
Visual Interpretation of Machine Learning: Genetical Classification of Apatite from Various Ore Sources
 ,
,
Abstract
:1. Introduction
2. Apatite Trace Element Dataset
3. Methods
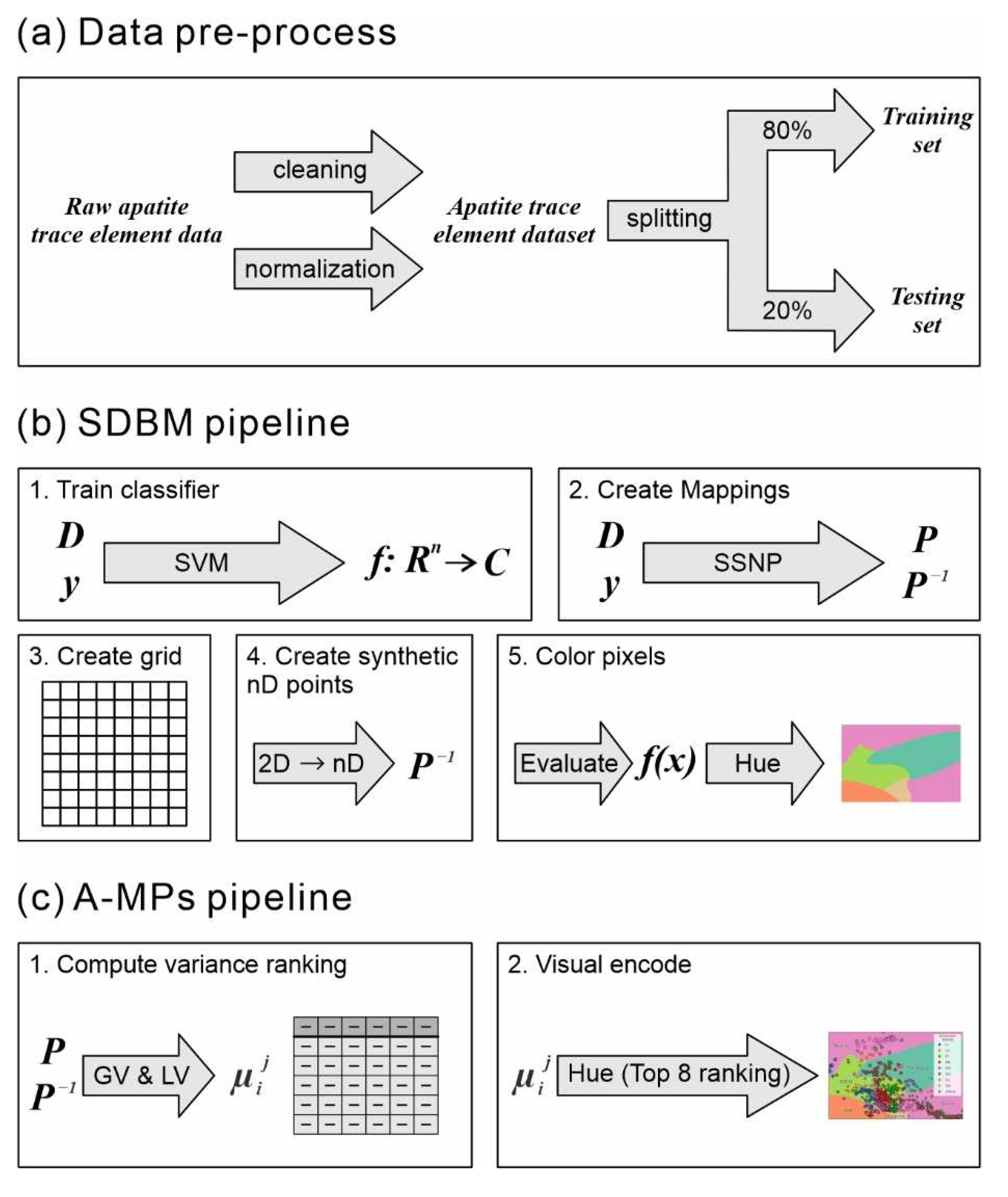
3.1. Data Pre-Processing
3.2. SDBM Visualization
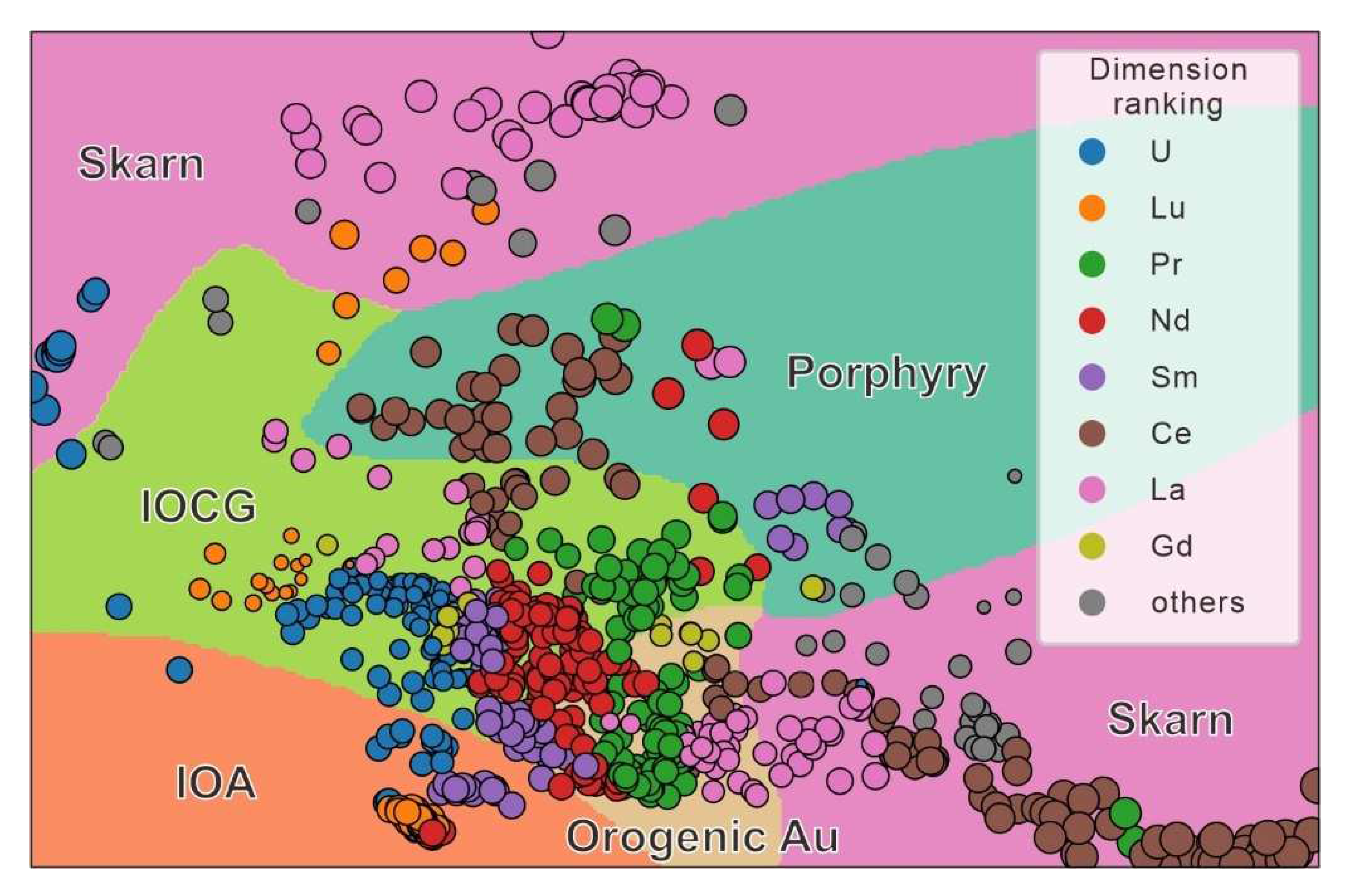
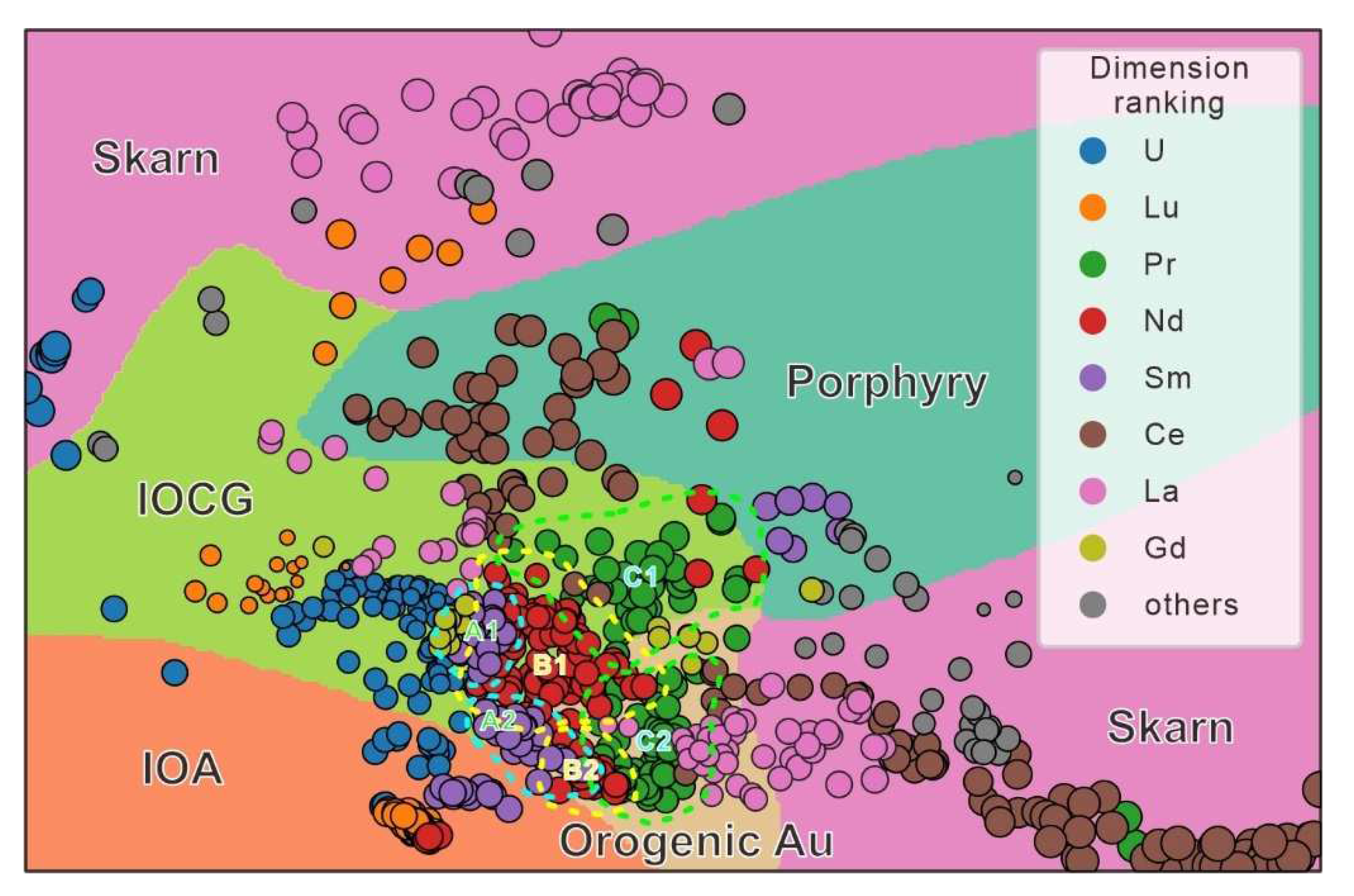
3.3. Attribute-Based Visual Explanation of Multidimensional Projections
3.4. Evaluation Metrics
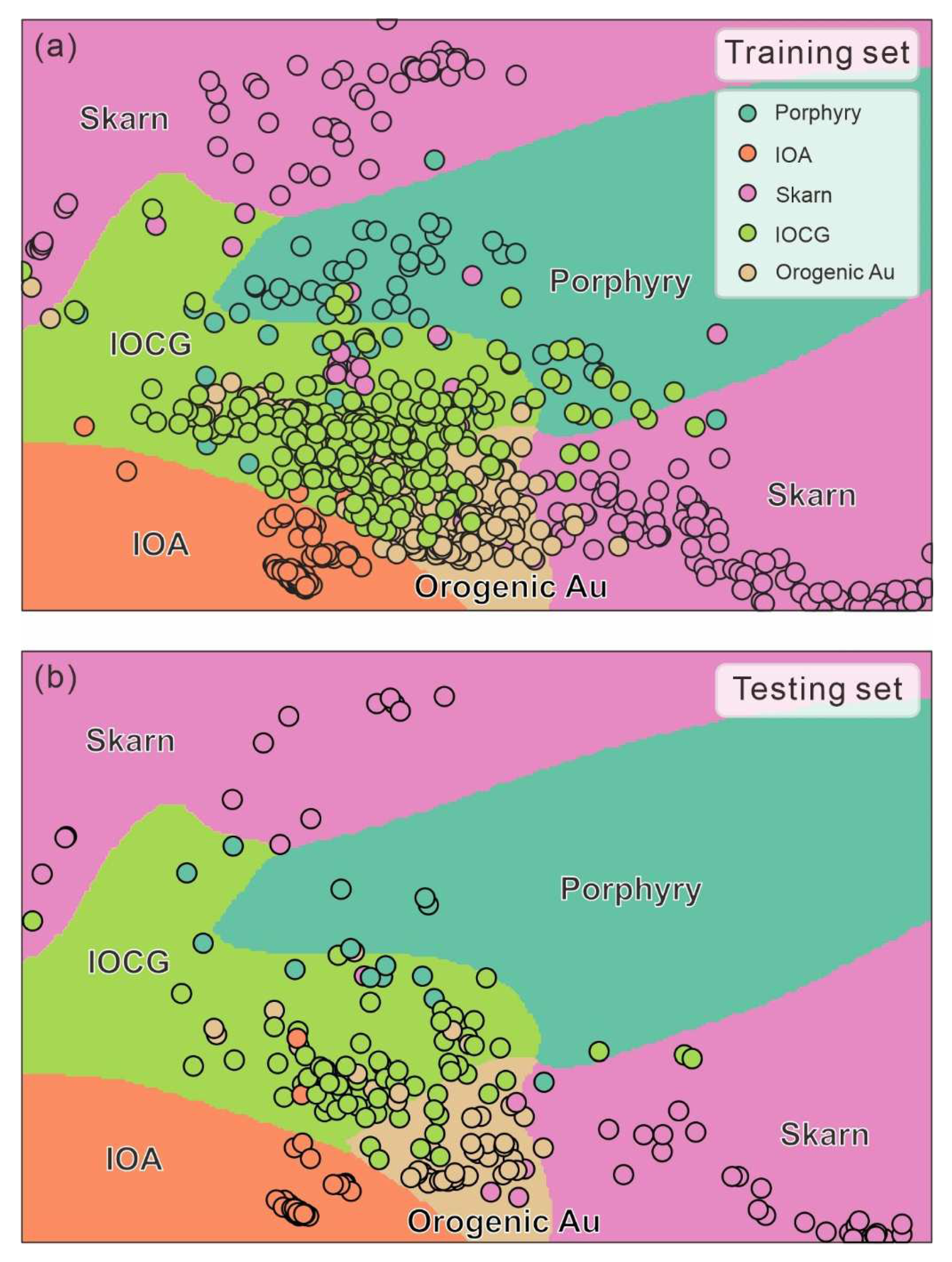
4. Results
5. Discussion
5.1. Visualization in High-Dimensional Space
5.2. Explanation of Multidimensional Projections
5.3. Other Interpretation Approaches
5.4. Future Work
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Dramsch, J.S. 70 years of machine learning in geoscience in review. Adv. Geophys. 2020, 61, 1–55. [Google Scholar]
- Bergen, K.J.; Johnson, P.A.; de Hoop, M.V.; Beroza, G.C. Machine learning for data-driven discovery in solid Earth geoscience. Science 2019, 363, eaau0323. [Google Scholar] [CrossRef]
- Kotsiantis, S.B.; Zaharakis, I.D.; Pintelas, P.E. Machine learning: A review of classification and combining techniques. Artif. Intell. Rev. 2006, 26, 159–190. [Google Scholar] [CrossRef]
- Nachtergaele, S.; De Grave, J. AI-Track-tive: Open-source software for automated recognition and counting of surface semi-tracks using computer vision (artificial intelligence). Geochronology 2021, 3, 383–394. [Google Scholar] [CrossRef]
- Wang, Y.; Qiu, K.F.; Müller, A.; Hou, Z.L.; Zhu, Z.H.; Yu, H.C. Machine learning prediction of quartz forming-environments. J. Geophys. Res. Solid Earth 2021, 126, e2021JB021925. [Google Scholar] [CrossRef]
- Chen, H.; Su, C.; Tang, Y.Q.; Li, A.Z.; Wu, S.S.; Xia, Q.K.; ZhangZhou, J. Machine learning for identification of primary water concentrations in mantle pyroxene. Geophys. Res. Lett. 2021, 48, e2021GL095191. [Google Scholar] [CrossRef]
- Gion, A.M.; Piccoli, P.M.; Candela, P.A. Characterization of biotite and amphibole compositions in granites. Contrib. Mineral. Petrol. 2022, 177, 43. [Google Scholar] [CrossRef]
- Zhong, R.; Deng, Y.; Li, W.; Danyushevsky, L.V.; Cracknell, M.J.; Belousov, I.; Chen, Y.; Li, L. Revealing the multi-stage ore-forming history of a mineral deposit using pyrite geochemistry and machine learning-based data interpretation. Ore Geol. Rev. 2021, 133, 104079. [Google Scholar] [CrossRef]
