
Analysis of G-Quadruplex-Forming Sequences in Drought Stress-Responsive Genes, and Synthesis Genes of Phenolic Compounds in Arabidopsis thaliana
 , ,
, ,  and
and 
Abstract
:1. Introduction
2. Materials and Methods
2.1. Data Acquisition and PQS Prediction
2.2. Data Visualization and Statistical Analysis
3. Results
3.1. Global Analysis of PQS Occurrence in the Arabidopsis thaliana Genome
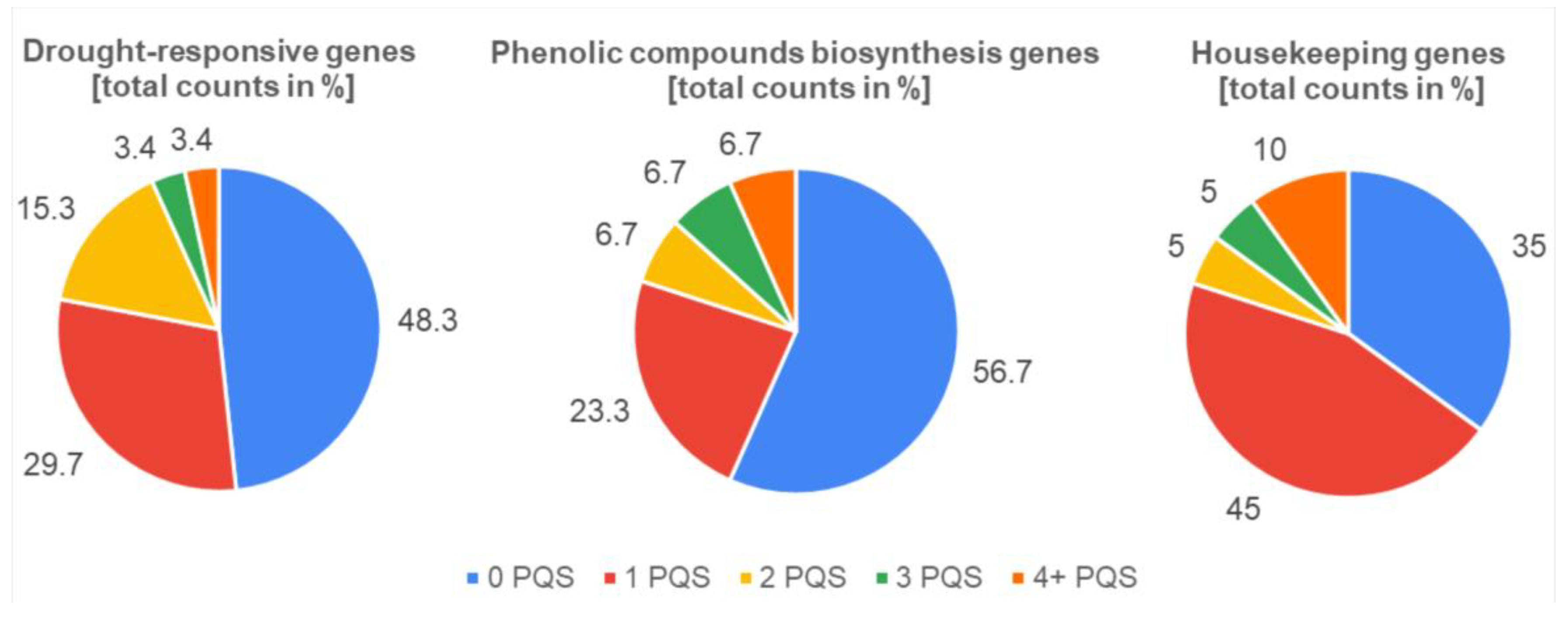
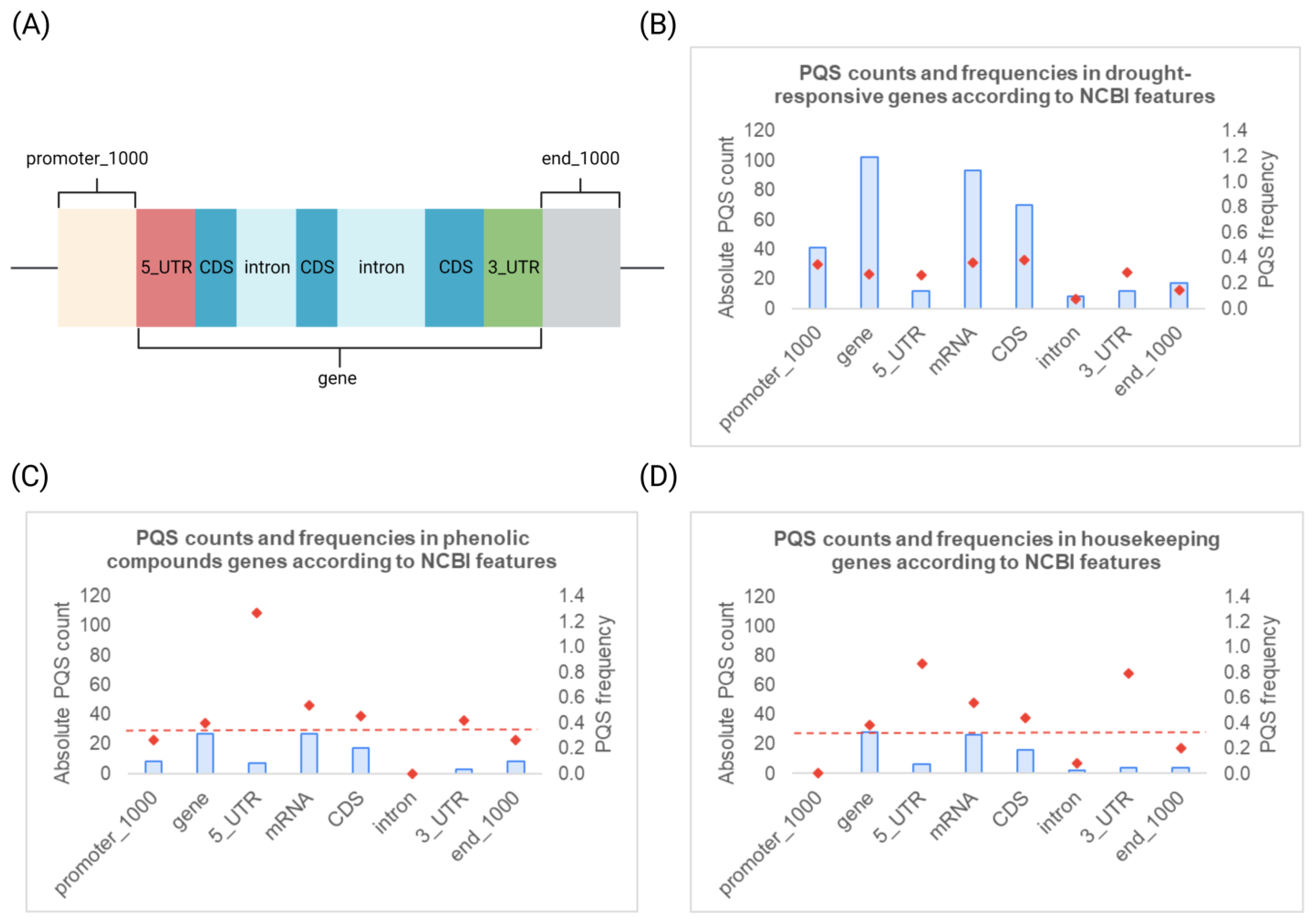
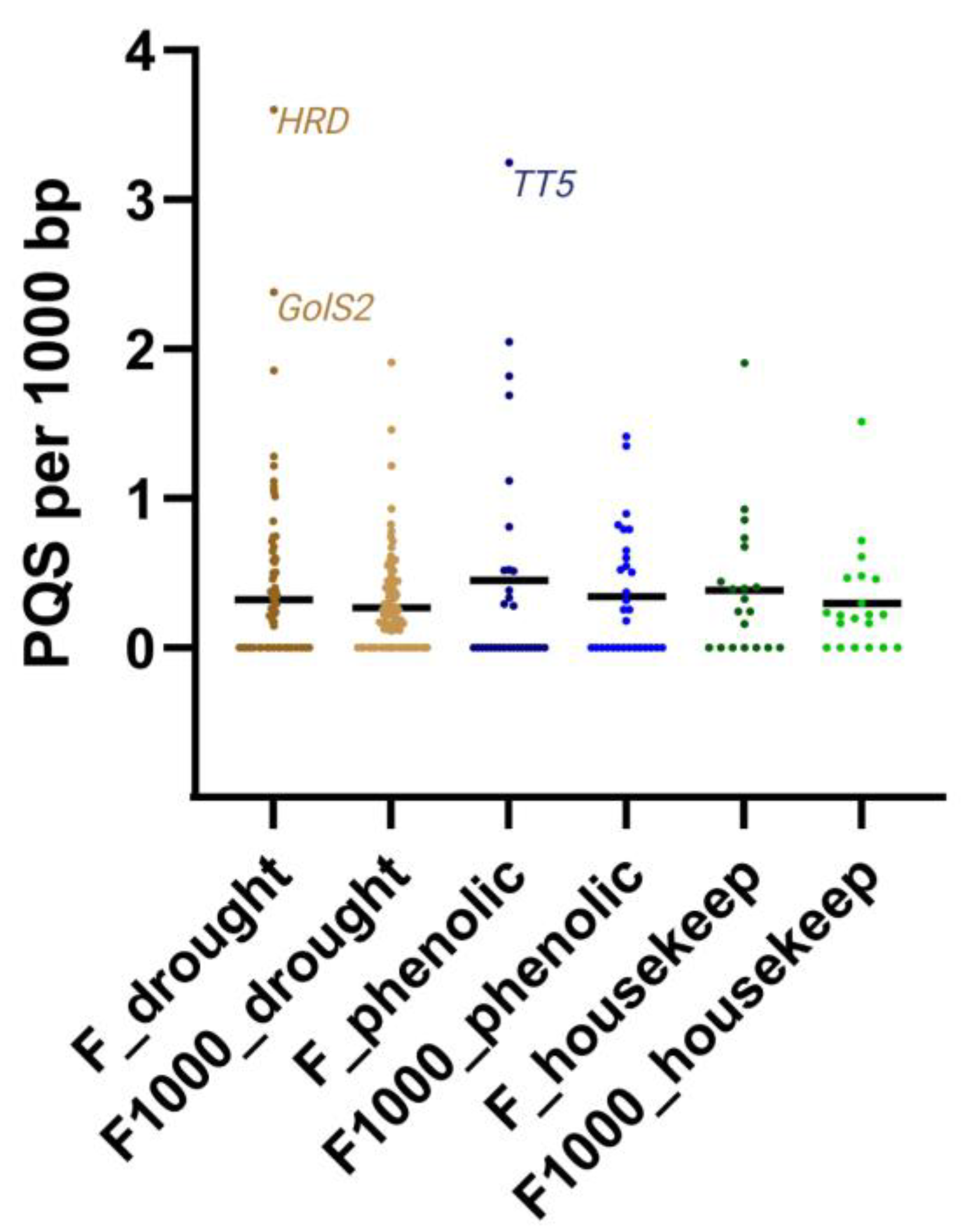
3.2. Descriptive Analyses of PQS Found within Different Gene Sets and NCBI Features Overlay
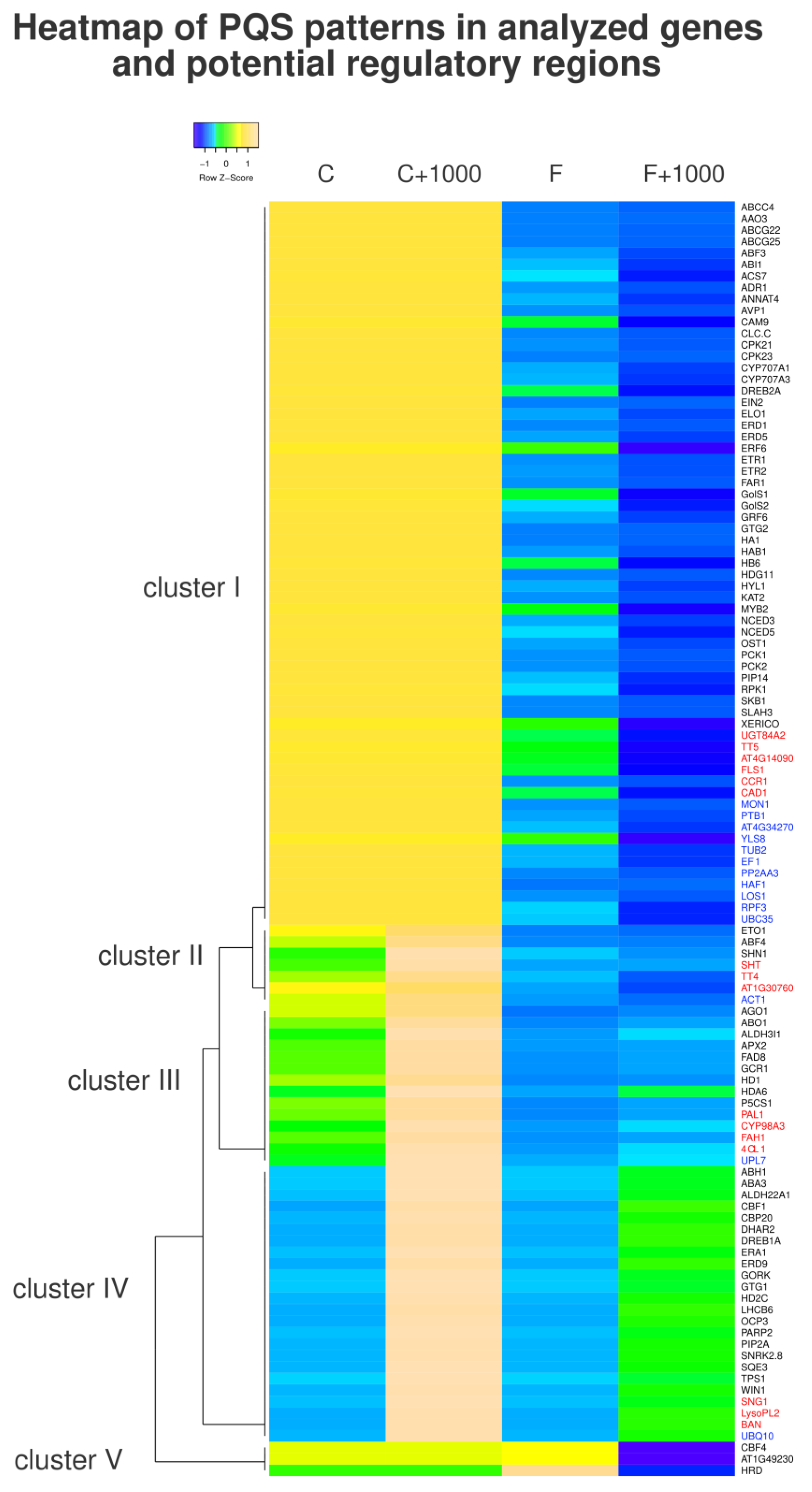
3.3. Clustering of PQS Patterns in Analyzed Genes
4. Discussion
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Data Availability Statement
Conflicts of Interest
References
- Watson, J.D.; Crick, F.H. Molecular Structure of Nucleic Acids: A Structure for Deoxyribose Nucleic Acid. Nature 1953, 171, 737–738. [Google Scholar] [CrossRef]
- Poggi, L.; Richard, G.-F. Alternative DNA Structures In Vivo: Molecular Evidence and Remaining Questions. Microbiol. Mol. Biol. Rev. 2020, 85, e00110-20. [Google Scholar] [CrossRef]
- Ghosh, A.; Bansal, M. A Glossary of DNA Structures from A to Z. Acta Crystallogr. Sect. D Biol. Crystallogr. 2003, 59, 620–626. [Google Scholar] [CrossRef] [Green Version]
