
The Reliability of Stored Water behind Dams Using the Multi-Component Stress-Strength System

Abstract
:1. Introduction
2. Reliability Function
3. Maximum-Likelihood Estimation
Fisher Information Matrix
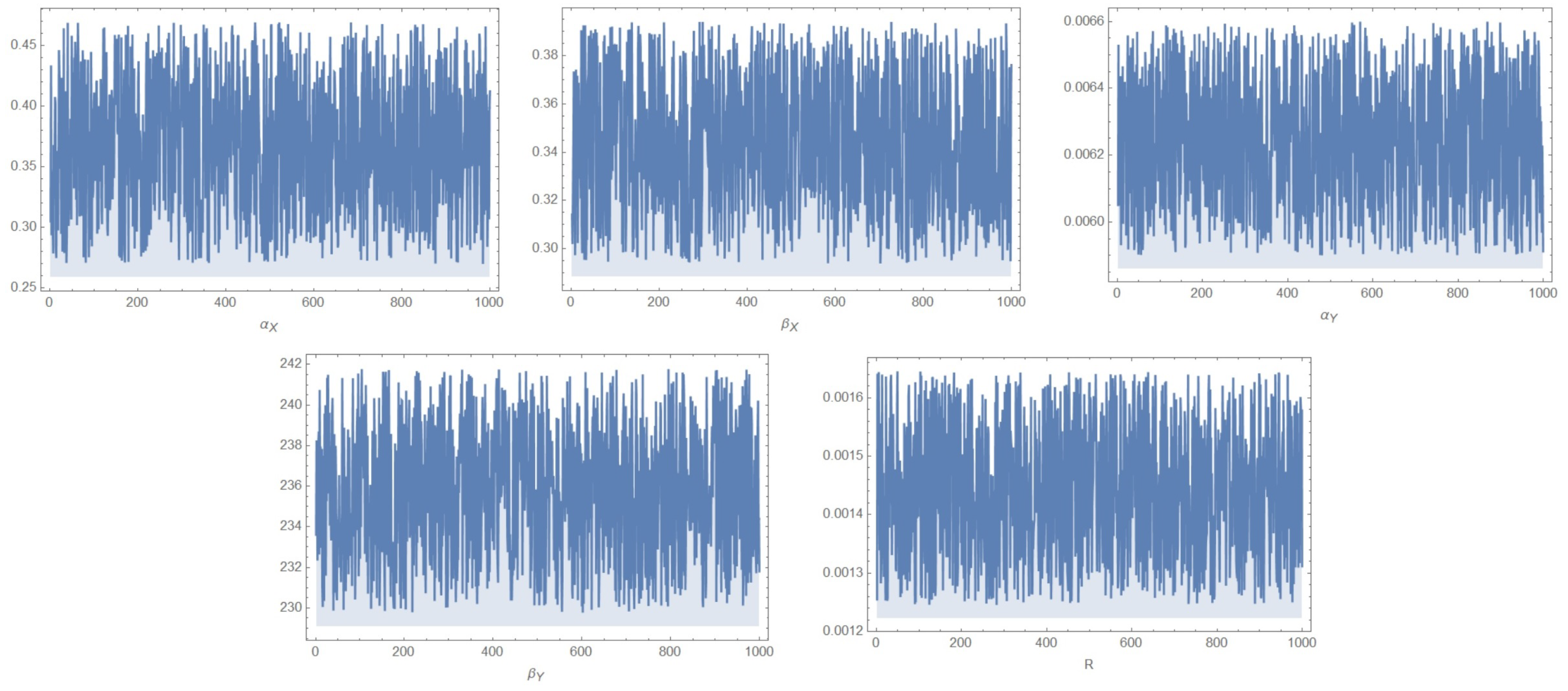
4. Bayesian Estimation
Gibbs Sampling
- Start with initial guess
- Set
- Using the following M–H algorithm, generate and fromand with the normal proposal distributionswhere and can be obtained from the main diagonal in the inverse Fisher information matrix.
- Generate a proposal from from from and from
- (i)
- Evaluate the acceptance probabilities
- (ii)
- Generate a , and from a uniform distribution.
- (iii)
- If , accept the proposal and set , else set .
- (iv)
- If , accept the proposal and set , else set .
- (v)
- If , accept the proposal and set , else set .
- (vi)
- If ,accept the proposal and set , else set
- 5.
- Compute at ().
- 6.
- Set
- 7.
- Repeat Steps N times and obtain and
- 8.
