
Toward Data Integrity Architecture for Cloud-Based AI Systems


Abstract
:1. Introduction
- Proposing a system architecture to ensure continuous data integrity provisioning in cloud-based AI systems based on the NIST cybersecurity framework.
- Providing modules that implement five main points from NIST cybersecurity framework guidance.
- Integrating our architecture based on blockchain and smart contracts to enhance integrity throughout ML pipeline in cloud-based AI system. The identity management and access control module to prevent adversaries from entering the system by impersonating real users. API token management module to prevent unauthorized users calls the API of AI services. Integrity module to keep track of data integrity and prevent data manipulation. Each module is connected to the smart contracts to ensure automation and policy enforcement.
2. Background
2.1. AI Environment
- Attacks against the data used for training and decision-making.
- Attacks against the classifier in the training environment.
- Attacks against models in the deployment environment.
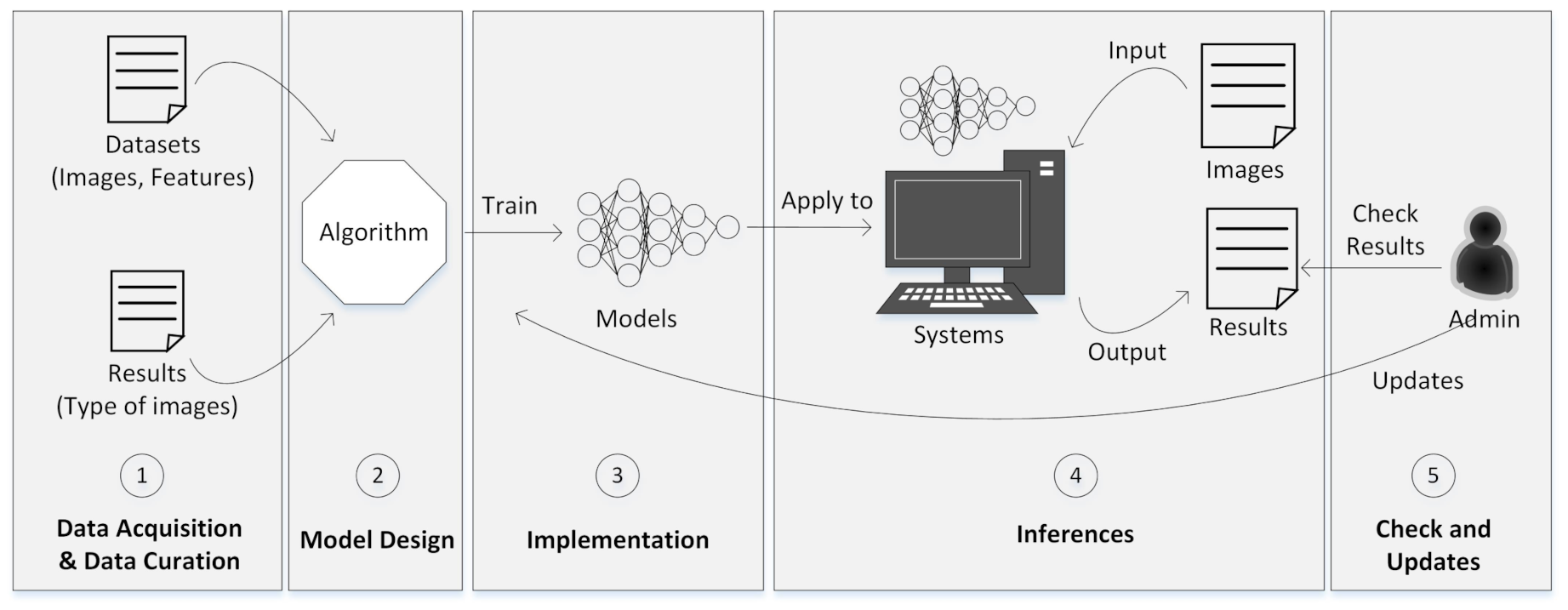
2.1.1. A1. Data Acquisition and Curation
2.1.2. A2. Model Design
2.1.3. A3. Implementation
2.1.4. A4. Inferences
- DeepFool. Moosavi-Dezfooli et al. [32] proposed to find minimal adversarial perturbations on both an affine binary classifier and a general binary differentiable classifier in an iterative manner. Their experiments show that the DeepFool algorithm can generate perturbations more minor than FGSM.
- Jacobian-based Saliency Map Attack (JSMA). Papernot et al. [33] introduce an efficient, targeted attack based on calculating the Jacobian matrix of the score function. It can fool the classifier by restricting the small perturbations.
- Universal perturbations. All adversarial examples above are working on a specific network. In contrast, universal perturbations can fool the classifier at ’any’ image with high probability [23]. Moosavi-Dezfooli et al. [36] successfully find a perturbation that can attack 85.4% of the test samples in the ILSVRC 2012 dataset under a ResNet-152 classifier.
2.1.5. A5. Check and Updates
2.2. How to Defend AI System
2.2.1. AI-Algorithm-Based
2.2.2. Architecture-Based
- Strengthen the authentication mechanism so the fake user cannot impersonate the real one.
- Enhance authorization mechanism by limiting the user’s permissions according to their given role. So, it can prevent malicious users from behaving arbitrarily, and only authorized users can interact with the services.
- Keep track of datasets’ integrity through the ML lifecycle phase using a hash algorithm. So, if an attacker alters the datasets, we can compare the hash of the datasets. If the result is different, it means the data has been compromised.
- Logging and monitoring data flow and user activities are necessary in order to detect suspicious actions.
2.3. Cloud Environment
2.3.1. System Access
2.3.2. Cloud Infrastructure
3. Related Work
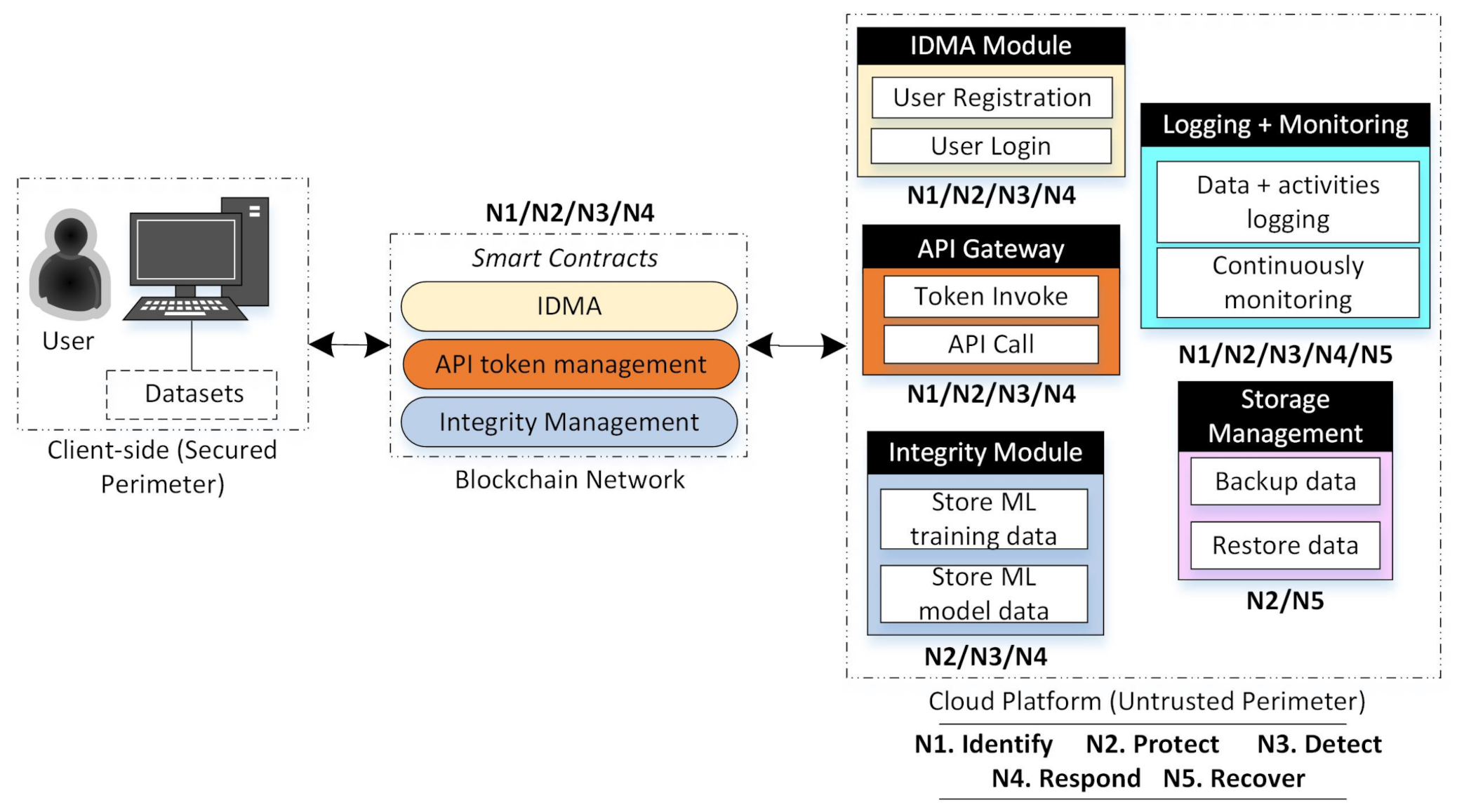
4. Proposed Architecture
4.1. Architecture Requirements
- Identity and Access Control Management. It is important to identify who accesses our system and what role he/she has before entering and using the cloud services. The cause of adversary can mostly compromise the data integrity because of lack of proper authentication and authorization mechanisms. This requirement aims to cover AI pipeline phase A2; also cloud vulnerabilities points C1 and C3–C5. Phase A2 is related to generic issues specifically associated with cloud services vulnerabilities in our paper. This case could lead to C1 and C3–C5, which explain the lack of identity and access control management. However, a small flaw like this will expose data integrity at risk. Our solutions—We use a digital signature to verify the user’s identity every time they enter the system and use services.
- Consistency and completeness. Consistency in our context is related to ML datasets. For instance, there are ten categories in image classification, and each category should have the same amount of images to be trained to achieve accurate results. If the adversary poisons the training data by adding or erasing some training images on one category, the datasets become unbalanced. Then, the decisions made by the AI system would be biased and compromised. Completeness. The adversary tries to compromise the training data by altering or tampering with the label of the data. So, the system will give the wrong results with high accuracy. Therefore, it is important to preserve the consistency and completeness of the AI system. This requirement aims to cover AI pipeline phases A1 and A5. The goal is to prevent falsifying data integrity as explained in Section 2.1. Our solutions—We use a hash function to ensure no violation of data integrity and record it in the blockchain. In the blockchain, there is no central record-keeping. It is decentralized to all nodes. Each block is chaining with the hash of the previous block. So, changes of one data reflect the hash changes and break this chain. Users or CSP will notice this as a signal of data alteration.
- Non-repudiation. One of the well-known threats to a system is malicious insiders. We do not expect that people inside the system will do such a thing. When the actual user becomes an imposter and depends on their access level, they can leak the information to the adversary or modify it undetected. Therefore, this requirement aims to cover AI pipeline phase A2 and cloud vulnerabilities point C2. These two vulnerabilities are related. In C2, we explained malicious insiders that could threaten the cloud environment. It means this vulnerability will also be a threat to the ML pipeline, specifically in phase A2. This person could leak essential information such as the algorithm we used, ML datasets, ML models, or even alter the data. Our solutions—User needs to sign the data whenever they change it to verify their identity. Furthermore, there is a module for logging and monitoring unusual user activities in the system.
- Trusted Service Level Agreement (SLA). SLA is a contract between customers and the CSP. It binds the trust of both parties. However, there is a possibility that one side breaks the agreement and causes a trust issue. State-of-the-art SLA required another third party as an auditor. Nevertheless, it does not fix the problem but raises another trust issue if the third party is compromised. This requirement aims to cover AI pipeline phases A1–A2, A5. Furthermore, cloud vulnerabilities C1–C6 by enhancing policy enforcement as well. By maintaining policy enforcement through trusted SLA, we can minimize exposed vulnerabilities to an unauthorized party. Our solutions—We use smart contracts to bind the trust between users and CSP that can automate the SLA process.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Requirement | Covered AI Pipeline | Covered Cloud Vulnerabilities | Description | Our Proposed Solutions |
|---|---|---|---|---|
| Identity and Access Control Management | A2 | C1, C3, C4, C5 | Prevent adversary to impersonate the real user to login to cloud environment and gain control over the data. | We use a digital signature to verify the user’s identity every time they enter the system and use services. |
| Consistency and Completeness | A1, A5 | Prevent adversary to alter the training data, mislabelled the training data to another value, and disrupt the consistency in datasets. | We use a hash function to keep track to ensure no violation of data integrity and record it in the blockchain. | |
| Non-repudiation | A2 | C2 | Prevent malicious insiders that has direct access to services and data to leak the information to the adversary or even modify it undetected. | Whenever users changes the data, they need to sign it to verify their identity. |
| Trusted SLA | A1, A2, A5 | C1–C6 | Trust issues between user and CSP. | We use smart contracts to bind the trust between users and CSP that can automate the SLA process. |
4.2. Architecture Details
- The IDMA module is responsible for managing the user registration (Protocol I) and login (Protocol II) process. Each user will be assigned a role limiting their activities and preventing arbitrary behavior. Furthermore, the IDMA module will provide the user with a credential that will be a token for authentication. Every time users want to log in to the cloud system, it is required. In addition, this module collaborates with smart contracts to validate information sent from both parties.
