
Pharmacogenetics of CYP2A6, CYP2B6, and UGT2B7 in the Context of HIV Treatments in African Populations


Abstract
:1. Introduction
1.1. Known Variants
1.1.1. CYP2A6
1.1.2. CYP2B6
1.1.3. CYP3A4
1.1.4. UGT2B7
1.2. Treatment and Dosage Guidelines
2. Materials and Methods
2.1. Data and Ethics
2.2. Analysis and Pipeline Development
Data Preparation
3. Analysis
4. Results
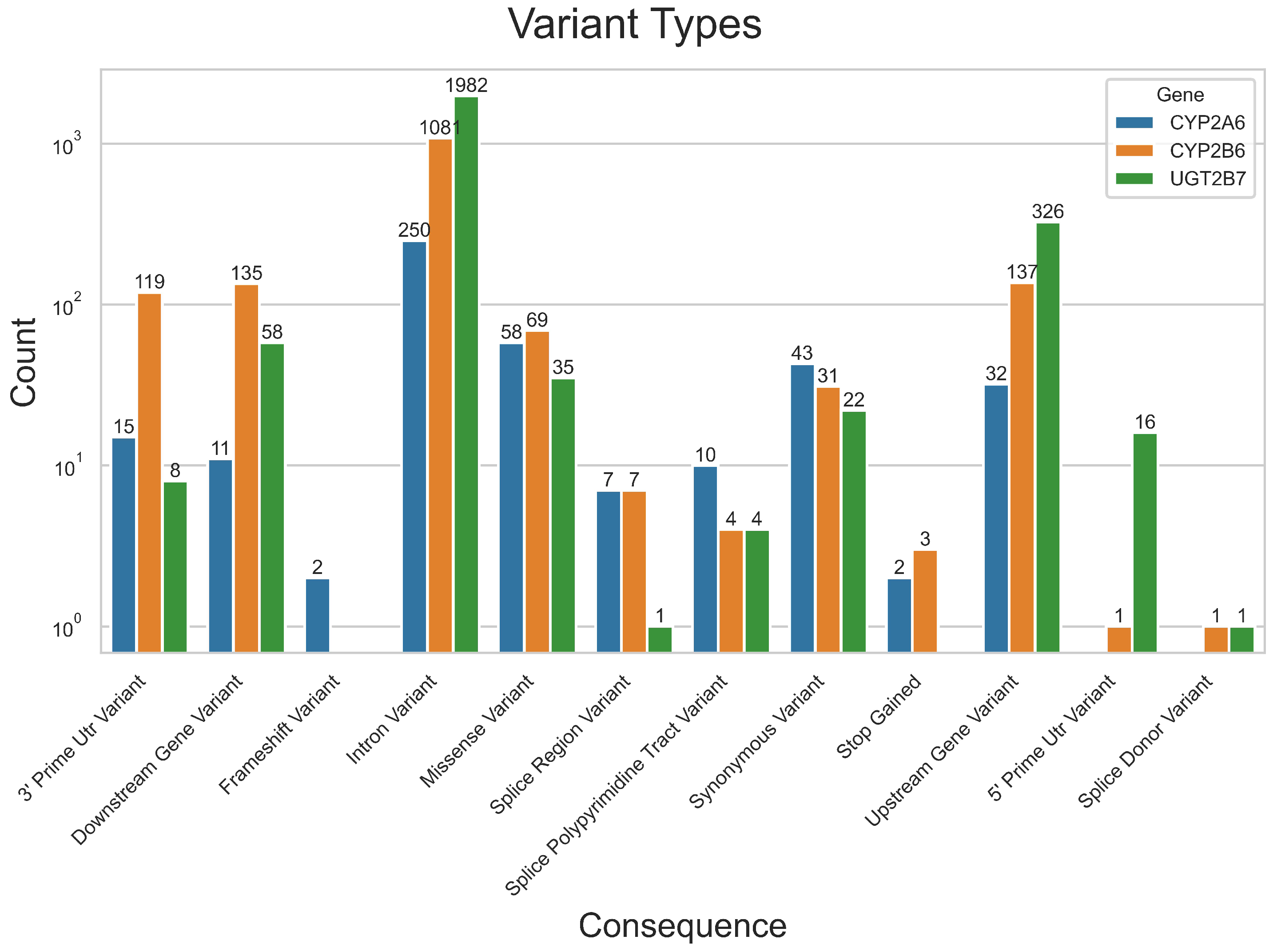
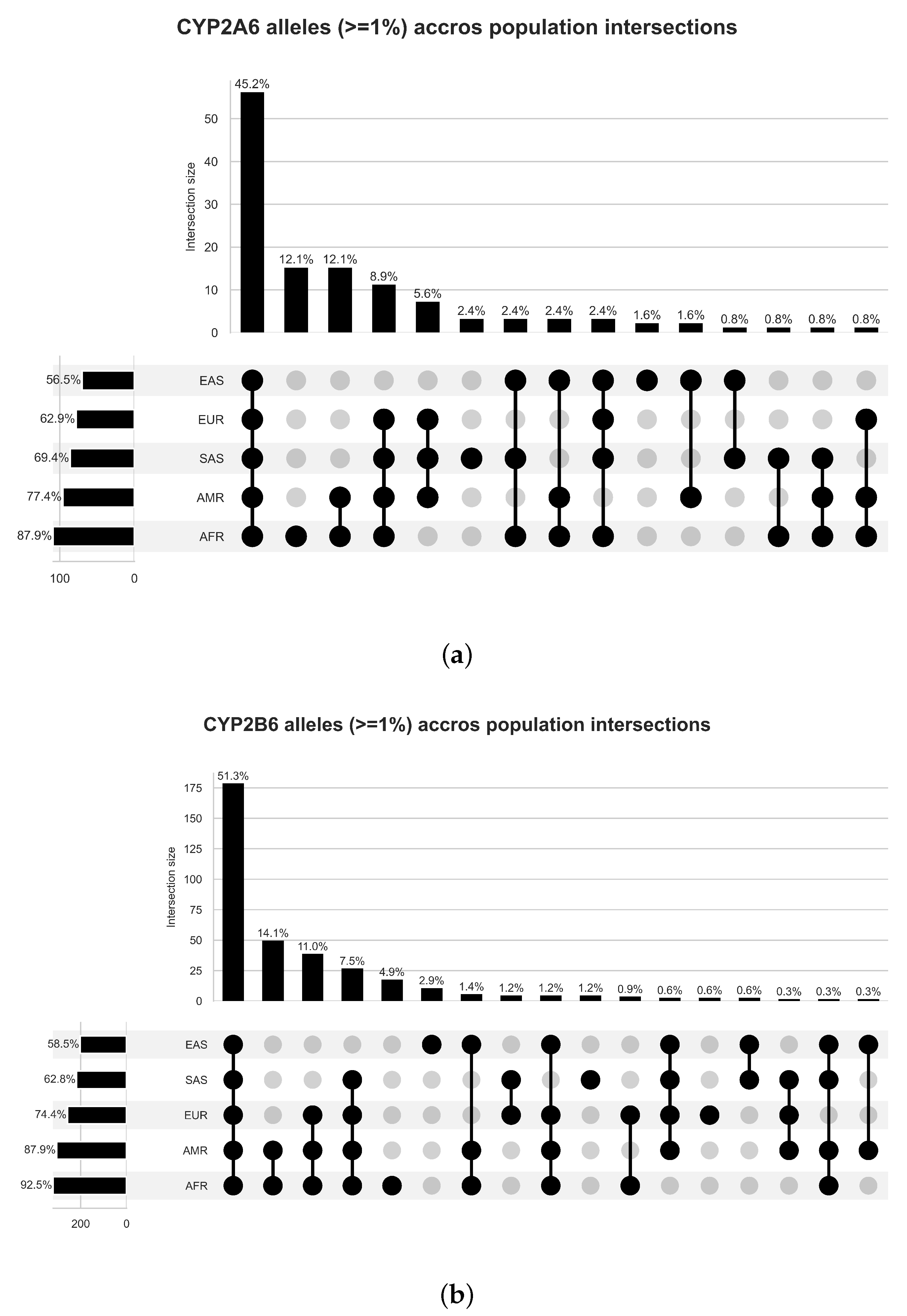
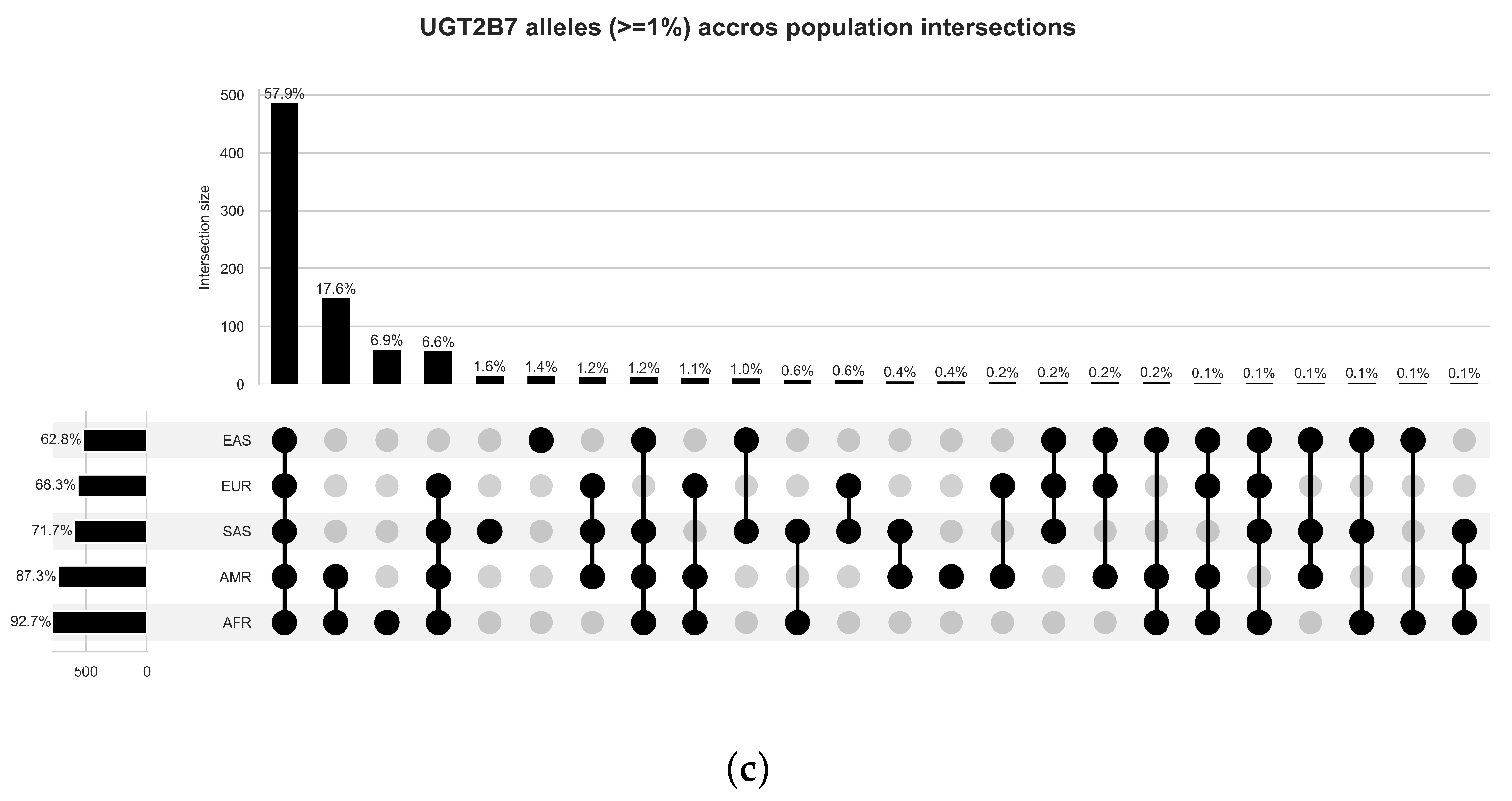
4.1. Variant and Population Partitions Characterisation
4.2. Fisher’s Exact Test
4.3. Variant Effect Prediction
4.3.1. Variants with Known Phenotype Associations
4.3.2. Novel Variants and Their Potential Pathogenicity
5. Discussion
5.1. Variant Frequency
5.2. Variant Impact
6. Conclusions
Limitations of the Study
