
Analysis of Hypergraph Signals via High-Order Total Variation


Abstract
:1. Introduction
1.1. Related Works
1.2. Main Works
- We propose an HOTV over hypergraphs, by which we obtain a hypergraph Laplacian and present an orthonormal basis reflecting distinct spectral information. The HOTV aggregates the HGS groupwise instead of pairwise, which describes the dissimilarity of the HGS over the topology in a more comprehensive way;
- We propose a novel signal transformation (a new HGFT) by the orthonormal basis which bridges the vertex domain and the spectral domain of an HGS. We then can process the HGS in the two domains, clearly provide spectral interpretations for all processing of the HGS and put forward a framework for the analysis and processing of the HGS;
- We present hypergraph filtering tasks in the two domains and discuss two specific forms of hypergraph filters, which do provide a new idea for the HGS filtering.
2. Hypergraph Signals
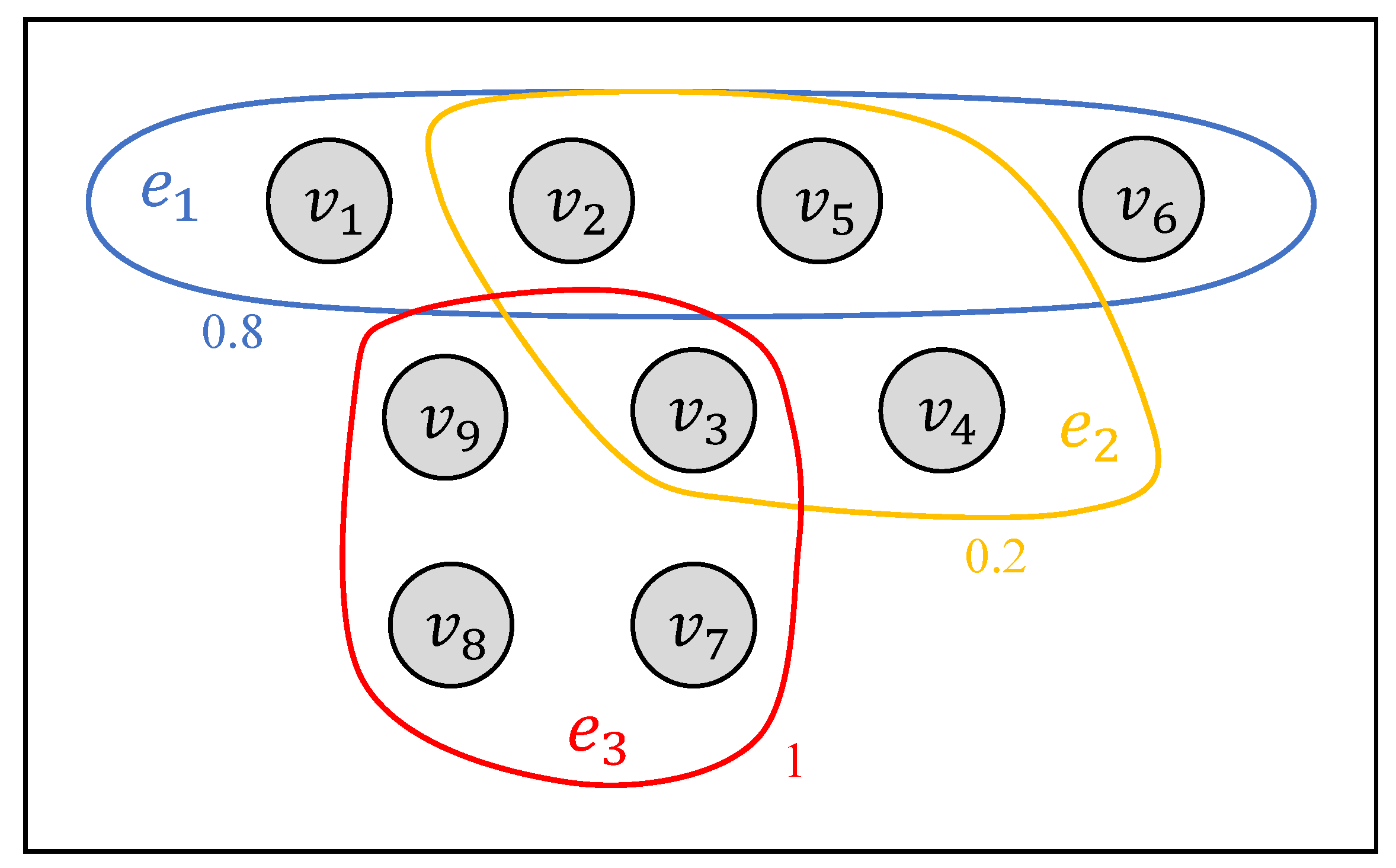
2.1. Total Variation of Hypergraph Signals
2.2. Tensor-Based Representations
2.2.1. Representations of Topologies
2.2.2. Representations of Signals
3. Hypergraph Fourier Transform
3.1. Construction of an Orthonormal Basis
3.2. Hypergraph Fourier Transform
3.3. Spectral Form of Total Variation
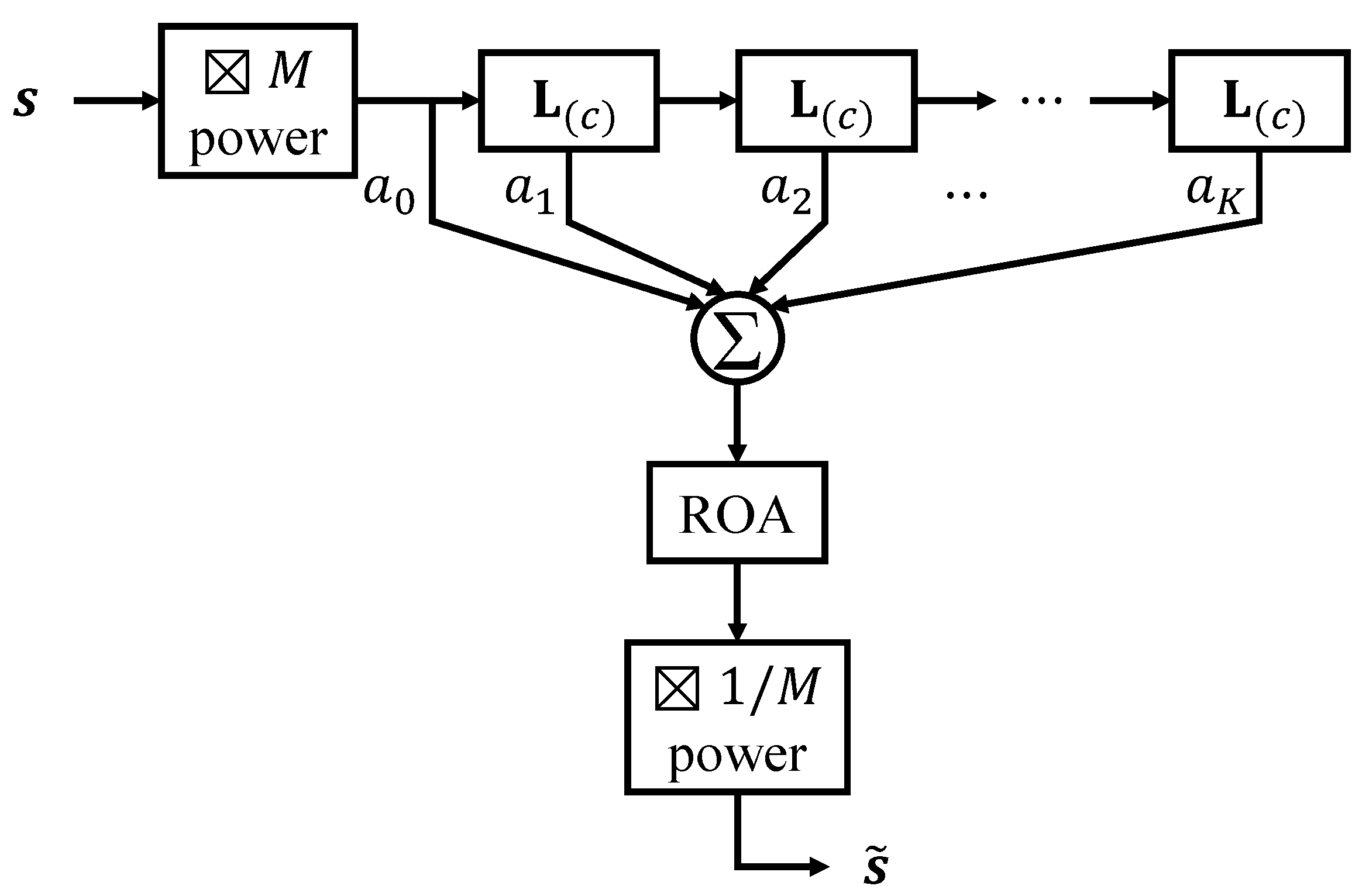
4. Hypergraph Filters
4.1. Polynomial Filters Based on the Hypergraph Laplacians
4.2. Reducible Filters
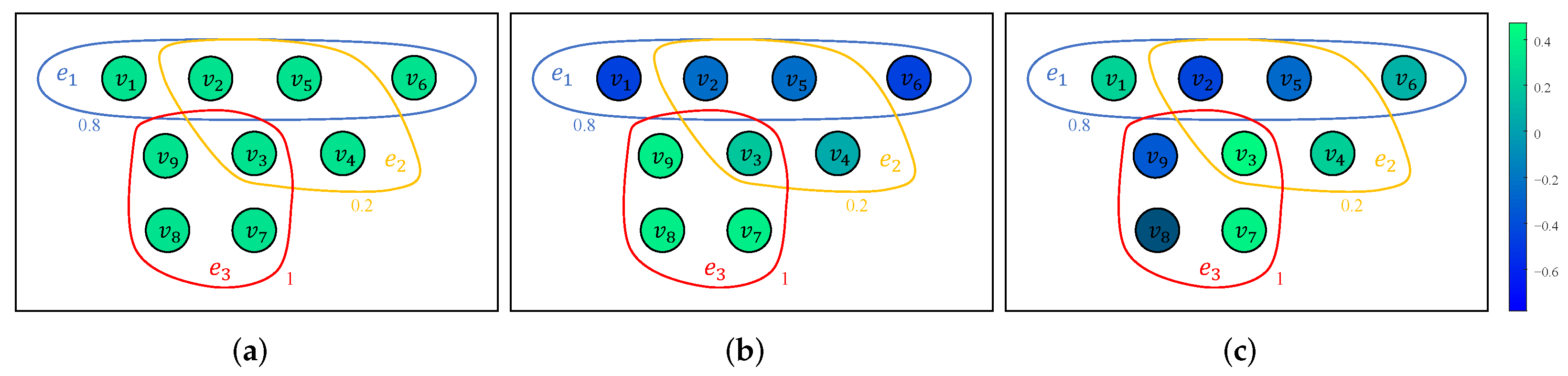
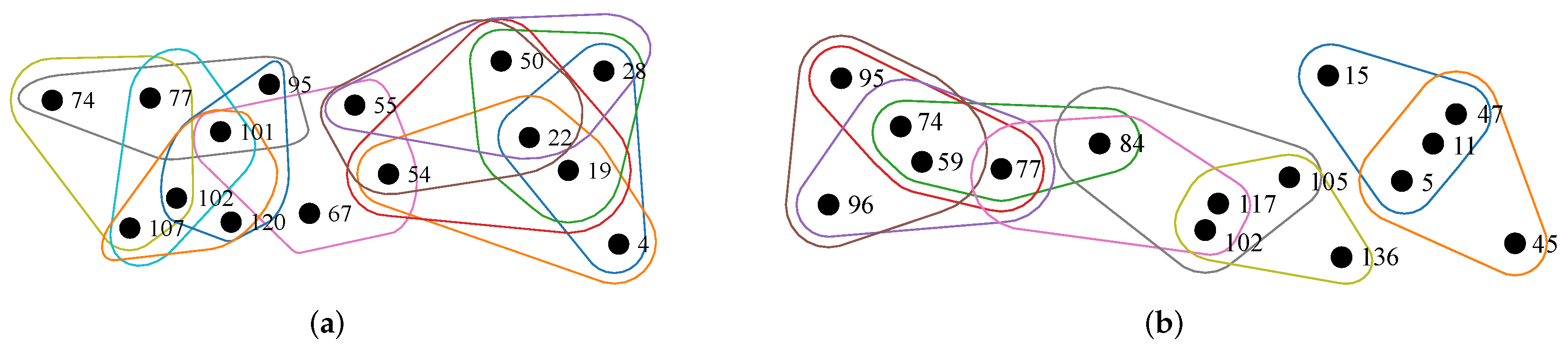
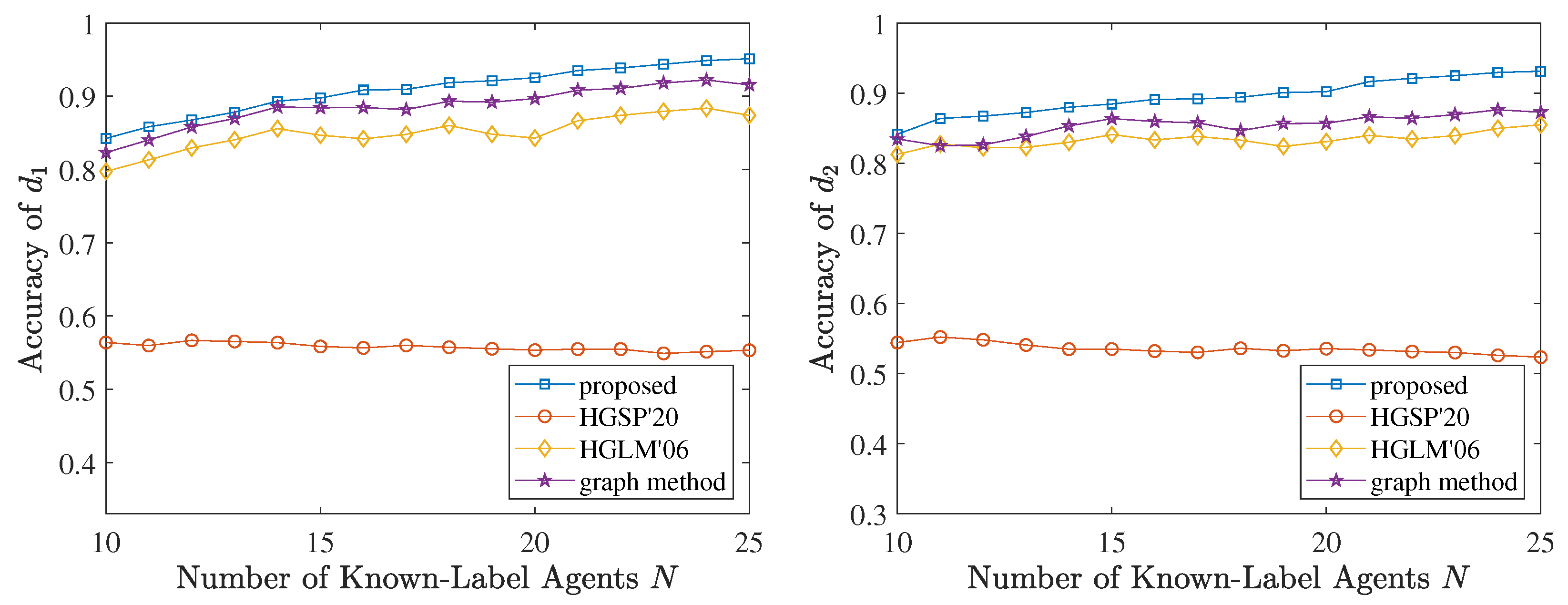
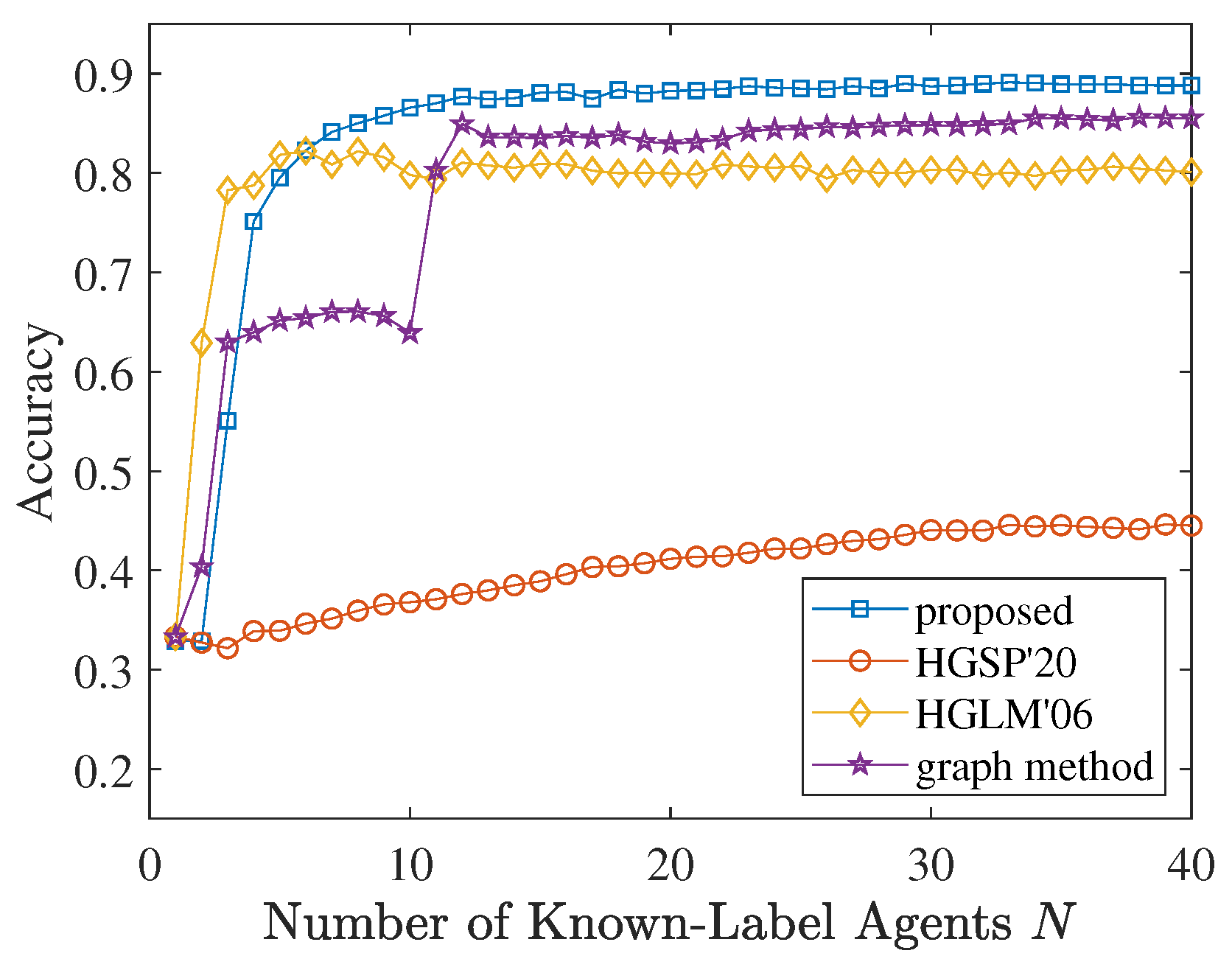
5. Application
5.1. Hypergraph Label Learning Model
5.2. Experimental Setups and Results
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| CP | CANDECOMP/PARAFAC |
| GFT | Graph Fourier transform |
