1. Introduction
When acquiring observations becomes challenging or when observational data is being lost during an experiment, records become significant. The concepts of record values, record times, and inter-record times for analyzing the breaking strength data of a specific material were initially introduced by Chandler [
1]. He concluded that the predicted value of the inter-record time is infinite for every particular probability distribution function of a random variable. Feller [
2] provided several examples of record values in the context of gambling issues.
Suppose that are a sequence of independent and identically distributed random variables with the cumulative probability distribution function .
Let
for
. We say
is a lower record value of
if
. When considering upper record values, a similar definition exists. By definition,
is a lower as well as upper record value. The record times reveal the indices at which the lower record values occur.
, where
, and
. The probability density function of
is given by the following:
And the cumulative probability distribution function of
is the following:
The joint probability density function of two lower record values,
and
, is given by
The concept of parametric inference for data breaking records was first introduced by Samaniego and Whitaker [
3]. They explored the characteristics of estimates using the maximum likelihood method for the mean of a basic exponential probability distribution. Gulati and Padgett [
4] expanded Samaniego and Whitaker’s technique to include the Weibull probability distribution. Raul et al. [
5] studied the maximum likelihood and Bayesian estimation of parameters and prediction of future records for the Weibull distribution using
-record data. Ahsanullah [
6] examined data from an exponential distribution, focusing on predicting the
record value based on the first
m record values
. Nigm [
7] was the first to present record values for the Inverse Weibull distribution (IW) along with explicit formulas for its means, variances, and covariances. Furthermore, certain concurrent inferences regarding the forecast of a future record value and the examination of the current record values for spuriousness were made.
Various random events, observed in specific survival, financial, or reliability studies, have been thoroughly modeled using asymmetrical models such as Gumbel, logistic, Weibull, and generalized extreme value distributions.
The Pareto distribution is well-known in various fields, including reliability analysis, actuarial science, survival analysis, life testing, economics, finance, hydrology, telecommunication, physics, and engineering. According to Johnson et al. [
8], the cumulative density function defines the Pareto distribution of the first kind.
In a novel approach to generating distributions with an application to the exponential distribution, Mahadevi and Kundu [
9] introduced the alpha power transformation (APT) distribution to incorporate skewness into the baseline distribution. The formula for the APT cumulative distribution function is
and the density function formula for APT is as follows:
There are several research papers that have applied this distribution in various ways. For instance, Mazen et al. [
10] focused on the finite sample characteristics of Monte Carlo simulation-based parameter estimates for the alpha power exponential distribution. They also examined a single real data set and estimated the distribution parameters under conflicting hazards using the maximum likelihood approach. Also, Refah et al. [
11] addressed estimation issues relating to the alpha power exponential distribution and employed an adaptive progressive Type-II hybrid censoring strategy. Maximum likelihood and Bayesian approaches were used to estimate unknown parameters, reliability, and hazard rate functions. Furthermore, in the study conducted by Fatehi and Chhaya [
12], the alpha power transformed extended power Lindley (APTEPL) distribution, which is a new generalization of the extended power Lindley distribution, was explored and introduced.
Now, let
X be a complete random variable
from the power function probability distribution, with CDF and PDF given by
where
v is the shape parameter,
is the location parameter, and
is the scale parameter.
This work aims to propose a new generalization of the Power distribution, known as the alpha power transformed of Power APTPO distribution, according to Equations (3) and (4). Approximate methods, such as the best linear unbiased estimates (BLUE), are frequently practical. The BLUE, which considers both individual uncertainties and their correlations, is commonly used. If the true uncertainties and their correlations are known, the approach is inherently impartial (see Luca [
13]). The Transformed Power Function distribution was expanded upon by Idika et al. [
14] as the APTPO. Here are some characteristics of the APTPO distribution. Three approaches were used for parameter estimation: maximum likelihood, ordinary least-squares, and weighted least-squares. After comparing the outcomes of a simulation research, the authors opted for maximum likelihood. For the APTPO distribution, breaking data is used to determine the coefficients for the parameters of our proposed distribution for both the best linear unbiased estimators (BLUE) and the best linear invariant estimators (BLIE). Forecasting future observations is possible by utilizing the return level for the entire sample from the APTPO distribution.
