
A Deep Learning System for Automated Quality Evaluation of Optic Disc Photographs in Neuro-Ophthalmic Disorders
 , and
, and
Abstract
:1. Introduction
2. Materials and Methods
2.1. Study Design
2.2. Image Acquisition
2.3. Generation of the Quality Reference Standard
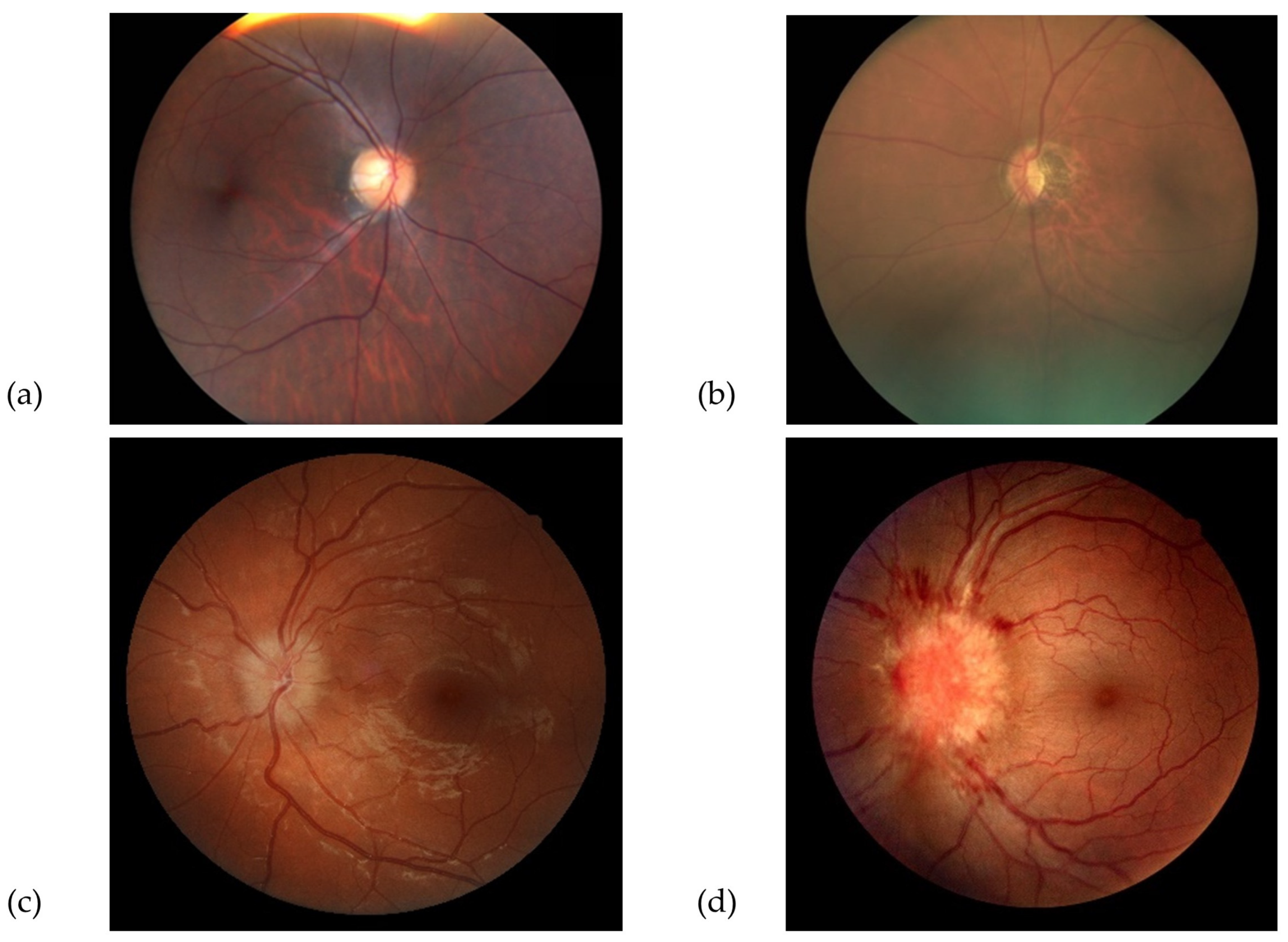
- Good quality photographs: defined as clear retinal images, including 100% of the ONH and peripapillary area, allowing for a confident assessment of the ONH appearance.