| GSP | Graph signal processing |
| HGFT | Hypergraph Fourier transform |
| HGLM | Hypergraph Laplacian matrix |
| HGS | Hypergraph signal |
| HGSP | Hypergraph signal processing |
| HOTV | High-order total variation |
| IHGFT | Inverse hypergraph Fourier transform |
| ROA | Rank-one approximation |
Appendix A. Solution of Problem (13)
Appendix B
Appendix C. Proof of (28)
Appendix D. Proof of Proposition 2
References
- Shuman, D.I.; Narang, S.K.; Frossard, P.; Ortega, A.; Vandergheynst, P. The emerging field of signal processing on graphs: Extending high-dimensional data analysis to networks and other irregular domains. IEEE Signal Process. Mag. 2013, 30, 83–98. [Google Scholar] [CrossRef] [Green Version]
- Sandryhaila, A.; Moura, J.M. Discrete signal processing on graphs: Frequency analysis. IEEE Trans. Signal Process. 2014, 62, 3042–3054. [Google Scholar] [CrossRef] [Green Version]
- Ortega, A.; Frossard, P.; Kovacevic, J.; Moura, J.M.; Vandergheynst, P. Graph Signal Processing: Overview, Challenges, and Applications. Proc. IEEE 2018, 106, 808–828. [Google Scholar] [CrossRef] [Green Version]
- Benson, A.R.; Gleich, D.F.; Leskovec, J. Higher-order organization of complex networks. Science 2016, 353, 163–166. [Google Scholar] [CrossRef] [Green Version]
- Gu, X.; Chen, L.; Krenn, M. Quantum experiments and hypergraphs: Multiphoton sources for quantum interference, quantum computation, and quantum entanglement. Phys. Rev. A 2020, 101, 33816. [Google Scholar] [CrossRef] [Green Version]
- Duck, I. Three-alpha-particle resonances via the Fadeev equation. Nucl. Phys. 1966, 84, 586–594. [Google Scholar] [CrossRef]
- Kim, H.Y.; Sofo, J.O.; Velegol, D.; Cole, M.W.; Lucas, A.A. Van der Waals forces between nanoclusters: Importance of many-body effects. J. Chem. Phys. 2006, 124, 74504. [Google Scholar] [CrossRef]
