
EcReID: Enhancing Correlations from Skeleton for Occluded Person Re-Identification
Abstract
:1. Introduction
2. Related Work
2.1. Occluded Person Re-Identification
2.2. Graph Model-Based Person Re-Identification
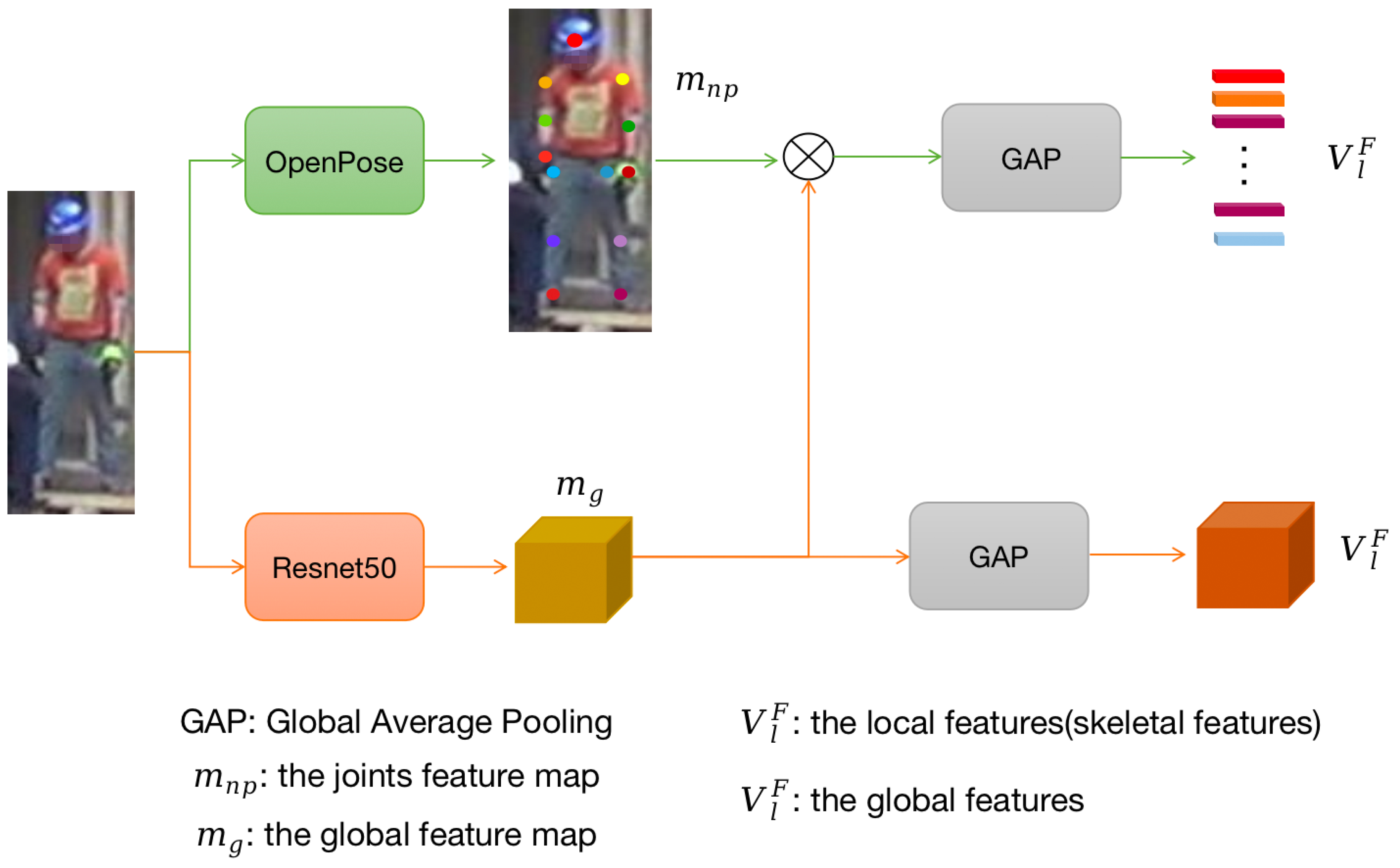
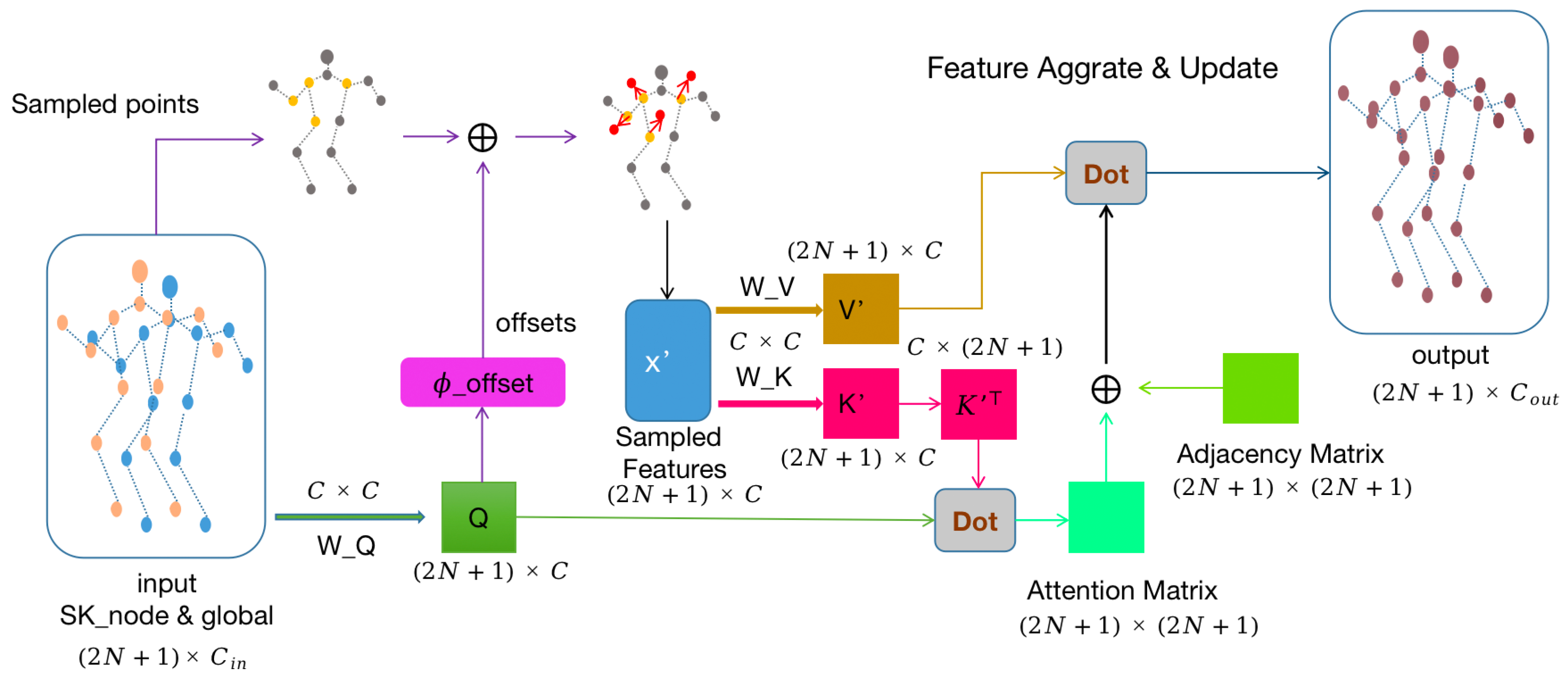
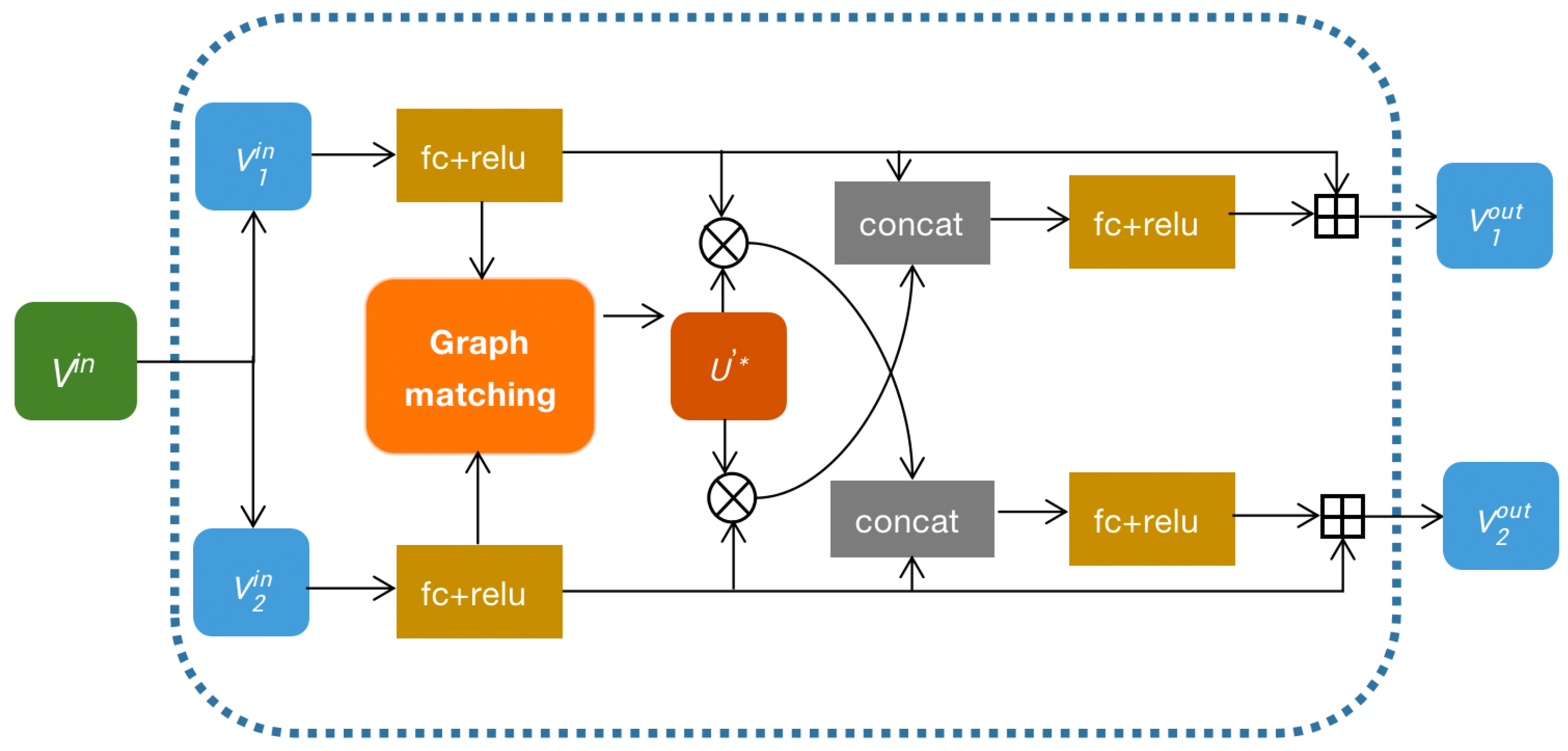
3. Network Structure Design
3.1. Mutual Help Denoising Module
3.2. Inter-Node Aggregation and Update
3.3. Graph Matching Module
4. Experiments and Analysis
4.1. Comparison with Other Methods
4.1.1. Comparison on Occluded Datasets
4.1.2. Comparison on Market-1501 and DukeMTMC-ReID
4.2. Ablation Experiments
4.2.1. Ablation Analysis of Different Models
4.2.2. Ablation Analysis of Different Network Layers
4.3. Parameter Analysis
4.4. Visualization of Experimental Results
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Ye, M.; Shen, J.; Lin, G.; Xiang, T.; Shao, L.; Hoi, S.C. Deep learning for person re-identification: A survey and outlook. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 44, 2872–2893. [Google Scholar] [CrossRef] [PubMed]
- Zheng, W.S.; Li, X.; Xiang, T.; Liao, S.; Lai, J.; Gong, S. Partial person re-identification. In Proceedings of the IEEE International Conference on Computer Vision, Seville, Spain, 17–19 March 2015; pp. 4678–4686. [Google Scholar]
- Dai, J.; Qi, H.; Xiong, Y.; Li, Y.; Zhang, G.; Hu, H.; Wei, Y. Deformable convolutional networks. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 764–773. [Google Scholar]
- Zheng, K.; Lan, C.; Zeng, W.; Liu, J.; Zhang, Z.; Zha, Z.J. Pose-guided feature learning with knowledge distillation for occluded person re-identification. In Proceedings of the 29th ACM International Conference on Multimedia, Virtual, 20–24 October 2021; pp. 4537–4545. [Google Scholar]
- Li, Y.; He, J.; Zhang, T.; Liu, X.; Zhang, Y.; Wu, F. Diverse part discovery: Occluded person re-identification with part-aware transformer. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 2898–2907. [Google Scholar]
- Zhuo, J.; Chen, Z.; Lai, J.; Wang, G. Occluded person re-identification. In Proceedings of the 2018 IEEE International Conference on Multimedia and Expo (ICME) IEEE, San Diego, CA, USA, 23–27 July 2018; pp. 1–6. [Google Scholar]
