
Towards a Data Lake for High Pressure Die Casting


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
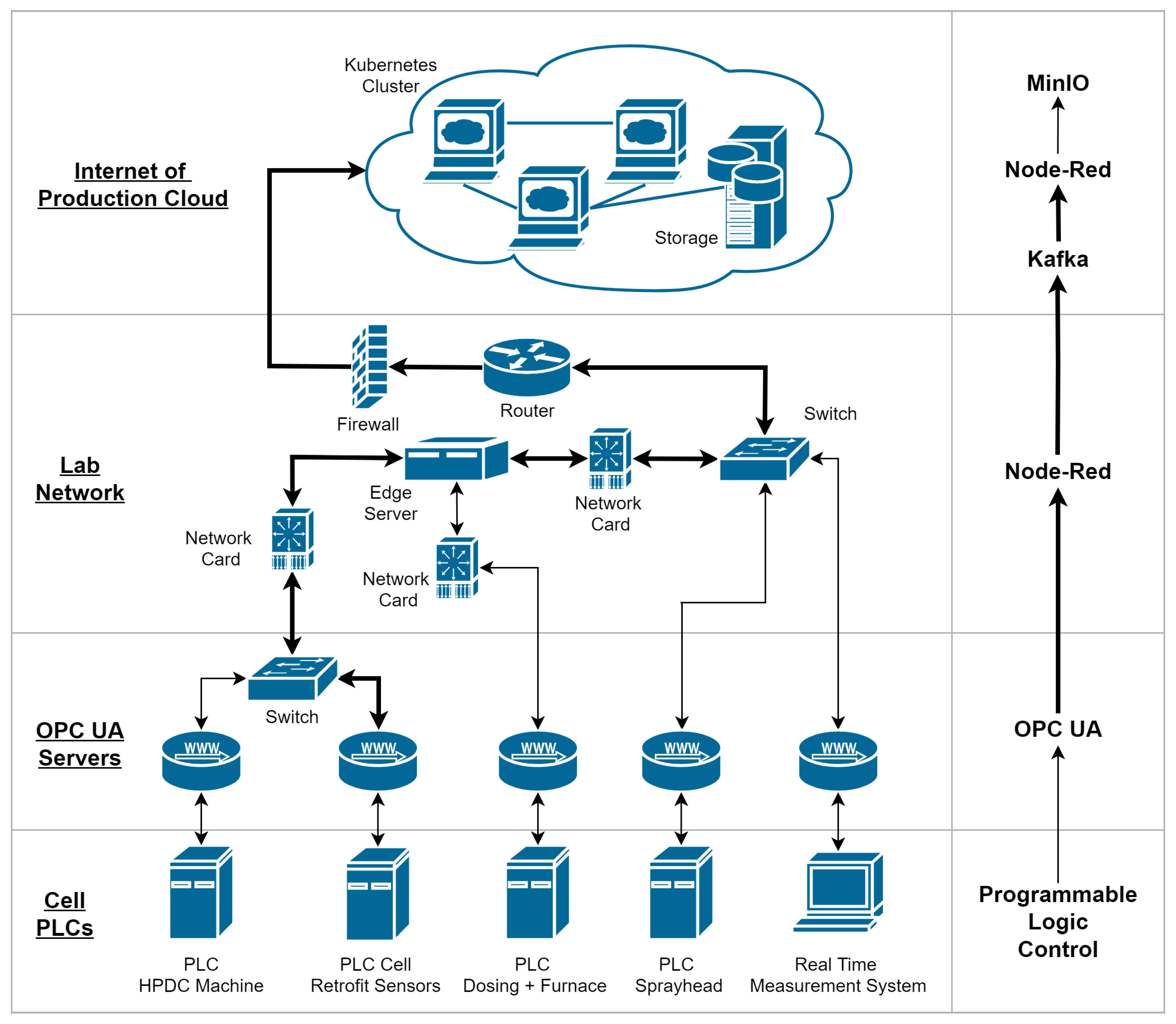
2. HPDC Cell PLC Structure
- PLC HPDC Machine: The PLC provides core data of the process which include the shot end velocities and pressures, the locking force for every lock, the HPDC die thermocouples as well as the step cycle time required for every suboperation such as dosing or part extraction of the HPDC cycle. Furthermore, the flow rates and temperatures from the thermal regulation units are accessed via this PLC.
