
K-Means Clustering for Shock Classification in Pediatric Intensive Care Units

 , , and
, , and
Abstract
:
1. Introduction
2. Materials and Methods
- The characteristics of each group were studied to determine whether there were differences between them.
- The correlation between the unsupervised classification and the discharge diagnosis was studied.
- It was assessed whether the classification was related to the outcomes (mortality and length of stay).
- It was tested whether the new classification had a greater association with outcomes than the classic classification.
3. Results
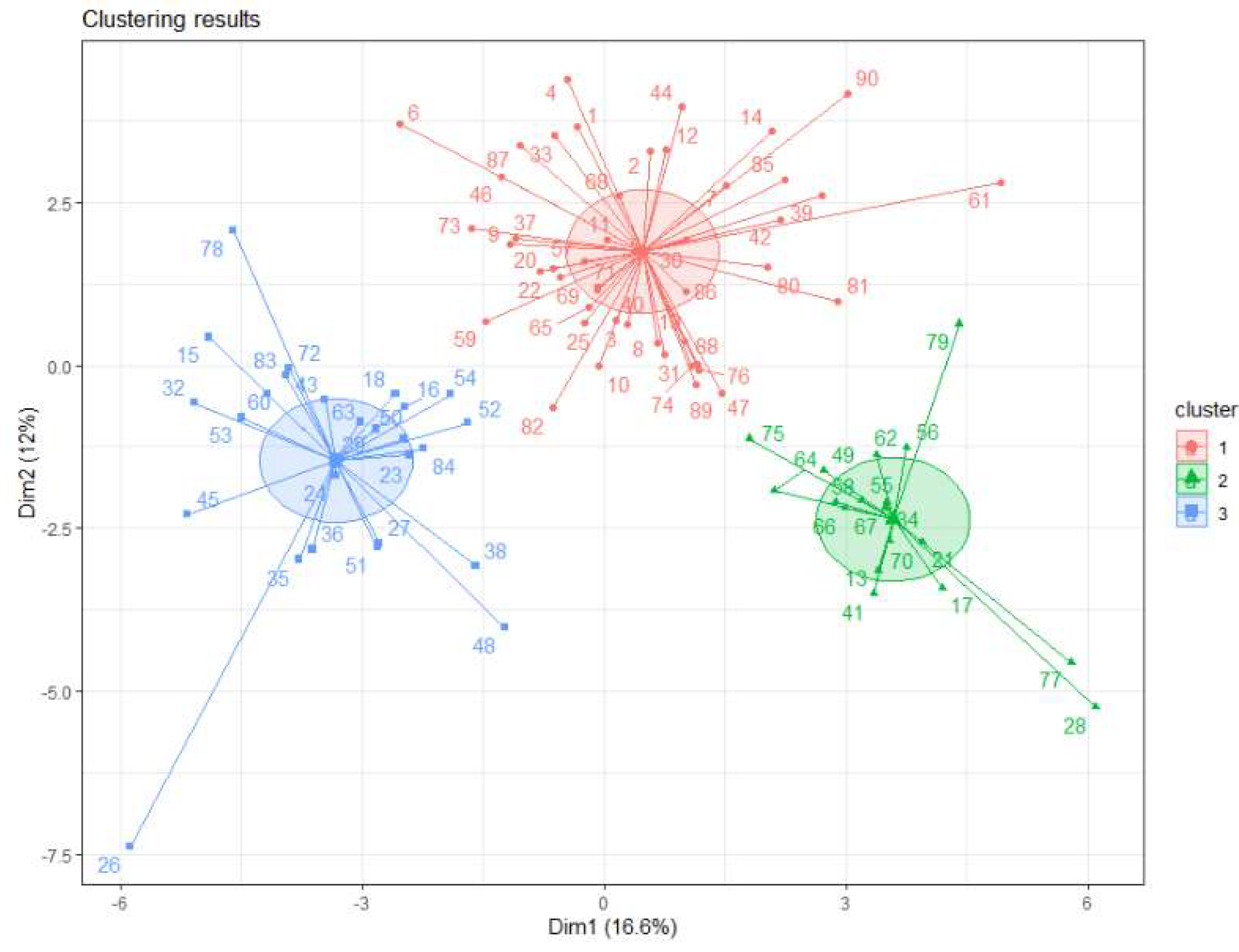
3.1. Analysis of Variables Used for Clustering
3.2. Analysis of Variables Not Used for Clustering
3.3. Relationship between Clustering and the Classic Classification
3.4. Analysis of Outcomes According to Clustering
3.5. Prediction of Outcomes by Classic Classification
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Cluster 1 | Cluster 2 | Cluster 3 | p Value | |
|---|---|---|---|---|
| Variables used for clustering | (Mean/Median (CI95%)) | (Mean/Median (CI95%)) | (Mean/Median (CI95%)) | |
| Female sex | p: 0.57 (0.42; 0.71) | p: 0.33 (0.09; 0.57) | p: 0.31 (0.12; 0.5) | 0.06 |
| Age in months | md: 33.63 (14.97; 55.17) | md: 3.25 (0.2; 8.77) | md: 137.13 (102.17; 169.43) | <0.001 |
| Weight z-score for age | md: −1.3 (−2.18; −0.51) | md: −0.93 (−2.07; 0.16) | md: 0.03 (−0.82; 2.05) | 0.02 |
| Hearth rate z-score for age (first 24 h min) | md: −0.32 (−0.62; 0.35) | md: −2.59 (−5.97; −0.14) | md: −0.27 (−1.26; 0.42) | 0.01 |
| “(first 24 h mean) | mn: 1.82 (1.4; 2.24) | mn: 0.77 (−0.11; 1.64) | mn: 1.99 (1.41; 2.58) | 0.93 |
| “(first 24 h max) | md: 3.82 (3.44; 4.31) | md: 2.7 (1.85; 5.36) | md: 5.13 (4.39; 5.45) | 0.002 |
| Respiratory rate z-score for age (first 24 h min) | md: −2.33 (−2.78; −1.99) | md: −3.61 (−5.14; −2.67) | md: −1.06 (−2.33; −0.63) | <0.001 |
