1. Introduction
Autonomous driving has become increasingly commonplace around the world. While small vehicles such as cars and mini-buses have seen extensive research and testing, large vehicles such as buses have little research despite their importance in transportation. Buses provide accessible and affordable mobility while reducing traffic congestion. In the coming years, connectivity between people will become increasingly vital as countries leverage intelligent solutions to reduce labor requirements for driving these large vehicles. The automation of large buses can improve the safety and reliability of bus services in an industry plagued by fatigue and stress on bus drivers [
1,
2,
3].
However, published advancements in autonomous driving currently focus on smaller vehicles rather than larger vehicles such as buses. In developing this autonomous bus, we find that new challenges arise, previously undiscovered by research focusing on the smaller autonomous vehicles alone. Most notably, buses have a longer reaction time due to their larger size (typically around 12 m). Due to their large size, these buses usually encounter a larger area of blind spots in the surrounding area; hence, more sensors are required to overcome this.
Autonomous vehicle systems plan future motion ahead of time to avoid making sudden manoeuvres. Planning for the future requires the system to predict the future locations of dynamic obstacles to avoid collisions. Smaller autonomous vehicles typically only require planning and prediction up to 5 or 6 s into the future. However, our autonomous buses, one of which is shown in
Figure 1, can travel up to 50 km/h and take at least 8 s to react to an obstacle, thereby requiring a longer prediction time horizon. The stopping time is calculated based on the speed limit of buses in Singapore, which is 50 km/h.
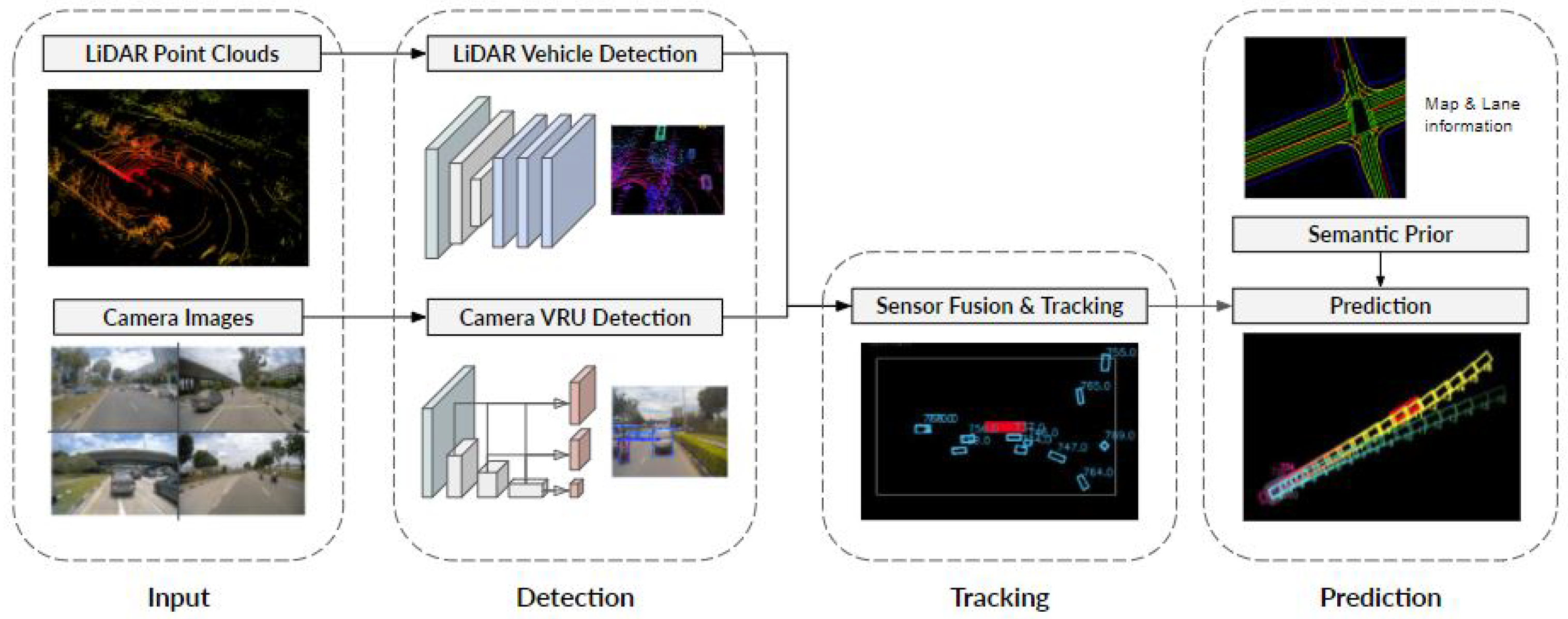
The autonomous bus performs the prediction using a modular prediction pipeline that takes in raw sensor data as input and outputs predicted future states of vehicles and vulnerable road users (VRUs). The perception pipeline is modular, consisting of different perception modules for the following tasks: camera object detection, LiDAR object detection, object tracking and trajectory prediction, as elaborated in
Section 4. The pipeline is as follows: raw sensor data are input to the detection modules, the detection modules’ outputs are inputs for the tracker module, and finally, the tracker module outputs are input for the prediction module.
