1. Introduction
The immense growth of computer performance and declining costs of storage devices over the past decades have led to the dominance of multimedia data in cyberspace, increasing the volumes of transmitted data and repositories to support a wide range of symmetric and future applications in mobile communication networks. In order for videos to be transmitted and stored efficiently with less memory, video compression is essential [
1,
2]. As an example, a computer with a screen resolution of 1024 by 728 and a screen refresh rate of 75 Hz is capable of producing more than 100 MB of data every second [
3], necessitating a large amount of storage against the normal practice of limited memory on mobile devices using multimedia platforms. Therefore, video compression has gained more attention due to the need for internet video streaming as well as for many other multimedia signals to be transmitted over a limited amount of bandwidth with a fixed number of video channels. In a forensic investigation, low-quality CCTV images are frequently enhanced for the extraction of potential evidence in digital forensic investigation [
4].
Several symmetric and asymmetric studies have been performed on video transmission to improve theoretical and practical aspects of the field. The study of developing new techniques for video compression is not only required for transmitting fast video signals over the internet but also for transmitting many other multimedia signals over a fixed number of limited-bandwidth channels. Fortunately, video contains a large amount of identically repetitive elements that can be excluded without losing the information content needed for human recognition capabilities [
5].
Thus, through video compression, symmetrical data and lossless information have been discarded without affecting visual quality and acuity, using various algorithm-driven AI techniques in the literature [
6].
Lossless data compression has been used to compress files to smaller sizes. As a result, software is often packaged before it is transmitted over the network to reduce the amount of bandwidth and time needed compared to it was transmitted as normal data files [
7,
8] Lossless data compression has a limitation in that uncompressed data must be identical to the original data that was compressed in the first place. As a result of the compression scheme for lossy compression in real-time video compression and decompression according to the lossy compression scheme, some metadata are ignored when it comes to video compressions such as JPG and MPEG. Among the most widely used video compression techniques, motion estimation-based video encoding is commonly used. The idea is to reduce processing and computing overhead by performing compression during sensing to minimize the time needed for the compression of gathered data. Motion estimation-based video encoding is commonly used among the most widely used video compression techniques. The encoding method is based on asymmetrical frame correlation. The idea is to provide good compression and remove temporal redundancy through this method [
9,
10].
In another aspect, the motion estimation process is computationally expensive and very difficult to achieve in real time [
11]. However, in order to achieve low-cost and efficiency in real time, the original video must be compressed before it is transmitted [
12]. The videos are digitally compressed by encoding algorithms, representing them as a reduced set of bits before being transmitted over a network. Video compression uses compression standards such as MPEG-1, MPEG-2, MPEG-4, and H.264/AVC. The quality of the transmitted sequences is highly dependent on the bandwidth of the network; that is, the larger the bandwidth, the less effect on quality. The authors in [
13] reported about the new H.264/AVC coding standard, which is a joint standard of the ITU-T video coding expert group (VCEG) and the ISO/IEC moving picture experts group (MPEG), incorporates many techniques to improve compression efficiency [
14]. Similarly, compression algorithms are important in the case of limited resources and low data transmission capacity, which are affected by bandwidth and poor speed [
15,
16].
However, it is worth noting that even though modern cellular and wireless LAN channels provide sufficient bandwidth, no devices support video transmission. This is mainly due to the heavy computational burden imposed on video compression. Standard video compression systems such as JPG, MPEG-1, MPEG-2, and MPEG-4 all rely on complex motion estimation algorithms for video compression [
17]. The computing power required to implement these algorithms is illustrated by the fact that only recently have personal computers been able to compress video in real time. A typical mobile device has much fewer computational resources than an ordinary computer [
18]. Although custom video compression chipsets are available, they have not yet been included in general technology due to their cost, power, and size limitations [
19,
20]. A technical barrier has prevented the deployment of video-enabled devices in wireless and other mobile networks [
21,
22]. Video streaming over networks can cause bandwidth issues if sent in their redundancy-loudened form, as video streams are made from the temporal distribution of symmetrical frames similar to the special distribution of pixels in pictures. The pictures suffer from special redundancy due to asymmetrical frame-encoding techniques, similar to videos suffering from temporal redundancy due to what is called asymmetrical frame-encoding techniques [
23,
24]. Video temporal redundancy mitigation techniques have been widely developed since the early 1980s, such as the new three-step search (NTSS) algorithm for motion-compensated asymmetrical frame coding for video conferencing [
25], where the utility of the technique was shown by comparing it with contemporary techniques using a statistical parameter of mean square error (MSE). The block-based gradient descent search (BBGDS) approach was proposed in [
26] and compared again in terms of MSE computational complexity using the concept of the motion vector. The distribution of motion vectors on several commonly experimented test image sequences was studied in [
27], using a diamond search algorithm and a novel cross-diamond search algorithm for fast block-based motion estimation [
28,
29]. These studies tested simulations on hypothetical scenarios, such as that of the travel salesman problem.
The contributions of this paper can be summarized as follows:
• We proposed a scheme that avoids the use of redundant features, representing bottlenecks in auto-encoders.
• In this paper, we proposed explicitly penalizing pairwise correlations between features as part of the auto-encoder loss. We further developed a method to learn diverse compressive embeddings of samples based on the correlations.
• The proposed method was extensively evaluated on three tasks: dimensionality reduction, image compression, and image denoising. Compared to the standard approach, the results showed that the performance boost was consistent and measurable.
As outlined in this paper, one of the goals of this work was to overcome these limitations by abandoning the existing motion estimation and compensation model in order to provide a video compression algorithm that can be implemented by a mobile communication network in a real-time scenario. Currently, video compression techniques have not been able to adequately handle the high degree of temporal redundancy among symmetrical video frames. Indeed, the RTR video compression technique takes temporal redundancy impartially into account. To improve this technique’s efficiency and data rate, temporally redundant video signals were discarded so that a minimal amount of complexity was introduced.
The rest of the sections of the paper are arranged as follows. The proposed approach is presented in
Section 2 of this document.
Section 3 of this paper presents the results and discusses the dimensionality reduction task using the removing temporal redundancy technique to compress images. In
Section 4 of the paper, we conclude our discussion.
