
A Deep Learning Framework for Cardiac MR Under-Sampled Image Reconstruction with a Hybrid Spatial and k-Space Loss Function


Abstract
:1. Introduction
- A new AI-based accurate parallel imaging reconstruction framework was proposed for better CMR image reconstruction.
- A new hybrid spatial and k-space loss function was proposed, which improves the SNR by taking into account the difference between the target (ground-truth, GT) and the reconstructed images in both spatial and frequency domains.
- Comprehensive reconstruction experimental studies were conducted with the aim to select the best AI model for the proposed framework. The model search additionally included the direct implementation of the conventional loss functions as well as their comparison with the proposed hybrid loss function.
2. Related Work
3. Materials and Methods
3.1. The Proposed RecCGAN Framework: End-to-End Execution Scenario
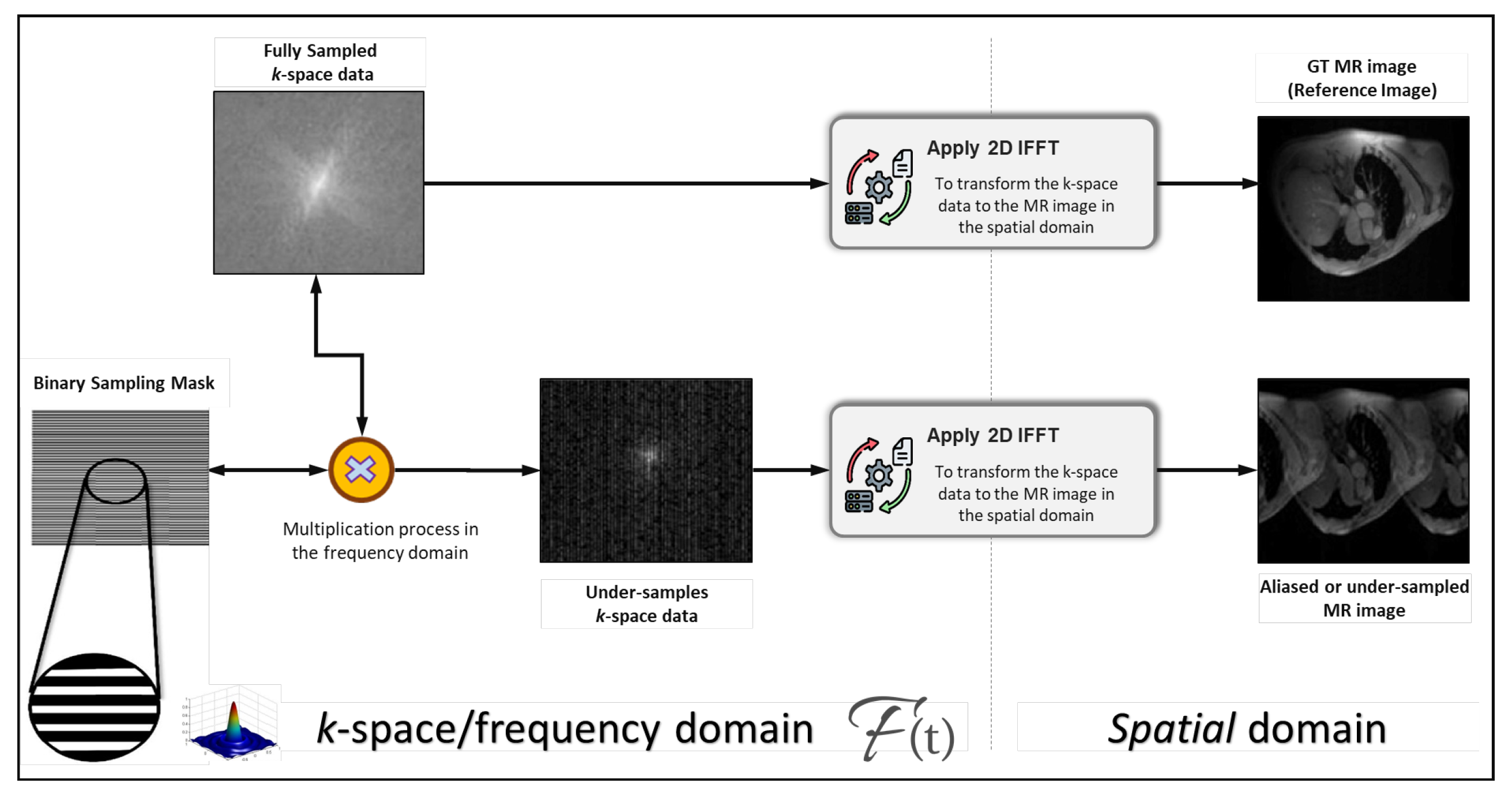
- The fast MRI raw k-space data are collected and transformed into the spatial domain using the inverse fast Fourier transformer (IFFT).