- Ziyi, Z.; Fei, Z.; Yu, W.; Tong, Z.; Zhaoliang, H.; Kunfeng, Q. Machine learning-based approach for zircon classification and genesis determination. Earth Sci. Front. 2022, 29, 464. [Google Scholar]
- Wu, Y.; Jia, M.; Xiang, C.; Fang, Y. Latent trajectories of frailty and risk prediction models among geriatric community dwellers: An interpretable machine learning perspective. BMC Geriatr. 2022, 22, 900. [Google Scholar] [CrossRef]
- Rodrigues, F.C.; Espadoto, M.; Hirata, R., Jr.; Telea, A.C. Constructing and visualizing high-quality classifier decision boundary maps. Information 2019, 10, 280. [Google Scholar] [CrossRef] [Green Version]
- Zou, C.; Zhao, L.; Xu, M.; Chen, Y.; Geng, J. Porosity prediction with uncertainty quantification from multiple seismic attributes using random forest. J. Geophys. Res. Solid Earth 2021, 126, e2021JB021826. [Google Scholar] [CrossRef]
- Roscher, R.; Bohn, B.; Duarte, M.; Garcke, J. Explain It to Me—Facing Remote Sensing Challenges in the Bio-and Geosciences With Explainable Machine Learning. ISPRS Ann. Photogramm. Remote Sens. Spat. Inf. Sci. 2020, 3, 817–824. [Google Scholar] [CrossRef]
- Nathwani, C.L.; Wilkinson, J.J.; Fry, G.; Armstrong, R.N.; Smith, D.J.; Ihlenfeld, C. Machine learning for geochemical exploration: Classifying metallogenic fertility in arc magmas and insights into porphyry copper deposit formation. Miner. Depos. 2022, 57, 1143–1166. [Google Scholar] [CrossRef]
- Al-Najjar, H.A.; Pradhan, B.; Beydoun, G.; Sarkar, R.; Park, H.-J.; Alamri, A. A novel method using explainable artificial intelligence (XAI)-based Shapley Additive Explanations for spatial landslide prediction using Time-Series SAR dataset. Gondwana Res. 2022, in press. [Google Scholar] [CrossRef]
- Chelgani, S.C. Estimation of gross calorific value based on coal analysis using an explainable artificial intelligence. Mach. Learn. Appl. 2021, 6, 100116. [Google Scholar] [CrossRef]
- Oliveira, A.A.; Espadoto, M.; Hirata, R., Jr.; Telea, A.C. SDBM: Supervised Decision Boundary Maps for Machine Learning Classifiers. In Proceedings of the VISIGRAPP (3: IVAPP), Online Streaming, 6–8 February 2022; pp. 77–87. [Google Scholar]
