
Comparative Performance of Deep Learning and Radiologists for the Diagnosis and Localization of Clinically Significant Prostate Cancer at MRI: A Systematic Review



Abstract
:1. Introduction
2. Materials and Methods
2.1. Eligibility Criteria
2.2. Search Strategy and Sources
2.3. Study Quality
2.4. Study Selection and Data Extraction
3. Results
3.1. Study Characteristics
3.1.1. MRI
3.1.2. Pathology Annotations
3.2. Deep Learning Modeling
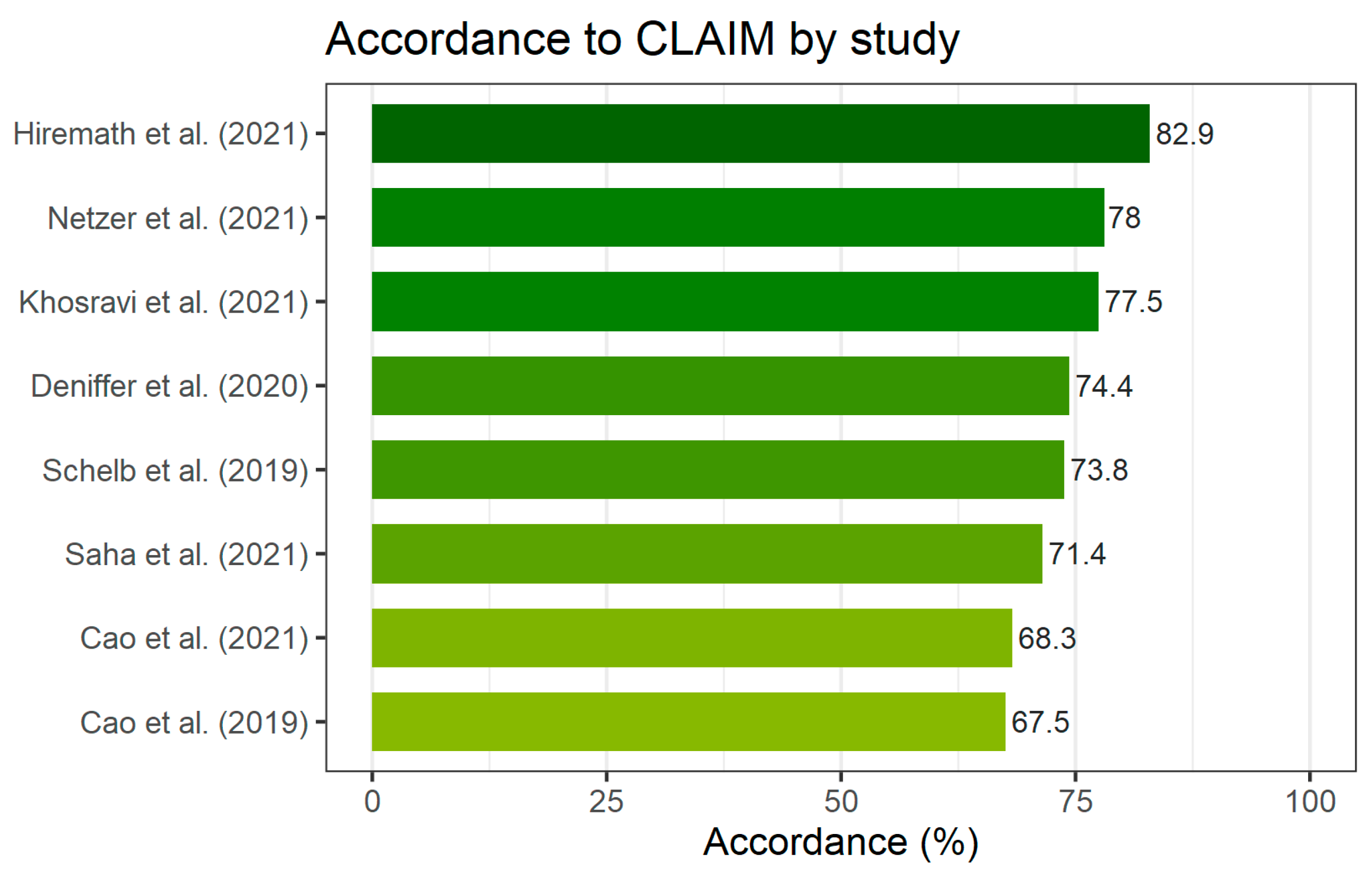
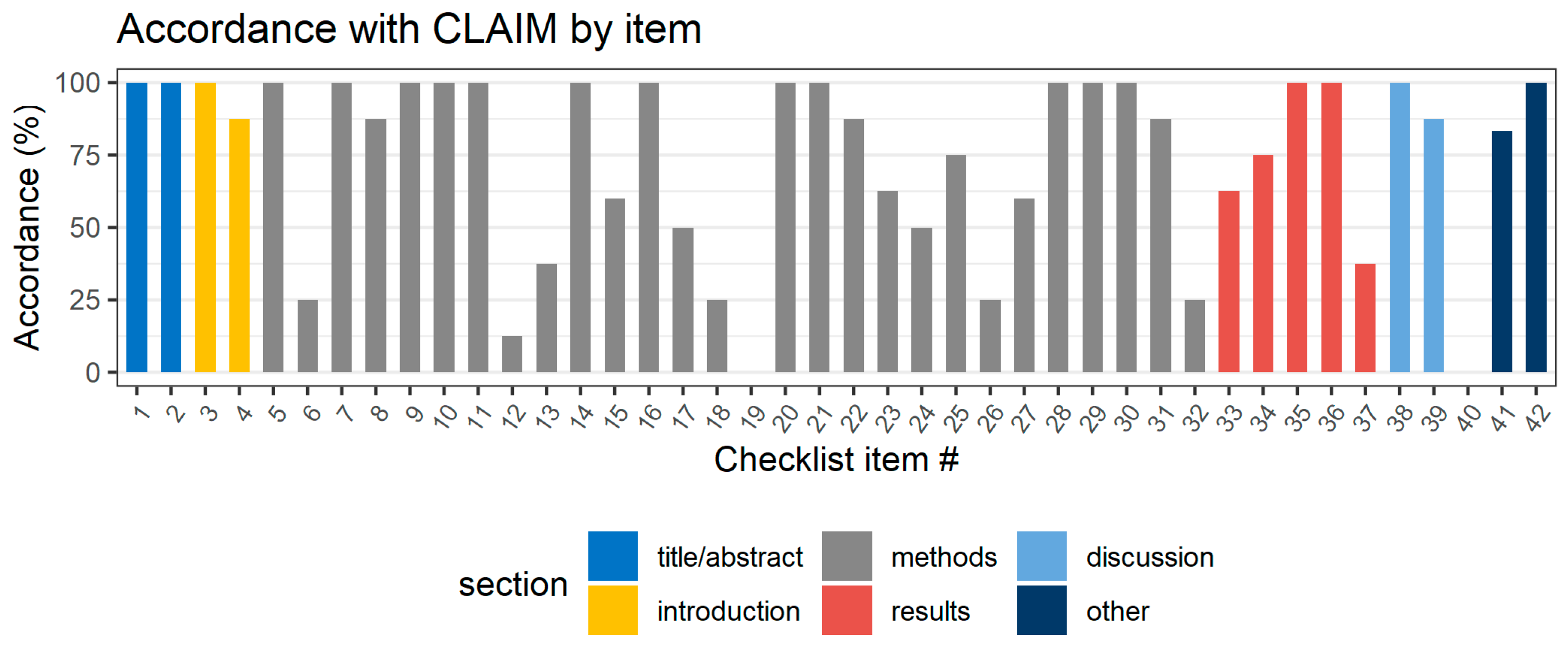
3.3. Quality of Included Studies
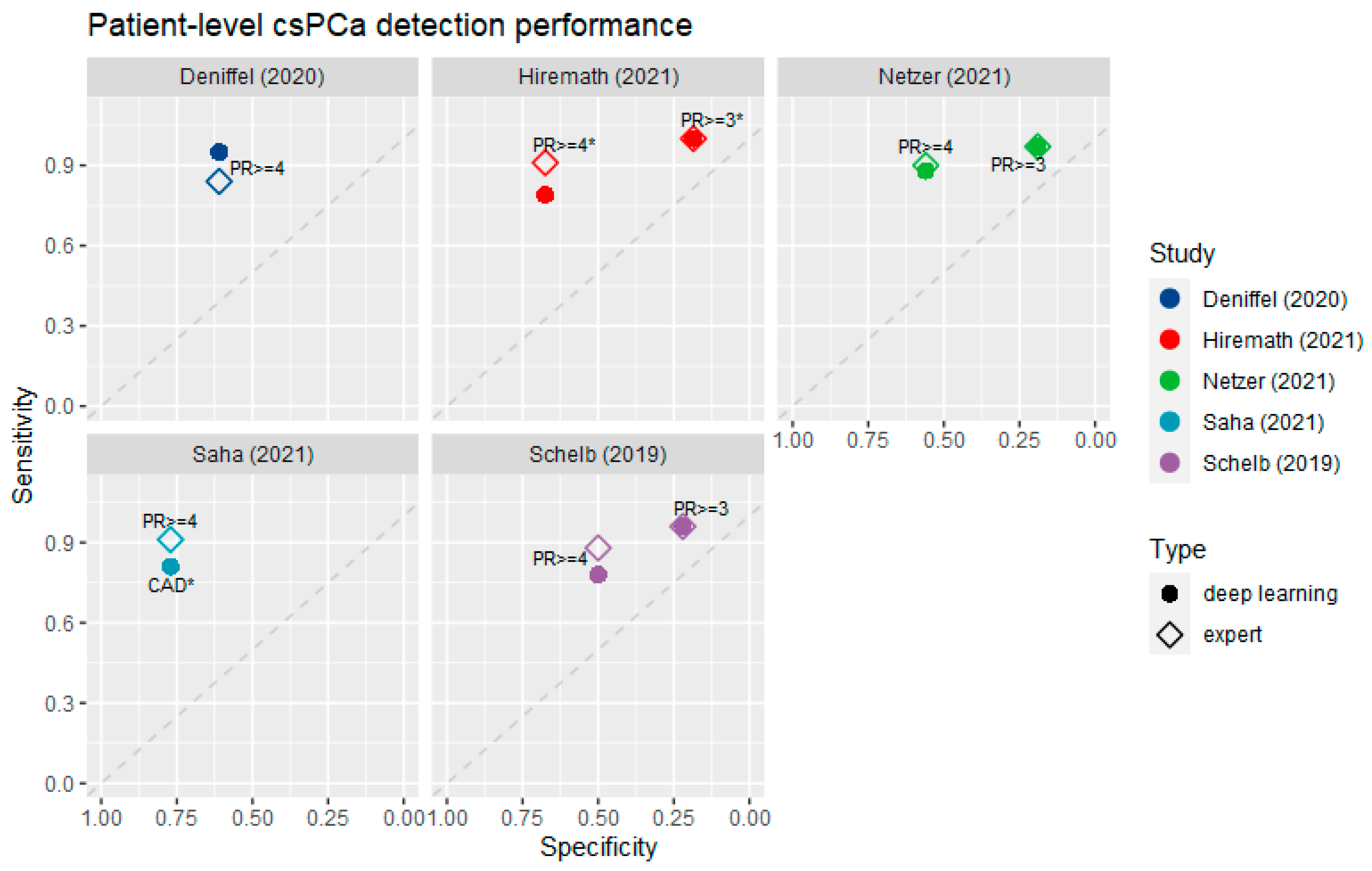
3.4. Diagnostic Accuracy at the Patient Level
3.5. Lesion Localization Performance
4. Discussion
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A

| Section/Topic | No. | Item |
|---|---|---|
| Title/Abstract | ||
| 1 | Identification as a study of AI methodology, specifying the category of technology used (e.g., deep learning) | |
| 2 | Structured summary of study design, methods, results, and conclusions | |
| Introduction | ||
| 3 | Scientific and clinical background, including the intended use and clinical role of the AI approach | |
| 4 | Study objectives and hypotheses | |
| Methods | ||
| Study Design | 5 | Prospective or retrospective study |
| 6 | Study goal, such as model creation, exploratory study, feasibility study, and non-inferiority trial | |
| Data | 7 | Data sources |
| 8 | Eligibility criteria: how, where, and when potentially eligible participants or studies were identified (e.g., symptoms, results from previous tests, inclusion in registry, patient-care setting, location, dates) | |
| 9 | Data pre-processing steps | |
| 10 | Selection of data subsets, if applicable | |
| 11 | Definitions of data elements, with references to Common Data Elements | |
| 12 | De-identification methods | |
| 13 | How missing data were handled | |
| Ground Truth | 14 | Definition of ground truth reference standard, in sufficient detail to allow for replication |
| 15 | Rationale for choosing the reference standard (if alternatives exist) | |
| 16 | Source of ground-truth annotations; qualifications and preparation of annotators | |