- API Gateway is designed to handle API requests from users wanting to use cloud services. Before utilizing cloud services, users must invoke a token from the API gateway (Protocol III). The API gateway also cooperates with smart contracts to record the user’s request for an API token and the token value. Both user and cloud systems can verify the token’s legitimacy to smart contracts. The token value is required every time user want to call an API for cloud services to the API gateway (Protocol IV).
- Integrity Module aims to preserve the integrity of ML training data (Protocol V) and model (Protocol VI) by leveraging blockchain. So, the user and cloud system can verify the data integrity to the smart contracts.
- Logging and Monitoring aims to record data flows and user activities. Furthermore, it will continuously monitor the system and raise a warning if there is malicious behavior.
- Storage Management aims to maintain the systems backup data process regularly. The data will be stored in an encrypted form to keep the confidentiality.
4.2.1. Notations
- is refers to s blockchain address.
- are a pair of secret key and public key of x.
- generates a digital signature for data Y using secret key of x.
- is a function to verifies whether blockchain address signs data N by generates digital signature M.
- is a asymmetric encryption of data Y using public key of x.
- is a asymmetric decryption of data Y using secret key of x.
- is generates a hash of data Y.
- is the smart contract for module z. It is resides in the blockchain network and act as trusted SLA to bind the trust between users and CSP.
- is a function to verifies the access token O using secret key of x.
4.2.2. Identity Management and Access Control Module (IDMA)
- General user. This role authorizes the users to access only their personal data, such as their training data and model. In addition, they can access the cloud services (e.g., AI service) through API calls, but users need to invoke an additional token to the API gateway.
- Log admin. This role authorizes the users to access only the logging data because this role is specified for the user who is in charge of analyzing the system (e.g., data flow, network traffic, etc.).
- System admin. This role has higher privilege than the previous two. It authorizes a user to access user information and logging data. A system admin will manage the user’s role and have the authority to revoke the user’s role if the user is compromised.
| Role | Personal Data (Training Data & Model) | Logging Data | Detail User Info | Cloud Services |
|---|---|---|---|---|
| General-user | √ | × | × | Δ |
| Log-admin | × | √ | × | × |
| System-admin | × | √ | √ | × |
- Role has three options, 1 is for a general user, 2 for log admin, and 3 for system admin.
- Scope limits what data users can access. This parameter also has three options, 1 for personal data (e.g., training data and model), 2 for logging data, and 3 for user information details.
- Access defines what the user can do to the data. It is filled with 3 bits. If the last digit is one (001 = 1), the user can edit the data. If the second digit is one (010 = 2), the user can delete the data. Lastly, users can view the data if the first digit is one (100 = 4). So, if all three digits are one (111 = 7), users can edit, delete, and view data.

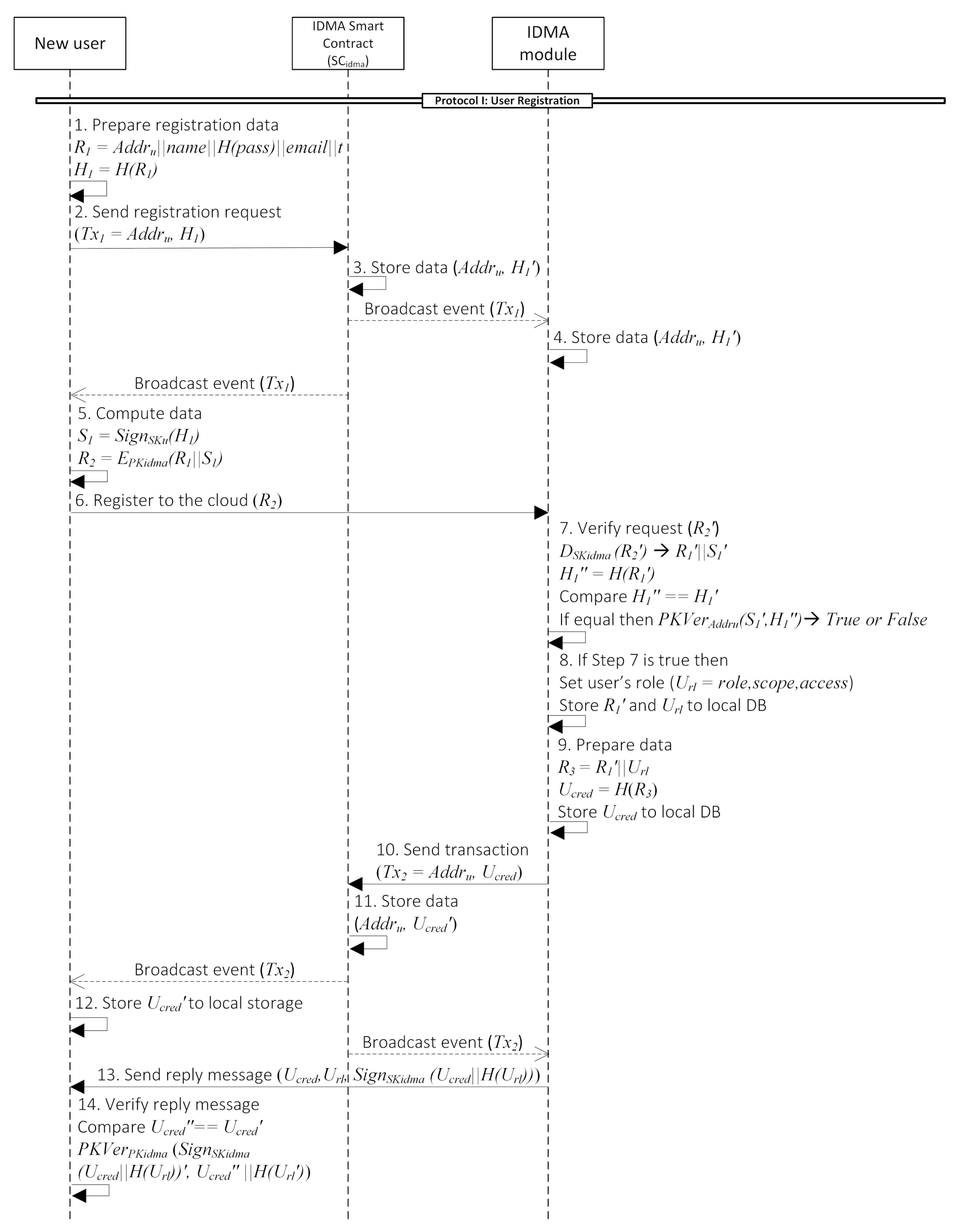
- Protocol I: User RegistrationBefore using the cloud services, new users need to go through the registration process. However, users cannot directly register themselves to the IDMA module. They need to send a transaction that contains their registration request to the smart contract (Steps 1–2). After their transaction is recorded to the blockchain, they can send registration data to the IDMA module (Steps 5–6). If the IDMA module cannot find the user’s data in the smart contract when the user sends a registration request, it will reject the request. The IDMA module can easily verify the corresponding user registration request by comparing the hash of registration data sent by user and the blockchain (Step 7). Subsequently, it also verify the message signature. If the user’s request is verified, the IDMA module will assign the user’s role and generate the user credential () in Steps 8–9. is required every time users want to log in to the system. IDMA module will also record the to the (Step 10). Then, the IDMA module will send and the user’s role value to the user together with its signature (Step 13). Users can verify the integrity of from the IDMA module by comparing it with the value from the blockchain. The user will also verify the message signature to ensure the sender is the IDMA module and not an adversary impersonating the IDMA module. By the end of this process, users will know their role and have a user credential in their local storage. Details description of each step is provided in the Appendix A.
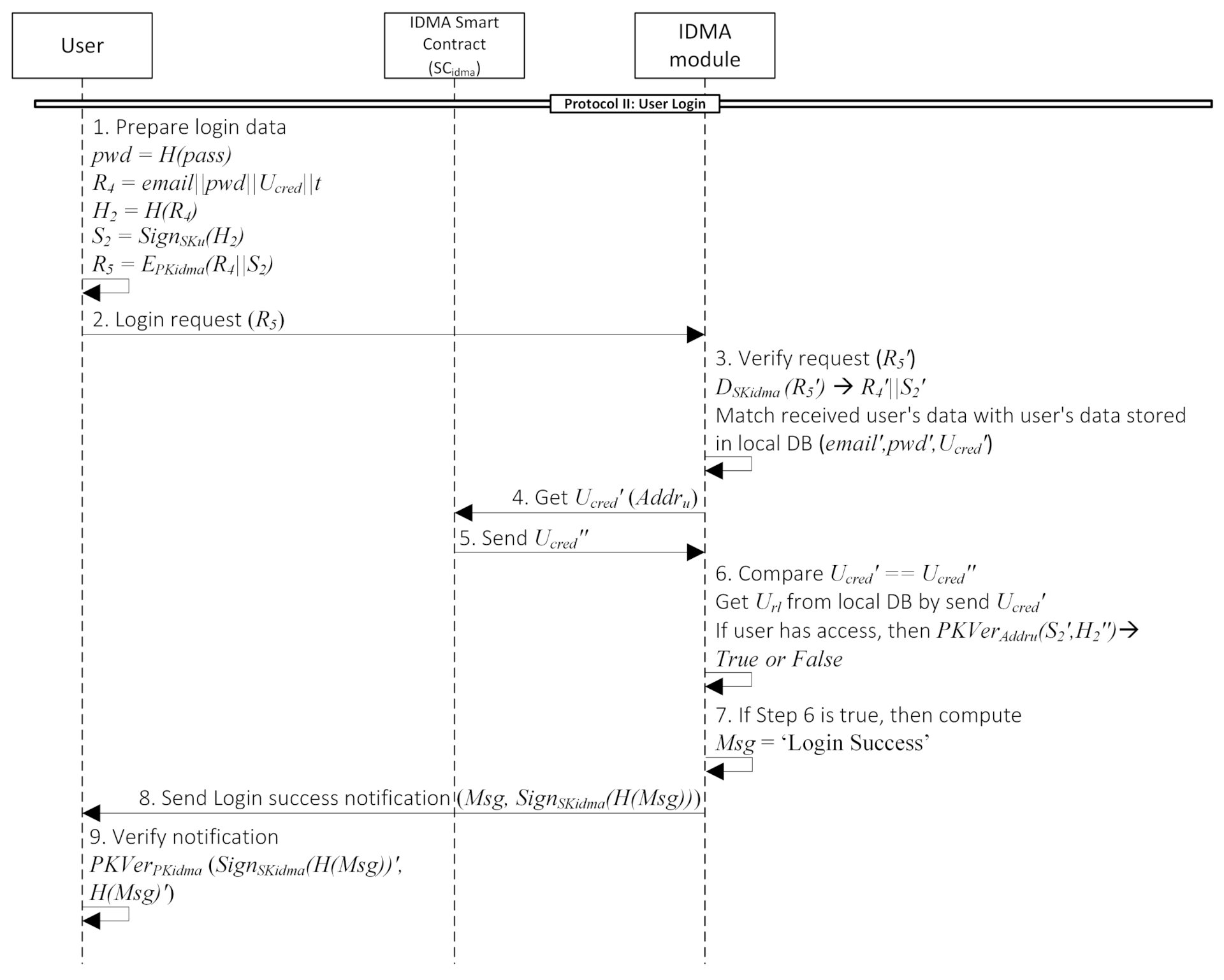
- Protocol II: User LoginAfter a new user successfully registered to the cloud system, he owned a user credential () in their local storage. Later, he will use this credential every time he log in to the cloud system.First, the user prepares the login data and send to the IDMA module as shown in Steps 1–2. Upon receiving the login request, the IDMA module begins the authentication and verification process (Step 3). First authentication step is by checking the email, password, and user credential to see whether it matches the recorded data in the local DB. After that, additional authentication process in IDMA module is by comparing value from user and the one existed in blockchain. This second authentication step is required to ensure that the sender is the authentic user. So, IDMA module will query the user credential from (Steps 4–5). Then, the IDMA module compares value from the user and the blockchain (Step 6). Subsequently, the IDMA module checks the user’s role and verify the message signature. This signature verification step is crucial to prove that the sender of is the same user who has sent a transaction to the smart contract. Furthermore, it will prevent the adversary from impersonating the user. If return true, send a signed message to the user that login is successful (Steps 7–8). In the last step, the user verifies the reply message to ensure that the sender is IDMA module and not altered on the transmission process. Details description of each step is provided in the Appendix B.
