
Statistical Inference for Odds Ratio of Two Proportions in Bilateral Correlated Data


Abstract
:1. Introduction
2. Data Structure and Donner’s Model
3. Unconstrained and Constrained MLEs
3.1. Unconstrained MLEs
3.2. Constrained MLEs
4. Test Methods
4.1. Likelihood Ratio Test
4.2. Wald-Type Log-Linear Test
4.3. Score Test
5. CI Methods
5.1. Profile Likelihood CI
5.2. Wald-Type CI
5.3. Score CI
6. Simulation Studies
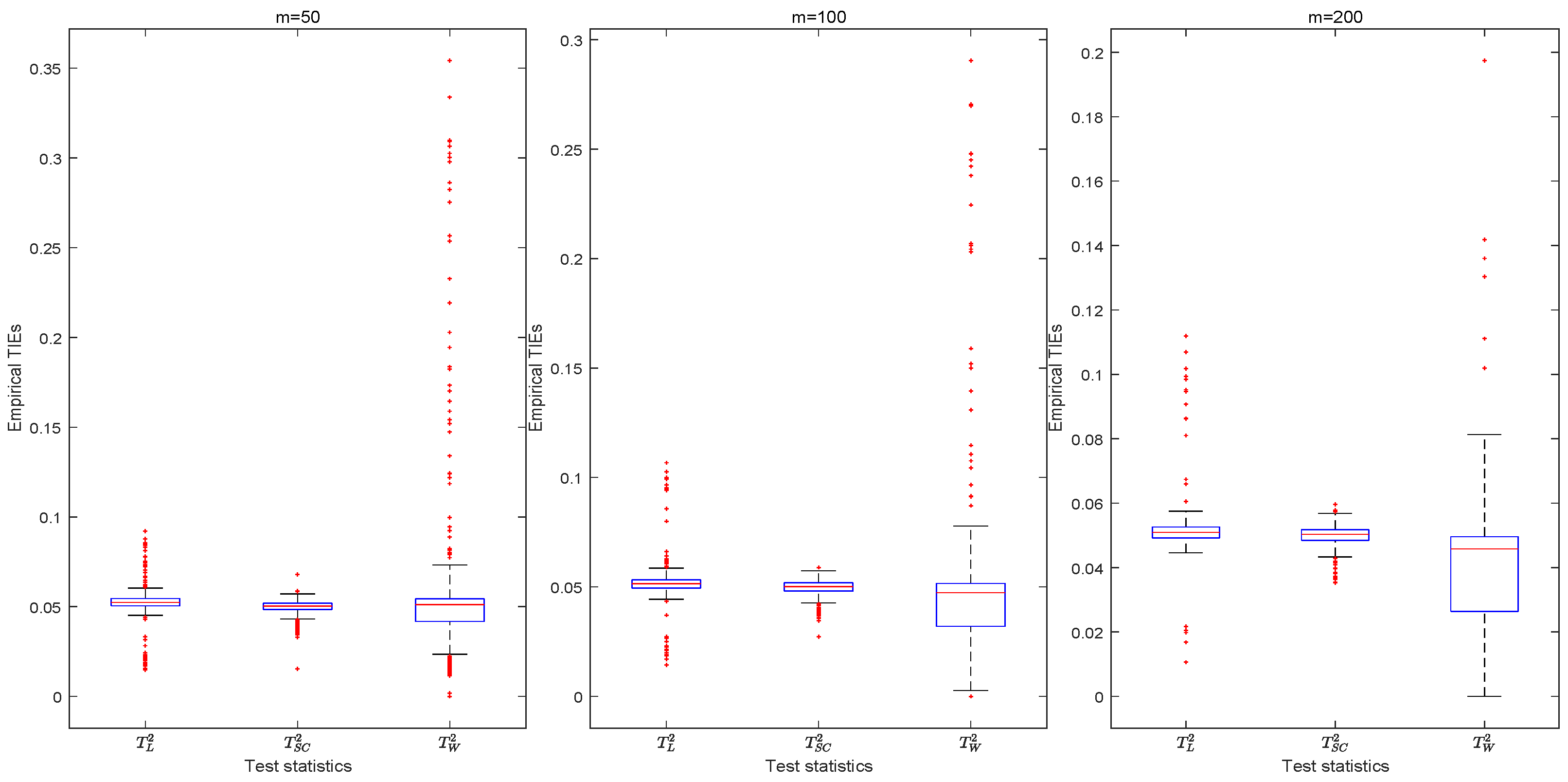
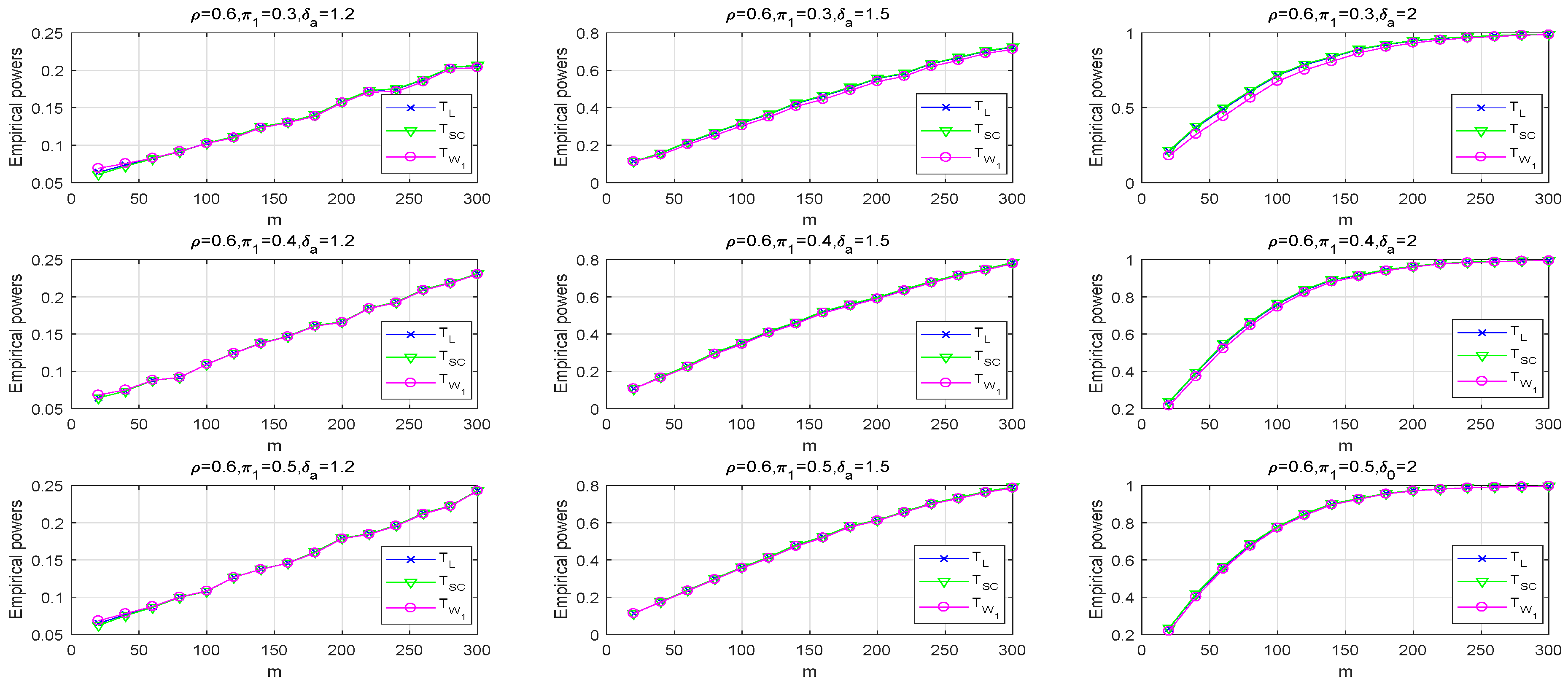
6.1. Odds Ratio Test
6.2. CI Construction
7. An Example
8. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A. Derivation and Information Matrix
Appendix A.1. Differential Equations and Information Matrix I
Appendix A.2. Differential Equations and Information Matrix Iθ
Appendix A.3. Information Matrix Iθ1
References
- Lewis, T.L.; Maurer, D.; Brent, H. Development of grating acuity in children treated for unilateral or bilateral congenital cataract. Investig. Ophthalmol. Vis. Sci. 1995, 36, 2080–2095. [Google Scholar]
- Pompeo, E.; Sergiacomi, G.; Nofroni, I.; Roscetti, W.; Simonetti, G.; Mineo, T.C. Morphologic grading of emphysema is useful in the selection of candidates for unilateral or bilateral reduction pneumoplasty. Eur. J.-Cardio-Thorac. Surg. 2000, 17, 680–686. [Google Scholar] [CrossRef]
- Brwon, M.M.; Brown, G.C.; Sharma, S.; Busbee, B.; Brown, H. Quality of life associated with unilateral and bilateral good vision. Ophthalmology 2001, 108, 643–648. [Google Scholar] [CrossRef]
- Newman, L.A.; Sahin, A.A.; Bondy, M.L.; Mirza, N.Q.; Vlastos, G.S.; Whitman, G.J.; Buchholz, T.A.; Lee, M.H.; Singletary, S.E. A case-control study of unilateral and bilateral breast carcinoma patients. Cancer 2001, 91, 1845–1853. [Google Scholar] [CrossRef]
- Mandel, E.M.; Bluestone, C.D.; Rockette, H.E.; Blatter, M.M.; Reisinger, K.S.; Wucher, F.P.; Harper, J. Duration of effusion after antibiotic treatment for acute otitis media: Comparison of cefaclor and amoxicillin. Pediatr. Infect. Dis. 1982, 1, 310–316. [Google Scholar] [CrossRef]
- Sainani, K. The importance of accounting for correlated observations. Am. Acad. Phys. Med. Rehabil. 2010, 2, 858–861. [Google Scholar] [CrossRef] [PubMed]
- Cessie, S.L.; Houwelingen, J.C. Logistic regression for correlated binary data. Appl. Stat. 1994, 43, 95–108. [Google Scholar] [CrossRef]
