

A Bimodal Emotion Recognition Approach through the Fusion of Electroencephalography and Facial Sequences

Abstract
:1. Introduction
- We proposed an efficient and lightweight multimodal emotion recognition model based on two modalities, i.e., EEG trials and facial video clips, by removing irrelevant channels from EEG trials and frames from video clips. In comparison to state-of-the-art approaches, the suggested method’s computational overhead is also low.
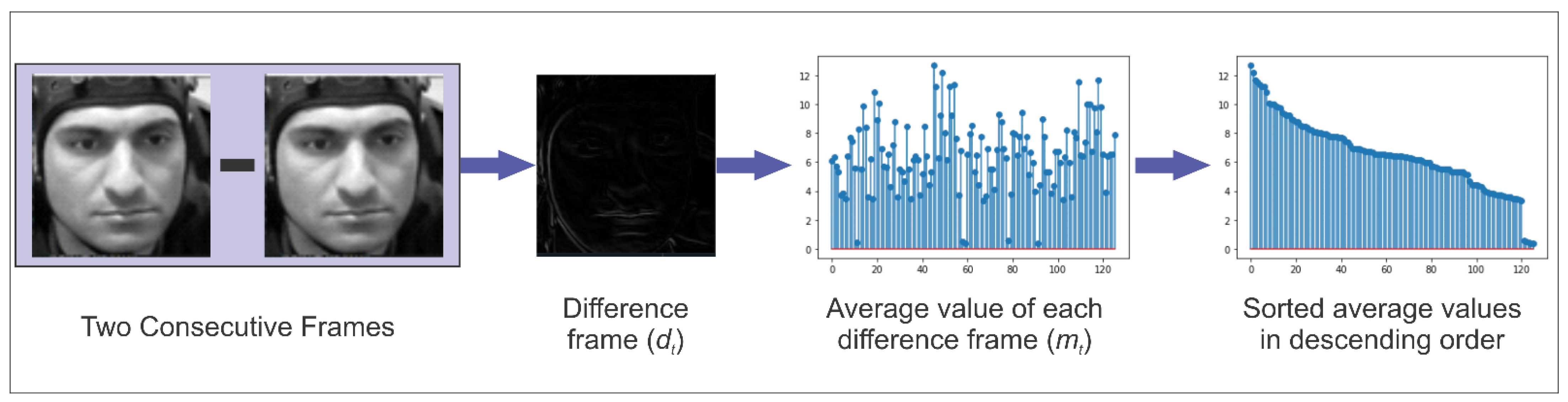
- A video clip contains a large number of redundant frames, which increases the computational overhead of a deep learning model. Selecting the most representative frames helps improve the performance of the method. We proposed a technique to reduce unnecessary frames by calculating the difference between successive frames, organizing the difference frames according to their respective information, and choosing the most discriminative frames from video clips.
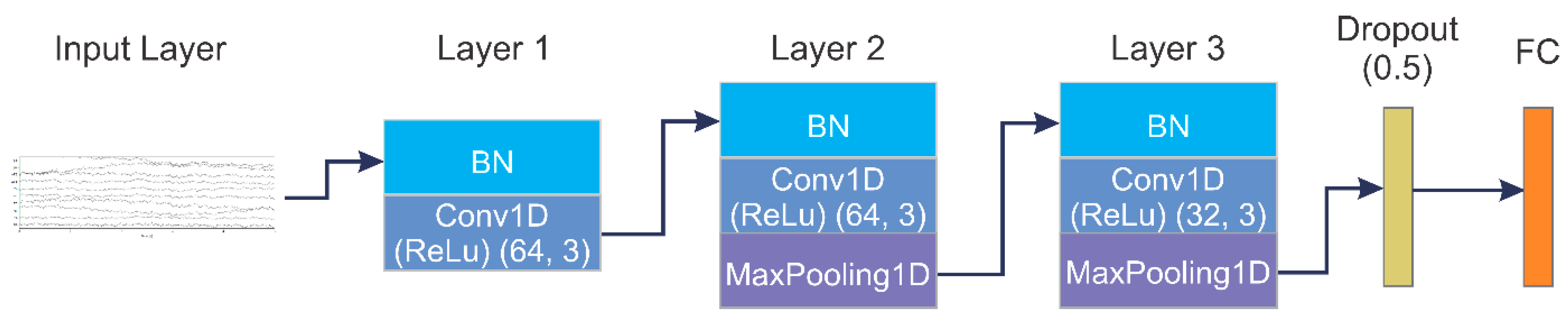
- In addition to wasting time and money by utilizing more electrodes, superfluous channels can impair performance by introducing noise and artifacts into the system. Therefore, in this work, the number of EEG channels used for