
ELM-Based Active Learning via Asymmetric Samplers: Constructing a Multi-Class Text Corpus for Emotion Classification



Abstract
:1. Introduction
2. Related Works
2.1. Extreme Learning Machine
2.2. Traditional Active Learning
2.3. Emotion Taxonomy
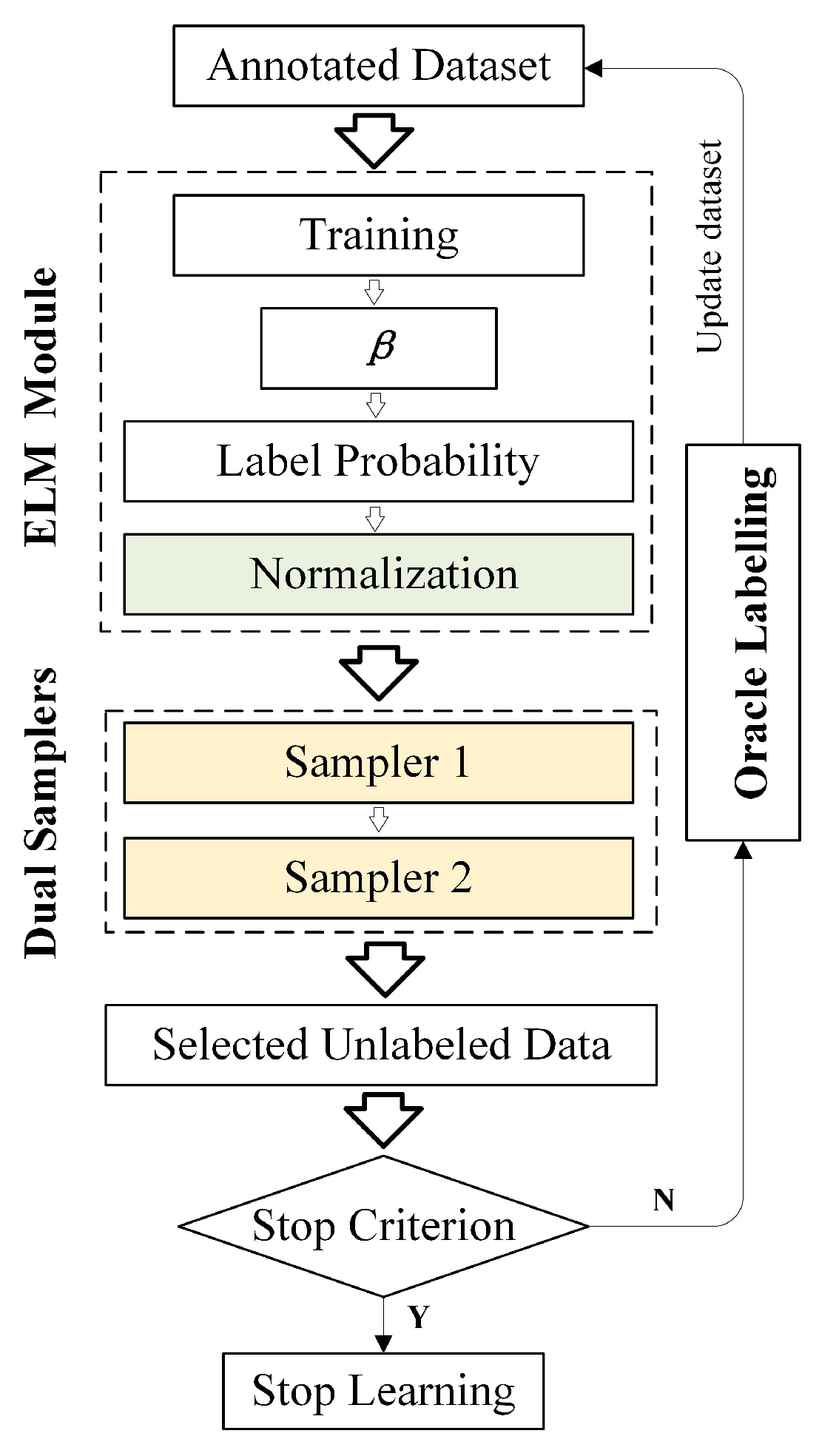
3. Methodology
| Algorithm 1. ELM-based active learning algorithm |
| Input: Training set , Raw set |
| Output: Updated training set |
| 1: repeat |
| 2: Learn a multi-label emotion classifier ELM on X; |
| 3: repeat |
| 4: i means the similarity measurements , , |
| 5: (Figure A1a) |
| 6: until stop criterion 1 |
| 7: repeat |
| 8: j means the similarity measurements , , |
| 9: (Figure A1b) |
| 10: until stop criterion 2 |
| 11: obtain ground truth label from Human Oracle for (Figure A2) |
| 12: |
| 13: until stop criterion 3 |
| 14: return |
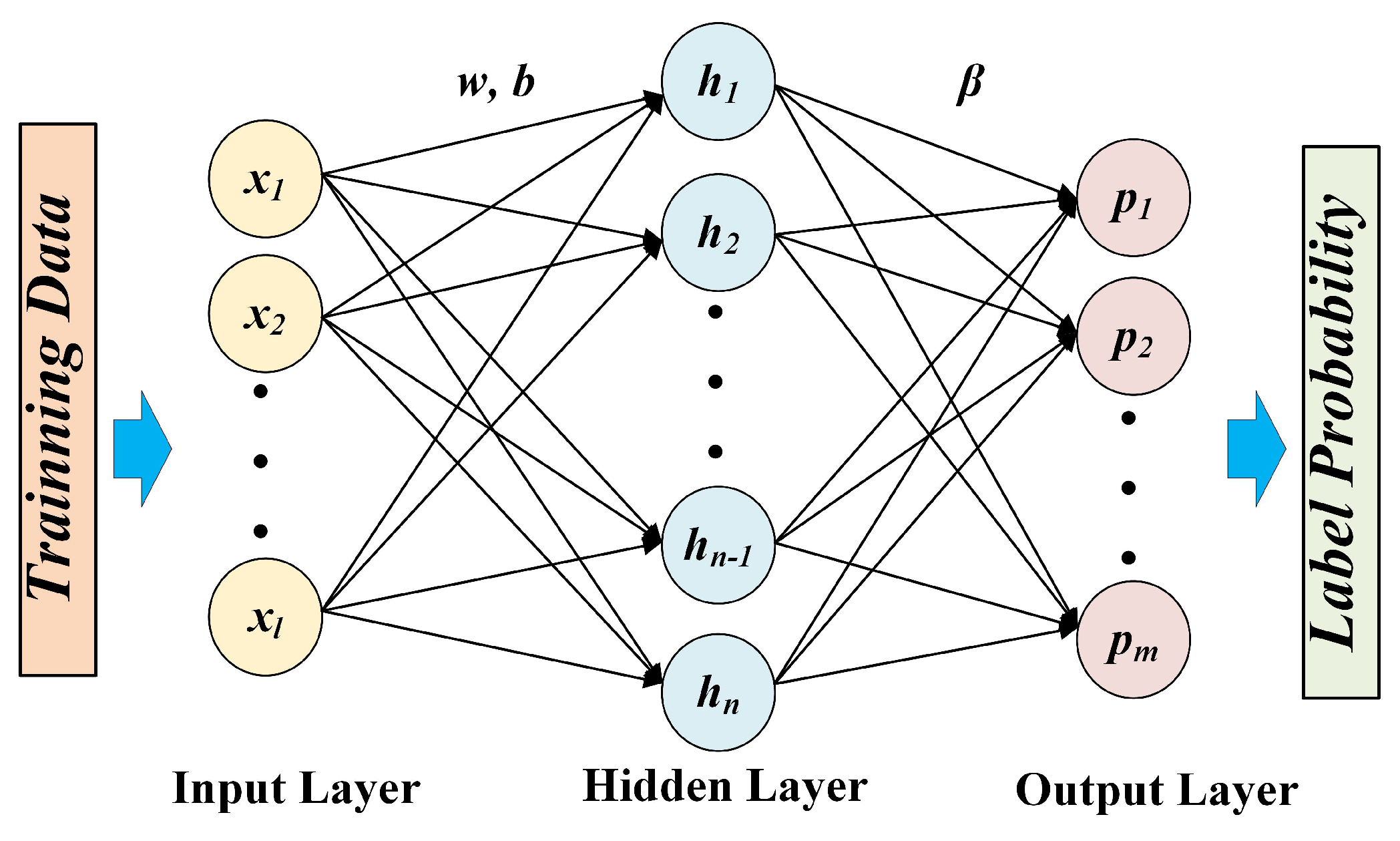
3.1. Working Procedure of ELM
3.2. Proposed Active Learning Method
3.2.1. Proposed Textual Label Predicting Mechanism
3.2.2. Query Strategies used in Asymmetric Samplers
4. Experiments and Discussion
4.1. Evaluations
4.2. Text Preprocessing
4.3. Experimental Setting
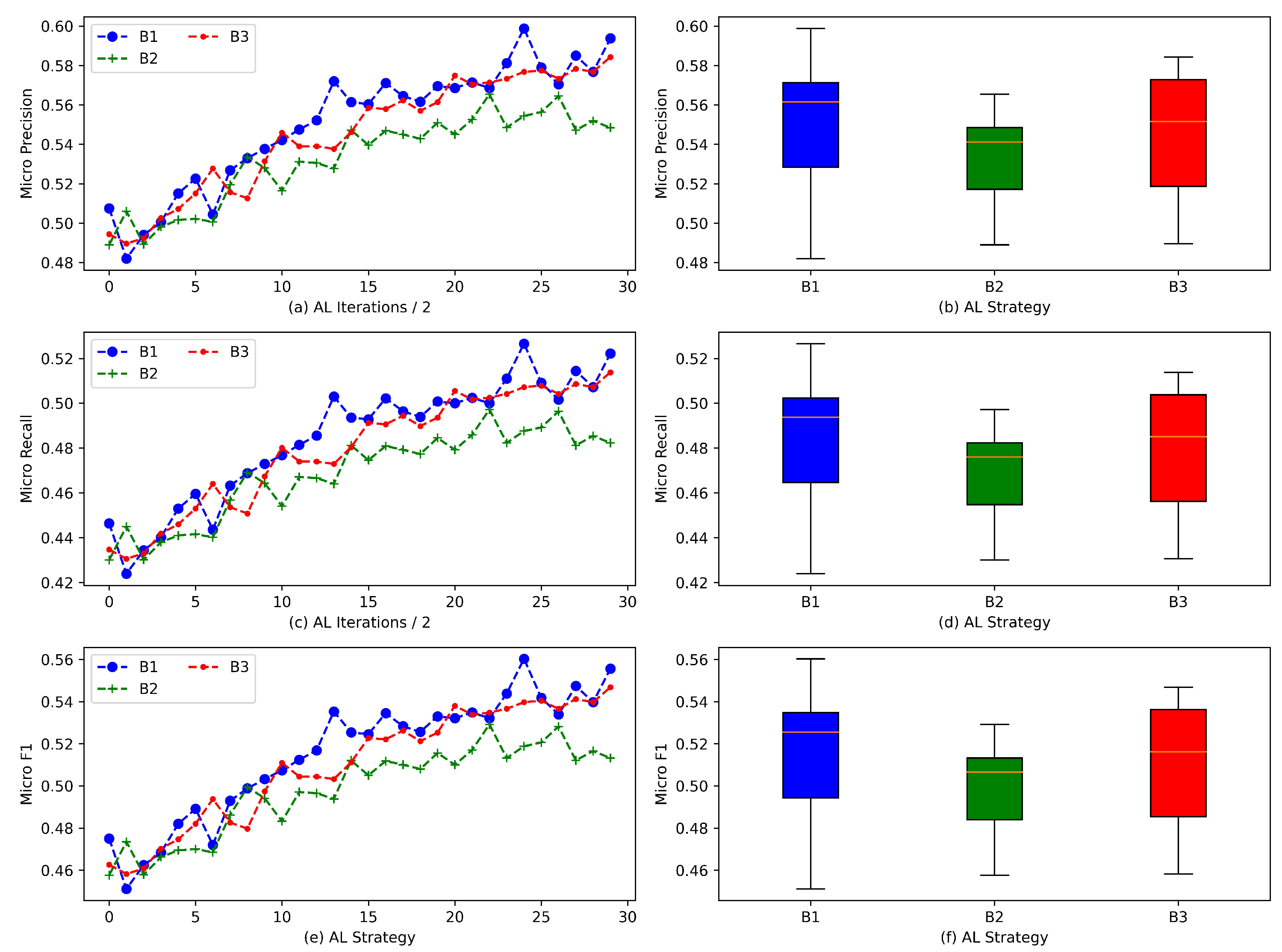
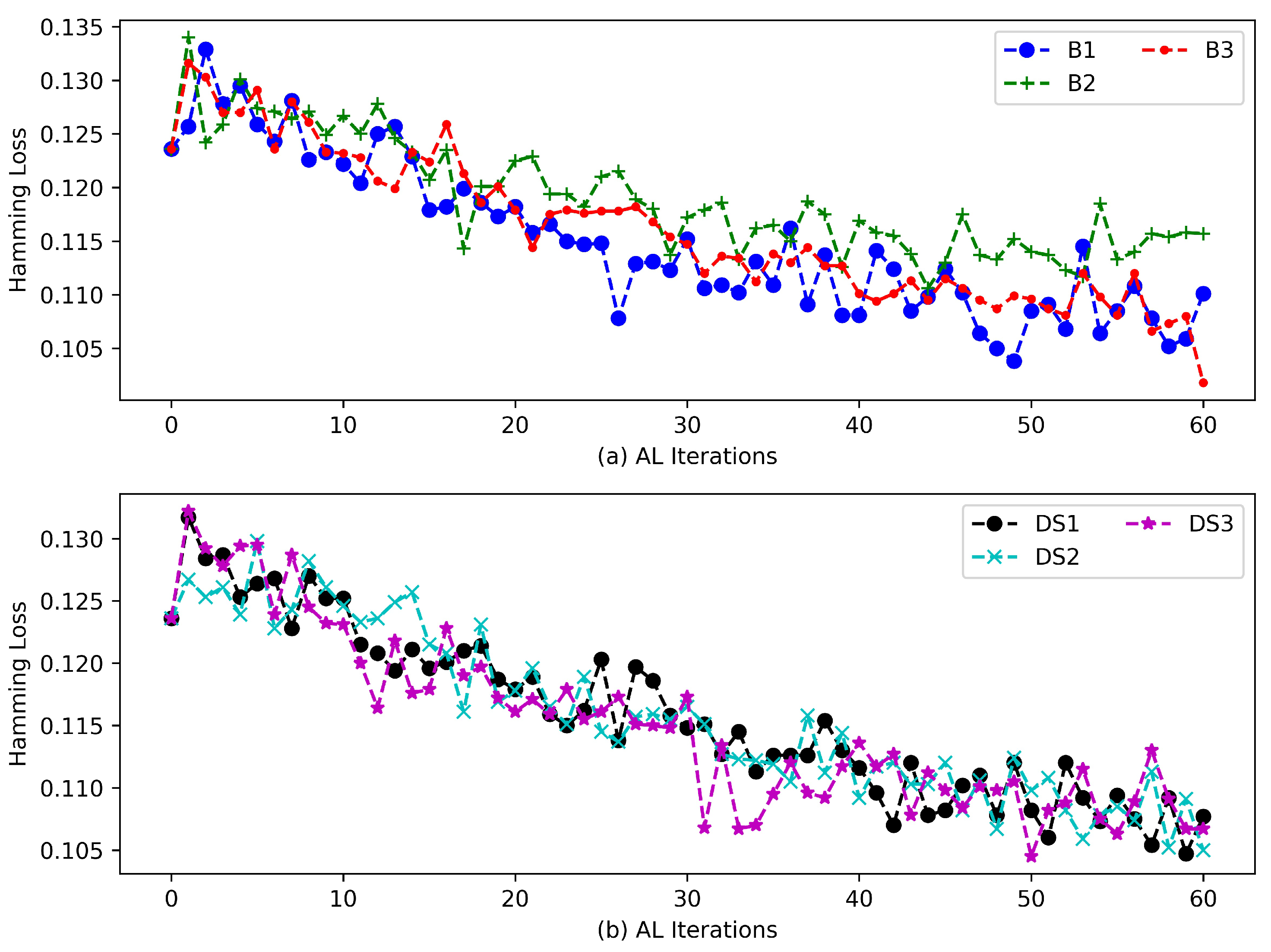
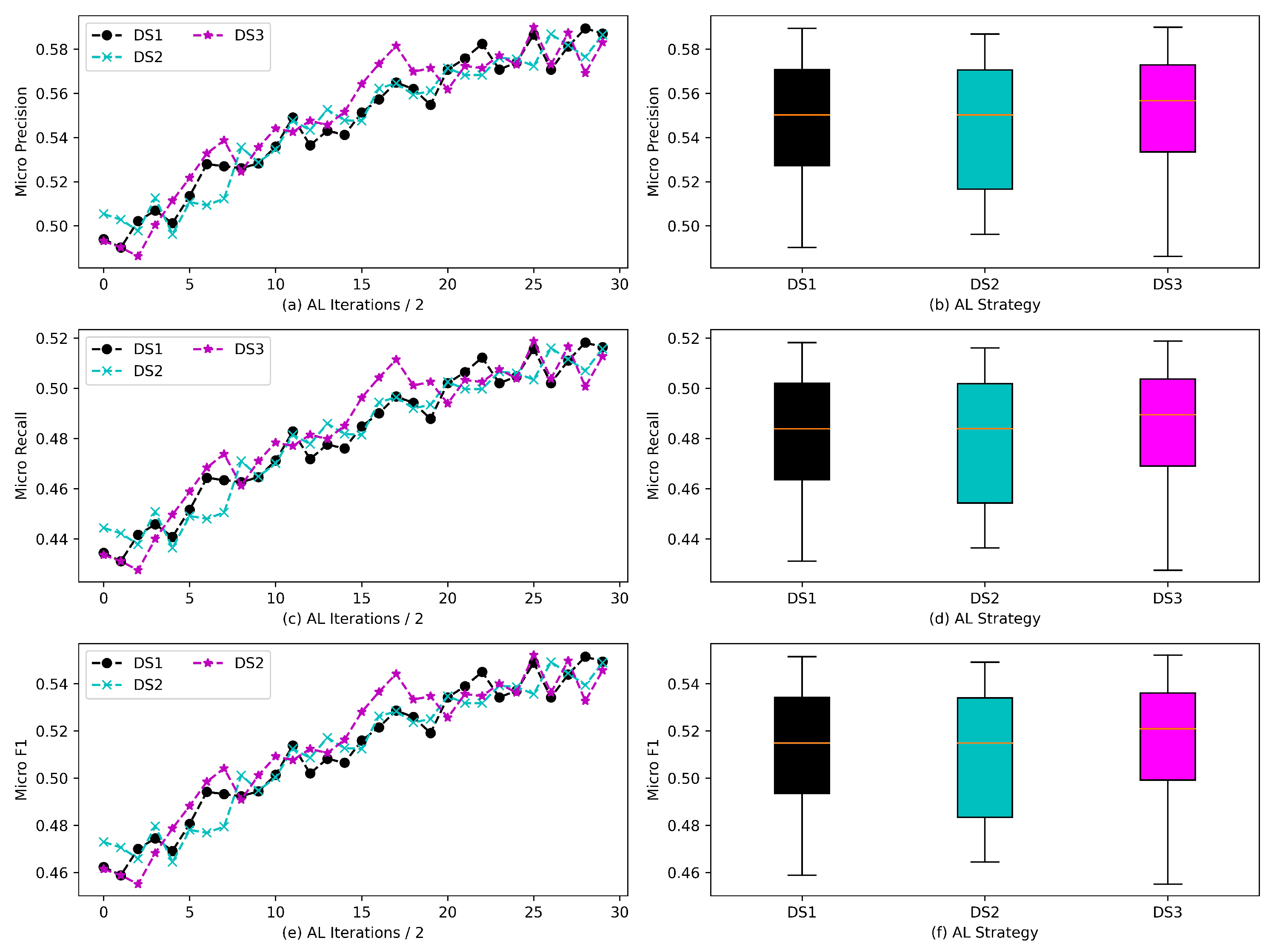
4.4. Experimental Results
4.4.1. Results of Baselines
4.4.2. Results of AL via Asymmetric Samplers
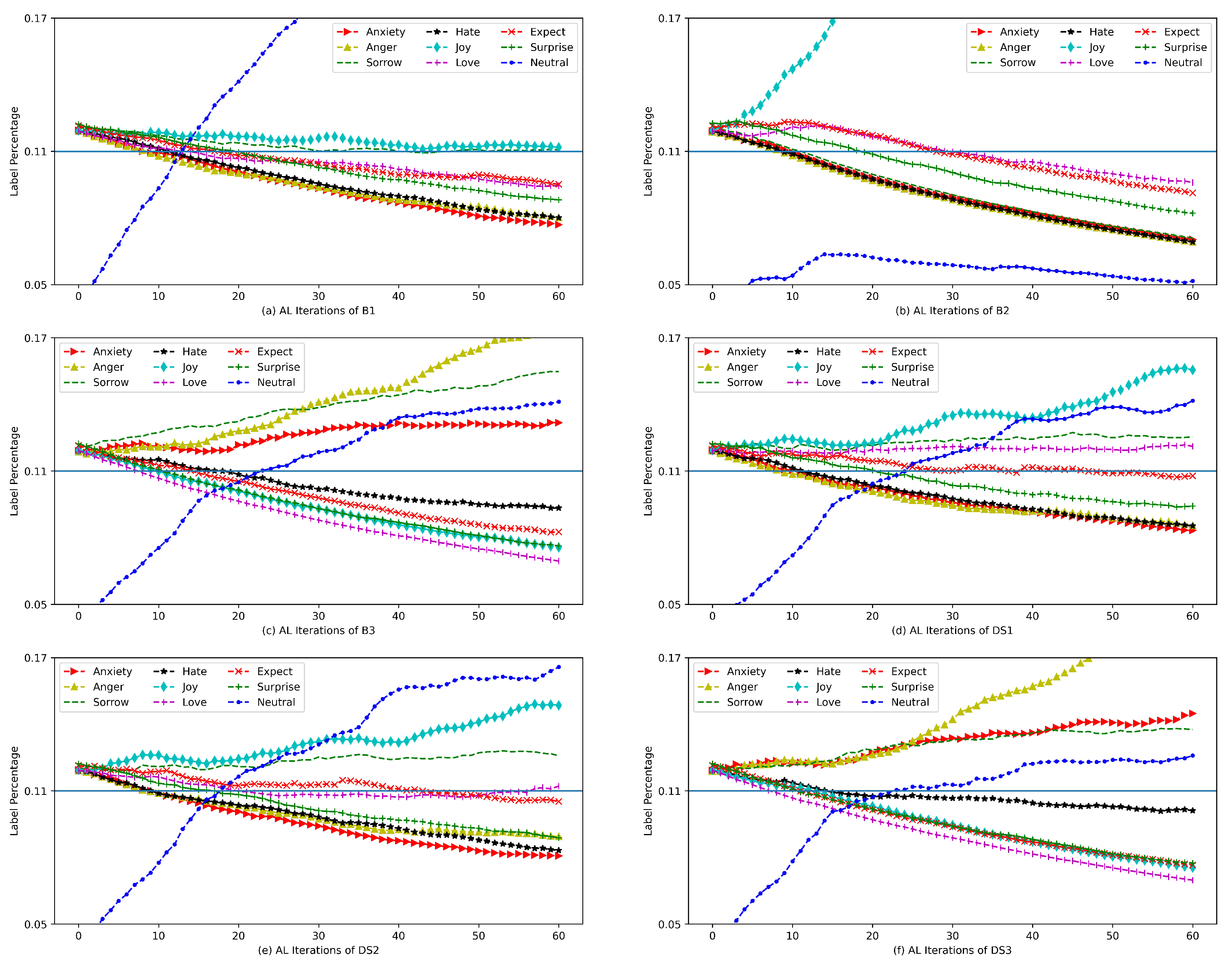
4.5. Emotional Information in Corpus Built by DS2
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A


References
- Deng, J.; Ren, F. Multi-label Emotion Detection via Emotion-Specified Feature Extraction and Emotion Correlation Learning. IEEE Trans. Affect. Comput. 2020. [Google Scholar] [CrossRef]
- Derhab, A.; Alawwad, R.; Dehwah, K.; Tariq, N.; Khan, F.A.; Al-Muhtadi, J. Tweet-based bot detection using big data analytics. IEEE Access 2021, 9, 65988–66005. [Google Scholar] [CrossRef]
- Feng, S.; Tan, Z.; Li, R.; Luo, M. Heterogeneity-aware twitter bot detection with relational graph transformers. In Proceedings of the AAAI Conference on Artificial Intelligence, online, 22 February–1 March 2022; Volume 36, pp. 3977–3985. [Google Scholar]
- Suchacka, G.; Cabri, A.; Rovetta, S.; Masulli, F. Efficient on-the-fly Web bot detection. Knowl.-Based Syst. 2021, 223, 107074. [Google Scholar] [CrossRef]
