
Statistical Analysis of Alpha Power Inverse Weibull Distribution under Hybrid Censored Scheme with Applications to Ball Bearings Technology and Biomedical Data


Abstract
:1. Introduction
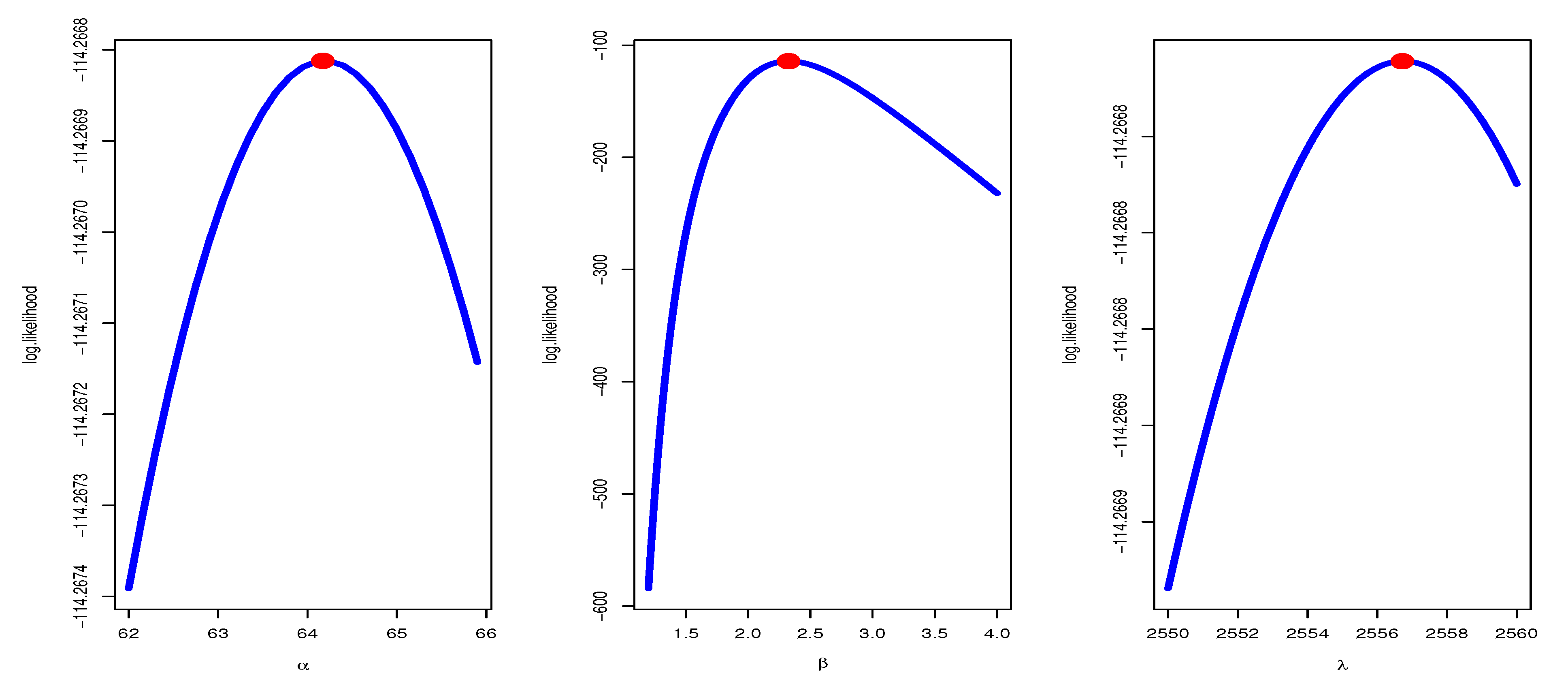
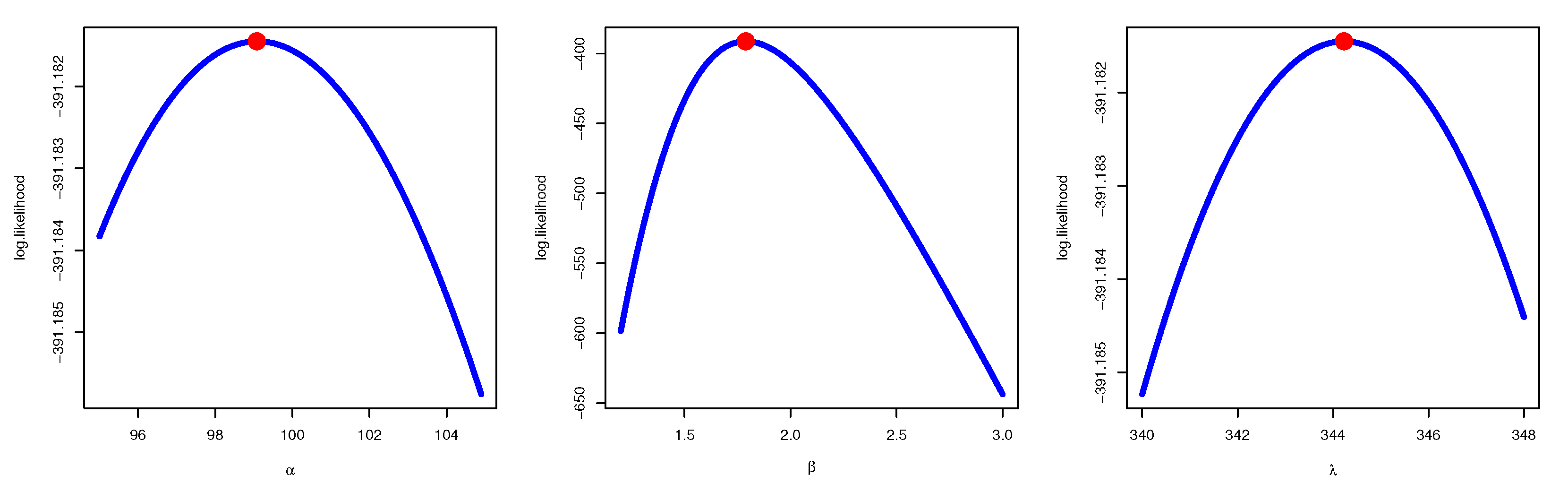
2. The Maximum Likelihood Estimator
3. Maximum Product Spacing
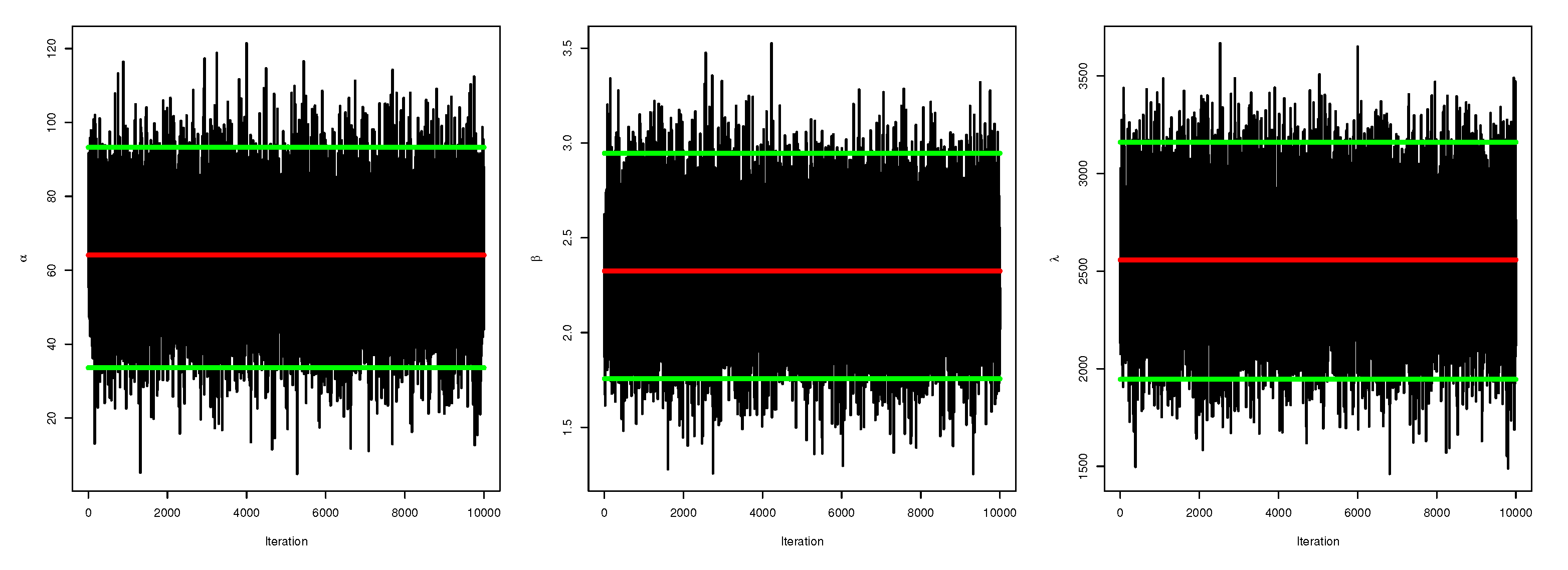
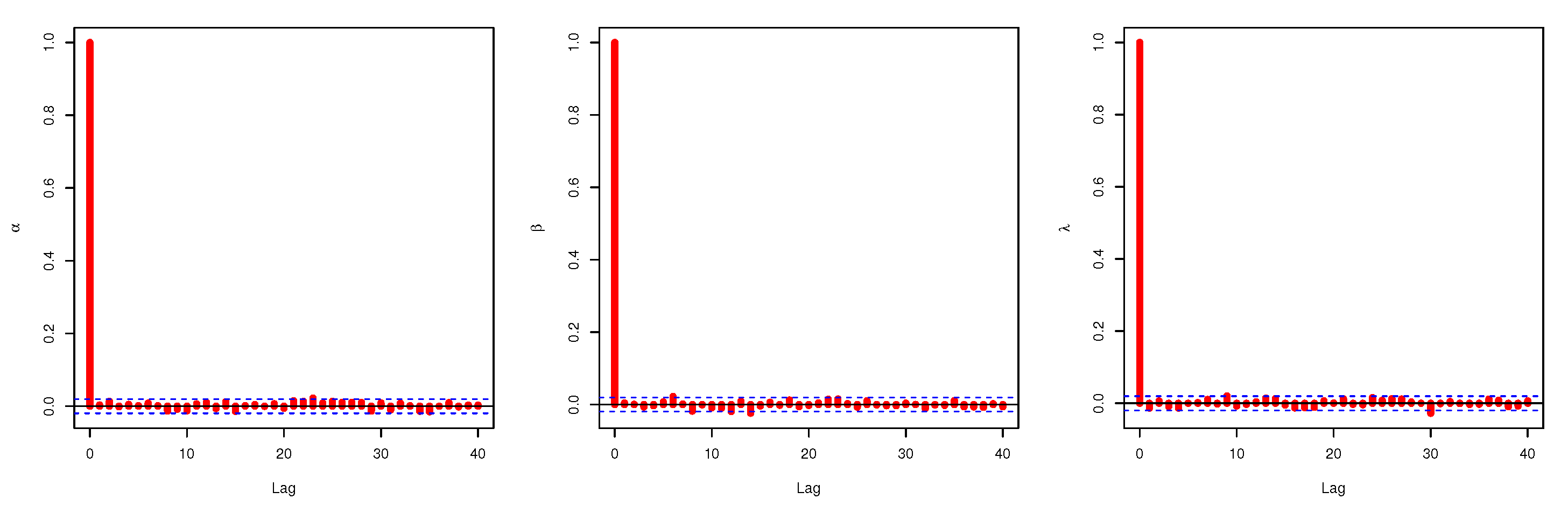
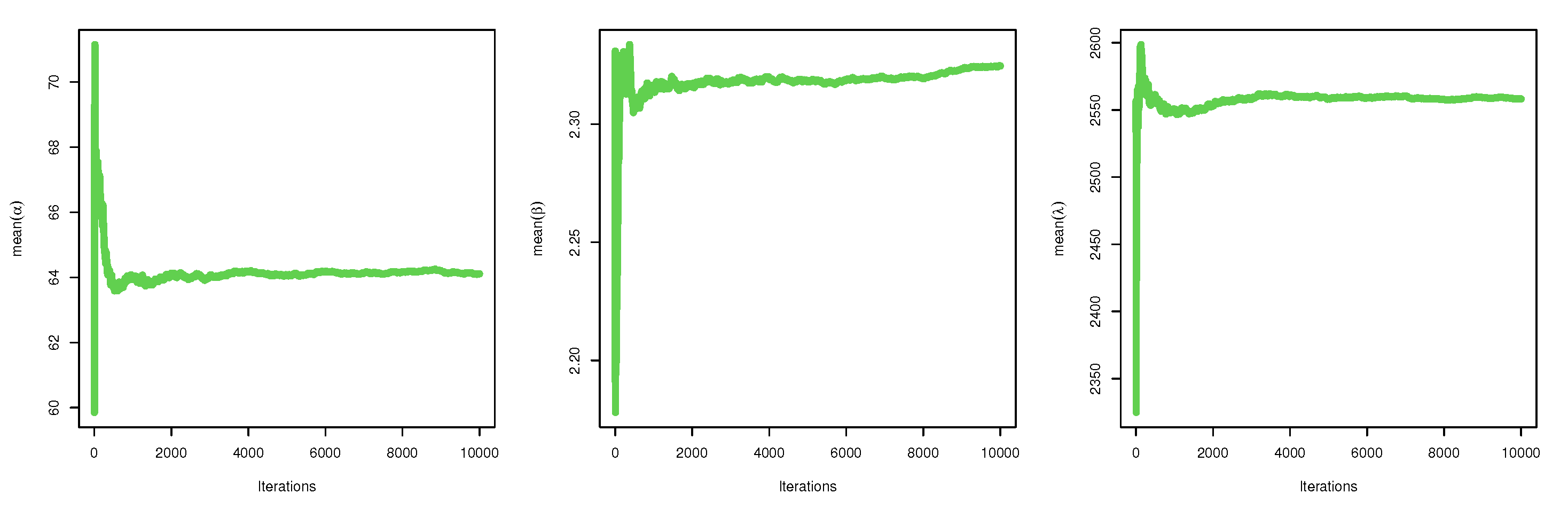
