1. Introduction
The inverse Gaussian (IG) distribution, also known as the Wald distribution, is of considerable significance in various scientific and applied research fields owing to its distinctive properties and flexibility [
1]. Researchers have widely applied the IG distribution across multiple disciplines since Schrödinger [
2] introduced it and Wald [
3] extensively studied it. Notably, its skewness and relationship with Brownian motion make it particularly effective for modeling asymmetric data. Folks and Chhikara [
1] have thoroughly explored the mathematical and statistical properties of this distribution.
Researchers utilized the IG distribution to examine particle movement in bloodstreams [
4], while Onar and Padgett [
5] applied it to determine the tensile strength of carbon fibers. Jain and Jain [
6] used it for estimating device failure time reliability. In finance, it has been instrumental in modeling stock returns, particularly addressing data skewness [
7]. Environmental applications include modeling ecological phenomena and air pollution, as explored in various studies [
8,
9]. The IG distribution has proven invaluable in medical research, especially in survival analysis, due to its efficacy in handling time-to-event data [
10]. Its application extends to engineering and quality control, aiding in reliability and life data analysis [
11].
The IG distribution has found applications in traffic engineering, where it models vehicular flow [
12], and in neuroscience, particularly in the study of spike-response variability in locust auditory neurons, which helps identify two noise sources that impact spike timing [
13]. Its adaptability is also evident in agricultural settings for modeling growth rates [
14]. In the field of insurance and risk analysis, the IG distribution has been used to model bodily injury claims and to analyze economic data concerning Italian households’ incomes [
15].
The IG distribution for a random variable X has a probability density function given by:
where
and
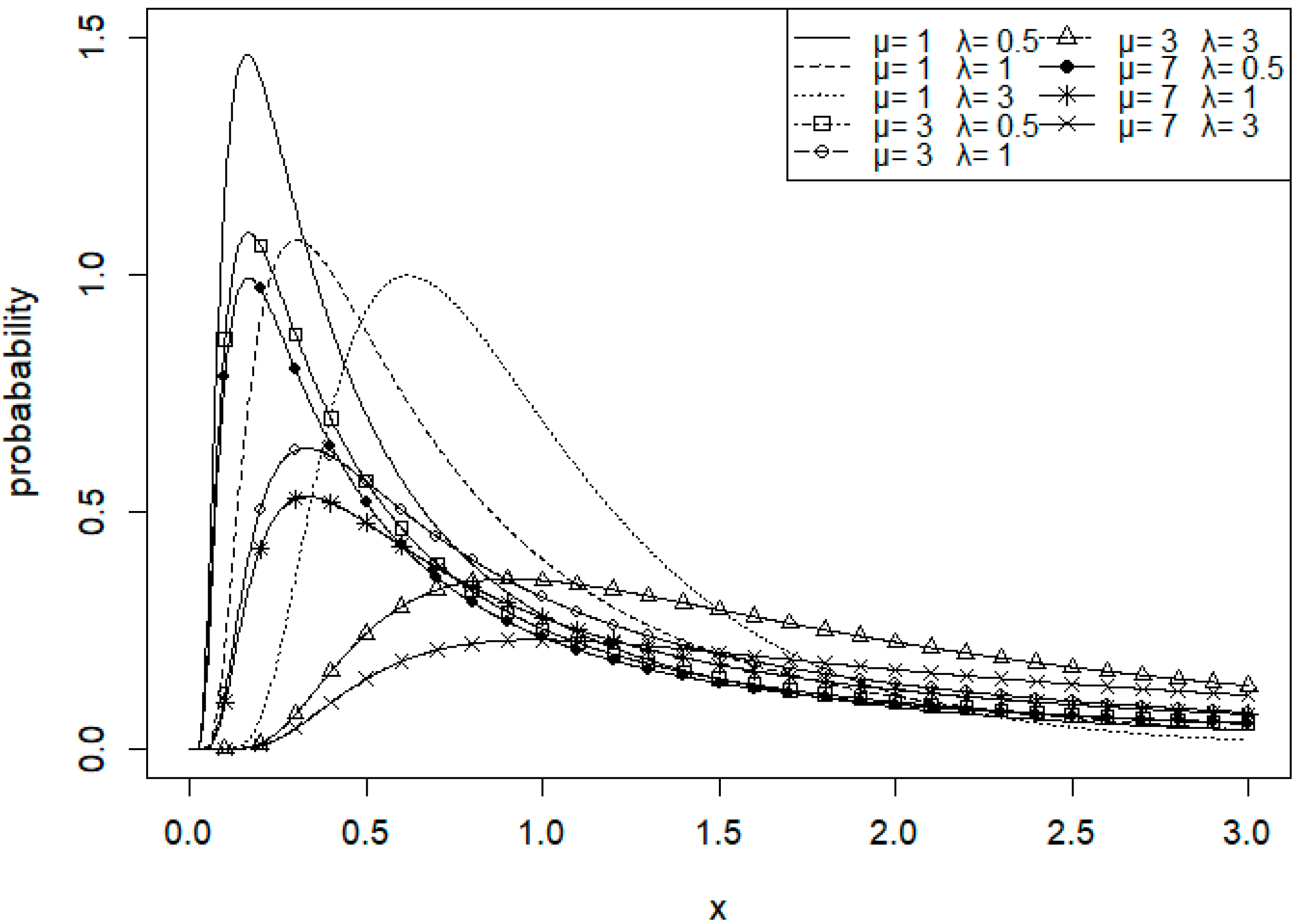
. The shapes of the IG distributions with varying parameter sets are depicted in
Figure 1. For lower values of
(0.5), the distribution demonstrates a higher peak and a steep decline in probability, which suggests a sharper distribution. As
increases, the peak becomes less pronounced, indicating a distribution with a heavier tail. Furthermore, an increase in
causes a rightward shift in the distribution, representing higher mean values.
The mean of the IG distribution is
μ, and the variance is
[
3]. The maximum likelihood estimates (MLEs) of
μ and
λ are:
where
are random samples from IG(
. Furthermore, it is also known that
,
, and
and
are independent [
16]. Folks and Chhikara [
1] proved that the uniformly minimum variance unbiased estimators for
μ and
λ are:
The necessity of using confidence intervals (CIs) for estimating the mean of the IG distribution rather than relying solely on point estimators is pivotal in statistical analysis. Confidence intervals provide a range within which the true mean is likely to fall, reflecting the uncertainty inherent in using sample data to estimate population parameters. In contrast to a single point estimate, confidence intervals offer a more nuanced and informative picture, essential for rigorous statistical inference and decision-making in fields like survival analysis and reliability engineering, where precise estimation is key [
17].
This paper focuses on Wald’s interval, a fundamental tool in statistical inference known for its simplicity and broad applicability. Wald’s interval is derived from the Wald test, which is based on the asymptotic normality of maximum likelihood estimators. It offers a direct method for constructing confidence intervals, particularly when the sample size is large [
18]. However, the finite sample distributions of Wald tests are often not well defined [
19]. Constructing Wald CIs for single-parameter models is straightforward, but when dealing with the IG distribution, which involves two parameters, the profile likelihood method is more advantageous. Non-normal distributions or small sample sizes may render Wald CIs unsuitable. To fix this, we can use reparameterization to create Wald CIs using the profile likelihood method. This makes sure that the sampling distribution is more like the normal distribution, which is a key assumption of the Wald method. Furthermore, using expected Fisher information in Wald CIs can offer more stability and be less sensitive to sample-specific irregularities.
In this study, CIs for the mean parameter of the IG distribution are constructed for scenarios where the shape parameter is unknown, focusing primarily on marginal intervals. We investigate two specific types of CIs: the first is the Wald-type CI using profile likelihood without reparameterization, and the second is the Wald-type CI incorporating reparameterization and utilizing expected Fisher information. These two proposed intervals are compared with existing intervals through simulation studies.
The rest of the paper is structured as follows:
Section 2 presents intervals in literature.
Section 3 presents the mathematical derivation of the Wald-type profile likelihood and Wald-type reparametrized profile likelihood with expected Fisher information intervals.
Section 4 details the properties of these proposed intervals.
Section 5 describes the simulation studies conducted to compare the performance of the proposed intervals with existing methods.
Section 6 applies the proposed intervals to a real dataset. The paper concludes with a discussion in
Section 7, where the findings are summarized and potential avenues for future research are outlined.
Table 1 provides a list of detailed abbreviations and definitions used in this paper.