- Dwarakanath, L.; Kamsin, A.; Rasheed, R.A.; Anandhan, A.; Shuib, L. Automated machine learning approaches for emergency response and coordination via social media in the aftermath of a disaster: A review. IEEE Access 2021, 9, 68917–68931. [Google Scholar] [CrossRef]
- Mansour, R.F.; El Amraoui, A.; Nouaouri, I.; Díaz, V.G.; Gupta, D.; Kumar, S. Artificial intelligence and internet of things enabled disease diagnosis model for smart healthcare systems. IEEE Access 2021, 9, 45137–45146. [Google Scholar] [CrossRef]
- Lin, Y.; Li, M.; Watanabe, Y.; Kimura, T.; Matsunawa, T.; Nojima, S.; Pan, D.Z. Data efficient lithography modeling with transfer learning and active data selection. IEEE Trans.-Comput.-Aided Des. Integr. Circuits Syst. 2018, 38, 1900–1913. [Google Scholar] [CrossRef]
- Yan, Y.; Huang, S.J. Cost-Effective Active Learning for Hierarchical Multi-Label Classification. In Proceedings of the IJCAI, Stockholm, Sweden, 13–19 July 2018; pp. 2962–2968. [Google Scholar]
- Yoo, D.; Kweon, I.S. Learning loss for active learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–17 June 2019; pp. 93–102. [Google Scholar]
- Le, Q.; Mikolov, T. Distributed representations of sentences and documents. In Proceedings of the International Conference on Machine Learning, Beijing, China, 21–26 June 2014; pp. 1188–1196. [Google Scholar]
- Zhang, A.; Li, B.; Wang, W.; Wan, S.; Chen, W. MII: A novel text classification model combining deep active learning with BERT. Comput. Mater. Contin. 2020, 63, 1499–1514. [Google Scholar] [CrossRef]
- Zhang, X.; Zhao, J.; LeCun, Y. Character-level convolutional networks for text classification. Adv. Neural Inf. Process. Syst. 2015, 28, 649–657. [Google Scholar]
- De Angeli, K.; Gao, S.; Alawad, M.; Yoon, H.J.; Schaefferkoetter, N.; Wu, X.C.; Durbin, E.B.; Doherty, J.; Stroup, A.; Coyle, L.; et al. Deep active learning for classifying cancer pathology reports. BMC Bioinform. 2021, 22, 1–25. [Google Scholar] [CrossRef]
- Dor, L.E.; Halfon, A.; Gera, A.; Shnarch, E.; Dankin, L.; Choshen, L.; Danilevsky, M.; Aharonov, R.; Katz, Y.; Slonim, N. Active learning for BERT: An empirical study. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), online, 1 May 2020; pp. 7949–7962. [Google Scholar]
- Khowaja, S.A.; Khuwaja, P. Q-learning and LSTM based deep active learning strategy for malware defense in industrial IoT applications. Multimed. Tools Appl. 2021, 80, 14637–14663. [Google Scholar] [CrossRef]