- To compute the CRIs of , and as then the CRIs of is
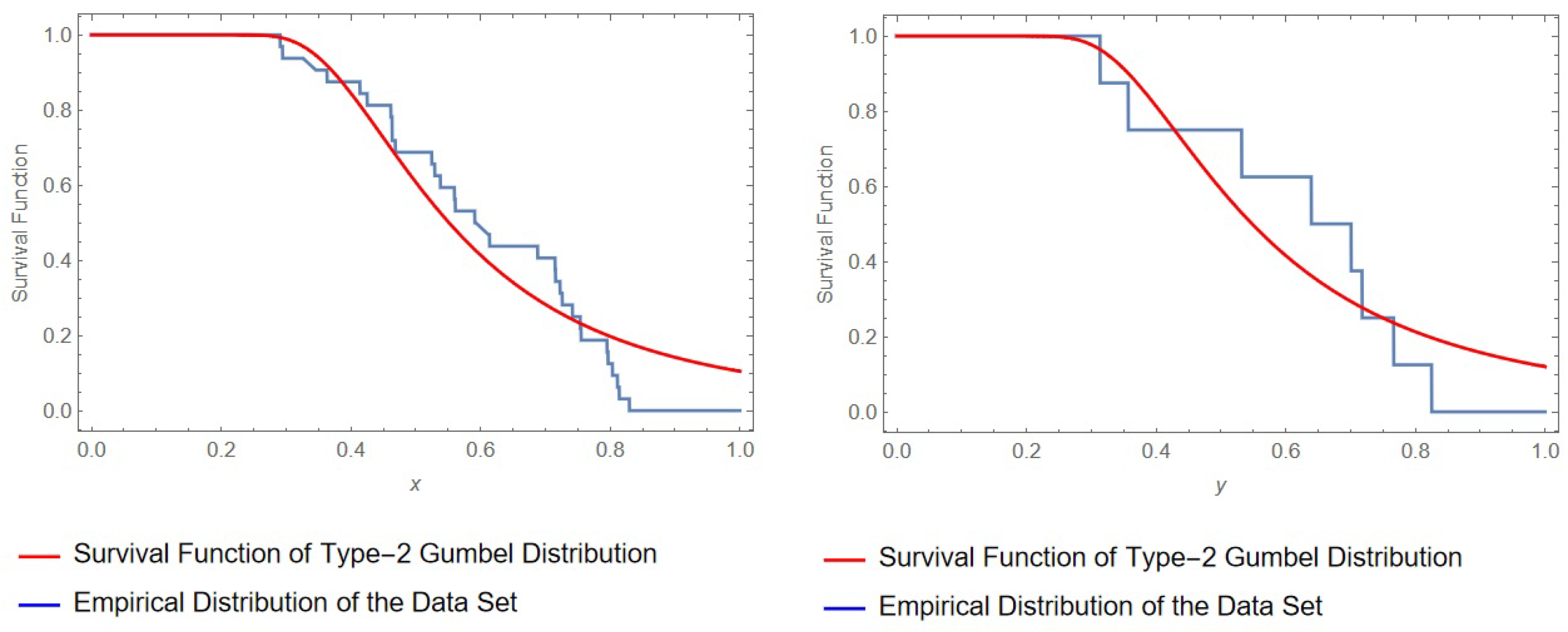
5. Real Data Analysis
6. Simulation Study
7. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Birnbaum, Z.W. On a use of Mann–Whitney statistics. Proc. Third Berkley Symp. Math. Stat. Probab. 1956, 1, 13–17. [Google Scholar]
- Hanagal, D.D. Estimation of system reliability. Stat. Pap. 1999, 40, 99–106. [Google Scholar] [CrossRef]
- Kotz, S.; Lumelskii, Y.; Pensky, M. The Stress-Strength Model and Its Generalization: Theory and Applications; World Scientific Publishing Company: Singapore, 2003. [Google Scholar]
- Raqab, M.Z.; Madi, M.T.; Kundu, D. Estimation of R = P(Y < X) for the 3-parameter generalized exponential distribution. Commun. Stat. 2008, 37, 2854–2864. [Google Scholar]
- Kundu, D.; Raqab, M.Z. Estimation of R = P(Y < X) for three parameter Weibull distribution. Stat. Probab. Lett. 2009, 79, 1839–1846. [Google Scholar]
- Lio, Y.L.; Tsai, T.R. Estimation of δ = P(X < Y) for Burr XII distribution based on the progressively first failure-censored samples. J. Appl. Stat. 2012, 39, 309–322. [Google Scholar]
- Nadar, M.; Kizilaslan, F.; Papadopoulos, A. Classical and Bayesian estimation of P(Y < X) for Kumaraswamy’s distribution. J. Stat. Comput. Simul. 2014, 84, 1505–1529. [Google Scholar]
- Rao, G.S.; Kantam, R.R.L. Estimation of reliability in multi-component stress-strength model: Log-logistic distribution. Electron. J. Appl. Stat. Anal. 2010, 3, 75–84. [Google Scholar]
- Rao, G.S. Estimation of reliability in multi-component stress-strength model based on Rayleigh distribution. Prob. Stat. Forum. 2012, 5, 155–161. [Google Scholar]
- Rao, G.S. Estimation of reliability in multi-component stress-strength model based on inverse exponential distribution. Int. J. Stat. Econ. 2013, 10, 28–37. [Google Scholar]
- Rao, G.S.; Kantam, R.R.L.; Rosaiah, K.; Reddy, J.P. Estimation of reliability in multi-component stress-strength model based on inverse Rayleigh distribution. J. Stat. Appl. Probab. 2013, 2, 261–267. [Google Scholar] [CrossRef]
- Kizilaslan, F.; Nadar, M. Estimation of reliability in a multi-component stress-strength model based on a bivariate Kumaraswamy distribution. Stat. Pap. 2018, 59, 307–340. [Google Scholar] [CrossRef]
- Nadar, M.; Kizilaslan, F. Estimation of reliability in a multi-component stress-strength model based on a Marshall–Olkin bivariate weibull Distribution. IEEE Trans. Reliab. 2016, 65, 370–380. [Google Scholar] [CrossRef]
- Dey, S.; Singh, S.; Tripathi, Y.M.; Asgharzadeh, A. Estimation and prediction for a progressively censored generalized inverted exponential distribution. Stat. Methodol. 2016, 32, 185–202. [Google Scholar] [CrossRef]
