
A Coding Basis and Three-in-One Integrated Data Visualization Method ‘Ana’ for the Rapid Analysis of Multidimensional Omics Dataset


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
2. Methods
2.1. Data Preparation
2.2. Software and Coding
2.3. Hardware
3. Results and Discussion
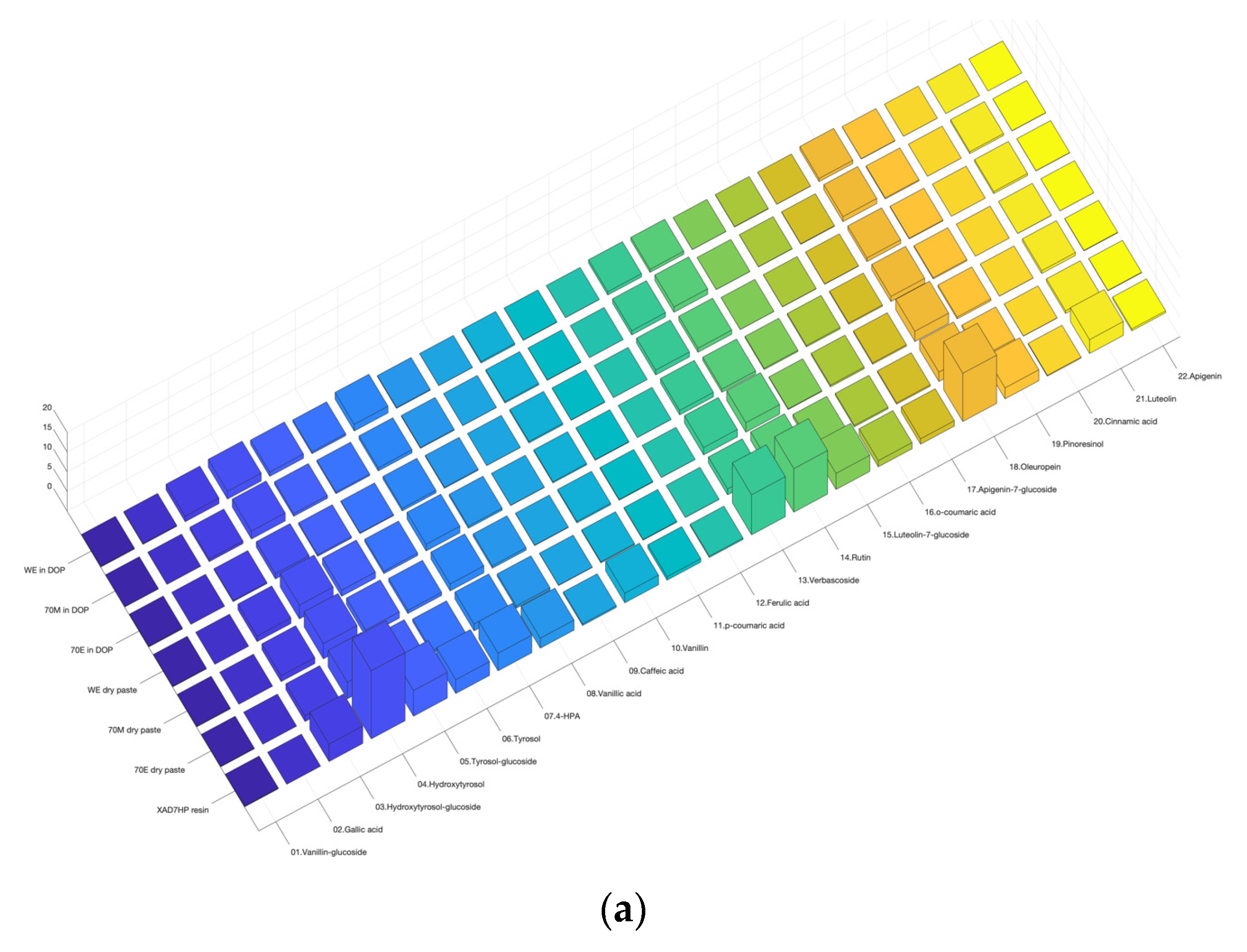
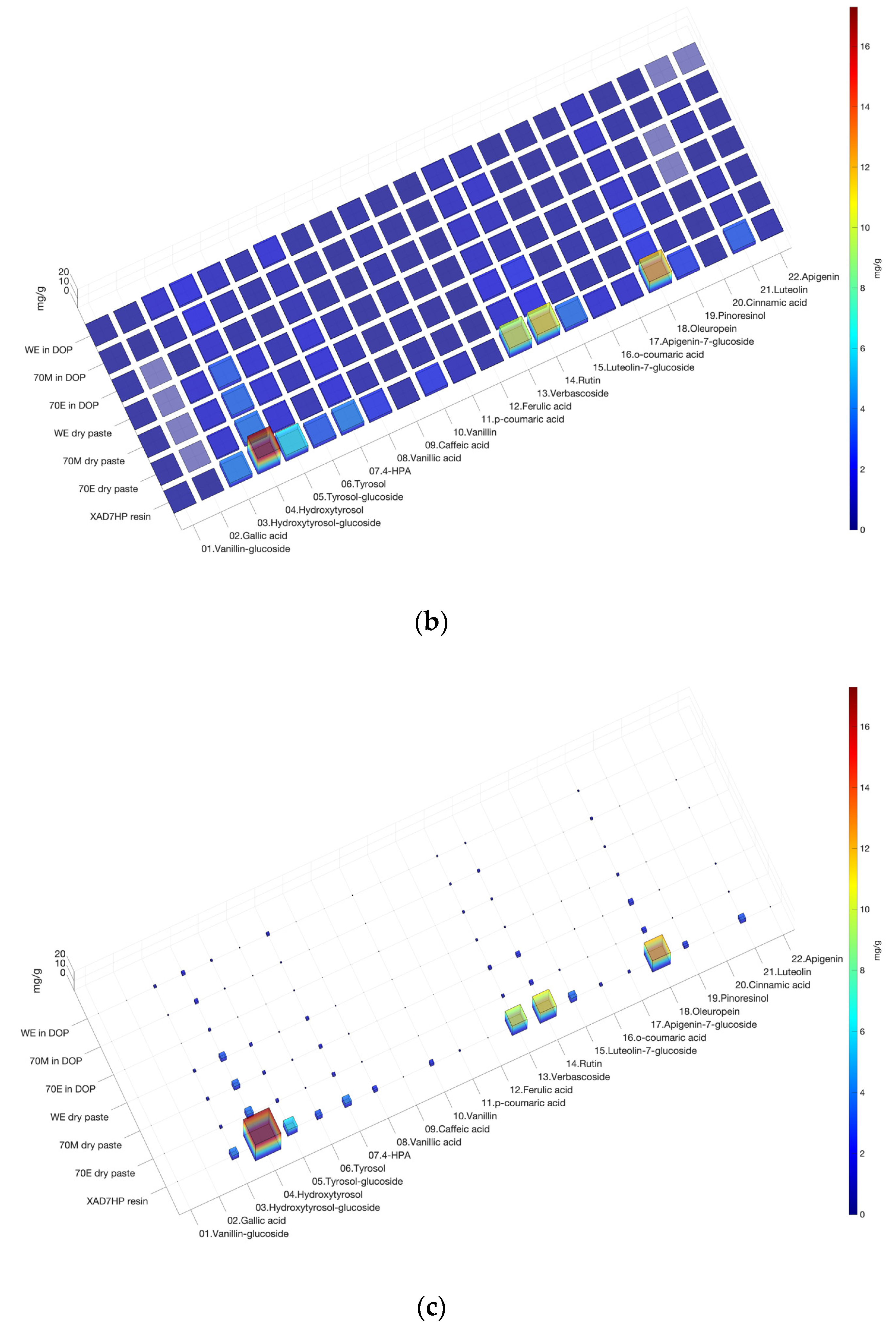
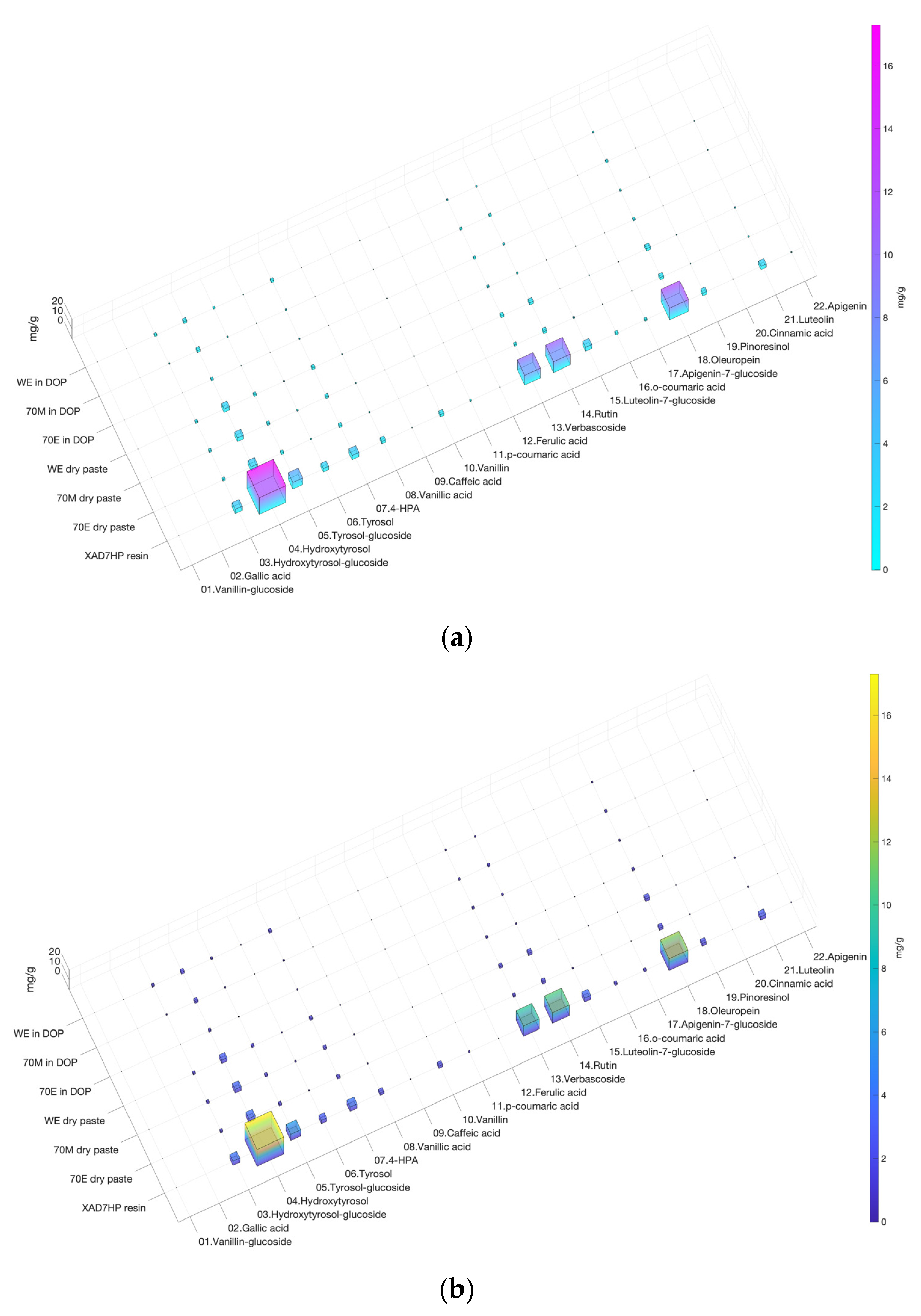
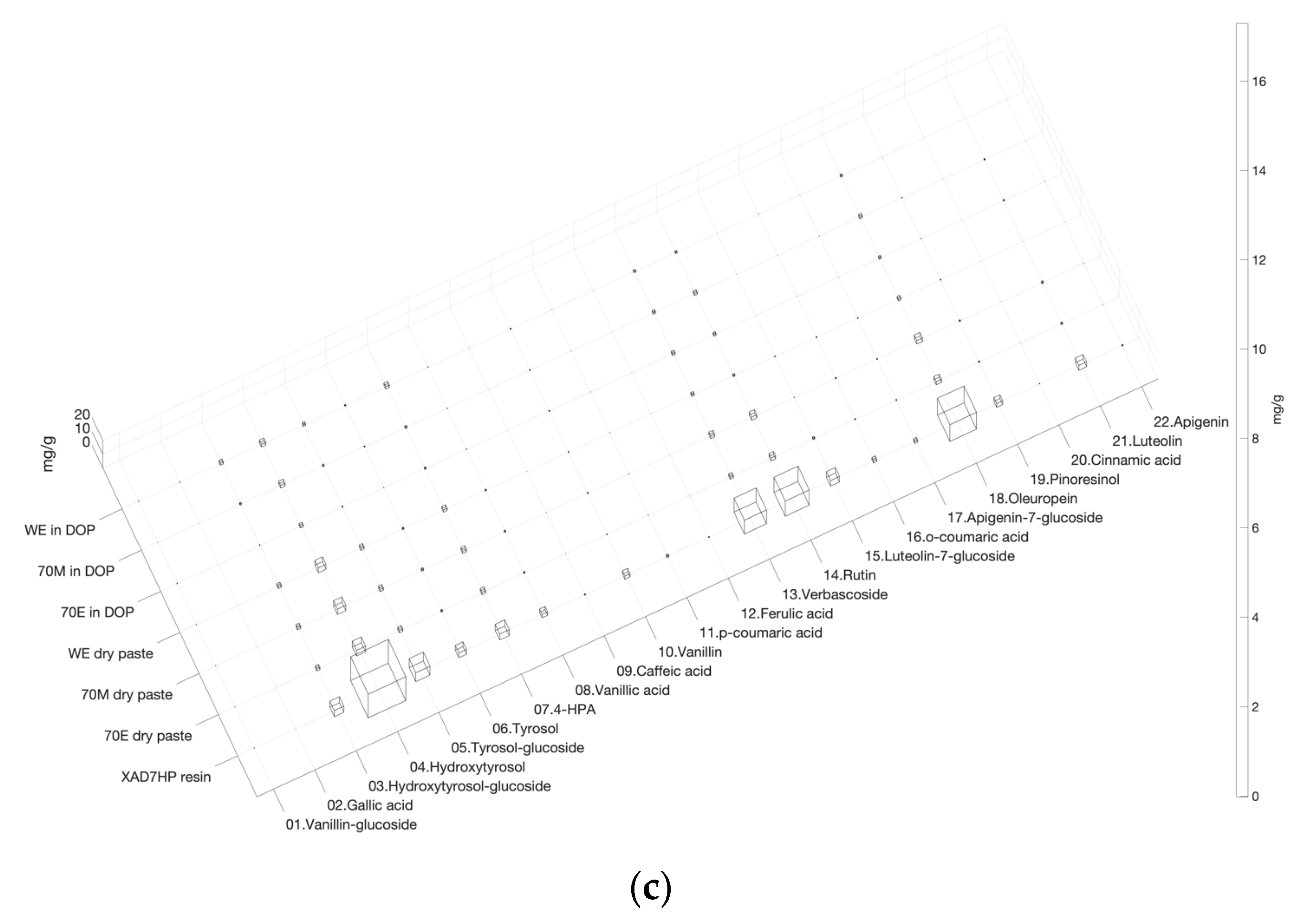
3.1. Heatmap 3D Bar Chart
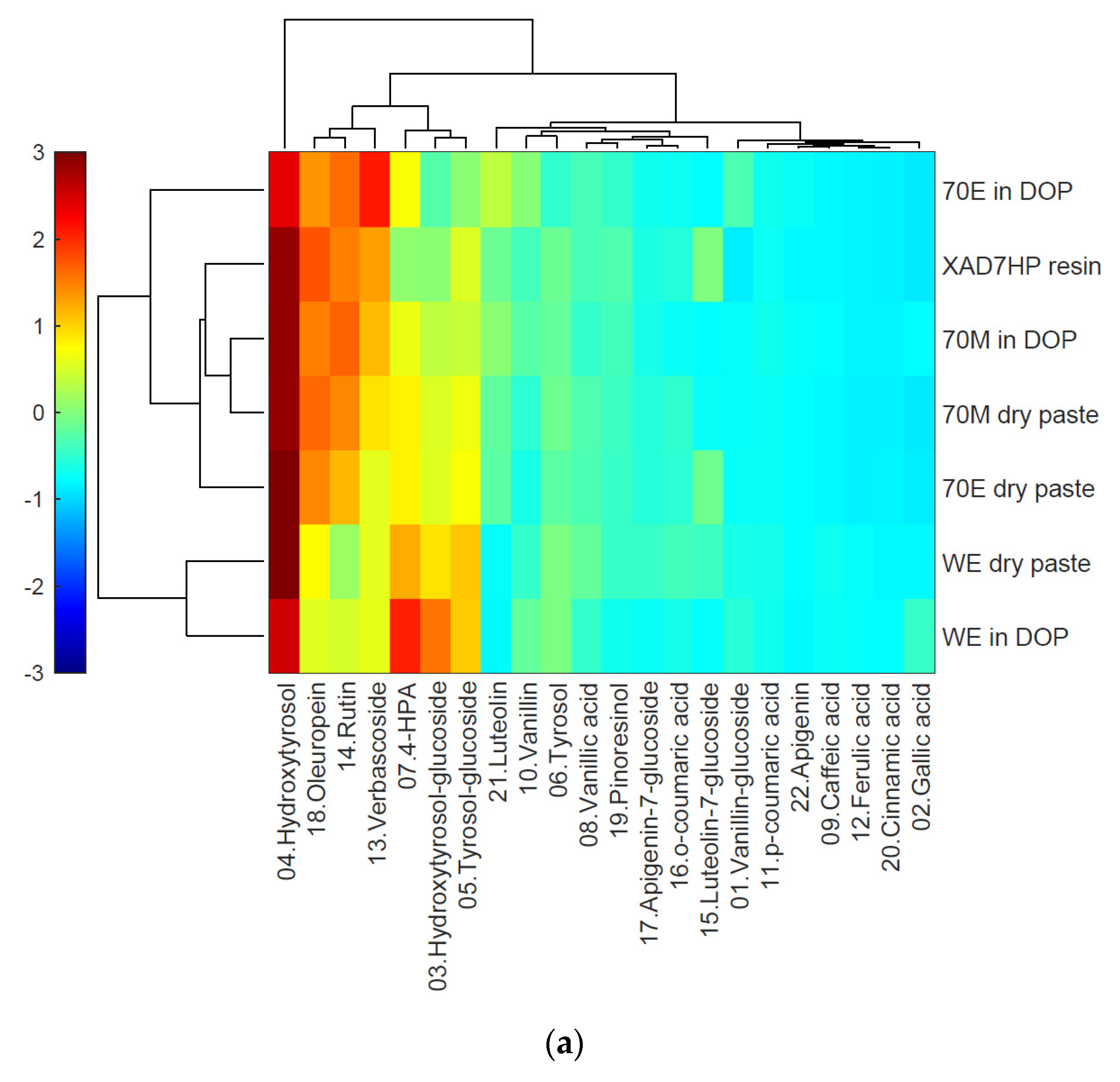
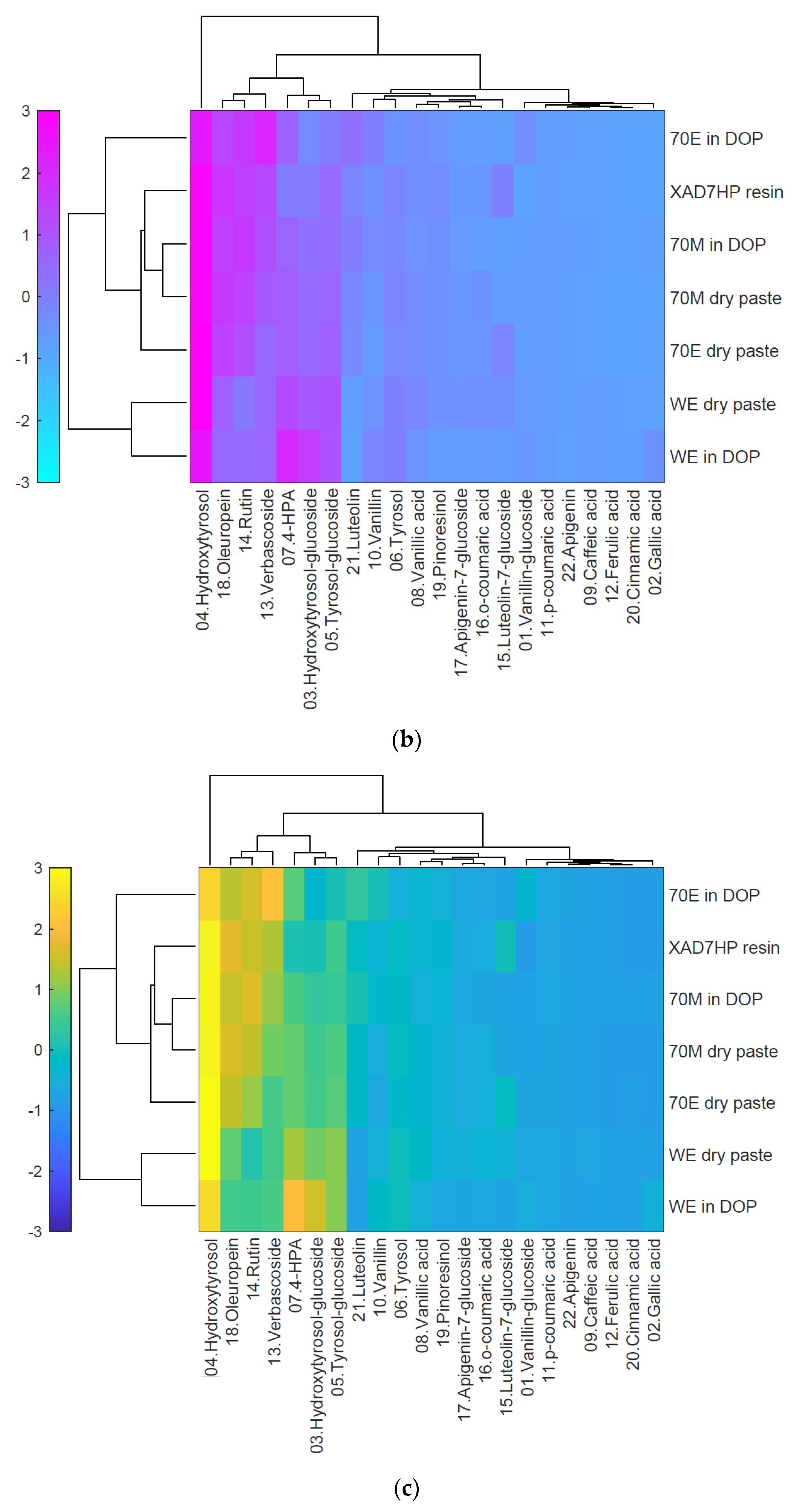
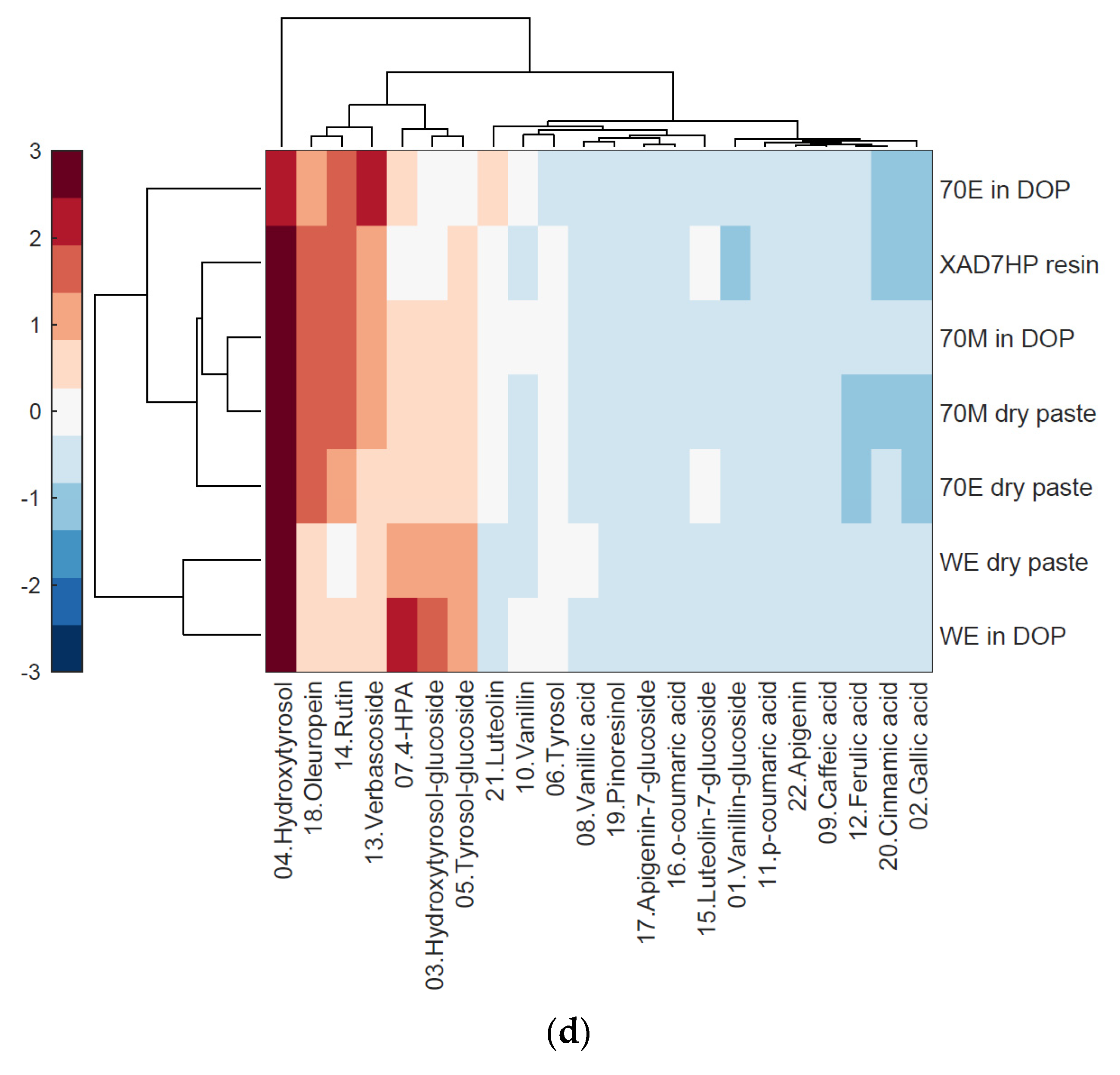
3.2. Heatmap Cluster Analysis
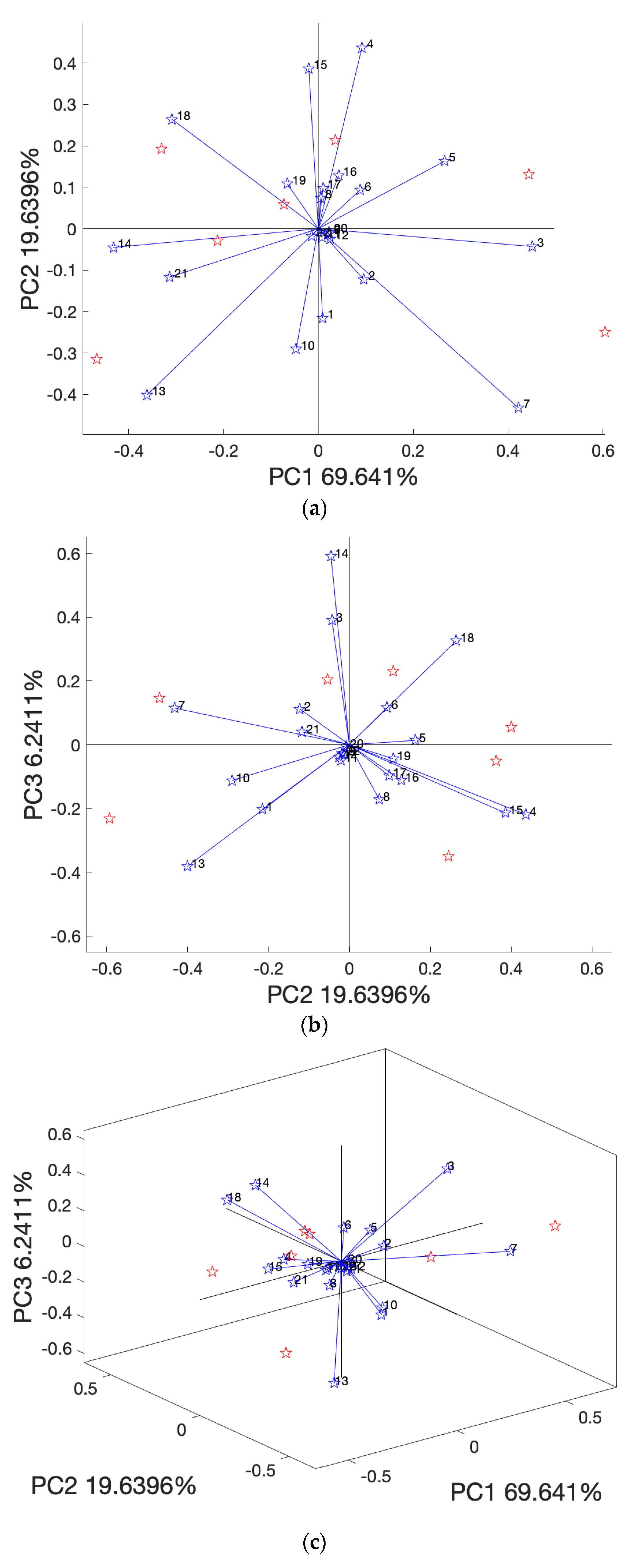
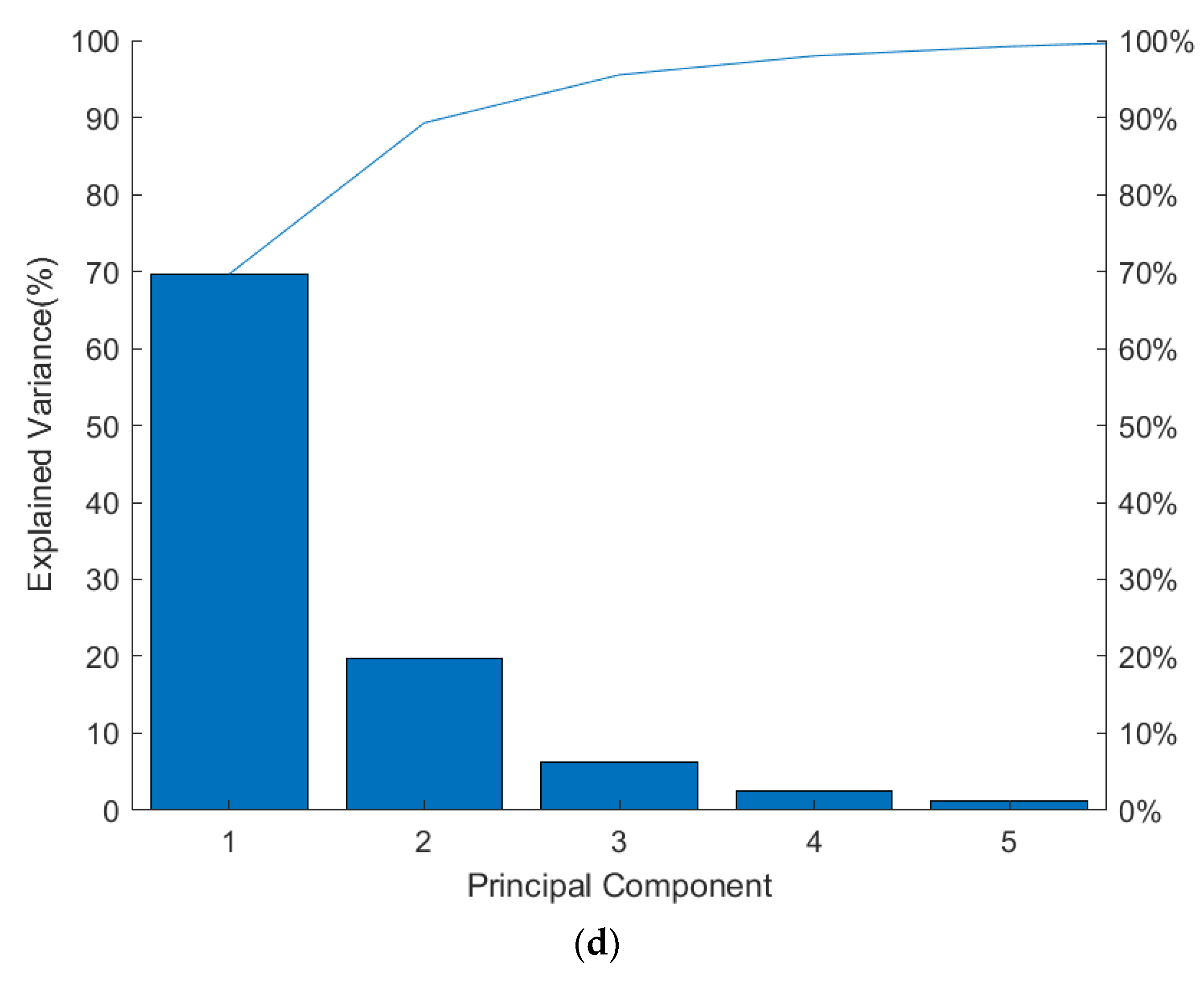
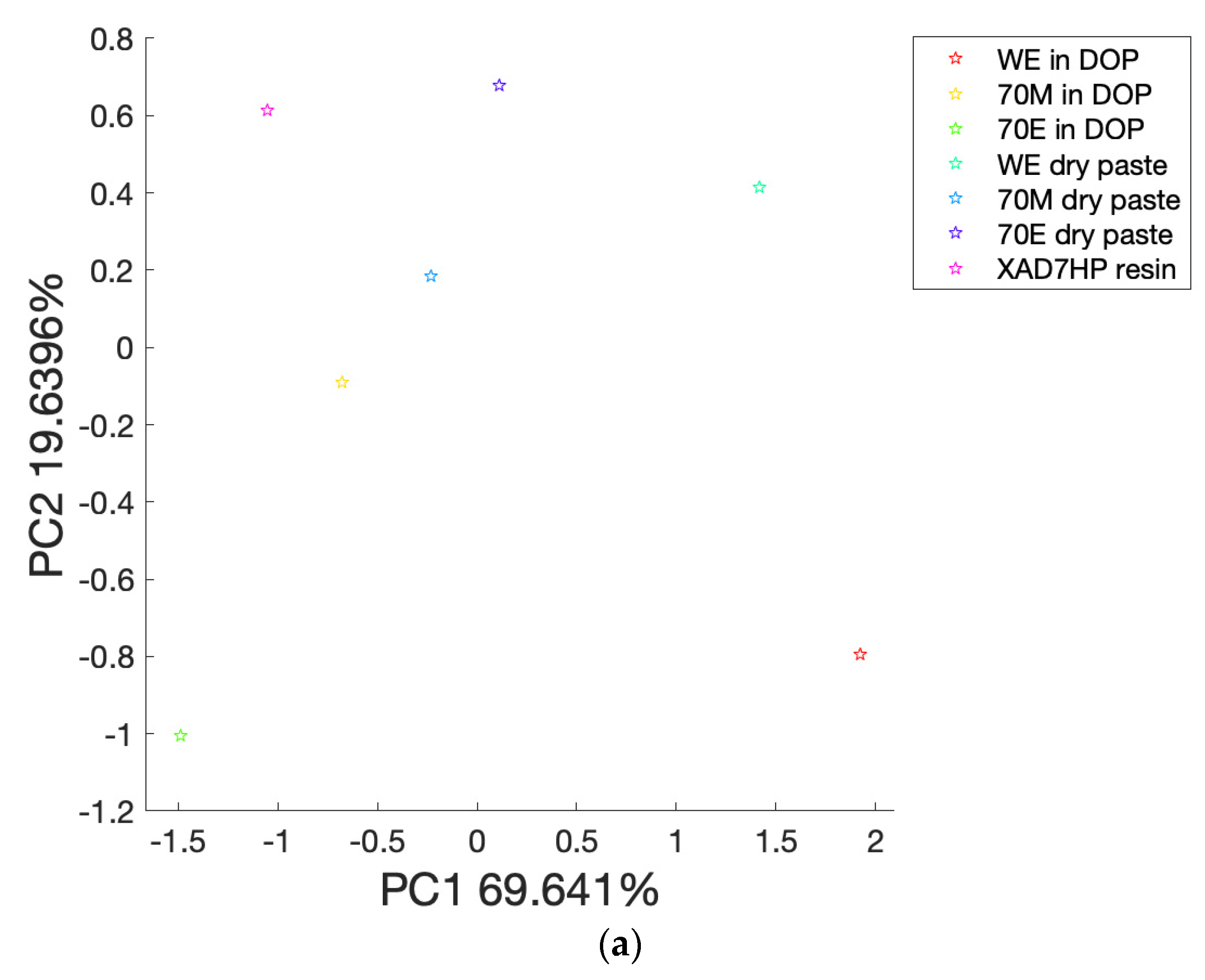
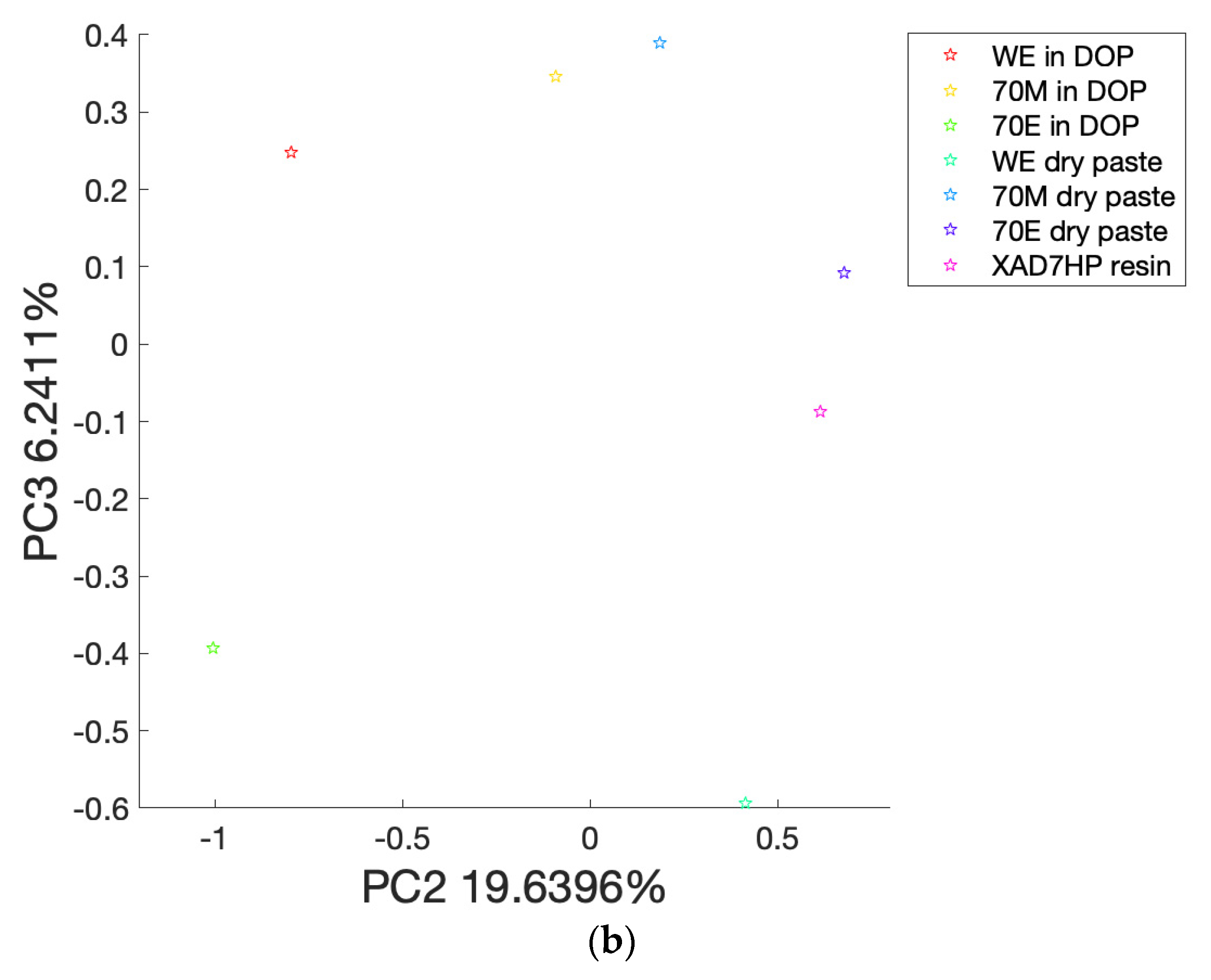
3.3. PCA Analysis
3.4. Time Taking and Code Compatibility
4. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Chen, J.-T. Phytochemical Omics in Medicinal Plants. Biomolecules 2020, 10, 936. [Google Scholar] [CrossRef]
- Cabrita, M.J. Portuguese Olive Oil Omics for Traceability and Authenticity. Impact 2017, 2017, 76–78. [Google Scholar] [CrossRef]
- Carrera, M. Proteomics and Food Analysis: Principles, Techniques, and Applications. Foods 2021, 10, 2538. [Google Scholar] [CrossRef]