- The MR images are resized into a fixed size of 256 × 256 pixels.
- After resizing, the FFT is applied to allow us to generate the under-sampled MR data in the frequency domain by removing each second column in the k-space domain (known as interleaved under-sampling).
- The IFFT is applied again to convert the under-sampled k-space data into the aliased MR images.
- All aliased images are normalized to fit all pixels within a fixed value range of [0, 255] to improve the AI learning process, and hence, the reconstruction performance. More detail about the data preparation can be found in Algorithm 1 (Section 3.2.2).
- The prepared aliased MR images are randomly split into 70% training, 10% validation, and 20% testing sets.
- To increase the number of training MR images, the augmentation strategy is applied to avoid any overfitting or bias, assist in better hyper-parameters’ optimization, and improve the reconstruction performance.
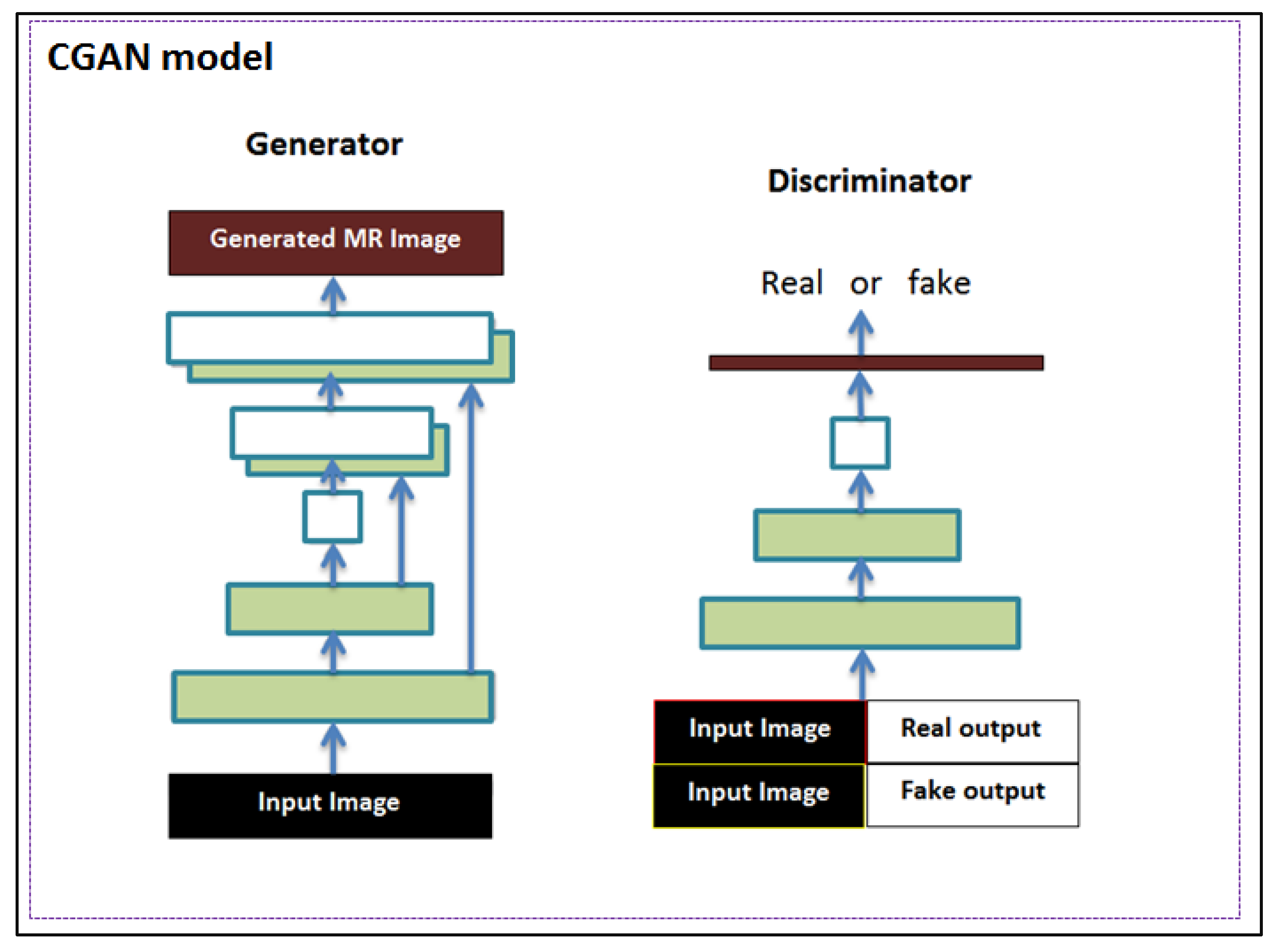
- For reconstruction purposes, two well-known deep learning architectures of U-Net and CGAN are adopted and used. The CGAN structure is adopted by using U-Net in an encoder–decoder fashion to build the generator network. However, we test and investigate the reconstruction performance of both U-Net and CGAN separately.