- Wu, X.Z. Implementing statistical fitting and reliability analysis for geotechnical engineering problems in R. Georisk Assess. Manag. Risk Eng. Syst. Geohazards 2017, 11, 173–188. [Google Scholar] [CrossRef]
- Kohansal, A. On estimation of reliability in a multi-component stress-strength model for a Kumaraswamy distribution based on progressively censored sample. Stat. Pap. 2019, 60, 2185–2224. [Google Scholar] [CrossRef]
- Xu, J.; Dang, C. A novel fractional moments-based maximum entropy method for high-dimensional reliability analysis. Appl. Math. Model. 2019, 75, 749–768. [Google Scholar] [CrossRef]
- Zhang, X.; Low, Y.M.; Koh, C.G. Maximum entropy distribution with fractional moments for reliability analysis. Struct. Saf. 2020, 83, 101904. [Google Scholar] [CrossRef]
- Akgul, F. Classical and Bayesian estimation of multi-component stress-strength reliability for exponentiated Pareto distribution. Soft Comput. 2021, 25, 9185–9197. [Google Scholar] [CrossRef]
- Wang, Z.Z.; Goh, S.H. A maximum entropy method using fractional moments and deep learning for geotechnical reliability analysis. Acta Geotech. 2022, 17, 1147–1166. [Google Scholar] [CrossRef]
- Wang, Z.Z.; Jiang, S.H. Characterizing geotechnical site investigation data: A comparative study using a novel distribution model. Acta Geotech. 2022. [Google Scholar] [CrossRef]
- Ahmad, H.H.; Almetwally, E.M.; Ramadan, D.A. A comparative inference on reliability estimation for a multi-component stress-strength model under power Lomax distribution with applications. AIMS Math. 2022, 7, 18050–18079. [Google Scholar] [CrossRef]
- Johari, A.; Vali, B.; Golkarfard, H. System reliability analysis of ground response based on peak ground acceleration considering soil layers cross-correlation. Soil Dyn. Earthq. Eng. 2021, 141, 106475. [Google Scholar] [CrossRef]
- Johari, A.; Rahmati, H. System reliability analysis of slopes based on the method of slices using sequential compounding method. Comput. Geotech. 2019, 114, 103116. [Google Scholar] [CrossRef]
- Johari, A.; Hajivand, A.K.; Binesh, S. System reliability analysis of soil nail wall using random finite element method. Bull. Eng. Geol. Environ. 2020, 79, 2777–2798. [Google Scholar] [CrossRef]
- Abbas, K.; Fu, J.; Tang, Y. Bayesian Estimation of Gumbel Type-II Distribution. Data Sci. J. 2013, 12, 33–46. [Google Scholar] [CrossRef] [Green Version]
- Kotz, S.; Nadarajah, S. Extreme Value Distributions: Theory and Applications; Imperial College Press: London, UK, 2000. [Google Scholar]
- Nadarajah, S.; Kotz, S. The exponentiated type distributions. Acta Appl. Math. 2006, 92, 97–111. [Google Scholar] [CrossRef]
- Feroze, N.; Muahmmad, A. Bayesian Analysis of Gumbel Type II Distribution under Censored Data, 1st ed.; LAP LAMBERT Academic Publishing: Saarbruecken, Germany, 2014. [Google Scholar]
