
A Time-Varying Coefficient Double Threshold GARCH Model with Explanatory Variables

Abstract
:1. Introduction
2. Model and Estimation
3. Simulation Studies
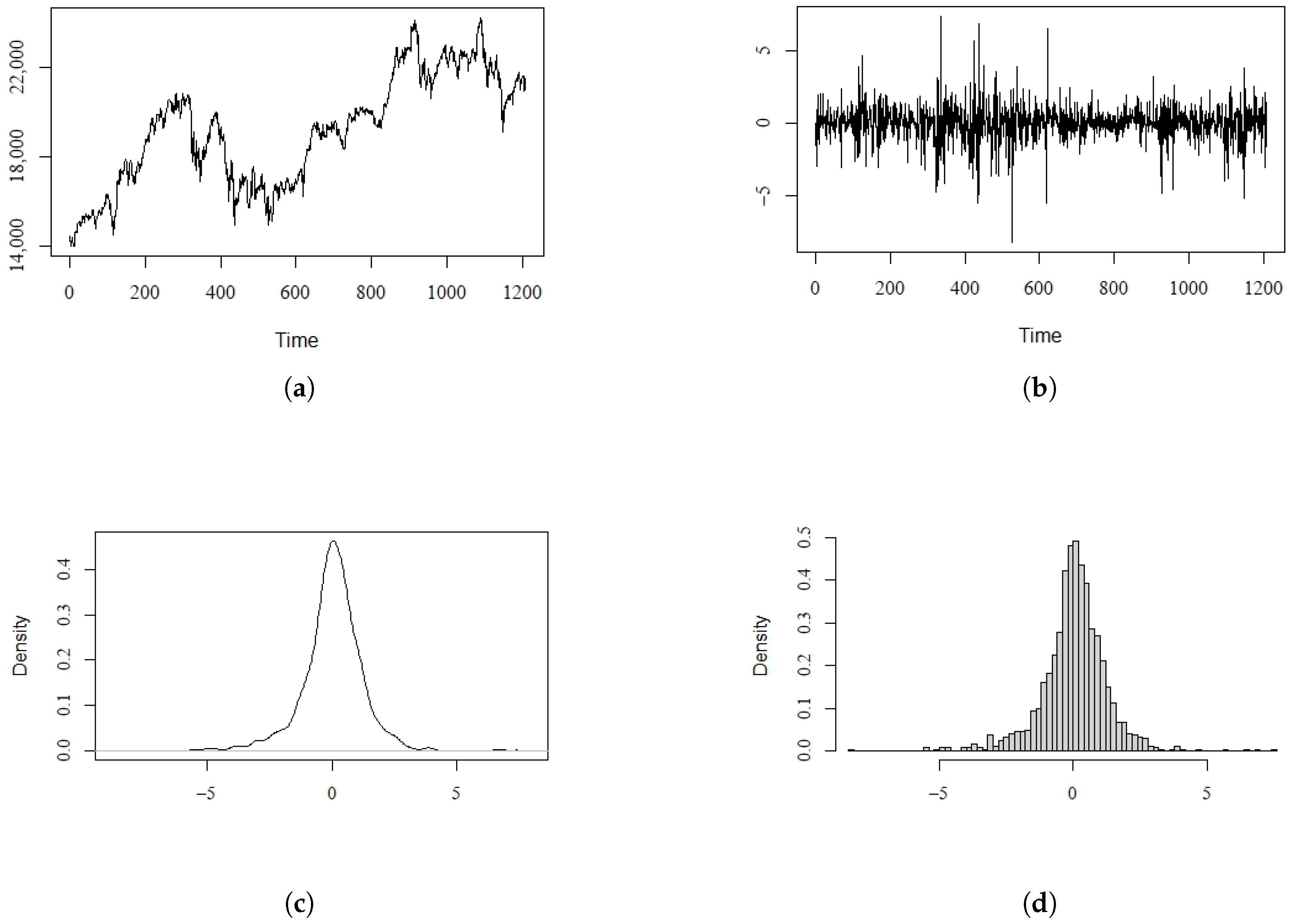
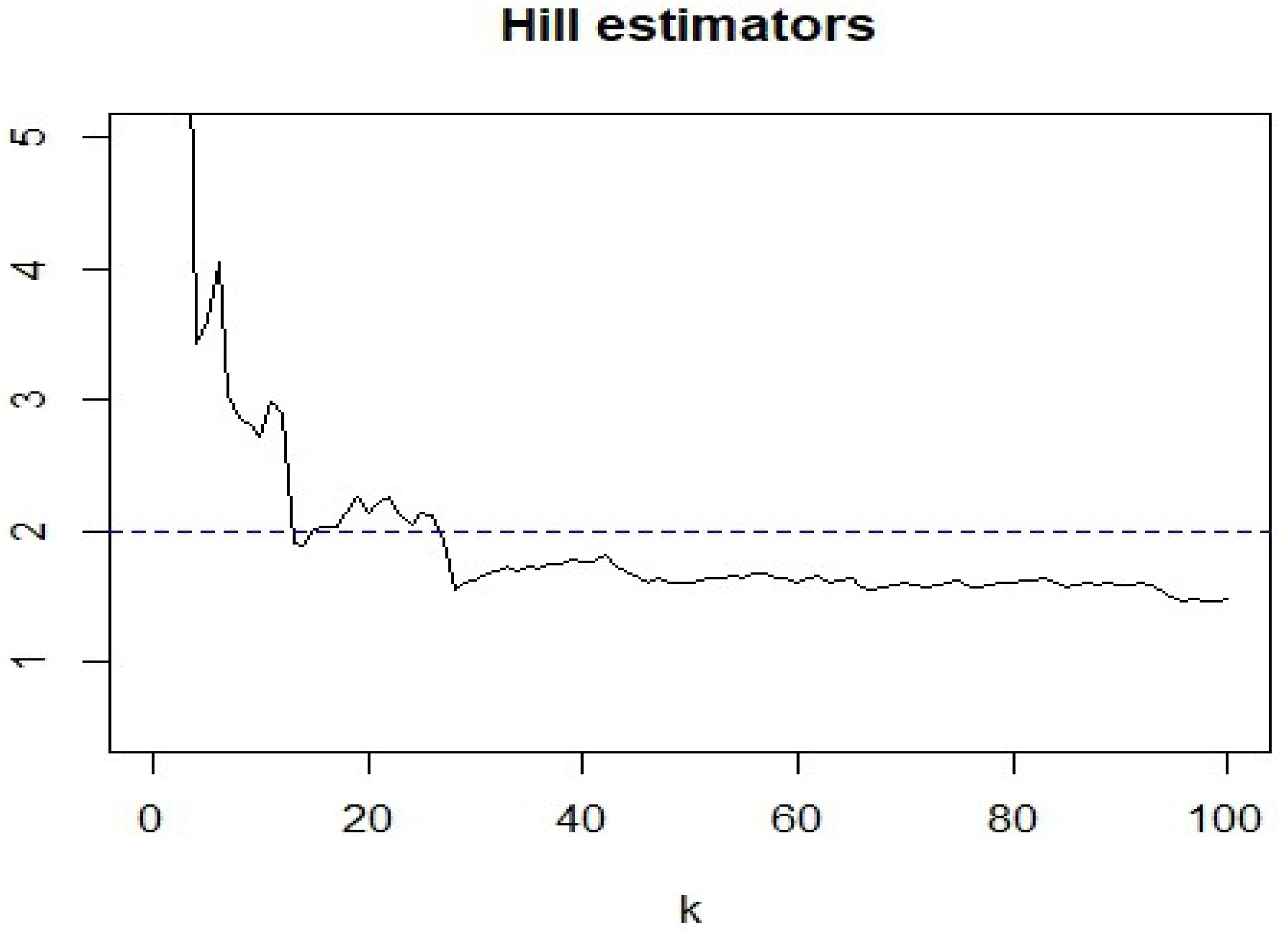
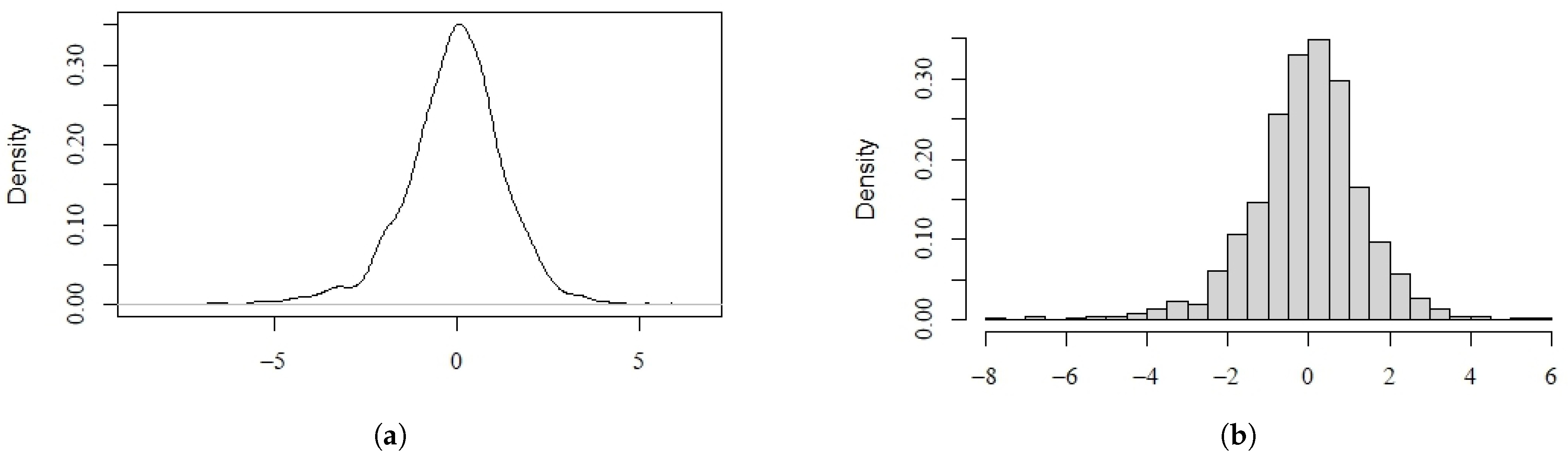
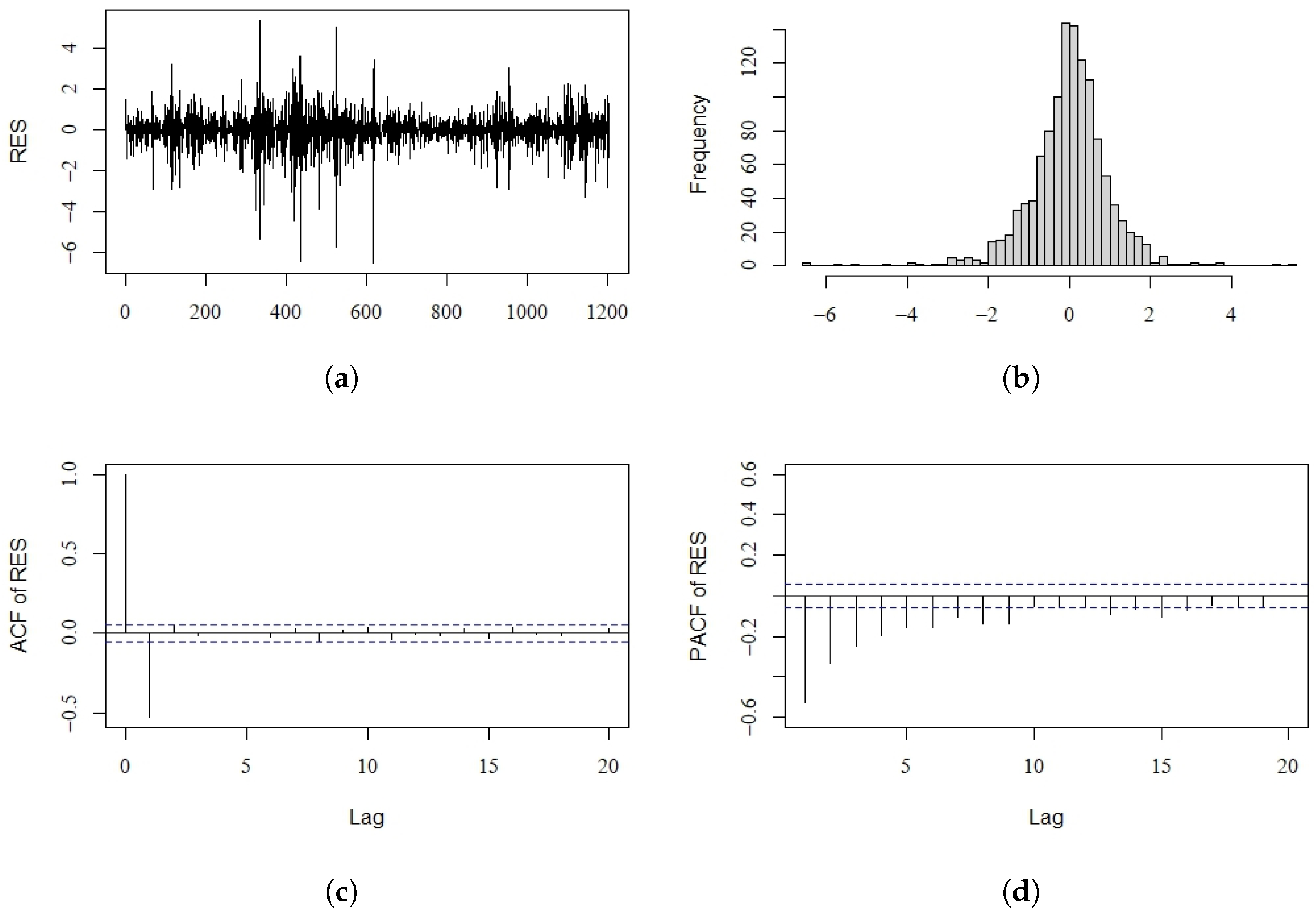
4. Real Data Example
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| ACF | Autocorrelation Function Plot |
| PACF | Partial Autocorrelation Function Plot |
Appendix A
References
- Nicholls, D.F.; Quinn, B.G. Random Coefficient Autoregressive Models: An Introduction; Springer: New York, NY, USA, 1982. [Google Scholar]
- Tjostheim, D. Estimation in nonlinear time series models. Stoch. Process. Their Appl. 1986, 21, 251–273. [Google Scholar] [CrossRef]
- Kim, Y.W.; Basawa, I.V. Empirical Bayes estimation for first order autoregressive processes. Aust. J. Stat. 1992, 34, 105–114. [Google Scholar] [CrossRef]
- Hwang, S.Y.; Basawa, I.V. Asymptotic optimal inference for a class of nonlinear time series models. Stoch. Process. Their Appl. 1993, 46, 91–113. [Google Scholar] [CrossRef]
- Hwang, S.Y.; Basawa, I.V. Large sample inference for conditional exponential families with applications to nonlinear time series. J. Stat. Plan. Inference 1994, 38, 141–157. [Google Scholar] [CrossRef]
- Hwang, S.Y.; Basawa, I.V. Parameter estimation for generalized random coefficient autoregressive processes. J. Stat. Plan. Inference 1998, 68, 323–337. [Google Scholar] [CrossRef]
- Aue, A. Strong approximation for RCA(1) time series with applications. Stat. Probab. Lett. 2004, 68, 369–382. [Google Scholar] [CrossRef]
- Aue, A.; Horvath, L.; Steinebach, J. Estimation in Random Coefficient Autoregressive Models. J. Time Ser. Anal. 2006, 27, 61–76. [Google Scholar] [CrossRef]
- Thavaneswaran, A.; Appadoo, S.S.; Ghahramani, M. RCA models with GARCH innovations. Appl. Math. Lett. 2009, 22, 110–114. [Google Scholar] [CrossRef]
- Tong, H. On a Threshold Model; Sijhoff & Noordhoff: Amsterdam, The Netherlands, 1978. [Google Scholar]
- Tong, H.; Lim, K.S. Threshold autoregression, limit cycles and cyclical data. J. R. Stat. Soc. Ser. B (Methodol.) 1980, 42, 245–268. [Google Scholar] [CrossRef]
- Engle, R.F. Autoregressive Conditional Heteroscedasticity with Estimates of the Variance of United Kingdom Inflation. Econometrica 1982, 50, 987–1007. [Google Scholar] [CrossRef]
