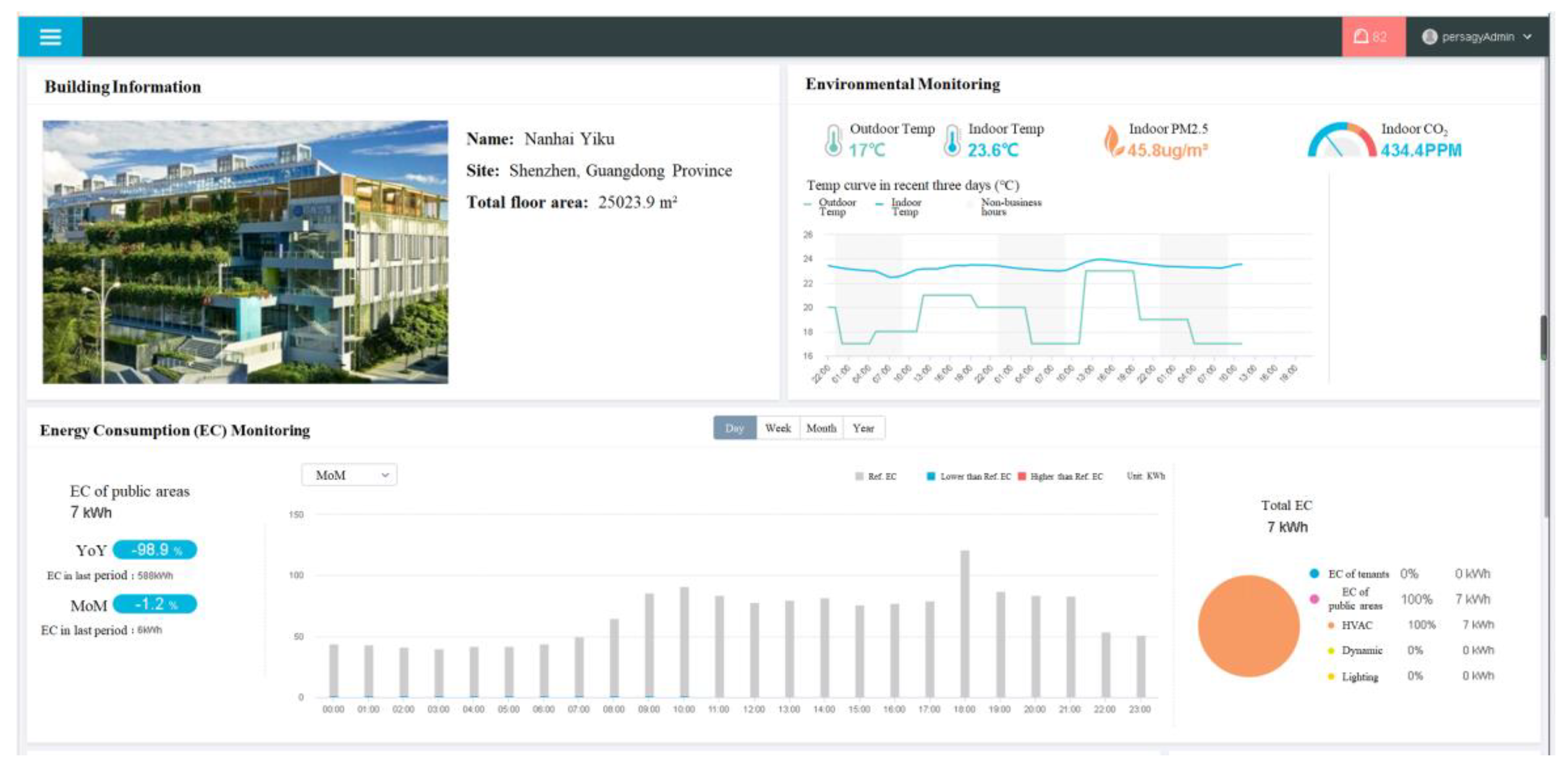
3.1. Building Description
3.2. Data Preparation
3.2.1. Data Collection
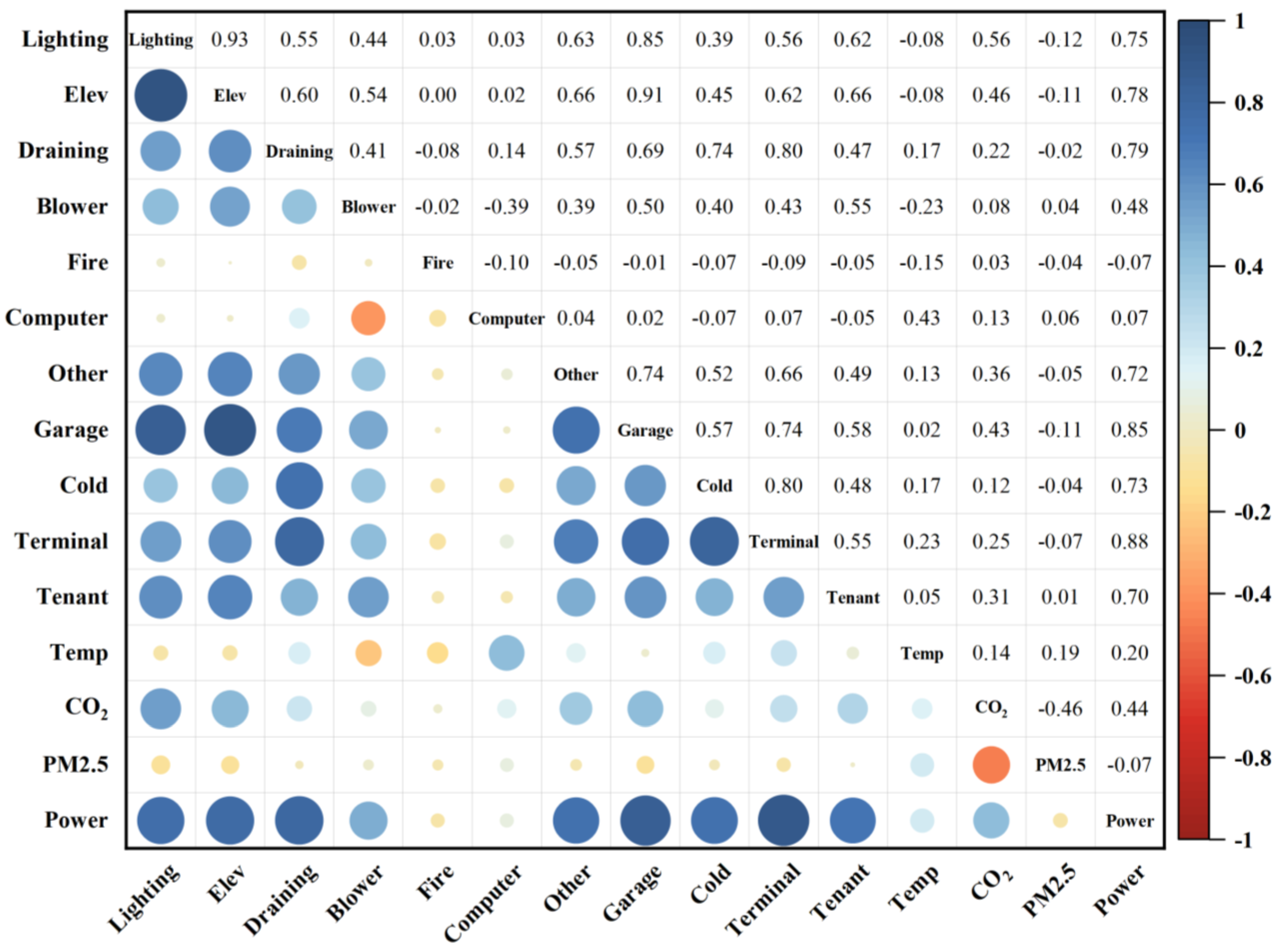
3.2.2. Feature Selection
3.3. Data Expansion
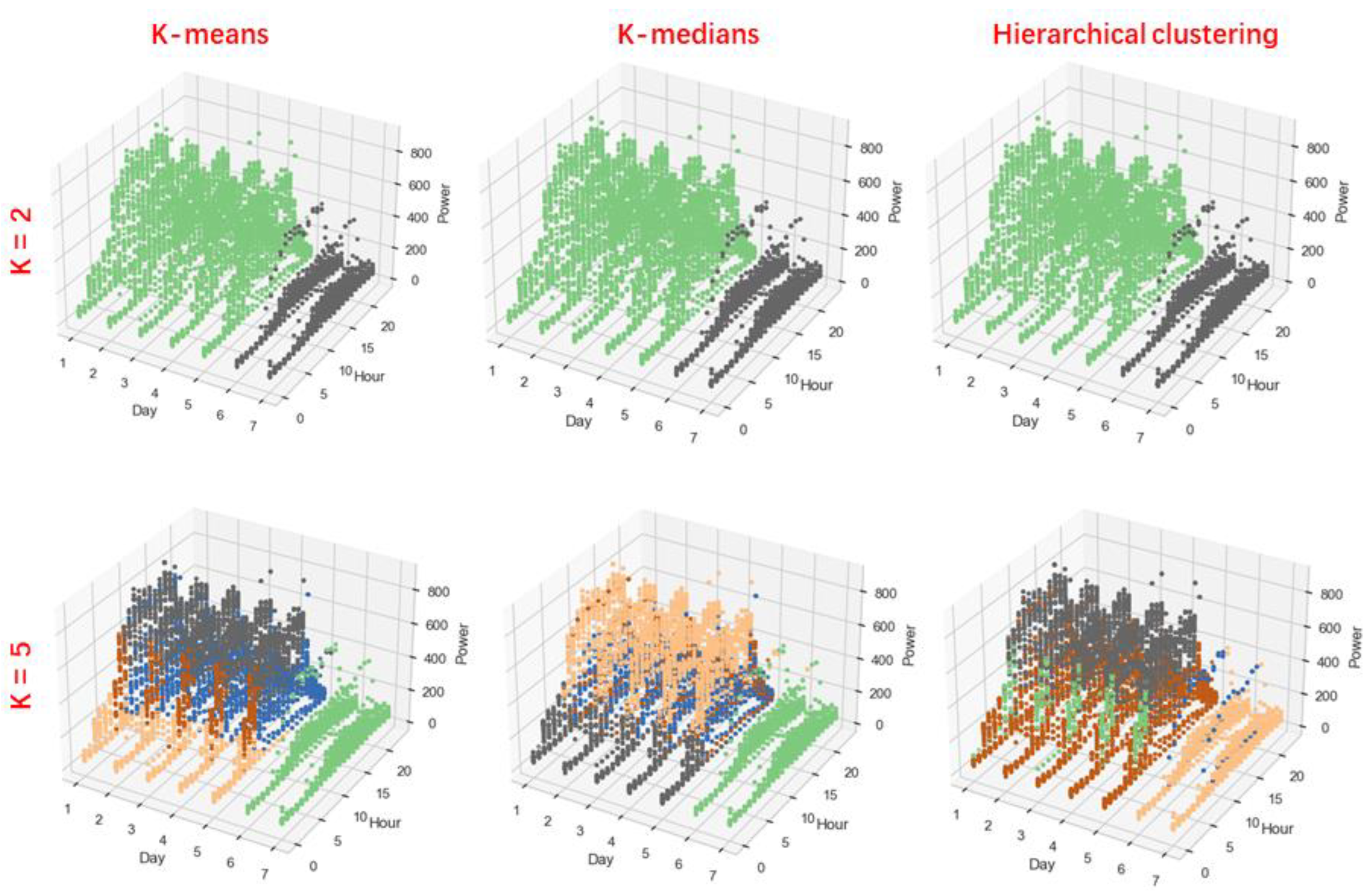
3.4. Cluster Analysis
3.5. Prediction Model Implementation
4. Results and Discussion
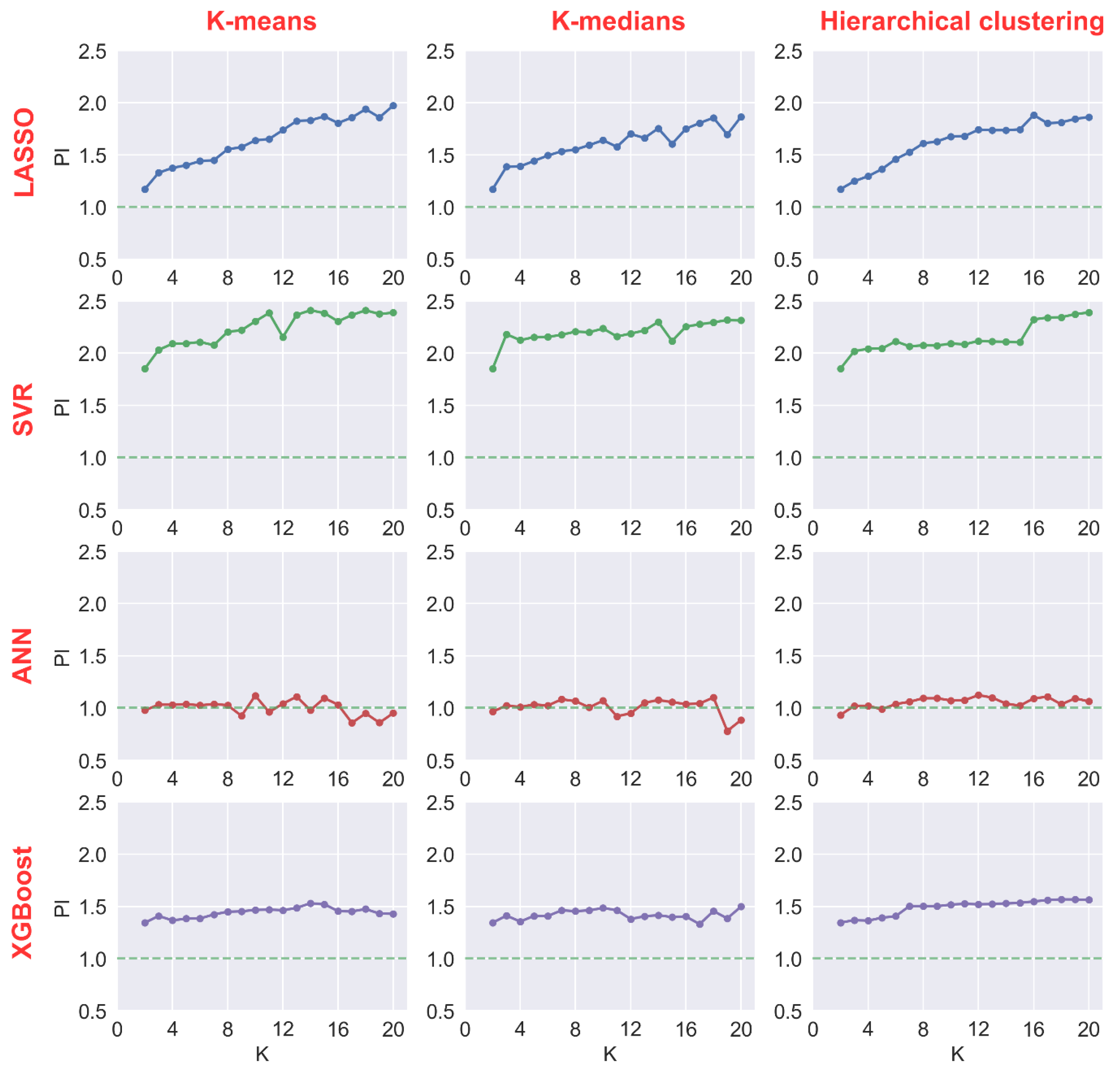
4.1. Performance Improvement by Integrating Clustering
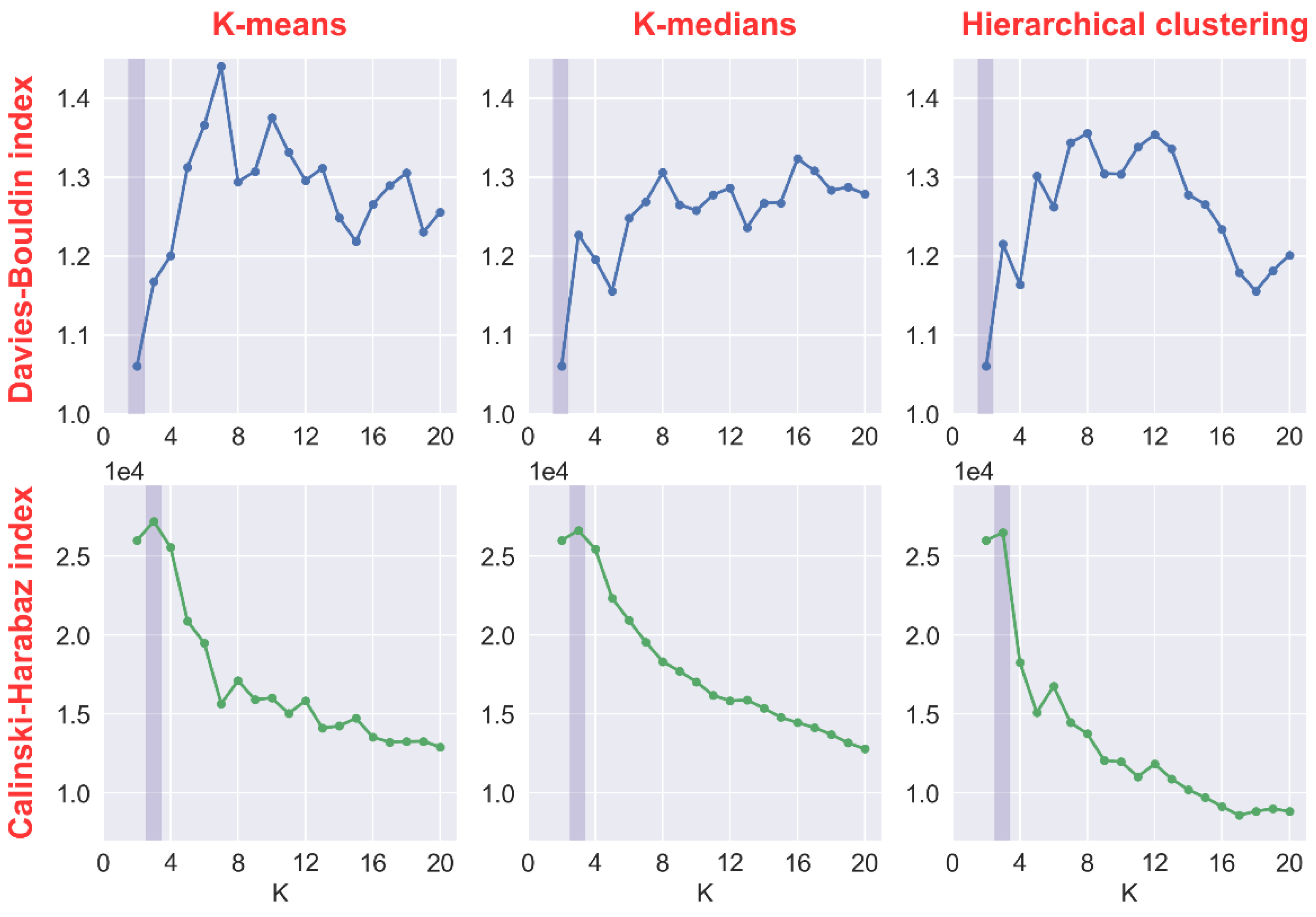
4.2. Optimal Cluster Number
4.3. Performance of Different Models in Energy Consumption Prediction Task
5. Conclusions
- In general, integrating clustering with regression can effectively improve the prediction performance of the regression model. In this study, the results show that the performance improvement by integrating clustering with different regression models from high to low is SVR, LASSO, XGBoost, and ANN. More specifically, integrating clustering almost has a negligible impact on the ANN model.
- The optimal cluster number determined by clustering evaluation metrics may not be the optimal number for the ensemble model (integration of clustering and regression). In this study, the optimal cluster numbers determined by clustering evaluation metrics are quite close to the optimal numbers of ANN and XGBoost. However, they are not closed to the optimal numbers of LASSO and SVR, especially for LASSO.
- In this study, there is no great difference among clustering methods (K-means, K-medians, and Hierarchical clustering) in the task of short-term building energy consumption prediction.
- In this study of predicting the energy consumption of the coming hour, the performance of different regression models integrated with clustering algorithms from high to low is XGBoost, SVR, ANN, and LASSO.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Conflicts of Interest
References