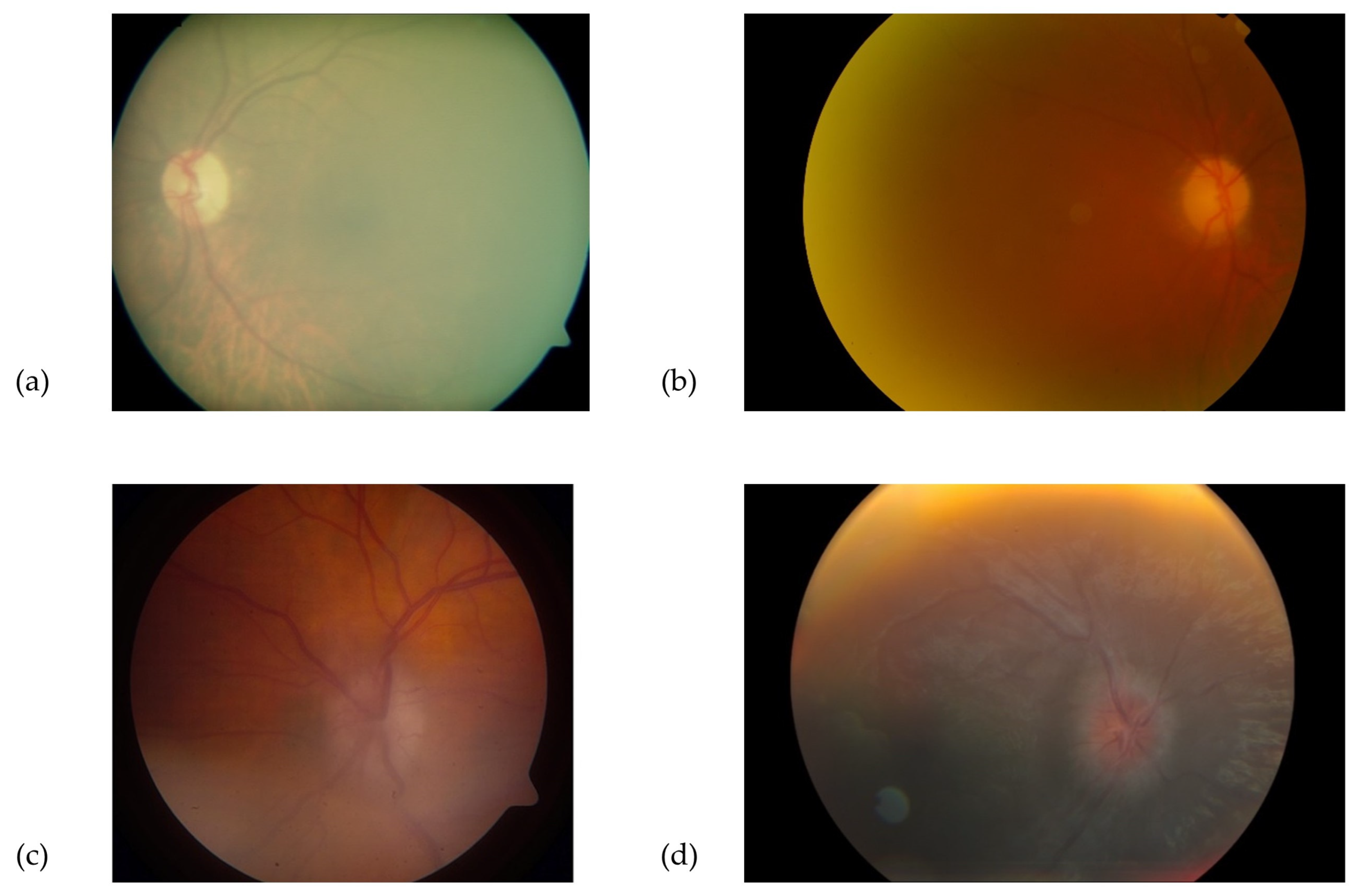
- Borderline quality photographs: defined as those with features allowing uncertain visual assessment of the ONH health, due to suboptimal image clarity, exposure, or partial obstruction of the image.