Although this pipeline appears straightforward, its application for the real-world autonomous bus is non-trivial. Specifically, each module’s performance is not perfect. In addition to the highly dynamic environment, there are computational constraints in running the entire pipeline online at a high frequency for reactive planning given the embedded system onboard the autonomous bus. Thus, methods were modified where necessary to achieve the desired computational speed. Due to these constraints, the error of each module may be more significant than that of more accurate but more computationally intensive methods. The erroneous output of the modules is used as input for the subsequent modules, affecting the final trajectory predictions of the prediction pipeline. This paper addresses practical problems that arise from realising ready-to-deploy autonomous buses. We highlight and address the gaps of current methods for each module in the prediction pipeline. Notably, we discuss the practical constraints of limited computing power and how our prediction pipeline balances the trade-off between the inference speed and each module’s performance.
We also introduce the Singapore autonomous bus (SGAB) dataset, which has also been made available publicly on October 2020 at
https://arc.nus.edu.sg/project/2020/10/abcd/ and was developed with data collected from our autonomous buses deployed on the public roads of Singapore. Our prediction pipeline was developed and tested on this dataset.
In summary, the contribution of this paper is as follows:
We introduce the publicly available dataset for developing autonomous buses, SGAB.
For each module in the pipeline shown in
Figure 2, we highlight the challenges unique to autonomous buses and propose methods to overcome them.
We underscore the effects of the error from the object detection and tracking modules on the performance of the trajectory prediction module and propose a method to reduce the performance degradation due to input error.
The paper is organised in the following manner.
Section 2 presents existing work in pipelines for prediction and relevant datasets.
Section 3 presents the development of the SGAB dataset.
Section 4 gives an overview of the modular prediction pipeline. The LiDAR and camera detection modules are elaborated in
Section 5 and
Section 6, respectively.
Section 7 presents the fusion of the results from the two detection methods and the tracking of dynamic obstacles.
Section 8 describes the long-term trajectory prediction module, the effects of erroneous inputs, and a proposed method to minimise error propagation. Finally, we conclude the paper in
Section 9.
2. Related Works
Existing literature detailing the development of autonomous buses has been sparse despite the presence of commercial applications [
4]. While there have been publications on the motion planning of autonomous buses [
5], there is almost no published work that elaborates on obstacle avoidance for autonomous buses. The few papers that cover obstacle avoidance for autonomous buses are either for smaller buses [
6] or driving at slow speeds [
7] where prediction is not critical since their reaction time is short. In comparison, our 12 m autonomous buses move at speeds up to 50 km/h on public roads with mixed traffic.
For autonomous driving on public roads, prolonged stopping for overly conservative obstacle avoidance is not feasible. Thus, long-term trajectory prediction, i.e., forecasts for longer than one second [
8], is necessary, particularly for dynamic obstacles. As publications on long-term trajectory predictions for autonomous buses do not exist to the authors’ knowledge, we instead discuss obstacle trajectory prediction used for autonomous cars. Although the prediction methods included are for generic people trajectory prediction, their approaches are relevant for autonomous buses.
The DARPA Urban Challenge saw the first few modular pipelines for autonomous driving developed. Notably, the Boss entry to this challenge [
9] classified tracked obstacles as stationary and moving obstacles; trajectories of moving obstacles were further subdivided into two types: moving obstacles on the road and moving obstacles in unstructured zones such as parking lots. (1) Moving obstacles detected on roads: Their predicted trajectories were under the assumption that they would keep within their lanes. (2) Moving obstacles in free space: Their predicted trajectories used either a bicycle motion model or a constant acceleration motion model using estimated states obtained from tracking. The prediction pipeline of Boss [
9] is similar to ours in that the multiple sensor inputs are used for object detection independently and later fused during the association step of tracking. However, there was no analysis of the prediction methods’ performance since the paper focused on implementing the challenge. Moreover, trajectory prediction methods have since improved beyond those used in Boss.
The trajectory prediction methods commonly used can generally be classified into three types: (1) motion model methods, (2) function fitting methods, and (3) deep learning methods. Trajectory prediction for vehicles commonly uses motion model methods [
10,
11,
12,
13] as vehicles are nonholonomic platforms that have a fixed range of motion. However, unlike vehicles, pedestrians’ motions tend to be more erratic and difficult to model. The accuracy of the motion model methods heavily relies on how closely the models used can estimate the motion of the target obstacles. Due to the simplicity of the motion models used, most studies predict a shorter time horizon. However, recent work [
14] had suggested the possibility that constant velocity motion models may outperform state-of-the-art approaches for longer time horizons. However, the explanation for such results is unique to the datasets where regions of interest are fixed. In contrast, the trajectory prediction for an autonomous vehicle has a moving region of interest following the ego vehicle’s movement. Their paper was also limited to predicting trajectories of people only. Trajectory prediction for the people class is insufficient for applications of the prediction pipeline that must predict trajectories of vehicles and pedestrians. Moreover, Ref. [
14] only explored the shorter time horizon of 4.8 s. Thus, this paper explores the relevance of the work presented in [
14] for long-term trajectory prediction in
Section 8.
Function fitting methods use polynomials [
15,
16,
17] and Chebyshev polynomials [
18] for trajectory prediction. The coefficients of the functions could be obtained using neural networks [
15,
16] or by using Expectation–Maximisation [
18]. Similar to motion model methods, function fitting prediction methods are limited by the functions used, and studies for long-term prediction are limited. However, given the low computational resources required for function fitting models, it was meaningful to explore the use of polynomials for long-term trajectory prediction.