- Lu, W.; Tam, V.W.; Chen, H.; Du, L. A holistic review of research on carbon emissions of green building construction industry. Eng. Constr. Arch. Manag. 2020, 27, 1065–1092. [Google Scholar] [CrossRef]
- Kneifel, J.; Webb, D. Predicting energy performance of a net-zero energy building: A statistical approach. Appl. Energy 2016, 178, 468–483. [Google Scholar] [CrossRef] [Green Version]
- Walker, S.; Labeodan, T.; Boxem, G.; Maassen, W.; Zeiler, W. An assessment methodology of sustainable energy transition scenarios for realizing energy neutral neighborhoods. Appl. Energy 2018, 228, 2346–2360. [Google Scholar] [CrossRef]
- Ramesh, T.; Prakash, R.; Shukla, K.K. Life cycle energy analysis of buildings: An overview. Energy Build. 2010, 42, 1592–1600. [Google Scholar] [CrossRef]
- Lu, X.; Hinkelman, K.; Fu, Y.; Wang, J.; Zuo, W.; Zhang, Q.; Saad, W. An Open Source Modeling Framework for Interdependent Energy-Transportation-Communication Infrastructure in Smart and Connected Communities. IEEE Access 2019, 7, 55458–55476. [Google Scholar] [CrossRef]
- Liu, Y.; Liang, J.; Wang, X.; Ouyang, Y. Status, Problems and Countermeasures of Energy-Saving Assessment for Building Energy-Saving Projects. Sustain. Dev. 2013, 3, 116–122. [Google Scholar]
- Turner, C.; Frankel, M. Green Building Performance Evaluation: Measured Results from LEED New Construction Buildings; Texas A&M University: College Station, TX, USA, 2008. [Google Scholar]
- Chen, Z.; Chen, Y.; Xiao, T.; Wang, H.; Hou, P. A novel short-term load forecasting framework based on time-series clustering and early classification algorithm. Energy Build. 2021, 251, 111375. [Google Scholar] [CrossRef]
- Wang, H.; Xu, P.; Lu, X.; Yuan, D. Methodology of comprehensive building energy performance diagnosis for large commercial buildings at multiple levels. Appl. Energy 2016, 169, 14–27. [Google Scholar] [CrossRef]
