
The Combinatorial Fusion Cascade to Generate the Standard Genetic Code

Abstract
:
{kind=link}
{kind=link}
{kind=link}
1. Introduction
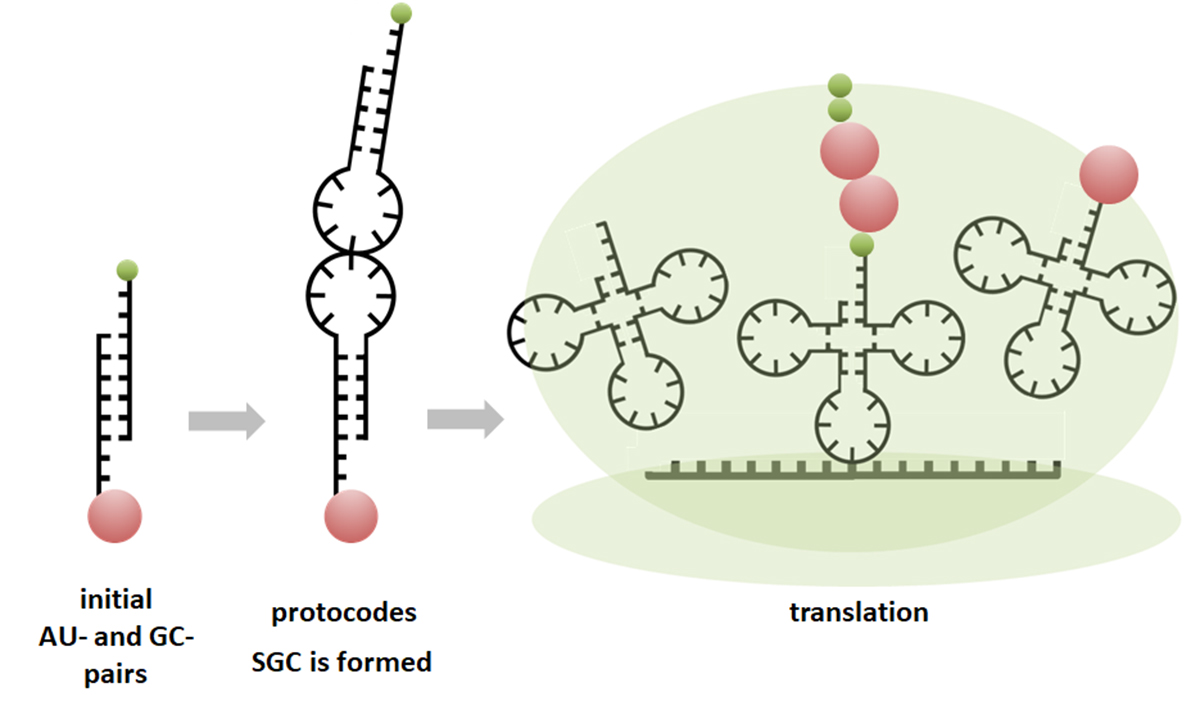
2. Combinatorial Fusion Cascade and Its Formalism
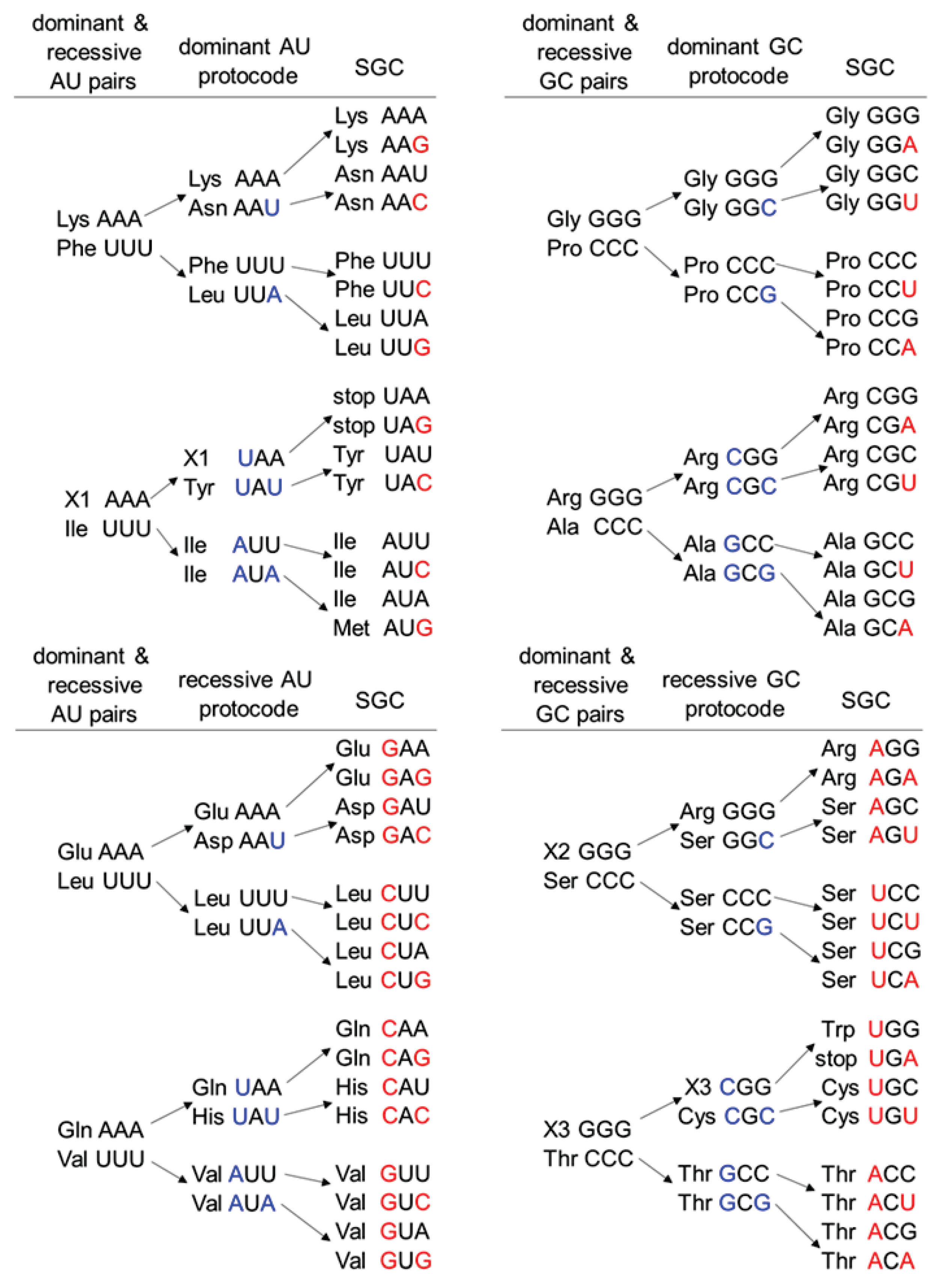
- Rule 1: The second-position bases do not change in any code.
- Rule 2: C and G as well as U and A are exchangeable only in the third position in the dominant initial pairs.
- Rule 3: C and G as well as U and A are exchangeable either in the first position or simultaneously in the first and third positions in the recessive initial pairs.
- Rule 1: The second-position bases do not change in any code.
- Rule 2: A and G as well as U and C are exchangeable only in the third position in the dominant protocodes.
- Rule 3: A and G as well as U and C are exchangeable either in the first position or simultaneously in the first and third positions in the recessive protocodes.