| “(first 24 h mean) | mn: 1.07 (0.2; 1.95) | mn: −1.04 (−2.6; 0.51) | mn: 2.18 (0.87; 3.49) | 0.32 |
| “(first 24 h max) | mn: 6 (3.49; 8.51) | mn: 2.63 (−0.38; 5.63) | mn: 7.49 (5.01; 9.98) | 0.59 |
| Diastolic arterial pressure z-score for age (first 24 h min) | md: −0.15 (−0.15; 0.02) | md: −0.09 | md: 0.05 (−0.1; 0.1) | 0.01 |
| “(first 24 h mean) | mn: 0.24 (0.19; 0.29) | mn: 0.44 (0.09; 0.78) | mn: 0.54 (0.48; 0.61) | <0.001 |
| “(first 24 h max) | mn: 0.78 (0.7; 0.87) | mn: 1.23 (0.31; 2.15) | mn: 1.15 (1.02; 1.28) | <0.001 |
| Median arterial pressure z-score for age (first 24 h min) | md: −0.18 (−0.23; 0.06) | md: −0.72 | md: 0.04 (−0.11; 0.09) | <0.001 |
| “(first 24 h mean) | mn: 0.15 (0.11; 0.18) | mn: 0.15 (−0.02; 0.32) | mn: 0.41 (0.35; 0.47) | <0.001 |
| “(first 24 h max) | mn: 0.54 (0.47; 0.62) | mn: 0.78 (0.06; 1.5) | mn: 0.85 (0.76; 0.94) | <0.001 |
| Systolic arterial pressure z-score for age (first 24 h min) | mn: −0.21 (−0.28; −0.14) | mn: −0.35 (−0.58; −0.12) | mn: −0.01 (−0.07; 0.06) | <0.001 |
| “(first 24 h mean) | mn: 0.1 (0.05; 0.14) | mn: −0.07 (−0.16; 0.02) | mn: 0.32 (0.27; 0.36) | <0.001 |
| “(first 24 h max) | md: 0.37 (0.35; 0.58) | md: 0.32 | md: 0.61 (0.56; 0.69) | <0.001 |
| First 24 h diuresis in mL/kg/h | mn: 1.85 (1.16; 2.54) | mn: 3.4 (0; 7.27) | mn: 1.51 (0.68; 2.33) | 0.90 |
| Temperature in °C (first 24 h min) | mn: 36.74 (36.46; 37.02) | mn: 34.82 (34.19; 35.46) | mn: 36.7 (36.22; 37.17) | 0.50 |
| “(first 24 h mean) | mn: 37.02 (36.75; 37.28) | mn: 35.57 (35.15; 35.98) | mn: 37.15 (36.72; 37.58) | 0.97 |
| “(first 24 h max) | mn: 37.31 (36.96; 37.67) | mn: 36.18 (35.65; 36.7) | mn: 37.7 (37.18; 38.21) | 0.43 |
| Oxygen saturation in % (first 24 h min) | md: 94 (93; 95) | md: 79 (61; 89) | md: 95.5 (94; 96) | 0.002 |
| “(first 24 h mean) | md: 97.88 (96.94; 98.48) | md: 94 (91.33; 98.71) | md: 98.27 (97.38; 98.86) | 0.02 |
