


Partial Decision Tree Forest: A Machine Learning Model for the Geosciences


Abstract
:1. Introduction
- An ensemble-based classifier, Partial Decision Tree (PART) Forest, was introduced to handle a geoscientific problem.
- Minerals’ crystal structure was predicted from two distinct points of view by considering either only the chemical compositions or only the materials’ characteristics or by making use of both features.
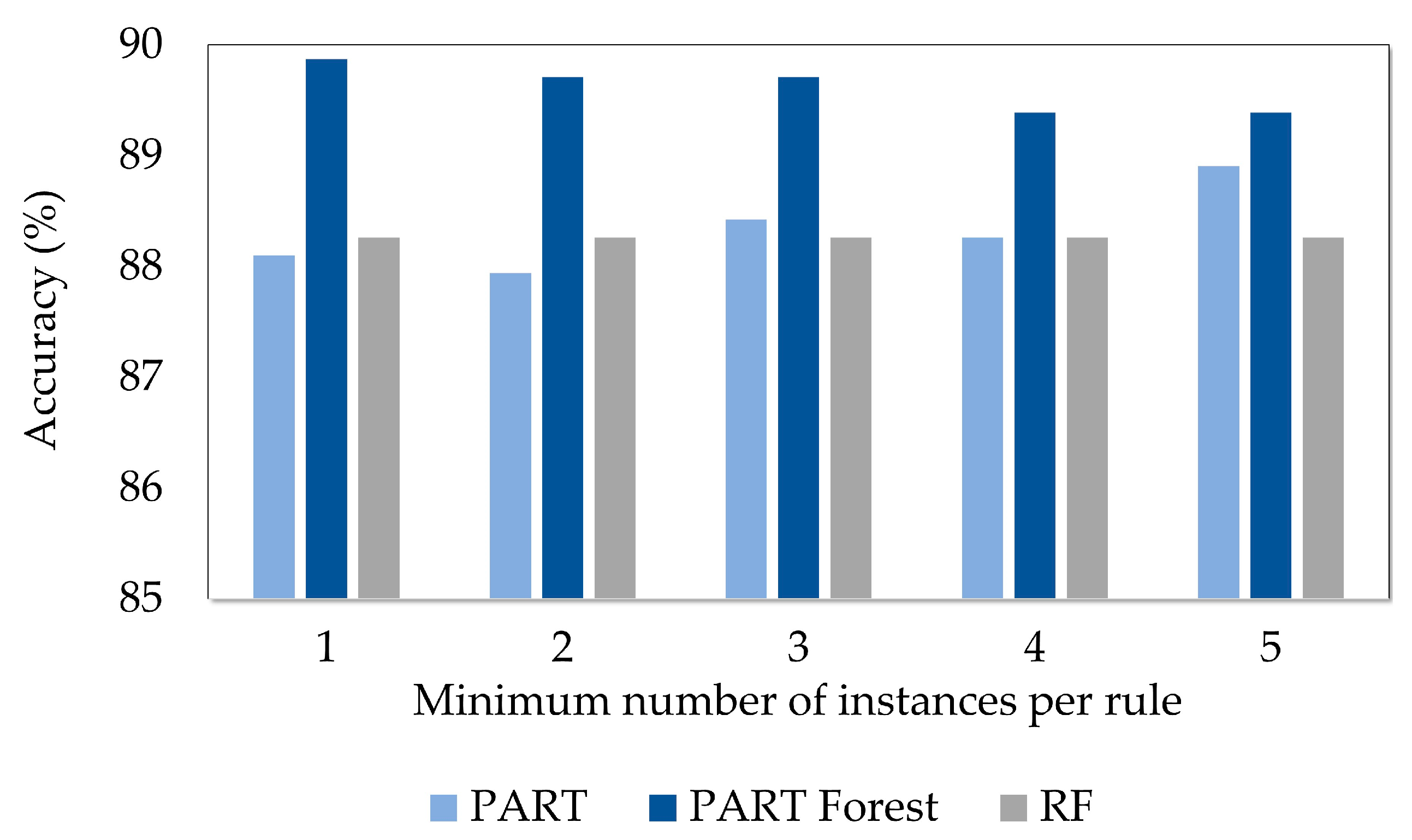
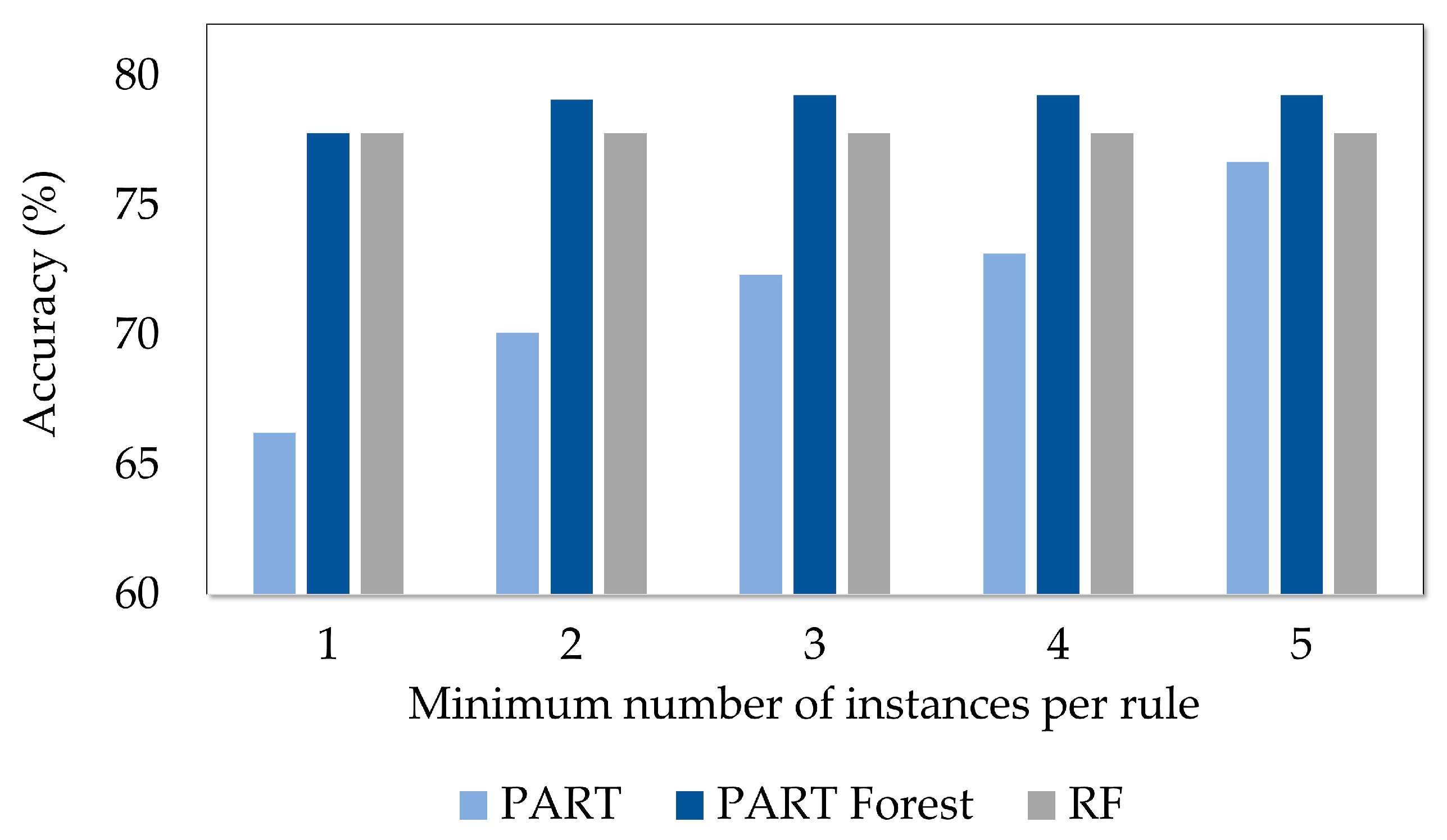