- Bollerslev, T. Generalized autoregressive conditional heteroskedasticity. J. Econom. 1986, 31, 307–327. [Google Scholar] [CrossRef]
- Karpoff, J.M. The Relation between Price Changes and Trading Volume: A Survey. J. Financ. Quant. Anal. 1987, 22, 109–126. [Google Scholar] [CrossRef]
- Tong, H. Non-Linear Time Series: A Dynamical System Approach; Oxford University Press: Oxford, UK, 1990. [Google Scholar]
- Li, C.W.; Li, W.K. On a Double-Threshold Autoregressive Heteroscedastic Time Series Model. J. Appl. Econometr. 1996, 11, 253–274. [Google Scholar] [CrossRef]
- Brooks, C. A Double-threshold GARCH Model for the French Franc/Deutschmark exchange rate. J. Forecast. 2001, 20, 135–143. [Google Scholar] [CrossRef]
- Chen, C.W.S.; Yang, M.J.; Gerlach, R.; Jim, L.H. The asymmetric reactions of mean and volatility of stock returns to domestic and international information based on a four-regime double-threshold GARCH model. Phys. Stat. Mech. Appl. 2006, 366, 401–418. [Google Scholar] [CrossRef]
- Yang, Y.L.; Chang, C.L. A double-threshold GARCH model of stock market and currency shocks on stock returns. Math. Comput. Simul. 2008, 79, 458–474. [Google Scholar] [CrossRef]
- Chen, C.W.S.; Gerlach, R. Semi-parametric quantile estimation for double threshold autoregressive models with heteroskedasticity. Comput. Stat. 2013, 28, 1103–1131. [Google Scholar] [CrossRef]
- Chen, C.W.S.; Chen, M.; Chen, H. Pairs Trading via Three-Regime Threshold Autoregressive GARCH Models. In Proceedings of the 7th International Conference of the Thailand Econometric Society, TES 2014, Chiang Mai, Thailand, 8–10 January 2014; pp. 127–140. [Google Scholar]
- Chen, C.W.S.; So, M.K.P.; Chiang, T.C. Evidence of Stock Returns and Abnormal Trading Volume: A Threshold Quantile Regression Approach. Jpn. Econ. Rev. 2016, 67, 96–124. [Google Scholar] [CrossRef]
- Luukkonen, R.; Saikkonen, P.; Teräsvirta, T. Testing linearity against smooth transition autoregressive models. Biometrika 1988, 75, 491–499. [Google Scholar] [CrossRef]
- Teräsvirta, T. Specification, estimation, and evaluation of smooth transition autoregressive models. J. Am. Stat. Assoc. 1994, 89, 208–218. [Google Scholar]
- Zheng, H.T.; Basawa, I.V. First-order observation-driven integer-valued autoregressive processes. Stat. Probab. Lett. 2008, 78, 1–9. [Google Scholar] [CrossRef]
- Yu, M.J.; Wang, D.H.; Yang, K. A class of observation-driven random coefficient INAR(1) processes based on negative binomial thinning. J. Korean Stat. Soc. 2019, 48, 248–264. [Google Scholar] [CrossRef]
