
A Comprehensive Literature Review on Artificial Dataset Generation for Repositioning Challenges in Shared Electric Automated and Connected Mobility †
 and
and
Abstract
:1. Introduction
1.1. Background and Motivation
- Autonomous driving technology (minimum level 2) will be integrated in 70% of new vehicles by 2030 around the world.
- A total of 96% of new vehicles worldwide would be equipped with integrated connectivity.
- A total of 24% of new cars will be electric by 2030.
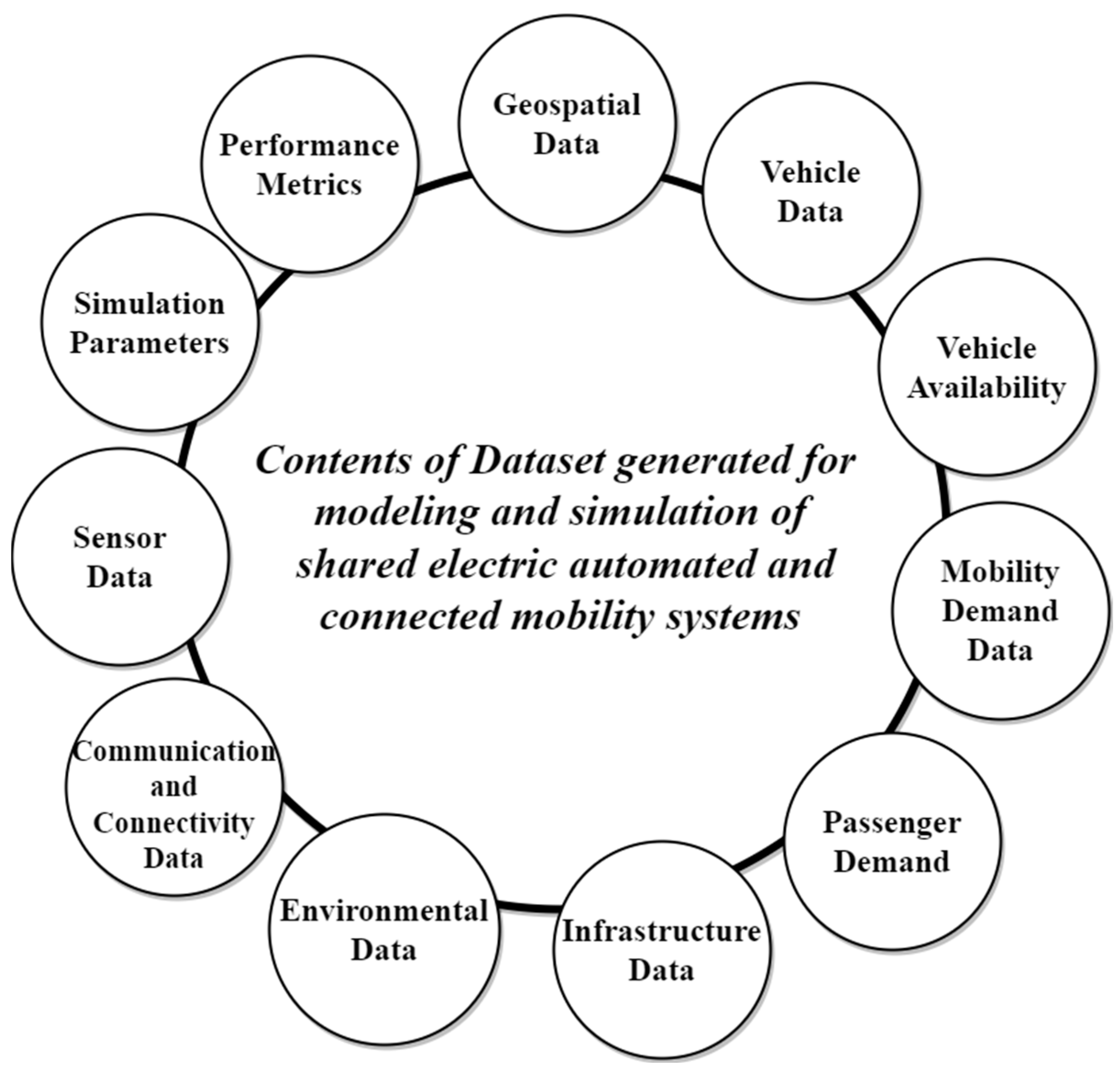
- Geospatial data: These comprise geographical information, including latitude, longitude, and elevation, representing the locations of vehicles, charging stations, and other infrastructure components within the mobility system [5].
- Vehicle data: These encompass vehicle details like unique identifiers, types (e.g., electric, autonomous), current and past locations, battery status, and operational parameters [5].