- Mansour, M.M.; Aboshady, M.S. Assessing The Performance of Insulating Fluids Via Point of Statistical Inference View. TWMS J. App. Eng. Math. 2022, 12, 469–480. [Google Scholar]
- Bhattacharyya, G.K.; Johnson, R.A. Estimation of reliability in a multi-component stress-strength model. J. Am. Stat. Assoc. 1974, 69, 966–970. [Google Scholar] [CrossRef]
- Azzalini, A. Statistical Inference Based on the Likelihood, 1st ed.; Chapman and Hall/CRC: London, UK, 1996. [Google Scholar]
- Louis, T.A. Finding the observed information matrix when using the EM algorithm. J. R. Statist. Soc. B 1982, 44, 226–233. [Google Scholar]
- Lawless, J.F. Statistical Models and Methods for Lifetime Data, 2nd ed.; Wiley-Interscience: New York, NY, USA, 2002. [Google Scholar]
- Kundu, D.; Howlader, H. Bayesian inference and prediction of the inverse Weibull distribution for Type-II censored data. Comput. Stat. Data Anal. 2010, 54, 1547–1558. [Google Scholar] [CrossRef]
- Dey, S.; Dey, T. On progressively censored generalized inverted exponential distribution. J. Appl. Stat. 2014, 41, 2557–2576. [Google Scholar] [CrossRef]
- Metropolis, N.; Rosenbluth, A.W.; Rosenbluth, M.N.; Teller, A.H. Equations of state calculations by fast computing machines. J. Chem. Phys. 1953, 21, 1087–1092. [Google Scholar] [CrossRef] [Green Version]
- Available online: https://cdec.water.ca.gov/dynamicapp/QueryMonthly?s=SHA&end=1986-10&span=5years (accessed on 1 July 2021).





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| MLE | 0.303858 | 0.402204 | 0.00569851 | 238.391 | 0.00789931 |
| Bayes | 0.469386 | 0.393857 | 0.00850074 | 237.782 | 0.00824543 |
| MLE | Bayesian | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| (0.2, 0.5, 0.05, 200) | (3, 5) | 30 | 0.20146 | 0.50203 | 0.04999 | 199.837 | 0.1808 | 0.45054 | 0.04486 | 198.838 | |
| (0.00017) | (0.00296) | (0.000) | (32.8054) | (0.0002) | (0.0034) | (0.000) | (33.0127) | ||||
| 40 | 0.2014 | 0.50013 | 0.05001 | 199.969 | 0.18074 | 0.44884 | 0.04488 | 198.969 | |||
| (0.00013) | (0.00225) | (0.000) | (31.3774) | (0.00014) | (0.00271) | (0.000) | (33.9823) | ||||
| 50 | 0.2011 | 0.50103 | 0.04998 | 199.897 | 0.18047 | 0.44964 | 0.04485 | 198.898 | |||
| (0.0001) | (0.00176) | (0.000) | (32.0521) | (0.00012) | (0.002) | (0.000) | (37.8047) | ||||
| 100 | 0.20071 | 0.49831 | 0.04993 | 199.688 | 0.18012 | 0.4472 | 0.04481 | 198.689 | |||
| (0.00005) | (0.0009) | (0.000) | (31.9973) | (0.00005) | (0.00116) | (0.000) | (39.0693) | ||||
| 150 | 0.20037 | 0.5002 | 0.04999 | 200.017 | 0.17982 | 0.4489 | 0.04486 | 199.017 | |||
| (0.00003) | (0.00059) | (0.000) | (33.7554) | (0.00004) | (0.00059) | (0.000) | (40.6417) | ||||