- Dong, Z.; Zhu, P.; Bobker, M.; Ascazubi, M. Simplified Characterization of Building Thermal Response Rates. Energy Procedia 2015, 78, 788–793. [Google Scholar] [CrossRef]
- Wang, Y.; Shen, Y.; Mao, S.; Chen, X.; Zou, H. LASSO and LSTM Integrated Temporal Model for Short-Term Solar Intensity Forecasting. IEEE Internet Things J. 2018, 6, 2933–2944. [Google Scholar] [CrossRef]
- Paudel, S.; Elmitri, M.; Couturier, S.; Nguyen, P.H.; Kamphuis, R.; Lacarrière, B.; Le Corre, O. A relevant data selection method for energy consumption prediction of low energy building based on support vector machine. Energy Build. 2017, 138, 240–256. [Google Scholar] [CrossRef]
- Zhang, F.; Deb, C.; Lee, S.E.; Yang, J.; Shah, K.W. Time series forecasting for building energy consumption using weighted Support Vector Regression with differential evolution optimization technique. Energy Build. 2016, 126, 94–103. [Google Scholar] [CrossRef]
- Azadeh, A.; Ghaderi, S.F.; Sohrabkhani, S. Annual electricity consumption forecasting by neural network in high energy consuming industrial sectors. Energy Convers. Manag. 2008, 49, 2272–2278. [Google Scholar] [CrossRef]
- Kalogirou, S.A. Artificial neural networks in energy applications in buildings. Int. J. Low-Carbon Technol. 2006, 1, 201–216. [Google Scholar] [CrossRef]
- Xue, P.; Jiang, Y.; Zhou, Z.; Chen, X.; Fang, X.; Liu, J. Multi-step ahead forecasting of heat load in district heating systems using machine learning algorithms. Energy 2019, 188, 116085. [Google Scholar] [CrossRef]
- Yang, J.; Ning, C.; Deb, C.; Zhang, F.; Cheong, D.; Lee, S.E.; Sekhar, C.; Tham, K.W. k-Shape clustering algorithm for building energy usage patterns analysis and forecasting model accuracy improvement. Energy Build. 2017, 146, 27–37. [Google Scholar] [CrossRef]
