
Hybrid Serving of DOE and RNN-Based Methods to Optimize and Simulate a Copper Flotation Circuit


Abstract
:1. Introduction
2. Materials and Methods
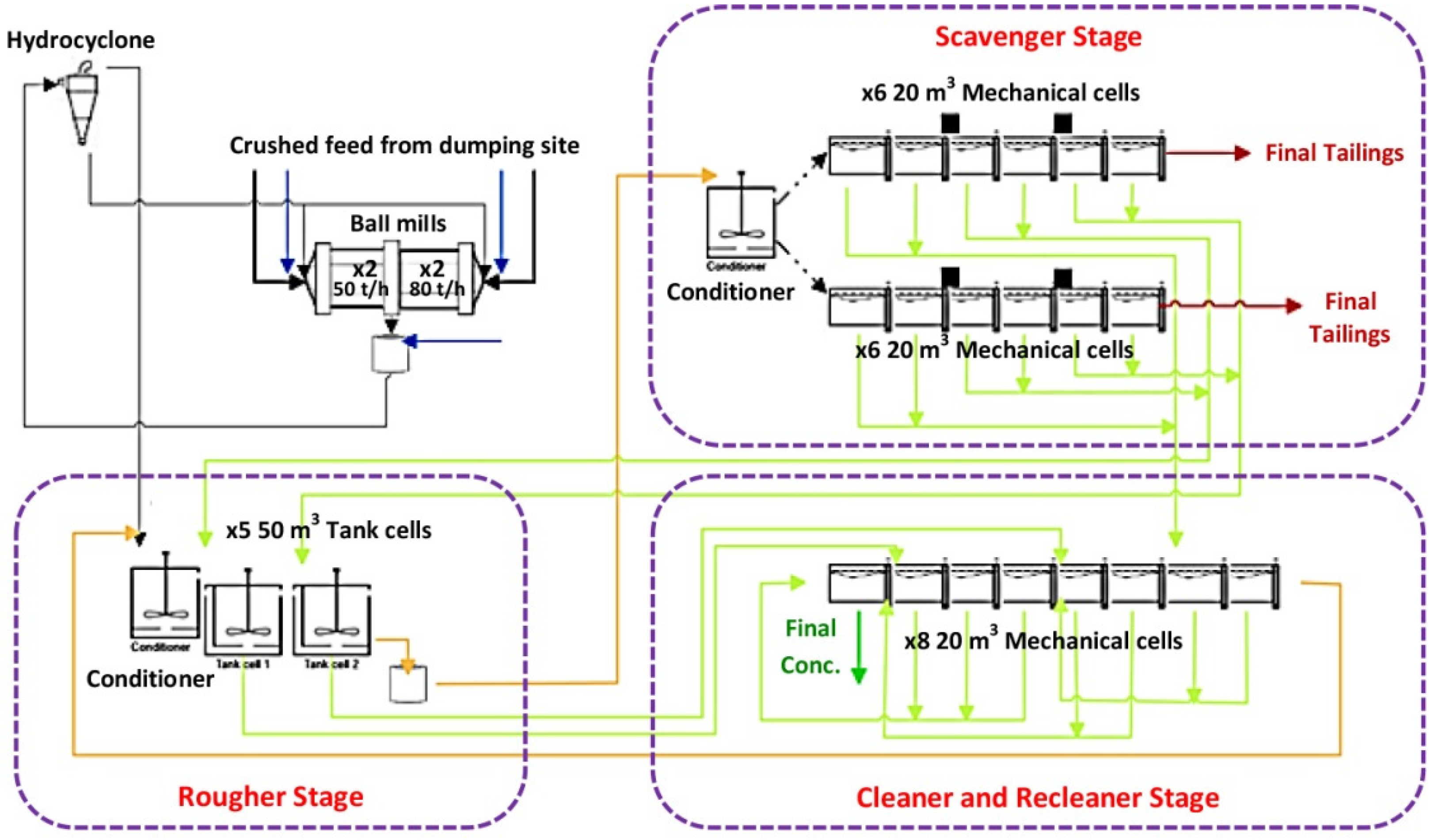
2.1. A Brief Description of the Processing Plant
2.2. Ore Sample and Reagents Used
2.3. Screening of Operational Variables
2.4. Statistical Optimization Studies
2.5. Flotation Experiments and Calculations
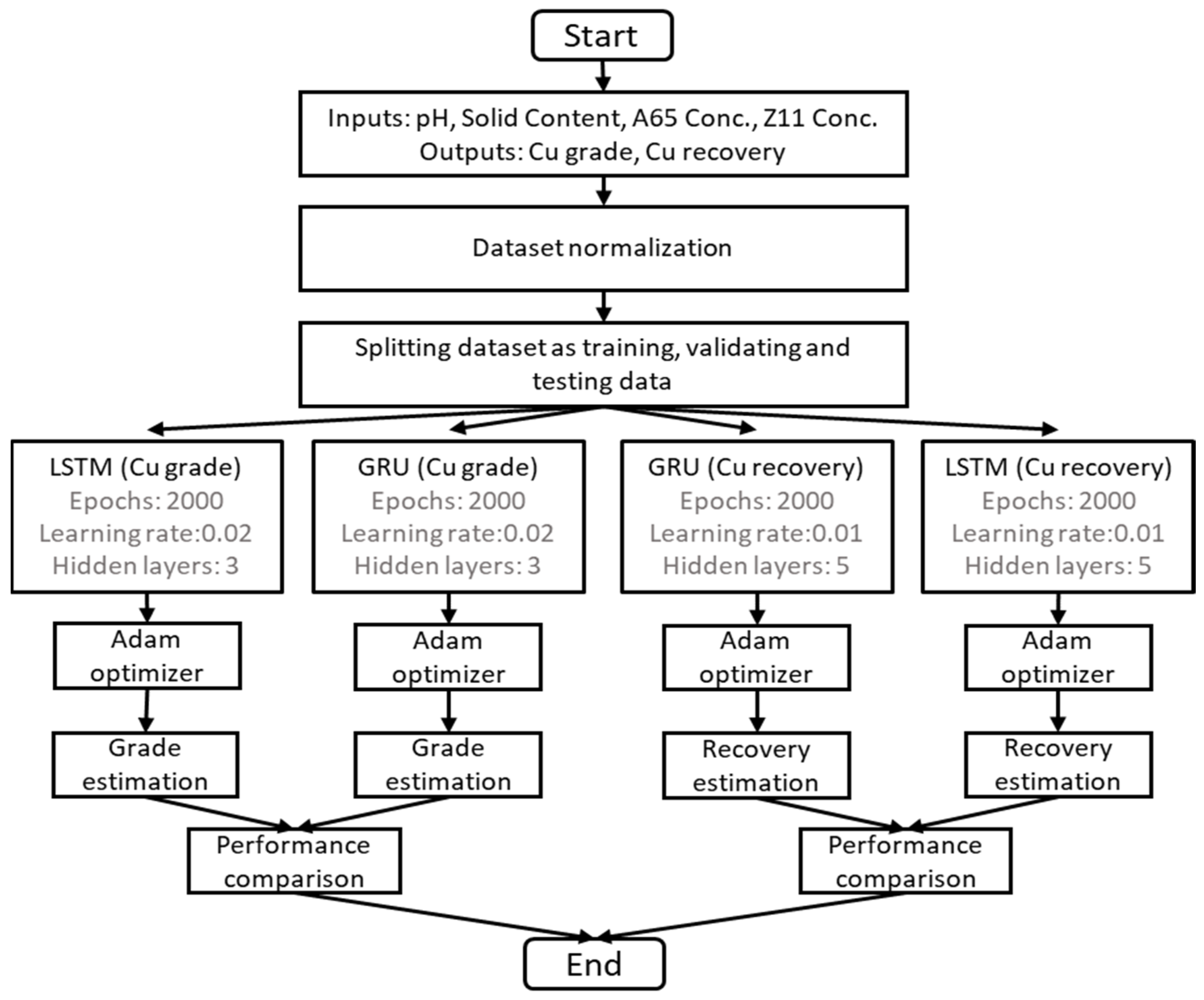
2.6. Recurrent Neural Network Simulation
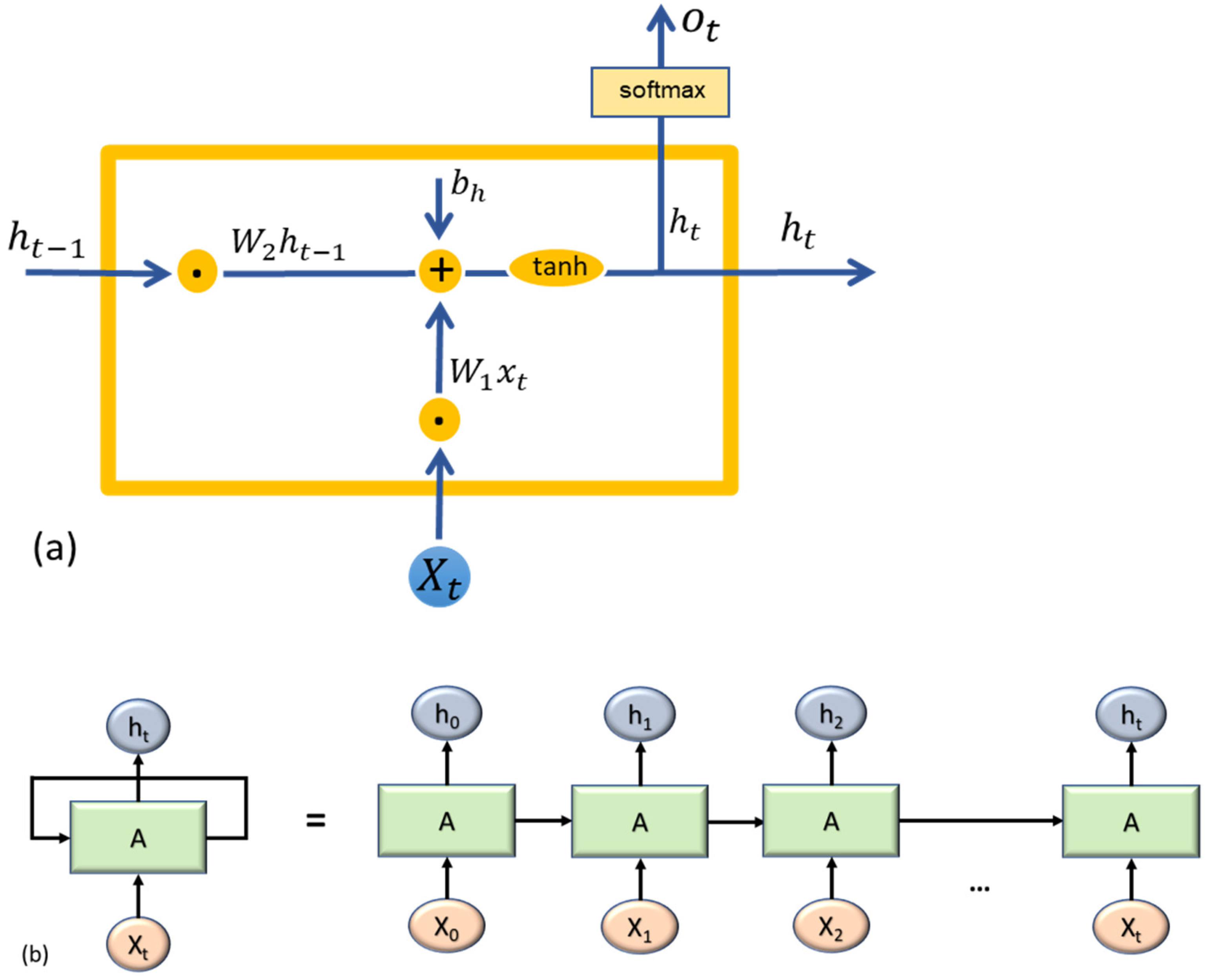
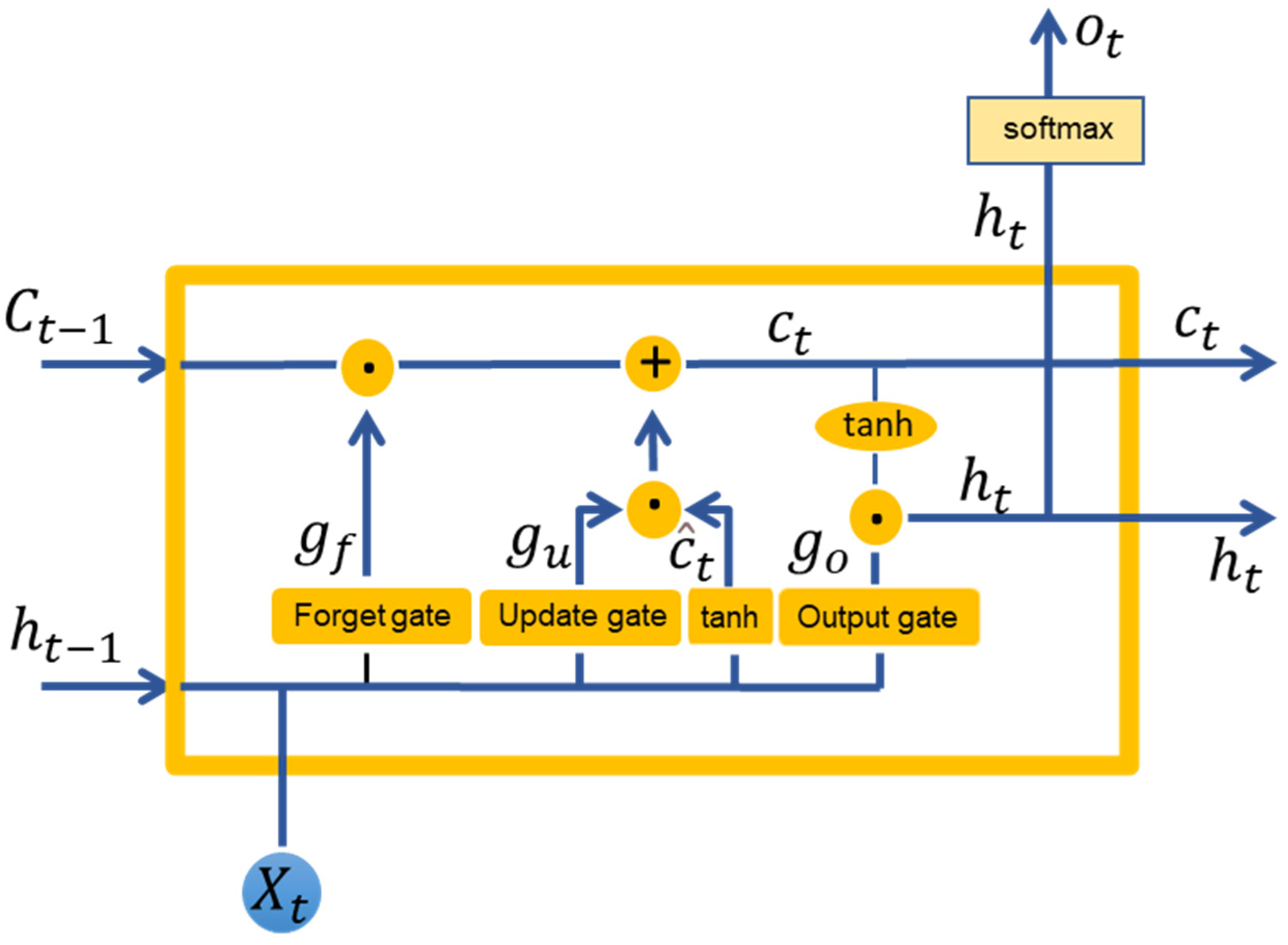
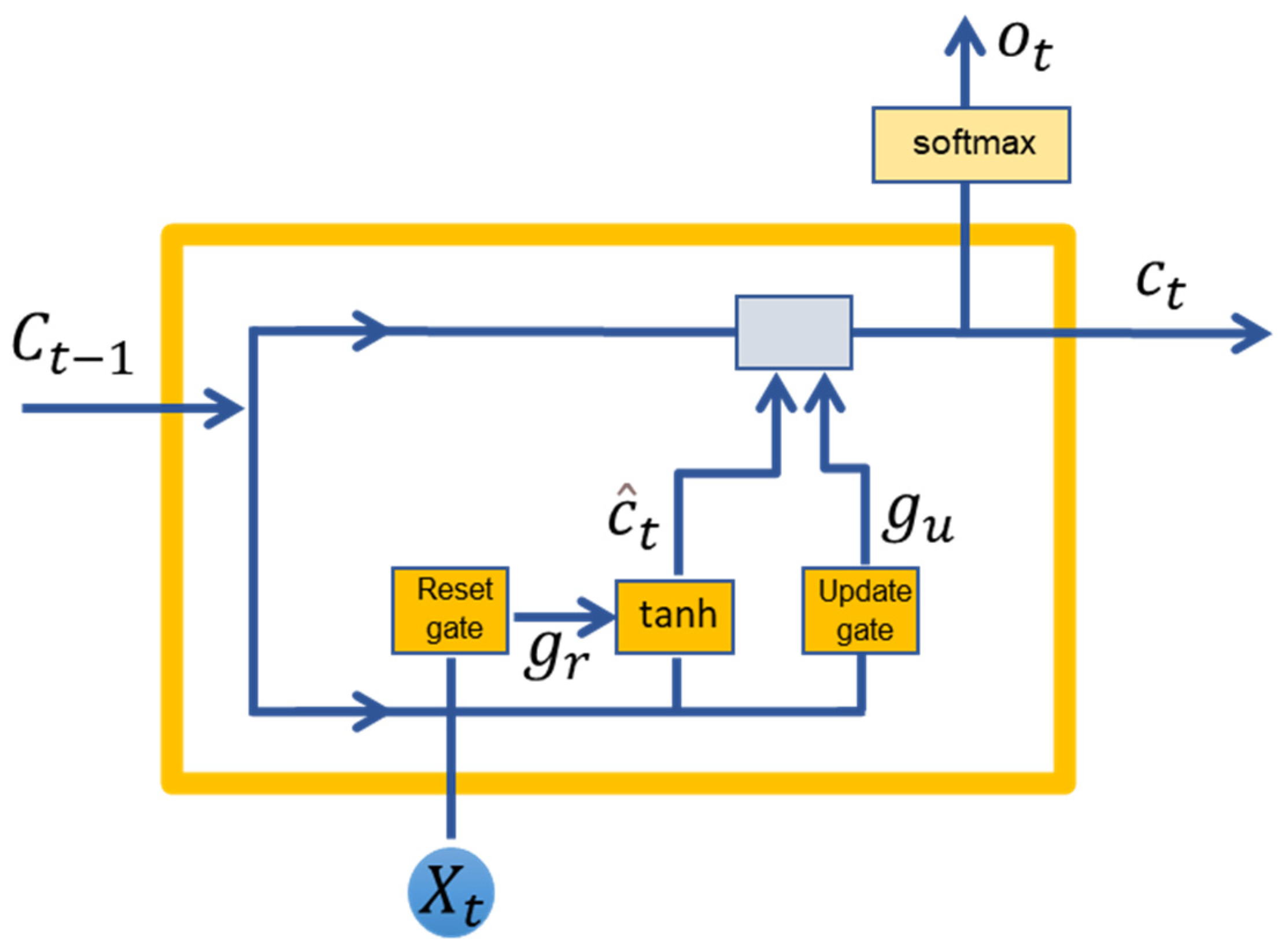
2.6.1. RNN-Based Methods
2.6.2. Modelling Process
- Random forest is a powerful learning method for classification and regression problems by constructing a multitude of decision trees at training time. This non-parametric method uses ensemble learning to avoid overfitting. To find the optimum number of trees, different numbers were tested. Based on the results, 26 and 22 trees were found to have the most accurate prediction for Cu grade and Cu recovery, respectively, and increasing the number of trees did not have significant impact on the accuracy of results. The optimum depth of the tree was also found to be 4 for both Cu grade and recovery models, and increasing the maximum depth of trees resulted in overfitting;
- LMA is known as the preferred method for minimization in nonlinear least squares problems. LMA interpolates between the Gauss–Newton algorithm and the gradient descent method. Compared with Gauss–Newton, Levenberg–Marquardt is more robust and, in many cases, it will find a solution even if it starts very far from the final minimum. ANN-LMA was found to be superior in Ref. [19] against other metaheuristic algorithms. The proper structure for ANN-LMA was found to be 5-12-4-1 for the Cu recovery model and 5-10-5-1 for the Cu grade model based on trial and error.
