
Estimating Real-Time qPCR Amplification Efficiency from Single-Reaction Data

Department of Chemistry, Vanderbilt University, Nashville, TN 37235, USA
Life 2021, 11(7), 693; https://doi.org/10.3390/life11070693
Submission received: 8 June 2021
/
Revised: 8 July 2021
/
Accepted: 13 July 2021
/
Published: 14 July 2021
(This article belongs to the Special Issue Analysis of Amplification Curve Data)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:Methods for estimating the qPCR amplification efficiency E from data for single reactions are tested on six multireplicate datasets, with emphasis on their performance as a function of the range of cycles n1–n2 included in the analysis. The two-parameter exponential growth (EG) model that has been relied upon almost exclusively does not allow for the decline of E(n) with increasing cycle number n through the growth region and accordingly gives low-biased estimates. Further, the standard procedure of “baselining”—separately estimating and subtracting a baseline before analysis—leads to reduced precision. The three-parameter logistic model (LRE) does allow for such decline and includes a parameter E0 that represents E through the baseline region. Several four-parameter extensions of this model that accommodate some asymmetry in the growth profiles but still retain the significance of E0 are tested against the LRE and EG models. The recursion method of Carr and Moore also describes a declining E(n) but tacitly assumes E0 = 2 in the baseline region. Two modifications that permit varying E0 are tested, as well as a recursion method that directly fits E(n) to a sigmoidal function. All but the last of these can give E0 estimates that agree fairly well with calibration-based estimates but perform best when the calculations are extended to only about one cycle below the first-derivative maximum (FDM). The LRE model performs as well as any of the four-parameter forms and is easier to use. Its proper implementation requires fitting to it plus a suitable baseline function, which typically requires four–six adjustable parameters in a nonlinear least-squares fit.
1. Introduction
Quantitative polymerase chain reaction (qPCR) is an analytical method for estimating numbers of molecules of specific genetic substances through amplification to easily detected quantities [1]. The standard approach for “absolute” quantification is calibration procedures that compare the unknown with results for the same substance measured at a range of known concentrations chosen to encompass the unknown [2,3]. The standard curve plots of quantification cycle Cq vs. the logarithm of the template number (N0) are ideally linear, with slope −1/log(E), where E is the amplification efficiency (AE). Recommendations for producing such curves involve three or more replicates at each of the five–seven concentrations for unknown estimation, or even more concentrations if the AE is to be estimated [4,5,6]. This procedure could then entail at least 15 and as many as ~30 individual PCR reactions, with an estimation of Cq for each.
It has long been a dream to reduce this time and materials demand by estimating the AE directly from the growth profile for a single reaction (SR) [7,8,9]. This would then permit quantitative estimation of the unknown with a single calibration reference, or even from the SR itself, if optical calibration could be trusted [10]. A number of such methods have been discussed in detail and their performance compared on several multireplicate datasets by Ruijter, et al. [11]. Clearly, the value of these methods depends upon their accuracy and precision.
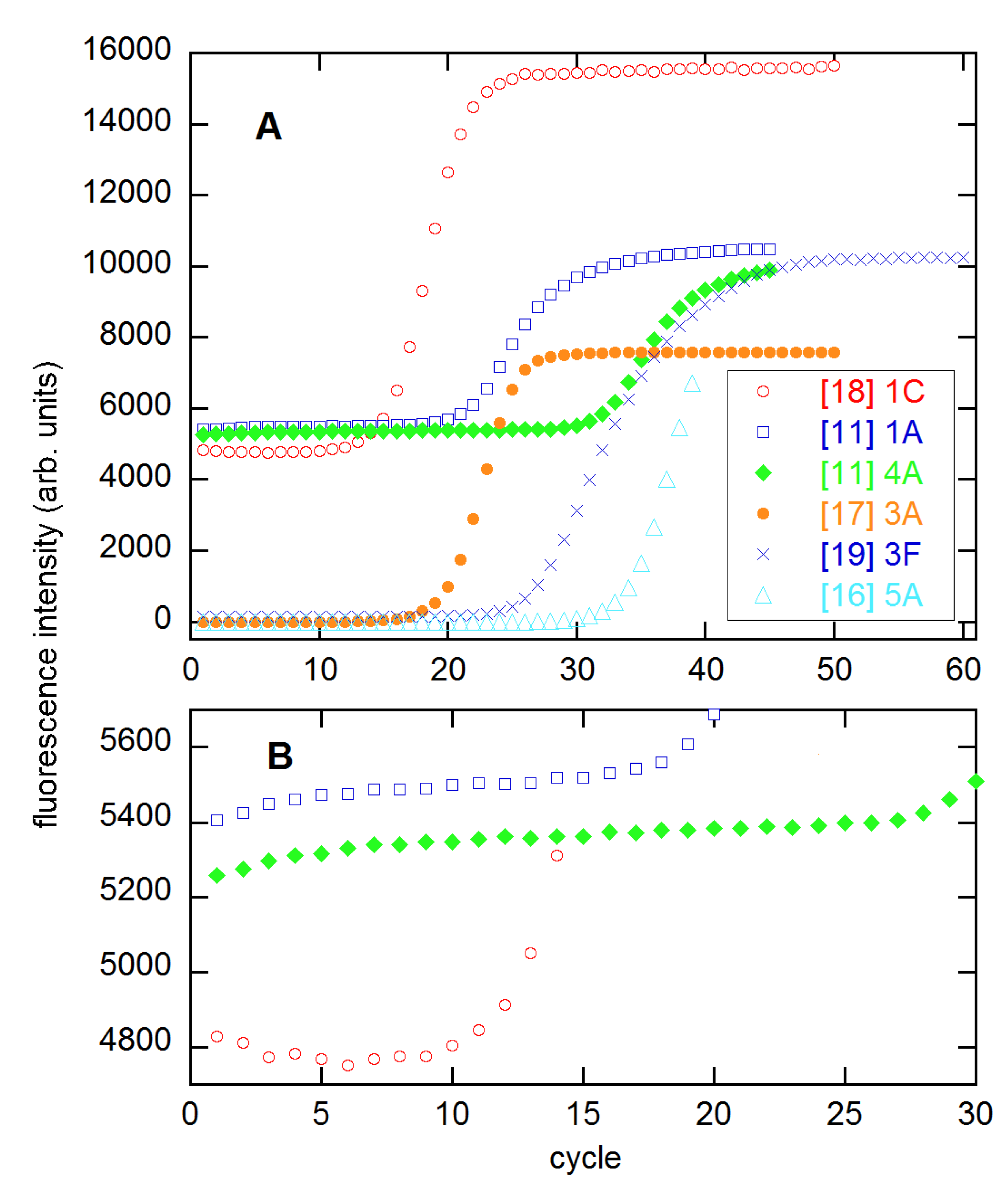
In [11], Ruijter and coauthors included much information about accuracy and precision in their comparisons. However, Spiess and I have pointed out statistical weaknesses in the implementations of many of these methods [12,13,14,15]. Moreover, there are other SR methods that were not considered in [11] that might perform better. The topic of the present work is a more detailed examination of such methods, especially including the dependence of the results on the range of cycles n1–n2 included in the analysis. To this end, I employ six multireplicate datasets, the same number included in the comparisons of [15], which focused on the estimation of Cq and its use in calibration. These datasets are from [3,11,16,17,18,19], representative profiles from which are shown in Figure 1.
Before getting to the details of the present calculations, it is useful to note the aforementioned statistical weaknesses in many methods. In almost all of those compared in [11], the baseline is estimated and then subtracted before the fluorescence data are analyzed. In fact, data are often presented after baselining, as is the case for at least three of the six datasets used here and shown in Figure 1. However if the model for the data is baseline + signal, then the proper statistical analysis should be a direct fit to this model, since the baseline is presumed to contribute to the total signal at all cycles. This requires nonlinear least squares (NLS), but user-friendly programs for NLS have been available for decades. Through Monte Carlo simulations, Spiess and I showed in the Supporting Information to [14] (Figures S1–S5) that this two-step procedure leads to an increase of 75% in the dispersion of AE estimates, which translates into an efficiency loss of 1.752 ≈ 3. This means that one reaction analyzed properly is the statistical equivalent of three analyzed in the two-step procedure. One method covered in [11] that did include a baseline in the fitting was PCR-Miner [20]; in fact, this method won out in the Cq precision comparisons in [12].
A second problem with most SR methods is reliance on the exponential growth model,
where the AE ranges from E = 1 (no amplification) to E = 2 (perfect doubling), n is the cycle number, and y represents the fluorescence signal, with y0 being that in Cycle 0. However, E must decline from ~2 in the baseline region to 1 in the plateau region at large n, so the use of Equation (1) for early growth cycles is questionable. In fact, using the LRE model [21] to generate data resembling typical growth profiles, Spiess and I showed that analysis with Equation (1) yields low-biased estimates of E when enough cycles are included to give good precision [14]. The extent of that problem for actual data is a major concern of the present work.
y = y0 En,
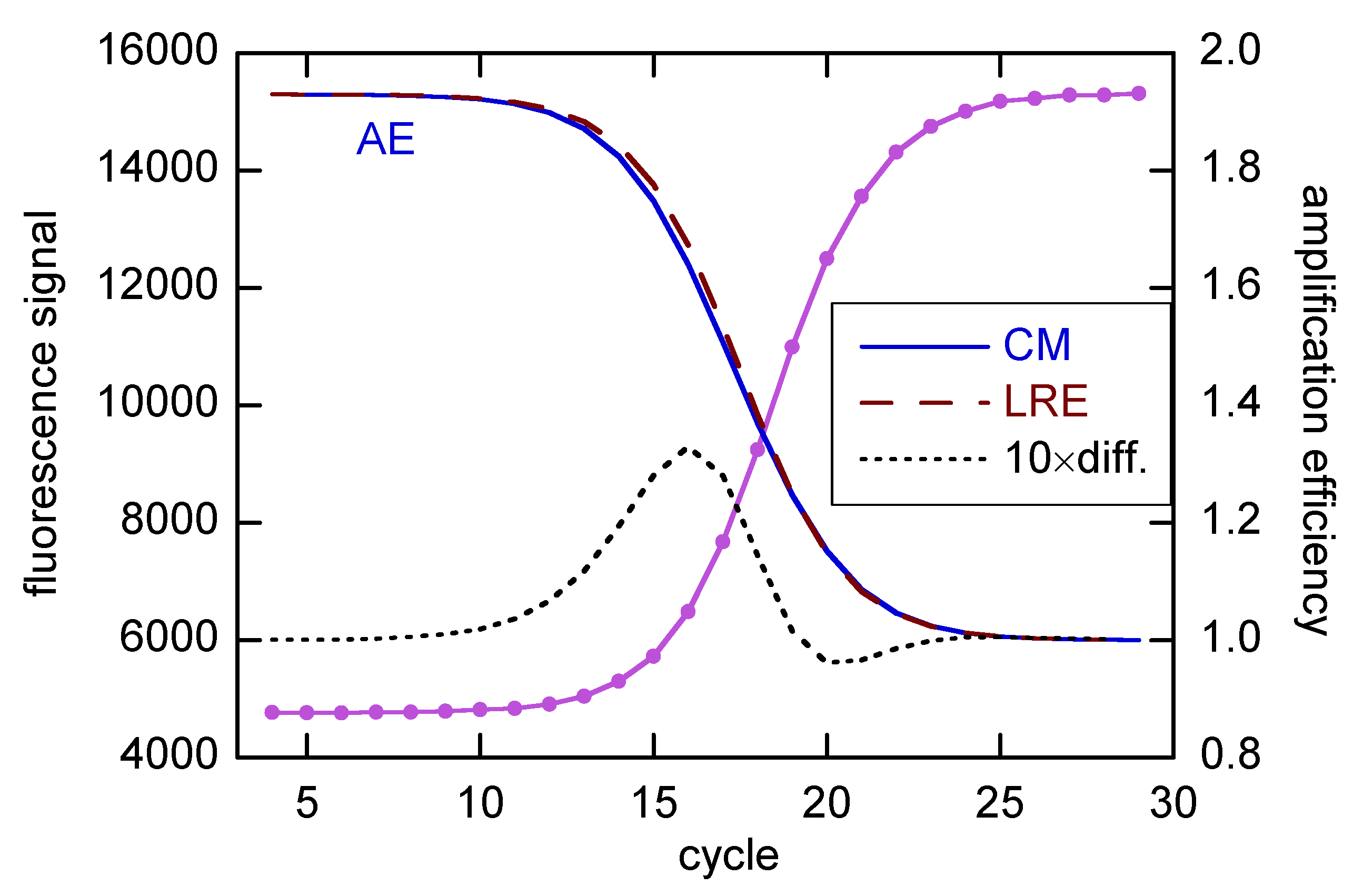
The LRE model contains a parameter (E0) for the AE in the baseline region, with E decreasing properly to 1 in the plateau region. The decline of E through the growth region is illustrated in Figure 2, with a comparison with one additional method, from Carr and Moore [22]. The CM method is an extension of the MAK2 method [23] (covered in [11]), but with one additional parameter that allows for the decline of E, leading to realistic sigmoidal profiles. Both methods tacitly assume E = 2 in the baseline region. However, with a minor modification, E can be made an adjustable parameter in the CM method.