- Karijadi, I.; Chou, S.Y.; Dewabharata, A.; Cheng, R.G. Electricity Load Prediction using Fuzzy c-means Clustering EMD based Support Vector Regression for University Building. In Proceedings of the 2019 International Conference on Fuzzy Theory and Its Applications (iFUZZY), New Taipei, Taiwan, 7–10 November 2019; pp. 163–168. [Google Scholar]
- Li, X.; Deng, Y.; Ding, L.; Jiang, L. Building cooling load forecasting using fuzzy support vector machine and fuzzy C-mean clustering. In Proceedings of the International Conference on Computer & Communication Technologies in Agriculture Engineering, Chengdu, China, 12–13 June 2010. [Google Scholar]
- Zhou, Z. Hybrid Modeling of Central Air-Conditioning Cold Source System Energy Consumption with K-means Cluster Algorithm. IOP Conf. Ser. Earth Environ. Sci. 2019, 295, 52035. [Google Scholar] [CrossRef]
- Zheng, H.; Wu, Y. A XGBoost Model with Weather Similarity Analysis and Feature Engineering for Short-Term Wind Power Forecasting. Appl. Sci. 2019, 9, 3019. [Google Scholar] [CrossRef] [Green Version]
- Luo, X. A novel clustering-enhanced adaptive artificial neural network model for predicting day-ahead building cooling demand. J. Build. Eng. 2020, 32, 101504. [Google Scholar] [CrossRef]
- Chen, H.; Wang, S.; Tian, Y. A new approach for power-saving analysis in consumer side based on big data mining. In Proceedings of the 2018 IEEE Power & Energy Society General Meeting (PESGM), Portland, OR, USA, 5–10 August 2018. [Google Scholar]
- Wang, Y.; Liu, Y.; Li, L.; Infield, D.; Han, S. Short-Term Wind Power Forecasting Based on Clustering Pre-Calculated CFD Method. Energies 2018, 11, 854. [Google Scholar] [CrossRef] [Green Version]
- Voyant, C.; Notton, G.; Kalogirou, S.; Nivet, M.-L.; Paoli, C.; Motte, F.; Fouilloy, A. Machine learning methods for solar radiation forecasting: A review. Renew. Energy 2017, 105, 569–582. [Google Scholar] [CrossRef]