The work is outlined as follows:
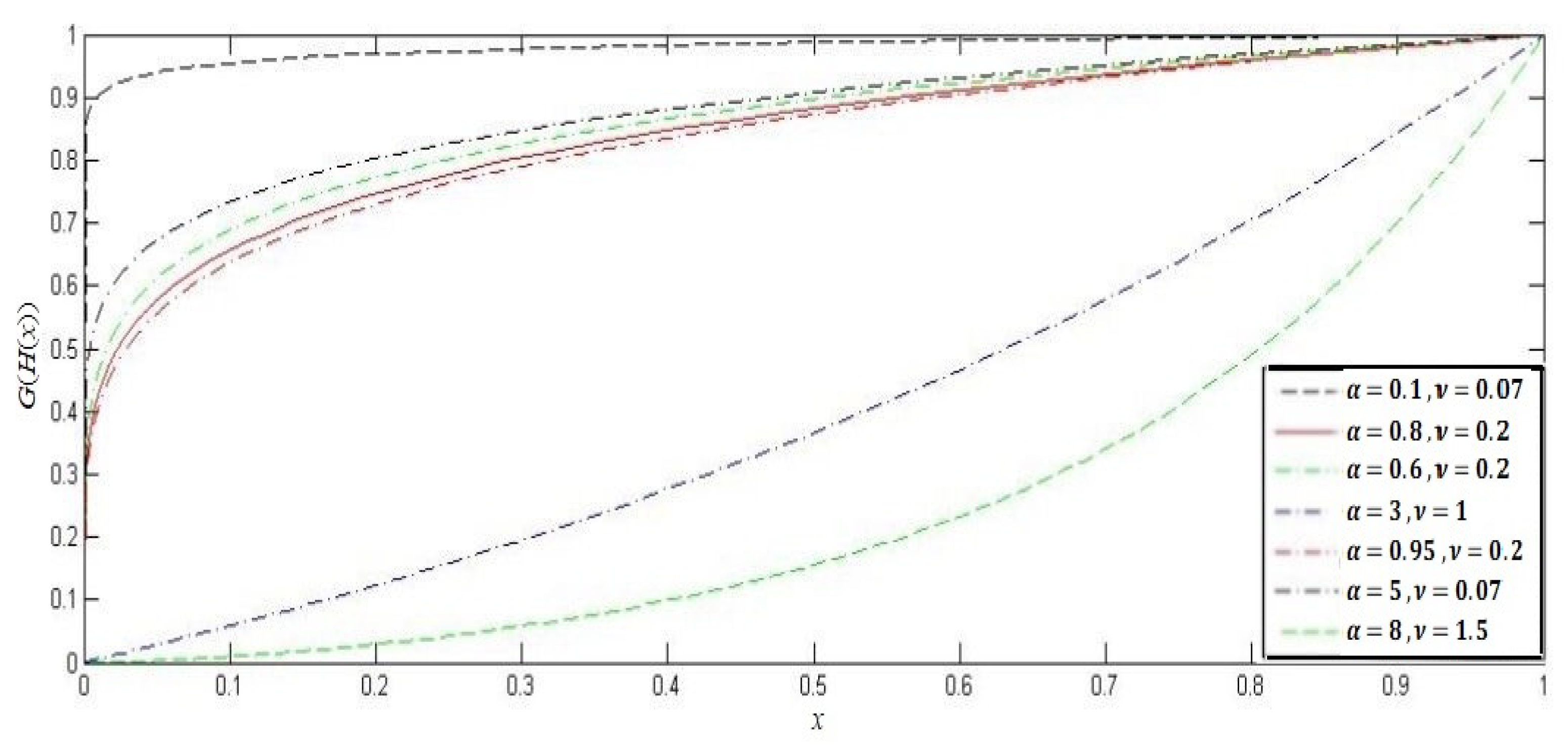
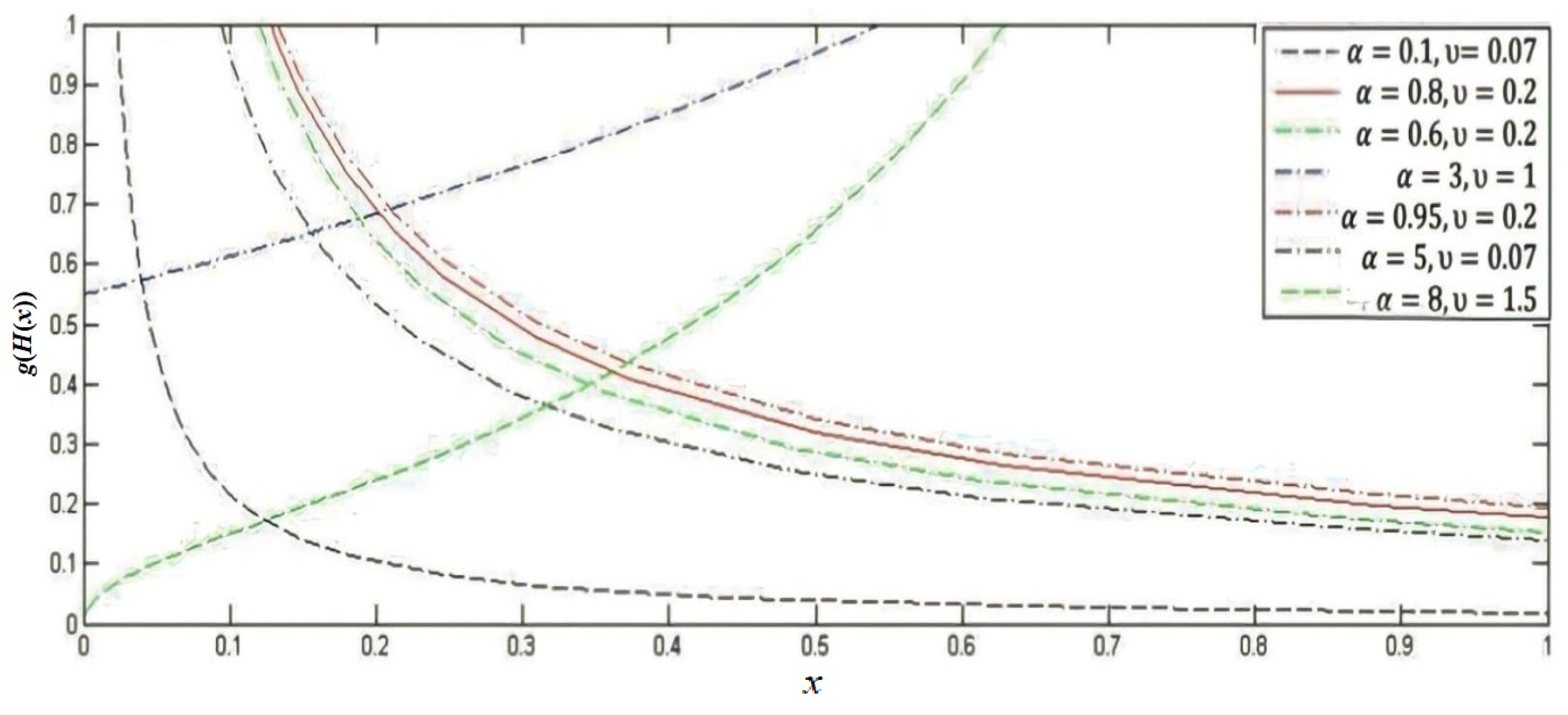
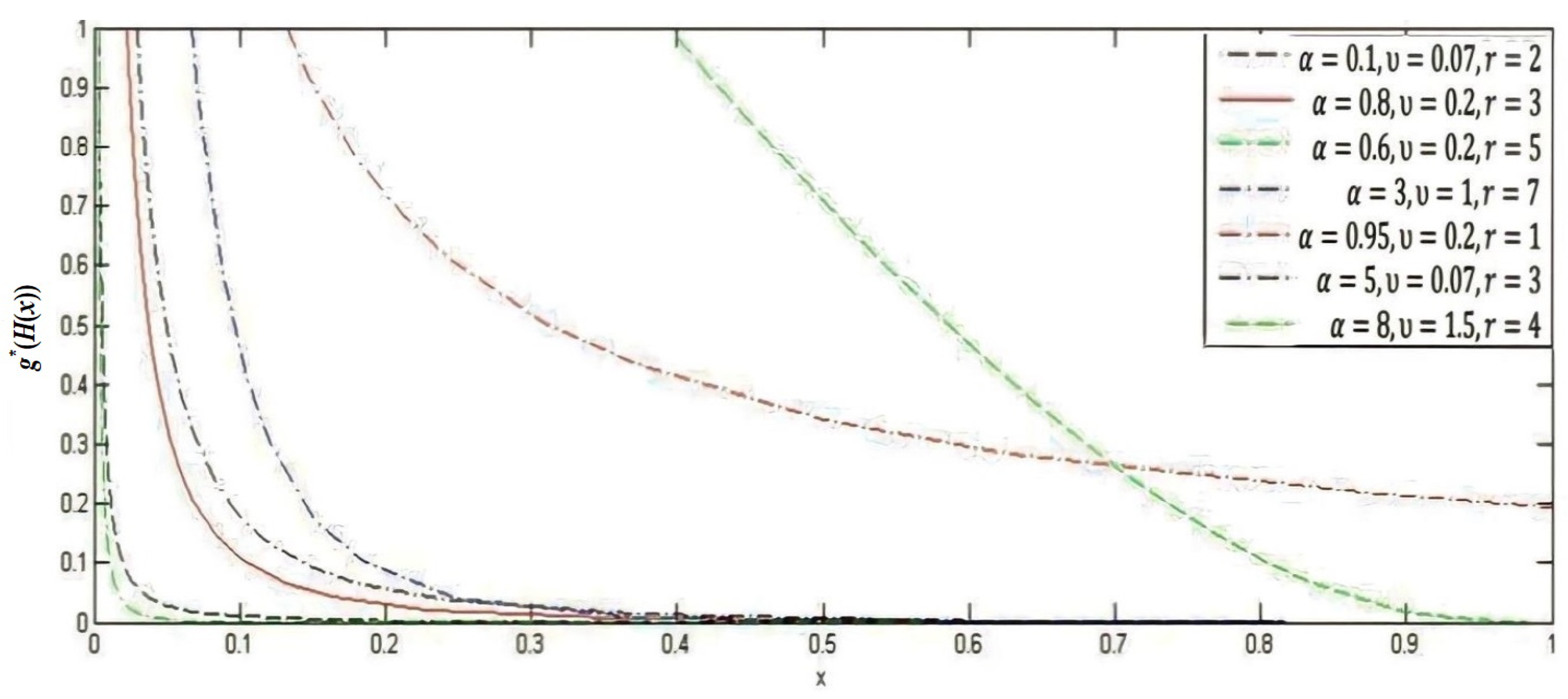
Section 2 determines the construction of our proposed distribution and the probability density function (PDF) of the lower record values. The effect of the parameters is also illustrated graphically.
Section 3 employs BLUE and BLIE methods to estimate the parameters of the APTPO distribution based on lower record values. This section covers future record prediction and simulation studies. In
Section 4, based on the inter-record time sequence and the complete sample, the APTPO distribution’s parameters are estimated using the maximum likelihood estimation method. The remaining portions of this section compare the parameters in the inter-record times and the entire sample using a goodness-of-fit test.
Section 5 provides an illustrative example to demonstrate the previous applications of the new distribution. Finally, in
Section 6, conclusions are presented.