- Vehicle availability: These data serve to formulate effective redistribution strategies for maximizing demand coverage. They include information such as electric autonomous vehicle (EAV) fleet size, vehicle availability, EAV locations, and charging status [5].
- Demand data: Capturing transportation service demand, these data incorporate origins, destinations, duration, distance, and travel preferences, along with reservation specifics, pick-up and drop-off points, distance, and travel time. They are essential for machine learning model training and optimizing SEACM’s vehicle redistribution efficiency [5].
- Infrastructure data: This category involves the location, capacity, availability, and connectivity of charging stations in SEACM systems, along with information on road traffic and network configuration.
- Environmental data: Essential for evaluating the SEACM system’s performance, these data include weather conditions (temperature, rain, wind, and snow), and seasonal variations.
- Communication and connectivity data: Encompassing details about communication networks, these include links between vehicles (V2V), communication between vehicles and infrastructure (V2I), as well as vehicle communication with pedestrian centers.
- Sensor data: This category incorporates information from various sensors in vehicles or infrastructure, such as lidar, battery charge levels, temperature sensors, and camera data for perception.
- Simulation parameters: These parameters control the simulation process, including simulation time, duration, traffic density, and repositioning strategies.
1.2. Research Objectives
- (1)
- Literature review: A comprehensive examination of the recent literature on artificial dataset generation for SEACM systems will be conducted. This review aims to identify both the strengths and gaps in proposed approaches, outlining diverse techniques, methods, and challenges associated with the generation of artificial datasets.
- (2)
- Analysis of synthetic dataset generation techniques: This section will scrutinize different techniques employed for generating synthetic datasets, including data augmentation, synthetic data generation, and the amalgamation of real and synthetic data. The evaluation will delve into the advantages, limitations, and relevance of each technique to SEACM systems.
- (3)
- Relevance of synthetic datasets in performance evaluation: The effectiveness of synthetic datasets in assessing the performance of SEACM systems will be examined. Emphasis will be placed on highlighting the importance of employing realistic and diverse artificial datasets and analyzing how various dataset characteristics impact system performance metrics.
- (4)
- Impact of synthetic datasets on deployment strategies: This segment will investigate the influence of synthetic datasets on the deployment strategy of shared electric automated and connected mobility systems. Furthermore, it will explore how the utilization of artificial datasets can contribute to decision-making processes, such as determining fleet size, planning infrastructure, and optimizing the system, through the examination of case studies and practical examples.
1.3. Structure of the Paper
2. Artificial Dataset Generation Techniques
2.1. Monte Carlo Simulations
2.2. Bayesian Network
2.3. Synthetic Data Generation
2.4. Data Augmentation
2.5. Transfer Learning
2.6. Other Techniques
3. Relevance of Artificial Datasets in Shared Electric Automated and Connected Mobility Systems
3.1. Data Requirements for Modeling and Simulation in Shared Electric Automated and Connected Mobility Systems
- Vehicle trajectories: Essential for dynamic modeling, this involves collecting data on the position, speed, acceleration, and direction of vehicles over time.
- Charging infrastructure data: This category includes details on the location, capacity, availability, and usage of charging stations, contributing to evaluating the effectiveness and efficiency of the dynamic system.
- Traffic patterns: Crucial for simulating shared mobility systems, traffic models aid in understanding traffic patterns, the impact of data on traffic levels, congestion, and the configuration of the road network.
- User behavior: These data encompass variables influencing system demand and operation, such as trip start and end points, travel preferences, and transportation mode choices.
- Environmental factors: Environmental conditions, including weather and road conditions, significantly impact system efficiency and user behavior. Additionally, these data contribute to designing more accurate and comprehensive models for SEACM systems, deepening the understanding of system dynamics, facilitating performance evaluation, and formulating effective deployment strategies.
3.2. Challenges in Data Collection from Real-World Scenarios
3.3. Benefits of Artificial Datasets in Simulation Studies
- (1)
- Enhanced control and systematic exploration: The utilization of artificial datasets provides researchers with the capability to operate within a controlled environment. This control facilitates the systematic exploration of various scenarios and parameters. Through extensive sensitivity analyses and performance evaluations, researchers can gain valuable insights into the behavior and performance of these intricate systems.
- (2)
- Coverage of diverse situations and edge cases: Artificial datasets empower the generation of data that span a broad spectrum of situations, capturing rare or challenging-to-obtain edge cases. In the real world, encountering these specific scenarios can be challenging or infrequent. Artificial datasets address this limitation by offering researchers the means to simulate and study these situations in a controlled manner. This comprehensive coverage contributes to a more thorough understanding of system behavior and performance. Synthetic datasets provide researchers with the tools needed to model and meticulously investigate these scenarios, which can be difficult to encounter in the actual world.