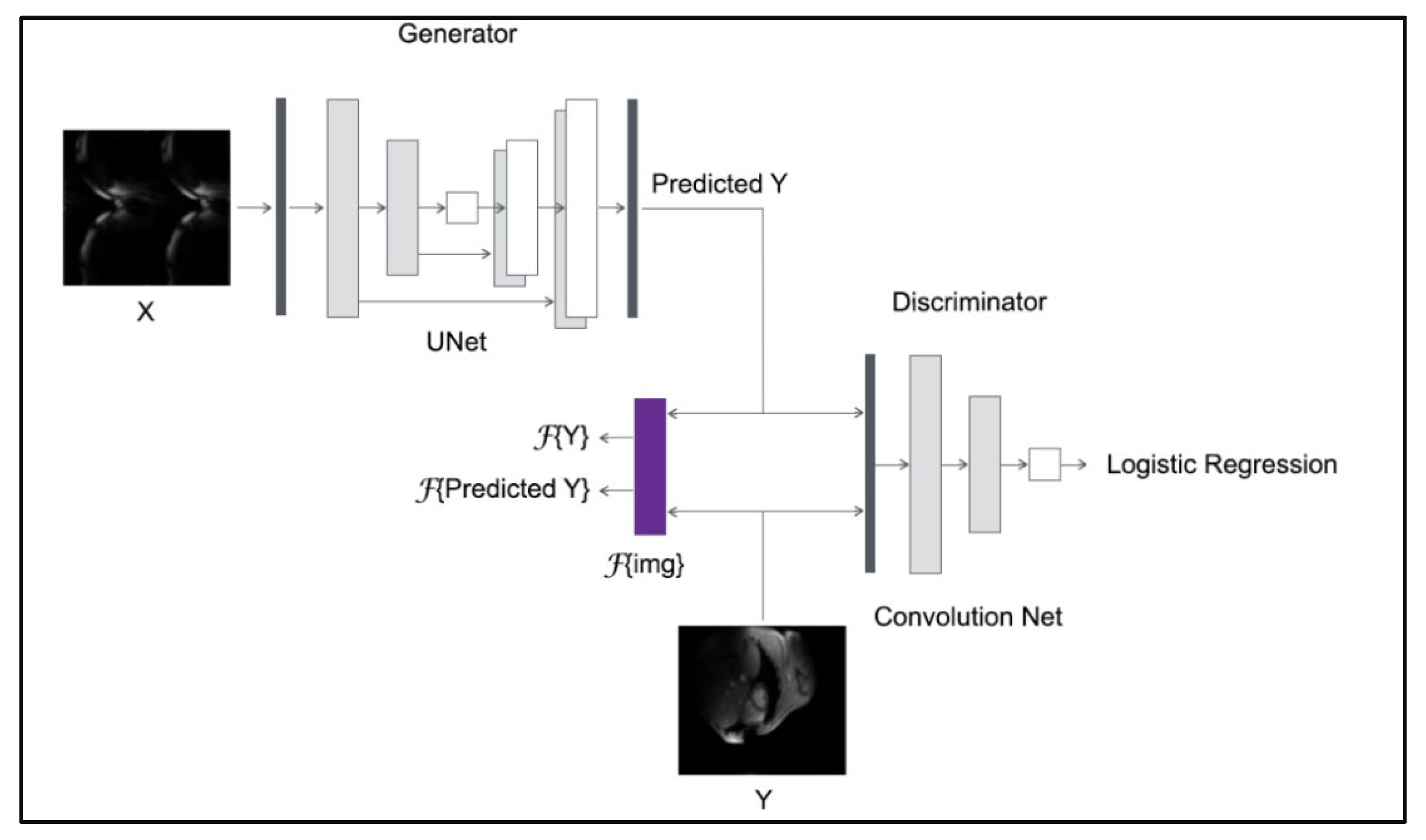
- The hybrid spatial and frequency loss function is proposed in order to improve the reconstructed image quality over conventional loss functions acting only in the spatial domain, such as L1-norm and GAN loss as a discriminator classification loss function.