4.2.3. API Gateway
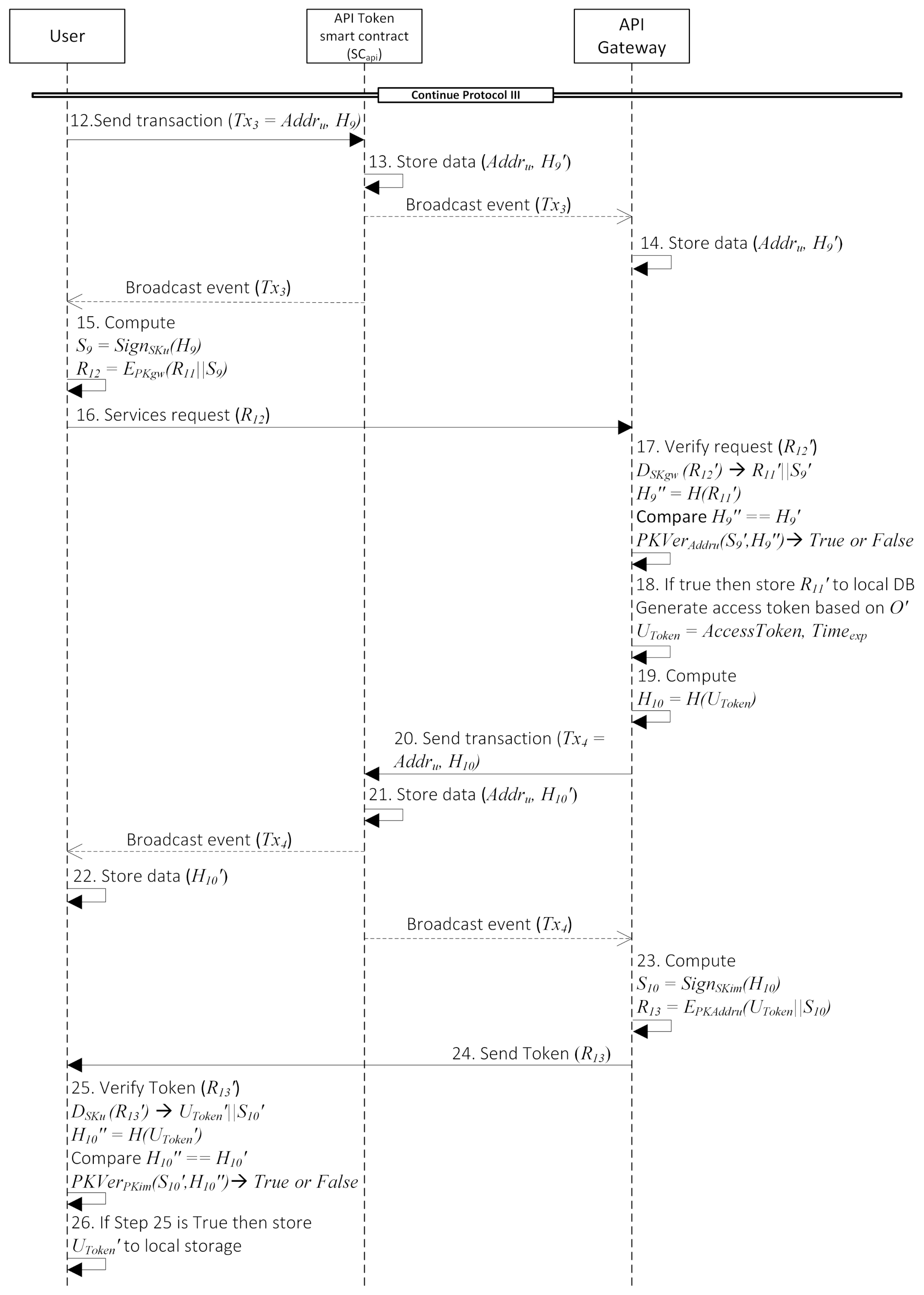
- Protocol III: Invoke TokenBefore requesting a token to the API gateway, we assume that the user has already login to the cloud system.First, the user needs to know a list of services that they can use. So, Steps 1–11 are when users request a list of services to the API gateway. Every time user or API gateway receives a request, they will verify the message first to ensure the message is not from the adversary and the message is not altered in the transmission. Before API gateway can give the list of services, it will check the user’s role beforehand to the IDMA module. At the end of Step 11, users receive the list of services they can access from the API gateway and choose what services they want to use. In Steps 12–26, there are some interactions with API Token smart contract (). Similar to Protocol I, the user needs to send a transaction to the that contains a list of services that the user wants to access. If the user sends a services request to the API gateway without sending a transaction to the smart contract beforehand, the API gateway will reject this request. The services request must be recorded in the smart contract so the API gateway can verify the integrity of the request. After the API gateway verifies the user’s service request, it will generate an API token () based on the user’s list of services (O) that is shown in Step 18. is a required parameter to be sent every time users call the corresponding API services. API gateway also stores this value to the smart contract and will be used later in the token verification process. By the end of Step 26, the user will possess the API token and store it in the local storage. Details description of each step is provided in the Appendix C.
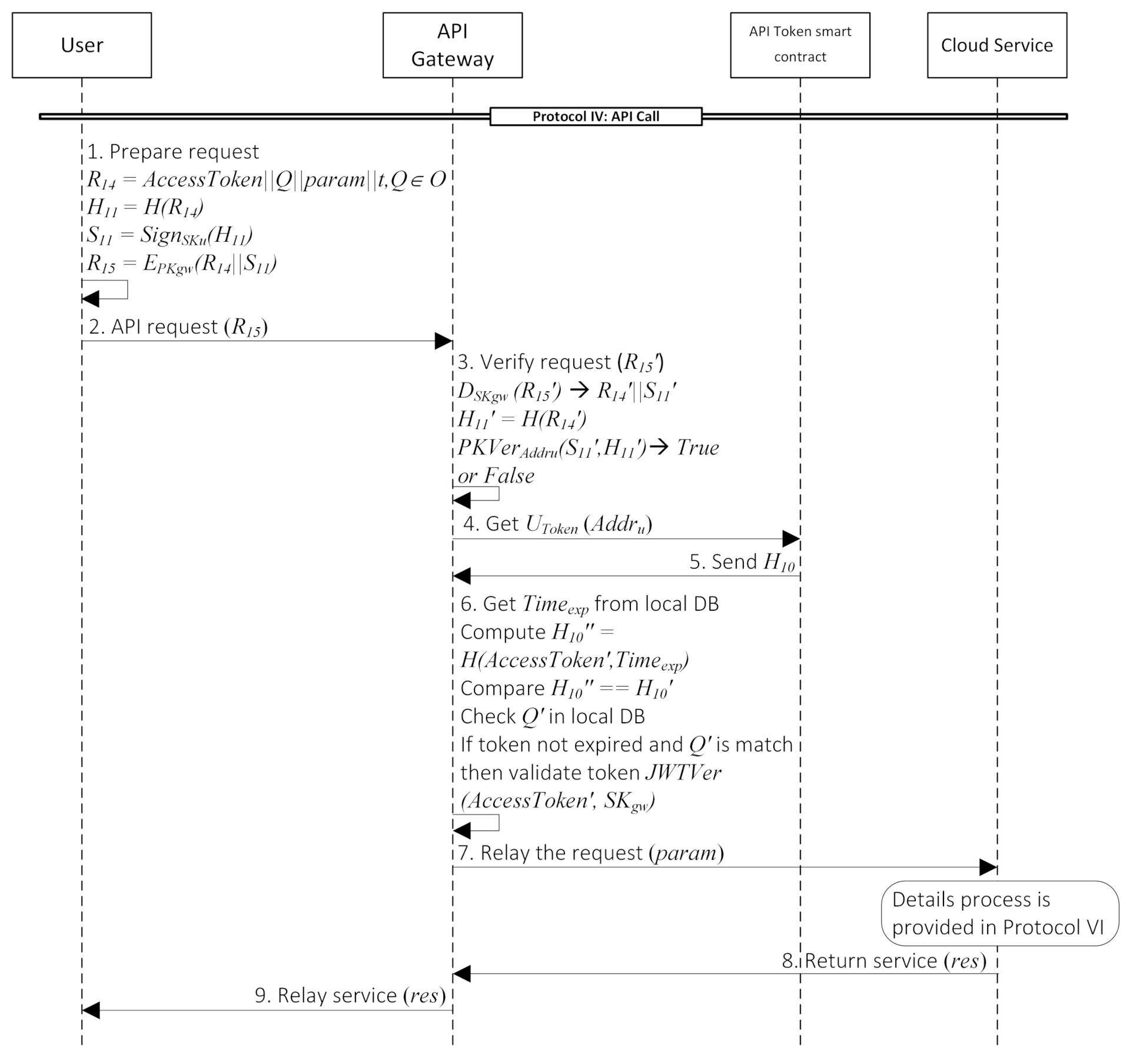
- Protocol IV: API CallThe user needs an API token to access cloud services through the API gateway. We assume that the user already invoked the token and has it in their local storage for this process.A user needs to prepare the request data to call the API service, as shown in Step 1. The process of API gateway verifies the user’s API call is presented in Steps 3–6. API gateway will verify this request by checking the signature (Step 3). Subsequently, it will get the value stored in (Step 4). Then, will send a hash of in a variable called as mentioned in the previous protocol (Step 5). The next step is necessary to prove the data integrity stored in the local DB and the value sent by the user. First, the API gateway gets the expiration time of the token () from the local DB. Then, computes by hashing and . After that, it will compare the value from the smart contract and the hashing computation result. If equal, continue next process; otherwise, reject. It means either value from DB or from the user was altered. Next, it checks whether the value is a member of O or not. If the token is not expired, and the previous condition is true, API gateway will validate the token using function with and as the inputs (Step 6). If this step is true, the API gateway will relay the request to the corresponding service in the system. Details process of the service is present in Protocol VI. At the end of this protocol, the user receives the corresponding service from the API gateway. Details description of each step is provided in the Appendix D.
- Token revoke. In our system, a token can be revoked because (i) Token expired. (ii) System detects a malicious activity such as user verification failed several times when using the Token.
4.2.4. Integrity Module (IM)
- The hash algorithm, such as SHA256, ensures no data integrity violation.
- Digital signature to verify the sender and provide non-repudiation.
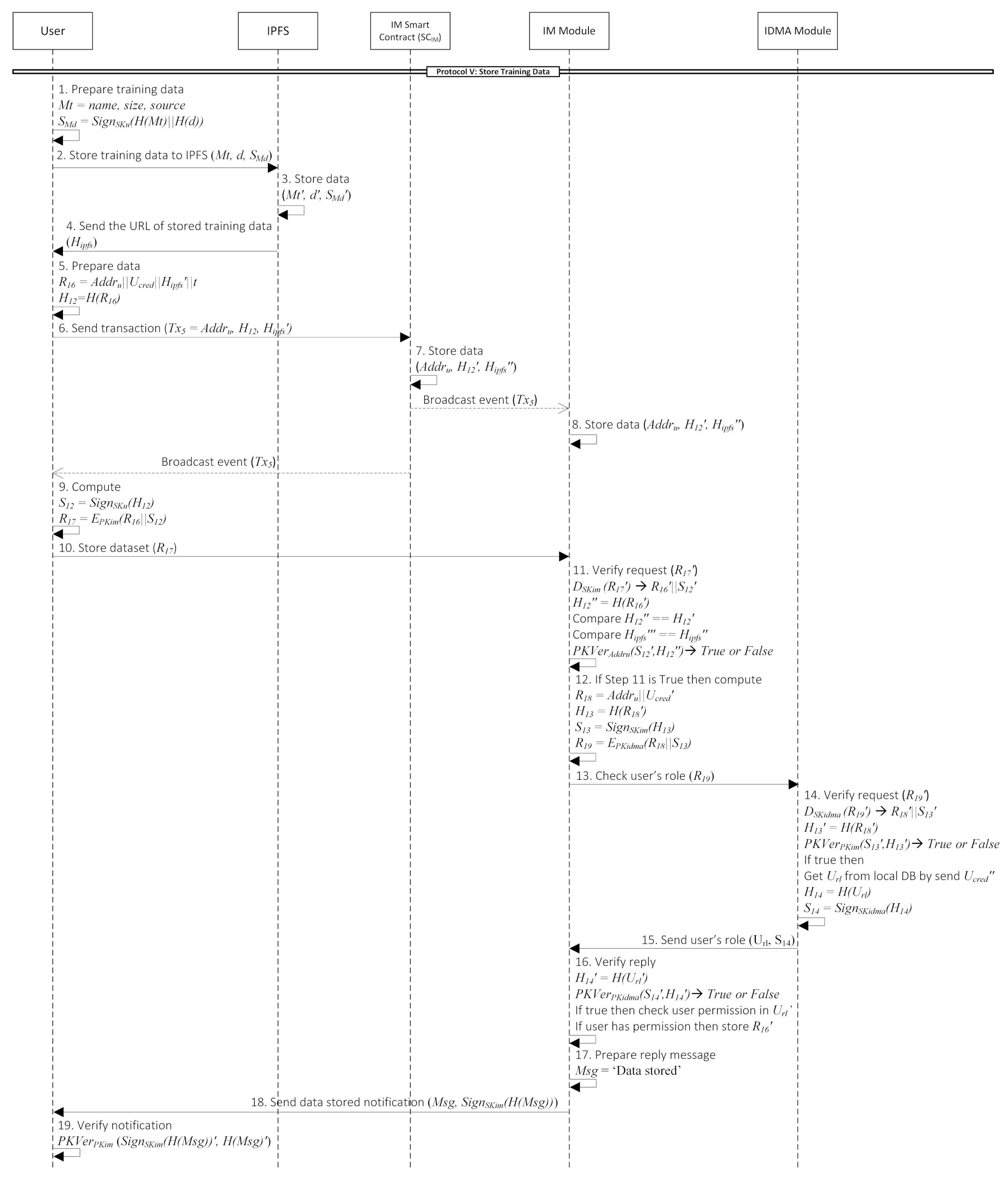
- Protocol V: Store training dataFirst, the user will store the training data, metadata, and its hash to the IPFS (Steps 1–2). After IPFS receive and store the data, it will return the path of the stored data in the form of hash () in Step 4. Subsequently, the user prepares the hash of these values, user blockchain address, user credential, IPFS hash, and current timestamp. So, the user will store this hash to the IM smart contract (). After successfully stores the user’s transaction in the blockchain, the user will store the dataset saved in variable to the IM module (Step 10). IM module will verify the integrity of the data to the smart contract first before storing it to the local DB. This process is shown in Steps 11–16. IM module compares the hash received from the user and the blockchain. This part is crucial to ensure that the adversary has not corrupted data integrity. If the data is not equal, there is a chance that the adversary has altered data. Then, the IM module will reject the data; otherwise, data integrity is assured, and the process continues. Furthermore, it also checks the user’s role in the IDMA module to assure whether the user has permission to store data or not. The IM module will stop the process if the user does not have permission. This part aims to strengthen access control in the cloud system and prevent users’ arbitrary behavior that can threaten data integrity. At the end of Step 16, data will be stored in the cloud storage. Furthermore, the IM module will notify the user that the data is stored (Steps 17–19). Details description of each step is provided in the Appendix E.