- Petri, G.; Expert, P.; Turkheimer, F.; Carhart-Harris, R.; Nutt, D.; Hellyer, P.J.; Vaccarino, F. Homological scaffolds of brain functional networks. J. R. Soc. Interface 2014, 11, 20140873. [Google Scholar] [CrossRef] [Green Version]
- Sizemore, A.E.; Giusti, C.; Kahn, A.; Vettel, J.M.; Betzel, R.F.; Bassett, D.S. Cliques and cavities in the human connectome. J. Comput. Neurosci. 2018, 44, 115–145. [Google Scholar] [CrossRef] [Green Version]
- Abrams, P.A. Arguments in Favor of Higher Order Interactions. Am. Nat. 1983, 121, 887–891. [Google Scholar] [CrossRef]
- Mayfield, M.M.; Stouffer, D.B. Higher-order interactions capture unexplained complexity in diverse communities. Nat. Ecol. Evol. 2017, 1, 0062. [Google Scholar] [CrossRef] [PubMed]
- Grilli, J.; Barabás, G.; Michalska-Smith, M.J.; Allesina, S. Higher-order interactions stabilize dynamics in competitive network models. Nature 2017, 548, 210–213. [Google Scholar] [CrossRef] [PubMed]
- Cervantes-Loreto, A.; Ayers, C.A.; Dobbs, E.K.; Brosi, B.J.; Stouffer, D.B. The context dependency of pollinator interference: How environmental conditions and co-foraging species impact floral visitation. Ecol. Lett. 2021, 24, 1443–1454. [Google Scholar] [CrossRef] [PubMed]
- Ritz, A.; Tegge, A.N.; Kim, H.; Poirel, C.L.; Murali, T.M. Signaling hypergraphs. Trends Biotechnol. 2014, 32, 356–362. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Sanchez-Gorostiaga, A.; Bajić, D.; Osborne, M.L.; Poyatos, J.F.; Sanchez, A. High-order interactions dominate the functional landscape of microbial consortia. bioRxiv 2018, 333534. [Google Scholar] [CrossRef] [Green Version]
- Battiston, F.; Cencetti, G.; Iacopini, I.; Latora, V.; Lucas, M.; Patania, A.; Young, J.G.; Petri, G. Networks beyond pairwise interactions: Structure and dynamics. Phys. Rep. 2020, 874, 1–92. [Google Scholar] [CrossRef]