- Yang, K.; Li, H.; Wang, D.H.; Zhang, C.H. Random coefficients integer-valued threshold autoregressive processes driven by logistic regression. AStA Adv. Stat. Anal. 2021, 105, 533–557. [Google Scholar] [CrossRef]
- Hwang, S.Y.; Basawa, I.V. Explosive Random Coefficient AR(1) Processes and Related Asymptotics for Least Squares Estimation. J. Time Ser. Anal. 2005, 26, 807–824. [Google Scholar] [CrossRef]
- Berkes, I.; Horvath, L.; Ling, S.Q. Estimation in nonstationary random coefficient autoregressive models. J. Time Ser. Anal. 2009, 30, 395–416. [Google Scholar] [CrossRef]
- Aue, A.; Horvath, L. Quasi-likelihood estimation in stationary and nonstationary autoregressive models with random coefficients. Stat. Sin. 2011, 21, 973–999. [Google Scholar]
- Weiss, A. Asymptotic theory for ARCH models: Estimation and testing. Econom. Theory 1986, 2, 107–131. [Google Scholar] [CrossRef]
- Engle, R.F.; Bollerslev, T. Modelling the persistence of conditional variances. Econom. Rev. 1986, 5, 1–50. [Google Scholar] [CrossRef]
- Berkes, I.; Horvath, L.; Kokoszka, P. GARCH processes: Structure and estimation. Bernoulli 2003, 9, 201–227. [Google Scholar] [CrossRef]
- Francq, C.; Zokaian, J.M. Maximum Likelihood Estimation of Pure GARCH and ARMA-GARCH Processes. Bernoulli 2004, 10, 605–637. [Google Scholar] [CrossRef]
- Hall, P.; Yao, Q. Inference in ARCH and GARCH models with heavy-tailed errors. Econometrica 2003, 71, 285–317. [Google Scholar] [CrossRef]
- Zhu, K.; Ling, S.Q. Global self-weighted and local quasi-maximum exponential likelihood estimators for ARMA-GARCH/IGARCH models. Ann. Stat. 2011, 39, 2131–2163. [Google Scholar] [CrossRef]
- Tsay, R.S. Testing and modeling threshold autoregressive processes. J. Am. Stat. Assoc. 1989, 84, 231–240. [Google Scholar] [CrossRef]
- Li, D.; Ling, S.Q. On the least squares estimation of multiple-regime threshold autoregressive models. J. Econom. 2012, 167, 240–253. [Google Scholar] [CrossRef]
- Yu, P. Likelihood estimation and inference in threshold regression. J. Econom. 2012, 167, 274–294. [Google Scholar] [CrossRef]
- Li, D.; Tong, H. Nested sub-sample search algorithm for estimation of threshold models. Stat. Sin. 2016, 26, 1543–1554. [Google Scholar] [CrossRef]
- Zhang, T.W.; Wang, D.H.; Yang, K. Quasi-maximum exponential likelihood estimation for double-threshold GARCH models. Can. J. Stat. 2021, 49, 1152–1178. [Google Scholar] [CrossRef]