Section 8 includes the experiments using function fitting methods.
Deep learning methods for trajectory prediction are gaining popularity over the other methods as deep neural networks can model complex trajectories. Many of the newer methods propose the use of Recurrent Neural Network (RNN) architectures, typically the Long Short-Term Memory (LSTM) [
19] or Gated Recurrent Unit (GRU) [
20], for trajectory prediction. Commonly, the RNNs are arranged to form an autoencoder, also referred to as the encoder–decoder (ED) network, where LSTM or GRU units create an encoder and another set of LSTM or GRU would form the decoder [
21,
22,
23,
24]. Existing methods can be categorised into deterministic and probabilistic methods. Deterministic methods predict discrete future trajectories. Conversely, probabilistic methods predict the probability distribution of multiple possible future trajectories. As predicting and using multiple possible future trajectories require significantly higher computational resources, this work only considers deterministic approaches. The ED has shown to be promising in the results in [
22], where the ED yielded the best results for deterministic trajectories. To better capture interactions between objects, some methods use a graph-based network to model the interaction between target objects [
25,
26,
27] but these methods require additional memory for the four-dimensional spatiotemporal graphs, which may grow to be significant for applications such as autonomous vehicles, where the region of interest is highly dynamic.
Other methods for interaction modelling include forming a matrix of hidden states [
21], performing iterative refinement [
22], or using the other objects around the target as inputs [
28]. Among these techniques, the last method gives the least impact on computational resources required with the smallest models. However, the implementation in [
28] is very limiting as only neighbouring vehicles at fixed locations are considered. Instead, we propose a different method to input the adjacent obstacles using a layer in the semantic map, as elaborated in
Section 8.
Currently, many methods evaluate the prediction module performance using ground truth information as inputs—assuming perfect detection and tracking. Using an ideal detector and tracker is problematic as error propagation from each module to the next along the pipeline would affect the performance of the trajectory prediction.
While we present a modular prediction pipeline, others have proposed end-to-end pipelines instead. In the end-to-end approaches, a deep learning model such as FAF [
29] or MMF [
30] is trained with sensor information as inputs and directly outputs objects detected, tracked trajectories, and trajectory predictions. These networks perform detection, tracking, and prediction in the same model and may implicitly overcome error propagating between the detection, tracking, and prediction. However, end-to-end methods do not have the benefits of modularity, such as ease of interpretation between tasks. They are also difficult to modify or improve, unlike modular pipelines, which can swap out poorly performing modules without affecting other modules. As end-to-end networks are a single deep learning model, they are also prone to adversarial attacks. Hence, this paper presents a prediction pipeline for autonomous driving leveraging the benefits of modularity but a method to overcome the disadvantage of error propagation between modules in the pipeline.
Overall, the existing literature presents a lack of studies on long-term trajectory prediction, with the most common prediction horizon being up to approximately 5 s [
14,
21,
23,
24,
25,
27]. The authors could only find a single paper that conducted long-term prediction up to 8 s into the future [
12]. However, their work heavily focused on predicting lane changes, in contrast to this paper’s mixed and dynamic obstacle trajectory prediction of interest. Moreover, there is no study published on the effects of imperfect inputs on the performance of the long-term trajectory predictions, to the authors’ knowledge. Therefore, this paper bridges this gap by analysing the effects of error in trajectory prediction for long time horizons of 8 s for implementation on autonomous buses. The proposed method also aims to reduce the error propagation in the pipeline.
For deep learning methods, datasets are pivotal in training and testing. There are several public datasets collected for autonomous cars, such as the KITTI [
31], Argoverse [
32], nuScenes [
33], and Waymo Open dataset [
34]. However, the only other dataset of data collected for autonomous buses is the Electric Bus Dataset by Autonomous Robots Lab [
35], but they do not provide ground truth information of objects in the dataset. Hence, the authors developed and released the annotated Singapore autonomous bus (SGAB) dataset [
36] publicly and used this dataset to evaluate the methods presented in this paper.
Section 3 elaborates further on the details of the SGAB dataset used.
3. Dataset Development
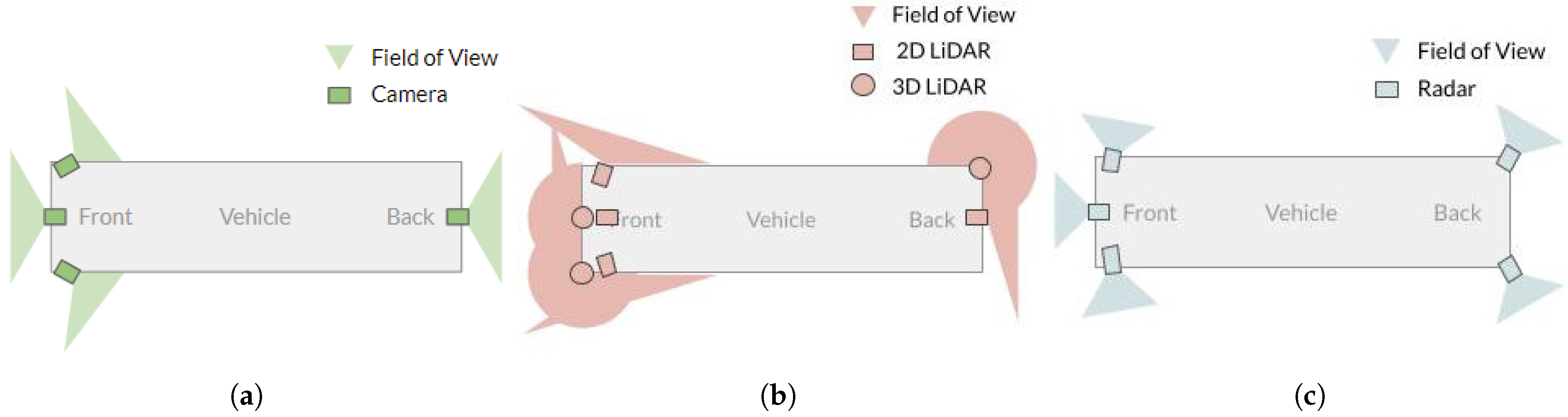
Camera sensors: The location and field of view of the cameras are shown in
Figure 3a. There are four 120
field of view cameras on the bus. The side cameras are not placed parallel to the ground.