- Ying, G.; Maguire, M.G.; Glynn, R.; Rosner, B. Tutorial on biostatistics: Linear regression analysis of continuous correlated eye data. Ophthalmic Epidemiol. 2017, 24, 130–140. [Google Scholar] [CrossRef]
- Rosner, B. Statistical methods in ophthalmology: An adjustment for the intraclass correlation between eyes. Biometrics 1982, 38, 105–114. [Google Scholar] [CrossRef]
- Ma, C.X.; Shan, G.; Liu, S. Homogeneity test for binary correlated data. PLoS ONE 2015, 10, e0124337. [Google Scholar] [CrossRef]
- Tang, M.L.; Tang, N.S.; Rosner, B. Statistical inference for correlated data in ophthalmologic studies. Stat. Med. 2006, 25, 2771–2783. [Google Scholar] [CrossRef] [PubMed]
- Tang, N.S.; Qiu, S.F.; Tang, M.L.; Pei, Y.B. Asymptotic confidence interval construction for proportion difference in medical studies with bilateral data. Stat. Meth. Med. Res. 2011, 20, 233–259. [Google Scholar] [CrossRef] [PubMed]
- Dallal, G.E. Paired Bernoulli trials. Biometrics 1988, 44, 253–257. [Google Scholar] [CrossRef]
- Sun, S.M.; Li, Z.M.; Ai, M.Y.; Jiang, H.J. Risk difference tests for stratified binary data under Dallal’s model. Stat. Meth. Med. Res. 2022, 31, 1135–1156. [Google Scholar] [CrossRef]
- Donner, A. Statistical methods in opthalmology: An adjusted chi-square approach. Biometrics 1989, 45, 605–611. [Google Scholar] [CrossRef] [PubMed]
- Liu, X.B.; Liu, S.; Ma, C.X. Testing equality of correlation coefficients for paired binary data from multiple groups. Stat. Compu. Simul. 2015, 86, 1686–1696. [Google Scholar] [CrossRef]
- Pei, Y.B.; Tang, M.L.; Wong, W.K.; Guo, J.H. Confidence intervals for correlated proportion differences from paired data in a two-arm randomised clinical trial. Stat. Meth. Med. Res. 2010, 21, 167–187. [Google Scholar] [CrossRef] [PubMed]
- Pei, Y.B.; Tian, G.L.; Tang, M.L. Testing homogeneity of proportion ratios for stratified correlated bilateral data in two-arm randomized clinical trials. Stat. Med. 2014, 33, 4370–4386. [Google Scholar] [CrossRef]
- Qiu, S.F.; Tang, N.S.; Tang, M.L.; Pei, Y.B. Sample Size for testing difference between two proportions for the bilateral-sample design. J. Biopharm. Stat. 2009, 19, 857–871. [Google Scholar] [CrossRef]
- Qiu, S.F.; Liu, Q.S.; Ge, Y. Confidence intervals of proportion differences for stratified combined unilateral and bilateral data. Commun. Stat. Simul. Comp. 2021. [Google Scholar] [CrossRef]