4. Bayes Estimation
5. Confidence Intervals
5.1. Approximate Confidence Intervals
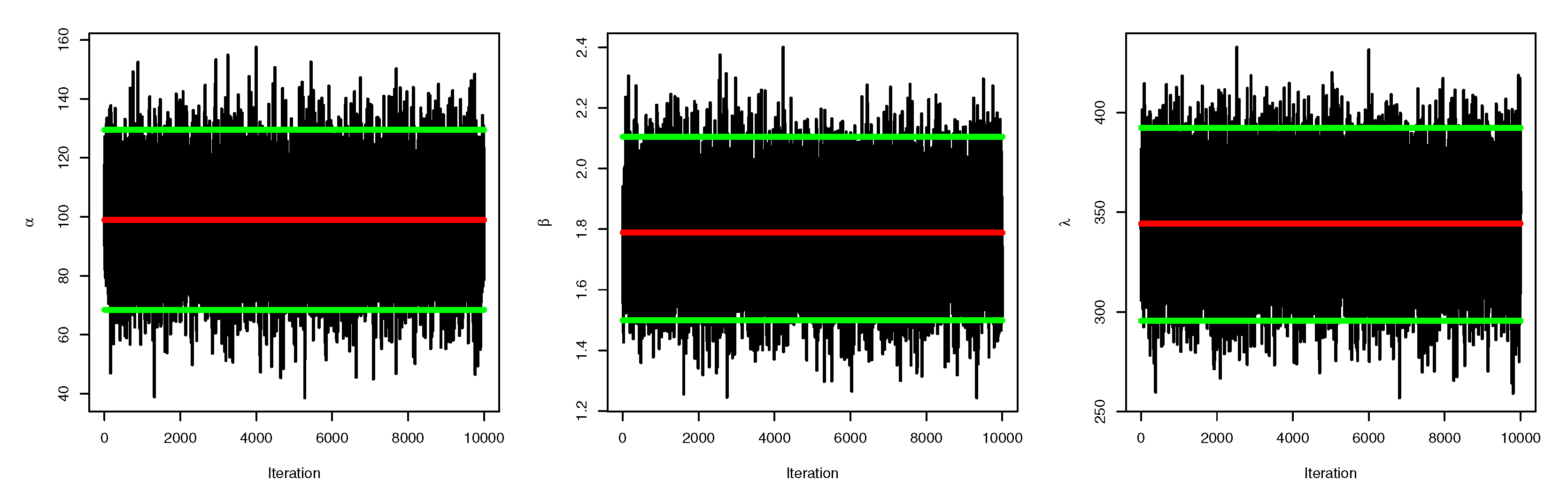
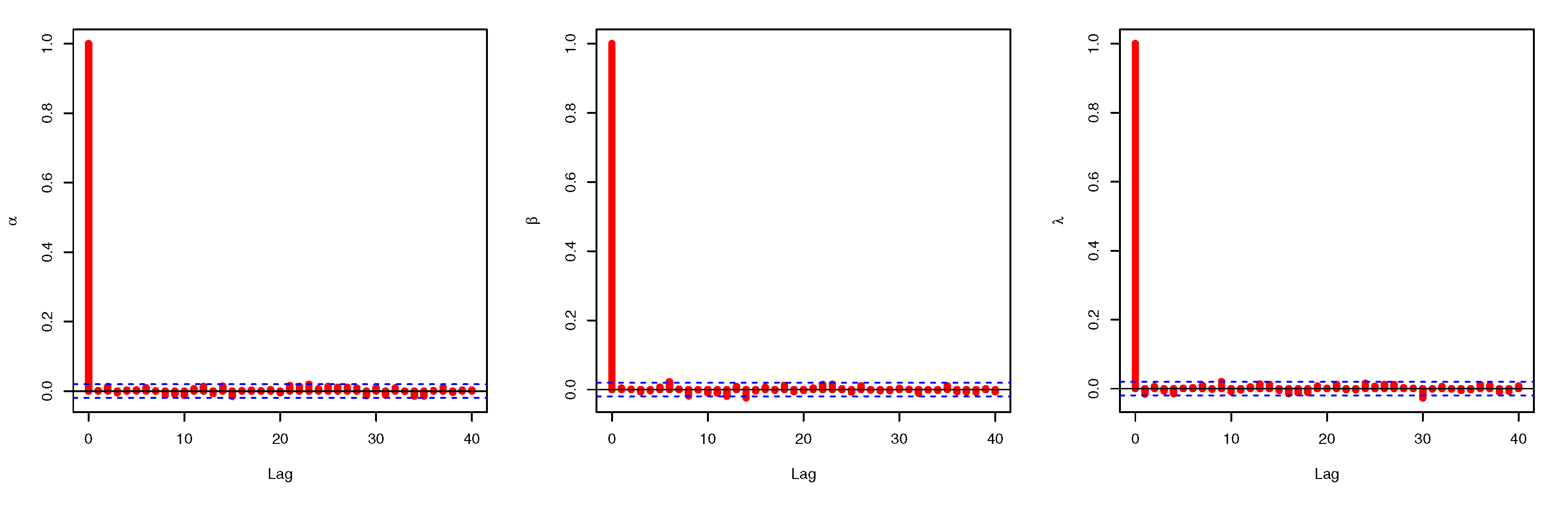
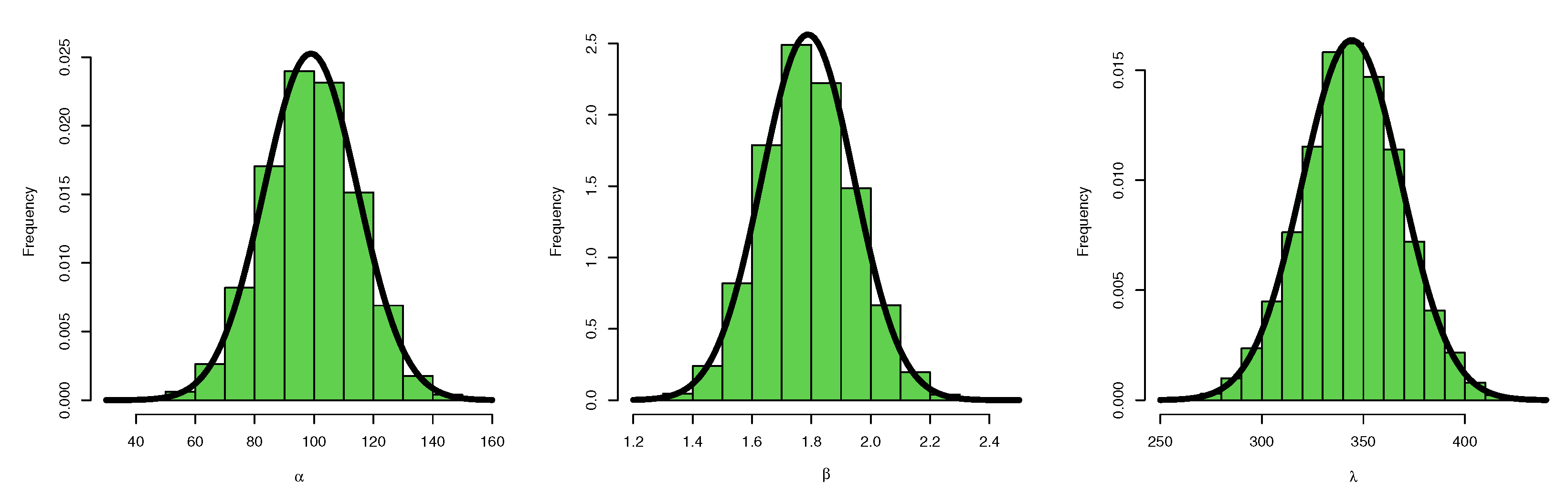
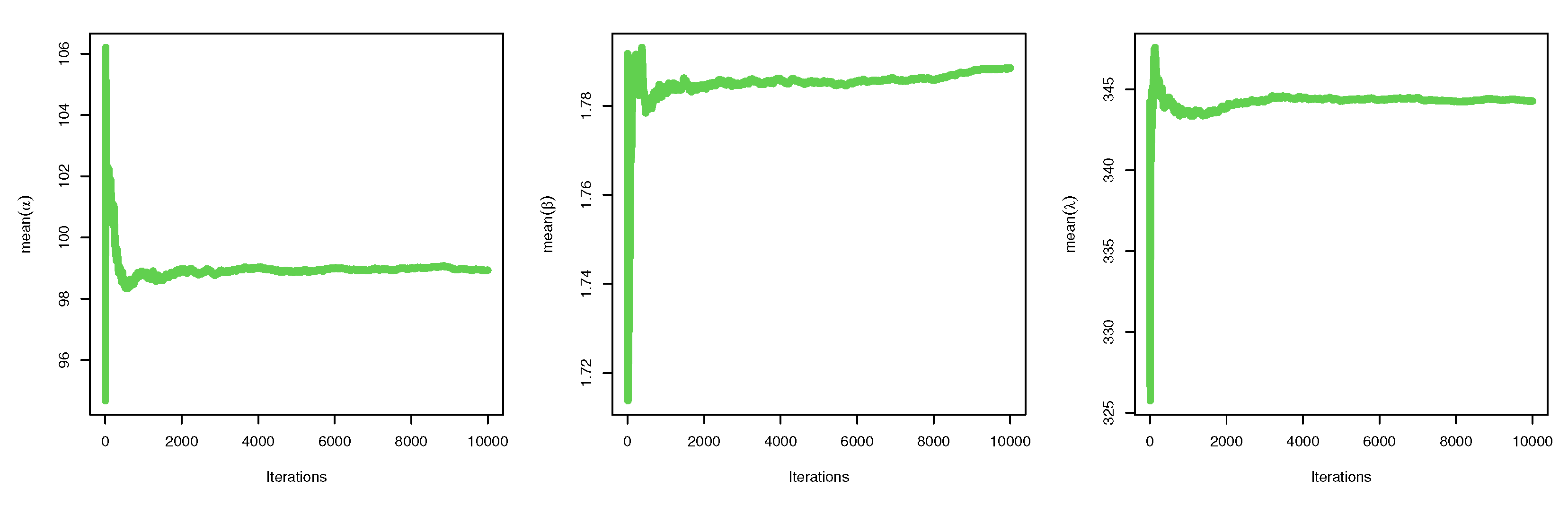
5.2. Credible CI
- (1)
- Start with initial guess
- (2)
- Set
- (3)
- From the normal proposal distributions and , generate and from , and and from the main crossways in inverse Fisher information matrix can be obtained and .