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Rehle, T.M.; Shisana, O. Epidemiological and demographic HIV/AIDS projections: South Africa. Afr. J. AIDS Res. 2003, 2, 1–8. [Google Scholar] [CrossRef] [PubMed]
- Bienczak, A.; Cook, A.; Wiesner, L.; Olagunju, A.; Mulenga, V.; Kityo, C.; Kekitiinwa, A.; Owen, A.; Walker, A.S.; Gibb, D.M.; et al. The impact of genetic polymorphisms on the pharmacokinetics of efavirenz in African children. Br. J. Clin. Pharmacol. 2016, 82, 185–198. Available online: https://bpspubs.onlinelibrary.wiley.com/doi/pdf/10.1111/bcp.12934 (accessed on 4 June 2019). [CrossRef] [PubMed] [Green Version]
- Melis, V.; Usach, I.; Gandía, P.; Peris, J.E. Inhibition of Efavirenz Metabolism by Sertraline and Nortriptyline and Their Effect on Efavirenz Plasma Concentrations. Antimicrob. Agents Chemother. 2016, 60, 1022–1028. Available online: https://journals.asm.org/doi/pdf/10.1128/AAC.02129-15 (accessed on 4 June 2019). [CrossRef] [PubMed] [Green Version]
- Mollan, K.R.; Tierney, C.; Hellwege, J.N.; Eron, J.J.; Hudgens, M.G.; Gulick, R.M.; Haubrich, R.; Sax, P.E.; Campbell, T.B.; Daar, E.S.; et al. Race/ethnicity and the pharmacogenetics of reported suicidality with efavirenz among clinical trials participants. J. Infect. Dis. 2017, 216, 554–564. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Lamorde, M.; Byakika-Kibwika, P.; Okaba-Kayom, V.; Ryan, M.; Coakley, P.; Boffito, M.; Namakula, R.; Kalemeera, F.; Colebunders, R.; Back, D.; et al. Nevirapine pharmacokinetics when initiated at 200 mg or 400 mg daily in HIV-1 and tuberculosis co-infected Ugandan adults on rifampicin. J. Antimicrob. Chemother. 2010, 66, 180–183. Available online: https://academic.oup.com/jac/article-pdf/66/1/180/2155703/dkq411.pdf (accessed on 15 July 2019). [CrossRef] [PubMed] [Green Version]
- Tornio, A.; Backman, J.T. Cytochrome P450 in pharmacogenetics: An update. Adv. Pharmacol. 2018, 83, 3–32. [Google Scholar] [PubMed] [Green Version]
- LLerena, A.; Peñas-LLedó, E.; de Andrés, F.; Mata-Martín, C.; Sánchez, C.L.; Pijierro, A.; Cobaleda, J. Clinical implementation of pharmacogenetics and personalized drug prescription based on e-health: The MedeA initiative. Drug Metab. Drug Interact. 2020, 35, 20200143. [Google Scholar] [CrossRef] [PubMed]
- South African Department of Health. Standard Treatment Guidelines and Essential Medicines List for South Africa, 6th ed.; South African Department of Health: Pretoria, South Africa, 2018; p. 589. [Google Scholar]
- The Human Protein Atlas. Available online: https://www.proteinatlas.org/ (accessed on 16 July 2019).