- Tang, N.S.; Tang, M.L.; Qiu, S.F. Testing the equality of proportions for correlated otolaryngologic data. Comput. Stat. Data Anal. 2008, 52, 3719–3729. [Google Scholar] [CrossRef]
- Tang, N.S.; Li, H.Q.; Tang, M.L.; Li, J. Confidence interval construction for the difference between two correlated proportions with missing observations. J. Biopharm. Stat. 2016, 26, 323–338. [Google Scholar] [CrossRef] [PubMed]
- Tang, M.L.; Pei, Y.B.; Wong, W.K.; Li, J.L. Goodness-of-fit tests for correlated paired binary data. Stat. Methods Med. Res. 2010, 21, 331–345. [Google Scholar] [CrossRef] [PubMed]
- Edwards, A.W.F. The measure of association in a 2 × 2 table. J. Roy. Stat. Soc. A Stat. 1963, 126, 109–114. [Google Scholar] [CrossRef]
- Chanda, K.C. A Note on the Consistency and Maxima of the Roots of Likelihood Equations. Biometrika 1954, 41, 56–61. [Google Scholar] [CrossRef]
- Mou, K.Y.; Li, Z.M. Homogeneity test of many-to-one risk differences for correlated binary data under optimal algorithms. Complexity 2021, 2021, 6685951. [Google Scholar] [CrossRef]
- Ma, C.X.; Liu, S. Testing equality of proportions for correlated binary data in ophthalmologic studies. J. Biopharm. Stat. 2017, 27, 611–619. [Google Scholar] [CrossRef]
- Cochran, W.G. The χ2 test of goodness of fit. Anal. Math. Stat. 1952, 23, 315–345. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
| Number of Responses (l) | Group | Total | |
|---|---|---|---|
| 1 | 2 | ||
| 0 | |||
| 1 | |||
| 2 | |||
| Total | N | ||
| 0.2 | 1.0 | 0.0548 | 0.0527 | 0.0586 | 0.0513 | 0.0496 | 0.0533 | 0.0551 | 0.0546 | 0.0570 | |
| 1.5 | 0.0530 | 0.0514 | 0.0521 | 0.0507 | 0.0492 | 0.0468 | 0.0512 | 0.0494 | 0.0471 | ||
| 2.0 | 0.0485 | 0.0470 | 0.0408 | 0.0522 | 0.0511 | 0.0422 | 0.0492 | 0.0481 | 0.0386 | ||
| 0.4 | 1.0 | 0.0538 | 0.0524 | 0.0548 | 0.0529 | 0.0521 | 0.0542 | 0.0511 | 0.0501 | 0.0519 | |
| 0.4 | 1.5 | 0.0484 | 0.0474 | 0.0498 | 0.0509 | 0.0509 | 0.0511 | 0.0504 | 0.0498 | 0.0513 | |
| 2.0 | 0.0481 | 0.0474 | 0.0494 | 0.0513 | 0.0502 | 0.0517 | 0.0540 | 0.0526 | 0.0546 | ||
| 0.6 | 1.0 | 0.0543 | 0.0526 | 0.0555 | 0.0517 | 0.0509 | 0.0526 | 0.0498 | 0.0495 | 0.0503 | |
| 1.5 | 0.0512 | 0.0502 | 0.0513 | 0.0476 | 0.0471 | 0.0467 | 0.0498 | 0.0493 | 0.0485 | ||
| 2.0 | 0.0508 | 0.0495 | 0.0464 | 0.0505 | 0.0502 | 0.0437 | 0.0497 | 0.0496 | 0.0440 | ||
| 0.2 | 1.0 | 0.0540 | 0.0522 | 0.0594 | 0.0509 | 0.0492 | 0.0544 | 0.0522 | 0.0508 | 0.0543 | |