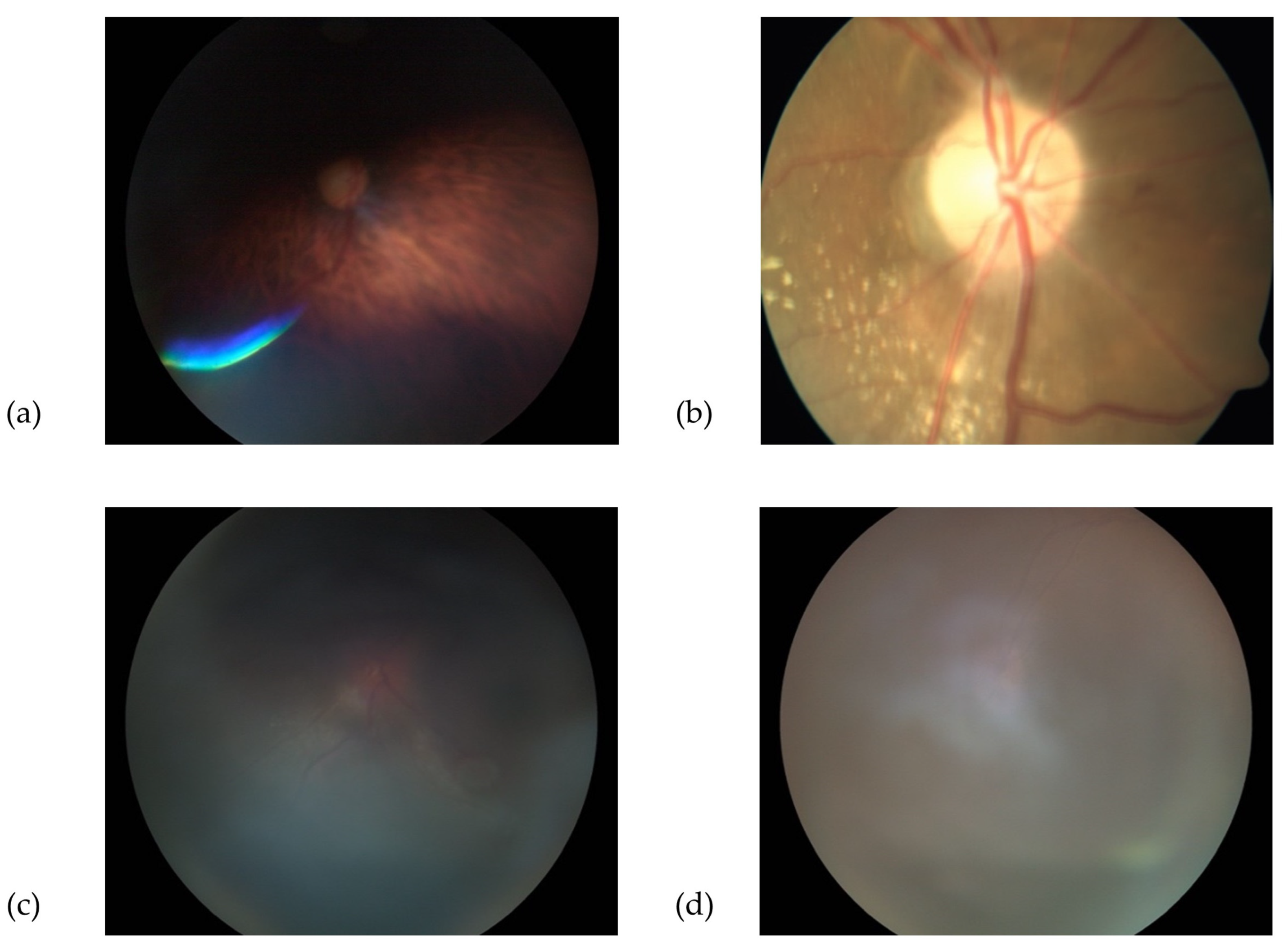
- Poor quality photographs: defined as images not allowing an ONH evaluation, due to various limitations, such as defocus, under- or overexposure, artefacts, poorly identifiable ONH features, or partially visible ONH. Similarly, photographs that were not compatible with the images used in the training dataset (e.g., fundus autofluorescence, wide-field retinal image) were included in this category. Examples of “good”, “borderline”, and “poor” images are shown in Figure 1, Figure 2 and Figure 3.
