This section starts by conducting some comparative analyses between various consistencies; then, a new consistency measure of the classification rule sets is proposed.
3.2. Comparative Analysis
In what follows, the differences between the aforementioned definitions are compared and analyzed in
Figure 1. Assume an algorithm has provided two rule sets
and
to divide the Dot from the Star observations and the rules in each rule set are mutually exclusive and exhaustive. For this example, it is assumed that all rules, except for
, and
, predict the class that will be Dot. We can observe from
Figure 1 that
A and
B create very similar (but not the same; the difference is shown by the colored part) decision boundaries between the two classes and that they make exactly the same predictions for all observations. This means that these two rule sets are completely consistent according to the definitions provided in [
26,
27], as they provide the same predictions and therefore the same level of accuracy. If a new sample, which lies in the colored part, is introduced, the predictions mad by these two rule sets would be different. Hence, the classification abilities of
A and
B are slightly different because of their different partitions of the feature space. Therefore, the consistency measure value should not be 1. The definitions in [
26,
27] should be improved for measuring the consistency of the two rule sets.
Let us look at the conclusion for
Figure 1 drawn from the definition in [
21]. The similarity of the two rule sets shown in
Figure 1 can be calculated with (
1) as 0.78. The figure shows that the classification abilities (or the rule sets of each class) of
A and
B are very similar. Therefore, 0.78 is lower than the estimatefor evaluating the similarity. The reason for this is that the paper [
21] focused on the similarity of individual rules, and ignored the similarity of the whole rule sets. The consistency value given by the proposed consistency measurement in Algorithm 2 is 0.98, which is in agreement with the estimate.
| Algorithm 2: The Consistency Measure Algorithm (CMA). |
- 1
Step 1: For each rule , where and are two different rule sets of class c, respectively, find the core spaces, and , using the algorithm shown in Algorithm 1. Then, compute the corresponding volumes: and . The volume of rule sets and of class c denoted by and can be calculated as follows:
|
- 2
|
- 3
Step 2: For each rule and for each rule , compute the volume of the intersection of the two core spaces, which is denoted as . Then, the volume of the intersection of the two rule sets and of class c can be computed as:
|
- 4
|
- 5
Step 3: The similarity measure between the two rule sets and of class c is defined as:
|
- 6
|
- 7
Step 4: The consistency measure between the rule sets A and B, which can be considered as a weighted average of the similarities between classes in both rule sets, is defined as:
|
- 8
|
- 9
The weight factors can be chosen as the proportion of the observations covered by and , respectively,
|
- 10
|
- 11
where , are numbers of the observations covered by the rule sets and , respectively. N is the numbers of the observations in the dataset X.
|
Figure 2 shows the variants,
and
, of rule set
A and rule set
B. We can see that
Figure 1 and
Figure 2 have consistent decision boundaries, but compared with rule set
A and
B, the individual rules in the new rule sets show some changes. The consistencies given by the definitions in [
26,
27] do not change, since the decision boundaries of
and
are same as those of
A and
B. The consistency given by the definition in [
21] greatly changed from 0.78 (between
A and
B) to 0.97 (between
and
) due to the changes in the individual rules in the new rule sets. This implies that the similarities between individual rules may lead to very different results being obtained for the consistency between a pair of rule sets. The consistency between the new rule sets
and
given by the proposed measurement is 0.98.
3.3. Core Space of a Rule
When considering the similarity of a pair of classification rules obtained from two different rule sets, whether the classification capacities are similar or not is considered. We usually care about whether the two rules assign the same class labels for both the observations and the unseen samples.
A rule can determine a region in the feature space by its antecedent and assign the samples that fall in this region the same class label using its consequence. We denote the region determined by rule r as . is composed of two different parts. The first one is the hyper-cuboid region in the feature space decided by the observations covered by rule r and denoted as . Naturally, the other one is . is called the generalizing region of rule r. For rule r, the region is more important than the generalizing region for the following two reasons. First, we have more confidence in the classification results of the samples located in the region than those falling in , because there are no observations in the region and the rule r could not provide enough information about the classification results over this region. Secondly, the boundaries of the generalizing region are mainly decided by the algorithm, while the boundaries of the region depend on both the observations and the algorithm. The boundaries of the generalizing region are variable according to different algorithms. Two similar rules obtained from different algorithms may have very different generalizing regions even if they covered the same observations.
Some regions determined by the rules and the observations covered by the rules are shown in
Figure 3.
Figure 3a shows the rule set obtained using C4.5 [
9] over a one-dimensional synthetic dataset and the regions determined by the rules and the observations covered by each rule. The rule set is:
: IF , THEN Class is Star;
: IF , THEN Class is Dot;
: IF , THEN Class is Star.
Figure 3b shows the rule set obtained by CART [
15] over the same one-dimensional synthetic dataset and the regions determined by the rules and the observations covered by each rule. The rule set is:
: IF , THEN Class is Star;
: IF , THEN Class is Dot;
: IF , THEN Class is Star.
