3.1. Accountability Metric
We design our FL environment to be public such that anyone can join the FL tasks; therefore, we must guarantee that only credible clients join and perform the task to produce accurate global models. For this reason, we use two metrics to assess clients’ trustability: leveling and credit score mechanism.
3.1.1. Leveling System
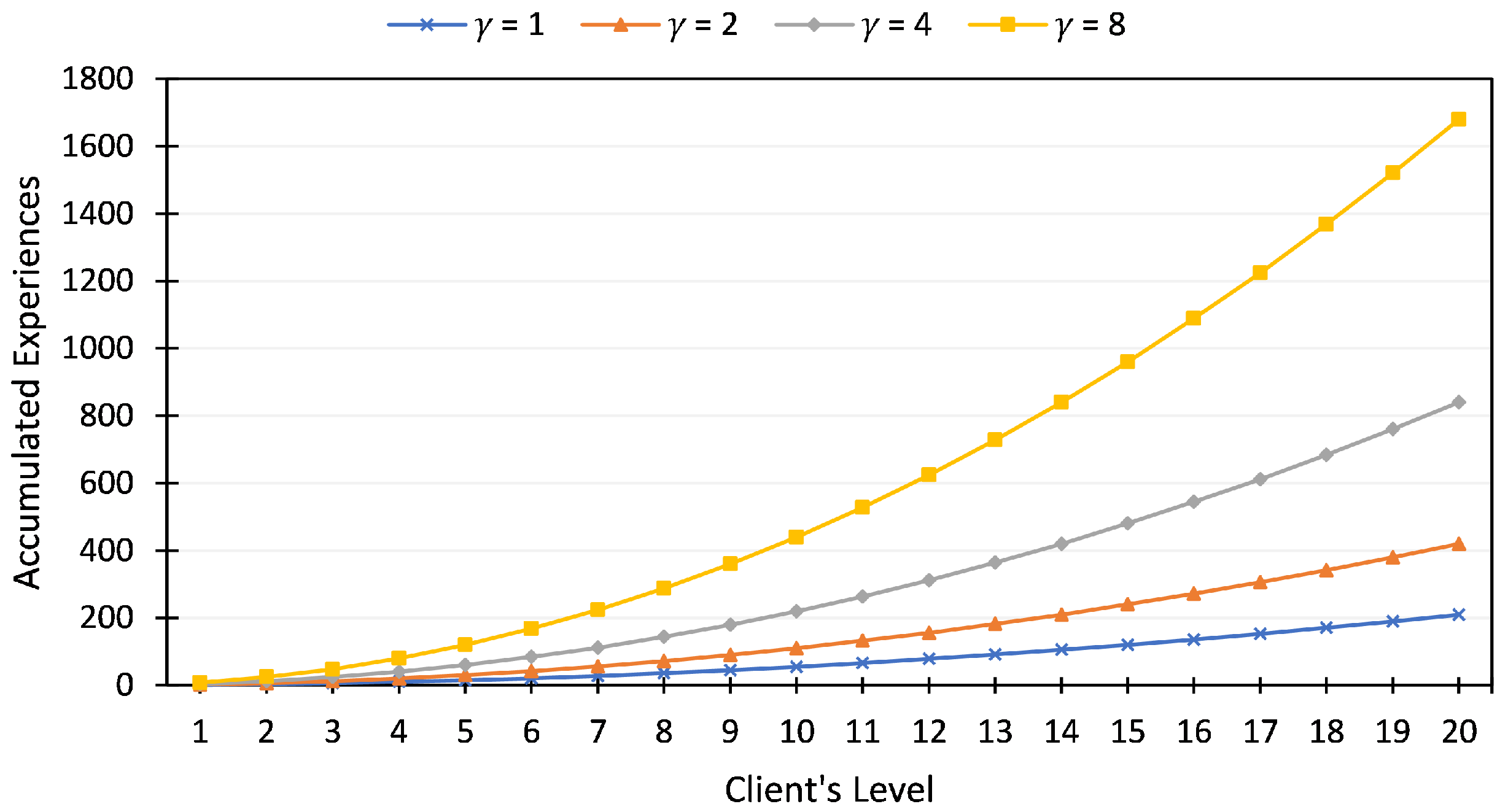
The leveling system is used to judge the clients’ experience of performing the FL tasks, which is summarized in Algorithm 1. The admin first sets
value, a multiplier to determine how many experiences are required to reach the next level
. New client will be given zero experience (
), which puts them into level one (
) by default. Every time clients successfully perform a task (e.g., training or evaluating), the
GainExperience(·) method will increase their experiences. The method also increments clients’ level if the required experience to level up is reached. Higher-level clients mean that they are veteran players and are most likely to be trustable.