- Huang, G.B.; Zhu, Q.Y.; Siew, C.K. Extreme learning machine: Theory and applications. Neurocomputing 2006, 70, 489–501. [Google Scholar] [CrossRef]
- Nguyen, V.L.; Shaker, M.H.; Hüllermeier, E. How to measure uncertainty in uncertainty sampling for active learning. Mach. Learn. 2022, 111, 89–122. [Google Scholar] [CrossRef]
- Huang, S.J.; Zhou, Z.H. Active query driven by uncertainty and diversity for incremental multi-label learning. In Proceedings of the 2013 IEEE 13th International Conference on Data Mining, Dallas, TX, USA, 7–10 December 2013; pp. 1079–1084. [Google Scholar]
- Du, B.; Wang, Z.; Zhang, L.; Zhang, L.; Liu, W.; Shen, J.; Tao, D. Exploring representativeness and informativeness for active learning. IEEE Trans. Cybern. 2015, 47, 14–26. [Google Scholar] [CrossRef] [PubMed]
- Liu, Z.; Jiang, X.; Luo, H.; Fang, W.; Liu, J.; Wu, D. Pool-based unsupervised active learning for regression using iterative representativeness-diversity maximization (iRDM). Pattern Recognit. Lett. 2021, 142, 11–19. [Google Scholar] [CrossRef]
- Kang, X.; Wu, Y.; Ren, F. Progressively improving supervised emotion classification through active learning. In Proceedings of the International Conference on Multi-disciplinary Trends in Artificial Intelligence, Hanoi, Vietnam, 18–20 November 2018; pp. 49–57. [Google Scholar]
- Yao, L.; Huang, H.; Wang, K.W.; Chen, S.H.; Xiong, Q. Fine-grained mechanical Chinese named entity recognition based on ALBERT-AttBiLSTM-CRF and transfer learning. Symmetry 2020, 12, 1986. [Google Scholar] [CrossRef]
- Khan, M.A.; Kadry, S.; Zhang, Y.D.; Akram, T.; Sharif, M.; Rehman, A.; Saba, T. Prediction of COVID-19-pneumonia based on selected deep features and one class kernel extreme learning machine. Comput. Electr. Eng. 2021, 90, 106960. [Google Scholar] [CrossRef]
- Zhang, L.; Zhang, D. Evolutionary cost-sensitive extreme learning machine. IEEE Trans. Neural Netw. Learn. Syst. 2016, 28, 3045–3060. [Google Scholar] [CrossRef]
- Muhammad, G.; Rahman, S.M.M.; Alelaiwi, A.; Alamri, A. Smart health solution integrating IoT and cloud: A case study of voice pathology monitoring. IEEE Commun. Mag. 2017, 55, 69–73. [Google Scholar] [CrossRef]
- Muhammad, G.; Alhamid, M.F.; Alsulaiman, M.; Gupta, B. Edge computing with cloud for voice disorder assessment and treatment. IEEE Commun. Mag. 2018, 56, 60–65. [Google Scholar] [CrossRef]
- Cambria, E.; Gastaldo, P.; Bisio, F.; Zunino, R. An ELM-based model for affective analogical reasoning. Neurocomputing 2015, 149, 443–455. [Google Scholar] [CrossRef]