- Finally, the proposed framework is evaluated using the individual U-Net and CGAN against the widely used conventional SENSE reconstruction algorithm. A direct, fair comparison is conducted using the same dataset and training environment settings.
3.2. Dataset
3.2.1. Dataset Description
3.2.2. Dataset Preparation
| Algorithm 1 Dataset preparation for parallel imaging simulation. |
| Start: |
| Input: Fully sampled k-space cardiac MRI data |
| Step 1: load data |
| k-space data = {‘kx’ ‘ky’ ‘kz’ ‘coil’ ‘phase’ ‘set’ ‘slice’ ‘rep’ ‘avg’} ← {read k-space data in *.h5 format} |
| ISMRMRD ← ISMRMRD; Python toolbox for MR image reconstruction [19] |
| Step 2: Average the k-space data accumulations (kData) if ‘avg’ > 1 k-space data ← numpy.mean(kData, axis= −1) |
| Step 3: Apply IFFT to transform the k-space averaged data into the spatial domain ImageSpaceData ← transform data from k-space into image space |
|
|
|
| END |
3.2.3. MR Data Splitting and Augmentation
3.3. Deep Learning Network Architecture and Training Details
3.3.1. U-Net with Hybrid Loss
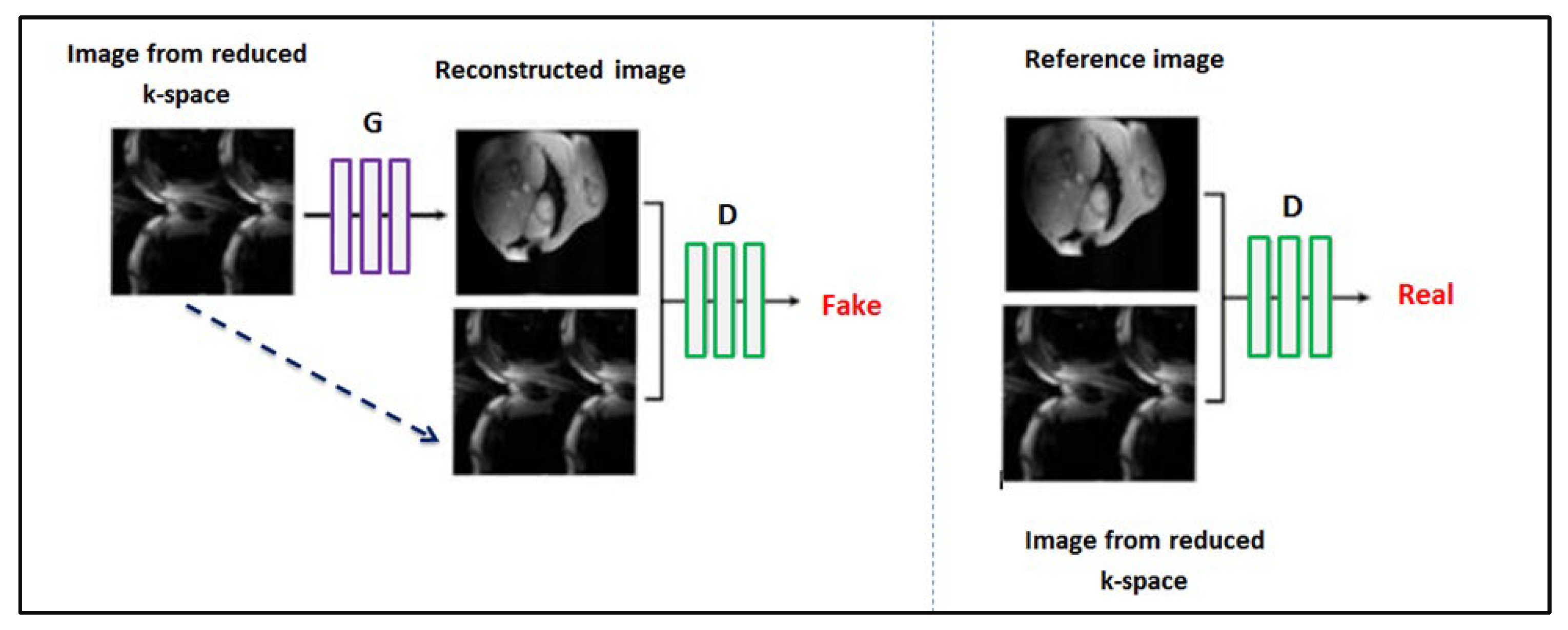
3.3.2. CGAN with Hybrid Loss
3.4. Evaluation Strategy
3.5. Experimental Setup
3.6. Execution Development Environment
4. Experimental Results
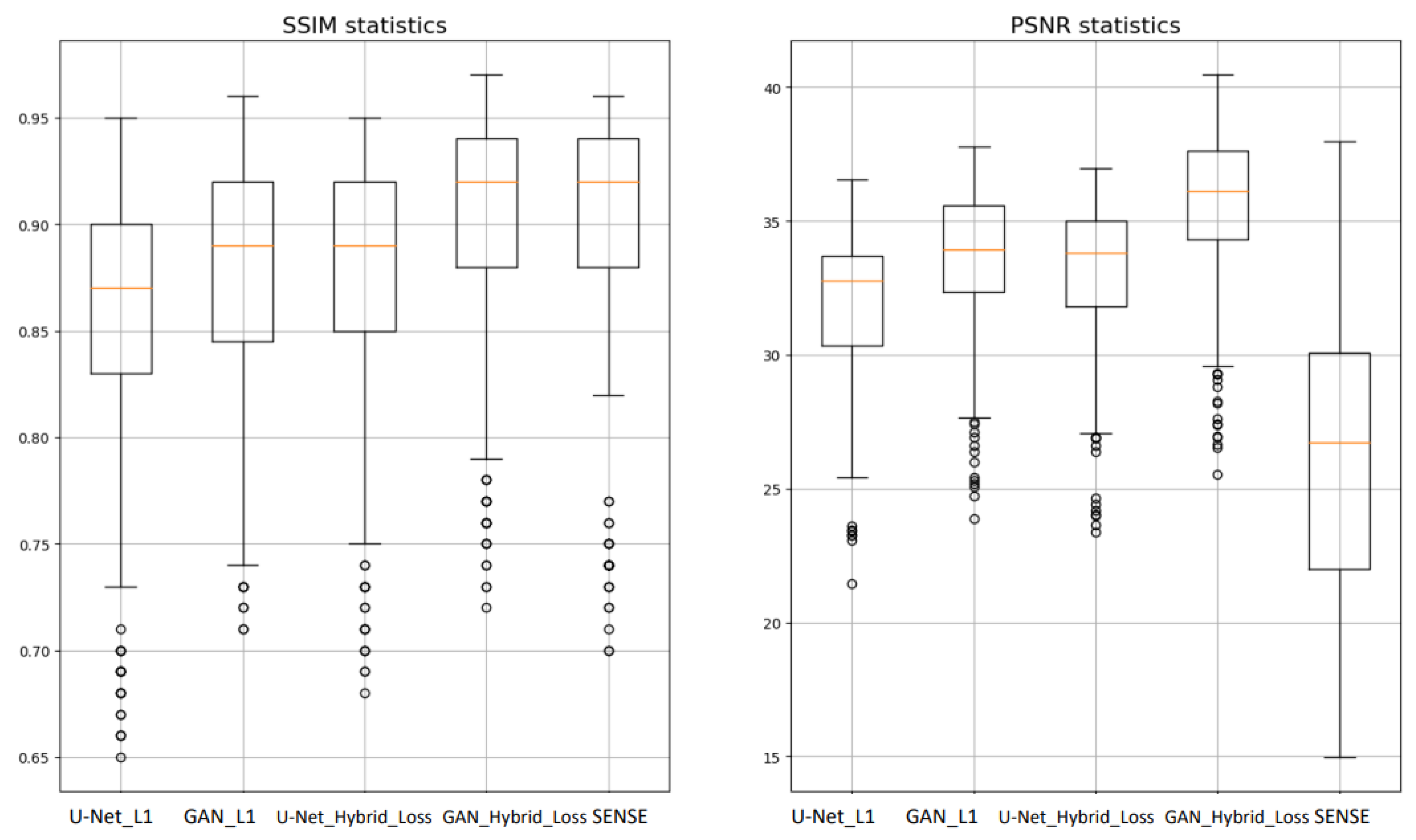
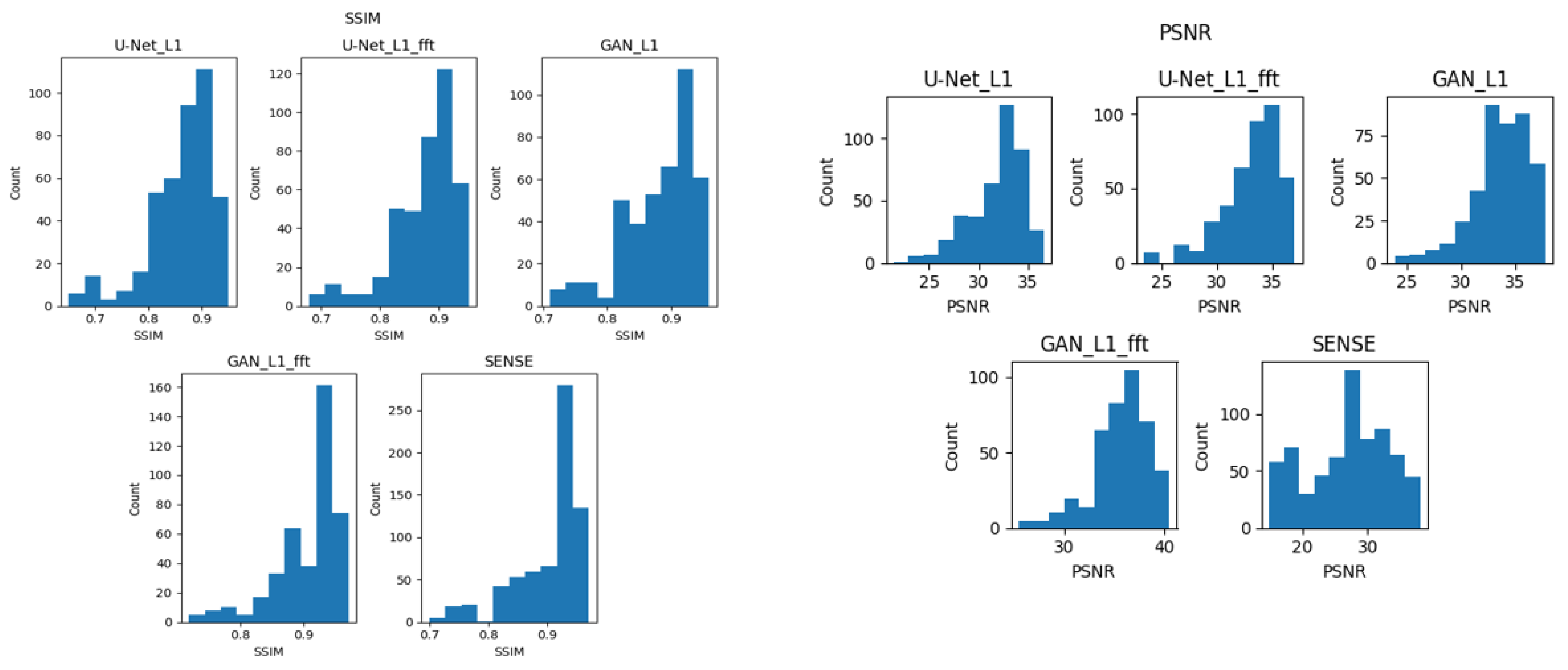
4.1. Quality of the MR Image Reconstruction against Different AI Architectures
4.2. Quality of the MR Image Reconstruction against the Proposed Hybrid Loss Function
5. Discussion