| Algorithm 1 Leveling system for client i |
- 1:
on startup: - 2:
admin initiates ▹ experience growth multiplier - 3:
for each new client, admin initiates: - 4:
and ▹ default level and experience - 5:
▹ experience required to level up - 6:
procedureGainExperience(i) - 7:
get the current experience e for client i - 8:
- 9:
if then ▹ level up is possible - 10:
- 11:
- 12:
- 13:
functionCalculateLevel(i) - 14:
return get the current level l for client i
|
3.1.2. Credit Score System
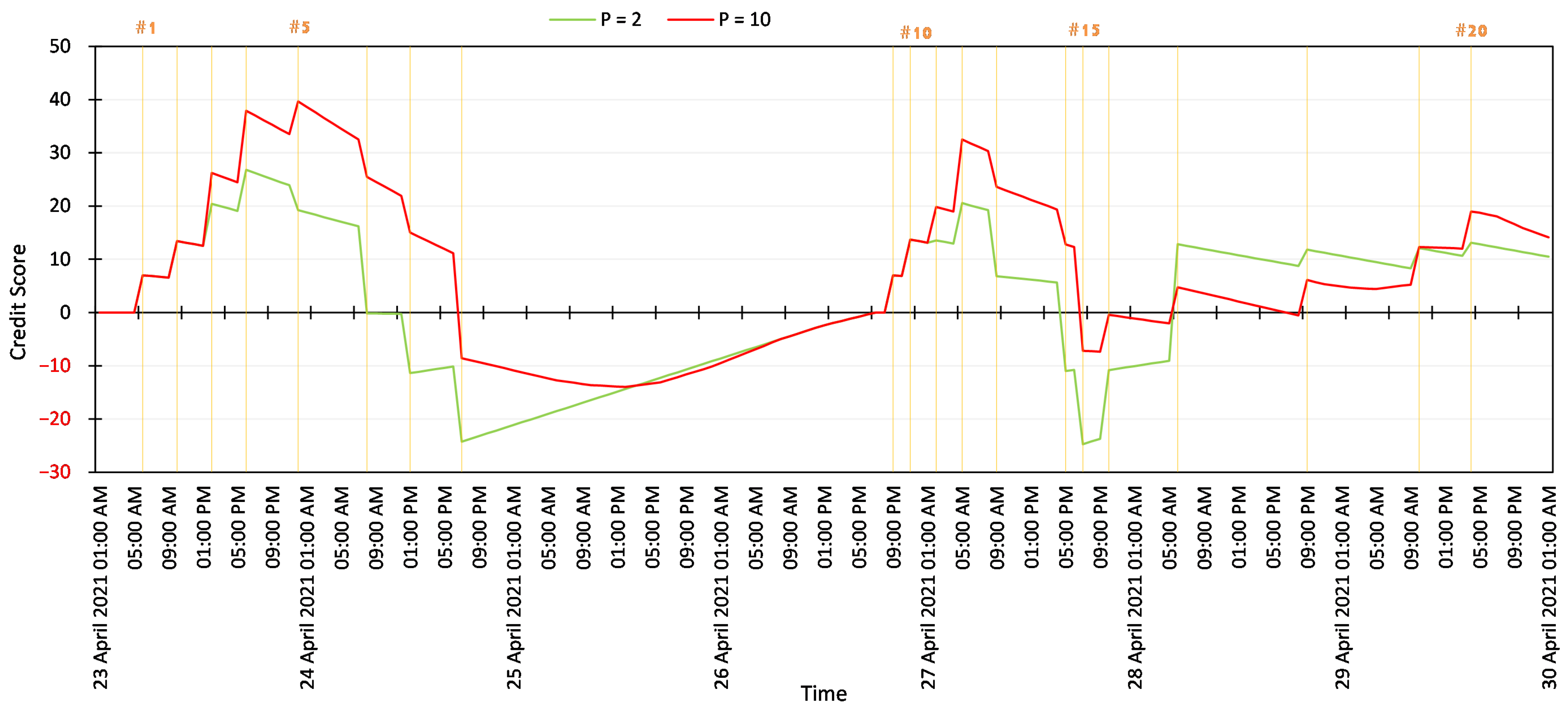
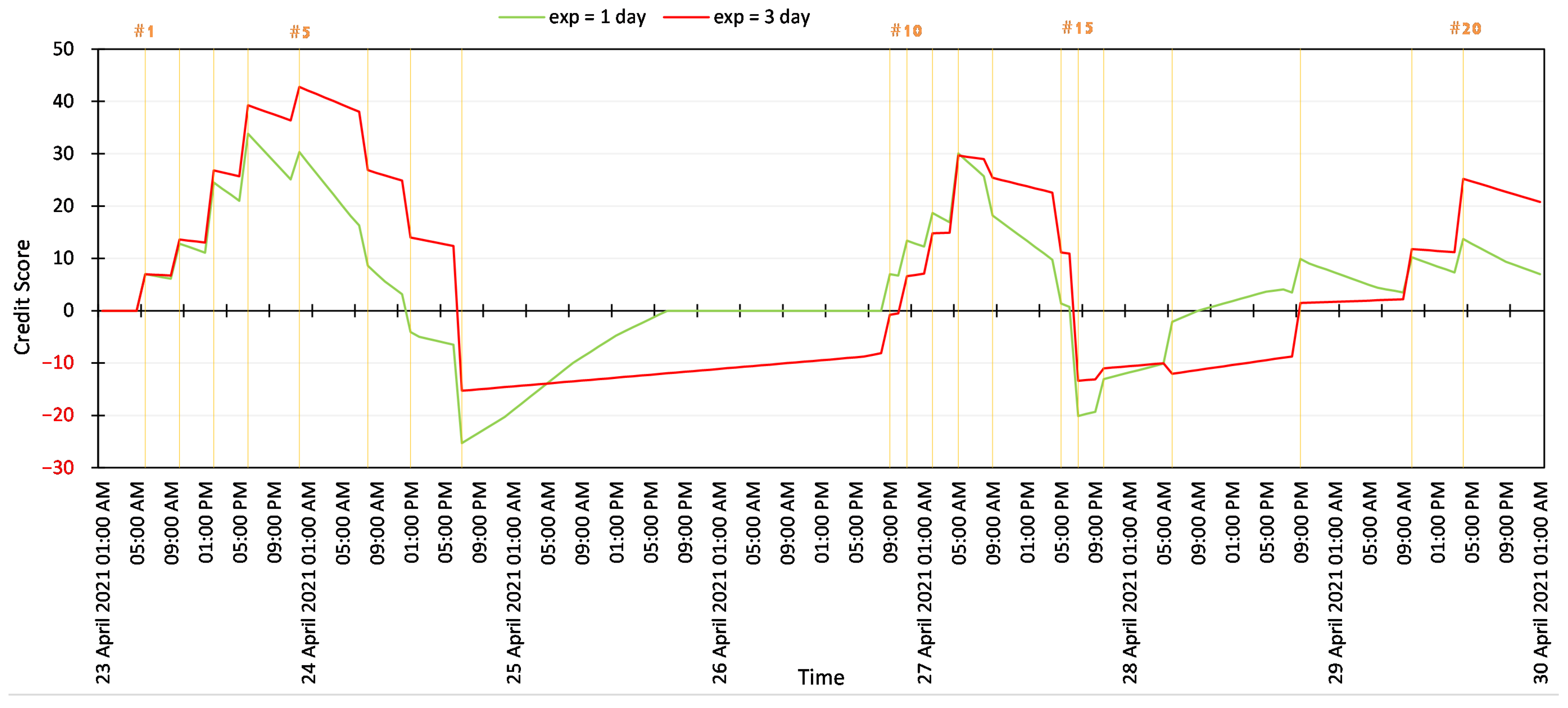
Unfortunately, high-level players are not always trustworthy because they can still act maliciously, intentionally, or not (e.g., the account is hacked by attackers). Because of that, we propose a credit score mechanism as our second trustability factor, which will monitor the history of clients’ honest/malicious activities throughout their lifetime. We summarize the logic in Algorithm 2.
On startup, the admin first needs to set three parameters: , P, and . The is a set of credit events containing credit values given when the client performs a particular task. We give positive scores for meaningful actions such as joining, training, and evaluating FL tasks. Meanwhile, we give negative values to punish malicious behaviors. is the index of where K is the total number of distinct types that is available in the system. P is a threshold number to control how many cumulative credit events can be stored for each client. The is a threshold to justify the freshness of . We measure in a block timestamp format.
The admin calls SaveCreditEvent(·) procedure to insert a new score for client i. This method should be called at the end of the FL task. First, we calculate for a given client i. The is based on the sum of all that the client receives during the FL task. The indicates the block timestamp when the is calculated and stored in the blockchain.
Any entity (e.g., model owner, client, or reviewer) can call
CalculateCreditScore(·) to receive the credit score of a given client
i. The system first gathers all last
P of
and determines its freshness by comparing to
. The outdated cumulative credit events will be ignored. The total credit score calculation is then scaled with
