

Generalized Support Vector Regression and Symmetry Functional Regression Approaches to Model the High-Dimensional Data


Abstract
:1. Introduction
2. Materials and Methods
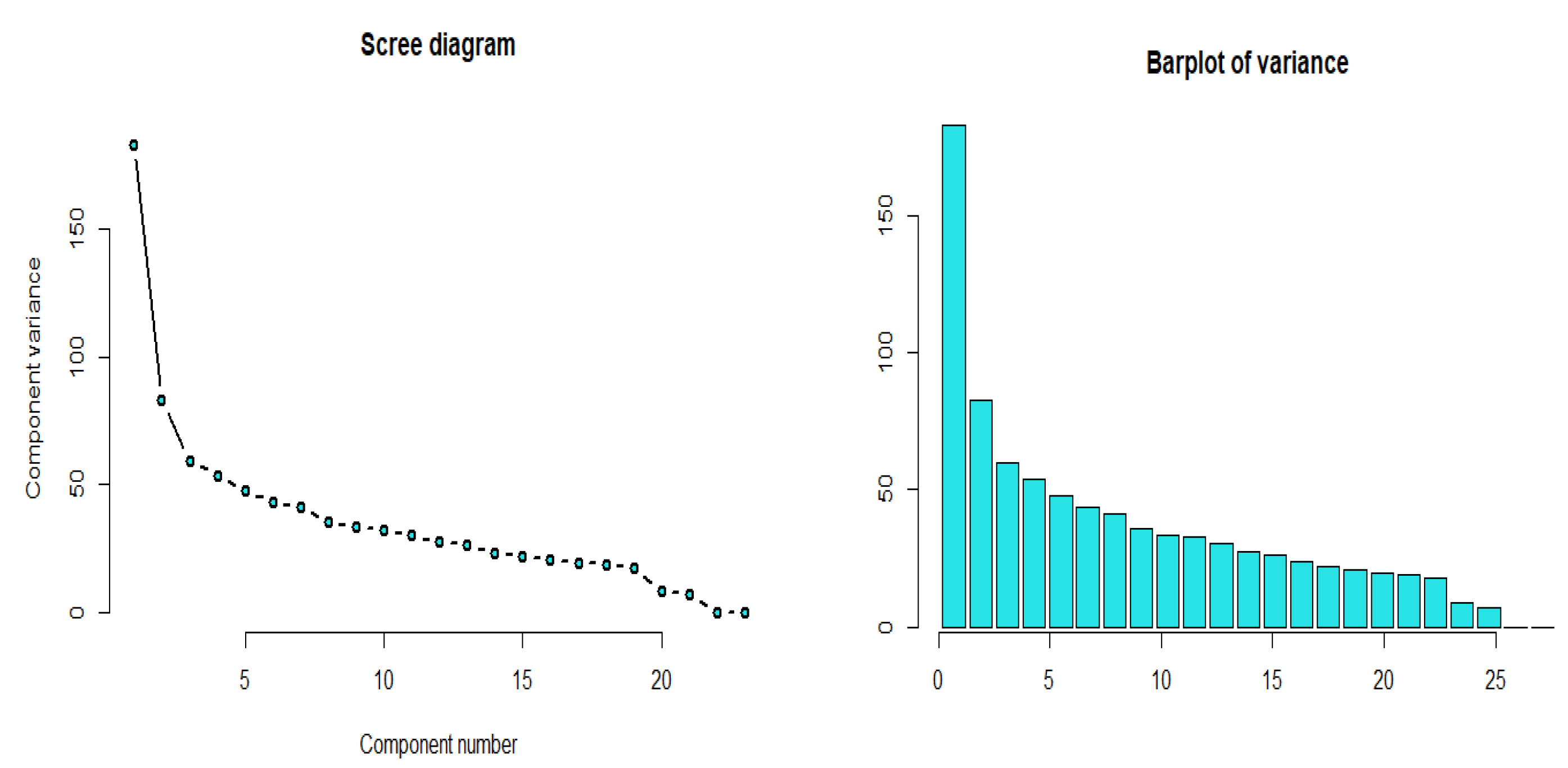
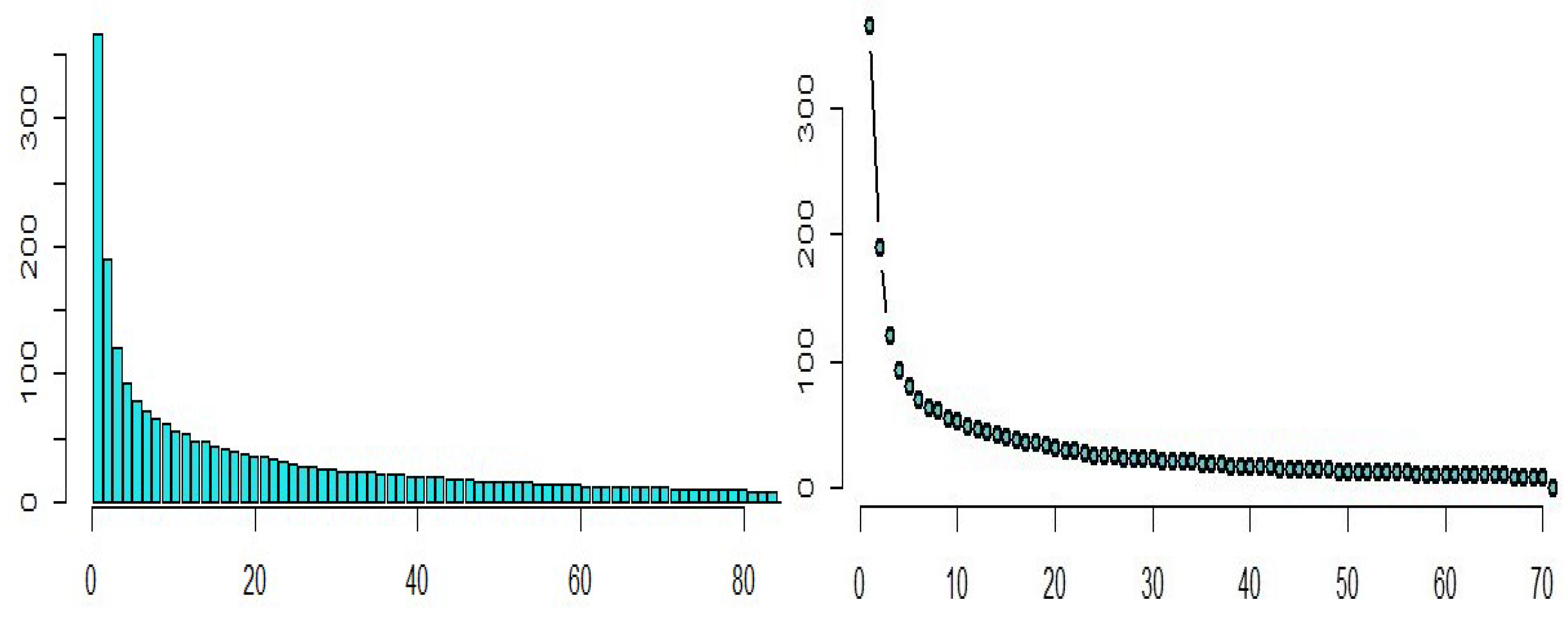
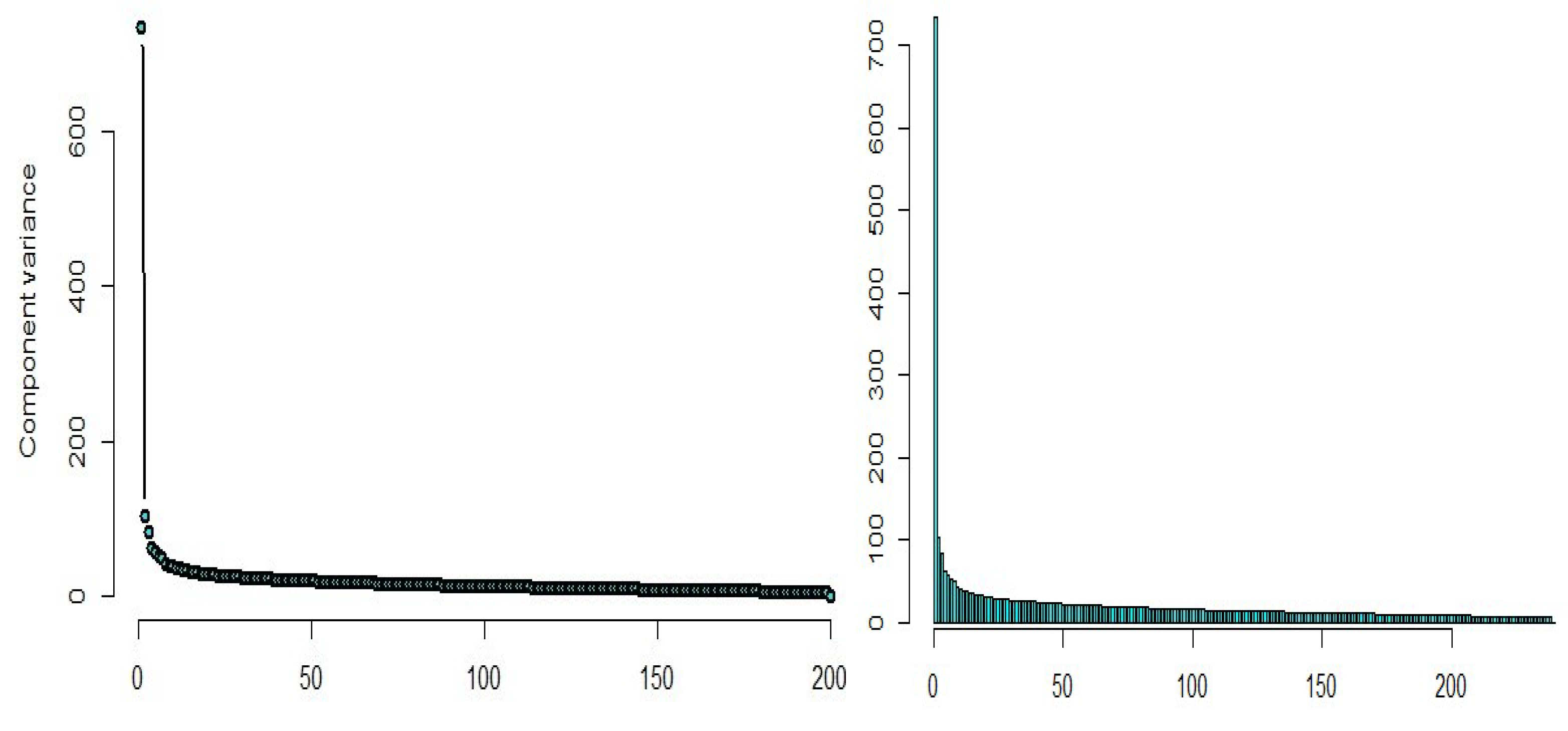
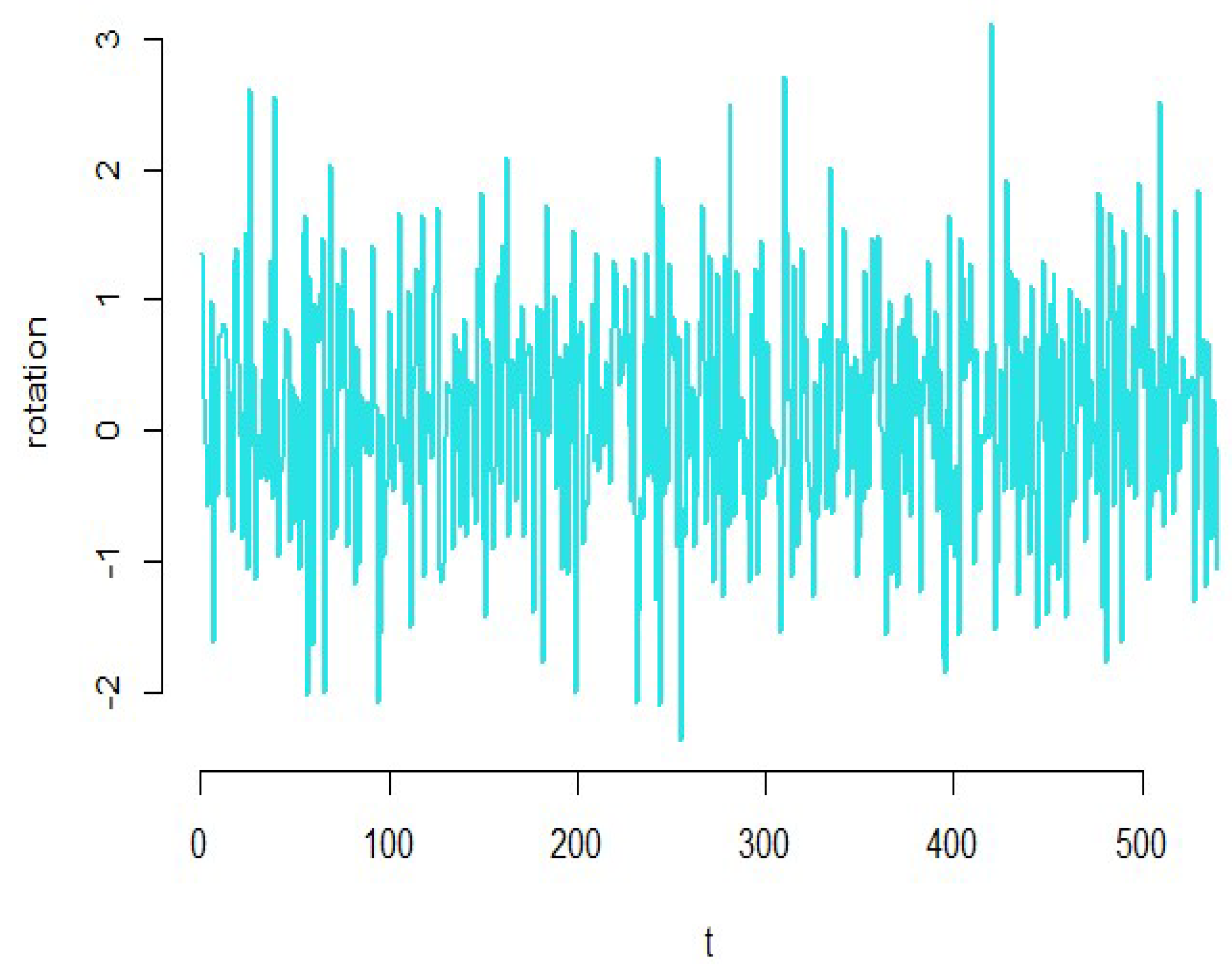
2.1. Principal Component Method
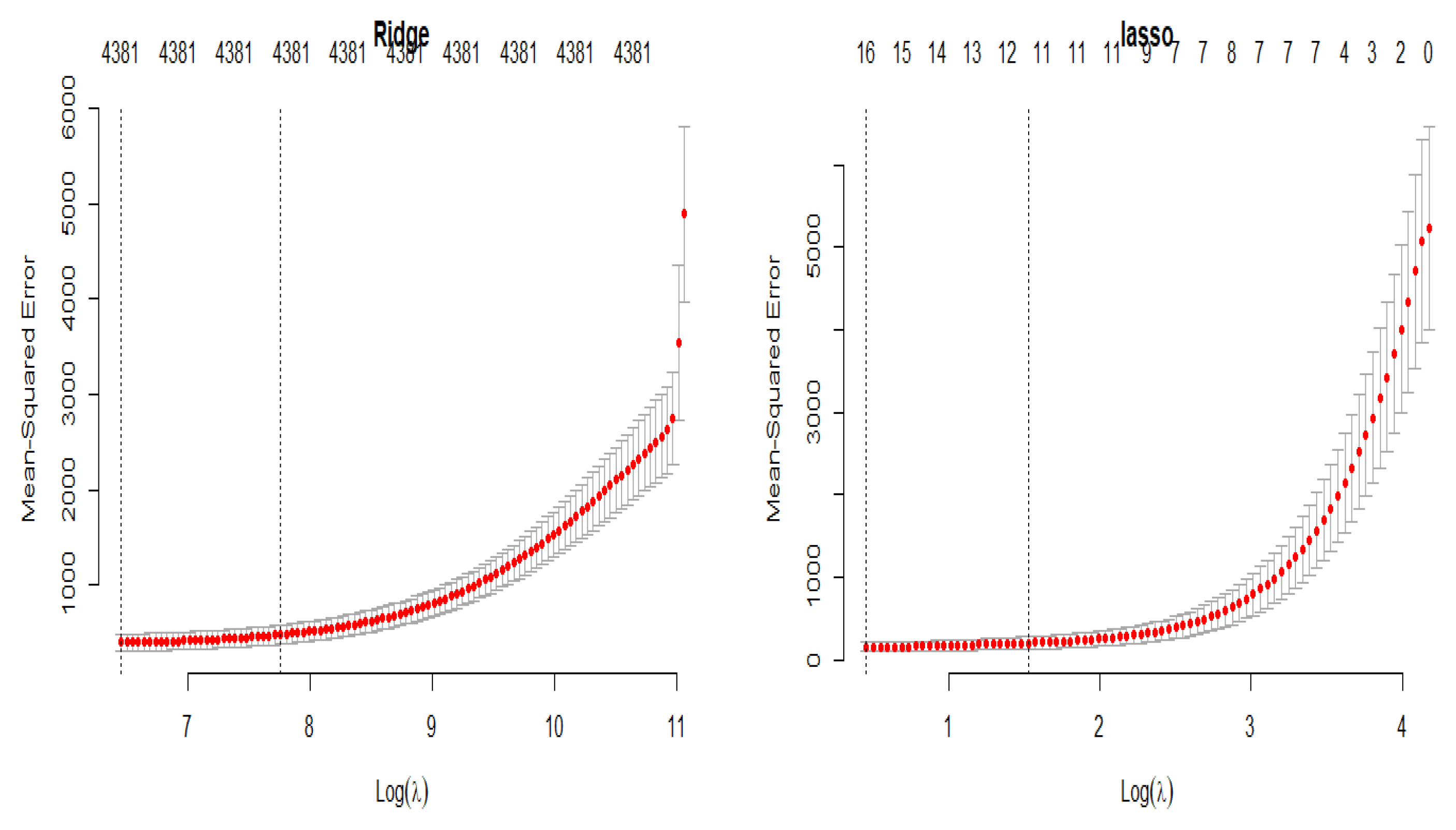
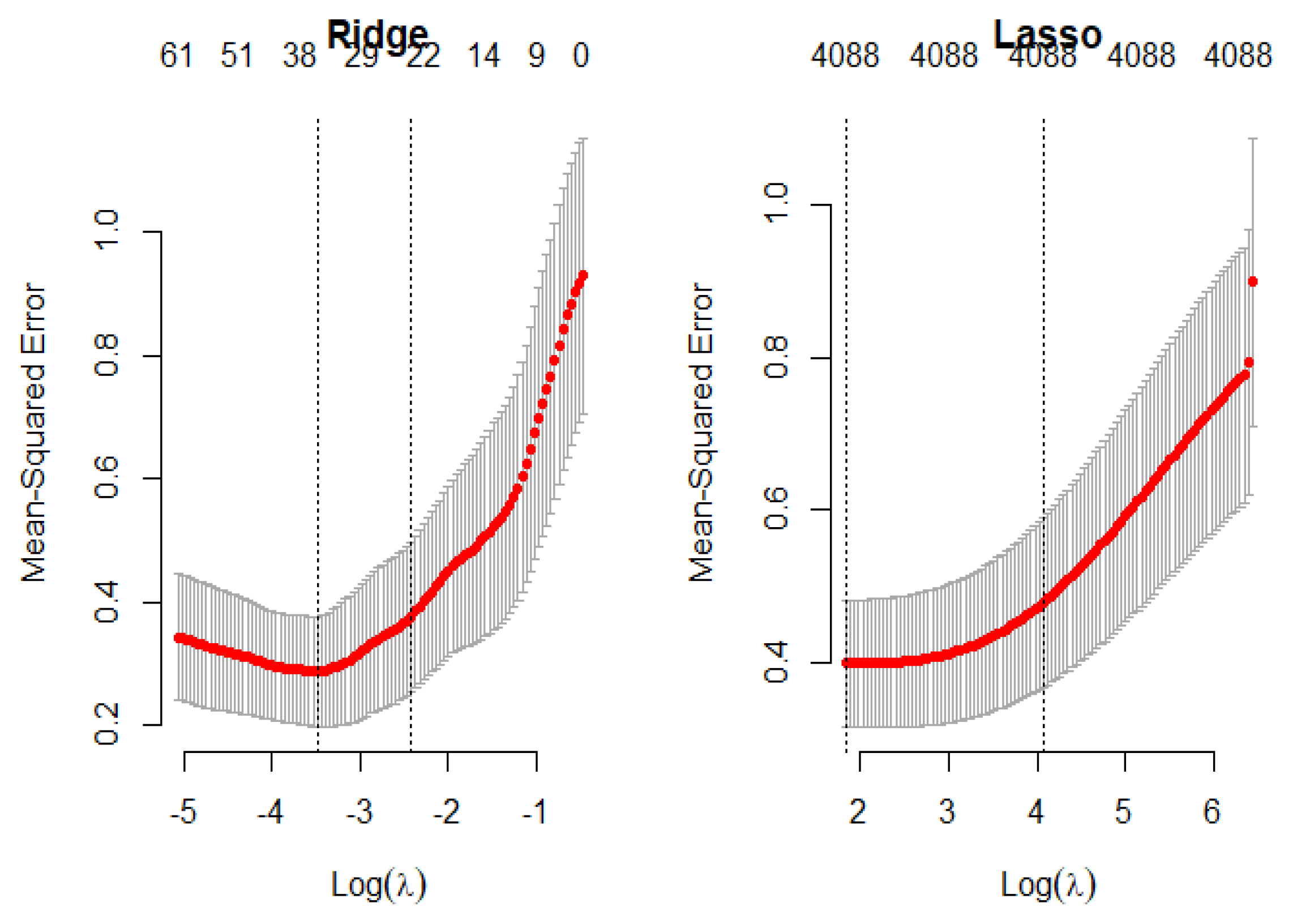
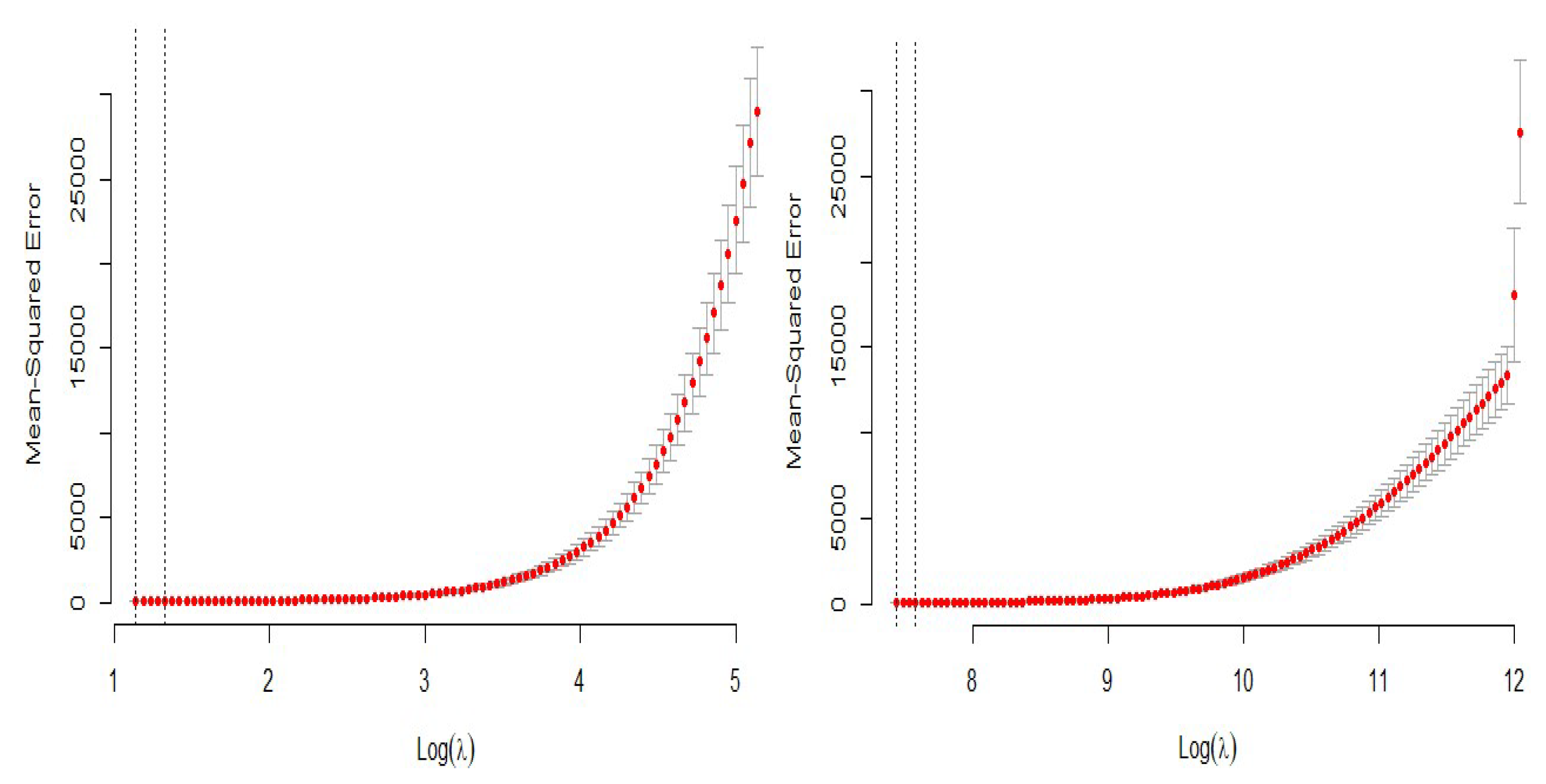
2.2. LASSO Regression
2.3. Ridge Regression
2.4. Functional Regression Model
Smoothing of Functional Data
- Fourier basis:The majority of the Fourier basis functions are used for a dataset that is periodical, such as weather datasets that denote that it is usually cold in winter and warm in summer. The Fourier bases are represented as follows:where is called the frequency period and is equal to , and p is the recurrence period. For instance, the recurring period for the weather dataset is 365 days;
- Spline basis:The spline functions are polynomial functions that first divide a discrete dataset into equal parts and then fit the best curve to each part. If its degree is zero, it estimates using the vertical and horizontal lines, and if its degree is one, it computes linearly and the higher degrees are computed as a curve. In addition, the area of the curve that is at the junction can be smoothed, and the points that are located at the junction are called knots. If there are numerous knots, they cause a low bias, and a high variance will lead to a rough fitting of the