3. Results and Discussion
3.1. Entering Amino Acids into the Combinatorial Fusion Cascade and Codon Assignment in the SGC
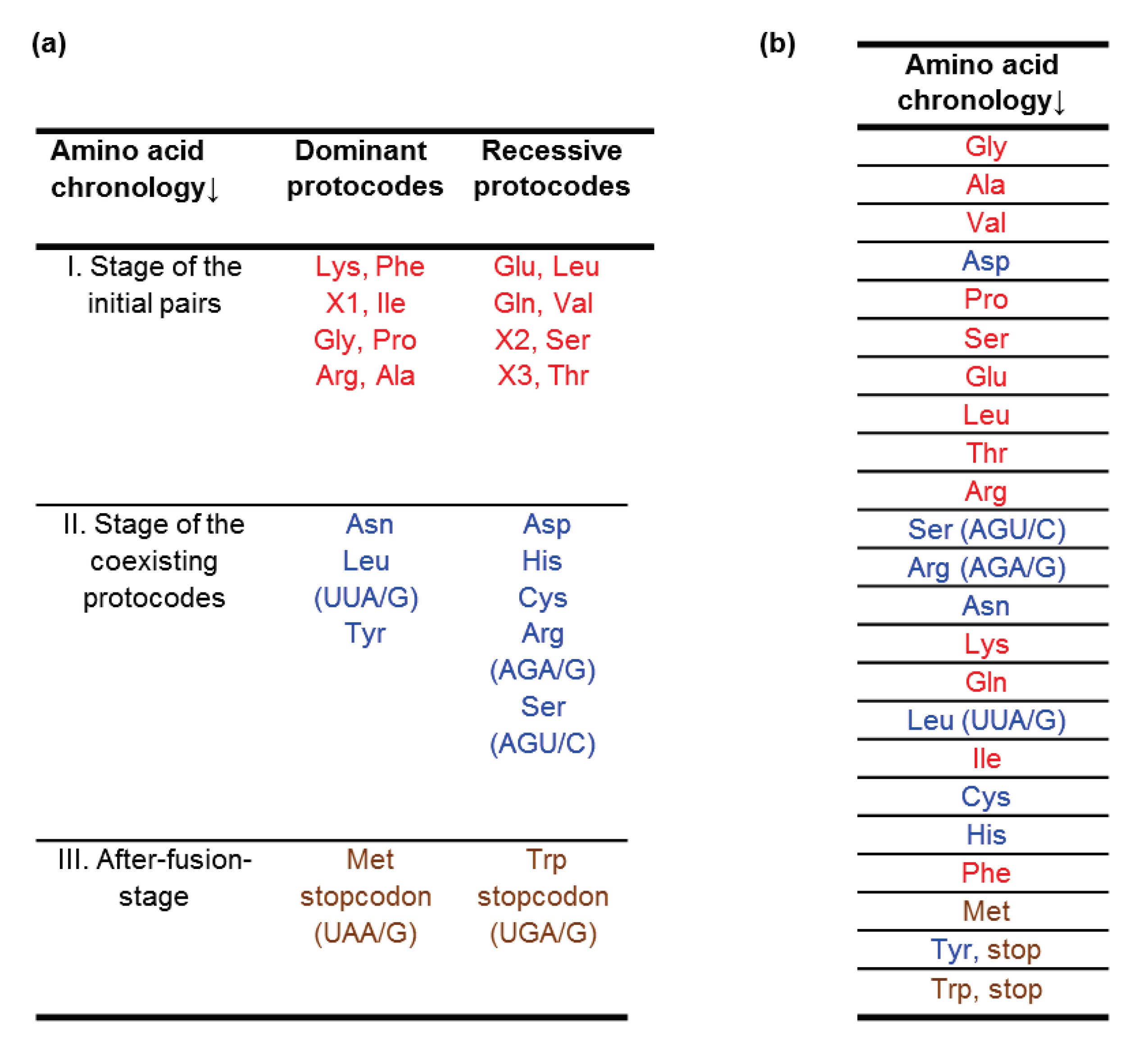
3.2. Temporal Order of Amino Acids
- The first amino acids to have been incorporated in early code were of abiotic origin, namely those that were obtained in classical imitation experiments by S. Miller.
- In the development of the triplet code, a major role was played by the thermostability of codon–anticodon interactions.
- New codons appeared in complementary pairs.
- New codons were simple derivatives of chronologically earlier ones.