. This way, the system puts more attention on the most recent events. They are more critical than obsolete ones; therefore, we give them higher weight.
| Algorithm 2 Credit score system for client i |
- 1:
on startup: - 2:
admin initiates , where - 3:
▹ successfully join the FL task - 4:
▹ successfully train the FL model - 5:
▹ successfully evaluate the FL model - 6:
▹ punishment if perform malicious actions - 7:
admin sets ▹ the number of object to store - 8:
admin defines ▹ epoch time till expires - 9:
procedureSaveCreditEvent(i) - 10:
gather all for client i - 11:
calculate , where is the number of occurence for - 12:
- 13:
- 14:
store and ▹ can save up to P times - 15:
functionCalculateCreditScore(i) - 16:
gather all for the last P for client i - 17:
for do - 18:
if then - 19:
▹ ignore outdated score - 20:
- 21:
return C
|
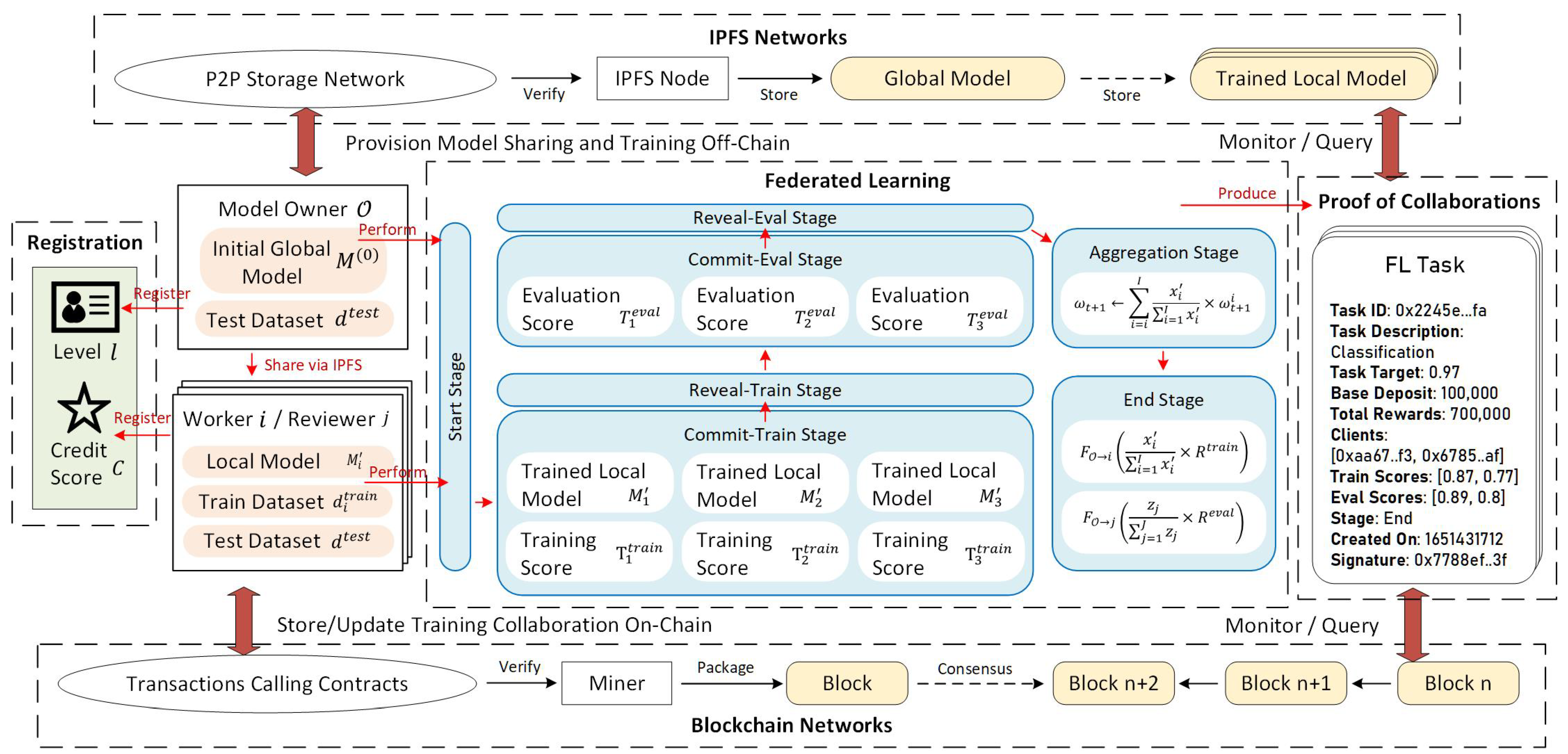
3.2. Federated Learning Stage
The FL tasks can be divided into seven stages: start, commit-train, reveal-train, commit-eval, reveal-eval, aggregate, and end stage. All parameters presented here are provided as bare minimum requirements. They can be customized further according to the actual FL use cases.
3.2.1. Start Stage
FL Task Creation: The model owner must first create a training smart contract along with its training properties. The model owner sets up training information and uploads it to the IPFS network, including, but not limited to: the initial global model
with its sample dataset for testing
; the task type description
(e.g., supervised, unsupervised, or reinforcement learning); a timestamp
; nonce
. Formally, this process can be defined as follows.
The model owner then uploads the task metadata to the smart contract, including, but not limited to: the IPFS hash of the task —this hash also becomes the task id ; the task target (e.g., achieving 90% accuracy); the base deposit value ; the total reward for this task R; the minimum clients’ level ; minimum reputation to join the task. Finally, the owner also puts a registration timeout , which indicates when the registration will be closed.
