
A New Regression Model for Depression Severity Prediction Based on Correlation among Audio Features Using a Graph Convolutional Neural Network
Abstract
:1. Introduction
2. Materials and Methods
2.1. Datasets
2.2. Definition of Depression Severity
2.3. Model Construction
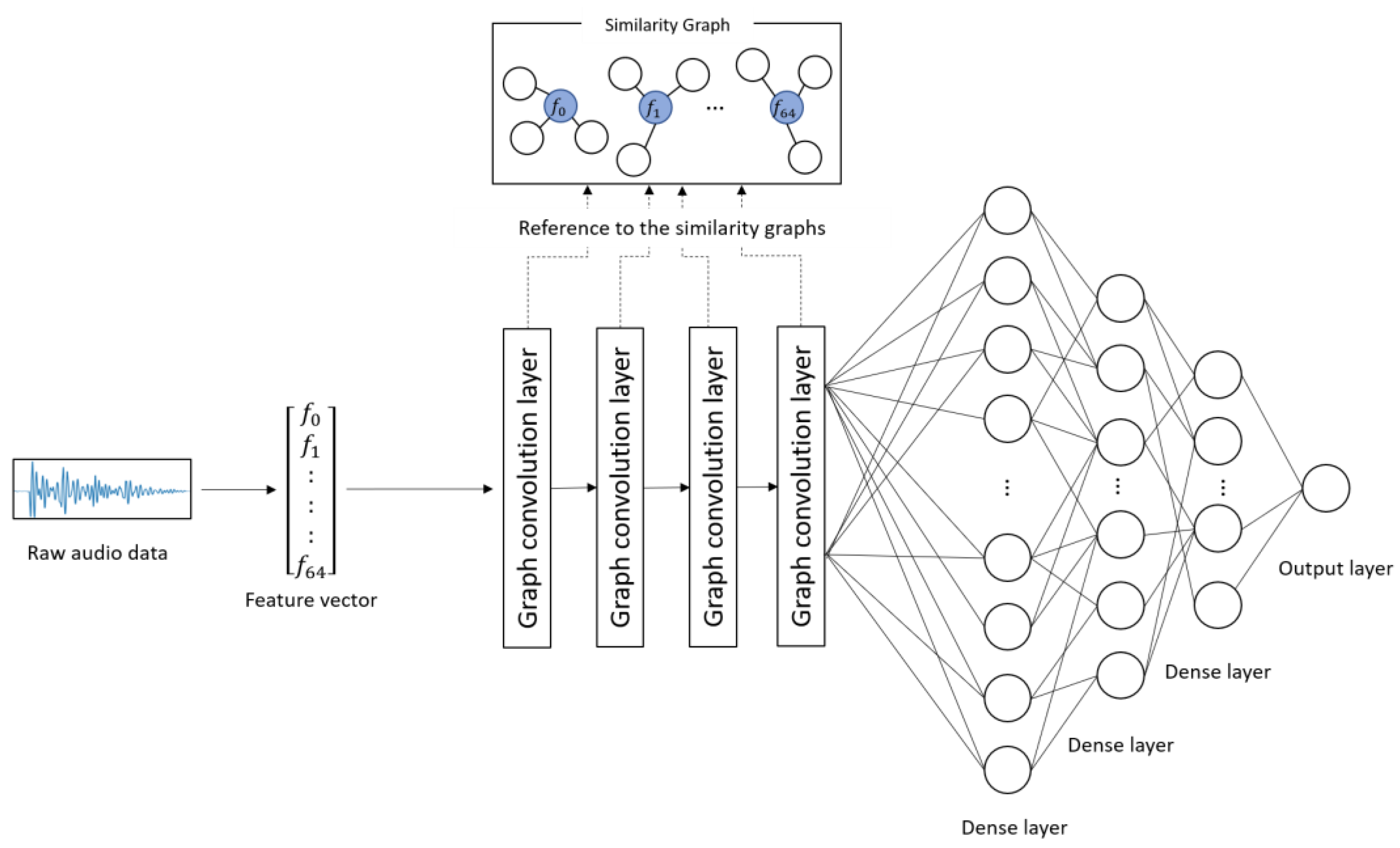
2.3.1. Creation of Similarity Graphs
2.3.2. Training and Prediction by GCNN
3. Experimental Results
3.1. Experimental Method
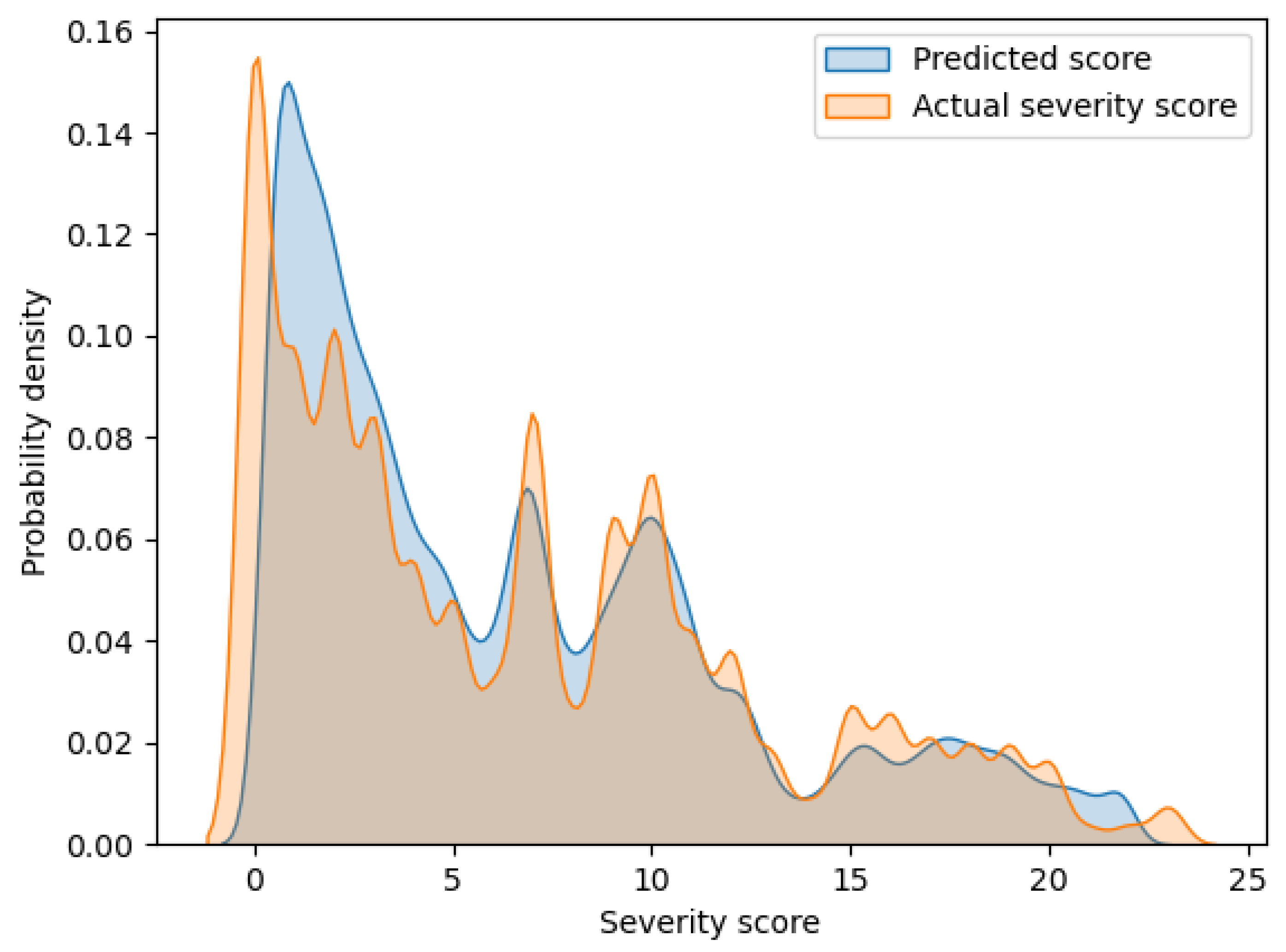
3.2. Results of Prediction Experiments
4. Discussion
- ▪
- The proposed model can predict depression severity based on the correlations among audio features obtained from speech data.
- ▪
- Despite the fact that the proposed model only uses speech data, it performs much better than the existing state-of-the-art models, including multimodal models.
- ▪
- A substantial amount of training data, high-performance computational resources, and a considerable amount of computational time are required for constructing the proposed model.
- ▪
- The number of neighborhoods with strong correlations may differ for each audio feature. However, the proposed model has a limitation in that the number of neighbors is fixed.
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Depression. Available online: https://www.who.int/news-room/fact-sheets/detail/depression (accessed on 15 November 2022).
- World Health Organization. Depression and Other Common Mental Disorders: Global Health Estimates; World Health Organization: Geneva, Switzerland, 2017.