- (4)
- From , and generate proposals , and .
- (i)
- Evaluate the acceptance probabilities
- (ii)
- From a uniform distribution, generate , and .
- (iii)
- If , accept and set ; else, set .
- (iv)
- If , accept and set ; else, set .
- (v)
- If , accept and set ; else, set
- (5)
- Set
- (6)
- Repeat Steps (3)–(5) N times and obtain and
- (7)
- To compute the CRs ofas then, the of is
5.3. Bootstrap CI
5.3.1. Parametric Boot-p
- (1)
- Based on obtain and by maximizing Equations (7)–(9).
- (2)
- Generate from the APIW distribution with parameters and based on hybrid Type-II censoring, using the algorithm described in [32].
- (3)
- Obtain the bootstrap estimate , by the MLEs under the bootstrap sample.
- (4)
- Repeat Steps (2) and (3) boot times, and obtain , where,
- (5)
- Obtain by arrange in ascending orders.
5.3.2. Parametric Boot-t
- (1)
- Repeat the steps of the parametric Boot-p from (1) to (3).
- (2)
- The variance–covariance matrix and the approximate estimates of the variance and based on the asymptotic variance–covariance matrix and delta method are computed.
- (3)
- The statistic is defined as
- (4)
- Obtain from repeating steps 2–5, NBoot times
- (5)
- Obtain the ordered sequences by arranging in in ascending order.
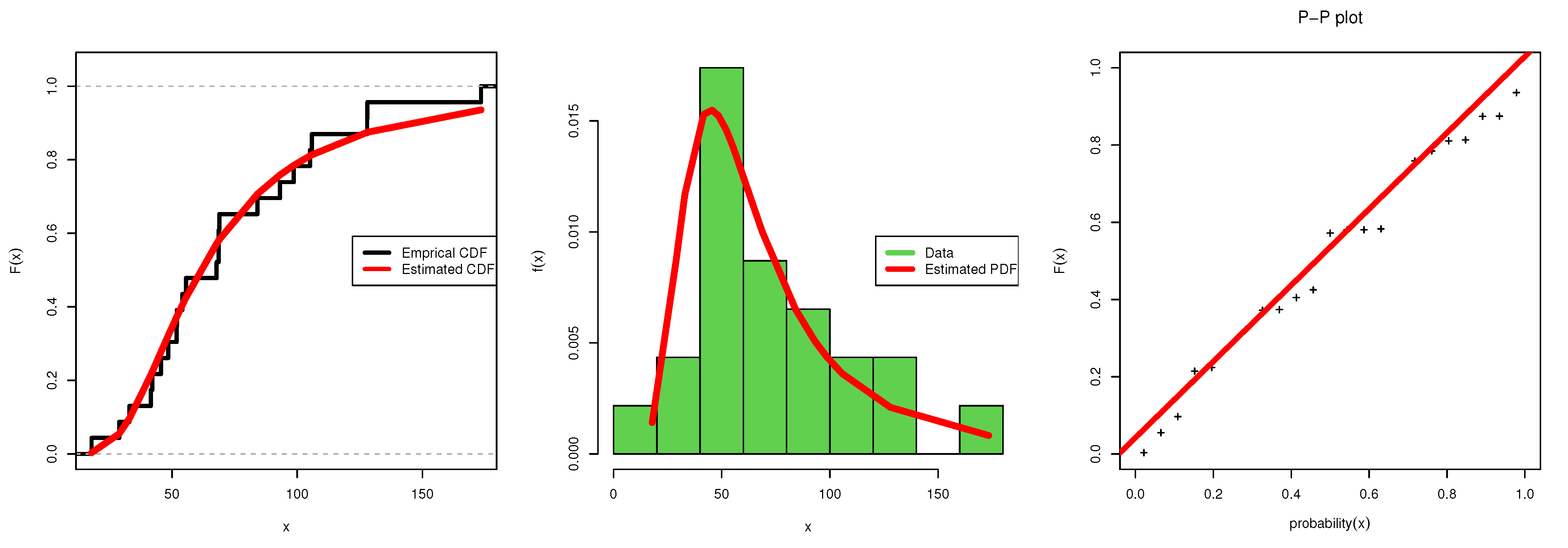
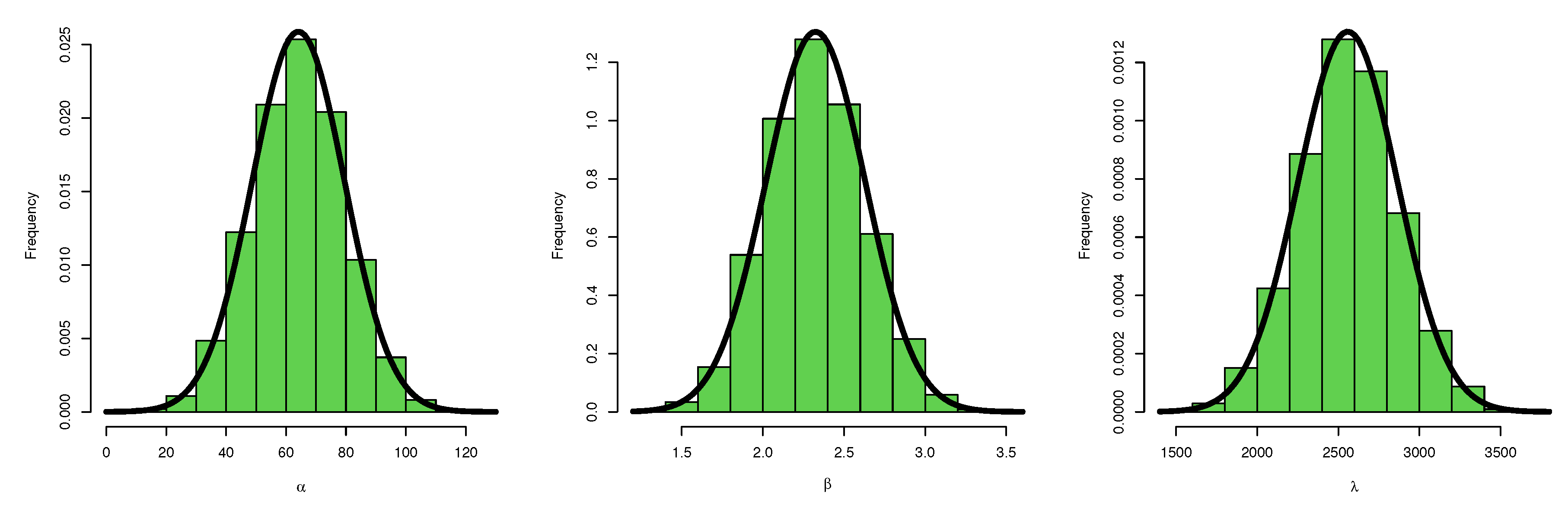
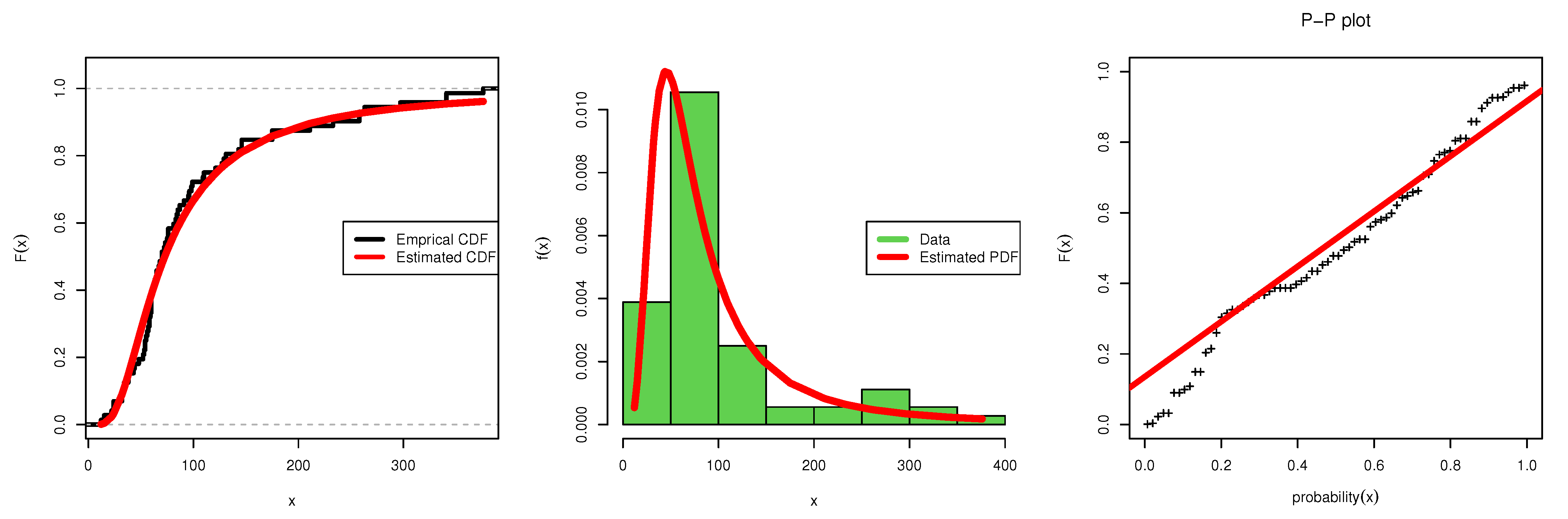
6. Application to Real-Life Data
6.1. Data Set I
6.2. Data Set II
7. A Simulation Study
- In almost all cases, the Bayes estimates perform better than the MLEs with respect to RB, MSE, LACI, LBP, and LBT.