2.4. Cross-Validation
2.5. Image Pre-Processing and Development of Model
2.6. Statistical Analyses
3. Results
3.1. Characteristics of Dataset
3.2. Grading Duration
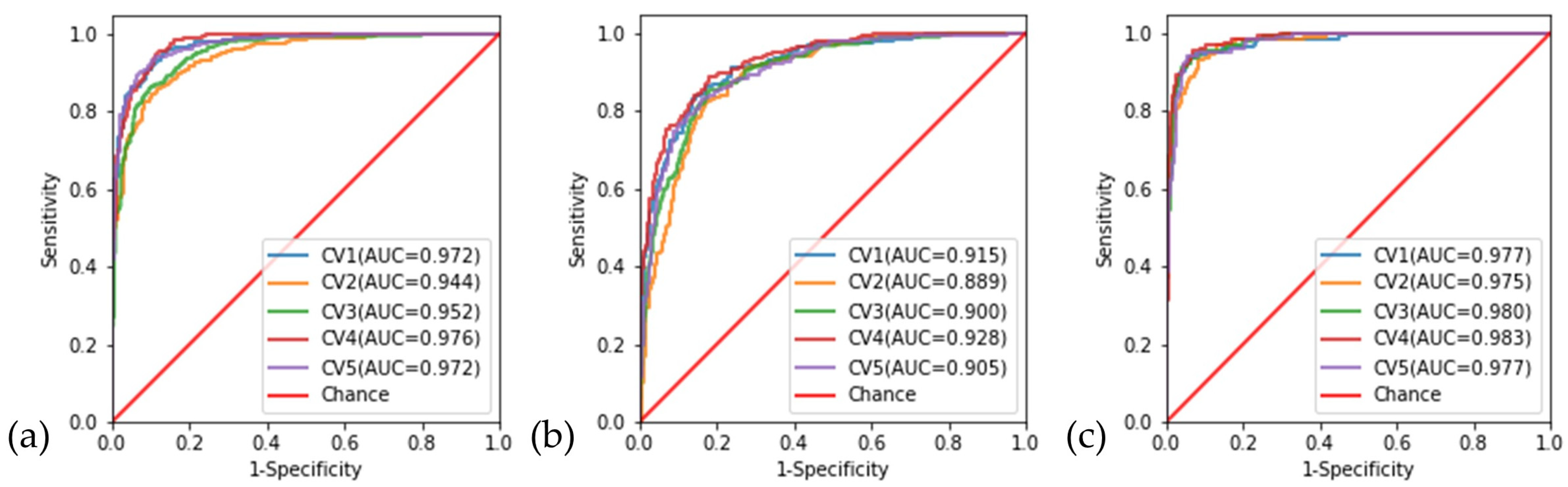
3.3. Cross-Validation
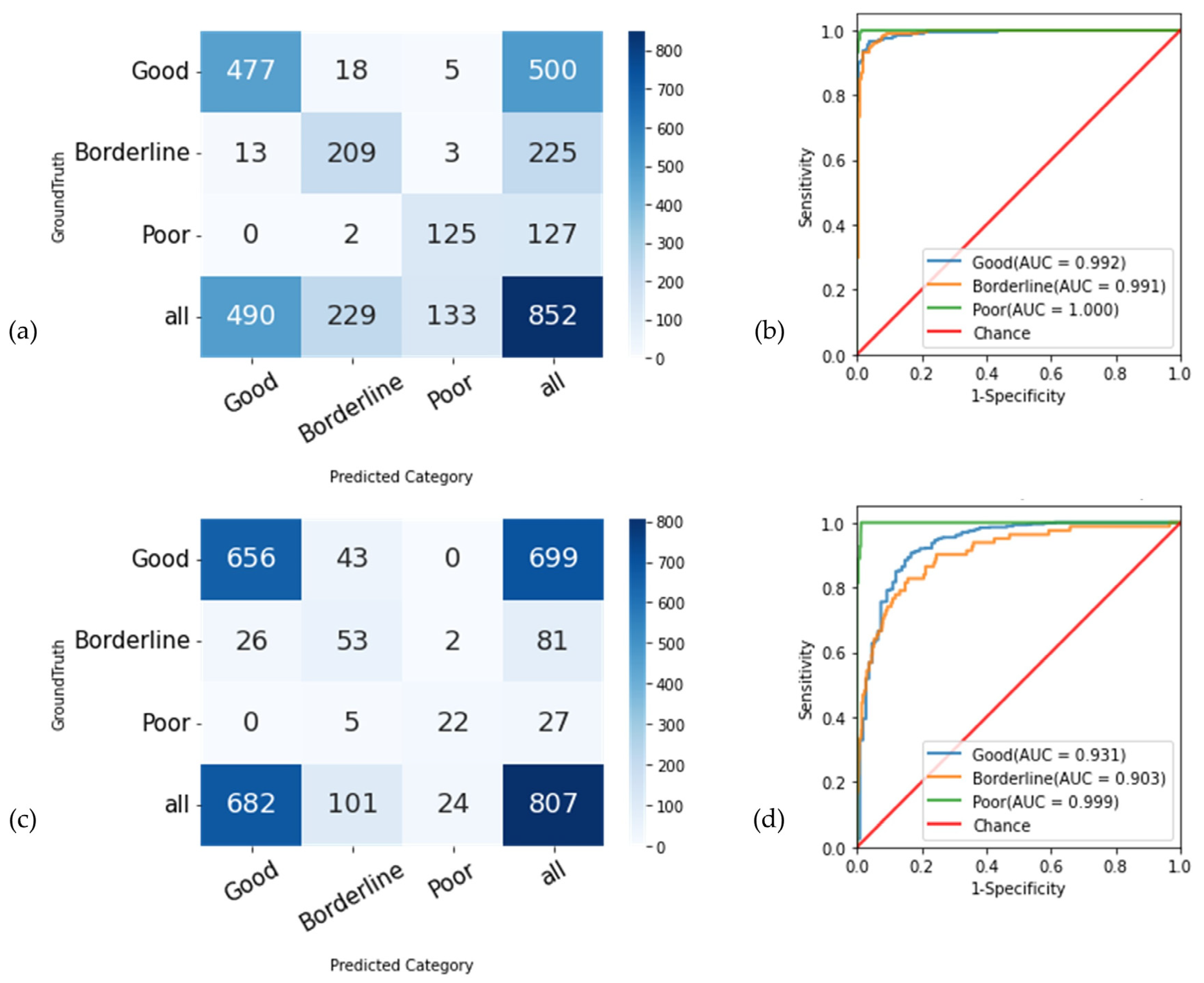
3.4. Overall Classification Performance
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Location of Center | Camera Model |
|---|---|
| Primary Training and Validation Datasets | |
| Amsterdam, Netherlands | Topcon-TRC-50DX |
| Angers, France | Topcon-TRC-NW6S |
| Atlanta, GA, United States | Topcon-TRC-50DX |
| Baltimore, MD, United States | Carl Zeiss-FF4 |
| Bordeaux, France | Carl Zeiss-VISUCAM |
| Calgary, Canada | Carl Zeiss-VISUCAM 224 Carl Zeiss-VISUCAM 524 |
| Chennai, India | Carl Zeiss-FF450 Plus IR |
| Coimbra, Portugal | Topcon-TRC-NW7SF Mark II |
| Copenhagen, Denmark | Topcon–TRC-50DX/TRC-NW8 |
| Eskisehir, Turkey | Kowa-Alpha-DIII |
| Freiburg, Germany | Carl Zeiss-SF 420 |
| Geneva, Switzerland | Carl Zeiss-FF450 Plus |
| Hong Kong, China | Topcon–TRC-50DX |
| Kinshasa, Democratic Republic of Congo | Carl Zeiss-VISUCAM |
| Kobe, Japan | Topcon-TRC-50DX Kowa-Nonmyd-WX |
| Lille, France | Nidek-AFC330 |
| London, United Kingdom | Topcon–TRC-50DX Canon-CR2 |
| Manila, Philippines | Carl Zeiss-VISUCAM 500 Meditec-NMFA |
| Nagpur, India | Carl Zeiss–FF450 |
| Ontario, Canada | Topcon–TRC-50DX Heidelberg-Spectralis |
| Paris, France | Canon-CRDGI Heidelberg–no model available |
| Rochester, NY, United States | Topcon–TRC-50DX |
| Seoul, South Korea | Kowa-VX-10a |
| Singapore, Singapore | Topcon–TRC-50DX/DRI OCT Triton Plus Canon-CR-Dgi Kowa-Nonmyd-WX3D Optomed-Aurora |
| Sydney, Australia | Carl Zeiss-VISUCAM 500 |
| Syracuse, NY, United States | Topcon-TRC-NW8/TRC-NW400 Carl Zeiss-FF 450 |
| Tehran, Iran | Canon-CR2 |
| Toronto, Canada | Carl Zeiss-VISUCAM 500 |
| Ufa, Russia | Carl Zeiss-VISUCAM 500 |
| External-Testing Dataset | |
| Atlanta, GA, United States | Topcon-TRC-50DX |
| Singapore, Singapore | Topcon-TRC-50DX/DRI OCT Triton Plus Canon-CR-Dgi Kowa-Nonmyd-WX3D Optomed-Aurora |
References
- McClelland, C.; Van Stavern, G.P.; Shepherd, J.B.; Gordon, M.; Huecker, J. Neuroimaging in patients referred to a neuro-ophthalmology service: The rates of appropriateness and concordance in interpretation. Ophthalmology 2012, 119, 1701–1704. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Muro-Fuentes, E.A.; Stunkel, L. Diagnostic Error in Neuro-ophthalmology: Avenues to Improve. Curr. Neurol. Neurosci. Rep. 2022, 22, 243–256. [Google Scholar] [CrossRef] [PubMed]