- Da Silva, R.R.; Rauber, P.E.; Martins, R.M.; Minghim, R.; Telea, A.C. Attribute-based Visual Explanation of Multidimensional Projections. In Proceedings of the EuroVA@ EuroVis, Sardinia, Italy, 25–26 May 2015; pp. 31–35. [Google Scholar]
- Sha, L.-K.; Chappell, B.W. Apatite chemical composition, determined by electron microprobe and laser-ablation inductively coupled plasma mass spectrometry, as a probe into granite petrogenesis. Geochim. Cosmochim. Acta 1999, 63, 3861–3881. [Google Scholar] [CrossRef]
- Zhou, T.; Qiu, K.; Wang, Y.; Yu, H.; Hou, Z. Apatite Eu/Y-Ce discrimination diagram: A big data based approach for provenance classification. Acta Petrol. Sin. 2022, 38, 291–299. [Google Scholar]
- Yu, H.-C.; Qiu, K.-F.; Hetherington, C.J.; Chew, D.; Huang, Y.-Q.; He, D.-Y.; Geng, J.-Z.; Xian, H.-Y. Apatite as an alternative petrochronometer to trace the evolution of magmatic systems containing metamict zircon. Contrib. Mineral. Petrol. 2021, 176, 68. [Google Scholar] [CrossRef]
- Qiu, K.-F.; Yu, H.-C.; Deng, J.; McIntire, D.; Gou, Z.-Y.; Geng, J.-Z.; Chang, Z.-S.; Zhu, R.; Li, K.-N.; Goldfarb, R. The giant Zaozigou Au-Sb deposit in West Qinling, China: Magmatic-or metamorphic-hydrothermal origin? Miner. Depos. 2020, 55, 345–362. [Google Scholar] [CrossRef]
- Chu, M.-F.; Wang, K.-L.; Griffin, W.L.; Chung, S.-L.; O’Reilly, S.Y.; Pearson, N.J.; Iizuka, Y. Apatite composition: Tracing petrogenetic processes in Transhimalayan granitoids. J. Petrol. 2009, 50, 1829–1855. [Google Scholar] [CrossRef]
- Yu, H.-C.; Qiu, K.-F.; Chew, D.; Yu, C.; Ding, Z.-J.; Zhou, T.; Li, S.; Sun, K.-F. Buried Triassic rocks and vertical distribution of ores in the giant Jiaodong gold province (China) revealed by apatite xenocrysts in hydrothermal quartz veins. Ore Geol. Rev. 2022, 140, 104612. [Google Scholar] [CrossRef]
- Chew, D.M.; Sylvester, P.J.; Tubrett, M.N. U–Pb and Th–Pb dating of apatite by LA-ICPMS. Chem. Geol. 2011, 280, 200–216. [Google Scholar] [CrossRef]
- Webster, J.D.; Piccoli, P.M. Magmatic apatite: A powerful, yet deceptive, mineral. Elements 2015, 11, 177–182. [Google Scholar] [CrossRef]
- Hughes, J.M.; Rakovan, J.F. Structurally robust, chemically diverse: Apatite and apatite supergroup minerals. Elements 2015, 11, 165–170. [Google Scholar] [CrossRef]