- Uhlén, M.; Fagerberg, L.; Hallström, B.M.; Lindskog, C.; Oksvold, P.; Mardinoglu, A.; Sivertsson, Å.; Kampf, C.; Sjöstedt, E.; Asplund, A.; et al. Tissue-based map of the human proteome. Science 2015, 347, 1260419. Available online: https://www.science.org/doi/pdf/10.1126/science.1260419 (accessed on 23 February 2022). [CrossRef] [PubMed]
- Gaedigk, A.; Casey, S.T.; Whirl-Carrillo, M.; Miller, N.A.; Klein, T.E. Pharmacogene Variation Consortium: A Global Resource and Repository for Pharmacogene Variation. Clin. Pharmacol. Ther. 2021, 110, 542–545. Available online: https://ascpt.onlinelibrary.wiley.com/doi/10.1002/cpt.2321 (accessed on 12 August 2022). [CrossRef] [PubMed]
- Phan, L.; Jin, Y.; Zhang, H.; Qiang, W.; Shekhtman, E.; Shao, D.; Revoe, D.; Villamarin, R.; Ivanchenko, E.; Kimura, M.; et al. ALFA: Allele Frequency Aggregator; National Center for Biotechnology Information: Bethesda, MD, USA, 2020. [Google Scholar]
- Sherry, S.T. dbSNP: The NCBI database of genetic variation. Nucleic Acids Res. 2001, 29, 308–311. [Google Scholar] [CrossRef] [PubMed]
- Fagerberg, L.; Hallstrom, B.M.; Oksvold, P.; Kampf, C.; Djureinovic, D.; Odeberg, J.; Habuka, M.; Tahmasebpoor, S.; Danielsson, A.; Edlund, K.; et al. Analysis of the human tissue-specific expression by genome-wide integration of transcriptomics and antibody-based proteomics. Mol. Cell. Proteom. 2014, 13, 397–406. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- UGT Nomenclature Commitee. UGT Alleles Nomenclature Home Page. June 2005. Available online: https://www.pharmacogenomics.pha.ulaval.ca/ugt-alleles-nomenclature/ (accessed on 1 August 2022).
- Genes-Drugs—CPIC. Available online: https://cpicpgx.org/genes-drugs/ (accessed on 3 August 2022).
- Gaibar, M.; Novillo, A.; Romero-Lorca, A.; Esteban, M.E.; Fernández-Santander, A. Pharmacogenetics of ugt genes in North African populations. Pharmacogenomics J. 2018, 18, 609–612. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Köster, J.; Rahmann, S. Snakemake-a scalable bioinformatics workflow engine. Bioinformatics 2012, 28, 2520–2522. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- DePristo, M.A.; Banks, E.; Poplin, R.; Garimella, K.V.; Maguire, J.R.; Hartl, C.; Philippakis, A.A.; del Angel, G.; Rivas, M.A.; Hanna, M.; et al. A framework for variation discovery and genotyping using next-generation DNA sequencing data. Nat. Genet. 2011, 43, 491–498. [Google Scholar] [CrossRef] [PubMed]
- Purcell, S.M.; Chang, C. PLINK 2.0. Available online: https://www.cog-genomics.org/plink/2.0/ (accessed on 12 March 2021).
- Li, H. A statistical framework for SNP calling, mutation discovery, association mapping and population genetical parameter estimation from sequencing data. Bioinformatics 2011, 27, 2987–2993. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Chang, C.C.; Chow, C.C.; Tellier, L.C.; Vattikuti, S.; Purcell, S.M.; Lee, J.J. Second-generation PLINK: Rising to the challenge of larger and richer datasets. GigaScience 2015, 4, 7. [Google Scholar] [CrossRef] [PubMed]
- Virtanen, P.; Gommers, R.; Oliphant, T.E.; Haberland, M.; Reddy, T.; Cournapeau, D.; Burovski, E.; Peterson, P.; Weckesser, W.; Bright, J.; et al. SciPy 1.0: Fundamental algorithms for scientific computing in Python. Nat. Methods 2020, 17, 261–272. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Yates, A.D.; Achuthan, P.; Akanni, W.; Allen, J.; Allen, J.; Alvarez-Jarreta, J.; Amode, M.R.; Armean, I.M.; Azov, A.G.; Bennett, R.; et al. Ensembl 2020. Nucleic Acids Res. 2019, 48, D682–D688. Available online: https://academic.oup.com/nar/article-pdf/48/D1/D682/31697830/gkz966.pdf (accessed on 20 August 2022). [CrossRef] [PubMed]
- González-Pérez, A.; López-Bigas, N. Improving the assessment of the outcome of nonsynonymous SNVs with a consensus deleteriousness score, Condel. Am. J. Hum. Genet. 2011, 88, 440–449. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Whirl-Carrillo, M.; Huddart, R.; Gong, L.; Sangkuhl, K.; Thorn, C.F.; Whaley, R.; Klein, T.E. An evidence-based framework for evaluating pharmacogenomics knowledge for personalized medicine. Clin. Pharmacol. Ther. 2021, 110, 563–572. [Google Scholar] [CrossRef] [PubMed]
- PharmVar. Gene Info CYP2A6. 2022. Available online: https://a.storyblok.com/f/70677/x/fc1538c603/gene-info_cyp2a6_v1-0.pdf (accessed on 21 October 2022).