| (5, 5) | 30 | 0.20222 | 0.49926 | 0.04997 | 199.657 | 0.18148 | 0.44805 | 0.04484 | 198.659 | ||
| (0.00017) | (0.00292) | (0.000) | (33.13) | (0.0002) | (0.00331) | (0.000) | (35.7178) | ||||
| 40 | 0.20177 | 0.50036 | 0.04999 | 199.715 | 0.18107 | 0.44904 | 0.04486 | 198.716 | |||
| (0.00012) | (0.00205) | (0.000) | (32.5364) | (0.00013) | (0.00232) | (0.000) | (38.4116) | ||||
| 50 | 0.20087 | 0.50181 | 0.04995 | 199.765 | 0.18027 | 0.45035 | 0.04483 | 198.767 | |||
| (0.0001) | (0.00176) | (0.000) | (34.8049) | (0.00012) | (0.00227) | (0.000) | (35.433) | ||||
| 100 | 0.20051 | 0.5015 | 0.04999 | 199.824 | 0.17994 | 0.45006 | 0.04486 | 198.824 | |||
| (0.00005) | (0.00088) | (0.000) | (31.978) | (0.00005) | (0.00114) | (0.000) | (36.2068) | ||||
| 150 | 0.20041 | 0.50021 | 0.05002 | 199.727 | 0.17986 | 0.44891 | 0.04489 | 198.728 | |||
| (0.00003) | (0.00058) | (0.000) | (32.943) | (0.00004) | (0.00058) | (0.000) | (34.9308) | ||||
| (5, 6) | 30 | 0.20152 | 0.50146 | 0.05001 | 199.8 | 0.18085 | 0.45003 | 0.04488 | 198.801 | ||
| (0.00014) | (0.0022) | (0.000) | (32.295) | (0.00015) | (0.00232) | (0.000) | (33.4603) | ||||
| 40 | 0.20155 | 0.50179 | 0.05005 | 199.89 | 0.18088 | 0.45032 | 0.04492 | 198.891 | |||
| (0.00011) | (0.0018) | (0.000) | (34.2618) | (0.00013) | (0.00204) | (0.000) | (34.2076) | ||||
| 50 | 0.20141 | 0.49875 | 0.05 | 199.765 | 0.18075 | 0.44759 | 0.04487 | 198.766 | |||
| (0.00009) | (0.00149) | (0.000) | (30.8775) | (0.0001) | (0.00175) | (0.000) | (32.8875) | ||||
| 100 | 0.20038 | 0.5005 | 0.04995 | 200.074 | 0.17983 | 0.44916 | 0.04483 | 199.074 | |||
| (0.00004) | (0.00067) | (0.000) | (31.4818) | (0.00005) | (0.00075) | (0.000) | (32.6242) | ||||
| 150 | 0.20014 | 0.50009 | 0.04999 | 200.067 | 0.17962 | 0.4488 | 0.04486 | 199.067 | |||
| (0.00003) | (0.00052) | (0.000) | (33.1109) | (0.00004) | (0.00064) | (0.000) | (36.4121) | ||||
| MLE | Bayesian | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| (0.3, 0.4, 0.05, 200) | (3, 5) | 30 | 0.3025 | 0.39763 | 0.05 | 199.822 | 0.27147 | 0.35685 | 0.04487 | 198.822 | |
| (0.00036) | (0.00226) | (0.000) | (33.8999) | (0.00038) | (0.00234) | (0.000) | (40.3491) | ||||
| 40 | 0.30229 | 0.39954 | 0.04984 | 199.835 | 0.27129 | 0.35856 | 0.04473 | 198.836 | |||
| (0.00026) | (0.0016) | (0.000) | (34.5172) | (0.00026) | (0.00166) | (0.000) | (35.5571) | ||||
| 50 | 0.30102 | 0.40185 | 0.05003 | 199.753 | 0.27014 | 0.36064 | 0.0449 | 198.754 | |||
| (0.00021) | (0.00123) | (0.000) | (34.6565) | (0.00025) | (0.00138) | (0.000) | (42.4399) | ||||
| 100 | 0.30021 | 0.40196 | 0.05007 | 200.059 | 0.26942 | 0.36074 | 0.04493 | 199.059 | |||
| (0.00012) | (0.0007) | (0.000) | (32.4818) | (0.00013) | (0.0007) | (0.000) | (32.5149) | ||||