3. Results and Discussion
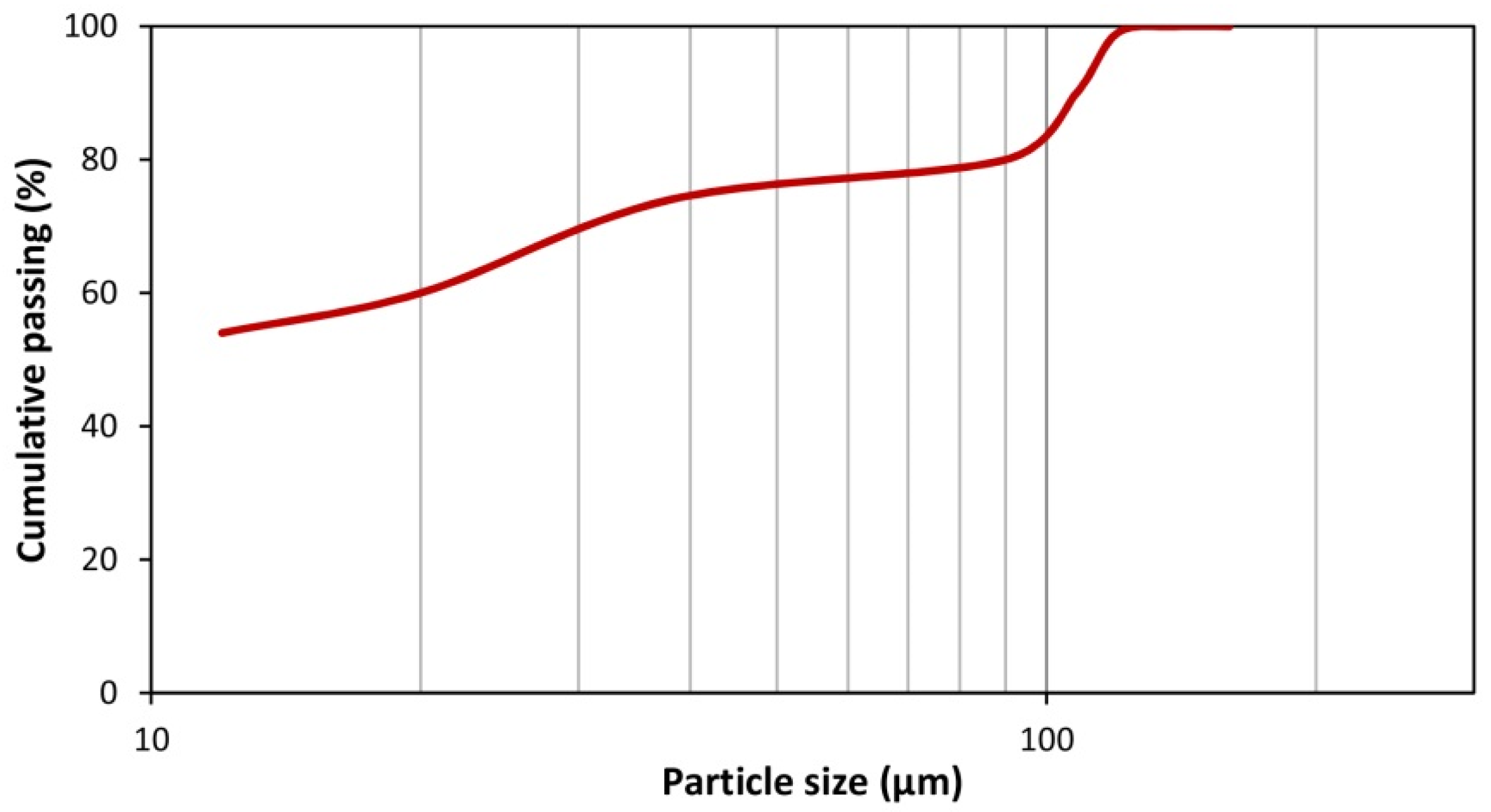
3.1. Results of Ore Characterization
3.2. Statistical Analysis of Screening DOE
3.3. Statistical Analysis of Optimization DOE
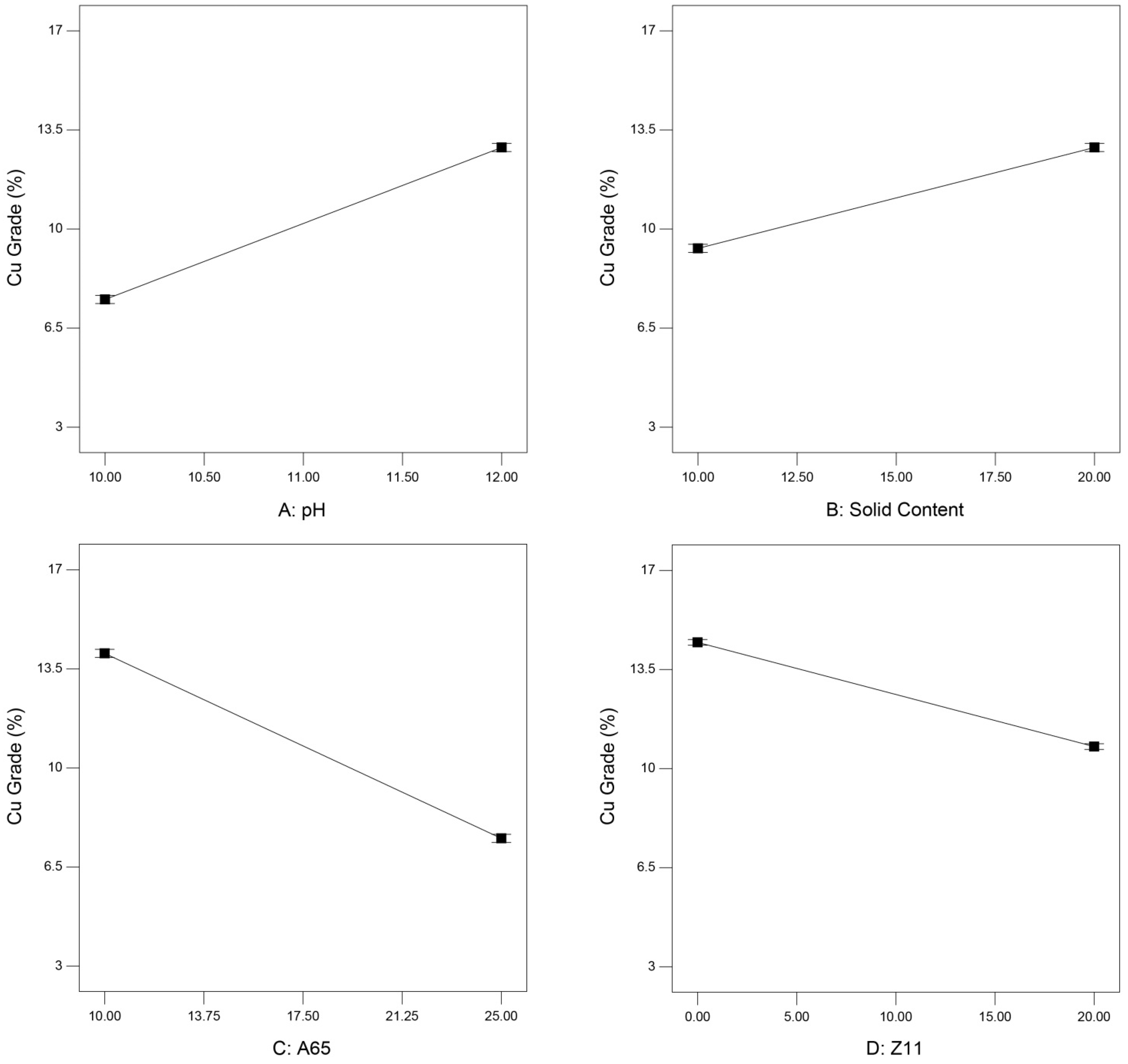
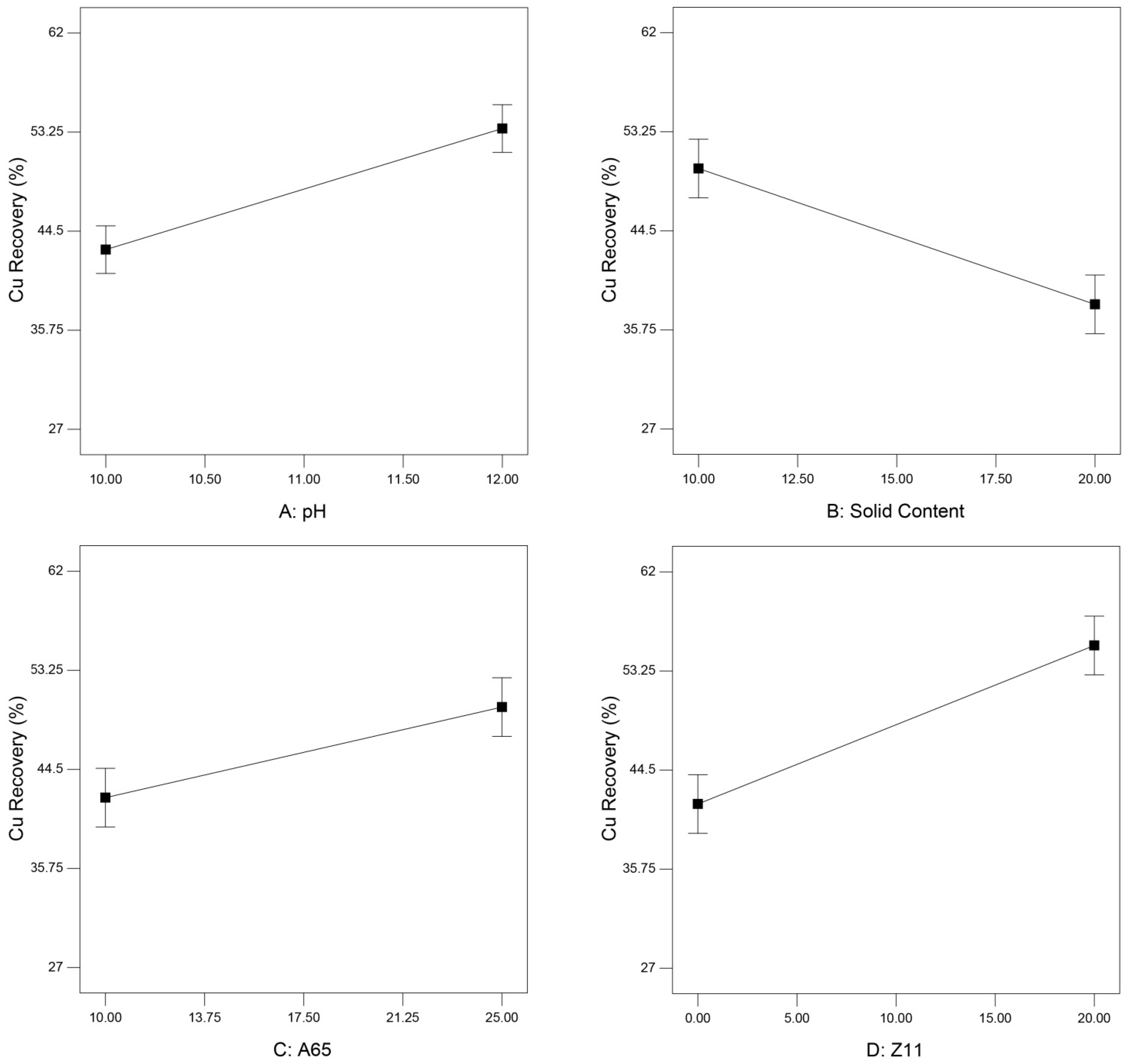
3.3.1. Interpretation of the Main Effects
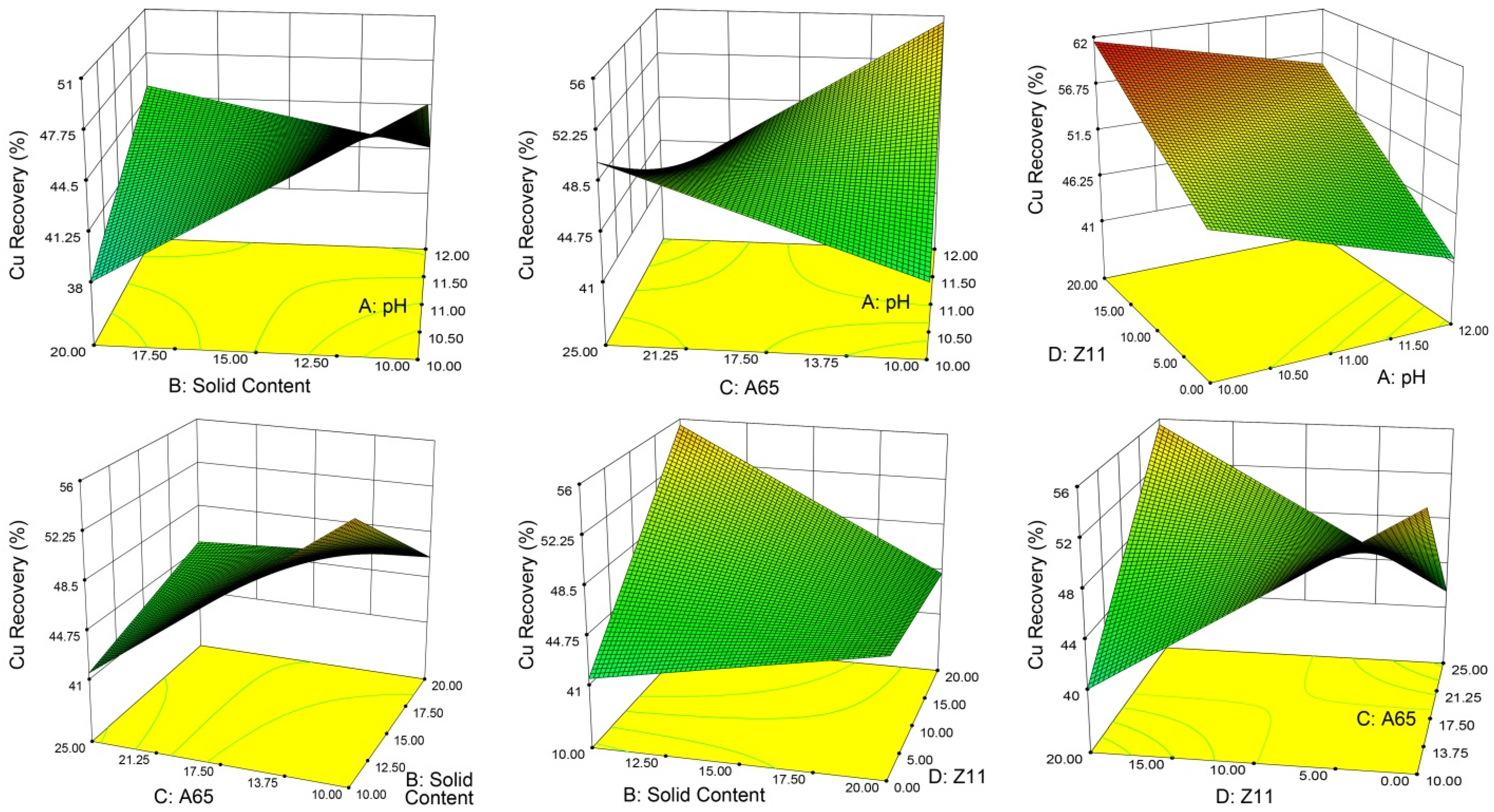
3.3.2. Evaluation of the Interactive Effects
3.3.3. Process Optimization and Verification Studies
3.4. Simulation Results
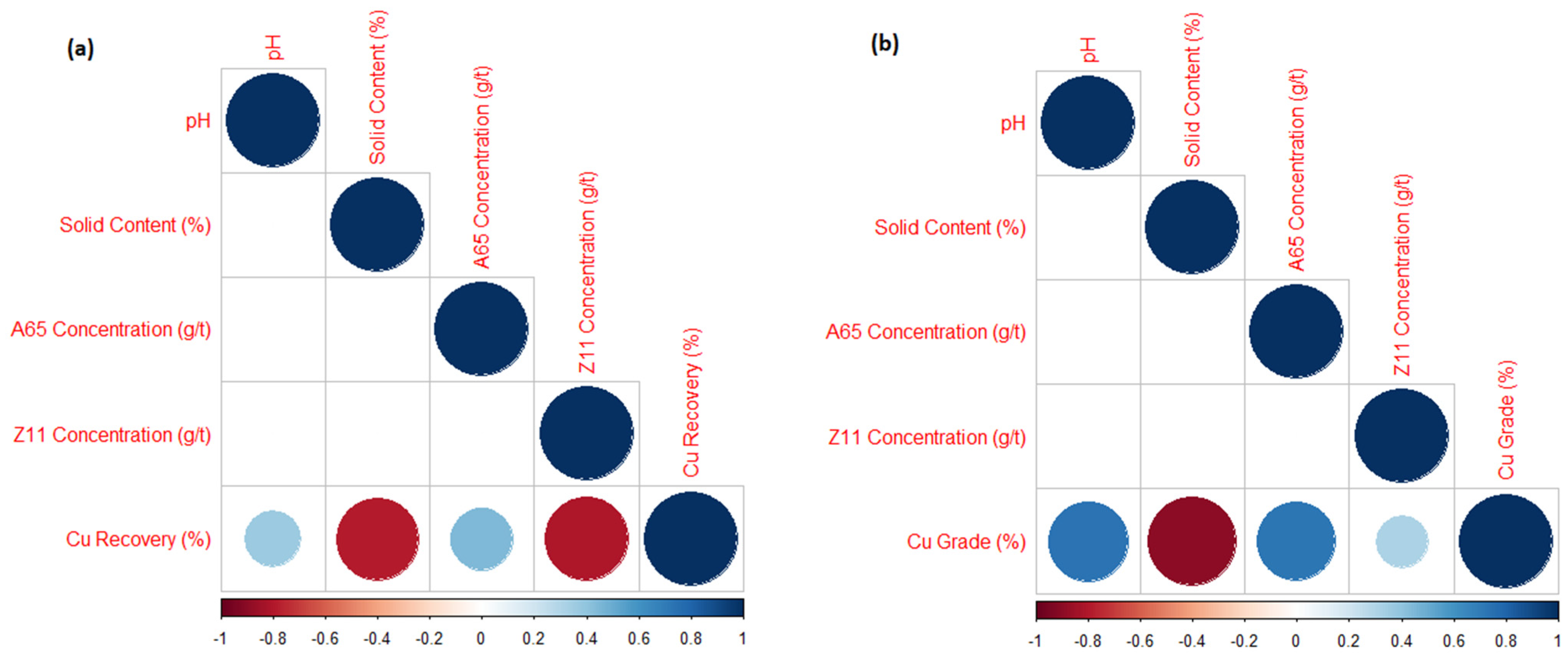
3.4.1. Correlation Coefficient Analysis
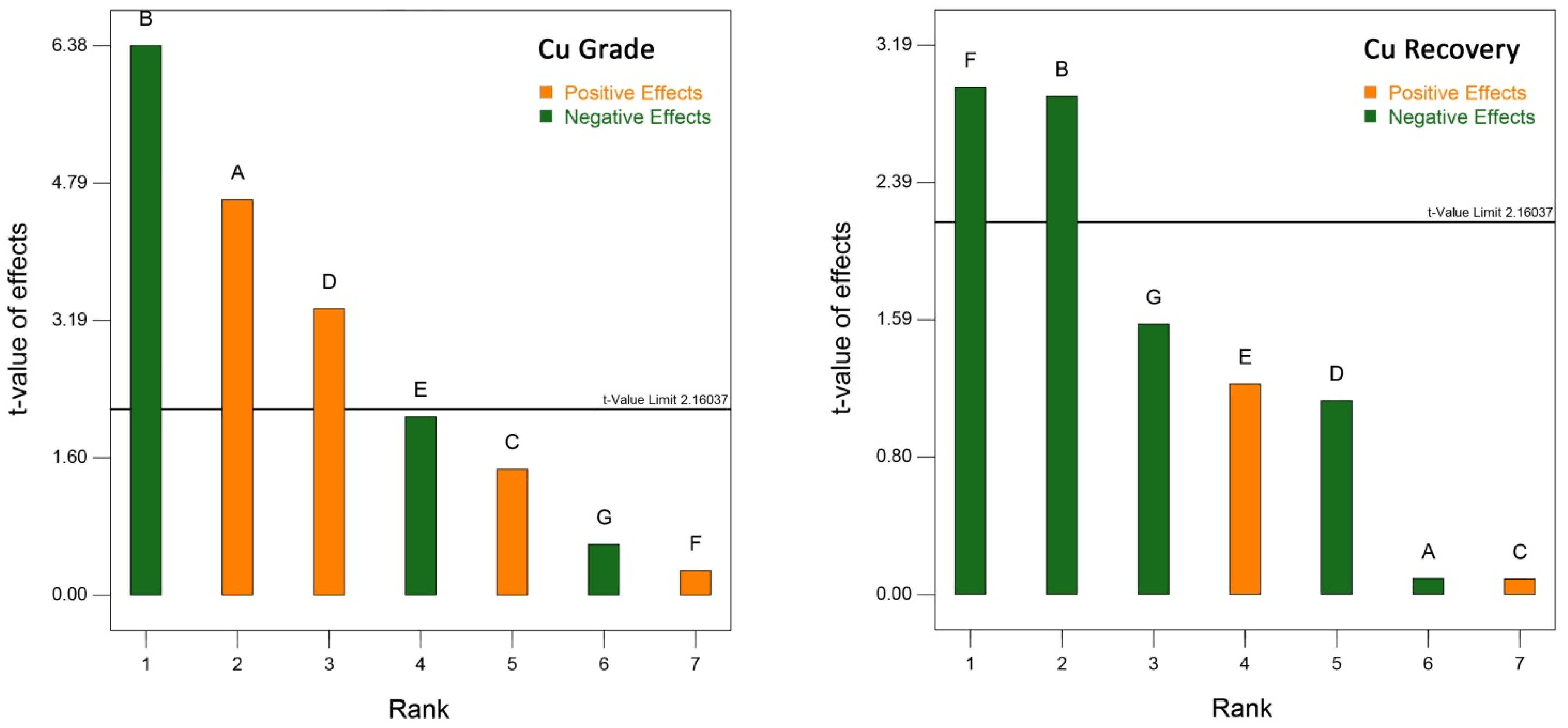
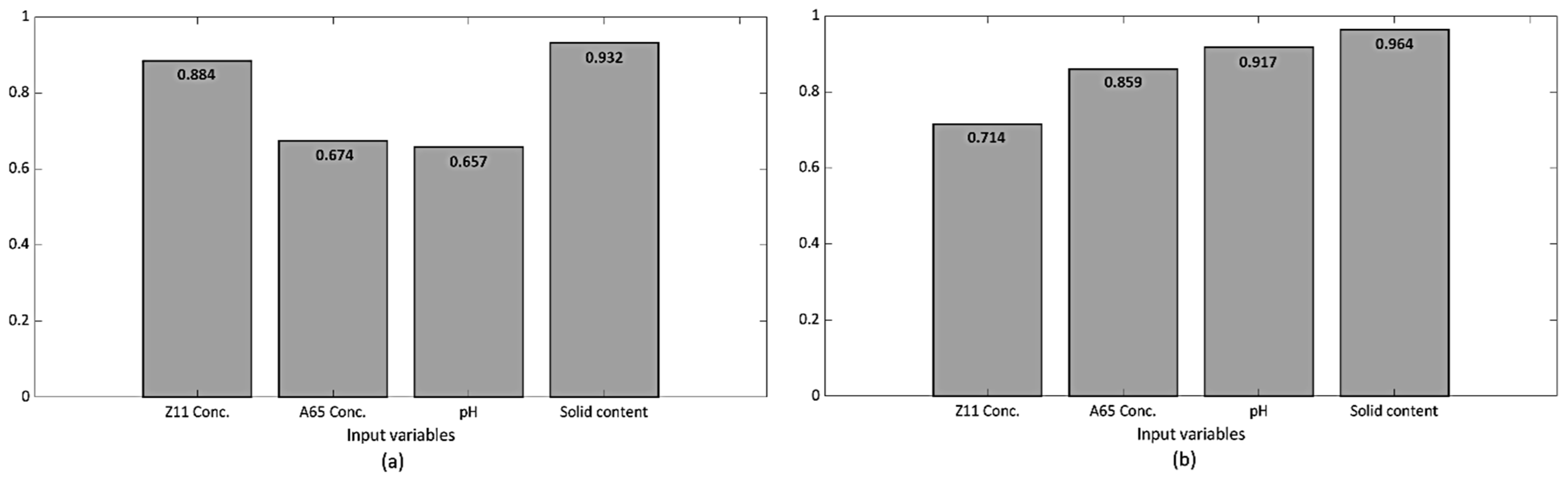
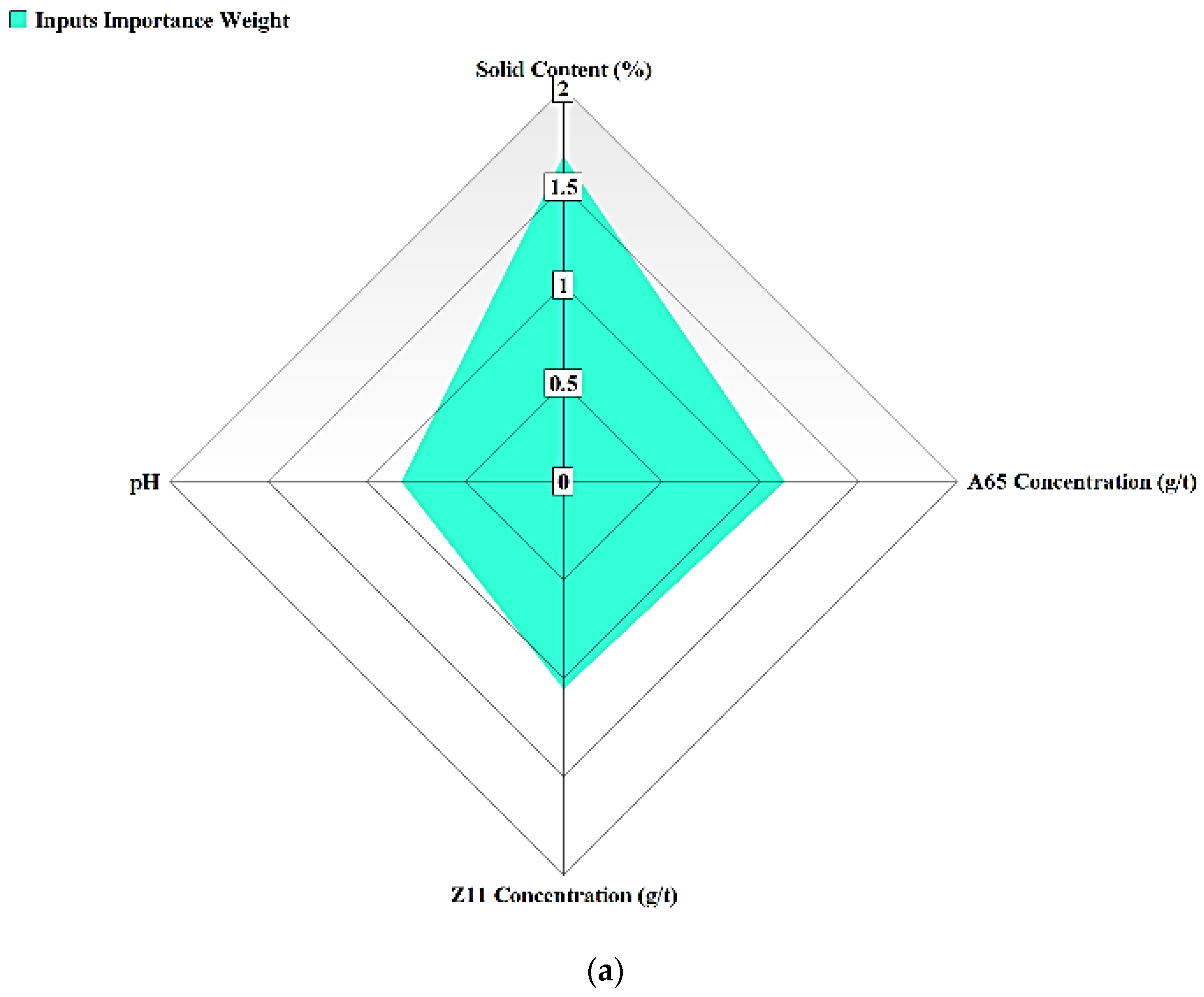
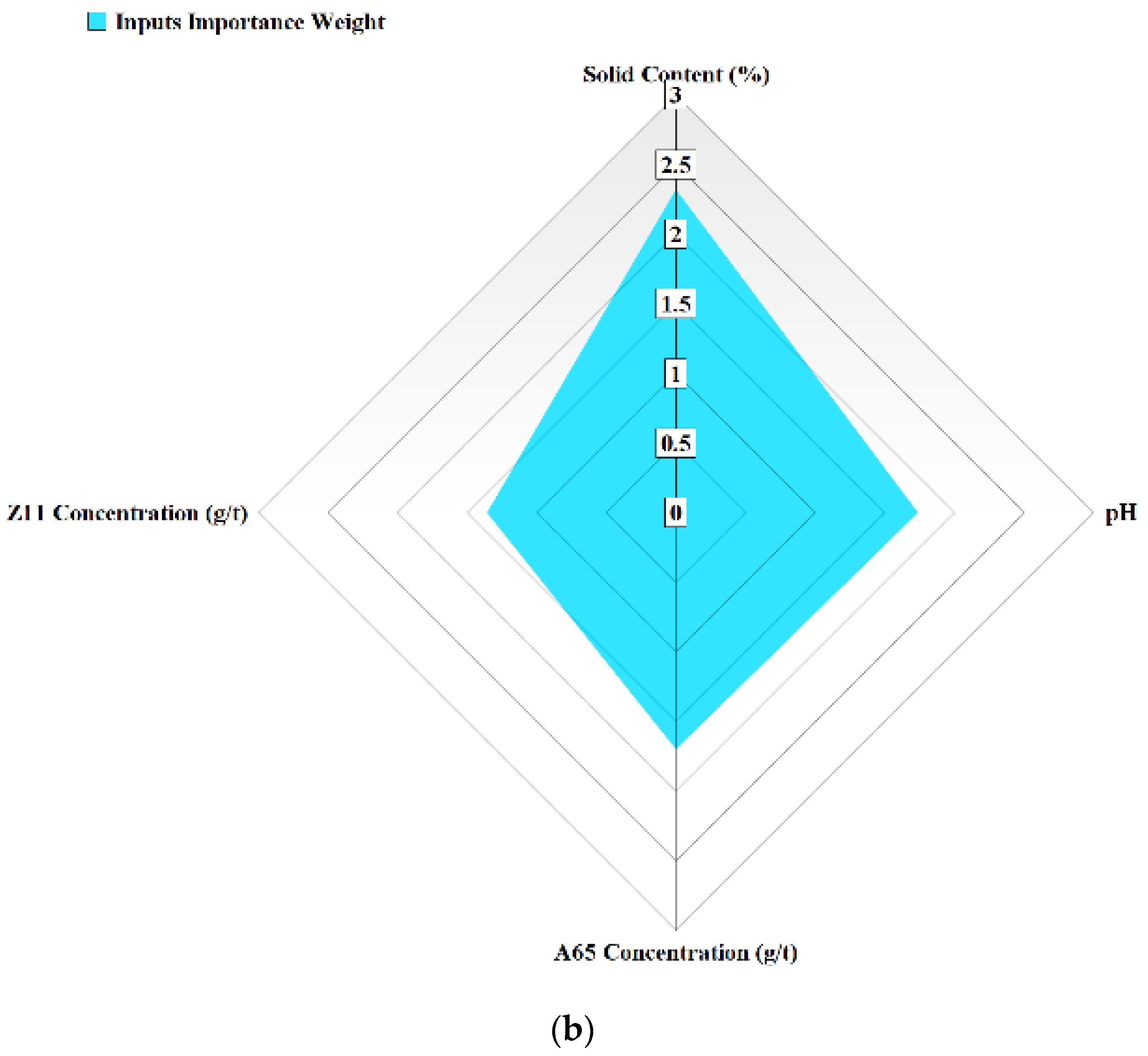
3.4.2. Sensitivity Analysis
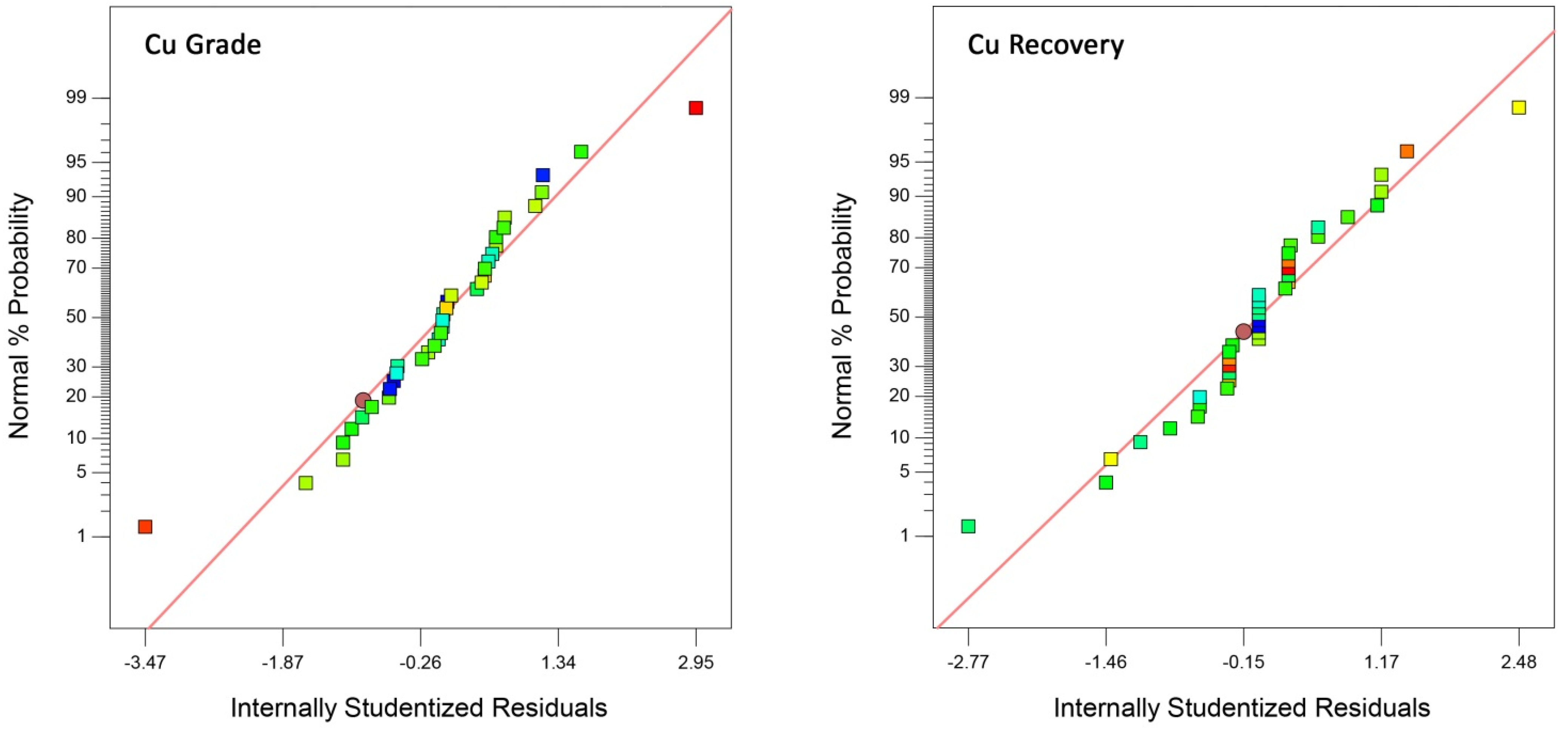
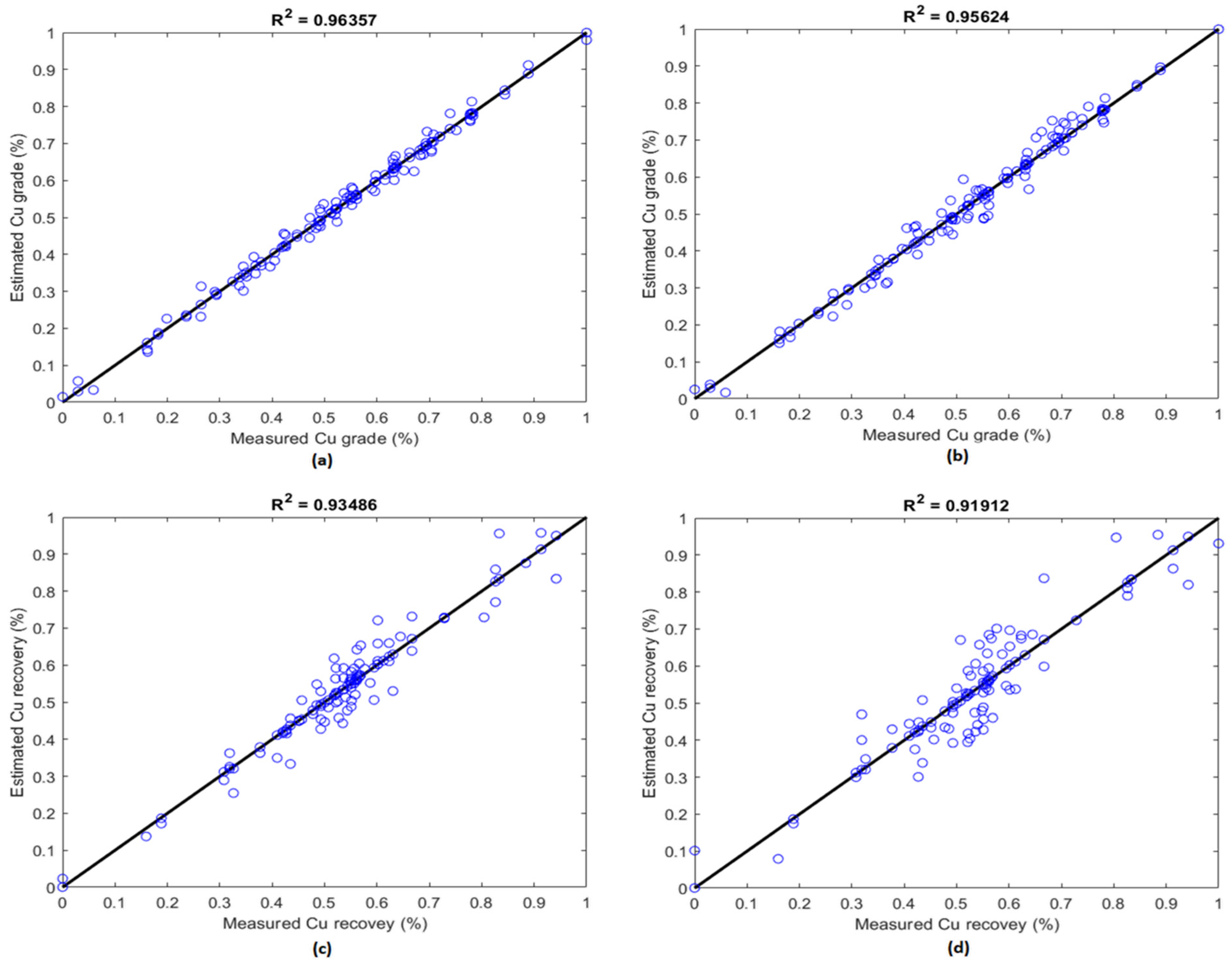
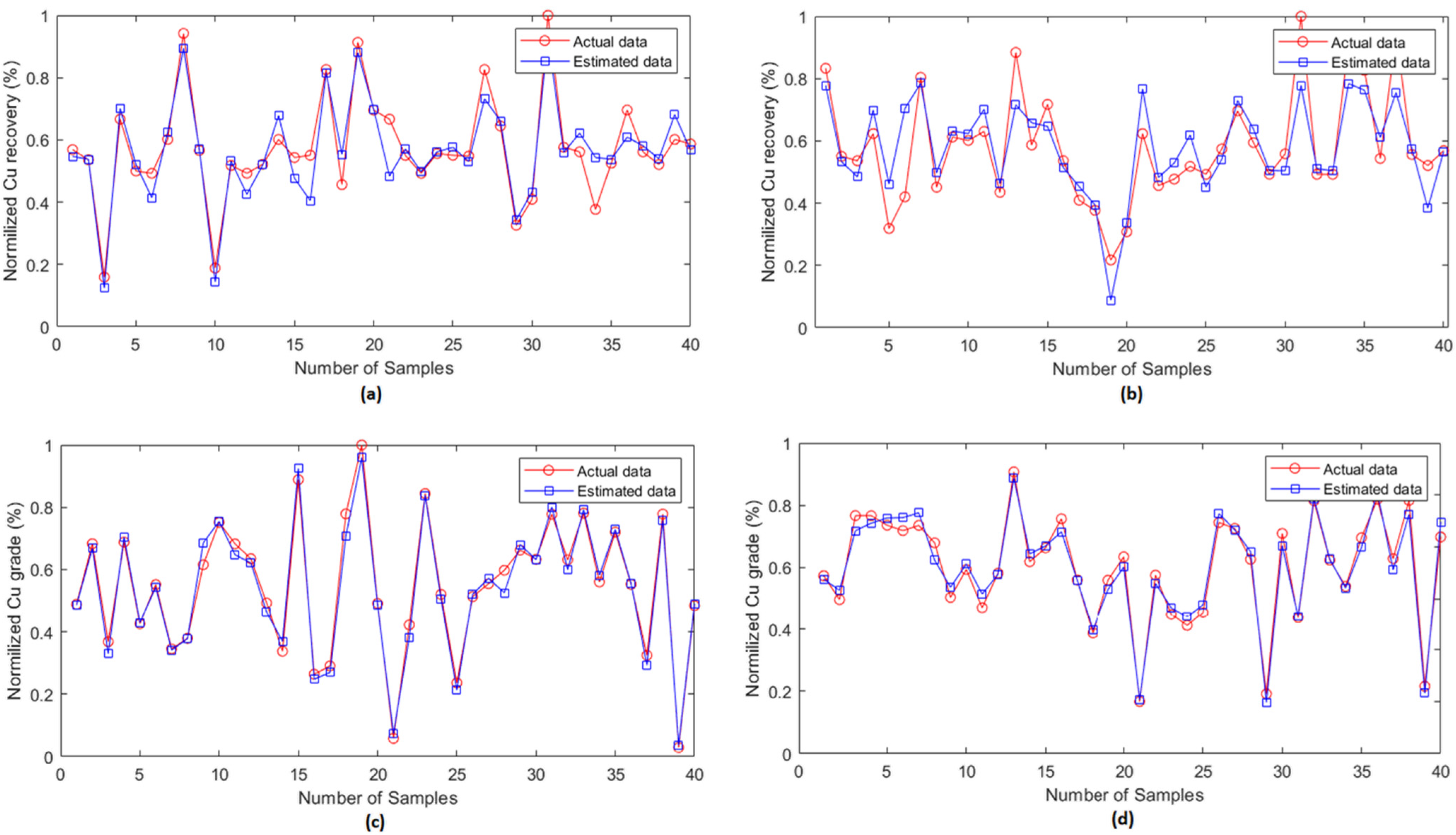
3.4.3. Model Prediction Analysis
4. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Adams, M.D. Advances in Gold Ore Processing; Elsevier: Amsterdam, The Netherlands, 2005. [Google Scholar]
- King, R.P. Modeling & Simulation of Mineral Processing Systems; Butterworth-Heinmann: Boston, MA, USA, 2012. [Google Scholar]
- Scharnhorst, A.; Börner, K.; van der Besselaar, P. Models of Science Dynamics; Springer: Berlin, Germany, 2012. [Google Scholar]
- Kuhn, M.; Johnson, K. Applied Predictive Modeling; Springer: Berlin, Germany, 2018. [Google Scholar]
- Herrell, F.E. Regression Modeling Strategies; Springer: Berlin, Germany, 2016. [Google Scholar]
- Montgomery, D.C. Design and Analysis of Experiments, 10th ed.; Wiley: Hoboken, NJ, USA, 2020. [Google Scholar]
- Asadi, E.; Isazadeh, M.; Samadianfard, S.; Ramli, M.F.; Mosavi, A.; Nabipour, N.; Shamshirband, S.; Hajnal, E.; Chau, K. Groundwater quality assessment for sustainable drinking and irrigation. Sustainability 2020, 12, 177. [Google Scholar] [CrossRef] [Green Version]
- Shamshirband, S.; Hashemi, S.; Salimi, H.; Samadianfard, S.; Asadi, E.; Shadkani, S.; Kargar, K.; Mosavi, A.; Nabipour, N.; Chau, K. Predicting standardized streamflow index for hydrological drought using machine learning models. Eng. Appl. Comput. Fluid Mech. 2020, 14, 339–350. [Google Scholar] [CrossRef]
- Apaydin, H.; Feizi, H.; Sattari, M.T.; Colak, M.S.; Shamshirband, S.; Chau, K. Comparative analysis of recurrent neural network architectures for reservoir inflow forecasting. Water 2020, 12, 1500. [Google Scholar] [CrossRef]
- Hoseinian, F.S.; Rezai, B.; Kowsari, E.; Safari, M. A hybrid neural network/genetic algorithm to predict Zn (II) removal by ion flotation. Sep. Sci. Technol. 2020, 55, 1197–1206. [Google Scholar] [CrossRef]
- Khoshdast, H.; Gholami, A.R.; Hassanzadeh, A.; Niedoba, T.; Surowiak, A. Advanced simulation of removing chromium from a synthetic wastewater by rhamnolipidic bioflotation using hybrid neural networks with metaheuristic algorithms. Materials 2021, 14, 2880. [Google Scholar] [CrossRef]
- Gholami, A.R.; Khoshdast, H.; Hassanzadeh, A. Using hybrid neural networks/genetic and artificial bee colony algorithms to simulate the bio-treatment of dye-polluted wastewater using rhamnolipid biosurfactants. J. Environ. Manag. 2021, 299, 113666. [Google Scholar] [CrossRef]