emotion recognition has been reduced, which ultimately allowed us to design a light weight 1D-CNN model with a small number of learnable parameters. To achieve this, we used pooling layers instead of fully connected layers and depth-wise separable convolution to subtly reduce a large number of parameters and make our network structure simpler for low-dimensional data.
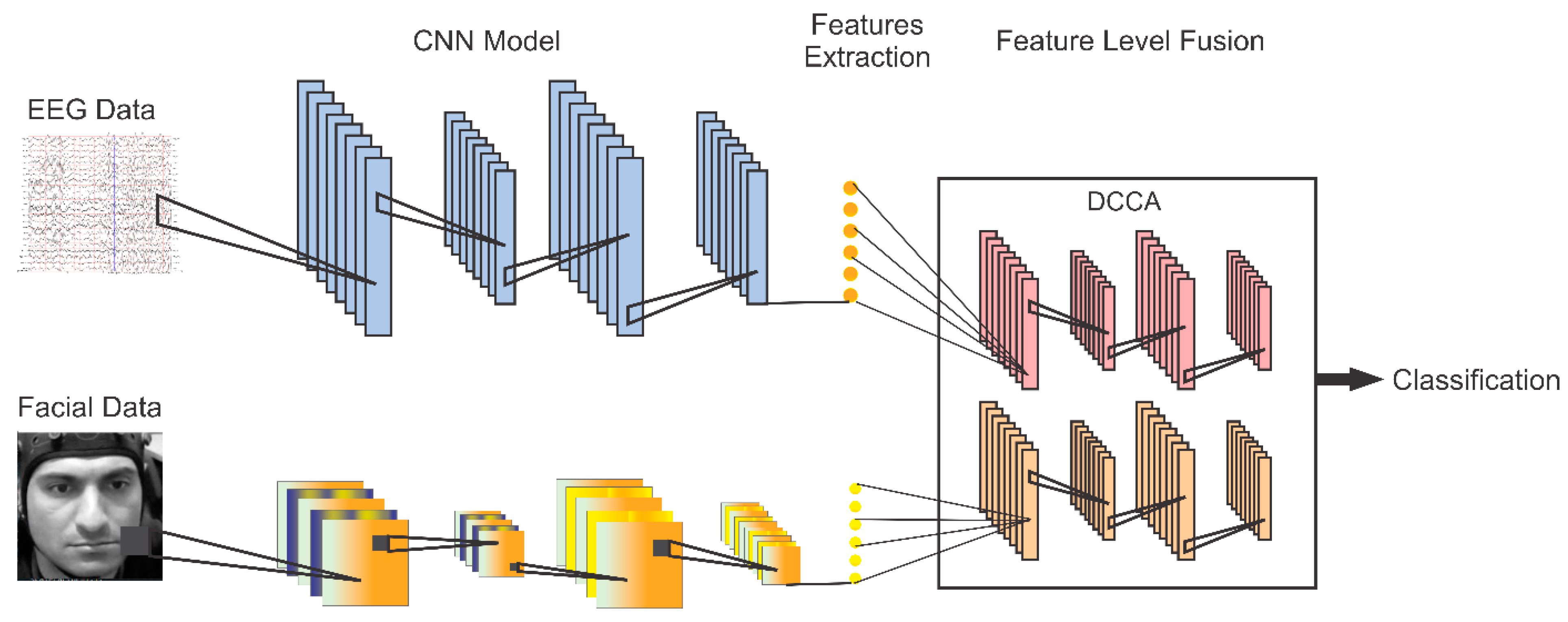
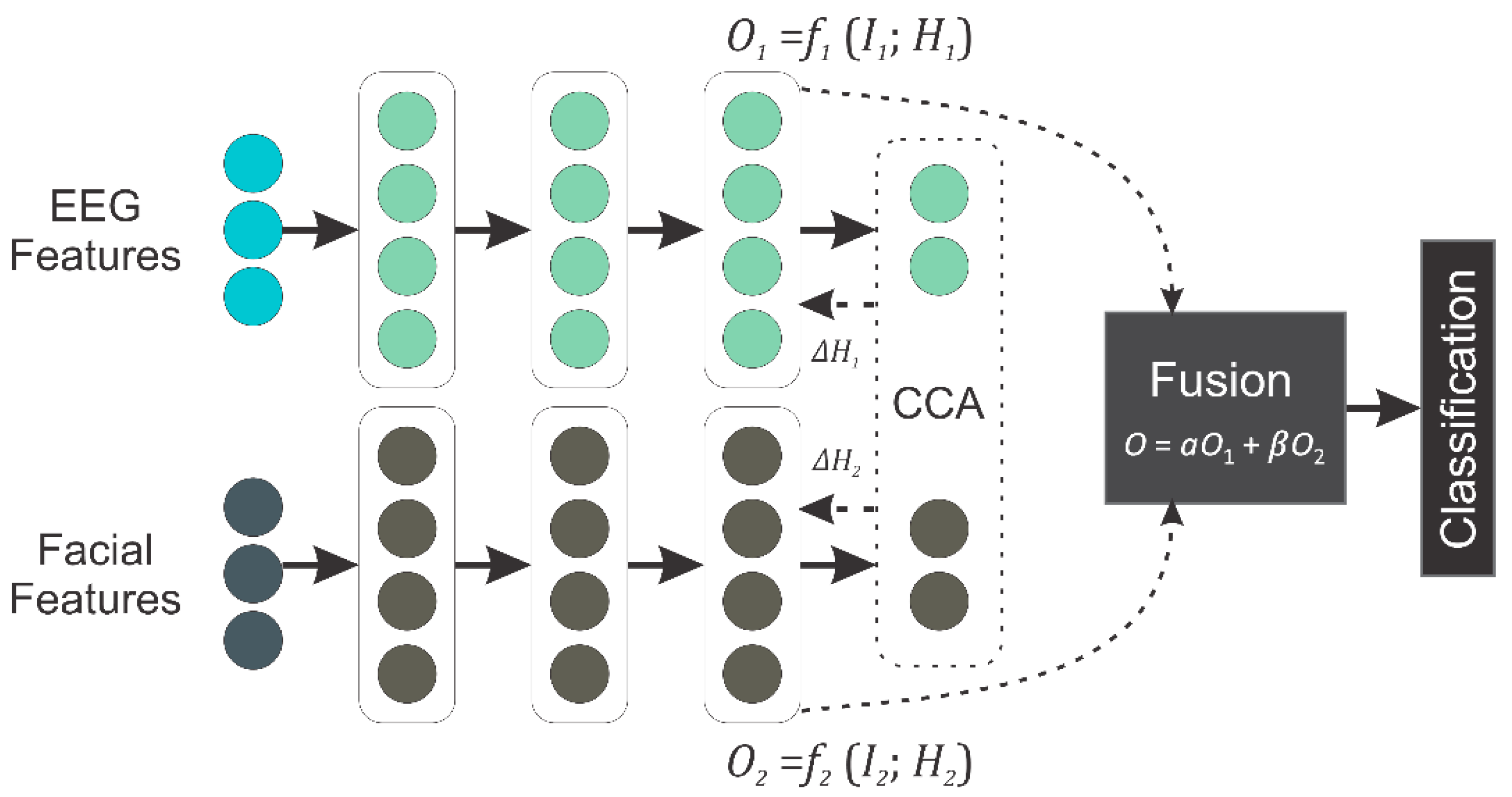
- We adapted ResNet50 for extracting discriminative information from video clips. Following that, DCCA was designed to fuse highly correlated features from the two modalities. In DCCA, the features from EEG and facial video clips are processed through the two 1D-NNs and then forwarded into a canonical correlation analysis (CCA) layer, which consists of two projections and a CCA loss calculator. While minimizing the CCA loss, highly correlated features are extracted that can be used for the classification. The 1D-NN model was specifically designed to transform the features into a better understanding for correlation analysis while keeping the complexity as low as possible. Extensive experiments were performed to validate the proposed method on two benchmark public datasets.