LiDAR sensors: Seven LiDARs are mounted onto the bus, three 3D LiDARs and four 2D LiDARs. The 3D LiDARs are Velodyne’s VLP-16s (16 layer LiDAR). The 2D LiDARs are Ibeo Scala LiDARs, and we fuse the point cloud data via the Ibeo ECU (a four-layer LiDAR). The LiDARs provide 360
coverage of the environment, as shown in
Figure 3b, due to their effective placement on the bus.
Radar sensors: The dataset also includes radar information from five radars mounted as shown in
Figure 3c. The radars are Delphi ESR and SRR radars.
The bus has an inertial navigation system (INS) fitted to locate the bus in the world coordinates. We use the Robot Operating System (ROS) middleware [
37] to log the sensor data using the rosbag function. We extract the raw sensor at 20 Hz and provide annotations in the LiDAR sensor frame for every ten frames (i.e., at 2 Hz). The annotations are bounding boxes in the LiDAR sensor frame and from the top-down view. We label the objects’ x-position, y-position, width, length, yaw, object class, and ID. Since the annotations are in a top-down view, the height and z-positions are negligible. We label objects within 40 m forward, back, left, and right of the ego vehicle (forms an 80 × 80 m grid). The object classes are: car, truck, bus, pedestrian, bicycle, motorbike, and personal mobility devices (PMD) [
36]. A unique ID is given to each tracked object across the sequences.
The data collected were divided into two sets: training and test set. The developed SGAB dataset was then used to test several methods, described in the following sections.
7. Fusion and Tracking
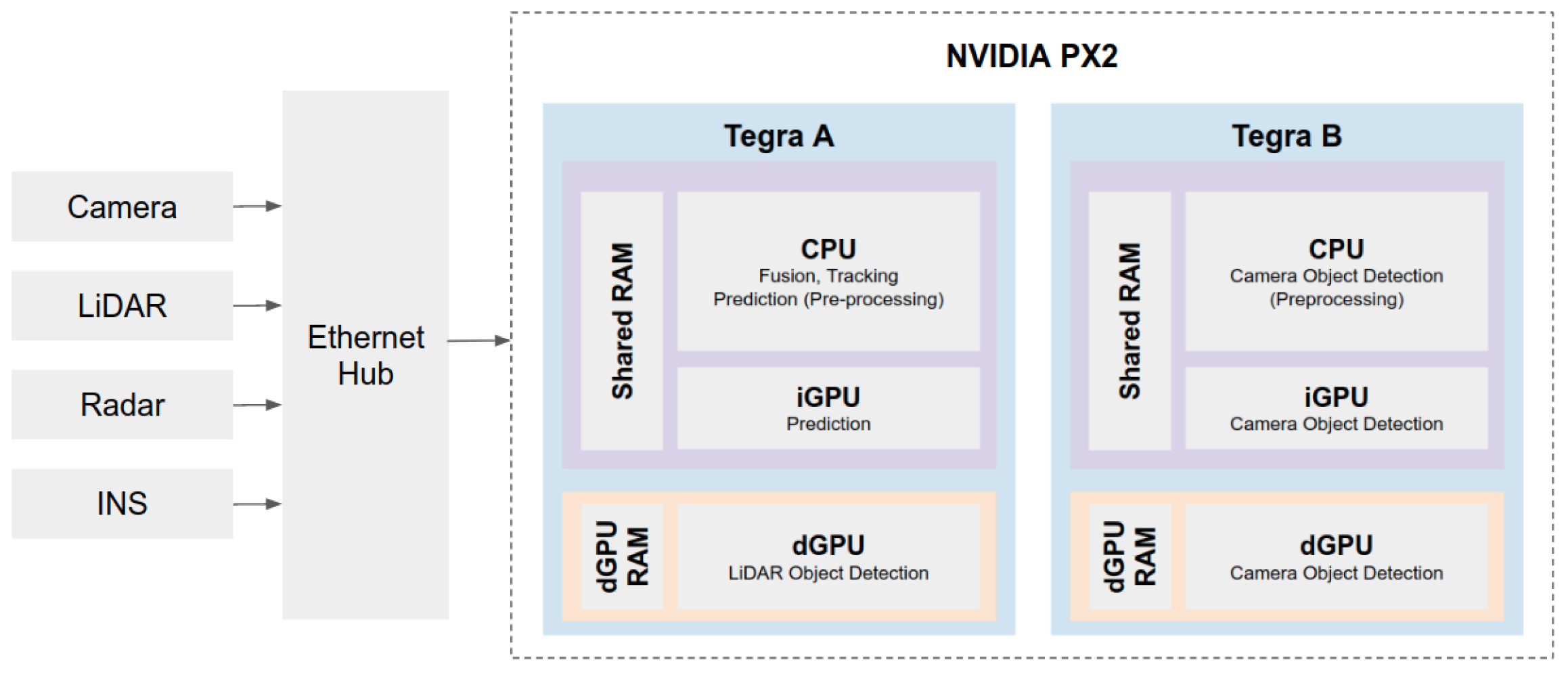
We perform sensor fusion to integrate information from the two sensor types onboard each autonomous bus: LiDARs and cameras. We adopt the late-fusion approach to integrate the LiDAR-based and camera-based detections while simultaneously performing multi-object tracking (MOT) in BEV. Firstly, we select the late fusion method to make full use of the limited GPUs available on the Nvidia PX2 and divide the detection models into two GPUs to improve memory usage. Secondly, the VLP-16 LiDAR’s sparsity made it challenging to perform LiDAR only detection for smaller objects such as pedestrians. It was also computationally expensive to perform feature fusion before detection—for example, generating a depth camera image and fusing it with the raw LiDAR data. Hence, a late fusion method was chosen.