- Mitchell, A.J.; Vaze, A.; Rao, S. Clinical diagnosis of depression in primary care: A meta-analysis. Lancet 2009, 374, 609–619. [Google Scholar] [CrossRef] [PubMed]
- Katon, W.; Von Korff, M.; Lin, E.; Bush, T.; Ormel, J. Adequacy and duration of antidepressant treatment in primary care. Med. Care 1992, 30, 67–76. [Google Scholar] [CrossRef] [PubMed]
- Brosse, A.L.; Sheets, E.S.; Lett, H.S.; Blumenthal, J.A. Exercise and the treatment of clinical depression in adults. Sports Med. 2002, 32, 741–760. [Google Scholar] [CrossRef] [PubMed]
- Niu, M.; Tao, J.; Liu, B.; Fan, C. Automatic depression level detection via lp-norm pooling. In Proceedings of the INTERSPEECH 2019, Graz, Austria, 15–19 September 2019; pp. 4559–4563. [Google Scholar]
- Niu, M.; Liu, B.; Tao, J.; Li, Q. A time-frequency channel attention and vectorization network for automatic depression level prediction. Neurocomputing 2021, 450, 208–218. [Google Scholar] [CrossRef]
- He, L.; Cao, C. Automated depression analysis using convolutional neural networks from speech. J. Biomed. Inform. 2018, 83, 103–111. [Google Scholar] [CrossRef]
- Rejaibi, E.; Komaty, A.; Meriaudeau, F.; Agrebi, S.; Othmani, A. MFCC-based recurrent neural network for automatic clinical depression recognition and assessment from speech. Biomed. Signal Process. Control 2022, 71, 103107. [Google Scholar] [CrossRef]
- Srimadhur, N.S.; Lalitha, S. An end-to-end model for detection and assessment of depression levels using speech. Procedia Comput. Sci. 2020, 171, 12–21. [Google Scholar] [CrossRef]
- Yang, L.; Jiang, D.; Xia, X.; Pei, E.; Oveneke, M.C.; Sahli, H. Multimodal measurement of depression using deep learning models. In Proceedings of the 7th Annual Workshop on Audio/Visual Emotion Challenge, Mountain View, CA, USA, 23 October 2017; pp. 53–59. [Google Scholar]
- Yang, L.; Jiang, D.; Sahli, H. Feature augmenting networks for improving depression severity estimation from speech signals. IEEE Access 2020, 8, 24033–24045. [Google Scholar] [CrossRef]
- Lu, J.; Liu, B.; Lian, Z.; Cai, C.; Tao, J.; Zhao, Z. Prediction of Depression Severity Based on Transformer Encoder and CNN Model. In Proceedings of the 13th International Symposium on Chinese Spoken Language Processing (ISCSLP 2022), Singapore, 11–14 December 2022; pp. 339–343. [Google Scholar]
- Fang, M.; Peng, S.; Liang, Y.; Hung, C.C.; Liu, S. A Multimodal Fusion Model with Multi-Level Attention Mechanism for Depression Detection. Biomed. Signal Process. Control 2023, 82, 104561. [Google Scholar] [CrossRef]
- Jain, V.; Crowley, J.L.; Dey, A.K.; Lux, A. Depression estimation using audiovisual features and fisher vector encoding. In Proceedings of the 4th International Workshop on Audio/Visual Emotion Challenge, Orlando, FL, USA, 7 November 2014; pp. 87–91. [Google Scholar]
- Silva, W.J.; Lopes, L.; Galdino, M.K.C.; Almeida, A.A. Voice Acoustic Parameters as Predictors of Depression. J. Voice, 2021; online ahead of print. [Google Scholar] [CrossRef] [PubMed]
- Scherer, S.; Stratou, G.; Gratch, J.; Morency, L.P. Investigating voice quality as a speaker-independent indicator of depression and PTSD. In Proceedings of the INTERSPEECH 2013, Lyon, France, 25–29 August 2013; pp. 847–851. [Google Scholar]
- Airas, M.; Alku, P. Comparison of multiple voice source parameters in different phonation types. In Proceedings of the INTERSPEECH 2007, Antwerp, Belgium, 27–31 August 2007; pp. 1410–1413. [Google Scholar]
- Hechtlinger, Y.; Chakravarti, P.; Qin, J. A generalization of convolutional neural networks to graph-structured data. arXiv 2017, arXiv:1704.08165. [Google Scholar]
- LeCun, Y.; Boser, B.; Denker, J.; Henderson, D.; Howard, R.; Hubbard, W.; Jackel, L. Handwritten digit recognition with a back-propagation network. Adv. Neural Inf. Process Syst. 1989, 2, 4559–4563. [Google Scholar]