- Sheng, D.S.; Wang, D.H.; Kang, Y. A new RCAR(1) model based on explanatory variables and observations. Commun. Stat.-Theory Methods 2022. [Google Scholar] [CrossRef]
- Li, G.D.; Guan, B.; Li, W.K.; Yu, P.L.H. Hysteretic autoregressive time series models. Biometrika 2015, 102, 717–723. [Google Scholar] [CrossRef]
- Silverman, B.W. Density Estimation for Statistics and Data Analysis; Chapman and Hall: New York, NY, USA, 1986. [Google Scholar]
- Ling, S.Q. Self-weighted and local quasi-maximum likelihood estimators for ARMA-GARCH/IGARCH models. J. Econom. 2007, 140, 849–873. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameters | r | r | ||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| n | True Value | 0.8 | 0.3 | 0.2 | 0.4 | 0.3 | 0.1 | 0.3 | 0.5 | 1 | 0.8 | 0.3 | 0.2 | 0.4 | 0.3 | 0.1 | 0.3 | 0.5 | 1 | |
| QMELE | Standard QMLE | |||||||||||||||||||
| 300 | Bias | 0.1007 | 0.0481 | 0.0039 | −0.0457 | −0.0236 | 0.0365 | −0.0077 | −0.0184 | 0.0210 | −0.0183 | 0.1870 | 0.1013 | 0.0089 | −0.0263 | 0.0828 | 0.1431 | −0.0126 | −0.1083 | |
| SD | 0.4195 | 0.1691 | 0.1211 | 0.2341 | 0.1584 | 0.1879 | 0.1231 | 0.1877 | 0.1306 | 0.3206 | 0.2072 | 0.1571 | 0.1966 | 0.1139 | 0.2533 | 0.1643 | 0.1717 | 0.1589 | ||
| ASD | 0.7650 | 0.1517 | 0.1401 | 0.1895 | 0.2446 | 0.1621 | 0.1020 | 0.1707 | – | 0.2697 | 0.1919 | 0.1278 | 0.1654 | 0.0588 | 0.2241 | 0.1436 | 0.1638 | – | ||
| 600 | Bias | 0.0586 | 0.0395 | 0.0152 | −0.0461 | −0.0147 | 0.0258 | −0.0075 | −0.0136 | 0.0294 | −0.0408 | 0.1681 | 0.1019 | 0.0171 | −0.0134 | 0.0728 | 0.1464 | −0.0036 | −0.1193 | |
| SD | 0.2860 | 0.1220 | 0.0784 | 0.1454 | 0.0955 | 0.1199 | 0.0837 | 0.1093 | 0.1049 | 0.2673 | 0.1523 | 0.1185 | 0.1424 | 0.0791 | 0.1588 | 0.1068 | 0.1061 | 0.1491 | ||
| ASD | 0.4960 | 0.1008 | 0.0682 | 0.1289 | 0.1112 | 0.1026 | 0.0733 | 0.1144 | – | 0.1953 | 0.1420 | 0.0965 | 0.1258 | 0.0407 | 0.1416 | 0.1034 | 0.1098 | – | ||
| 900 | Bias | 0.0564 | 0.0328 | 0.0153 | −0.0403 | −0.0039 | 0.0219 | −0.0008 | −0.0176 | 0.0177 | −0.0600 | 0.1651 | 0.1013 | 0.0205 | −0.0103 | 0.0679 | 0.1444 | 0.0036 | −0.1163 | |
| SD | 0.2456 | 0.1135 | 0.0665 | 0.1201 | 0.0750 | 0.0933 | 0.0626 | 0.0864 | 0.0945 | 0.1840 | 0.1405 | 0.0916 | 0.1132 | 0.0694 | 0.1139 | 0.0867 | 0.0798 | 0.1219 | ||
| ASD | 0.4346 | 0.0893 | 0.0636 | 0.1130 | 0.0798 | 0.0764 | 0.0596 | 0.0893 | – | 0.1569 | 0.1229 | 0.0821 | 0.1050 | 0.0345 | 0.1081 | 0.0838 | 0.0867 | – | ||