5.1. Deep Learning Approach against Classical Algorithms of MR Image Reconstruction
5.2. Statistical Significance of the Results
5.3. Comparison Results against the Recent Research Works
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| AI | Artificial Intelligence |
| GAN | Generative Adversarial Network |
| CGAN | Conditional Generative Adversarial Network |
| MRI | Magnetic Resonance Imaging |
| PSNR | Peak Signal to Noise Ratio |
| SSIM | Structure Similarity |
| SENSE | Sensitivity Encoding |
| GRAPPA | Generalized Autocalibrating Partial Parallel Acquisition |
| FFT | Fast Fourier Transform |
| IFFT | Inverse Fast Fourier Transform |
References
- Sobol, W.T. Recent advances in MRI technology: Implications for image quality and patient safety. Saudi J. Ophthalmol. 2012, 26, 393–399. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Krupa, K.; Bekiesińska-Figatowska, M. Artifacts in Magnetic Resonance Imaging. Pol. J. Radiol. 2015, 80, 93–106. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Zbontar, J.; Knoll, F.; Sriram, A.; Murrell, T.; Huang, Z.; Muckley, M.J.; Defazio, A.; Stern, R.; Johnson, P.; Bruno, M.; et al. fastMRI: An Open Dataset and Benchmarks for Accelerated MRI. arXiv 2018, arXiv:1811.08839. [Google Scholar]
- Martí-Bonmatí, L. MR Image Acquisition: From 2D to 3D. In 3D Image Processing: Techniques and Clinical Applications; Caramella, D., Bartolozzi, C., Eds.; Springer: Berlin/Heidelberg, Germany, 2002; pp. 21–295. [Google Scholar]