- Utpott, M.; Rodrigues, E.; de OliveiraRios, A.; Mercali, G.D.; Flôres, S.H. Metabolomics: An Analytical Technique for Food Processing Evaluation. Food Chem. 2022, 366, 130685. [Google Scholar] [CrossRef] [PubMed]
- Tang, W.; Liu, D.; Nie, S.-P. Food Glycomics in Food Science: Recent Advances and Future Perspectives. Curr. Opin. Food Sci. 2022, 46, 100850. [Google Scholar] [CrossRef]
- Jia, W.; Dong, X.; Shi, L.; Chu, X. Discrimination of Milk from Different Animal Species by a Foodomics Approach Based on High-Resolution Mass Spectrometry. J. Agric. Food Chem. 2020, 68, 6638–6645. [Google Scholar] [CrossRef]
- Wu, B.; Wei, F.; Xu, S.; Xie, Y.; Lv, X.; Chen, H.; Huang, F. Mass Spectrometry-Based Lipidomics as a Powerful Platform in Foodomics Research. Trends Food Sci. Technol. 2021, 107, 358–376. [Google Scholar] [CrossRef]
- Wang, S.; Zhang, Q.; Zhao, P.; Ma, Z.; Zhang, J.; Ma, W.; Wang, X. Investigating the Effect of Three Phenolic Fractions on the Volatility of Floral, Fruity, and Aged Aromas by HS-SPME-GC-MS and NMR in Model Wine. Food Chem. X 2022, 13, 100281. [Google Scholar] [CrossRef] [PubMed]
- Varunjikar, M.S.; Belghit, I.; Gjerde, J.; Palmblad, M.; Oveland, E.; Rasinger, J.D. Shotgun Proteomics Approaches for Authentication, Biological Analyses, and Allergen Detection in Feed and Food-Grade Insect Species. Food Control 2022, 137, 108888. [Google Scholar] [CrossRef]