- Gratch, J.; Artstein, R.; Lucas, G.; Stratou, G.; Scherer, S.; Nazarian, A.; Wood, R.; Boberg, J.; DeVault, D.; Marsella, S.; et al. The distress analysis interview corpus of human and computer interviews. In Proceedings of the Ninth International Conference on Language Resources and Evaluation, Reykjavik, Iceland, 26–31 May 2014; pp. 3123–3128. [Google Scholar]
- Kroenke, K.; Strine, T.W.; Spitzer, R.L.; Williams, J.B.; Berry, J.T.; Mokdad, A.H. The PHQ-8 as a measure of current depression in the general population. J. Affect. Disord. 2009, 114, 163–173. [Google Scholar] [CrossRef] [PubMed]
- Degottex, G.; Kane, J.; Drugman, T.; Raitio, T.; Scherer, S. COVAREP—A collaborative voice analysis repository for speech technologies. In Proceedings of the 2014 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Florence, Italy, 4–9 May 2014; pp. 960–964. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Peng, P.; You, M.; Xu, W.; Li, J. Fully integer-based quantization for mobile convolutional neural network inference. Neurocomputing 2021, 432, 194–205. [Google Scholar] [CrossRef]
- Choudhary, T.; Mishra, V.; Goswami, A.; Sarangapani, J. Inference-aware convolutional neural network pruning. Future Gener. Comput. Syst. 2022, 135, 44–56. [Google Scholar] [CrossRef]
- Kantamaneni, S.; Charles, A.; Babu, T.R. Speech enhancement with noise estimation and filtration using deep learning models. Theor. Comput. Sci. 2023, 941, 14–28. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
| PHQ-8 Scores | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 | 16 | 17 | 18 | 19 | 20 | 21 | 22 | 23 | 24 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Diagnosis | Non-depression | Depression | |||||||||||||||||||||||
| Severity level | Nonsignificant | Mild | Moderate | Moderately severe | Severe | ||||||||||||||||||||
| Layer | Number of Kernels | Kernel Size | Dropout Rate | Activation Function |
|---|---|---|---|---|
| Graph_conv1 | 64 | 1 × 9 × 64 | - | ReLU |
| Graph_conv2 | 128 | 64 × 9 × 128 | - | ReLU |
| Graph_conv3 | 256 | 128 × 9 × 256 | - | ReLU |
| Graph_conv4 | 512 | 256 × 9 × 512 | - | ReLU |
| Dense1 | - | - | 0.1 | tanh |
| Dense2 | - | - | 0.1 | tanh |
| Dense3 | - | - | 0.1 | tanh |
| Author | Year | Modality | Method | Feature | RMSE | MAE | SMAPE |
|---|---|---|---|---|---|---|---|
| Yang et al. [11] | 2017 | A | DCNN-DNN | GeMAPS based audio features | 5.63 | 4.85 | - |
| V | DCNN-DNN | Histogram of Displacement Range | 5.40 | 4.75 | - | ||
| T | DCNN-DNN | Paragraph Vector | 4.38 | 3.64 | - | ||
| A + V + T | DCNN-DNN fusion framework | - | 5.97 | 5.16 | - | ||
| Yang et al. [12] | 2020 | A | DCNN | DCGAN generated features | 5.52 | 4.63 | - |
| Lu et al. [13] | 2022 | A | Transformer Encoder + CNN | eGeMAPS based audio features | 5.37 | 4.48 | - |
| Fang et al. [14] | 2023 | A | LSTM + FFN | COVAREP based audio features and Formant | 6.13 | 5.21 | - |
| V | LSTM + FFN | 3D facial_landmark, Head Pose, Action Units, Eye Gaze | 5.44 | 4.12 | - | ||
| T | Bi-LSTM + Attention | USE Embedding | 4.76 | 3.61 | - | ||
| A + V + T | Feature fusion network | - | 3.68 | 3.18 | - | ||
| Ours | 2023 | A | GCNN | 65 audio features | 2.15 | 1.25 | 50.96% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ishimaru, M.; Okada, Y.; Uchiyama, R.; Horiguchi, R.; Toyoshima, I. A New Regression Model for Depression Severity Prediction Based on Correlation among Audio Features Using a Graph Convolutional Neural Network. Diagnostics 2023, 13, 727. https://doi.org/10.3390/diagnostics13040727
Ishimaru M, Okada Y, Uchiyama R, Horiguchi R, Toyoshima I. A New Regression Model for Depression Severity Prediction Based on Correlation among Audio Features Using a Graph Convolutional Neural Network. Diagnostics. 2023; 13(4):727. https://doi.org/10.3390/diagnostics13040727
Chicago/Turabian StyleIshimaru, Momoko, Yoshifumi Okada, Ryunosuke Uchiyama, Ryo Horiguchi, and Itsuki Toyoshima. 2023. "A New Regression Model for Depression Severity Prediction Based on Correlation among Audio Features Using a Graph Convolutional Neural Network" Diagnostics 13, no. 4: 727. https://doi.org/10.3390/diagnostics13040727