- Battiston, F.; Amico, E.; Barrat, A.; Bianconi, G.; Ferraz de Arruda, G.; Franceschiello, B.; Iacopini, I.; Kéfi, S.; Latora, V.; Moreno, Y.; et al. The physics of higher-order interactions in complex systems. Nat. Phys. 2021, 17, 1093–1098. [Google Scholar] [CrossRef]
- Berge, C. Graphs and Hypergraphs; North-Holland Pub. Co.: Amsterdam, The Netherlands, 1973. [Google Scholar]
- Cooper, J.; Dutle, A. Spectra of uniform hypergraphs. Linear Algebra Appl. 2012, 436, 3268–3292. [Google Scholar] [CrossRef] [Green Version]
- Qi, L. H+-eigenvalues of Laplacian tensor and signless Laplacians. Commun. Math. Sci. 2014, 12, 1045–1064. [Google Scholar] [CrossRef] [Green Version]
- Banerjee, A.; Char, A.; Mondal, B. Spectra of general hypergraphs. Linear Algebra Appl. 2017, 518, 14–30. [Google Scholar] [CrossRef] [Green Version]
- Hu, S.; Qi, L. Algebraic connectivity of an even uniform hypergraph. J. Comb. Optim. 2012, 24, 564–579. [Google Scholar] [CrossRef]
- Chang, J.; Chen, Y.; Qi, L.; Yan, H. Hypergraph clustering using a new laplacian tensor with applications in image processing. SIAM J. Imag. Sci. 2020, 13, 1157–1178. [Google Scholar] [CrossRef]
- Ouvrard, X.; Le Goff, J.M.; Marchand-Maillet, S. On Adjacency and e-Adjacency in General Hypergraphs: Towards a New e-Adjacency Tensor. Electron. Notes Discret. Math. 2018, 70, 71–76. [Google Scholar] [CrossRef] [Green Version]
- Zhang, S.; Ding, Z.; Cui, S. Introducing Hypergraph Signal Processing: Theoretical Foundation and Practical Applications. IEEE Internet Things 2020, 7, 639–660. [Google Scholar] [CrossRef] [Green Version]