| 17 | Annotation tools | |
| 18 | Measurement of inter- and intrarater variability; methods to mitigate variability and/or resolve discrepancies | |
| Data Partitions | 19 | Intended sample size and how it was determined |
| 20 | How data were assigned to partitions; specify proportions | |
| 21 | Level at which partitions are disjoint (e.g., image, study, patient, institution) | |
| Model | 22 | Detailed description of model, including inputs, outputs, and all intermediate layers and connections |
| 23 | Software libraries, frameworks, and packages | |
| 24 | Initialization of model parameters (e.g., randomization, transfer learning) | |
| Training | 25 | Details of training approach, including data augmentation, hyperparameters, and number of models trained |
| 26 | Method of selecting the final model | |
| 27 | Ensembling techniques, if applicable | |
| Evaluation | 28 | Metrics of model performance |
| 29 | Statistical measures of significance and uncertainty (e.g., confidence intervals) | |
| 30 | Robustness or sensitivity analysis | |
| 31 | Methods for explainability or interpretability (e.g., saliency maps), and how they were validated | |
| 32 | Validation or testing on external data | |
| Results | ||
| Data | 33 | Flow of participants or cases, using a diagram to indicate inclusion and exclusion |
| 34 | Demographic and clinical characteristics of cases in each partition | |
| Model performance | 35 | Performance metrics for optimal model(s) on all data partitions |
| 36 | Estimates of diagnostic accuracy and their precision (such as 95% confidence intervals) | |
| 37 | Failure analysis of incorrectly classified cases | |
| Discussion | ||
| 38 | Study limitations, including potential bias, statistical uncertainty, and generalizability | |
| 39 | Implications for practice, including the intended use and/or clinical role | |
| Other information | ||
| 40 | Registration number and name of registry | |
| 41 | Where the full study protocol can be accessed | |
| 42 | Sources of funding and other support; role of funders |
Appendix B

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