- Bartholomew, D.J. Time Series Analysis Forecasting and Control; JSTOR: New York, NY, USA, 1971. [Google Scholar]
- Bourdeau, M.; Zhai, X.Q.; Nefzaoui, E.; Guo, X.; Chatellier, P. Modeling and forecasting building energy consumption: A review of data-driven techniques. Sustain. Cities Soc. 2019, 48, 101533. [Google Scholar] [CrossRef]
- Raju, V.N.G.; Lakshmi, K.P.; Jain, V.M.; Kalidindi, A.; Padma, V. Study the Influence of Normalization/Transformation Process on the Accuracy of Supervised Classification. In Proceedings of the 2020 Third International Conference on Smart Systems and Inventive Technology (ICSSIT), Tirunelveli, India, 20–22 August 2020. [Google Scholar]
- Morán, A.; Fuertes, J.J.; Prada, M.A.; Alonso, S.; Barrientos, P.; Díaz, I.; Domínguez, M. Analysis of electricity consumption profiles in public buildings with dimensionality reduction techniques. Eng. Appl. Artif. Intell. 2013, 26, 1872–1880. [Google Scholar] [CrossRef]
- Fan, C.; Xiao, F.; Zhao, Y. A short-term building cooling load prediction method using deep learning algorithms. Appl. Energy 2017, 195, 222–233. [Google Scholar] [CrossRef]
- Edelmann, D.; Móri, T.F.; Székely, G.J. On relationships between the Pearson and the distance correlation coefficients. Stat. Probab. Lett. 2020, 169, 108960. [Google Scholar] [CrossRef]
- Efron, B.; Tibshirani, R.J. An Introduction to the Bootstrap; Chapman & Hall: New York, NY, USA, 1993; p. 436. [Google Scholar]
- MacQueen, J. Some methods for classification and analysis of multivariate observations. In Proceedings of the Fifth Berkeley Symposium on Mathematical Statistics and Probability, Oakland, CA, USA, 1 January 1967; pp. 281–297. [Google Scholar]
- Bradley, P.S.; Mangasarian, O.L.; Street, W.N. Clustering via concave minimization. Adv. Neural Inf. Process. Syst. 1997, 9, 368–374. [Google Scholar]
