1. Introduction
The city of Wuhan in Hubei Province, China, made history as the first point of the spread of the coronavirus disease (COVID-19) due to severe respiratory syndrome. On January 31, the World Health Organization (WHO) declared for the first time that COVID-19 is a “public health emergency of international concern” [
1]. The virus was originally thought to have come from a fish market in Wuhan. On 11 January 2020, the gene sequence that China openly shared through personal contacts fueled its rapid spread, with a total of 9,129,146 confirmed cases, including 473,797 deaths worldwide as of 24 June 2020 [
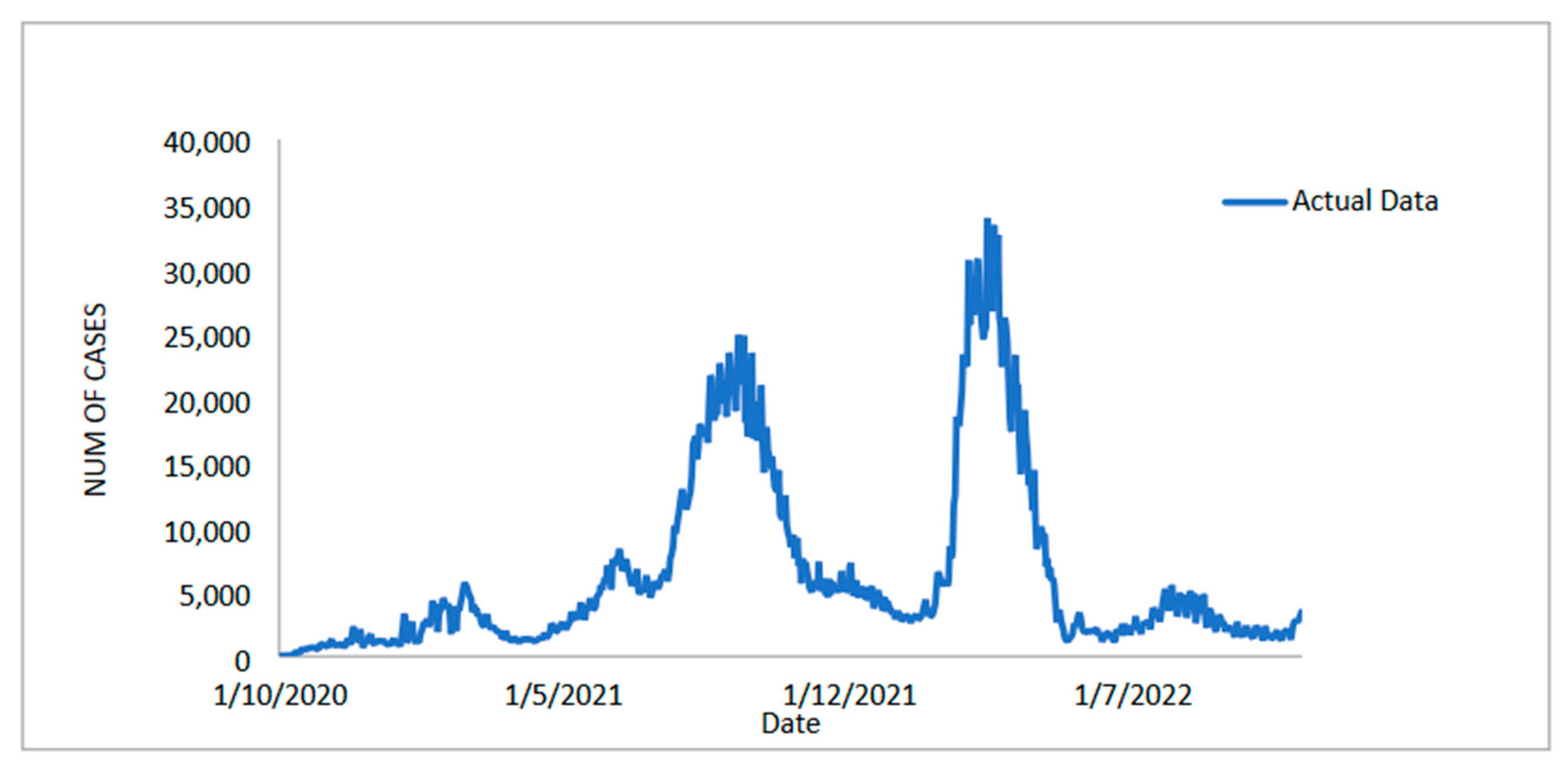
2]. However, as of 1 May 2021, COVID-19 has infected more than 151 million people and caused three million deaths worldwide. Countries such as the USA, Brazil, Russia, Spain, UK, Italy, France, Germany, China, India, Iran, and Pakistan have been hit the hardest by COVID-19. The first cases of COVID-19 reported in Malaysia on 2 January 2020 were detected by Chinese tourists entering the country from Singapore [
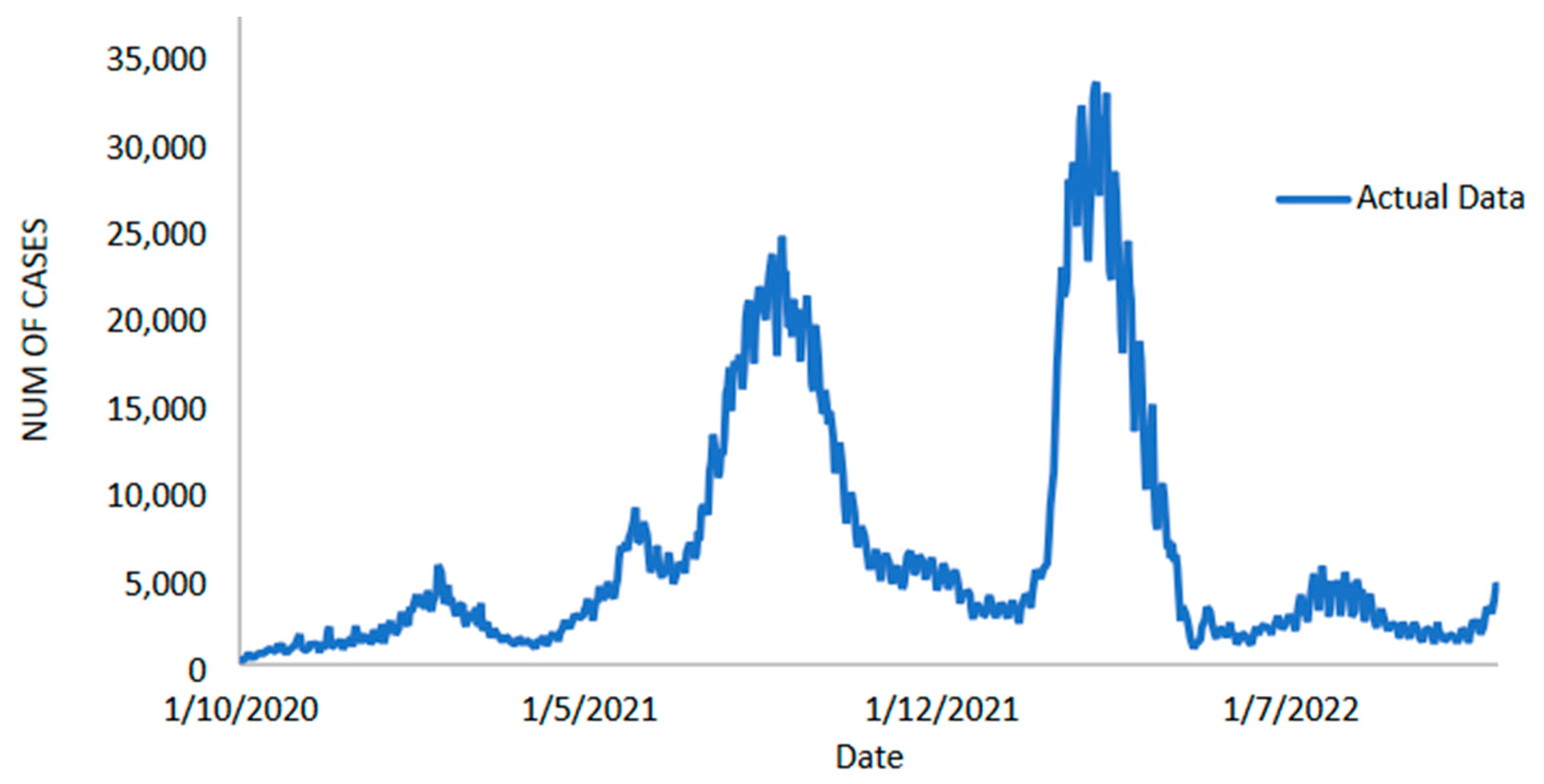
3]. Only single-digit daily cases were reported in the initial phase, but this increased to 235 by 26 March [
4]. The number of daily cases in Malaysia continued to increase exponentially by reaching around 20,000 in August 2021. The Malaysian government declared the implementation the Movement Control Order (MCO) from 18 March to 3 May 2020, the Conditional MCO (CMCO) from 4 May to 9 June 2020, and the Recovery MCO (RMCO) from 10 June 2020 to 31 March 2021. All travel and socio-economic activities (religious and cultural gatherings were not allowed) have been restricted across the country to keep new infections at bay and avoid overloading the country’s healthcare system during this time. All government and private offices and educational institutions, including transportation hubs, have been closed, citizens have been ordered to stay at home, and interstate travel has been banned, with fines of up to RM 10,000 for violators.
Since the WHO declared the COVID-19 outbreak a pandemic, not only governments from around the world, but also dedicated medical institutions have made many efforts to find vaccines and treatments to control the spread of the virus. Statisticians and public health scientists have also performed extensive statistical modelling, especially regarding the forecasting of COVID-19 cases, to help the health system prevent the contagion catastrophe. In this scenario, the ability to most effectively determine the growth rate at which the epidemic is spreading is very critical to counterattack and help governments, social planning, and policy making to accurately address the epidemic. Therefore, the motivation behind this research compared to the existing research is to (i) develop the most accurate and efficient predictive model related to the spread of COVID-19 in Malaysia and (ii) compare the performance of this new model with autoregressive integrated moving average (ARIMA), support vector machine (SVM), least-squares support vector machine (LSSVM), autoregressive integrated moving average-support vector machine ARIMA–SVM, and autoregressive integrated moving average–least-squares support vector machine models (ARIMA–LSSVM).
During the pandemic, many studies have been conducted using various mathematical and statistical models to predict the spread of the COVID-19 pandemic. One of the most popular time-series prognostic models for analyzing and predicting disease spread is the ARIMA (
p,
d,
q) model [
5,
6,