The initial inputs from the detector modules are the camera bounding box detections in the image plane and the LiDAR bounding box detection in BEV. We project the camera bounding boxes into BEV in two steps at this stage. First, we transform the LiDAR point clouds to the image coordinate reference frame as shown in
Figure 7. Then, we select the depth value with the highest frequency amongst all points within an object’s 2D bounding box.
7.1. Fusion and Tracking Method
Inspired by AB3DMOT [
46], we implemented Kalman filter-based tracking for the multi-object detection state estimation. All detected objects are birthed after being observed for a minimum number of frames and removed after being unseen for a maximum number of frames. During each time step, the module uses a constant velocity (CV) motion model to perform short-term predictions on the states of each object. The predicted states are matched with the detection modules’ outputs. Our method performs sensor fusion from sensor data with different input timestamps. To handle the timestamp differences, we include the time intervals in the CV motion model to give better short-term prediction estimations.
We match the predicted states with the detection modules’ outputs in the association step. We use the IOU to associate the objects with the target for a deterministic tracker. We notice a drawback of using intersection over union (IOU) as a distance measure between predicted and detected states. Mainly, for objects such as people and bicycles, their sizes in BEV are small. Thus, we use a distance-based (L2-norm) association within a threshold to associate currently tracked objects with their corresponding new detections. Finally, the Kalman Filter is utilised to update an object state with associated detections.
To expand on the original AB3DMOT, which uses detections only from the LiDAR point cloud, we use detections from both the LiDAR and camera. We take the camera and LiDAR sensor detections as input to the 3D Kalman filter. This proposed method is agnostic to the type of sensor used as detections are represented as the state information. We consider 14 states in the motion model: .
7.2. Results and Discussion
We present the network’s performance using a deterministic tracker on the SGAB dataset. We evaluated the module using the following tracking metrics: Average Multi-Object Tracking Accuracy (AMOTA) and Average Multi-Object Tracking Precision (AMOTP) [
47]. The AMOTA and AMOTP performance calculate the average MOTA and MOTP across the different classes—car, truck, bus, and VRUs (pedestrian, motorcycle, and cyclist), respectively. We use the following covariance matrix values for the tracker.
In our implementation, we tune the covariance matrix of the Kalman filter based on the initial accuracy of the sensor. Using the training split of the SGAB dataset, we calculate the errors in the position and orientation of the detections and further tune the values of the Kalman filter after.
The original AB3DMOT achieves AMOTA of 37.72% and AMOTP% of 64.78% on the KITTI dataset overall for three classes—car, cyclist, and pedestrian. Our final result is a module that outputs at minimally 20 Hz, with AMOTA of 25.61% and AMOTP of 94.52%. Whilst the performance drops compared to the original AB3DMOT work, we highlight that our version is a more accurate reflection of the real-world environment with more classes—truck, bus, and motorcycles. The AMOTP result is high, showing the considerable percentage overlap between the tracked object and the ground truth object. The poor AMOTA value is due to the low detection values from the camera and LiDAR module. Poor detection values in the sparse LiDAR data are found in the SGAB dataset compared to the KITTI dataset.
8. Long-Term Trajectory Prediction
The trajectory prediction module estimates the future position, , and orientation, , of the target obstacle at a given time step, t, where the current time step is ; the module aims to predict the future trajectory, , for time steps s. The time horizon of 8.0 s was chosen to provide sufficient time for the autonomous buses to brake smoothly when avoiding collisions with dynamic obstacles.
The predicted future trajectories are conditioned on the past trajectories of the target object. The past trajectories are obtained from the tracker module during autonomous driving since ground truth information is unknown. However, the past trajectories tracked by the tracker module, i.e., the tracker trajectories, are imperfect, as discussed in
Section 7. The error in the tracker trajectories may negatively affect the prediction performance when used as inputs. The implementation of the prediction module compensates for this error due to the modification and delineation, as shown in
Section 8.3.
Similar to the other modules in the pipeline, the computational efficiency of the prediction module is a crucial consideration in module development. The method must be able to run on the Nvidia Drive PX2 system alongside other modules for autonomous driving. Thus, a small deep learning model performs prediction, as described in
Section 8.2. The model takes in pre-processed data and its outputs are post-processed as described in
Section 8.1, and the results of the model are discussed in
Section 8.4.