- Lin, Z.; Pattathil, S.; Hahn, M.G.; Wicker, L. Blueberry Cell Wall Fractionation, Characterization and Glycome Profiling. Food Hydrocoll. 2019, 90, 385–393. [Google Scholar] [CrossRef]
- Yang, Y.; Wang, B.; Fu, Y.; Shi, Y.; Chen, F.; Guan, H.; Liu, L.; Zhang, C.; Zhu, P.; Liu, Y.; et al. HS-GC-IMS with PCA to Analyze Volatile Flavor Compounds across Different Production Stages of Fermented Soybean Whey Tofu. Food Chem. 2021, 346, 128880. [Google Scholar] [CrossRef]
- Green, H.S.; Wang, S.C. Evaluation of Proposed CODEX Purity Standards for Avocado Oil. Food Control 2023, 143, 109277. [Google Scholar] [CrossRef]
- Zhao, H.; Zhan, Y.; Xu, Z.; John Nduwamungu, J.; Zhou, Y.; Powers, R.; Xu, C. The Application of Machine-Learning and Raman Spectroscopy for the Rapid Detection of Edible Oils Type and Adulteration. Food Chem. 2022, 373, 131471. [Google Scholar] [CrossRef] [PubMed]
- Zhao, H.; Xie, X.; Read, P.; Loseke, B.; Gamet, S.; Li, W.; Xu, C. Biofortification with Selenium and Lithium Improves Nutraceutical Properties of Major Winery Grapes in the Midwestern United States. Int. J. Food Sci. Technol. 2021, 56, 825–837. [Google Scholar] [CrossRef]