- Griffin, B.D.; Bass, H.W. Plant G-Quadruplex (G4) Motifs in DNA and RNA.; Abundant, Intriguing Sequences of Unknown Function. Plant Sci. 2018, 269, 143–147. [Google Scholar] [CrossRef]
- Kim, J.-M.; Sasaki, T.; Ueda, M.; Sako, K.; Seki, M. Chromatin Changes in Response to Drought, Salinity, Heat, and Cold Stresses in Plants. Front. Plant Sci. 2015, 6, 114. [Google Scholar] [CrossRef] [Green Version]
- Bartas, M.; Čutová, M.; Brázda, V.; Kaura, P.; Šťastný, J.; Kolomazník, J.; Coufal, J.; Goswami, P.; Červeň, J.; Pečinka, P. The Presence and Localization of G-Quadruplex Forming Sequences in the Domain of Bacteria. Molecules 2019, 24, 1711. [Google Scholar] [CrossRef] [Green Version]
- Brázda, V.; Luo, Y.; Bartas, M.; Kaura, P.; Porubiaková, O.; Št’astnỳ, J.; Pečinka, P.; Verga, D.; Da Cunha, V.; Takahashi, T.S. G-Quadruplexes in the Archaea Domain. Biomolecules 2020, 10, 1349. [Google Scholar] [CrossRef]
- Bedrat, A.; Lacroix, L.; Mergny, J.-L. Re-Evaluation of G-Quadruplex Propensity with G4Hunter. Nucleic Acids Res. 2016, 44, 1746–1759. [Google Scholar] [CrossRef]
- Gellert, M.; Lipsett, M.N.; Davies, D.R. Helix Formation by Guanylic Acid. Proc. Natl. Acad. Sci. USA 1962, 48, 2013. [Google Scholar] [CrossRef] [Green Version]