- Zhou, R.-J.; Wen, G.; Li, J.-W.; Jiang, S.-Y.; Hu, H.; Deng, X.-D.; Zhao, X.-F.; Yan, D.-R.; Wei, K.-T.; Cai, H.-A. Apatite chemistry as a petrogenetic–metallogenic indicator for skarn ore-related granitoids: An example from the Daye Fe–Cu–(Au–Mo–W) district, Eastern China. Contrib. Mineral. Petrol. 2022, 177, 23. [Google Scholar] [CrossRef]
- Mao, M.; Rukhlov, A.S.; Rowins, S.M.; Spence, J.; Coogan, L.A. Apatite trace element compositions: A robust new tool for mineral exploration. Econ. Geol. 2016, 111, 1187–1222. [Google Scholar] [CrossRef] [Green Version]
- O’Sullivan, G.; Chew, D.; Kenny, G.; Henrichs, I.; Mulligan, D. The trace element composition of apatite and its application to detrital provenance studies. Earth Sci. Rev. 2020, 201, 103044. [Google Scholar] [CrossRef]
- Belousova, E.; Griffin, W.; O’Reilly, S.Y.; Fisher, N. Apatite as an indicator mineral for mineral exploration: Trace-element compositions and their relationship to host rock type. J. Geochem. Explor. 2002, 76, 45–69. [Google Scholar] [CrossRef]
- Deng, J.; Yang, L.-Q.; Groves, D.I.; Zhang, L.; Qiu, K.-F.; Wang, Q.-F. An integrated mineral system model for the gold deposits of the giant Jiaodong province, eastern China. Earth Sci. Rev. 2020, 208, 103274. [Google Scholar] [CrossRef]
- Qiu, K.-F.; Yu, H.-C.; Hetherington, C.; Huang, Y.-Q.; Yang, T.; Deng, J. Tourmaline composition and boron isotope signature as a tracer of magmatic-hydrothermal processes. Am. Mineral. J. Earth Planet. Mater. 2021, 106, 1033–1044. [Google Scholar] [CrossRef]
- Wu, M.; Samson, I.; Qiu, K.; Zhang, D. Concentration mechanisms of REE-Nb-Zr-Be mineralization in the Baerzhe deposit, NE China: Insights from textural and chemical features of amphibole and rare-metal minerals. Econ. Geol. 2021, 116, 651–679. [Google Scholar] [CrossRef]
- Li, C.; Arndt, N.T.; Tang, Q.; Ripley, E.M. Trace element indiscrimination diagrams. Lithos 2015, 232, 76–83. [Google Scholar] [CrossRef]
- Pearce, J.A. A user’s guide to basalt discrimination diagrams. In Trace Element Geochemistry of Volcanic Rocks: Applications for Massive Sulphide Exploration. Geological Association of Canada, Short Course Notes; Geological Association of Canada: St. John’s, NL, Canada, 1996; Volume 12, p. 113. [Google Scholar]