- (3)
- Reproducibility and comparability: The use of generated datasets brings about several advantages, including the ease with which research results can be replicated and compared. Researchers can share the datasets they develop, enabling others to use the same data for evaluation and analysis. This fosters transparency and collaboration within the scientific community. Additionally, researchers employing comparable artificial datasets can compare results, facilitating accurate comparisons and meta-analyses.
4. Training ML Models for Performance Evaluation
4.1. ML Models in Shared Mobility Systems
4.2. Supervised and Unsupervised Learning Approaches
- A.
- Supervised Learning:
- B.
- Unsupervised Learning:
4.3. Feature Engineering and Selection
4.4. Training on Artificial Datasets
5. Deployment Considerations
5.1. Real-World Challenges and Limitations
5.1.1. Uncertainties in Data Quality and Availability
5.1.2. System Dynamics and Evolution
5.1.3. Impact of External Factors
5.1.4. Transferability to Real Scenarios
5.2. Generalization of ML Models Trained on Artificial Datasets
5.3. Ethical and Privacy Concerns
6. How to Design/Conceive/Manage Case Studies and Experiments
6.1. Description of the Case Studies
6.1.1. Urban Transportation Network Optimization
6.1.2. Micro-Mobility Service Planning
6.1.3. Charging Infrastructure Optimization
6.1.4. Demand Forecasting and Dynamic Pricing
6.1.5. User Behavior Analysis and Recommendation Systems
6.2. Experimental Setup
6.2.1. Simulation Platform
6.2.2. Artificial Datasets
6.2.3. ML Models and Algorithms
6.3. Results and Analysis
6.3.1. Performance Metrics
6.3.2. Strengths and Limitations
6.3.3. Potential Benefits and Challenges
6.3.4. Contextualization of Findings
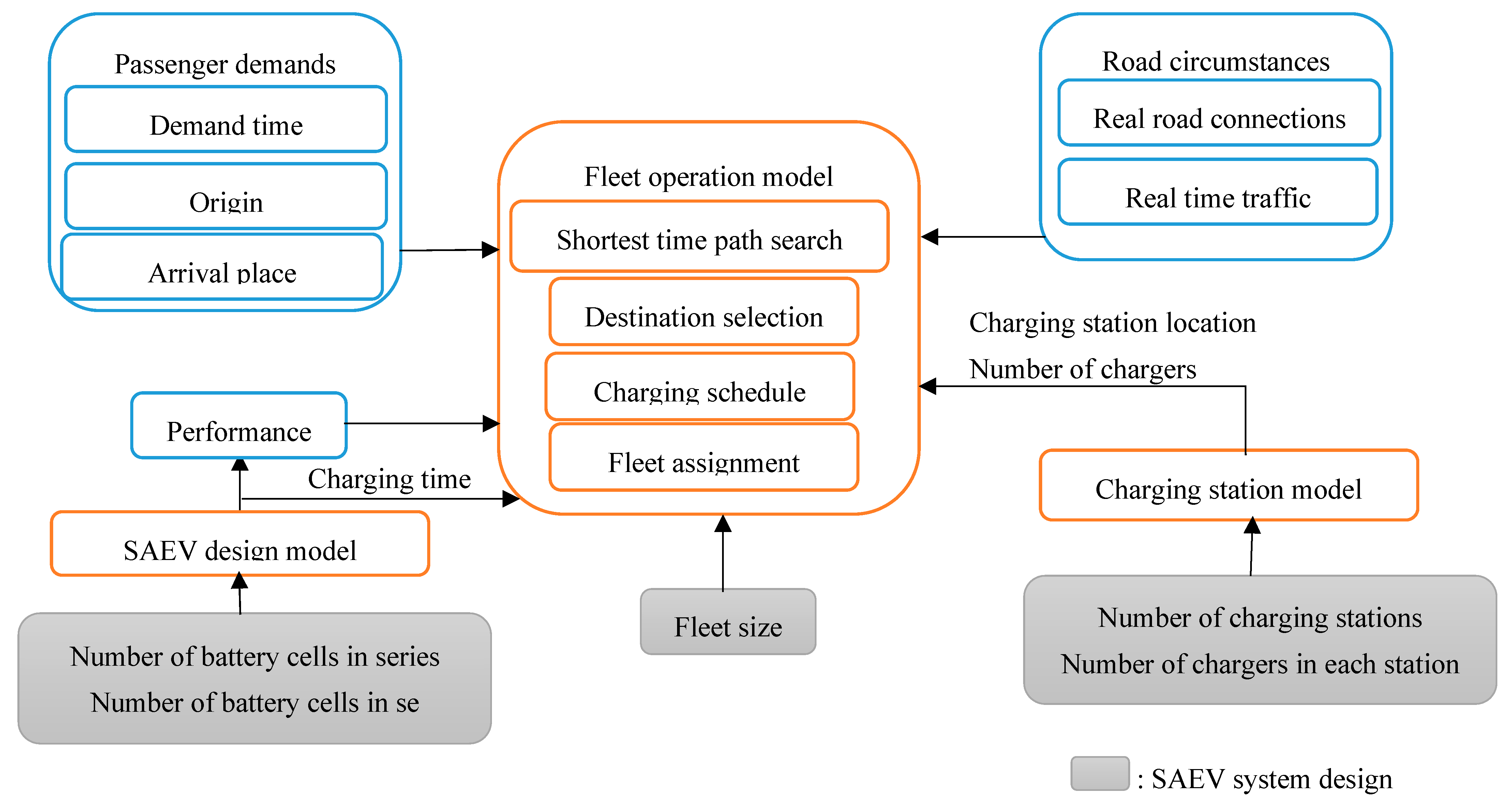
6.4. Case Study Specification of SEACM Systems, Categories of Data Needed to Address Repositioning and Assignement Issues
- Navigate to serve the next request as long as no available EAV is parked in the area, provided that its battery range is sufficiently charged for the next trip.