- Richter, B.; Gurk, S.; Wagner, D.; Bockmayr, M.; Fischer, M. Food Authentication: Multi-Elemental Analysis of White Asparagus for Provenance Discrimination. Food Chem. 2019, 286, 475–482. [Google Scholar] [CrossRef] [PubMed]
- Zou, Y.; Gaida, M.; Franchina, F.A.; Stefanuto, P.-H.; Focant, J.-F. Distinguishing between Decaffeinated and Regular Coffee by HS-SPME-GC×GC-TOFMS, Chemometrics, and Machine Learning. Molecules 2022, 27, 1806. [Google Scholar]
- Muguruma, Y.; Nunome, M.; Inoue, K. A Review on the Foodomics Based on Liquid Chromatography Mass Spectrometry. Chem. Pharm. Bull. 2022, 70, 12–18. [Google Scholar] [CrossRef]
- Freire, R.; Fernandez, L.; Mallafré-Muro, C.; Martín-Gómez, A.; Madrid-Gambin, F.; Oliveira, L.; Pardo, A.; Arce, L.; Marco, S. Full Workflows for the Analysis of Gas Chromatography—Ion Mobility Spectrometry in Foodomics: Application to the Analysis of Iberian Ham Aroma. Sensors 2021, 21, 6156. [Google Scholar] [CrossRef]
- Valdés, A.; Álvarez-Rivera, G.; Socas-Rodríguez, B.; Herrero, M.; Ibáñez, E.; Cifuentes, A. Foodomics: Analytical Opportunities and Challenges. Anal. Chem. 2022, 94, 366–381. [Google Scholar] [CrossRef]
- Jimenez-Carvelo, A.M.; Cuadros-Rodríguez, L. Data Mining/Machine Learning Methods in Foodomics. Curr. Opin. Food Sci. 2021, 37, 76–82. [Google Scholar] [CrossRef]