Client Assignment: At any given time, FL clients may join the tasks they are interested in. They can download the FL task information from the corresponding IPFS and smart contract. Based on all that information, they can analyze their capabilities to determine whether they can perform the task and earn profits.
For all clients
with
I is the total number of the available clients, the client
i must submit their address
and public key
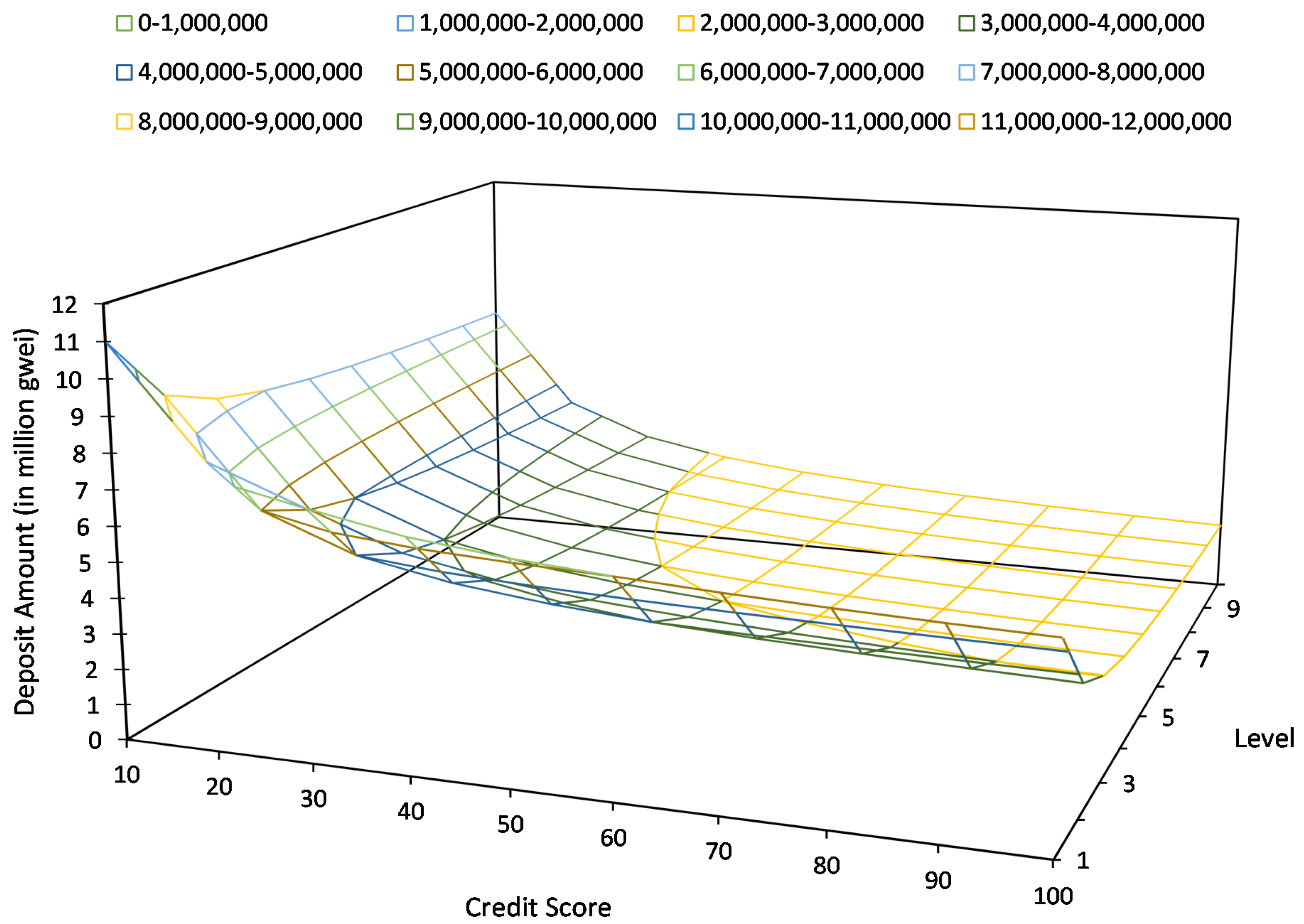
to register the FL task. Moreover, the clients also need pay deposits
to the smart contract
, which is
. The deposit is calculated as follows, where
and
are the current client’s level and credit scores (obtainable from Algorithms 1 and 2).
Each client will pay a different amount of deposit from one another depending on their trustworthiness. In general, clients with higher levels and more honest behaviors (i.e., having higher credit scores) will receive discounts on their deposits, while the lower level and dishonest clients will pay more deposits. The discounts or markups scale based on their gaps toward and .
When nearing timeout, the model owner has options to prolong the registration step. The owner can extend the timeout if he cannot find enough suitable clients; however, it cannot be prolonged forever because the deposit must be returned to clients. If the owner feels satisfied with the registered clients, they can move on to the next steps. Otherwise, they can also cancel the task, and all clients will receive their deposits back.
3.2.2. Commit-Train Stage
The model owner queries the registration results from the smart contract, which includes a list of addresses and public keys of all registered clients.
Distribution of Initial Global Model: The model owner
creates a random secret key
k. They then sign the key with
, which is
, and encrypt the key with
. In particular, for all
i, the owner performs
. The owner then uploads the encrypted keys to the IPFS.
The model owner then uploads the to the smart contract, which eventually notifies all clients that the key is ready in the given IPFS address.
Local Training: All clients query and from IPFS using . They then decrypt the key with and verifies that is the signer of . Formally, clients calculate and . After that, the clients can begin to train using their own private dataset .