- Navigate to the charging station to achieve either a full charge or a 50% charge level.
- Navigate to park somewhere if no charging points are accessible.
- Proceed to the control center if any technical issues are identified, necessitating further diagnostics and resolution.
6.5. Real World Application in the Context of Shared Electric Automated and Connected Mobility
7. Discussion and Future Directions
7.1. Evaluation of Artificial Dataset Generation Techniques
7.2. Integration of Real and Artificial Data
7.3. Potential Research Directions
- (1)
- Investigating advanced machine learning methods: To create more varied and lifelike simulated datasets, future research could focus on applying advanced machine learning methods, such as generative models and deep learning [16,17,19,67]. These methods could improve the accuracy of simulations of real-world situations and boost the dependability of generated datasets.
- (2)
- Reviewing how data generation methods affect machine learning models: Investigating the effects of various data production methods on the functionality of machine learning models in simulation experiments is essential. Selecting the best methods to produce useful synthetic datasets for the modeling and assessment of the SEACM network will be made easier by being aware of its advantages and disadvantages.
- (3)
- In order to address issues with data lack and privacy, approaches for maintaining privacy can be developed during the creation of synthetic datasets. While protecting the privacy of sensitive data, these techniques must retain the statistical properties of actual data. Researcher access to realistic datasets for simulation studies can be expanded and data restrictions can be solved by addressing these issues.
7.4. Discussion of Research Outcomes on Automated Shared Mobility Systems in the Context of Data
8. Conclusions
- In what ways can the methods for creating synthetic datasets capture the essential features of these dynamic and stochastic systems while maintaining their realistic nature?
- Which strategies are used to generate synthetic datasets of SEACM systems, and what are their strengths and limitations in terms of performance?
- How is the SEACM network’s simulation more realistic and reliable when it combines actual and artificial datasets?
- How might machine learning model performance and generalization be impacted by the creation of diverse datasets in SEACM system simulations?
- Can real-world scenarios be effectively used with machine learning models that were trained on artificial datasets?
- How may machine learning approaches advance to improve the variety and realism of synthetic datasets?
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Afshar, V. The Car of the Future Is Connected, Autonomous, Shared, and Electric. Available online: https://www.zdnet.com/article/the-car-of-the-future-is-connected-autonomous-shared-and-electric/ (accessed on 8 December 2020).