The C4.5 algorithm and the CART algorithm create different partitions of the one-dimensional feature space; see
and
(
) in
Figure 3. When considering the consistency between the two rule sets, while they might seem slightly different at first, closer inspection will reveal that the regions
and
took up by the observations determined by the rule
and
(
) are exactly same. In other words, the two rule sets create different decision boundaries—i.e., the boundaries of
and
. Thus,
is different from
(
). The reason for this is the difference in the generalizing regions of each rule, which is caused by the different methods used by the C4.5 algorithm and the CART algorithm for the partition of the margins. The two rule sets seem to have an identical classification ability when considering the regions
and
. When considering the uncertainty of generalizing regions, the similarity between two rules
and
(
) derived from the comparison of
and
may be more reasonable. However, this may fail in situations where the regions
and
of a pair of rules
r and
q suffer from the unlimited boundary problem.
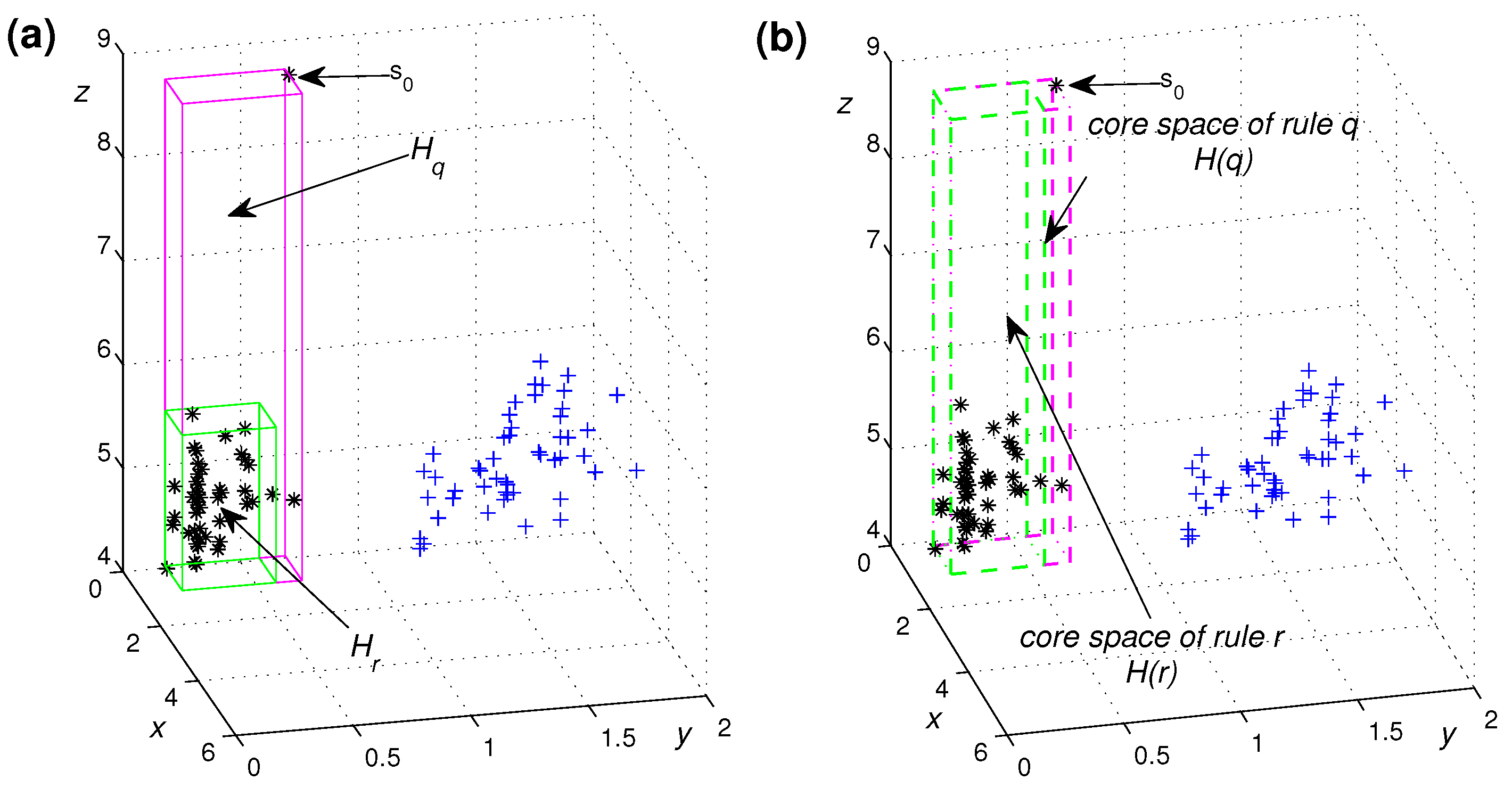
Figure 4a shows two rules
r: IF
and
, THEN Class is *;
q: IF
and
, THEN Class is *. The rules
r and
q come from two different rule sets over a three-dimensional synthetic dataset and are very similar. However, neither have any conditions for the third feature
z. The regions
and
are not similar as the rules show, since the observation
is not covered by rule
r. To deal with unlimited boundary issue, the regions
and
should be tuned to a uniform finite bound for the unconditional features (e.g, feature z) in order to fairly evaluate the similarity of the two rules. We propose Algorithm 1 to redetermine proper boundaries of the region
determined by the observations covered by rule
r. The tuned region is called the
core space of the rule
r, denoted as
. The core space of a rule can not only describe the classification ability of the rule well, but can also deal with the unlimited boundary problem. As shown in
Figure 4b, the core spaces of the two rules
r and
q are similar.
