
Neural Network Prediction Model for Sinter Mixture Water Content Based on KPCA-GA Optimization

Abstract
:1. Introduction
- A new hybrid intelligence algorithm was developed to predict the moisture content of the mix in real time during the sintering process.
- Analysis and modeling of the dynamic, non-linear, and other characteristics of the predicted object were performed for the two-stage mixing and water addition method commonly used in sintering plants.
- The GA optimization algorithm was used to reduce the shortcomings of BP neural networks, such as slow convergence, a long training time, and the tendency to fall into local minima, comparing the effect before and after optimization to illustrate its necessity.
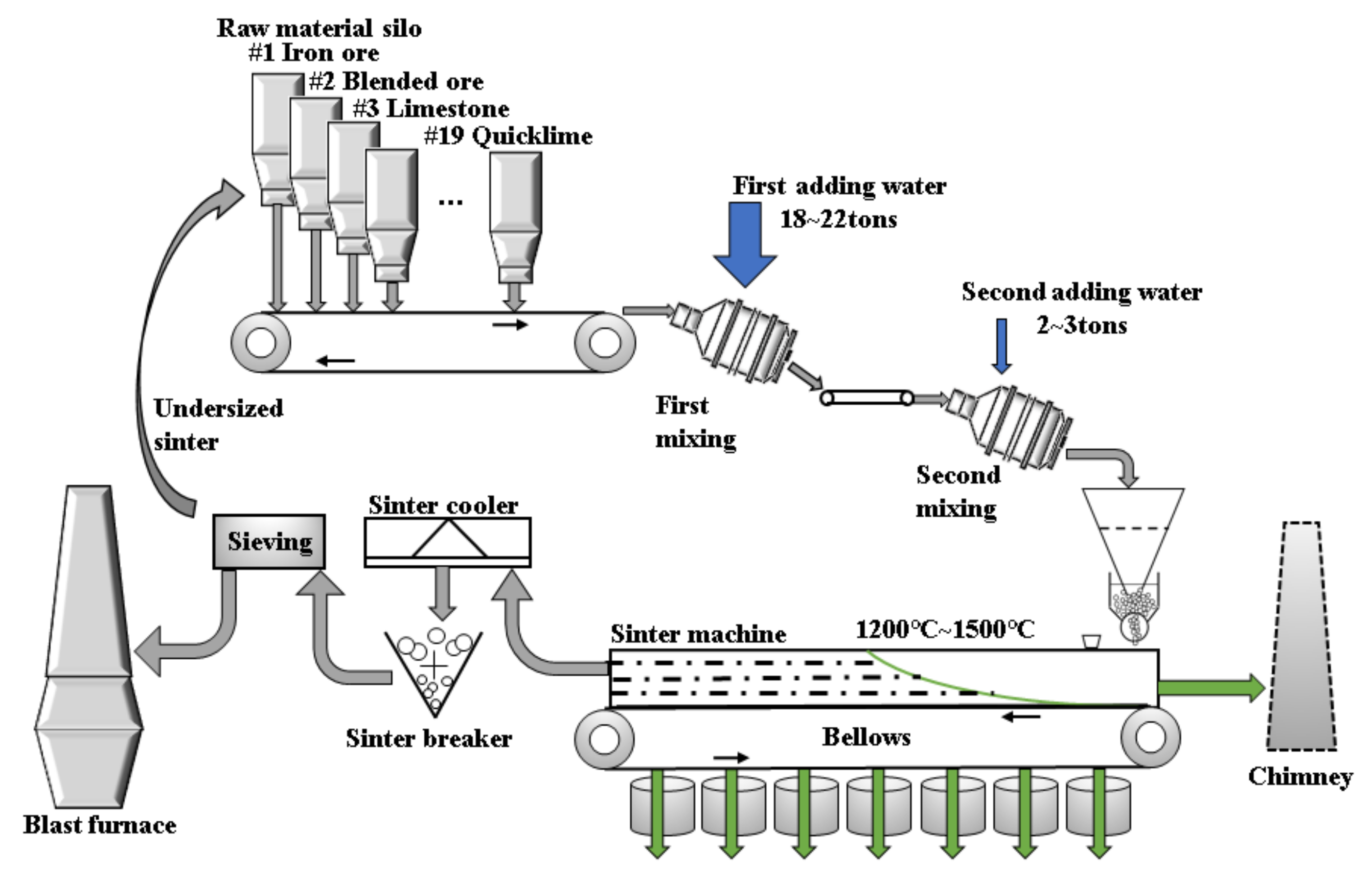
2. Sintering Mixing and Water Addition Process Mechanism
2.1. Material Conservation Moisture Content Model
2.2. Prediction Problem Description
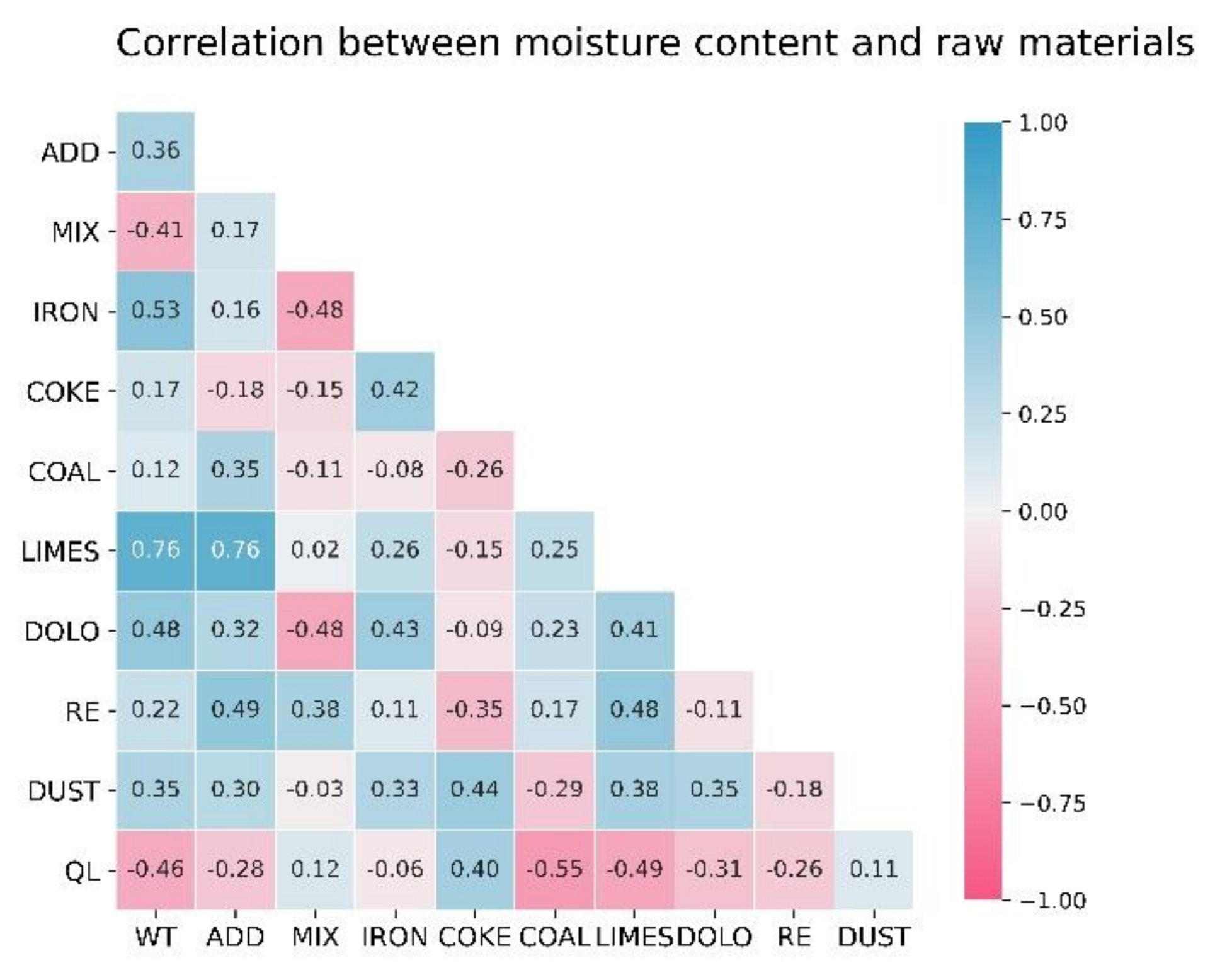
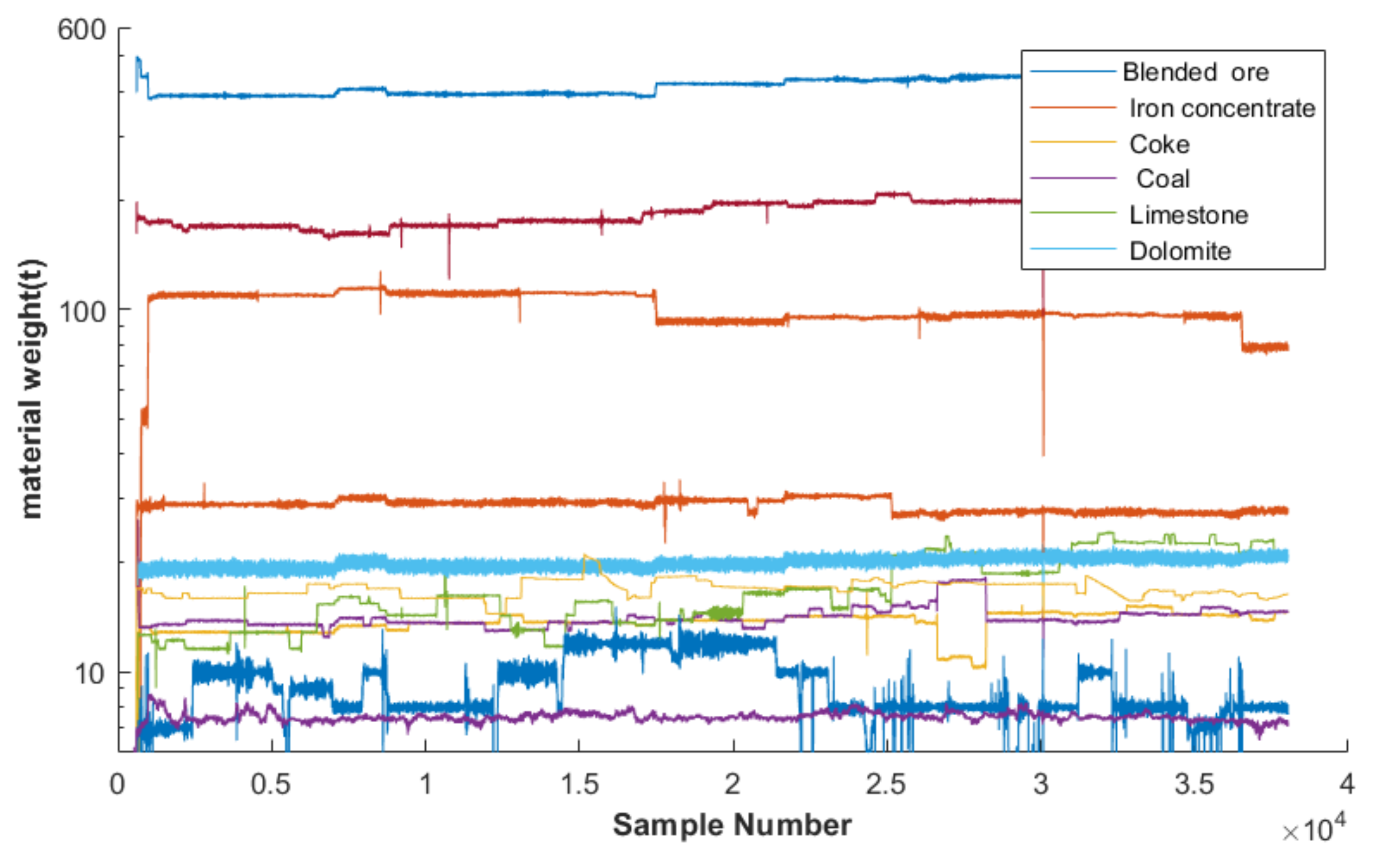
2.3. Factors Influencing the Moisture Content of the Mixture
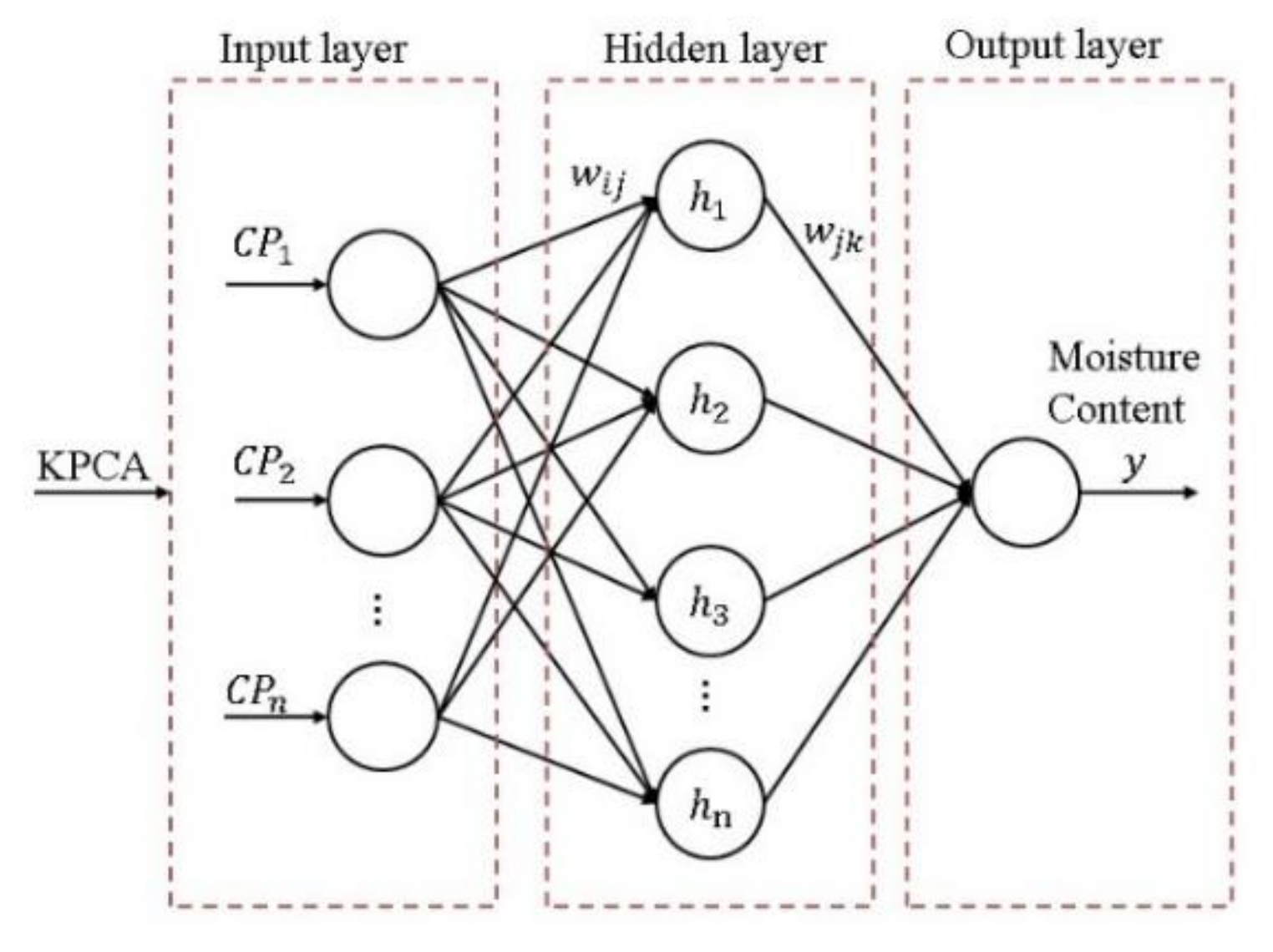
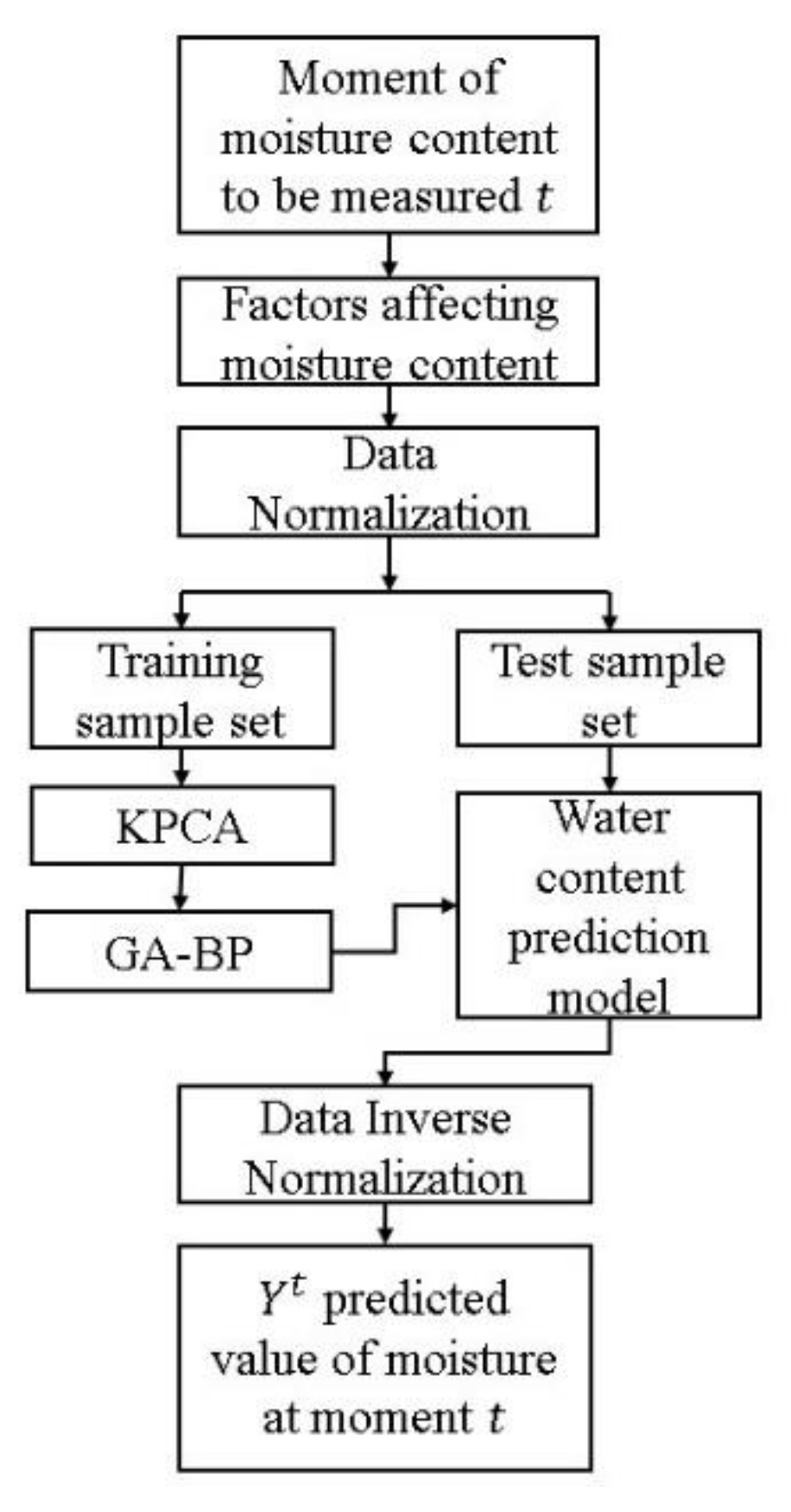
3. Moisture Prediction Model
3.1. KPCA
3.2. Improved Genetic Algorithm for Multilayer Neural Networks
4. Simulation Results and Analysis