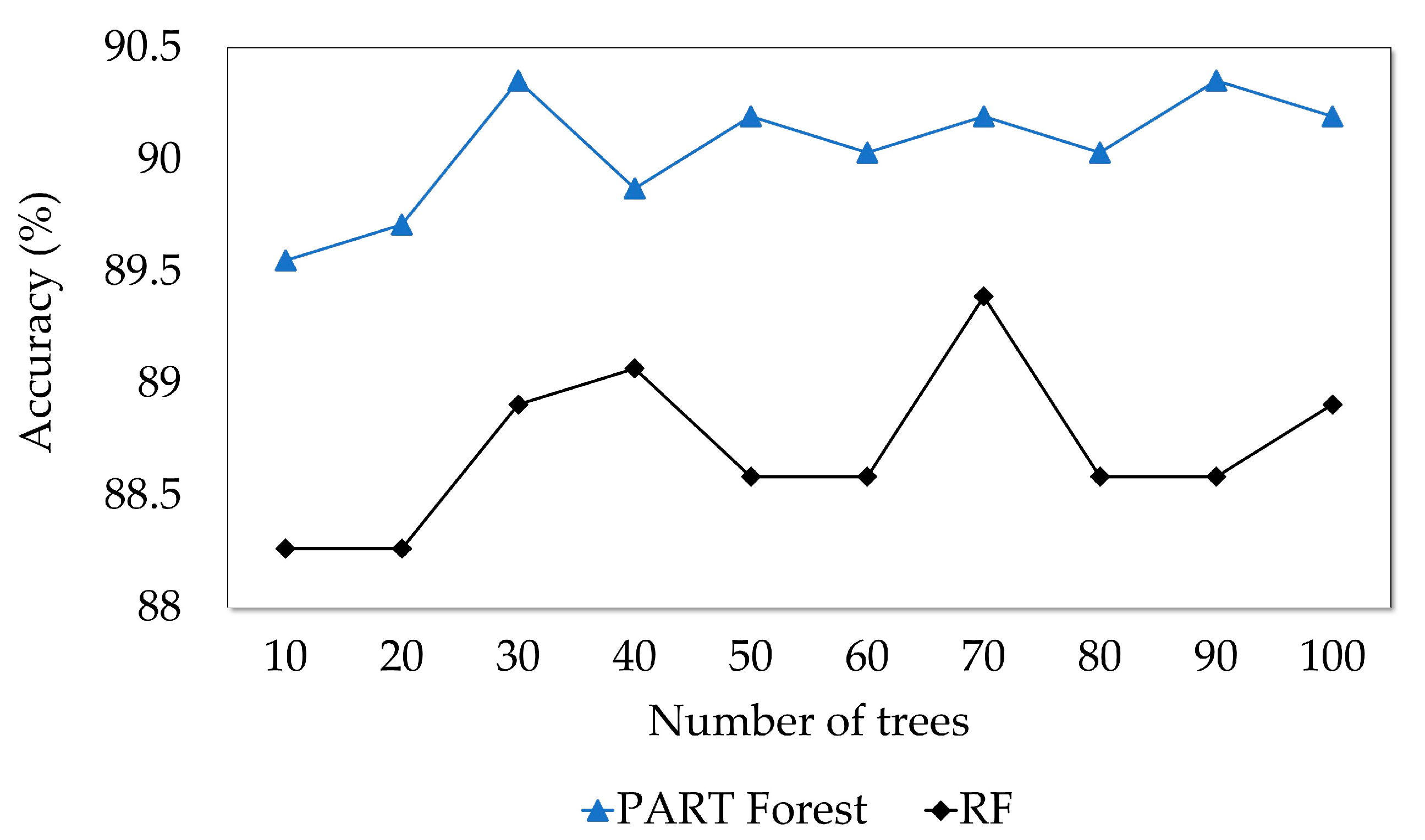
- The proposed PART Forest method outperformed the standard PART classifier and the RF classifier, which is one of the most applied methods under ensemble learning, on the given dataset.