- Jorjani, E.; Bagherieh, A.; Mesroghli, S.; Chelgani, S.C. Prediction of yttrium, lanthanum, cerium, and neodymium leaching recovery from apatite concentrate using artificial neural networks. J. Uni. Sci. Technol. Beijing Min. Metal. Mat. 2008, 15, 367–374. [Google Scholar] [CrossRef]
- Milivojevic, M.; Stopic, S.; Friedrich, B.; Stojanovic, B.; Drndarevic, D. Computer modeling of high-pressure leaching process of nickel laterite by design of experiments and neural networks. Int. J. Miner. Metal. Mat. 2012, 19, 584–594. [Google Scholar] [CrossRef]
- Hoseinian, F.S.; Abdollahzade, A.; Mohamadi, S.S.; Hashemzadeh, M. Recovery prediction of copper oxide ore column leaching by hybrid neural genetic algorithm. Trans. Nonfer. Metal Soc. China 2017, 27, 686–693. [Google Scholar] [CrossRef]
- Sobouti, A.; Hoseinian, F.S.; Rezai, B.; Jalili, S. The lead recovery prediction from lead concentrate by an artificial neural network and particle swarm optimization. Geosys. Eng. 2019, 22, 319–327. [Google Scholar] [CrossRef]
- Vyas, S.; Das, S.; Ting, Y.-P. Predictive modeling and response analysis of spent catalyst bioleaching using artificial neural network. Biores. Technol. Rep. 2020, 9, 100389. [Google Scholar] [CrossRef]
- Ghobadi, P.; Yahyaei, M.; Banisi, S. Optimization of the performance of flotation circuits using a genetic algorithm oriented by process-based rules. Int. J. Miner. Process. 2011, 98, 174–181. [Google Scholar] [CrossRef]
- Gholami, A.R.; Khoshdast, H. Using artificial neural networks for the intelligent estimation of selectivity index and metallurgical responses of a sample coal bioflotation by rhamnolipid biosurfactants. Energy Sources Part A Recovery Util. Environ. Eff. 2020, 2020, 1857477. [Google Scholar] [CrossRef]
- Gholami, A.R.; Asgari, K.; Khoshdast, H.; Hassanzadeh, A. A hybrid geometallurgical study using coupled Historical Data (HD) and Deep Learning (DL) techniques on a copper ore mine. Physicochem. Prob. Miner. Process. 2022, 58, 147841. [Google Scholar] [CrossRef]
- Nakhaei, F.; Irannajad, M. Application and comparison of RNN, RBFNN and MNLR approaches on prediction of flotation column performance. Int. J. Min. Sci. Technol. 2015, 25, 983–990. [Google Scholar] [CrossRef]
- Zhang, D.; Gao, X. Soft sensor of flotation froth grade classification based on hybrid deep neural network. Int. J. Prod. Res. 2021, 59, 4794–4810. [Google Scholar] [CrossRef]
- Pu, Y.; Szmigiel, A.; Apel, D.B. Purities prediction in a manufacturing froth flotation plant: The deep learning techniques. Neural Comput. Appl. 2020, 32, 13639–13649. [Google Scholar] [CrossRef]
- Inapakurthi, R.K.; Miriyala, S.S.; Mitra, K. Recurrent neural networks based modelling of industrial grinding operation. Chem. Eng. Sci. 2020, 219, 115585. [Google Scholar] [CrossRef]
- Khoshdast, H.; Soflaeian, A.; Shojaei, V. Coupled fuzzy logic and experimental design application for simulation of a coal classifier in an industrial environment. Physicochem. Prob. Miner. Process. 2019, 55, 504–515. [Google Scholar] [CrossRef]
- Khoshdast, H.; Sam, A.; Vali, H.; Akbari Noghabi, K. Effect of rhamnolipid biosurfactants on performance of coal and minerals flotation. Int. Biodeter. Biodegrad. 2011, 65, 1238–1243. [Google Scholar] [CrossRef]
- Khoshdast, H.; Sam, A.; Manafi, Z. The use of rhamnolipid biosurfactants as a frothing agent and a sample copper ore response. Miner. Eng. 2012, 26, 41–49. [Google Scholar] [CrossRef]