- García-Cañas, V.; Simó, C.; Herrero, M.; Ibáñez, E.; Cifuentes, A. Present and Future Challenges in Food Analysis: Foodomics. Anal. Chem. 2012, 84, 10150–10159. [Google Scholar] [CrossRef] [PubMed]
- Song, H.S.; Lee, S.H.; Ahn, S.W.; Kim, J.Y.; Rhee, J.-K.; Roh, S.W. Effects of the Main Ingredients of the Fermented Food, Kimchi, on Bacterial Composition and Metabolite Profile. Food Res. Int. 2021, 149, 110668. [Google Scholar] [CrossRef] [PubMed]
- Barea-Sepúlveda, M.; Espada-Bellido, E.; Ferreiro-González, M.; Bouziane, H.; López-Castillo, J.G.; Palma, M.; Barbero, G.F. Toxic Elements and Trace Elements in Macrolepiota Procera Mushrooms from Southern Spain and Northern Morocco. J. Food Compos. Anal. 2022, 108, 104419. [Google Scholar] [CrossRef]
- Cerqueira, F.; Matamoros, V.; Bayona, J.M.; Berendonk, T.U.; Elsinga, G.; Hornstra, L.M.; Piña, B. Antibiotic Resistance Gene Distribution in Agricultural Fields and Crops. A Soil-to-Food Analysis. Environ. Res. 2019, 177, 108608. [Google Scholar] [CrossRef] [PubMed]
- Zhao, H.; Avena-Bustillos, R.J.; Wang, S.C. Extraction, Purification and In Vitro Antioxidant Activity Evaluation of Phenolic Compounds in California Olive Pomace. Foods 2022, 11, 174. [Google Scholar] [CrossRef] [PubMed]