graph. It is important to note that there must be at least one observation in each knot.Some other basis functions include the constant, power, exponential, etc. The non-parametric regression function can be demonstrated as follows:where the errors are independent and have an identical distribution with the zero mean and variance . To estimate , according to the basis functions, we havewhere is the basis function that depends on the type of data and are the coefficients. For estimating the functional coefficients, the sum of squares error is minimized as follows:The above equation can be rewritten in matrix formAccording to the least squares problem, the solution of the above minimization problem is . So, we have:where is called a smoothing matrix.Selecting the number of basis functions is very important because the small number of basis functions leads to a large bias value and small variance value that yield to the under-fitting of the fitted model, and a large number of basis functions leads to a small bias value and a large variance value that yield to the over fitting of the fitted model.
2.5. Support Vector Regression Approach
2.5.1. The Kernel Tricks in the Support Vector Machine
- Linear kernel: The simplest kernel function is the product of the inner product of plus an optional constant value of c as the intercept:
- Polynomial kernel: When all training data are normalized, the polynomial kernel is appropriate. Its kernel form is as follows:where the parameters intercept (c), slope (), and the degree of polynomials (d) can be adjusted according to the data;
- Gaussian kernel: A sample of a radial function and its kernel are as follows:where parameter is adjustable and significantly determines the smoothness of the Gaussian kernel;
- Sigmoid kernel: It is known as a multilayer perceptron (MLP) kernel. The sigmoid kernel originates from the neural network technique, where the bipolar sigmoid function is often utilized as an activation function for artificial neurons. This kernel function is defined as follows:in which there are two adjustable parameters, the slope () and the intercept (c).
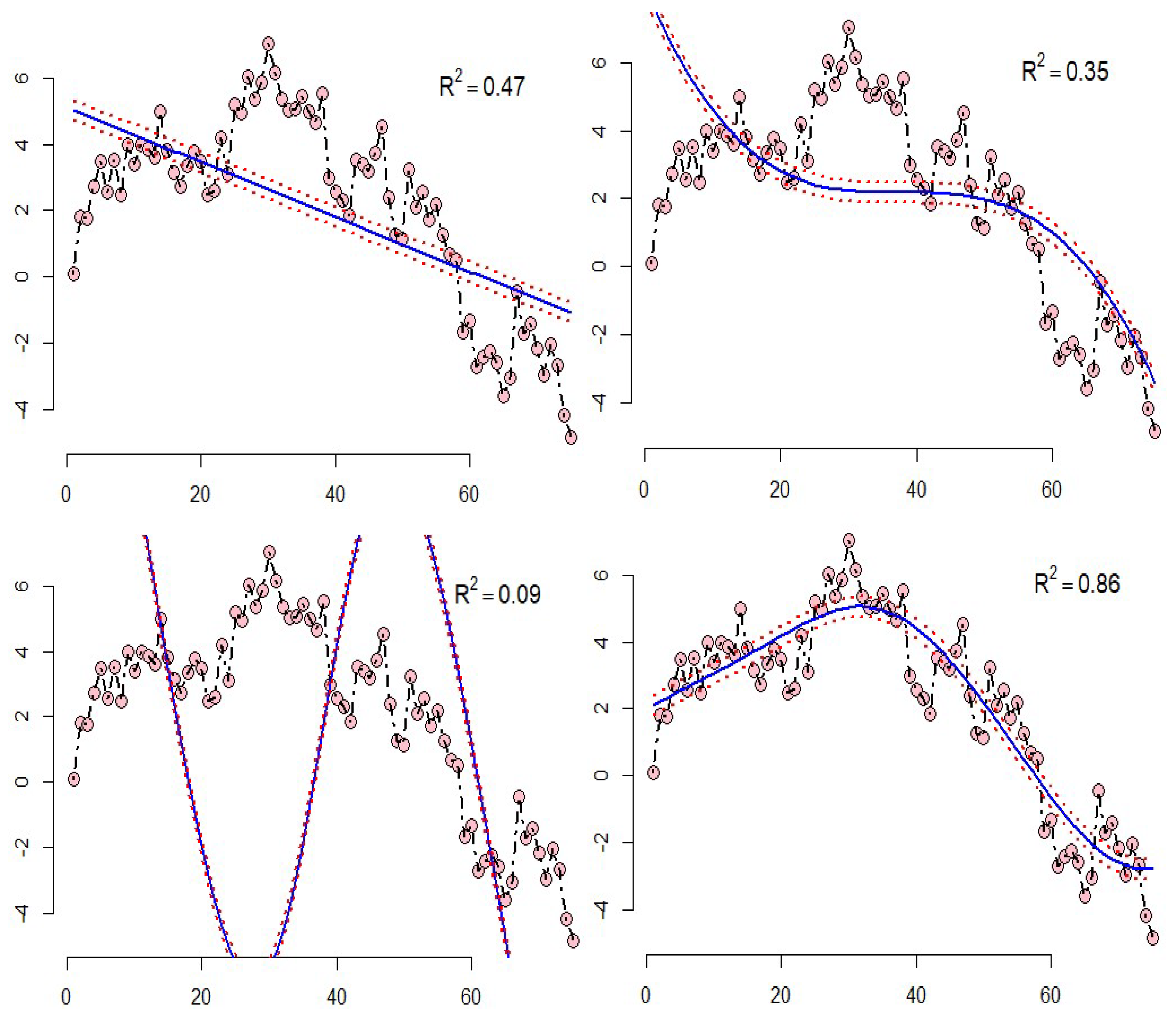
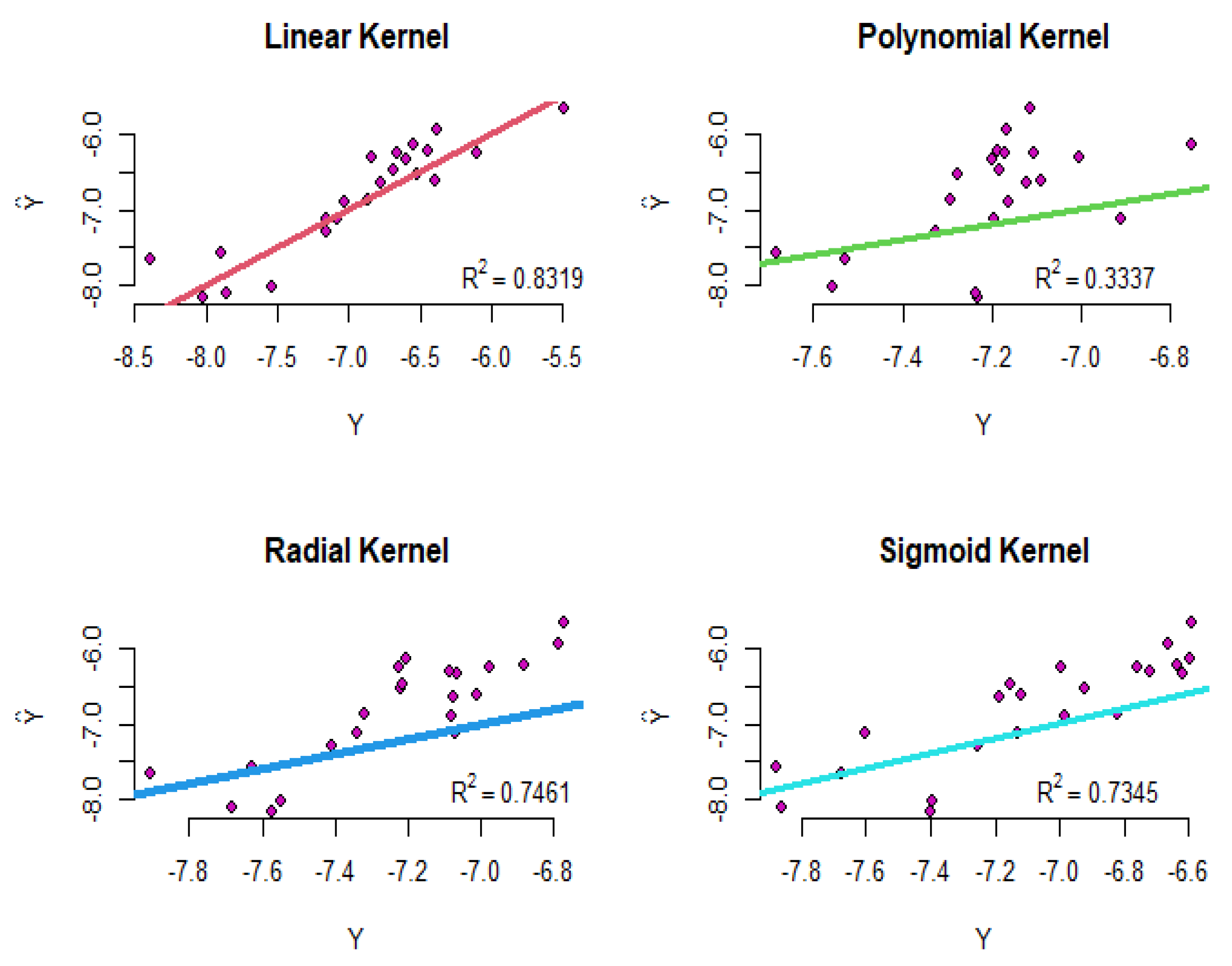
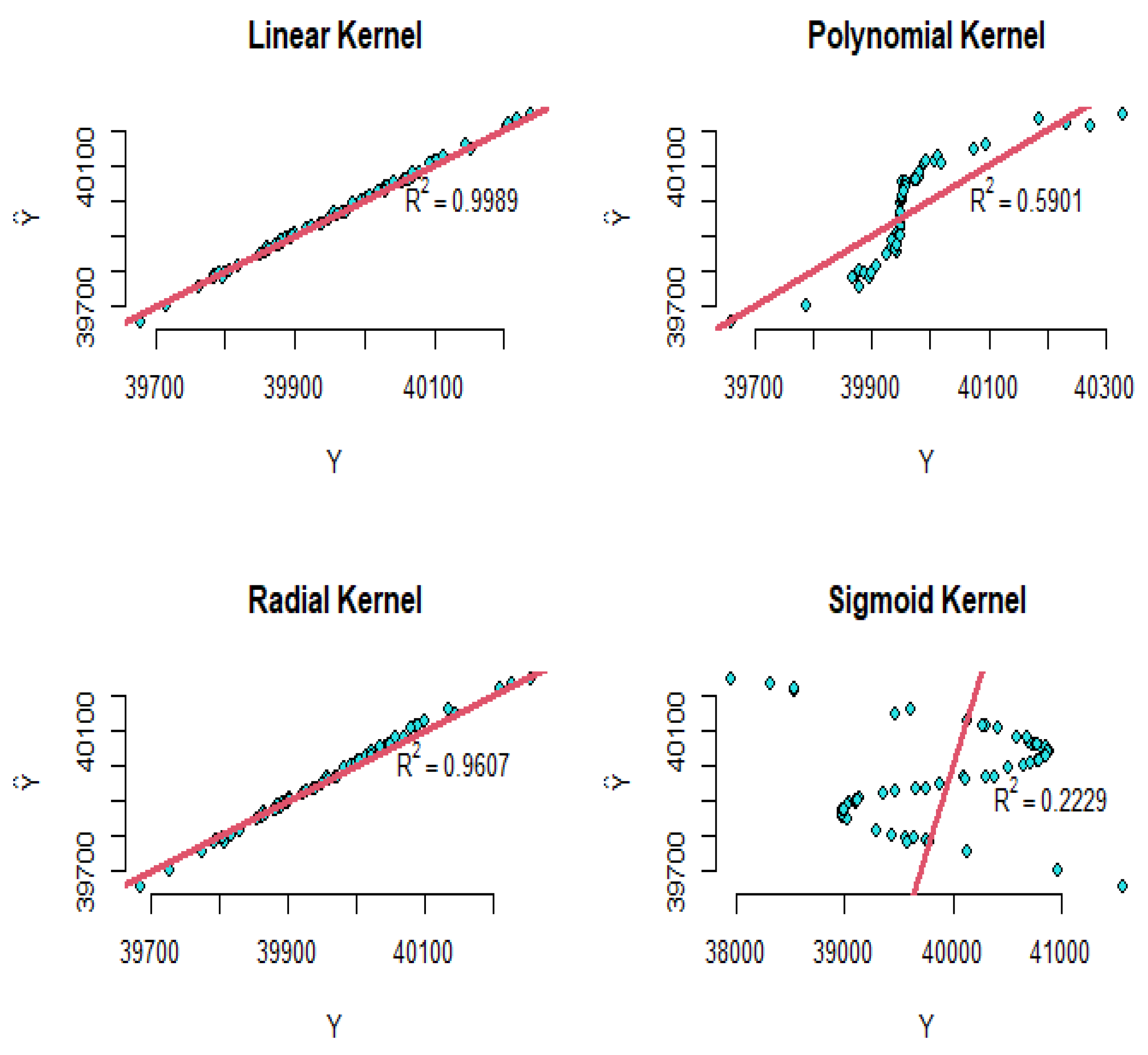
- Example 1: The results of the SVR for the two-dimensional data, which is simulated with the four mentioned kernels, can be shown in Figure 1. The top right diagram shows the SVR model with a linear kernel, the top left diagram shows the polynomial kernel, the bottom right diagram shows the sigmoid kernel, and the bottom left diagram shows the radial kernel in which the squared correlation between the real data and predicted data are shown. According to Figure 1, it can be concluded that the model with the radial kernel has better performance than the other kernels;
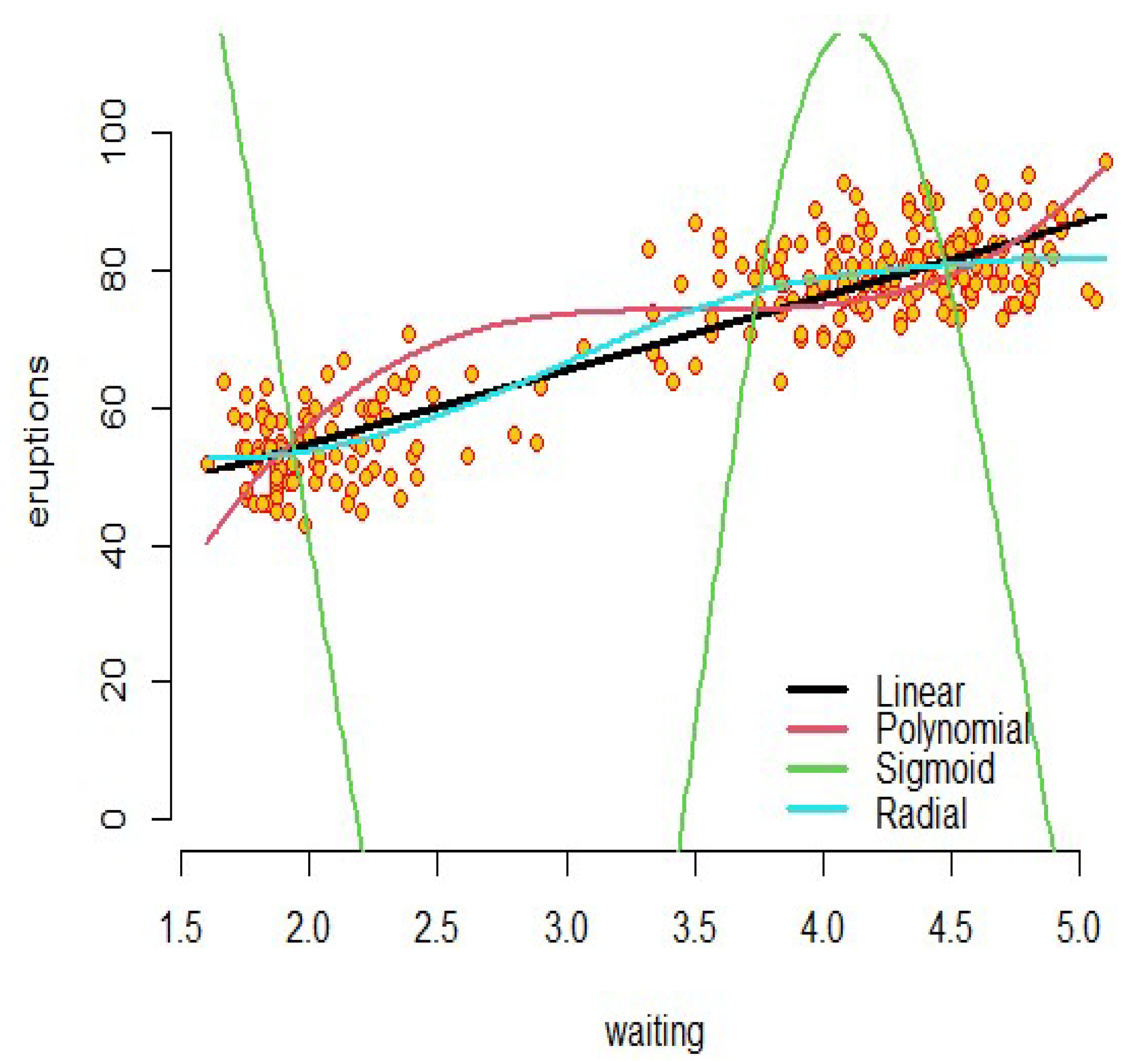
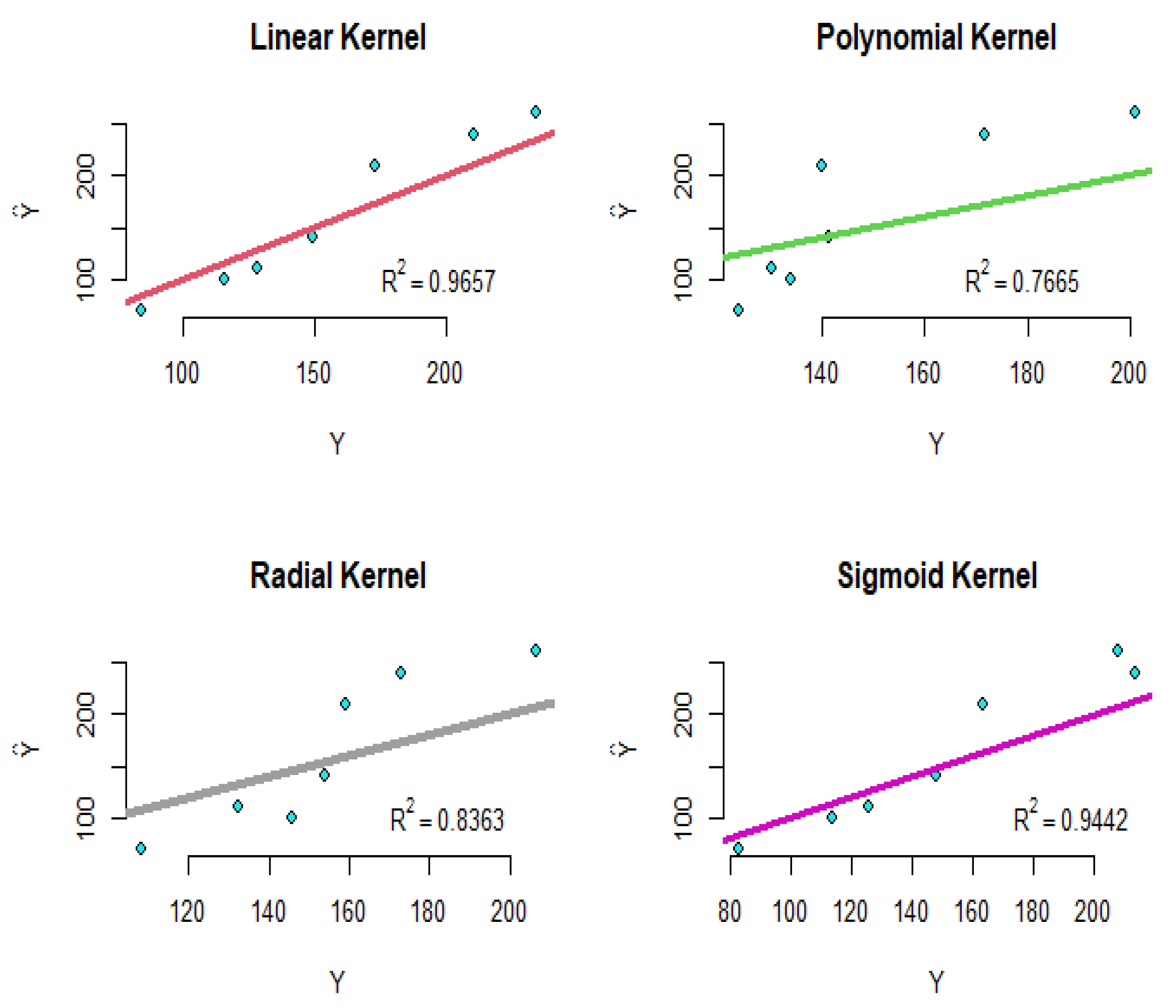
- Example 2: As an interesting example, we can refer to real data (faithful) in R software. The dataset contains two variables: “eruptions” is the eruption time in minutes of the old faithful geyser, and is used as the response variable; and “waiting” is the waiting time between eruptions in minutes in Yellowstone National Park, Wyoming, USA as the predictor. The results of the support vector regression with introduced kernels are shown in Figure 2. For these fitted models, the sigmoid kernel has not performed well, but the other kernels have had acceptable results.
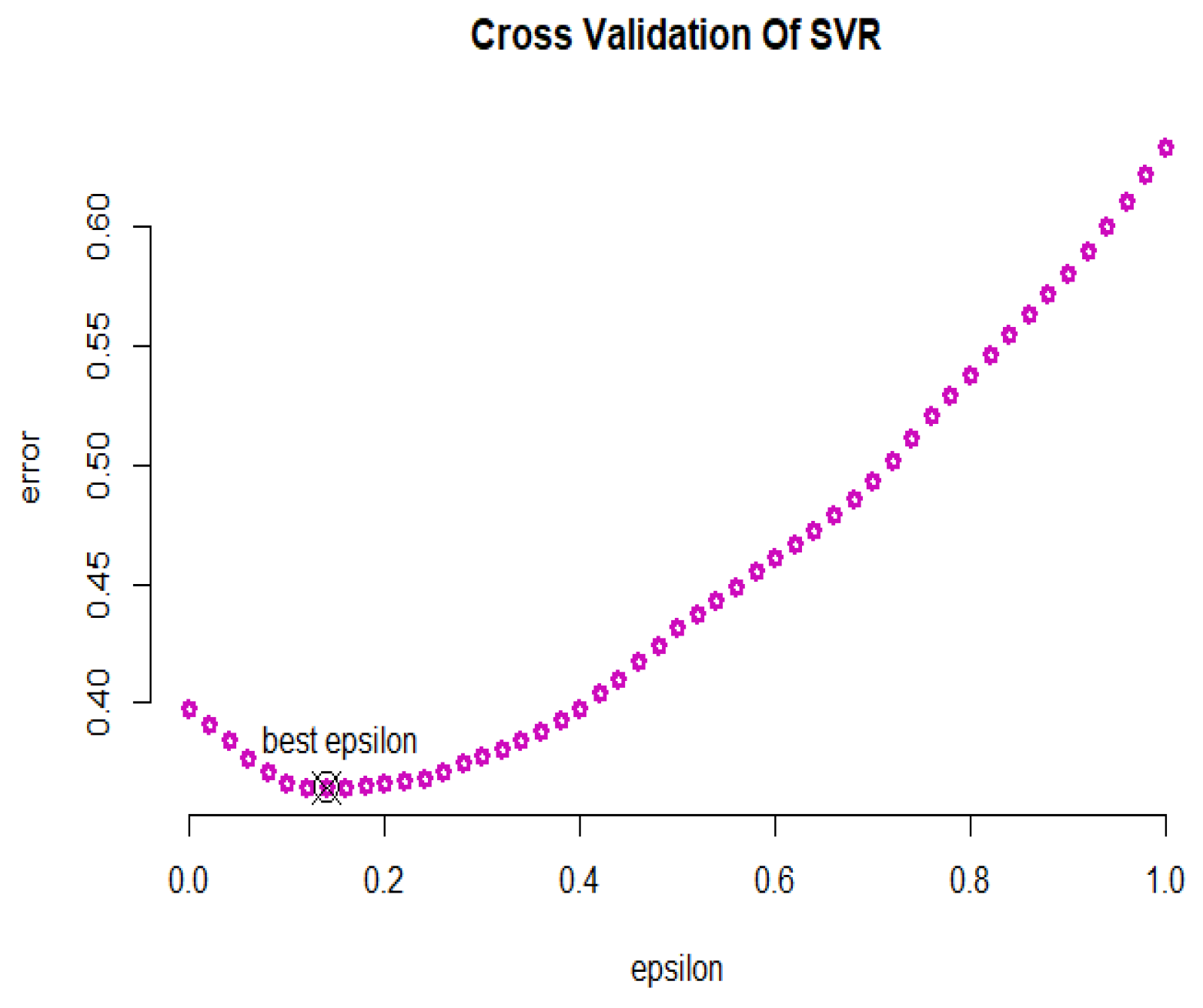
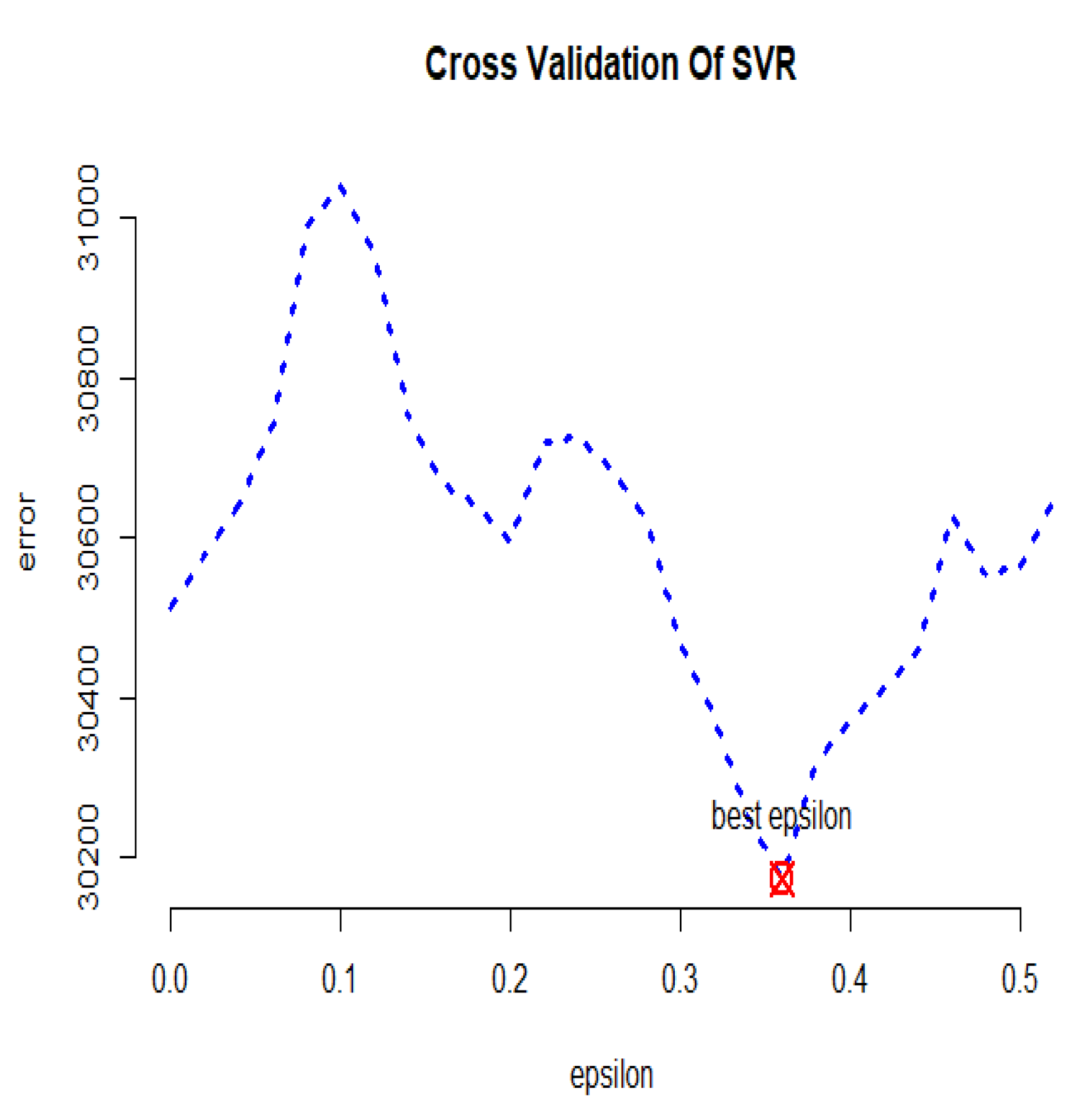
2.5.2. Generalized Support Vector Regression
3. Results Based on the Analysis of Real Datasets
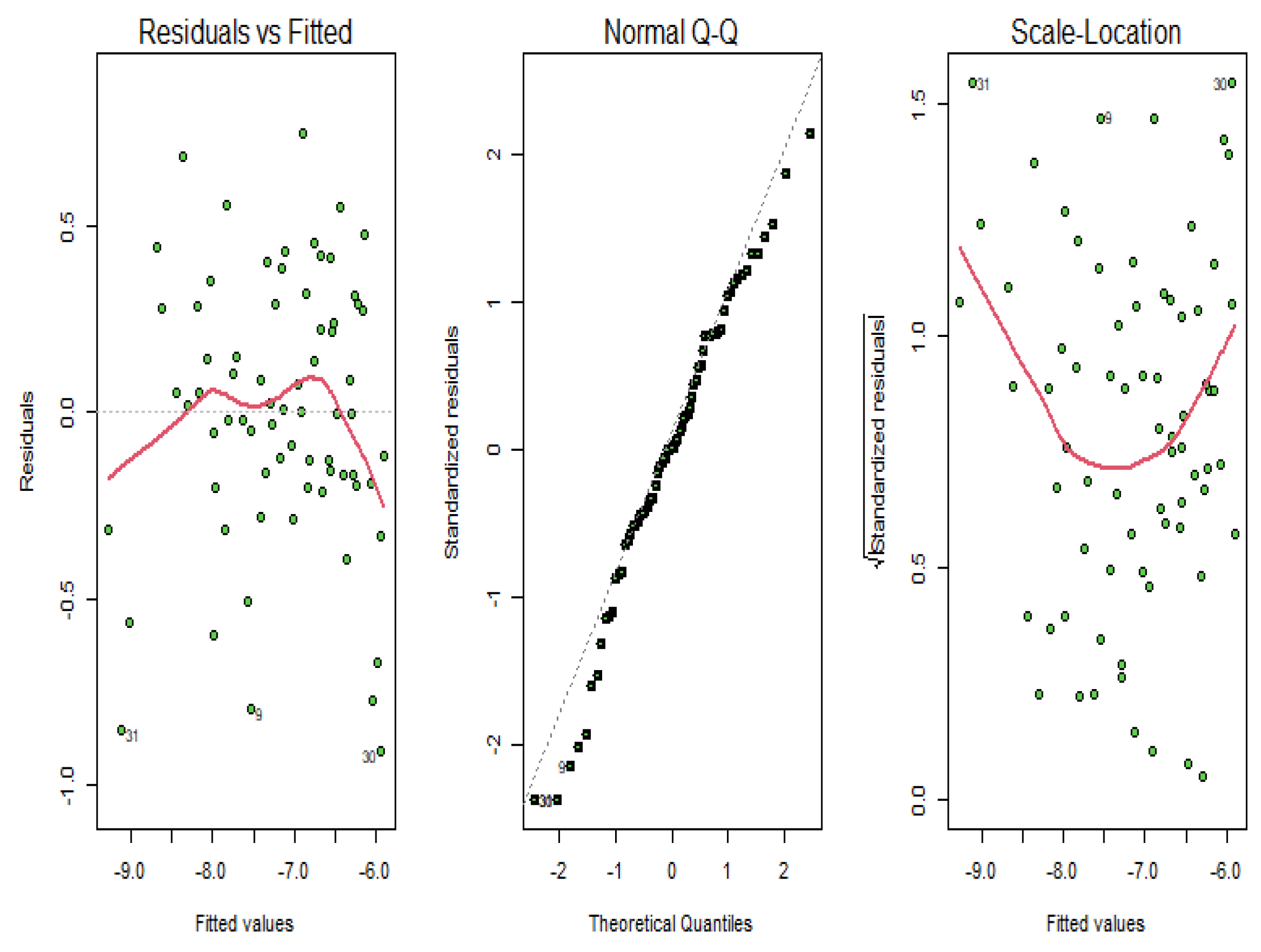
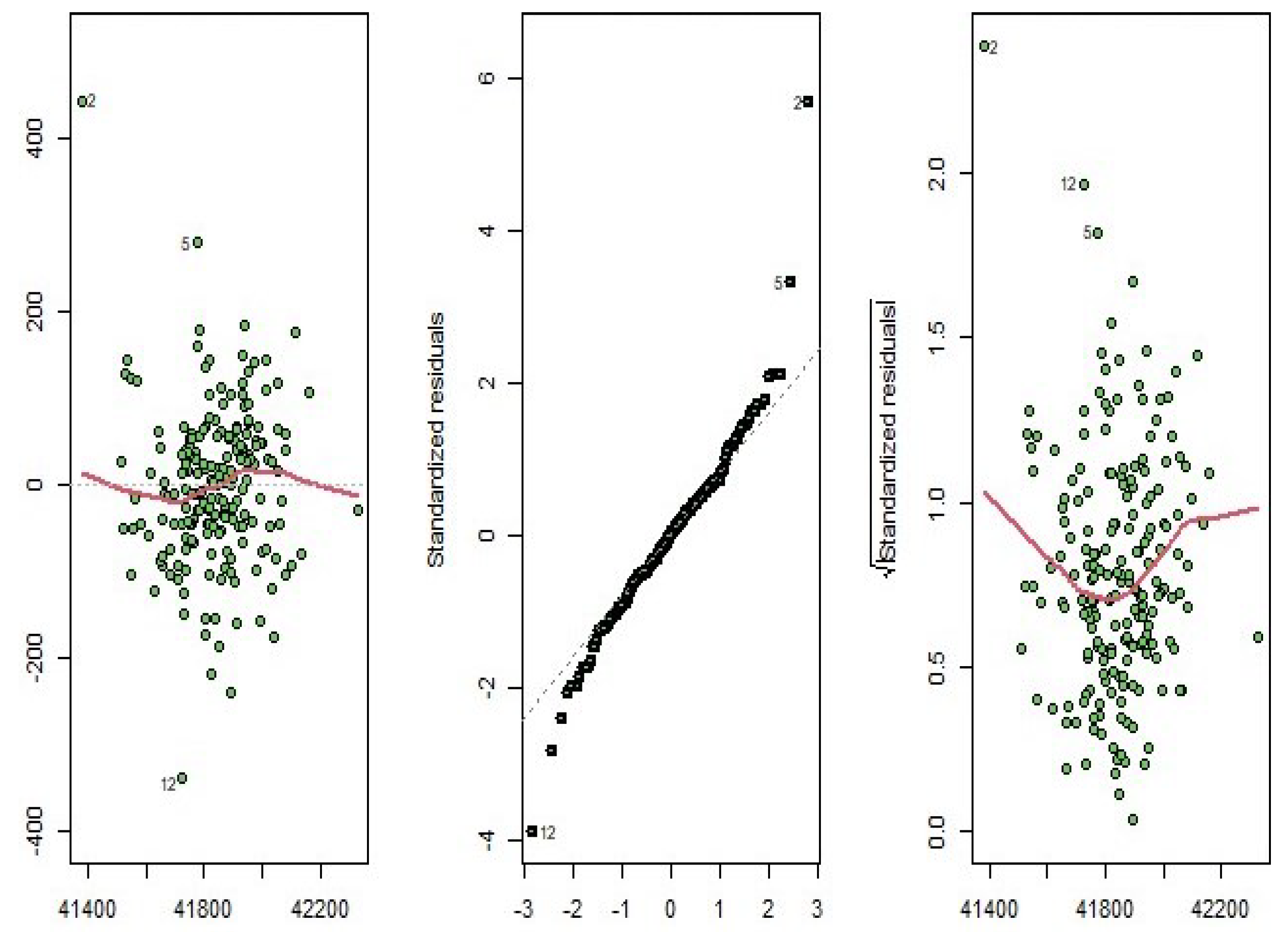
3.1. Yeast Gene Data
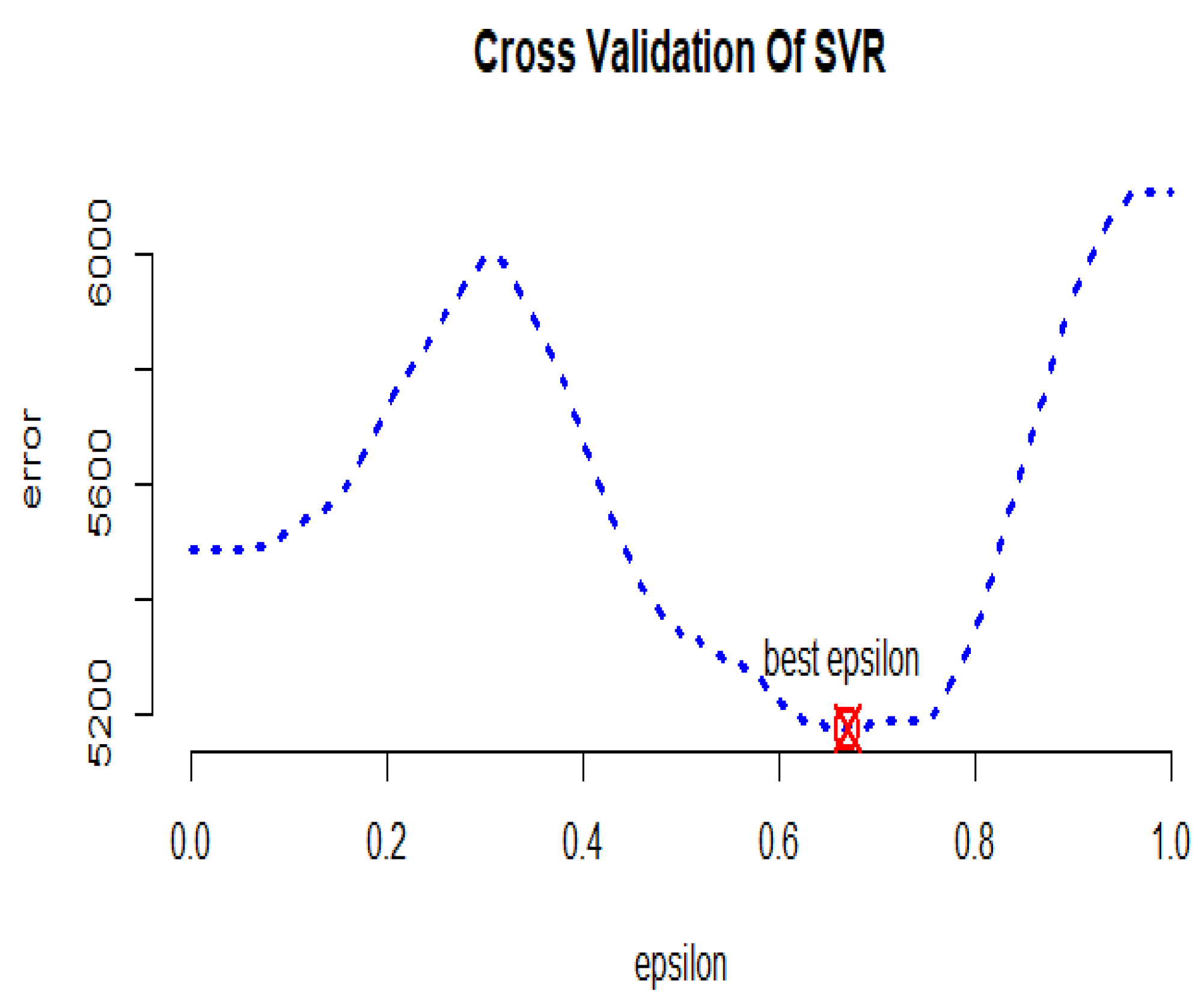
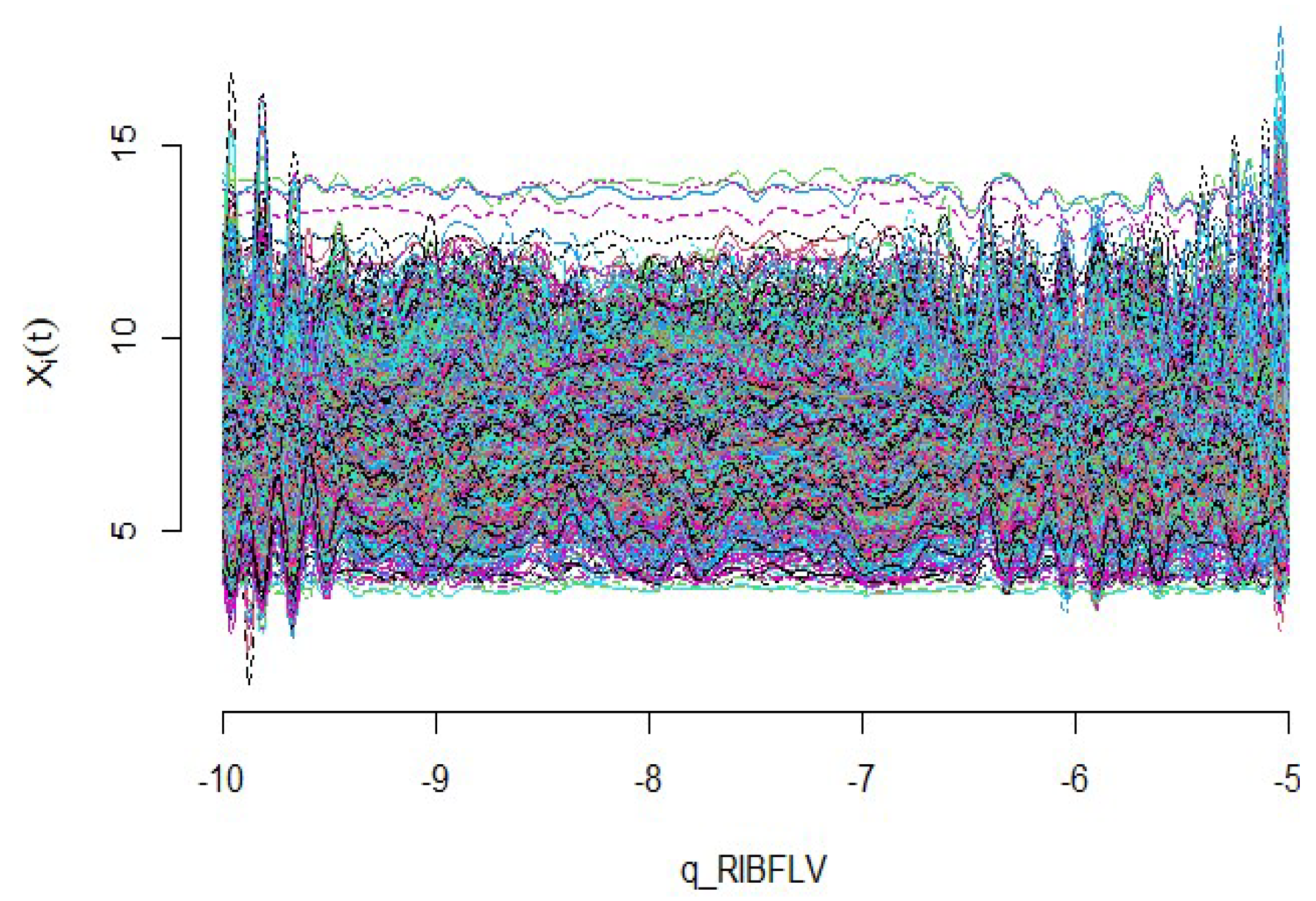
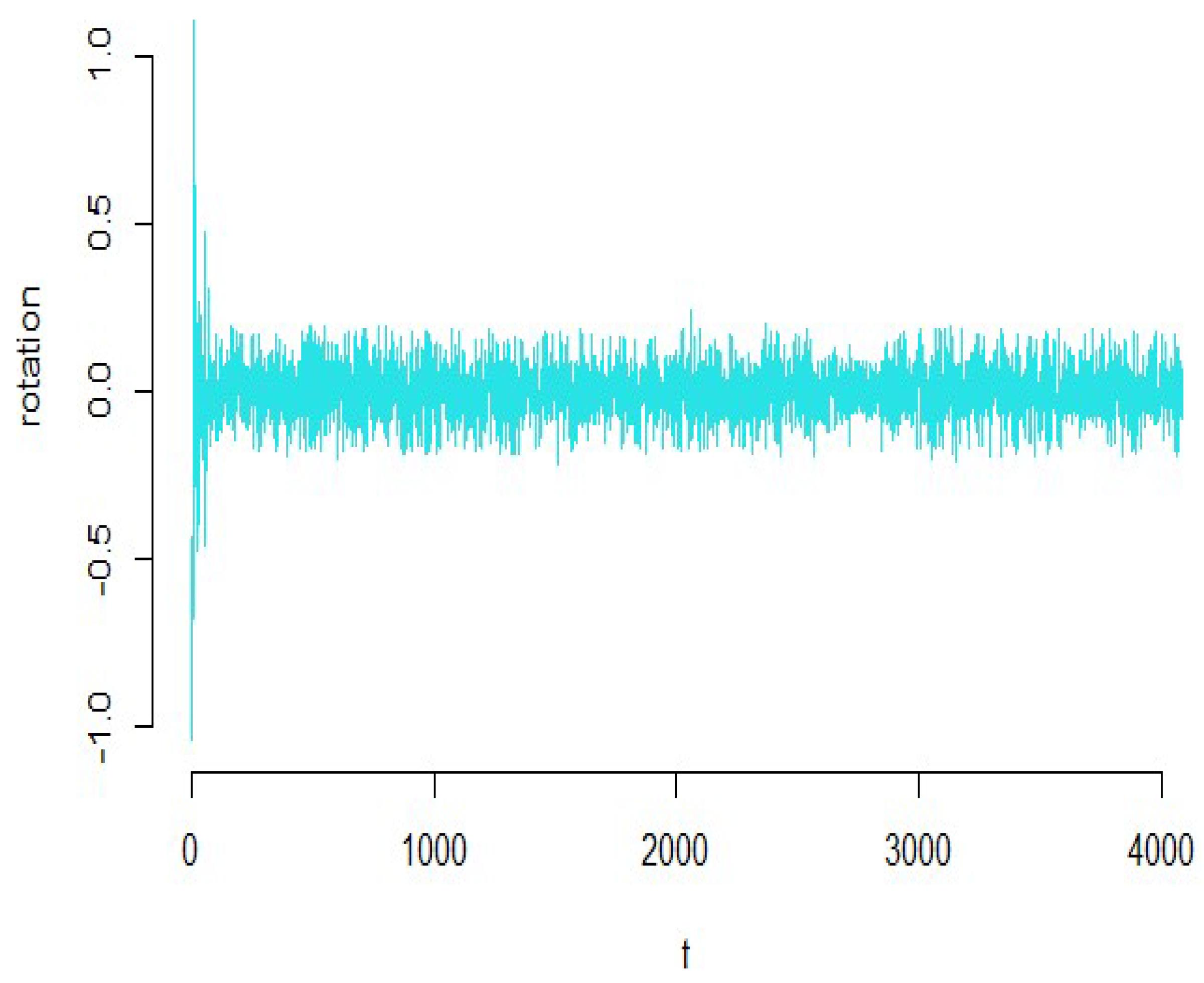
3.2. Riboflavin Data
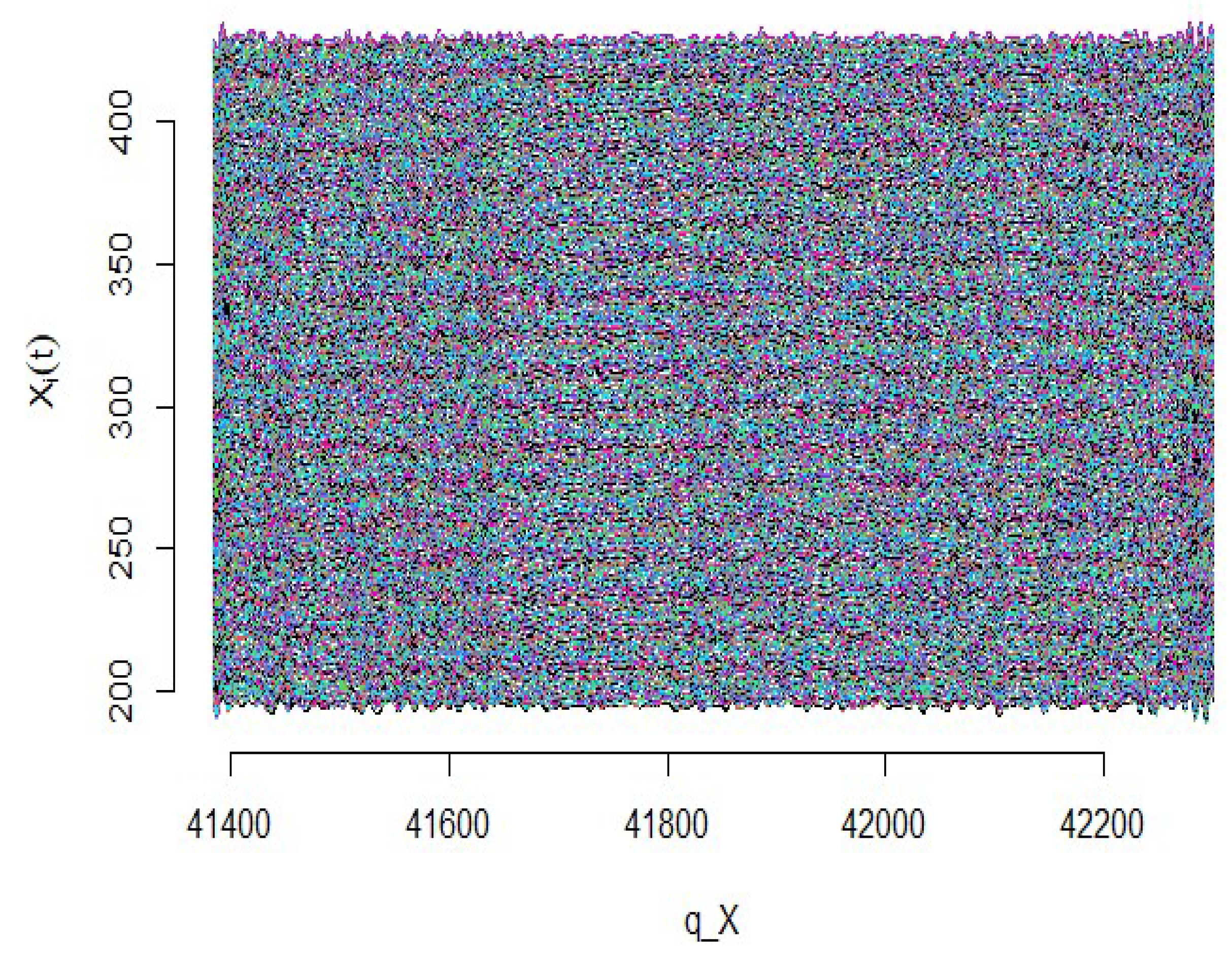
3.3. Simulated Dataset
4. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Taavoni, M.; Arashi, M. High-dimensional generalized semiparametric model for longitudinal data. Statistics 2021, 55, 831–850. [Google Scholar] [CrossRef]
- Efron, B.; Hastie, T. Computer Age Statistical Inference; Cambridge University Press: Cambridge, UK, 2016. [Google Scholar]
- Jolliffe, I.T. Principal Component Analysis; Springer: Aberdeen, UK, 2002. [Google Scholar]
- Tibshirani, R. Regression Shrinkage and Selection via the Lasso. J. R. Stat. Soc. Ser. B 1996, 58, 267–288. [Google Scholar] [CrossRef]
- Hoerl, A.E.; Kennard, R.W. Ridge regression: Some simulation. Commun. Stat. 1975, 4, 105–123. [Google Scholar] [CrossRef]
- Vapni, V.N. The Nature of Statistical Learning Theory; Springer: New York, NY, USA, 1995. [Google Scholar]