| Venous oxygen saturation in % (first 24 h min) | mn: 56.12 (50.16; 62.08) | mn: 34.53 (24.92; 44.14) | mn: 62.96 (57.16; 68.76) | 0.30 |
| “(first 24 h max) | mn: 77.24 (71.62; 82.85) | mn: 71.73 (59.86; 83.61) | mn: 78.6 (74.59; 82.61) | 0.81 |
| Carboxyhemoglobin in % (first 24 h max) | mn: 2.3 (1.89; 2.71) | mn: 2.49 (2.03; 2.94) | mn: 2.55 (2.1; 3) | 0.38 |
| Inspirited oxygen fraction in % (first 24 h max) | mn: 57.78 (46.9; 68.65) | mn: 88.33 (76.73; 99.93) | mn: 46.53 (31.11; 61.96) | 0.81 |
| “(first 24 h mean) | md: 36.19 (33.1; 55.62) | md: 55.59 (40; 69.76) | md: 26 (26; NA) | <0.001 |
| Capillary glucose in mg/dL (first 24 h min) | mn: 100.11 (90.91; 109.31) | mn: 75.53 (53.84; 97.22) | mn: 111.77 (96.74; 126.81) | 0.39 |
| “(first 24 h max) | md: 156.5 (126; 224) | md: 228 (199; 310) | md: 160.5 (135; 253) | 0.01 |
| Calcium ion in mg/dL (first 24 h min) | md: 4.6 (4.5; 4.9) | md: 3.6 (3.2; 4) | md: 4.54 (4.4; 4.7) | <0.001 |
| Creatinine in mg/dL (first 24 h max) | mn: 3.18 (0; 7.05) | mn: 3.92 (0; 10.08) | mn: 3.98 (0; 7.98) | 0.77 |
| Phosphate in mg/dL (first 24 h max) | md: 4.8 (4.5; 6.7) | md: 8 (5.8; 10.7) | md: 4.25 (3.9; 5.1) | <0.001 |
| Reactive C protein in mg/L (first 24 h max) | md: 55.9 (50.2; 198.09) | md: 11.4 (7.73; 38.94) | md: 163.6 (109.65; 265.62) | <0.001 |
| Lymphocytes · 1000/µL (first 24 h min) | md: 1.4 (0.92; 4.6) | md: 0.9 (0.6; 2.33) | md: 0.21 (0.05; 0.8) | <0.001 |
| “(first 24 h max) | md: 3.24 (2.88; 25) | md: 4.42 (1.5; 21) | md: 0.24 (0.1; 1.2) | <0.001 |
| Neutrophils · 1000/µL (first 24 h min) | md: 7.25 (6.5; 21.88) | md: 2.65 (2; 4.62) | md: 1.43 (0.05; 6.73) | <0.001 |
| “(first 24 h max) | mn: 13.65 (9.61; 17.69) | mn: 5.53 (3.83; 7.23) | mn: 6.01 (2.77; 9.25) | 0.002 |
| Mechanical ventilation | mn: 0.78 (0.66; 0.91) | mn: 1 | mn: 0.58 (0.37; 0.78) | 0.005 |
| Hemodiafiltration | p: 0.02 (0; 0.07) | p: 0.28 (0.05; 0.51) | p: 0.04 (0; 0.12) | 0.002 |