- Stunkel, L.; Mackay, D.D.; Bruce, B.B.; Newman, N.J.; Biousse, V. Referral patterns in neuro-ophthalmology. J. Neuro-Ophthalmol. 2020, 40, 485–493. [Google Scholar] [CrossRef] [PubMed]
- Ahn, J.M.; Kim, S.; Ahn, K.-S.; Cho, S.-H.; Kim, U.S. Accuracy of machine learning for differentiation between optic neuropathies and pseudopapilledema. BMC Ophthalmol. 2019, 19, 178. [Google Scholar] [CrossRef] [Green Version]
- Christopher, M.; Belghith, A.; Bowd, C.; Proudfoot, J.A.; Goldbaum, M.H.; Weinreb, R.N.; Girkin, C.A.; Liebmann, J.M.; Zangwill, L.M. Performance of deep learning architectures and transfer learning for detecting glaucomatous optic neuropathy in fundus photographs. Sci. Rep. 2018, 8, 16685. [Google Scholar] [CrossRef] [Green Version]
- Liu, H.; Li, L.; Wormstone, I.M.; Qiao, C.; Zhang, C.; Liu, P.; Li, S.; Wang, H.; Mou, D.; Pang, R. Development and validation of a deep learning system to detect glaucomatous optic neuropathy using fundus photographs. JAMA Ophthalmol. 2019, 137, 1353–1360. [Google Scholar] [CrossRef]
- Milea, D.; Najjar, R.P.; Jiang, Z.; Ting, D.; Vasseneix, C.; Xu, X.; Aghsaei Fard, M.; Fonseca, P.; Vanikieti, K.; Lagrèze, W.A. Artificial intelligence to detect papilledema from ocular fundus photographs. N. Engl. J. Med. 2020, 382, 1687–1695. [Google Scholar] [CrossRef]
- Biousse, V.; Newman, N.J.; Najjar, R.P.; Vasseneix, C.; Xu, X.; Ting, D.S.; Milea, L.B.; Hwang, J.M.; Kim, D.H.; Yang, H.K. Optic disc classification by deep learning versus expert neuro-ophthalmologists. Ann. Neurol. 2020, 88, 785–795. [Google Scholar] [CrossRef]
- Fleming, A.D.; Philip, S.; Goatman, K.A.; Olson, J.A.; Sharp, P.F. Automated assessment of diabetic retinal image quality based on clarity and field definition. Investig. Ophthalmol. Vis. Sci. 2006, 47, 1120–1125. [Google Scholar] [CrossRef] [Green Version]
- Scanlon, P.H.; Malhotra, R.; Thomas, G.; Foy, C.; Kirkpatrick, J.; Lewis-Barned, N.; Harney, B.; Aldington, S. The effectiveness of screening for diabetic retinopathy by digital imaging photography and technician ophthalmoscopy. Diabet. Med. 2003, 20, 467–474. [Google Scholar] [CrossRef]
- Philip, S.; Cowie, L.; Olson, J. The impact of the Health Technology Board for Scotland’s grading model on referrals to ophthalmology services. Br. J. Ophthalmol. 2005, 89, 891–896. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Zimmer-Galler, I.; Zeimer, R. Results of implementation of the DigiScope for diabetic retinopathy assessment in the primary care environment. Telemed. J. e-Health 2006, 12, 89–98. [Google Scholar] [CrossRef] [PubMed]