2. Related Work
2.1. Recent Studies Related to Minerals’ Crystal Structure Classification
2.2. Recent Studies Taking the PART Classifier as the Main Subject
- Handling noisy data: The PART algorithm is capable of dealing with noisy data by generating rules that account for exceptions. This enables the algorithm to create rules that encompass the majority of the data, while also taking into account any outliers or noise present in the dataset [28].
- Interpretability: The PART algorithm generates rules that are easy to interpret. The resulting decision tree can be converted into a set of IF–THEN rules that are easy to understand [25].
- Flexibility: The PART algorithm allows the users to set various parameters to control the generated tree, such as the minimum number of instances required to split a node and the maximum number of rules permitted in the decision tree [28].
3. Materials and Methods
3.1. Proposed Method
3.2. Formal Definitions
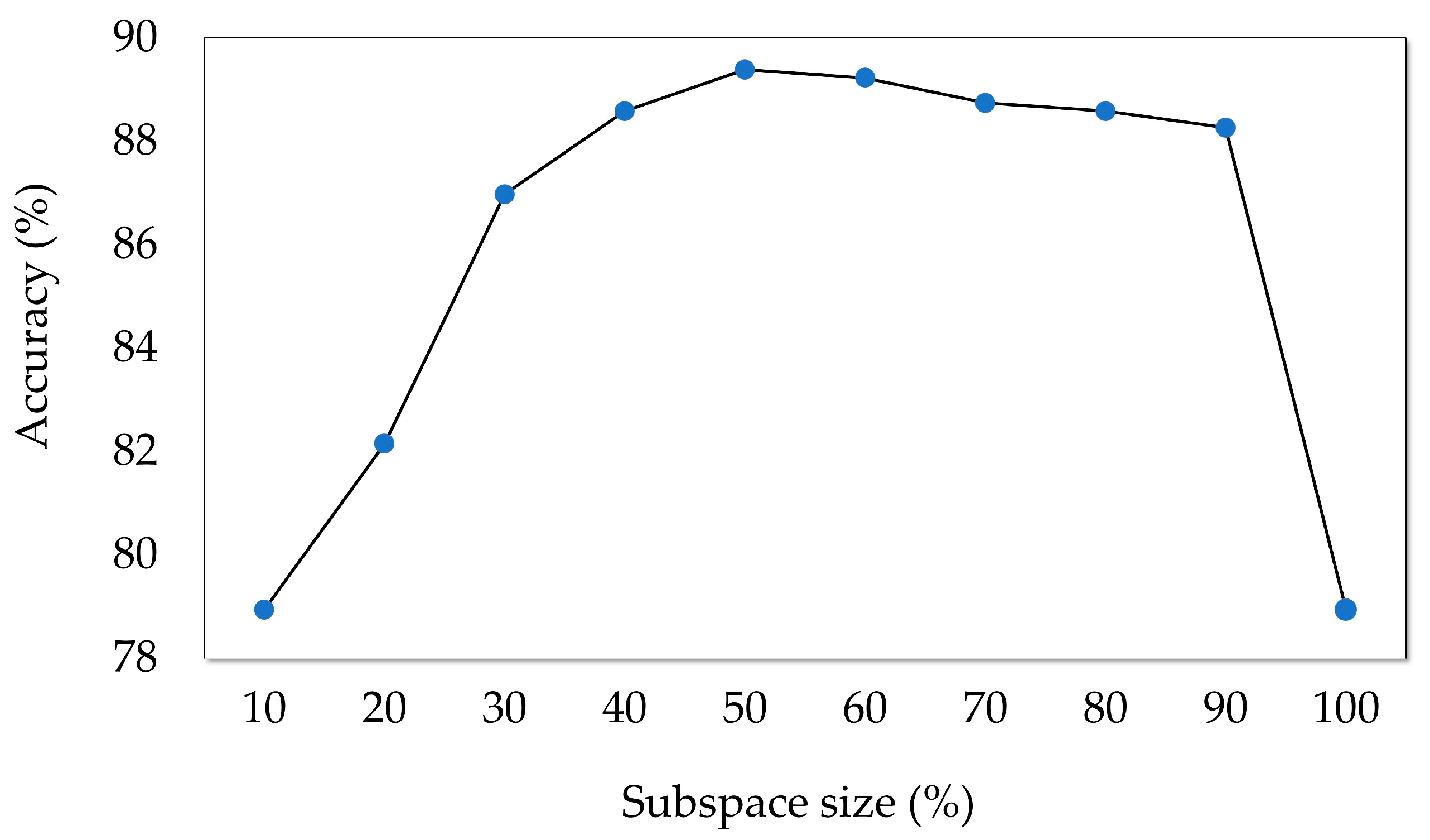
- For each tree from i = 1 to I, randomly select a subspace from the feature set F.