| ECMO | p: 0.02 (0; 0.07) | p: 0.83 (0.64; 1.02) | p: 0 | <0.001 |
| Thermic blanket | p: 0.11 (0.02; 0.2) | p: 0.06 (0; 0.17) | p: 0 | 0.20 |
| Non-clustering variables | (mean/median (CI95%)) | (mean/median (CI95%)) | (mean/median (CI95%)) | |
| EtCO2 in Torr (first 24 h min) | md: 30 (40; NA) | md: 9 (8; NA) | md: 31 | <0.001 |
| “(first 24 h mean) | mn: 42.56 (35.27; 49.86) | mn: 22.33 (16.54; 28.12) | mn: 35.19 (25.63; 44.74) | 0.02 |
| “(first 24 h max) | mn: 51.35 (43.8; 58.9) | mn: 33.08 (22.85; 43.32) | mn: 43.25 (32.67; 53.83) | 0.04 |
| End expiratory pressure (first 24 h mean) | md: 5.5 | md: 6.97 | md: 5.14 | 0.13 |
| “(first 24 h max) | md: 6 | md: 9 | md: 6 | 0.10 |
| Cerebral NIRS in % (first 24 h min) | mn: 49.67 (39.43; 59.9) | mn: 47.25 (35.27; 59.23) | mn: 61.25 (45.11; 77.39) | 0.44 |
| “(first 24 h mean) | mn: 59.59 (47.6; 71.59) | mn: 66.11 (59.64; 72.58) | mn: 70.73 (64.26; 77.2) | 0.12 |
| Troponin in ng/L (first 24 h max) | md: 249 (35; 1653) | md: 2732 (533; 149197.5) | md: 29 (20; 35) | 0.01 |
| Cardiogenic shock | p: 0.2 (0.08; 0.31) | p: 0.72 (0.49; 0.95) | p: 0.08 (0; 0.19) | <0.001 |
| Inflammatory shock | p: 0.52 (0.37; 0.67) | p: 0.17 (0; 0.36) | p: 0.81 (0.65; 0.97) | <0.001 |
| Septic shock | p: 0.5 (0.35; 0.65) | p: 0.17 (0; 0.36) | p: 0.77 (0.6; 0.94) | <0.001 |
| Anaphylactic shock | p: 0.04 (0; 0.1) | p: 0 | p: 0 | 0.38 |
| Hypovolemic shock | p: 0.15 (0.04; 0.26) | p: 0.28 (0.05; 0.51) | p: 0.12 (0; 0.25) | 0.34 |
| Hypovolemic secondary to traumatism | p: 0.07 (0; 0.14) | p: 0 | p: 0.04 (0; 0.12) | 0.52 |
| Hypovolemic secondary to surgery | p: 0.02 (0; 0.07) | p: 0.06 (0; 0.17) | p: 0.04 (0; 0.12) | 0.78 |
| Non-specified shock | p: 0.2 (0.08; 0.31) | p: 0 | p: 0.04 (0; 0.12) | 0.03 |
| Cardiac surgery | mn: 0.2 (0.08; 0.31) | mn: 0.72 (0.49; 0.95) | mn: 0.08 (0; 0.19) | <0.001 |
| Oncologic patients | mn: 0.04 (0; 0.1) | mn: 0.06 (0; 0.17) | mn: 0.31 (0.12; 0.5) | 0.003 |