2. Proposed Approach
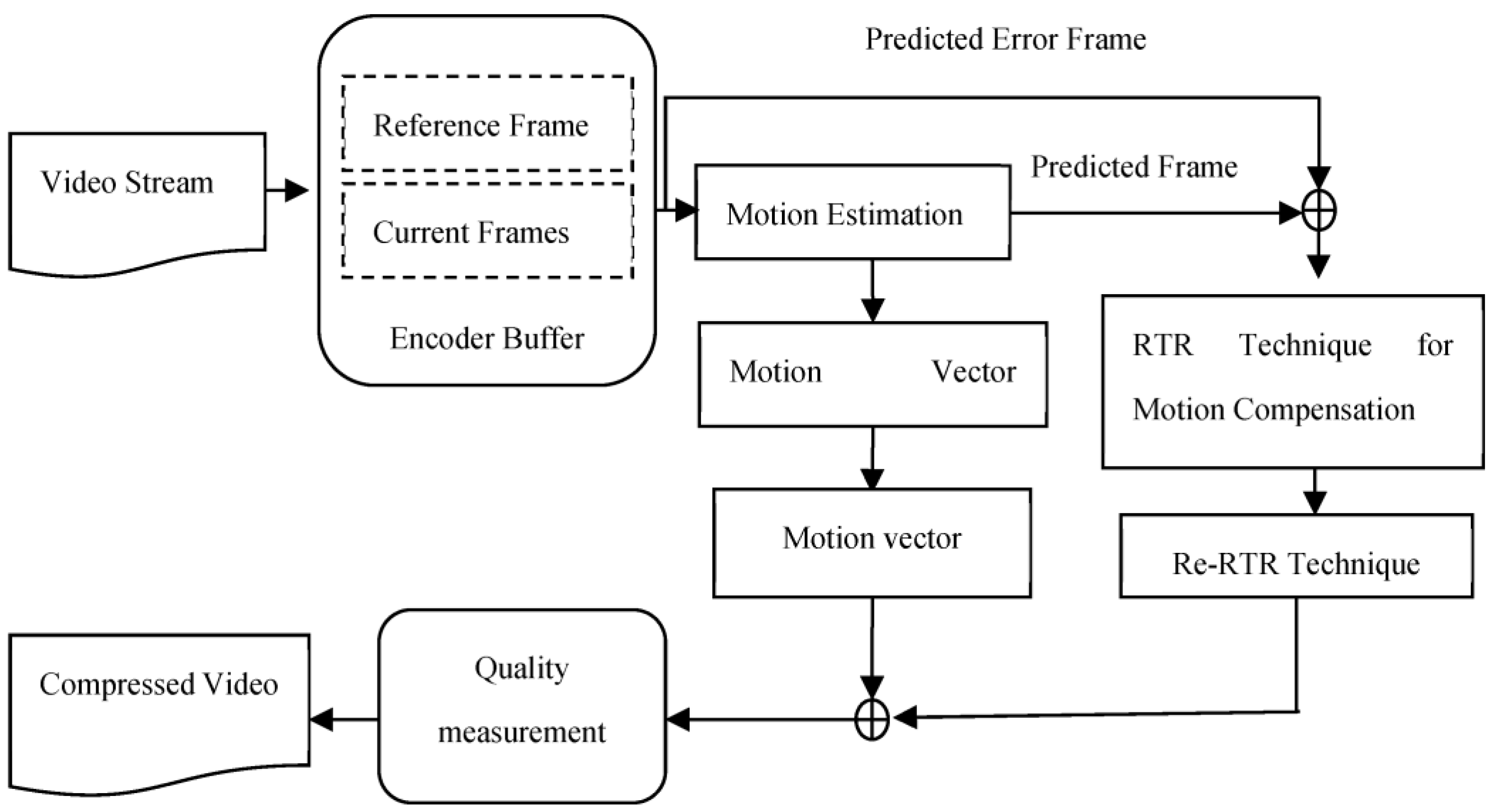
Compression is required in online video streaming and broadcast applications to transmit multimedia signals over a wireless network due to the fixed and limited amount of bandwidth available in a wireless network. Wireless communication systems face a big challenge in transmitting large video files. Therefore, video compression techniques save storage space by reducing the file size. Various techniques are used to find the redundancies in moving frames and correlations between the scenes. The main goal of the proposed technique was to compress the video using more efficient compression redundancy in the temporal domain in order to achieve improved compression results while maintaining the same acuity vision. This paper describes the application of RTR to check the performance of the proposed technique based on the compression ratio, as shown in
Figure 1.
2.1. Encoder Buffer
The video is captured in real time and sent to the encoding buffer for conversion to several frames as the input of the RTR, which are then rendered as still images in JPEG format. All images have a number assigned to them. In the encoder, the 1st or previous frame is considered to be the current symmetric frame, while the 2nd or next frame is considered to be the reference frame. However, the encoder contains a sequence of frames as follows:
where r represents distinct objects from n objects without replacement.
The previous frames are encoded without data loss so that the decoder decodes I(n − 1) flawlessly. These symmetrical frames are sent to the matching algorithm to find the estimated movement in each block. The idea of the motion vector has been previously elaborated in some simulation algorithms trying three-step-search (NTSS) in [
25,
26] and four-step search (4SS) in [
27]; however, these were all tested on some hypothetical scenarios comparing the results in the form of MSE per pixels. The need for implementation in a real-time scenario was addressed in this paper. Further, our approach appears to be based on the results of these well-established approaches from more than a decade ago and hence is better suited for real-time applications. RTR is compared with contemporary protocols in
Table 1.
2.2. Motion Vectors
Each block of symmetrical frames is represented by a vector that shows the motion within it. Therefore, the encoder sends motion vectors of frame I(n) relative to frame I(n − 1) to prepare the motion-compensated predicted frame PF(n). The selected video shows a total of 345 motion vectors in both the encoder and decoder for all frames.