- Generate a new subset dataset Di by selecting the instances along with their corresponding values for the selected features.
- Choose the attribute a, providing the highest accuracy on this current subset dataset Di (root node).
- If Di is empty or all the instances in D belong to the same class, create a leaf node with the majority class label in D.
- Otherwise, recursively build a subtree Ti for the subset Di starting with the smallest entropy.
- If the subset Di expanded into a leaf, start backtracking.
- If during backtracking a node is encountered whose children are all not leaves, then the remaining subsets are left unexplored.
- Once a partial tree Ti has been built, a single rule Ri is extracted.
- Repeat steps 1–8 for all base models.
- Aggregate the predictions of the models using majority voting.
- The random subspace method reduces the correlation between models by choosing different features.
- The PART algorithm constructs a decision tree by dividing the data into smaller subsets based on the selected feature and the chosen split. The algorithm also employs a coverage measure to decide when to stop growing the tree, followed by pruning to prevent overfitting and create a more concise tree.
- The results of partial decision trees are aggregated for prediction.
4. Dataset Description
5. Results and Discussion
5.1. Experiments Carried Out Using Only the Material Characteristics
5.2. Experiments Carried Out Using Only the Chemical Composition Information
5.3. Experiments Carried Out Using Both the Material Characteristics and the Chemical Composition Information
6. Conclusions and Future Work
- A geoscientific problem was handled by our method (PART Forest) with satisfactory results above 90% accuracy.
- The proposed method beat the PART and RF methods in the classification of minerals.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Shin, Y.; Shin, S. Rock classification in a vanadiferous titanomagnetite deposit based on supervised machine learning. Minerals 2022, 12, 461. [Google Scholar] [CrossRef]
- Han, X.; Hou, D.; Cheng, X.; Li, Y.; Niu, C.; Chen, S. Prediction of TOC in Lishui–Jiaojiang Sag using geochemical analysis, well logs, and machine learning. Energies 2022, 15, 9480. [Google Scholar] [CrossRef]
- Alqahtani, A.; He, X.; Yan, B.; Hoteit, H. Uncertainty analysis of CO2 storage in deep saline aquifers using machine learning and Bayesian optimization. Energies 2023, 16, 1684. [Google Scholar] [CrossRef]
- Wagle, N.; Acharya, T.D.; Kolluru, V.; Huang, H.; Lee, D.H. Multi-temporal land cover change mapping using Google Earth engine and ensemble learning methods. Appl. Sci. 2020, 10, 8083. [Google Scholar] [CrossRef]
- Sun, T.; Li, H.; Wu, K.; Chen, F.; Zhu, Z.; Hu, Z. Data-driven predictive modelling of mineral prospectivity using machine learning and deep learning methods: A case study from southern Jiangxi Province, China. Minerals 2020, 10, 102. [Google Scholar] [CrossRef] [Green Version]
- Karpatne, A.; Ebert-Uphoff, I.; Ravela, S.; Babaie, H.A.; Kumar, V. Machine learning for the geosciences: Challenges and opportunities. IEEE Trans. Knowl. Data Eng. 2018, 31, 1544–1554. [Google Scholar] [CrossRef] [Green Version]
- De′ath, G.; Fabricius, K.E. Classification and regression trees: A powerful yet simple technique for ecological data analysis. Ecology 2000, 81, 3178–3192. [Google Scholar] [CrossRef]