References
- Sung, H.; Ferlay, J.; Siegel, R.L.; Laversanne, M.; Soerjomataram, I.; Jemal, A.; Bray, F. Global Cancer Statistics 2020: GLOBOCAN Estimates of Incidence and Mortality Worldwide for 36 Cancers in 185 Countries. CA A Cancer J. Clin. 2021, 71, 209–249. [Google Scholar] [CrossRef] [PubMed]
- Egevad, L.; Granfors, T.; Karlberg, L.; Bergh, A.; Stattin, P. Prognostic Value of the Gleason Score in Prostate Cancer. BJU Int. 2002, 89, 538–542. [Google Scholar] [CrossRef] [PubMed]
- Weinreb, C.J.; Barentsz, J.O.; Choyke, P.L.; Cornud, F.; Haider, M.A.; Macura, K.J.; Margolis, D.; Shtern, F.; Tempany, C.M.; Thoeny, H.C.; et al. PI-RADS Prostate Imaging—Reporting and Data System: 2015, Version 2. Eur. Urol. 2016, 69, 16–40. [Google Scholar] [CrossRef] [PubMed]
- Daun, M.; Fardin, S.; Ushinsky, A.; Batra, S.; Nguyentat, M.; Lee, T.; Uchio, E.; Lall, C.; Houshyar, R. PI-RADS Version 2 Is an Excellent Screening Tool for Clinically Significant Prostate Cancer as Designated by the Validated International Society of Urological Pathology Criteria: A Retrospective Analysis. Curr. Probl. Diagn. Radiol. 2020, 49, 407–411. [Google Scholar] [CrossRef]
- Smith, C.P.; Harmon, S.A.; Barrett, T.; Bittencourt, L.K.; Law, Y.M.; Shebel, H.; An, J.Y.; Czarniecki, M.; Mehralivand, S.; Coskun, M.; et al. Intra-and Interreader Reproducibility of PI-RADSv2: A Multireader Study. J. Magn. Reson. Imaging 2019, 49, 1694–1703. [Google Scholar] [CrossRef]
- Rosenkrantz, A.B.; Ginocchio, L.A.; Cornfeld, D.; Froemming, A.T.; Gupta, R.T.; Turkbey, B.; Westphalen, A.C.; Babb, J.S.; Margolis, D.J. Interobserver Reproducibility of the PI-RADS Version 2 Lexicon: A Multicenter Study of Six Experienced Prostate Radiologists. Radiology 2016, 280, 793–804. [Google Scholar] [CrossRef]
- Müller, S.; Lilleaasen, G.; Sand, T.E.; Løfsgaard, L.; Estop-Garanto, M.; Helgø, D.; Sund, P.; Mygland, V. Poor Reproducibility of PIRADS Score in Two Multiparametric MRIs before Biopsy in Men with Elevated PSA. World J. Urol. 2018, 36, 687–691. [Google Scholar] [CrossRef]
- Fujita, H. AI-Based Computer-Aided Diagnosis (AI-CAD): The Latest Review to Read First. Radiol. Phys. Technol. 2020, 13, 6–19. [Google Scholar] [CrossRef]