7]. Predicting new daily cases of COVID-19 was a difficult task, as cases increased daily. In the first wave, the pattern of COVID-19 cases has been continuously increasing for a period and then decreasing. However, for the second wave, it appears to be picking up again, and some of the COVID-19 cases are difficult to predict. In this scenario, some researchers predict the pattern of COVID-19 using ARIMA [
8,
9,
10,
11,
12,
13,
14]. However, the ARIMA model has a limitation in that it typically can only handle a linear time-series data structure [
15]. ARIMA model approximations are insufficient to pose a time-series prediction obstacle for researchers, especially for nonlinear patterns [
16]. Despite its superior performance, the classification performance of Support Vector Machines (SVMs) and the generalizability of the classifier are often affected by the dimension or number of feature variables used, as mentioned by Lee [
17]. As a result of the development of Vector Machines models, this process will be able to provide the most accurate and efficient result in each prediction case. SVMs, first introduced in 1995 by Vladimir Vapnik [
18] in the field of statistical learning theory and structural risk minimization, have proven useful in a variety of prediction problems and classifications. SVMs could also manage or address difficulties such as non-linearity, local minimum, and high dimension where the ARIMA model could not [
15,
19,
20,
21]. SVM models have recently been used to handle problems such as nonlinear, local minimum, and high dimension. SVM can even guarantee higher accuracy for long-term predictions compared to other computational approaches in many practical applications. However, the single SVM model as a single ARIMA model also has some limitations, as the SVM model can only handle non-linear data and not linear data. With the limitations of a single ARIMA and SVM model, as well as an in-depth analysis of time-series prediction, hybrid approaches have become the best approach to overcome both limitations, and have a very significant impact in many areas due to their dynamic nature and higher level of predicting accuracy, efficiency, and precision. This approach is crucial because of the problems encountered in time-series forecasting, where almost all real time series contain linear and nonlinear correlation patterns between the data. Recently, the hybridization of prediction methods has been used with great success to achieve higher prediction accuracy [
15,
16,
19,
20,
22,
23,
24,
25,
26].
Regarding the spread of COVID-19, the hybrid time-series model approach is crucial for predicting the impact of the COVID-19 outbreak, and has proven successful in predicting COVID-19 [
27,
28,
29,
30,
31,
32,
33]. This study aims to (a) propose the ARIMA–LSSVM hybrid model approach to achieve better forecast results when it is able to produce the best estimator, i.e., produce small error terms; additionally, it aims to (b) examine the performance of the proposed models by comparing them to ARIMA and SVM models using three daily cases of COVID-19 data in Malaysia, that is, daily new positive cases, daily new deaths, and daily new recovered cases. Despite recent advances in time series and on COVID-19, the modelling process does not include COVID-19 cases specifically in Malaysia to help authorities manage the spread of this outbreak by producing more efficient, more accurate data, and more accurate forecasting results.
This study makes a significant contribution to the field of pandemic prediction and prevention by introducing novel approaches to dealing with COVID-19 data. Rather than relying on traditional methods, this research utilizes evidence-based prediction techniques, which have been shown to be more accurate and efficient. The use of these intelligent forecasting models enables local health authorities to create more precise and effective preventive measures, especially in the face of future outbreaks.