- Abramoff, M.D.; Suttorp-Schulten, M.S. Web-based screening for diabetic retinopathy in a primary care population: The EyeCheck project. Telemed. J. e-Health 2005, 11, 668–674. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Raj, A.; Tiwari, A.K.; Martini, M.G. Fundus image quality assessment: Survey, challenges, and future scope. IET Image Process. 2019, 13, 1211–1224. [Google Scholar] [CrossRef] [Green Version]
- Bosse, S.; Maniry, D.; Müller, K.-R.; Wiegand, T.; Samek, W. Deep neural networks for no-reference and full-reference image quality assessment. IEEE Trans. Image Process. 2017, 27, 206–219. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Mahapatra, D.; Roy, P.K.; Sedai, S.; Garnavi, R. A cnn based neurobiology inspired approach for retinal image quality assessment. In Proceedings of the 2016 38th Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC), Orlando, FL, USA, 16–20 August 2016; pp. 1304–1307. [Google Scholar]
- Saha, S.K.; Fernando, B.; Cuadros, J.; Xiao, D.; Kanagasingam, Y. Automated quality assessment of colour fundus images for diabetic retinopathy screening in telemedicine. J. Digit. Imaging 2018, 31, 869–878. [Google Scholar] [CrossRef]
- Zago, G.T.; Andreao, R.V.; Dorizzi, B.; Salles, E.O.T. Retinal image quality assessment using deep learning. Comput. Biol. Med. 2018, 103, 64–70. [Google Scholar] [CrossRef]
- Chalakkal, R.J.; Abdulla, W.H.; Thulaseedharan, S.S. Quality and content analysis of fundus images using deep learning. Comput. Biol. Med. 2019, 108, 317–331. [Google Scholar] [CrossRef]
- Shen, Y.; Sheng, B.; Fang, R.; Li, H.; Dai, L.; Stolte, S.; Qin, J.; Jia, W.; Shen, D. Domain-invariant interpretable fundus image quality assessment. Med. Image Anal. 2020, 61, 101654. [Google Scholar] [CrossRef]
- Raj, A.; Shah, N.A.; Tiwari, A.K.; Martini, M.G. Multivariate regression-based convolutional neural network model for fundus image quality assessment. IEEE Access 2020, 8, 57810–57821. [Google Scholar] [CrossRef]