- Wickham, H.; Averick, M.; Bryan, J.; Chang, W.; McGowan, L.D.; François, R.; Grolemund, G.; Hayes, A.; Henry, L.; Hester, J. Welcome to the Tidyverse. J. Open Source Softw. 2019, 4, 1686. [Google Scholar] [CrossRef] [Green Version]
- Zhao, H.; Wang, C.S. A 3in1 Omics Data Visualization and Analytical Method—File Exchange—MATLAB Central. Available online: https://www.mathworks.com/matlabcentral/fileexchange/117370-a-3in1-omics-data-visualization-and-analytical-method (accessed on 8 September 2022).
- 3-D Bar Graph-MATLAB Bar3. Available online: https://www.mathworks.com/help/matlab/ref/bar3.html (accessed on 3 September 2022).
- Object Containing Hierarchical Clustering Analysis Data—MATLAB. Available online: https://www.mathworks.com/help/bioinfo/ref/clustergram.html?searchHighlight=clustergram&s_tid=srchtitle_clustergram_1 (accessed on 3 September 2022).
- Biplot—MATLAB Biplot. Available online: https://www.mathworks.com/help/stats/biplot.html?s_tid=doc_ta (accessed on 3 September 2022).
- Matlab—How I Obtain Bars with Function Bar3 and Different Widths for Each Bar?—Stack Overflow. Available online: https://stackoverflow.com/questions/24269516/how-i-obtain-bars-with-function-bar3-and-different-widths-for-each-bar (accessed on 3 September 2022).
- Engle, S.; Whalen, S.; Joshi, A.; Pollard, K.S. Unboxing Cluster Heatmaps. BMC Bioinform. 2017, 18, 63. [Google Scholar] [CrossRef] [Green Version]