- Benarbia, T.; Kyamakya, K.; Al Machot, F.; Kambale, W.V. Modeling and Simulation of Shared Electric Automated and Connected Mobility Systems with Autonomous Repositioning: Performance Evaluation and Deployment. Sustainability 2023, 15, 881. [Google Scholar] [CrossRef]
- Li, L.; Pantelidis, T.; Chow, J.Y.; Jabari, S.E. A real-time dispatching strategy for shared automated electric vehicles with performance guarantees. Transp. Res. Part E Logist. Transp. Rev. 2021, 152, 102392. [Google Scholar] [CrossRef]
- Zhang, W.; Wang, K.; Wang, S.; Jiang, Z.; Mondschein, A.; Noland, R.B. Synthesizing neighborhood preferences for automated vehicles. Transp. Res. Part C Emerg. Technol. 2020, 120, 102774. [Google Scholar] [CrossRef]
- Sanchez, N.C.; Martinez, I.; Pastor, L.A.; Larson, K. On the simulation of shared autonomous micro-mobility. Commun. Transp. Res. 2022, 2, 100065. [Google Scholar] [CrossRef]
- Hu, L.; Dong, J. An Artificial-Neural-Network-Based Model for Real-Time Dispatching of Electric Autonomous Taxis. IEEE Trans. Intell. Transp. Syst. 2020, 23, 1519–1528. [Google Scholar] [CrossRef]
- Yuan, Y.; Cheng, H.; Sester, M. Keypoints-based deep feature fusion for cooperative vehicle detection of autonomous driving. IEEE Robot. Autom. Lett. 2022, 7, 3054–3061. [Google Scholar] [CrossRef]
- Patella, S.M.; Scrucca, F.; Asdrubali, F.; Carrese, S. Carbon Footprint of autonomous vehicles at the urban mobility system level: A traffic simulation-based approach. Transp. Res. Part D Transp. Environ. 2019, 74, 189–200. [Google Scholar] [CrossRef]
- Rath, S.; Liu, B.; Yoon, G.; Chow, J.Y. Microtransit deployment portfolio management using simulation-based scenario data upscaling. Transp. Res. Part A Policy Pract. 2023, 169, 103584. [Google Scholar] [CrossRef]
- Wang, X.; Mavromatis, I.; Tassi, A.; Santos-Rodriguez, R.; Piechocki, R.J. Location anomalies detection for connected and autonomous vehicles. In Proceedings of the 2019 IEEE 2nd Connected and Automated Vehicles Symposium (CAVS), Honolulu, HI, USA, 22–23 September 2019; pp. 1–5. [Google Scholar]
- Muthurajan, S.; Loganathan, R.; Hemamalini, R.R. Deep Reinforcement Learning Algorithm based PMSM Motor Control for Energy Management of Hybrid Electric Vehicles. WSEAS Trans. Power Syst. 2023, 18, 18–25. [Google Scholar] [CrossRef]
- Karandinou, A.A.; Kanellos, F.D. A Method for the Assessment of Multi-objective Optimal Charging of Plug-in Electric Vehicles at Power System Level. WSEAS Trans. Syst. Control 2022, 17, 314–323. [Google Scholar] [CrossRef]
- Miok, K.; Nguyen-Doan, D.; Zaharie, D. Generating Data using Monte Carlo Dropout. arXiv 2019, arXiv:1909.05755v2. [Google Scholar]
- Frick, M.; Axhausen, K.W. Generating Synthetic Populations using Iterative Proportional Fitting (IPF) and Monte Carlo Techniques. In Proceedings of the 3rd Swiss Transport Research Conference (STRC 2003), Ascona, Switzerland, 19–21 March 2003. [Google Scholar]
- Ilahi, A.; Axhausen, K.W. Integrating Bayesian network and generalized raking for population synthesis in Greater Jakarta. Reg. Stud. Reg. Sci. 2019, 6, 623–636. [Google Scholar] [CrossRef]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial nets. Adv. Neural Inf. Process. Syst. 2014, 27, 2672–2680. [Google Scholar]
- Islam, Z.; Abdel-Aty, M.; Cai, Q.; Yuan, J. Crash data augmentation using variational autoencoder. Accid. Anal. Prev. 2021, 151, 105950. [Google Scholar] [CrossRef] [PubMed]
- Hinton, G.E. Deep belief networks. Scholarpedia 2009, 4, 5947. [Google Scholar] [CrossRef]
- Mumuni, A.; Mumuni, F. Data augmentation: A comprehensive survey of modern approaches. Array 2022, 16, 100258. [Google Scholar] [CrossRef]
- Shorten, C.; Khoshgoftaar, T.M. A survey on image data augmentation for deep learning. J. Big Data 2019, 6, 1–48. [Google Scholar] [CrossRef]
- Perez, L.; Wang, J. The effectiveness of data augmentation in image classification using deep learning. arXiv 2017, arXiv:1712.04621. [Google Scholar]
- Pan, S.J.; Yang, Q. A survey on transfer learning. IEEE Trans. Knowl. Data Eng. 2009, 22, 1345–1359. [Google Scholar] [CrossRef]
- Yosinski, J.; Clune, J.; Bengio, Y.; Lipson, H. How transferable are features in deep neural networks? Adv. Neural Inf. Process. Syst. 2014, 3320–3328, 3320–3328. [Google Scholar]