- In most cases, the MPS estimates are better than the MLE with respect to MSE.
- The performance increases when the censored sample size r increases, such that the sample size n and the time of the hybrid censored sample are kept fixed.
- The performance increases when the time of a hybrid censored sample increases when keeping sample size n and censored sample size r as fixed values.
- The MSEs and the widths of the confidence intervals of the ACI, BP, and BT of the MLEs, MPS, and Bayes estimations decrease as the number of failures r increases for a fixed sample size n.
- As the sample size n increases, the average length of all intervals decreases. On average, the credible CI estimates are better than the ACI.
- As the sample size n increases, the bootstrap CI estimates are better than the traditional CI.
8. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Ghalme, S.G.; Mankar, A.; Bhalerao, Y. Biomaterials in Hip Joint Replacement. Int. J. Mater. Sci. Eng. 2016, 4, 113–125. [Google Scholar] [CrossRef]
- Kochi, A. The global tuberculosis situation and the new control strategy of the World Health Organization. Tubercle 1991, 72, 1–6. [Google Scholar] [CrossRef] [Green Version]
- Epstein, B. Truncated life tests in the exponential case. Ann. Socite Pol. Math. 1954, 25, 555–564. [Google Scholar] [CrossRef]
- Ebrahimi, N. Estimating the parameters of an exponential distribution from hybrid life test. J. Stat. Plan. Inference 1986, 14, 255–261. [Google Scholar] [CrossRef]
- Childs, A.; Chand Rasekhar, B.; Balakrishnan, N.; Kundu, D.E. Likelihood inference based on type-I and type-II hybrid censored samples from the exponential distribution. Ann. Inst. Stat. Math. 2003, 55, 319–330. [Google Scholar] [CrossRef]
- Mansour, M.M.M.; Ramadan, D.A. Statistical inference of the parameters of the modified extended exponential distribution under the type-II hybrid censoring scheme. J. Appl. Probab. Stat. 2020, 15, 19–44. [Google Scholar]
- Salah, M.M.; Ahmed, E.A.; Alhussain, Z.A.; Ahmed, H.H.; El-Morshedy, M.; Eliwa, M.S. Statistical inferences for type-II hybrid censoring data from the alpha power exponential distribution. PLoS ONE 2021, 16, e0244316. [Google Scholar] [CrossRef] [PubMed]
- Yousef, M.M.; Almetwally, E.M. Bayesian Inference for the Parameters of Exponential Chen Distribution Based on Hybrid Censoring. Pak. J. Stat. 2022, 38, 145–164. [Google Scholar]
- Yadav, A.S.; Singh, S.K.; Singh, U. On hybrid censored inverse Lomax distribution: Application to the survival data. Statistica 2016, 76, 185–203. [Google Scholar]
- Mahmoud, M.A.W.; Ramadan, D.A.; Mansour, M.M.M. Estimation of lifetime parameters of the modified extended exponential distribution with application to a mechanical model. Commun. Stat. Simul. Comput. 2020, 51, 7005–7018. [Google Scholar] [CrossRef]
- Aldahlan, M.A.; Bakoban, R.A.; Alzahrani, L.S. On Estimating the Parameters of the Beta Inverted Exponential Distribution under Type-II Censored Samples. Mathematics 2022, 10, 506. [Google Scholar] [CrossRef]
- Mohammed, H.S.; Nassar, M.; Alotaibi, R.; Elshahhat, A. Analysis of Adaptive Progressive Type-II Hybrid Censored Dagum Data with Applications. Symmetry 2022, 14, 2146. [Google Scholar] [CrossRef]
- Ramadan, D.A.; Aboshady, M.S.; Mansour, M.M.M. Inference for modified extended exponential distribution based on progressively Type-I hybrid censored data with application to some mechanical models. J. Appl. Probab. Stat. 2022, 17, 69–88. [Google Scholar]
- Nassr, S.G.; Almetwally, E.M.; El Azm, W.S.A. Statistical inference for the extended weibull distribution based on adaptive type-II progressive hybrid censored competing risks data. Thail. Stat. 2021, 19, 547–564. [Google Scholar]
- Ramadan, D.A.; Magdy, W.A. On the alpha-power inverse Weibull. Int. J. Comput. Appl. 2018, 181, 975–8887. [Google Scholar]
- El-Sagheer, R.M. Estimation of parameters of Weibull-Gamma distribution based on progressively censored data. Stat. Pap. 2018, 59, 725–757. [Google Scholar] [CrossRef]
- Cheng, R.C.H.; Amin, N.A.K. Estimating parameters in continuous univariate distributions with a shifted origin. J. R. Stat. Soc. Ser. B Methodol. 1983, 45, 394–403. [Google Scholar] [CrossRef]
- Kundu, D.; Howlader, H. Bayesian inference and prediction of the inverse Weibull distribution for Type-II censored data. Comput. Stat. Data Anal. 2010, 54, 1547–1558. [Google Scholar] [CrossRef]
- Dey, S.; Dey, T. On progressively censored generalized inverted exponential distribution. J. Appl. Stat. 2014, 41, 2557–2576. [Google Scholar] [CrossRef]
- Dey, S.; Ali, S.; Park, C. Weighted exponential distribution: Properties and different methods of estimation. J. Stat. Comput. Simul. 2015, 85, 3641–3661. [Google Scholar] [CrossRef]
- Dey, S.; Singh, S.; Tripathi, Y.M.; Asgharzadeh, A. Estimation and prediction for a progressively censored generalized inverted exponential distribution. Stat. Methodol. 2016, 32, 185–202. [Google Scholar] [CrossRef]
- Varian, H.R. Bayesian approach to real estate assessment. In Studies in Bayesian Econometrics and Statistics in Honor of L.J. Savage; Feinderg, S.E., Zellner, A., Eds.; North-Holland: Amsterdam, The Netherlands, 1975; pp. 195–208. [Google Scholar]
- Robert, C.P. Monte Carlo Statistical Methods; Springer: New York, NY, USA, 2004. [Google Scholar]
- Tolba, A. Bayesian and Non-Bayesian Estimation Methods for Simulating the Parameter of the Akshaya Distribution. Comput. J. Math. Stat. Sci. 2022, 1, 13–25. [Google Scholar] [CrossRef]
- Lawless, J.F. Statistical Models and Methods for Lifetime Data; John Wiley and Sons: New York, NY, USA, 1982. [Google Scholar]
- Greene, W.H. Econometric Analysis, 4th ed.; Prentice-Hall: NewYork, NY, USA, 2000. [Google Scholar]
- Meeker, W.Q.; Escobar, L.A. Statistical Methods for Reliability Data; Wiley: New York, NY, USA, 1998. [Google Scholar]
- Efron, B. The bootstrap and other resampling plans. In CBMS-NSF Regional Conference Series in Applied Mathematics; SIAM: Philadelphia, PA, USA, 1982. [Google Scholar]
- Hall, P. Theoretical Comparison of Bootstrap Confidence Intervals. Ann. Stat. 1988, 16, 927–953. [Google Scholar] [CrossRef]
- Almongy, H.M.; Almetwally, E.M.; Alharbi, R.; Alnagar, D.; Hafez, E.H.; Mohie El-Din, M.M. The Weibull generalized exponential distribution with censored sample: Estimation and application on real data. Complexity 2021, 2021, 6653534. [Google Scholar] [CrossRef]