2. Intervals in Literature
2.1. Wald-Type Confidence Interval
The Wald confidence interval is typically constructed around a maximum likelihood estimator (MLE), leveraging the properties of a normal distribution, especially for large samples [
20]. The calculation of this interval is based on the Wald test, which is used to evaluate the null hypothesis
against an alternative
. Under
, two key statistics are used, both exhibiting asymptotic normal distributions as the sample size increases:
where
and
represent the estimated observed and expected Fisher information, respectively [
21]. The observed and expected Fisher information are defined as:
Construct the Wald confidence interval using the formula:
It is worth noting that the Wald statistics can be written in
which is the quadratic approximation of
. The Wald statistic follows an asymptotic chi-squared distribution, with the degrees of freedom equal to the number of parameters being tested.
2.2. Profile-Likelihood-Based Confidence Interval
Statistical inference uses the profile likelihood confidence interval method to estimate confidence intervals for a parameter of interest in a model with multiple parameters. This approach is particularly useful in complex models where direct computation of the confidence interval for a parameter is challenging due to the presence of nuisance parameters—other parameters in the model that are not of primary interest [
22,
23]. In the profile likelihood method, the process involves:
The likelihood function: Suppose we have a likelihood function , where is the parameter of interest and represents nuisance parameters. The full likelihood is a function of both of these sets of parameters.
Profiling out nuisance parameters: To focus on , we maximize the likelihood function over the nuisance parameters for each fixed value of . This gives us the profile likelihood function for : .
Estimation of the parameter of interest: The estimate is obtained by maximizing the profile likelihood as follows:
- 4.
Constructing the confidence interval: The confidence interval for is then constructed based on the profile likelihood, so the interval is as follows:
where
is the critical value from the chi-squared distribution with degrees of freedom equal to the number of parameters being estimated (often 1 for a single parameter), and
is the significance level (e.g., 0.05 for a 95% confidence interval).
While likelihood-based and profile-likelihood-based intervals typically lack a closed form, which can be seen as a drawback compared to the more straightforward Wald-type interval with its closed-form solutions for many situations, this study focuses on applying the construction of a Wald-type interval to the profile likelihood. This approach aims to leverage the benefits of both methods, offering a more practical solution for statistical analysis.
2.3. Existing Confidence Intervals
For the IG distribution, as shown in (1), there are two parameters. In cases where the shape parameter is known, Arefi et al. [
24] proposed CIs for the mean parameter, which are (1) the Wald CI:
; (2) the score CI, derived from solving
; and (3) the CI obtained from the likelihood ratio:
where
and
. In a case where both parameters are unknown, Srisuradetchai [
25] proposed the formula for the profile-likelihood-based (PL) CI as:
where
. Díaz-Francés [
26] derived the reparameterized profile likelihood (RPL) CI as:
where
and
. Srisuradetchai [
27] used reparameterized profile likelihoods to construct a Wald-type reparameterized profile likelihood using observed Fisher information (WRPLO) CI for the mean of the IG distribution. The interval is:
where
.
In the literature, the Wald-type profile-likelihood-based (WPL) interval and the Wald-type reparameterized profile-likelihood interval with expected Fisher information (WRPLE) are not present. Using expected Fisher information generally leads to intervals that are more stable across different samples, while intervals based on observed Fisher information can be more sensitive to the specificities of the data set. Furthermore, these two types of CIs will be derived and compared to the PL, RPL, and WRPLO through Monte Carlo simulations.
3. Mathematical Results
This section will focus on the mathematical derivation of two statistical intervals: the WPL and the WRPLE.
3.1. Wald-Type Profile-Likelihood-Based Interval
The full log-likelihood function based on the observed random sample size of
,
is as follows:
To focus on
, we maximize the likelihood function over the nuisance parameters
for each fixed value of
by solving
. Then,
This gives us the log profile likelihood function for
:
The estimate
is obtained by maximizing the profile likelihood
. Consider
Then, solving
will give
. Next, we will find the observed Fisher information:
And the inverse of the Fisher information is
. Term
can be simplified as follows:
Thus, the
WPL interval is
and when we substitute
, the corresponding WPL interval for
will be
where
is the
th quantile of the standard normal.