4.1. KPCA Data Pre-Processing
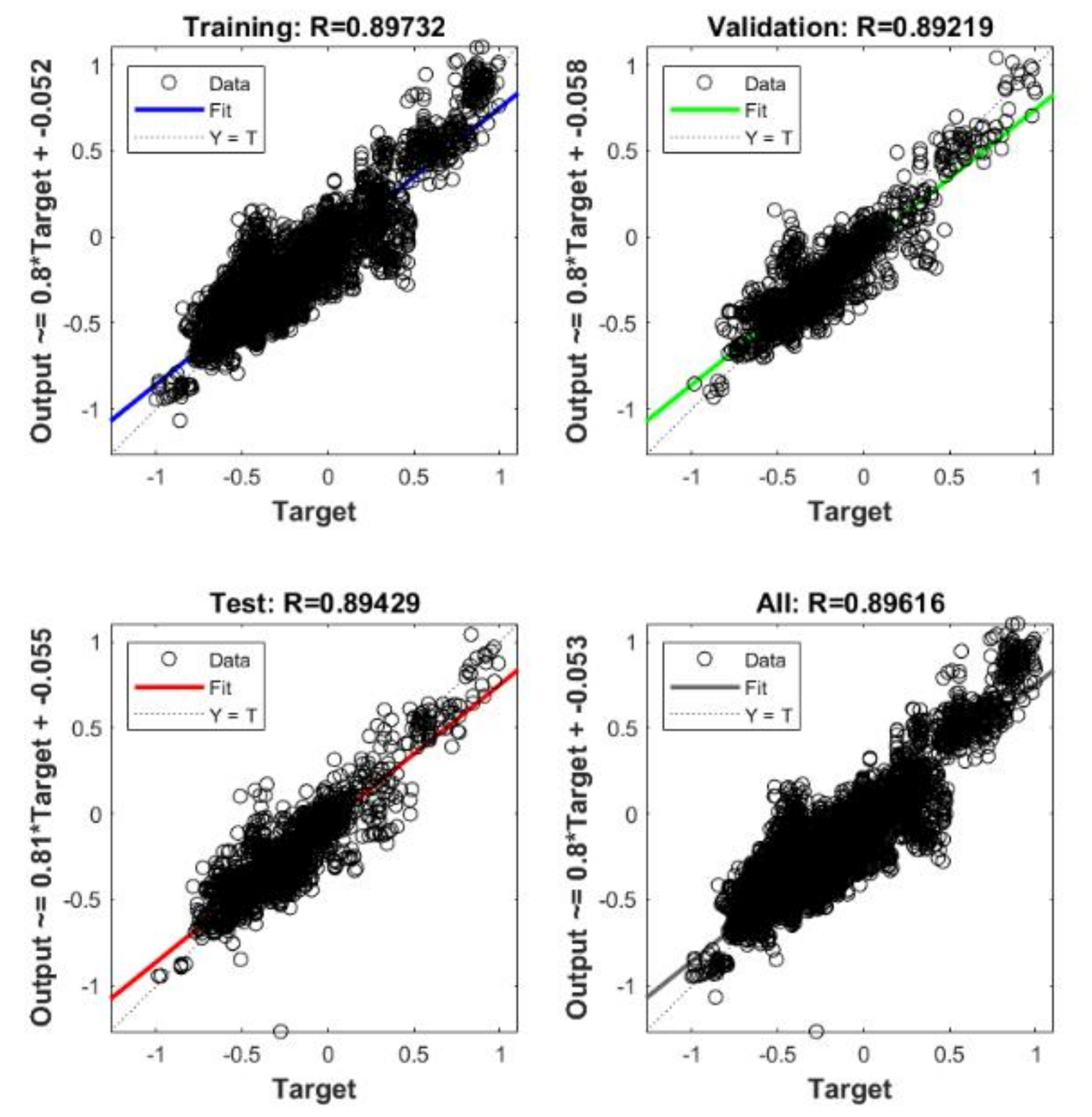
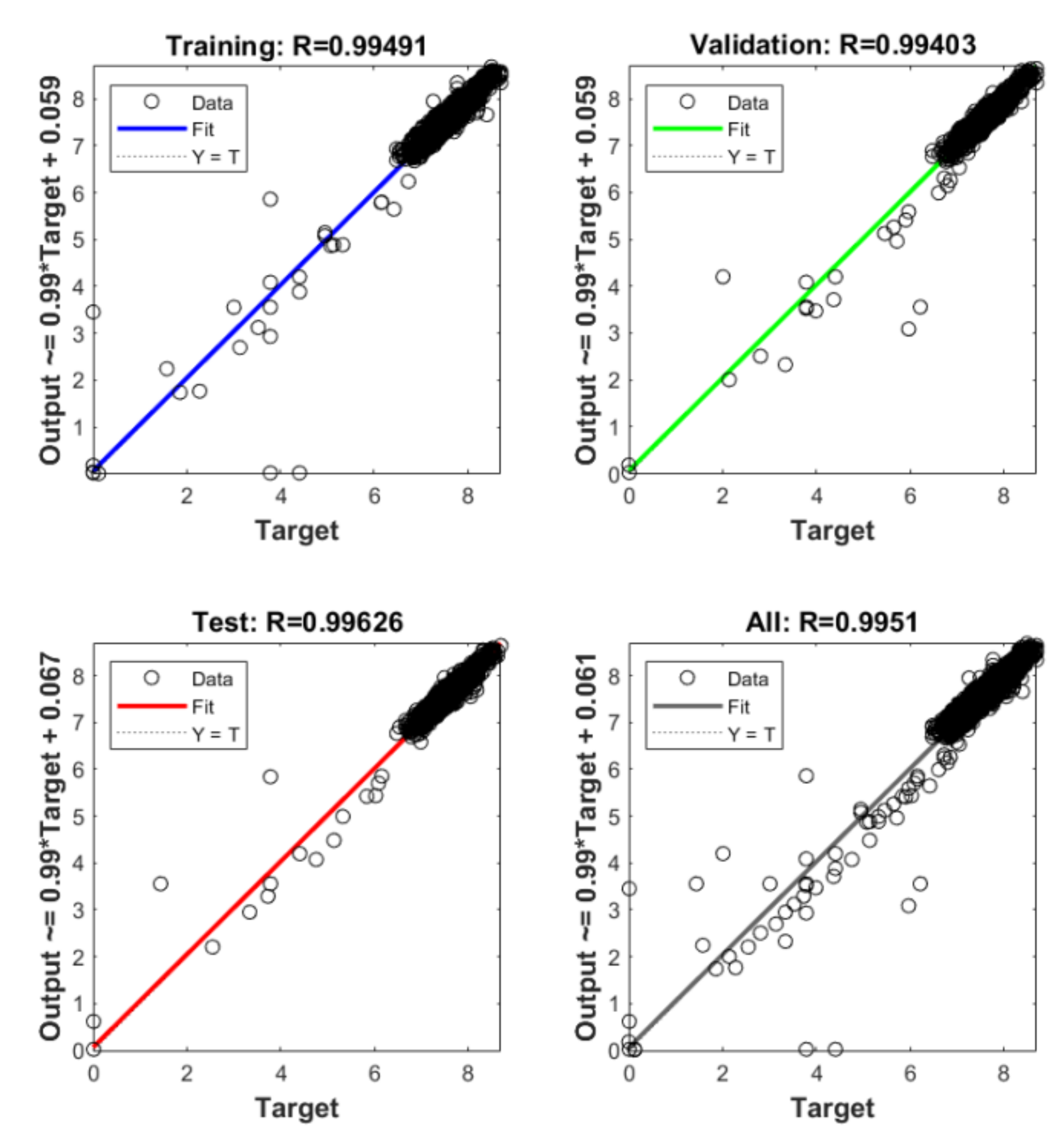
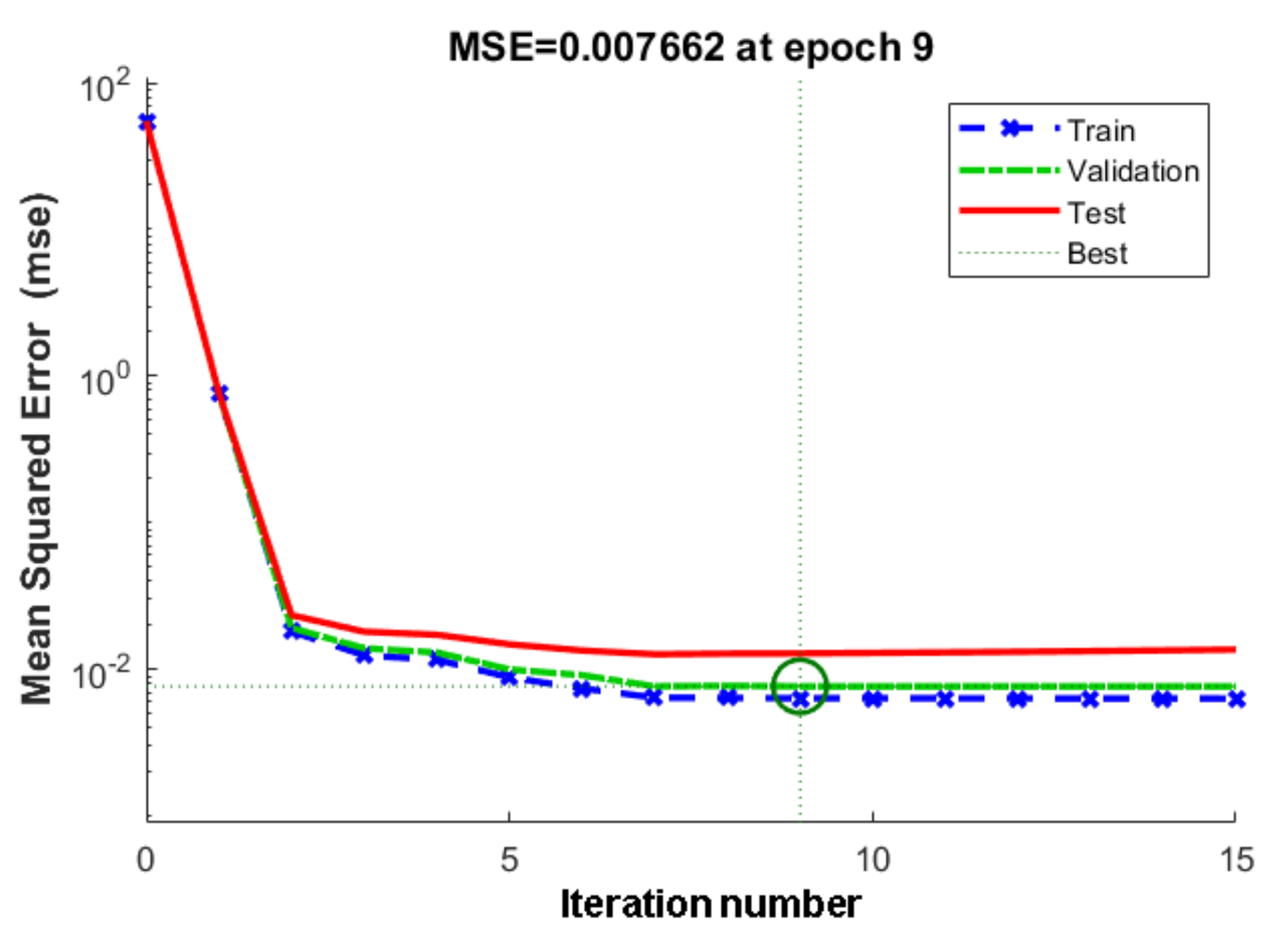
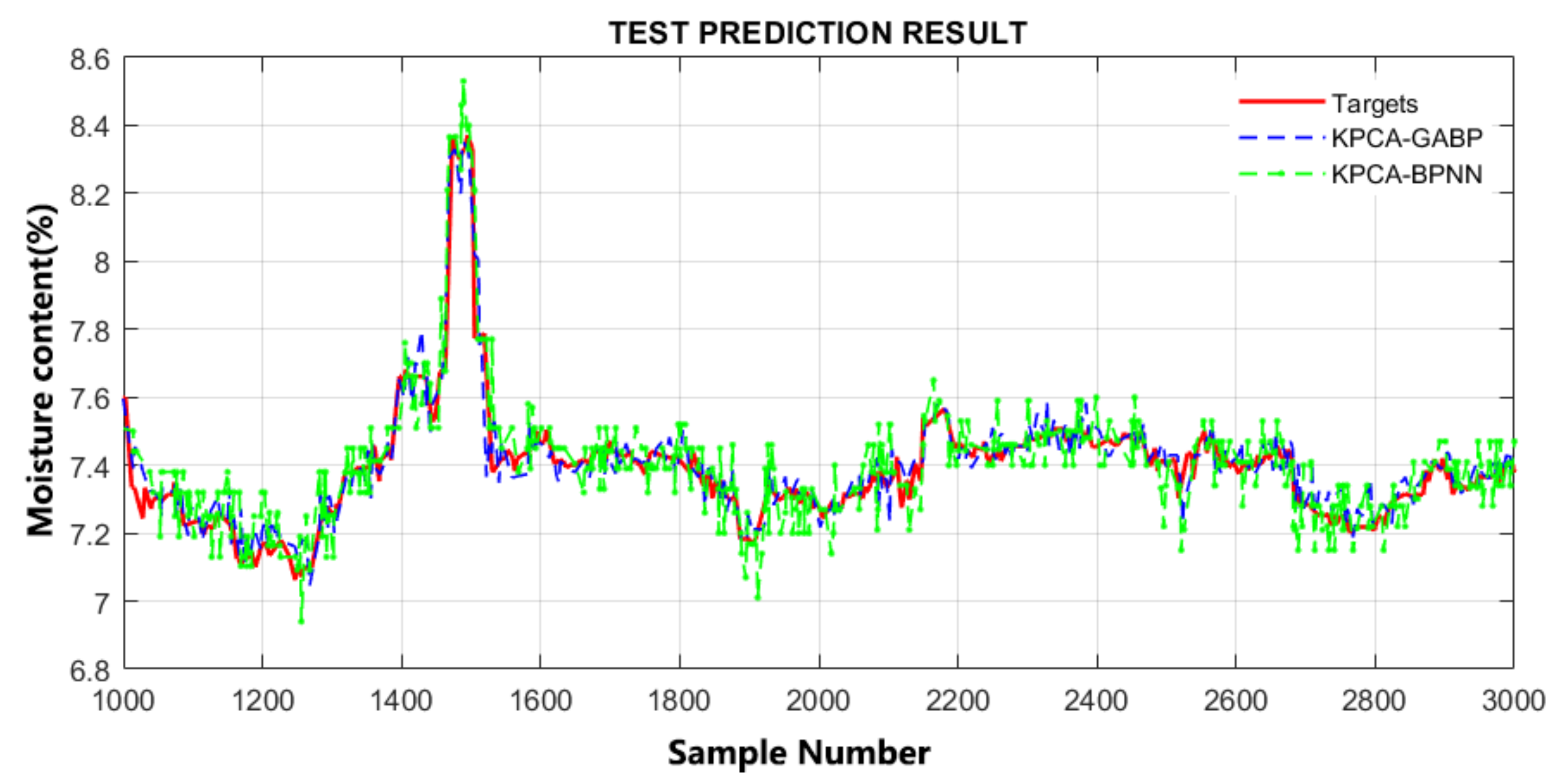
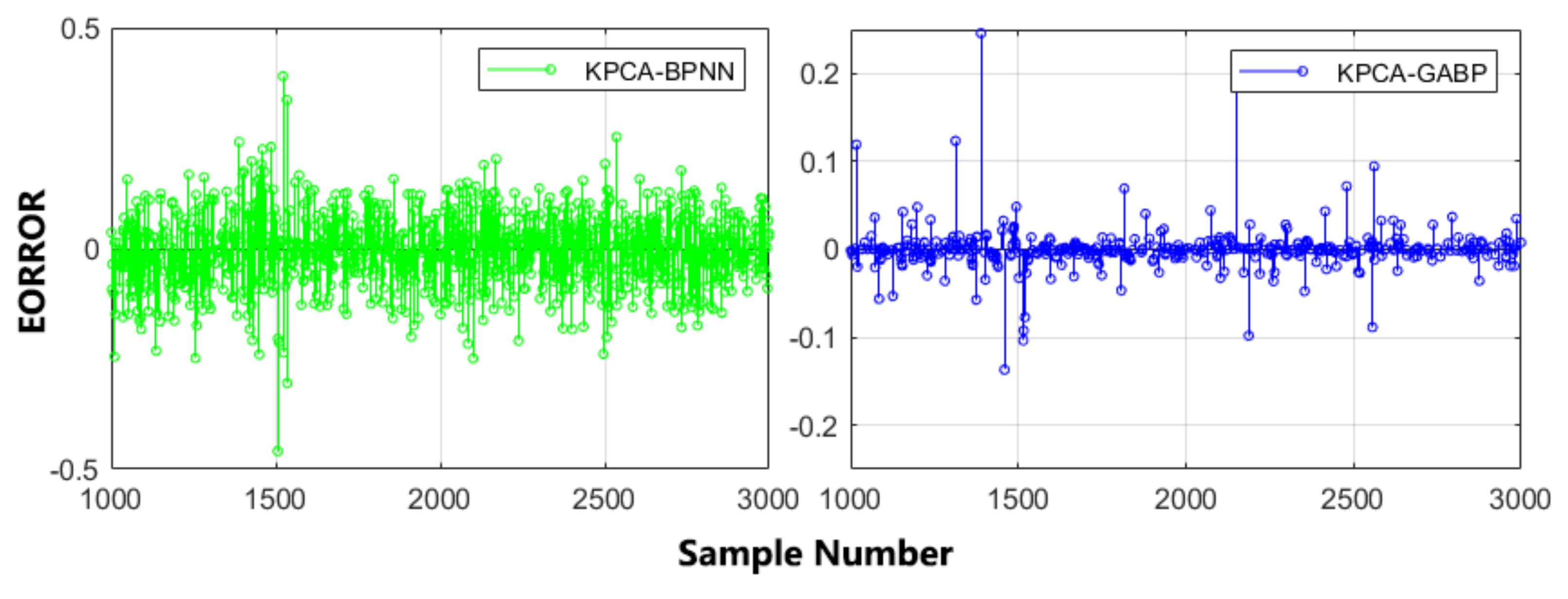
4.2. GA-BP Prediction Results
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| BPNN | Back-propagation neural network |
| GA | Genetic algorithm |
| GRBK | Gaussian radial basis kernel |
| KPCA | Kernel principal component analysis |
| PCA | Principal component analysis |
| MFO | Moth flame optimizer |
| ML | Machine learning |
| NARX | Nonlinear autoregressive with exogenous inputs neural network |
References
- Lu, L.; Ishiyama, O.; Higuchi, T.; Matsumura, M.; Higuchi, K. Iron ore sintering. In Iron Ore; Woodhead Publishing: Cambridge, UK, 2022; pp. 489–538. [Google Scholar]
- Li, T.G.; Gong, Q.H. The Sinter Mixture Moisture Control System Based on Fuzzy PID Controller. In Applied Mechanics and Materials; Trans Tech Publications Ltd.: Freienbach, Switzerland, 2014; Volume 457, pp. 899–904. [Google Scholar]
- Wu, M.; Ma, J.; Hu, J.; Chen, X.; Cao, W.; She, J. Optimization of coke ratio for the second proportioning phase in a sintering process base on a model of temperature field of material layer. Neurocomputing 2018, 275, 10–18. [Google Scholar] [CrossRef]