8.1. Inputs and Outputs
The trajectory prediction module takes in the past trajectories of 3 s from the tracker module detailed in
Section 7 to perform predictions. We normalise these input trajectories for the deep learning method by scaling the change in position and orientation between time steps of the past trajectories to fit the range from −1 to 1.
The prediction model also takes in a priori information such as kerbs, lane lines, and footpaths in the form of a semantic map. This information is obtained from the DataMall [
48], which is a collection of land transport-related data maintained by the Land and Transport Authority of Singapore. The kerbs, lane lines, and footpaths are drawn with 1 pixel thickness onto separate channels onto an image.
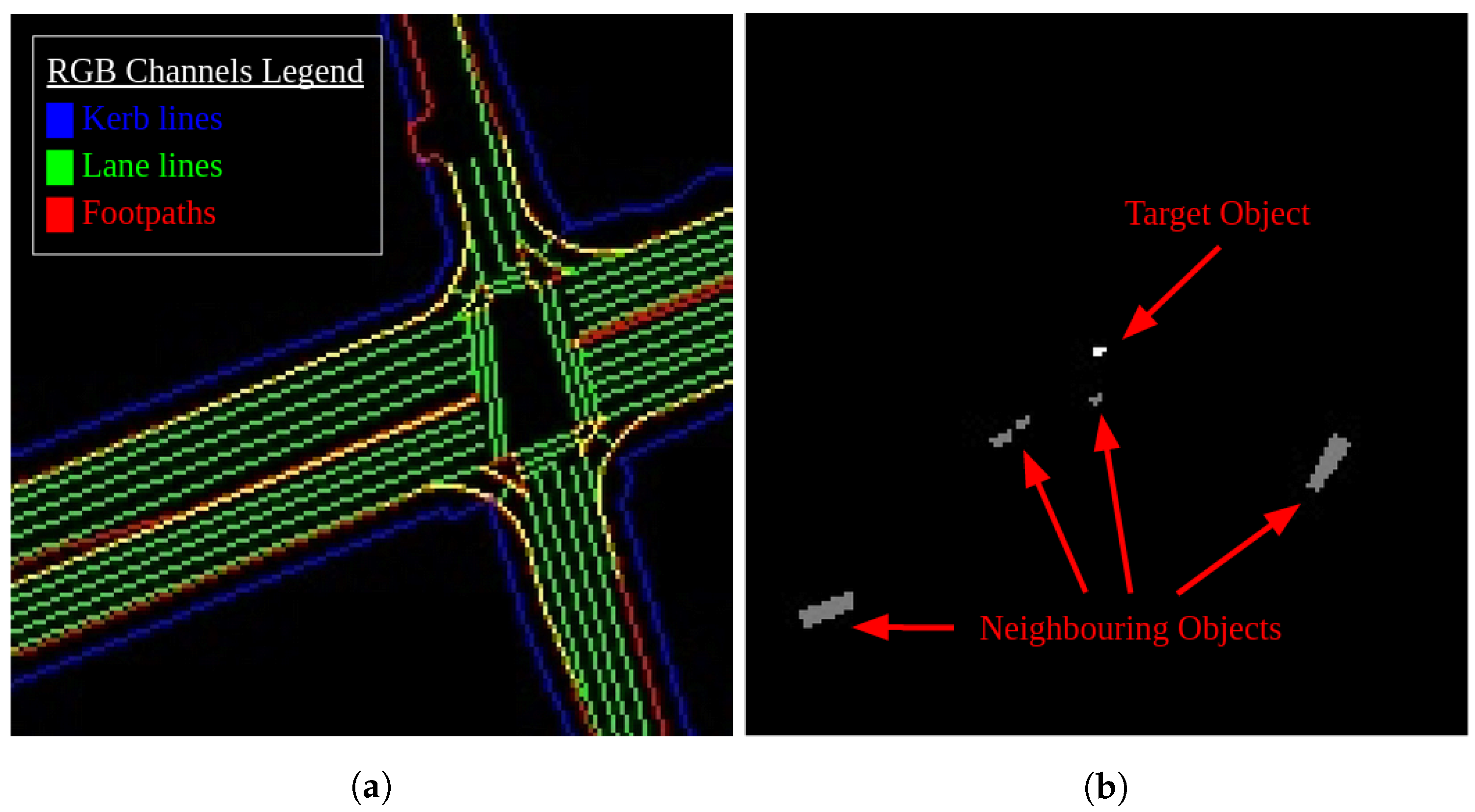
Additionally, the other obstacles in the neighbourhood of the target obstacle are also included in the semantic map to model the interaction between neighbouring obstacles. The resultant semantic map contains four channels, each containing the following semantic information: (i) kerb lines, (ii) lane lines, (iii) footpaths, and (iv) obstacles in the neighbourhood.
Figure 8 shows an example of such a semantic map. Each image is centred around the autonomous bus and not the target objects. Instead, the target objects’ location, position, and size are encoded in the semantic map in the obstacles’ channel with a different pixel value. The encoding method reduces the computational requirement for generating new semantic maps for each target object in the scene. For the implementation in ROS, the semantic maps with the kerb lines, lane lines, and footpaths were generated offline and stored as a tiff file such that the global positioning of each pixel is accounted for. During the run, the relevant pixels are read from the tiff file, and the obstacle channel is added based on the outputs of the fusion and tracking module.