- Bleker, J.; Yakar, D.; van Noort, B.; Rouw, D.; jan de Jong, I.; Dierckx, R.A.J.O.; Kwee, T.C.; Huisman, H. Single-Center versus Multi-Center Biparametric MRI Radiomics Approach for Clinically Significant Peripheral Zone Prostate Cancer. Insights Into Imaging 2021, 12, 150. [Google Scholar] [CrossRef]
- Reuzé, S.; Orlhac, F.; Chargari, C.; Nioche, C.; Limkin, E.; Riet, F.; Escande, A.; Haie-Meder, C.; Dercle, L.; Gouy, S.; et al. Prediction of Cervical Cancer Recurrence Using Textural Features Extracted from 18F-FDG PET Images Acquired with Different Scanners. Oncotarget 2017, 8, 43169. [Google Scholar] [CrossRef] [Green Version]
- Yoo, S.; Gujrathi, I.; Haider, M.A.; Khalvati, F. Prostate Cancer Detection Using Deep Convolutional Neural Networks. Sci. Rep. 2019, 9, 19518. [Google Scholar] [CrossRef]
- Le, M.H.; Chen, J.; Wang, L.; Wang, Z.; Liu, W.; Cheng, K.-T.; Yang, X. Automated Diagnosis of Prostate Cancer in Multi-Parametric MRI Based on Multimodal Convolutional Neural Networks. Phys. Med. Biol. 2017, 62, 6497–6514. [Google Scholar] [CrossRef]
- Chamberlin, J.; Kocher, M.R.; Waltz, J.; Snoddy, M.; Stringer, N.F.C.; Stephenson, J.; Sahbaee, P.; Sharma, P.; Rapaka, S.; Schoepf, U.J.; et al. Automated Detection of Lung Nodules and Coronary Artery Calcium Using Artificial Intelligence on Low-Dose CT Scans for Lung Cancer Screening: Accuracy and Prognostic Value. BMC Med. 2021, 19, 55. [Google Scholar] [CrossRef] [PubMed]
- Twilt, J.J.; van Leeuwen, K.G.; Huisman, H.J.; Fütterer, J.J.; de Rooij, M. Artificial Intelligence Based Algorithms for Prostate Cancer Classification and Detection on Magnetic Resonance Imaging: A Narrative Review. Diagnostics 2021, 11, 959. [Google Scholar] [CrossRef]
- Syer, T.; Mehta, P.; Antonelli, M.; Mallet, S.; Atkinson, D.; Ourselin, S.; Punwani, S. Artificial Intelligence Compared to Radiologists for the Initial Diagnosis of Prostate Cancer on Magnetic Resonance Imaging: A Systematic Review and Recommendations for Future Studies. Cancers 2021, 13, 3318. [Google Scholar] [CrossRef]