- Kao, L.J.; Chiu, C.C.; Lu, C.J.; Yang, J.L. Integration of nonlinear independent component analysis and support vector regression for stock price forecasting. Neurocomputing 2013, 99, 534–542. [Google Scholar] [CrossRef]
- Xiao, Y.; Xiao, J.; Lu, F.; Wang, S. Ensemble anns-pso-ga approach for day-ahead stock e-exchange prices forecasting. Int. J. Comput. Intell. Syst. 2014, 7, 272–290. [Google Scholar] [CrossRef] [Green Version]
- Ramsay, J.O.; Silverman, B.W. Functional Data Analysis; Springer: New York, NY, USA, 2005. [Google Scholar]
- Ferraty, F.; Vieu, P. Nonparametric Functional Data Analysis: Theory and Practice; Springer: New York, NY, USA, 2006. [Google Scholar]
- Goldsmith, J.; Scheipl, F. Estimator selection and combination in scalar-on-function regression. Comput. Stat. Data Anal. 2014, 70, 362–372. [Google Scholar] [CrossRef]
- Choudhury, S.; Ghosh, S.; Bhattacharya, A.; Fernandes, K.J.; Tiwari, M.K. A real time clustering and SVM based price-volatility prediction for optimal trading strategy. Neurocomputing 2014, 131, 419–426. [Google Scholar] [CrossRef]
- Nayak, R.K.; Mishra, D.; Rath, A.K. A naïve svm-knn based stock market trend reversal analysis for indian benchmark indices. Appl. Soft Comput. 2015, 35, 670–680. [Google Scholar] [CrossRef]
- Patel, J.; Shah, S.; Thakkar, P.; Kotecha, K. Predicting stock market index using fusion of machine learning techniques. Expert Syst. Appl. 2015, 42, 2162–2172. [Google Scholar] [CrossRef]