- Oneto, L.; Bisio, F.; Cambria, E.; Anguita, D. Statistical learning theory and ELM for big social data analysis. IEEE Comput. Intell. Mag. 2016, 11, 45–55. [Google Scholar] [CrossRef]
- Shi, L.C.; Lu, B.L. EEG-based vigilance estimation using extreme learning machines. Neurocomputing 2013, 102, 135–143. [Google Scholar] [CrossRef]
- Murugavel, A.M.; Ramakrishnan, S. Hierarchical multi-class SVM with ELM kernel for epileptic EEG signal classification. Med. Biol. Eng. Comput. 2016, 54, 149–161. [Google Scholar] [CrossRef] [PubMed]
- Yang, Y.; Wu, Q.J. Extreme learning machine with subnetwork hidden nodes for regression and classification. IEEE Trans. Cybern. 2015, 46, 2885–2898. [Google Scholar] [CrossRef]
- Tissera, M.D.; McDonnell, M.D. Deep extreme learning machines: Supervised autoencoding architecture for classification. Neurocomputing 2016, 174, 42–49. [Google Scholar] [CrossRef]
- Deng, W.Y.; Bai, Z.; Huang, G.B.; Zheng, Q.H. A fast SVD-Hidden-nodes based extreme learning machine for large-scale data Analytics. Neural Netw. 2016, 77, 14–28. [Google Scholar] [CrossRef]
- Li, K.; Kong, X.; Lu, Z.; Wenyin, L.; Yin, J. Boosting weighted ELM for imbalanced learning. Neurocomputing 2014, 128, 15–21. [Google Scholar] [CrossRef]
- Li, J.; Du, Q.; Li, W.; Li, Y. Optimizing extreme learning machine for hyperspectral image classification. J. Appl. Remote. Sens. 2015, 9, 097296. [Google Scholar] [CrossRef]
- Huang, S.J.; Chen, J.L.; Mu, X.; Zhou, Z.H. Cost-Effective Active Learning from Diverse Labelers. In Proceedings of the IJCAI, Melbourne, Australia, 20 August 2017; pp. 1879–1885. [Google Scholar]
- Neutatz, F.; Mahdavi, M.; Abedjan, Z. ED2: A case for active learning in error detection. In Proceedings of the 28th ACM International Conference on Information and Knowledge Management, Beijing, China, 3–7 November 2019; pp. 2249–2252. [Google Scholar]
- Cai, J.J.; Tang, J.; Chen, Q.G.; Hu, Y.; Wang, X.; Huang, S.J. Multi-View Active Learning for Video Recommendation. In Proceedings of the IJCAI, Macao, China, 11–12 August 2019; pp. 2053–2059. [Google Scholar]
- Wang, M.; Fu, K.; Min, F.; Jia, X. Active learning through label error statistical methods. Knowl.-Based Syst. 2020, 189, 105140. [Google Scholar] [CrossRef]
- Miller, T.L.; Grimes, M.G.; McMullen, J.S.; Vogus, T.J. Venturing for others with heart and head: How compassion encourages social entrepreneurship. Acad. Manag. Rev. 2012, 37, 616–640. [Google Scholar] [CrossRef]