2.3. Motion Estimation
In the entire motion-based video compression process, motion estimation is the most time-consuming and expensive step in the process. This is because the block-matching technique is more efficient than other motion estimation techniques. Every 16 × 16 block in a temporally prior frame of the current symmetrical frame and the latter frame of the reference frame is subject to block matching. The destination block is defined as the resultant of the most closely matched frame from the previous frame. The motion vector is defined as the displacement of a block between its original and destination blocks. The motion vector gives a rough indication of how objects move in a sequence between frames.
The spatial domain process is also involved in the block-matching process. As a result, the pixels in the video signal are more correlated. A highly correlated video signal is generated by exploiting temporary redundancy elements in the video signal. In Equation (2), the threshold value is checked to ensure that it is equal to the value that can be used to remove the temporal redundancy from the received frames of the video [
21].
where x and y are the pixel space coordinates, and
t is the video instance time.
2.4. Motion Compensation
Video frames can suffer from changes due to camera motion effects, such as zooming, camera panning, and swiveling, rotating, or tilting of the camera. There are several specific algorithms designed to detect and compensate for camera effects in video frames due to changes associated with camera movement. In addition to these changes, there may be changes that occur as a result of the movement of the object, such as translation, rotation, occlusion, uncovering, or morphing. The frame is constructed by motion compensation, where each block is a copy of the block from the previous frame shifted by the computed motion vector. The difference between the compensated and reference frames is calculated from the sequence and is referred to as an error or residual frame. In the residual frame, the signal energy tends to be very small, so compression happens more easily as a result.
2.5. Removing Temporal Redundancy (RTR) Technique
In
Figure 2, a block diagram of the RTR procedure is shown. Video sequences contain redundant data in terms of temporal information compared to spatial information. Thus, they are converted into video frames consisting of more spatially redundant data as a result of using the transformation algorithm. The spatially redundant data are efficiently decoded, stored in memory, and the redundant data are discarded. After decoding the stored data with the help of the RTR decoder, the video data are reconstructed. This was based on the proposed RTR technique to perform video compression using a block-matching technique.
The technique compares two frame estimates from the current symmetric frame to the reference frame in order to produce a compensated predicted frame (PF). After it is calculated, the PF is sent to the output buffer. This threshold value is used to determine which PFs should be merged with reference frames based on the minimum signal-to-noise ratio among all available PF information, using Equation (3) of
Section 2.7.
This assumption is made based on the RTR technique, where pixels with high temporal correlation are used to achieve good image quality. Various quality measurement techniques are used to measure the performance of each RTR technique.
2.6. Techniques for Measuring Quality
Obviously, for an effective comparison of compression techniques, it should be possible to quantify the degradation caused by the compression process on the video frame. Since the perceived quality of the video frame image depends on its use and the viewer, quantifying this perception is a mystery. Further, image quality has many components, and the general problem of producing a cost function that incorporates all of these components is believed to be intractable. Nevertheless, several metrics have been proposed to allow comparisons to be made between compression schemes. In this study, PSNR, MSE, and MAE were used to measure the quality of compressed images [
22].
2.7. Peak Signal-to-Noise Ratio (PSNR)
The PSNR measurement indicates how much error is present in the eight-bit PF. The PSNR is a normalized quality metric based on MSE, which is a distortion metric. Accordingly, the normalized PSNR of the PF can be defined as given in Equation (3).
The mean square error (MSE) of a frame pixel is defined as Equation (4).
where
and
are the dimensions of the frame in pixels,
represents the pixel at the
x and
y direction in the current symmetric frame, and
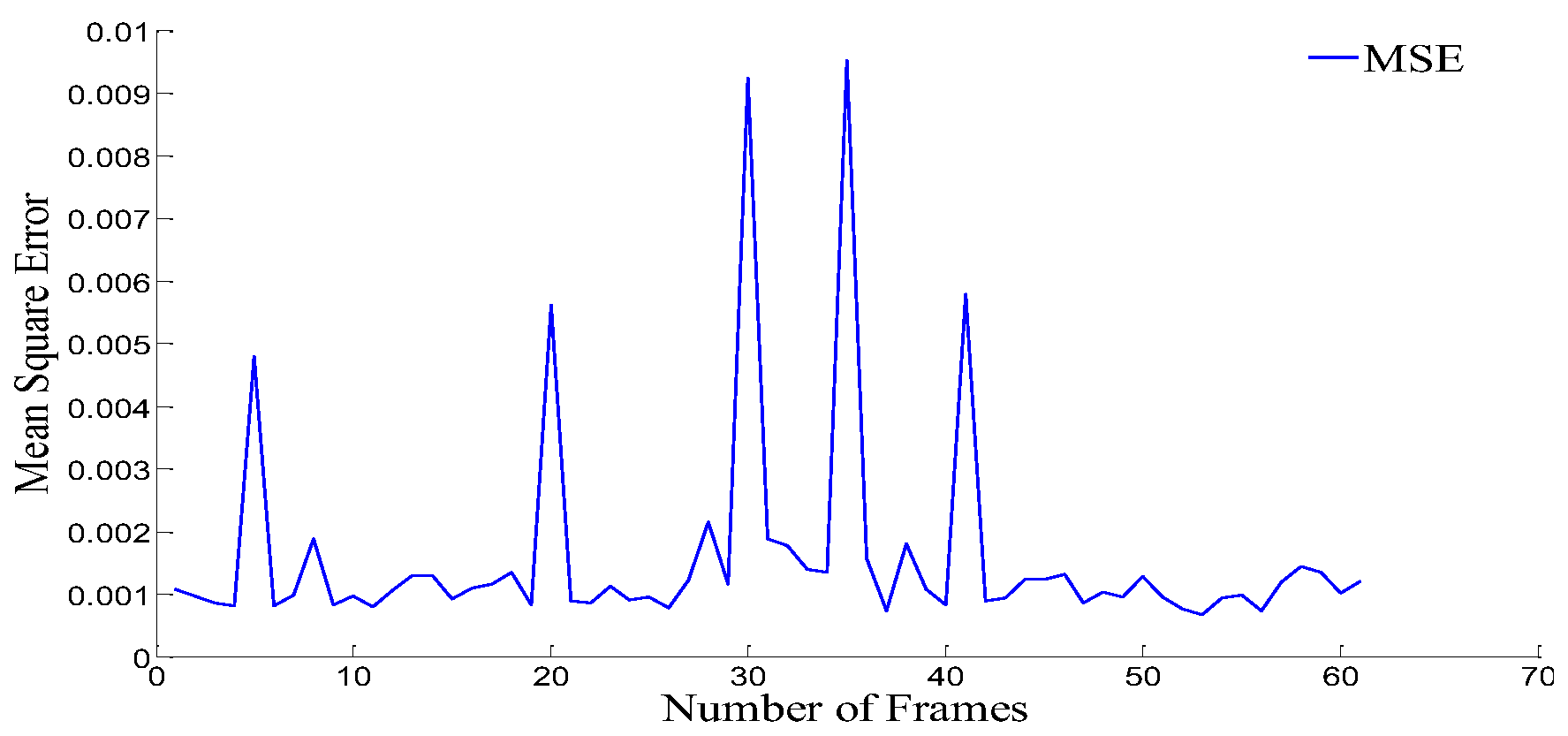
represents the pixel at the x and y direction in the reference frame. The MSE values of current symmetric frames were available for 61 frames, providing an aggregated measure of error for an entire frame, as shown in
Figure 3. During the encoding of video signals for video compression, the RTR technique was used to encode the video signals. The MAE is also used to differentiate between two frames based on whether a camera or object within a frame is moving.