- Cozzolino, D.; Power, A.; Chapman, J. Interpreting and Reporting Principal Component Analysis in Food Science Analysis and Beyond. Food Anal. Methods 2019, 12, 2469–2473. [Google Scholar] [CrossRef]
- Buvé, C.; Saeys, W.; Rasmussen, M.A.; Neckebroeck, B.; Hendrickx, M.; Grauwet, T.; Van Loey, A. Application of Multivariate Data Analysis for Food Quality Investigations: An Example-Based Review. Food Res. Int. 2022, 151, 110878. [Google Scholar] [CrossRef]
- Xue, C.; He, Z.; Qin, F.; Chen, J.; Zeng, M. Effects of Amides from Pungent Spices on the Free and Protein-Bound Heterocyclic Amine Profiles of Roast Beef Patties by UPLC–MS/MS and Multivariate Statistical Analysis. Food Res. Int. 2020, 135, 109299. [Google Scholar] [CrossRef]
- Peng, C.; Zhu, Y.; Yan, F.; Su, Y.; Zhu, Y.; Zhang, Z.; Zuo, C.; Wu, H.; Zhang, Y.; Kan, J.; et al. The Difference of Origin and Extraction Method Significantly Affects the Intrinsic Quality of Licorice: A New Method for Quality Evaluation of Homologous Materials of Medicine and Food. Food Chem. 2021, 340, 127907. [Google Scholar] [CrossRef] [PubMed]
- Zhao, H.; Han, A.; Nduwamungu, J.J.; Nishijima, N.; Oda, Y.; Handa, A.; Zhang, Y.; Majumder, K.; Xu, C. Improving Textural Properties of Gluten-Free Veggie Sausage with Egg White Proteins. Food Bioeng. 2022. [Google Scholar] [CrossRef]