- Yanasak, N.; Clarke, G.; Stafford, R.J.; Goerner, F.; Steckner, M.; Bercha, I.; Och, J.; Amurao, M. Parallel Imaging in MRI: Technology, Applications, and Quality Control; American Association of Physicists in Medicine: Alexandria, VA, USA, 2015. [Google Scholar] [CrossRef]
- Blaimer, M.; Breuer, F.; Mueller, M.; Heidemann, R.M.; Griswold, M.A.; Jakob, P.M. SMASH, SENSE, PILS, GRAPPA: How to choose the optimal method. Top Magn. Reason. Imaging TMRI 2004, 15, 223–236. [Google Scholar] [CrossRef] [PubMed]
- Pruessmann, K.P.; Weiger, M.; Scheidegger, M.B.; Boesiger, P. SENSE: Sensitivity encoding for fast MRI. Magn. Reason. Med. 1999, 42, 952–962. [Google Scholar] [CrossRef]
- Hoge, W.S.; Brooks, D.H. On the complimentarity of SENSE and GRAPPA in parallel MR imaging. In Proceedings of the 2006 International Conference of the IEEE Engineering in Medicine and Biology Society, New York, NY, USA, 30 August–3 September 2006; pp. 755–758. [Google Scholar] [CrossRef]
- Chen, C.; Liu, Y.; Schniter, P.; Tong, M.; Zareba, K.; Simonetti, O.; Potter, L.; Ahmad, R. OCMR (v1.0)--Open-Access Multi-Coil k-Space Dataset for Cardiovascular Magnetic Resonance Imaging. arXiv 2020, arXiv:2008.03410. [Google Scholar]
- Nilsson, J.; Akenine-Möller, T. Understanding SSIM. arXiv 2020, arXiv:2006.13846. [Google Scholar]
- Wang, Z.; Bovik, A.C.; Sheikh, H.R.; Simoncelli, E.P. Image quality assessment: From error visibility to structural similarity. IEEE Trans. Image Process 2004, 13, 600–612. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Tao, D.; Di, S.; Liang, X.; Chen, Z.; Cappello, F. Fixed-PSNR Lossy Compression for Scientific Data. In Proceedings of the 2018 IEEE International Conference on Cluster Computing (CLUSTER), Belfast, UK, 10–13 September 2018; pp. 314–318. [Google Scholar]