- Bartas, M.; Brázda, V.; Karlický, V.; Červeň, J.; Pečinka, P. Bioinformatics Analyses and in Vitro Evidence for Five and Six Stacked G-Quadruplex Forming Sequences. Biochimie 2018, 150, 70–75. [Google Scholar] [CrossRef]
- Li, X.; Sánchez-Ferrer, A.; Bagnani, M.; Adamcik, J.; Azzari, P.; Hao, J.; Song, A.; Liu, H.; Mezzenga, R. Metal Ions Confinement Defines the Architecture of G-Quartet, G-Quadruplex Fibrils and Their Assembly into Nematic Tactoids. Proc. Natl. Acad. Sci. USA 2020, 117, 9832–9839. [Google Scholar] [CrossRef]
- Havlová, K.; Fajkus, J. G4 Structures in Control of Replication and Transcription of RRNA Genes. Front. Plant Sci. 2020, 11, 593692. [Google Scholar] [CrossRef]
- Kim, N. The Interplay between G-Quadruplex and Transcription. Curr. Med. Chem. 2019, 26, 2898–2917. [Google Scholar] [CrossRef]
- Cho, H.; Cho, H.S.; Nam, H.; Jo, H.; Yoon, J.; Park, C.; Dang, T.V.T.; Kim, E.; Jeong, J.; Park, S.; et al. Translational Control of Phloem Development by RNA G-Quadruplex–JULGI Determines Plant Sink Strength. Nat. Plants 2018, 4, 376–390. [Google Scholar] [CrossRef]
- Bugaut, A.; Balasubramanian, S. 5′-UTR RNA G-Quadruplexes: Translation Regulation and Targeting. Nucleic Acids Res. 2012, 40, 4727–4741. [Google Scholar] [CrossRef] [Green Version]
- Feng, Y.; Tao, S.; Zhang, P.; Sperti, F.R.; Liu, G.; Cheng, X.; Zhang, T.; Yu, H.; Wang, X.; Chen, C. Epigenomic Features of DNA G-Quadruplexes and Their Roles in Regulating Rice Gene Transcription. Plant Physiol. 2022, 188, 1632–1648. [Google Scholar] [CrossRef]