A parallel may be drawn with similar results in [
25,
26,
27,
28,
29], which appeared to be based on a simulation of hypothetical scenarios. Nevertheless, our results are based on compressing the transmission of a real-time video clip and appear to be based on their work, which is cross-validated with contemporary protocols in
Table 1.
2.8. Mean Absolute Error (MAE)
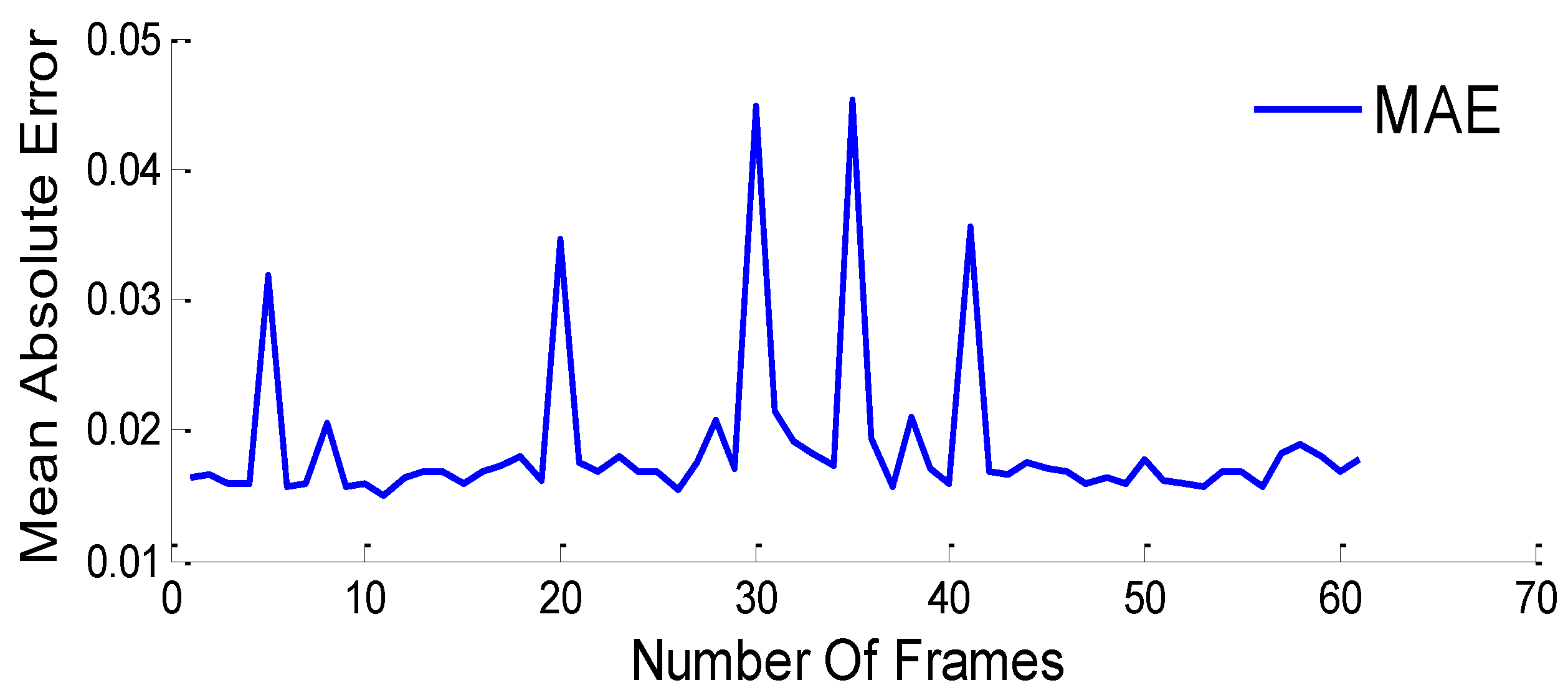
Figure 4 shows the MAE values of the first 61 frames. The MAE shows how far predicted values in a given frame are away from observed values in the reference frame and is calculated by subtracting the symmetric current frame from the previous frame. The MAE is obtained by taking the square root of Equation (5).
Now, the absolute of Equation (6) is taken to get the normalized form of MSE.
Thus, in a video signal, much of the information that represents a current symmetric frame is the same as the information that represents the reference frame.
Figure 4.
Mean absolute error of the first 61 frames.
Figure 4.
Mean absolute error of the first 61 frames.
3. Results and Discussion
There was the possibility of transmitting a test video signal from the signal source to the signal destination via a real-time wireless communication system. It was a 9 s clip of 67.7 MB in “AVI” format. Video compression is the method by which a video stream is transmitted over a channel with limited bandwidth. Video transmission can sometimes cause fluctuations in the received video signal as a result of transmission. There are several target networks, video coding and multiplexing standards, and transmission characteristics listed in
Table 1. These characteristics include things such as packet size and error rates using the RTR technique.