- Thessen, A. Adoption of machine learning techniques in ecology and earth science. One Ecosyst. 2016, 1, e8621. [Google Scholar] [CrossRef] [Green Version]
- Singh, M.; Kumar, B.; Chattopadhyay, R.; Amarjyothi, K.; Sutar, A.K.; Roy, S.; Rao, S.A.; Nanjundiah, R.S. Machine learning for Earth System Science (ESS): A survey, status and future directions for South Asia. arXiv 2021, arXiv:2112.12966. [Google Scholar]
- Costa, I.S.L.; Tavares, F.M.; de Oliveira, J.K.M. Predictive lithological mapping through machine learning methods: A case study in the Cinzento Lineament, Carajás Province, Brazil. JGSB 2019, 2, 26–36. [Google Scholar] [CrossRef]
- Latifovic, R.; Pouliot, D.; Campbell, J. Assessment of convolution neural networks for surficial geology mapping in the South Rae geological region, Northwest Territories, Canada. Remote Sens. 2018, 10, 307. [Google Scholar] [CrossRef] [Green Version]
- Culverhouse, P.F.; Williams, R.; Reguera, B.; Herry, V.; González-Gil, S. Do experts make mistakes? A comparison of human and machine indentification of dinoflagellates. Mar. Ecol. Prog. Ser. 2003, 247, 17–25. [Google Scholar] [CrossRef] [Green Version]
- Ali, A.; Chiang, Y.W.; Santos, R.M. X-ray diffraction techniques for mineral characterization: A review for engineers of the fundamentals, applications, and research directions. Minerals 2022, 12, 205. [Google Scholar] [CrossRef]
- Jarin, S.; Yuan, Y.; Zhang, M.; Hu, M.; Rana, M.; Wang, S.; Knibbe, R. Predicting the crystal structure and lattice parameters of the perovskite materials via different machine learning models based on basic atom properties. Crystals 2022, 12, 1570. [Google Scholar] [CrossRef]
- Priyadarshini, R.; Joardar, H.; Bisoy, S.K.; Badapanda, T. Crystal structural prediction of perovskite materials using machine learning: A comparative study. Solid. State Commun. 2023, 361, 115062. [Google Scholar] [CrossRef]
- Zhao, Y.; Cui, Y.; Xiong, Z.; Jin, J.; Liu, Z.; Dong, R.; Hu, J. Machine learning-based prediction of crystal systems and space groups from inorganic materials compositions. ACS Omega 2020, 5, 3596–3606. [Google Scholar] [CrossRef] [PubMed]
- Corriero, N.; Rizzi, R.; Settembre, G.; Del Buono, N.; Diacono, D. CrystalMELA: A new crystallographic machine learning platform for crystal system determination. J. Appl. Crystallogr. 2023, 56, 409–419. [Google Scholar] [CrossRef]
- Li, Y.; Dong, R.; Yang, W.; Hu, J. Composition based crystal materials symmetry prediction using machine learning with enhanced descriptors. Comput. Mater. Sci. 2021, 198, 110686. [Google Scholar] [CrossRef]
- Aguiar, J.A.; Gong, M.L.; Tasdizen, T. Crystallographic prediction from diffraction and chemistry data for higher throughput classification using machine learning. Comput. Mater. Sci. 2020, 173, 109409. [Google Scholar] [CrossRef]
- Taamneh, M.; Alkheder, S.; Taamneh, S. Data-mining techniques for traffic accident modeling and prediction in the United Arab Emirates. J. Transp. Saf. Secur. 2017, 9, 146–166. [Google Scholar] [CrossRef]
- Krishnaveni, S.; Hemalatha, M. A perspective analysis of traffic accident using data mining techniques. Int. J. Comput. Appl. 2011, 23, 40–48. [Google Scholar] [CrossRef]
- Pirdavani, A.; De Pauw, E.; Brijs, T.; Daniels, S.; Magis, M.; Bellemans, T.; Wets, G. Application of a rule-based approach in real-time crash risk prediction model development using loop detector data. Traffic Inj. Prev. 2015, 16, 786–791. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Gaikwad, D.P. Intrusion detection system using ensemble of rule learners and first search algorithm as feature selectors. Int. J. Comput. Netw. Inf. Secur. 2021, 13, 26–34. [Google Scholar] [CrossRef]