- Muhammed, H.Z.; Almetwally, E.M. Bayesian and non-Bayesian estimation for the bivariate inverse weibull distribution under progressive type-II censoring. Ann. Data Sci. 2020, 1–32. [Google Scholar] [CrossRef]
- Balakrishnan, N.; Sandhu, R.A. Best linear unbiased and maximum likelihood estimation for exponential distributions under general progressive Type-ll censored samples. Indian J. Stat. Ser. B 1996, 58, 1–9. [Google Scholar]
- Leiblein, J.; Zelen, M. Statistical investigation of fatigue life of deep groove ball bearings. Res. Natl. Bur. Stand. 1956, 57, 273–316. [Google Scholar] [CrossRef]
- Okasha, H.M.; El-Baz, A.H.; Tarabia, A.M.K.; Basheer, A.M. Extended inverse weibull distribution with reliability application. J. Egypt. Math. Soc. 2017, 25, 343–349. [Google Scholar] [CrossRef]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Estimates | SE | KSD | PVKS | ||
|---|---|---|---|---|---|
| MLE | 64.1705 | 154.1028 | 0.0937 | 0.9876 | |
| 2.3255 | 0.3061 | ||||
| 2556.7180 | 3050.7065 | ||||
| MPS | 74.6228 | 49.1516 | 0.1136 | 0.9281 | |
| 2.0332 | 0.0634 | ||||
| 745.7198 | 16.0139 | ||||
| Bayesian | 64.1103 | 15.4170 | 0.0924 | 0.9894 | |
| 2.3246 | 0.3057 | ||||
| 2558.2005 | 305.4596 |
| T | r | MLE | MPS | Bayesian | ||||
|---|---|---|---|---|---|---|---|---|
| Estimates | SE | Estimates | SE | Estimates | SE | |||
| 68 | 12 | 46.3400 | 163.7701 | 83.8863 | 351.3109 | 46.3076 | 3.9134 | |
| 1.9705 | 0.4337 | 1.6145 | 0.4176 | 1.9692 | 0.4331 | |||
| 747.1634 | 1407.1232 | 156.5471 | 329.6032 | 747.8127 | 156.7151 | |||
| 16 | 46.0169 | 162.8815 | 74.4494 | 322.0154 | 45.9893 | 3.2896 | ||
| 1.9650 | 0.4308 | 2.0330 | 0.2510 | 1.9637 | 0.4302 | |||
| 733.8110 | 1375.322 | 745.4669 | 10.3476 | 734.6510 | 131.6786 | |||
| 110 | 16 | 55.8774 | 166.4168 | 79.4264 | 16.2216 | 55.8488 | 3.2118 | |
| 2.1265 | 0.3848 | 1.8119 | 0.0638 | 2.1254 | 0.3742 | |||
| 1246.7484 | 2026.3962 | 320.7453 | 8.6051 | 1247.550 | 169.1073 | |||
| 20 | 60.7348 | 157.5242 | 75.2723 | 10.3590 | 60.7075 | 3.0404 | ||
| 2.2491 | 0.3624 | 1.9606 | 0.0645 | 2.2480 | 0.3319 | |||
| 1935.9909 | 1875.5629 | 565.5794 | 10.3615 | 1937.155 | 139.9357 | |||
| T | r | MLE | MPS | Bayesian | |
|---|---|---|---|---|---|
| 68 | 12 | survival | 0.4857 | 0.5113 | 0.4877 |
| hazard | 0.0188 | 0.0150 | 0.0188 | ||
| 16 | survival | 0.4850 | 0.5107 | 0.4869 | |
| hazard | 0.0188 | 0.0150 | 0.0187 | ||
| 110 | 16 | survival | 0.3253 | 0.3563 | 0.3268 |
| hazard | 0.0197 | 0.0163 | 0.0197 | ||
| 20 | survival | 0.1978 | 0.2277 | 0.1988 | |
| hazard | 0.0185 | 0.0158 | 0.0185 |
| 12 38 55 60 70 85 121 211 | 15 38 56 61 72 87 127 233 | 22 43 57 62 73 91 129 258 | 24 44 58 63 75 95 131 258 | 24 48 58 65 76 96 143 263 | 32 52 59 65 76 98 146 297 | 32 53 60 67 81 99 146 341 | 33 54 60 68 83 109 175 341 |
| Estimates | SE | Lower | Upper | KSD | PVKS | ||
|---|---|---|---|---|---|---|---|
| MLE | 99.0793 | 46.2628 | 8.4043 | 189.7544 | 0.1096 | 0.3524 | |
| 1.7889 | 0.1558 | 1.4835 | 2.0944 | ||||
| 344.2289 | 143.1508 | 63.6533 | 624.8045 | ||||
| MPS | 122.7002 | 4.7472 | 113.3957 | 132.0046 | 0.1186 | 0.2637 | |
| 1.6840 | 0.0358 | 1.6139 | 1.7542 | ||||
| 210.6960 | 2.5855 | 205.6284 | 215.7635 | ||||
| Bayesian | 98.9326 | 15.7863 | 68.4324 | 129.4730 | 0.1091 | 0.3581 | |
| 1.7885 | 0.1556 | 1.4991 | 2.1047 | ||||
| 344.2667 | 24.3636 | 295.4979 | 392.3949 |
| T | r | MLE | MPS | Bayesian | ||||
|---|---|---|---|---|---|---|---|---|
| Estimates | SE | Estimates | SE | Estimates | SE | |||
| 100 | 50 | 101.0733 | 164.6184 | 125.1150 | 67.7176 | 101.0304 | 3.9380 | |
| 1.7786 | 0.1811 | 1.6609 | 0.0656 | 1.7781 | 0.1809 | |||
| 327.2383 | 259.4398 | 191.2807 | 22.0057 | 327.2877 | 28.8832 | |||
| 60 | 103.0959 | 164.5881 | 126.4073 | 9.2812 | 103.0530 | 3.9373 | ||
| 1.7976 | 0.1786 | 1.6819 | 0.0363 | 1.7970 | 0.1783 | |||
| 349.4182 | 271.6575 | 206.2780 | 5.2838 | 349.4698 | 30.2434 | |||
| 110 | 50 | 101.0733 | 164.6184 | 125.1150 | 67.7176 | 101.0304 | 3.9380 | |
| 1.7786 | 0.1811 | 1.6609 | 0.0656 | 1.7781 | 0.1809 | |||
| 327.2383 | 259.4398 | 191.2807 | 22.0057 | 327.2877 | 28.8832 | |||
| 60 | 101.2719 | 164.0169 | 125.7735 | 16.0496 | 101.2291 | 3.9237 | ||
| 1.7814 | 0.1748 | 1.6686 | 0.0365 | 1.7808 | 0.1745 | |||
| 330.4588 | 255.2788 | 196.5964 | 4.9556 | 330.5050 | 28.4200 | |||
| T | r | MLE | MPS | Bayesian | |
|---|---|---|---|---|---|
| 100 | 50 | survival | 0.3523 | 0.3647 | 0.3530 |
| hazard | 0.0141 | 0.0130 | 0.0141 | ||
| 60 | survival | 0.3286 | 0.3412 | 0.3293 | |
| hazard | 0.0140 | 0.0130 | 0.0140 | ||
| 110 | 50 | survival | 0.3523 | 0.3647 | 0.3530 |
| hazard | 0.0141 | 0.0130 | 0.0141 | ||
| 60 | survival | 0.2906 | 0.3040 | 0.2912 | |
| hazard | 0.0131 | 0.0121 | 0.0131 |
| Minimum | Q1 | Q2 | Mean | Q3 | Maximum | SD | SK | KT | |||
|---|---|---|---|---|---|---|---|---|---|---|---|
| 0.6 | 0.6 | 0.2 | 0.0019 | 0.0375 | 0.0968 | 9.3625 | 0.3837 | 2525.81 | 117.8092 | 17.2574 | 320.5176 |
| 0.7 | 0.0341 | 0.2744 | 0.781 | 28.6615 | 3.2646 | 3533.482 | 188.5746 | 12.4815 | 188.0099 | ||
| 1.2 | 0.0504 | 0.564 | 1.6943 | 554.9259 | 6.8621 | 373,379.5 | 12,016.08 | 30.0298 | 929.0447 | ||
| 1.7 | 0.1445 | 1.1408 | 3.2773 | 112.0147 | 12.4232 | 25308.46 | 988.7543 | 18.8949 | 440.0531 | ||
| 2.2 | 0.1183 | 1.7701 | 4.6629 | 758.7959 | 18.144 | 254,110.1 | 9603.757 | 21.2078 | 516.2217 | ||
| 2.7 | 0.136 | 2.4891 | 7.0995 | 12,403.68 | 29.2255 | 621,3521 | 244,427.2 | 22.5586 | 527.7023 | ||
| 1.5 | 0.2 | 0.0817 | 0.2689 | 0.3929 | 0.7271 | 0.6817 | 22.9594 | 1.492 | 9.6082 | 119.4912 | |
| 0.7 | 0.2587 | 0.5961 | 0.9059 | 1.6512 | 1.6052 | 26.2592 | 2.4575 | 4.8751 | 34.0851 | ||
| 1.2 | 0.3026 | 0.7953 | 1.2348 | 2.449 | 2.1606 | 169.3792 | 7.1983 | 15.4838 | 314.6141 | ||
| 1.7 | 0.4613 | 1.0541 | 1.6077 | 2.8005 | 2.7396 | 57.7173 | 4.1289 | 6.1401 | 56.8222 | ||
| 2.2 | 0.4258 | 1.2566 | 1.8512 | 3.8492 | 3.1878 | 145.2141 | 8.8066 | 9.0808 | 110.2727 | ||
| 2.7 | 0.4502 | 1.4402 | 2.1902 | 5.3273 | 3.8574 | 521.597 | 24.5777 | 16.9134 | 322.1059 | ||
| 3 | 0.2 | 0.2859 | 0.5186 | 0.6269 | 0.7411 | 0.8256 | 4.7916 | 0.4218 | 4.1298 | 29.9656 | |
| 0.7 | 0.5087 | 0.7721 | 0.9518 | 1.1322 | 1.267 | 5.1244 | 0.608 | 2.6053 | 11.9396 | ||
| 1.2 | 0.5501 | 0.8918 | 1.1112 | 1.3201 | 1.4699 | 13.0146 | 0.8409 | 5.8075 | 58.3727 | ||
| 1.7 | 0.6792 | 1.0267 | 1.268 | 1.4908 | 1.6552 | 7.5972 | 0.7606 | 2.7864 | 14.7529 | ||