- Miao, J.; Wu, Y.; Liu, P.; Ding, Y.; Yang, Y. Pose-guided feature alignment for occluded person re-identification. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 542–551. [Google Scholar]
- Fan, X.; Luo, H.; Zhang, X.; He, L.; Zhang, C.; Jiang, W. Scpnet: Spatial-channel parallelism network for joint holistic and partial person re-identification. In Proceedings of the Asian Conference on Computer Vision, Perth, Australia, 2–6 December 2018; Springer: Berlin/Heidelberg, Germany, 2018; pp. 19–34. [Google Scholar]
- Luo, H.; Jiang, W.; Fan, X.; Zhang, C. Stnreid: Deep convolutional networks with pairwise spatial transformer networks for partial person re-identification. IEEE Trans. Multimed. 2020, 22, 2905–2913. [Google Scholar] [CrossRef] [Green Version]
- Li, Y.; He, Z.; Ye, X.; He, Z.; Han, K. Spatial temporal graph convolutional networks for skeleton-based dynamic hand gesture recognition. EURASIP J. Image Video Process. 2019, 2019, 1–7. [Google Scholar] [CrossRef] [Green Version]
- Xing, Y.; Zhu, J. Deep Learning-Based Action Recognition with 3D Skeleton: A Survey; Wiley: Hoboken, NJ, USA, 2021. [Google Scholar]
- Zhou, J.; Lin, K.Y.; Li, H.; Zheng, W.S. Graph-based high-order relation modeling for long-term action recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 8984–8993. [Google Scholar]
- Zhang, J.; Ye, G.; Tu, Z.; Qin, Y.; Qin, Q.; Zhang, J.; Liu, J. A spatial attentive and temporal dilated (SATD) GCN for skeleton-based action recognition. CAAI Trans. Intell. Technol. 2022, 7, 46–55. [Google Scholar] [CrossRef]
- Chen, Z.M.; Wei, X.S.; Wang, P.; Guo, Y. Multi-label image recognition with graph convolutional networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 5177–5186. [Google Scholar]
- Zheng, K.; Liu, W.; He, L.; Mei, T.; Luo, J.; Zha, Z.J. Group-aware label transfer for domain adaptive person re-identification. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 5310–5319. [Google Scholar]