| 1.5 | 0.0532 | 0.0520 | 0.0525 | 0.0504 | 0.0493 | 0.0472 | 0.0509 | 0.0504 | 0.0481 | ||
| 2.0 | 0.0487 | 0.0462 | 0.0404 | 0.0509 | 0.0491 | 0.0408 | 0.0514 | 0.0501 | 0.0405 | ||
| 0.4 | 1.0 | 0.0519 | 0.0507 | 0.0540 | 0.0500 | 0.0492 | 0.0513 | 0.0502 | 0.0495 | 0.0512 | |
| 0.6 | 1.5 | 0.0499 | 0.0485 | 0.0515 | 0.0514 | 0.0511 | 0.0522 | 0.0526 | 0.0519 | 0.0529 | |
| 2.0 | 0.0496 | 0.0483 | 0.0518 | 0.0521 | 0.0511 | 0.0515 | 0.0508 | 0.0516 | 0.0511 | ||
| 0.6 | 1.0 | 0.0525 | 0.0510 | 0.0543 | 0.0517 | 0.0512 | 0.0530 | 0.0503 | 0.0499 | 0.0516 | |
| 1.5 | 0.0484 | 0.0469 | 0.0489 | 0.0525 | 0.0515 | 0.0513 | 0.0480 | 0.0475 | 0.0472 | ||
| 2.0 | 0.0524 | 0.0500 | 0.0468 | 0.0498 | 0.0496 | 0.0444 | 0.0512 | 0.0511 | 0.0453 | ||
| 0.2 | 1.0 | 0.0533 | 0.0505 | 0.0607 | 0.0533 | 0.0518 | 0.0572 | 0.0522 | 0.0508 | 0.0544 | |
| 1.5 | 0.0552 | 0.0530 | 0.0544 | 0.0527 | 0.0515 | 0.0511 | 0.0493 | 0.0485 | 0.0467 | ||
| 2.0 | 0.0496 | 0.0477 | 0.0422 | 0.0520 | 0.0507 | 0.0448 | 0.0544 | 0.0536 | 0.0442 | ||
| 0.4 | 1.0 | 0.0500 | 0.0493 | 0.0522 | 0.0496 | 0.0491 | 0.0508 | 0.0498 | 0.0495 | 0.0509 | |
| 0.8 | 1.5 | 0.0527 | 0.0519 | 0.0533 | 0.0509 | 0.0505 | 0.0523 | 0.0557 | 0.0550 | 0.0556 | |
| 2.0 | 0.0532 | 0.0523 | 0.0564 | 0.0526 | 0.0540 | 0.0537 | 0.0514 | 0.0525 | 0.0522 | ||
| 0.6 | 1.0 | 0.0528 | 0.0517 | 0.0557 | 0.0526 | 0.0520 | 0.0536 | 0.0524 | 0.0522 | 0.0531 | |
| 1.5 | 0.0504 | 0.0489 | 0.0518 | 0.0520 | 0.0509 | 0.0520 | 0.0534 | 0.0525 | 0.0533 | ||
| 2.0 | 0.0532 | 0.0514 | 0.0511 | 0.0511 | 0.0522 | 0.0445 | 0.0514 | 0.0521 | 0.0460 | ||
| 0.2 | 1.2 | 0.0749 | 0.0741 | 0.0768 | 0.0837 | 0.0831 | 0.0834 | 0.1056 | 0.1057 | 0.1036 | |
| 1.5 | 0.1702 | 0.1720 | 0.1522 | 0.2399 | 0.2439 | 0.2141 | 0.2846 | 0.2886 | 0.2591 | ||
| 2.0 | 0.3854 | 0.3941 | 0.2991 | 0.5362 | 0.5458 | 0.4463 | 0.6566 | 0.6654 | 0.5696 | ||
| 0.4 | 1.2 | 0.0859 | 0.0851 | 0.0862 | 0.0983 | 0.0979 | 0.0981 | 0.1205 | 0.1203 | 0.1199 | |
| 0.4 | 1.5 | 0.2147 | 0.2158 | 0.2101 | 0.3190 | 0.3212 | 0.3125 | 0.3920 | 0.3939 | 0.3849 | |
| 2.0 | 0.5164 | 0.5216 | 0.4964 | 0.6908 | 0.6954 | 0.6742 | 0.8183 | 0.8214 | 0.8067 | ||
| 0.6 | 1.2 | 0.0855 | 0.0850 | 0.0859 | 0.1007 | 0.1007 | 0.1000 | 0.1226 | 0.1223 | 0.1220 | |
| 1.5 | 0.2188 | 0.2201 | 0.2135 | 0.3152 | 0.3169 | 0.3084 | 0.3858 | 0.3879 | 0.3788 | ||