| 2.2 | 0.6526 | 1.121 | 1.3606 | 1.662 | 1.7854 | 12.0505 | 1.0431 | 4.2566 | 29.2693 | ||
| 2.7 | 0.671 | 1.2001 | 1.4799 | 1.8111 | 1.964 | 22.8385 | 1.4315 | 8.0332 | 97.9213 | ||
| 1.5 | 0.6 | 0.2 | 0.0021 | 0.0576 | 0.1675 | 20.1354 | 0.7441 | 5453.285 | 254.3222 | 17.2608 | 320.6308 |
| 0.7 | 0.0395 | 0.4161 | 1.3517 | 61.1988 | 6.3512 | 7620.369 | 406.3593 | 12.502 | 188.5294 | ||
| 1.2 | 0.0561 | 0.8339 | 2.8926 | 1196.982 | 13.2257 | 806,474.1 | 25,953.44 | 30.0314 | 929.1182 | ||
| 1.7 | 0.167 | 1.7169 | 5.6449 | 239.0572 | 23.9633 | 54,604.49 | 2132.057 | 18.9211 | 441.0744 | ||
| 2.2 | 0.1306 | 2.6675 | 7.9627 | 1633.918 | 34.8865 | 548,731.3 | 20,735.8 | 21.2142 | 516.483 | ||
| 2.7 | 0.1484 | 3.7507 | 12.2307 | 26,786.65 | 56.6635 | 13,422,188 | 527,997 | 22.5588 | 527.7134 | ||
| 1.5 | 0.2 | 0.0989 | 0.343 | 0.5117 | 0.9127 | 0.8951 | 25.1911 | 1.6971 | 8.8703 | 105.0283 | |
| 0.7 | 0.2976 | 0.7198 | 1.1197 | 1.9816 | 2.0002 | 28.5589 | 2.7859 | 4.5374 | 30.0123 | ||
| 1.2 | 0.3396 | 0.9341 | 1.4893 | 2.8184 | 2.6335 | 164.0482 | 7.2539 | 14.1928 | 271.0224 | ||
| 1.7 | 0.5111 | 1.2247 | 1.9137 | 3.2503 | 3.291 | 59.7669 | 4.4974 | 5.6013 | 48.348 | ||
| 2.2 | 0.4661 | 1.4447 | 2.1772 | 4.3322 | 3.7888 | 141.9907 | 8.9929 | 8.4079 | 96.0569 | ||
| 2.7 | 0.4889 | 1.6417 | 2.5574 | 5.7369 | 4.5445 | 470.9055 | 22.6724 | 16.1496 | 299.0034 | ||
| 3 | 0.2 | 0.2912 | 0.5651 | 0.6995 | 0.8348 | 0.9426 | 5.589 | 0.502 | 4.0018 | 28.582 | |
| 0.7 | 0.5239 | 0.8392 | 1.0621 | 1.2755 | 1.4473 | 5.9758 | 0.7261 | 2.5326 | 11.4722 | ||
| 1.2 | 0.5622 | 0.9643 | 1.2367 | 1.4842 | 1.676 | 15.1816 | 0.9981 | 5.6295 | 55.6979 | ||
| 1.7 | 0.6991 | 1.1142 | 1.4136 | 1.6778 | 1.8876 | 8.8602 | 0.9095 | 2.6968 | 14.0562 | ||
| 2.2 | 0.6655 | 1.2168 | 1.5143 | 1.8717 | 2.0348 | 14.0563 | 1.2387 | 4.1458 | 28.1226 | ||
| 2.7 | 0.6828 | 1.3026 | 1.65 | 2.0412 | 2.2421 | 26.6419 | 1.6898 | 7.8521 | 94.6963 | ||
| 3 | 0.6 | 0.2 | 0.0023 | 0.0837 | 0.2587 | 33.3614 | 1.1989 | 9044.133 | 421.7753 | 17.2616 | 320.6565 |
| 0.7 | 0.0453 | 0.5991 | 2.0877 | 101.2154 | 10.2436 | 12,634.96 | 673.6439 | 12.5066 | 188.6474 | ||
| 1.2 | 0.062 | 1.1807 | 4.4402 | 1984.686 | 21.2686 | 1,337,645 | 43,047.07 | 30.0318 | 929.1349 | ||
| 1.7 | 0.191 | 2.4597 | 8.6994 | 395.314 | 38.5459 | 90,546.07 | 3534.951 | 18.9271 | 441.3064 | ||
| 2.2 | 0.1428 | 3.825 | 12.2242 | 2708.01 | 56.0588 | 910,095.2 | 34,390.2 | 21.2156 | 516.5424 | ||
| 2.7 | 0.1605 | 5.3781 | 18.8508 | 44,427.34 | 91.2935 | 22,263,025 | 875,773 | 22.5589 | 527.7159 | ||
| 1.5 | 0.2 | 0.102 | 0.3945 | 0.6023 | 1.0877 | 1.0704 | 30.4535 | 2.0548 | 8.8479 | 104.636 | |
| 0.7 | 0.3133 | 0.8252 | 1.3179 | 2.3613 | 2.3929 | 34.5215 | 3.3769 | 4.5215 | 29.8511 | ||
| 1.2 | 0.3524 | 1.0643 | 1.7489 | 3.3579 | 3.147 | 198.3252 | 8.7774 | 14.1699 | 270.3686 | ||
| 1.7 | 0.5375 | 1.4015 | 2.2507 | 3.869 | 3.9332 | 72.248 | 5.4519 | 5.5778 | 48.0366 | ||
| 2.2 | 0.4819 | 1.6538 | 2.5569 | 5.1663 | 4.5263 | 171.6554 | 10.8861 | 8.3911 | 95.7611 | ||
| 2.7 | 0.5035 | 1.8793 | 3.0078 | 6.855 | 5.4345 | 569.3038 | 27.4201 | 16.1402 | 298.7514 | ||
| 3 | 0.2 | 0.296 | 0.6089 | 0.7631 | 0.9119 | 1.037 | 6.1841 | 0.5605 | 3.9338 | 27.9076 | |
| 0.7 | 0.5385 | 0.9026 | 1.1586 | 1.3933 | 1.5925 | 6.6117 | 0.8119 | 2.4899 | 11.2289 | ||
| 1.2 | 0.5734 | 1.0338 | 1.3473 | 1.6196 | 1.8431 | 16.7984 | 1.1133 | 5.5364 | 54.3872 | ||
| 1.7 | 0.7182 | 1.1972 | 1.5413 | 1.8319 | 2.0758 | 9.8033 | 1.0177 | 2.6452 | 13.7014 | ||
| 2.2 | 0.6775 | 1.3078 | 1.6498 | 2.0443 | 2.2373 | 15.5531 | 1.3815 | 4.0881 | 27.5711 | ||
| 2.7 | 0.6935 | 1.4 | 1.7991 | 2.2299 | 2.4665 | 29.4793 | 1.8797 | 7.7641 | 93.1916 |
| MLE | MPS | Bayesian | |||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| n | T | r | RB | MSE | LACI | LBP | LBT | RB | MSE | LACI | LBP | LBT | RB | MSE | LCCI | ||
| 1.3 | 50 | 1.4 | 30 | 0.0012 | 0.0791 | 1.1039 | 0.0476 | 0.0483 | −0.0249 | 0.0679 | 1.0143 | 0.0437 | 0.0464 | 0.0748 | 0.0256 | 0.5025 | |
| 0.0365 | 0.0108 | 0.3989 | 0.0199 | 0.0199 | −0.0496 | 0.0100 | 0.3743 | 0.0167 | 0.0167 | −0.2786 | 0.0091 | 0.4369 | |||||
| 0.0200 | 0.0255 | 0.6239 | 0.0298 | 0.0298 | 0.0520 | 0.0264 | 0.6212 | 0.0302 | 0.0318 | −0.2234 | 0.0240 | 0.4759 | |||||
| 7 | 40 | 0.0010 | 0.0619 | 1.0723 | 0.0479 | 0.0479 | −0.0024 | 0.0176 | 1.0065 | 0.0372 | 0.0371 | 0.0627 | 0.0178 | 0.4171 | |||
| 0.0267 | 0.0070 | 0.3228 | 0.0146 | 0.0148 | −0.0412 | 0.0066 | 0.3030 | 0.0139 | 0.0135 | −0.2631 | 0.0061 | 0.3763 | |||||
| 0.0182 | 0.0219 | 0.5790 | 0.0244 | 0.0239 | 0.0309 | 0.0235 | 0.5961 | 0.0249 | 0.0248 | −0.2190 | 0.0140 | 0.3908 | |||||
| 999 | 50 | −0.0014 | 0.0507 | 0.9554 | 0.0386 | 0.0468 | −0.0019 | 0.0125 | 0.9899 | 0.0287 | 0.0288 | 0.0313 | 0.0073 | 0.2778 | |||
| 0.0102 | 0.0053 | 0.2839 | 0.0119 | 0.0120 | −0.0416 | 0.0058 | 0.2590 | 0.0107 | 0.0108 | −0.2344 | 0.0046 | 0.2703 | |||||
| 0.0162 | 0.0204 | 0.4719 | 0.0233 | 0.0233 | 0.0291 | 0.0214 | 0.5761 | 0.0237 | 0.0237 | −0.2109 | 0.0128 | 0.2981 | |||||
| 100 | 1.4 | 70 | 0.0360 | 0.2776 | 2.0930 | 0.1478 | 0.1481 | −0.0577 | 0.1186 | 1.3516 | 0.0622 | 0.0625 | 0.1368 | 0.0470 | 0.4726 | ||
| 0.0195 | 0.0043 | 0.2520 | 0.0119 | 0.0119 | −0.0311 | 0.0045 | 0.2529 | 0.0116 | 0.0115 | −0.3606 | 0.0016 | 0.3682 | |||||
| 0.0083 | 0.0211 | 0.4019 | 0.0273 | 0.0172 | 0.0316 | 0.0143 | 0.4616 | 0.0211 | 0.0212 | −0.3061 | 0.0155 | 0.3704 | |||||
| 7 | 90 | 0.0308 | 0.2697 | 1.9132 | 0.1309 | 0.0908 | 0.0405 | 0.1041 | 1.2503 | 0.0611 | 0.0611 | 0.1163 | 0.0344 | 0.4199 | |||
| 0.0101 | 0.0039 | 0.2443 | 0.0101 | 0.0101 | −0.0304 | 0.0042 | 0.2455 | 0.0111 | 0.0109 | −0.4388 | 0.0015 | 0.3200 | |||||
| 0.0318 | 0.0197 | 0.3944 | 0.0234 | 0.0162 | 0.0314 | 0.0123 | 0.3602 | 0.0202 | 0.0209 | −0.4305 | 0.0150 | 0.3220 | |||||
| 999 | 100 | 0.0428 | 0.2500 | 1.7648 | 0.1216 | 0.0812 | −0.0401 | 0.0985 | 1.2854 | 0.0513 | 0.0513 | 0.0623 | 0.0114 | 0.2600 | |||
| −0.0045 | 0.0038 | 0.2419 | 0.0091 | 0.0100 | −0.0316 | 0.0042 | 0.2354 | 0.0107 | 0.0106 | −0.3557 | 0.0009 | 0.2399 | |||||
| 0.0263 | 0.0137 | 0.3735 | 0.0213 | 0.0133 | 0.0291 | 0.0106 | 0.3488 | 0.0200 | 0.0237 | −0.3547 | 0.0114 | 0.2948 | |||||
| 0.6 | 50 | 0.5 | 30 | 0.0616 | 0.0412 | 0.7829 | 0.0350 | 0.0348 | −0.0301 | 0.0370 | 0.7512 | 0.0352 | 0.0355 | 0.1988 | 0.0290 | 0.4688 | |