- Hu, J.; Wu, M.; Chen, X.; Du, S.; Zhang, P.; Cao, W.; She, J. A multilevel prediction model of carbon efficiency based on the differential evolution algorithm for the iron ore sintering process. IEEE Trans. Ind. Electron. 2018, 65, 8778–8787. [Google Scholar] [CrossRef]
- Liu, D.; Tang, C.; Shi, X.; Cao, H.; Li, J. Optimization of Modeling Parameters for Temperature Field of Iron Ore Fines Sintering Based on Sintering Velocity. In Proceedings of the 2019 25th International Conference on Automation and Computing (ICAC), Lancaster, UK, 5–7 September 2019; pp. 1–4. [Google Scholar] [CrossRef]
- Jiang, Y.; Yang, N.; Yao, Q.; Wu, Z.; Jin, W. Real-time moisture control in sintering process using offline–online NARX neural networks. Neurocomputing 2020, 396, 209–215. [Google Scholar] [CrossRef]
- Li, H.-X.; Xu, S.-G.; Fan, C.-R. Long-term prediction of runoff based on Bayesian regulation neural network. J. Dalian Univ. Technol. 2006, 2006, 174–177. [Google Scholar]
- Wu, M.; Xu, C.; She, J.; Cao, W. Neural-network-based integrated model for predicting burn-through point in lead–zinc sintering process. J. Process Control. 2012, 22, 925–934. [Google Scholar] [CrossRef]