- Afshar, A.; Perros, I.; Ho, J.C.; Khalil, E.B.; Sunderam, V.; Dilkina, B.; Xiong, L. CP-ORTHO: An Orthogonal Tensor Factorization Framework for Spatio-Temporal Data. In Proceedings of the GIS Proc. ACM International Symposium on Advances in Geographic Information Systems, SIGSPATIAL’17, Redondo Beach, CA, USA, 7–10 November 2017; Association for Computing Machinery: New York, NY, USA, 2017; Volume 2017-Novem. [Google Scholar] [CrossRef]
- Kolda, T.G.; Bader, B.W. Tensor decompositions and applications. SIAM Rev. 2009, 51, 455–500. [Google Scholar] [CrossRef]
- Comon, P.; Golub, G.; Lim, L.H.; Mourrain, B. Symmetric Tensors and Symmetric Tensor Rank. SIAM J. Matrix Anal. Appl. 2008, 30, 1254–1279. [Google Scholar] [CrossRef] [Green Version]
- Hein, M.; Setzer, S.; Jost, L.; Rangapuram, S.S. The total variation on hypergraphs-learning on hypergraphs revisited. Adv. Neural Inf. Process. Syst. 2013, 26. Available online: https://proceedings.neurips.cc/paper/2013/hash/8a3363abe792db2d8761d6403605aeb7-Abstract.html (accessed on 14 January 2022).
- Nguyen, C.H.; Mamitsuka, H. Learning on Hypergraphs With Sparsity. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 43, 2710–2722. [Google Scholar] [CrossRef] [Green Version]
- Zien, J.Y.; Schlag, M.D.; Chan, P.K. Multilevel spectral hypergraph partitioning with arbitrary vertex sizes. IEEE Trans. Comput. Des. Integr. Circuits Syst. 1999, 18, 1389–1399. [Google Scholar] [CrossRef]
- Zhou, D.; Huang, J.; Schölkopf, B. Learning with Hypergraphs: Clustering, Classification, and Embedding. In Proceedings of the 19th International Conference on Neural Information Processing Systems, Vancouver, BC, Canada, 4–7 December 2006; MIT Press: Cambridge, MA, USA, 2006; pp. 1601–1608. [Google Scholar]