{kind=link}
{kind=link}
{kind=link}
| Gene | Start Coordinates (Source—100 bp) | Stop Coordinates (Source +100 bp) | Region Size |
|---|---|---|---|
| CYP2A6 | 41,349,343 bp (e! and UCSC) | 41,356,460 bp (NCBI) | 7117 bp |
| CYP2B6 | 41,497,104 bp (e! and UCSC) | 41,524,408 bp (NCBI) | 27,304 bp |
| UGT2B7 | 69,916,981 bp (e!) | 69,978,805 bp (All) | 61,624 bp |
| Gene | Variants Identified | Alleles (1% or More) | Two-Tailed Significance ( = 0.05) |
|---|---|---|---|
| CYP2A6 | 413 | 103 | 159 |
| CYP2B6 | 1586 | 322 | 771 |
| UGT2B7 | 2469 | 736 | 957 |
| rsID | Haplotypes(pheno.) | AFR vs. other | AMR vs. AFR | EUR vs. AFR | EAS vs. AFR | SAS vs. AFR |
|---|---|---|---|---|---|---|
| rs6413474 | *1, *1×2↑, *21† | 0% ↓ | 0.58% ↑ | 1.19% ↑ | - | 0.82% ↑ |
| rs28399463 | *1, *1×2↑, *28†, *44† | 2.65% ↑ | 0.29% ↓ | 0% ↓ | 0% ↓ | 0.1% ↓ |
| rs1809810 | *1, *1× 2↑, *18†, *19† | 0.61% ↓ | 1.59% ↑ | 1.59% ↑ | - | 2.25% ↑ |
| rs28399454 | *1, *1× 2↑, *17↓ | 11.9% ↑ | 0.58% ↓ | 0% ↓ | 0.1% ↓ | 0% ↓ |
| rs56256500 | *1, *1× 2↑, *16†, *23† | 1.97% ↑ | 0% ↓ | 0% ↓ | 0% ↓ | 0% ↓ |
| rs199916117 | - | 0% ↓ | - | - | 1.49% ↑ | - |
| rs1801272 | *1, *1×2↑, *2↓ | 0.08% ↓ | 0.72% ↑ | 3.38% ↑ | - | 0.61% ↑ |
| rs28399440 | *1, *1×2↑, *9↓, *13†, *15†, *50† | 1.81% ↑ | 0% ↓ | 0% ↓ | 0% ↓ | 0% ↓ |
| rs72549435 | *1, *1× 2↑, *24†, *49† | 1.06% ↑ | 0.14% ↓ | 0% ↓ | 0.1% ↓ | 0% ↓ |
| rs145308399 | - | 0.15% ↕ | 0% ↓ | - | - | 2.15% ↑ |
| rs28399435 | *1, *1×2↑, *14† | 0.38% ↓ | 1.73% ↑ | 3.28% ↑ | - | 2.25% ↑ |
| rs72549432 | *1, *1× 2↑, *31† | 1.13% ↑ | 0% ↓ | 0% ↓ | 0% ↓ | 0% ↓ |
| rs34883432 | *1, *10‡ | 0% ↓ | 1.3% ↑ | 0.7% ↑ | - | - |
| rs8192709 | *1, *2, *10‡ | 4.3% ↑ | 0.29% ↓ | 6.26% ↓ | - | - |
| rs33980385 | *1, *17 | 1.29% ↑ | - | 0% ↓ | 0% ↓ | 0% ↓ |
| rs33926104 | *1, *17 | 1.29% ↑ | 0.29% ↓ | 0% ↓ | 0% ↓ | 0% ↓ |
| rs34284776 | *1, *17 | 1.29% ↑ | 0.29% ↓ | 0% ↓ | 0% ↓ | 0% ↓ |
| rs3745274 | *1, *6↓, *7↓, *9↓, *13⊘, *19↓, *20↓, *26↓, *34↓, *36↓, *37⊘, *38⊘ | 37.95% ↑ | - | 23.56% ↓ | 21.53% ↓ | - |
| rs139029625 | *1, *35⊘ | 1.21% ↑ | 0% ↓ | 0% ↓ | 0% ↓ | 0% ↓ |
| rs28399499 | *1, *18⊘ | 8.56% ↑ | 1.01% ↓ | 0% ↓ | 0% ↓ | 0% ↓ |
| rs3211371 | *1, *5, *7↓, *33‡, *34↓ | 1.21% ↕ | 7.21% ↑ | 11.23% ↑ | 0.3% ↓ | 8.9% ↑ |