- Plutchik, R.; Kellerman, H. Theories of Emotion; Academic Press: Cambridge, MA, USA, 2013; Volume 1. [Google Scholar]
- Mohammad, S.M.; Turney, P.D. Crowdsourcing a word-emotion association lexicon. Comput. Intell. 2013, 29, 436–465. [Google Scholar] [CrossRef]
- Quan, C.; Ren, F. A blog emotion corpus for emotional expression analysis in Chinese. Comput. Speech Lang. 2010, 24, 726–749. [Google Scholar] [CrossRef]
- Ren, F.; Quan, C. Linguistic-based emotion analysis and recognition for measuring consumer satisfaction: An application of affective computing. Inf. Technol. Manag. 2012, 13, 321–332. [Google Scholar] [CrossRef]
- Ren, F.; Kang, X. Employing hierarchical Bayesian networks in simple and complex emotion topic analysis. Comput. Speech Lang. 2013, 27, 943–968. [Google Scholar] [CrossRef]
- Ptaszynski, M.; Rzepka, R.; Araki, K.; Momouchi, Y. Automatically annotating a five-billion-word corpus of Japanese blogs for sentiment and affect analysis. Comput. Speech Lang. 2014, 28, 38–55. [Google Scholar] [CrossRef]
- Shi, W.; Wang, H.; He, S. Sentiment analysis of Chinese microblogging based on sentiment ontology: A case study of ‘7.23 Wenzhou Train Collision’. Connect. Sci. 2013, 25, 161–178. [Google Scholar] [CrossRef]
- Gunter, B.; Koteyko, N.; Atanasova, D. Sentiment analysis: A market-relevant and reliable measure of public feeling? Int. J. Mark. Res. 2014, 56, 231–247. [Google Scholar] [CrossRef]
- He, Q.; Shang, T.; Zhuang, F.; Shi, Z. Parallel extreme learning machine for regression based on MapReduce. Neurocomputing 2013, 102, 52–58. [Google Scholar] [CrossRef]
- Tan, Y.; Yang, L.; Hu, Q.; Du, Z. Batch mode active learning for semantic segmentation based on multi-clue sample selection. In Proceedings of the 28th ACM International Conference on Information and Knowledge Management, Beijing, China, 3–7 November 2019; pp. 831–840. [Google Scholar]
- Guo, Y.; Ding, G.; Gao, Y.; Han, J. Active learning with cross-class similarity transfer. In Proceedings of the AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 4–9 February 2017; Volume 31. [Google Scholar]
- Jamshidpour, N.; Aria, E.H.; Safari, A.; Homayouni, S. Adaptive Self-Learned Active Learning Framework for Hyperspectral Classification. In Proceedings of the 2019 10th Workshop on Hyperspectral Imaging and Signal Processing: Evolution in Remote Sensing (WHISPERS), Amsterdam, The Netherlands, 24–26 September 2019; pp. 1–5. [Google Scholar]