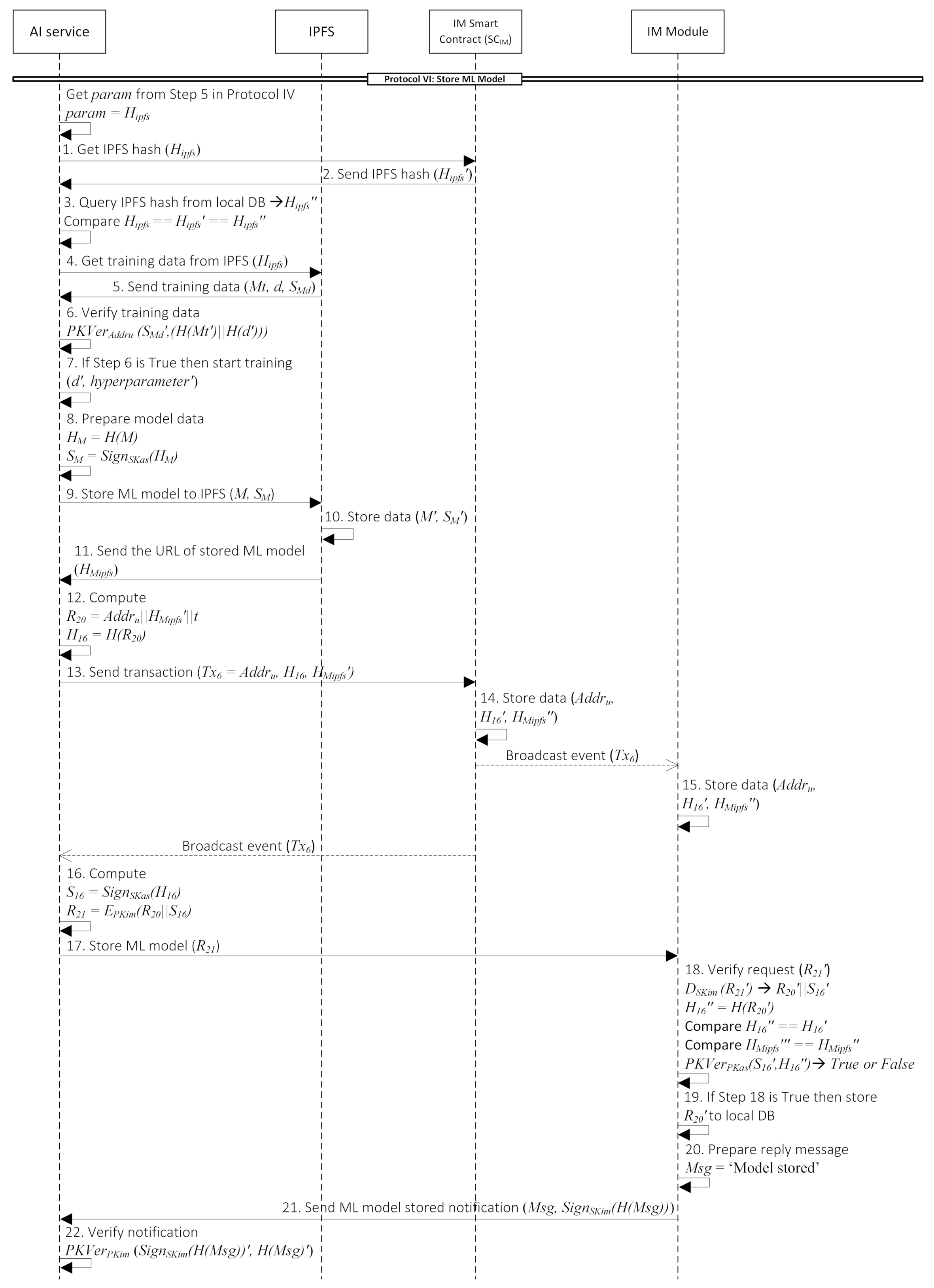
- Protocol VI: Store ML modelThe second protocol of our integrity module is depicted in Figure A8 (Appendix F). It is the case when the user wants to store the ML model after the training process. We assume that:
- –
- User already past the previous protocol process then uses the AI service to start ML training step and store the model.
- –
- User receives variable that relayed from API gateway (see Figure A6). Specific to this protocol, contains parameters for training the data in the cloud system, such as the IPFS hash () that shows the location of training data and hyperparameters for training the AI system (e.g., number of nodes and layers, learning rate, bias, weight, activation function).
After the AI service receives from the previous step, it will check whether the same hash value recorded in the IM smart contract (Steps 1–2). Then, it also gets the IPFS hash from the local DB. Finally, it compares three values: IPFS hash relayed from API gateway, smart contract, and local DB. If the comparison does not match, there is a possibility that either data relayed from the API gateway or local DB has been altered. Therefore, it will reject the request. Otherwise, it means there is no alteration of the data, and the data integrity is assured. AI service continues to get the training data from IPFS and start the training process (Steps 4–7). At the end of the training process, there will be an ML model that needs to be stored and preserve the model integrity. Then, the AI service will store the ML model to the IPFS and get the path of the stored ML model in hash form () (Steps 9–11). To guarantee the data integrity, the AI service will also record ML model IPFS hash to the (Steps 13–14). Then, when the AI service stores the ML model to the IM module, the IM module can verify the data by comparing the hash from the AI service and the blockchain (Steps 18–19). If the hash is not matched, there is a chance that the data received was altered; then, the IM module will reject the request. Otherwise, the IM module stores data received to local DB. Lastly, the IM module sends a message notification to the AI service that data is successfully stored (Steps 20–22). Details description of each step is provided in the Appendix F.
4.2.5. Logging and Monitoring
- First, from the IDMA module, it will monitor the registration and login activities. For example, if a user has a high number of failed authentication attempts in a row, it can be a sign of malicious activity. Then, this module will notify the IDMA to suspend the corresponding user from login for several amounts of time. If the same case happens again from the same user, this module will notify the IDMA to revoke the user credential.
- Second, this module will monitor the invoke token and API call activities from the API gateway. Use case example, if one API token has been called from a different location simultaneously, it is considered suspicious activity. So, this module will notify the API gateway to suspend/revoke the corresponding API token.
- Lastly, from the IM module, it will also monitor the storing training data and ML model activities. Use case example, when storing the ML training data/model, the IM module needs to verify the message signature. However, if there is a high number of failed verification, there is potential that someone alters the message. Then, the logging and monitoring module will notify the IM module to stop the corresponding process.
4.2.6. Storage Management
5. Evaluation and Discussion
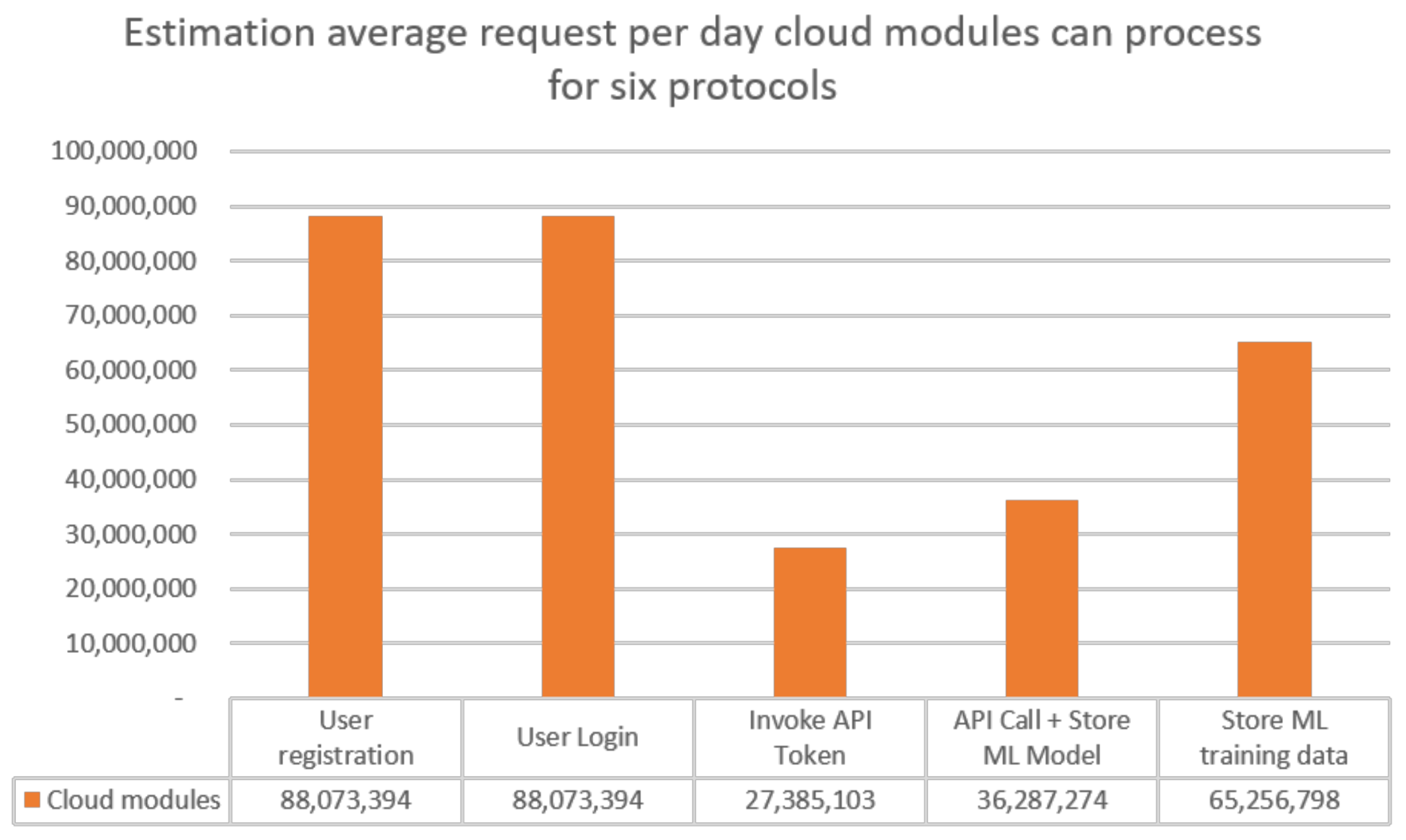
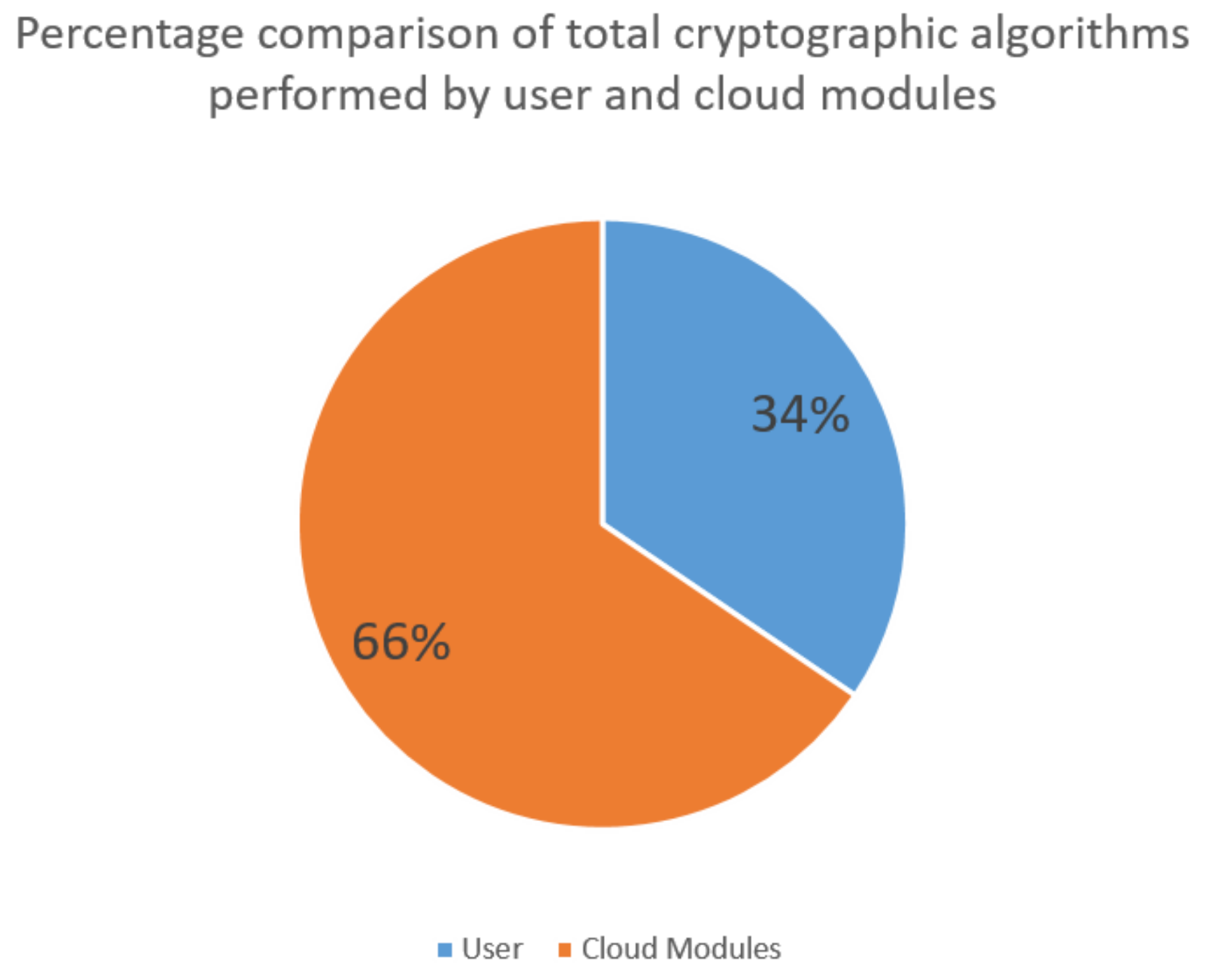
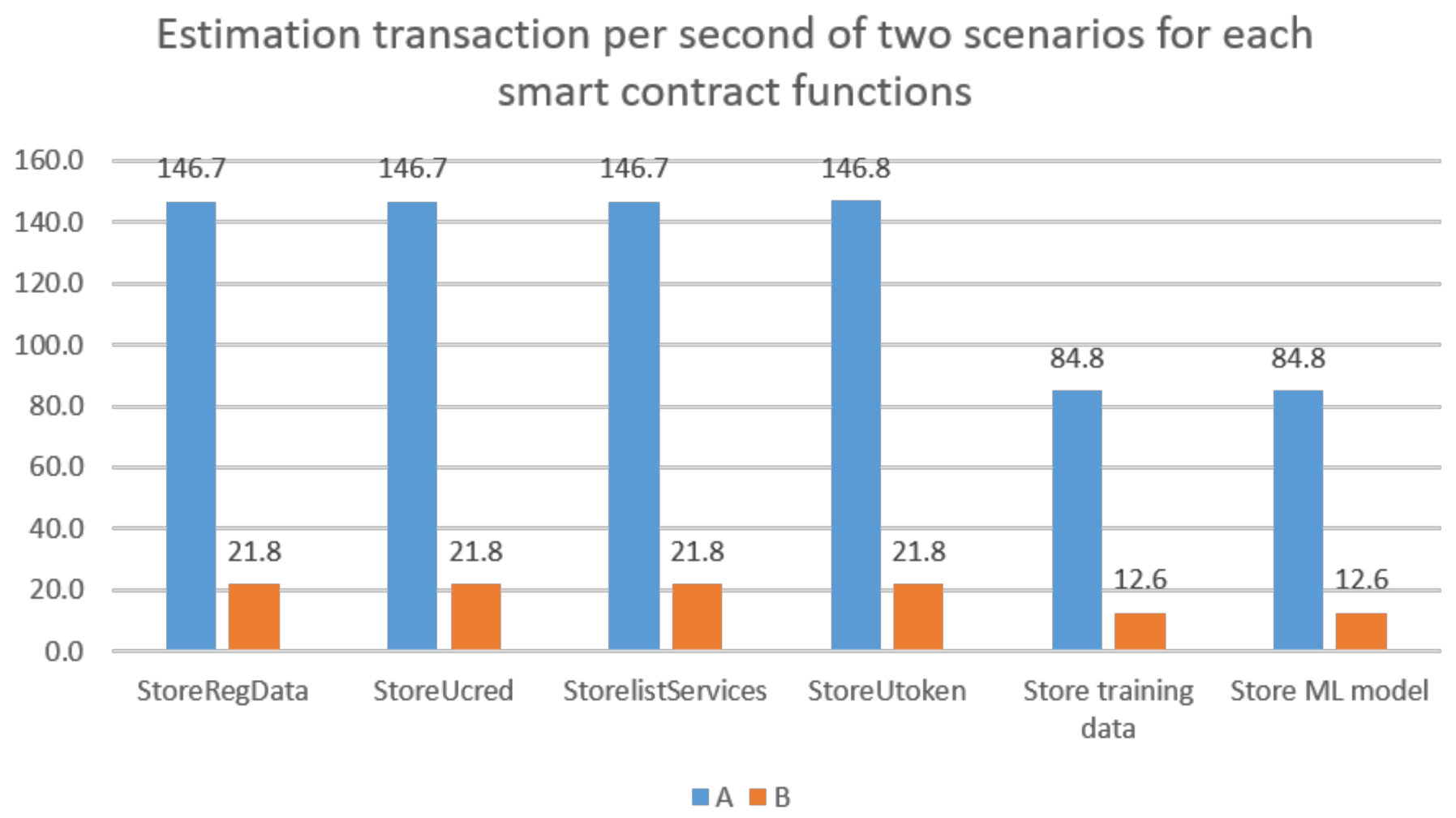
5.1. Off-Chain Computational Complexity
5.2. Smart Contracts’ Complexity
5.3. NIST Framework Mapping
- N1. Identify: We need to identify and manage resources that enable the organization to focus and prioritize its efforts to finish the goal. In our case, the goal is to ensure no violation of data integrity in cloud-based AI systems. In order to do that, we have identified threats and vulnerabilities in Section 2 along with the integrity issues in AI and cloud environments. We use these data to identify which assets and resources need protection to achieve our goal.N1-1. Document information flows. It is necessary to understand the information stored in the cloud storage and its flows. Therefore, our proposed architecture’s logging and monitoring module will continuously record information, including the data flow.N1-2. Maintain system access. It is crucial to define and monitor who can access the system because it is most likely the adversary’s entrance. In our proposed architecture, there are Identity Management and Access control (IDMA) and API gateway modules connected to two smart contracts for each module, respectively, to guard the system access.N1-3. Establish policies for cybersecurity that include roles and responsibilities. There are two or more parties that have interaction in a cloud-based AI system. They do not know whether they can trust each other or not. Therefore policies are needed to increase the trust between parties and prevent arbitrary actions. Our proposed architecture utilizes blockchain smart contracts to enforce the policy as a trusted Service Level Agreement (SLA).
- N2. Protect: Based on our analysis in Section 2, the system access and cloud infrastructure category need protection from the existing vulnerabilities in the cloud environment. Besides, we need to protect the data transmission from the user to the cloud storage to ensure the data integrity of training data in the ML pipeline.N2-1. Manage access to assets and information. IDMA module and its smart contracts will manage authentication and authorization for each user to log in to the right account and get the corresponding access control. At the same time, the API gateway and its smart contract verify the users’ permission when they call queries to request the AI service.N2-2. Conduct regular backups. Backup data has a significant impact, yet users often neglect maintaining it regularly because they underestimate its purpose. Therefore, in our proposed architecture, there is storage management to automate regular backups in a secure form.N2-3. Data integrity protection. It is the vital part since it is the goal of our paper, manage data integrity. Therefore, we append an Integrity Management (IM) module to achieve it in our proposed architecture. This module collaborates with smart contracts to increase the difficulty of falsifying the data and further enhances data integrity. By recording the data in the blockchain, both parties, users and CSP, can verify the received data integrity. It is difficult and expensive for adversaries to alter blockchain data since it is required to overcome more than 50% computing power.