Once the training completes, the clients produce the updated local models
with their associated results
. Before submitting the results, the clients must encrypts the trained model using
and signs the model using
. They then upload the encrypted model along with its signature to IPFS and generate commitment hashes
, which can be described as follows.
After that, clients submits and to the smart contract; however, clients keep secret for now.
This stage completes when one of the following cases happens. First, when all clients have submitted and to the smart contract. Second, a stage timeout is triggered, which is indicated by .
3.2.3. Reveal-Train Stage
Before a
timeout, clients need to disclose their
from Equation (
4) to the smart contract. The smart contract will verify that the revealed IPFS hashes match the ones previously submitted in the previous stage. When the hash matches, the smart contract records the
in the storage and continues to the next stage. If the hash does not match, the smart contract will punish the sender by depleting their deposit.
3.2.4. Commit-Eval Stage
Local Model Evaluation: During this stage, all clients must validate each other training results and thus, become reviewers for other clients. We define the reviewers as , where J is the total number of reviewers.
First of all, reviewers download other clients’ model from IPFS using
. They then perform the necessary decryption to obtain the model and verify its signature. Formally, for all
i, the reviewers obtain
and make sure that
. All invalid models are ignored in the system. The reviewers then evaluate the
using the test dataset
. Once completed, the reviewers produce the
for all
i, which are the evaluation scores for client
i’s model from reviewer
j. Before submitting the result, reviewers generate commitment hashes
as follows.
After that, the reviewer submits to the smart contract but keeps the value of secret for now.
This stage completes when one of the following cases happens. First, when all reviewers already submitted to the smart contract. Second, a timeout is triggered which is indicated by .