3.3. Horizontal Transfer of “Complex Elements among the Evolving Entities”
4. Conclusions and Outlook
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Acknowledgments
Conflicts of Interest
References
- Koonin, E.V. Frozen Accident Pushing 50: Stereochemistry, Expansion, and Chance in the Evolution of the Genetic Code. Life 2017, 7, 22. [Google Scholar] [CrossRef]
- Higgs, P.G. A four-column theory for the origin of the genetic code: Tracing the evolutionary pathways that gave rise to an optimized code. Biol. Direct 2009, 4, 16. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Massey, S.E. The neutral emergence of error minimized genetic codes superior to the standard genetic code. J. Theor. Biol. 2016, 408, 237–242. [Google Scholar] [CrossRef]
- Di Giulio, M. A Non-neutral Origin for Error Minimization in the Origin of the Genetic Code. J. Mol. Evol. 2018, 86, 593–597. [Google Scholar] [CrossRef] [PubMed]
- Wong, J.T. A co-evolution theory of the genetic code. Proc. Natl. Acad. Sci. USA 1975, 72, 1909–1912. [Google Scholar] [CrossRef] [Green Version]
- Muchowska, K.B.; Varma, S.J.; Moran, J. Synthesis and breakdown of universal metabolic precursors promoted by iron. Nature 2019, 569, 104. [Google Scholar] [CrossRef]
- Preiner, M.; Xavier, J.C.; Vieira, A.D.; Kleinermanns, K.; Allen, J.F.; Martin, W.F. Catalysts, autocatalysis and the origin of metabolism. Interface Focus 2019, 9. [Google Scholar] [CrossRef]
- Di Giulio, M. The origin of the genetic code: Theories and their relationships, a review. Biosystems 2005, 80, 175–184. [Google Scholar] [CrossRef]
- Wong, J.T.F. Coevolution theory of the genetic code at age thirty. Bioessays 2005, 27, 416–425. [Google Scholar] [CrossRef] [PubMed]
- Di Giulio, M. An extension of the coevolution theory of the origin of the genetic code. Biol. Direct 2008, 3, 37. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Gospodinov, A.; Kunnev, D. Universal Codons with Enrichment from GC to AU Nucleotide Composition Reveal a Chronological Assignment from Early to Late Along with LUCA Formation. Life 2020, 10, 81. [Google Scholar] [CrossRef] [PubMed]
- Higgs, P.G.; Pudritz, R.E. A Thermodynamic Basis for Prebiotic Amino Acid Synthesis and the Nature of the First Genetic Code. Astrobiology 2009, 9, 483–490. [Google Scholar] [CrossRef] [PubMed]
- Carter, C.W.; Wills, P.R. Hierarchical groove discrimination by Class I and II aminoacyl-tRNA synthetases reveals a palimpsest of the operational RNA code in the tRNA acceptor-stem bases. Nucleic Acids Res. 2018, 46, 9667–9683. [Google Scholar] [CrossRef] [Green Version]
- Caetano-Anolles, G.; Wang, M.L.; Caetano-Anolles, D. Structural Phylogenomics Retrodicts the Origin of the Genetic Code and Uncovers the Evolutionary Impact of Protein Flexibility. PLoS ONE 2013, 8, e72225. [Google Scholar] [CrossRef] [Green Version]
- Hartman, H.; Smith, T.F. The evolution of the ribosome and the genetic code. Life 2014, 4, 227–249. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Kubyshkin, V.; Budisa, N. The Alanine World Model for the Development of the Amino Acid Repertoire in Protein Biosynthesis. Int. J. Mol. Sci. 2019, 20, 5507. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Giege, R.; Sissler, M.; Florentz, C. Universal rules and idiosyncratic features in tRNA identity. Nucleic Acids Res. 1998, 26, 5017–5035. [Google Scholar] [CrossRef] [Green Version]
- Pang, Y.L.; Poruri, K.; Martinis, S.A. tRNA synthetase: tRNA aminoacylation and beyond. Wiley Interdiscip Rev. RNA 2014, 5, 461–480. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Yarus, M. Amino acids as RNA ligands: A direct-RNA-template theory for the code’s origin. J. Mol. Evol. 1998, 47, 109–117. [Google Scholar] [CrossRef]