The AE from the LRE fit in Figure 2 agrees closely (~0.02) with the calibration estimate [15]. I will use such agreement as the quality marker in the present study, as there seems no better way to judge the SR estimates for quantifying N0 in unknowns. However, there are reasons the two estimates may not agree. Most importantly, the SR estimates pertain to the early growth region, while the calibration estimates actually cover the early cycles in the baseline region up to the first cycle for the most concentrated calibrant [12]. This follows from the assumption that a dilute reaction amplifies the same as a more concentrated one after N for the dilute reaction matches N0 for the concentrated one. Thus, all of the difference comes from the first ΔCq cycles of the dilute sample, and that ΔCq determines E for the pair.
In the present work, I emphasize the performance of the simple growth model of Equation (1) and the essentially logistic LRE model. I also consider variations of the latter with an additional parameter to handle asymmetry in the amplification profiles, as well as the CM model and a direct-fitting approach that assumes a logistic E(n). In general, for the present tests, these methods do not perform as well as just fitting to the LRE model over a limited cycle range, namely, to about the half-intensity point or the first-derivative maximum (FDM).
2. Mathematical Background
The simplest way to estimate the AE from SR data is by fitting to Equation (1), which contains just two parameters apart from those needed to represent the baseline. As already noted, most of the methods reviewed in [11] are variations on this theme, with several ways of treating the baseline, which is estimated separately and subtracted. Some methods select a range of cycles where the logarithmic transformation of the “baseline-corrected” data appears to be linear and then estimate E from a linear fit of these transformed data. In testing this model here, which I will call the EG (exponential growth) model, I will employ the statistically best approach: fit the data to Equation (1) plus a baseline function. The issue is then how far into the growth phase to extend this fit, and the usual answer is to about the second derivative maximum (SDM) cycle. I will examine results for fitting to cycle n2 spanning a range including the SDM.
The LRE method devised by Rutledge and Stewart [21] involves several steps. However, the results are equivalent to just fitting to the three-parameter model [24],
for which I will retain the LRE label. Here, ymax is the limiting growth and E0 the initial AE. The second expression is the logistic model and is obtained by neglecting y0 in the denominator of the first; n1/2 is the half-intensity point and the FDM, with b = ln(E0) and ymax/y0 = E0n1/2. Because normally y0 << ymax, there is insignificant difference in results obtained with Equations (2) and (3). Figure 2 shows that this model can give very good results for E(n), which is typically found to have declined by about 0.2 at the SDM [14]. However, it is inherently symmetrical about the half-intensity point (also the FDM), which most qPCR curves are not. Accordingly, it does not perform well in whole-curve fitting of asymmetrical growth profiles. Below, I describe how to include an asymmetry parameter to improve the fit quality.
The log-logistic model is a sigmoidal alternative to Equation (3), and in the four-parameter form [25],
it can accommodate some asymmetry. With p = 1, it is nearly symmetrical, and g ≈ n1/2 (≈nFDM). This model was used in [15] to obtain the most precise Cq estimates, by fitting to typically 22–26 cycles centered on the FDM. It cannot predict E0 in the baseline region, because there are no parameters for this. However, it is useful for estimating ymax in calculations where this parameter is held fixed in the LRE models.
LL4(n) = ymax [1 + (g/n)h]−p
2.1. The Logistic Model with Asymmetry
One can incorporate asymmetry in the model of Equation (2) by raising the denominator to the power p, as in Equation (4). In both cases there are two modes of convergence that are statistically inequivalent. An alternative is to raise ymax in the denominator of Equation (2) to the power p and then raise the entire denominator to the power p−1. This approach ensures that at small n, where ymax dominates the denominator, E0 retains its significance as the initial AE, with physically reasonable prediction of E(n) into the growth region. Similarly, the addition of the asymmetry parameter to Equation (3) preserves its ability to predict physically reasonable E(n). The issue again is how well do the results agree with calibration-based E for asymmetrical profiles?
We want to express the modified versions of Equation (3) in ways that contain E0 and the FDM as adjustable parameters, so that the LS fits return these and their standard errors (SE) directly. We first note that n1/2 in Equation (3) is the FDM, and by replacing b by ln(E0), we obtain E0 directly. Taking Mode A as the four-parameter version of Equation (3), we have
In Mode B the sigmoidal function can be expressed as a subtraction from the plateau level [15], but it can also be written as
in which form it is added to base(n). Mode C is obtained from Equation (2) as already described, by raising ymax in the denominator to power p and the entire denominator to power p−1:
We obtain a nearly equivalent expression by replacing y0 as a parameter with the FDM,
in the same way that we went from Equation (2) to Equation (3). All of these expressions revert to LRE when p = 1.
2.2. Recursion Models
The “mechanistic” models of [22,23] employ recursion relations to generate y(n) from y(n − 1), based on elements of the reaction chemistry thought to hold in the PCR process. As already shown in Figure 2, the Carr–Moore (CM) model, with three adjustable parameters, can predict realistic behavior for both the profiles and E(n) [22]. The MAK2 model of [23], like the EG model of Equation (1), grows without limit, so must be restricted to the early growth region in analysis. Because of these limitations and because the CM model is an extension of it, I do not consider MAK2 any further here.
An alternative recursion approach defines E(n) as a sigmoidal function, with data fitted to
y(n) = y(n−1) E(n−1)
For the datasets I have analyzed with this method, its performance has been poorer than that of the other approaches, so I provide only limited results for it below.
The recursion relation of the CM model is
where I have retained their notation (i = n) of [22] and have used A in place of ymax, because I have found that A does not have the physical significance of ymax, typically being a factor of 3 larger than the plateau. The final version of the relation makes it clear that E0 = 2 in the baseline region, where y is small. One can accommodate variable E0 by (a) replacing 2 with E0 in this expression (Mode a), or (2) scaling the entire quantity in square brackets by E0/2 (Mode b). I have tested both modes, which I will refer to as CMa and CMb.
Carr and Moore provided the KaleidaGraph routine they used to analyze their data with Equation (10). However, this routine does not properly implement the recursion relation; rather, it just predicts yi from the experimental yi−1. Accordingly, it contains just the two parameters, A and Kd. A true recursion implementation starts with y0 as a third parameter and generates a full set of y values, which are then altered iteratively with adjustment of all three parameters in a nonlinear LS routine. (The FORTRAN function routine for doing this is included in the Supplementary Material.) I have tested the model in this way, with a 4th adjustable parameter for E0. The method used by CM does converge readily and can provide good initial estimates of the parameters apart from y0, as needed for the full calculation.
2.3. Baseline Functions
The choice of function for base(n) can depend on the range of early cycles included in the fit. I have commonly used linear and quadratic functions of n, in which the need for parameters beyond the minimal single constant is judged by their statistical significance in the fit. Any parameter having SE greater than its magnitude is statistically undefined in ad hoc fitting [26]. Baselines such as the two from [11] shown in Figure 1B exhibit “saturation” behavior, so are represented as
sometimes with an added linear term. The other baseline in this figure is represented as a constant, after deletion of the first four or five cycles.
base(n) = a − q exp(−rn)
2.4. Least-Squares Fitting
The NLS fitting was done using routines such as those described before [12,13,14,15]: KaleidaGraph for preliminary work and for the preparation of figures, in-house FORTRAN codes similar to those in [26] for production work on the multireplicate datasets. Weighted fitting was discussed in [15]; although weighting is less important in fitting growth profiles than for Cq calibration data, I have used the same weighting here for consistency.
In assessing the quality of LS fits, important metrics are the sum of weighted squared residuals, S = Σ wiδi2, and the estimated variance for unit weight, sy2 = S/v, where the number of statistical degrees of freedom v is the number of fitted points minus the number of adjustable parameters. In typical fits of qPCR rx data to the models under investigation here, the model will begin to fail as the number of cycles included in the fit increases, and this failure will manifest as a pronounced rise in the fit variance sy2.
For readers who code, I have a useful tip. Parameters such as y0 (and to a lesser extent, ymax) can vary considerably—for example, by an order of magnitude with dilution change for 10-fold dilutions. The annoying nonconvergences of NLS fits can be greatly reduced by representing y0 through its logarithm, e.g., y0 = 10d, with d now being the adjustable parameter [27].
3. Results and Discussion
As Figure 1 shows, the amplification profiles vary considerably over the six datasets, with some having highly symmetrical growth regions (3 × 5 from [18]) and some quite asymmetrical (94 × 4 from [11]). Some develop level plateaus, while others do not. The baselines vary from constant or sloping, to the saturation form of Equation (11). All of these properties can affect the quality of the NLS fits to the models being compared here.
3.1. The 3 × 5 Data
I start with and devote much detail to the 3 × 5 data from [18], for which the high symmetry favors the LRE model. As noted earlier in connection with Figure 2, both the LRE and CM models predict realistic transition from E0 in the baseline region to E = 1 in the plateau. However, to prepare this illustration, I had to freeze E0 in the CM fit at the LRE value; when freely fitted, it was 2.10(11) [≡2.10 ± 0.11] in Mode a and 2.17(7) in Mode b. The S values (unweighted fitting) were 1.85 × 104 and 1.36 × 104, respectively, as compared with 1.26 × 104 for the LRE model (with one fewer parameters). With the addition of the asymmetry parameter p to the LRE model, the estimated E0 was 2.066(33) for LREA (S = 5237), 1.988(13) for LREB (S = 4130), and 1.939(10) for LREC/D (S = 7399). Only the last value is within error of the calibration result (1.916(13) from [15]), and it is the statistically poorest of the LRE4 fits.
Figure 3 compares the CMa and LRE methods on the full 3 × 5 dataset, now giving averages and standard deviations (SD) for the three replicates at each concentration. The CMa E0s are lower with weighted fitting but are still about 0.1 above the calibration estimate, while the LRE estimates are within about 0.02 of calibration and more precise.