- N3. Detect: In order to detect malicious activities, continuous logging and monitoring are needed. So, for instance, if there are unusual activities in login, writing, or executing the file, the system can send a warning to the user.N3-1. Maintain and monitor logs. There are four modules in our proposed architecture to ensure the success of anomaly behavior detection, IDMA, IM, API gateway, Logging and monitoring. Furthermore, three smart contracts will cooperate with the first three modules as a trusted SLA. The data flow from the first three modules will be recorded in the logging and monitoring module. Consequently, this module will continuously monitor the user activities whether there is malicious behavior or not. Besides recording and monitoring the data flow, this module also monitors system errors, network traffic, and statistics. By analyzing those data, the system can warn the user of suspicious behavior.
- N4. Respond: The response plan should be prepared prior to the attack happens. For instance, user and system can have their responsibility to mitigate the attack, respectively.N4-1. Maintain response plan. There are four modules included in the response plan, IDMA, IM, API gateway, Logging and monitoring.
- –
- IDMA secures the entrance point of the system. It authenticates the user that wants to log in to the system. If failed prove their identity several times, IDMA will reject the user from entering the system. This activity will be recorded by logging and monitoring module.
- –
- IM preserves the integrity of training data and model by leveraging smart contracts as a trusted SLA. If training/model data has been compromised in the process, IM will cancel the store data process. This activity will be recorded by logging and monitoring module.
- –
- API gateway guards the system against an unauthorized API call. Each user has a unique token to access a specific cloud’s services/resources. If the user accessed the system with the wrong token several times, the system will reject the request and revoke the token used. This activity will be recorded by logging and monitoring module.
- –
- The logging and monitoring module will analyze IDMA, API gateway, and IM data. If it finds suspicious behavior, it will warn the user and limit access to the system. Details explained in Section 4.2.
- N5. Recover: The recovery plan also should be prepared previously and communicated to the members inside organizations. For instance, maintain backup regularly, so if an incident happens, the user already has the last data before it is compromised.N5-1. Maintain a recovery plan. For this point to work, sub-points N2-2 needed to be done beforehand. If the backup data exists, the Storage management module could conduct a recovery plan to restore the last backup data after attacks.
5.4. Architecture Analysis
- For our first requirement, identity and access control management, only our proposed idea covers this part; the other five are not. Sometimes we diminish the importance of authentication and authorization, even though we know it is essential for the system. The lack of these two functions could expose our data integrity to the edge. Our proposed architecture enhanced our identity management and access control module by utilizing the smart contract.
- For our second requirement, consistency and completeness, four out of five satisfy this requirement. So, most of other works fulfilled this requirement. Although, there are different approach from ours that we already explained in Section 3.
- For our third requirement, non-repudiation, three out of five cover this part. Non-repudiation is required to prove who is in charge of some actions inside the systems. Furthermore, it could prevent malicious insiders from leaking or modifying the data because we could track their signatures.
- For the last requirement, trusted SLA, one out of five ideas meet this requirement. In [64], they also use blockchain to bind the trust between client and server. However, they only implement it to cover the second requirement since our trusted SLA will cover the first to third requirements.
| Reference | Identity and Access Control Management | Consistency and Completeness | Non-Repudiation | Trusted SLA |
|---|---|---|---|---|
| [59] | × | × | × | × |
| [61] | × | √ | √ | × |
| [11] | × | √ | √ | × |
| [62] | × | √ | √ | × |
| [64] | × | √ | × | √ |
| Ours | √ | √ | √ | √ |
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A. Protocol I: User Registration

- New user prepares data:
- t, current timestamp
- , user’s password
contains new users’ information that will be registered to the cloud system. Whilst is the corresponding hash. It plays a vital role in the authentication process. - New user send a registration request that contains their blockchain address () and to the .
- then will record the request to the blockchain with as the key and as the value. We use the variable instead of to differentiate the original value from the sender and the current value that was received. There is also one parameter, , that is set as by default in this smart contract. This value stores the authorization token for registered users and will be needed every time they log in to the system. After the transaction is stored in the blockchain, will broadcast this event to blockchain network, so every node in the same network will get this broadcast, including the IDMA module and user.
- After receiving the broadcast event, IDMA module stores the corresponding information ( and ) to its local database.
- A new user also receives the broadcast event of request from Step 3, it indicates that their request was successfully inserted into the blockchain. Then, he will compute values as follows.consists of encrypted form of and its signature () and will be sent off-chain.
- User send to the IDMA module.
- After receiving , IDMA module begins the verification process.
- (a)
- First, it will decrypt to get .
- (b)
- Compute from .
- (c)
- Compare value and to ensure no alteration during the transmission process. If equal, then continue to the signature validation process; otherwise, reject it.
- (d)
- To validate the signature, IDMA module use function with and as the input values. This step is crucial to prove that the sender of is the same user who has sent a registration request to the smart contract. Furthermore, it will prevent the adversary from impersonating the user.