| 2.0 | 0.5193 | 0.5242 | 0.4984 | 0.6957 | 0.6999 | 0.6809 | 0.8145 | 0.8173 | 0.8042 | ||
| 0.2 | 1.2 | 0.0718 | 0.0707 | 0.0748 | 0.0770 | 0.0765 | 0.0777 | 0.0967 | 0.0962 | 0.0960 | |
| 1.5 | 0.1552 | 0.1575 | 0.1401 | 0.2133 | 0.2168 | 0.1923 | 0.2566 | 0.2606 | 0.2302 | ||
| 2.0 | 0.3449 | 0.3544 | 0.2607 | 0.4828 | 0.4932 | 0.3942 | 0.6006 | 0.6100 | 0.5140 | ||
| 0.4 | 1.2 | 0.0845 | 0.0836 | 0.0850 | 0.0915 | 0.0911 | 0.0915 | 0.1152 | 0.1152 | 0.1154 | |
| 0.6 | 1.5 | 0.1976 | 0.1988 | 0.1930 | 0.2826 | 0.2844 | 0.2769 | 0.3503 | 0.3516 | 0.3424 | |
| 2.0 | 0.4656 | 0.4714 | 0.4457 | 0.6384 | 0.6430 | 0.6185 | 0.7607 | 0.7643 | 0.7456 | ||
| 0.6 | 1.2 | 0.0854 | 0.0842 | 0.0866 | 0.0936 | 0.0929 | 0.0935 | 0.1164 | 0.1162 | 0.1160 | |
| 1.5 | 0.1908 | 0.1913 | 0.1863 | 0.2825 | 0.2838 | 0.2760 | 0.3495 | 0.3513 | 0.3433 | ||
| 2.0 | 0.4654 | 0.4729 | 0.4452 | 0.6350 | 0.6425 | 0.6163 | 0.7626 | 0.7675 | 0.7493 | ||
| 0.2 | 1.2 | 0.0695 | 0.0679 | 0.0731 | 0.0751 | 0.0747 | 0.0768 | 0.0926 | 0.0925 | 0.0932 | |
| 1.5 | 0.1403 | 0.1427 | 0.1276 | 0.1941 | 0.1974 | 0.1724 | 0.2305 | 0.2342 | 0.2097 | ||
| 2.0 | 0.3112 | 0.3239 | 0.2377 | 0.4344 | 0.4457 | 0.3500 | 0.5510 | 0.5605 | 0.4567 | ||
| 0.4 | 1.2 | 0.0771 | 0.0766 | 0.0785 | 0.0859 | 0.0856 | 0.0868 | 0.1025 | 0.1023 | 0.1024 | |
| 0.8 | 1.5 | 0.1816 | 0.1827 | 0.1786 | 0.2417 | 0.2440 | 0.2372 | 0.3186 | 0.3210 | 0.3136 | |
| 2.0 | 0.4328 | 0.4378 | 0.4141 | 0.5952 | 0.6012 | 0.5769 | 0.7183 | 0.7242 | 0.7031 | ||
| 0.6 | 1.2 | 0.0792 | 0.0783 | 0.0809 | 0.0887 | 0.0886 | 0.0894 | 0.1052 | 0.1052 | 0.1054 | |
| 1.5 | 0.1838 | 0.1849 | 0.1808 | 0.2459 | 0.2478 | 0.2399 | 0.3180 | 0.3204 | 0.3117 | ||
| 2.0 | 0.4282 | 0.4350 | 0.4070 | 0.5946 | 0.6019 | 0.5750 | 0.7178 | 0.7256 | 0.7004 | ||
| m | MCPs | MIWs | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| 0.2 | 1.0 | 50 | 0.9493 | 0.9523 | 0.9830 | 0.9452 | 2.0316 | 1.9674 | 2.1187 | 5.5245 | |
| 75 | 0.9453 | 0.9466 | 0.9704 | 0.9423 | 1.5344 | 1.5018 | 1.5711 | 2.9333 | |||
| 100 | 0.9442 | 0.9448 | 0.9649 | 0.9425 | 1.2713 | 1.2512 | 1.2923 | 1.7555 | |||
| 1.5 | 50 | 0.9475 | 0.9492 | 0.9745 | 0.9492 | 2.9290 | 2.8005 | 3.1746 | 8.2801 | ||
| 75 | 0.9449 | 0.9463 | 0.9654 | 0.9479 | 2.2036 | 2.1224 | 2.3304 | 4.8852 | |||
| 100 | 0.9460 | 0.9467 | 0.9624 | 0.9488 | 1.8224 | 1.7568 | 1.9075 | 2.9070 | |||