- Hyun, C.M.; Kim, H.P.; Lee, S.M.; Lee, S.; Seo, J.K. Deep learning for undersampled MRI reconstruction. Phys. Med. Biol. 2017, 63, 135007. [Google Scholar] [CrossRef] [PubMed]
- Ghodrati, V.; Shao, J.; Bydder, M.; Zhou, Z.; Yin, W.; Nguyen, K.L.; Yang, Y.; Hu, P. MR image reconstruction using deep learning: Evaluation of network structure and loss functions. Quant. Imaging Med. Surg. 2019, 9, 1516–1527. [Google Scholar] [CrossRef] [PubMed]
- Cole, E.K.; Pauly, J.M.; Vasanawala, S.S.; Ong, F. Unsupervised MRI Reconstruction with Generative Adversarial Networks. arXiv 2020, arXiv:2008.13065. [Google Scholar] [CrossRef]
- Li, W.; Feng, X.; An, H.; Ng, X.Y.; Zhang, Y.J. MRI Reconstruction with Interpretable Pixel-Wise Operations Using Reinforcement Learning. Proc. AAAI Conf. Artif. Intell. 2020, 34, 792–799. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. In Medical Image Computing and Computer-Assisted—MICCAI; Navab, N., Hornegger, J., Wells, W., Frangi, A., Eds.; Lecture Notes in Computer Science; Springer: Cham, Switzerland, 2015; Volume 9351. [Google Scholar] [CrossRef] [Green Version]
- Isola, P.; Zhu, J.-Y.; Zhou, T.; Efros, A.A. Image-to-Image Translation with Conditional Adversarial Networks. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 5967–5976. [Google Scholar]
- Available online: https://github.com/ismrmrd/ismrmrd-python (accessed on 25 February 2023).