- Araújo, R.D.A.; Oliveira, A.L.; Meira, S. A hybrid model for high-frequency stock market forecasting. Expert Syst. Appl. 2015, 42, 4081–4096. [Google Scholar] [CrossRef]
- Sheather, S. A Modern Approach to Regression with R; Springer: New York, NY, USA, 2009. [Google Scholar]
- Roozbeh, M.; Babaie–Kafaki, S.; Manavi, M. A heuristic algorithm to combat outliers and multicollinearity in regression model analysis. Iran. J. Numer. Anal. Optim. 2022, 12, 173–186. [Google Scholar]
- Arashi, M.; Golam Kibria, B.M.; Valizadeh, T. On ridge parameter estimators under stochastic subspace hypothesis. J. Stat. Comput. Simul. 2017, 87, 966–983. [Google Scholar] [CrossRef]
- Fallah, R.; Arashi, M.; Tabatabaey, S.M.M. On the ridge regression estimator with sub-space restriction. Commun. Stat. Theory Methods 2017, 46, 11854–11865. [Google Scholar] [CrossRef]
- Roozbeh, M. Optimal QR-based estimation in partially linear regression models with correlated errors using GCV criterion. Comput. Stat. Data Anal. 2018, 117, 45–61. [Google Scholar] [CrossRef]
- Roozbeh, M.; Najarian, M. Efficiency of the QR class estimator in semiparametric regression models to combat multicollinearity. J. Stat. Comput. Simul. 2018, 88, 1804–1825. [Google Scholar] [CrossRef]
- Yüzbaşi, B.; Arashi, M.; Akdeniz, F. Penalized regression via the restricted bridge estimator. Soft Comput. 2021, 25, 8401–8416. [Google Scholar] [CrossRef]
- Zhang, X.; Xue, W.; Wang, Q. Covariate balancing functional propensity score for functional treatments in cross-sectional observational studies. Comput. Stat. Data Anal. 2021, 163, 107303. [Google Scholar] [CrossRef]