| 2.0 | 50 | 0.9472 | 0.9501 | 0.9726 | 0.9555 | 3.8250 | 3.5607 | 4.3147 | 10.725 | ||
| 75 | 0.9456 | 0.9464 | 0.9680 | 0.9539 | 2.8792 | 2.6584 | 3.1555 | 6.7246 | |||
| 100 | 0.9453 | 0.9460 | 0.9645 | 0.9566 | 2.3808 | 2.1818 | 2.5795 | 4.1505 | |||
| 0.4 | 1.0 | 50 | 0.9485 | 0.9496 | 0.9518 | 0.9473 | 1.5394 | 1.5225 | 1.5367 | 1.6188 | |
| 75 | 0.9468 | 0.9474 | 0.9488 | 0.9460 | 1.1985 | 1.1902 | 1.1969 | 1.2290 | |||
| 100 | 0.9458 | 0.9469 | 0.9479 | 0.9451 | 1.0129 | 1.0080 | 1.0119 | 1.0303 | |||
| 1.5 | 50 | 0.9481 | 0.9493 | 0.9499 | 0.9472 | 2.3032 | 2.2362 | 2.3022 | 2.4288 | ||
| 0.4 | 75 | 0.9448 | 0.9458 | 0.9462 | 0.9451 | 1.7860 | 1.7360 | 1.7889 | 1.8407 | ||
| 100 | 0.9473 | 0.9479 | 0.9489 | 0.9469 | 1.5066 | 1.4641 | 1.5100 | 1.5401 | |||
| 2.0 | 50 | 0.9478 | 0.9487 | 0.9498 | 0.9473 | 3.1016 | 2.9648 | 3.1195 | 3.3004 | ||
| 75 | 0.9449 | 0.9456 | 0.9458 | 0.9452 | 2.3874 | 2.2899 | 2.4076 | 2.4824 | |||
| 100 | 0.9447 | 0.9442 | 0.9451 | 0.9442 | 2.0080 | 1.9323 | 2.0304 | 2.0740 | |||
| 0.6 | 1.0 | 50 | 0.9477 | 0.9503 | 0.9534 | 0.9463 | 1.5410 | 1.5188 | 1.5399 | 1.6211 | |
| 75 | 0.9479 | 0.9485 | 0.9498 | 0.9470 | 1.1945 | 1.1820 | 1.1943 | 1.2265 | |||
| 100 | 0.9475 | 0.9479 | 0.9493 | 0.9468 | 1.0104 | 1.0025 | 1.0103 | 1.0287 | |||
| 1.5 | 50 | 0.9686 | 0.9694 | 0.9779 | 0.9568 | 2.3816 | 2.3061 | 2.4202 | 3.0219 | ||
| 75 | 0.9488 | 0.9497 | 0.9541 | 0.9496 | 1.8622 | 1.8107 | 1.8940 | 2.0624 | |||
| 100 | 0.9447 | 0.9448 | 0.9505 | 0.9453 | 1.5702 | 1.5296 | 1.5959 | 1.6858 | |||
| 2.0 | 50 | 0.9522 | 0.9507 | 0.9542 | 0.9504 | 3.3840 | 3.3309 | 3.4267 | 3.6675 | ||
| 75 | 0.9488 | 0.9436 | 0.9502 | 0.9470 | 2.6095 | 2.5402 | 2.6397 | 2.7368 | |||
| 100 | 0.9508 | 0.9421 | 0.9623 | 0.9421 | 2.1988 | 2.1379 | 2.3058 | 2.1379 | |||
| 0.2 | 1.0 | 50 | 0.9499 | 0.9522 | 0.9897 | 0.9450 | 2.2557 | 2.1620 | 2.3876 | 7.2516 | |
| 75 | 0.9428 | 0.9447 | 0.9747 | 0.9388 | 1.6813 | 1.6380 | 1.7318 | 4.0515 | |||
| 100 | 0.9475 | 0.9488 | 0.9693 | 0.9455 | 1.3810 | 1.3539 | 1.4082 | 2.2598 | |||
| 1.5 | 50 | 0.9505 | 0.9526 | 0.9777 | 0.9519 | 3.2400 | 3.0097 | 3.5806 | 10.147 | ||
| 75 | 0.9439 | 0.9454 | 0.9684 | 0.9473 | 2.4165 | 2.2439 | 2.5794 | 6.4631 | |||
| 100 | 0.9457 | 0.9467 | 0.9653 | 0.9490 | 1.9799 | 1.8306 | 2.0828 | 3.8025 | |||
| 2.0 | 50 | 0.9473 | 0.9496 | 0.9731 | 0.9550 | 4.2432 | 3.6543 | 4.9050 | 12.504 | ||