- Zhao, J.; Yan, K.; Zhao, Y.; Guo, X.; Huang, F.; Li, J. Transformer-based dual relation graph for multi-label image recognition. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 163–172. [Google Scholar]
- Chen, Z.; Wei, X.S.; Wang, P.; Guo, Y. Learning graph convolutional networks for multi-label recognition and applications. IEEE Trans. Pattern Anal. Mach. Intell. 2021. [Google Scholar] [CrossRef] [PubMed]
- Huang, Z.; Qiao, S.; Han, N.; Yuan, C.A.; Song, X.; Xiao, Y. Survey on vehicle map matching techniques. CAAI Trans. Intell. Technol. 2021, 6, 55–71. [Google Scholar] [CrossRef]
- Wang, X.; Gupta, A. Videos as space-time region graphs. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 399–417. [Google Scholar]
- Pan, B.; Cai, H.; Huang, D.A.; Lee, K.H.; Gaidon, A.; Adeli, E.; Niebles, J.C. Spatio-temporal graph for video captioning with knowledge distillation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 10870–10879. [Google Scholar]
- Yang, J.; Zheng, W.S.; Yang, Q.; Chen, Y.C.; Tian, Q. Spatial-temporal graph convolutional network for video-based person re-identification. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 3289–3299. [Google Scholar]
- Wu, Y.; Bourahla, O.E.F.; Li, X.; Wu, F.; Tian, Q.; Zhou, X. Adaptive graph representation learning for video person re-identification. IEEE Trans. Image Process. 2020, 29, 8821–8830. [Google Scholar] [CrossRef] [PubMed]
- Barman, A.; Shah, S.K. Shape: A novel graph theoretic algorithm for making consensus-based decisions in person re-identification systems. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 1115–1124. [Google Scholar]
- Ye, M.; Ma, A.J.; Zheng, L.; Li, J.; Yuen, P.C. Dynamic label graph matching for unsupervised video re-identification. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 5142–5150. [Google Scholar]
- Cheng, D.; Gong, Y.; Chang, X.; Shi, W.; Hauptmann, A.; Zheng, N. Deep feature learning via structured graph Laplacian embedding for person re-identification. Pattern Recognit. 2018, 82, 94–104. [Google Scholar] [CrossRef] [Green Version]
- Wu, X.; An, W.; Yu, S.; Guo, W.; García, E.B. Spatial-temporal graph attention network for video-based gait recognition. In Proceedings of the Asian Conference on Pattern Recognition; Springer: Berlin/Heidelberg, Germany, 2019; pp. 274–286. [Google Scholar]