Both models fit the 3 × 5 data well for all n2, with the variances in these weighted fits varying with n2 by only a factor of ~2, CMa’s being larger than LRE’s by less than a factor of 2. This is in contrast with the behavior for the other datasets, where the variances usually rise sharply around the FDM (see below). Accordingly, I show in Figure 4 the E0 estimates for n2 near the FDM, along with EG E estimates for n2 near the SDM. The latter exhibit the behavior predicted by the modeling in [14]: negative bias, minimal near the SDM, with precision increasing with n2. The CM and LRE estimates agree well with the calibration-based estimate; however, the CM calculations failed to converge for n2 smaller than ~2 cycles above the FDM, so these CM results are for the lowest converged n2 values.
In the weighted fits of these data, CMb and CMa gave nearly identical results for both E0 and sy2 in the range depicted in Figure 4, but the CMb E0s rose to ~0.01 higher for the largest n2s covered in Figure 3. The E-recursion method of Equation (9) was tried on the data for the highest concentration in this set and gave E estimates close to those from CM.
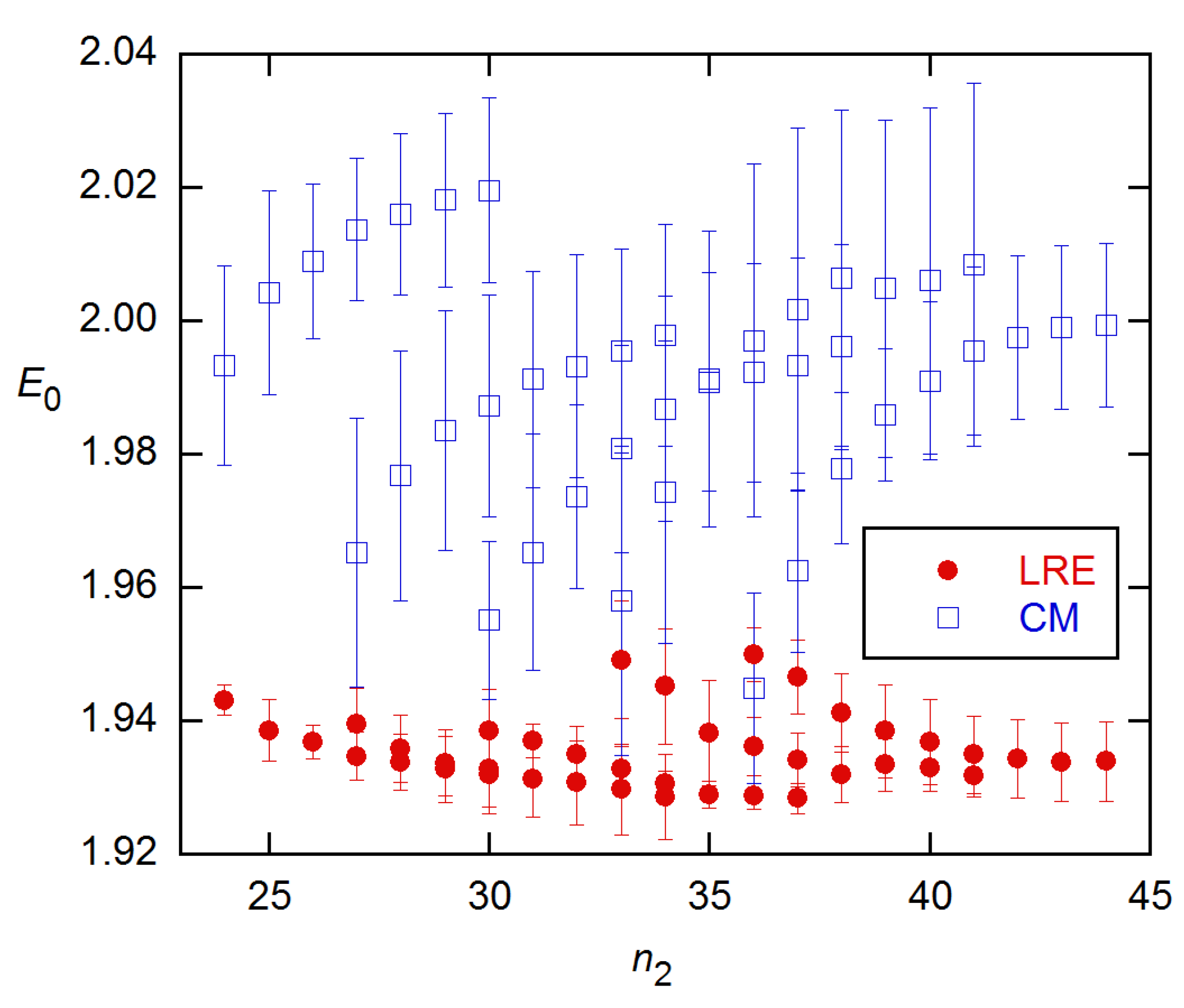
However, these were much more disperse, with SDs four times larger than for CM. This greatly reduced precision (and even poorer performance on the 94 × 4 data (below)) led me to drop further consideration of this model. The LRE4 models gave generally lower E0 estimates than CM for all covered n2, with the estimates for n2 < 22 almost all falling within 0.01 of the calibration value (Figure 5). The values for the parameter p (Equations (5)–(8)) were mostly close to 1.0 and within their SEs of this value for the lowest several n2 values, which means the LRE model is statistically better in this region [26].
The mentioned convergence problems occurred for the CM methods for n2 < FDM + 1 and for LRE with n2 < FDM − 3. Convergence can be achieved for lower n2 by freezing a parameter. For LRE, the obvious choice is ymax, and for n2 < FDM the results are not very sensitive to the value chosen, so values obtained for higher n2 can be used or even just the approximate plateau value if the plateau is achieved. For the CM method, either Kd or A may be frozen, but unfortunately, both begin to change just as convergence becomes problematic. Moreover, these parameters are not related to the plateau in an obvious way; in particular, A is about three times the ymax value. However, I have obtained reasonable E0 by freezing A at either the trend from large n2 or at the values for nearby n2, where A becomes increasingly uncertain. Since the plateau value can be obtained by simple inspection of the data, the LRE method is easier to use in this way.
3.2. Other Datasets
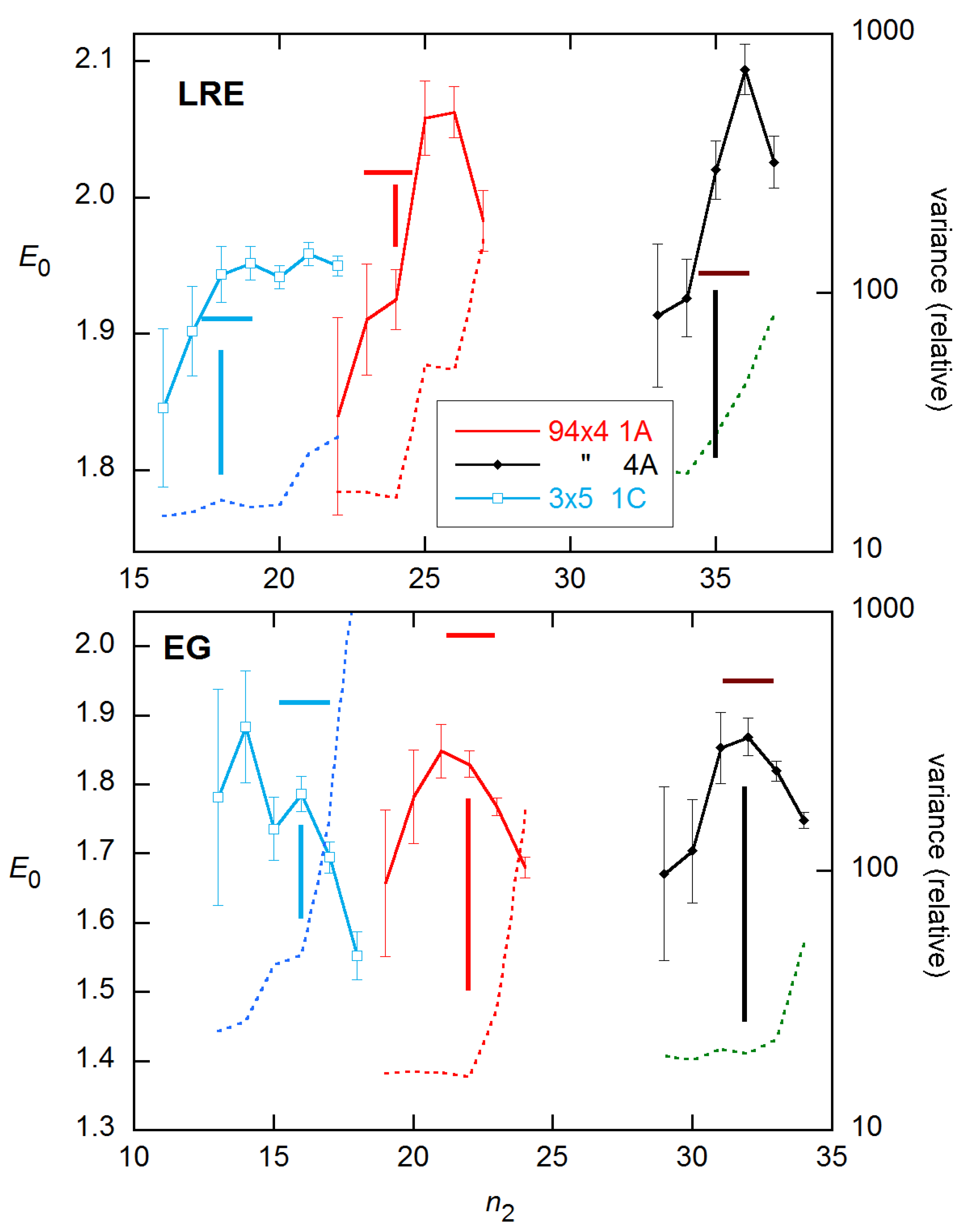
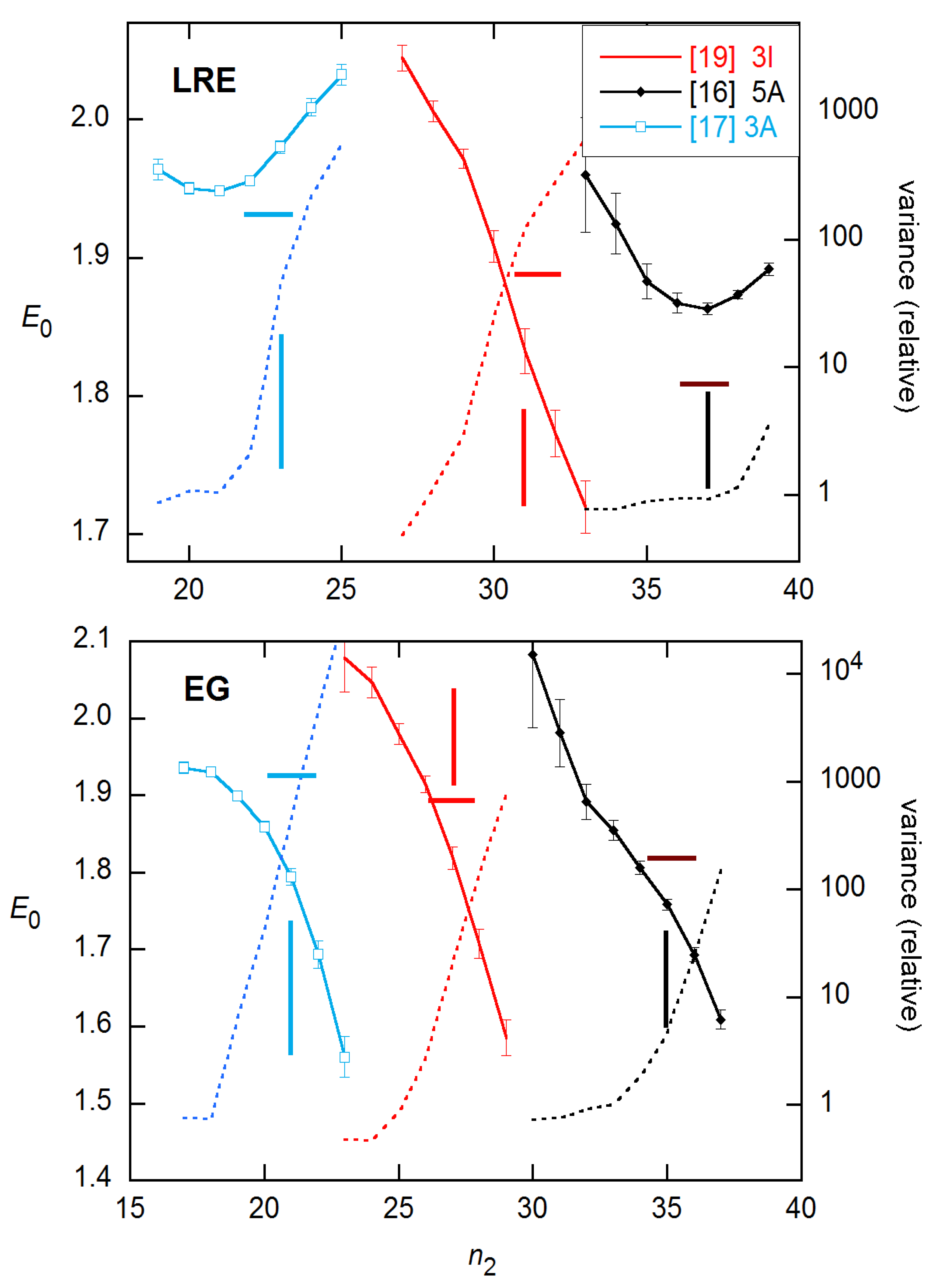
For the 3 × 5 data examined above, the LRE model performs best and is easiest to employ of the three- and four-parameter methods. Accordingly, in Figure 6 and Figure 7, I compare this method with the EG method that has dominated the literature in various forms, on the representative reactions shown in Figure 1. The LRE results are obtained for n2 near the FDM cycle, while the EG results center on the SDM cycle. From inspection, the closest agreement with calibration E estimates occurs about one cycle below these references in both cases. Comparing statistics for the two methods at these n2 values, the LRE mean discrepancy is only −0.004, while that for EG is −0.082 (with only one positive difference). The rms differences are 0.053 for LRE and 0.112 for EG.