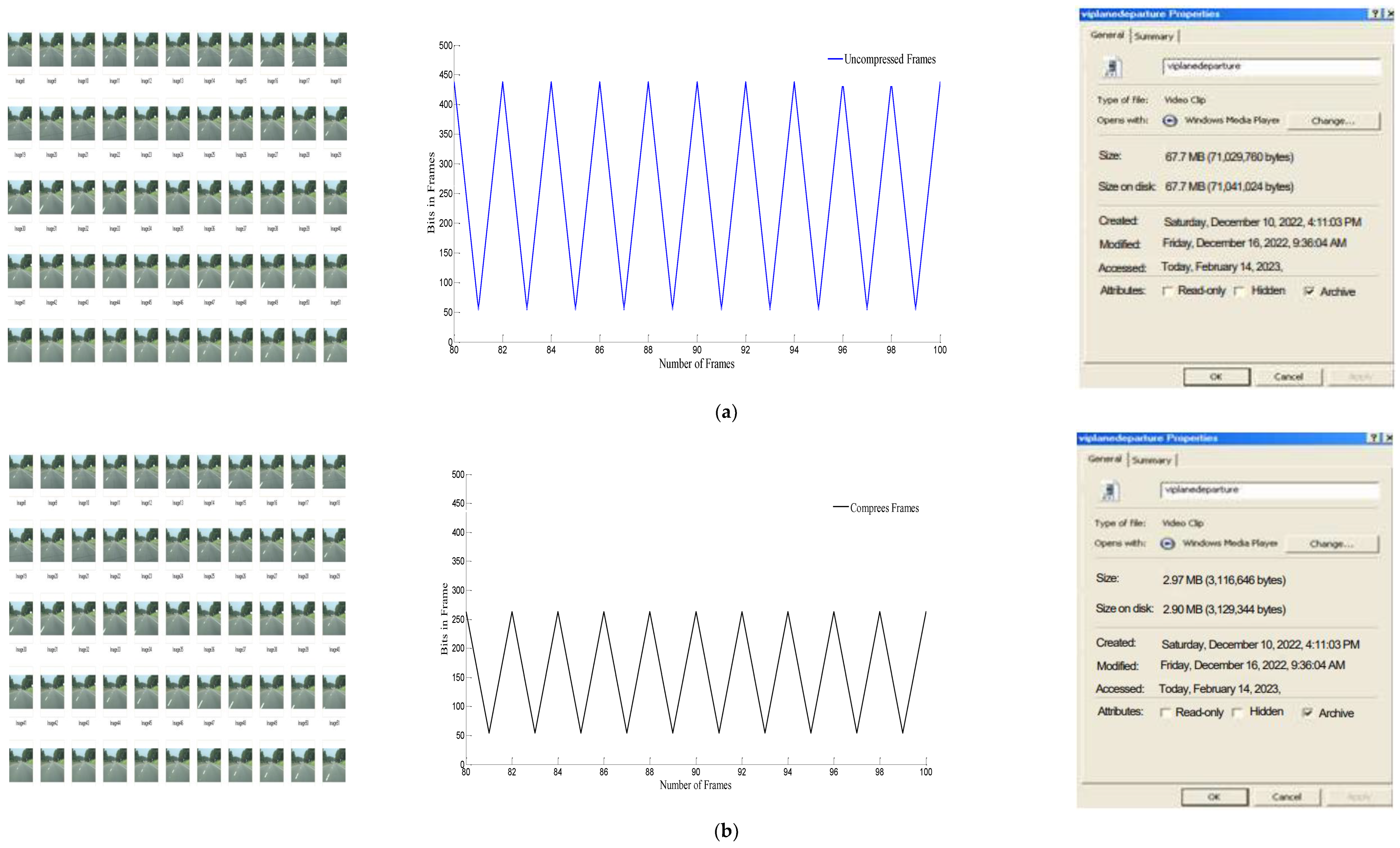
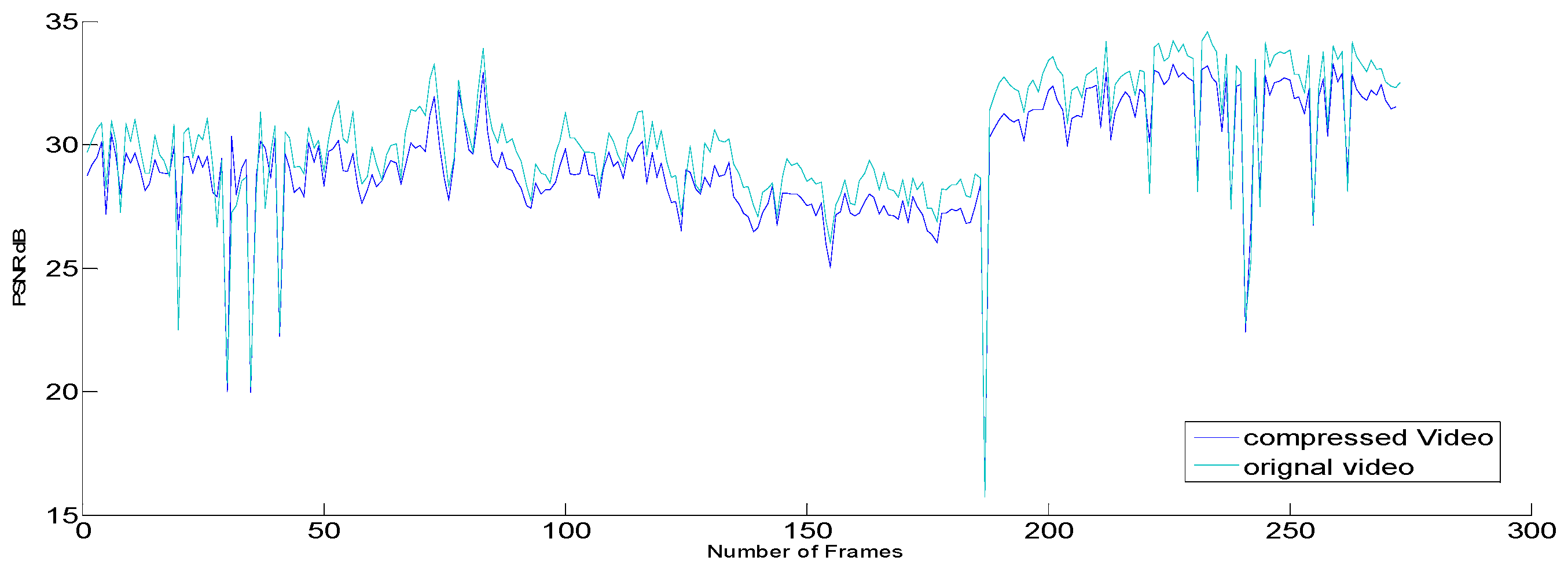
Figure 5 shows a comparison between the original and compressed video signals. The study showed that by using the RTR control algorithm, the bits in the frame became more stable and so more suitable for real-time transmission in the current symmetric network environment. The largest burst was reduced from 450 to 250 kB, which was only half of the original network burst. The compressed video file size was reduced from 67.7 to 2.97 MB, which was 95.61% of the original network burst size shown in
Table 1. As a result, the RTR was more suitable for the real-time transmission of compound video sequences to avoid temporal redundancy.