This study is particularly innovative in its use of hybrid forecasting models by machine learning for Malaysia’s future pandemics, such as avian flu or novel coronavirus strains. According to Moore [
34], the scenario is for the next possible new pandemic of avian influenza virus strain H7N9 or a novel coronavirus. The predictive models developed are more precise, accurate, and efficient in anticipating the dynamic spread of the virus. This approach has been tested on real-world data, including daily new cases, daily new death cases, and daily new recovered cases of COVID-19, making it a valuable tool for public health officials and researchers. This research also has significant implications for future outbreaks, particularly in countries with tropical rainforests such as Malaysia. By predicting the spread of COVID-19 early on, this model can help policymakers build better healthcare facilities, take legislative action, and avoid economic losses. While a vaccine is now available, this model remains useful in accurately forecasting and preventing the impact of future pandemics, including those caused by new virus strains.
This study’s innovative and evidence-based methods make a valuable contribution to pandemic prediction and prevention, providing significant insights that can be used to mitigate the impact of future outbreaks. The implications of this research extend to public health authorities, policymakers, and researchers worldwide, offering powerful tools for mitigating the devastating effects of pandemics. The remainder of this paper is structured as follows. Materials and Methods goes into detail about the method we used to develop our proposed model. The hybrid ARIMA–SVM model used in this study is then briefly described. The results and discussion present the performance of our proposed model based on three known COVID-19 case datasets. Finally, we wrap up the article and make suggestions for future research.
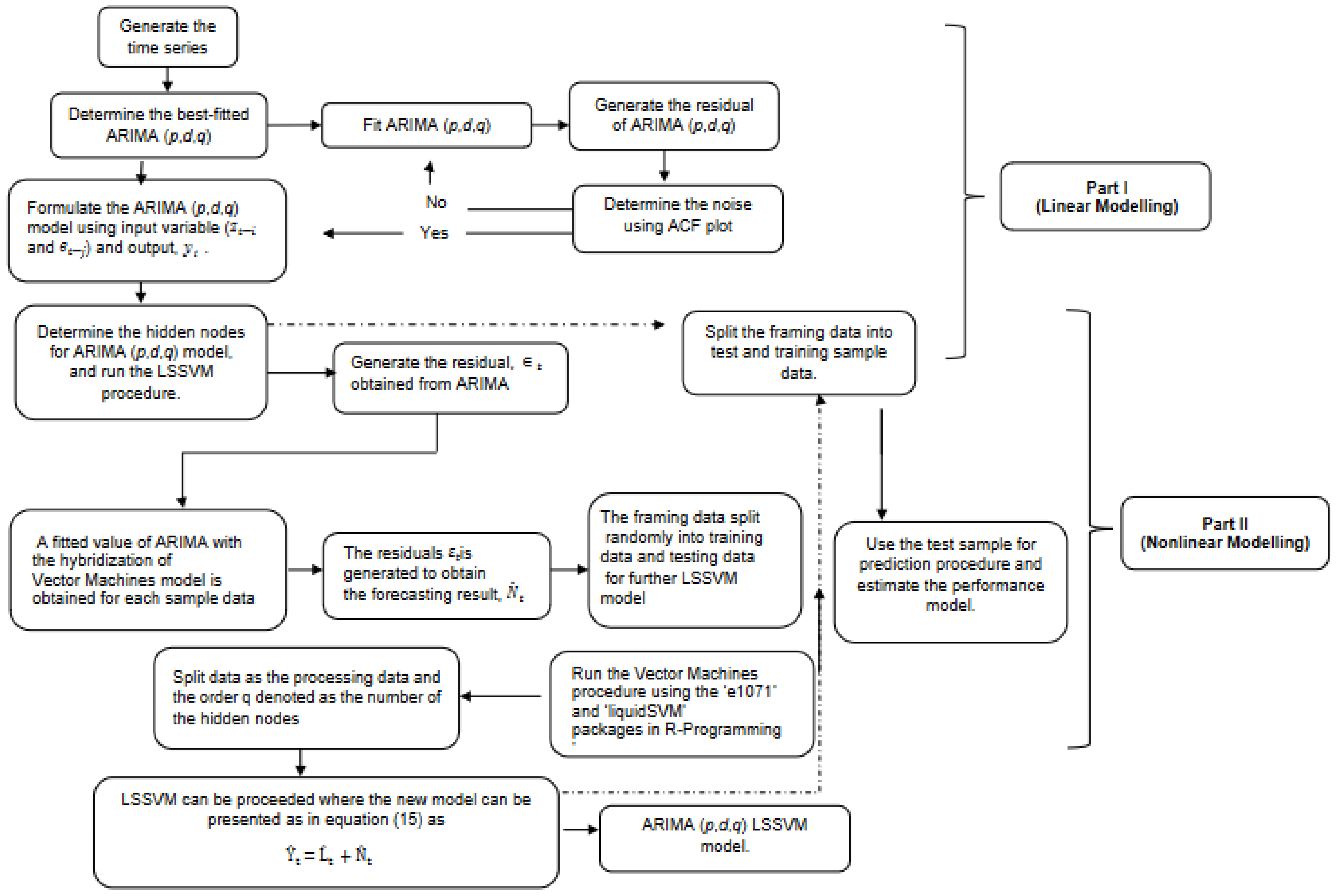
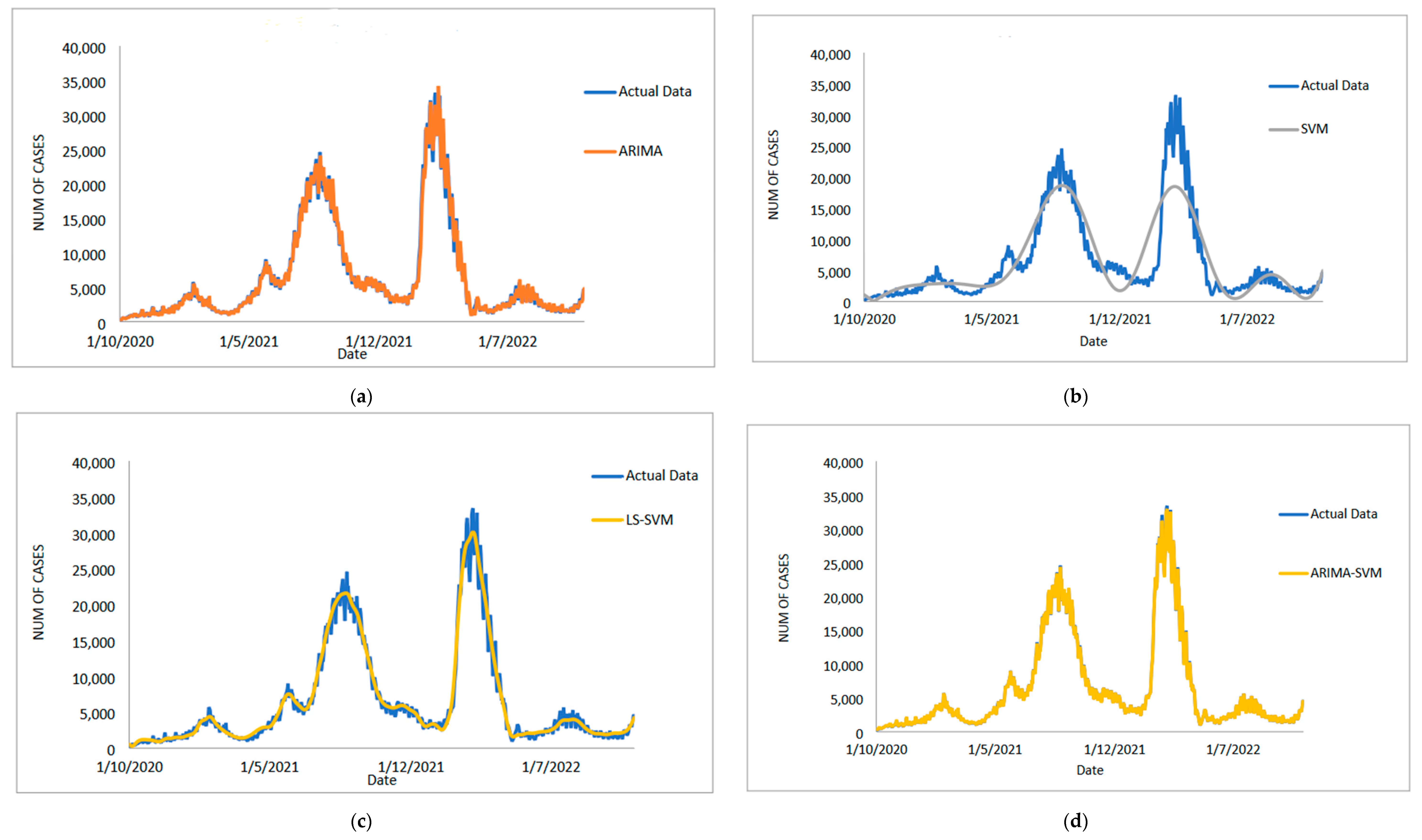
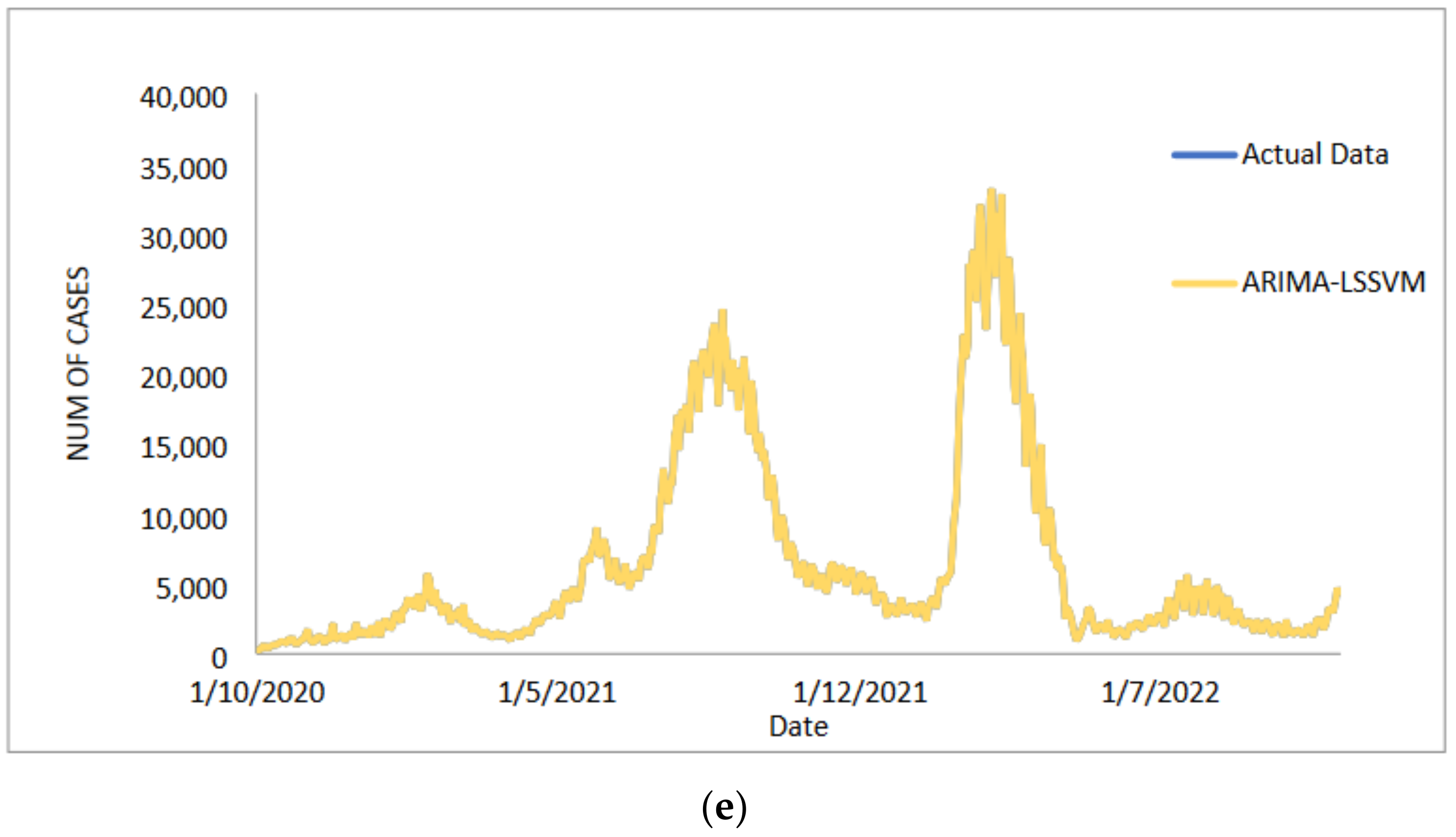