- If the verification result is true, the IDMA module will set the role () for the new user. filled with which each value of those parameters has explained before. will determine the user’s privileges in the cloud system to prevent arbitrary behavior. Then, it stores both and to the local database.
- Next, IDMA module will prepares user credential () by compute hash of and . Subsequently, store to the local database.
- IDMA module sending that contains and to the .
- Upon receiving , stores . Then, it will broadcast an event to the blockchain network.
- New user receiving a broadcast event from Step 11 contains value. Then, he stores it in the local storage.
- IDMA module also receives it means the value has successfully been stored in the blockchain. Next, the IDMA module will send and to the user along with its digital signature signed by IDMA module secret key ().
- New user will verify the value received. First, compare the value from IDMA module and from the . If the value does not equal, there is a chance that someone alters the value when it is on transmission. Then the user will reject this value; otherwise, the user will continue the signature verification process. He validates the signature using function with the digital signature and hash of the and as the inputs. If the function’s output is true, it means the actual sender is the IDMA module, so the user keep the value received from the smart contract earlier. He will use it every time he wants to log in to the cloud system.
Appendix B. Protocol II: User Login

- User prepares data for login:contains data for user login along with its corresponding hash , while contains encrypted and using IDMA module public key ().
- Then user submits a login request to the cloud through the IDMA module by sending to the IDMA module.
- IDMA module receive and begins the verification process. First, decrypt with its secret key () to get and . Then, it will check two things:
- Whether the user information already registered in database or not.
- Compare the user information (email, password, user credential) from the user and from database match or not.
If one of those two conditions is false, reject the user login request; otherwise, continue the process. - Additional authentication process in IDMA module is by comparing value from user and the one existed in blockchain. This multi-authentication is required to ensure that the sender is the authentic user. So, IDMA module will query value by user blockchain address to the .
- reply the query by sending .
- Then IDMA module will compare value from the user and from the blockchain. We want to ensure that in local DB is not compromised by adversary. If the value is equal, we can assured that the data in local DB is authentic and unaltered. Next, ensure the user’s role and privilege in DB. If user has permission, continue to signature validation process; otherwise, reject it. To validate the signature, the IDMA module use function with and as the input values. This step is crucial to prove that the sender of is the same user who has sent a transaction to the smart contract. Furthermore, it will prevent the adversary from impersonating the user.
- If Step 6 is true, the IDMA module computes a message containing a ‘Login Success’ notification.
- IDMA module sends a signed message () to the user to notify that he successfully logged in to the cloud system.
- User verifies this message by checking the digital signature with the function.
Appendix C. Protocol III: Invoke Token


- User prepares data:The user needs to include their credential to prove that he has the privilege to request a token to the API gateway. So, the user prepares a message containing , current timestamp (t), and its signature to prove the sender’s authenticity. Then, encrypt it because the user will send it off-chain.
- User gets the list of services they can use by sending and to the API gateway.
- Upon receiving , the API gateway begins the verification process.
- (a)
- First, it will decrypt to get and .
- (b)
- Compute from .
- (c)
- To validate the signature, API gateway use function with and as the inputs. This step is crucial to prove that the sender of is not an adversary impersonating the authentic user.
- If the previous step is true, then the API gateway computes some values to check the user’s permission to the IDMA module.
- API gateway sends to the IDMA module off-chain.
- IDMA module receive and begin the verification process.
- (a)
- First, it will decrypt to get and .
- (b)
- Compute from .
- (c)
- To validate the signature, the IDMA module use function with and as the input values.
If the signature is valid, then the IDMA module will get the user’s role () from DB by sending . After that, it will sign the hash with IDMA module’s secret key (). - IDMA module reply the user’s role request by sending and the signature.
- Upon receiving the reply message, the API gateway begins to verify it.
- (a)
- Compute hash of user’s role ().
- (b)
- To validate the signature, API gateway use function with and as the inputs.
If verification success, check the user permission in . If the user has a permission to request an API token, then API gateway will computes:- {}
- API gateway reply user’s request by sending the list of services (N) and its signature ().
- After receiving the reply message from the API gateway, the user starts the verification process.
- (a)
- Compute the hash of the list of services ().
- (b)
- To validate the signature, API gateway uses function with and as the inputs.
- If the previous step is true, then the user prepares the list of services he wants to access.
- {}, where
- User send that contains and to the API token smart contract ().
- then stores to the blockchain with as the key. Then, it will broadcast an event to the blockchain network.
- API gateway receiving the broadcast event of from Step 13 then stores and to the local database.
- User also receiving the broadcast event of from Step 13, indicates that their request was successfully stored in the blockchain. Then, he prepares values:is encrypted message that contains list of cloud services that user want to access and its signature.
- User sends a services request () to the API gateway off-chain.
- Upon receiving from the user, the API gateway starts the verification process.
- (a)
- First, it will decrypt to get .
- (b)
- Compute from .
- (c)
- Compare value and to ensure no alteration during the transmission process. If equal, continue to signature validation process; otherwise, reject it.
- (d)
- To validate the signature, API gateway use function with and as the inputs. This step is crucial to prove the sender of is the same user who has sent the payload to the smart contract. Furthermore, it will prevent the adversary from impersonating the user.
- If the previous step is true, then API gateway stores to the local database. Next, it will generate an with JWT format based on the list of services requested by the user (). This value is combined with into variable. shows the time that token will be valid. The user cannot use a token that is expired. We present the example of in Figure A5.
- API gateway compute hash of the value.
- Then, API gateway store it to the by sending .
- After receiving this request, it will store to the blockchain with as the key. Then, it will broadcast an event to the blockchain network.
- After user receiving a broadcast event of , he store value to their local storage.
- API gateway also receiving the broadcast event of . After that, it will computes:
- API gateway sends that contains the encrypted and its signature to the user off-chain.
- Upon receiving from API gateway, user begin the verification process.
- (a)
- First, it will decrypt to get .
- (b)
- Compute from .
- (c)
- Compare value and to ensure that there is no alteration during the transmission process. If equal, continue to signature validation process; otherwise, reject it.
- (d)
- To validate the signature, API gateway use function with and as the input values.
- If previous step true, then user stores to their local storage.

Appendix D. Protocol IV: API Call

- User will prepares data before call the API as follows:
- , where
is an encrypted message that consists of the user’s access token (), the cloud service (Q), specific parameters for the corresponding cloud service (), current timestamp (t), and also the signature (). - User sends an API request to the API gateway by sending .
- After receiving , API gateway begins the verification process.
- (a)
- Decrypt to get .
- (b)
- Compute from .
- (c)
- To validate the signature, API gateway use function with the input and .
- If the previous step is true, then API gateway will query value from smart contract by sending as parameter.
- will send the hash of which is .
- API gateway get the expiration time of the token () first to the local DB. Then, computes by hashing and . After that, it will compare the value from the smart contract and from the result of hashing computation. If equal, continue next process; otherwise, reject. It means either value from DB or from the user was altered. Next, it checks whether the value is a member of O or not. If token is not expired and previous condition is true, API gateway will validate the token using function with and as the inputs.
- If the verification result is true, then API gateway will relay the user’s request to the corresponding cloud service along with the . Detail process in the cloud service is explained in Protocol VI that depicted in Figure A8.
- The related cloud service will return the result () to the API gateway.
- Lastly, API gateway relay the service back to the user ().
Appendix E. Protocol V: Store Training Data

- User prepares three data, metadata of training data , the training data , and the signature of two previous data . contains the name of the dataset, size, and source URL to download the original dataset.
- User stores to the IPFS.
- IPFS then stores and to its storage. Subsequently, it computes a unique fingerprint called content identifier (CID). This CID act as a permanent record and a URL of the files.
- IPFS sends the CID, that denoted as in our protocol, to the user.
- After that, user computes that contains and the hash .
- Continuously, user sends transaction that contains to the IM smart contract .
- then store those three values () to the blockchain. After that, it broadcast an event to the blockchain network.
- Upon receiving a broadcast event of , the IM module stores three values in the local DB.
- User also receives a broadcast event , which means their request is successfully stored in the blockchain. So, he computes that is an encrypted message of and its signature.
- User submits a request to the IM module to store the training data information by sending .
- Next, the IM module will verify the message.
- (a)
- Decrypt to get .
- (b)
- Compute from .
- (c)
- Compare value and to ensure that there is no alteration during the transmission process. If equal, continue to the next process; otherwise, reject it.
- (d)
- In this case, the IM module also compares the IPFS hash from the user and the one that received from blockchain . If equal, continue to signature validation process; otherwise, reject it.
- (e)
- To validate the signature, API gateway use function with the input and .
- If the previous step is true, the IM module needs to check the user’s role to the IDMA module whether he has the permission or not. Therefore, it will compute that is an encrypted message consists of and its signature.
- IM module send to the IDMA module.
- IDMA module begins to verify .
- (a)
- First, it will decrypt to get and .
- (b)
- Compute from .
- (c)
- To validate the signature, IDMA module use function with and as the inputs.
If the signature is valid, then, IDMA module will get the user’s role () from DB by sending . After that, it will sign the hash with IDMA module’s secret key (). - IDMA reply the user’s request by sending .
- Upon receiving the reply message, IM module begin to verify it.
- (a)
- Compute hash of user’s role ().
- (b)
- To validate the signature, API gateway use function with and as the inputs.
If signature validation is true, IM checks the user’s permission in . If the user has permission, stores to the local database. - After the training data is successfully stored, the IM module computes a message () that contains a notification to the user about the status of their request.
- IM module gives notification to the user by sending and its signature.
- Upon receiving the reply from the IM module, the user verifies the message first. He computes function with the signature and hash of as the inputs.
Appendix F. Protocol VI: Store ML Model

- AI service receives from the user through the API gateway and wants to verify this value. First, it will get the IPFS hash value from .
- If the value exist, sends the corresponding IPFS hash to the AI service.
- Then, AI service will check is it recorded in DB or not. If recorded, then compare the IPFS hashes values from the user (), from the smart contract (), and from the DB ().
- If the hashes comparison matches, then the AI service gets the training data to IPFS by sending as a parameter.
- IPFS will give the corresponding training data, metadata, and signature to the AI service ().
- AI service will verify the training data by using function with and as the inputs.
- If the previous step is true, then the AI service starts the training process with training data and as the inputs.
- After the training process is finished, the AI service will prepare ML model to be stored (M). ML model also will be stored in IPFS. Therefore, the AI service computes a hash of the model () and its signature ().
- AI service sends the ML model (M) and the signature () to the IPFS.
- IPFS then store these two values ( and ).
- Subsequently, IPFS generates the IPFS hash of the ML model denoted as and sends it to the AI service.
- Next, AI service will prepare data to be stored in the which are and the corresponding hash .
- AI service sends transaction to the that contains .
- Upon receiving from AI service, then stores those values to the blockchain. Then, it will broadcast an event to the blockchain network.
- IM module that receiving broadcast event of will also store to the local DB. These values will later be used for the verification process.
- AI service also receives a broadcast event of , which means their request is successfully stored in the blockchain. So, it will compute an encrypted message of and the corresponding signature ().
- Next, the AI service sends to the IM module in order to store the ML model.
- Then, the IM module will begin to verify .
- (a)
- Decrypt to get .
- (b)
- Compute from .
- (c)
- Compare value and to ensure that there is no alteration during the transmission process. If equal, continue to the next process; otherwise, reject it.
- (d)
- Continuously, the IM module also compares the IPFS hashes of the ML model from the AI service and from the blockchain . If equal, continue to the signature validation process; otherwise, reject it.
- (e)
- To validate the signature, API gateway use function with the input and .
- If the previous step is true, then the IM module stores the model () to the local database.
- Subsequently, it prepares a reply message () to notify the AI service that the model is successfully stored.
- IM module sends and its signature to the AI service.
- Upon receiving the reply from the IM module, the AI service verify the message first. It computes function with the signature and hash of as the inputs.
References
- Anyoha, R. The History of Artificial Intelligence. Available online: https://bit.ly/3x2jid7 (accessed on 3 March 2021).
- Marr, B. The Most Amazing Artificial Intelligence Milestones So Far. Available online: https://bit.ly/3oLq2s3 (accessed on 1 December 2020).
- West, D.M.; Allen, J.R. How Artificial Intelligence Transforming the World. Available online: https://brook.gs/3CyGQrp (accessed on 1 December 2020).
- Herpig, D.S. Securing Artificial Intelligence. 2019, p. 48. Available online: https://bit.ly/3nMt2F9 (accessed on 15 September 2020).
- Brundage, M.; Avin, S.; Clark, J.; Toner, H.; Eckersley, P.; Garfinkel, B.; Dafoe, A.; Scharre, P.; Zeitzoff, T.; Filar, B.; et al. The malicious use of artificial intelligence: Forecasting, prevention, and mitigation. arXiv 2018, arXiv:1802.07228. [Google Scholar]
- Tom Foremski. Survey: Trust in Tech Giants Is ‘Broken’. Available online: https://zd.net/3mCATVe (accessed on 18 May 2021).