3.2.5. Reveal-Eval Stage
Before a
timeout, reviewers need to disclose their
and
to the smart contract. The smart contract validates whether the revealed evaluation scores match the ones previously submitted in the previous stage. The smart contract will punish the clients by depleting their deposits if they do not match. When the hash matches, the smart contract saves the
in the blockchain and continues to the next stage.
3.2.6. Aggregate Stage
After the smart contract obtains all the evaluation scores from all clients, the system can begin the model aggregation stage.
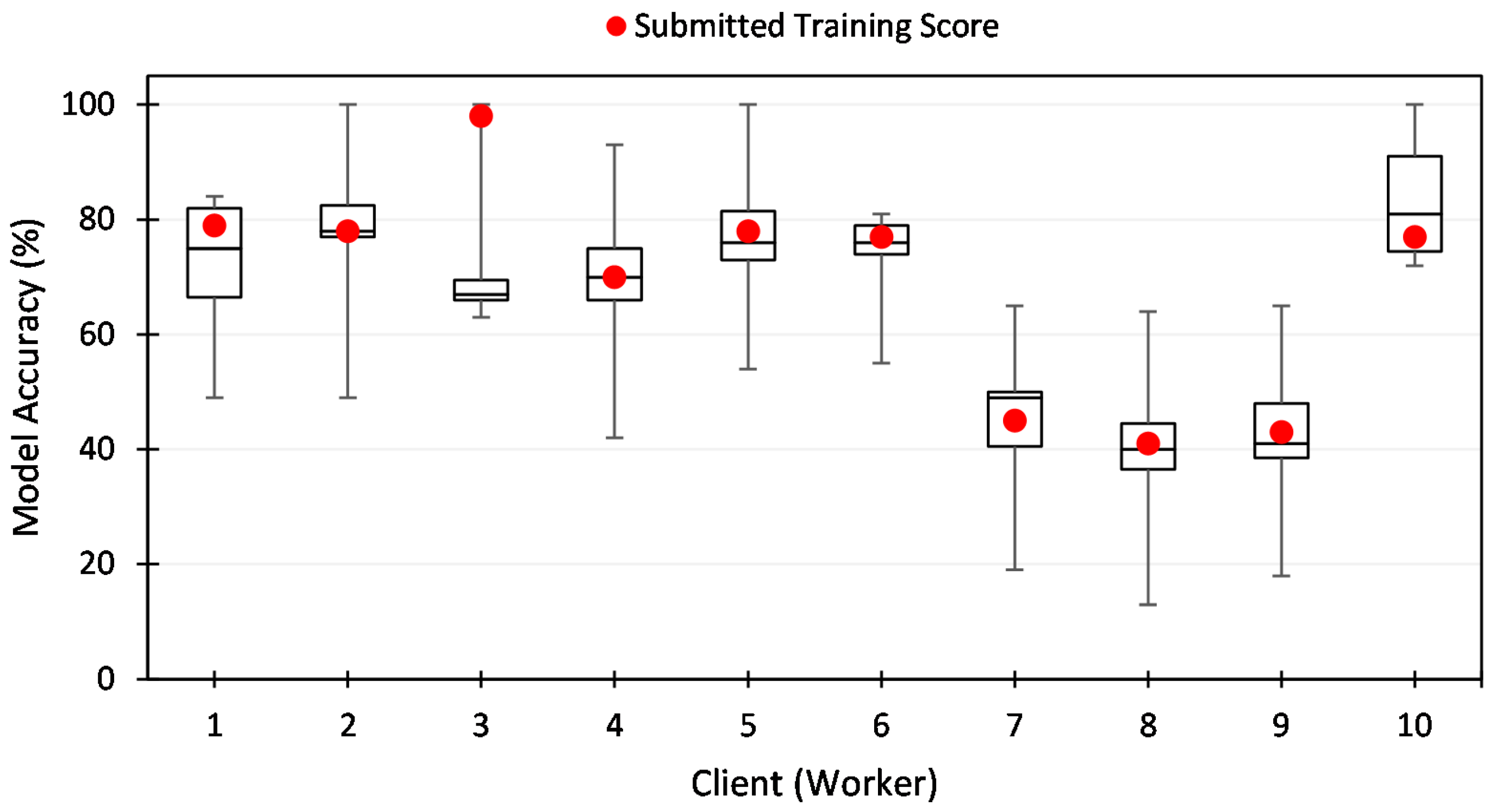
Calculating Contribution Scores: The CalculateWorkerContribution(·) function in Algorithm 3 is used to calculate the training contributions of client i with respect to its corresponding evaluation scores . We calculate the first quarter , the second quarter (the median) , and the third quarter of all . We then check if the previously claimed training score resides outside the boundary of and . We assume that 50% of the client is always honest and 50% of submitted evaluation scores can be trusted. If is out of range, we punish client i. Finally, we return the median of all evaluation scores as an accepted training score for .