| Length of stay in days | md: 6 (3; 9) | md: 11 (4; 29) | md: 4 (2; 7) | 0.02 |
| Exitus | p: 0.07 (0; 0.14) | p: 0.33 (0.09; 0.57) | p: 0.04 (0; 0.12) | 0.004 |
References
- Nichols, D.G.; Shaffner, D.H.; Argent, A.C. Rogers’ Textbook of Pediatric Intensive Care; Wolters Kluwer: Philadelphia, PA, USA, 2016. [Google Scholar]
- Kliegman, R.; Marcdante, K.J. Nelson Essentials of Pediatrics; Elsevier: Amsterdam, The Netherlands, 2019. [Google Scholar]
- Standl, T.; Annecke, T.; Cascorbi, I.; Heller, A.R.; Sabashnikov, A.; Teske, W. The Nomenclature, Definition and Distinction of Types of Shock. Dtsch. Arztebl. Int. 2018, 115, 757–768. [Google Scholar] [CrossRef] [PubMed]
- Kislitsina, O.N.; Rich, J.D.; Wilcox, J.E.; Pham, D.T.; Churyla, A.; Vorovich, E.B.; Ghafourian, K.; Yancy, C.W. Shock—Classification and Pathophysiological Principles of Therapeutics. Curr. Cardiol. Rev. 2019, 15, 102–113. [Google Scholar] [CrossRef] [PubMed]
- Peters, M.J.; Shipley, R. Clinical Classification of Cold and Warm Shock: Is There a Signal in the Noise? Pediatr. Crit. Care Med. 2020, 21, 1085–1087. [Google Scholar] [CrossRef] [PubMed]
- Tibby, S.M.; Hatherill, M.; Marsh, M.J.; Murdoch, I.A. Clinicians’ abilities to estimate cardiac index in ventilated children and infants. Arch. Dis. Child. 1997, 77, 516–518. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Benke, K.; Benke, G. Artificial Intelligence and Big Data in Public Health. Int. J. Environ. Res. Public Health 2018, 15, 2796. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Growth Charts—Data Table of Infant Weight-for-Age Charts. Centers for Disease Control and Prevention. Available online: https://www.cdc.gov/growthcharts/html_charts/wtageinf.htm (accessed on 9 August 2022).
- Growth Charts—Data Table of Weight-for-Age Charts. Centers for Disease Control and Prevention. Available online: https://www.cdc.gov/growthcharts/html_charts/wtage.htm (accessed on 9 August 2022).