- Snow, C.A. A reevaluation of tectonic discrimination diagrams and a new probabilistic approach using large geochemical databases: Moving beyond binary and ternary plots. J. Geophys. Res. Solid Earth 2006, 111. [Google Scholar] [CrossRef] [Green Version]
- Andersson, S.S.; Wagner, T.; Jonsson, E.; Fusswinkel, T.; Whitehouse, M.J. Apatite as a tracer of the source, chemistry and evolution of ore-forming fluids: The case of the Olserum-Djupedal REE-phosphate mineralisation, SE Sweden. Geochim. Cosmochim. Acta 2019, 255, 163–187. [Google Scholar] [CrossRef]
- Li, R.; Xu, Z.; Su, C.; Yang, R. Automatic identification of semi-tracks on apatite and mica using a deep learning method. Comput. Geosci. 2022, 162, 105081. [Google Scholar] [CrossRef]
- Cao, M.; Li, G.; Qin, K.; Seitmuratova, E.Y.; Liu, Y. Major and trace element characteristics of apatites in granitoids from Central Kazakhstan: Implications for petrogenesis and mineralization. Resour. Geol. 2012, 62, 63–83. [Google Scholar] [CrossRef]
- Pan, L.-C.; Hu, R.-Z.; Wang, X.-S.; Bi, X.-W.; Zhu, J.-J.; Li, C. Apatite trace element and halogen compositions as petrogenetic-metallogenic indicators: Examples from four granite plutons in the Sanjiang region, SW China. Lithos 2016, 254, 118–130. [Google Scholar] [CrossRef]
- Xing, K.; Shu, Q.; Lentz, D.R. Constraints on the formation of the giant Daheishan porphyry Mo deposit (NE China) from whole-rock and accessory mineral geochemistry. J. Petrol. 2021, 62, egab018. [Google Scholar] [CrossRef]
- Adlakha, E.; Hanley, J.; Falck, H.; Boucher, B. The origin of mineralizing hydrothermal fluids recorded in apatite chemistry at the Cantung W–Cu skarn deposit, NWT, Canada. Eur. J. Mineral. 2018, 30, 1095–1113. [Google Scholar] [CrossRef]
- Yang, J.-H.; Kang, L.-F.; Peng, J.-T.; Zhong, H.; Gao, J.-F.; Liu, L. In-situ elemental and isotopic compositions of apatite and zircon from the Shuikoushan and Xihuashan granitic plutons: Implication for Jurassic granitoid-related Cu-Pb-Zn and W mineralization in the Nanling Range, South China. Ore Geol. Rev. 2018, 93, 382–403. [Google Scholar] [CrossRef]
- Jia, F.; Zhang, C.; Liu, H.; Meng, X.; Kong, Z. In situ major and trace element compositions of apatite from the Yangla skarn Cu deposit, southwest China: Implications for petrogenesis and mineralization. Ore Geol. Rev. 2020, 127, 103360. [Google Scholar] [CrossRef]