3.2. Wald-Type Reparameterized Profile Likelihood with Expected Fisher Information
The full log-likelihood function based on the observed random sample size of
,
is as follows:
Using reparameterization
, the full log-likelihood function becomes
To focus on
, we maximize
over the nuisance parameters
for each fixed value of
by solving
. Then,
By plugging in
into
, we obtain the log reparameterized profile likelihood function as follows:
where
. The score function of log reparametrized profile likelihood is as follows:
The observed Fisher information is the negative of the second derivative of log reparameterized profile likelihood, as follows:
The expectation of the observed Fisher information can be calculated as follows:
Using a first-order Taylor approximation for a function of two variables, the expectation becomes:
Since
,
,
and
, term
The denominator of (18) can also be expressed as:
The expected Fisher information is calculated as follows:
and the corresponding standard error of the estimator
is as follows:
The WRPLE interval of
will be
where
is the
th quantile of the standard normal. Therefore, the WRPLE interval of
is as follows:
4. Some Properties of the Proposed Intervals
Because the Wald statistics in (6) is the quadratic approximation of and from (7), some conditions are required for constructing a confidence interval.
4.1. A Condition for the WPL Interval
Let
be a random sample of size
n from a population with an inverse Gaussian distribution with unknown mean parameter
and shape parameter
Because the Wald statistics is a quadratic approximation of
, and
has asymptotically chi-squared distribution, the lower and upper bounds of the WPL interval can be obtained if
respectively. Because
, and from (14)
By substituting
and
, the condition for the lower bound of the WPL interval is as follows:
And , which is always greater than . This means that an upper bound for the WPL interval does always exist, but a lower bound does depend on the data.
4.2. A Condition for the WRPLE Interval
Like the conditions of the WPL interval, the WRPLE interval can be found if and only if
Because
and from (18), the condition for the lower bound of the WPL interval is
For the upper bound, , so the upper bound does always exist.
5. Simulation Studies
In the simulation studies, the sample sizes vary, including 5, 10, 15, 30, 45, 60, and 100. The mean parameter values are set at 1, 3, and 7, while the shape parameter values are 0.5, 1, and 3. The performance of two proposed distributions will be compared with the PL interval proposed by Srisuradetchai [
25], the RPL approach by Díaz-Francés [
26], and the WRPLO interval by Srisuradetchai [
27]. Performance is evaluated in terms of coverage probability (CP) and average interval length (AIL). Results for the PL, RPL, and WRPLO are summarized in
Table 2,
Table 3 and
Table 4, and those for the proposed intervals are in
Table 5 and
Table 6.
From
Table 2,
Table 3,
Table 4,
Table 5 and
Table 6, we observe that with a constant shape parameter and sample size, an increase in the mean of the IG distribution tends to decrease the CP value, while the AIL increases noticeably. Conversely, with a fixed mean and sample size, an increase in the shape parameter slightly raises the CP. For instance,