To improve the quality of compressed videos, scientists have relied on the importance of ensuring that the communication network is error resistant [
24]. The RTR technique implied that the compressed video was entirely appropriate for mobile communication, as listed in
Table 1. The input video frames were separated and converted into grayscale still images in JPEG format. The motion estimation and compensation operations are usually performed using the block-based motion estimation algorithm. The proposed RTR technique achieved motion-compensated frames with a compression ratio that resulted in 95.61% data rate reduction. The PSNR value was obtained from the motion-compensated frame. This technique was also used to obtain the reconstructed image after performing the compression, as shown in
Figure 6 There was a significant reduction in the size of the compressed video, which ultimately resulted in a lower data transmission rate.
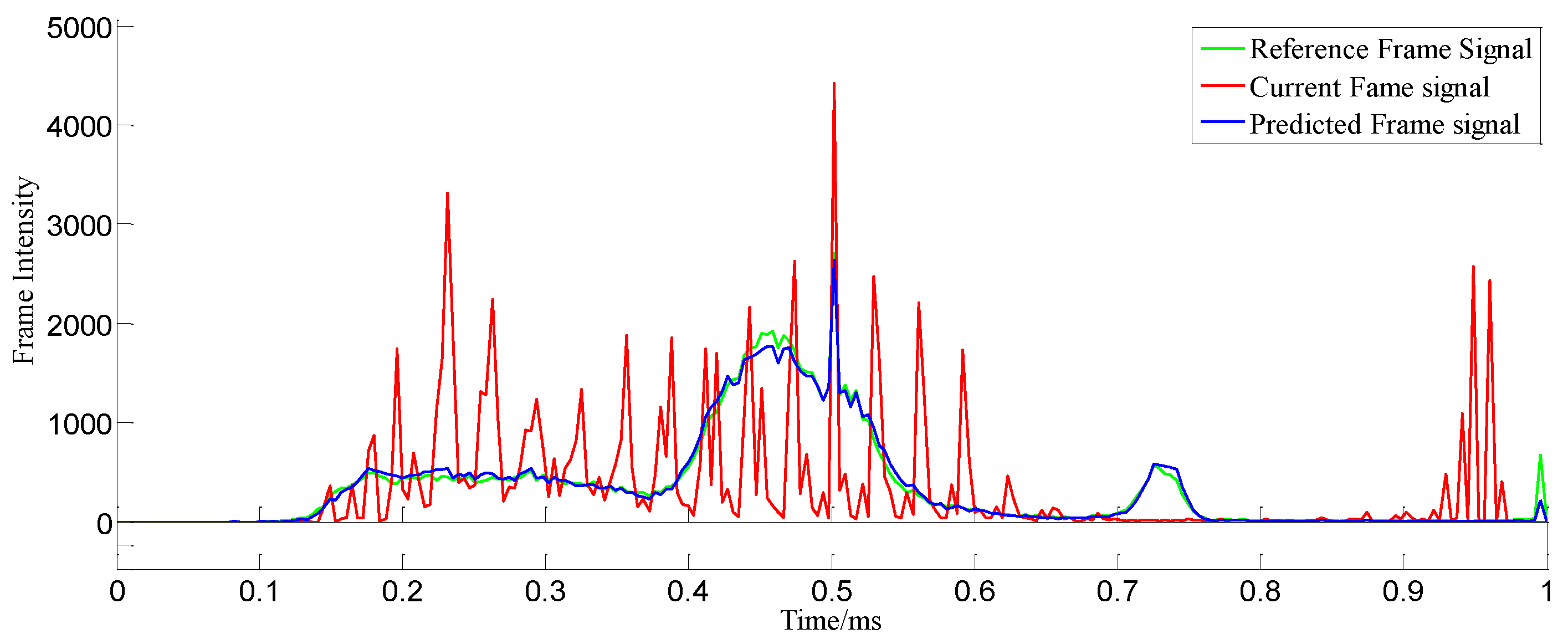
Figure 6 shows the performance of the RTR algorithm with different intensities of frames. In this experiment, the target data rates were scalable from 500 to 6000 kbps for the video clip Viplanedeparture.avi at 30 frames per second frame rate. Scaling the data rate across