- Wang, Y.; Wen, J.; Zhou, W.; Luo, F. A novel dynamic cloud service trust evaluation model in cloud computing. In Proceedings of the 2018 17th IEEE International Conference on Trust, Security and Privacy in Computing and Communications/12th IEEE International Conference on Big Data Science Furthermore, Engineering (TrustCom/BigDataSE), New York, NY, USA, 1–3 August 2018; pp. 10–15. [Google Scholar]
- Dave, M.; Saxena, A.B. Loss of trust at IAAS level: Causing factors & mitigation techniques. In Proceedings of the 2017 International Conference on Computing and Communication Technologies for Smart Nation (IC3TSN), Gurgaon, India, 12–14 October 2017; pp. 137–143. [Google Scholar]
- Huang, J.; Nicol, D.M. Trust mechanisms for cloud computing. J. Cloud Comput. Adv. Syst. Appl. 2013, 2, 9. [Google Scholar] [CrossRef] [Green Version]
- Yang, Y.; Chen, Y.; Chen, F. A Compressive Integrity Auditing Protocol for Secure Cloud Storage. IEEE/ACM Trans. Netw. 2021, 29, 1197–1209. [Google Scholar] [CrossRef]
- Garg, N.; Bawa, S.; Kumar, N. An efficient data integrity auditing protocol for cloud computing. Future Gener. Comput. Syst. 2020, 109, 306–316. [Google Scholar] [CrossRef]
- Yu, Y.; Xue, L.; Au, M.H.; Susilo, W.; Ni, J.; Zhang, Y.; Vasilakos, A.V.; Shen, J. Cloud data integrity checking with an identity-based auditing mechanism from RSA. Future Gener. Comput. Syst. 2016, 62, 85–91. [Google Scholar] [CrossRef]
- Fonseca, J.; Vieira, M. A Survey on Secure Software Development Lifecycles. Available online: https://bit.ly/3fOyumr (accessed on 1 December 2020).
- 5 Key Changes Made to the NIST Cybersecurity Framework V1.1. Available online: https://bit.ly/3FtfWD4 (accessed on 1 December 2020).
- Cybersecurity Framework. Available online: https://bit.ly/3oM7XKH (accessed on 1 December 2020).
- Mobasher, B.; Burke, R.; Bhaumik, R.; Williams, C. Toward trustworthy recommender systems: An analysis of attack models and algorithm robustness. ACM Trans. Internet Technol. (TOIT) 2007, 7, 23-es. [Google Scholar] [CrossRef]
- Fang, M.; Yang, G.; Gong, N.Z.; Liu, J. Poisoning attacks to graph-based recommender systems. In Proceedings of the 34th Annual Computer Security Applications Conference, San Juan, PR, USA, 3–7 December 2018; pp. 381–392. [Google Scholar]
- Fang, M.; Gong, N.Z.; Liu, J. Influence function based data poisoning attacks to top-n recommender systems. In Proceedings of the Web Conference 2020, Taipei, Taiwan, 20–24 April 2020; pp. 3019–3025. [Google Scholar]
- Huang, H.; Mu, J.; Gong, N.Z.; Li, Q.; Liu, B.; Xu, M. Data Poisoning Attacks to Deep Learning Based Recommender Systems. arXiv 2021, arXiv:2101.02644. [Google Scholar]
- Gu, T.; Dolan-Gavitt, B.; Garg, S. Badnets: Identifying vulnerabilities in the machine learning model supply chain. arXiv 2017, arXiv:1708.06733. [Google Scholar]
- Gu, T.; Liu, K.; Dolan-Gavitt, B.; Garg, S. Badnets: Evaluating backdooring attacks on deep neural networks. IEEE Access 2019, 7, 47230–47244. [Google Scholar] [CrossRef]
- Papernot, N.; McDaniel, P.; Sinha, A.; Wellman, M.P. Sok: Security and privacy in machine learning. In Proceedings of the 2018 IEEE European Symposium on Security and Privacy (EuroS&P), London, UK, 24–26 April 2018; pp. 399–414. [Google Scholar]
- Akhtar, N.; Mian, A. Threat of adversarial attacks on deep learning in computer vision: A survey. IEEE Access 2018, 6, 14410–14430. [Google Scholar] [CrossRef]
- Lu, J.; Sibai, H.; Fabry, E.; Forsyth, D. No need to worry about adversarial examples in object detection in autonomous vehicles. arXiv 2017, arXiv:1707.03501. [Google Scholar]
- Brown, T.B.; Mané, D.; Roy, A.; Abadi, M.; Gilmer, J. Adversarial patch. arXiv 2017, arXiv:1712.09665. [Google Scholar]
- Iter, D.; Huang, J.; Jermann, M. Generating Adversarial Examples for Speech Recognition. Available online: https://bit.ly/3IMpSJJ (accessed on 2 February 2021).
- Ketith Manville. Adversarial Machine Learning 101. Available online: https://bit.ly/3oFMzXr (accessed on 18 February 2021).
- ETSI. Securing AI: Problem Statement. Available online: https://bit.ly/3cuv1rG (accessed on 1 April 2021).
- Hapke, H.; Nelson, C. Building Machine Learning Pipeline; O’Reilly Media Inc.: Sebastopol, CA, USA, 2020. [Google Scholar]
- Goodfellow, I.J.; Shlens, J.; Szegedy, C. Explaining and harnessing adversarial examples. arXiv 2014, arXiv:1412.657. [Google Scholar]
- Xu, H.; Ma, Y.; Liu, H.C.; Deb, D.; Liu, H.; Tang, J.L.; Jain, A.K. Adversarial attacks and defenses in images, graphs and text: A review. Int. J. Autom. Comput. 2020, 17, 151–178. [Google Scholar] [CrossRef] [Green Version]
- Moosavi-Dezfooli, S.M.; Fawzi, A.; Frossard, P. Deepfool: A simple and accurate method to fool deep neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 2574–2582. [Google Scholar]
- Papernot, N.; McDaniel, P.; Jha, S.; Fredrikson, M.; Celik, Z.B.; Swami, A. The limitations of deep learning in adversarial settings. In Proceedings of the 2016 IEEE European Symposium on Security and Privacy (EuroS&P), Saarbruecken, Germany, 21–24 March 2016; pp. 372–387. [Google Scholar]
- Kurakin, A.; Goodfellow, I.; Bengio, S. Adversarial Examples in the Physical World. 2017. Available online: https://bit.ly/3qSB0yf (accessed on 17 March 2021).
- Ren, K.; Zheng, T.; Qin, Z.; Liu, X. Adversarial attacks and defenses in deep learning. Engineering 2020, 6, 346–360. [Google Scholar] [CrossRef]
- Moosavi-Dezfooli, S.M.; Fawzi, A.; Fawzi, O.; Frossard, P. Universal adversarial perturbations. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1765–1773. [Google Scholar]
- Tramèr, F.; Kurakin, A.; Papernot, N.; Goodfellow, I.; Boneh, D.; McDaniel, P. Ensemble adversarial training: Attacks and defenses. arXiv 2017, arXiv:1705.07204. [Google Scholar]
- Na, T.; Ko, J.H.; Mukhopadhyay, S. Cascade adversarial machine learning regularized with a unified embedding. arXiv 2017, arXiv:1708.02582. [Google Scholar]
- Madry, A.; Makelov, A.; Schmidt, L.; Tsipras, D.; Vladu, A. Towards deep learning models resistant to adversarial attacks. arXiv 2017, arXiv:1706.06083. [Google Scholar]
- Farnia, F.; Zhang, J.M.; Tse, D. Generalizable adversarial training via spectral normalization. arXiv 2018, arXiv:1811.07457. [Google Scholar]
- Das, N.; Shanbhogue, M.; Chen, S.T.; Hohman, F.; Chen, L.; Kounavis, M.E.; Chau, D.H. Keeping the bad guys out: Protecting and vaccinating deep learning with jpeg compression. arXiv 2017, arXiv:1705.02900. [Google Scholar]
- Xie, C.; Wang, J.; Zhang, Z.; Ren, Z.; Yuille, A. Mitigating adversarial effects through randomization. arXiv 2017, arXiv:1711.01991. [Google Scholar]
- Ross, A.S.; Doshi-Velez, F. Improving the adversarial robustness and interpretability of deep neural networks by regularizing their input gradients. In Proceedings of the Thirty-Second AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018; Available online: https://bit.ly/341U9oq (accessed on 17 March 2021).
- Lu, J.; Issaranon, T.; Forsyth, D. Safetynet: Detecting and rejecting adversarial examples robustly. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 446–454. [Google Scholar]
- Li, X.; Li, F. Adversarial examples detection in deep networks with convolutional filter statistics. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 5764–5772. [Google Scholar]
- Akhtar, N.; Liu, J.; Mian, A. Defense against universal adversarial perturbations. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 3389–3398. [Google Scholar]
- Lee, H.; Han, S.; Lee, J. Generative adversarial trainer: Defense to adversarial perturbations with gan. arXiv 2017, arXiv:1705.03387. [Google Scholar]
- Shen, S.; Jin, G.; Gao, K.; Zhang, Y. Ape-gan: Adversarial perturbation elimination with gan. arXiv 2017, arXiv:1707.05474. [Google Scholar]
- Xu, W.; Evans, D.; Qi, Y. Feature squeezing: Detecting adversarial examples in deep neural networks. arXiv 2017, arXiv:1704.01155. [Google Scholar]
- Xu, W.; Evans, D.; Qi, Y. Feature squeezing mitigates and detects carlini/wagner adversarial examples. arXiv 2017, arXiv:1705.10686. [Google Scholar]
- Alex Stamos. Cloud Computing Security. Available online: https://bit.ly/3Euu5Px (accessed on 23 December 2021).
- Ezhil Arasan Babaraj. Cloud Security—An Overview. Available online: https://bit.ly/3EvjPX9 (accessed on 23 December 2021).
- Ludovic Petit. OWASP Top 10 Cloud Security Risks. Available online: https://bit.ly/3mVx1in (accessed on 23 December 2021).
- Hitachi Systems Security. The Top 10 OWASP Cloud Security Risks. Available online: https://bit.ly/3qkkNR6 (accessed on 23 December 2021).
- Khalil, I.M.; Khreishah, A.; Azeem, M. Cloud computing security: A survey. Computers 2014, 3, 1–35. [Google Scholar] [CrossRef] [Green Version]
- Munir, K.; Palaniappan, S. Framework for secure cloud computing. Adv. Int. J. Cloud Comput. Serv. Archit. (IJCCSA) 2013, 3, 21–35. [Google Scholar] [CrossRef]
- Pandey, S.; Farik, M. Cloud computing security: Latest issues & countermeasures. Int. J. Sci. 2015, 4, 3–6. [Google Scholar]
- Abdelaziz, A.; Elhoseny, M.; Salama, A.S.; Riad, A. A machine learning model for improving healthcare services on cloud computing environment. Measurement 2018, 119, 117–128. [Google Scholar] [CrossRef]
- García, Á.L.; De Lucas, J.M.; Antonacci, M.; Zu Castell, W.; David, M.; Hardt, M.; Iglesias, L.L.; Moltó, G.; Plociennik, M.; Tran, V.; et al. A cloud-based framework for machine learning workloads and applications. IEEE Access 2020, 8, 18681–18692. [Google Scholar] [CrossRef]
- DEEP Hybrid Data Cloud. Available online: https://bit.ly/3FsfQM3 (accessed on 1 March 2021).
- Zhao, X.P.; Jiang, R. Distributed Machine Learning Oriented Data Integrity Verification Scheme in Cloud Computing Environment. IEEE Access 2020, 8, 26372–26384. [Google Scholar] [CrossRef]
- Nepal, S.; Chen, S.; Yao, J.; Thilakanathan, D. DIaaS: Data integrity as a service in the cloud. In Proceedings of the 2011 IEEE 4th International Conference on Cloud Computing, Washington, DC, USA, 4–9 July 2011; pp. 308–315. [Google Scholar]
- Gu, Z.; Huang, H.; Zhang, J.; Su, D.; Lamba, A.; Pendarakis, D.; Molloy, I. Securing input data of deep learning inference systems via partitioned enclave execution. arXiv 2018, arXiv:1807.00969. [Google Scholar]
- Kim, J.; Park, N. Blockchain-Based Data-Preserving AI Learning Environment Model for AI Cybersecurity Systems in IoT Service Environments. Appl. Sci. 2020, 10, 4718. [Google Scholar] [CrossRef]
- CodeNotary. Immudb Introduction. Available online: https://bit.ly/3JYdzuW (accessed on 4 January 2022).
- AWS. Amazon Quantum Ledger Database (QLDB). Available online: https://go.aws/3f9sFzw (accessed on 5 January 2022).
- Microsoft. Azure SQL Database Append-Only Ledger Tables. Available online: https://bit.ly/3r7WFkV (accessed on 5 January 2022).
- Ethereum. Ethereum Proof-of-Stake. Available online: https://ethereum.org/en/developers/docs/consensus-mechanisms/pos/ (accessed on 9 January 2022).
- How IAM Works. Available online: https://bit.ly/3HDYm1d (accessed on 1 April 2021).
- Introduction to JSON Web Tokens. Available online: https://bit.ly/30BJCiN (accessed on 1 October 2021).
- What Is IPFS. Available online: https://bit.ly/3HEPAQj (accessed on 1 October 2021).
- Swarm. Ethereum Swarm. Available online: https://bit.ly/3f9BZDw (accessed on 6 January 2022).