- Nikolaou, T.G.; Kolokotsa, D.; Stavrakakis, G.S.; Skias, I.D. On the Application of Clustering Techniques for Office Buildings’ Energy and Thermal Comfort Classification. IEEE Trans. Smart Grid 2012, 3, 2196–2210. [Google Scholar] [CrossRef]
- Tibshirani, R. Regression shrinkage and selection via the lasso. J. R. Stat. Soc. Ser. B 1996, 58, 267–288. [Google Scholar] [CrossRef]
- Vapnik, V.; Golowich, S.E.; Smola, A. Support vector method for function approximation, regression estimation, and signal processing. Adv. Neural Inf. Process. Syst. 1997, 281–287. [Google Scholar] [CrossRef]
- Vapnik, V. The Nature of Statistical Learning Theory; Springer: Berlin/Heidelberg, Germany, 1999. [Google Scholar]
- Chen, T. Introduction to Boosted Trees; University of Washington Computer Science: Seattle, DC, USA, 2014; Volume 22, pp. 14–40. [Google Scholar]
- Natekin, A.; Knoll, A. Gradient boosting machines, a tutorial. Front. Neurorobotics 2013, 7, 21. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Friedman, J.H. Stochastic gradient boosting. Comput. Stat. Data Anal. 2002, 38, 367–378. [Google Scholar] [CrossRef]
- Davies, D.L.; Bouldin, D.W. A cluster separation measure. IEEE Trans. Pattern Anal. Mach. Intell. 1979, 1, 224–227. [Google Scholar] [CrossRef]
- Caliński, T.; Harabasz, J. A dendrite method for cluster analysis. Commun. Stat.-Theory Methods 1974, 3, 1–27. [Google Scholar] [CrossRef]
- Wang, H.; Lu, X.; Xu, P.; Yuan, D. Short-term Prediction of Power Consumption for Large-scale Public Buildings based on Regression Algorithm. Procedia Eng. 2015, 121, 1318–1325. [Google Scholar] [CrossRef] [Green Version]
- Garreta, R.; Moncecchi, G. Learning Scikit-Learn: Machine Learning in Python; Packt Publishing: Birmingham, UK, 2013. [Google Scholar]