- Sun, Y.; Zheng, L.; Yang, Y.; Tian, Q.; Wang, S. Beyond part models: Person retrieval with refined part pooling (and a strong convolutional baseline). In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 480–496. [Google Scholar]
- Wang, R.; Yan, J.; Yang, X. Learning combinatorial embedding networks for deep graph matching. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 3056–3065. [Google Scholar]
- Zheng, L.; Shen, L.; Tian, L.; Wang, S.; Wang, J.; Tian, Q. Scalable person re-identification: A benchmark. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1116–1124. [Google Scholar]
- Zheng, Z.; Zheng, L.; Yang, Y. Unlabeled samples generated by gan improve the person re-identification baseline in vitro. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 3754–3762. [Google Scholar]
- Zhao, L.; Li, X.; Zhuang, Y.; Wang, J. Deeply-learned part-aligned representations for person re-identification. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 3219–3228. [Google Scholar]
- Suh, Y.; Wang, J.; Tang, S.; Mei, T.; Lee, K.M. Part-aligned bilinear representations for person re-identification. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 402–419. [Google Scholar]
- Ge, Y.; Li, Z.; Zhao, H.; Yin, G.; Yi, S.; Wang, X.; Li, H. Fd-gan: Pose-guided feature distilling gan for robust person re-identification. Adv. Neural Inf. Process. Syst. 2018, 31. [Google Scholar] [CrossRef]
- He, L.; Liang, J.; Li, H.; Sun, Z. Deep spatial feature reconstruction for partial person re-identification: Alignment-free approach. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7073–7082. [Google Scholar]
- He, L.; Sun, Z.; Zhu, Y.; Wang, Y. Recognizing partial biometric patterns. arXiv 2018, arXiv:1810.07399. [Google Scholar]
- Huang, H.; Li, D.; Zhang, Z.; Chen, X.; Huang, K. Adversarially occluded samples for person re-identification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 5098–5107. [Google Scholar]