different data rates and keeping the video quality relatively constant irrespective of the data rate is referred to as block-based motion compensation. With fewer motion-compensating blocks, the PSNR value decreased much more rapidly. At 15.7 dB PSNR, the target frame intensity increased to 4000 kbps, as shown in
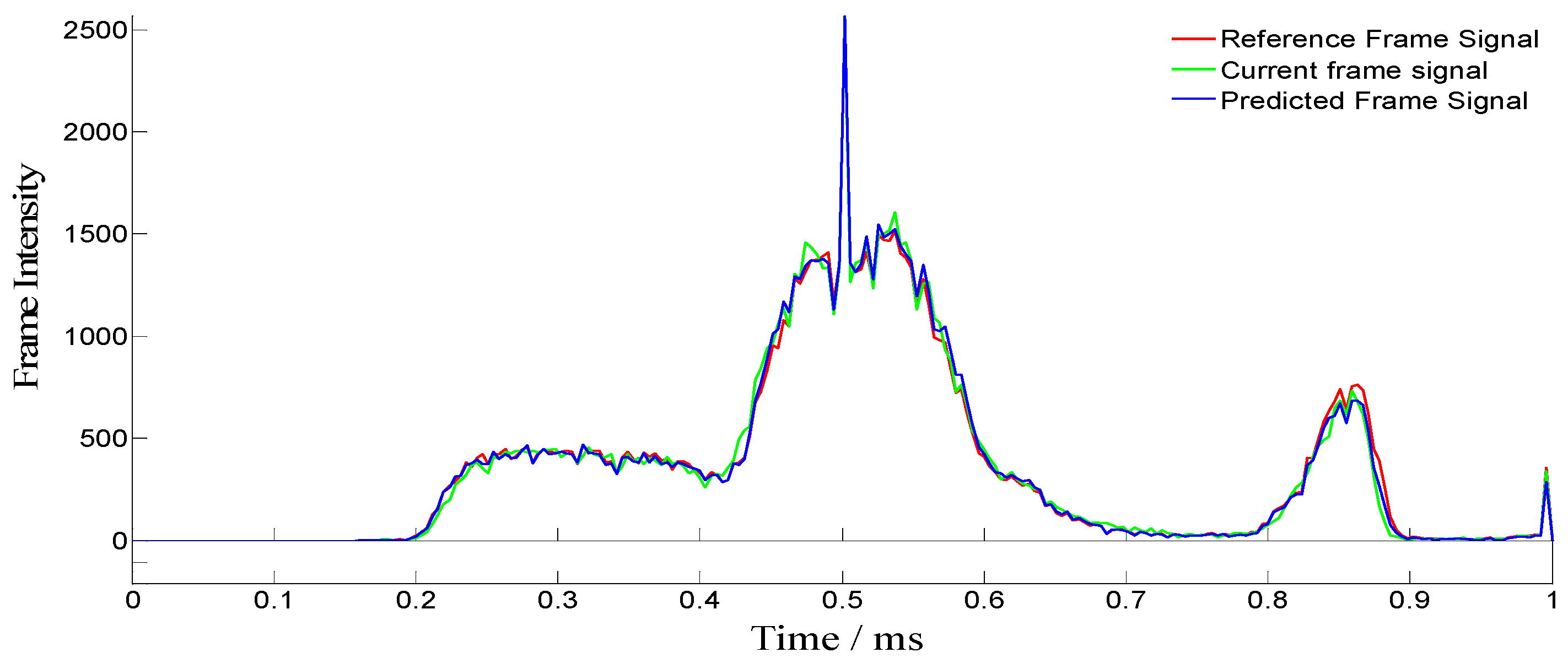
Figure 6, while this value decreased at an increased PSNR of 23.4 dB and 34.7 dB PSNR, as shown in
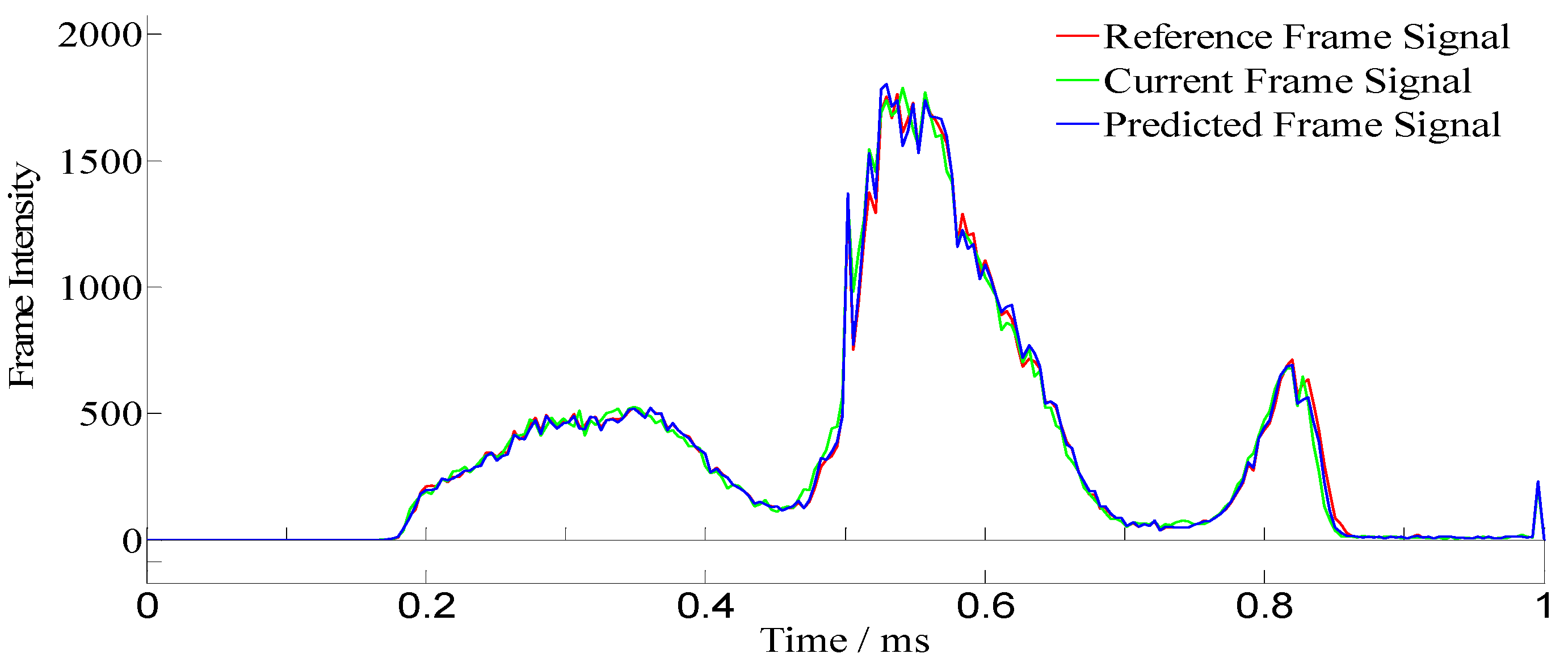
Figure 7 and
Figure 8 respectively. As can be seen from
Figure 9, where the differences between the minimum and maximum PSNR values within motion-compensated blocks are illustrated and compared with the PSNR values of the uncompensated frames, the PSNR values increased and decreased. Although standard JPEG compression had a similar effect regarding maximum and minimum PSNR values, the RTR compression technique achieved better results than JPEG compression regarding maximum and minimum PSNR values. From one frame to another, the PSNR curve was constantly changing from 15.7 to 34.7 dB, and the disparity fluctuated from frame to frame. At this point, in addition to increasing the PSNR values, the motion-compensated frame showed a reasonable amount of consistency.