- Karatzoglou, A.; Meyer, D.; Hornik, K. Support Vector Machines in R. J. Stat. Softw. 2006, 15, 1–28. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Item | Detail |
|---|---|
| Building type | Office building |
| Location | Shenzhen, China |
| Build time | 1980s |
| Floors | 5 |
| Height (m) | 21.5 |
| Building area (m2) | 25,000 |
| Air conditioning area (m2) | 16,259 |
| Parameter | Abbreviation | Unit | ||
|---|---|---|---|---|
| Input | Time-related features | Month * | Month | |
| Day type * | Day type | |||
| Working day type * | Working type | |||
| Hour * | Hour | |||
| Environmental features | Indoor temperature | T | °C | |
| CO2 concentration | CO2 | ppm | ||
| PM2.5 concentration * | PM2.5 | μg/m3 | ||
| Energy consumption (EC) features | EC of tenants * | Tenant | kW·h | |
| EC of air conditioning (AC) terminals * | Terminal | kW·h | ||
| EC of cold/heat source of AC systems * | Cold/heat | kW·h | ||
| EC of the public lighting system* | Lighting | kW·h | ||
| EC of the firefighting system | Firefighting | kW·h | ||
| EC of the garage | Garage | kW·h | ||
| EC of elevators | Elevator | kW·h | ||
| EC of draining pumps * | Draining | kW·h | ||
| EC of blowers * | Blower | kW·h | ||
| EC of computer rooms | Computer | kW·h | ||
| Other energy consumption * | Other | kW·h | ||
| Output | Total energy consumption | Total | kW·h |
| Method | Parameters | Optimal Value | MAE | MAPE | RMSE |
|---|---|---|---|---|---|
| LASSO | Lambda | 0.00001 | 37.96 | 26.87 | 61.79 |
| SVR | Kernel function | RBF | 34.5 | 21.74 | 64.37 |
| C | 1 | ||||
| Gamma | 0.01 | ||||
| ANN | Hidden neurons | 25 | 20.02 | 11.37 | 34.39 |
| Activation | Sigmoid | ||||
| XGBoost | Number of estimators | 140 | 21.87 | 12.22 | 40.36 |
| Learning rate | 0.3 | ||||
| Max depth | 7 |
| Cluster Number | Maximum/Minimum and Proportion | K-Means | K-Medians | Hierarchical Clustering |
|---|---|---|---|---|
| K = 2 | Maximum | 31,104 | 31,104 | 31,104 |