- Ding, S.; Su, C.; Yu, J. An optimizing BP neural network algorithm based on genetic algorithm. Artif. Intell. Rev. 2011, 36, 153–162. [Google Scholar] [CrossRef]
- Guo, L.; Wu, P.; Lou, S.; Gao, J.; Liu, Y. A multi-feature extraction technique based on principal component analysis for nonlinear dynamic process monitoring. J. Process Control. 2020, 85, 159–172. [Google Scholar] [CrossRef]
- Zhang, Y.F.; Fitch, P.; Thorburn, P.J. Predicting the trend of dissolved oxygen based on the kPCA-RNN model. Water 2020, 12, 585. [Google Scholar] [CrossRef] [Green Version]
- Zhang, J.; Chen, M.; Hong, X. Nonlinear process monitoring using a mixture of probabilistic PCA with clusterings. Neurocomputing 2021, 458, 319–326. [Google Scholar] [CrossRef]
- Neffati, S.; Ben Abdellafou, K.; Taouali, O.; Bouzrara, K. Enhanced SVM–KPCA method for brain MR image classification. Comput. J. 2020, 63, 383–394. [Google Scholar] [CrossRef]
- Xie, L.; Tao, J.; Zhang, Q.; Zhou, H. CNN and KPCA-based automated feature extraction for real time driving pattern recognition. IEEE Access 2019, 7, 123765–123775. [Google Scholar] [CrossRef]
- Xie, L.; Tao, J. Real-time Driving Pattern Prediction Based on KPCA and Neural Network. In Proceedings of the 2019 1st International Conference on Industrial Artificial Intelligence (IAI), Shenyang, China, 22–26 July 2019; pp. 1–5. [Google Scholar]