| 75 | 0.9438 | 0.9453 | 0.9681 | 0.9543 | 3.1368 | 2.6729 | 3.4960 | 8.4027 | |||
| 100 | 0.9455 | 0.9465 | 0.9660 | 0.9559 | 2.5611 | 2.1940 | 2.8188 | 5.3252 | |||
| 0.4 | 1.0 | 50 | 0.9484 | 0.9497 | 0.9535 | 0.9471 | 1.6799 | 1.6372 | 1.6812 | 1.7960 | |
| 75 | 0.9465 | 0.9472 | 0.9488 | 0.9438 | 1.2961 | 1.2737 | 1.2967 | 1.3371 | |||
| 100 | 0.9454 | 0.9460 | 0.9481 | 0.9446 | 1.0922 | 1.0775 | 1.0926 | 1.1152 | |||
| 1.5 | 50 | 0.9485 | 0.9499 | 0.9524 | 0.9474 | 2.4973 | 2.3678 | 2.5249 | 2.6951 | ||
| 0.6 | 75 | 0.9463 | 0.9472 | 0.9480 | 0.9452 | 1.9173 | 1.8280 | 1.9388 | 2.0037 | ||
| 100 | 0.9471 | 0.9474 | 0.9484 | 0.9468 | 1.6092 | 1.5373 | 1.6314 | 1.6683 | |||
| 2.0 | 50 | 0.9491 | 0.9499 | 0.9514 | 0.9483 | 3.3828 | 3.2200 | 3.4235 | 3.6697 | ||
| 75 | 0.9480 | 0.9477 | 0.9496 | 0.9470 | 2.5817 | 2.4907 | 2.6138 | 2.7080 | |||
| 100 | 0.9455 | 0.9446 | 0.9465 | 0.9444 | 2.1741 | 2.1157 | 2.1988 | 2.2527 | |||
| 0.6 | 1.0 | 50 | 0.9521 | 0.9530 | 0.9573 | 0.9500 | 1.6774 | 1.6321 | 1.6835 | 1.7933 | |
| 75 | 0.9471 | 0.9471 | 0.9503 | 0.9465 | 1.2904 | 1.2657 | 1.2941 | 1.3347 | |||
| 100 | 0.9494 | 0.9494 | 0.9515 | 0.9483 | 1.0904 | 1.0734 | 1.0936 | 1.1162 | |||
| 1.5 | 50 | 0.9508 | 0.9500 | 0.9568 | 0.9587 | 2.5422 | 2.4373 | 2.5845 | 3.1324 | ||
| 75 | 0.9483 | 0.9488 | 0.9544 | 0.9483 | 2.0101 | 1.9410 | 2.0545 | 2.2830 | |||
| 100 | 0.9474 | 0.9477 | 0.9535 | 0.9481 | 1.6926 | 1.6416 | 1.7286 | 1.8467 | |||
| 2.0 | 50 | 0.9498 | 0.9509 | 0.9677 | 0.9435 | 3.8470 | 3.6810 | 4.1480 | 4.3245 | ||
| 75 | 0.9462 | 0.9426 | 0.9619 | 0.9534 | 2.8526 | 2.7697 | 3.0117 | 3.4562 | |||
| 100 | 0.9552 | 0.9417 | 0.9686 | 0.9579 | 2.3734 | 2.3234 | 2.4872 | 2.9232 | |||
| 0.2 | 1.0 | 50 | 0.9528 | 0.9555 | 0.9922 | 0.9464 | 2.5289 | 2.3713 | 2.7335 | 8.7236 | |
| 75 | 0.9463 | 0.9479 | 0.9783 | 0.9425 | 1.8500 | 1.7662 | 1.9150 | 5.3330 | |||
| 100 | 0.9475 | 0.9490 | 0.9715 | 0.9445 | 1.5029 | 1.4441 | 1.5372 | 3.0518 | |||
| 1.5 | 50 | 0.9501 | 0.9527 | 0.9787 | 0.9490 | 3.6306 | 3.1170 | 4.1349 | 11.568 | ||
| 75 | 0.9446 | 0.9460 | 0.9705 | 0.9472 | 2.6451 | 2.2278 | 2.8486 | 7.9263 | |||
| 100 | 0.9464 | 0.9472 | 0.9660 | 0.9507 | 2.1423 | 1.7948 | 2.2715 | 4.9722 | |||
| 2.0 | 50 | 0.9491 | 0.9510 | 0.9746 | 0.9551 | 4.6967 | 3.5029 | 5.6867 | 13.775 | ||
| 75 | 0.9450 | 0.9468 | 0.9689 | 0.9552 | 3.3559 | 2.5244 | 3.8704 | 9.9300 | |||