- Lejault, P.; Mitteaux, J.; Sperti, F.R.; Monchaud, D. How to Untie G-Quadruplex Knots and Why? Cell Chem. Biol. 2021, 28, 436–455. [Google Scholar] [CrossRef]
- Król, A.; Amarowicz, R.; Weidner, S. Changes in the Composition of Phenolic Compounds and Antioxidant Properties of Grapevine Roots and Leaves (Vitis Vinifera L.) under Continuous of Long-Term Drought Stress. Acta Physiol. Plant 2014, 36, 1491–1499. [Google Scholar] [CrossRef] [Green Version]
- Varela, M.C.; Arslan, I.; Reginato, M.A.; Cenzano, A.M.; Luna, M.V. Phenolic Compounds as Indicators of Drought Resistance in Shrubs from Patagonian Shrublands (Argentina). Plant Physiol. Biochem. 2016, 104, 81–91. [Google Scholar] [CrossRef]
- Sarker, U.; Oba, S. Drought Stress Enhances Nutritional and Bioactive Compounds, Phenolic Acids and Antioxidant Capacity of Amaranthus Leafy Vegetable. BMC Plant Biol. 2018, 18, 258. [Google Scholar] [CrossRef]
- Alter, S.; Bader, K.C.; Spannagl, M.; Wang, Y.; Bauer, E.; Schön, C.-C.; Mayer, K.F.X. DroughtDB: An Expert-Curated Compilation of Plant Drought Stress Genes and Their Homologs in Nine Species. Database 2015, 2015, bav046. [Google Scholar] [CrossRef] [Green Version]