Although the results shown in Figure 6 and Figure 7 are for single reactions, the ensemble statistics for replicates closely resemble them, as is shown in Figure 8 for the datasets and concentrations of Figure 7. The ensemble SDs of Figure 8 do exceed the SR SEs of Figure 7 in several cases. However, the excess is not as great as found for the Cq estimates in [15].
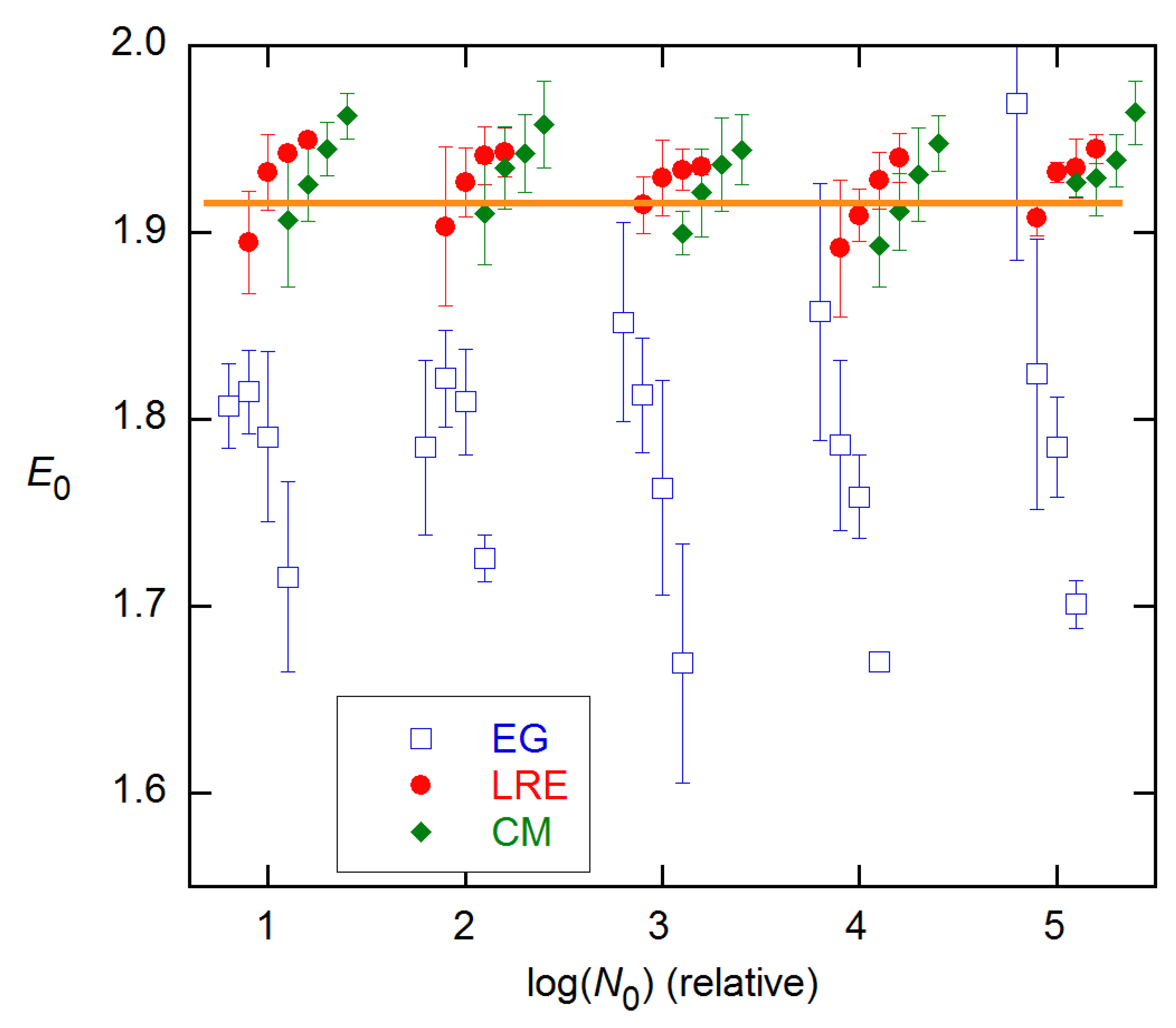
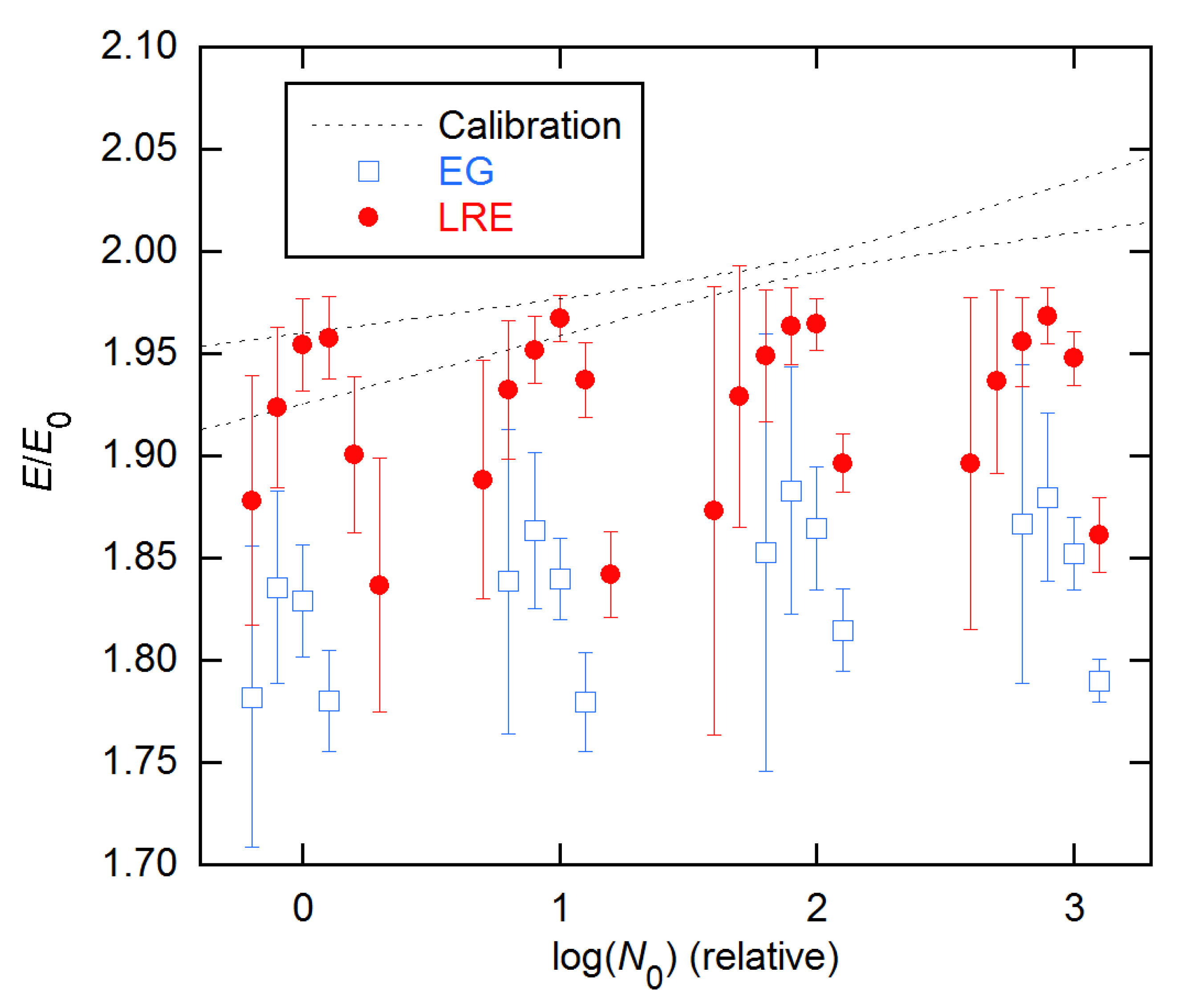
LRE and EG estimates are compared with the calibration results for all concentrations of the 94 × 4 data in Figure 9. Here, again the EG estimates systematically undershoot the calibration values, while the LRE values agree at the lower concentrations but fall short for higher. These estimates were obtained by fixing the ymax values; this will be discussed further below.