- Che, Z.; Purushotham, S.; Cho, K.; Sontag, D.; Liu, Y. Recurrent neural networks for multivariate time series with missing values. Sci. Rep. 2018, 8, 6085. [Google Scholar] [CrossRef] [Green Version]
- Mandic, D.; Chambers, J. Recurrent Neural Metworks for Prediction: Learning Algorithms, Architectures and Stability; Wiley: Hoboken, NJ, USA, 2001. [Google Scholar]
- Fei, H.; Tan, F. Bidirectional grid long short-term memory (bigridlstm): A method to address context-sensitivity and vanishing gradient. Algorithms 2018, 11, 172. [Google Scholar] [CrossRef] [Green Version]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neur. Comp. 1997, 9, 1735–1780. [Google Scholar] [CrossRef]
- Graves, A. Supervised sequence labelling. In Supervised Sequence Labelling with Recurrent Neural Networks; Graves, A., Ed.; Springer: Berlin, Germany, 2012; pp. 5–13. [Google Scholar]
- Chung, J.; Gulcehre, C.; Cho, K.; Bengio, Y. Empirical evaluation of gated recurrent neural networks on sequence modeling. arXiv 2014, arXiv:1412.3555. [Google Scholar]
- Fu, R.; Zhang, Z.; Li, L. Using LSTM and GRU neural network methods for traffic flow prediction. In Proceedings of the 31st Youth Academic Annual Conference of Chinese Association of Automation (YAC), Wuhan, China, 11 November 2016; pp. 324–328. [Google Scholar] [CrossRef]
- Agheli, S.; Hassanzadeh, A.; Hassas, B.V.; Hassanzadeh, M. Effect of pyrite content of feed and configuration of locked particles on rougher flotation of copper in low and high pyritic ore types. Int. J. Min. Sci. Technol. 2018, 28, 167–176. [Google Scholar] [CrossRef]
- Azizi, A.; Hassanzadeh, A.; Fadaei, B. Investigating the first-order flotation kinetics models for Sarcheshmeh copper sulfide ore. Int. J. Min. Sci. Technol. 2015, 25, 849–854. [Google Scholar] [CrossRef]
- Boveiri, R.; Shojaei, V.; Khoshdast, H. Efficient cadmium removal from aqueous solutions using a sample coal waste activated by rhamnolipid biosurfactant. J. Environ. Manag. 2019, 231, 1182–1192. [Google Scholar] [CrossRef]
- Yetilmezsoy, K.; Demirel, S.; Vanderbei, R.J. Response surface modeling of Pb(II) removal from aqueous solution by Pistacia vera L.: Box–Behnken experimental design. J. Hazard. Mater. 2009, 171, 551–562. [Google Scholar] [CrossRef]
- Shak, K.P.Y.; Wu, T.Y. Optimized use of alum together with unmodified Cassia obtusifolia seed gum as a coagulant aid in treatment of palm oil mill effluent under natural pH of wastewater. Ind. Crop. Prod. 2015, 76, 1169–1178. [Google Scholar] [CrossRef]
- Zahab-Nazouri, A.; Shojaei, V.; Khoshdast, H.; Hassanzadeh, A. Hybrid CFD-experimental investigation into the effect of sparger orifice size on the metallurgical response of coal in a pilot-scale flotation column. Int. J. Coal Prep. 2022, 42, 349–368. [Google Scholar] [CrossRef]
- Khoshdast, H.; Hassanzadeh, A.; Kowalczuk, P.B.; Farrokhpay, S. Characterization of flotation frothers–A review. Miner. Process. Extrac. Metal. Rev. 2022, 43, 2024822. [Google Scholar] [CrossRef]
- Azizi, A.; Masdarian, M.; Hassanzadeh, A.; Bahri, Z.; Niedoba, T.; Surowiak, A. Parametric optimization in rougher flotation performance of a sulfidized mixed copper ore. Minerals 2020, 10, 660. [Google Scholar] [CrossRef]