- PLC Cell Retrofit Sensors: Retrofitting sensors to an existing HPDC cell and integration into the cell can be difficult and costly, especially if the data are to be available on the core machine PLC and the HMI. Therefore, a second standalone PLC with a separate OPC UA server is used to acquire retrofitted sensor signals which include the plunger water flow rate and temperature as well as the heat exchanger water flow rates of the thermal regulation units, the facility temperature and humidity, the electrical power draw of various cell components as well as additional thermocouples, the air flow towards the sprayhead and, if necessary, additional 0–10 V or 4…20 mA signals.
- PLC Dosing + Furnace: The furnace and the dosing system are controlled by this PLC which provides information from the furnace such as the melt temperature, chamber temperature, the power draw and the fill level as well as data from the vacuum dosing system which include the time to take in the metal, the time to reach the pour hole as well as the determined shot weight for every cycle as long as that option is active in the control.
- PLC Sprayhead: Provides the spraying time for every circuit of the sprayhead.
- Real Time Measurement System: A third party measurement system which can acquire cavity surface temperature and pressure measurement values as well as high resolution shot end data. This system can also provide certain process data via an integrated OPC UA server.
3. Results
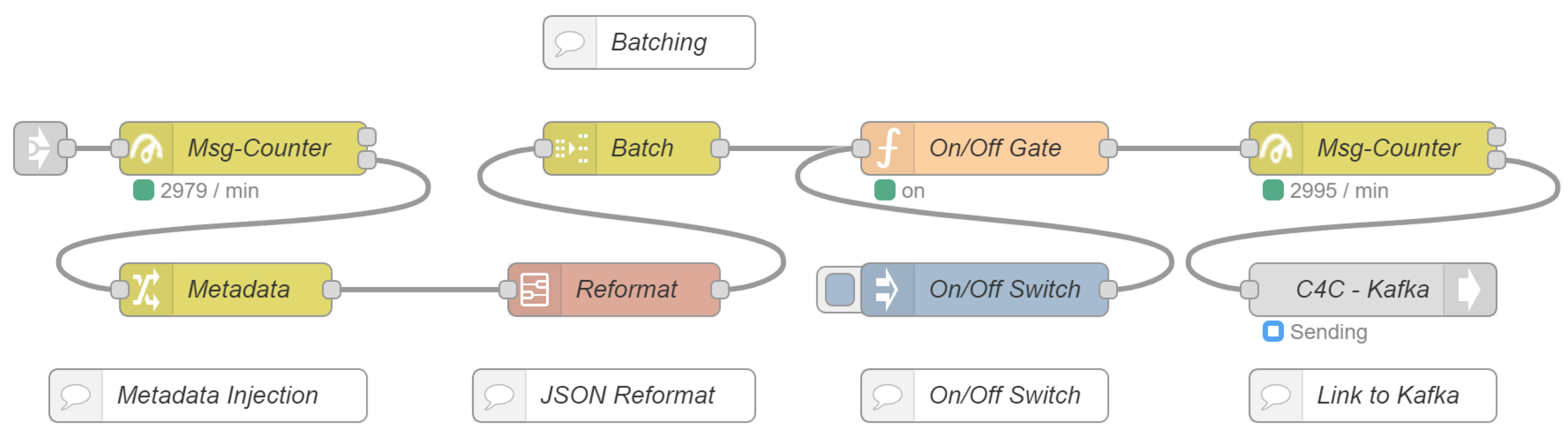
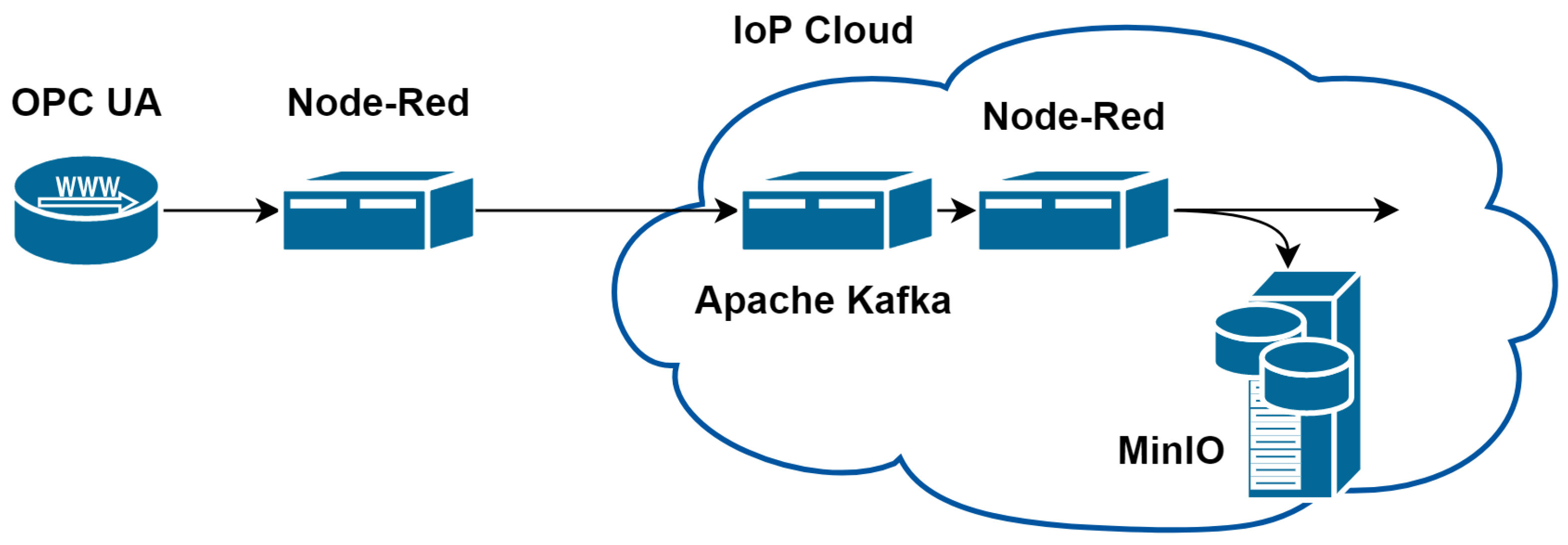
3.1. Data Architecture
- Adding higher level source descriptions that apply to all compounded flows.
- Reformatting the messages as JavaScript Object Notation (JSON) files.
- Optional batching of the messages.
- Sending the batches to the Kafka message broker running in the IoP cloud.
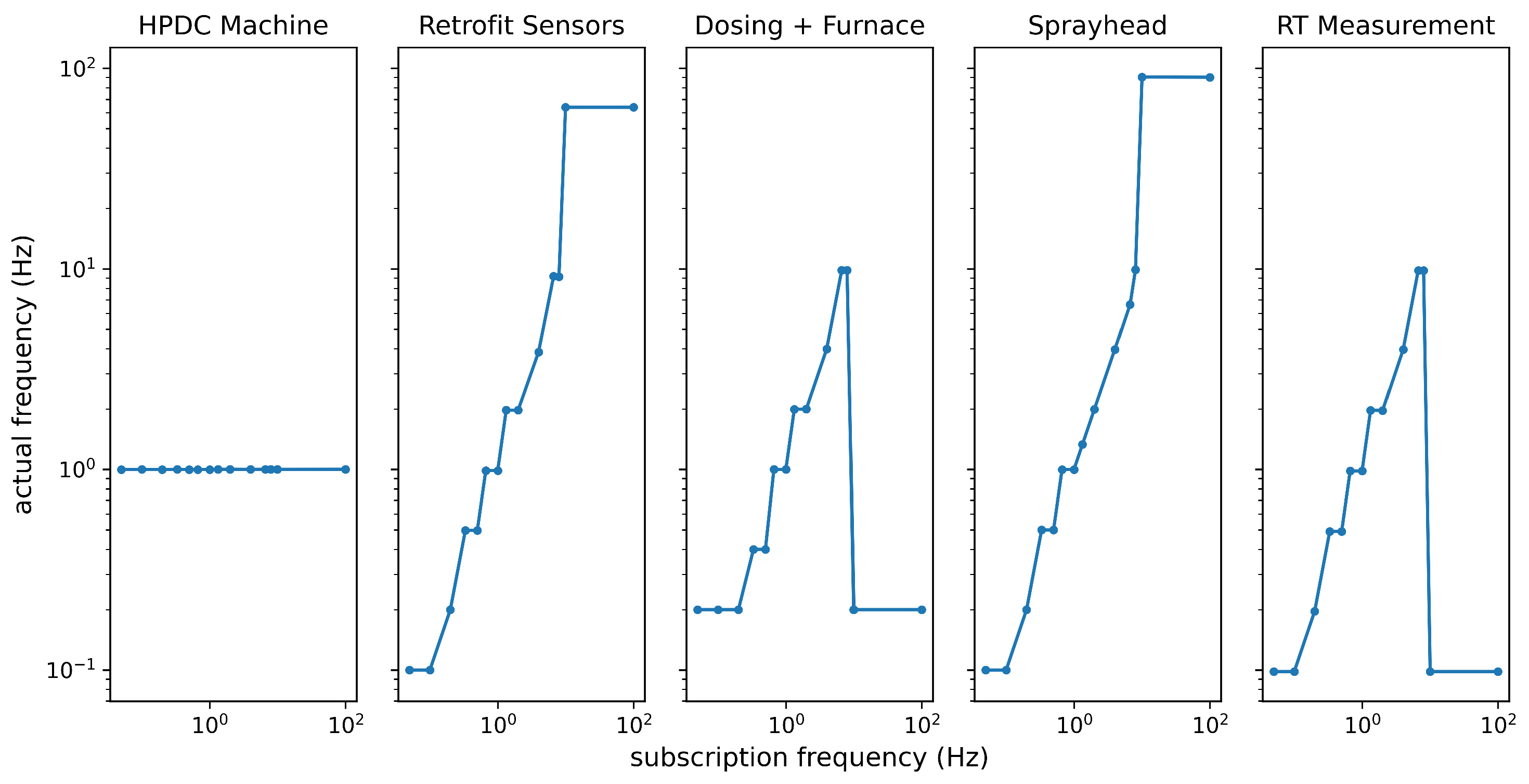
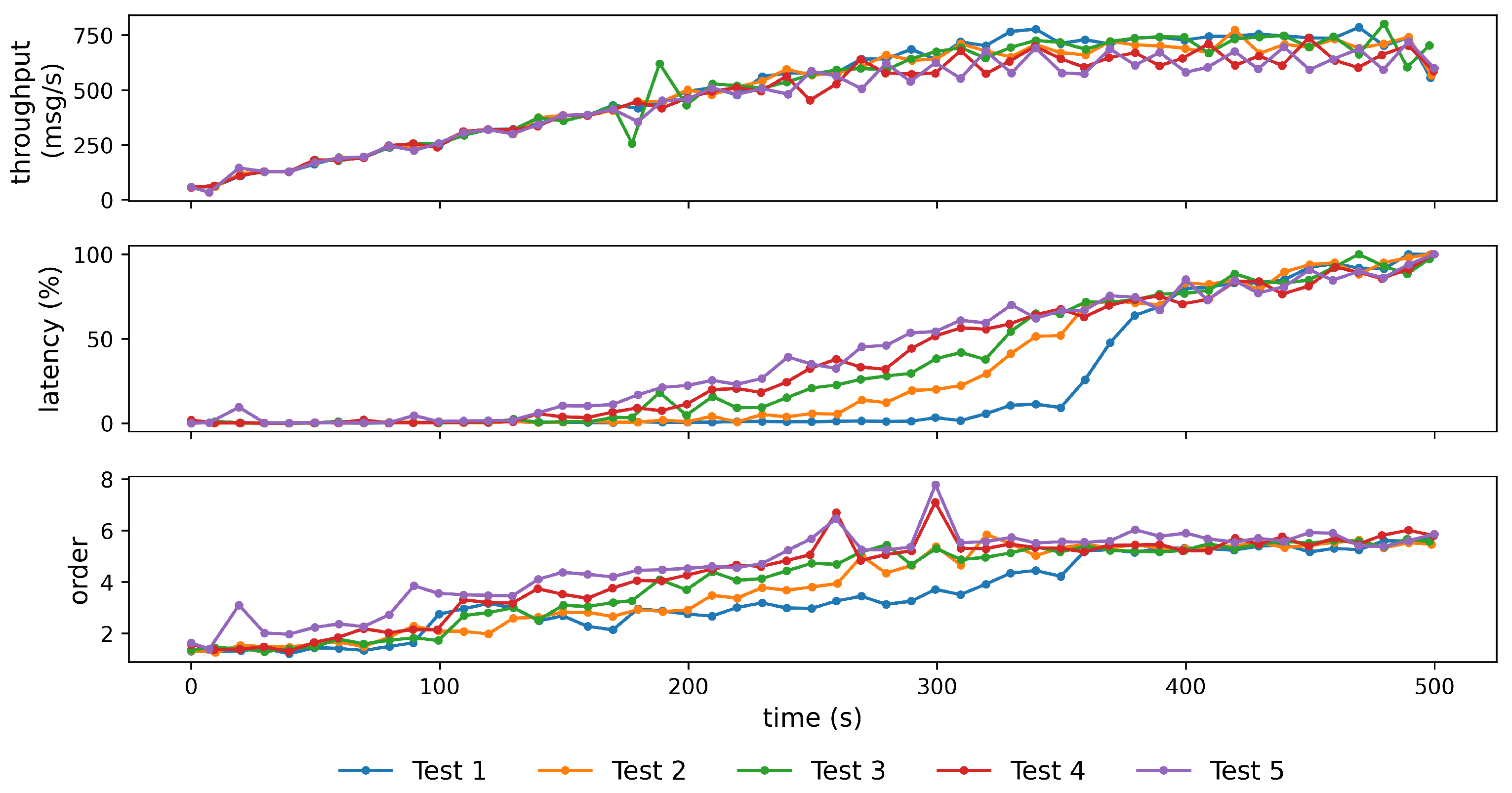
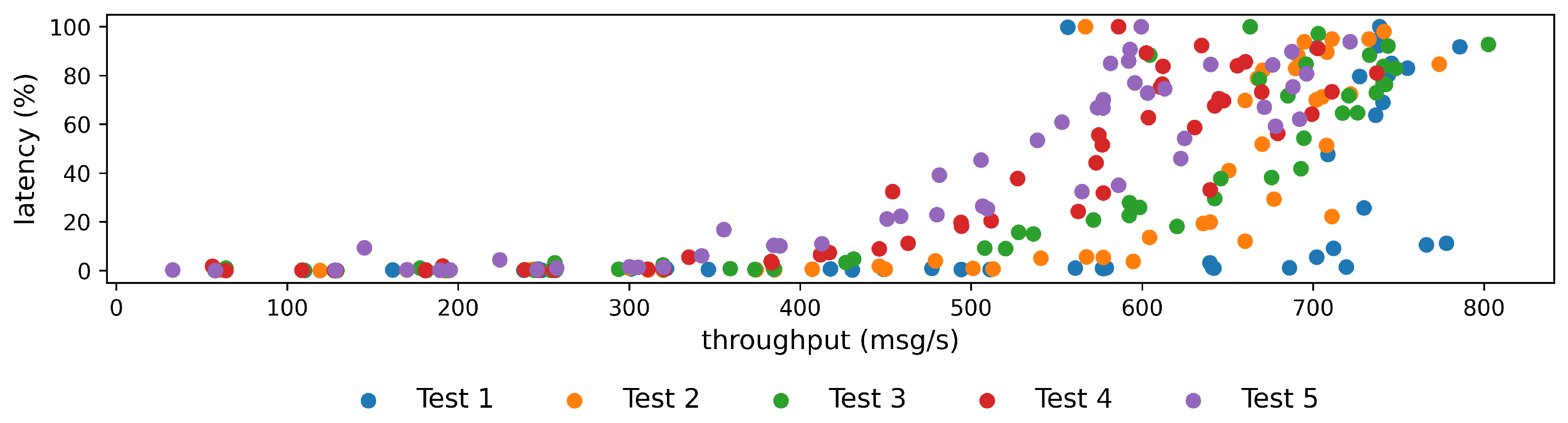
3.2. Load Tests
3.3. Preliminary Tests
3.4. Pipeline Tests
3.5. Data Usage
4. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Abbreviations
| CSV | Comma Separated Values |
| HTCs | Heat Transfer Coefficients |
| HPDC | High Pressure Die Casting |
| IP | Internet Protocol |
| JSON | JavaScript Object Notation |
| OLAP | Online Analytical Processing |
| OPC UA | Open Platform Communications Unified Architecture |
| PLC | Programmable Logic Control |
| RAM | Random Access Memory |
| SBC | Single Board Computer |
References
- OPC Unified Architecture. Available online: https://opcfoundation.org (accessed on 6 January 2022).