| 150 | 0.30078 | 0.39987 | 0.04999 | 199.555 | 0.26993 | 0.35886 | 0.04486 | 198.558 | |||
| (0.00007) | (0.00043) | (0.000) | (33.0983) | (0.00009) | (0.00052) | (0.000) | (38.4439) | ||||
| (5, 5) | 30 | 0.30285 | 0.4029 | 0.04994 | 199.654 | 0.27179 | 0.36157 | 0.04482 | 198.656 | ||
| (0.00038) | (0.00225) | (0.000) | (33.433) | (0.00049) | (0.00238) | (0.000) | (40.4265) | ||||
| 40 | 0.30167 | 0.40134 | 0.04994 | 200.091 | 0.27073 | 0.36017 | 0.04482 | 199.09 | |||
| (0.00026) | (0.00166) | (0.000) | (34.0351) | (0.00032) | (0.00196) | (0.000) | (33.7554) | ||||
| 50 | 0.30159 | 0.40057 | 0.04993 | 200.15 | 0.27065 | 0.35949 | 0.04481 | 199.149 | |||
| (0.00022) | (0.00129) | (0.000) | (34.2804) | (0.00026) | (0.00164) | (0.000) | (43.0006) | ||||
| 100 | 0.30051 | 0.40013 | 0.04995 | 199.983 | 0.26969 | 0.35909 | 0.04483 | 198.983 | |||
| (0.00011) | (0.00068) | (0.000) | (32.9482) | (0.00011) | (0.00069) | (0.000) | (33.3591) | ||||
| 150 | 0.30005 | 0.40084 | 0.04996 | 199.626 | 0.26928 | 0.35973 | 0.04484 | 198.628 | |||
| (0.00007) | (0.00044) | (0.000) | (33.8825) | (0.00008) | (0.00051) | (0.000) | (35.5814) | ||||
| (5, 6) | 30 | 0.30217 | 0.40028 | 0.04992 | 200.064 | 0.27118 | 0.35923 | 0.0448 | 199.063 | ||
| (0.00031) | (0.00158) | (0.000) | (33.822) | (0.0004) | (0.00236) | (0.000) | (36.4273) | ||||
| 40 | 0.30233 | 0.39868 | 0.05001 | 199.671 | 0.27132 | 0.35779 | 0.04488 | 198.672 | |||
| (0.00025) | (0.00129) | (0.000) | (32.1462) | (0.0003) | (0.00168) | (0.000) | (37.4052) | ||||
| 50 | 0.30195 | 0.39879 | 0.05 | 200.079 | 0.27098 | 0.35789 | 0.04487 | 199.079 | |||
| (0.0002) | (0.00109) | (0.000) | (33.8499) | (0.00021) | (0.00116) | (0.000) | (40.087) | ||||
| 100 | 0.30038 | 0.40072 | 0.05001 | 199.938 | 0.26957 | 0.35962 | 0.04489 | 198.938 | |||
| (0.00009) | (0.00055) | (0.000) | (32.5754) | (0.00011) | (0.00064) | (0.000) | (36.7374) | ||||
| 150 | 0.30054 | 0.40001 | 0.04998 | 200.075 | 0.26971 | 0.35899 | 0.04486 | 199.075 | |||
| (0.00006) | (0.00036) | (0.000) | (33.7145) | (0.00006) | (0.0004) | (0.000) | (38.2541) | ||||
| MLE | Bayesian | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| (0.2, 0.5, 0.05, 200) | (3, 5) | 30 | 0.0507 | 0.2109 | 0.0281 | 567.508 | 0.0304 | 0.1265 | 0.0169 | 29.5104 | |
| (0.95) | (0.951) | (1.000) | (1.000) | (0.9949) | (0.9951) | (0.995) | (0.995) | ||||
| 40 | 0.0436 | 0.1833 | 0.0244 | 491.674 | 0.0261 | 0.11 | 0.0146 | 25.567 | |||
| (0.944) | (0.944) | (1.000) | (1.000) | (0.995) | (0.995) | (0.995) | (0.9949) | ||||
| 50 | 0.0389 | 0.1643 | 0.0218 | 438.494 | 0.0233 | 0.0986 | 0.0131 | 22.8017 | |||
| (0.951) | (0.948) | (1.000) | (1.000) | (0.9951) | (0.9951) | (0.9951) | (0.9949) | ||||
| 100 | 0.0275 | 0.1159 | 0.0153 | 308.949 | 0.0165 | 0.0695 | 0.0092 | 16.0653 | |||