- Storj. Available online: https://bit.ly/3zIR7l0 (accessed on 6 January 2022).
- MaidSafe. Intro to MaidSafe. Available online: https://bit.ly/33lSvOe (accessed on 6 January 2022).
- wolfSSL. wolfCrypt Benchmarking. Available online: https://www.wolfssl.com/docs/benchmarks/ (accessed on 14 January 2022).
- Paul Wackerow. Gas and Fees. Available online: https://bit.ly/3zCzS4D (accessed on 6 January 2022).
- Ganache Overview. Available online: https://www.trufflesuite.com/docs/ganache/overview (accessed on 20 February 2020).
- Truffle Overview. Available online: https://bit.ly/3q03i9O (accessed on 7 November 2021).
- Concourse Open Community. ETH Gas Station. Available online: https://bit.ly/3zySXVm (accessed on 15 January 2022).
- Truffe Suite. Truffle Suite Configuration. Available online: https://bit.ly/3qRHsWr (accessed on 15 January 2022).
- Ethereum. Blocks Ethereum. Available online: https://ethereum.org/en/developers/docs/blocks/ (accessed on 9 January 2022).
- Paul Wackerow. Layer 2 Rollup. Available online: https://bit.ly/3HNXOFf (accessed on 6 January 2022).
- NIST. Getting Started with the NIST Cybersecurity Framework: A Quick Start Guide. Available online: https://bit.ly/3oLeh50 (accessed on 30 July 2021).
- National Institute of Standards and Technology. Framework for Improving Critical Infrastructure Cybersecurity, Version 1.1; Technical Report NIST CSWP 04162018; National Institute of Standards and Technology: Gaithersburg, MD, USA, 2018. [Google Scholar] [CrossRef]






| Phase | Vulnerabilities and Attacks | Integrity Issues |
|---|---|---|
| A1. Data acquisition and curation | Data poisoning [16,17,18,19] | Adversary alter the datasets, so the results will be in a way that attacker desires. |
| A2. Model design | No specific issue related to ML | Generic issues related to choices of hardware/software deployment, or external services. |
| A3. Implementation | Data Poisoning [16,17,18,19], Backdoor attack [20,21] | Such as phase A1, adversary attempts to corrupt the training datasets. Furthermore, this phase could be an entrance to backdoor attack. |
| A4. Inferences | Adversarial examples [22,23,24,25,26] | Adversary try to manipulating the inputs that cause AI system to misclassify it and behave incorrectly. |
| A5. Check and updates | Backdoor attack [20,21] | This attack is being triggered if the adversary successfully manipulated the training datasets at training phase. |
| Defense Mechanisms | Effective to | Category |
|---|---|---|
| Adversarial training | Adversarial examples | Complete-defense |
| Data compression | FGSM, DeepFool | Complete-defense |
| Randomization | Adversarial examples | Complete-defense |
| Gradient regularizations + adversarial training | FGSM, JSMA | Complete-defense |
| SafetyNet | FGSM, BIM, DeepFool | Detection-only |
| Convolution filter statistics | Adversarial examples | Detection-only |
| Perturbation Rectifying Network (PRN) | Universal perturbations | Complete-defense |
| GAN-based | Adversarial perturbations | Complete-defense |
| Denoising/Feature squeezing | Adversarial perturbation to an image | Detection-only |
| Phase | AI-Algorithm-Based | Architecture-Based |
|---|---|---|
| Data acquisition and curation | − | + |
| Model design | − | + |
| Implementation | + | + |
| Inferences | + | + |
| Check and updates | + | + |
| Category | Risks [53] | Vulnerabilities | Issues |
|---|---|---|---|
| System Access | R1. Accountability and Data Ownership, R6. Service and Data Integration | C1. Account and service hijacking | Adversary could gain access to the cloud resources and services |
| C2. Malicious insiders | Leaked important data to adversary | ||
| C3. Lack of authentication and authorization mechanisms | Impersonate real user to compromise the data, resources, and services | ||
| Cloud Infrastructure | R7. Multi-tenancy, R9. Infrastructure Security | C4. Insecure API gateway | Exposed to unauthorized data access that could lead to a black-box attack |
| C5. Security misconfiguration | Breach in API, account and service hijacking | ||
| C6. Multi-tenancy failure | One tenant can access neighbor’s data or resources. Adversary could use it to harm data integrity |
| Immutable/Append-Only Databases | Blockchain | |
|---|---|---|
| System Access | Centralized | Decentralized |
| Agreement mechanism | Do not have agreement mechanism | Have consensus protocol as an agreement mechanism |
| Throughput | High throughput | Depends on the consensus protocol |
| Cryptographic Algorithm | AT (ms) | User Registration | User Login | Invoke Token | API Call | Store ML Training Data | |||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| U | U × AT (ms) | U | U × AT (ms) | U | U × AT (ms) | U | U × AT (ms) | U | U × AT (ms) | ||
| Asymmetric-Enc | 0.027 | 1 | 0.03 | 1 | 0.03 | 2 | 0.05 | 1 | 0.03 | 1 | 0.03 |
| Asymmetric-Dec | 0.823 | 0 | 0.00 | 0 | 0.00 | 1 | 0.82 | 0 | 0.00 | 1 | 0.82 |
| Signature | 0.041 | 1 | 0.04 | 1 | 0.04 | 2 | 0.08 | 1 | 0.04 | 2 | 0.08 |
| Verify | 0.117 | 1 | 0.12 | 1 | 0.12 | 2 | 0.23 | 0 | 0.00 | 1 | 0.12 |
| Total | 3 | 0.19 | 3 | 0.19 | 7 | 1.19 | 2 | 0.07 | 5 | 1.05 | |
| Cryptographic Algorithm | AT (ms) | User Registration | User Login | Invoke Token | API Call + Store ML Model | Store ML Training Data | |||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| CM | CM × AT (ms) | CM | CM × AT (ms) | CM | CM × AT (ms) | CM | CM × AT (ms) | CM | CM × AT (ms) | ||
| Asymmetric-Enc | 0.027 | 0 | 0.00 | 0 | 0.00 | 2.00 | 0.05 | 1 | 0.03 | 1 | 0.03 |
| Asymmetric-Dec | 0.823 | 1 | 0.82 | 1 | 0.82 | 3 | 2.47 | 2 | 1.65 | 1 | 0.82 |
| Signature | 0.041 | 1 | 0.04 | 1 | 0.04 | 4 | 0.16 | 3 | 0.12 | 3 | 0.12 |
| Verify | 0.117 | 1 | 0.12 | 1 | 0.12 | 4 | 0.47 | 5 | 0.59 | 3 | 0.35 |
| Total | 3 | 0.98 | 3 | 0.98 | 13 | 3.16 | 11 | 2.38 | 8 | 1.32 | |
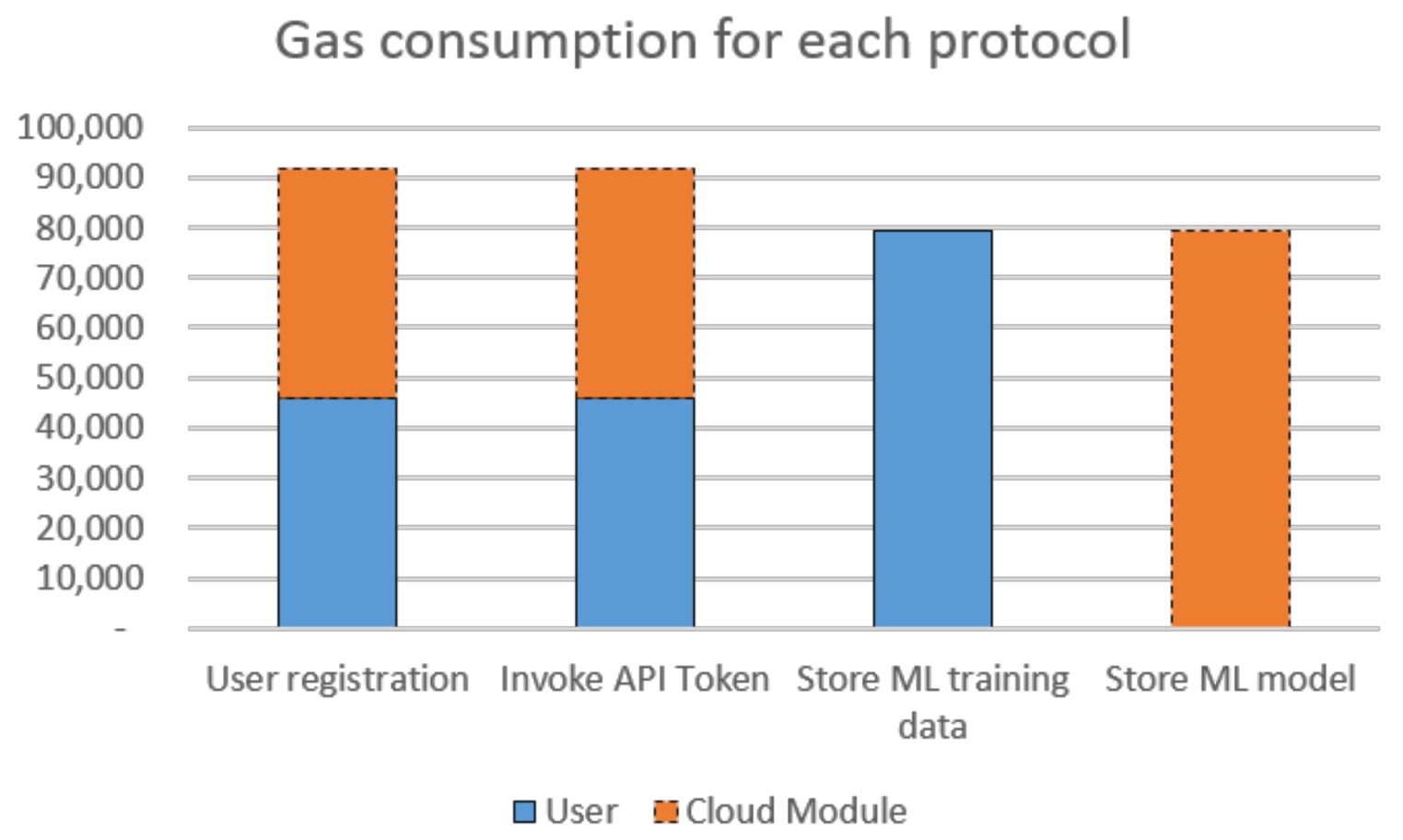
| Function | Description | Caller | Gas Used | Tx Fee (USD) * |
|---|---|---|---|---|
| StoreRegData | Store hash of registration data from user | User | 45,811 | 16.72 |
| StoreUcred | Store user credential from IDMA | Cloud | 45,833 | 16.73 |
| StorelistServices | Store hash of list services requested by user | User | 45,811 | 16.72 |
| StoreUtoken | Store user token from API gateway | Cloud | 45,789 | 16.72 |
| StoreTdataHash | Store training data store message hash + IPFS hash of training data | User | 79,260 | 28.94 |
| StoreMdataHash | Store model data store message hash + IPFS hash of model | Cloud | 79,260 | 28.94 |
| Sub Points | NIST Expected Outcomes | NIST Related Sub Category | Our Proposed Architecture |
|---|---|---|---|
| N1-1 | Document information flows | ID.AM-4, ID.GV-1, ID-RA-1, ID-RA-3, ID-RM-2 | Logging and monitoring |
| N1-2 | Maintain inventory access | IDMA, API gateway + smart contracts | |
| N1-3 | Establish policies for cybersecurity that include roles and responsibilities | Blockchain smart contracts as trusted SLA | |
| N2-1 | Manage access to assets and information | PR-AC-1, PR-AC-4, PR-AC-6-7, PR-DS-1-2,PR-DS-5-6, PR-IP-3-4, R-IP-9,PR-MA-1, PR-PT-1, PR-PT-3 | IDMA, API gateway + smart contracts |
| N2-2 | Conduct regular backups | Storage Management | |
| N2-3 | Data Integrity Protection | IM + smart contracts | |
| N3-1 | Maintain and monitor logs | DE.AE-3, DE-AE-5, DE-CM-3, DE-CM-7, DE-DP-1, DE-DP-4 | Logging and monitoring, IDMA, IM, API gateway + smart contracts |
| N4-1 | Maintain Response plan | RS-RP-1, RS-CO-2, RS-AN-1-2, RS-MI-1-2 | IDMA, IM, API gateway, Logging and monitoring |
| N5-1 | Maintain recovery plan | RC-RP-1 | Logging and monitoring, Storage management |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Witanto, E.N.; Oktian, Y.E.; Lee, S.-G. Toward Data Integrity Architecture for Cloud-Based AI Systems. Symmetry 2022, 14, 273. https://doi.org/10.3390/sym14020273
Witanto EN, Oktian YE, Lee S-G. Toward Data Integrity Architecture for Cloud-Based AI Systems. Symmetry. 2022; 14(2):273. https://doi.org/10.3390/sym14020273
Chicago/Turabian StyleWitanto, Elizabeth Nathania, Yustus Eko Oktian, and Sang-Gon Lee. 2022. "Toward Data Integrity Architecture for Cloud-Based AI Systems" Symmetry 14, no. 2: 273. https://doi.org/10.3390/sym14020273