- Navi, M.; Meskin, N.; Davoodi, M. Sensor fault detection and isolation of an industrial gas turbine using partial adaptive KPCA. J. Process Control. 2018, 64, 37–48. [Google Scholar] [CrossRef]
- Lin, J.; Sheng, G.; Yan, Y.; Dai, J.; Jiang, X. Prediction of dissolved gas concentrations in transformer oil based on the KPCA-FFOA-GRNN model. Energies 2018, 11, 225. [Google Scholar] [CrossRef] [Green Version]
- Khoshaim, A.B.; Moustafa, E.B.; Bafakeeh, O.T.; Elsheikh, A.H. An optimized multilayer perceptrons model using grey wolf optimizer to predict mechanical and microstructural properties of friction stir processed aluminum alloy reinforced by nanoparticles. Coatings 2021, 11, 1476. [Google Scholar] [CrossRef]
- Elsheikh, A.H.; Panchal, H.; Ahmadein, M.; Mosleh, A.O.; Sadasivuni, K.K.; Alsaleh, N.A. Productivity forecasting of solar distiller integrated with evacuated tubes and external condenser using artificial intelligence model and moth-flame optimizer. Case Stud. Therm. Eng. 2021, 28, 101671. [Google Scholar] [CrossRef]
- Elsheikh, A.H.; Muthuramalingam, T.; Shanmugan, S.; Ibrahim, A.M.M.; Ramesh, B.; Khoshaim, A.B.; Moustafa, E.B.; Bedairi, B.; Panchal, H.; Sathyamurthy, R. Fine-tuned artificial intelligence model using pigeon optimizer for prediction of residual stresses during turning of Inconel 718. J. Mater. Res. Technol. 2021, 15, 3622–3634. [Google Scholar] [CrossRef]
- Huang, X.; Sresakoolchai, J.; Qin, X.; Ho, Y.F.; Kaewunruen, S. Self-Healing Performance Assessment of Bacterial-Based Concrete Using Machine Learning Approaches. Materials 2022, 15, 4436. [Google Scholar] [CrossRef]
- Kaewunruen, S.; Sresakoolchai, J.; Xiang, Y. Identification of weather influences on flight punctuality using machine learning approach. Climate 2021, 9, 127. [Google Scholar] [CrossRef]
- BKA, M.A.R.; Ngamkhanong, C.; Wu, Y.; Kaewunruen, S. Recycled aggregates concrete compressive strength prediction using artificial neural networks (ANNs). Infrastructures 2021, 6, 17. [Google Scholar]
- Li, X.; Jia, R.; Zhang, R.; Yang, S.; Chen, G. A KPCA-BRANN based data-driven approach to model corrosion degradation of subsea oil pipelines. Reliab. Eng. Syst. Saf. 2022, 219, 108231. [Google Scholar] [CrossRef]
- Yang, X.S.; Zhou, J.J.; Wen, D.Q. An optimized BP neural network model for teaching management evaluation. J. Intell. Fuzzy Syst. 2021, 40, 3215–3221. [Google Scholar] [CrossRef]