| (0.954) | (0.935) | (1.000) | (1.000) | (0.9949) | (0.995) | (0.9949) | (0.995) | ||||
| 150 | 0.0224 | 0.0948 | 0.0125 | 252.359 | 0.0134 | 0.0569 | 0.0075 | 13.1227 | |||
| (0.962) | (0.948) | (1.000) | (1.000) | (0.9949) | (0.9951) | (0.9949) | (0.995) | ||||
| (5, 5) | 30 | 0.0506 | 0.2115 | 0.0283 | 570.071 | 0.0303 | 0.1269 | 0.017 | 29.6437 | ||
| (0.951) | (0.933) | (1.000) | (1.000) | (0.9949) | (0.995) | (0.9952) | (0.9949) | ||||
| 40 | 0.0435 | 0.1839 | 0.0245 | 492.382 | 0.0261 | 0.1103 | 0.0147 | 25.6038 | |||
| (0.949) | (0.945) | (1.000) | (1.000) | (0.9949) | (0.9949) | (0.995) | (0.995) | ||||
| 50 | 0.039 | 0.164 | 0.0218 | 439.355 | 0.0234 | 0.0984 | 0.0131 | 22.8464 | |||
| (0.964) | (0.956) | (1.000) | (1.000) | (0.995) | (0.9951) | (0.9949) | (0.9951) | ||||
| 100 | 0.0274 | 0.1165 | 0.0154 | 309.768 | 0.0164 | 0.0699 | 0.0092 | 16.1079 | |||
| (0.954) | (0.941) | (1.000) | (1.000) | (0.995) | (0.995) | (0.9951) | (0.995) | ||||
| 150 | 0.0224 | 0.0949 | 0.0125 | 252.428 | 0.0134 | 0.057 | 0.0075 | 13.1262 | |||
| (0.953) | (0.952) | (1.000) | (1.000) | (0.9951) | (0.9951) | (0.9951) | (0.995) | ||||
| (5, 6) | 30 | 0.046 | 0.1931 | 0.0282 | 567.143 | 0.0276 | 0.1159 | 0.0169 | 29.4914 | ||
| (0.946) | (0.951) | (1.000) | (1.000) | (0.9951) | (0.995) | (0.995) | (0.995) | ||||
| 40 | 0.0397 | 0.168 | 0.0245 | 493.172 | 0.0238 | 0.1008 | 0.0147 | 25.6449 | |||
| (0.945) | (0.951) | (1.000) | (1.000) | (0.9949) | (0.9952) | (0.995) | (0.995) | ||||
| 50 | 0.0356 | 0.1499 | 0.0218 | 439.107 | 0.0213 | 0.09 | 0.0131 | 22.8335 | |||
| (0.938) | (0.941) | (1.000) | (1.000) | (0.9949) | (0.995) | (0.9951) | (0.9948) | ||||
| 100 | 0.025 | 0.106 | 0.0153 | 308.724 | 0.015 | 0.0636 | 0.0092 | 16.0537 | |||
| (0.957) | (0.958) | (1.000) | (1.000) | (0.9951) | (0.9951) | (0.9949) | (0.9949) | ||||
| 150 | 0.0204 | 0.0866 | 0.0125 | 251.642 | 0.0123 | 0.052 | 0.0075 | 13.0854 | |||
| (0.955) | (0.941) | (1.000) | (1.000) | (0.9949) | (0.9951) | (0.995) | (0.995) | ||||
| MLE | Bayesian | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| (0.3, 0.4, 0.05, 200) | (3, 5) | 30 | 0.0759 | 0.1848 | 0.0283 | 571.737 | 0.0455 | 0.1109 | 0.017 | 29.7303 | |
| (0.952) | (0.938) | (1.000) | (1.000) | (0.9951) | (0.995) | (0.995) | (0.995) | ||||
| 40 | 0.0656 | 0.1594 | 0.0244 | 492.21 | 0.0394 | 0.0957 | 0.0147 | 25.5949 | |||
| (0.959) | (0.949) | (1.000) | (1.000) | (0.995) | (0.995) | (0.9951) | (0.9949) | ||||
| 50 | 0.0582 | 0.1438 | 0.0217 | 437.88 | 0.0349 | 0.0863 | 0.013 | 22.7697 | |||
| (0.954) | (0.953) | (1.000) | (1.000) | (0.9948) | (0.9948) | (0.9951) | (0.995) | ||||
| 100 | 0.0412 | 0.1013 | 0.0154 | 309.34 | 0.0247 | 0.0608 | 0.0092 | 16.0857 | |||