2. Related Work
2.1. Methods Based on EEG Signals
2.2. Methods Based on Facial Video Clips
2.3. Multimodal Emotion Recognition Methods
3. Materials and Methods
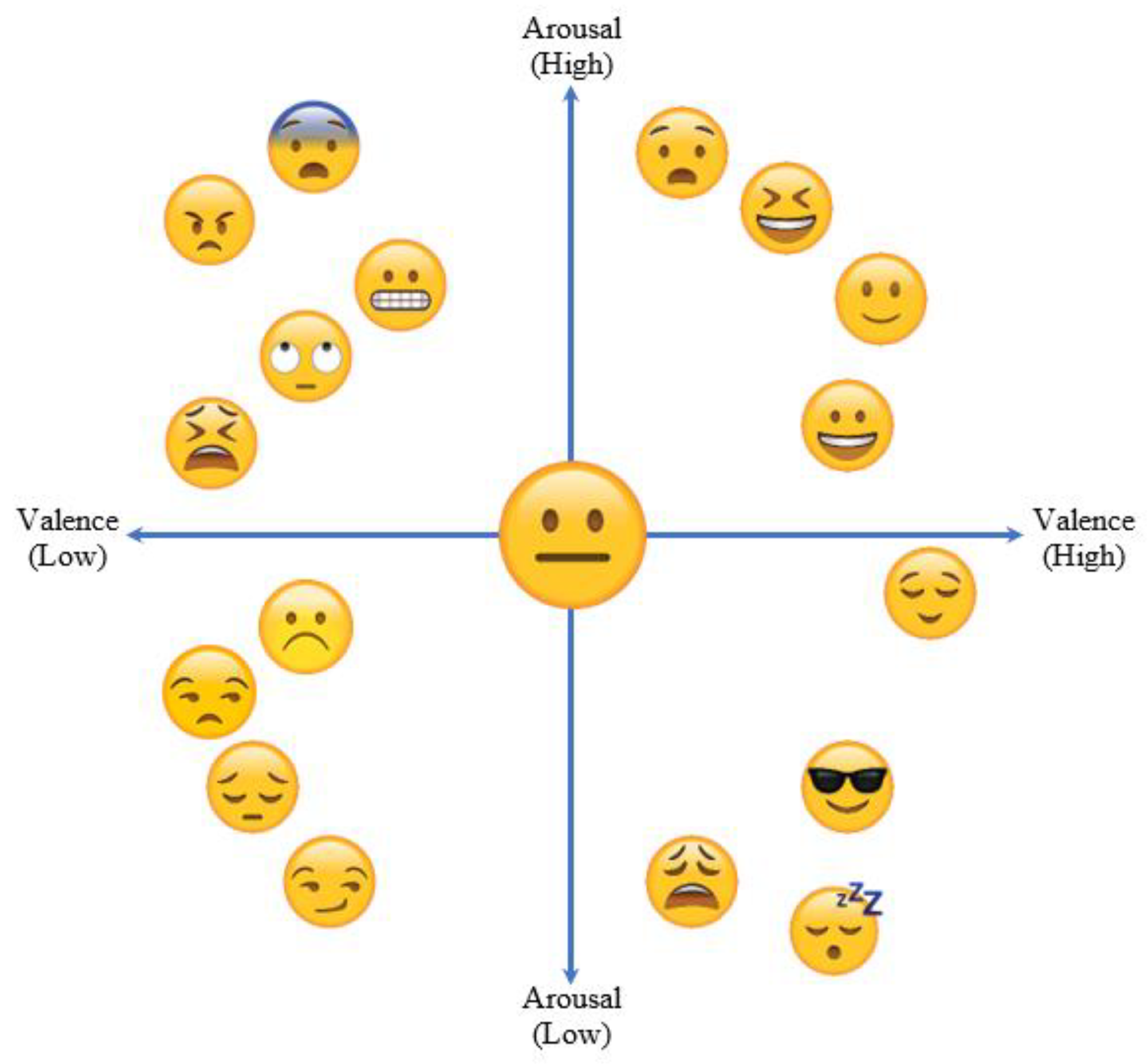
3.1. Emotions
3.2. Datasets and Pre-Processing
3.2.1. MAHNOB-HCI Dataset
3.2.2. DEAP Dataset
3.2.3. Data Pre-Processing and Augmentation
3.3. Proposed Method
3.3.1. CNN Model for EEG
3.3.2. CNN Model for Facial Video Clips
3.3.3. Feature Level Fusion Using DCCA
3.3.4. Baseline Fusion Methods
4. Experimental Results
4.1. Experimental Setup
4.2. EEG-Based Results
4.3. Facial Video Clips-Based Results
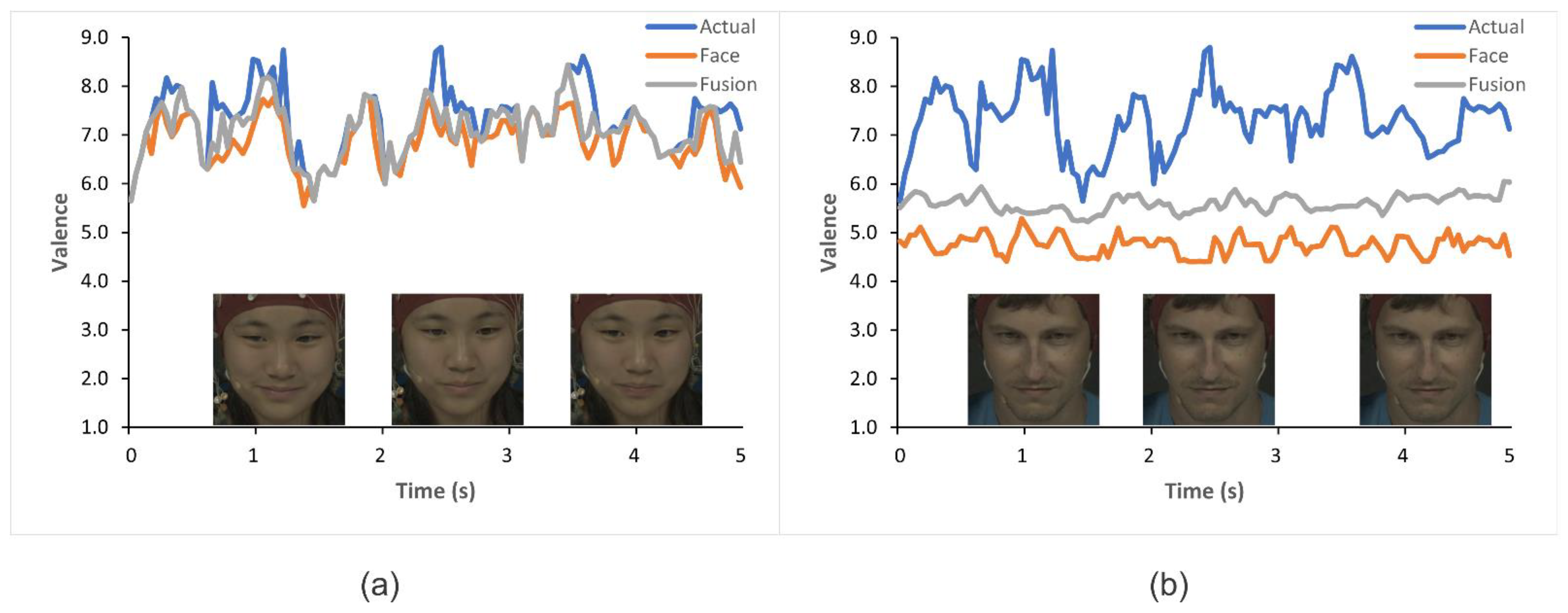
4.4. Results of Fusion of EEG and Facial Video Clips Using DCCA
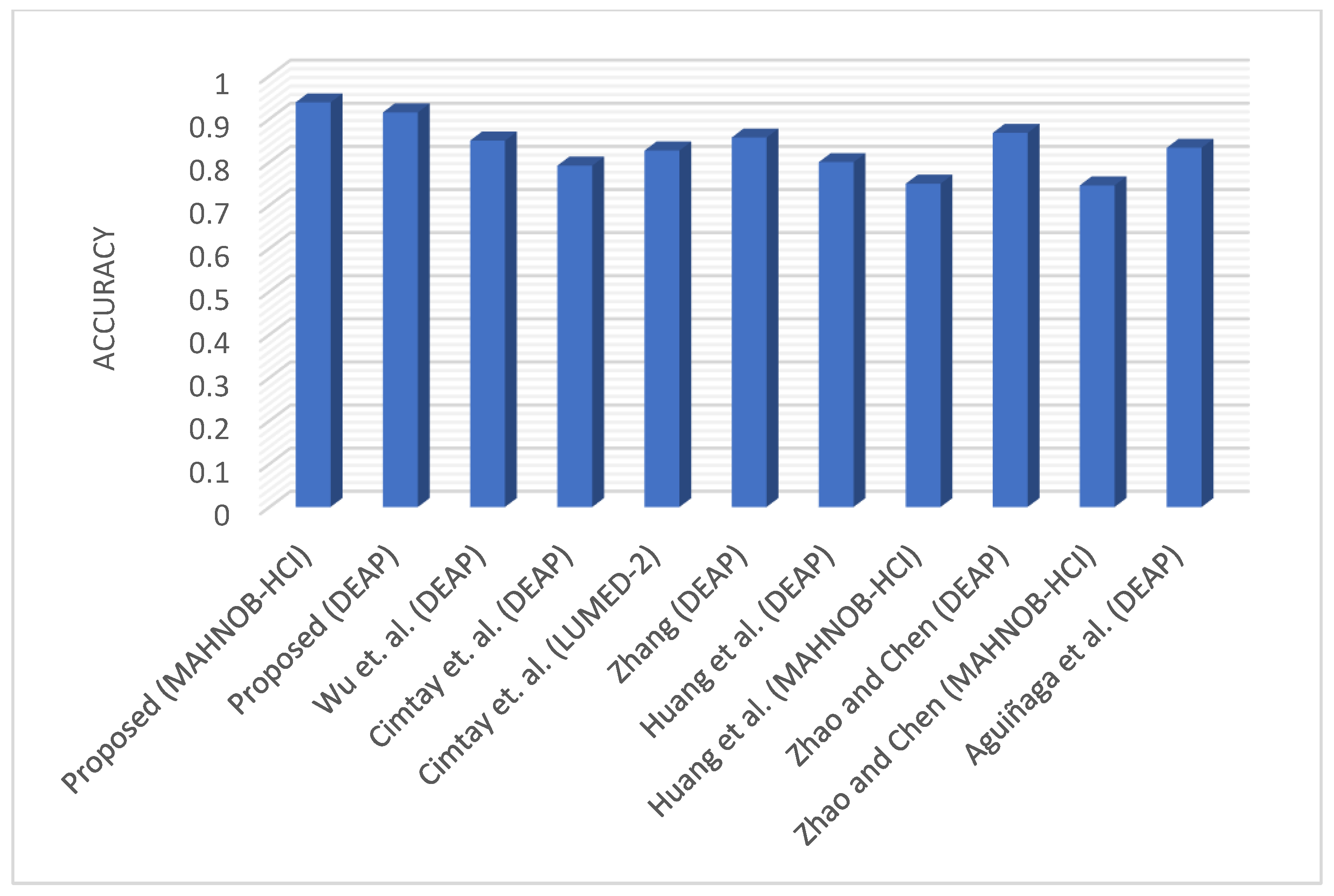
4.5. Comparison of Results with the State-of-the-Art
5. Discussion
6. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Hossain, M.; Muhammad, G. An Audio-Visual Emotion Recognition System Using Deep Learning Fusion for a Cognitive Wireless Framework. IEEE Wirel. Commun. 2019, 26, 62–68. [Google Scholar] [CrossRef]
- Gica, S.; Poyraz, B.; Gulec, H. Are Emotion Recognition Deficits in Patients with Schizophrenia States or Traits? A 6-Month Follow-up Study. Indian J. Psychiatry 2019, 61, 45–52. [Google Scholar]
- Ferrari, C.; Papagno, C.; Todorov, A.; Cattaneo, Z. Differences in Emotion Recognition from Body and Face Cues between Deaf and Hearing Individuals. Multisens. Res. 2019, 32, 499–519. [Google Scholar] [CrossRef]
- Iannattone, S.; Miscioscia, M.; Raffagnato, A.; Gatta, M. The Role of Alexithymia in Social Withdrawal during Adolescence: A Case–Control Study. Children 2021, 8, 165. [Google Scholar] [CrossRef]
- Cirino, E.; Currin-Sheehan, K. The Effects of Depression on the Brain. Available online: https://www.healthline.com/health/depression/effects-brain (accessed on 4 September 2020).
- Liu, Z.; Wu, M.; Cao, W.; Chen, L.; Xu, J.; Zhang, R.; Zhou, M.; Mao, J. A Facial Expression Emotion Recognition Based Human-Robot Interaction System. IEEE/CAA J. Autom. Sin. 2017, 4, 668–676. [Google Scholar] [CrossRef]
- Ghafurian, M.; Lakatos, G.; Tao, Z.; Dautenhahn, K. Design and Evaluation of Affective Expressions of a Zoomorphic Robot. In Proceedings of the Lecture Notes in Computer Science; Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics; Springer: Berlin/Heidelberg, Germany, 2020; Volume 12483. [Google Scholar]
- Ekman, P. Expression and the Nature of Emotion. In Approaches to Emotion; Psychology Press: London, UK, 1984. [Google Scholar]
- Mollahosseini, A.; Hasani, B.; Mahoor, M.H. AffectNet: A Database for Facial Expression, Valence, and Arousal Computing in the Wild. IEEE Trans. Affect. Comput. 2019, 10, 18–31. [Google Scholar] [CrossRef]
- Saarimäki, H.; Gotsopoulos, A.; Jääskeläinen, I.P.; Lampinen, J.; Vuilleumier, P.; Hari, R.; Sams, M.; Nummenmaa, L. Discrete Neural Signatures of Basic Emotions. Cereb. Cortex 2016, 26, 2563–2573. [Google Scholar] [CrossRef]
- Maithri, M.; Raghavendra, U.; Gudigar, A.; Samanth, J.; Barua, P.D.; Murugappan, M.; Chakole, Y.; Acharya, U.R. Automated Emotion Recognition: Current Trends and Future Perspectives. Comput. Methods Programs Biomed. 2022, 215, 106646. [Google Scholar] [CrossRef]
- Wang, J.; Wang, M. Review of the Emotional Feature Extraction and Classification Using EEG Signals. Cogn. Robot. 2021, 1, 29–40. [Google Scholar] [CrossRef]
- Doma, V.; Pirouz, M. A Comparative Analysis of Machine Learning Methods for Emotion Recognition Using EEG and Peripheral Physiological Signals. J. Big Data 2020, 7, 18. [Google Scholar] [CrossRef]
- Zhang, J.; Zhao, S.; Huang, W.; Hu, S. Brain Effective Connectivity Analysis from EEG for Positive and Negative Emotion. In Proceedings of the Lecture Notes in Computer Science; Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics; Springer: Berlin/Heidelberg, Germany, 2017; Volume 10637. [Google Scholar]
- Daros, A.R.; Zakzanis, K.K.; Ruocco, A.C. Facial Emotion Recognition in Borderline Personality Disorder. Psychol. Med. 2013, 43, 1953–1963. [Google Scholar] [CrossRef] [PubMed]
- Zhao, M.; Adib, F.; Katabi, D. Emotion Recognition Using Wireless Signals. Commun. ACM 2018, 61, 91–100. [Google Scholar] [CrossRef]
- D’Mello, S.K.; Kory, J. A Review and Meta-Analysis of Multimodal Affect Detection Systems. ACM Comput. Surv. 2015, 47, 1–36. [Google Scholar] [CrossRef]