- Zhao, Y.; Dong, S.; Jiang, F.; Incecik, A. Mooring tension prediction based on BP neural network for semi-submersible platform. Ocean. Eng. 2021, 223, 108714. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| No. | First Moisture Content (%) | Second Moisture Content (%) | Total Water Added (t) | Blended Ore (t) | Iron Ore Concentrate (t) | Dust (t) | Quicklime (t) | Date and Time |
|---|---|---|---|---|---|---|---|---|
| 3529 | 7.62 | 7.34 | 15.89 | 390.96 | 110.85 | 10.89 | 29.58 | 18 October 2020 13:44 |
| 3530 | 7.56 | 7.34 | 16.04 | 390.31 | 109.68 | 10.78 | 29.84 | 18 October 2020 13:44 |
| 3531 | 7.62 | 7.21 | 15.92 | 380.49 | 108.22 | 9.99 | 29.06 | 18 October 2020 13:43 |
| 3532 | 7.62 | 7.34 | 16 | 399.17 | 108.34 | 9.24 | 29.14 | 18 October 2020 13:43 |
| 3533 | 7.69 | 7.47 | 15.97 | 378.95 | 105.96 | 9.11 | 28.75 | 18 October 2020 13:43 |
| 3534 | 7.49 | 7.22 | 16.03 | 399.05 | 112.44 | 9.54 | 28.82 | 18 October 2020 13:42 |
| 3535 | 7.62 | 7.41 | 15.9 | 375.54 | 108.33 | 9.66 | 28.87 | 18 October 2020 13:42 |
| 3536 | 7.56 | 7.02 | 15.99 | 389.96 | 112.8 | 10.59 | 28.43 | 18 October 2020 13:42 |
| Principal Components | Variance Contribution Rate (%) | Cumulative Contribution Rate (%) |
|---|---|---|