| 300 | Bias | 0.0879 | 0.0315 | 0.0132 | −0.0071 | 0.0027 | 0.0324 | −0.0120 | 0.-0029 | 0.0238 | −0.1411 | 0.2665 | 0.1933 | 0.0543 | −0.0094 | 0.1366 | 0.2501 | −0.0133 | -0.2345 | |
| SD | 0.4255 | 0.3210 | 0.1480 | 0.2814 | 0.2419 | 0.1818 | 0.1322 | 0.1676 | 0.1953 | 0.3770 | 0.3246 | 0.2838 | 0.2625 | 0.1409 | 0.2843 | 0.2467 | 0.1624 | 0.2522 | ||
| ASD | 0.9172 | 0.2465 | 0.1407 | 0.2424 | 0.1672 | 0.1560 | 0.1086 | 0.1498 | – | 0.4344 | 0.3131 | 0.2361 | 0.1998 | 0.0905 | 0.2697 | 0.1977 | 0.1553 | – | ||
| 600 | Bias | 0.0266 | 0.0169 | 0.0379 | 0.0037 | 0.0044 | 0.0171 | −0.0085 | −0.0025 | 0.0140 | −0.1510 | 0.2746 | 0.1852 | 0.0438 | −0.0050 | 0.1284 | 0.2671 | −0.0070 | −0.2326 | |
| SD | 0.3477 | 0.1625 | 0.1254 | 0.2269 | 0.1197 | 0.0923 | 0.0790 | 0.0923 | 0.1361 | 0.2698 | 0.2885 | 0.2609 | 0.1927 | 0.1019 | 0.1769 | 0.1781 | 0.1063 | 0.2089 | ||
| ASD | 0.7976 | 0.1744 | 0.1417 | 0.1869 | 0.1223 | 0.0803 | 0.0754 | 0.0923 | – | 0.4236 | 0.3202 | 0.5972 | 0.1711 | 0.0677 | 0.1664 | 0.1524 | 0.1054 | – | ||
| 900 | Bias | 0.0503 | 0.0134 | 0.0131 | 0.0007 | 0.0017 | 0.0142 | −0.0017 | −0.0073 | 0.0145 | −0.1730 | 0.2729 | 0.1861 | 0.0388 | 0.0040 | 0.1163 | 0.2783 | −0.0051 | −0.2459 | |
| SD | 0.3070 | 0.1306 | 0.1145 | 0.1761 | 0.0893 | 0.0684 | 0.0631 | 0.0674 | 0.1015 | 0.2359 | 0.2300 | 0.1948 | 0.1692 | 0.0856 | 0.1308 | 0.1371 | 0.0798 | 0.1986 | ||
| ASD | 0.4979 | 0.1286 | 0.0985 | 0.1458 | 0.0854 | 0.0574 | 0.0616 | 0.0719 | – | 0.2980 | 0.2428 | 0.1846 | 0.1643 | 0.0551 | 0.1198 | 0.1261 | 0.0810 | – | ||
| 300 | Bias | 0.0460 | 0.0254 | 0.0361 | 0.0062 | 0.0094 | 0.0353 | −0.0110 | −0.0175 | 0.0181 | −0.2024 | 0.2828 | 0.2106 | 0.1221 | 0.0182 | 0.1552 | 0.3058 | −0.0198 | -0.2972 | |
| SD | 0.3874 | 0.2762 | 0.2336 | 0.3134 | 0.1696 | 0.1785 | 0.1516 | 0.1837 | 0.1897 | 0.5492 | 0.5434 | 0.4623 | 0.3884 | 0.3693 | 0.3681 | 0.4019 | 0.1990 | 0.4593 | ||
| ASD | 0.9868 | 0.2649 | 0.3477 | 0.2615 | 0.2322 | 0.1526 | 0.1204 | 0.1602 | – | 0.5655 | 0.4292 | 0.3356 | 0.2399 | 0.1469 | 0.3580 | 0.2790 | 0.1928 | – | ||
| 600 | Bias | 0.0744 | 0.0221 | 0.0321 | −0.0030 | 0.0076 | 0.0197 | 0.0061 | −0.0095 | 0.0157 | −0.2257 | 0.3067 | 0.2134 | 0.1114 | 0.0139 | 0.1650 | 0.3656 | −0.0168 | −0.3080 | |
| SD | 0.3170 | 0.1761 | 0.2035 | 0.2539 | 0.1337 | 0.0953 | 0.0971 | 0.1008 | 0.1807 | 0.3958 | 0.3814 | 0.4269 | 0.3802 | 0.2285 | 0.2714 | 0.3876 | 0.1416 | 0.3693 | ||