- Han, X.; Zhang, Z.; Ding, N.; Gu, Y.; Liu, X.; Huo, Y.; Qiu, J.; Yao, Y.; Zhang, A.; Zhang, L.; et al. Pre-trained models: Past, present and future. AI Open 2021, 2, 225–250. [Google Scholar] [CrossRef]
- Chiba, S.; Sasaoka, H. Basic study for transfer learning for autonomous driving in car race of model car. In Proceedings of the 2021 6th International Conference on Business and Industrial Research (ICBIR), Bangkok, Thailand, 20–21 May 2021; pp. 138–141. [Google Scholar]
- Liberty, E.; Lang, K.; Shmakov, K. Stratified sampling meets machine learning. In Proceedings of the International Conference on Machine Learning, New York, NY, USA, 19–24 June 2016; pp. 2320–2329. [Google Scholar]
- Breiman, L. Bagging predictors. Mach. Learn. 1996, 24, 123–140. [Google Scholar] [CrossRef]
- Cyril, P.; Jürg, S.; Faez, A. Guidelines for Creating Synthetic Datasets for Engineering Design Applications. arXiv 2023, arXiv:2305.09018v1. [Google Scholar]
- El Emam, K.; Mosquera, L.; Hoptroff, R. Practical Synthetic Data Generation: Balancing Privacy and the Broad Availability of Data; O’Reilly Media: Sebastopol, CA, USA, 2020. [Google Scholar]
- Narayanan, S.; Chaniotakis, E.; Antoniou, C. Shared autonomous vehicle services: A comprehensive review. Transp. Res. Part C Emerg. Technol. 2020, 111, 255–293. [Google Scholar] [CrossRef]
- Cai, J.; Deng, W.; Guang, H.; Wang, Y.; Li, J.; Ding, J. A survey on data-driven scenario generation for automated vehicle testing. Machines 2022, 10, 1101. [Google Scholar] [CrossRef]
- Tang, S.; Zhang, Z.; Zhang, Y.; Zhou, J.; Guo, Y.; Liu, S.; Guo, S.; Li, Y.-F.; Ma, L.; Xue, Y.; et al. A Survey on Automated Driving System Testing: Landscapes and Trends. ACM Trans. Softw. Eng. Methodol. 2023, 32, 1–62. [Google Scholar] [CrossRef]
- Huang, Z.; Hale, D.K.; Shladover, S.E.; Lu, X.Y.; Liu, H.; Li, Q.; Li, X.; Mahmassani, H.; Talebpour, A.; Hosseini, M.; et al. Developing Analysis, Modeling, and Simulation Tools for Connected and Automated Vehicle Applications; No. FHWA-HRT-21-077; Federal Highway Administration, Office of Operations Research and Development: McLean, VA, USA, 2021.
- Wang, C.; Xie, Y.; Huang, H.; Liu, P. A review of surrogate safety measures and their applications in connected and automated vehicles safety modeling. Accid. Anal. Prev. 2021, 157, 106157. [Google Scholar] [CrossRef] [PubMed]
- Zhong, Z.; Tang, Y.; Zhou, Y.; Neves, V.D.O.; Liu, Y.; Ray, B. A survey on scenario-based testing for automated driving systems in high-fidelity simulation. arXiv 2021, arXiv:2112.00964. [Google Scholar]
- Yu, L.; Feng, T.; Li, T.; Cheng, L. Demand prediction and optimal allocation of shared bikes around urban rail transit stations. Urban Rail Transit 2023, 9, 57–71. [Google Scholar] [CrossRef]
- Abouelela, M.; Lyu, C.; Antoniou, C. Exploring the Potentials of Open-Source Big Data and Machine Learning in Shared Mobility Fleet Utilization Prediction. Data Sci. Transp. 2023, 5, 5. [Google Scholar] [CrossRef]
- Fauser, J.; Hertweck, D. Identifying e-scooter sharing customer segments using clustering. In Proceedings of the 2018 IEEE International Conference on Engineering, Technology and Innovation (ICE/ITMC), Stuttgart, Germany, 17–20 June 2018; pp. 1–8. [Google Scholar]
- Liang, Y.; Ding, Z.; Ding, T.; Lee, W.J. Mobility-aware charging scheduling for shared on-demand electric vehicle fleet using deep reinforcement learning. IEEE Trans. Smart Grid 2020, 12, 1380–1393. [Google Scholar] [CrossRef]
- Chang, M.; Bae, S.; Cha, G.; Yoo, J. Aggregated electric vehicle fast-charging power demand analysis and forecast based on LSTM neural network. Sustainability 2021, 13, 13783. [Google Scholar] [CrossRef]
- Nazari, M.; Hussain, A.; Musilek, P. Applications of Clustering Methods for Different Aspects of Electric Vehicles. Electronics 2023, 12, 790. [Google Scholar] [CrossRef]
- Xiong, Y.; Wang, B.; Chu, C.-C.; Gadh, R. Electric Vehicle Driver Clustering using Statistical Model and Machine Learning. In Proceedings of the 2018 IEEE Power & Energy Society General Meeting (PESGM), Portland, OR, USA, 5–10 August 2018; pp. 1–5. [Google Scholar] [CrossRef]
- Orzechowski, A.; Lugosch, L.; Shu, H.; Yang, R.; Li, W.; Meyer, B.H. A data-driven framework for medium-term electric vehicle charging demand forecasting. Energy AI 2023, 14, 100267. [Google Scholar] [CrossRef]