- Brázda, V.; Kolomazník, J.; Lỳsek, J.; Bartas, M.; Fojta, M.; Št’astnỳ, J.; Mergny, J.-L. G4Hunter Web Application: A Web Server for G-Quadruplex Prediction. Bioinformatics 2019, 35, 3493–3495. [Google Scholar] [CrossRef] [Green Version]
- Babicki, S.; Arndt, D.; Marcu, A.; Liang, Y.; Grant, J.R.; Maciejewski, A.; Wishart, D.S. Heatmapper: Web-Enabled Heat Mapping for All. Nucleic Acids Res. 2016, 44, W147–W153. [Google Scholar] [CrossRef]
- Pasha, A.; Subramaniam, S.; Cleary, A.; Chen, X.; Berardini, T.; Farmer, A.; Town, C.; Provart, N. Araport Lives: An Updated Framework for Arabidopsis Bioinformatics. Plant Cell 2020, 32, 2683–2686. [Google Scholar] [CrossRef]
- Dobrovolná, M.; Bohálová, N.; Peška, V.; Wang, J.; Luo, Y.; Bartas, M.; Volná, A.; Mergny, J.-L.; Brázda, V. The Newly Sequenced Genome of Pisum Sativum Is Replete with Potential G-Quadruplex-Forming Sequences—Implications for Evolution and Biological Regulation. Int. J. Mol. Sci. 2022, 23, 8482. [Google Scholar] [CrossRef]
- Bohálová, N.; Dobrovolná, M.; Brázda, V.; Bidula, S. Conservation and Over-Representation of G-Quadruplex Sequences in Regulatory Regions of Mitochondrial DNA across Distinct Taxonomic Sub-Groups. Biochimie 2022, 194, 28–34. [Google Scholar] [CrossRef]
- Vannutelli, A.; Perreault, J.-P.; Ouangraoua, A. G-Quadruplex Occurrence and Conservation: More than Just a Question of Guanine–Cytosine Content. NAR Genom. Bioinform. 2022, 4, lqac010. [Google Scholar] [CrossRef]