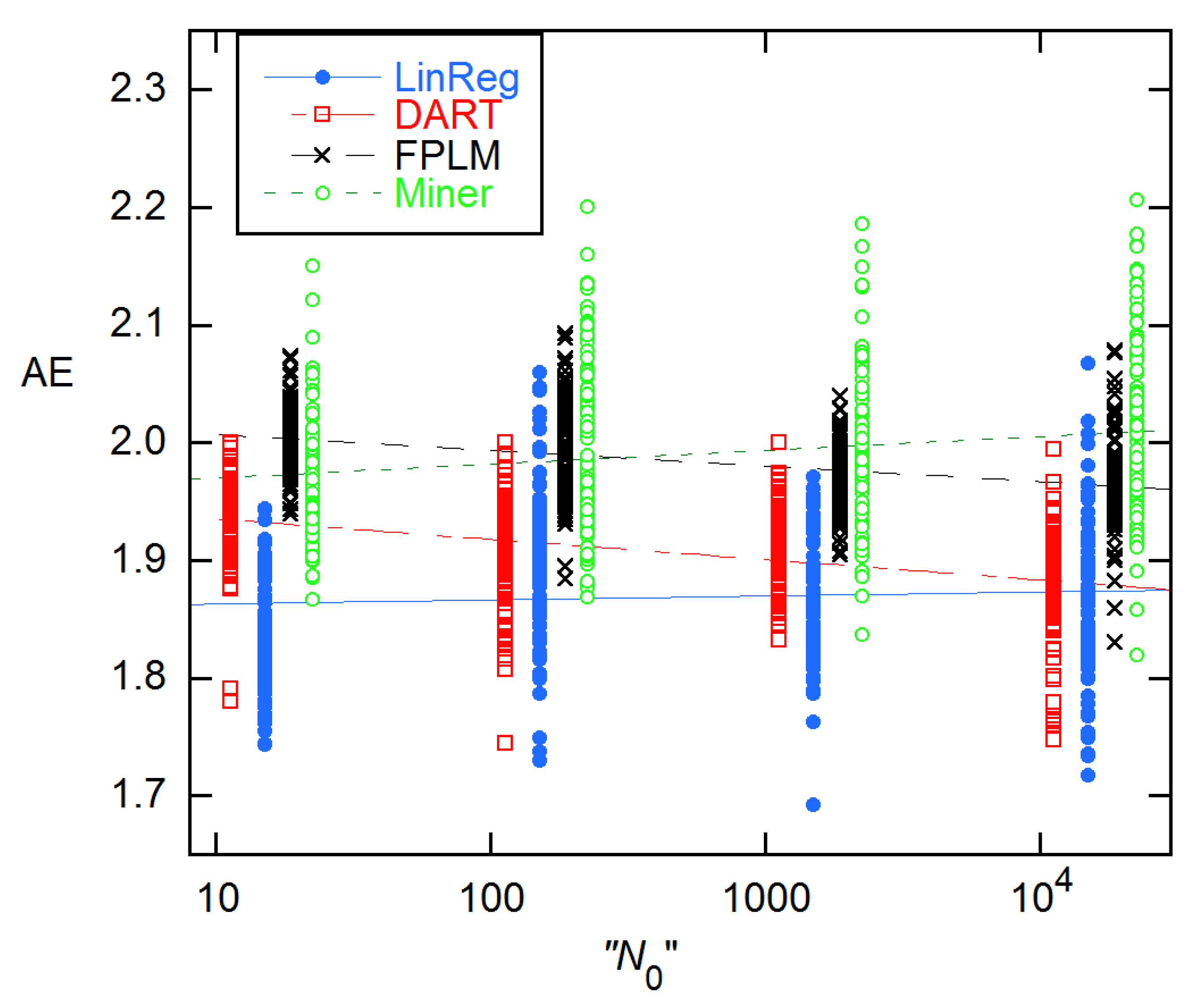
It is instructive to compare the EG results with those given in the supplement to [11], where four of the discussed methods employ the EG model in different ways, two using direct fitting, two using logarithmic transformation, and three subtracting an estimated baseline before fitting. As Figure 10 shows, the results are quite different, giving average AEs ranging from 1.869(62) for LinReg to 1.991(75) for Miner. All sets show a statistically significant slope in log(N0), and two—LinReg and Miner—support a quadratic dependence.
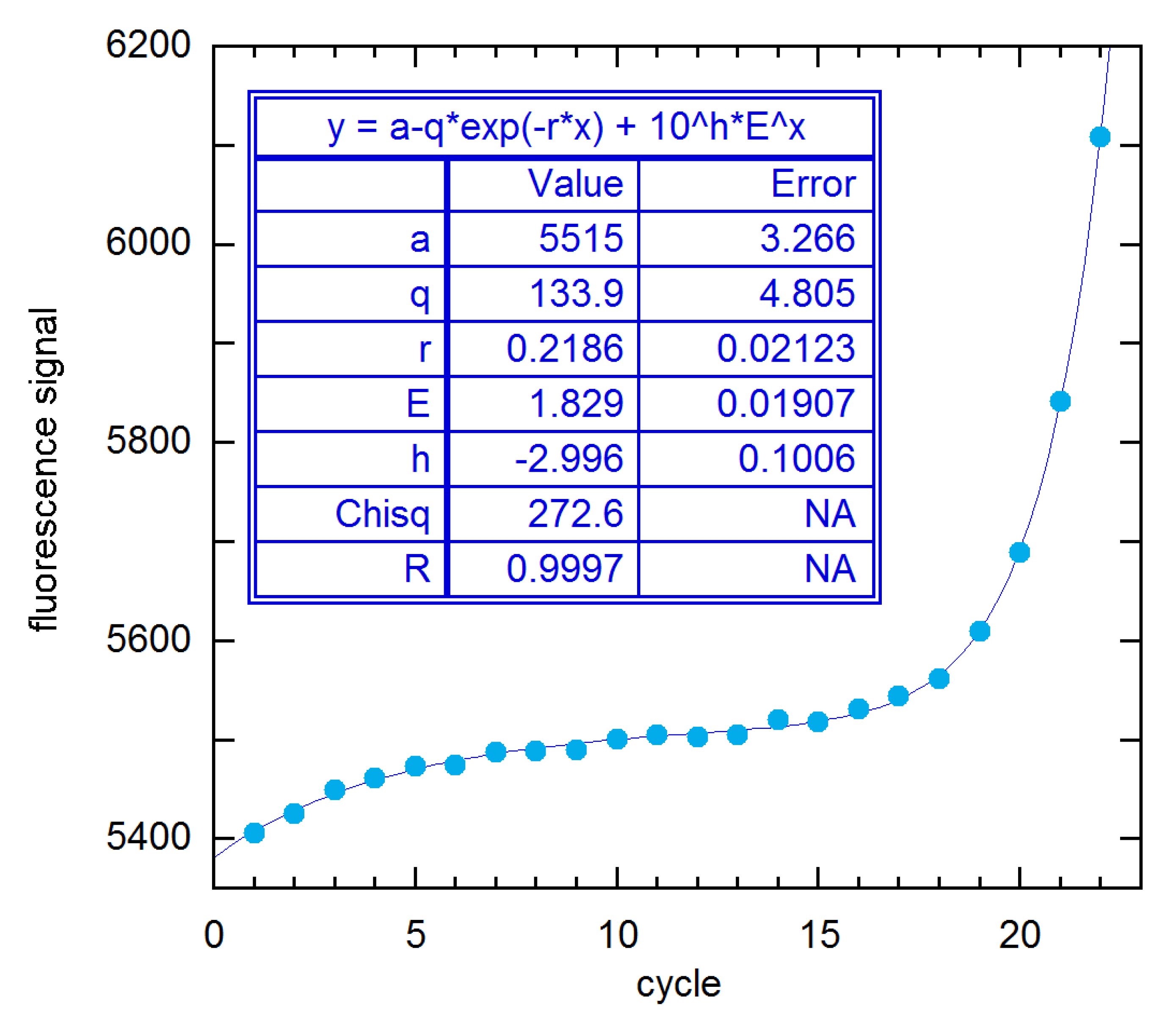
In an attempt to understand how such ostensibly similar methods can give such disparate results, I have examined results for the 94 × 4 1A rx (MYCN_STDA15–1) of Figure 1 in detail. Figure 11 shows the five-parameter fit of all cycles up to the SDM (22) to Equation (1) plus saturation baseline (Equation (11)). The E estimate is smaller than those given for all of the methods shown in Figure 10 and reaches its maximum value (1.848(38)) when n2 = 21. This is closest to the 1.884 for this rx from LinReg (supplement to [11]), which subtracts a constant baseline and fits a limited range of early growth channels to a straight line after logarithmic transformation. Using the baseline values provided by the authors of this method, I was able to verify their E estimates by trial-and-error variation of the fitted cycle range, for example, Cycles 16–22 for the 1A rx. The DART and FPLM methods both subtract a saturation baseline obtained by fitting Cycles 2–10 to Equation (11). That procedure yields a baseline close to that given by the first three parameters in the fit results box in Figure 11. Then FPLM fits the baseline-corrected cycles n1-SDM to Equation (1) plus a constant, where n1 is determined from statistical tests. The result in [11] is 2.012. For n1 = 11–18 and n2 = 22 (the SDM), this procedure yielded a maximum E of 1.800(18) in my calculations. By reducing n2, I found a maximum E of 1.95(10) for Cycles 16–20. Similarly, the Miner method fits to the same 3-parameter expression, but without first subtracting a saturation baseline. The largest E I could get this way was 1.93(10) fitting Cycles 16–20, as compared with the Miner estimate of 1.992. While the discrepancy is within statistical error for these five-cycle fits, both methods claim to fit cycles to the SDM, and there the differences are clearly an irreconcilable 0.2 in magnitude. As a further illustration of such baseline and cycle-range problems, I note that adding a baseline slope to the Miner procedure gives E = 1.986(63) fitting Cycles 9–21, as compared with a maximum of 1.900(34) for n2 = 21 and any n1, with a constant baseline.
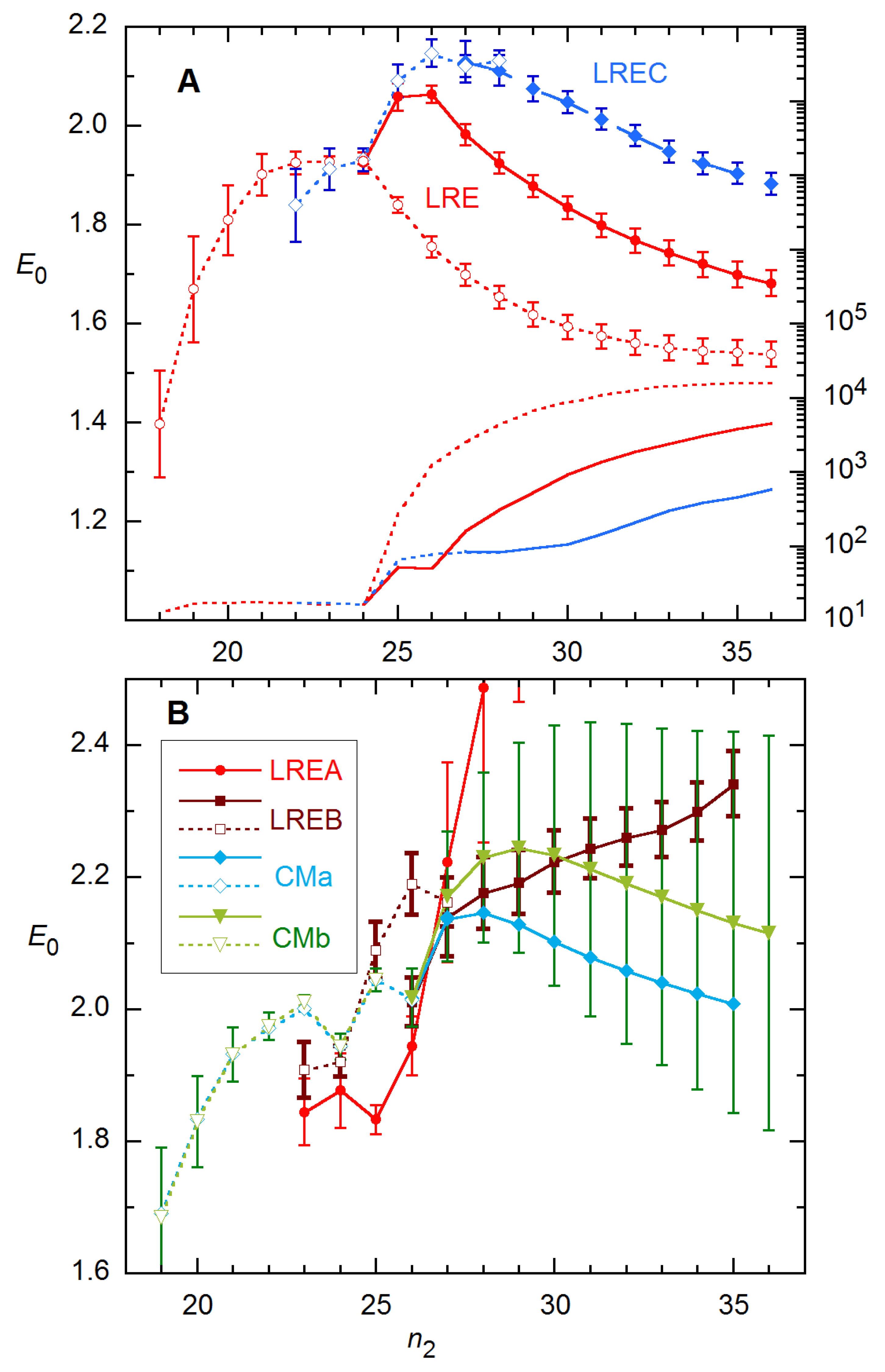
Results for this rx obtained with the four-parameter models are shown in Figure 12. For estimating E0, the best performers are the simple LRE model (i.e., p = 1) and LREC, illustrated in Frame A. The fit variance rises sharply beyond n2 = 24 (the FDM) for all CM and LRE modes except LREA (n2 = 25), indicating that the fit models are inadequate over cycle ranges extending beyond these n2s. Further, for all methods except LRE and LREA, I had to freeze at least one parameter in order to achieve convergence for n2 ≤ 24. For the CM methods, this requires fitting the data for larger n2 to arrive at appropriate values for the frozen parameter(s). Figure 12A includes results obtained for LRE at all n2 with the plateau level frozen at the value of y for the last cycle (making ymax the difference between this yi value and the baseline a).