- Zhuo, J.; Lai, J.; Chen, P. A Novel Teacher-Student Learning Framework For Occluded Person Re-Identification. arXiv 2019, arXiv:1907.03253. [Google Scholar]
- He, L.; Wang, Y.; Liu, W.; Zhao, H.; Sun, Z.; Feng, J. Foreground-aware pyramid reconstruction for alignment-free occluded person re-identification. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 8450–8459. [Google Scholar]
- Wang, G.; Yang, S.; Liu, H.; Wang, Z.; Yang, Y.; Wang, S.; Yu, G.; Zhou, E.; Sun, J. High-order information matters: Learning relation and topology for occluded person re-identification. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 6449–6458. [Google Scholar]
- Jia, M.; Cheng, X.; Zhai, Y.; Lu, S.; Ma, S.; Tian, Y.; Zhang, J. Matching on sets: Conquer occluded person re-identification without alignment. In Proceedings of the AAAI Conference on Artificial Intelligence, Virtual, 2–9 February 2021; Volume 35, pp. 1673–1681. [Google Scholar]
- Sun, Y.; Xu, Q.; Li, Y.; Zhang, C.; Li, Y.; Wang, S.; Sun, J. Perceive where to focus: Learning visibility-aware part-level features for partial person re-identification. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 10–15 June 2019; pp. 393–402. [Google Scholar]
- Luo, H.; Gu, Y.; Liao, X.; Lai, S.; Jiang, W. Bag of tricks and a strong baseline for deep person re-identification. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Long Beach, CA, USA, 16–17 June 2019; pp. 1487–1495. [Google Scholar]
- Song, C.; Huang, Y.; Ouyang, W.; Wang, L. Mask-guided contrastive attention model for person re-identification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 1179–1188. [Google Scholar]
- Liu, J.; Ni, B.; Yan, Y.; Zhou, P.; Cheng, S.; Hu, J. Pose transferrable person re-identification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 4099–4108. [Google Scholar]
- Sarfraz, M.S.; Schumann, A.; Eberle, A.; Stiefelhagen, R. A pose-sensitive embedding for person re-identification with expanded cross neighborhood re-ranking. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 420–429. [Google Scholar]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Methods | Occluded-Duke | Occluded-ReID | ||
|---|---|---|---|---|
| Rank-1 (%) | mAP (%) | Rank-1 (%) | mAP (%) | |