- An, S.; Kim, S.; Chikontwe, P.; Park, S.H. Few-Shot Relation Learning with Attention for EEG-Based Motor Imagery Classification. In Proceedings of the IEEE International Conference on Intelligent Robots and Systems, Las Vegas, NV, USA, 25–29 October 2020. [Google Scholar]
- Liu, D.; Wang, Z.; Wang, L.; Chen, L. Multi-Modal Fusion Emotion Recognition Method of Speech Expression Based on Deep Learning. Front. Neurorobot. 2021, 15, 697634. [Google Scholar] [CrossRef]
- Asghar, M.A.; Khan, M.J.; Rizwan, M.; Shorfuzzaman, M.; Mehmood, R.M. AI Inspired EEG-Based Spatial Feature Selection Method Using Multivariate Empirical Mode Decomposition for Emotion Classification. In Proceedings of the Multimedia Systems, Athlone, Ireland, 14 June 2022; Volume 28. [Google Scholar]
- Alazrai, R.; Homoud, R.; Alwanni, H.; Daoud, M.I. EEG-Based Emotion Recognition Using Quadratic Time-Frequency Distribution. Sensors 2018, 18, 2739. [Google Scholar] [CrossRef]
- Li, R.; Liang, Y.; Liu, X.; Wang, B.; Huang, W.; Cai, Z.; Ye, Y.; Qiu, L.; Pan, J. MindLink-Eumpy: An Open-Source Python Toolbox for Multimodal Emotion Recognition. Front. Hum. Neurosci. 2021, 15, 621493. [Google Scholar] [CrossRef]
- Liu, W.; Qiu, J.; Zheng, W.; Lu, B.L. Multimodal Emotion Recognition Using Deep Canonical Correlation Analysis. arxiv 2019, arXiv:1908.05349. [Google Scholar]
- Al-Sumaidaee, S.A.M.; Abdullah, M.A.M.; Al-Nima, R.R.O.; Dlay, S.S.; Chambers, J.A. Multi-Gradient Features and Elongated Quinary Pattern Encoding for Image-Based Facial Expression Recognition. Pattern Recognit. 2017, 71, 249–263. [Google Scholar] [CrossRef]
- Xiaohua, W.; Muzi, P.; Lijuan, P.; Min, H.; Chunhua, J.; Fuji, R. Two-Level Attention with Two-Stage Multi-Task Learning for Facial Emotion Recognition. J. Vis. Commun. Image Represent. 2019, 62, 217–225. [Google Scholar] [CrossRef]
- Zhang, X.; Liu, J.; Shen, J.; Li, S.; Hou, K.; Hu, B.; Gao, J.; Zhang, T. Emotion Recognition from Multimodal Physiological Signals Using a Regularized Deep Fusion of Kernel Machine. IEEE Trans. Cybern. 2021, 51, 4386–4399. [Google Scholar] [CrossRef]
- He, Z.; Li, Z.; Yang, F.; Wang, L.; Li, J.; Zhou, C.; Pan, J. Advances in Multimodal Emotion Recognition Based on Brain–Computer Interfaces. Brain Sci. 2020, 10, 687. [Google Scholar] [CrossRef]
- Yin, Y.; Zheng, X.; Hu, B.; Zhang, Y.; Cui, X. EEG Emotion Recognition Using Fusion Model of Graph Convolutional Neural Networks and LSTM. Appl. Soft Comput. 2021, 100, 106954. [Google Scholar] [CrossRef]
- Liang, Z.; Oba, S.; Ishii, S. An Unsupervised EEG Decoding System for Human Emotion Recognition. Neural Netw. 2019, 116, 257–268. [Google Scholar] [CrossRef]
- Wu, X.; Zheng, W.L.; Li, Z.; Lu, B.L. Investigating EEG-Based Functional Connectivity Patterns for Multimodal Emotion Recognition. J. Neural Eng. 2022, 19, 016012. [Google Scholar] [CrossRef]
- Wei, C.; Chen, L.L.; Song, Z.Z.; Lou, X.G.; Li, D.D. EEG-Based Emotion Recognition Using Simple Recurrent Units Network and Ensemble Learning. Biomed. Signal. Process Control 2020, 58, 101756. [Google Scholar] [CrossRef]
- Li, J.; Qiu, S.; Shen, Y.Y.; Liu, C.L.; He, H. Multisource Transfer Learning for Cross-Subject EEG Emotion Recognition. IEEE Trans. Cybern. 2020, 50, 3281–3293. [Google Scholar] [CrossRef]
- Anjana, K.; Ganesan, M.; Lavanya, R. Emotional Classification of EEG Signal Using Image Encoding and Deep Learning. In Proceedings of the 2021 IEEE 7th International Conference on Bio Signals, Images and Instrumentation, ICBSII 2021, Chennai, India, 25–27 March 2021. [Google Scholar]
- Phan, T.D.T.; Kim, S.H.; Yang, H.J.; Lee, G.S. Eeg-Based Emotion Recognition by Convolutional Neural Network with Multi-Scale Kernels. Sensors 2021, 21, 5092. [Google Scholar] [CrossRef]
- Cai, J.; Xiao, R.; Cui, W.; Zhang, S.; Liu, G. Application of Electroencephalography-Based Machine Learning in Emotion Recognition: A Review. Front. Syst. Neurosci. 2021, 15, 729707. [Google Scholar] [CrossRef]
- Zhang, L.; Verma, B.; Tjondronegoro, D.; Chandran, V. Facial Expression Analysis under Partial Occlusion: A Survey. ACM Comput. Surv. 2018, 51, 1–49. [Google Scholar] [CrossRef]
- Li, S.; Deng, W. Deep Facial Expression Recognition: A Survey. IEEE Trans. Affect. Comput. 2022, 13, 1195–1215. [Google Scholar] [CrossRef]
- Iandola, F.N.; Han, S.; Moskewicz, M.W.; Ashraf, K.; Dally, W.J.; Keutzer, K. SqueezeNet: AlexNet-Level Accuracy with 50x Fewer Parameters and <0.5MB Model Size. arXiv 2016, arXiv:1602.07360. [Google Scholar]