| 0.0596 | 0.0126 | 0.4182 | 0.0194 | 0.0195 | −0.0571 | 0.0106 | 0.3818 | 0.0166 | 0.0166 | −0.1291 | 0.0106 | 0.3893 | |||||
| −0.0187 | 0.0261 | 0.6321 | 0.0271 | 0.0272 | 0.0902 | 0.0374 | 0.7172 | 0.0312 | 0.0308 | −0.1567 | 0.0128 | 0.5101 | |||||
| 5 | 40 | 0.0577 | 0.0417 | 0.7004 | 0.0344 | 0.0315 | −0.0301 | 0.0353 | 0.6903 | 0.0341 | 0.0341 | 0.1239 | 0.0283 | 0.3812 | |||
| 0.0320 | 0.0079 | 0.3413 | 0.0157 | 0.0159 | −0.0493 | 0.0072 | 0.3116 | 0.0143 | 0.0143 | −0.1234 | 0.0079 | 0.3346 | |||||
| 0.0106 | 0.0257 | 0.6404 | 0.0260 | 0.0270 | 0.0752 | 0.0330 | 0.6827 | 0.0279 | 0.0277 | −0.1271 | 0.0125 | 0.3717 | |||||
| 99,999 | 50 | 0.1308 | 0.0125 | 0.6835 | 0.0316 | 0.0259 | −0.0280 | 0.0311 | 0.5259 | 0.0354 | 0.0255 | 0.1137 | 0.0121 | 0.2803 | |||
| 0.0335 | 0.0068 | 0.3139 | 0.0141 | 0.0144 | −0.0467 | 0.0070 | 0.2986 | 0.0141 | 0.0137 | −0.1197 | 0.0069 | 0.2393 | |||||
| 0.0064 | 0.0231 | 0.6191 | 0.0213 | 0.0231 | 0.0612 | 0.0349 | 0.6180 | 0.0238 | 0.0238 | −0.1090 | 0.0102 | 0.3190 | |||||
| 100 | 0.5 | 70 | 0.1568 | 0.1709 | 1.5798 | 0.0743 | 0.0745 | −0.0893 | 0.1224 | 1.3568 | 0.0605 | 0.0605 | 0.3783 | 0.0640 | 0.4302 | ||
| 0.0221 | 0.0086 | 0.3598 | 0.0154 | 0.0154 | −0.0714 | 0.0096 | 0.3456 | 0.0164 | 0.0161 | −0.1407 | 0.0091 | 0.3560 | |||||
| 0.0357 | 0.0532 | 0.8997 | 0.0411 | 0.0408 | 0.1771 | 0.0779 | 0.9813 | 0.0448 | 0.0448 | −0.2168 | 0.0351 | 0.4293 | |||||
| 5 | 90 | 0.2180 | 0.1523 | 1.2823 | 0.0750 | 0.0682 | 0.0120 | 0.1182 | 1.3675 | 0.0607 | 0.0602 | 0.3728 | 0.0618 | 0.3257 | |||
| 0.0170 | 0.0044 | 0.2584 | 0.0110 | 0.0111 | −0.0487 | 0.0054 | 0.2634 | 0.0123 | 0.0126 | −0.1287 | 0.0036 | 0.2954 | |||||
| 0.0075 | 0.0344 | 0.7277 | 0.0330 | 0.0329 | 0.1039 | 0.0532 | 0.8592 | 0.0391 | 0.0398 | −0.2042 | 0.0294 | 0.3247 | |||||
| 99,999 | 100 | 0.1976 | 0.1224 | 1.2799 | 0.0677 | 0.0658 | −0.0169 | 0.1022 | 1.2844 | 0.0585 | 0.0588 | 0.2379 | 0.0244 | 0.2489 | |||
| 0.0124 | 0.0042 | 0.2468 | 0.0102 | 0.0102 | −0.0371 | 0.0047 | 0.2484 | 0.0123 | 0.0123 | −0.1264 | 0.0035 | 0.2385 | |||||
| 0.0226 | 0.0315 | 0.7310 | 0.0318 | 0.0319 | 0.1007 | 0.0471 | 0.7933 | 0.0342 | 0.0342 | −0.1321 | 0.0156 | 0.3095 | |||||
| MLE | MPS | Bayesian | |||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| n | T | r | RB | MSE | LACI | LBP | LBT | RB | MSE | LACI | LBP | LBT | RB | MSE | LCCI | ||
| 0.6 | 50 | 1.4 | 30 | 0.5022 | 0.6443 | 2.9192 | 0.1332 | 0.1314 | 0.1281 | 0.5495 | 2.8997 | 0.1347 | 0.1377 | 0.1649 | 0.0247 | 0.4886 | |
| 0.0198 | 0.0100 | 0.3889 | 0.0179 | 0.0198 | −0.1065 | 0.0135 | 0.3808 | 0.0179 | 0.0177 | −0.3502 | 0.0095 | 0.3791 | |||||
| 0.0087 | 0.2139 | 1.8136 | 0.0792 | 0.0792 | 0.0566 | 0.2394 | 1.8677 | 0.0874 | 0.0867 | −0.0478 | 0.0295 | 0.5636 | |||||
| 7 | 40 | 0.5263 | 0.6337 | 2.8674 | 0.1257 | 0.1282 | 0.1210 | 0.4745 | 2.6878 | 0.1160 | 0.1163 | 0.1672 | 0.0216 | 0.4103 | |||
| 0.0547 | 0.0091 | 0.3410 | 0.0169 | 0.0185 | −0.0678 | 0.0128 | 0.3414 | 0.0178 | 0.0181 | −0.3339 | 0.0085 | 0.2883 | |||||
| −0.0097 | 0.1465 | 1.4999 | 0.0718 | 0.0725 | 0.0304 | 0.1519 | 1.5104 | 0.0703 | 0.0700 | −0.0326 | 0.0241 | 0.4540 | |||||
| 999 | 50 | 0.1792 | 0.1318 | 1.3605 | 0.0603 | 0.0607 | −0.1141 | 0.1057 | 1.2317 | 0.0537 | 0.0545 | 0.1095 | 0.0096 | 0.2808 | |||
| 0.0535 | 0.0081 | 0.3249 | 0.0159 | 0.0172 | −0.0579 | 0.0126 | 0.3246 | 0.0168 | 0.0172 | −0.2406 | 0.0062 | 0.2289 | |||||
| 0.0389 | 0.1410 | 1.4413 | 0.0648 | 0.0651 | 0.0302 | 0.1495 | 1.4070 | 0.0613 | 0.0598 | −0.0301 | 0.0098 | 0.2934 | |||||
| 100 | 1.4 | 70 | 0.1216 | 0.1193 | 1.3246 | 0.0623 | 0.0652 | −0.1856 | 0.0907 | 1.0981 | 0.0497 | 0.0497 | 0.2768 | 0.0400 | 0.4275 | ||
| 0.0154 | 0.0074 | 0.3355 | 0.0153 | 0.0153 | −0.0829 | 0.0088 | 0.3113 | 0.0124 | 0.0125 | −0.5069 | 0.0070 | 0.2629 | |||||
| 0.0214 | 0.0974 | 1.2132 | 0.0568 | 0.0604 | 0.0675 | 0.1189 | 1.2450 | 0.0545 | 0.0545 | −0.0894 | 0.0496 | 0.5074 | |||||
| 7 | 90 | 0.1407 | 0.1028 | 1.2361 | 0.0614 | 0.0620 | −0.0333 | 0.0787 | 1.0978 | 0.0451 | 0.0496 | 0.2681 | 0.0384 | 0.3780 | |||
| 0.0190 | 0.0050 | 0.2728 | 0.0119 | 0.0120 | −0.0413 | 0.0051 | 0.2624 | 0.0116 | 0.0121 | −0.4668 | 0.0048 | 0.2168 | |||||
| 0.0001 | 0.0430 | 1.1381 | 0.0361 | 0.0368 | 0.0078 | 0.0413 | 0.7955 | 0.0355 | 0.0355 | −0.0891 | 0.0145 | 0.4277 | |||||
| 999 | 100 | 0.0442 | 0.0941 | 1.1989 | 0.0546 | 0.0550 | −0.0220 | 0.0611 | 1.0021 | 0.0436 | 0.0456 | 0.1824 | 0.0168 | 0.2568 | |||
| 0.0031 | 0.0042 | 0.2554 | 0.0106 | 0.0107 | −0.0181 | 0.0048 | 0.2488 | 0.0103 | 0.0112 | −0.3617 | 0.0025 | 0.1912 | |||||
| 0.0275 | 0.0372 | 1.0306 | 0.0346 | 0.0346 | 0.0072 | 0.0412 | 0.6226 | 0.0305 | 0.0315 | −0.0541 | 0.0138 | 0.3084 | |||||
| 2 | 50 | 4 | 30 | −0.0049 | 0.8570 | 3.6322 | 0.1661 | 0.1670 | −0.0257 | 0.8294 | 3.5679 | 0.1661 | 0.1658 | 0.0166 | 0.0233 | 0.5513 | |
| 0.0138 | 0.0083 | 0.2758 | 0.0131 | 0.0127 | −0.0575 | 0.0054 | 0.2558 | 0.0112 | 0.0152 | −0.2798 | 0.0078 | 0.3962 | |||||
| 0.0657 | 0.1980 | 1.6680 | 0.0756 | 0.0754 | −0.0072 | 0.1540 | 1.5390 | 0.0704 | 0.0701 | −0.0401 | 0.0252 | 0.5318 | |||||
| 22 | 40 | 0.0194 | 0.4354 | 2.5847 | 0.1154 | 0.1161 | 0.0256 | 0.5350 | 2.8432 | 0.1193 | 0.1216 | 0.0159 | 0.0131 | 0.4276 | |||
| 0.0253 | 0.0068 | 0.2319 | 0.0125 | 0.0121 | −0.0430 | 0.0046 | 0.2305 | 0.0110 | 0.0142 | −0.2492 | 0.0064 | 0.2740 | |||||
| 0.0454 | 0.1786 | 1.6195 | 0.0749 | 0.0716 | −0.0092 | 0.1392 | 1.4333 | 0.0655 | 0.0653 | −0.0470 | 0.0232 | 0.4449 | |||||
| 99,999 | 50 | 0.0068 | 0.0965 | 1.2178 | 0.0534 | 0.0535 | −0.0116 | 0.1648 | 1.5901 | 0.0698 | 0.0694 | 0.0132 | 0.0064 | 0.2937 | |||
| 0.0597 | 0.0062 | 0.2137 | 0.0116 | 0.0110 | −0.0357 | 0.0030 | 0.2155 | 0.0195 | 0.0135 | −0.2189 | 0.0052 | 0.2133 | |||||
| 0.0522 | 0.1581 | 0.8506 | 0.0709 | 0.0691 | −0.0062 | 0.1013 | 1.2392 | 0.0558 | 0.0551 | −0.0328 | 0.0106 | 0.3105 | |||||
| 100 | 4 | 70 | 0.0254 | 0.4205 | 2.5368 | 0.1136 | 0.1155 | −0.0166 | 0.2736 | 2.0482 | 0.0951 | 0.0953 | 0.0236 | 0.0187 | 0.4739 | ||
| 0.0297 | 0.0084 | 0.3525 | 0.0157 | 0.0158 | −0.0443 | 0.0079 | 0.3325 | 0.0151 | 0.0152 | −0.4132 | 0.0068 | 0.3206 | |||||
| 0.0263 | 0.0757 | 1.0599 | 0.0477 | 0.0474 | −0.0081 | 0.0649 | 0.9977 | 0.0460 | 0.0472 | −0.0764 | 0.0431 | 0.5429 | |||||
| 22 | 90 | −0.0065 | 0.0729 | 1.0584 | 0.0463 | 0.0453 | −0.0135 | 0.0375 | 0.7523 | 0.0323 | 0.0322 | 0.0210 | 0.0157 | 0.4303 | |||