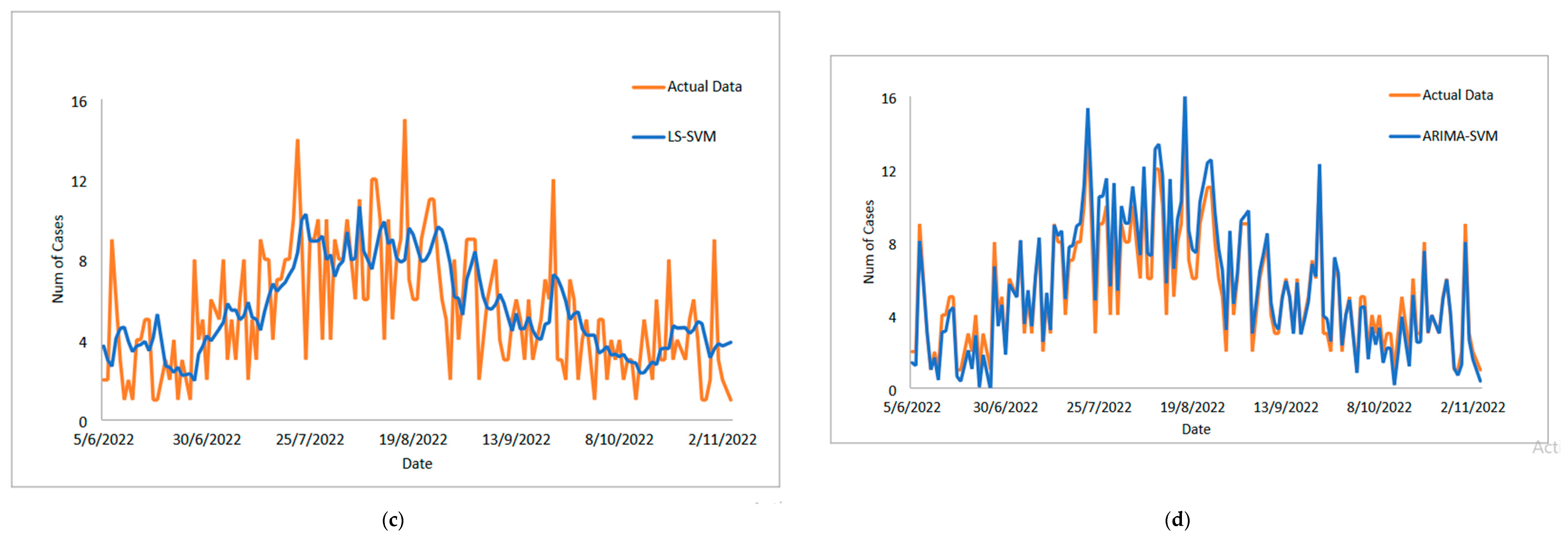
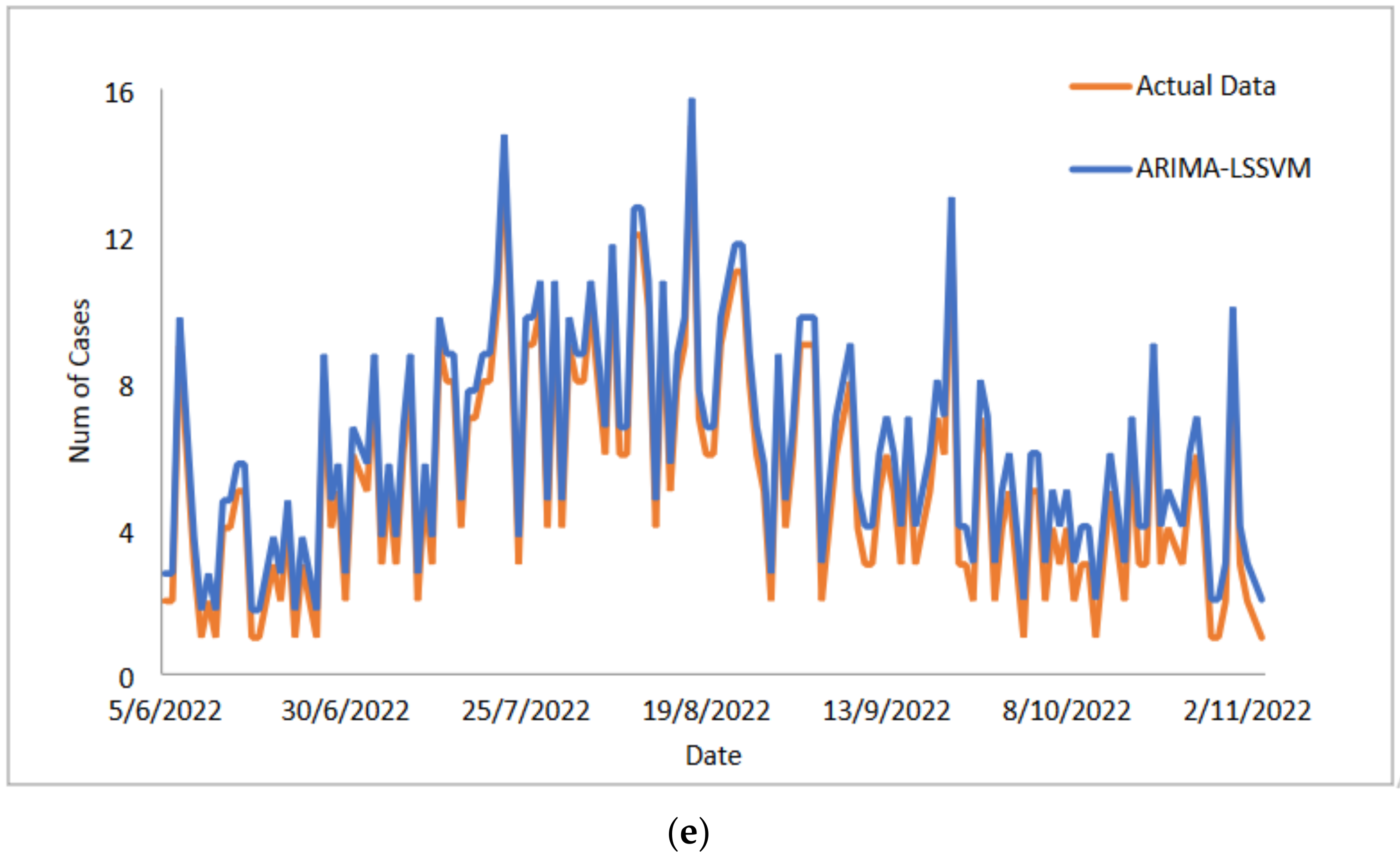
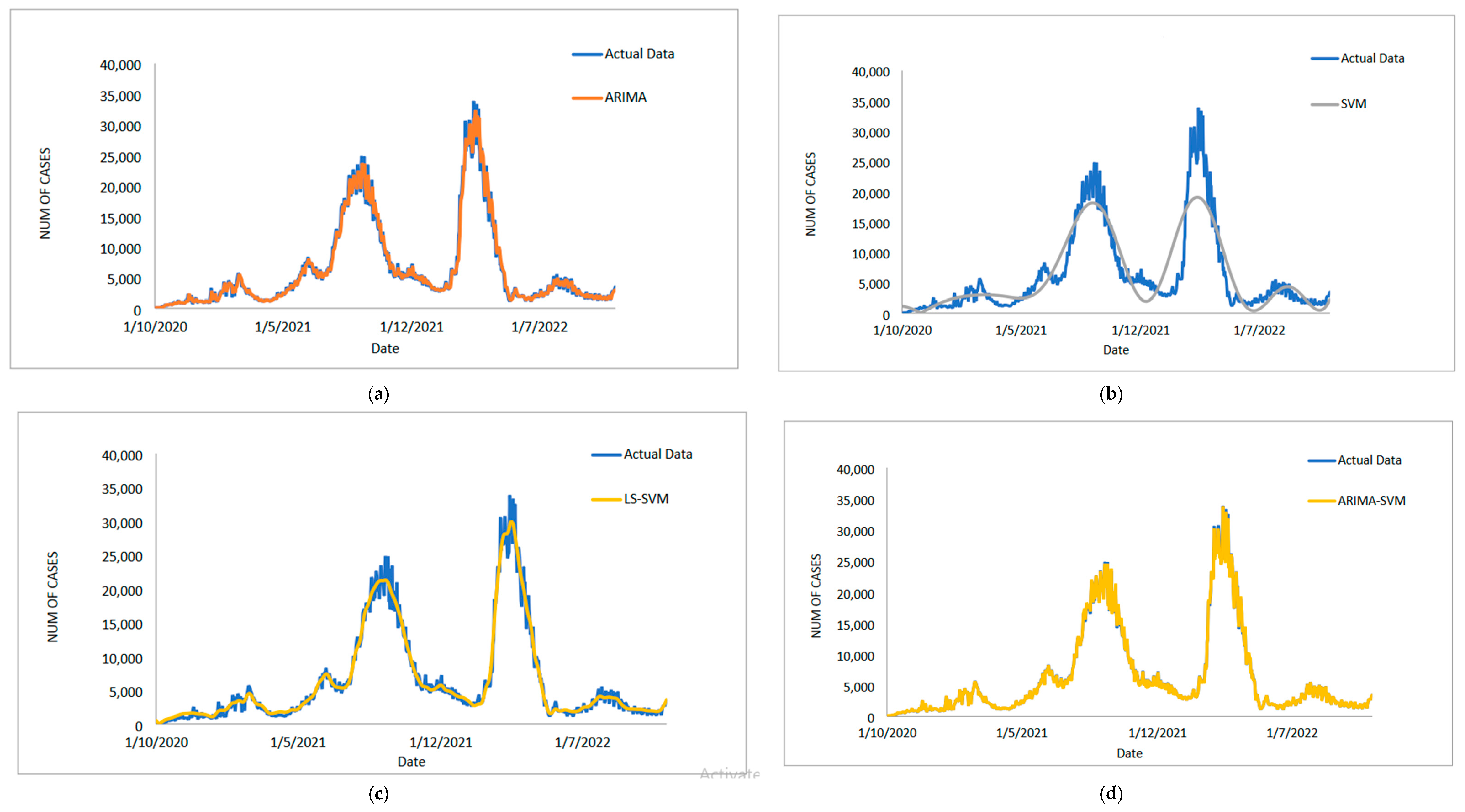
4. Conclusions
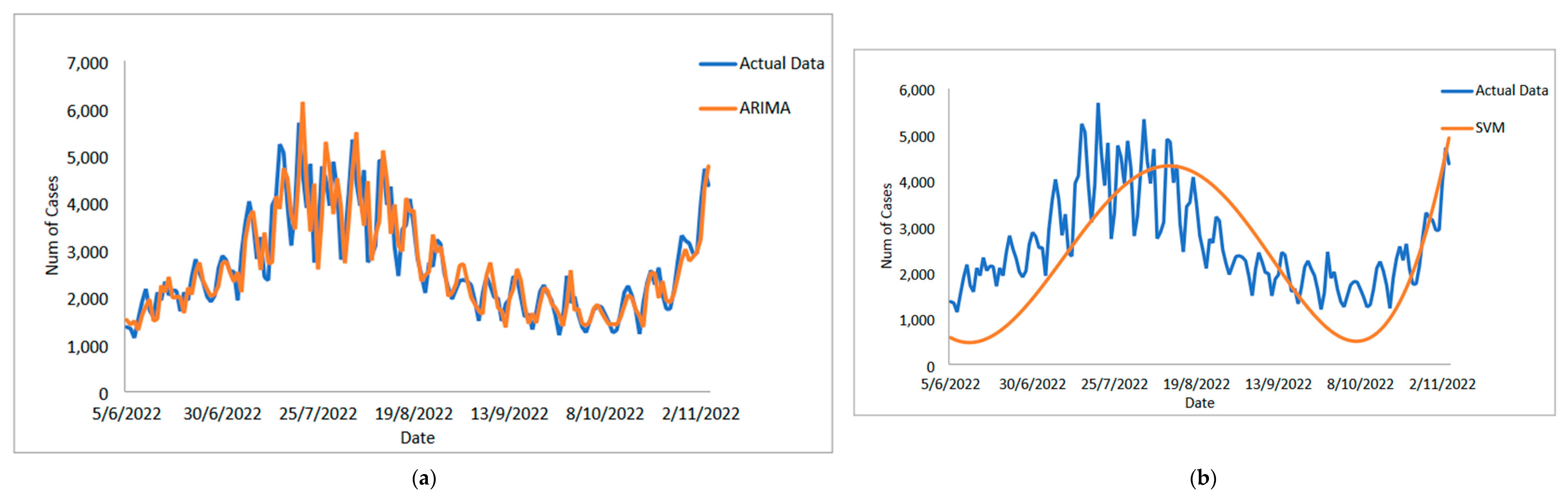
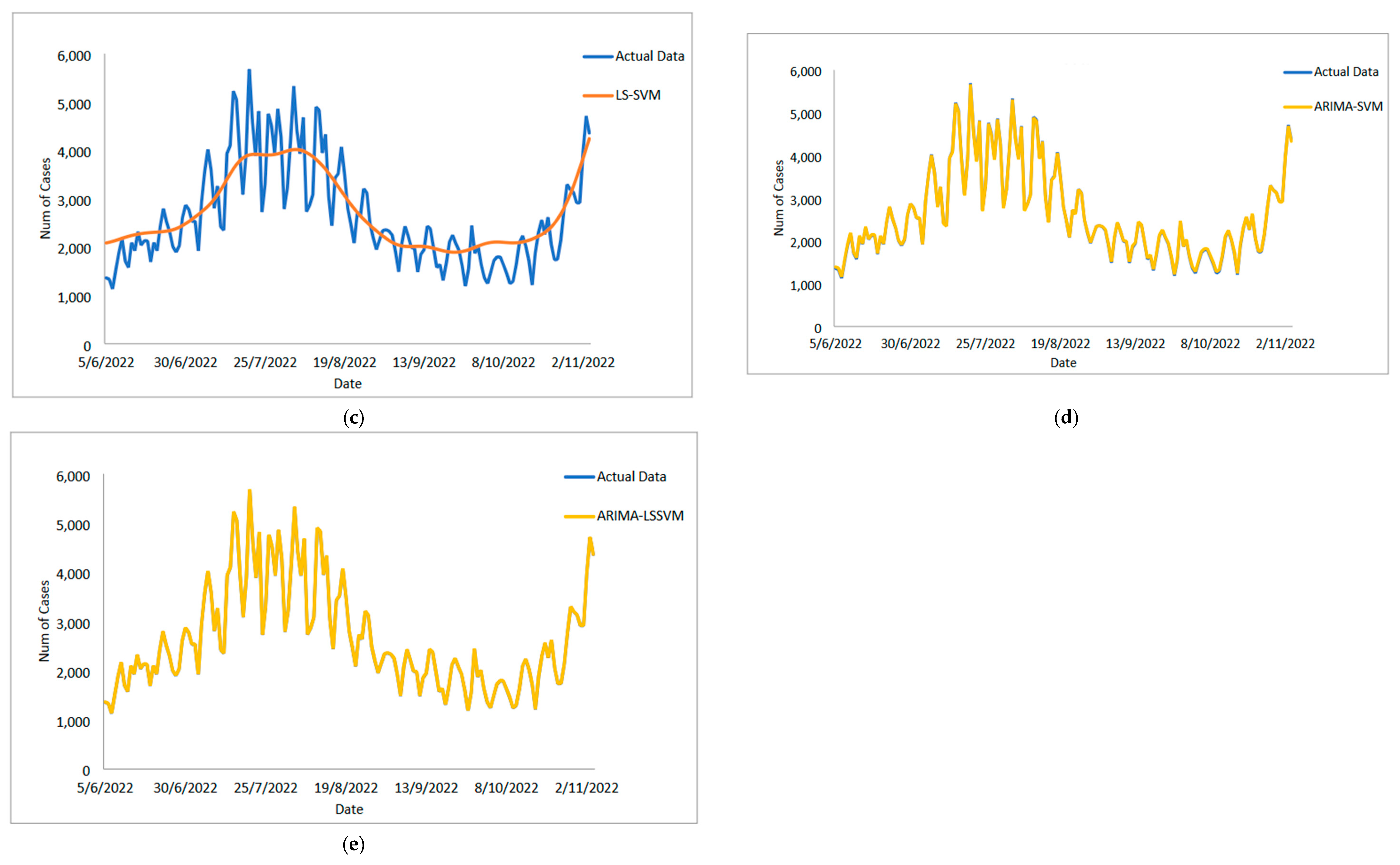
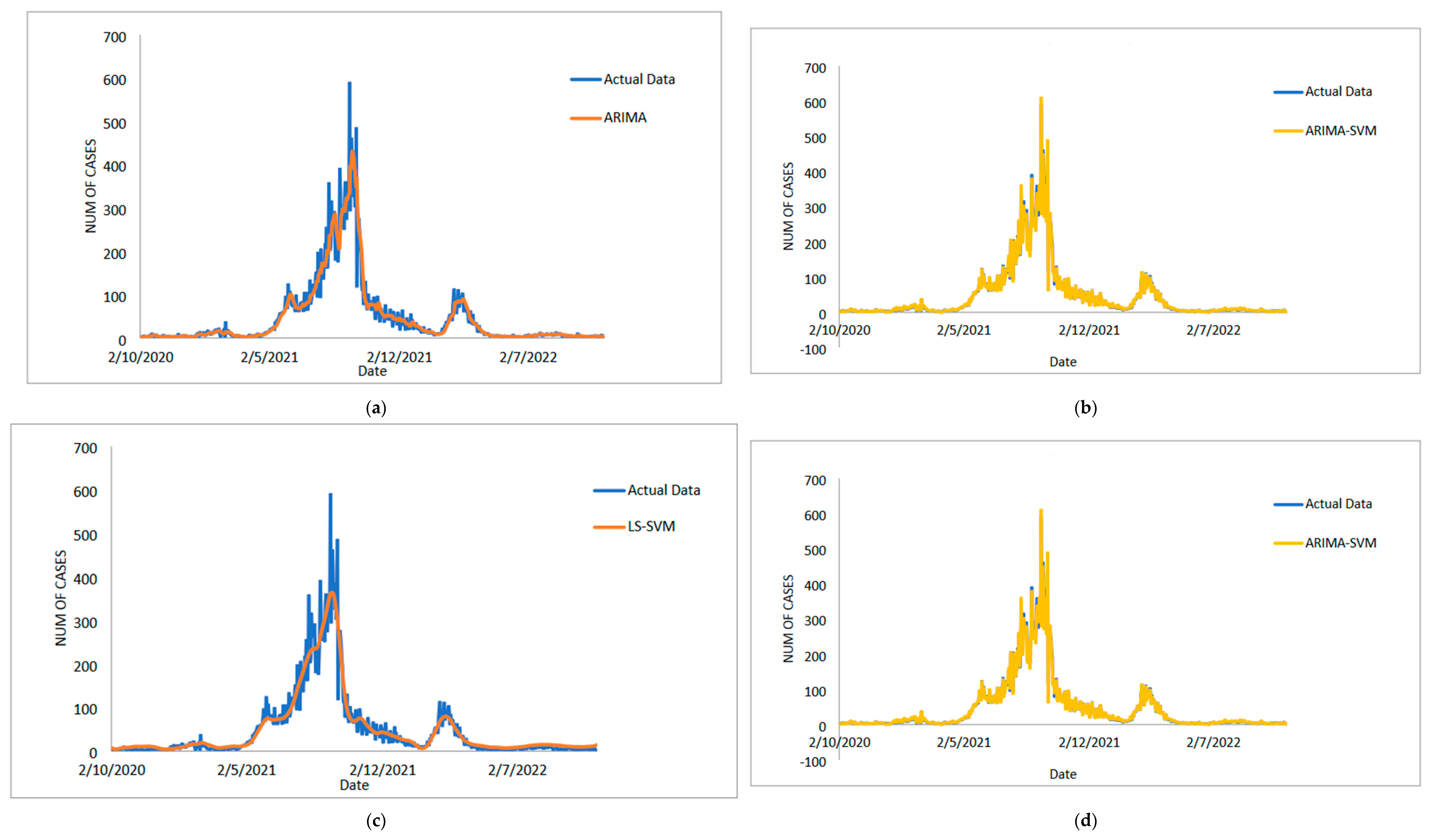
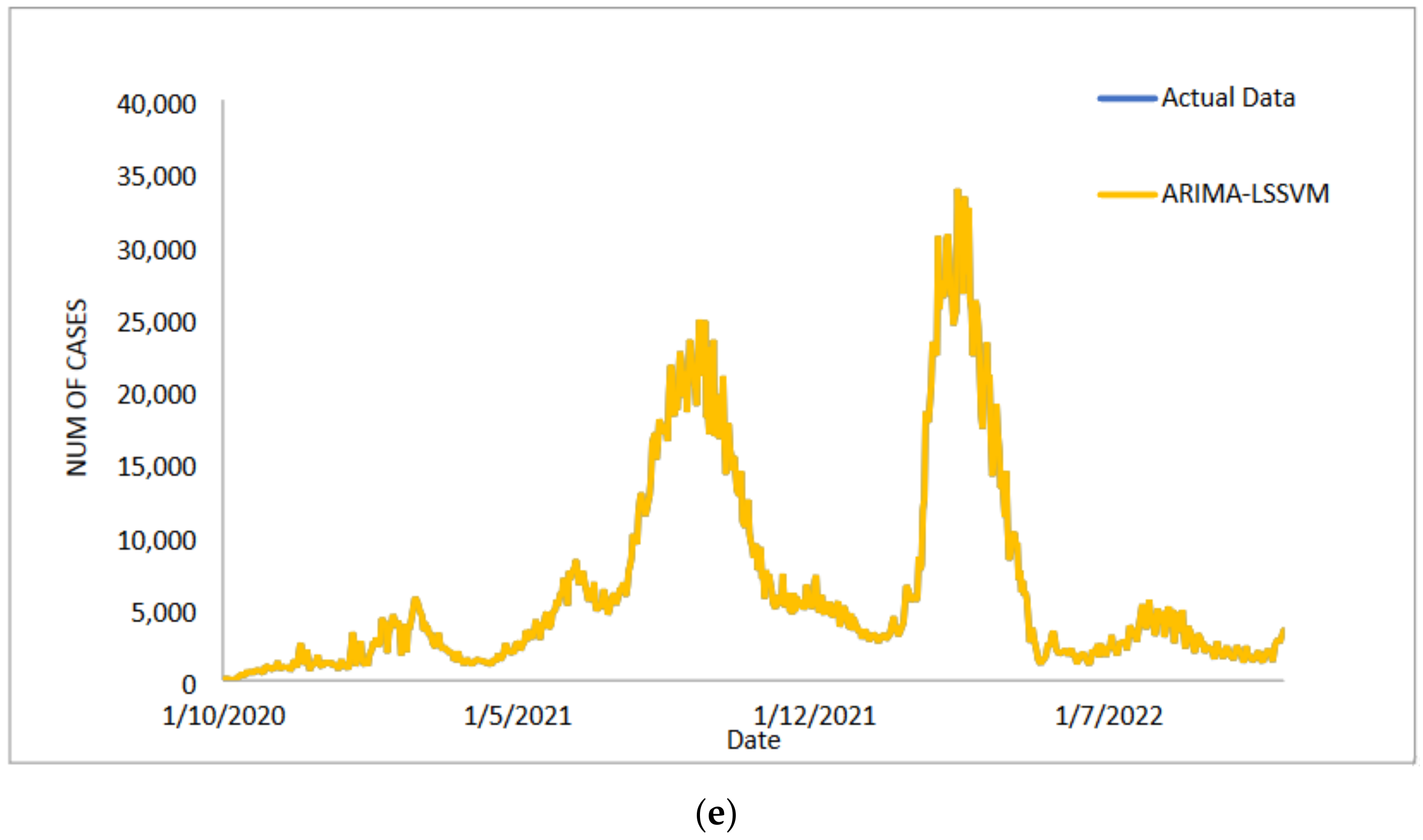
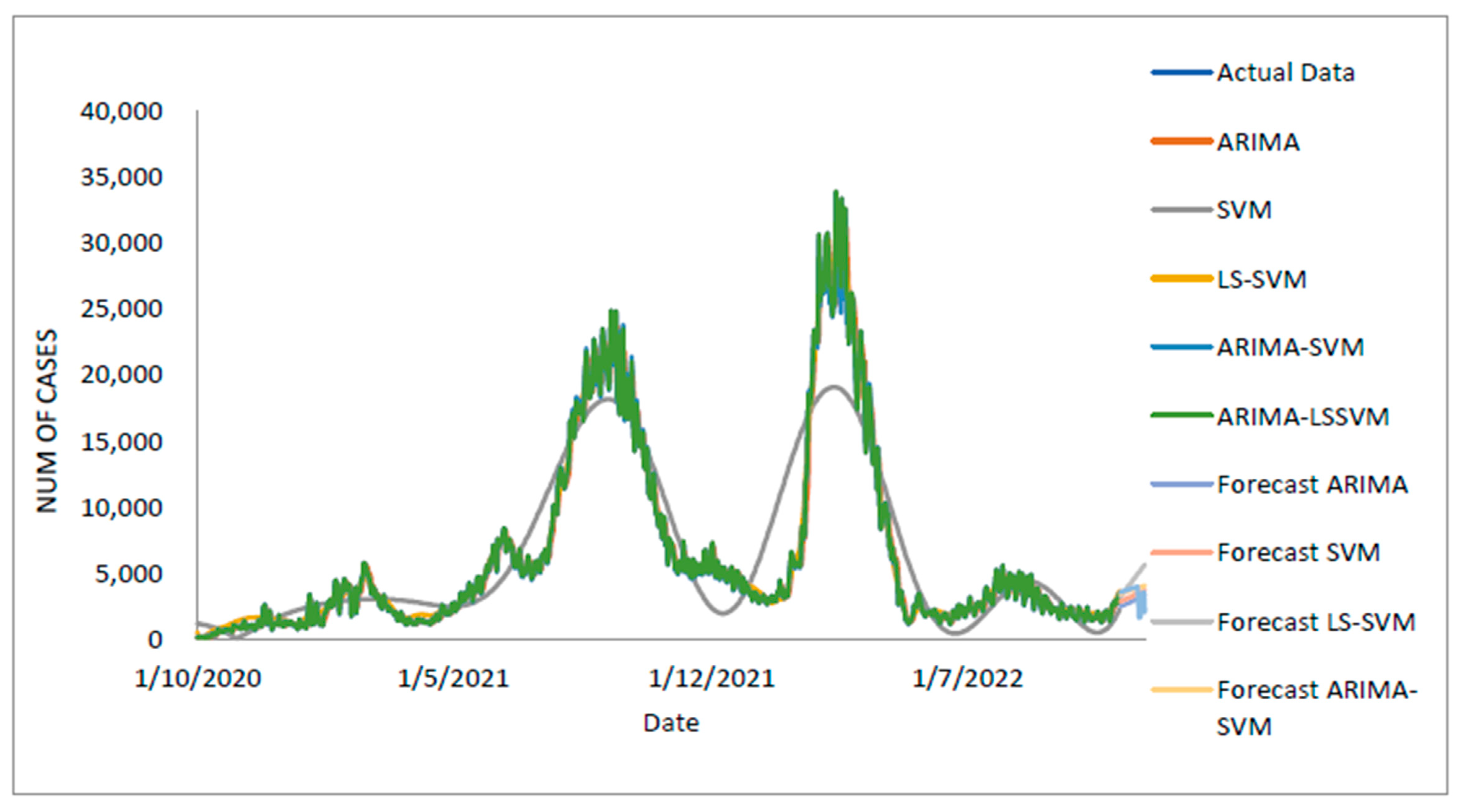
In conclusion, predicting the spread of COVID-19 with accuracy and efficiency is essential but frequently challenging for decision-makers, especially the front-line workers and health care authorities. Despite what might seem to be an endless spread of COVID-19, there have been numerous efforts to develop time-series models and ongoing research to enhance forecasting model efficacy. One of the most well-liked types of hybrid models that divide time series into linear and non-linear forms is the hybrid approach. In this study, a hybrid model that combines some linear and non-linear predictions is proposed. Utilizing three well-known COVID-19 datasets—daily new positive cases, daily new death cases, and daily new recovered cases—revealed that our proposed models were demonstrated as having the highest efficiency, accuracy, and precision. In comparison to ARIMA, SVM, LSSVM, and ARIMA–SVM models, the proposed model with cross-validation check based on MSE, RMSE, MAE, and MAPE makes the most accurate predictions. In terms of performance (the proposed models compared to ARIMA, SVM, LSSVM and ARIMA–SVM models) for both the training and testing datasets, the proposed models’ performance yields the smallest values of MSE, RMSE, MAE, and MAPE. This indicates that the proposed model’s predicted value is more closely aligned with the observed value. Therefore, our proposed models had a higher level of precision and could be suggested for COVID-19 forecasting. It can be concluded that the proposed model may be the most efficient and effective way to increase prediction accuracy performance, especially since it is important to anticipate and stop the spread of COVID-19 cases.

 ,
, 






















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}