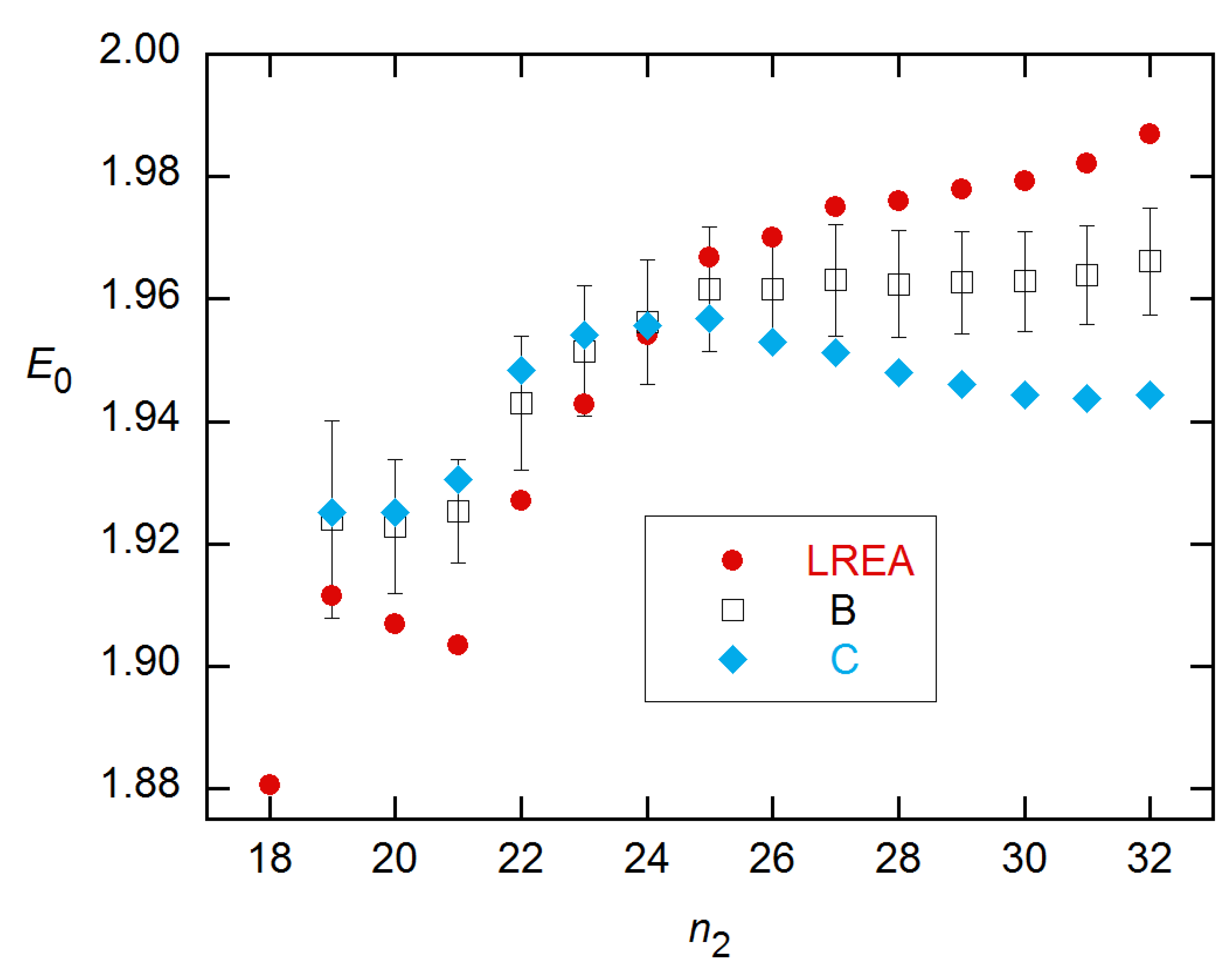
It is noteworthy that the E0 estimates at n2 = 24 are the closest to the calibration value for most variations on these methods: 1.925(22) for LRE, 1.88(6) for LREA [1.94(4) at n2 = 26], 1.921(23) for LREB, 1.926(22) for LREC, 1.945(19) for both CMa and CMb [1.97(2) at n2 = 22]. These values all undershoot the “true” E0 = 1.99 but are mostly within ~0.05. For reference, the FDM for this profile is 24.4. So again, here, the best estimates of E0 and the rise in variance occur near the FDM.
A few additional details of these calculations warrant mention. (1) For most of the E0 results stated just above, at least one parameter had to be held fixed in the fit—Kd for the CM estimates (and A at n2 = 22), ymax for LRE4. (2) While the E0 parameter correctly describes E(n) in the baseline region for all models, E(n) does not go properly to 1 in the plateau region for LREC and LRED. (3) Correspondingly, ymax in the expression for LREC (Equation (7)) and nFDM for LRED depart from their “true” values with increasing n2. (4) The SE error bars for the CMb method in Figure 12B are greatly pessimistic, as the ensemble SDs are close to those for the LRE4 methods for both CM modes. (5) The E(n) recursion method of Equation (9) performs poorly on these data, giving E0 > 2.5 with SD > 0.15 for data at the highest concentration. With regard to point (1), all parameters can be fitted for LRE; and for LREB and LREC, E0 is insensitive to the fixed plateau, changing by <0.01 for ±1000 change from the actual plateau of ~10500.
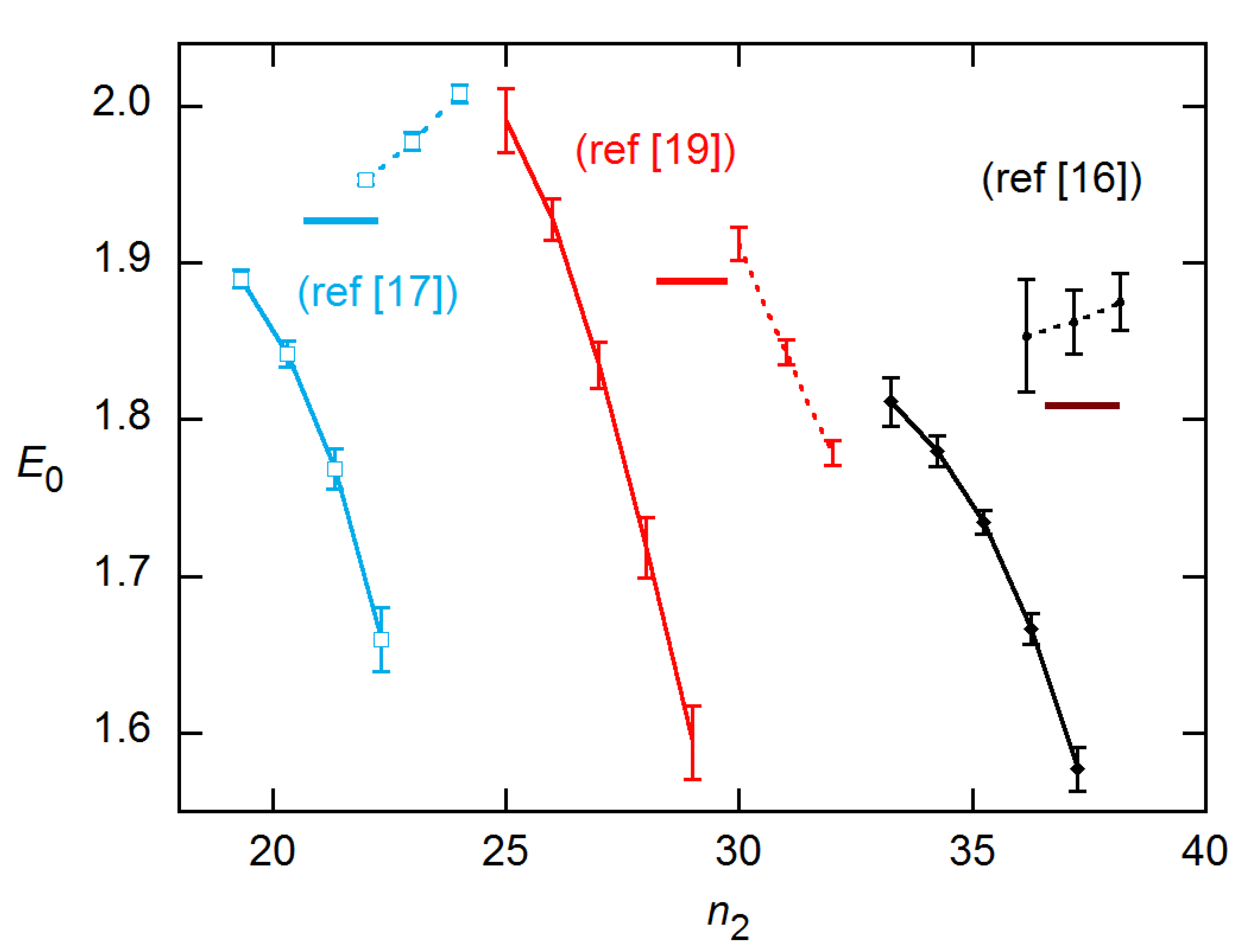
LRE and EG results are compared for the data from Rutledge and Cote [3] in Figure 13. The amplification profiles are fairly symmetrical for these data, and again the LRE results agree well with calibration, while EG fall below. Similar results are shown for the datasets from [16], [17], and [19] in the online supplement. For two of these, the Cq-based calibration estimates are themselves uncertain, as the dependence of Cq on log(N0) is not linear, and the AE values vary significantly with the fit order [15].