The RTR technique compressed 67.7 MB (the equivalent of 71,029,760 bytes) to 2.97 MB (the equivalent of 3,116,646 bytes), as shown in
Figure 8, with an error of 0.01–0.3 Mbit, which indicated the applicability of RTR in mitigating bandwidth-related issues more effectively. The results were produced through purposefully developed code that directly used data frames, referred to as experimental implementation of RTR. A shown in
Table 1, the paper relied on identically produced contemporary algorithms for cross-validation instead of ML-based networks that required training on datasets [
26]. The authors believe that the results exhibited similarity with the results of [
30], if the latter range of 0.1 to 0.5 bits per pixel was extended to the 0–250 frames range. As shown in
Table 1, the authors proposed the use of an algorithm that selected AVI files and compared them with a variety of contemporary standards instead of AVC (H264), HEVC (H265), and VVC (H266), which are already established techniques using the database.
The PSNR values of the original and compressed video JPEG frames in
Figure 8 attested to the utility of the method by so closely resembling the predicted frame signal of
Figure 9 using the RTR technique at 34.7 dB PSNR, which was comparable to 44 dB tested under more demanding conditions. The trend in the PSNR graphs was comparable to that obtained by the authors in [
31,
32], where an improved method of embedding a watermark in a high-quality video based on DNN under high-efficiency video coding (HEVC) compression conditions was presented. The graphs in this work showed an upward trend beyond epoch 180, contrary to that in [
33], indicating a reduction in the PSNR values for epochs beyond 200.
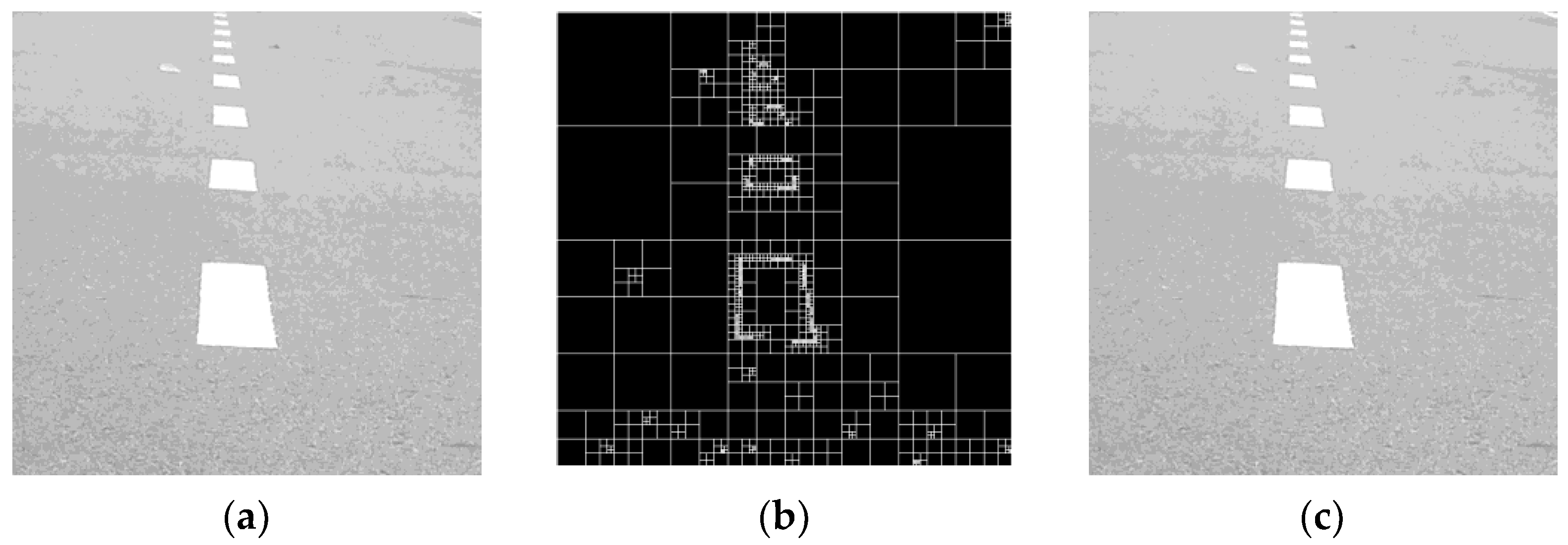
Evaluation of the proposed method was simulated on grayscale images taken from real-time video, including road images, as shown in
Figure 10. The test image was 8 bits/pixel, and the reduction scheme was tested on images of 256 × 256 and 512 × 512 in size. The largest block sizes for 512 × 512 and 256 × 256 images were 32 × 32 and 16 × 16 pixels, respectively. The simulation platform was Microsoft Windows XP, Pentium III, and the suggested approach was implemented using MATLAB. The performance of the reduction scheme was evaluated.
A reduction scheme is used to increase internal space and bandwidth in order to increase the communication speed. The compression process was completed for different image block sizes.
Figure 10 shows how the image blocks were maximized when the image was decomposed and shuffling was performed. For varying image sizes, the results indicated similarity in the images.

 ,
, 











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}