- Zapata, M.A.; Royo-Fibla, D.; Font, O.; Vela, J.I.; Marcantonio, I.; Moya-Sánchez, E.U.; Sánchez-Pérez, A.; Garcia-Gasulla, D.; Cortés, U.; Ayguadé, E. Artificial intelligence to identify retinal fundus images, quality validation, laterality evaluation, macular degeneration, and suspected glaucoma. Clin. Ophthalmol. 2020, 14, 419. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Yuen, V.; Ran, A.; Shi, J.; Sham, K.; Yang, D.; Chan, V.T.; Chan, R.; Yam, J.C.; Tham, C.C.; McKay, G.J. Deep-Learning–Based Pre-Diagnosis Assessment Module for Retinal Photographs: A Multicenter Study. Transl. Vis. Sci. Technol. 2021, 10, 16. [Google Scholar] [CrossRef]
- Li, Z.; He, Y.; Keel, S.; Meng, W.; Chang, R.T.; He, M. Efficacy of a deep learning system for detecting glaucomatous optic neuropathy based on color fundus photographs. Ophthalmology 2018, 125, 1199–1206. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Leong, Y.-Y.; Vasseneix, C.; Finkelstein, M.T.; Milea, D.; Najjar, R.P. Artificial intelligence meets neuro-ophthalmology. Asia-Pac. J. Ophthalmol. 2022, 11, 111–125. [Google Scholar] [CrossRef] [PubMed]
- Chan, E.J.J.; Najjar, R.P.; Tang, Z.; Milea, D. Deep learning for retinal image quality assessment of optic nerve head disorders. Asia-Pac. J. Ophthalmol. 2021, 10, 282–288. [Google Scholar] [CrossRef]
- Kubin, A.M.; Wirkkala, J.; Keskitalo, A.; Ohtonen, P.; Hautala, N. Handheld fundus camera performance, image quality and outcomes of diabetic retinopathy grading in a pilot screening study. Acta Ophthalmol. 2021, 99, e1415–e1420. [Google Scholar] [CrossRef]
- Milea, L.; Najjar, R. Classif-Eye: A semi-automated image classification application. 2020. GitHub repository. 2020.
- Tan, M.; Le, Q. Efficientnet: Rethinking model scaling for convolutional neural networks. In Proceedings of the 36th International Conference on Machine Learning, Long Beach, CA, USA, 9–15 June 2019; pp. 6105–6114. [Google Scholar]
- Deng, J.; Dong, W.; Socher, R.; Li, L.-J.; Li, K.; Fei-Fei, L. Imagenet: A large-scale hierarchical image database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Software, Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar]
- Bloice, M.D.; Roth, P.M.; Holzinger, A. Biomedical image augmentation using Augmentor. Bioinformatics 2019, 35, 4522–4524. [Google Scholar] [CrossRef]
- Lever, J.; Krzywinski, M.; Altman, N. Points of significance: Model selection and overfitting. Nat. Methods 2016, 13, 703–705. [Google Scholar] [CrossRef]
- Fu, H.; Wang, B.; Shen, J.; Cui, S.; Xu, Y.; Liu, J.; Shao, L. Evaluation of retinal image quality assessment networks in different color-spaces. In International Conference on Medical Image Computing and Computer-Assisted Intervention; Springer: Berlin/Heidelberg, Germany; pp. 48–56.