If two rules from different rule sets cover the same observations, essentially, they are very similar because the core spaces of the two rules are same. The intersection of the core spaces can indicate the similarity of classification abilities of two rules. The similarity between the two rules is evaluated by comparing the core spaces of the rules.
3.4. The New Consistency Measure
When considering the consistency of the classification rule sets, whether their classification ability is similar or not is crucial. Hence, we consider the rules for one class as a rule set of the class and measure the similarity of two rule sets for this class. Firstly, the similarity of the two rule sets of a class is defined by comparing the core spaces of the rules in the two rule sets of this class. Then, the consistency between the two rule sets of classifiers is defined as the weighted average of the similarities between the rule sets of each class. The main idea behind our proposed consistency measure is that two rule sets of classifiers are consistent if their partitions of the feature space are similar. The consistency not only considers the similarity of the assignment of class labels of two rule sets but also the similarity of the partitions of the feature space. i.e., they predict the samples under similar probability distributions.
When the regions covered by two rules contain infinite boundaries, it is difficult to calculate the similarity of the two rule directly and simply. Algorithm 1 constrains the infinite boundary to the region covered by the observations, which is conducive to the simplicity of the comparison for similarity of a pair of rules. In fact, partition of the feature space by a rule set represents its classification ability. The similarity of a pair of rules based on the similarity of their core spaces is defined. The reason is which core space of rule covered by observations is more reliable for classification.
The similarity of a pair of rule sets (or a pair of rules) is considered as the similarity of their classification abilities—that is, the partition of the whole feature space by the rule set. When the rule contains an infinite boundary, it is difficult to make the comparison of a pair of rule sets (or pair of rules). We limit the infinite region covered by the rules within the scope covered by the observations. The core space of a rule is the limit of the region covered by the rule on the coverage area of the observations. We analyze the similarity of a pair of rules by comparing their core spaces. The reason for this is that the classification algorithms tend to partition the region covered by the observations, and the classification boundary usually lies in the margin of different classes, while we tend not to care much about the region far away from the observation points.
Given two rule sets A and B and a dataset X of the observations, it can be seen that the rules in each rule set are mutually exclusive and exhaustive. and are the rule sets of class c, respectively. For each rule , the core space can be determined using the algorithm shown in Algorithm 1. represents the volume of . The proposed consistency measure algorithm is as follows:
It is easy to prove that the proposed consistency measure satisfied the following properties. For two rule sets and , we have:
Symmetric: ;
Non-negativity: ;
If the two rule sets and are exactly the same, then the consistency should be maximal—i.e., ;
If the two rule sets and provide different classifications for each input observation, then the consistency should be minimal—i.e., ;
For the similarity of (
1),
if and only if for all
, there exists a rule
, such that
r and
q cover the same samples and assign the same class labels to the samples. Therefore, the number of rules in rule set
A is equal to that of rule set
B. Meanwhile, the proposed similarity has less request, which focuses more on the similarity of the partitions of the feature space by the rule sets for each class. Furthermore, let
denote the assignments of the samples in the dataset
X by rule set
A, and
denote the accuracy of rule set
A for the dataset
X. We have the following proposition about the relation of the four mentioned kinds of consistency measures.
Proposition 1. Let A and B be two rule sets which contains mutually exclusive rules on dataset X. denotes the similarity between A and B using the definition shown in Equation (1), and denotes the consistency between A and B defined in Algorithm 2. We have Proof. (1)
:
where
is the number of samples covered by
r. This implies that
, there is a rule
, where
r and
q cover the same samples and give the same class label to the samples. Thus, we find that
. Because it is assumed that each rule set contains mutually exclusive rules,
, we have
,
(2) :
implies and have the same partition of the feature space, so .
(3) :
Straightforward. □
It is easy to apply the proposed consistency algorithm to the rule sets visualized in
Figure 1. Furthermore, as shown in the next section, the proposed consistency algorithm can be applicable to the rule sets altered from other representation forms, such as decision trees and decision tables. Since the rule extraction algorithms, such as the algorithm shown in [
14], are able to extract mutually exclusive rules from different types of black box models, the proposed measure of consistency can also help to test whether the extracted rule sets are similar to other rule sets or the black box models are consistent with the existing knowledge.













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}