- Miao, R.; Zhang, X.; Wong, R.K. A Wavelet-Based Independence Test for Functional Data with an Application to MEG Functional Connectivity. J. Am. Stat. Assoc. 2022, 1–14. [Google Scholar] [CrossRef]
- Spellman, P.T.; Sherlock, G.; Zhang, M.Q.; Iyer, V.R.; Anders, K.; Eisen, M.B.; Brown, P.O.; Botstein, D.; Futcher, B. Comprehensive Identification of Cell Cycle–regulated Genes of the Yeast Saccharomyces cerevisiae by Microarray Hybridization. Mol. Biol. Cell 1998, 9, 3273–3297. [Google Scholar] [CrossRef]
- Carlson, M.; Zhang, B.; Fang, Z.; Mischel, P.; Horvath, S.; Nelson, S.F. Gene Connectivity. Function, and Sequence Conservation: Predictions from Modular Yeast Co-expression Networks. BMC Genom. 2006, 7, 40. [Google Scholar] [CrossRef] [PubMed]
- McDonald, G.C.; Galarneau, D.I. A Monte Carlo evaluation of some ridge-type estimators. J. Am. Stat. Assoc. 1975, 70, 407–416. [Google Scholar] [CrossRef]
- Roozbeh, M.; Babaie–Kafaki, S.; Aminifard, Z. Two penalized mixed–integer nonlinear programming approaches to tackle multicollinearity and outliers effects in linear regression model. J. Ind. Manag. Optim. 2020, 17, 3475–3491. [Google Scholar] [CrossRef]
- Roozbeh, M.; Babaie–Kafaki, S.; Aminifard, Z. Improved high-dimensional regression models with matrix approximations applied to the comparative case studies with support vector machines. Optim. Methods Softw. 2022, 37, 1912–1929. [Google Scholar] [CrossRef]
























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Criterion | R | RMSE | MAPE |
|---|---|---|---|
| Method | |||
| Functional principal component | |||