- Shami, R.B.; Shojaei, V.; Khoshdast, H. Removal of some cationic contaminants from aqueous solutions using sodium dodecyl sulfate-modified coal tailings. Iran. J. Chem. Chem. Eng. 2021, 40, 1105–1120. [Google Scholar] [CrossRef]
- Dodge, Y. The Concise Encyclopedia of Statistics; Springer Science & Business Media: Berlin, Germany, 2008. [Google Scholar]
- Asadi, M.; Soltani, F.; Mohammadi, M.R.; Khodadadi, D.A.; Abdollahy, M. A successful operational initiative in copper oxide flotation: Sequential sulphidisation-flotation technique. Physicochem. Prob. Miner. Process. 2019, 55, 356–369. [Google Scholar] [CrossRef]
- Monjezi, M.; Hasanipanah, M.; Khandelwal, M. Evaluation and prediction of blast-induced ground vibration at Shur River Dam, Iran, by artificial neural network. Neur. Comp. Appl. 2013, 22, 1637–1643. [Google Scholar] [CrossRef]
- Gulec, M.; Gulbandilar, E. Determination of the lower calorific and ash values of the lignite coal by using artificial neural networks and multiple regression analysis. Physicochem. Prob. Miner. Process. 2019, 55, 400–406. [Google Scholar] [CrossRef]
- Krause, P.; Boyle, D.P.; Bäse, F. Comparison of different efficiency criteria for hydrological model assessment. Adv. Geosci. 2005, 5, 89–97. [Google Scholar] [CrossRef] [Green Version]
- Hassanzadeh, A.; Hoang, D.H.; Brockmann, M. Assessment of flotation kinetics modeling using information criteria; case studies of elevated-pyritic copper sulfide and high-grade carbonaceous sedimentary apatite ores. J. Dispers. Sci. Technol. 2020, 41, 1083–1094. [Google Scholar] [CrossRef]
- Cahuantzi, R.; Chen, X.; Güttel, S. A comparison of LSTM and GRU networks for learning symbolic sequences. arXiv 2021, arXiv:2107.02248. [Google Scholar]
- Yang, S.; Yu, X.; Zhou, Y. LSTM and GRU neural network performance comparison study: Taking yelp review dataset as an example. In Proceedings of the 2020 International Workshop on Electronic Communication and Artificial Intelligence (IWECAI), Shanghai, China, 12–14 June 2020; pp. 98–101. [Google Scholar] [CrossRef]



















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Factor | Variable | Unit | Low Actual | High Actual | Mid Level | Std. Dev. |
|---|---|---|---|---|---|---|
| A | pH | - | 10 | 12 | 11 | 0.85 |
| B | Solid content | (%) | 20 | 30 | 25 | 4.26 |
| C | MIBC conc. | (g/t) | 5 | 35 | 20 | 12.79 |
| D | A65 conc. | (g/t) | 5 | 15 | 10 | 4.26 |
| E | DTU conc. | (g/t) | 5 | 35 | 20 | 12.79 |
| F | Z11 conc. | (g/t) | 5 | 25 | 15 | 8.53 |
| G | NaHS conc. | (g/t) | 0 | 10 | 5 | 4.26 |
| Operating Factors | Responses | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| Run | A: pH | B: Solid Content (%) | C: MIBC (g/t) | D: A65 (g/t) | E: DTU (g/t) | F: Z11 (g/t) | G: NaHS (g/t) | Cu Grade (%) | Cu Recovery (%) |
| 1 | 10 | 20 | 35 | 15 | 5 | 5 | 10 | 4.90 | 71.53 |
| 2 | 12 | 20 | 35 | 5 | 35 | 5 | 0 | 4.90 | 86.87 |
| 3 | 11 | 25 | 20 | 10 | 20 | 15 | 5 | 3.60 | 53.88 |
| 4 | 10 | 30 | 5 | 5 | 35 | 5 | 10 | 2.96 | 64.92 |
| 5 | 12 | 30 | 35 | 15 | 35 | 25 | 10 | 4.30 | 44.00 |
| 6 | 10 | 20 | 5 | 15 | 35 | 25 | 0 | 4.70 | 58.28 |
| 7 | 12 | 30 | 5 | 15 | 5 | 5 | 0 | 4.40 | 58.17 |
| 8 | 12 | 20 | 5 | 5 | 5 | 25 | 10 | 5.20 | 55.82 |
| 9 | 11 | 25 | 20 | 10 | 20 | 15 | 5 | 2.60 | 62.42 |
| 10 | 12 | 30 | 5 | 15 | 5 | 5 | 0 | 4.80 | 59.59 |
| 11 | 12 | 20 | 35 | 5 | 35 | 5 | 0 | 5.10 | 68.90 |
| 12 | 10 | 20 | 35 | 15 | 5 | 5 | 10 | 5.17 | 56.97 |