- Zhang, F.; Li, W.; White, N.C.; Zhang, L.; Qiao, X.; Yao, Z. Geochemical and isotopic study of metasomatic apatite: Implications for gold mineralization in Xindigou, northern China. Ore Geol. Rev. 2020, 127, 103853. [Google Scholar] [CrossRef]
- Hazarika, P.; Mishra, B.; Pruseth, K.L. Scheelite, apatite, calcite and tourmaline compositions from the late Archean Hutti orogenic gold deposit: Implications for analogous two stage ore fluids. Ore Geol. Rev. 2016, 72, 989–1003. [Google Scholar] [CrossRef]
- Krneta, S.; Cook, N.J.; Ciobanu, C.L.; Ehrig, K.; Kontonikas-Charos, A. The Wirrda Well and Acropolis prospects, Gawler Craton, South Australia: Insights into evolving fluid conditions through apatite chemistry. J. Geochem. Explor. 2017, 181, 276–291. [Google Scholar] [CrossRef]
- Mukherjee, R.; Venkatesh, A. Chemistry of magnetite-apatite from albitite and carbonate-hosted Bhukia Gold Deposit, Rajasthan, western India—An IOCG-IOA analogue from Paleoproterozoic Aravalli Supergroup: Evidence from petrographic, LA-ICP-MS and EPMA studies. Ore Geol. Rev. 2017, 91, 509–529. [Google Scholar] [CrossRef]
- Rebala, G.; Ravi, A.; Churiwala, S. Machine learning definition and basics. In Introduction to Machine Learning; Springer: Cham, Switzerland, 2019; pp. 1–17. [Google Scholar]
- Parsons, V.L. Stratified sampling. In Wiley StatsRef: Statistics Reference Online; Wiley: Hoboken, NJ, USA, 2014; pp. 1–11. [Google Scholar]
- Chawla, N.V.; Bowyer, K.W.; Hall, L.O.; Kegelmeyer, W.P. SMOTE: Synthetic minority over-sampling technique. J. Artif. Intell. Res. 2002, 16, 321–357. [Google Scholar] [CrossRef]
- He, H.; Garcia, E.A. Learning from imbalanced data. IEEE Trans. Knowl. Data Eng. 2009, 21, 1263–1284. [Google Scholar]
- Espadoto, M.; Rodrigues, F.C.M.; Telea, A.C. Visual Analytics of Multidimensional Projections for Constructing Classifier Decision Boundary Maps. In Proceedings of the VISIGRAPP (3: IVAPP), Prague, Czech Republic, 25–27 February 2019; pp. 28–38. [Google Scholar]
- Rodrigues, F.C. Visual Analytics for Machine Learning. Ph.D. Thesis, University of Groningen, Groningen, The Netherlands, 2020. [Google Scholar]