- Agarwal, S.; Branson, K.; Belongie, S. Higher order learning with graphs. In Proceedings of the 23rd International Conference on Machine Learning ( ICML ’06), Pittsburgh, PA, USA, 25–29 June 2006; Association for Computing Machinery: New York, NY, USA, 2006; Volume 148, pp. 17–24. [Google Scholar] [CrossRef] [Green Version]
- Barbarossa, S.; Tsitsvero, M. An introduction to hypergraph signal processing. In Proceedings of the 2016 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Shanghai, China, 20–25 March 2016; Volume 2016-May, pp. 6425–6429. [Google Scholar] [CrossRef]
- Barbarossa, S.; Sardellitti, S. Topological Signal Processing over Simplicial Complexes. IEEE Trans. Signal Process. 2020, 68, 2992–3007. [Google Scholar] [CrossRef] [Green Version]
- Qu, R.; He, J.; Feng, H.; Xu, C.; Hu, B. Regularized recovery by multi-order partial hypergraph total variation. In Proceedings of the ICASSP—2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Virtual, 6–12 June 2021; Volume 2021-June, pp. 2930–2934. [Google Scholar] [CrossRef]
- Bourbaki, N. Elements of Mathematics, Algebra I, Chapter 1–3; Springer: Berlin/Heidelberg, Germany, 1989; ISBN 3-540-64243-9. [Google Scholar]
- Ng, M.K.; Weiss, P.; Yuan, X. Solving constrained total-variation image restoration and reconstruction problems via alternating direction methods. SIAM J. Sci. Comput. 2010, 32, 2710–2736. [Google Scholar] [CrossRef]
- Fiedler, M. Algebraic connectivity of graphs. Czechoslov. Math. J. 1973, 23, 298–305. [Google Scholar] [CrossRef]
- Barik, S.; Bapat, R.B.; Pati, S. On the laplacian spectra of product graphs. Appl. Anal. Discret. Math. 2015, 9, 39–58. [Google Scholar] [CrossRef] [Green Version]
- Kofidis, E.; Regalia, P.A. On the best rank-1 approximation of higher-order supersymmetric tensors. SIAM J. Matrix Anal. Appl. 2002, 23, 863–884. [Google Scholar] [CrossRef] [Green Version]