- Wang, K.; Peng, X.; Yang, J.; Lu, S.; Qiao, Y. Suppressing Uncertainties for Large-Scale Facial Expression Recognition. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020. [Google Scholar]
- Yang, H.; Ciftci, U.; Yin, L. Facial Expression Recognition by De-Expression Residue Learning. In Proceedings of the Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2018. [Google Scholar]
- Jia, X.; Zheng, X.; Li, W.; Zhang, C.; Li, Z. Facial Emotion Distribution Learning by Exploiting Low-Rank Label Correlations Locally. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–16 June 2019; Volume 2019. [Google Scholar]
- Basbrain, A.; Gan, J.Q. One-Shot Only Real-Time Video Classification: A Case Study in Facial Emotion Recognition. In Proceedings of the Lecture Notes in Computer Science; Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics; Springer: Berlin/Heidelberg, Germany, 2020; Volume 12489. [Google Scholar]
- Zhan, C.; She, D.; Zhao, S.; Cheng, M.M.; Yang, J. Zero-Shot Emotion Recognition via Affective Structural Embedding. In Proceedings of the IEEE International Conference on Computer Vision, Seoul, Republic of Korea, 27 Octomber–2 November 2019; Volume 2019. [Google Scholar]
- Minaee, S.; Minaei, M.; Abdolrashidi, A. Deep-Emotion: Facial Expression Recognition Using Attentional Convolutional Network. Sensors 2021, 21, 3046. [Google Scholar] [CrossRef] [PubMed]
- Küntzler, T.; Höfling, T.T.A.; Alpers, G.W. Automatic Facial Expression Recognition in Standardized and Non-Standardized Emotional Expressions. Front. Psychol. 2021, 12, 627561. [Google Scholar] [CrossRef] [PubMed]
- Revina, I.M.; Emmanuel, W.R.S. A Survey on Human Face Expression Recognition Techniques. J. King Saud Univ. -Comput. Inf. Sci. 2021, 33, 619–628. [Google Scholar] [CrossRef]
- Jiang, T.; Wang, J.; Liu, Z.; Ling, Y. Fusion-Extraction Network for Multimodal Sentiment Analysis. In Proceedings of the Lecture Notes in Computer Science; Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics; Springer: Berlin/Heidelberg, Germany, 2020; Volume 12085. [Google Scholar]
- Zadeh, A.; Chen, M.; Cambria, E.; Poria, S.; Morency, L.P. Tensor Fusion Network for Multimodal Sentiment Analysis. In Proceedings of the EMNLP 2017-Conference on Empirical Methods in Natural Language Processing; Association for Computational Linguistics: Copenhagen, Denmark, 2017. [Google Scholar]
- Liao, J.; Zhong, Q.; Zhu, Y.; Cai, D. Multimodal Physiological Signal Emotion Recognition Based on Convolutional Recurrent Neural Network. In Proceedings of the IOP Conference Series: Materials Science and Engineering, Ulaanbaatar, Mongolia, 10–13 September 2020; Volume 782. [Google Scholar]
- Zheng, W.L.; Liu, W.; Lu, Y.; Lu, B.L.; Cichocki, A. EmotionMeter: A Multimodal Framework for Recognizing Human Emotions. IEEE Trans. Cybern. 2019, 49, 1110–1122. [Google Scholar] [CrossRef]
- Val-Calvo, M.; Alvarez-Sanchez, J.R.; Ferrandez-Vicente, J.M.; Fernandez, E. Affective Robot Story-Telling Human-Robot Interaction: Exploratory Real-Time Emotion Estimation Analysis Using Facial Expressions and Physiological Signals. IEEE Access 2020, 8, 134051–134066. [Google Scholar] [CrossRef]
- Rutter, L.A.; Norton, D.J.; Brown, T.A. The Impact of Self-Reported Depression Severity and Age on Facial Emotion Recognition in Outpatients with Anxiety and Mood Disorders. J. Psychopathol. Behav. Assess. 2020, 42, 86–92. [Google Scholar] [CrossRef]
- Aguiñaga, A.R.; Hernandez, D.E.; Quezada, A.; Calvillo Téllez, A. Emotion Recognition by Correlating Facial Expressions and EEG Analysis. Appl. Sci. 2021, 11, 6987. [Google Scholar] [CrossRef]
- Song, B.C.; Kim, D.H. Hidden Emotion Detection Using Multi-Modal Signals. In Proceedings of the 2021 CHI Conference on Human Factors in Computing Systems, Yokohama, Japan, 8–13 May 2021. [Google Scholar]
- Hassouneh, A.; Mutawa, A.M.; Murugappan, M. Development of a Real-Time Emotion Recognition System Using Facial Expressions and EEG Based on Machine Learning and Deep Neural Network Methods. Inform. Med. Unlocked 2020, 20, 100372. [Google Scholar] [CrossRef]
- Lu, Y.; Zhang, H.; Shi, L.; Yang, F.; Li, J. Expression-EEG Bimodal Fusion Emotion Recognition Method Based on Deep Learning. Comput. Math. Methods Med. 2021, 2021, 9940148. [Google Scholar] [CrossRef]
- Zhao, Y.; Chen, D. Expression EEG Multimodal Emotion Recognition Method Based on the Bidirectional LSTM and Attention Mechanism. Comput. Math. Methods Med. 2021, 2021, 9967592. [Google Scholar] [CrossRef]