- Rodrigues, F.C.M.; Hirata, R.; Telea, A.C. Image-based visualization of classifier decision boundaries. In Proceedings of the 2018 31st SIBGRAPI Conference on Graphics, Patterns and Images (SIBGRAPI), Paraná, Brazil, 29 October–1 November 2018; pp. 353–360. [Google Scholar]
- Espadoto, M.; Hirata, N.S.T.; Telea, A.C. Self-Supervised Dimensionality Reduction with Neural Networks and Pseudo-Labeling. In IVAPP; Hurter, C., Purchase, H., Braz, J., Bouatouch, K., Eds.; SciTePress: Setúbal, Portugal, 2021; pp. 27–37. [Google Scholar]
- Cortes, C.; Vapnik, V. Support-vector networks. Mach. Learn. 1995, 20, 273–297. [Google Scholar] [CrossRef]
- Bouzari, F.; Hart, C.; Barker, S.; Bissig, T. Exploration for concealed deposits using porphyry indicator minerals (PIMs): Application of apatite texture and chemistry [abs.]. 25th Int. Appl. Geochem. Sympos. 2011, 92, 89–90. [Google Scholar]
- Sillitoe, R.H. Porphyry copper systems. Econ. Geol. 2010, 105, 3–41. [Google Scholar] [CrossRef] [Green Version]
- Qiu, K.-F.; Taylor, R.D.; Song, Y.-H.; Yu, H.-C.; Song, K.-R.; Li, N. Geologic and geochemical insights into the formation of the Taiyangshan porphyry copper–molybdenum deposit, Western Qinling Orogenic Belt, China. Gondwana Res. 2016, 35, 40–58. [Google Scholar] [CrossRef]
- Espadoto, M.; Rodrigues, F.; Hirata, N.S.T.; Telea, A.C. Deep learning inverse multidimensional projections. In Proceedings of the 10th International EuroVis Workshop on Visual Analytics, Porto, Portugal, 3 June 2019. [Google Scholar] [CrossRef]
- Lundberg, S.M.; Lee, S.-I. A unified approach to interpreting model predictions. Adv. Neural Inf. Process. Syst. 2017, 30, 4768–4777. [Google Scholar]
- Zhou, T.; Qiu, K.-F.; Wang, Y. From Trace Elements to Petrogenesis: A Machine Learning Approach to Determine Ore Deposit Type from Trace Elements Analysis of Apatite. In Proceedings of the Copernicus Meetings, Vienna, Austria, 23–28 April 2023. [Google Scholar]
- Qiu, K.-F.; Zhou, T.; Chew, D.; Hou, Z.L.; Müller, A.; Yu, H.-C.; Lee, R.G.; Chen, H.; Deng, J. Apatite trace element composition as an indicator of ore deposit types: A machine learning approach. Am. Mineral. 2023. accepted. [Google Scholar]