- Chitra, U.; Raphael, B.J. Random walks on hypergraphs with edge-dependent vertex weights. In Proceedings of the 36th International Conference on Machine Learning (ICML 2019), Long Beach, CA, USA, 9–15 June 2019; Proceedings of Machine Learning Research. Chaudhuri, K., Salakhutdinov, R., Eds.; 2019; Volume 97, pp. 2002–2011. [Google Scholar]
- Tang, C.; Liu, X.; Wang, P.; Zhang, C.; Li, M.; Wang, L. Adaptive Hypergraph Embedded Semi-Supervised Multi-Label Image Annotation. IEEE Trans. Multimed. 2019, 21, 2837–2849. [Google Scholar] [CrossRef]
- Yu, J.; Tao, D.; Wang, M. Adaptive hypergraph learning and its application in image classification. IEEE Trans. Image Process. 2012, 21, 3262–3272. [Google Scholar] [CrossRef] [PubMed]
- Wang, M.; Liu, X.; Wu, X. Visual Classification by ℓ1-Hypergraph Modeling. IEEE Trans. Knowl. Data Eng. 2015, 27, 2564–2574. [Google Scholar] [CrossRef]
- Zhang, Z.; Lin, H.; Zhao, X.; Ji, R.; Gao, Y. Inductive Multi-Hypergraph Learning and Its Application on View-Based 3D Object Classification. IEEE Trans. Image Process. 2018, 27, 5957–5968. [Google Scholar] [CrossRef]
- Van Lierde, H.; Chow, T.W.S. A Hypergraph Model for Incorporating Social Interactions in Collaborative Filtering. In Proceedings of the 2017 International Conference on Data Mining, Communications and Information Technology (DMCIT 2017), Phuket, Thailand, 25–27 May 2017; Association for Computing Machinery: New York, NY, USA, 2017. [Google Scholar] [CrossRef]
- Gharahighehi, A.; Vens, C.; Pliakos, K. An Ensemble Hypergraph Learning Framework for Recommendation. In Discovery Science, Proceedings of the 24th International Conference, DS 2021; Halifax, NS, Canada, 11–13 October 2021; Carlos, S., Torgo, L., Eds.; Springer International Publishing: Cham, Switzerland, 2021; pp. 295–304. [Google Scholar] [CrossRef]