- Rubner, Y.; Tomasi, C.; Guibas, L.J. The earth mover’s distance as a metric for image retrieval. Int. J. Comput. Vis. 2000, 40, 99–121. [Google Scholar] [CrossRef]
- Kang, X.; Shi, X.; Wu, Y.; Ren, F. Active learning with complementary sampling for instructing class-biased multi-label text emotion classification. IEEE Trans. Affect. Comput. 2020, 1. [Google Scholar] [CrossRef]
- Li, Y.; Lv, Y.; Wang, S.; Liang, J.; Li, J.; Li, X. Cooperative hybrid semi-supervised learning for text sentiment classification. Symmetry 2019, 11, 133. [Google Scholar] [CrossRef]
- Sarker, I.H.; Abushark, Y.B.; Alsolami, F.; Khan, A.I. Intrudtree: A machine learning based cyber security intrusion detection model. Symmetry 2020, 12, 754. [Google Scholar] [CrossRef]
- Zhu, S.; Li, S.; Chen, Y.; Zhou, G. Corpus fusion for emotion classification. In Proceedings of the COLING 2016, the 26th International Conference on Computational Linguistics: Technical Papers, Osaka, Japan, 11–16 December 2016; pp. 3287–3297. [Google Scholar]
- Iosifidis, A.; Tefas, A.; Pitas, I. Minimum variance extreme learning machine for human action recognition. In Proceedings of the 2014 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Florence, Italy, 4–9 May 2014; pp. 5427–5431. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Precision | recall | F1 | |||||||
|---|---|---|---|---|---|---|---|---|---|
| Initial (%) | Final (%) | (%) | Initial (%) | Final (%) | (%) | Initial (%) | Final (%) | (%) | |
| B1 | 51.23 | 57.33 | 6.10↑ | 45.05 | 50.42 | 5.37↑ | 47.94 | 53.65 | 5.71↑ |
| B2 | 51.23 | 54.81 | 3.58↑ | 45.05 | 48.20 | 3.15↑ | 47.94 | 51.30 | 3.36↑ |
| B3 | 51.23 | 61.04 | 9.18↑ | 45.05 | 53.68 | 8.63↑ | 47.94 | 57.13 | 9.19↑ |
| Precision | Recall | F1 | |||||||
|---|---|---|---|---|---|---|---|---|---|
| Initial (%) | Final (%) | (%) | Initial (%) | Final (%) | (%) | Initial (%) | Final (%) | (%) | |
| B1 | 57.32 | 61.63 | 4.31↑ | 65.19 | 68.46 | 3.27↑ | 61.00 | 64.87 | 3.87↑ |
| B2 | 57.32 | 61.75 | 4.43↑ | 65.19 | 68.62 | 3.43↑ | 61.00 | 65.01 | 4.01↑ |
| B3 | 57.32 | 60.14 | 2.82↑ | 65.19 | 67.29 | 2.10↑ | 61.00 | 63.52 | 2.52↑ |
| Precision | Recall | F1 | |||||||
|---|---|---|---|---|---|---|---|---|---|
| Initial (%) | Final (%) | (%) | Initial (%) | Final (%) | (%) | Initial (%) | Final (%) | (%) | |