- Kareem, M.I.; Jasim, M.N. DDOS Attack Detection Using Lightweight Partial Decision Tree Algorithm. In Proceedings of the International Conference on Computer Science and Software Engineering (CSASE), Duhok, Iraq, 15–17 March 2022; pp. 362–367. [Google Scholar] [CrossRef]
- Al-diabat, M. Arabic text categorization using classification rule mining. Appl. Math. Sci. 2012, 6, 4033–4046. [Google Scholar]
- Berger, H.; Merkl, D.; Dittenbach, M. Exploiting Partial Decision Trees for Feature Subset Selection in E-Mail Categorization. In Proceedings of the 2006 ACM Symposium on Applied Computing (SAC), Dijon, France, 23–27 April 2006; pp. 1105–1109. [Google Scholar] [CrossRef]
- Mehdiyev, N.; Krumeich, J.; Enke, D.; Werth, D.; Loos, P. Determination of rule patterns in complex event processing using machine learning techniques. Procedia Comput. Sci. 2015, 61, 395–401. [Google Scholar] [CrossRef] [Green Version]
- Mazid, M.M.; Ali, A.S.; Tickle, K.S. Input space reduction for rule based classification. WSEAS Trans. Inf. Sci. Appl. 2010, 7, 749–759. [Google Scholar]
- Sorker, M.A.W.; Siddika, A.; Titly, T.A.; Mia, M.J.; Bijoy, M.H.I. Online Consumer Alignment using Supervised Machine Learning Technique. In Proceedings of the 13th International Conference on Computing Communication and Networking Technologies (ICCCNT), Kharagpur, India, 3–5 October 2022; pp. 1–7. [Google Scholar] [CrossRef]
- Jijo, B.T.; Abdulazeez, A.M. Classification based on decision tree algorithm for machine learning. JASTT 2021, 2, 20–28. [Google Scholar] [CrossRef]
- Comprehensive Database of Minerals. Available online: https://www.kaggle.com/datasets/vinven7/comprehensive-database-of-minerals (accessed on 22 February 2023).
- Frank, E.; Hall, M.A.; Witten, I.H. The WEKA Workbench. In Online Appendix for Data Mining: Practical Machine Learning Tools and Techniques, Morgan Kaufmann, 4th ed.; Elsevier: San Francisco, CA, USA, 2016; pp. 1–128. [Google Scholar]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Data | Method | Accuracy | Precision | Recall | F-Score | AUC |
|---|---|---|---|---|---|---|
| MAT_CHAR | RF | 89.23 | 0.880 | 0.892 | 0.880 | 0.958 |
| PART | 88.91 | 0.885 | 0.889 | 0.873 | 0.938 | |
| PART Forest | 90.35 | 0.903 | 0.904 | 0.889 | 0.957 | |
| CHEM_COMP | RF | 78.46 | 0.686 | 0.785 | 0.699 | 0.633 |
| PART | 76.69 | 0.676 | 0.767 | 0.706 | 0.630 | |
| PART Forest | 79.26 | 0.802 | 0.793 | 0.850 | 0.661 | |
| ALL | RF | 90.03 | 0.895 | 0.900 | 0.888 | 0.952 |
| PART | 88.10 | 0.870 | 0.881 | 0.873 | 0.901 | |
| PART Forest | 90.35 | 0.906 | 0.904 | 0.889 | 0.959 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ozturk Kiyak, E.; Tuysuzoglu, G.; Birant, D. Partial Decision Tree Forest: A Machine Learning Model for the Geosciences. Minerals 2023, 13, 800. https://doi.org/10.3390/min13060800
Ozturk Kiyak E, Tuysuzoglu G, Birant D. Partial Decision Tree Forest: A Machine Learning Model for the Geosciences. Minerals. 2023; 13(6):800. https://doi.org/10.3390/min13060800
Chicago/Turabian StyleOzturk Kiyak, Elife, Goksu Tuysuzoglu, and Derya Birant. 2023. "Partial Decision Tree Forest: A Machine Learning Model for the Geosciences" Minerals 13, no. 6: 800. https://doi.org/10.3390/min13060800