- Czerniak, J.; Zarzycki, H. Application of rough sets in the presumptive diagnosis of urinary system diseases. In Artificial Intelligence and Security in Computing Systems; Springer: Boston, MA, USA, 2003; pp. 41–51. [Google Scholar] [CrossRef]
- Dua, D.; Graff, C. UCI Machine Learning Repository; University of California, Irvine, School of Information and Computer Sciences: Irvine, CA, USA, 2019. [Google Scholar]
- Bertsekas, D.P. Nonlinear Programming; Athena Scientific: Belmont, MA, USA, 1999. [Google Scholar]
- Qi, L. Eigenvalues of a real supersymmetric tensor. J. Symb. Comput. 2005, 40, 1302–1324. [Google Scholar] [CrossRef] [Green Version]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Notation | Description |
|---|---|
| a c-uniform weighted undirected hypergraph | |
| the Laplacian tensor of | |
| an HGS | |
| an Mth-order HGS | |
| the Mth-order HGS set | |
| a spectral-domain HGS | |
| a vertex-domain hypergraph filter | |
| a spectral-domain hypergraph filter | |
| ⊗ | the Kronecker product |
| ⊠ | the outer product |
| the n-mode product | |
| ⊙ | the Khatri–Rao product |
| tensor matricization | |
| tensor vectorization | |
| tensorization of a matrix or a vector | |
| the rank-one approximation of any form of a tensor |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Qu, R.; Feng, H.; Xu, C.; Hu, B. Analysis of Hypergraph Signals via High-Order Total Variation. Symmetry 2022, 14, 543. https://doi.org/10.3390/sym14030543
Qu R, Feng H, Xu C, Hu B. Analysis of Hypergraph Signals via High-Order Total Variation. Symmetry. 2022; 14(3):543. https://doi.org/10.3390/sym14030543
Chicago/Turabian StyleQu, Ruyuan, Hui Feng, Chongbin Xu, and Bo Hu. 2022. "Analysis of Hypergraph Signals via High-Order Total Variation" Symmetry 14, no. 3: 543. https://doi.org/10.3390/sym14030543