- Scherer, K.R. What Are Emotions? And How Can They Be Measured? Soc. Sci. Inf. 2005, 44, 695–729. [Google Scholar] [CrossRef]
- Ekman, P.; Friesen, W.V.; O’Sullivan, M.; Chan, A.; Diacoyanni-Tarlatzis, I.; Heider, K.; Krause, R.; LeCompte, W.A.; Pitcairn, T.; Ricci-Bitti, P.E.; et al. Universals and Cultural Differences in the Judgments of Facial Expressions of Emotion. J. Pers. Soc. Psychol. 1987, 53, 712–717. [Google Scholar] [CrossRef]
- Russell, J.A. A Circumplex Model of Affect. J. Pers. Soc. Psychol. 1980, 39, 1161–1178. [Google Scholar] [CrossRef]
- Soleymani, M.; Member, S.; Lichtenauer, J.; Pun, T. A Multi-Modal Affective Database for Affect Recognition and Implicit Tagging. Am. Hist. 2011, 3, 42–55. [Google Scholar]
- Koelstra, S.; Mühl, C.; Soleymani, M.; Lee, J.S.; Yazdani, A.; Ebrahimi, T.; Pun, T.; Nijholt, A.; Patras, I. DEAP: A Database for Emotion Analysis; Using Physiological Signals. IEEE Trans. Affect. Comput. 2012, 3, 18–31. [Google Scholar] [CrossRef]
- Ekmekcioglu, E. Yucel CIMTAY Loughborough University Multimodal Emotion Dataset-2. Figshare. 2020. Available online: https://doi:10.6084/m9.figshare.12644033.v5 (accessed on 9 December 2022).
- Zhu, J.; Zhao, X.; Hu, H.; Gao, Y. Emotion Recognition from Physiological Signals Using Multi-Hypergraph Neural Networks. In Proceedings of the 2019 IEEE International Conference on Multimedia and Expo (ICME), Shanghai, China, 8–12 July 2019; pp. 610–615. [Google Scholar]
- Yang, Y.; Gao, Q.; Song, X.; Song, Y.; Mao, Z.; Liu, J. Facial Expression and EEG Fusion for Investigating Continuous Emotions of Deaf Subjects. IEEE Sens. J. 2021, 21, 16894–16903. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; Volume 2016. [Google Scholar]
- Andrew, G.; Arora, R.; Bilmes, J.; Livescu, K. Deep Canonical Correlation Analysis. In Proceedings of the 30th International Conference on Machine Learning, ICML, Atlanta, GA, USA, 16–21 June 2013. [Google Scholar]
- Lu, Y.; Zheng, W.L.; Li, B.; Lu, B.L. Combining Eye Movements and EEG to Enhance Emotion Recognition. In Proceedings of the IJCAI International Joint Conference on Artificial Intelligence, Buenos Aires, Argentina, 25–31 July 2015; Volume 2015. [Google Scholar]
- Cai, J.; Meng, Z.; Khan, A.S.; Li, Z.; Oreilly, J.; Han, S.; Liu, P.; Chen, M.; Tong, Y. Feature-Level and Model-Level Audiovisual Fusion for Emotion Recognition in the Wild. In Proceedings of the 2nd International Conference on Multimedia Information Processing and Retrieval, MIPR 2019, San Jose, CA, USA, 28–30 March 2019. [Google Scholar]
- Tanaka, K.; Sugeno, M. A Study on Subjective Evaluations of Printed Color Images. Int. J. Approx. Reason. 1991, 5, 213–222. [Google Scholar] [CrossRef]
- Wu, D.; Zhang, J.; Zhao, Q. Multimodal Fused Emotion Recognition about Expression-EEG Interaction and Collaboration Using Deep Learning. IEEE Access 2020, 8, 133180–133189. [Google Scholar] [CrossRef]
- Cimtay, Y.; Ekmekcioglu, E.; Caglar-Ozhan, S. Cross-Subject Multimodal Emotion Recognition Based on Hybrid Fusion. IEEE Access 2020, 8, 168865–168878. [Google Scholar] [CrossRef]
- Zhang, H. Expression-Eeg Based Collaborative Multimodal Emotion Recognition Using Deep Autoencoder. IEEE Access 2020, 8, 164130–164143. [Google Scholar] [CrossRef]
- Huang, Y.; Yang, J.; Liu, S.; Pan, J. Combining Facial Expressions and Electroencephalography to Enhance Emotion Recognition. Future Internet 2019, 11, 105. [Google Scholar] [CrossRef]
- Shi, D.; Ye, Y.; Gillwald, M.; Hecht, M. Designing a Lightweight 1D Convolutional Neural Network with Bayesian Optimization for Wheel Flat Detection Using Carbody Accelerations. Int. J. Rail Transp. 2021, 9, 311–341. [Google Scholar] [CrossRef]
- Saini, M.; Satija, U.; Upadhayay, M.D. Light-Weight 1-D Convolutional Neural Network Architecture for Mental Task Identification and Classification Based on Single-Channel EEG. Biomed. Signal Process. Control 2020, 74, 103494. [Google Scholar] [CrossRef]
- Cordeiro, J.R.; Raimundo, A.; Postolache, O.; Sebastião, P. Neural Architecture Search for 1d Cnns. Different Approaches Tests and Measurements. Sensors 2021, 21, 7990. [Google Scholar] [CrossRef]
- Qazi, E.-H.; Hussain, M.; AboAlsamh, H.; Ullah, I. Automatic Emotion Recognition (AER) System Based on Two-Level Ensemble of Lightweight Deep CNN Models. arXiv 2019, arXiv:1904.13234. [Google Scholar]