| ASD | 0.7293 | 0.2212 | 0.1850 | 0.2129 | 0.1535 | 0.0796 | 0.0887 | 0.1002 | – | 0.5430 | 0.4499 | 0.3654 | 0.2585 | 0.1619 | 0.2369 | 0.2451 | 0.1423 | – | ||
| 900 | Bias | 0.0520 | 0.0206 | 0.0228 | −0.0016 | 0.0017 | 0.0129 | 0.0004 | −0.0094 | 0.0061 | −0.2230 | 0.2876 | 0.2341 | 0.1072 | 0.0171 | 0.1515 | 0.3606 | −0.0065 | −0.2269 | |
| SD | 0.2963 | 0.1592 | 0.1857 | 0.1934 | 0.1109 | 0.0695 | 0.0752 | 0.0756 | 0.1606 | 0.3703 | 0.3629 | 0.3925 | 0.2976 | 0.1730 | 0.1937 | 0.3382 | 0.1224 | 0.3537 | ||
| ASD | 0.6693 | 0.1832 | 0.1587 | 0.1825 | 0.0965 | 0.0558 | 0.0732 | 0.0921 | – | 0.5329 | 0.3752 | 0.3568 | 0.2486 | 0.1112 | 0.1798 | 0.2185 | 0.1162 | – | ||
| Parameters | r | r | ||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| n | True Value | 0.7 | 0.2 | 0.1 | 0.5 | 0.3 | 0.3 | 0.5 | 0.1 | 0.2 | 0.6 | 0 | 0.7 | 0.2 | 0.1 | 0.5 | 0.3 | 0.3 | 0.5 | 0.1 | 0.2 | 0.6 | 0 | |
| QMELE | Standard QMLE | |||||||||||||||||||||||
| 300 | Bias | 0.0359 | −0.0137 | 0.0481 | −0.0328 | 0.0155 | −0.0096 | 0.0320 | 0.0422 | −0.0195 | −0.0178 | −0.0383 | −0.0959 | −0.0917 | 0.1259 | 0.2274 | 0.0363 | −0.0223 | −0.0126 | 0.1800 | 0.0783 | 0.0138 | −0.2076 | |
| SD | 0.5409 | 0.5306 | 0.0847 | 0.2338 | 0.1485 | 0.2010 | 0.3838 | 0.1125 | 0.0926 | 0.1354 | 0.3876 | 0.2759 | 0.2987 | 0.1185 | 0.2273 | 0.1475 | 0.1171 | 0.2492 | 0.1677 | 0.1213 | 0.1296 | 0.3679 | ||
| ASD | 1.4229 | 1.1241 | 0.1953 | 0.1500 | 0.2043 | 0.1847 | 0.5038 | 0.0768 | 0.0908 | 0.1192 | – | 0.3105 | 0.3780 | 0.3915 | 0.2390 | 0.2067 | 0.0621 | 0.1651 | 0.1051 | 0.1172 | 0.1092 | – | ||
| 600 | Bias | 0.0198 | −0.0096 | 0.0458 | −0.0116 | 0.0102 | −0.0006 | 0.0146 | 0.0295 | −0.0191 | −0.0035 | −0.0181 | −0.1068 | −0.0656 | 0.1197 | 0.2145 | 0.0495 | −0.0100 | −0.0167 | 0.1522 | 0.0097 | 0.0237 | −0.1926 | |
| SD | 0.2824 | 0.3030 | 0.0940 | 0.1476 | 0.1451 | 0.1057 | 0.2527 | 0.0700 | 0.0667 | 0.0818 | 0.3152 | 0.1887 | 0.2099 | 0.0820 | 0.1782 | 0.1074 | 0.0769 | 0.1600 | 0.1049 | 0.0972 | 0.0845 | 0.2622 | ||
| ASD | 0.5658 | 0.5857 | 0.0770 | 0.1148 | 0.1335 | 0.1799 | 0.3272 | 0.0526 | 0.0638 | 0.0826 | − | 0.2092 | 0.2739 | 0.1385 | 0.1560 | 0.1255 | 0.0389 | 0.1155 | 0.0706 | 0.0833 | 0.0748 | − | ||
| 900 | Bias | 0.0046 | −0.0109 | 0.0426 | −0.0187 | 0.0185 | 0.0059 | 0.0153 | 0.0198 | −0.0166 | 0.0019 | 0.0009 | −0.1023 | −0.0685 | 0.1242 | 0.2012 | 0.0554 | −0.0090 | −0.0188 | 0.1448 | 0.0912 | 0.0307 | −0.1842 | |