- Yarus, M. RNA-ligand chemistry: A testable source for the genetic code. RNA 2000, 6, 475–484. [Google Scholar] [CrossRef] [Green Version]
- Yarus, M.; Caporaso, J.G.; Knight, R. Origins of the genetic code: The escaped triplet theory. Annu. Rev. Biochem. 2005, 74, 179–198. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Yarus, M.; Widmann, J.J.; Knight, R. RNA-Amino Acid Binding: A Stereochemical Era for the Genetic Code. J. Mol. Evol. 2009, 69, 406–429. [Google Scholar] [CrossRef] [Green Version]
- Koonin, E.V.; Novozhilov, A.S. Origin and Evolution of the Universal Genetic Code. Annu. Rev. Genet. 2017, 51, 45–62. [Google Scholar] [CrossRef]
- Miller, S.L. A Production of Amino Acids under Possible Primitive Earth Conditions. Science 1953, 117, 528–529. [Google Scholar] [CrossRef] [Green Version]
- Bada, J.L. New insights into prebiotic chemistry from Stanley Miller’s spark discharge experiments. Chem. Soc. Rev. 2013, 42, 2186–2196. [Google Scholar] [CrossRef]
- Brooks, D.J.; Fresco, J.R.; Lesk, A.M.; Singh, M. Evolution of amino acid frequencies in proteins over deep time: Inferred order of introduction of amino acids into the genetic code. Mol. Biol. Evol. 2002, 19, 1645–1655. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Woese, C.R.; Olsen, G.J.; Ibba, M.; Soll, D. Aminoacyl-tRNA synthetases, the genetic code, and the evolutionary process. Microbiol. Mol. Biol. Rev. 2000, 64, 202–236. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Haig, D.; Hurst, L.D. A Quantitative Measure of Error Minimization in the Genetic-Code. J. Mol. Evol. 1991, 33, 412–417. [Google Scholar] [CrossRef] [PubMed]
- Weiss, M.C.; Preiner, M.; Xavier, J.C.; Zimorski, V.; Martin, W.F. The last universal common ancestor between ancient Earth chemistry and the onset of genetics. PLoS Genet. 2018, 14, e1007518. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Vetsigian, K.; Woese, C.; Goldenfeld, N. Collective evolution and the genetic code. Proc. Natl. Acad. Sci. USA 2006, 103, 10696–10701. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Nesterov-Müller, A.; Popov, R. Die Botschaft von LUCA—Der letzte universelle gemeinsame Vorfahre. Biospektrum 2020, 26, 488–489. [Google Scholar] [CrossRef]
- Nesterov-Mueller, A.; Popov, R.; Seligmann, H. Combinatorial Fusion Rules to Describe Codon Assignment in the Standard Genetic Code. Life 2021, 11, 4. [Google Scholar] [CrossRef]
- Lei, L.; Burton, Z.F. Evolution of Life on Earth: tRNA, Aminoacyl-tRNA Synthetases and the Genetic Code. Life 2020, 10, 21. [Google Scholar] [CrossRef] [Green Version]
- Copley, S.D.; Smith, E.; Morowitz, H.J. A mechanism for the association of amino acids with their codons and the origin of the genetic code. Proc. Natl. Acad. Sci. USA 2005, 102, 4442–4447. [Google Scholar] [CrossRef] [Green Version]
- Rodin, S.N.; Ohno, S. Four primordial modes of tRNA-synthetase recognition, determined by the (G,C) operational code. Proc. Natl. Acad. Sci. USA 1997, 94, 5183–5188. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Rumer, Y.B. Translation of ‘Systematization of Codons in the Genetic Code [I]’ by Yu. B. Rumer (1966). Philos. Trans. R. Soc. A 2016, 374, 20150446. [Google Scholar] [CrossRef] [PubMed]
- Antoneli, F.; Forger, M. Symmetry breaking in the genetic code: Finite groups. Math. Comput. Model. 2011, 53, 1469–1488. [Google Scholar] [CrossRef]