| 100 | 0.9454 | 0.9455 | 0.9674 | 0.9549 | 2.6568 | 2.0836 | 3.0760 | 6.6606 | |||
| 0.4 | 1.0 | 50 | 0.9500 | 0.9507 | 0.9560 | 0.9478 | 1.8165 | 1.7262 | 1.8307 | 2.0030 | |
| 75 | 0.9453 | 0.9455 | 0.9488 | 0.9434 | 1.3881 | 1.3349 | 1.3975 | 1.4489 | |||
| 100 | 0.9473 | 0.9475 | 0.9492 | 0.9462 | 1.1663 | 1.1254 | 1.1726 | 1.2006 | |||
| 1.5 | 50 | 0.9467 | 0.9485 | 0.9510 | 0.9454 | 2.6973 | 2.5073 | 2.7506 | 2.9965 | ||
| 0.8 | 75 | 0.9471 | 0.9475 | 0.9493 | 0.9457 | 2.0383 | 1.9086 | 2.0880 | 2.1704 | ||
| 100 | 0.9447 | 0.9453 | 0.9465 | 0.9445 | 1.7059 | 1.6064 | 1.7512 | 1.7970 | |||
| 2.0 | 50 | 0.9510 | 0.9520 | 0.9543 | 0.9487 | 3.6860 | 3.4993 | 3.7225 | 4.0628 | ||
| 75 | 0.9460 | 0.9441 | 0.9469 | 0.9449 | 2.7847 | 2.6841 | 2.8147 | 2.9357 | |||
| 100 | 0.9457 | 0.9435 | 0.9469 | 0.9456 | 2.3368 | 2.2760 | 2.3590 | 2.4272 | |||
| 0.6 | 1.0 | 50 | 0.9501 | 0.9512 | 0.9564 | 0.9462 | 1.8097 | 1.7452 | 1.8189 | 1.9620 | |
| 75 | 0.9483 | 0.9486 | 0.9522 | 0.9466 | 1.3874 | 1.3450 | 1.3960 | 1.4484 | |||
| 100 | 0.9468 | 0.9472 | 0.9498 | 0.9461 | 1.1667 | 1.1337 | 1.1736 | 1.2018 | |||
| 1.5 | 50 | 0.9481 | 0.9494 | 0.9614 | 0.9624 | 2.9340 | 2.8031 | 3.0144 | 3.3773 | ||
| 75 | 0.9471 | 0.9476 | 0.9546 | 0.9512 | 2.1868 | 2.1098 | 2.2356 | 2.5099 | |||
| 100 | 0.9490 | 0.9498 | 0.9558 | 0.9501 | 1.8275 | 1.7677 | 1.8656 | 2.0184 | |||
| 2.0 | 50 | 0.9478 | 0.9495 | 0.9684 | 0.9623 | 4.2564 | 4.0509 | 4.6223 | 3.3772 | ||
| 75 | 0.9483 | 0.9404 | 0.9639 | 0.9512 | 3.1063 | 3.0129 | 3.2850 | 2.5099 | |||
| 100 | 0.9483 | 0.9400 | 0.9612 | 0.9501 | 2.5767 | 2.5198 | 2.7035 | 2.0184 | |||
| OME Status | Treatment | Total | |
|---|---|---|---|
| Cefaclor | Amoxicillin | ||
| None cured | 14 | 15 | 29 |
| Unilateral cured | 9 | 3 | 12 |
| Bilateral cured | 21 | 13 | 34 |
| Total | 44 | 31 | 75 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, Z.; Ma, C. Statistical Inference for Odds Ratio of Two Proportions in Bilateral Correlated Data. Axioms 2022, 11, 502. https://doi.org/10.3390/axioms11100502
Li Z, Ma C. Statistical Inference for Odds Ratio of Two Proportions in Bilateral Correlated Data. Axioms. 2022; 11(10):502. https://doi.org/10.3390/axioms11100502
Chicago/Turabian StyleLi, Zhiming, and Changxing Ma. 2022. "Statistical Inference for Odds Ratio of Two Proportions in Bilateral Correlated Data" Axioms 11, no. 10: 502. https://doi.org/10.3390/axioms11100502