From these examples, we see that both the CM and LRE methods can give reasonable estimates of E0 for both symmetrical and unsymmetrical growth profiles. For the latter, however, practical problems—especially convergence difficulties and for CM, problems choosing the values for frozen parameters—make implementation difficult for large-scale applications processing many profiles without operator intervention. The simplest approach is just the LRE method (i.e., p = 1) with ymax either fitted or determined by yi for the last cycle: As the fitted estimates of ymax become progressively more uncertain with decreasing n2, the so-fixed ymax values are generally within the statistical uncertainty given by the parametric SE, and the E0 estimates are not very sensitive to this choice anyway.
As was noted in the discussion of Figure 6 and Figure 7, overall, the best EG E estimates come from n2 = SDM – 1, and the best LRE E0s come from n2 = FDM − 1, where the computations generally converge easily. With the latter, freezing ymax at either the last yi or the estimate from a fit of the data in the transition region to the LL4 model of Equation (4) sometimes lowers the estimated E0, and it sometimes raises it. For the six datasets examined here, freezing ymax improved agreement with calibration for three datasets, but worsened it for the other three.
4. Conclusions
The standard approaches for estimating qPCR amplification efficiency from single-reaction data have relied on the two-parameter exponential growth model of Equation (1), with various ways of treating (and usually subtracting) the baseline and selecting the cycle range for the AE estimation. These methods have previously been shown to lead to bias and loss of precision. In this work, I have examined several models that allow for reasonable decline of E(n) in the growth region: (1) the three-parameter LRE model [21,24], (2) four four-parameter extensions of LRE that preserve the physical significance of E0 as the AE through the baseline region, (3) two four-parameter modifications of the recursion method of Carr and Moore [22] that also permit estimation of E0 ≠ 2 in the baseline region, and (4) a four-parameter recursion method that fits directly to a sigmoidal E(n) function. All but the last of these can give good estimates of E0, and for the six multireplicate datasets considered here, give results closest to the calibration-based AE estimates when the data are fitted to about one cycle below the FDM. For such small n2, the four-parameter methods can give convergence problems, necessitating that at least one parameter be held fixed.
For the six multireplicate datasets tested here, the LRE method rarely presented such problems. Since, overall, its E0 estimates were as good as those from the four-parameter methods, my presently recommended procedure is to fit the three-parameter LRE model to data extending to one cycle below the FDM. Importantly, a suitable baseline function must be included in the fit model for optimal performance. The resulting four–six parameter models are easily handled by readily available nonlinear least-squares algorithms.
Given that the SR methods are destined to remain uncertain in their estimation of E0 for new systems, it may be necessary to benchmark them against standard calibration methods for similar systems and experimental procedures. Of course, such corrections can also be used for the EG method, which, however, is typically less precise near n2 = nSDM and varies more with a change in n2. It is also useful to consider how much error can be expected and/or tolerated in SR estimates for unknowns. This error will depend upon how far removed the unknown is from some known reference, as given by ΔCq. If the E0 estimate is off by 5% (0.1 for E0 ≈ 2), the error will be about E00.05 ΔCq, which, for example, is +65%/−40% for ΔCq = ±10. From the present work, 5% error in E0 is a conservative estimate of the LRE reliability. It was only clearly exceeded for the data from Guescini et al. [17] (see supplement), where the estimates exceeded 2.0 and so would be reduced to that value in recognition of the physical limit on E0.
Supplementary Materials
The following are available online at https://www.mdpi.com/article/10.3390/life11070693/s1, includes three Figures S1–S3 comparing EG and LRE results for the datasets from refs [16,17,19], and two Figures S4 and S5 giving FORTRAN function routines for the two recursion models examined in this work.
Funding
This work received no external funding.
Institutional Review Board Statement
This study involved only statistical analysis of existing datasets.
Informed Consent Statement
Not applicable.
Data Availability Statement
Any datasets that are no longer available from the cited data sources may be obtained at www.dr-spiess.de, accessed on 13 July 2021.
Conflicts of Interest
The author declares no conflict of interest.
References
- Higuchi, R.; Fockler, C.; Dollinger, G.; Watson, R. Kinetic PCR analysis: Realtime monitoring of DNA amplification reactions. Biotechnology 1993, 11, 1026–1030. [Google Scholar] [CrossRef]
- Bustin, S.A. Absolute quantification of mRNA using real-time reverse transcription polymerase chain reaction assays. J. Mol. Endocrinol. 2000, 25, 169–193. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Rutledge, R.G.; Cote, C. Mathematics of quantitative kinetic PCR and the application of standard curves. Nucleic Acids Res. 2003, 31, e93. [Google Scholar] [CrossRef]
- Clinical and Laboratory Standards Institute. CLSI Document EP06-A: Evaluation of the Linearity of Quantitative Measurement Procedures; Clinical and Laboratory Standards Institute: Wayne, PA, USA, 2003. [Google Scholar]
- Clinical and Laboratory Standards Institute. CLSI Document EP05-A3: Evaluation of Precision Performance of Quantitative Measurement Methods, 2nd ed.; Clinical and Laboratory Standards Institute: Wayne, PA, USA, 2014. [Google Scholar]
- Svec, D.; Tichopad, A.; Novosadova, V.; Pfaffl, M.W.; Kubista, M. How good is a PCR efficiency estimate: Recommendations for precise and robust qPCR efficiency estimates. Biomol. Detect. Quantif. 2015, 3, 9–16. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Liu, W.; Saint, D.A. A new quantitative method of real time reverse transcription polymerase chain reaction assay based on simulation of polymerase chain reaction kinetics. Anal. Biochem. 2002, 302, 52–59. [Google Scholar] [CrossRef] [Green Version]
- Tichopad, A.; Dilger, M.; Schwarz, G.; Pfaffl, M.W. Standardized determination of real-time PCR efficiency from a single reaction set-up. Nucleic Acids Res. 2003, 31, e122. [Google Scholar] [CrossRef] [PubMed]
- Rutledge, R.G. Sigmoidal curve-fitting redefines quantitative real-time PCR with the prospective of developing automated high-throughput applications. Nucleic Acids Res. 2004, 32, e178. [Google Scholar] [CrossRef] [Green Version]
- Rutledge, R.; Stewart, D. Assessing the Performance Capabilities of LRE-Based Assays for Absolute Quantitative Real-Time PCR. PLoS ONE 2010, 5, e9731. [Google Scholar] [CrossRef] [Green Version]
- Ruijter, J.M.; Pfaffl, M.W.; Zhao, S.; Spiess, A.N.; Boggy, G.; Blom, J.; Rutledge, R.G.; Sisti, D.; Lievens, A.; de Preter, K.; et al. Evaluation of qPCR curve analysis methods for reliable biomarker discovery: Bias, resolution, precision, and implications. Methods 2013, 59, 32–46. [Google Scholar] [CrossRef] [PubMed]
- Tellinghuisen, J.; Spiess, A.-N. Comparing real-time quantitative polymerase chain reaction analysis methods for precision, linearity, and accuracy of estimating amplification efficiency. Anal. Biochem. 2014, 449, 76–82. [Google Scholar] [CrossRef] [PubMed]
- Tellinghuisen, J.; Spiess, A.-N. Statistical uncertainty and its propagation in the analysis of quantitative polymerase chain reaction data: Comparison of methods. Anal. Biochem. 2014, 464, 94–102. [Google Scholar] [CrossRef]
- Tellinghuisen, J.; Spiess, A.-N. Bias and imprecision in analysis of real-time quantitative polymerase chain reaction data. Anal. Chem. 2015, 87, 8925–8931. [Google Scholar] [CrossRef]
- Tellinghuisen, J.; Spiess, A.-N. qPCR data analysis: Better results through iconoclasm. Biomol. Detect. Quantif. 2019, 17, 100084. [Google Scholar] [CrossRef]
- Karlen, Y.; McNair, A.; Perseguers, S.; Mazza, C.; Mermod, N. Statistical significance of quantitative PCR. BMC Bioinform. 2007, 8, 131. [Google Scholar] [CrossRef] [Green Version]
- Guescini, M.; Sisti, D.; Rocchi, M.B.; Stocchi, L.; Stocchi, V. A new real-time PCR method to overcome significant quantitative inaccuracy due to slight amplification inhibition. BMC Bioinform. 2008, 9, 326. [Google Scholar] [CrossRef] [Green Version]
- Rutledge, R.; Stewart, D. Critical evaluation of methods used to determine amplification efficiency refutes the exponential character of real-time PCR. BMC Mol. Biol. 2008, 9, 96. [Google Scholar] [CrossRef] [Green Version]
- Lievens, A.; van Aelst, S.; van den Bulcke, M.; Goetghebeur, E. Enhanced analysis of real-time PCR data by using a variable efficiency model: FPK-PCR. Nucleic Acids Res. 2012, 40, e10. [Google Scholar] [CrossRef]
- Zhao, S.; Fernald, R.D. Comprehensive algorithm for quantitative real-time polymerase chain reaction. J. Comput. Biol. 2005, 12, 1047–1064. [Google Scholar] [CrossRef]
- Rutledge, R.; Stewart, D. A kinetic-based sigmoidal model for the polymerase chain reaction and its application to high-capacity quantitative real-time PCR. BMC Biotechnol. 2008, 8, 47. [Google Scholar] [CrossRef] [Green Version]
- Carr, A.C.; Moore, S.D. Robust quantification of polymerase chain reactions using global fitting. PLoS ONE 2012, 7, e37640. [Google Scholar] [CrossRef]
- Boggy, G.J.; Woolf, P.J. A mechanistic model of PCR for accurate quantification of quantitative PCR data. PLoS ONE 2010, 5, e12355. [Google Scholar] [CrossRef] [PubMed]
- Chervoneva, I.; Li, Y.Y.; Iglewicz, B.; Waldman, S.; Hyslop, T. Relative quantification based on logistic models for individual polymerase chain reactions. Stat. Med. 2007, 26, 5596–5611. [Google Scholar] [CrossRef] [PubMed]
- Spiess, A.N.; Feig, C.; Ritz, C. Highly accurate sigmoidal fitting of real-time PCR data by introducing a parameter for asymmetry. BMC Bioinform. 2008, 9, 221. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Bevington, P.R. Data Reduction and Error Analysis for the Physical Sciences; McGraw-Hill: New York, NY, USA, 1969. [Google Scholar]
- Tellinghuisen, J. Can you trust the parametric standard errors in nonlinear least squares? Yes, with provisos. Biochim. Biophys. Acta Gen. Subj. 2018, 1862, 886–894. [Google Scholar] [CrossRef]
Figure 1.
Representative growth profiles (A) and expanded baselines (B) from the indicated references. Numbers give the concentration, from highest to lowest, and letters represent the replicate of that concentration. The two profiles from [11] are from the 94 × 4 technical replicates set. The profiles from [16,17] have been scaled up by factors of 2000 and 200, respectively, for presentation. These data and those from [3] (not shown) appear to have had baselines subtracted.
Figure 1.
Representative growth profiles (A) and expanded baselines (B) from the indicated references. Numbers give the concentration, from highest to lowest, and letters represent the replicate of that concentration. The two profiles from [11] are from the 94 × 4 technical replicates set. The profiles from [16,17] have been scaled up by factors of 2000 and 200, respectively, for presentation. These data and those from [3] (not shown) appear to have had baselines subtracted.

Figure 2.
Comparison of CMa and LRE estimates of amplification efficiency (scale to right) for rx std1 from [18], which is an average of rxs 1A-1C. For the purpose of this figure, E0 for both fits was fixed at 1.93, as obtained for the LRE model (see below). The AE difference (LRE-CM) has been scaled by a factor of 10 and incremented by 1, for display on the same AE grid. The baseline was taken as linear, and the fits were done for Cycles 4–29.
Figure 2.