- Uchimiya, M. Aromaticity of Secondary Products as the Marker for Sweet Sorghum [Sorghum Bicolor (L.) Moench] Genotype and Environment Effects. J. Agric. Food Res. 2022, 9, 100338. [Google Scholar] [CrossRef]
- Hu, Q.; Woldt, W.; Neale, C.; Zhou, Y.; Drahota, J.; Varner, D.; Bishop, A.; LaGrange, T.; Zhang, L.; Tang, Z. Utilizing Unsupervised Learning, Multi-View Imaging, and CNN-Based Attention Facilitates Cost-Effective Wetland Mapping. Remote Sens. Environ. 2021, 267, 112757. [Google Scholar] [CrossRef]











Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhao, H.; Wang, S.C. A Coding Basis and Three-in-One Integrated Data Visualization Method ‘Ana’ for the Rapid Analysis of Multidimensional Omics Dataset. Life 2022, 12, 1864. https://doi.org/10.3390/life12111864
Zhao H, Wang SC. A Coding Basis and Three-in-One Integrated Data Visualization Method ‘Ana’ for the Rapid Analysis of Multidimensional Omics Dataset. Life. 2022; 12(11):1864. https://doi.org/10.3390/life12111864
Chicago/Turabian StyleZhao, Hefei, and Selina C. Wang. 2022. "A Coding Basis and Three-in-One Integrated Data Visualization Method ‘Ana’ for the Rapid Analysis of Multidimensional Omics Dataset" Life 12, no. 11: 1864. https://doi.org/10.3390/life12111864