- Cuocolo, R.; Cipullo, M.B.; Stanzione, A.; Romeo, V.; Green, R.; Cantoni, V.; Ponsiglione, A.; Ugga, L.; Imbriaco, M. Machine Learning for the Identification of Clinically Significant Prostate Cancer on MRI: A Meta-Analysis. Eur. Radiol. 2020, 30, 6877–6887. [Google Scholar] [CrossRef] [PubMed]
- Sushentsev, N.; da Silva, N.M.; Yeung, M.; Barrett, T.; Sala, E.; Roberts, M.; Rundo, L. Comparative Performance of Fully-Automated and Semi-Automated Artificial Intelligence Methods for the Detection of Clinically Significant Prostate Cancer on MRI: A Systematic Review. Insights Into Imaging 2022, 13, 59. [Google Scholar] [CrossRef] [PubMed]
- Page, M.J.; McKenzie, J.E.; Bossuyt, P.M.; Boutron, I.; Hoffmann, T.C.; Mulrow, C.D.; Shamseer, L.; Tetzlaff, J.M.; Akl, E.A.; Brennan, S.E.; et al. The PRISMA 2020 Statement: An Updated Guideline for Reporting Systematic Reviews. Int. J. Surg. 2021, 88, 105906. [Google Scholar] [CrossRef]
- Mongan, J.; Moy, L.; Kahn, C.E., Jr. Checklist for Artificial Intelligence in Medical Imaging (CLAIM): A Guide for Authors and Reviewers. Radiology: Artificial Intelligence. Radiol. Soc. N. Am. 2020, 2, e200029. [Google Scholar]
- Whiting, P.F.; Rutjes, A.W.S.; Westwood, M.E.; Mallett, S.; Deeks, J.J.; Reitsma, J.B.; Leeflang, M.M.G.; Sterne, J.A.C.; Bossuyt, P.M.M. QUADAS-2: A Revised Tool for the Quality Assessment of Diagnostic Accuracy Studies. Ann. Intern. Med. 2011, 155, 529–536. [Google Scholar] [CrossRef]
- Khosravi, P.; Lysandrou, M.; Eljalby, M.; Li, Q.; Kazemi, E.; Zisimopoulos, P.; Sigaras, A.; Matthew Brendel, M.; Barnes, J.; Ricketts, C.; et al. A Deep Learning Approach to Diagnostic Classification of Prostate Cancer Using Pathology–Radiology Fusion. J. Magn. Reson. Imaging 2021, 54, 462–471. [Google Scholar] [CrossRef] [PubMed]
- Hiremath, A.; Shiradkar, R.; Fu, P.; Mahran, A.; Rastinehad, A.R.; Tewari, A.; Tirumani, S.H.; Purysko, A.; Ponsky, L.; Madabhushi, A. An Integrated Nomogram Combining Deep Learning, Prostate Imaging–Reporting and Data System (PI-RADS) Scoring, and Clinical Variables for Identification of Clinically Significant Prostate Cancer on Biparametric MRI: A Retrospective Multicentre Study. Lancet Digit. Health 2021, 3, e445–e454. [Google Scholar] [CrossRef]