| 13 | 12 | 30 | 35 | 15 | 35 | 25 | 10 | 4.60 | 50.91 |
| 14 | 10 | 30 | 35 | 5 | 5 | 25 | 0 | 3.57 | 52.75 |
| 15 | 11 | 25 | 20 | 10 | 20 | 15 | 5 | 3.15 | 58.14 |
| 16 | 11 | 25 | 20 | 10 | 20 | 15 | 5 | 3.10 | 58.83 |
| 17 | 12 | 20 | 5 | 5 | 5 | 25 | 10 | 4.90 | 58.38 |
| 18 | 10 | 20 | 5 | 15 | 35 | 25 | 0 | 4.50 | 68.48 |
| 19 | 11 | 25 | 20 | 10 | 20 | 15 | 5 | 2.44 | 41.96 |
| 20 | 10 | 30 | 35 | 5 | 5 | 25 | 0 | 3.61 | 53.32 |
| 21 | 11 | 25 | 20 | 10 | 20 | 15 | 5 | 3.54 | 62.53 |
| 22 | 10 | 30 | 5 | 5 | 35 | 5 | 10 | 2.78 | 59.05 |
| Factor | Parameter | Unit | Low Level | High Level | Mid Level | Std. Dev. |
|---|---|---|---|---|---|---|
| A | pH | 10 | 12 | 11 | 0.92 | |
| B | Solid Content | (%) | 10 | 20 | 15 | 4.59 |
| C | A65 Conc. | (g/t) | 10 | 25 | 17.5 | 6.88 |
| D | Z11 Conc. | (g/t) | 0 | 20 | 10 | 9.18 |
| Operating Factors | Responses | |||||
|---|---|---|---|---|---|---|
| Run | A: pH | B: Solid Content (%) | C: A65 (g/t) | D: Z11 (g/t) | Cu Grade (%) | Cu Recovery (%) |
| 1 | 11 | 15 | 17.5 | 10 | 11.07 | 41.01 |
| 2 | 10 | 20 | 25 | 20 | 7.45 | 57.32 |
| 3 | 12 | 10 | 25 | 20 | 9.36 | 53.72 |
| 4 | 12 | 10 | 25 | 0 | 8.33 | 41.69 |
| 5 | 10 | 20 | 10 | 0 | 12.50 | 45.33 |
| 6 | 11 | 15 | 17.5 | 10 | 11.00 | 44.18 |
| 7 | 10 | 10 | 10 | 0 | 12.30 | 40.67 |
| 8 | 12 | 10 | 25 | 20 | 9.21 | 58.05 |
| 9 | 12 | 20 | 25 | 20 | 12.93 | 44.11 |
| 10 | 10 | 10 | 10 | 20 | 3.82 | 27.09 |
| 11 | 10 | 20 | 10 | 20 | 14.10 | 38.82 |
| 12 | 12 | 10 | 25 | 0 | 8.39 | 42.41 |
| 13 | 10 | 20 | 10 | 20 | 14.05 | 38.59 |
| 14 | 10 | 20 | 25 | 0 | 16.83 | 37.40 |
| 15 | 10 | 10 | 25 | 0 | 7.81 | 50.11 |
| 16 | 10 | 10 | 25 | 20 | 4.00 | 62.39 |
| 17 | 11 | 15 | 17.5 | 10 | 10.97 | 46.31 |
| 18 | 11 | 15 | 17.5 | 10 | 10.89 | 50.27 |
| 19 | 12 | 20 | 25 | 20 | 12.89 | 45.49 |
| 20 | 11 | 15 | 17.5 | 10 | 10.99 | 53.26 |
| 21 | 12 | 10 | 10 | 0 | 10.80 | 55.61 |
| 22 | 10 | 20 | 10 | 0 | 12.40 | 47.01 |
| 23 | 10 | 10 | 25 | 20 | 4.20 | 61.19 |
| 24 | 11 | 15 | 17.5 | 10 | 11.10 | 50.42 |
| 25 | 12 | 20 | 10 | 0 | 10.60 | 47.07 |
| 26 | 10 | 20 | 25 | 0 | 16.11 | 39.09 |
| 27 | 12 | 20 | 10 | 20 | 12.80 | 44.21 |
| 28 | 12 | 10 | 10 | 0 | 10.50 | 56.77 |
| 29 | 12 | 20 | 10 | 20 | 12.50 | 47.39 |
| 30 | 10 | 10 | 10 | 0 | 12.50 | 44.46 |
| 31 | 12 | 10 | 10 | 20 | 7.81 | 40.29 |
| 32 | 12 | 10 | 10 | 20 | 7.75 | 40.85 |
| 33 | 12 | 20 | 25 | 0 | 11.90 | 45.40 |
| 34 | 10 | 10 | 25 | 0 | 7.88 | 50.21 |
| 35 | 12 | 20 | 25 | 0 | 11.70 | 45.66 |
| 36 | 12 | 20 | 10 | 0 | 10.80 | 46.32 |
| 37 | 10 | 20 | 25 | 20 | 7.51 | 58.60 |
| 38 | 10 | 10 | 10 | 20 | 3.75 | 27.00 |
| Model | F-Value | p-Value | R2 (%) | Adj R2 (%) | Pred R2 (%) | Adeq Precision |
|---|---|---|---|---|---|---|
| Cu Grade | 1251.23 | <0.0001 | 99.86 | 99.78 | 99.57 | 134.99 |
| Cu Recovery | 24.07 | <0.0001 | 94.50 | 90.58 | 88.62 | 20.59 |
| Source | Sum of Squares | df | Mean Square | F-Value | p-Value (Prob > F) |
|---|---|---|---|---|---|
| Model | 363.8967 | 13 | 27.99206 | 1251.234 | <0.0001 |
| A-pH | 3.822613 | 1 | 3.822613 | 170.8693 | <0.0001 |
| B-Solid Content | 147.3186 | 1 | 147.3186 | 6585.085 | <0.0001 |
| C-A65 | 4.8672 | 1 | 4.8672 | 217.562 | <0.0001 |
| D-Z11 | 43.29151 | 1 | 43.29151 | 1935.114 | <0.0001 |
| AB | 13.4162 | 1 | 13.4162 | 599.699 | <0.0001 |