- Anvarjon, T.; Mustaqeem; Kwon, S. Deep-Net: A Lightweight Cnn-Based Speech Emotion Recognition System Using Deep Frequency Features. Sensors 2020, 20, 5212. [Google Scholar] [CrossRef]
- Oh, S.; Lee, J.Y.; Kim, D.K. The Design of CNN Architectures for Optimal Six Basic Emotion Classification Using Multiple Physiological Signals. Sensors 2020, 20, 866. [Google Scholar] [CrossRef]
- Asperger, H. Das Psychisch Abnormale Kind. Wien Klin. Wochenschr. 1938, 51, 1314–1317. [Google Scholar]
- Kanner, L. Autistic Disturbances of Affective Contact. Nerv. Child 1943, 2, 217–250. [Google Scholar]
- American Psychiatric Association. Diagnostic and Statistical Manual of Mental Disorders; American Psychiatric Association: Washington, DC, USA, 2013; ISBN 0-89042-555-8. [Google Scholar]
- Kasai, K.; Kawakubo, Y.; Kuwabara, H.; Yamasue, H. Neuroimaging in Autism Spectrum Disorders. Neurosci. Res. 2007, 58, S27. [Google Scholar] [CrossRef]
- Connelly, M.; Denney, D.R. Regulation of Emotions during Experimental Stress in Alexithymia. J. Psychosom. Res. 2007, 62, 649–656. [Google Scholar] [CrossRef] [PubMed]
- Poquérusse, J.; Pastore, L.; Dellantonio, S.; Esposito, G. Alexithymia and Autism Spectrum Disorder: A Complex Relationship. Front. Psychol. 2018, 9, 1196. [Google Scholar] [CrossRef] [PubMed]
- Landowska, A.; Karpus, A.; Zawadzka, T.; Robins, B.; Barkana, D.E.; Kose, H.; Zorcec, T.; Cummins, N. Automatic Emotion Recognition in Children with Autism: A Systematic Literature Review. Sensors 2022, 22, 1649. [Google Scholar] [CrossRef]
- Castellano, G.; Kessous, L.; Caridakis, G. Emotion Recognition through Multiple Modalities: Face, Body Gesture, Speech. In Proceedings of the Lecture Notes in Computer Science; Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics; Springer: Berlin/Heidelberg, Germany, 2008; Volume 4868. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Hyperparameter | Range | Optimal Value |
|---|---|---|
| Layers | 1–5 | 3 |
| Batch size | 18–40 | 32 |
| Epochs | 20–50 | 40 |
| Learning rate | 0.1–0.0001 | 0.001 |
| Number of convolution filters (Layer 1) | 16–100 | 64 |
| Filter size (Layer 1) | 3–5 | 3 |
| Number of convolution filters (Layer 2) | 16–100 | 64 |
| Filter size (Layer 2) | 3–5 | 3 |
| Number of convolution filters (Layer 3) | 16–128 | 32 |
| Filter size (Layer 3) | 3–5 | 3 |
| Number of convolution filters (Layer 4) | 16–128 | - |
| Filter size (Layer 4) | 3–5 | - |
| Number of convolution filters (Layer 5) | 16–128 | - |
| Filter size (Layer 5) | 3–5 | - |
| Hyperparameter | Range | Optimal Value |
|---|---|---|
| Layers | 1–4 | 3 |
| Batch size | 18–50 | 32 |
| Epochs | 20–60 | 40 |
| Learning rate | 0.1–0.0001 | 0.001 |
| Number of convolution filters (Layer 1) | 100–150 | 128 |
| Filter size (Layer 1) | 3–5 | 3 |
| Number of convolution filters (Layer 2) | 100–300 | 256 |
| Filter size (Layer 2) | 3–5 | 5 |
| Number of convolution filters (Layer 3) | 200–512 | 512 |
| Filter size (Layer 3) | 3–5 | 3 |
| Number of convolution filters (Layer 4) | 200–512 | - |
| Filter size (Layer 4) | 3–5 | - |
| Users | MAHNOB Dataset | DEAP Dataset |
|---|---|---|
| User 1 | 89.3 | 73.7 |
| User 2 | 84.9 | 74.5 |
| User 3 | 78.8 | 74.1 |
| User 4 | 95.1 | 75.6 |
| User 5 | 83.7 | 75.9 |
| User 6 | 96.4 | 85.4 |
| User 7 | 79.7 | 77.5 |
| User 8 | 76.1 | 75.3 |
| User 9 | 90.2 | 70.9 |
| User 10 | 84.8 | 73.6 |
| User 11 | 83.1 | 72.5 |
| User 12 | 86.5 | 70.8 |
| User 13 | 94.2 | 74.9 |
| User 14 | 92.8 | 72.8 |
| User 15 | 92.6 | 74.2 |
| User 16 | 83.6 | 72.1 |
| User 17 | 72.4 | 72.5 |
| User 18 | 71.1 | 78.3 |
| User 19 | 72.9 | 73.1 |
| User 20 | 87.8 | 75.2 |
| User 21 | 74.8 | 72.8 |
| User 22 | 71.9 | 73.3 |
| User 23 | 78.7 | - |
| User 24 | 80.3 | - |
| User 25 | 72.1 | - |
| User 26 | 85.6 | - |
| User 27 | 78.8 | - |
| Average | 83.27 | 74.57 |
| Users | MAHNOB Dataset | DEAP Dataset |
|---|---|---|
| User 1 | 92.2 | 88.8 |
| User 2 | 91.3 | 88.6 |
| User 3 | 93.1 | 90.4 |
| User 4 | 90.3 | 89.7 |
| User 5 | 91.8 | 89.7 |
| User 6 | 92.5 | 91.9 |
| User 7 | 92.4 | 91.6 |
| User 8 | 92.1 | 93.4 |
| User 9 | 90.7 | 87.2 |
| User 10 | 95.2 | 87.9 |
| User 11 | 95.1 | 91.1 |
| User 12 | 93.6 | 92.5 |
| User 13 | 94.1 | 92.1 |
| User 14 | 93.2 | 90.6 |
| User 15 | 92.8 | 92.8 |
| User 16 | 94.8 | 87.6 |
| User 17 | 94.7 | 90.0 |
| User 18 | 94.0 | 91.6 |
| User 19 | 90.8 | 91.7 |