| Part-Aligned [31] | 28.8 | 20.2 | - | - |
| PCB [27] | 42.6 | 33.7 | 41.3 | 38.9 |
| Part Bilinear [32] | 36.9 | - | - | - |
| FD-GAN [33] | 40.8 | - | - | - |
| AMC + SWM [2] | - | - | 31.2 | 27.3 |
| DSR [34] | 40.8 | 30.4 | 72.8 | 62.8 |
| SFR [35] | 42.3 | 32 | - | - |
| Ad-Occluded [36] | 44.5 | 32.2 | - | - |
| TCSDO [37] | - | - | 73.7 | 77.9 |
| FPR [38] | - | - | 78.3 | 68.0 |
| PGFA [4] | 51.4 | 37.3 | - | - |
| HOReID [39] | 55.1 | 43.8 | 80.3 | 70.2 |
| MoS [40] | 67.0 | 49.2 | - | - |
| EcReID (ours) | 64.8 | 52.7 | 84.5 | 75.1 |
| Methods | Market-1501 | DukeMTMC-ReID | ||
|---|---|---|---|---|
| Rank-1(%) | mAP(%) | Rank-1(%) | mAP(%) | |
| PCB [27] | 92.3 | 77.4 | 81.8 | 66.1 |
| VPM [41] | 93.0 | 80.8 | 83.6 | 72.6 |
| BOT [42] | 94.1 | 85.7 | 86.4 | 76.4 |
| MGCAM [43] | 83.8 | 74.3 | 46.7 | 46.0 |
| FPR [38] | 95.4 | 86.6 | 88.6 | 78.4 |
| Pose-transfer [44] | 87.7 | 68.9 | 30.1 | 28.2 |
| PSE [45] | 97.7 | 69.0 | 27.3 | 30.2 |
| PGFA [7] | 91.2 | 76.8 | 82.6 | 65.5 |
| HOReID [39] | 94.2 | 84.9 | 86.9 | 75.6 |
| MoS [40] | 94.7 | 86.8 | 88.7 | 77.0 |
| EcReID (ours) | 95.5 | 87.2 | 88.3 | 78.5 |
| Index | F | G | M | Rank-1 (%) | mAP (%) |
|---|---|---|---|---|---|
| 1 | × | × | × | 49.9 | 39.5 |
| 2 | √ | × | × | 62.2 | 45.9 |
| 3 | √ | √ | × | 62.7 | 48.4 |
| 4 | √ | √ | √ | 64.8 | 52.7 |
| Index | symDGAT | DGCN | GM | Rank-1 (%) | mAP (%) |
|---|---|---|---|---|---|
| 1 | × | √ | √ | 59.8 | 47.3 |
| 2 | √ | × | √ | 61.2 | 48.9 |
| 3 | √ | √ | × | 63.3 | 50.8 |
| 4 | √ | √ | √ | 64.8 | 52.7 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhu, M.; Zhou, H. EcReID: Enhancing Correlations from Skeleton for Occluded Person Re-Identification. Symmetry 2023, 15, 906. https://doi.org/10.3390/sym15040906
Zhu M, Zhou H. EcReID: Enhancing Correlations from Skeleton for Occluded Person Re-Identification. Symmetry. 2023; 15(4):906. https://doi.org/10.3390/sym15040906
Chicago/Turabian StyleZhu, Minling, and Huimin Zhou. 2023. "EcReID: Enhancing Correlations from Skeleton for Occluded Person Re-Identification" Symmetry 15, no. 4: 906. https://doi.org/10.3390/sym15040906