- Mahnke, W.; Leitner, S.H.; Damm, M. OPC Unified Architecture; Springer Science & Business Media: Berlin, Germany, 2009. [Google Scholar]
- Rix, M.; Kujat, B.; Meisen, T.; Jeschke, S. An agile information processing framework for high pressure die casting applications in modern manufacturing systems. Procedia CIRP 2016, 41, 1084–1089. [Google Scholar] [CrossRef] [Green Version]
- Pennekamp, J.; Glebke, R.; Henze, M.; Meisen, T.; Quix, C.; Hai, R.; Gleim, L.; Niemietz, P.; Rudack, M.; Knape, S.; et al. Towards an infrastructure enabling the internet of production. In Proceedings of the 2019 IEEE International Conference on Industrial Cyber Physical Systems (ICPS), Taipei, Taiwan, 6–9 May 2019; pp. 31–37. [Google Scholar]
- Dai, H.N.; Wang, H.; Xu, G.; Wan, J.; Imran, M. Big data analytics for manufacturing internet of things: Opportunities, challenges and enabling technologies. Enterp. Inf. Syst. 2020, 14, 1279–1303. [Google Scholar] [CrossRef] [Green Version]
- Rath, M.; Gannouni, A.; Luetticke, D.; Gries, T. Digitizing a Distributed Textile Production Process using Industrial Internet of Things: A Use-Case. In Proceedings of the 2021 4th IEEE International Conference on Industrial Cyber-Physical Systems (ICPS), Victoria, BC, Canada, 10–12 May 2021; pp. 315–320. [Google Scholar]
- Lee, J.Y.; Yoon, J.S.; Kim, B.H. A big data analytics platform for smart factories in small and medium-sized manufacturing enterprises: An empirical case study of a die casting factory. Int. J. Precis. Eng. Manuf. 2017, 18, 1353–1361. [Google Scholar] [CrossRef]
- Chen, K.Y.; Wu, T.C. Data warehouse design for manufacturing execution systems. In Proceedings of the IEEE International Conference on Mechatronics (ICM’05), Taipei, Taiwan, 10–12 July 2005; pp. 751–756. [Google Scholar]
- Hai, R.; Geisler, S.; Quix, C. Constance: An intelligent data lake system. In Proceedings of the 2016 International Conference on Management of Data, San Francisco, CA, USA, 26 June–1 July 2016; pp. 2097–2100. [Google Scholar]
- Lipp, J.; Rath, M.; Rudack, M.; Vroomen, U.; Bührig-Polaczek, A. Flexible OPC UA Data Load Optimizations on the Edge of Production. In Enterprise Information Systems, Proceedings of the 22nd International Conference (ICEIS 2020), Virtual Event, 5–7 May 2020; Revised Selected Papers; Springer: Cham, Switzerland, 2020; pp. 43–61. [Google Scholar]
- Raj, A.; Bosch, J.; Olsson, H.H.; Wang, T.J. Modelling Data Pipelines. In Proceedings of the 2020 46th Euromicro Conference on Software Engineering and Advanced Applications (SEAA), Portoroz, Slovenia, 26–28 August 2020; pp. 13–20. [Google Scholar]
- Node-Red. Available online: https://nodered.org (accessed on 6 January 2022).
- Nicolae, A.; Korodi, A. Node-Red and OPC UA Based Lightweight and Low-Cost Historian with Application in the Water Industry. In Proceedings of the 2018 IEEE 16th International Conference on Industrial Informatics (INDIN), Porto, Portugal, 18–20 July 2018; pp. 1012–1017. [Google Scholar]
- Apache Kafka. Available online: https://kafka.apache.org (accessed on 6 January 2022).
- Docker. Available online: https://www.docker.com (accessed on 6 January 2022).
- Kubernetes. Available online: https://kubernetes.io (accessed on 6 January 2022).
- Burns, B.; Grant, B.; Oppenheimer, D.; Brewer, E.; Wilkes, J. Borg, omega, and kubernetes. Commun. ACM 2016, 59, 50–57. [Google Scholar] [CrossRef]
- MinIO. Available online: https://min.io (accessed on 6 January 2022).
- OPC UA Foundation. OPC Unified Architecture—Part 4: Services, Version 1.05; OPC UA Foundation: Scottsdale, AZ, USA, 2021. [Google Scholar]








Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Rudack, M.; Rath, M.; Vroomen, U.; Bührig-Polaczek, A. Towards a Data Lake for High Pressure Die Casting. Metals 2022, 12, 349. https://doi.org/10.3390/met12020349
Rudack M, Rath M, Vroomen U, Bührig-Polaczek A. Towards a Data Lake for High Pressure Die Casting. Metals. 2022; 12(2):349. https://doi.org/10.3390/met12020349
Chicago/Turabian StyleRudack, Maximilian, Michael Rath, Uwe Vroomen, and Andreas Bührig-Polaczek. 2022. "Towards a Data Lake for High Pressure Die Casting" Metals 12, no. 2: 349. https://doi.org/10.3390/met12020349