- Chang, N.; Sun, Q.; Hu, J.; An, C.; Gao, H. Large Introns of 5 to 10 Kilo Base Pairs Can Be Spliced out in Arabidopsis. Genes 2017, 8, 200. [Google Scholar] [CrossRef] [Green Version]
- Bryan, T.M. G-Quadruplexes at Telomeres: Friend or Foe? Molecules 2020, 25, 3686. [Google Scholar] [CrossRef]
- Yadav, V.; Kim, N.; Tuteja, N.; Yadav, P. G Quadruplex in Plants: A Ubiquitous Regulatory Element and Its Biological Relevance. Front. Plant Sci. 2017, 8, 1163. [Google Scholar] [CrossRef]
- Kwok, C.K.; Ding, Y.; Shahid, S.; Assmann, S.M.; Bevilacqua, P.C. A Stable RNA G-Quadruplex within the 5′-UTR of Arabidopsis Thaliana ATR MRNA Inhibits Translation. Biochem. J. 2015, 467, 91–102. [Google Scholar] [CrossRef]
- Liu, H.; Chu, Z.; Yang, X. A Key Molecular Regulator, RNA G-Quadruplex and Its Function in Plants. Front Plant Sci. 2022, 13, 926953. [Google Scholar] [CrossRef]
- Volná, A.; Bartas, M.; Karlický, V.; Nezval, J.; Kundrátová, K.; Pečinka, P.; Špunda, V.; Červeň, J. G-Quadruplex in Gene Encoding Large Subunit of Plant RNA Polymerase II: A Billion-Year-Old Story. Int. J. Mol. Sci. 2021, 22, 7381. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Chromosome | NCBI ID | Length | GC Content | PQS Count | Frequency per 1000 bp |
|---|---|---|---|---|---|