| Ridge regression | |||
| LASSO regression | |||
| SVR with linear kernel | |||
| SVR with polynomial kernel | |||
| SVR with sigmoid kernel | |||
| SVR with radial kernel | |||
| GSVR |
| Criterion | R | RMSE | MAPE |
|---|---|---|---|
| Method | |||
| Functional principal component | |||
| Ridge regression | |||
| LASSO regression | |||
| SVR with linear kernel | |||
| SVR with polynomial kernel | |||
| SVR with sigmoid kernel | |||
| SVR with radial kernel | |||
| GSVR |
| Criterion | R | RMSE | MAPE |
|---|---|---|---|
| Method | |||
| Functional principal component | |||
| Ridge regression | |||
| LASSO regression | |||
| SVR with linear kernel | |||
| SVR with polynomial kernel | |||
| SVR with sigmoid kernel | |||
| SVR with radial kernel | |||
| GSVR |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Roozbeh, M.; Rouhi, A.; Mohamed, N.A.; Jahadi, F. Generalized Support Vector Regression and Symmetry Functional Regression Approaches to Model the High-Dimensional Data. Symmetry 2023, 15, 1262. https://doi.org/10.3390/sym15061262
Roozbeh M, Rouhi A, Mohamed NA, Jahadi F. Generalized Support Vector Regression and Symmetry Functional Regression Approaches to Model the High-Dimensional Data. Symmetry. 2023; 15(6):1262. https://doi.org/10.3390/sym15061262
Chicago/Turabian StyleRoozbeh, Mahdi, Arta Rouhi, Nur Anisah Mohamed, and Fatemeh Jahadi. 2023. "Generalized Support Vector Regression and Symmetry Functional Regression Approaches to Model the High-Dimensional Data" Symmetry 15, no. 6: 1262. https://doi.org/10.3390/sym15061262