| CP1 | 22.30 | 22.30 |
| CP2 | 19.17 | 41.47 |
| CP3 | 17.10 | 58.57 |
| CP4 | 10.03 | 68.60 |
| CP5 | 9.21 | 77.81 |
| CP6 | 8.05 | 85.86 |
| CP7 | 7.14 | 93 |
| CP8 | 7.0 | 100 |
| Parameters | KPCA-GABP Model |
|---|---|
| Initial generation | 10 |
| Population size | 100 |
| Crossover rate | 0.3 |
| Variation rate | 0.15 |
| Number of genes | random 1–3 |
| Gene value boundary | −15~15 |
| Evaluation Indicators | MSE | RMSE | MAE | R2 | EC |
|---|---|---|---|---|---|
| KPCA-BPNN | 0.131 | 0.362 | 0.276 | 0.720 | 0.735 |
| KPCA-GABP | 0.046 | 0.067 | 0.053 | 0.992 | 0.975 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ren, Y.; Huang, C.; Jiang, Y.; Wu, Z. Neural Network Prediction Model for Sinter Mixture Water Content Based on KPCA-GA Optimization. Metals 2022, 12, 1287. https://doi.org/10.3390/met12081287
Ren Y, Huang C, Jiang Y, Wu Z. Neural Network Prediction Model for Sinter Mixture Water Content Based on KPCA-GA Optimization. Metals. 2022; 12(8):1287. https://doi.org/10.3390/met12081287
Chicago/Turabian StyleRen, Yuqian, Chuanqi Huang, Yushan Jiang, and Zhaoxia Wu. 2022. "Neural Network Prediction Model for Sinter Mixture Water Content Based on KPCA-GA Optimization" Metals 12, no. 8: 1287. https://doi.org/10.3390/met12081287