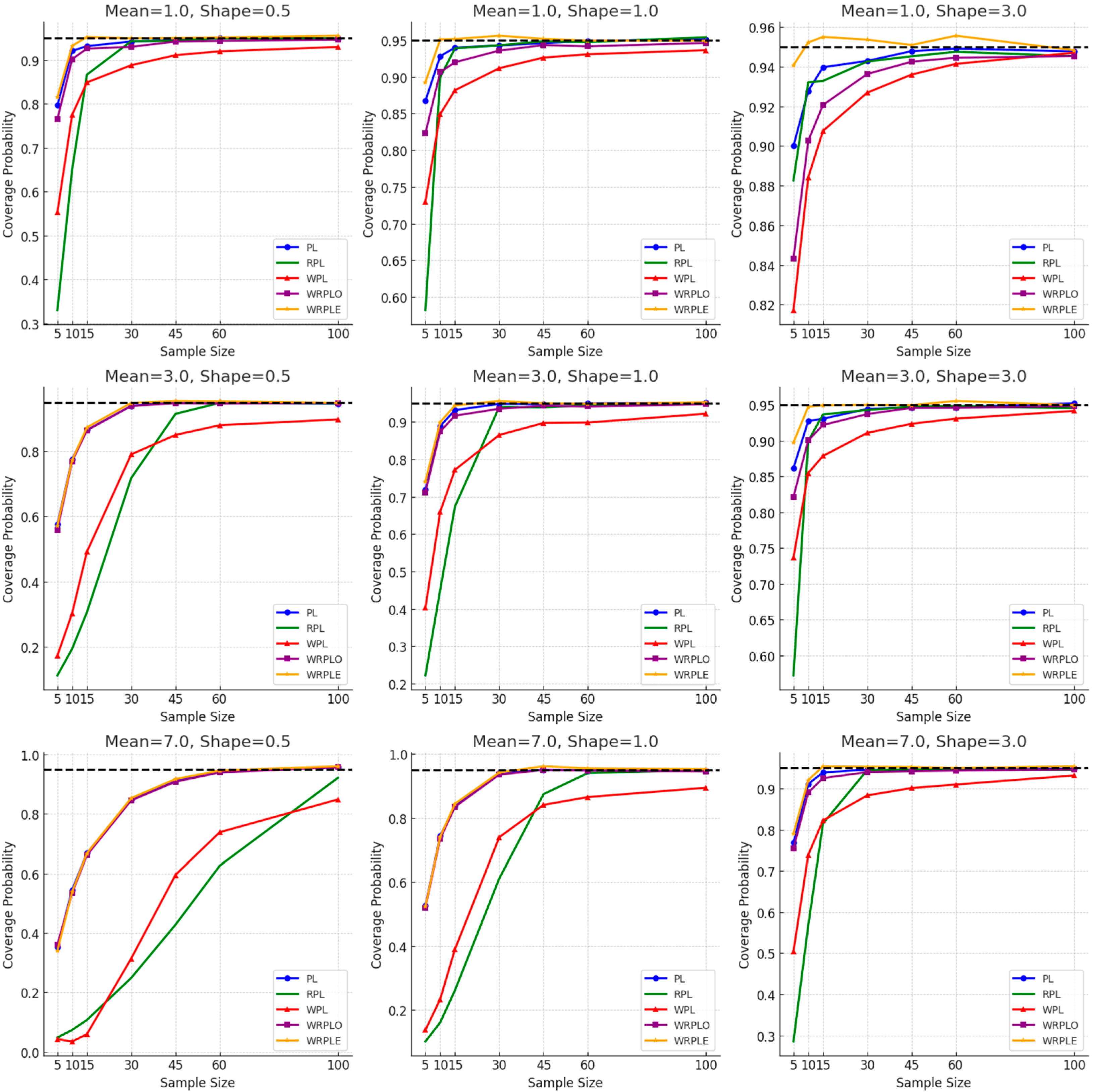
Table 5 shows that with a mean of 3 and a sample size of 15, the CPs are 0.4913, 0.7718, and 0.8788 for shape parameters of 0.5, 1, and 3, respectively. Moreover, as the sample size increases, the CP generally increases, but the AIL decreases.
Table 3 illustrates that for the RPL approach, a larger sample size is required as the mean and/or shape of the IG distribution increase.
Generally, the average lengths of the intervals PL, RPL, WRPLO, WRPLE, and WPL vary notably. The WPL tends to provide shorter intervals compared to WRPLE, which exhibits longer average lengths in many scenarios. PL and RPL usually fall in between these extremes, with WRPLO showing variable performance.
Figure 2 shows the performance of the proposed intervals WRPLE and WPL compared with the existing intervals PL, RPL, and WRPLO. The WRPLE method demonstrates high CP across various sample sizes and distribution parameters, making it a strong contender. Interestingly, the PL method also shows robust performance, particularly in certain conditions, potentially ranking as the second best in terms of CP. For instance, with a mean of 3 and a shape parameter of 0.5 at a sample size of 15, PL achieves a CP of around 0.92, notably higher than WPL. This highlights PL’s effectiveness under specific parameter configurations.
Both the mean and shape parameters of the IG distribution indeed affect the CP. A higher mean tends to decrease CP across most methods, indicating sensitivity to central tendency changes. Conversely, an increase in the shape parameter generally leads to a slight increase in CP, reflecting its impact on data skewness and variability.
Sample size is a crucial factor affecting CP. As the sample size increases, the CP generally improves, aligning more closely with the nominal level. This increase in CP with larger sample sizes is particularly pronounced for the WRPLE and WPL methods, underscoring their suitability for larger datasets.
In summary, the WRPLE method consistently shows the highest CP, making it the top performer. The PL method, often outperforming the WPL, ranks second in many scenarios. The WRPLO method follows, demonstrating solid performance but not quite matching the PL. The RPL and WPL methods, while effective, generally show lower CPs, positioning them lower in the hierarchy. This ranking, based on our simulation studies, suggests that while the WRPLE method is the most reliable overall, the effectiveness of each method varies significantly depending on the specific sample size, mean, and shape parameters of the inverse Gaussian distribution.
6. Application to a Real Dataset
The dataset, sourced from Lu and Chi [
28], comprises 30 sequential observations of March precipitation in Minneapolis/St. Paul. The dataset is as follows:
0.77, 1.74, 0.81, 1.20, 1.95, 1.20, 0.47, 1.43, 3.37, 2.20, 3.00, 3.09, 1.51, 2.10, 0.52,
1.62, 1.31, 0.32, 0.59, 0.81, 2.81, 1.87, 1.18, 1.35, 4.75, 2.48, 0.96, 1.89, 0.90, 2.05.