| B1 | 57.17 | 59.02 | 1.85↑ | 56.72 | 57.06 | 0.34↑ | 56.94 | 58.02 | 1.08↑ |
| B2 | 57.17 | 55.86 | 1.31↓ | 56.72 | 53.79 | 2.93↓ | 56.94 | 54.81 | 2.13↓ |
| B3 | 57.17 | 58.76 | 1.59↑ | 56.72 | 56.45 | 0.27↓ | 56.94 | 57.58 | 0.64↑ |
| Anxiety | Anger | Sorrow | Hate | Joy | Love | Expect | Surprise | Neutral | |
|---|---|---|---|---|---|---|---|---|---|
| Initial | 301 | 300 | 304 | 300 | 301 | 300 | 306 | 308 | 99 |
| B1 | 338 | 352 | 486 | 352 | 491 | 415 | 418 | 387 | 1153 |
| B2 | 316 | 311 | 319 | 311 | 1794 | 431 | 410 | 369 | 232 |
| B3 | 584 | 774 | 686 | 414 | 335 | 308 | 366 | 338 | 626 |
| Precision | Recall | F1 | |||||||
|---|---|---|---|---|---|---|---|---|---|
| Initial (%) | Final (%) | (%) | Initial (%) | Final (%) | (%) | Initial (%) | Final (%) | (%) | |
| Anxiety | 49.76 | 64.90 | 15.14↑ | 57.30 | 55.06 | 2.24↓ | 53.26 | 59.57 | 6.31↑ |
| Anger | 38.15 | 61.19 | 23.04↑ | 32.84 | 40.80 | 7.96↑ | 35.29 | 48.96 | 13.67↑ |
| Sorrow | 51.63 | 65.05 | 13.43↑ | 43.18 | 55.00 | 11.82↑ | 47.03 | 59.61 | 12.58↑ |
| Hate | 38.89 | 53.19 | 14.30↑ | 43.26 | 28.09 | 15.17↓ | 40.96 | 36.76 | 4.20↓ |
| Joy | 70.00 | 84.02 | 14.02↑ | 58.88 | 66.36 | 7.48↑ | 63.96 | 74.15 | 10.19↑ |
| Love | 68.47 | 79.33 | 10.83↑ | 65.57 | 56.13 | 9.44↓ | 66.99 | 65.75 | 1.24↓ |
| Expect | 52.83 | 65.73 | 12.90↑ | 50.00 | 52.23 | 2.23↑ | 51.38 | 58.21 | 6.83↑ |
| Surprise | 43.72 | 56.70 | 12.98↑ | 42.55 | 29.26 | 13.29↓ | 43.13 | 38.60 | 4.53↓ |
| Neutral | 33.33 | 29.53 | 3.80↓ | 8.85 | 66.15 | 57.30↑ | 13.99 | 40.84 | 26.85↑ |
| Precision | Recall | F1 | |||||||
|---|---|---|---|---|---|---|---|---|---|
| Initial (%) | Final (%) | (%) | Initial (%) | Final (%) | (%) | Initial (%) | Final (%) | (%) | |
| DS1 | 51.23 | 58.40 | 7.17↑ | 45.05 | 51.36 | 6.31↑ | 47.94 | 54.65 | 6.71↑ |
| DS2 | 51.23 | 59.60 | 8.37↑ | 45.05 | 52.41 | 7.36↑ | 47.94 | 55.77 | 7.83↑ |
| DS3 | 51.23 | 58.84 | 3.61↑ | 45.05 | 51.74 | 6.69↑ | 47.94 | 55.06 | 7.12↑ |
| Precision | Recall | F1 | |||||||
|---|---|---|---|---|---|---|---|---|---|
| Initial (%) | Final (%) | (%) | Initial (%) | Final (%) | (%) | Initial (%) | Final (%) | (%) | |
| DS1 | 57.32 | 61.87 | 4.55↑ | 65.19 | 66.63 | 1.44↑ | 61.00 | 64.16 | 3.16↑ |
| DS2 | 57.32 | 61.15 | 3.83↑ | 65.19 | 65.41 | 0.22↑ | 61.00 | 63.21 | 2.21↑ |
| DS3 | 57.32 | 60.63 | 3.31↑ | 65.19 | 67.24 | 2.05↑ | 61.00 | 63.76 | 2.76↑ |
| Precision | Recall | F1 | |||||||