Comparison of CMa and LRE estimates of amplification efficiency (scale to right) for rx std1 from [18], which is an average of rxs 1A-1C. For the purpose of this figure, E0 for both fits was fixed at 1.93, as obtained for the LRE model (see below). The AE difference (LRE-CM) has been scaled by a factor of 10 and incremented by 1, for display on the same AE grid. The baseline was taken as linear, and the fits were done for Cycles 4–29.

Figure 3.
Estimates of initial AE values for the 5 concentrations of the 3 × 5 data from [18], obtained using the LRE and CMa methods and weighted fitting from n1 = 4 to n2. Each value is an average of the 3 replicates at that concentration, with error bars being standard deviations (SD). Both methods assumed a constant baseline and used the weighting from [15]. The calibration-based AE is 1.916(13).
Figure 3.
Estimates of initial AE values for the 5 concentrations of the 3 × 5 data from [18], obtained using the LRE and CMa methods and weighted fitting from n1 = 4 to n2. Each value is an average of the 3 replicates at that concentration, with error bars being standard deviations (SD). Both methods assumed a constant baseline and used the weighting from [15]. The calibration-based AE is 1.916(13).

Figure 4.
E0 estimates (averages of 3 replicates) for the 3 × 5 data from [18], obtained for n2 values near the FDMs for LRE and CMa and the SDMs for EG. Specifically, the LRE estimates start one cycle below the FDMs, the CM one above, and the EG two cycles below the SDMs. With decreasing concentration, the FDMs are 18.5, 22.0, 25.5, 29.3, and 32.4; the SDMs are ~2 cycles lower.
Figure 4.
E0 estimates (averages of 3 replicates) for the 3 × 5 data from [18], obtained for n2 values near the FDMs for LRE and CMa and the SDMs for EG. Specifically, the LRE estimates start one cycle below the FDMs, the CM one above, and the EG two cycles below the SDMs. With decreasing concentration, the FDMs are 18.5, 22.0, 25.5, 29.3, and 32.4; the SDMs are ~2 cycles lower.

Figure 5.
E0 estimates from the LRE4 models, obtained for the stnd1 data from [18] as a function of n2. Error bars are SEs from the weighted NLS fits and are comparable for all modes but are shown for only Mode B. Convergence problems limited results at small n2 to about the FDM (18.5).
Figure 5.
E0 estimates from the LRE4 models, obtained for the stnd1 data from [18] as a function of n2. Error bars are SEs from the weighted NLS fits and are comparable for all modes but are shown for only Mode B. Convergence problems limited results at small n2 to about the FDM (18.5).

Figure 6.
E0 estimates and fit variances (dashed lines, axes right) for 3 of the reactions shown in Figure 1, obtained using unweighted NLS with the LRE model (top) and the EG model, for the indicated n2 values. Error bars are SEs from the fits. Vertical lines mark the FDMs (top) and SDMs (bottom); horizontal lines indicate the calibration E values.
Figure 6.
E0 estimates and fit variances (dashed lines, axes right) for 3 of the reactions shown in Figure 1, obtained using unweighted NLS with the LRE model (top) and the EG model, for the indicated n2 values. Error bars are SEs from the fits. Vertical lines mark the FDMs (top) and SDMs (bottom); horizontal lines indicate the calibration E values.

Figure 7.
E0 estimates and fit variances for the other 3 reactions shown in Figure 1, obtained and labeled as in Figure 6.

Figure 8.
Ensemble results for datasets and concentrations in Figure 7. EG—solid curves; LRE—dashed. Error bars are ensemble SDs.
Figure 8.
Ensemble results for datasets and concentrations in Figure 7. EG—solid curves; LRE—dashed. Error bars are ensemble SDs.

Figure 9.
Ensemble AE results for EG and LRE methods on 94 × 4 data from [11], compared with the calibration error band (1 σ) from [15]. EG and LRE estimates are displayed for n2 values near the SDM and FDM, respectively, with integer values of the abscissa representing those references. In the LRE calculations, ymax was fixed at the y value of the last cycle for each rx.
Figure 9.
Ensemble AE results for EG and LRE methods on 94 × 4 data from [11], compared with the calibration error band (1 σ) from [15]. EG and LRE estimates are displayed for n2 values near the SDM and FDM, respectively, with integer values of the abscissa representing those references. In the LRE calculations, ymax was fixed at the y value of the last cycle for each rx.

Figure 10.
AEs for 94 × 4 data from [11] for four methods that use Equation (1) in various ways. The LinReg values are displayed at the given N0, while the others have been displaced by ~25% from one another to facilitate display. The lines are LS fits to a straight line in log(N0); the slopes are significant in all cases, though only marginally so for LinReg. The quotation marks on the n-axis label are to indicate that the actual concentrations are the reverse of the labeling given in the Excel data file from [11].
Figure 10.
AEs for 94 × 4 data from [11] for four methods that use Equation (1) in various ways. The LinReg values are displayed at the given N0, while the others have been displaced by ~25% from one another to facilitate display. The lines are LS fits to a straight line in log(N0); the slopes are significant in all cases, though only marginally so for LinReg. The quotation marks on the n-axis label are to indicate that the actual concentrations are the reverse of the labeling given in the Excel data file from [11].

Figure 11.
NLS fit of 94 × 4 rx 1A data to the EG model with saturation baseline, from n1 = 1 to the SDM (n2 = 22). For this unweighted fit Chisq is S, and h is log(y0).
Figure 11.
NLS fit of 94 × 4 rx 1A data to the EG model with saturation baseline, from n1 = 1 to the SDM (n2 = 22). For this unweighted fit Chisq is S, and h is log(y0).

Figure 12.
E0 and fit variance for 94 × 4 rx 1A analyzed as a function of n2 for 4 LRE (A,B) and 2 CM modes (B). Solid curves and points indicate that all parameters were fitted, while dashed curves and open points represent results obtained with parameters frozen—ymax for the LRE models, Kd for CM and then A also below n2 = FDM (24). The fitted cycles start with n1 = 1, and the saturated baseline function is used. Error bars are estimated SEs from the fits; for CMa (not shown), they are comparable to those for CMb.
Figure 12.
E0 and fit variance for 94 × 4 rx 1A analyzed as a function of n2 for 4 LRE (A,B) and 2 CM modes (B). Solid curves and points indicate that all parameters were fitted, while dashed curves and open points represent results obtained with parameters frozen—ymax for the LRE models, Kd for CM and then A also below n2 = FDM (24). The fitted cycles start with n1 = 1, and the saturated baseline function is used. Error bars are estimated SEs from the fits; for CMa (not shown), they are comparable to those for CMb.

Figure 13.
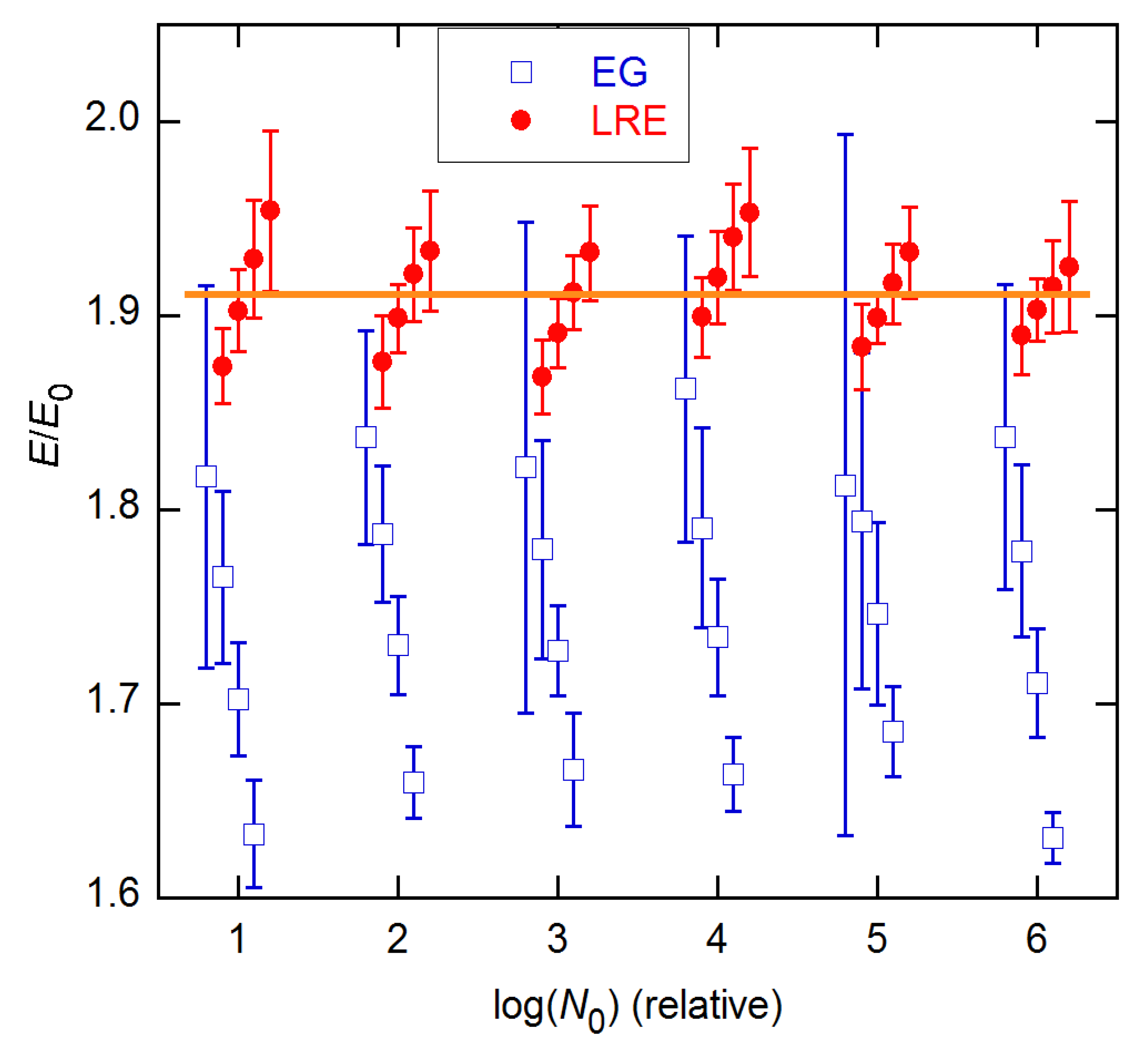
Ensemble AE results for EG and LRE methods on 20 × 6 data from [3]. The horizontal line indicates the calibration estimate from [15]. The EG and LRE estimates are displayed for n2 values near the SDM and FDM, respectively, with integer values of the abscissa representing those references. In the LRE calculations, ymax was fixed at the value determined from fits to the LL4 model of Equation (4).
Figure 13.
Ensemble AE results for EG and LRE methods on 20 × 6 data from [3]. The horizontal line indicates the calibration estimate from [15]. The EG and LRE estimates are displayed for n2 values near the SDM and FDM, respectively, with integer values of the abscissa representing those references. In the LRE calculations, ymax was fixed at the value determined from fits to the LL4 model of Equation (4).

Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Tellinghuisen, J. Estimating Real-Time qPCR Amplification Efficiency from Single-Reaction Data. Life 2021, 11, 693. https://doi.org/10.3390/life11070693
AMA Style
Tellinghuisen J. Estimating Real-Time qPCR Amplification Efficiency from Single-Reaction Data. Life. 2021; 11(7):693. https://doi.org/10.3390/life11070693
Chicago/Turabian StyleTellinghuisen, Joel. 2021. "Estimating Real-Time qPCR Amplification Efficiency from Single-Reaction Data" Life 11, no. 7: 693. https://doi.org/10.3390/life11070693
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.