Table 7 summarizes the descriptive statistics. The mean and standard deviation of precipitation are 1.675 and 1, respectively. Four candidate distributions—exponential, Cauchy, log-logistic, and inverse Gaussian—are fitted to the dataset. The results, summarized in
Table 8, indicate that the fitted inverse Gaussian distribution has the highest
p-value and the lowest Akaike information criterion (AIC), suggesting that it is the most suitable for this dataset. The estimated mean and shape parameters for the inverse Gaussian distribution are 1.675 and 3.584, respectively. From
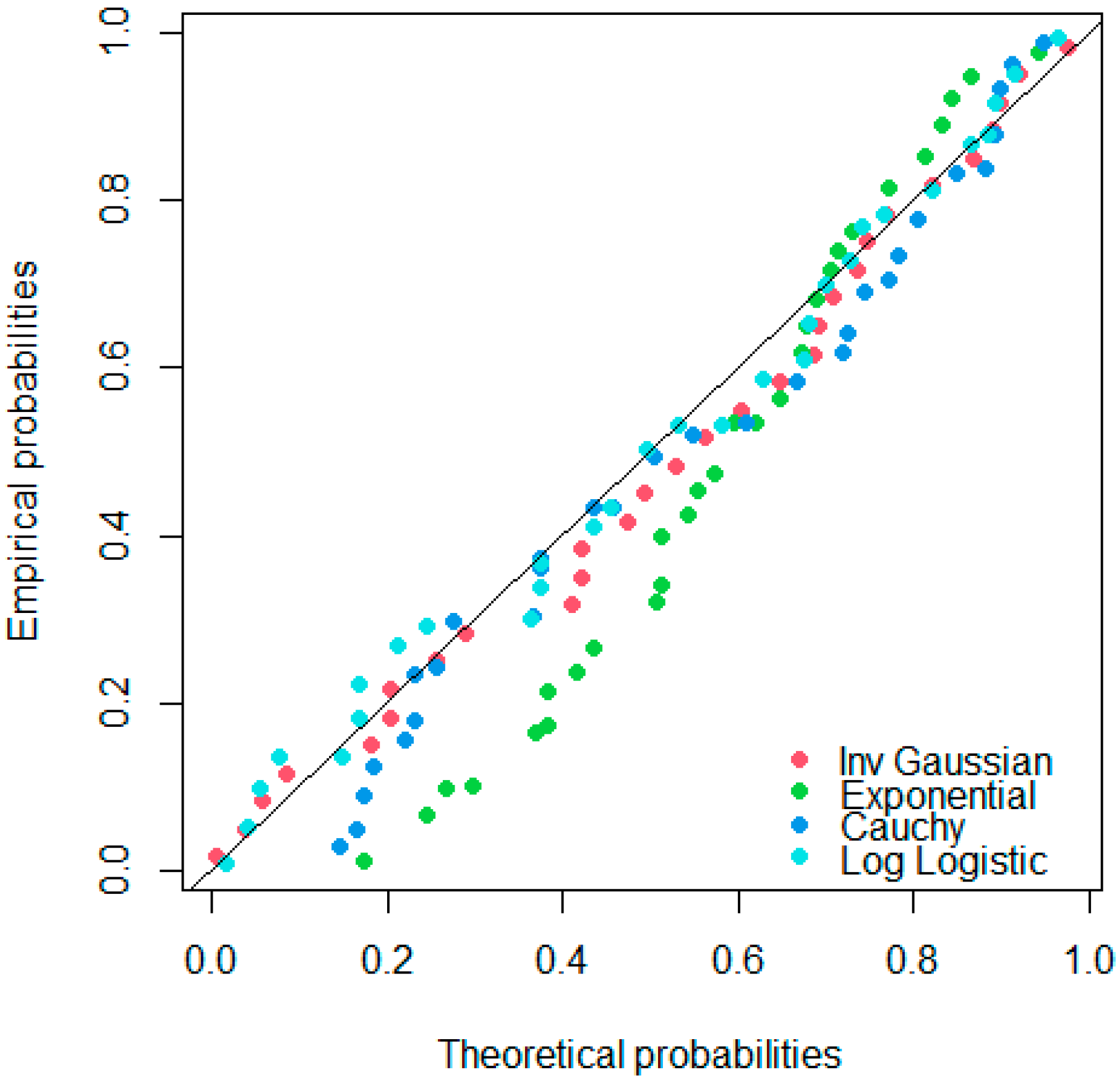
Figure 3, which displays the probability plot, it is evident that the points of the log-logistic and inverse Gaussian distributions align more closely with the diagonal line compared to the exponential and Cauchy distributions.