|---|---|---|---|---|---|---|---|---|---|
| Initial (%) | Final (%) | (%) | Initial (%) | Final (%) | (%) | Initial (%) | Final (%) | (%) | |
| DS1 | 57.17 | 59.57 | 2.40↑ | 56.72 | 57.33 | 0.61↑ | 56.94 | 58.43 | 1.49↑ |
| DS2 | 57.17 | 58.13 | 0.94↑ | 56.72 | 55.62 | 1.10↓ | 56.94 | 56.84 | 0.10↓ |
| DS3 | 57.17 | 59.38 | 2.21↑ | 56.72 | 56.78 | 0.06↑ | 56.94 | 58.05 | 1.11↑ |
| Anxiety | Anger | Sorrow | Hate | Joy | Love | Expect | Surprise | Neutral | |
|---|---|---|---|---|---|---|---|---|---|
| Initial | 301 | 300 | 304 | 300 | 301 | 300 | 306 | 308 | 99 |
| DS1 | 372 | 382 | 560 | 381 | 695 | 541 | 482 | 421 | 633 |
| DS2 | 360 | 399 | 561 | 371 | 662 | 500 | 469 | 396 | 739 |
| DS3 | 643 | 848 | 611 | 449 | 335 | 310 | 340 | 344 | 559 |
| Precision | Recall | F1 | |||||||
|---|---|---|---|---|---|---|---|---|---|
| Initial (%) | Final (%) | (%) | Initial (%) | Final (%) | (%) | Initial (%) | Final (%) | (%) | |
| Anxiety | 49.76 | 57.39 | 7.63↑ | 57.30 | 56.74 | 0.56↓ | 53.26 | 57.06 | 3.80↑ |
| Anger | 38.15 | 55.28 | 17.13↑ | 32.84 | 44.28 | 11.44↑ | 35.29 | 49.17 | 13.88↑ |
| Sorrow | 51.63 | 61.72 | 10.09↑ | 43.18 | 58.64 | 15.46↑ | 47.03 | 60.14 | 13.11↑ |
| Hate | 38.89 | 55.38 | 16.49↑ | 43.26 | 40.45 | 2.81↓ | 40.96 | 46.75 | 5.79↑ |
| Joy | 70.00 | 74.23 | 4.23↑ | 58.88 | 67.29 | 8.41↑ | 63.96 | 70.59 | 6.63↑ |
| Love | 68.47 | 76.00 | 7.53↑ | 65.57 | 62.74 | 2.83↓ | 66.99 | 68.73 | 1.74↑ |
| Expect | 52.83 | 61.11 | 8.28↑ | 50.00 | 54.02 | 4.02↑ | 51.38 | 57.35 | 5.97↑ |
| Surprise | 43.72 | 48.59 | 4.87↑ | 42.55 | 36.70 | 5.85↓ | 43.13 | 41.82 | 1.31↓ |
| Neutral | 33.33 | 34.31 | 0.98↑ | 8.85 | 36.46 | 27.61↑ | 13.99 | 35.35 | 21.36↑ |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Shi, X.; Hu, M.; Ren, F.; Shi, P.; Sun, X. ELM-Based Active Learning via Asymmetric Samplers: Constructing a Multi-Class Text Corpus for Emotion Classification. Symmetry 2022, 14, 1698. https://doi.org/10.3390/sym14081698
Shi X, Hu M, Ren F, Shi P, Sun X. ELM-Based Active Learning via Asymmetric Samplers: Constructing a Multi-Class Text Corpus for Emotion Classification. Symmetry. 2022; 14(8):1698. https://doi.org/10.3390/sym14081698
Chicago/Turabian StyleShi, Xuefeng, Min Hu, Fuji Ren, Piao Shi, and Xiao Sun. 2022. "ELM-Based Active Learning via Asymmetric Samplers: Constructing a Multi-Class Text Corpus for Emotion Classification" Symmetry 14, no. 8: 1698. https://doi.org/10.3390/sym14081698