The
CalculateReviewerContribution(·) function is used to measure the evaluation contributions of reviewer
j towards the model of client
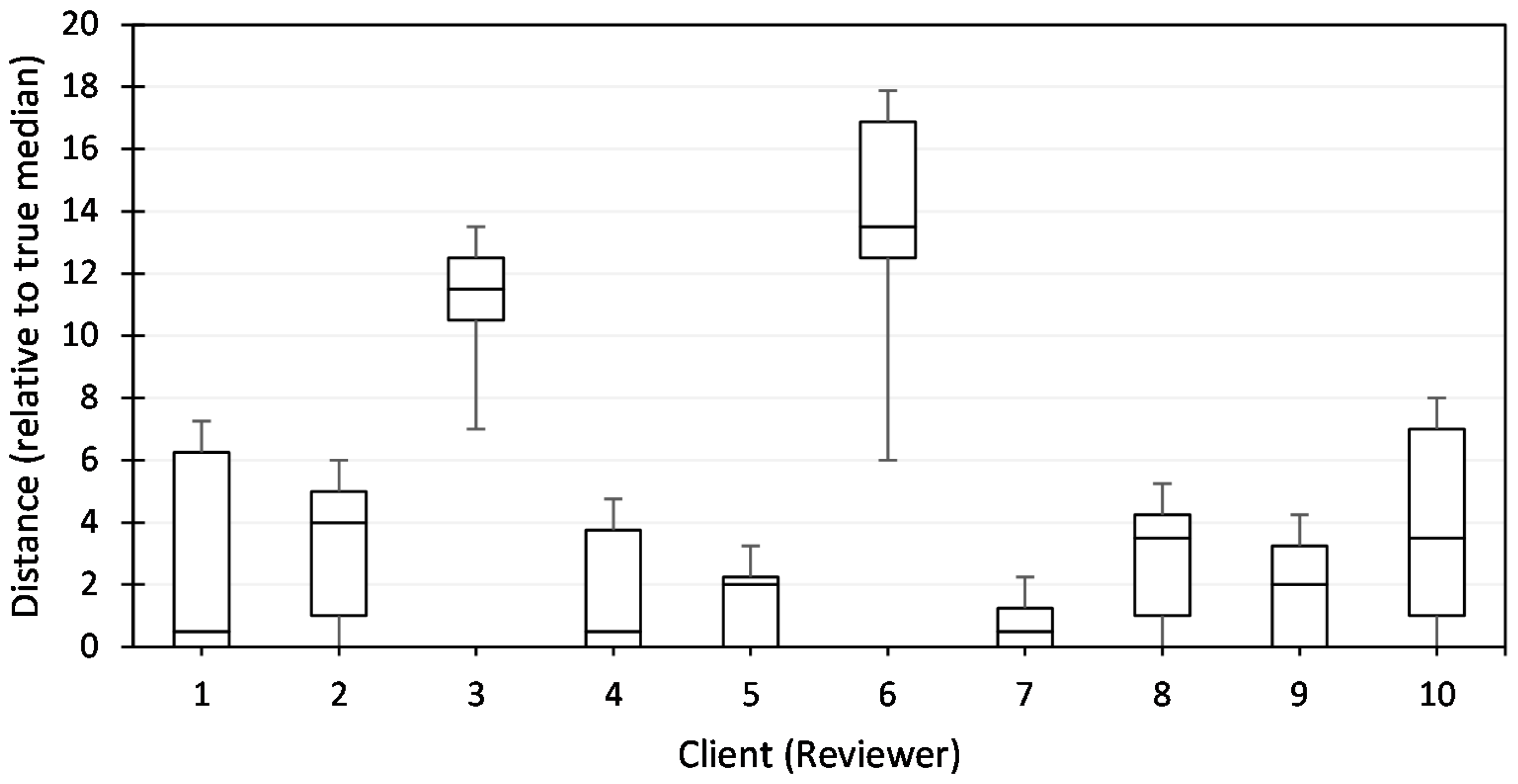
i. Similar to the previous function, we first calculate
,
, and
of all
. We then calculate
, which is the difference between the submitted eval scores
from each
j towards the median
. Because we assume that 50% of the client is honest, we expect that 50% of their submitted evaluation scores will be closer to the median. We then normalize
and flip the score so that the higher
values now become the score closer to the median instead of the lower ones. Finally, we ignore
that is outside the boundary of
and
, and give them the lowest value possible.
| Algorithm 3 Processing contributions from client i and reviewer j |
- 1:
functionCalculateWorkerContribution(i) - 2:
, gather all - 3:
calculate , , and from all - 4:
calculate - 5:
get previously claimed training score - 6:
if or then - 7:
punish worker i ▹ client submitted fake training score - 8:
return - 9:
functionCalculateReviewerContribution(j) - 10:
for all i do - 11:
, gather all - 12:
calculate , , and from all - 13:
calculate - 14:
if then - 15:
- 16:
punish reviewer j ▹ client submitted fake evaluation score - 17:
else if then - 18:
- 19:
punish reviewer j ▹ client submitted fake evaluation score - 20:
else - 21:
- 22:
normalize and flip, - 23:
return
|
Aggregating the Global Model: In vanilla FL [
2], we perform aggregation as follows.
is the total number of data owned by client i while n is the total dataset from all clients. Using this formula, the aggregation weight is calculated based on the dataset ownership.
Meanwhile, we slightly modify the formula to adjust the weight based on the models’ accuracy. More specifically, for all
i, the owner calculates the following.
The model owner gathers all median scores from reviewers. The owner then perform normalization on the scores and aggregates the global model based on each client accuracy, which is weighted as . For this matter, we prefer a more accurate rather than the less accurate one.