The 95% confidence intervals for the March precipitation dataset are computed using formulas (9), (10), (11), (15), and (23) for the PL, RPL, WRPLO, WPL, and WRPLE methods, respectively. Observation of the interval lengths in
Table 9 indicates that the results align with the simulation study. This study found that WPL typically produces shorter intervals compared to WRPLE, while both PL and RPL generally fall between these two in terms of interval length.
7. Conclusions
The mathematically derived WPL and WRPLE intervals have a closed form, making them easy for users to calculate for a given dataset. Simulation studies show the WRPLE interval provides a coverage probability close to 0.95, the nominal confidence level, compared to other intervals. For large sample sizes (at least 30), WRPLE and WRPLO are comparable, but WRPLE is superior for small sample sizes. The WPL, however, seems to have lower performance relative to WRPLE and other existing intervals in many cases; this implies that reparameterization is essential for constructing Wald-type confidence intervals. Additionally, as sample size increases, coverage probability improves for all interval types.
Future research could explore the simultaneous confidence interval construction for both parameters of the IG distribution. Additionally, there is potential to focus on other characteristics as parameters of interest, such as the variance of the IG distribution. This could broaden the applicability of confidence intervals in various statistical contexts. Another significant direction for future work includes developing software packages to facilitate the practical application of these intervals, enhancing their usability in statistical analysis.
Author Contributions
Conceptualization, P.S. and W.P.; methodology, P.S.; software, A.N.; validation, P.S., A.N. and W.P.; formal analysis, P.S.; investigation, W.P. and A.N.; resources, W.P.; data curation, A.N.; writing—original draft preparation, P.S. and A.N.; writing—review and editing, W.P.; visualization, P.S. and A.N.; supervision, P.S.; project administration, W.P.; funding acquisition, W.P. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by King Mongkut’s University of Technology North Bangkok. Contract no. KMUTNB-66-BASIC-04.
Data Availability Statement
The dataset used in this study can be found in the work of Lu and Chi [
28].
Acknowledgments
The authors would like to thank the editor and the reviewers for their valuable comments and suggestions to improve this paper.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Folks, J.L.; Chhikara, R.S. The Inverse Gaussian Distribution and Its Statistical Application—A Review. J. R. Stat. Soc. Ser. B Methodol. 1978, 40, 263–289. [Google Scholar] [CrossRef]
- Schrödinger, E. Theory of Parabolic and Rising Experiments on Particles with Brownian Motion. Phys. Z. 1915, 16, 289–295. [Google Scholar]
- Wald, A. Sequential Analysis; Wiley: New York, NY, USA, 1947. [Google Scholar]
- Wise, M.E. Skew Distributions in Biomedicine Including Some with Negative Powers of Time. In A Modern Course on Statistical Distributions in Scientific Work; Patil, G.P., Kotz, S., Ord, J.K., Eds.; NATO Advanced Study Institutes Series; Springer: Dordrecht, The Netherlands, 1975; Volume 17. [Google Scholar]
- Onar, A.; Padgett, W.J. Accelerated Test Models with the Inverse Gaussian Distribution. J. Stat. Plan. Inference 2000, 89, 119–133. [Google Scholar] [CrossRef]
- Jain, R.K.; Jain, S. Inverse Gaussian Distribution and Its Application to Reliability. Microelectron. Reliab. 1996, 36, 1323–1335. [Google Scholar] [CrossRef]
- Barndorff-Nielsen, O.E.; Shephard, N. Modelling by Lévy Processes for Financial Econometrics. In Lévy Processes; Barndorff-Nielsen, O.E., Resnick, S.I., Mikosch, T., Eds.; Birkhäuser: Boston, MA, USA, 2001. [Google Scholar]