- Lucini, F. The real deal about synthetic data. MIT Sloan Manag. Rev. 2022, 63, 11–13. [Google Scholar]
- Lu, Y.; Wang, H.; Wei, W. Machine Learning for Synthetic Data Generation: A Review. arXiv 2023, arXiv:2302.04062. [Google Scholar]
- Kar, A.; Prakash, A.; Liu, M.Y.; Cameracci, E.; Yuan, J.; Rusiniak, M.; Fidler, S. Meta-sim: Learning to generate synthetic datasets. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 4551–4560. [Google Scholar]
- Li, P.; Liang, X.; Jia, D.; Xing, E.P. Semantic-aware grad-gan for virtual-to-real urban scene adaption. arXiv 2018, arXiv:1801.01726. [Google Scholar]
- Prakash, A.; Boochoon, S.; Brophy, M.; Acuna, D.; Cameracci, E.; State, G.; Shapira, O.; Birchfield, S. Structured domain randomization: Bridging the reality gap by context-aware synthetic data. In Proceedings of the 2019 International Conference on Robotics and Automation (ICRA), Montreal, QC, Canada, 20–24 May 2019; pp. 7249–7255. [Google Scholar]
- Tobin, J.; Fong, R.; Ray, A.; Schneider, J.; Zaremba, W.; Abbeel, P. Domain randomization for transferring deep neural networks from simulation to the real world. In Proceedings of the 2017 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Vancouver, BC, Canada, 24–28 September 2017; pp. 23–30. [Google Scholar]
- Song, Q.C.; Tang, C.; Wee, S. Making sense of model generalizability: A tutorial on cross-validation in R and Shiny. Adv. Methods Pract. Psychol. Sci. 2021, 4, 2515245920947067. [Google Scholar] [CrossRef]
- Hua, M.; Pereira, F.C.; Jiang, Y.; Chen, X. Transfer learning for cross-modal demand prediction of bike-share and public transit. arXiv 2022, arXiv:2203.09279. [Google Scholar]
- Huang, Y.; Song, X.; Zhang, S.; James, J.Q. Transfer learning in traffic prediction with graph neural networks. In Proceedings of the 2021 IEEE International Intelligent Transportation Systems Conference (ITSC), Indianapolis, IN, USA, 19–22 September 2021; pp. 3732–3737. [Google Scholar]
- Bonnefon, J.F.; Černy, D.; Danaher, J.; Devillier, N.; Johansson, V.; Kovacikova, T.; Martens, M.; Mladenovic, M.; Palade, P.; Reed, N.; et al. Ethics of Connected and Automated Vehicles: Recommendations on Road Safety, Privacy, Fairness, Explainability and Responsibility; Directorate-General for Research and Innovation (European Commission): Brussels, Belgium, 2020. [Google Scholar]
- Wang, G.; Zhong, S.; Wang, S.; Miao, F.; Dong, Z.; Zhang, D. Data-driven fairness-aware vehicle displacement for large-scale electric taxi fleets. In Proceedings of the 2021 IEEE 37th International Conference on Data Engineering (ICDE), Chania, Greece, 19–22 April 2021; pp. 1200–1211. [Google Scholar]
- Hahn, D.; Munir, A.; Behzadan, V. Security and privacy issues in intelligent transportation systems: Classification and challenges. IEEE Intell. Transp. Syst. Mag. 2019, 13, 181–196. [Google Scholar] [CrossRef]
- Zhao, D.; Li, X.; Cui, J. A simulation-based optimization model for infrastructure planning for electric autonomous vehicle sharing. Comput. Aided Civ. Infrastruct. Eng. 2021, 36, 858–876. [Google Scholar] [CrossRef]
- Comi, A.; Polimeni, A.; Nuzzolo, A. An innovative methodology for micro-mobility network planning. Transp. Res. Procedia 2022, 60, 20–27. [Google Scholar] [CrossRef]
- Wang, G.; Zhang, Y.; Fang, Z.; Wang, S.; Zhang, F.; Zhang, D. FairCharge: A data-driven fairness-aware charging recommendation system for large-scale electric taxi fleets. Proc. ACM Interact. Mob. Wearable Ubiquitous Technol. 2020, 4, 1–25. [Google Scholar] [CrossRef]
- Zhao, L.; Malikopoulos, A.A. Enhanced Mobility with Connectivity and Automation: A Review of Shared Autonomous Vehicle Systems. IEEE Intell. Transp. Syst. Mag. 2019, 14, 87–102. [Google Scholar] [CrossRef]
- Vosooghi, R. Shared Autonomous Vehicle Service Design, Modeling, and Simulation. Ph.D. Thesis, l’Université Paris-Saclay préparée à CentraleSupélec, Paris, France, 2019. [Google Scholar]
- Wang, N.; Guo, J. Multi-task dispatch of shared autonomous electric vehicles for Mobility-on-Demand services—Combination of deep reinforcement learning and combinatorial optimization method. Heliyon 2022, 8, 11. [Google Scholar] [CrossRef]