| SD | 0.3039 | 0.2515 | 0.0648 | 0.1971 | 0.1064 | 0.1343 | 0.2373 | 0.0542 | 0.0551 | 0.0674 | 0.2467 | 0.1693 | 0.1691 | 0.0824 | 0.1452 | 0.1005 | 0.0593 | 0.1332 | 0.0848 | 0.0834 | 0.0676 | 0.2431 | ||
| ASD | 0.6637 | 0.5310 | 0.0552 | 0.0906 | 0.0916 | 0.2017 | 0.2595 | 0.0421 | 0.0524 | 0.0671 | − | 0.1756 | 0.1883 | 0.1045 | 0.1291 | 0.1011 | 0.0329 | 0.0982 | 0.0574 | 0.0681 | 0.0608 | − | ||
| 300 | Bias | 0.0313 | −0.0120 | 0.0486 | 0.0056 | 0.0191 | 0.0014 | 0.0238 | 0.0368 | −0.0076 | −0.0164 | −0.0621 | −0.1206 | −0.1771 | 0.1924 | 0.4032 | 0.0585 | 0.0047 | −0.0641 | 0.2774 | 0.1512 | 0.0214 | −0.3335 | |
| SD | 0.3193 | 0.3897 | 0.1095 | 0.2640 | 0.2000 | 0.1172 | 0.2773 | 0.1165 | 0.1037 | 0.1224 | 0.4687 | 0.4313 | 0.4547 | 0.2527 | 0.4925 | 0.2187 | 0.1716 | 0.3933 | 0.2575 | 0.1904 | 0.1513 | 0.5577 | ||
| ASD | 1.3226 | 1.5866 | 0.3796 | 0.2624 | 0.3878 | 0.1525 | 0.4386 | 0.0834 | 0.1069 | 0.1185 | − | 1.1642 | 1.1136 | 1.2507 | 0.5134 | 0.4134 | 0.1286 | 0.3395 | 0.1632 | 0.1804 | 0.1230 | − | ||
| 600 | Bias | 0.0017 | −0.0226 | 0.0514 | 0.0135 | 0.0135 | 0.0002 | 0.0154 | 0.0266 | -0.0064 | -0.0123 | −0.0289 | −0.1515 | −0.1625 | 0.1936 | 0.3808 | 0.0636 | 0.0094 | −0.0631 | 0.2444 | 0.1841 | 0.0100 | 0.4300 | |
| SD | 0.3227 | 0.3890 | 0.1052 | 0.2181 | 0.1335 | 0.0716 | 0.2301 | 0.0723 | 0.0705 | 0.0805 | 0.3505 | 0.3311 | 0.3739 | 0.1699 | 0.3582 | 0.2084 | 0.1188 | 0.3481 | 0.1662 | 0.1664 | 0.0978 | 0.4905 | ||
| ASD | 0.8516 | 0.9170 | 0.1992 | 0.1811 | 0.2317 | 0.0831 | 0.2878 | 0.0570 | 0.0753 | 0.0816 | − | 0.6877 | 0.9354 | 1.0392 | 0.4891 | 0.6041 | 0.1211 | 0.2533 | 0.1125 | 0.1332 | 0.0848 | − | ||
| 900 | Bias | 0.0030 | −0.0069 | 0.0504 | 0.0061 | 0.0173 | 0.0056 | 0.0215 | 0.0192 | −0.0101 | −0.0014 | −0.0393 | −0.1409 | −0.1552 | 0.1997 | 0.3613 | 0.0740 | 0.0146 | −0.0530 | 0.2273 | 0.1980 | 0.0318 | −0.3594 | |
| SD | 0.2428 | 0.2748 | 0.0846 | 0.1918 | 0.1305 | 0.0869 | 0.1885 | 0.0550 | 0.0593 | 0.0623 | 0.3283 | 0.3440 | 0.3244 | 0.1704 | 0.2986 | 0.1644 | 0.1552 | 0.3282 | 0.1290 | 0.1459 | 0.0834 | 0.4708 | ||
| ASD | 0.5947 | 0.6394 | 0.1459 | 0.1683 | 0.1894 | 0.1004 | 0.2974 | 0.0452 | 0.0592 | 0.0651 | – | 0.8345 | 1.0395 | 0.8602 | 0.3704 | 0.2656 | 0.0864 | 0.2290 | 0.0915 | 0.1107 | 0.0691 | – | ||
| 300 | Bias | 0.0433 | −0.0023 | 0.0626 | 0.0229 | 0.0030 | 0.0154 | 0.0112 | 0.0438 | −0.0093 | −0.0229 | −0.0537 | −0.1922 | −0.2268 | 0.2413 | 0.4413 | 0.0825 | 0.0270 | −0.0813 | 0.3328 | 0.1905 | 0.0208 | −0.3948 | |