| 0.0131 | 0.0032 | 0.2204 | 0.0099 | 0.0100 | −0.0286 | 0.0033 | 0.2136 | 0.0096 | 0.0095 | −0.4079 | 0.0016 | 0.2093 | |||||
| 0.0255 | 0.0650 | 0.9804 | 0.0449 | 0.0450 | −0.0081 | 0.0540 | 0.9009 | 0.0405 | 0.0405 | −0.0696 | 0.0410 | 0.4314 | |||||
| 99,999 | 100 | 0.0028 | 0.0629 | 1.0104 | 0.0390 | 0.0389 | 0.0124 | 0.0246 | 0.5092 | 0.0319 | 0.0239 | 0.0213 | 0.0082 | 0.2936 | |||
| 0.0066 | 0.0027 | 0.2032 | 0.0097 | 0.0095 | −0.0236 | 0.0033 | 0.2080 | 0.0092 | 0.0092 | −0.3042 | 0.0011 | 0.1713 | |||||
| 0.0163 | 0.0579 | 0.9094 | 0.0436 | 0.0426 | −0.0072 | 0.0485 | 0.8127 | 0.0353 | 0.0395 | −0.0621 | 0.0215 | 0.3091 | |||||
| MLE | MPS | Bayesian | |||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| n | T | r | RB | MSE | LACI | LBP | LBT | RB | MSE | LACI | LBP | LBT | RB | MSE | LCCI | ||
| 0.8 | 50 | 1.5 | 30 | 0.3767 | 0.7387 | 3.1630 | 0.2334 | 0.2282 | −0.1050 | 0.4568 | 2.6352 | 0.1943 | 0.1950 | 0.1140 | 0.0253 | 0.5532 | |
| 0.0402 | 0.2281 | 1.8497 | 0.1278 | 0.1290 | −0.1186 | 0.2520 | 1.7381 | 0.1227 | 0.1230 | −0.0496 | 0.0303 | 0.5508 | |||||
| 0.0631 | 0.3817 | 2.3764 | 0.1554 | 0.1548 | 0.1214 | 0.3962 | 2.2821 | 0.1698 | 0.1678 | −0.0505 | 0.0310 | 0.6040 | |||||
| 3 | 40 | 0.3105 | 0.6978 | 3.0153 | 0.2033 | 0.2013 | 0.1029 | 0.4169 | 2.6153 | 0.1820 | 0.2934 | 0.1240 | 0.0211 | 0.4089 | |||
| 0.0495 | 0.1812 | 1.6247 | 0.0694 | 0.0687 | −0.0569 | 0.1871 | 1.6375 | 0.0732 | 0.0738 | −0.0484 | 0.0214 | 0.4397 | |||||
| −0.0143 | 0.2779 | 2.0654 | 0.0892 | 0.0886 | 0.0860 | 0.3350 | 2.2711 | 0.1008 | 0.1019 | −0.0502 | 0.0249 | 0.4433 | |||||
| 99 | 50 | 0.2901 | 0.6495 | 2.6126 | 0.1931 | 0.1873 | 0.1026 | 0.4053 | 2.5852 | 0.1830 | 0.1830 | 0.0791 | 0.0094 | 0.2958 | |||
| 0.0211 | 0.1413 | 1.4660 | 0.0672 | 0.0667 | −0.0512 | 0.1822 | 1.5636 | 0.0726 | 0.0777 | −0.0279 | 0.0089 | 0.2905 | |||||
| 0.0131 | 0.2533 | 2.0125 | 0.0820 | 0.0830 | 0.0092 | 0.2464 | 2.0574 | 0.0711 | 0.0710 | −0.0305 | 0.0104 | 0.3250 | |||||
| 100 | 1.5 | 70 | 0.3635 | 0.6536 | 2.9600 | 0.1373 | 0.1360 | −0.0689 | 0.5129 | 2.8018 | 0.1278 | 0.1259 | 0.1916 | 0.0383 | 0.4662 | ||
| 0.0276 | 0.1214 | 1.3497 | 0.0604 | 0.0585 | −0.0964 | 0.1572 | 1.3598 | 0.0586 | 0.0589 | −0.0749 | 0.0426 | 0.5332 | |||||
| 0.0189 | 0.2072 | 1.7800 | 0.0849 | 0.0864 | 0.1073 | 0.2985 | 1.9715 | 0.0853 | 0.0872 | −0.0803 | 0.0451 | 0.5308 | |||||
| 3 | 90 | 0.3467 | 0.6173 | 2.3847 | 0.1241 | 0.1129 | 0.0598 | 0.4938 | 2.7555 | 0.1218 | 0.1128 | 0.1924 | 0.0453 | 0.3753 | |||
| 0.0129 | 0.0916 | 1.1830 | 0.0551 | 0.0553 | −0.0558 | 0.1249 | 1.3158 | 0.0585 | 0.0589 | −0.0718 | 0.0393 | 0.3852 | |||||
| 0.0248 | 0.2013 | 1.6856 | 0.0823 | 0.0825 | 0.0462 | 0.3020 | 1.9125 | 0.0799 | 0.0878 | −0.0791 | 0.0462 | 0.4199 | |||||
| 99 | 100 | 0.2929 | 0.5981 | 2.1152 | 0.1127 | 0.1113 | 0.0463 | 0.4866 | 2.3417 | 0.1206 | 0.1027 | 0.1378 | 0.0171 | 0.2769 | |||
| 0.0152 | 0.0916 | 1.1818 | 0.0523 | 0.0523 | −0.0479 | 0.1140 | 1.3319 | 0.0580 | 0.0561 | −0.0549 | 0.0179 | 0.2981 | |||||
| −0.0062 | 0.1928 | 1.6020 | 0.0819 | 0.0810 | 0.0458 | 0.3008 | 1.8910 | 0.0798 | 0.0799 | −0.0534 | 0.0177 | 0.3142 | |||||
| 2 | 50 | 2 | 30 | 0.1108 | 2.1771 | 5.7241 | 0.2747 | 0.2759 | 0.1555 | 3.6273 | 7.3730 | 0.3179 | 0.3503 | 0.0246 | 0.0212 | 0.5163 | |
| 0.0198 | 0.1346 | 1.4314 | 0.0680 | 0.0668 | −0.0698 | 0.1504 | 1.4197 | 0.0647 | 0.0647 | −0.0524 | 0.0317 | 0.5489 | |||||
| 0.0679 | 0.2229 | 1.7742 | 0.0785 | 0.0785 | 0.0013 | 0.1940 | 1.7283 | 0.0803 | 0.0774 | −0.0535 | 0.0339 | 0.5863 | |||||
| 4 | 40 | 0.1034 | 1.0666 | 4.2958 | 0.2410 | 0.2312 | 0.1426 | 3.4818 | 6.6843 | 0.3142 | 0.3227 | 0.0236 | 0.0151 | 0.4241 | |||
| 0.0055 | 0.1049 | 1.2701 | 0.0589 | 0.0590 | −0.0623 | 0.1218 | 1.2788 | 0.0587 | 0.0600 | −0.0497 | 0.0220 | 0.4423 | |||||
| 0.0881 | 0.2039 | 1.3575 | 0.0711 | 0.0781 | 0.0013 | 0.1837 | 1.6395 | 0.0801 | 0.0691 | −0.0524 | 0.0253 | 0.4364 | |||||
| 99 | 50 | 0.0924 | 0.9740 | 4.0544 | 0.2419 | 0.2147 | 0.1448 | 3.0179 | 5.8231 | 0.2763 | 0.3081 | 0.0151 | 0.0075 | 0.3239 | |||
| −0.0106 | 0.1007 | 1.2482 | 0.0577 | 0.0575 | −0.0610 | 0.1161 | 1.1344 | 0.0575 | 0.0572 | −0.0312 | 0.0104 | 0.3003 | |||||
| 0.1231 | 0.1504 | 1.1614 | 0.0612 | 0.0612 | 0.0019 | 0.1853 | 1.4771 | 0.0361 | 0.0611 | −0.0289 | 0.0099 | 0.3013 | |||||
| 100 | 2 | 70 | 0.0622 | 1.2694 | 4.3940 | 0.1994 | 0.1961 | 0.0554 | 1.4031 | 4.6277 | 0.1925 | 0.1922 | 0.0492 | 0.0269 | 0.5138 | ||
| −0.0048 | 0.0576 | 0.9413 | 0.0446 | 0.0447 | −0.0582 | 0.0725 | 0.9522 | 0.0446 | 0.0443 | −0.0921 | 0.0513 | 0.5276 | |||||
| 0.0432 | 0.1285 | 1.3653 | 0.0648 | 0.0645 | 0.0080 | 0.1371 | 1.4517 | 0.0694 | 0.0689 | −0.0955 | 0.0556 | 0.5253 | |||||
| 4 | 90 | 0.0522 | 0.9516 | 2.2214 | 0.1909 | 0.1900 | 0.0512 | 0.9671 | 2.0285 | 0.1832 | 0.1823 | 0.0483 | 0.0211 | 0.4262 | |||
| −0.0227 | 0.0583 | 0.9304 | 0.0407 | 0.0400 | −0.0600 | 0.0772 | 0.9828 | 0.0462 | 0.0462 | −0.0868 | 0.0407 | 0.4078 | |||||
| 0.0907 | 0.1267 | 1.0897 | 0.0618 | 0.0584 | 0.0074 | 0.1285 | 0.1064 | 0.0592 | 0.0590 | −0.1036 | 0.0554 | 0.4244 | |||||
| 99 | 100 | 0.0413 | 0.9290 | 1.6319 | 0.1897 | 0.1880 | 0.0501 | 0.9155 | 2.0033 | 0.1733 | 0.1633 | 0.0277 | 0.0095 | 0.3026 | |||
| −0.0144 | 0.0582 | 0.9397 | 0.0394 | 0.0395 | −0.0617 | 0.0695 | 0.9060 | 0.0451 | 0.0451 | −0.0534 | 0.0175 | 0.2841 | |||||
| 0.0831 | 0.1133 | 0.9915 | 0.0619 | 0.0493 | 0.0041 | 0.1141 | 0.1005 | 0.0411 | 0.0401 | −0.0552 | 0.0184 | 0.3156 | |||||
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Haj Ahmad, H.; Almetwally, E.M.; Rabaiah, A.; Ramadan, D.A. Statistical Analysis of Alpha Power Inverse Weibull Distribution under Hybrid Censored Scheme with Applications to Ball Bearings Technology and Biomedical Data. Symmetry 2023, 15, 161. https://doi.org/10.3390/sym15010161
Haj Ahmad H, Almetwally EM, Rabaiah A, Ramadan DA. Statistical Analysis of Alpha Power Inverse Weibull Distribution under Hybrid Censored Scheme with Applications to Ball Bearings Technology and Biomedical Data. Symmetry. 2023; 15(1):161. https://doi.org/10.3390/sym15010161
Chicago/Turabian StyleHaj Ahmad, Hanan, Ehab M. Almetwally, Ahmed Rabaiah, and Dina A. Ramadan. 2023. "Statistical Analysis of Alpha Power Inverse Weibull Distribution under Hybrid Censored Scheme with Applications to Ball Bearings Technology and Biomedical Data" Symmetry 15, no. 1: 161. https://doi.org/10.3390/sym15010161