- Lenstra, R. Evolution of the genetic code through progressive symmetry breaking. J. Theor. Biol. 2014, 347, 95–108. [Google Scholar] [CrossRef] [Green Version]
- Hornos, J.E.M.; Hornos, Y.M.M. Algebraic Model for the Evolution of the Genetic-Code. Phys. Rev. Lett. 1993, 71, 4401–4404. [Google Scholar] [CrossRef]
- Gonzalez, D.L.; Giannerini, S.; Rosa, R. On the origin of degeneracy in the genetic code. Interface Focus 2019, 9, 20190038. [Google Scholar] [CrossRef] [PubMed]
- Emmert, E.A.B.; Milner, J.L.; Lee, J.C.; Pulvermacher, K.L.; Olivares, H.A.; Clardy, J.; Handelsman, J. Effect of canavanine from alfalfa seeds on the population biology of Bacillus cereus. Appl. Environ. Microb. 1998, 64, 4683–4688. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Kamo, T.; Sakurai, S.; Yamanashi, T.; Todoroki, Y. Cyanamide is biosynthesized from L-canavanine in plants. Sci. Rep. 2015, 5, 10527. [Google Scholar] [CrossRef] [Green Version]
- Srinivasan, G.; James, C.M.; Krzycki, J.A. Pyrrolysine encoded by UAG in Archaea: Charging of a UAG-decoding specialized tRNA. Science 2002, 296, 1459–1462. [Google Scholar] [CrossRef]
- Hao, B.; Gong, W.M.; Ferguson, T.K.; James, C.M.; Krzycki, J.A.; Chan, M.K. A new UAG-encoded residue in the structure of a methanogen methyltransferase. Science 2002, 296, 1462–1466. [Google Scholar] [CrossRef] [PubMed]
- Donovan, J.; Copeland, P.R. The Efficiency of Selenocysteine Incorporation Is Regulated by Translation Initiation Factors. J. Mol. Biol. 2010, 400, 659–664. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Trifonov, E.N. Consensus temporal order of amino acids and evolution of the triplet code. Gene 2000, 261, 139–151. [Google Scholar] [CrossRef]
- Jia, T.Z.; Chandru, K.; Hongo, Y.; Afrin, R.; Usui, T.; Myojo, K.; Cleaves, H.J. Membraneless polyester microdroplets as primordial compartments at the origins of life. Proc. Natl. Acad. Sci. USA 2019, 116, 15830–15835. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Szostak, J.W.; Bartel, D.P.; Luisi, P.L. Synthesizing life. Nature 2001, 409, 387–390. [Google Scholar] [CrossRef] [PubMed]
- Schreiber, U.; Locker-Grutjen, O.; Mayer, C. Hypothesis: Origin of Life in Deep-Reaching Tectonic Faults. Orig. Life Evol. Biosph. 2012, 42, 47–54. [Google Scholar] [CrossRef] [PubMed]
- New, R.; Bansal, G.S.; Bogus, M.; Zajkowska, K.; Rickelt, S.; Toth, I. Use of Mixed Micelles for Presentation of Building Blocks in a New Combinatorial Discovery Methodology: Proof-of-Concept Studies. Molecules 2013, 18, 3427–3441. [Google Scholar] [CrossRef] [Green Version]
- Stueken, E.E.; Anderson, R.E.; Bowman, J.S.; Brazelton, W.J.; Colangelo-Lillis, J.; Goldman, A.D.; Som, S.M.; Baross, J.A. Did life originate from a global chemical reactor? Geobiology 2013, 11, 101–126. [Google Scholar] [CrossRef] [PubMed]
- Kudella, P.W.; Tkachenko, A.V.; Salditt, A.; Maslov, S.; Braun, D. Structured sequences emerge from random pool when replicated by templated ligation. Proc. Natl. Acad. Sci. USA 2021, 118, e2018830118. [Google Scholar] [CrossRef] [PubMed]


Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Nesterov-Mueller, A.; Popov, R. The Combinatorial Fusion Cascade to Generate the Standard Genetic Code. Life 2021, 11, 975. https://doi.org/10.3390/life11090975
Nesterov-Mueller A, Popov R. The Combinatorial Fusion Cascade to Generate the Standard Genetic Code. Life. 2021; 11(9):975. https://doi.org/10.3390/life11090975
Chicago/Turabian StyleNesterov-Mueller, Alexander, and Roman Popov. 2021. "The Combinatorial Fusion Cascade to Generate the Standard Genetic Code" Life 11, no. 9: 975. https://doi.org/10.3390/life11090975