| chr1 | NC_003070.9 | 30,427,671 | 35.68 | 10,989 | 0.36 |
| chr2 | NC_003071.7 | 19,698,289 | 35.86 | 6613 | 0.34 |
| chr3 | NC_003074.8 | 23,459,830 | 36.32 | 7893 | 0.34 |
| chr4 | NC_003075.7 | 18,585,056 | 36.20 | 6781 | 0.36 |
| chr5 | NC_003076.8 | 26,975,502 | 35.93 | 8664 | 0.32 |
| mtDNA | NC_037304.1 | 367,808 | 44.79 | 492 | 1.34 |
| cpDNA | NC_000932.1 | 154,478 | 36.29 | 125 | 0.81 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Pečinka, P.; Bohálová, N.; Volná, A.; Kundrátová, K.; Brázda, V.; Bartas, M. Analysis of G-Quadruplex-Forming Sequences in Drought Stress-Responsive Genes, and Synthesis Genes of Phenolic Compounds in Arabidopsis thaliana. Life 2023, 13, 199. https://doi.org/10.3390/life13010199
Pečinka P, Bohálová N, Volná A, Kundrátová K, Brázda V, Bartas M. Analysis of G-Quadruplex-Forming Sequences in Drought Stress-Responsive Genes, and Synthesis Genes of Phenolic Compounds in Arabidopsis thaliana. Life. 2023; 13(1):199. https://doi.org/10.3390/life13010199
Chicago/Turabian StylePečinka, Petr, Natália Bohálová, Adriana Volná, Kristýna Kundrátová, Václav Brázda, and Martin Bartas. 2023. "Analysis of G-Quadruplex-Forming Sequences in Drought Stress-Responsive Genes, and Synthesis Genes of Phenolic Compounds in Arabidopsis thaliana" Life 13, no. 1: 199. https://doi.org/10.3390/life13010199