| (0.96) | (0.95) | (1.000) | (1.000) | (0.995) | (0.9951) | (0.9949) | (0.995) | ||||
| 150 | 0.0335 | 0.0827 | 0.0125 | 251.705 | 0.0201 | 0.0496 | 0.0075 | 13.0887 | |||
| (0.946) | (0.946) | (1.000) | (1.000) | (0.995) | (0.995) | (0.995) | (0.9949) | ||||
| (5, 5) | 30 | 0.0759 | 0.1844 | 0.0282 | 568.27 | 0.0456 | 0.1106 | 0.0169 | 29.55 | ||
| (0.94) | (0.95) | (1.000) | (1.000) | (0.995) | (0.995) | (0.9951) | (0.9952) | ||||
| 40 | 0.0655 | 0.1599 | 0.0245 | 493.459 | 0.0393 | 0.0959 | 0.0147 | 25.6599 | |||
| (0.95) | (0.942) | (1.000) | (1.000) | (0.9951) | (0.9948) | (0.995) | (0.995) | ||||
| 50 | 0.0584 | 0.1429 | 0.0218 | 438.597 | 0.035 | 0.0857 | 0.0131 | 22.807 | |||
| (0.947) | (0.94) | (1.000) | (1.000) | (0.9951) | (0.9951) | (0.9949) | (0.9949) | ||||
| 100 | 0.0411 | 0.1015 | 0.0153 | 309.374 | 0.0247 | 0.0609 | 0.0092 | 16.0874 | |||
| (0.954) | (0.95) | (1.000) | (1.000) | (0.995) | (0.9951) | (0.9951) | (0.995) | ||||
| 150 | 0.0336 | 0.0827 | 0.0125 | 252.025 | 0.0201 | 0.0496 | 0.0075 | 13.1053 | |||
| (0.953) | (0.964) | (1.000) | (1.000) | (0.9952) | (0.9951) | (0.995) | (0.9949) | ||||
| (5, 6) | 30 | 0.0689 | 0.1689 | 0.0283 | 570.784 | 0.0413 | 0.1014 | 0.017 | 29.6808 | ||
| (0.956) | (0.945) | (1.000) | (1.000) | (0.995) | (0.9951) | (0.995) | (0.9951) | ||||
| 40 | 0.0597 | 0.1463 | 0.0245 | 494.035 | 0.0358 | 0.0878 | 0.0147 | 25.6898 | |||
| (0.953) | (0.948) | (1.000) | (1.000) | (0.995) | (0.9951) | (0.995) | (0.995) | ||||
| 50 | 0.0533 | 0.1305 | 0.0217 | 437.669 | 0.032 | 0.0783 | 0.013 | 22.7588 | |||
| (0.944) | (0.945) | (1.000) | (1.000) | (0.9951) | (0.995) | (0.995) | (0.9953) | ||||
| 100 | 0.0376 | 0.0925 | 0.0153 | 308.903 | 0.0225 | 0.0555 | 0.0092 | 16.063 | |||
| (0.949) | (0.954) | (1.000) | (1.000) | (0.9951) | (0.9951) | (0.995) | (0.9949) | ||||
| 150 | 0.0306 | 0.0756 | 0.0125 | 252.177 | 0.0184 | 0.0453 | 0.0075 | 13.1132 | |||
| (0.957) | (0.952) | (1.000) | (1.000) | (0.9951) | (0.9947) | (0.995) | (0.995) | ||||
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Haj Ahmad, H.; Ramadan, D.A.; Mansour, M.M.M.; Aboshady, M.S. The Reliability of Stored Water behind Dams Using the Multi-Component Stress-Strength System. Symmetry 2023, 15, 766. https://doi.org/10.3390/sym15030766
Haj Ahmad H, Ramadan DA, Mansour MMM, Aboshady MS. The Reliability of Stored Water behind Dams Using the Multi-Component Stress-Strength System. Symmetry. 2023; 15(3):766. https://doi.org/10.3390/sym15030766
Chicago/Turabian StyleHaj Ahmad, Hanan, Dina A. Ramadan, Mahmoud M. M. Mansour, and Mohamed S. Aboshady. 2023. "The Reliability of Stored Water behind Dams Using the Multi-Component Stress-Strength System" Symmetry 15, no. 3: 766. https://doi.org/10.3390/sym15030766