| Proportion | 71.01% | 71.01% | 71.01% | |
| Minimum | 12696 | 12696 | 12696 | |
| Proportion | 28.99% | 28.99% | 28.99% | |
| K = 5 | Maximum | 12674 | 12633 | 19268 |
| Proportion | 28.94% | 28.84% | 43.99% | |
| Minimum | 2477 | 4869 | 321 | |
| Proportion | 5.65% | 11.12% | 0.73% | |
| K = 10 | Maximum | 7156 | 8461 | 12375 |
| Proportion | 16.34% | 19.32% | 28.25% | |
| Minimum | 1865 | 2328 | 58 | |
| Proportion | 4.26% | 5.31% | 0.13% | |
| K = 20 | Maximum | 4095 | 4704 | 8845 |
| Proportion | 9.35% | 10.74% | 20.19% | |
| Minimum | 54 | 326 | 13 | |
| Proportion | 0.12% | 0.74% | 0.03% |
| ARIMA | LASSO | SVR | ANN | XGBoost | |
|---|---|---|---|---|---|
| Clustering Algorithm | K-Means | K-Means | Hierarchical Clustering | Hierarchical Clustering | |
| MAE | 29.86 | 21.65 | 16.32 | 19.13 | 14.94 |
| MAPE | 13.68 | 11.65 | 8.15 | 10.26 | 7.51 |
| RMSE | 54.71 | 33.21 | 26.27 | 28.42 | 25.06 |
| PI vs. ARIMA | 1.00 | 1.40 | 1.86 | 1.61 | 2.00 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ding, Z.; Wang, Z.; Hu, T.; Wang, H. A Comprehensive Study on Integrating Clustering with Regression for Short-Term Forecasting of Building Energy Consumption: Case Study of a Green Building. Buildings 2022, 12, 1701. https://doi.org/10.3390/buildings12101701
Ding Z, Wang Z, Hu T, Wang H. A Comprehensive Study on Integrating Clustering with Regression for Short-Term Forecasting of Building Energy Consumption: Case Study of a Green Building. Buildings. 2022; 12(10):1701. https://doi.org/10.3390/buildings12101701
Chicago/Turabian StyleDing, Zhikun, Zhan Wang, Ting Hu, and Huilong Wang. 2022. "A Comprehensive Study on Integrating Clustering with Regression for Short-Term Forecasting of Building Energy Consumption: Case Study of a Green Building" Buildings 12, no. 10: 1701. https://doi.org/10.3390/buildings12101701