- Netzer, N.; Weißer, C.; Schelb, P.; Wang, X.; Qin, X.; Görtz, M.; Schütz, V.; Radtke, J.P.; Hielscher, T.; Schwab, C.; et al. Fully Automatic Deep Learning in Bi-Institutional Prostate Magnetic Resonance Imaging: Effects of Cohort Size and Heterogeneity. Investig. Radiol. 2021, 56, 799–808. [Google Scholar] [CrossRef] [PubMed]
- Schelb, P.; Kohl, S.; Radtke, J.P.; Wiesenfarth, M.; Kickingereder, P.; Bickelhaupt, S.; Kuder, T.A.; Stenzinger, A.; Hohenfellner, M.; Schlemmer, H.-P.; et al. Classification of Cancer at Prostate MRI: Deep Learning versus Clinical PI-RADS Assessment. Radiology 2019, 293, 607–617. [Google Scholar] [CrossRef]
- Cao, R.; Zhong, X.; Afshari, S.; Felker, E.; Suvannarerg, V.; Tubtawee, T.; Vangala, S.; Scalzo, F.; Raman, S.; Sung, K. Performance of Deep Learning and Genitourinary Radiologists in Detection of Prostate Cancer Using 3-T Multiparametric Magnetic Resonance Imaging. J. Magn. Reson. Imaging 2021, 54, 474–483. [Google Scholar] [CrossRef]
- Cao, R.; Bajgiran, A.M.; Mirak, S.A.; Shakeri, S.; Zhong, X.; Enzmann, D.; Raman, S.; Sung, K. Joint Prostate Cancer Detection and Gleason Score Prediction in Mp-MRI via FocalNet. IEEE Trans. Med. Imaging 2019, 38, 2496–2506. [Google Scholar] [CrossRef]
- Saha, A.; Hosseinzadeh, M.; Huisman, H. End-to-End Prostate Cancer Detection in BpMRI via 3D CNNs: Effects of Attention Mechanisms, Clinical Priori and Decoupled False Positive Reduction. Med. Image Anal. 2021, 73, 102155. [Google Scholar] [CrossRef]
- Deniffel, D.; Abraham, N.; Namdar, K.; Dong, X.; Salinas, E.; Milot, L.; Khalvati, F.; Haider, M.A. Using Decision Curve Analysis to Benchmark Performance of a Magnetic Resonance Imaging–Based Deep Learning Model for Prostate Cancer Risk Assessment. Eur. Radiol. 2020, 30, 6867–6876. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. In Medical Image Computing and Computer-Assisted Intervention (MICCAI). LNCS; Springer: Cham, Switzerland, 2015; Volume 9351, pp. 234–241. Available online: http://lmb.informatik.uni-freiburg.de/Publications/2015/RFB15a (accessed on 12 January 2022).