- Beede, E.; Baylor, E.; Hersch, F.; Iurchenko, A.; Wilcox, L.; Ruamviboonsuk, P.; Vardoulakis, L.M. A human-centered evaluation of a deep learning system deployed in clinics for the detection of diabetic retinopathy. In Proceedings of the 2020 CHI Conference on Human Factors in Computing Systems, Honolulu, HI, USA, 25–30 April 2020; pp. 1–12. [Google Scholar]
- Davila, J.R.; Sengupta, S.S.; Niziol, L.M.; Sindal, M.D.; Besirli, C.G.; Upadhyaya, S.; Woodward, M.A.; Venkatesh, R.; Robin, A.L.; Grubbs, J., Jr. Predictors of photographic quality with a handheld nonmydriatic fundus camera used for screening of vision-threatening diabetic retinopathy. Ophthalmologica 2017, 238, 89–99. [Google Scholar] [CrossRef]





| Good | Borderline | Poor | Total | |
|---|---|---|---|---|
| Diagnosis | number of images | |||
| Main dataset (training, validation,and internal-testing) | ||||
| Normal Discs | 1472 | 637 | 400 | 2509 |
| Optic Discs with Papilledema | 394 | 76 | 10 | 480 |
| Optic Discs with Other Abnormalities | 646 | 314 | 253 | 1213 |
| Unknown Diagnosis Due to No Visible Optic Disc | - | - | 6 | 6 |
| External-testingdataset | ||||
| Normal Discs | 488 | 67 | 24 | 579 |
| Optic Discs with Papilledema | 56 | 1 | 0 | 57 |
| Optic Discs with Other Abnormalities | 155 | 13 | 3 | 171 |
| One-vs.-Rest Classification | Total | Good | Borderline | Poor | AUC (95% CI) | Sensitivity (95% CI) | Specificity (95% CI) | Accuracy (95% CI) |
|---|---|---|---|---|---|---|---|---|
| No. of images | % (percentage) | |||||||
| Internal-testing dataset | ||||||||
| Good vs. (Borderline + Poor) | 852 | 500 | 225 | 127 | 0.99 (0.99–1.00) | 95.4 (94.0–96.8) | 96.3 (94.9–97.8) | 95.8 (94.8–96.8) |
| Borderline vs. (Good + Poor) | 852 | 500 | 225 | 127 | 0.99 (0.99–1.00) | 92.9 (90.3–95.6) | 96.8 (95.8–97.9) | 95.8 (94.8–96.8) |
| Poor vs. (Good + Borderline) | 852 | 500 | 225 | 127 | 1.00 (0.99–1.00) | 98.4 (97.3–100.0) | 98.9 (98.4–99.6) | 98.8 (98.3–99.4) |
| External-testing dataset | ||||||||
| Good vs. (Borderline + Poor) | 807 | 699 | 81 | 27 | 0.93 (0.91–0.95) | 93.8 (92.5–95.2) | 75.9 (69.7–82.1) | 91.4 (90.0–92.9) |
| Borderline vs. (Good + Poor) | 807 | 699 | 81 | 27 | 0.90 (0.88–0.93) | 65.4 (56.6–72.9) | 93.4 (92.1–94.8) | 90.6 (89.1–92.2) |
| Poor vs. (Good + Borderline) | 807 | 699 | 81 | 27 | 1.00 (0.99–1.00) | 81.5 (70.6–93.8) | 99.7 (99.6–100.0) | 99.1 (98.6–99.6) |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chan, E.; Tang, Z.; Najjar, R.P.; Narayanaswamy, A.; Sathianvichitr, K.; Newman, N.J.; Biousse, V.; Milea, D.; for the BONSAI Group. A Deep Learning System for Automated Quality Evaluation of Optic Disc Photographs in Neuro-Ophthalmic Disorders. Diagnostics 2023, 13, 160. https://doi.org/10.3390/diagnostics13010160
Chan E, Tang Z, Najjar RP, Narayanaswamy A, Sathianvichitr K, Newman NJ, Biousse V, Milea D, for the BONSAI Group. A Deep Learning System for Automated Quality Evaluation of Optic Disc Photographs in Neuro-Ophthalmic Disorders. Diagnostics. 2023; 13(1):160. https://doi.org/10.3390/diagnostics13010160
Chicago/Turabian StyleChan, Ebenezer, Zhiqun Tang, Raymond P. Najjar, Arun Narayanaswamy, Kanchalika Sathianvichitr, Nancy J. Newman, Valérie Biousse, Dan Milea, and for the BONSAI Group. 2023. "A Deep Learning System for Automated Quality Evaluation of Optic Disc Photographs in Neuro-Ophthalmic Disorders" Diagnostics 13, no. 1: 160. https://doi.org/10.3390/diagnostics13010160