- Meneses-Cime, K.; Aksun Guvenc, B.; Guvenc, L. Optimization of On-Demand Shared Autonomous Vehicle Deployments Utilizing Reinforcement Learning. Sensors 2022, 22, 8317. [Google Scholar] [CrossRef]
- Kim, S.; Lee, U.; Lee, I.; Kang, N. Idle Vehicle Relocation Strategy through Deep Learning for Shared Autonomous Electric Vehicle System Optimization. J. Clean. Prod. 2022, 333, 130055. [Google Scholar] [CrossRef]
- Donovan, B.; Work, D. New York City Taxi Trip Data (2010–2013); The University of Illinois Urbana-Champaign: Champaign, IL, USA, 2016. [Google Scholar] [CrossRef]
- Song, Z.; He, Z.; Li, X.; Ma, Q.; Ming, R.; Mao, Z.; Pei, H.; Peng, L.; Hu, J.; Yao, D.; et al. Synthetic Datasets for Autonomous Driving: A Survey. arXiv 2023, arXiv:2304.12205. [Google Scholar] [CrossRef]
- Mütsch, F.; Gremmelmaier, H.; Becker, N.; Bogdoll, D.; Zofka, M.R.; Zöllner, J.M. From Model-Based to Data-Driven Simulation: Challenges and Trends in Autonomous Driving. arXiv 2023, arXiv:2305.13960. [Google Scholar]
- Suo, S.; Regalado, S.; Casas, S.; Urtasun, R. Trafficsim: Learning to simulate realistic multi-agent behaviors. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 10400–10409. [Google Scholar]
- Vosooghia, R.; Puchingera, J.; Jankovicb, M.; Vouillon, A. Shared autonomous vehicle simulation and service design. Transp. Res. Part C 2019, 107, 15–33. [Google Scholar] [CrossRef]
- Turoń, K.; Kubik, A.; Chen, F. Operational Aspects of Electric Vehicles from Car-Sharing Systems. Energies 2019, 12, 4614. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset Generation Technique | Strengths | Limitations | Application in Transportation | Mathematical Theory/ Architecture |
|---|---|---|---|---|
| Data Augmentation |
|
| Contributes in augmenting real traffic data to improve the accuracy of traffic flow prediction models. | Applies mathematical functions (e.g., Markov chain process, kernel classifier, Gaussian noise, and affine transformations) |
| Generative Adversarial Network (GAN) |
|
| Might be used in generating synthetic urban movement patterns for vehicles, pedestrians, and cyclists to assist in urban mobility planning. | Applies mathematical functions (e.g., Markov chain process, kernel classifier, Gaussian noise, and affine transformations) |
| VAE (Variational Autoencoder) |
|
| Can contribute to improve traffic flow reconstruction and contributes to improve traffic management. | Encoder-Decoder architecture |
| Deep Belief Network |
|
| Can provide valuable insights for designing traffic signal timing and strategies that minimize congestion. | Constructs multilayered generative models with latent variables, using deep neural networks to model |
| Transfer Learning |
|
| Can be used in vehicle trajectory prediction and public transit demand forecasting. | Fine-tunes pre-trained models using target domain data |
| Bayesian Networks |
|
| Might be used in modeling probabilistic relationships between traffic flow and road conditions to optimize traffic signal timing and reduce congestion. | Probabilistic graphical model represents the conditional probability for the corresponding random variables [9] |
| Monte Carlo Simulation |
|
| Used in traffic impact assessment | Employs random sampling from defined input distributions, using statistical methods |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kayisu, A.K.; Kambale, W.V.; Benarbia, T.; Bokoro, P.N.; Kyamakya, K. A Comprehensive Literature Review on Artificial Dataset Generation for Repositioning Challenges in Shared Electric Automated and Connected Mobility. Symmetry 2024, 16, 128. https://doi.org/10.3390/sym16010128
Kayisu AK, Kambale WV, Benarbia T, Bokoro PN, Kyamakya K. A Comprehensive Literature Review on Artificial Dataset Generation for Repositioning Challenges in Shared Electric Automated and Connected Mobility. Symmetry. 2024; 16(1):128. https://doi.org/10.3390/sym16010128
Chicago/Turabian StyleKayisu, Antoine Kazadi, Witesyavwirwa Vianney Kambale, Taha Benarbia, Pitshou Ntambu Bokoro, and Kyandoghere Kyamakya. 2024. "A Comprehensive Literature Review on Artificial Dataset Generation for Repositioning Challenges in Shared Electric Automated and Connected Mobility" Symmetry 16, no. 1: 128. https://doi.org/10.3390/sym16010128