The prediction model outputs the scaled change in position and heading of the target object. The predicted future trajectories in the world frame are obtained by scaling back and adding the current position coordinates to the outputs.
8.2. Model Architecture
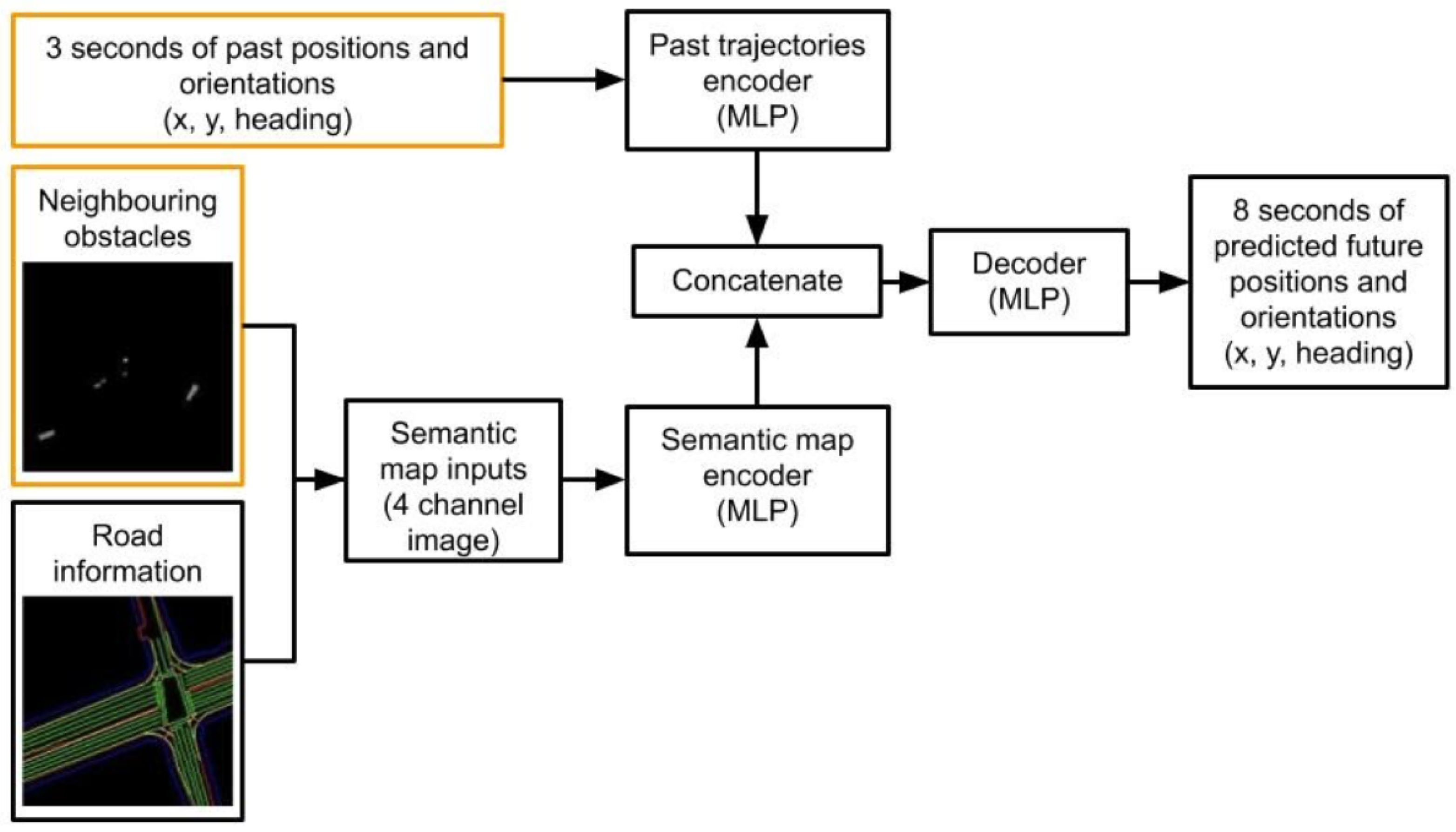
Figure 9 shows the architecture of the prediction model. The model is an autoencoder (AE), with an encoder for past trajectories and semantic maps. Features extracted from these encoders are concatenated and passed to the decoder, producing the predicted future trajectories. This paper implements the encoders and decoders using Multi-Layer Perceptrons (MLPs) due to their simplicity and inference speed compared to RNN architectures.
We flatten the semantic map inputs into a one-dimensional array before being fed into the semantic map encoder. The semantic map encoder is an MLP of depth 6 with tanh activation functions, where the number of features in each layer reduces subsequently. Similarly, the past trajectories encoder is an MLP, executed with one hidden layer with a tanh activation function, and the decoder is an MLP with three hidden layers.