- Deng, J.; Dong, W.; Socher, R.; Li, L.; Li, K.; Li, F.-F. Imagenet: A Large-Scale Hierarchical Image Database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar]
- Selvaraju, R.R.; Das, A.; Vedantam, R.; Cogswell, M.; Parikh, D.; Batra, D. Grad-Cam: Why Did You Say That? arXiv 2016, arXiv:1611.07450. [Google Scholar]
- Hosseinzadeh, M.; Saha, A.; Brand, P.; Slootweg, I.; de Rooij, M.; Huisman, H. Deep Learning–Assisted Prostate Cancer Detection on Bi-Parametric MRI: Minimum Training Data Size Requirements and Effect of Prior Knowledge. Eur. Radiol. 2022, 32, 2224–2234. [Google Scholar] [CrossRef]
- Beyer, F.; Zierott, L.; Fallenberg, E.M.; Juergens, K.U.; Stoeckel, J.; Heindel, W.; Wormanns, D. Comparison of Sensitivity and Reading Time for the Use of Computer-Aided Detection (CAD) of Pulmonary Nodules at MDCT as Concurrent or Second Reader. Eur. Radiol. 2007, 17, 2941–2947. [Google Scholar] [CrossRef] [PubMed]
- Van Leeuwen, K.G.; Schalekamp, S.; Rutten, M.J.C.M.; van Ginneken, B.; de Rooij, M. Artificial Intelligence in Radiology: 100 Commercially Available Products and Their Scientific Evidence. Eur. Radiol. 2021, 31, 3797–3804. [Google Scholar] [CrossRef] [PubMed]
- Isensee, F.; Petersen, J.; Klein, A.; Zimmerer, D.; Jaeger, P.F.; Kohl, S.; Wasserthal, J.; Koehler, G.; Norajitra, T.; Wirkert, S.; et al. Nnu-Net: Self-Adapting Framework for u-Net-Based Medical Image Segmentation. arXiv 2018, arXiv:1809.10486. [Google Scholar]
- Ahmed, H.U.; Bosaily, A.E.; Brown, L.C.; Gabe, R.; Kaplan, R.; Parmar, M.K.; Collaco-Moraes, Y.; Ward, K.; Hindley, R.G.; Freeman, A.; et al. Diagnostic Accuracy of Multi-Parametric MRI and TRUS Biopsy in Prostate Cancer (PROMIS): A Paired Validating Confirmatory Study. Lancet 2017, 389, 815–822. [Google Scholar] [CrossRef]
- Padhani, A.R.; Barentsz, J.; Villeirs, G.; Rosenkrantz, A.B.; Margolis, D.J.; Turkbey, B.; Thoeny, H.C.; Cornud, F.; Haider, M.A.; Macura, K.J.; et al. PI-RADS Steering Committee: The PI-RADS Multiparametric MRI and MRI-Directed Biopsy Pathway. Radiology 2019, 292, 464. [Google Scholar] [CrossRef]




| Author | Country | No. Pat. | Sequences | Scanner | Vendor | Rad. Exp. | PSA (mg/L) | Age | Scoring Level | DL Approach | Required Expert Input | Interpretability | AUC (Patient Level) | Sens. at 0.1 FPP | Sens. at 1 FPP |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Saha et al. [27] | The Netherlands | 2732 | T2W, ADC, DWI | 3T (Trio, Skyra, Prisma) | Siemens | 25 yrs | 7.85 | 65.8 | Patients, lesion | U-Net | - | Heatmaps | 0.862 | 0.64 | 0.9 |
| Cao et al. [25] | US | 553 | T2W, ADC | 3T (Trio, Verio, Skyra, Prisma) | Siemens | 19 yrs | 6.2 | 62.5 | Patient, lesion | U-Net (FocalNet) | - | Heatmaps | - | 0.3 | 0.65 |
| Netzer et al. [23] | Germany | 1832 | T2W, ADC, DWI | 3T (Prisma), 1.5T (Aera) | Siemens | 11 yrs | 7.1 | 64.0 | Patient, sextant | U-Net (nnUNet) | - | Heatmaps | 0.85 | - | - |
| Cao et al. [26] | US | 417 | T2W, ADC | 3T (Trio, Verio, Skyra, Prisma) | Siemens | 10 yrs | - | - | Lesion, voxel | U-Net (FocalNet) | - | Heatmaps (by Gleason) | - | 0.42 | 0.9 |
| Deniffel et al. [28] | Canada | 499 | T2W, ADC, DWI | 3T (Achieva) | Philips | 15 yrs | 7.2 | 64.4 | Lesion | Classifier | Prostate location | - | 0.85 | - | - |