- Parsa, A.B.; Movahedi, A.; Taghipour, H.; Derrible, S.; Mohammadian, A.K. Toward safer highways, application of XGBoost and SHAP for real-time accident detection and feature analysis. Accid. Anal. Prev. 2020, 136, 105405. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
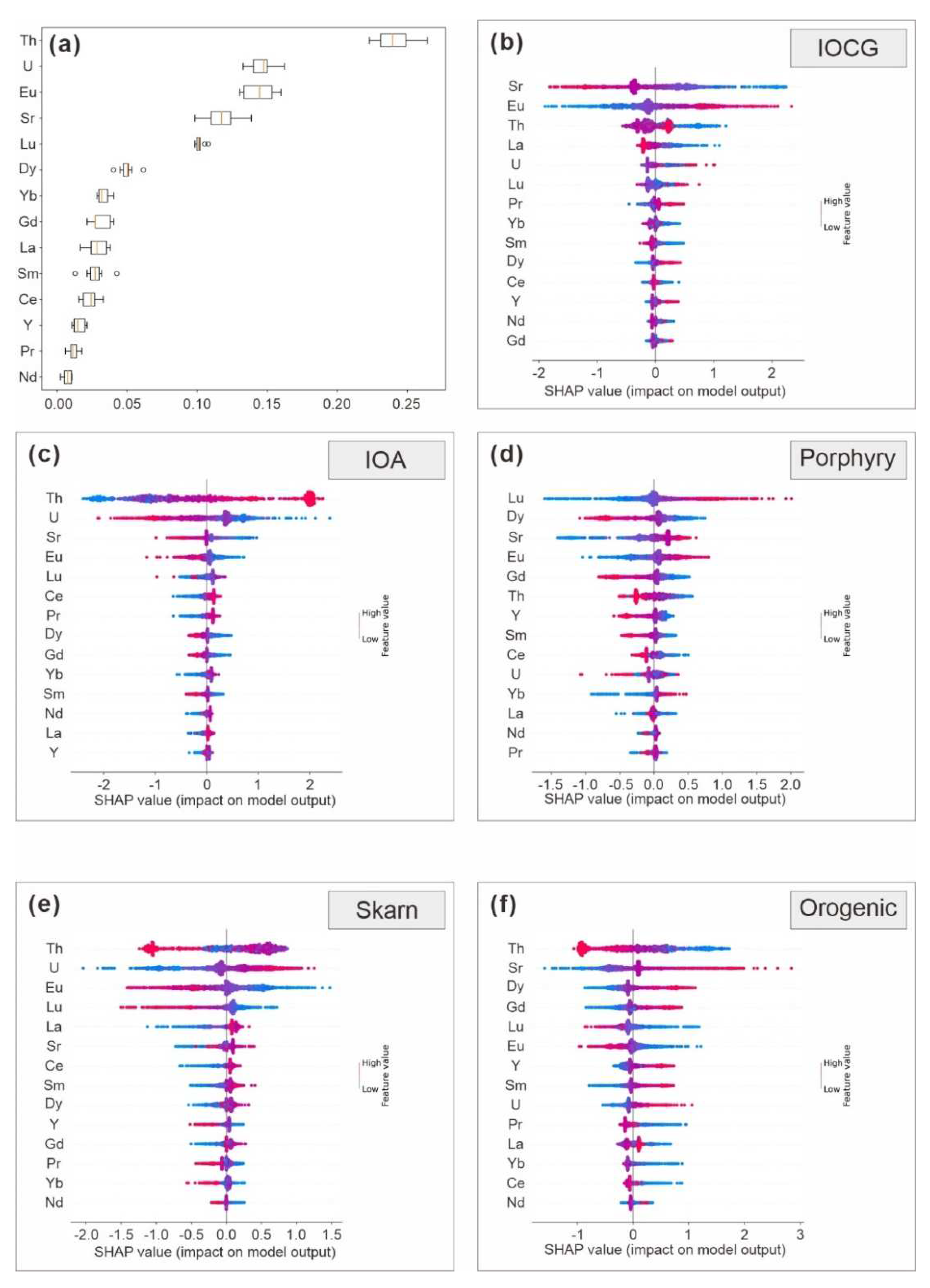{kind=link}
| Deposit Type | Number of Apatite Samples | Source Deposit | Reference |
|---|---|---|---|
| Porphyry | 422 | Boss Mountain, Brenda, Cassiar Moly, Daheishan, Dobbin, Endako, Gibraltar, Highland Valley, Highmont, Kemess South, Lornex, Mount Polley, Shiko, and Willa | [30,41,42,43] |
| Skarn | 534 | Cantung, Gold Canyon, Little Billie, Minyari, Molly, O’Callagham’s, Racine, Shuikoushan, and Yangla | [30,41,44,45,46] |
| Orogenic Au | 250 | Congress (Lou), Dentonia, Hutti, Kirkland Lake, Laodou, Seabee, and Xindigou | [30,47,48] |
| IOCG | 78 | Acropolis prospect, Bhukia, Wernecke, ad Wirrda Well prospect | [30,49,50] |
| IOA | 267 | Aoshan, Durango, and Great Bear | [30] |
| Predicted Label | Positive | Negative | |
|---|---|---|---|
| True Label | |||
| Positive | True Positive (TP) | False Negative (FN) | |
| Negative | False Positive (FP) | True Negative (TN) | |
| Precision | Recall | F1-Score | Support | |
|---|---|---|---|---|
| IOCG | 0.67 | 0.71 | 0.69 | 14 |
| IOA | 1.00 | 1,00 | 1.00 | 40 |
| Orogenic | 0.89 | 0.89 | 0.89 | 44 |
| Porphyry | 0.91 | 0.89 | 0.90 | 70 |
| Skarn | 0.82 | 0.84 | 0.83 | 44 |
| Accuracy | 0.89 | 212 | ||
| Macro avg | 0.86 | 0.87 | 0.86 | 212 |
| Weighted avg | 0.89 | 0.89 | 0.89 | 212 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhou, T.; Cai, Y.-W.; An, M.-G.; Zhou, F.; Zhi, C.-L.; Sun, X.-C.; Tamer, M. Visual Interpretation of Machine Learning: Genetical Classification of Apatite from Various Ore Sources. Minerals 2023, 13, 491. https://doi.org/10.3390/min13040491
Zhou T, Cai Y-W, An M-G, Zhou F, Zhi C-L, Sun X-C, Tamer M. Visual Interpretation of Machine Learning: Genetical Classification of Apatite from Various Ore Sources. Minerals. 2023; 13(4):491. https://doi.org/10.3390/min13040491
Chicago/Turabian StyleZhou, Tong, Yi-Wei Cai, Mao-Guo An, Fei Zhou, Cheng-Long Zhi, Xin-Chun Sun, and Murat Tamer. 2023. "Visual Interpretation of Machine Learning: Genetical Classification of Apatite from Various Ore Sources" Minerals 13, no. 4: 491. https://doi.org/10.3390/min13040491