| AC | 6.826513 | 1 | 6.826513 | 305.1425 | <0.0001 |
| AD | 54.2882 | 1 | 54.2882 | 2426.662 | <0.0001 |
| BC | 1.814513 | 1 | 1.814513 | 81.10801 | <0.0001 |
| BD | 12.5 | 1 | 12.5 | 558.7452 | <0.0001 |
| CD | 0.973012 | 1 | 0.973012 | 43.49328 | <0.0001 |
| ACD | 9.46125 | 1 | 9.46125 | 422.9142 | <0.0001 |
| BCD | 50.6018 | 1 | 50.6018 | 2261.881 | <0.0001 |
| ABCD | 14.71531 | 1 | 14.71531 | 657.7688 | <0.0001 |
| Pure Error | 0.485733 | 21 | 0.02313 | ||
| Cor Total | 367.9095 | 37 |
| Source | Sum of Squares | df | Mean Square | F-Value | p-Value (Prob > F) |
|---|---|---|---|---|---|
| Model | 2266.4 | 15 | 151.0933 | 24.07371 | <0.0001 |
| A-pH | 31.7761 | 1 | 31.7761 | 10.309121 | 0.0043 |
| B-Solid Content | 35.5092 | 1 | 35.5092 | 12.092561 | 0.0031 |
| C-A65 | 356.5785 | 1 | 356.5785 | 56.81369 | <0.0001 |
| D-Z11 | 44.2345 | 1 | 44.2345 | 14.291302 | 0.0021 |
| AB | 11.3288 | 1 | 11.3288 | 1.805019 | 0.1934 |
| AC | 372.5085 | 1 | 372.5085 | 59.35182 | <0.0001 |
| AD | 16.4738 | 1 | 16.4738 | 2.624772 | 0.1201 |
| BC | 149.5585 | 1 | 149.5585 | 23.82917 | <0.0001 |
| BD | 26.3538 | 1 | 26.3538 | 4.198954 | 0.0531 |
| CD | 873.411 | 1 | 873.411 | 139.1607 | <0.0001 |
| ABC | 93.91351 | 1 | 93.91351 | 14.96325 | 0.0009 |
| ABD | 29.9538 | 1 | 29.9538 | 4.772542 | 0.0404 |
| ACD | 74.48101 | 1 | 74.48101 | 11.86707 | 0.0024 |
| BCD | 100.891 | 1 | 100.891 | 16.07498 | 0.0006 |
| ABCD | 115.596 | 1 | 115.596 | 18.41792 | 0.0003 |
| Pure Error | 131.8018 | 21 | 6.276278 | ||
| Cor Total | 2408.51 | 37 |
| Goal (Max) | pH | Solid Content (%) | A65 Conc. (g/t) | Z11 Conc. (g/t) | Predicted Responses (%) | Practical Results (%) | ||
|---|---|---|---|---|---|---|---|---|
| G. | R. | G. | R. | |||||
| Grade (G) | 10.00 | 20.00 | 25.00 | 0.14 | 16.44 | 38.41 | 15.32 | 34.03 |
| Recovery (R) | 10.00 | 19.93 | 25.00 | 9.91 | 12.00 | 47.72 | 11.48 | 44.39 |
| Variable | pH | Solid Content (%) | A65 Conc. (g/t) | Z11 Conc. (g/t) |
|---|---|---|---|---|
| Cu grade (%) | 0.7391 | −0.8936 | 0.7234 | 0.3155 |
| Cu recovery (%) | 0.3653 | −0.7880 | 0.4490 | −0.8041 |
| Model | MSE | RMSE | MAPE | R2 |
|---|---|---|---|---|
| LSTM | 5.5 × 10−3 | 0.074 | 5.7 × 10−5 | 0.963 |
| GRU | 8.7 × 10−3 | 0.093 | 6.3 × 10−5 | 0.956 |
| RF | 9.8 × 10−3 | 0.098 | 7.4 × 10−5 | 0.939 |
| ANN-LMA | 1.3 × 10−2 | 0.114 | 8.6 × 10−5 | 0.921 |
| Model | MSE | RMSE | MAPE | R2 |
|---|---|---|---|---|
| LSTM | 0.017 | 0.132 | 7.8 × 10−5 | 0.934 |
| GRU | 0.026 | 0.162 | 9.6 × 10−5 | 0.919 |
| RF | 0.028 | 0.167 | 1.1 × 10−4 | 0.915 |
| ANN-LMA | 0.029 | 0.170 | 1.3 × 10−4 | 0.914 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Gholami, A.; Movahedifar, M.; Khoshdast, H.; Hassanzadeh, A. Hybrid Serving of DOE and RNN-Based Methods to Optimize and Simulate a Copper Flotation Circuit. Minerals 2022, 12, 857. https://doi.org/10.3390/min12070857
Gholami A, Movahedifar M, Khoshdast H, Hassanzadeh A. Hybrid Serving of DOE and RNN-Based Methods to Optimize and Simulate a Copper Flotation Circuit. Minerals. 2022; 12(7):857. https://doi.org/10.3390/min12070857
Chicago/Turabian StyleGholami, Alireza, Meysam Movahedifar, Hamid Khoshdast, and Ahmad Hassanzadeh. 2022. "Hybrid Serving of DOE and RNN-Based Methods to Optimize and Simulate a Copper Flotation Circuit" Minerals 12, no. 7: 857. https://doi.org/10.3390/min12070857