| Schelb et al. [24] | Germany | 312 | T2W, ADC, DWI | 3T (Prisma) | Siemens | 10 yrs | 6.9 | 64.0 | Patient, sextant | U-Net | - | Heatmaps | - | - | - |
| Hiremath et al. [22] | US | 592 | T2W, ADC | 3T (Trio, Verio, Skyra, Achieva) | Siemens, Philips | 15 yrs | 6.4 | 63.9 | Lesion | Classifier (AlexNet, DenseNet) | Lesion segmentation | GradCAM | 0.76 | - | - |
| Khosravi et al. [21] | US | 400 | T2W | 3T, 1.5T | Siemens, GE | 17 yrs | - | - | Patient | Classifier (Inception V1) | - | Class activation maps | 0.78 | - | - |
| Author | Description of Test Cohort | Biopsy Method | Train Size | Test Size | csPCa in Test Cohort | Cohort Split | Evaluation Strategy |
|---|---|---|---|---|---|---|---|
| Saha et al. [27] | Biopsy naive men with elevated PSA | SB; TB (in-bore) | 1584 studies | 296 patients | 86 patients (29%) | institution | held-out test set |
| Cao et al. [25] | Patients who underwent RP | RP | 427 patients | 126 patients | 114 patients (90%) | temporal | held-out test set |
| Netzer et al. [23] | Consecutive patients with clinical indication for biopsy | TB | 806 studies | 682 studies | 235 exams (34%) | temporal | held-out test set |
| Cao et al. [26] | Preoperative patients who later underwent RP | RP | 333–334 studies | 84–83 studies | 442 lesions (61%) * | CV | CV (five-fold) |
| Deniffel et al. [28] | Patients without prior known csPCa | TB | 449 patients | 50 patients | 19 patients (38%) | random selection | held-out test set |
| Schelb et al. [24] | Consecutive patients with clinical indication for biopsy | TB; SB | 250 patients | 62 patients | 26 patients (42%) | random selection | held-out test set |
| Hiremath et al. [22] | Patients with prostate cancer (various datasets) | TB; SB; RP | 368 patients | 224 patients | 199 lesions (63%) | institution | held-out test set |
| Khosravi et al. [21] | Patients suspected for prostate cancer (various datasets) | TB; SB; RP | 243 patients | 40 patients | 20 patients (50%) ** | random selection | held-out test set |
| Study | FP Per Patient | Sensitivity (Expert) | Sensitivity (DL) | Difference |
|---|---|---|---|---|
| Cao et al. [26] | 0.625 | 81% | 79% | −2% |
| Cao et al. [25] * | 0.15 | 48.7% | 40.6% | −8.1% |
| 0.5 | 65% | 52.5% | −12.5% | |
| 1.24 | 77.5% | 65.6% | −11.9% | |
| Saha et al. [27] | 0.29 | 91% | 78.5% | −12.5% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Roest, C.; Fransen, S.J.; Kwee, T.C.; Yakar, D. Comparative Performance of Deep Learning and Radiologists for the Diagnosis and Localization of Clinically Significant Prostate Cancer at MRI: A Systematic Review. Life 2022, 12, 1490. https://doi.org/10.3390/life12101490
Roest C, Fransen SJ, Kwee TC, Yakar D. Comparative Performance of Deep Learning and Radiologists for the Diagnosis and Localization of Clinically Significant Prostate Cancer at MRI: A Systematic Review. Life. 2022; 12(10):1490. https://doi.org/10.3390/life12101490
Chicago/Turabian StyleRoest, Christian, Stefan J Fransen, Thomas C Kwee, and Derya Yakar. 2022. "Comparative Performance of Deep Learning and Radiologists for the Diagnosis and Localization of Clinically Significant Prostate Cancer at MRI: A Systematic Review" Life 12, no. 10: 1490. https://doi.org/10.3390/life12101490