Distributing Reward: The model owner
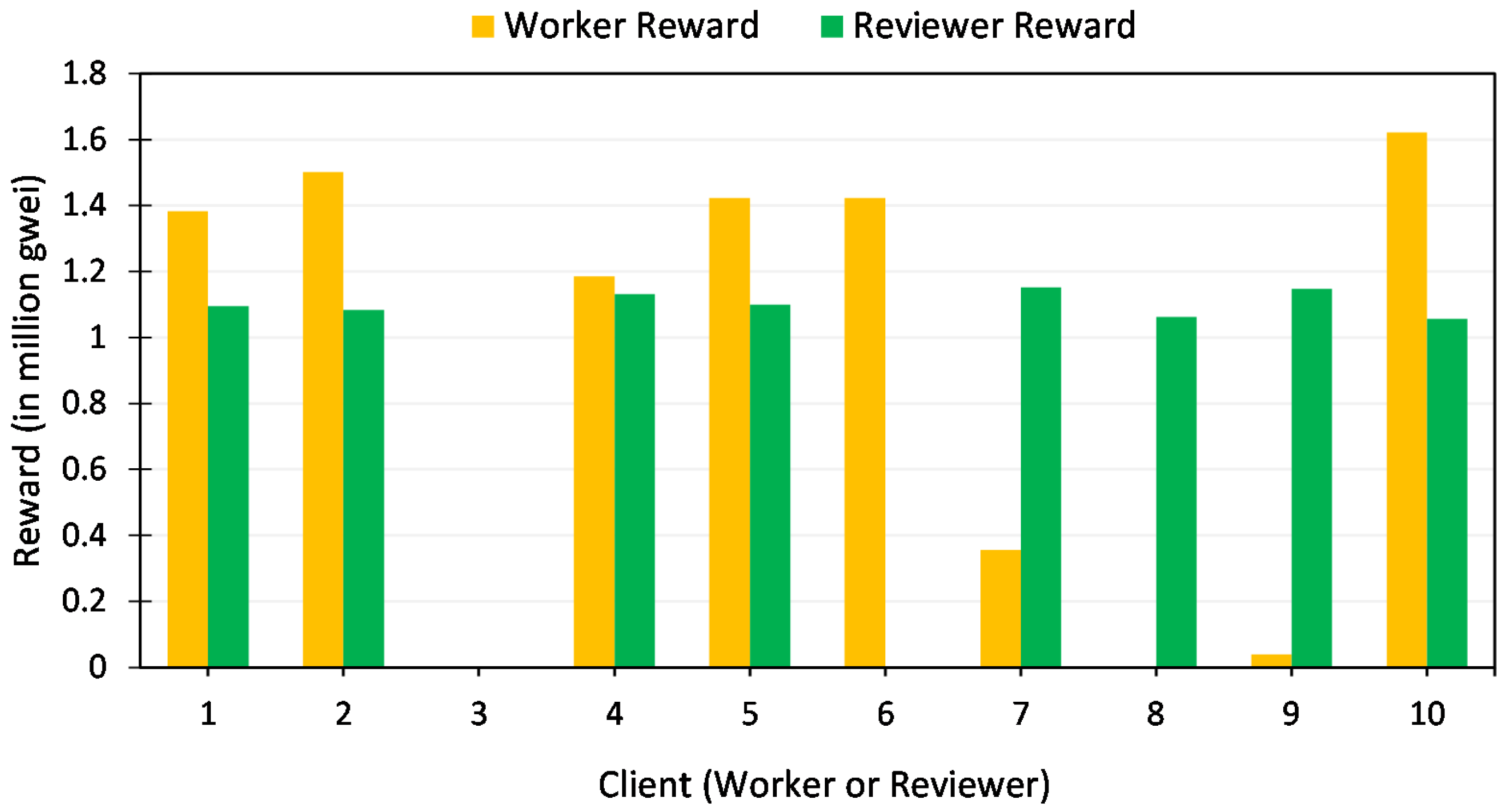
splits the total rewards for workers and reviewers as follows.
is a parameter determined by the owner, where .
To distribute the rewards for all workers, for each
i, the owner performs:
Note that the reward is weighted as , similar to the aggregation rules. Hence, the client that submits models with more accurate results will be rewarded more than the less accurate ones.
To distribute the rewards for all reviewers, for each
j, the owner performs:
is the average distance of evaluation scores. The reward is then weighted as in which reviewers that submitted scores closer to the median scores will be given more rewards.
Updating Clients’ Level and Credit Scores: The model owners give experience values to all clients that contribute to the FL task by invoking the GainExperience(·) procedure in Algorithm 1. When adding experience, the owner may also eventually increase the clients’ level when the number of experience required is met. Note that malicious clients (e.g., dropping out or submitting fake scores) will not receive any experience.
Moreover, the owner also gathers all of the credit events for all joined clients, calculates the cumulative credit events , and then saves the score in the smart contract using SaveCreditEvent(·) procedure in Algorithm 2. Honest clients will receive positive scores, while malicious clients will receive negative scores.
The clients’ updated levels and credit scores will determine the number of deposits that the clients need to pay when joining future tasks.
3.2.7. End Stage
When all the steps in the aggregation stage finish, the owner will receive the updated global model, and the clients receive compensation for their efforts in training or evaluating the local models. The task now moves to the last stage, where no one can modify this FL task state in the smart contract. This frozen state is used for auditing or as a reference for future tasks related to this task.













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}