| User 20 | 92.8 | 91.3 |
| User 21 | 95.1 | 90.4 |
| User 22 | 93.2 | 91.6 |
| User 23 | 92.8 | - |
| User 24 | 93.7 | - |
| User 25 | 95.8 | - |
| User 26 | 90.5 | - |
| User 27 | 93.1 | - |
| Average | 92.4 | 90.5 |
| Users | MAHNOB Dataset | DEAP Dataset |
|---|---|---|
| User 1 | 94.91 | 89.21 |
| User 2 | 93.63 | 91.97 |
| User 3 | 95.43 | 90.92 |
| User 4 | 92.6 | 92.07 |
| User 5 | 92.12 | 90.24 |
| User 6 | 92.91 | 92.39 |
| User 7 | 92.72 | 91.96 |
| User 8 | 92.39 | 93.86 |
| User 9 | 91.68 | 89.65 |
| User 10 | 95.56 | 90.86 |
| User 11 | 95.45 | 91.52 |
| User 12 | 94.01 | 92.99 |
| User 13 | 94.42 | 92.61 |
| User 14 | 93.65 | 91.04 |
| User 15 | 93.18 | 93.32 |
| User 16 | 95.21 | 89.92 |
| User 17 | 95.94 | 90.57 |
| User 18 | 94.34 | 92.01 |
| User 19 | 91.14 | 92.15 |
| User 20 | 93.25 | 91.73 |
| User 21 | 95.42 | 90.84 |
| User 22 | 93.66 | 92.09 |
| User 23 | 93.16 | - |
| User 24 | 94.98 | - |
| User 25 | 96.19 | - |
| User 26 | 92.88 | - |
| User 27 | 93.45 | - |
| Average | 93.86 | 91.54 |
| Accuracy (%) | Recall (%) | Precision (%) | F1-Score | |
|---|---|---|---|---|
| MAHNOB-HCI | 93.86 | 92.24 | 92.70 | 0.9351 |
| DEAP | 91.54 | 90.82 | 90.80 | 0.9107 |
| Accuracy (%) | Recall (%) | Precision (%) | F1-Score | |
|---|---|---|---|---|
| Happy | 93.4 | 91.1 | 91.4 | 0.9127 |
| Sad | 90.52 | 91.3 | 90.1 | 0.9004 |
| Neutral | 90.7 | 90.06 | 90.9 | 0.919 |
| Accuracy (%) | Recall (%) | Precision (%) | F1-Score | |
|---|---|---|---|---|
| Happy | 94.2 | 93 | 93.1 | 0.9413 |
| Sad | 94.1 | 92.32 | 92.4 | 0.936 |
| Neutral | 93.28 | 91.4 | 92.6 | 0.928 |
| Fusion Methods | MAHNOB-HCI | DEAP |
|---|---|---|
| Simple Concatenation [69] | 88.32 | 85.71 |
| MKL [70] | 88.81 | 86.55 |
| MAX [69] | 89.47 | 87.15 |
| Fuzzy Integral [69] | 90.83 | 88.08 |
| Adaptive Fusion [54] | 90.92 | 88.69 |
| BLSM [57] | 88.79 | 88.14 |
| DCCA [68] | 93.86 | 91.54 |
| Reference | No. of Emotions | Dataset | Accuracy (%) |
|---|---|---|---|
| Proposed | 3 | MAHNOB-HCI DEAP | 93.86 91.54 |
| Wu et al. [72] | 2 | DEAP | 85 |
| Cimtay et al. [73] | 2 | DEAP LUMED-2 | 79.2 82.7 |
| Zhang [74] | 4 | DEAP | 85.71 |
| Huang et al. [75] | 2 | DEAP MAHNOB-HCI | 80 75 |
| Aguiñaga et al. [53] | 3 | DEAP | 83.33 |
| Zhao and Chen [57] | 2 | DEAP MAHNOB-HCI | 86.8 74.6 |
| Method | Accuracy (%) |
|---|---|
| LIBSVM | 85.71 |
| Spiking neural networks | 73.15 |
| CNN | 69.38 |
| SVM | 73.69 |
| SVM, 3 Nearest Neighbors | 66.28 |
| Random Forest, SVM, logistic regression (LR) | 73.08 |
| LSTM-CNN | 93.13 |
| 1D-CNN and neural networks | 89.60 |
| LSTM | 91.00 |
| Proposed | 93.86 |
| Methods | Network Parameters | Processing Time (s) | Accuracy on DEAP Dataset (%) | Accuracy on MAHNOB-HCI Dataset (%) |
|---|---|---|---|---|
| Proposed 1D-CNN model for EEG | 19,042 | 3.823 | 74.57 | 83.27 |
| Shi et al. [76] | 1482 | 1.142 | 68.26 | 78.76 |
| Saini et al. [77] | 2688 | 2.257 | 70.13 | 79.98 |
| Cordeiro et al. [78] | 26,224,952 | 113.484 | 75.79 | 85.52 |
| Qazi et al. [79] | 1,028,516 | 59.711 | 75.08 | 84.63 |
| Anvarjon et al. [80] | 5,137,260 | 22.231 | 75.74 | 84.72 |
| Methods | Overall Processing Capacity Usage Test/Train (%) | Memory Test/Train (%) | Accuracy on DEAP Dataset (%) | Accuracy on MAHNOB-HCI Dataset (%) |
|---|---|---|---|---|
| Proposed 1D-CNN model for EEG | 19.5/20.5 | 10.9/8.7 | 74.57 | 83.27 |
| Shi et al. [76] | 17.3/19.67 | 8.3/7.9 | 68.26 | 78.76 |
| Saini et al. [77] | 18.5/21.8 | 9.6/9.0 | 70.13 | 79.98 |
| Cordeiro et al. [78] | 53.4/65.2 | 31.9/30.1 | 75.79 | 85.52 |
| Qazi et al. [79] | 31.49/30.9 | 24.1/21.4 | 75.08 | 84.63 |
| Anvarjon et al. [80] | 31.8/29.0 | 32.5/29/2 | 75.74 | 84.72 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Muhammad, F.; Hussain, M.; Aboalsamh, H. A Bimodal Emotion Recognition Approach through the Fusion of Electroencephalography and Facial Sequences. Diagnostics 2023, 13, 977. https://doi.org/10.3390/diagnostics13050977
Muhammad F, Hussain M, Aboalsamh H. A Bimodal Emotion Recognition Approach through the Fusion of Electroencephalography and Facial Sequences. Diagnostics. 2023; 13(5):977. https://doi.org/10.3390/diagnostics13050977
Chicago/Turabian StyleMuhammad, Farah, Muhammad Hussain, and Hatim Aboalsamh. 2023. "A Bimodal Emotion Recognition Approach through the Fusion of Electroencephalography and Facial Sequences" Diagnostics 13, no. 5: 977. https://doi.org/10.3390/diagnostics13050977