- McCarthy, M. Bayesian Methods for Ecology; Cambridge University Press: Cambridge, UK, 2007. [Google Scholar]
- Chankham, W.; Niwitpong, S.; Niwitpong, S. Measurement of Dispersion of PM 2.5 in Thailand Using Confidence Intervals for the Coefficient of Variation of an Inverse Gaussian Distribution. PeerJ 2022, 10, e12988. [Google Scholar] [CrossRef] [PubMed]
- Hougaard, P. Frailty Models for Survival Data. Lifetime Data Anal. 1995, 1, 255–273. [Google Scholar] [CrossRef] [PubMed]
- Lai, C.-D.; Xie, M. Stochastic Ageing and Dependence for Reliability, 1st ed.; Springer: New York, NY, USA, 2006. [Google Scholar]
- Krbálek, M.; Hobza, T.; Patočka, M.; Krbálková, M.; Apeltauer, J.; Groverová, N. Statistical Aspects of Gap-Acceptance Theory for Unsignalized Intersection Capacity. Physica A Stat. Mech. Appl. 2022, 594, 127043. [Google Scholar] [CrossRef]
- Fisch, K.; Schwalger, T.; Lindner, B.; Herz, A.V.M.; Benda, J. Channel Noise from Both Slow Adaptation Currents and Fast Currents Is Required to Explain Spike-Response Variability in a Sensory Neuron. J. Neurosci. 2012, 32, 17332–17344. [Google Scholar] [CrossRef]
- Stein, A.J.; Lindsey, J.K. Statistical Analysis of Stochastic Processes in Time. Environ. Ecol. Stat. 2006, 13, 247–248. [Google Scholar]
- Punzo, A. A New Look at the Inverse Gaussian Distribution with Applications to Insurance and Economic Data. J. Appl. Stat. 2019, 46, 1260–1287. [Google Scholar] [CrossRef]
- Tweedie, M.C.K. Statistical Properties of Inverse Gaussian Distributions. II. Ann. Math. Statist. 1957, 28, 696–705. [Google Scholar] [CrossRef]
- Hougaard, P. Univariate Survival Data. In Analysis of Multivariate Survival Data. Statistics for Biology and Health; Springer: New York, NY, USA, 2000. [Google Scholar]
- Davidson, R.; MacKinnon, J.G. Estimation and Inference in Econometrics; Oxford University Press: New York, NY, USA, 1993. [Google Scholar]
- Martin, V.; Hurn, S.; Harris, D. Econometric Modelling with Time Series: Specification, Estimation and Testing; Cambridge University Press: Cambridge, UK, 2013; p. 138. [Google Scholar]
- Rohde, C.A. Introductory Statistical Inference with the Likelihood Function, 1st ed.; Springer: London, UK, 2014. [Google Scholar]
- Kummaraka, U.; Srisuradetchai, P. Interval Estimation of the Dependence Parameter in Bivariate Clayton Copulas. Emerg. Sci. J. 2023, 7, 1478–1490. [Google Scholar] [CrossRef]
- Pawitan, Y. In All Likelihood: Statistical Modelling and Inference Using Likelihood; Clarendon Press: Oxford, UK, 2001. [Google Scholar]
- Murphy, S.A.; van der Vaart, A.W. On Profile Likelihood. J. Am. Stat. Assoc. 2000, 95, 449–465. [Google Scholar] [CrossRef]
- Arefi, M.; Mohtashami Borzadaran, G.R.; Vaghei, Y. A Note on Interval Estimation for the Mean of Inverse Gaussian Distribution. SORT 2008, 32, 49–56. [Google Scholar]
- Srisuradetchai, P. Simple Formulas for Profile- and Estimated-Likelihood Based Confidence Intervals for the Mean of Inverse Gaussian. J. KMUTNB 2017, 27, 467–479. (In Thai) [Google Scholar]
- Díaz-Francés, E. Simple Estimation Intervals for Poisson, Exponential, and Inverse Gaussian Means Obtained by Symmetrizing the Likelihood Function. Am. Stat. 2016, 70, 171–180. [Google Scholar] [CrossRef]
- Srisuradetchai, P. Using Re-Parametrized Profile Likelihoods to Construct Wald Confidence Intervals for the Mean of Inverse Gaussian Distribution. In Proceedings of the 19th National Graduate Research Conference, Khon Kaen University, Khon Kaen, Thailand, 9 March 2018. (In Thai). [Google Scholar]
- Lu, W.; Shi, D. A New Compounding Life Distribution: The Weibull–Poisson Distribution. J. Appl. Stat. 2012, 39, 21–38. [Google Scholar] [CrossRef]
| Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).










{kind=link}
{kind=link}
{kind=link}