| SD | 0.3766 | 0.3797 | 0.1479 | 0.3230 | 0.2228 | 0.2949 | 0.3053 | 0.1284 | 0.1131 | 0.1362 | 0.4103 | 0.5678 | 0.6324 | 0.3059 | 0.6310 | 0.2967 | 0.2549 | 0.5479 | 0.3934 | 0.3245 | 0.1924 | 0.7518 | ||
| ASD | 1.6808 | 1.3841 | 0.3948 | 0.3133 | 0.4711 | 0.1528 | 0.4242 | 0.0921 | 0.1236 | 0.1341 | – | 2.1121 | 3.5392 | 4.8341 | 1.2046 | 0.6966 | 0.3020 | 0.7381 | 0.2889 | 0.3147 | 0.1813 | – | ||
| 600 | Bias | 0.0107 | −0.0194 | 0.0550 | 0.0115 | 0.0276 | 0.0079 | −0.0195 | 0.0282 | −0.0095 | -0.0107 | -0.0467 | -0.1745 | -0.2191 | 0.2423 | 0.4505 | 0.0855 | 0.0376 | -0.1391 | 0.3091 | 0.2309 | 0.0266 | -0.4178 | |
| SD | 0.3062 | 0.5962 | 0.1808 | 1.3040 | 0.1933 | 0.1042 | 0.4318 | 0.0865 | 0.0850 | 0.0948 | 0.4613 | 0.4070 | 0.5125 | 0.3649 | 0.6025 | 0.2615 | 0.2436 | 0.5146 | 0.3219 | 0.2968 | 0.1420 | 0.6121 | ||
| ASD | 0.7485 | 0.8655 | 0.3999 | 0.2782 | 0.2164 | 0.1242 | 0.4406 | 0.0638 | 0.0879 | 0.0947 | – | 1.9790 | 2.8621 | 4.0155 | 1.3184 | 0.7723 | 0.5350 | 0.8205 | 0.2876 | 0.2960 | 0.1757 | – | ||
| 900 | Bias | 0.0111 | -0.0158 | 0.0544 | 0.0121 | 0.0280 | 0.0124 | 0.0082 | 0.0208 | -0.0076 | -0.0082 | -0.0466 | -0.1752 | -0.1976 | 0.2217 | 0.4025 | 0.0938 | 0.0281 | -0.1299 | 0.3051 | 0.2509 | 0.0400 | -0.3946 | |
| SD | 0.3003 | 0.3518 | 0.1512 | 0.2689 | 0.1855 | 0.1521 | 0.2643 | 0.0634 | 0.0707 | 0.0719 | 0.3832 | 0.3332 | 0.4359 | 0.2450 | 0.4416 | 0.2084 | 0.1844 | 0.4231 | 0.3072 | 0.2867 | 0.1272 | 0.5482 | ||
| ASD | 0.8089 | 0.8741 | 0.1964 | 0.2315 | 0.1794 | 0.1236 | 0.3430 | 0.0511 | 0.0719 | 0.0767 | − | 1.4053 | 1.8931 | 4.5213 | 0.9127 | 0.5223 | 0.2029 | 0.4696 | 0.1930 | 0.2297 | 0.1177 | − | ||
| TVCDT-GARCH | DT-GARCH | |
|---|---|---|
| AIC | 1922.522 | 1925.186 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, T.; Fu, L.; Wang, D.; Yu, Z. A Time-Varying Coefficient Double Threshold GARCH Model with Explanatory Variables. Axioms 2023, 12, 476. https://doi.org/10.3390/axioms12050476
Zhang T, Fu L, Wang D, Yu Z. A Time-Varying Coefficient Double Threshold GARCH Model with Explanatory Variables. Axioms. 2023; 12(5):476. https://doi.org/10.3390/axioms12050476
Chicago/Turabian StyleZhang, Tongwei, Lianyan Fu, Dehui Wang, and Zhuoxi Yu. 2023. "A Time-Varying Coefficient Double Threshold GARCH Model with Explanatory Variables" Axioms 12, no. 5: 476. https://doi.org/10.3390/axioms12050476