- Hossain, K.F.; Kamran, S.A.; Tavakkoli, A.; Pan, L.; Ma, X.; Rajasegarar, S.; Karmaker, C. ECG-Adv-GAN: Detecting ECG Adversarial Examples with Conditional Generative Adversarial Networks. In Proceedings of the 2021 20th IEEE International Conference on Machine Learning and Applications (ICMLA), Online, 13–15 December 2021; pp. 50–56. [Google Scholar]
- Bernstein, M.A.; King, K.F.; Zhou, Z.J. Handbook of MRI Pulse Sequences; Academic Press: Amsterdam, The Netherlands, 2004. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Training (70%) | Validation (10%) | Testing (30%) | |
|---|---|---|---|
| Original Dataset | 887 | 99 | 415 |
| Augmented Dataset | 3548 |
| AI Model | SSIM | PSNR | No. of Trainable Parameters (Million) | Training Time/Epoch (s) | Testing Time/Image (s) | ||
|---|---|---|---|---|---|---|---|
| Mean ± SD | Median | Mean ± SD | Median | ||||
| U-Net_L1_Loss | 0.857 ± 0.059 | 0.87 | 31.834 ± 2.66 | 32.77 | 54.41 | 1.23 | 0.1 |
| GAN_L1_Loss | 0.880 ± 0.054 | 0.89 | 33.678 ± 2.6 | 33.91 | 61.38 | 4 | 0.15 |
| U-Net_Hybrid_Loss | 0.876 ± 0.054 | 0.89 | 33.112 ± 2.56 | 33.79 | 54.41 | 1.23 | 0.1 |
| GAN_ Hybrid_Loss | 0.903 ± 0.050 | 0.92 | 35.683 ± 2.77 | 36.11 | 61.38 | 4 | 0.15 |
| SENSE | 0.902 ± 0.058 | 0.92 | 26.288 ± 5.48 | 26.70 | - | - | 0.29 |
| AI Model | SSIM | PSNR | ||||
|---|---|---|---|---|---|---|
| Statistics | df | p-Value | Statistics | df | p-Value | |
| U-Net_L1_Loss | 0.885 | 414 | 5.3 × 10−17 | 0.925 | 414 | 1.61 × 10−13 |
| GAN_L1_Loss | 0.921 | 7 × 10−14 | 0.943 | 1.66 × 10−11 | ||
| U-Net_Hybrid_Loss | 0.882 | 2.8 × 10−17 | 0.905 | 2.30 × 10−15 | ||
| SENSE | 0.819 | 5.75 × 10−17 | 0.954 | 1.11 × 10−13 | ||
| GAN_Hybrid_Loss | 0.868 | 3 × 10−18 | 0.941 | 9.46 × 10−12 | ||
| AI Model | SSIM | PSNR |
|---|---|---|
| p-Value | p-Value | |
| U-Net_L1_Loss | 3.26 × 10−38 | 3.20 × 10−74 |
| GAN_L1_Loss | 3.83 × 10−12 | 2.02 × 10−28 |
| U-Net_Hybrid_Loss | 2.02 × 10−18 | 2.12 × 10−43 |
| SENSE | 0.092 | 2.40 × 10−116 |
| Reference | Model | Loss Function | SSIM | PSNR |
|---|---|---|---|---|
| Hyun CM et al. (2017), [9] | U-net with k-space correction | L2-norm | 0.903 | - |
| Ghodrati V et al. (2019), [10] | Resnet-L1 | L1-norm | 0.81 | 26.39 |
| Ghodrati V et al. (2019), [10] | Unet–Dssim | Structural dissimilarity | 0.86 | 27.04 |
| Cole, Elizabeth et al. (2020), [11] | Unsupervised GAN | GAN loss | 0.88 | 29 |
| The proposed, (U-Net_Hybrid_Loss) | U-Net | Hybrid Loss function Hybridd Loss | 0.876 ± 0.03 | 33.11 ± 2.56 |
| The proposed, (GAN_Hybrid_Loss) | CGAN | 0.903 ± 0.05 | 35.68 ± 2.77 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Al-Haidri, W.; Matveev, I.; Al-antari, M.A.; Zubkov, M. A Deep Learning Framework for Cardiac MR Under-Sampled Image Reconstruction with a Hybrid Spatial and k-Space Loss Function. Diagnostics 2023, 13, 1120. https://doi.org/10.3390/diagnostics13061120
Al-Haidri W, Matveev I, Al-antari MA, Zubkov M. A Deep Learning Framework for Cardiac MR Under-Sampled Image Reconstruction with a Hybrid Spatial and k-Space Loss Function. Diagnostics. 2023; 13(6):1120. https://doi.org/10.3390/diagnostics13061120
Chicago/Turabian StyleAl-Haidri, Walid, Igor Matveev, Mugahed A. Al-antari, and Mikhail Zubkov. 2023. "A Deep Learning Framework for Cardiac MR Under-Sampled Image Reconstruction with a Hybrid Spatial and k-Space Loss Function" Diagnostics 13, no. 6: 1120. https://doi.org/10.3390/diagnostics13061120