- Flynn, J.T.; Kaelber, D.C.; Baker-Smith, C.M.; Blowey, D.; Carroll, A.E.; Daniels, S.R.; De Ferranti, S.D.; Dionne, J.M.; Falkner, B.; Flinn, S.K.; et al. Clinical Practice Guideline for Screening and Management of High Blood Pressure in Children and Adolescents. Pediatrics 2017, 140, e20171904. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Fleming, S.; Thompson, M.; Stevens, R.; Heneghan, C.; Plüddemann, A.; Maconochie, I.; Tarassenko, L.; Mant, D. Normal ranges of heart rate and respiratory rate in children from birth to 18 years of age: A systematic review of observational studies. Lancet 2011, 377, 1011. [Google Scholar] [CrossRef] [Green Version]
- Likas, A.; Vlassis, N.; Verbeek, J.J. The global K-means clustering algorithm. Pattern Recognit. 2003, 36, 451–461. [Google Scholar] [CrossRef] [Green Version]
- Dokmanic, I.; Parhizkar, R.; Ranieri, J.; Vetterli, M. Euclidean distance matrices: Essential theory, algorithms, and applications. IEEE Signal Processing Mag. 2015, 32, 12–30. [Google Scholar] [CrossRef] [Green Version]
- Mohamad, I.B.; Usman, D. Standardization and its effects on K-means clustering algorithm. Res. J. Appl. Sci. Eng. Technol. 2013, 6, 3299–3303. [Google Scholar] [CrossRef]
- Jia, Z.; Lu, X.; Duan, H.; Li, H. Using the distance between sets of hierarchical taxonomic clinical concepts to measure patient similarity. BMC Med. Inform. Decis. Mak. 2019, 19, 91. [Google Scholar] [CrossRef]
- Marlin, B.M.; Kale, D.C.; Khemani, R.G.; Wetzel, R.C. Unsupervised pattern discovery in electronic health care data using probabilistic clustering models. In Proceedings of the 2nd ACM SIGHIT International Health Informatics Symposium, Miami, FL, USA, 28–30 January 2012; ACM: New York, NY, USA, 2012; pp. 389–398. [Google Scholar]
- Williams, J.B.; Ghosh, D.; Wetzel, R.C. Applying Machine Learning to Pediatric Critical Care Data. Pediatr. Crit. Care Med. 2018, 19, 599–608. [Google Scholar] [CrossRef]
- Hug, C.W.; Clifford, G.D.; Reisner, A.T. Clinician blood pressure documentation of stable intensive care patients: An intelligent archiving agent has a higher association with future hypotension. Crit. Care Med. 2011, 39, 1006–1014. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Wetzel, R.C. First get the data—Then do the science. Pediatr. Crit. Care Med. 2018, 19, 382–383. [Google Scholar] [CrossRef] [PubMed]



| Types of Shock | No Cardiogenic | Cardiogenic | Wilcoxon/χ2 (p Value) | Log-Rank (p Value) |
| Median length of stay (days) | 5 (3; 7) | 9 (4; 24) | 0.02 | 0.01 |
| Exitus | 0.08 (0.01; 0.14) | 0.21 (0.03; 0.38) | 0.16 | - |
| No inflammatory | Inflammatory | Wilcoxon/χ2 (p value) | Log-Rank (p value) | |
| Median length of stay (days) | 7.5 (5; 13) | 3 (2; 6) | 0.01 | 0.05 |
| Exitus | 0.14 (0.03; 0.25) | 0.08 (0; 0.16) | 0.58 | - |
| No hypovolemic | Hypovolemic | Wilcoxon/χ2 (p value) | Log-Rank (p value) | |
| Median length of stay (days) | 5 (3; 7) | 7 (5; 14) | 0.17 | 1 |
| Exitus | 0.11 (0.04; 0.18) | 0.13 (0; 0.33) | 1 | - |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Rollán-Martínez-Herrera, M.; Kerexeta-Sarriegi, J.; Gil-Antón, J.; Pilar-Orive, J.; Macía-Oliver, I. K-Means Clustering for Shock Classification in Pediatric Intensive Care Units. Diagnostics 2022, 12, 1932. https://doi.org/10.3390/diagnostics12081932
Rollán-Martínez-Herrera M, Kerexeta-Sarriegi J, Gil-Antón J, Pilar-Orive J, Macía-Oliver I. K-Means Clustering for Shock Classification in Pediatric Intensive Care Units. Diagnostics. 2022; 12(8):1932. https://doi.org/10.3390/diagnostics12081932
Chicago/Turabian StyleRollán-Martínez-Herrera, María, Jon Kerexeta-Sarriegi, Javier Gil-Antón, Javier Pilar-Orive, and Iván Macía-Oliver. 2022. "K-Means Clustering for Shock Classification in Pediatric Intensive Care Units" Diagnostics 12, no. 8: 1932. https://doi.org/10.3390/diagnostics12081932