| rs12233719 | - | 0.08% ↓ | - | - | 13.19% ↑ | 0.72% ↑ |
| rs7439366 | - | 77.49% ↑ | 68.01 ↓ | 51.49% ↓ | 72.52% ↓ | 60.12% ↓ |
| Gene | Position | Reference | Alternate | Consequence |
|---|---|---|---|---|
| CYP2A6 | 40843668 | T | C | 3’ UTR variant |
| CYP2A6 | 40848968 | G | GA | Intron variant |
| CYP2B6 | 40992518 | T | C | Intron variant |
| CYP2B6 | 40995794 | ATGATATT | A | Intron variant |
| CYP2B6 | 40996689 | T | C | Intron variant |
| CYP2B6 | 41001709 | G | A | Intron variant |
| CYP2B6 | 41008210 | T | TTTG | Intron variant |
| CYP2B6 | 41017322 | C | A | 3’ UTR variant |
| UGT2B7 | 69046035 | T | A | Downstream gene variant |
| UGT2B7 | 69052469 | G | GT | Mapping Failure * |
| UGT2B7 | 69053111 | A | G | Intron variant |
| UGT2B7 | 69056859 | T | C | Intron variant |
| UGT2B7 | 69058254 | C | T | Intron variant |
| UGT2B7 | 69059862 | C | G | Intron variant |
| UGT2B7 | 69060704 | G | C | Intron variant |
| UGT2B7 | 69063327 | A | AAAAAAGG | Intron variant |
| UGT2B7 | 69063329 | A | AAAAGAAAG | Intron variant |
| UGT2B7 | 69064070 | A | AAG | Intron variant |
| UGT2B7 | 69064096 | G | GAA | Intron variant |
| UGT2B7 | 69070106 | G | C | Intron variant |
| UGT2B7 | 69078334 | C | T | Intron variant |
| UGT2B7 | 69092102 | A | AT | Mapping Failure * |
| UGT2B7 | 69099275 | AAAAG | A | Intron variant |
| UGT2B7 | 69100656 | G | A | Intron variant |
| UGT2B7 | 69104655 | G | A | Intron variant |
| UGT2B7 | 69107691 | T | C | Intron variant |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ford, G.R.; Niehaus, A.; Joubert, F.; Pepper, M.S. Pharmacogenetics of CYP2A6, CYP2B6, and UGT2B7 in the Context of HIV Treatments in African Populations. J. Pers. Med. 2022, 12, 2013. https://doi.org/10.3390/jpm12122013
Ford GR, Niehaus A, Joubert F, Pepper MS. Pharmacogenetics of CYP2A6, CYP2B6, and UGT2B7 in the Context of HIV Treatments in African Populations. Journal of Personalized Medicine. 2022; 12(12):2013. https://doi.org/10.3390/jpm12122013
Chicago/Turabian StyleFord, Graeme R., Antoinette Niehaus, Fourie Joubert, and Michael S. Pepper. 2022. "Pharmacogenetics of CYP2A6, CYP2B6, and UGT2B7 in the Context of HIV Treatments in African Populations" Journal of Personalized Medicine 12, no. 12: 2013. https://doi.org/10.3390/jpm12122013