4. The Maximum Likelihood Technique
Let follow a completely random sampling from the APTPO distribution function (7). The records required for this investigation were obtained as follows: The first recording, , is , so the first observation is . Observing the independently distributed random variables with the same distribution sequentially from yields the second record value, . Let the next observation that is less than need a number of trials to acquire equal to . For example, let the next observation that is less than be , so the number of trials to obtain will be .
Let , where is the record value sequence and and is the inter-record time sequence. Note that the number of records acquired will be smaller than n, the size of the entire random data sample, when this approach is used. It’s important to emphasize that the lower record values are the record numbers that do not include the inter-record times.
The likelihood function can be stated as
For the record-breaking samples, let , where and are the PDF and CDF, respectively, of the random variable from which the record observations are obtained.
Applying the likelihood function to the record observations obtained from the APTPO distribution, we obtain that
where,
.
The log of the likelihood function is
By taking the partial derivative of Equation (
21) with respect to
and
, we obtain the following equations:
The maximum likelihood estimators for and for the record samples are obtained by setting Equations (22) and (23) to zero.
The estimates of the parameters inherent in Equations (20) and (21) are obtained as follows for the complete sample .
We can write the log-likelihood from the APTPO probability density function, given by Equation (
8), as follows:
By taking the partial derivative of (24) with respect to
and
, we obtain the following equations:
and
The maximum likelihood estimators for and for the complete samples are obtained by setting Equations (25) and (26) to zero.
To estimate the approximate confidence intervals for the parameters of the APTPO distribution, one needs the
observed information matrices for the record-breaking samples and complete sample, which are denoted by
and
where
and
. Then, the
total observed information matrix associated with the APTPO distribution for the record-breaking samples is given by
, where their parameters are replaced by their
, where
with
The
total observed information matrix associated with the APTPO distribution is given by
wherein the parameters are replaced by their
, where
with
Under standard regularity conditions,
asymptotically follows the multivariate normal distribution
and the asymptotic distribution of
is
. These distributions can be utilized to construct approximate confidence intervals for the model parameters. Thus, denoting, for example, the total observed information matrix evaluated at
, that is,
, by
, one would have the following approximate
confidence intervals for the parameters of the APTPO distribution:
where
denotes the
percentile of the standard normal distribution.
Goodness of Fit Tests
The goodness of fit for a statistical model describes how well it matches a set of data. Goodness of fit measures are frequently used to characterize the discrepancy between actual values and values that would have been anticipated under the relevant model. When testing statistical hypotheses, such data can be used, for illustration, to check for residual normality and determine whether two samples were drawn from the same distribution. When applying an Akaike information criterion (AIC) (see Akaike [
16]), this can be evaluated as follows:
where
L is the likelihood of the function and
K is the number of estimated parameters. Note that smaller values indicate a better model.
5. Simulation Study
The performance of the estimators established in the preceding section can be verified through the following simulation studies.
1. The APTPO distribution is used with
, and
from a small random sample of size
to serve as a model:
Four record values can be collected from the given random sample, such as
We determined the
and
estimation parameters for
and 4 by applying the BLUE and BLIE methods. The standard error for each case is calculated. Applying Equation (
19) in each situation yields the prediction for the fifth future observation. The results are listed in
Table 3.
On the other hand, applying the MLE method to estimate the parameters of the APTPO distribution (see
Section 4) for complete data and using inter-record time
, along with applying the AIC method (Equation (
27)), provides the results shown in
Table 4. This table indicates that the value of AIC in the case of inter-record times is smaller than the value in the case of the complete sample. This implies that the use of inter-record times is preferable.
2. The APTPO distribution is used with
, and
from a large random sample of size
to serve as a model:
Eleven record values can be collected from the given random sample, such as
We determined the
and
estimation parameters for
and 4 by applying the BLUE and BLIE methods. The standard error for each case is calculated. Applying Equation (
19) in each situation yields the prediction for the 12th future observation. The results are listed in
Table 5.
On the other hand, applying the MLE method to estimate the parameters of the APTPO distribution (see
Section 4) for complete data and using inter-record time
provides the results shown in
Table 6.






{kind=link}
{kind=link}
{kind=link}