8.3. Implementation Details
We train the AE model with past trajectories obtained from the manually annotated ground truths at 2 Hz and the tracker trajectories at 20 Hz. We interpolate the ground truth labels linearly to form the past trajectories at 20 Hz to reconcile the difference in time steps between data points. The semantic map used was 160 by 160 pixels with a resolution of 1 m per pixel. We apply the root mean squared error (RMSE) loss function and the Adam’s optimiser for training in Tensorflow 1.13 with Keras. The weights of the AE model were optimised using the Adam optimiser with a learning rate of 0.001, of 0.9, and of 0.999. We ran the training with a batch size of 2 for 100 epochs. The input and output values were normalised by dividing the values by 10.0 m and 100.0 m, respectively. For the positional past trajectories encoder, semantic map encoder, and decoder, 100 hidden units were used in the first hidden layer and progressively reduced along with the depth of the MLP. The tanh activation function was used in all MLPs.
8.4. Experiments, Results, and Discussion
Due to the challenges unique to the autonomous bus, published baselines are not relevant for this section’s scope because they use ideal inputs into a prediction module. The sparser sensor data and larger ROI attributed to the larger size of the autonomous buses result in a more challenging dataset. Thus, several baselines were trained and tested on our dataset, the SGAB dataset [
36], to serve as baselines instead. To fully illustrate the impact of the error, we first present experiments on existing methods and their performance, given that the input to the prediction module is ideal. Specifically, we compare the performance of the following prediction methods:
Constant position: The future position and orientation of the target object is predicted to remain the same, i.e., the object is assumed to be stationary.
Linear fitting: The future trajectories are extrapolated linearly from the past trajectories using least-squares fitting.
Quadratic fitting: The future x-positions, y-positions, and orientations are extrapolated from the past trajectories using least-squares fitting onto a quadratic function, respectively.
Kalman filter: A Kalman filter with a CV motion model generates the future trajectories by repeatedly using the prediction step. The covariances of the models are hand-tuned on a separate validation set.
AE: The future trajectories are obtained using the model described in this paper.
We use the metrics proposed in [
21], where the Final Displacement Error (FDE), which is the distance between the ground truth and the prediction at the final time step, and the Average Displacement Error (ADE), which is the average distance between the ground truth and the prediction across time steps, are shown in
Table 3.
The high error for the constant position method validates the need for a trajectory prediction module for obstacle avoidance as objects surrounding the vehicle are dynamic in nature and move over a large area over time. The error for the linear fitting method using the SGAB dataset gives the third-highest FDE and ADE error, indicating that the trajectories captured are reasonably non-linear. The method’s performance using the AE model is better than that of the linear fitting method, suggesting that the AE model can better represent the non-linear relationship between the past data with the predicted future trajectories. However, the Kalman filter method achieves a lower FDE and ADE than the AE model and is the best-performing method. The Kalman filter model uses the constant velocity model, which differs from the linear fitting model in that the uncertainty in states is captured as Gaussian noise. Although the Kalman filter method performs better than other methods, the covariances used in the Kalman filter method had to be hand-tuned. While this may have contributed to the better performance, the process was also fairly labour-intensive. Due to this, AE methods are more prevalent in the recent literature. It is also likely that the hand-tuned covariance values used in the Kalman filter are less robust to errors in the input. To study this, we compare the Kalman filter and AE methods when performing prediction with trajectories from
Section 7. The variations of the methods implemented with tracker trajectories are as follows:
Kalman Filter: The same Kalman filter method used for prediction with labelled ground truth was applied to the tracker trajectories.
AE: The tracker outputs were used as input to the same model weights used for prediction with labelled ground truth.
AE-T: The AE model architecture described in
Section 8.2 was trained on tracker trajectories as past trajectories input with the corresponding ground truth future trajectories.
AE-GT: The AE model architecture, described in
Section 8.2, was trained on labelled ground truth data. Subsequently, we fine-tuned the network weights using the corresponding tracker trajectories inputs.
AE-GT+T (Proposed method): The AE model was trained using the combined data from the labelled ground truth and tracked trajectories.
The evaluation of methods using tracker trajectories differs slightly from the evaluation presented for labelled ground truth input in that incomplete ground truth future trajectories are also used for evaluation. Calculation of the prediction results using tracker trajectories requires the association between the tracker and ground truth labels. However, due to the non-ideal performance of the tracker, the number of tracked objects able to be associated with the labels with complete future ground truth trajectories is too few for evaluation.
Table 4 shows the performance of the methods when using tracking trajectories as input.
There is a significant decrease in the performance of the predictions using trajectories from the tracker module compared to using trajectories from ground truth for both the Kalman filter and AE methods. For the Kalman filter method, the error increase from using erroneous inputs is not as significant as that of the AE method. The Kalman filter’s better performance is likely due to good modelling of input uncertainty using Gaussian distributions with zero mean. However, the AE model does not represent input uncertainty, which explains why the error was almost double that of when ground truth annotations were inputs.
In many deep learning applications, improved performance on a different input distribution is achieved by fine-tuning the weights of the model with the new distribution. This was employed in the AE-GT method, but the performance of the model did not improve, suggesting that the erroneous input data were too different from those of the ground truth, and the learning may have reached the local minima instead.
Instead, the AE-T learning to predict the tracker trajectories from scratch yielded significantly improved performance. However, the Kalman filter method still outperformed these methods.
In the AE-GT+T method, we trained the model with ground truth and both types of the tracker to further improve the generalization of the AE model. This process can also be understood as a form of data augmentation, where ground truth data are augmented with imperfect data such that the tracker can predict the correct future trajectory regardless of the input type. Thus, we propose using an AE model trained on both ground truth and tracker inputs with an ADE of 8.24 m.


 ,
, 









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}